
Abstract
The widespread integration of artificial intelligence (AI) into our daily lives has spurred an escalating demand for explainable AI (XAI). This demand is particularly pronounced in critical domains such as healthcare and finance, where understanding the decision-making processes of AI models is paramount. Despite noteworthy strides in XAI, prevailing approaches often neglect the crucial dimension of context, resulting in explanations that are challenging to comprehend and act upon for different stakeholders. This paper advocates for a paradigm shift towards context-sensitive explainability, tailoring explanations to users’ specific needs and understanding promoting inclusivity and accessibility. We propose a novel context taxonomy and a versatile framework, “ConEX” for developing context-sensitive explanations using any state-of-the-art post hoc explainer. Our empirical user study highlights diverse preferences for contextualization levels, emphasizing the importance of catering to these preferences to build trust and satisfaction in AI systems. Our contributions extend beyond the theoretical realm, offering practical guidance for developing context-sensitive explanations that are tailored to the specific needs of diverse stakeholders. By embracing context-sensitive explainability, we can unlock the true potential of AI, fostering trust, transparency, and informed decision-making across various domains.
Introduction
The pervasiveness of artificial intelligence (AI) in our daily lives has brought about a growing demand for explainable AI (XAI). This demand stems from the need to understand how AI models make decisions, particularly in high-stakes domains such as healthcare and finance to enhance transparency and trustworthiness. Regulatory reforms, such as the General Data Protection Regulation in Europe and government initiatives like the Defense Advanced Research Projects Agency (DARPA)’s XAI research program in the USA, have further accelerated interest in the field (Gunning & Aha, 2019). In the literature, various attempts have been made to define explainability, often using terms such as “Interpretability” and “Explainability” interchangeably. Interpretability in AI primarily focuses on discerning the meaning of AI-generated outcomes, while Explainability aims to make these outcomes comprehensible to users (Schneider & Handali, 2019). In essence, the goal of explainability is to make AI systems and AI systems’ decisions understandable to humans, whether they are developers, lay users, regulators, etc.
XAI algorithms are often categorized according to scope (local vs. global), stage (ante-hoc vs. post hoc), and applicability (model-agnostic vs. model-specific) (Speith, 2022). Local models (Lundberg & Lee, 2017; Ribeiro et al., 2016) aim at explaining a certain local prediction while global explainers (Gregorutti et al., 2015) are concerned with explaining the task model as a whole. As for the explanation stage, ante-hoc explainability refers to training intrinsically interpretable models. They represent a set of models that are understood as a whole or can be decomposed into interpretable parts or mathematically understood such as linear classifiers or discretization methods (decision trees, etc.). Thus explainability is achieved during decision-making. On the other hand, post hoc explainability relies on an external helper model to explain the results of the task model. In most cases, the helper model is an interpretable model that aims to approximate the original model. These types of explainers are often referred to as surrogate or proxy models. Amongst these models, some are model-specific where they are specifically designed for a certain task model, and others are model-agnostic where they can be applied to various task models. Regrettably, most of the current XAI approaches are predominantly tailored to meet the explainability needs of AI experts and tend to overlook the broader spectrum of stakeholders defying the goal of explainability in making AI systems understandable to all types of users Srinivasan and Chander (2021).
Explanations should be tailored to the model’s audience of all types (Barredo Arrieta et al., 2020; Longo et al., 2024). Haresamudram et al. (2023) discussed the notion of transparency under three levels: Algorithmic, interactive, and social. Algorithmic transparency focuses on unveiling the internal functioning of AI models while interactive transparency sheds light on the importance of the adaptability of the AI systems with the interactions of their users. As for social transparency, it addresses ethical concerns including privacy and social norms, as well as, compliance with regulations. The authors argued that not all levels of transparency are equally important to different stakeholders. For instance, lay users may not be concerned with all the algorithmic details of an explanation and their existence can cause an excessive unnecessary mental effort since they care more for concepts rather than data. Therefore, an explanation’s content, format, and presentation should align with the stakeholder’s needs to achieve both understandability and the required level of transparency without overloading the explanation with irrelevant information.
Goal-oriented explanations are closely related to the stakeholder at hand and understanding the informational needs of each stakeholder will ensure that the goal of explanations is met effectively. Enriching explanations semantically can help tailor explanations further. This can be done by integrating multiple XAI methods or using external information resources such as external datasets or ontologies representing domain knowledge (Longo et al., 2024). Domain knowledge can facilitate formal and common-sense reasoning providing more meaningful explanations that align with the current context. Another motivation to include external symbolic knowledge is to mitigate uncertainty and wrong explanations, provided by the explainers, by validating that the explanations are not irrelevant or unclear. Otherwise, reporting a misalignment accordingly.
Context plays a pivotal role in determining the effectiveness of an explanation. An explanation that is perfectly intelligible in one context may be irrelevant or even misleading in another. Consider a system that predicts the likelihood of a user developing diabetes. If the system explains that a nine-year-old user is at high risk due to their age, this explanation is contextually inappropriate, as it disregards the age-specific factors that influence diabetes risk ( does not align with the domain knowledge about the disease). One of the main objectives of explainability is to help users make more informed decisions (Ali et al., 2023) and producing out-of-context explanations can jeopardise that goal. In the previous example, even if that nine-year-old was truly at risk of developing diabetes, his caregiver might not have taken any preventive measures since the explanation did not support the prediction with factual information encouraging a loss of trust in the system. Therefore, acknowledging the importance of context, several researchers have called for a reconceptualization of explainability, emphasizing its sensitivity to context, audience, and purpose (Robinson & Nyrup, 2022).
Formally, Context can be defined as any information that can be used to characterize the situation of any entity. In an AI system, any person, place, or object relevant to the interaction between a user and a system—including the user and the system—can be considered a part of the context (Dey, 2009). Therefore, context can be known as a priori or a posteriori depending on its use (Brézillon, 2012b). In other words, context can be static representing knowledge, or dynamic such that it can be modeled only during an interaction with the system. Consequently, we can consider domain knowledge, XAI stakeholders and their goals as a part of the interaction’s context.
This paper advocates for a paradigm shift in XAI, adapting the concept of context-sensitive explainability. Context-sensitive explainability addresses tailoring explanations to the specific needs and understanding of the user addressing inclusivity and accessibility challenges. This approach ensures that explanations are not only informative but also actionable, enabling users to make informed decisions based on the insights gained from the explanation. We argue that a good explanation should be constructed based on two fundamental aspects: (1) Algorithmic knowledge considered during the problem-solving process of the instance in question to achieve algorithmic transparency and (2) contextual knowledge that surrounds that instance to achieve interactive and social transparency. Contextual knowledge provides a frame of reference for excluding or introducing information within an explanation to suit a specific context (Brézillon, 2012a; McCarthy, 1993). To the best of our knowledge, there are currently no comprehensive taxonomies that delineate the contextual knowledge elements relevant for explaining a given instance. Moreover, most of the existing XAI approaches often focus on developing novel explainers rather than leveraging existing explainers in a user-centric manner. An explainer-agnostic approach to contextualizing explanations, adaptable to any existing explainer, to the best of our knowledge, is conspicuously absent.
To address these existing gaps, we make the following contributions:
We propose a novel and comprehensive taxonomy of context, providing guidance on the key contextual considerations for creating context-sensitive explanations. Building upon our context taxonomy, we introduce a general framework, named “ConEX” serving as a roadmap for developing context-sensitive explanations using any state-of-the-art post hoc explainer. To demonstrate the applicability of our framework, we apply the design guidelines of “ConEX” to build a prototype system that delivers context-sensitive explanations in the domain of movie recommendations. We evaluate the prototype by conducting an empirical user study.
The rest of this paper is structured as follows. In Section 2, we start by reviewing the existing effort in addressing context in XAI approaches. Then, in Section 3, we present our novel taxonomy of context. Next, we introduce our ConEX framework for explainable movie recommendation in Section 4. This is followed by showcasing the application of ConEX in the movie recommendation domain in Section 5. Afterwards, in Section 6, we present an empirical user study that evaluates the effect of context-sensitive explanations on user satisfaction and trust. A discussion about how ConEX is different than the existing approaches is then presented in Section 7, followed by a hypothetical proposal on applying ConEX in the medical domain in Section 8. Finally, concluding remarks are highlighted in Section 9.
Unlike other AI fields that rarely involve end-users in the technical development and evaluation phase, XAI needs to consider its end-users since the user is the one interpreting the explanation. Different stakeholders have varying expectations regarding the complexity and presentation formats of explanations as discussed before. Although the XAI field has been booming and many XAI techniques have been proposed, most efforts remain at an algorithmic level. Technical aspects are mainly considered rather than usability requirements and the majority of algorithms are technical-user-oriented, not end-user-oriented (Jin et al., 2021). Consequently, recent research has been going in the direction of defining context-aware and user-centered explanations. Although the reviewed work did not explicitly refer to their contributions as context-sensitive, according to the definition of context, they implicitly incorporated dimensions of context in their synthesized explanations. We categorized the reviewed effort according to the aspects of context tackled into goal-based, history-based, knowledge-based, user-based, and scenario-based approaches, as shown below.
Goal-Based Approaches
Some efforts tackled context in terms of purpose (user’s goal of using an explanation) such as those that discussed situation awareness (SA). The concept of SA defines the informational needs of humans operating in any scenario (Endsley, 1995). Sanneman and Shah (2022) proposed the situation awareness framework for explainable AI (SAFE-AI), a three-level framework for the development and evaluation of explanations about AI system behavior. SAFE-AI starts by acknowledging that the basis of SA is understanding the main goal of the AI model and that is level 1 SA. Then building on that, understanding why a system took a certain decision by highlighting the model’s decision-making process is level 2. Afterwards, using the previous two levels, accomplishing full SA is achieved when a user can use explanations to predict what will happen if the situation changes in a system using counterfactuals. These three levels help users to reason about what will happen in different contexts and what exactly would need to change to alter the model’s outputs. Although SAFE-AI provided a roadmap for what XAI designers should consider when building situation-aware XAI, no implementation was provided. In fact, the authors stated that building systems capable of producing explanations that fully consider user contexts and tasks remains an understudied area.
A closely related work was the one done by Avetisyan et al. (2022). The authors proposed an SA-level-based explanation framework and investigated how it benefited human and autonomous vehicle interaction by using Endsley’s SA model (Endsley, 1995). They found out that providing situation-aware explanations fostered drivers’ SA thus improving trust, however, level 2 SA explanations increased the required cognitive workload. These findings support the fact that context-aware explanations do build more trustworthy AI systems and the choice of context-level adaptation requires a tradeoff between user’s goal, effort, and satisfaction.
History-Based Approaches
Some approaches considered the past events as a part of the context to relate to the current instance. Amit et al. (2023), for instance, combined situations derived by a complex event processing (CEP) engine with traces of business process executions to produce situation-aware explanations. CEP enables SA by applying temporal and contextual reasoning on incoming events to produce higher-level insights. Their approach uses historical process execution logs that are enriched by the CEP. An XAI tool is then employed to explain individual process execution cases by feature ranking concerning specific outcomes of interest. The results demonstrated that the temporal contextual information can be leveraged to improve and enrich explanations making them more situation-aware. They supported the claim that explanations derived from “local” inference can sometimes be inadequate and require reasoning about situational contextual conditions derived from some actions in the past to be coherent.
Knowledge-Based Approaches
Other approaches tackled the static aspect of the context in terms of domain knowledge, that is knowledge about the system or facts. Pesquita (2021) stressed the fact that for AI outcomes to be truly useful, they need to support interpretation, and this requires semantic context. Therefore, the author proposed a model-agnostic methodology for semantic explanations in the biomedical domain that is based on the semantic annotation, leveraging the existence of multiple medical ontologies in the semantic web, and integration of heterogenous data in the forms of knowledge graphs (KGs) to help build domain-aware explanations. Even though this approach incorporates domain knowledge in explanation building, it is not supported by the deployment of a prototype nor includes any user-centered explainability aspects.
User-Based Approaches
Arfini et al. (2023) stated that “user-centered design can utilizes data to represent the user’s perspective and cater to the broader non-mainstream population.” With the motive to understand audience needs as a part of the context in an explanation, recent research has explored question-driven designs for XAI systems to understand what a user is expecting to see in an explanation (Liao et al., 2020, 2021). Additionally, conversational interfaces have emerged as a promising avenue for delivering explanations through dialog, fostering a more natural and interactive approach (Madumal et al., 2019; Malandri et al., 2023). Other efforts, (Anjomshoae et al., 2021; Apicella et al., 2022, 2019), have focused on extracting human-understandable input features or concepts from AI models using auto-encoders along with heat maps, for example, extracting middle-level features like the ears and whiskers instead of highlighting pixels when explaining why an image is classified as a cat. Pixels of interest are segmented into super-pixels representing middle-level features that are naturally more understandable to humans. Yet, these approaches largely neglect other crucial dimensions of context and thus might lead to explanations that are difficult to understand or act upon.
Scenario-Based Approaches
Leveraging scenarios of possible use early on in system development as a basis for scenario-based explainability was also an attempt to account for context in explanations. Wolf (2019) discussed the importance of incorporating several scenario-based explanations in system design to account for future scenario explanations. The problem with this approach is the capacity of brainstorming scenarios during production which might not be flexible with different variables in the future. On top of that, the authors did not support their proposal with a tangible prototype. Another related work in this area is the work done by Cirqueira et al. (2020) where scenario-based requirement elicitation in designing a user-centric XAI system for fraud detection was applied. Even though these approaches attempted to tackle a big chunk of context when explaining, they lack flexibility and adaptation in new scenarios and they missed the domain knowledge aspect of context.
