
Abstract
A multifeature fusion small-target detection network (MF-Net) is proposed based on PointRCNN, aimed at enhancing the detection accuracy of small targets in vehicle-mounted LiDAR systems. Semantically controlled farthest point sampling and multisampling strategies are presented to achieve uniform sampling and retain a greater number of small target points. Additionally, a local feature aggregation module is utilized to learn the intensity features of small target point clouds through spatial intensity encoding. Furthermore, PointPillars technology is implemented to convert the three-dimensional point cloud into a pseudo-image, allowing for the extraction of features at various scales using a feature pyramid network. Experimental results demonstrate that MF-Net improves the mean average precision for pedestrian and cyclist detection by 2.49% and 2.88%, respectively, compared to the baseline network PointRCNN. The false detection rate is reduced significantly and the detection accuracy is enhanced across diverse scenarios.
Introduction
In automatic driving systems, environmental perception is intricately linked to a diverse array of sensors. The environmental perception data acquired by vehicle sensors serves as the cornerstone for subsequent processes, including positioning, path planning, decision-making, and control. Fully capturing and leveraging data acquired from existing sensors for environmental assessment represents a pivotal aspect of autonomous driving technology (Song et al., 2024). Among the numerous onboard sensors, laser radars have garnered significant attention due to their ability to offer extensive three-dimensional (3D) data and their immunity to disruptions caused by light (Lee et al., 2024).The laser radar sensor acquires point-cloud data by emitting a laser beam and capturing the echo signal reflected back from the 3D objects in space. In recent years, as autonomous driving technology has continued to advance, deep learning techniques have become widely utilized in the detection of 3D targets using vehicle-mounted LiDAR, enabling the effective extraction and utilization of fine point cloud features from small targets. Classic studies, such as VoxelNet (Zhou & Tuzel, 2018), PointPillars (Lang et al., 2019), and PointRCNN (Shi et al., 2019), have paved the way for subsequent enhancements and optimizations in point-cloud-based 3D target detection performance. Currently, the approach to utilizing deep learning for detecting 3D targets in LiDAR point clouds can be categorized into three methods: Multiview, voxel-based, and pure point-cloud, based on the varying data processing techniques employed for the point clouds.
In the multiview approach, the VeloFCN (Li et al., 2016) network projects a 3D point cloud into two-dimensional space for processing. However, this projection results in information loss and poses accuracy limitations, primarily due to the constraints in unit coding ability, which are unable to address the challenges arising from point-cloud discretization. Beltrán et al.’s BirdNet (Beltrán et al., 2018) network is a 3D detection framework specifically tailored for Bird’s-Eye-View projection of LiDAR point clouds. It leverages the elimination of 3D bounding box post-processing to enhance detection rates. The BirdNet+ (Barrera et al., 2020) network further refines the detection rate of 3D objects. However, despite these advancements, this method still generates substantial ambiguities, and feature extraction is hindered by the sparsity of the point cloud. For example, MV3D (Chen et al., 2017) integrates data from multiple viewpoints for feature extraction, which is effective but demands considerable computational resources and lacks robustness. It cannot transcend the visual constraints imposed by its own sensors and falls short in addressing the challenges associated with small-target feature extraction and detection accuracy. Additionally, MVMM (Li et al., 2023) merges data from different sensors and viewpoints through point cloud coloring, achieving high detection accuracy but with complex computations and challenging hyperparameter tuning.
The voxel method discretizes a sparse 3D point cloud into a voxel grid, using voxels as representations of the point cloud. Compared to the multiview method, the voxel method processes less data and attains higher detection accuracy. Vote3Deep (Engelcke et al., 2017) incorporates a convolution layer grounded in centrosymmetric voting and a modified linear unit to manage sparse point clouds, yet it encounters challenges in effectively extracting local features. Subsequently, Voxel-RCNN (Jiang et al., 2024) elevates feature extraction and refinement through a two-stage detection strategy, mitigating the information loss stemming from voxelization and enhancing detection accuracy, albeit at the expense of detection speed. Additionally, MVTR (Ai et al., 2024) integrates point cloud semantics, sparsity, and non-empty voxel features, facilitating easier access to global feature information, yet its performance in extracting features from small target point clouds remains limited. PV-SSD (Shao et al., 2024) proposes a multimodal feature fusion network that combines projection features and voxel features, but its ability to extract features