Discussion
To summarize, different efforts tackled different pieces of context. Some reviewed the importance of including static context in terms of knowledge. Others focused on situational context and using historical events to explain current ones. Some focused on the mental models of the users and their workload considerations. Last but not least, a portion of the research focused on the social aspect of explanations improving accessibility and control of the users over the explanation. However, according to our knowledge, there does not exist a work that combines different static and dynamic pieces of context in one framework. That’s mainly because there is no formal guide of what pieces of context should be considered when building an explanation. That is why in this paper we aim to introduce a context taxonomy that categorizes different pieces of context. Then propose a design guideline that uses our taxonomy to build context-sensitive user-centered explanations.
Context Taxonomy
In our pursuit of context-sensitive explainability within AI, we present a systematic taxonomy that dissects the various dimensions of a context. As depicted in Figure 1, this taxonomy provides a conceptual roadmap for understanding the intricate layers of context that are essential in guiding the development of context-sensitive explanations. We argue that a context comprises static and dynamic aspects.
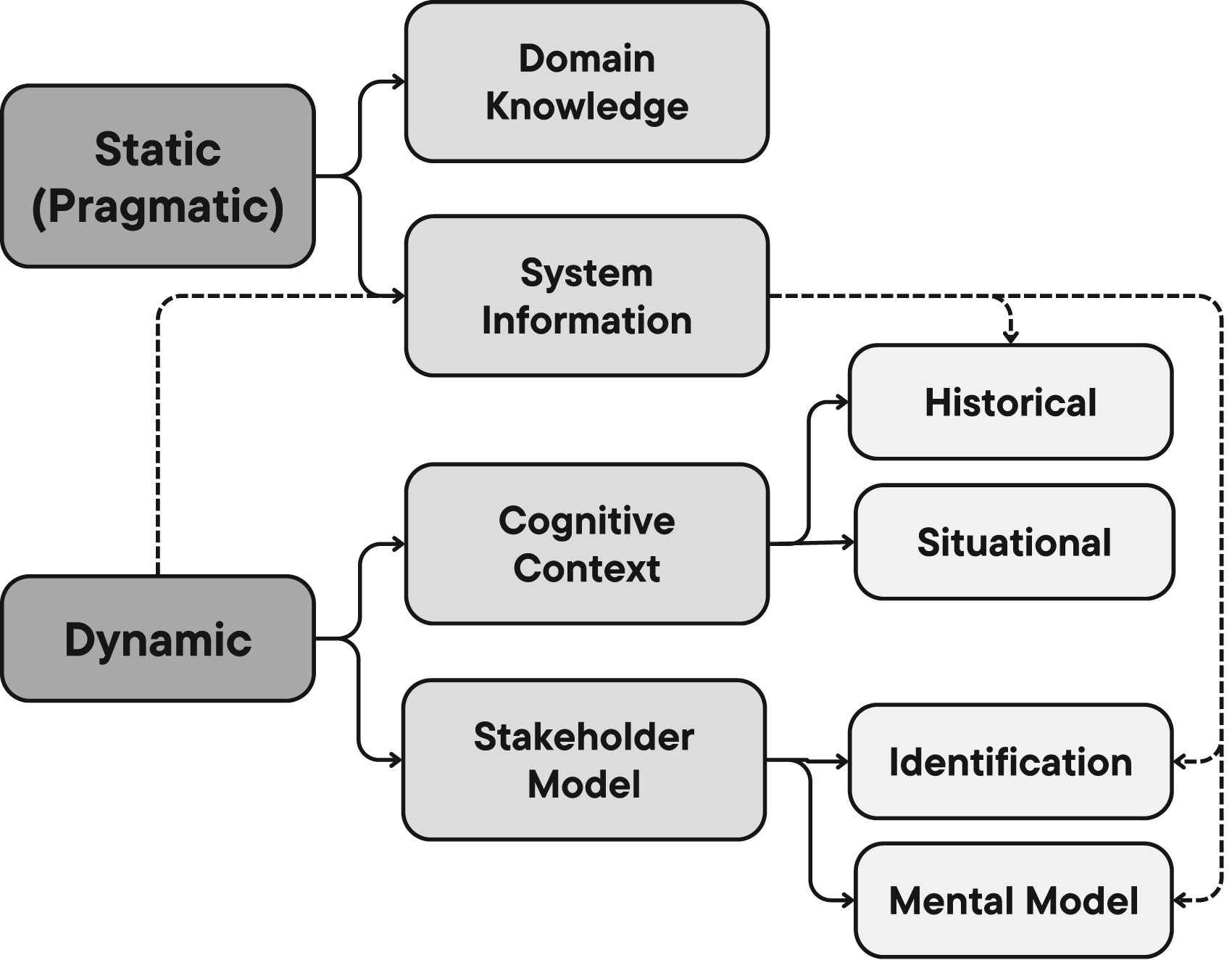
Proposed Context Taxonomy.
We commence our exploration with the notion of static context, which serves as the unchanging foundation for the problem at hand. Within this realm, we encounter two key components: Domain knowledge and system information.
Domain Knowledge: Factual Information
Domain knowledge represents a repository of facts within a given domain and is typically curated by domain experts. For instance, in a movie recommendation system, it encompasses details about all available movies, including actors, directors, and other relevant information. In a diagnostic AI system, it contains critical information about risk factors and disease interrelationships. The static component of a context ensures that explanations align with the bedrock of domain knowledge.
System Information: System Facts and User Connections
On the other hand, system information encompasses the definitions of system features and the significance of user connections. For example, a movie rating system distinguishes the importance of a 5-star rating from a 4-star one. Additionally, it can include user attributes like age groups or postal codes, facilitating user clustering. These insights enable the system to cater to the unique needs of different user groups, making it a vital component of the static context. System information also includes the users’ identities and history of interactions with the system that are factual during the time of the current interaction.
Dynamic Aspects
Transitioning to dynamic context, we encounter a dynamic landscape categorized into two entities: the stakeholder model and the cognitive context. Dynamic context represents pieces of context that are needed to characterize the current interaction and can only be built because of the interaction with the system. Some pieces can only be present during the interaction, such as the state of the stakeholder and the world, but most of the dynamic context pieces are originally stored in the system information module, however, only relevant pieces are fetched during the interaction. Fetched information changes depending on the interaction stakeholder and the interaction type which is why it is considered dynamic due to the dynamic nature of the interaction. In other words, the state of the information changes from static to dynamic when they are involved in an ongoing interaction. They are also labeled as dynamic since they are built because of an interaction of the stakeholder with the system and cannot be built in any other way. After the interaction ends, the information gathered from the dynamic interaction is moved to the static context and can be used to draw inferences since it now represents factual information.
Stakeholder Model: Dynamic Personas
The Stakeholder Model introduces the concept of dynamic personas, recognizing that stakeholders evolve with each interaction. It comprises two key aspects: Stakeholder identification and the stakeholder mental model.
Stakeholder identification involves capturing personal attributes such as the stakeholder’s role (e.g., developer, lay user), age, and cues for interaction personalization. Understanding each stakeholder’s objectives in an interaction becomes crucial. For instance, AI experts seek to optimize systems and are familiar with technical nuances, whereas lay users rely on explanations for decision support. This underscores the need for personalized explanations tailored to individual goals.
The stakeholder’s mental model is an internal construct shaped by real-world experiences, enabling them to comprehend a given phenomenon—in our case, explanations (Kulesza et al., 2013). Depending on the domain, this mental repository may house decision-related information, such as genre and actor preferences in a movie streaming platform. It may also encompass preferences for explanation content, presentation, and complexity level, ensuring alignment with user preferences and cognitive ability. This mental reservoir often contains tacit knowledge, derived from user interactions and contextual cues (Schneider & Handali, 2019). Determining what to explicitly collect and what to infer from interactions is a delicate decision entrusted to system designers.
The European Commission Ethics Guidelines for Trustworthy AI (Smuha, 2019) advocate for more lawful AI technology that is also more inclusive. Inclusion is defined as“the process of proactively involving and representing humans with diverse attributes; those who are impacted by, and have an impact on, the AI ecosystem context” (Girard et al., 2024). Tielman et al. (2024), for instance, discussed the importance of the ability to process and express explanations to stakeholders, including those with specific and atypical characteristics such as cognitive disabilities. Hearing impairments, visual impairments, neurodiversity and other diverse aspects including language, culture, gender, and age are also important when designing for inclusivity (Arfini et al., 2023) and those considerations should also be applied to explanations with the aim of more inclusive, accessible and user-centered XAI. Context can pinpoint the mental model of the users and their comprehension level based on their identity, paving the way for the XAI system to adapt explanations accordingly.
Cognitive Context: Navigating the User’s World
The cognitive context presents a dynamic panorama of the user’s worldview, further categorized into two dimensions: Situational and historical.
Situational cognitive context captures the immediate context of the user and their environment during an interaction. This encompasses emotions, the user’s companions, and real-world elements such as date, time, and weather. This contextual layer enriches explanations by incorporating relevant information or adjusting tone based on the user’s current state. For instance, an e-commerce platform recommending Halloween chocolates may acknowledge the holiday, tailoring the explanation accordingly. For example, the generated explanation can contain a contextual statement that these chocolates are perfect for “trick or treating.”
Historical cognitive context delves into past interactions, forming the backdrop against which the current interaction unfolds. It also can include situational details from previous encounters. For example, a user’s 5-star rating of “Home Alone” on Christmas Eve informs their present interaction with insights into expected behavior. Stakeholder preferences may also be inferred from this historical repository, enabling personalized tailoring. The duration of historical context retention is a decision left to system designers, with recent interactions holding more weight than distant ones.
Conclusion: A Comprehensive Taxonomy of Context
As we navigate this conceptual framework, we encounter the intricate interplay of static and dynamic context, each playing a unique role in the realm of context-sensitive explainability. The static context includes factual information like domain knowledge and system information. While dynamic context contains the stakeholder model in terms of identification and mental model. This part is concerned with the stakeholder identity and decision information. Dynamic context also holds situational and historical cognitive context which represents the user’s and the world’s dynamic state during the time of the interaction and past interactions with the system respectively. It is important to note that not all systems require every facet of this context framework, emphasizing the contextual nature of its application. For instance, non-interactive systems do not require modeling a dynamic context.
Static context represents factual information till the instance of the current interaction. It houses all the knowledge about the domain, the system, and the users. Dynamic context, on the other hand, represents information that characterizes the interaction with the stakeholder involved in the current interaction. The state of some information can be static or dynamic depending on their usage. For example, a user gave a five-star rating to movie X. This piece of information is built due to a dynamic interaction of the user with the system, but after the interaction is finished, it is moved to the static context as a part of the factual information about all the users on that system. Now, this same user is recommended movie Y. During this instance, the stakeholder is the user. His identification and mental model are fetched from the system information. Mental models can include the user’s preferences, for instance. Previous interactions that are only relevant to this specific user are fetched in the shape of historical context to explain, including the rating of movie X. The rating of movie X is now considered a dynamic piece of context since it characterizes the current interaction with the user and would not have been fetched if another user is the stakeholder of that interaction. The situation can include the users’ mood, for instance. Based on all this information, along with factual information about the movies, an explanation can be given using the current context.
This context taxonomy provides a comprehensive framework for understanding and integrating context into explanations, enabling more effective, user-centric AI systems. In the following section, we will introduce “ConEX” a framework that leverages this taxonomy to create context-sensitive explanations.
The ConEX framework
One approach to incorporating contextual knowledge into XAI systems is intrinsic contextualization, where the model is optimized to both solve a task and generate context-sensitive explanations. However, this approach has inherent challenges. It intertwines the contextualization process with the model itself, making it difficult to isolate issues with the explanation process or the contextualization itself. Additionally, optimizing the model for explanation generation can potentially compromise its primary objective–predictive accuracy.
This leads us to an alternative approach, the ConEX framework, illustrated in Figure 2. ConEX offers a general framework for generating context-sensitive explanations while decoupling the model from the explanation generation process, preserving its predictive accuracy. ConEX introduces two distinct modules: (1) A post hoc explainer and (2) a context model, based on the context taxonomy detailed in Section 3. The outputs of these modules are combined to create context-sensitive explanations. ConEX can serve as a guideline for enhancing existing systems with context-sensitive explainability or for designing new XAI systems. Below, we delve into the roles of each module within ConEX.
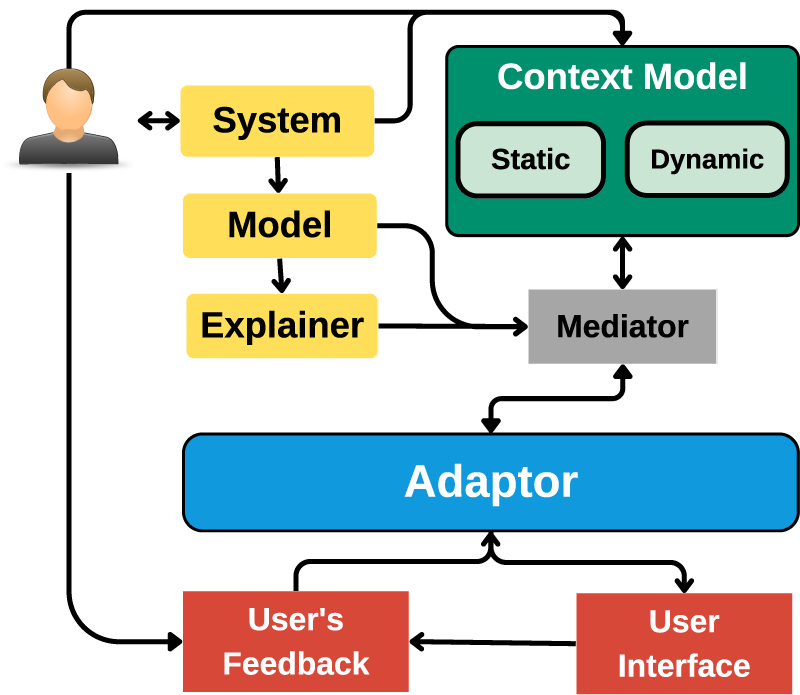
The ConEX Framework.
The AI model is initially trained for a specific task within a specific domain. In our design, the task model’s sole responsibility is to excel at its designated task. It is not burdened with the additional role of explaining its predictions. This separation allows for optimizing the task model for accuracy without compromising explainability. Users expect accurate results, and this design choice ensures that the model is fine-tuned for this purpose.
Explainer
State-of-the-art post hoc explainers have demonstrated their capabilities in approximating task models and elucidating input-output relationships. However, they often lack the ability to adapt explanations to the diverse needs and contexts of various stakeholders (Apicella et al., 2022). In our design, the role of the post hoc explainer is limited to providing fundamental explanations of the task model’s results, focusing on aspects such as feature importance and decision rules. These primitive explanations directly contribute to the prediction and serve as the foundation for the subsequent context-sensitive explanations.
Context Model
The context model is tasked with supplying all relevant contextual information for ongoing interactions, leveraging the context taxonomy presented in Section 3. It should furnish pertinent domain knowledge components, and the expectations of the stakeholders based on their role and their mental models. Furthermore, it should consider the complexity of the explanation presentation and content, tailored to the situational and historical contexts promoting accessibility and inclusivity. In essence, the context model should offer any contextual details that can enhance the understanding of the current interaction, irrespective of the model’s inner workings. However, the context model is not responsible for generating the explanations themselves but rather acts as a knowledge reservoir.
Mediator
The mediator acts as a gateway between the explainer, the context model, and the adaptor. It processes the output from the post hoc explainer and queries the context model to retrieve contextual information about the instance of interest. It then shapes the results to the format expected by the adaptor.
Adaptor
Contextual knowledge plays a crucial role in filtering and determining the relevant information to consider during a given interaction (Brézillon, 1999). Therefore, we contend that excluding irrelevant data from an explanation or supplementing it with external information should not be perceived as misleading. In different contexts, the comprehensive disclosure of the entire decision-making process may prove unnecessary. That is the role of the adaptor module.
The adaptor module plays a pivotal role in creating the final explanation presented to the user. It merges the primitive explanation from the explainer with relevant static and dynamic contexts, following a two-step process: (1) Pragmatic fitting and (2) dynamic fitting. In the first step, the primitive explanation is aligned with domain knowledge. In the second step, the resulting explanation is balanced between complexity and comprehensibility, tailored to the user’s identity, mental model, and situational context, facilitating informed decision-making. The extent of this fitting is highly dependent on the stakeholder requesting the explanation. For developers, they can see the primitive explanations along with all the fitting results to be able to debug the system. However, for lay users, showing irrelevant information can cause mental overload and can lead to losing trust in the system, therefore, fitting the results will match the users’ goals better. The available levels of fitting per stakeholder is a choice to be made by the system designers while ensuring inclusivity and accessibility to various individuals. The generated context-sensitive explanation is then forwarded to the User Interface module for presentation.
The Adaptor is also responsible for verifying the prediction itself. If the primitive explanation does not align with domain knowledge, the adaptor may conclude that the current prediction should be excluded, ensuring that the explanation does not inadvertently mislead the user, especially in the case of lay users, but that might not apply to other stakeholder types who care about identifying system failures.
User Interface and Feedback
The final step involves presenting the explanation to the user and collecting feedback. The User Interface module is responsible for delivering explanations in the format suggested by the Adaptor. It can be in the shape of personalized text templates, images, etc, depending on the users’ cognitive ability and/or preferences. Users can then provide feedback on various aspects of the explanation. This feedback is invaluable for improving the explanation’s alignment with user preferences and needs, ensuring that it effectively serves its purpose.
Feedback not only facilitates explanation refinement but also empowers users by giving them a sense of controllability over the explanation process, ultimately enhancing user satisfaction and trust in AI systems.
An Application: Movie Recommendation
There are various explainable recommender systems algorithms presented in the literature. For instance, there are graph-based models like the ones used in He et al. (2015) and Park et al. (2017). Graphs define relations among information, so they can be useful in representing user–user or user–item or item–item relationships. Relations are constructed for the recommendations and then different aspects are ranked. Afterwards, explanations are given based on the top-ranked aspects concerning the target user and the recommended item. Other models leverage data mining for both recommendations and explanations. For example, the YouTube video recommendation system adopts association rule mining to create associations between pairs of co-watched videos within the same session (Davidson et al., 2010). The explanations in this case are the association rules themselves. Those approaches of explanation are dependent on the model itself, but there exists another set of approaches that work in a post hoc manner.
Post hoc approaches are typically used when it is difficult to incorporate explainability in the model itself (Marconi et al., 2022). Association rules were used in a post hoc manner for justifying recommendations by Peake and Wang (2018). The problem with this approach is that the explanations might not be faithful to the recommendation model itself even though they are reasonably aligned with the recommendation. Surrogate models were also used for post hoc explainability in recommenders. Lime for recommender systems (LIME-RSs) (Nóbrega & Marinho, 2019) is a model-agnostic local post hoc surrogate-model-based explainer that outputs feature importance as an explanation for the recommendation. Verma et al. (2022) stressed on the point that the field of recommender systems does lack post hoc explainers, whilst the need for post hoc explainers in such a domain is high. This is because the already existing recommenders should not be retrained just to incorporate explainability and thereby post hoc explanability is the way to go.
The problem with the reviewed models is context ignorance whether in terms of the user or the domain and thus some explanations might appear irrelevant to the current context. Therefore in our work, we attempt to contextualize LIME-RS explanations using the context model that we will propose. We chose LIME-RS since it is open-source.
In this section, we unveil our movie recommendation prototype, developed following the design guidelines of ConEX to create context-sensitive explanations, as depicted in Figure 3.
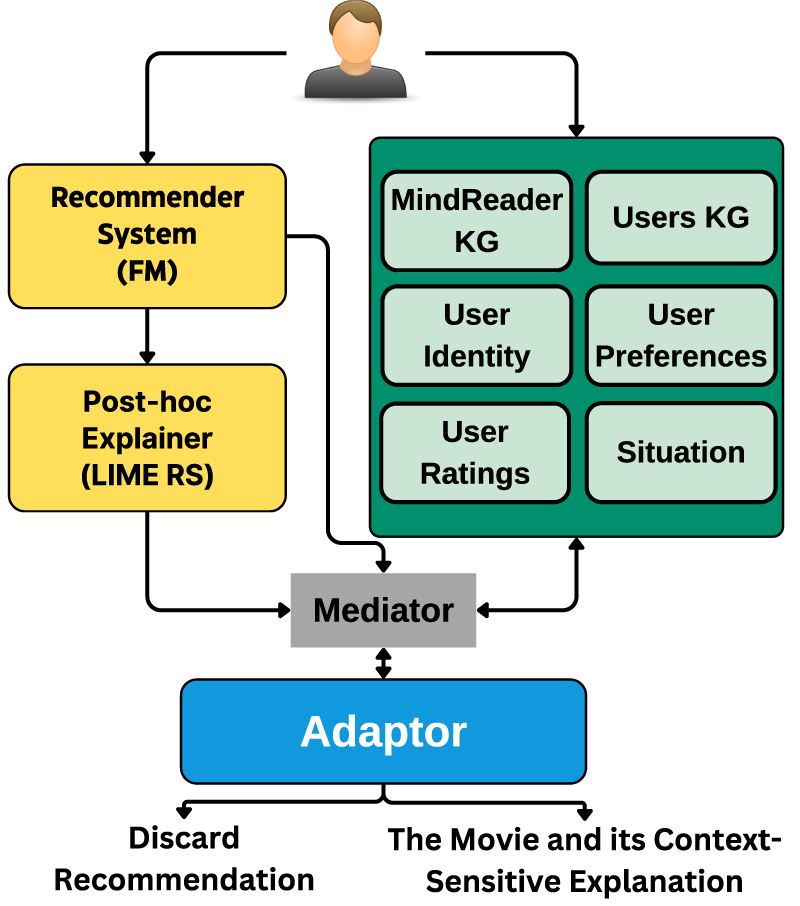
ConEx Prototype in Movie Recommendation.
The first two blocks are the task model, which is a recommender system responsible for creating the predictions, and the post hoc explainer used to extract primitive explanations about the recommended instance.
Recommender System
Factorization machines (FMs) (Rendle, 2010) were used as the recommender system in our prototype. FM models sparse pairwise interactions between all possible pairs of available features. The base features are binary vectors of user and movie indicators, such that each training sample has two non-zero entries corresponding to a given user-movie interaction which we extended with movie genre features. We trained the model using pyFM lib with 50 latent factors and using 10 iterations as the stop criteria. The other parameters are set to the default values following Nóbrega and Marinho (2019) experiment.
The model was trained on the well-known MovieLens 1M dataset, which consists of user ratings made on a 5-star scale for movies (Harper & Konstan, 2015). The dataset also contains some movie information, such as titles and movie genres. In addition to demographic data about the users such as gender, age range, etc. The ratings were filtered by the interaction frequency of the users such that users with at least 200 interactions were considered. The resulting data was split chronologically (based on the timestamp of the rating) into 70% training and 30% testing. We assumed that relevant movies were those rated 3.5 or above.
To measure the accuracy of the recommender, we first calculated percision@10. Precision at
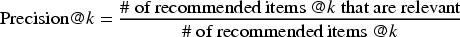
We considered an item to be relevant if it has a true rating
Moreover, we calculated recall@10. Recall at k is the proportion of relevant items found in the top-k recommendations as defined in equation ??. Therefore to calculate recall@10, we retrieved the number of recommended items @10 that are relevant the same way we did it for percision@10 for each user. Then, we divided that number by the total number of relevant items in the test dataset per user. Afterwards, we calculated the average recall@10 using the equation below:
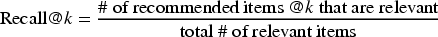
Finally, we calculated the root mean squared error (RMSE) defined below:
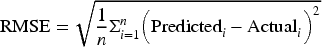
The results of precision@10, recall@10, and RMSE can be seen in Table 1.
Factorization Machine (FM) Results with Genre Features.

Factorization Machine (FM) Results with Genre Features.
FM: factorization machine; RMSE: root mean squared error.
(Nóbrega & Marinho, 2019) was chosen as the post hoc explainer. LIME-RS is a local post hoc explainer designed to output feature-based explanations for recommendations. It follows from the concept of LIME (Ribeiro et al., 2016). Unlike LIME, LIME-RS does not perturb data points. This is because training data is represented by binary feature vectors. Thereby, permutations will lead to spurious data that can never occur in reality. To overcome that, LIME-RS generate samples by fixing the user and sampling movies according to their empirical distribution. Afterwards, a ridge regression model
1
is trained on the data outputting the top-n most important features as explanations. We chose
In order to measure the faithfulness of the ridge regression model with respect to the recommender, we used the Model Fidelity metric (Peake & Wang, 2018). Fidelity is defined as the fraction of data samples for which a predictive model and an explainer make the same decision (Nauta et al., 2022), in our case, recommending or not recommending a movie to a user. We used the fidelity metric to get an estimate of how well can LIME-RS approximate the recommender.
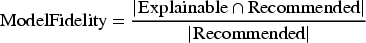
To measure the global fidelity of the ridge regression model, we used the same procedure in Nóbrega and Marinho (2019) and that is to train it on the top 30 predictions for each user from a list of predictions for all items. The average global fidelity of our ridge regression model was 0.429. This means that the interpretable model can retrieve 42.9% of items. In the original work of LIME-RS (Nóbrega & Marinho, 2019), the global fidelity score was 0.522 which is comparable to our results given that their recommender was trained on more data. These results indicate that the explainer can be further improved but by using our proposed context model a robust explanation can still be made as will be discussed in the following section.
Context Model
As shown in the previous results there is room for improvement in both the recommender’s accuracy and the explainer’s fidelity. However, using the context model, the recommendations and the explanations can still be grounded in their correct context. Below we will describe how the context model was built for this prototype based on the proposed taxonomy in Section 3.
Static Context
In the static context, we leverage KGs to represent domain knowledge and user-system information. KGs offer rich semantic information, enabling a comprehensive understanding of hierarchical data and facilitating data interpretation.
We chose KGs to represent this part of the context. That is because of the rich semantics KGs hold by representing entities and their relationships with other entities. This helps provide a comprehensive view of hierarchical information and thus improves data interpretation. On top of that, KGs facilitate inference and reasoning of data to validate existing knowledge and discover new insights and relationships. Movies’ information represented the domain knowledge part of the static context while users’ connections represented system information.
Domain Knowledge
The MindReader KG (Brams et al., 2020) steps in as our source of movie-related entities, from movies and actors to directors and genres. It’s the brain behind understanding everything about movies. MindReader KG consists of 18,133 movie-related entities that were built using a subset of 9000 movies from the MovieLens dataset, which was good enough to run our prototype. Entities include
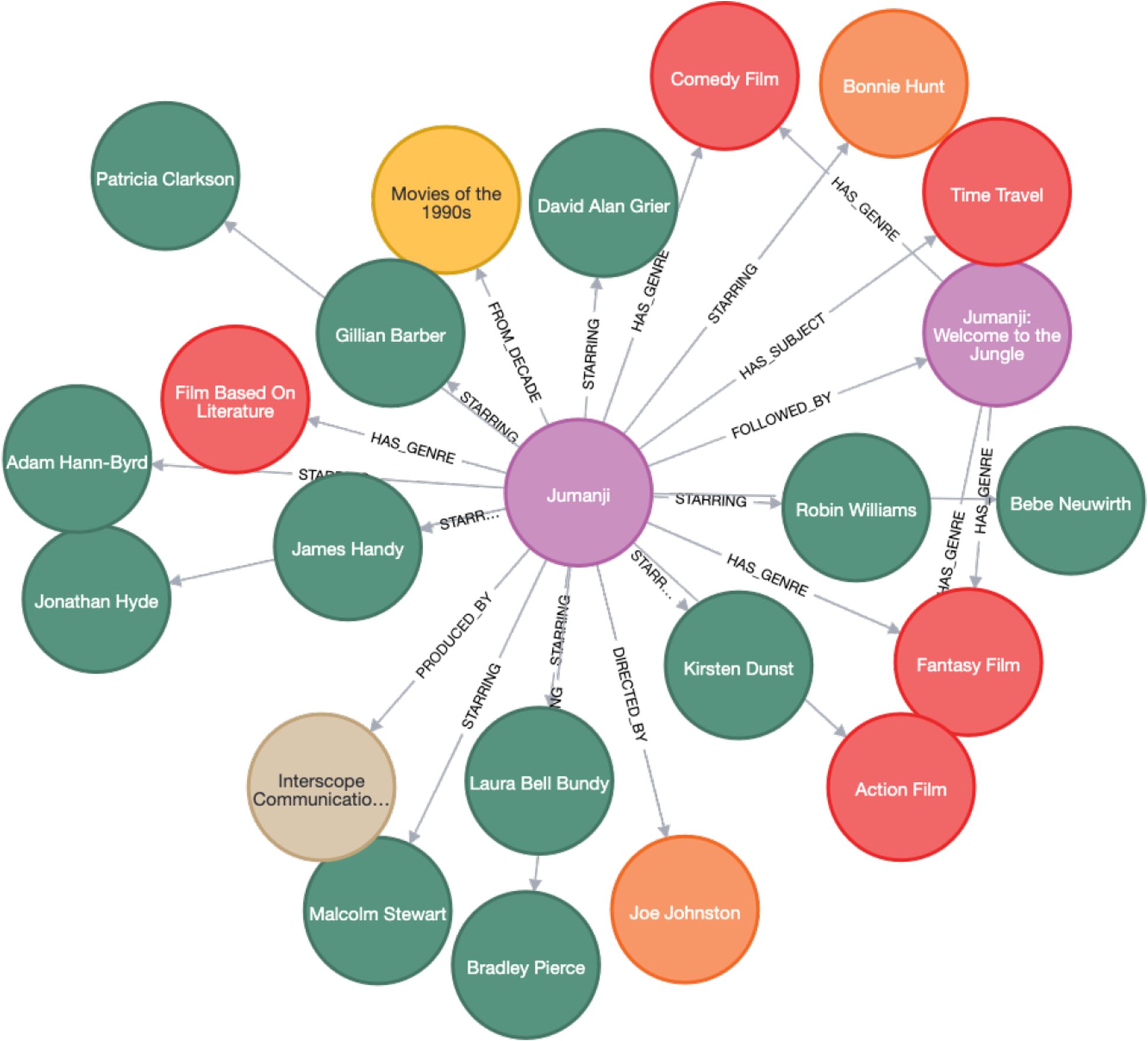
MindReader Example.
System Information
User connections and demographic data come alive in the form of a knowledge graph, offering a glimpse into user attributes. It’s the heart of our system, understanding the user an individual. To represent the users’ connections, we used the demographic data CSV file provided in MovieLens 1M, and created a knowledge graph from it using GraphXR. Entities include
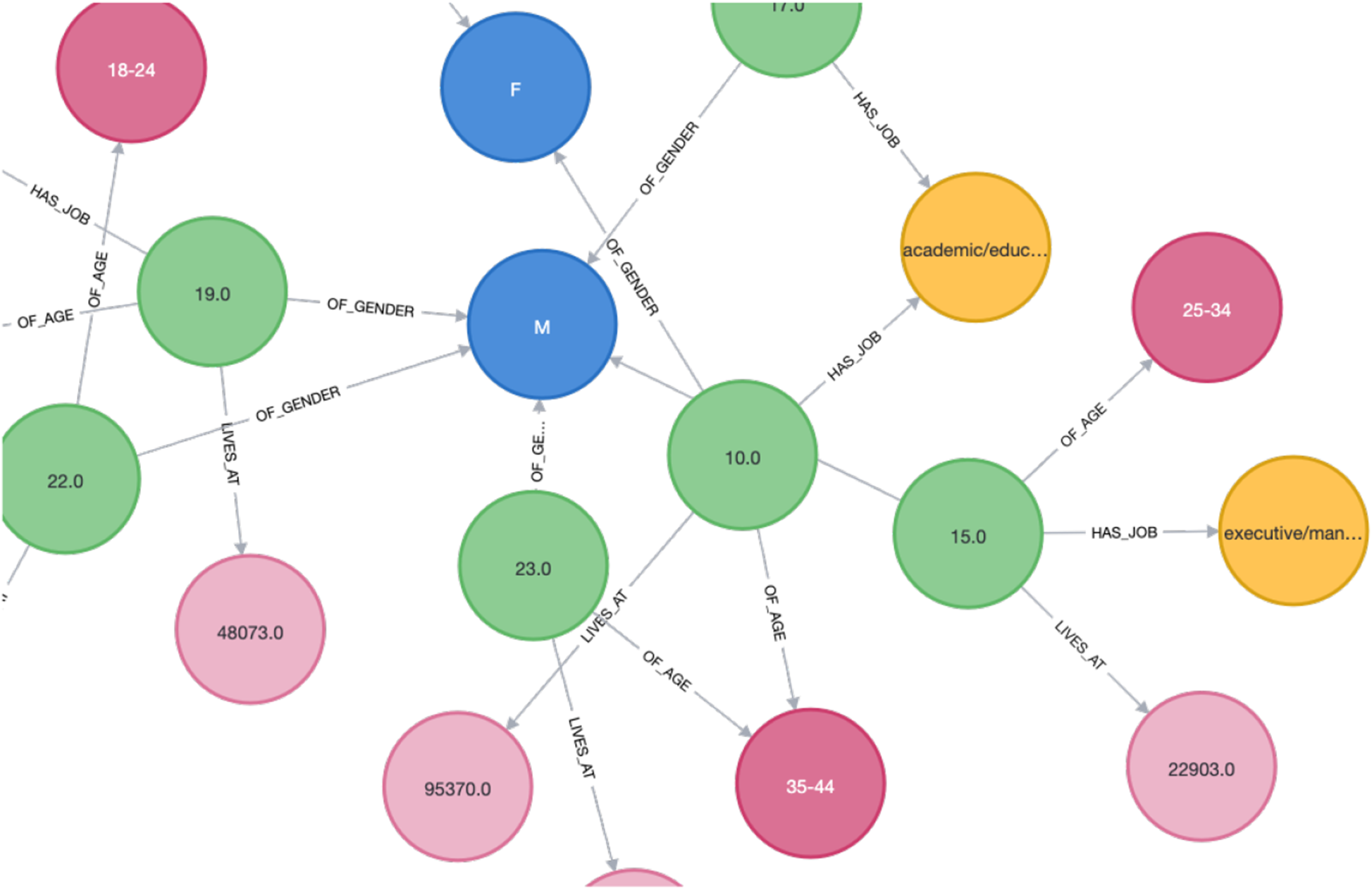
Example of Users Knowledge Graph.
Each part of the dynamic context is represented differently. We will discuss below what we included in each layer.
Cognitive Context
As previously discussed, cognitive context is mainly concerned with two aspects: Situational and historical contexts. The situational context represents the current state of affairs making sure that the explanation perfectly timed and aligned with your situation. The historical context, on the other hand, is a stroll along memory lane making sure the user gets the recommendations and explanations you generally prefer according to your recorded history.
For situational context, we chose three situational factors that a user can typically provide during the interaction: Mood, company (alone or watching with others), and time of Day. Mood can include happy, sad, angry, and neutral. Company can include partner, family, and alone. Time of day is either in the morning or at night. During the testing phase of the prototype combinations of different situations were randomized and passed to the system.
We set the historical context of a user to be all his ratings of movies in the training dataset. And since Movielens does not contain any situational data accompanying the ratings, the historical context is concluded in a set of
Stakeholder Model
Not all users are the same. For this reason, we create a stakeholder model. First of all, the Identification dimension helps distinguish between different types of users to output explanations according to their goals. We created a class Person that has two sub-classes. One for lay users with type user, and one for developers with type developer. An attribute ID was added to both sub-classes and extra attributes like age, gender, occupation, and zip code were added to the lay user subclass. This Person class can be further expanded with other stakeholder types. When an explanation is requested, the adaptor identifies the type of the requester and provides explanations accordingly.
Second, in representing the Stakeholder Mental Model, we only considered the mental models of the lay users. We assumed in our prototype that the users’ decision-making (whether to watch a movie or not) depends on the genres and the actors of that movie. Therefore, we represented the mental model of the users according to their genre and actor preferences. Those preferences were derived from the users’ historical cognitive context with respect to their existing highly rated movies. MindReader knowledge graph was also used since it holds the corresponding actors of these movies.
In order to infer the user’s preferences in terms of genres and actors, the following steps are followed:
The user’s historical context was filtered to get the movies rated 4 or above. High ratings were assumed to have a positive correlation with genre and actor preferences. Lists of genres of the filtered movies were retrieved from the Movielens dataset. Then, Frequent pattern-growth (Han et al., 2004) (FP-Growth) was used on the genres lists to mine frequent itemsets of genres. An itemset is considered frequent if it meets a specified support threshold. We set the support threshold to be The actors of the filtered movies were retrieved by querying (using neo4j cypher) the MindReader KG. Then FP-Growth was run on the actors lists with a support threshold of
User 1004 Genre Preference.

User 1004 Actor Preference.

The higher the support the itemset has, the more impact we think it has on the user’s decision. This will help determine which itemset to choose in an explanation to further personalize it and help the user make an informed decision.
Hypothetical explanation content and presentation shape preferences (text or images) were randomly assigned to the lay users’ mental models as well.
As it can be observed, this context model represents a pinnacle of personalization, shaping each movie experience to be as unique as the individual. This diverse context model transcends personalized recommendations; it offers an immersive journey where every choice and explanation can be tailored meticulously to the user’s profile.
After outlining the essential components of the recommender system, post hoc explainer, and the comprehensive context model, we can now illustrate how a context-sensitive explanation unfolds for a specific instance. In this case, we’re focusing on the recommendation of the movie Lethal Weapon 4 for a user, specifically User 1004, whose preferences are listed in Tables 2 and 3.
Generating Primitive Explanations
First of all, the movie Lethal Weapon 4 was recommended to user 1004. The recommendation is forwarded to LIME-RS which generates a primitive feature importance explanation that includes the positive and negative attribution values of all the genres present in the training data as seen in Figure 6. LIME-RS treats all the genres as features and thus the explanations engulf all the genres’ importance not only the movie-related ones. Therefore, there will exist genres that are not associated with the movie being explained since the input includes the user and that is a limitation in LIME-RS (Nóbrega & Marinho, 2019).

Primitive Explanation of Movie Lethal Weapon 4 Recommended for User 1004.
In Figure 6, it can be observed that the top positive genre is Film-Noir. However, it is interesting to note that this genre is not present in the genres of the movie Lethal Weapon 4. Upon running LIME-RS on all records of the testing dataset, we discovered that in 88.4% of the cases, the highest positive genre predicted by LIME-RS did not match the genres of the corresponding movie record. This is because LIME-RS does not consider context and treats all genres as separate features. Developers might not have an issue with the highest positive genre being displayed as an explanation, as it could offer valuable insights about the recommender. However, if this genre is shown as an explanation to a lay user, it might not be meaningful since this particular genre might not even exist in the movie. Therefore, it’s crucial to contextualize the primitive explanation to make it comprehensible to the lay user.
When generating context-sensitive explanations, two vital elements demand attention: The movie itself and the user. Through the mediator, we retrieve various context pieces, which encompass:
Movie Lethal Weapon 4 genres: Comedy, Crime, Action, and Drama. Movie Lethal Weapon 4 actors which are retrieved from MindReader KG: Mel Gibson, Danny Glover, Mary Ellen Trainor, etc. User 1004 identification. Type: Lay user, age: 25–34, gender: Male, occupation: Clerical/admin, zip-code: 95136. User 1004 genre and actor preferences from the user’s mental model: Presented in Tables 2 and 3. User 1004 preferred explanation content and presentation shape from the user’s mental model: Level 2—Image (this means the user prefers explanations displayed as images). User 1004 randomized current situation: (Sad, With Partner, In the Morning).
The mediator converts the data types of the primitive explanation and the context data to the ones expected by the adaptor. Subsequently, the adaptor takes the reins in crafting the ultimate context-sensitive explanation, using a three-level approach, with each level building upon the preceding one.
Level 1: Pragmatic Fitting
The first level of contextualization, known as Pragmatic Alignment involves aligning the primitive explanation with the domain knowledge. In this instance, the domain knowledge relates is the actual movie genres that were previously gathered through the mediator. This involves the following steps:

Pragmatic Fitting of Movie Lethal Weapon 4.
The outcome of this step consists of genres that contributed positively to the recommendation, according to LIME-RS, and align with the movie’s actual genre. These genres form the foundation for presenting explanations that directly link the recommendation to these genres. For instance, we can choose the highest attributing genre to explain, as shown in Figure 8.

Pragmatically Fit Explanation of Movie Lethal Weapon 4.
Level 2: Dynamic Fitting without Situational Context
At the second level of contextualization, the goal is to enrich the pragmatic alignment outcome with additional user-related context information, excluding situational context. The explanation aims to guide the user’s decision on whether to watch the movie, hence it must resonate with their decision-making process. Thus, out of the pragmatically fit result, we choose the genre with the highest expected positive impact on the user’s decisions. This is achieved through the following steps:
Filtering out genres present in the user’s preferences, as detailed in Table 2, from the pragmatic fitting results shown in Figure 7. The genre Drama is filtered out since it does not exist in the user’s preference as seen in Figure 9. The remaining genres after this step hold positive attribution according to LIME-RS and exist in both the pragmatic context and the user’s mental model. Aggregating the attribution of the filtered genres with the support these genres have in the user’s genre preferences from Table 2. Selecting the genre with the highest expected positive impact on the user’s decisions, which, in this instance, is Action.

Dynamic Fitting of Movie Lethal Weapon 4 for User 1004.
Even though the genre Comedy was the highest attributing genre in the pragmatically fit result, the genre Action was chosen since it holds a higher impact on the user’s preferences. And since genre Action did have a positive attribution in the pragmatically fit result, choosing it over the genre Comedy is not obscuring the truth of the recommendation reason but rather choosing the highest relevant piece of information to the user.
It can now be observed that the process of dynamic fitting emphasizes genre alignment with user preferences, providing a genre-based explanation that not only resonates with the actual reason for the recommendation (shown in the previous explanation) but is also personalized to the user. The resulting explanation is detailed in Figure 10.

Dynamically Fit Explanation of Movie Lethal Weapon 4 for User 1004 with Respect to his Mental Model.
To further personalize the explanation, extra information that wasn’t included in the training of the recommender can be fetched from the context and used to enrich the dynamically fit explanation as seen in Figure 11. Lethal Weapon 4 actors, fetched in section 5.3.2, are matched against the user’s actor preferences in Table 3. Both actors Mel Gibson and Mary Ellen Trainor result from this intersection. Since Mary Ellen Trainor has a higher support value, she was chosen to further support the genre explanation

Extra Information to Support the Explanation Shown in Figure 10.
Moreover, extra insights about similar users can be inferred from the System information. For instance, the percentage of the users of the same age group as user 1004 who highly rated movie Lethal Weapon 4 can be calculated and shown to the user. This external knowledge augments the explanation, bringing it closer to the user’s context and facilitating a more informed decision about whether to watch the movie or not.
Level 3: Incorporating Situation
The third and final level focuses on contextualizing the outcome of Level 2 with situational information. The user, either manually or automatically, inputs their current state when requesting an explanation. For testing purposes, we employed randomized user states, involving mood, company, and time of day.
The aim of including the user’s situation is to be able to further personalize the interaction. The resulting genre and actor (if exists) from Level 2 are used as the base information in this level. The situation can then be used to create different paragraphs of explanations each with different tones and information to match the user’s current state.
To achieve this, we used DeepAI text generator API. DeepAI text generator API is backed by a large-scale unsupervised language model that can generate paragraphs of text. It is a transformer-based LLM, which intakes a sentence or partial sentence and predicts subsequent text from that input. Below is an ideal prompt passed to the API:
Thus, the explanation of Lethal weapon 4 for user 1004 should include genre Action and actress Mary Ellen Trainer. Using the state of the user 1004 which is (Sad, With Partner, In the Morning), the API outputs a result like the one shown in Figure 12.

DeepAI API Result Example.
The final step entails presenting the explanation to the user and gathering their feedback. In our prototype, user feedback was not collected, but this component can be seamlessly implemented in real systems. For illustration purposes, suppose that User 1004 prefers Level 2 contextualization with image shape presentation. Therefore, the information derived from Level 2 can be shown as in Figure 13.
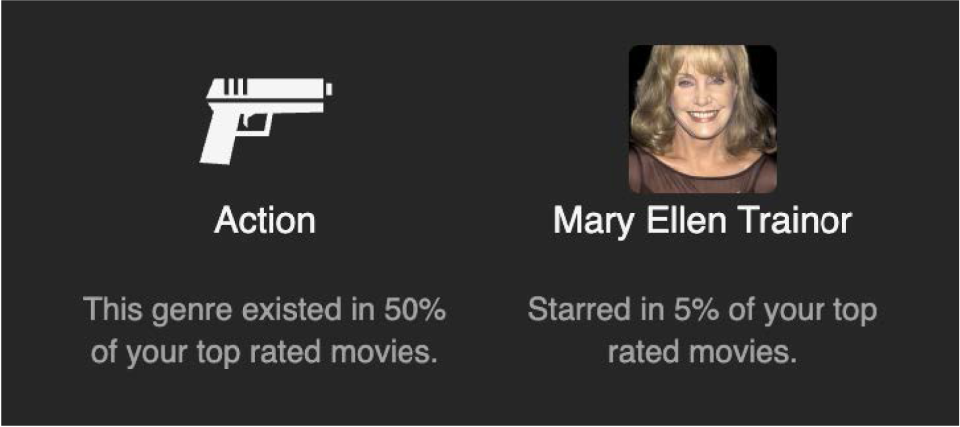
Image Presentation Shape for Level 2 Contextualization Result of Movie Lethal Weapon 4 to User 1004.
Real users can be given the option to select their preferred level of contextualization, content, and presentation format for explanations. The feedback collected from users can then be utilized to understand their preferences, fine-tuning the explanation style to better match their expectations.
For developers seeking explanations to debug recommendation instances, the prototype logs the primitive explanation, along with all the results from each level of contextualization. This comprehensive log allows developers to dissect the process and pinpoint areas for system optimization.
By tailoring explanations to both lay users and developers, our system offers a versatile and adaptable approach to provide context-sensitive insights that cater to the specific needs of each user type. The stakeholder model keeps track of the information needed to personalize an explanation and can be expanded with extra stakeholder types. Personalizing explanations ensures their alignment with the user’s purpose, level of comprehension, and decision-making information, thus gaining the optimal benefit from the explanation.
It is worth pointing out that, within the contextualization process especially at Level 1 discussed in 5.3.3, there are scenarios in which no genres present in the movie have a positive attribution in the primitive explanation. In such cases, it is prudent to consider excluding the recommendation and not presenting it to the user. The rationale behind this is that attempting to offer an explanation would result in a misaligned, misleading explanation due to the negative attributions.
Another potential situation arises when a user specifically prefers Level 2 contextualization discussed in 5.3.3, but none of the genres pragmatically aligned with the movie match the user’s genre preferences. In such instances, the recommendation can either be omitted or, alternatively, be explained using level 1 contextualization.
In essence, the role of the adaptor goes beyond contextualization; it also serves as a truth-checker, filtering out explanations that may lack coherence and, in doing so, enhances the reliability and trustworthiness of the system.
Empirical User Study
In this paper, we hypothesized that diverse stakeholders require tailored explanations to address the same problem. Moreover, we posited that individuals within the same stakeholder category particularly lay users, prioritize distinct facets of an explanation. Lay users, as a notably heterogeneous stakeholder group, were expected to hold varying preferences regarding different levels of contextualization. To substantiate our theory, we conducted an empirical user study that investigated:
Curiosity: Why would a user ask for explanations when recommended a movie? Explanation Satisfaction: The perspective of lay users on contextualization levels 1, 2, and 3 for different aspects of satisfaction. Explanation Trust: The preferences of lay users regarding contextualization levels 1, 2, and 3 concerning different dimensions of trust. Explanation Controllability: The view of the users on having control over explanation content and shape.
A total of 136 participants of different ages and technical backgrounds filled out our survey. Figure 14(a) shows the participants’ age groups. The dominating age group was from 18–24 representing 80.1% of the total participants. This is due to the fact that the survey was spread out using the university portals and through social media. The participants were asked to rank their level of experience in AI development and the results are shown in Figure 14(b). The reason for requesting this information is to align it with the participants’ choice of curiosity motive which will be discussed later on.
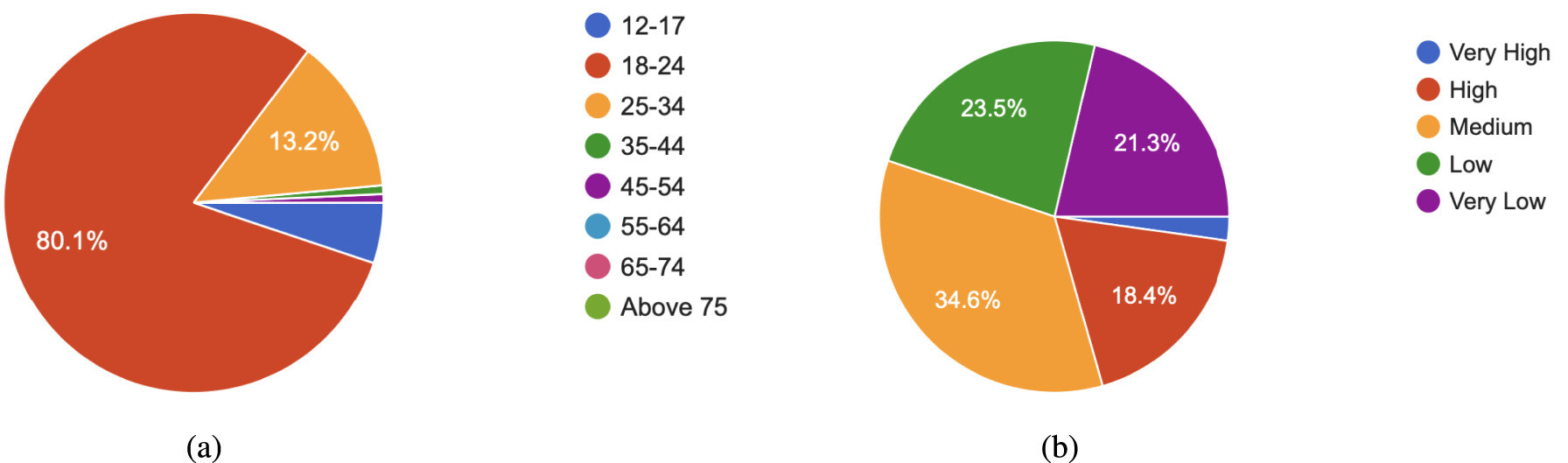
Participants’ Age Groups and Artificial Intelligence (AI) Development Level of Experience. (a) Participants’ Age Groups and (b) Participants AI Development Level of Experience.
Curiosity could be an important factor in why people seek explanations in the first place (Hoffman et al., 2018). On a movie recommendation platform, explanation curiosity can be triggered by different factors including the desire to learn more about a movie or knowing the mere reason for the recommendation in case it matches or mismatches the user’s expectations. Talking from the point of view of lay users, we expect that only a few will ask for an explanation because they are interested in the recommender’s behavior. Those might have a related background in system development but they are not classified as developers since they are not the ones responsible for maintaining the system.
Curiosity can actually encourage the behavior of using explanations in making a decision when such an explanation is known to match the user’s goal. If a user requests an explanation about a recommendation and the explanation contains all the details the user expected to see, then the user will be more willing to rely on such explanations to make future decisions. that is the user will be curious about what will the explanation provide in the next interaction. Thus, this will increase the percentage of the user’s engagement which can be translated to financial profits afterwards. However, if an explanation contains more details than needed by the users, or for instance complicated terms that can overwhelm the user, the user might actually lose interest in using explanations to make a decision and this might lead to a lower engagement rate with the system since the user will not be provided by aspects that might encourage him to watch a recommended movie.
We wanted to test two hypotheses in this section and those are :
We asked the participants to
I want to decide whether to watch the movie or not. I want to know the reason for the recommendation I got. I want to understand the recommender’s behavior better.
Those three reasons were enough to understand what users expect to see in an explanation. The first reason indicates that the user merely needs more information about the movie. The second reason shows that the user is interested in why was this specific movie recommended to him which indicates his interest in understanding its relation with his previous interactions with the system. The third reason shows that the user is not a typical lay user but someone with a higher knowledge about recommender systems and in this case he is trying to figure out the recommender’s behavior to either validate it or debug it. Our main assumption in proposing the idea of creating different explanation shapes was that different users possess different goals for using an explanation and this factor was measured using the curiosity motives. The insights from this section are shown in Figure 15.
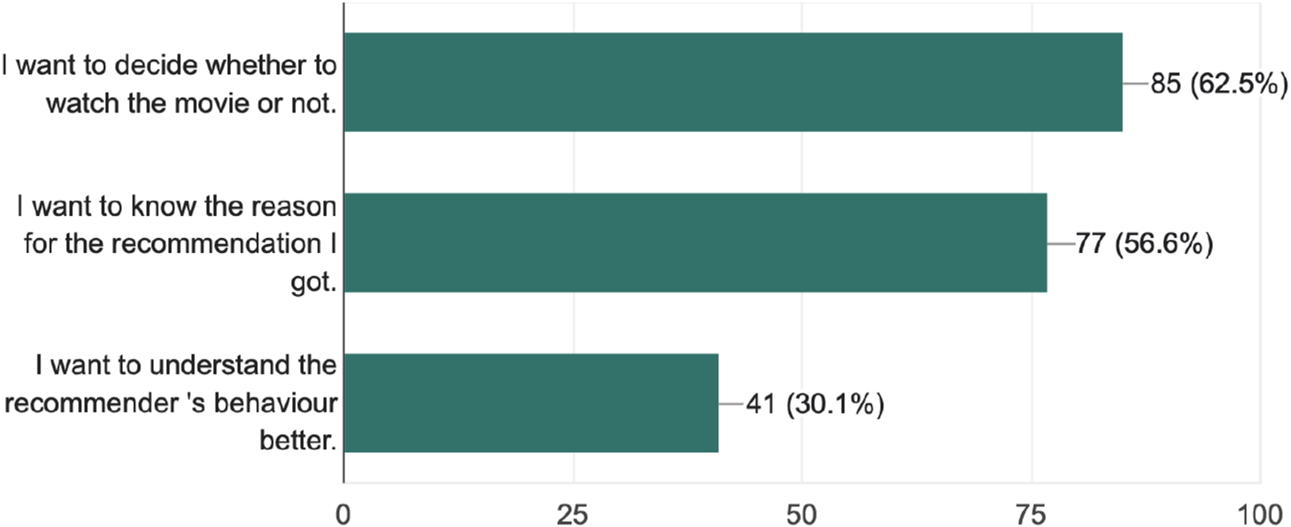
Curiosity Responses.
The results demonstrate that lay users mostly pursue explanations to decide whether to watch the recommended movie or not. However,
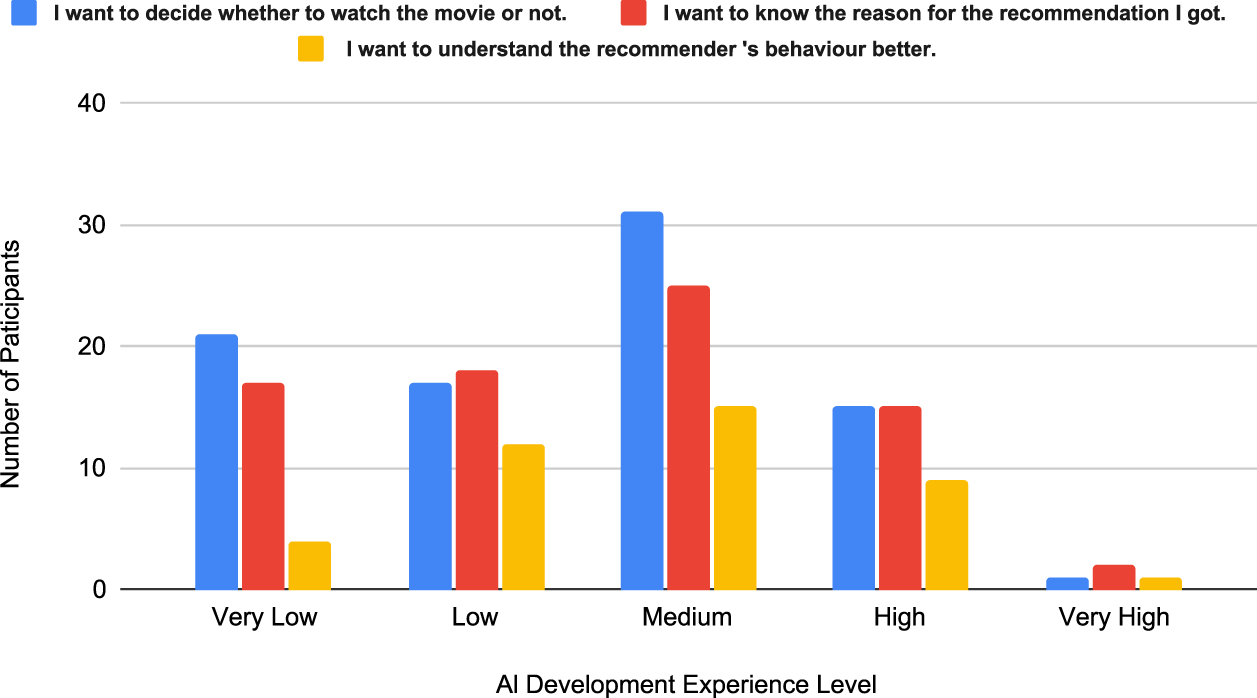
Curiosity Responses with Respect to Artificial Intelligence (AI) Development Experience Level.
Following the curiosity motives, the participants were presented with a sample screen of explanations of levels 1,2, and 3 of the same movie before asking about each explanation level individually. Levels 1, 2, and 3 were denoted by Explanation A, B, and C respectively which can be seen in Appendix 10. The main goal of this screen is to reduce anchoring bias. Anchoring bias emerges from the tendency to focus on the first piece of information learnt and use it to measure later pieces of information (Azzopardi, 2021).
After the sample screen, a section for each explanation level was shown to the user with extra examples (check Appendix 11) and an introduction outlining how each explanation was generated by our prototype. The main goal of each section was to measure the participant satisfaction with each explanation level individually. Thus, for each explanation level, the same five questions were presented to the participants and those are:
The explanation is understandable. The explanation is satisfying. The explanation has sufficient detail. The explanation is useful to my goals. (The ones you chose in the curiosity measures above). The explanation convinces me to rely on the system.
Each question was formulated as a five-point Likert scale in which 1 indicates strongly disagree and 5 indicates strongly agree. Those questions were adapted from Hoffman et al. (2018).
There were three hypotheses we wanted to test in this section and those are:
Figure 17 shows that the majority of the participants perceived Explanation A as understandable, however, regarding the other 4 aspects their satisfaction levels were low leading to an overall satisfaction mean of 2.3. The overall mean satisfaction was measured by getting the mean of the 5 questions per response and getting the mean of all the means of the responses per Explanation level.
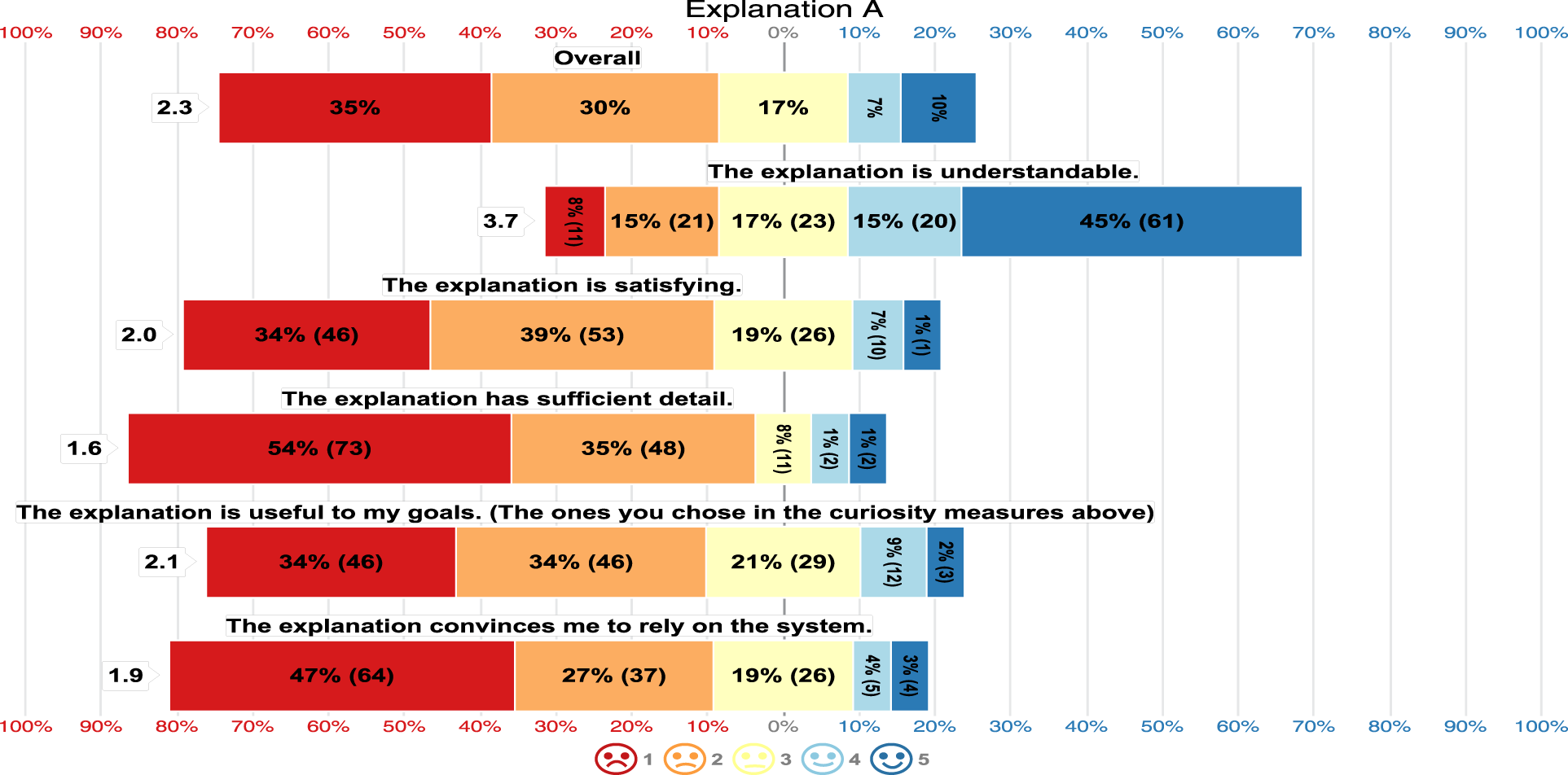
Explanation A Satisfaction.
As for Explanations B and C, the majority highly rated the five aspects of satisfaction as seen in Figure 18 and Figure 19. Explanation B had an overall mean satisfaction of 3.9, while Explanation C had an overall mean satisfaction of 4.2. This indicates that Explanation C exhibits the highest satisfaction rate while Explanation A provides the lowest. Thus
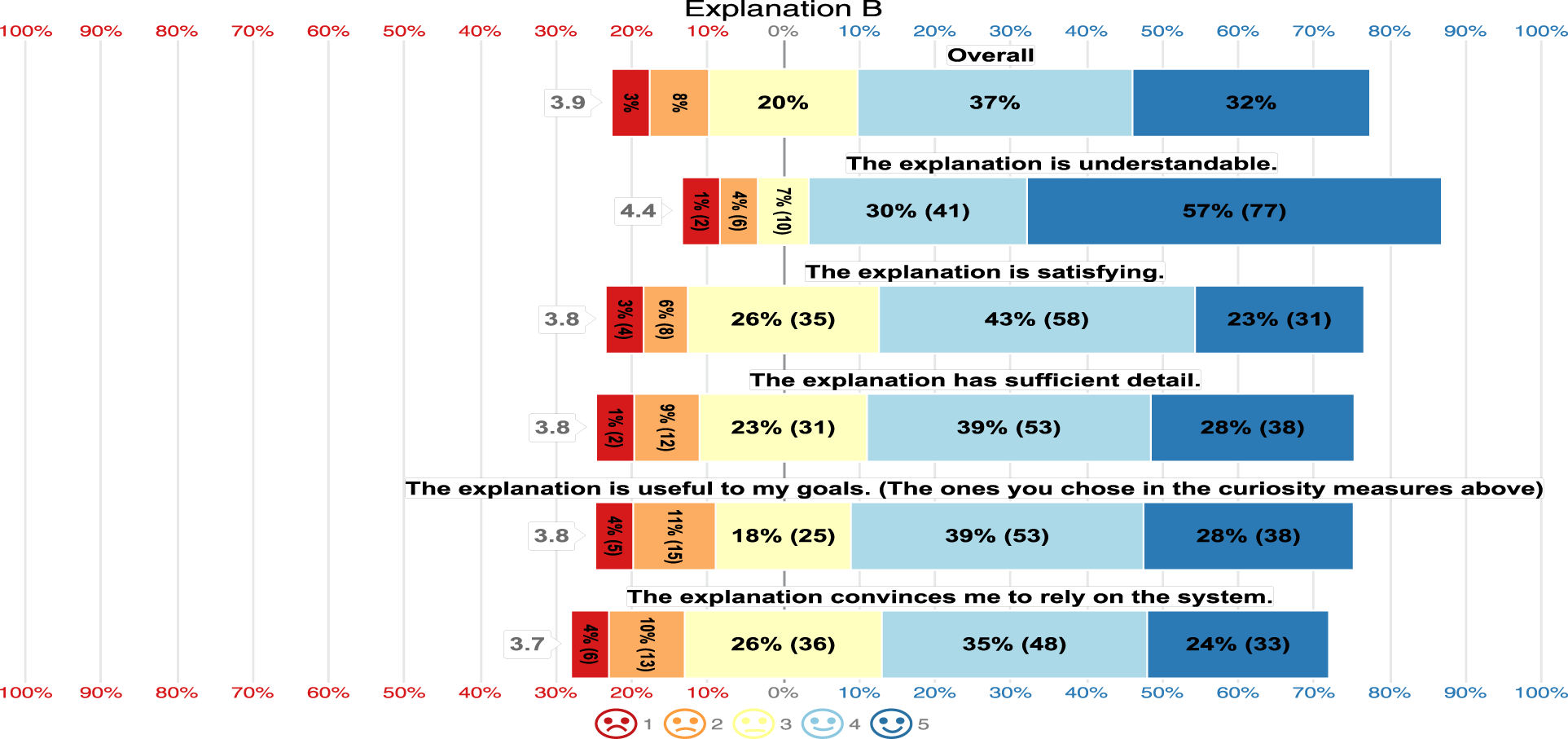
Explanation B Satisfaction.
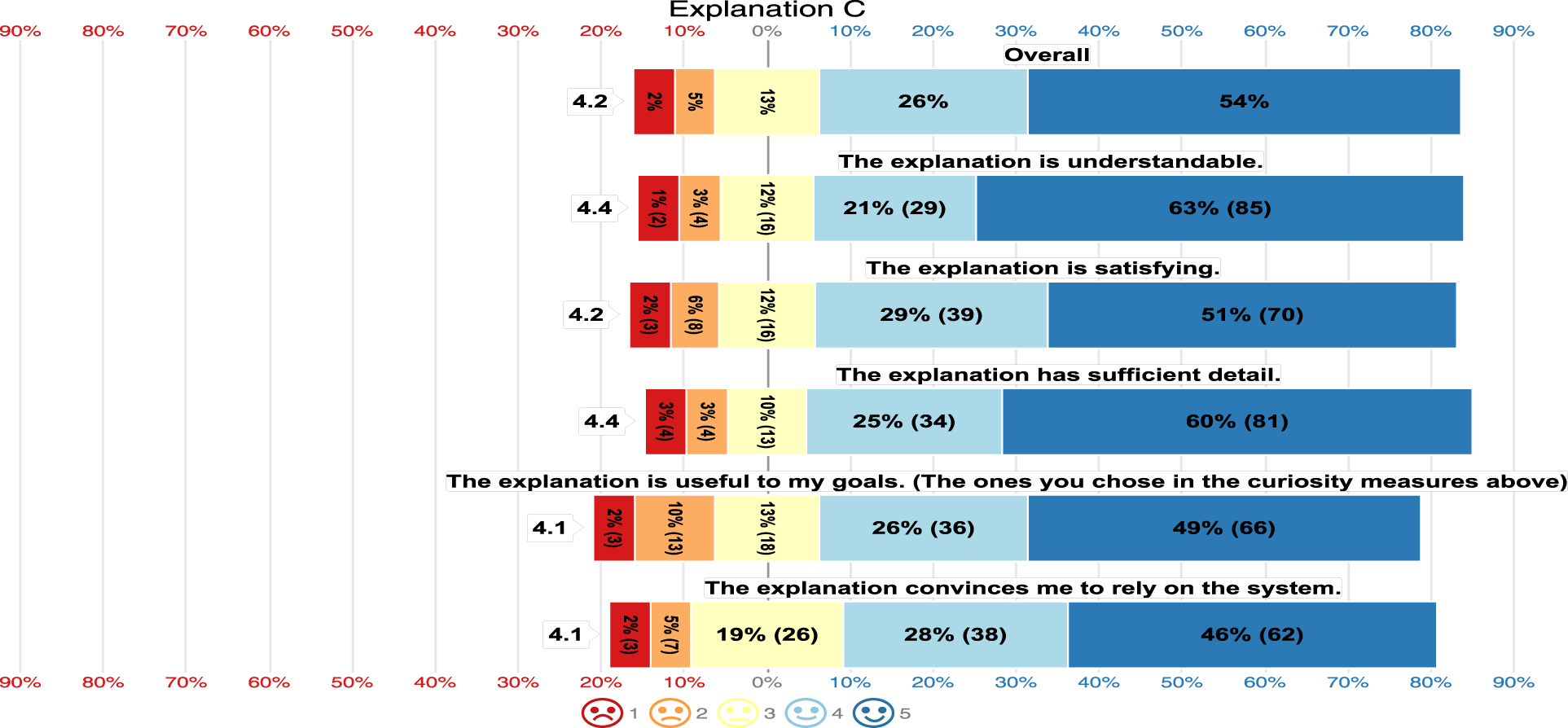
Explanation C Satisfaction.
We computed three new variables ASAT (explanation A satisfaction), BSAT (explanation B satisfaction), and CSAT (explanation C satisfaction) which represent the overall mean satisfaction per response for Explanations A, B, and C respectively. In other words, we computed the average of the five satisfaction questions per explanation type per response in new variables ASAT, BSAT, and CSAT. Table 4 shows the percentiles of the three explanations. It can be seen that the overall satisfaction median of CSAT is the highest while ASAT is the lowest.
Explanation A, B, and C Satisfaction Median Percentile.
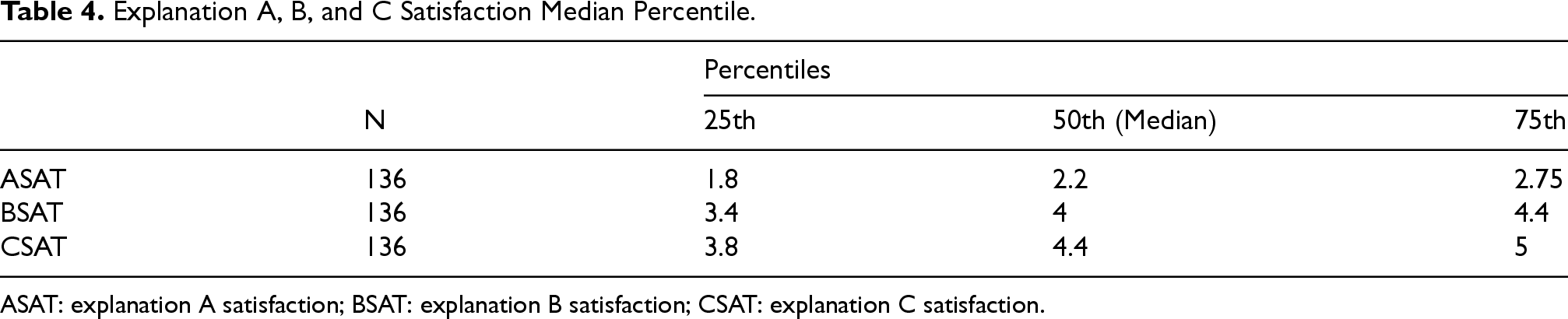
Explanation A, B, and C Satisfaction Median Percentile.
ASAT: explanation A satisfaction; BSAT: explanation B satisfaction; CSAT: explanation C satisfaction.
In order to measure the significance of satisfaction change between Explanations A, B and C, we conducted the Friedman Test (Friedman, 1937) on ASAT, BSAT, and CSAT. There was a statistically significant difference in satisfaction depending on the Explanation level,
Post hoc analysis with Wilcoxon signed-rank tests (Wilcoxon, 1945) was conducted afterwards with a Bonferroni correction (Bonferroni, 1936) applied, resulting in a significance level set at
Wilcoxon Signed-rank Tests Results.

The results indicate that there is a large increase in satisfaction when explanation B or C is used instead of explanation A. Furthermore, there is a small yet significant increase in satisfaction when using explanation C instead of B, which overall supports
The dimensions of trust were adapted from the work of Berkovsky et al. (2017), originally designed for assessing trust in various recommender systems. We rephrased these dimensions to pertain to explanations, as illustrated below:
We wanted to test
The results are depicted in Figure 20. Notably, Explanation A received the least favorability across all trust dimensions, suggesting a general preference for more personalized explanations. Explanation B received the highest scores in the dimensions of Integrity, Transparency, and Overall trustworthiness. This indicates that participants preferred personalized, quantitatively structured explanations when seeking to comprehend the recommender system’s behavior or establish trust in it. On the other hand, Explanation C scored highest in the dimensions of Competence, Benevolence, and Re-use, implying that the use of the DeepAI API enriched explanations with additional movie-related information and made them more adaptable to user interests, increasing the likelihood of being selected for choosing a movie to watch.
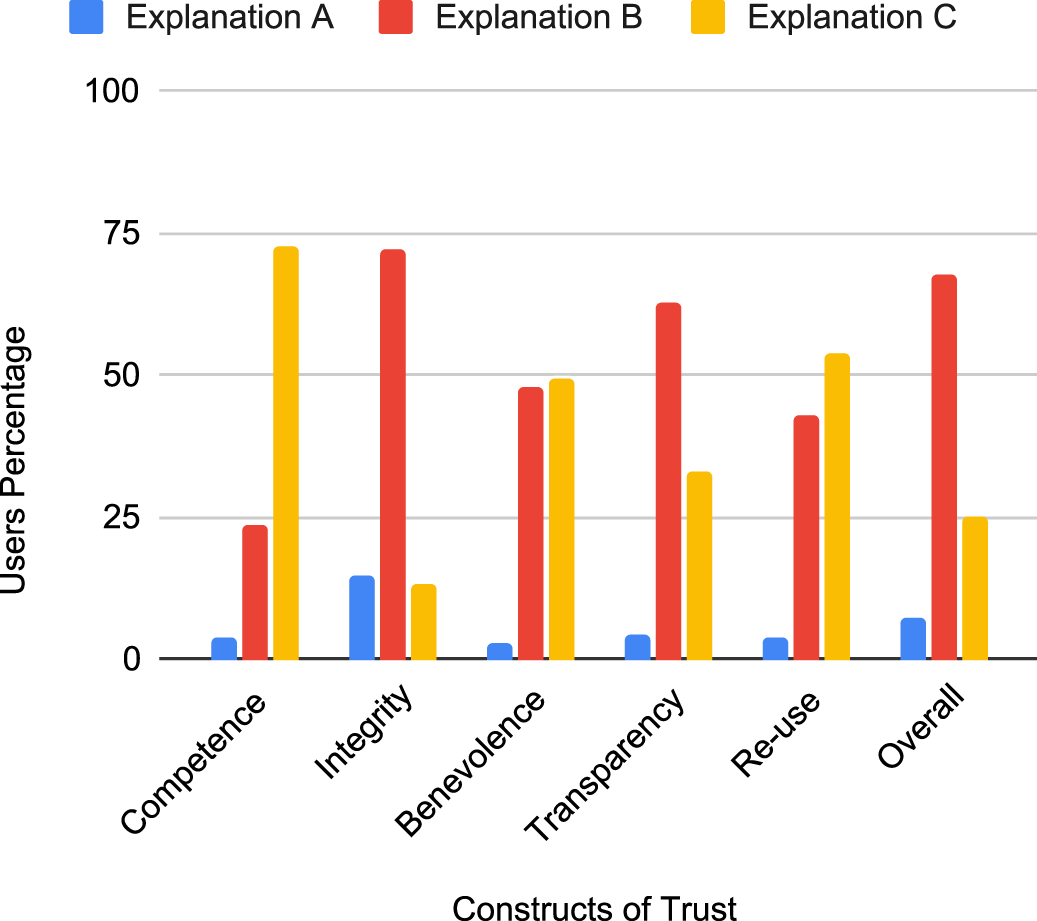
Constructs of Trust Results.
The results affirm
Constructs of Trust Most Valued Features in a System.
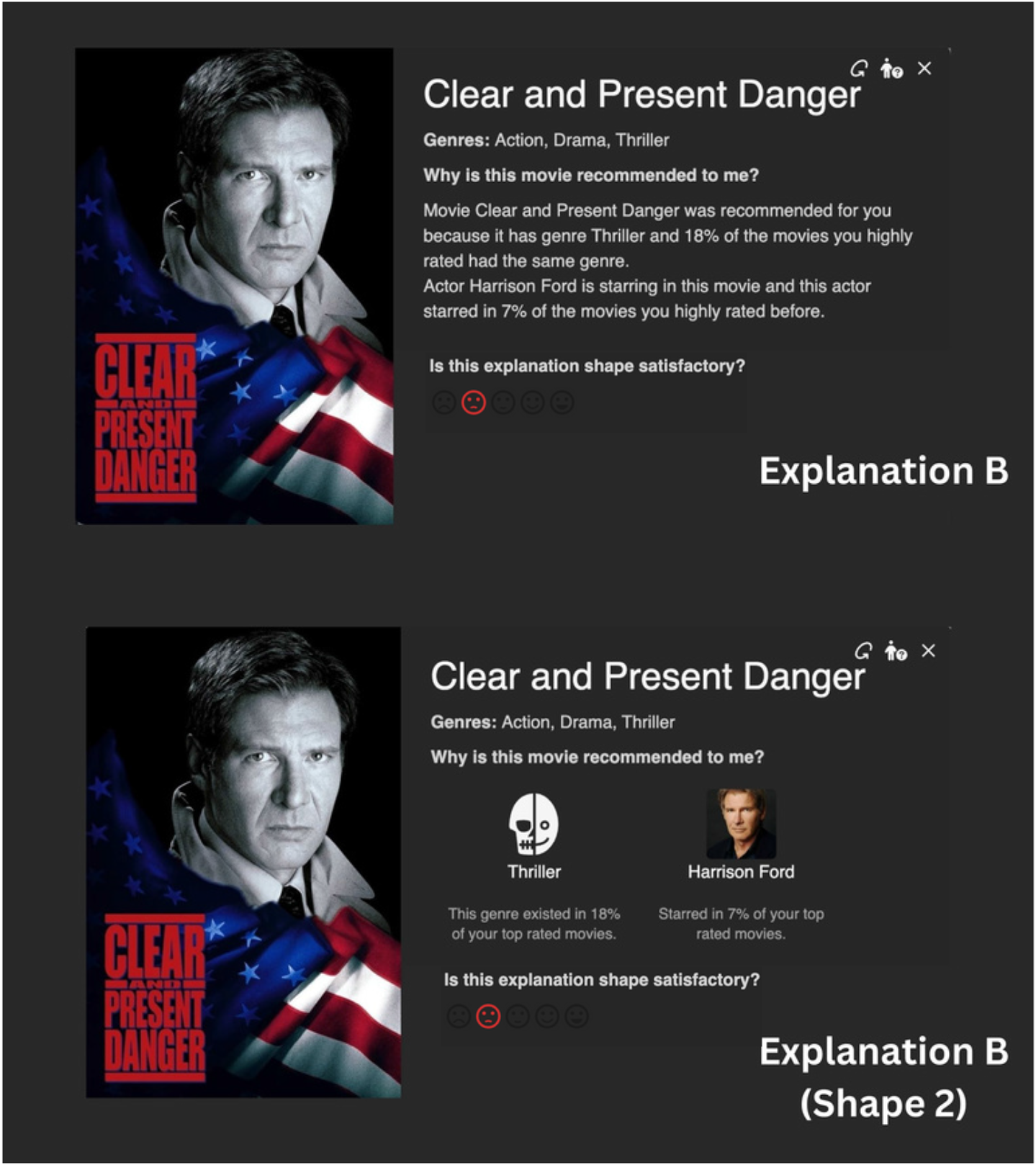
Explanation Shape Change Example.
As discussed in the previous sections, participants prefer different explanation levels for different purposes, therefore, it is logical to allow the users to have an option of the contextualization level they need in an explanation. The last section of the survey was collecting opinions on such matter. The participants were asked two yes or no questions stating that if the previous system that created the explanations they saw before wanted to add a feature that allows the users to change the level (A, B, or C) and shape of the explanation provided giving them the example seen in Figure 22.
The questions asked are as follows:
Being able to change the explanation shape via feedback or choice gives a sense of controllability? (yes or no). It would have been better if the explanation shape was static (unchangeable via feedback or choice)? (yes or no).
As illustrated in Table 6, the majority think that being able to change the explanation level and view gives them a sense of controllability on the system. On top of that, leaving the view static is frowned upon. A further discussion about the evaluation can be found in Appendix 12.
Controllability Questions Responses.
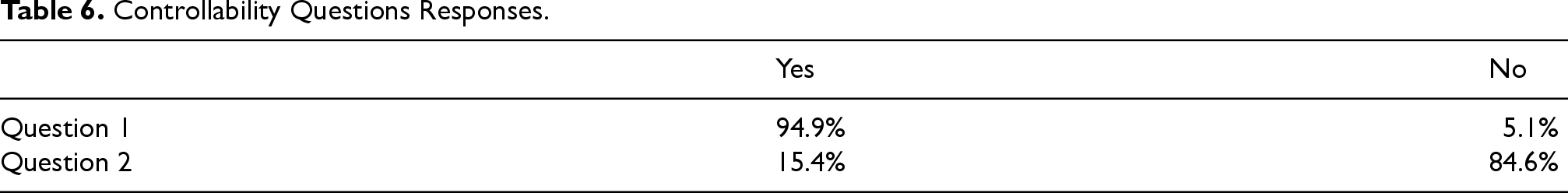
The existing context-sensitive explainers tend to overlook some dimensions of context because there does not exist a formal taxonomy that dissects intricate pieces of context. Not only that but also the current approaches of contextualizing explainability mostly work on the design of new explainers rather than catering to the existing explainers. ConEX is designed based on those two main points. ConEX’s context model allows it to access the three main modules of context which represent the user, the system, and the interaction of the user with the system. Moreover, decoupling the explainer from context will allow for the usage of the currently existing state-of-the-art explainers, which might be already deployed in real systems, along with the context model to build context-sensitive explanations.
To summarize ConEX builds context-sensitive explanations based on two main factors:
Algorithmic knowledge considered during problem-solving. Contextual knowledge that provides a frame of reference for tailoring explanations.
Algorithmic knowledge represents information coming from the explainer module itself. This knowledge is the pillar for algorithmic transparency in context-sensitive explanations since it contains all the reasons a model had for its prediction. Then contextual knowledge aims to provide all pieces of context that surround the current instance of explanation to validate the reasons according to the context and remove irrelevant pieces of information. Moreover, it can further provide context-relevant support to the explanation as well. The adaptor in ConEX is in charge of adapting this collaboration of knowledge to different levels based on the current context.
The task model in ConEX is a detached module unconcerned with explainability, thus its accuracy can be maintained and improved regularly without affecting explainability. The plug-and-play design of ConEX also allows for replacing different modules with minor compatibility changes in the mediator making it transferable across domains. Moreover, context considerations are handled via the context model. Furthermore, the adaptor module adapts the content of the explanations based on the stakeholder using explicit and implicit knowledge ensuring transparency and understandability. It also signals the convenient presentation shape to the user interface allowing the user to further interact with the explanation and have control over what to see in an explanation and how to see it, thus adapting content and presentation while accommodating the user needs ensuring explanation quality and inclusivity.
In this section, we will present our vision of how ConEX guidelines can be applied in the medical domain as a discussion of the applicability of ConEX in other domains.
In a diagnosis AI system, the input can be patients’ symptoms or medical images, for instance. The prediction of the task model will be a diagnosis and the explanation will vary depending on the input data. An explanation can be in a form of a text highlighting the symptoms that led to the diagnosis or region of interest with middle-level understandable features in the case of medical images. Lundberg and Lee (2017) can be used as a feature-importance explainer in case of tabular data, and Grad-CAM (Selvaraju et al., 2016) for the medical images, for example.
To build a context model for such a system, we need to have a well-defined disease ontology that links different diseases together and provides a baseline for related symptoms and medications as a crucial part of the static context. The DO-KB Knowledge base (Baron et al., 2024) is an example of a well-structured disease ontology. Regarding the system information, it should contain connections between different patients in terms of their age group, diseases, residence, etc. This can be represented as a knowledge graph and it will help in grouping similar patients to help gain more insights about the diagnosis.
Dynamic context, on the other hand, represents the set of information needed during an interaction to better suit the stakeholder. It is important to first understand the stakeholder types. Apart from the developers of the system, there can be doctors and patients as a simple set of users. Doctors are considered domain experts and are familiar with complex medical terms, unlike most patients. Therefore, each stakeholder is concerned with different information in an explanation. Historical context will contain the medical history of the patient in the current interaction. We believe that there will be no need to include situational context in such a system though. Regarding the stakeholder model, the information fetched will depend on the requester of the explanation. If the requester is a patient, then the patient’s identity is fetched and we also believe that maintaining a patient’s mental model is unnecessary in this scenario. A patient’s mood or preferences have nothing to do with the presented diagnosis or explanation. However, the patient’s identity will allow for presenting an explanation in understandable terms and might relate it to his medical history as well. On the other hand, if the requester is a doctor, then a compact mental model can be saved for each doctor representing their explanation presentation preferences. This can include visual or text explanations. An overview of the context model can be seen in Figure 23.
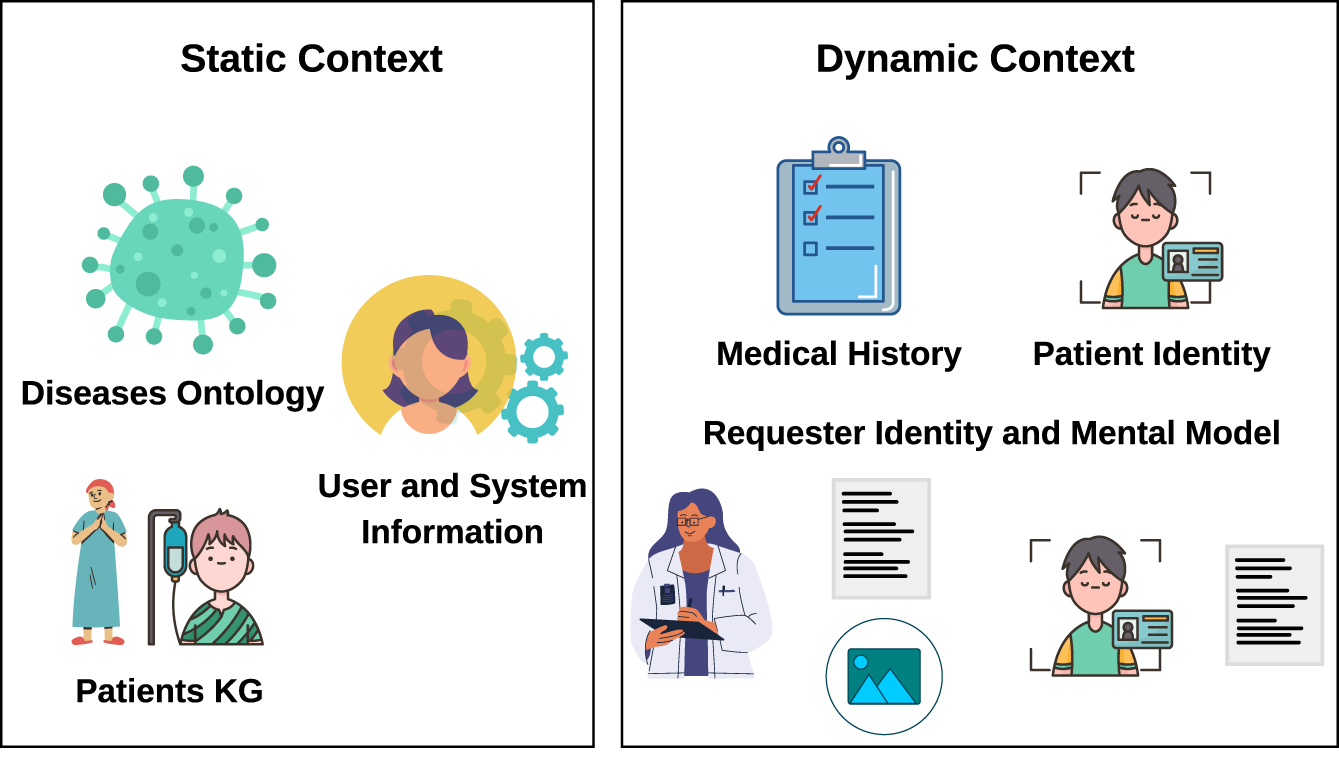
Static and Dynamic Context Proposal in a Medical System.
In the scenario that the requester is a patient, the adaptor should do static fitting along with level 2 dynamic fitting excluding preferences but including relations to medical history or similar users for instance. But if the requester is a doctor, then the adaptor should adjust the static fitting to not exclude irrelevant contributing features but rather point them out as irrelevant and keep them for the doctor’s judgment. Longo et al. (2024) introduced this type of explanation, under the name perorative explanations. In perorative explanations, a set of possible explanations including opposing and contradictory ones are shown, and this type of explanation will be a great fit for doctors.
In this paper, we have introduced a comprehensive taxonomy of context that finds relevance across diverse domains and systems. To practically realize context-sensitive explanations, we have presented ConEX, a general framework founded on our context conceptualization, along with the incorporation of a post hoc explainer that promotes context-aware and inclusive explanation generation. We assert that our guideline adeptly allows for the optimization of different stages of prediction and explanation generation separately without affecting the rest of the modules.
We presented an application of ConEX that leverages context-sensitive explanations to enhance the personalization of movie recommendations. By combining elements of a recommender system, a post hoc explainer, and a sophisticated context model, we have demonstrated how recommendations can be tailored meticulously to the individual user. This approach transcends generic recommendations, offering an immersive journey where every choice and explanation is intricately aligned with the user’s profile.
Our application comprises three contextualization levels. These levels progressively enrich the recommendation explanations, ensuring alignment with the user’s preferences and the movie’s characteristics. The integration of the user’s current situation in the final level adds a new dimension of personalization.
Additionally, we conducted a user study to empirically demonstrate that context-sensitive explanations enhance user trust and satisfaction. The user study gathered responses from 136 participants within different age groups and with diverse technical backgrounds in the field of AI development. The results of this study, involving the evaluation of different levels of contextualization, were encouraging. The findings indicated that there was a significant increase in the participants’ overall satisfaction when presented with more personalized explanations. Level 1 contextualization yielded the least overall satisfaction among all the other levels. Whilst there was a small but significant increase in satisfaction when moving to level 3 contextualization from level 2. The participants appeared to have diverse preferences for the depth of contextualization in explanations related to different aspects of trust which include integrity, re-use, transparency, etc. This study has further strengthened our belief in the importance of providing users with the flexibility to choose the level of contextualization that best suits their informational needs, thus fostering a higher degree of trust and satisfaction. This was supported by the majority of the participants’ responses indicating that having the option to choose which level of contextualization when using a system provides them with a sense of controllability and that it is rather satisfying than having one static shape of explanations all the time. And to showcase ConEX’s generalizability we discussed a proposal for its application in the medical domain.
Future work in this domain can explore several exciting avenues. Research into automated situation recognition, reducing user input, and tracking their current state, will make the system even more seamless and user-friendly. Moreover, addressing the challenge of temporal changes in user preferences and maintaining the context model’s accuracy over time is a promising avenue for future research. On top of that, applying ConEX in different domains with different implementation techniques and quantitative evaluation metrics of explanation goodness, if applicable, encouraging the development of contextually sensitive explanation datasets , is a promising piece of future work.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix A. Explanation Sample Screen
Appendix B. Extra Examples Shown to Participants of Empirical User Study
Appendix C. A Discussion on the Metrics Evaluated in Our Prototype
One of the main ideas of ConEX is to use an already existing explainer along with a context model built based on our context taxonomy discussed in section 3 to build a context-sensitive explanation in a post-hoc manner. Based on that, ConEX depends on the fact that the existing post-hoc explainer has already been evaluated and is being optimized as a stand-alone module. In other words, ConEX does not aim to improve the algorithmic accuracy of an explainer but rather uses the primitive explanation provided by that explainer. However, modularizing components of explainability in this way will allow for improving the accuracy of the used explainer without affecting the rest of the steps.
With that said, in section 5.1, we started by evaluating the
In our user study mentioned in section 6, we focused on the subjective aspects of explanations. Stakeholders are included as a part of the context which is why it was important to measure if personalizing explanations affects different subjective quality criteria. The criteria we focused on in our user study are:
Other factors like understandability and reliance were also implicitly evaluated as a part of the satisfaction scale.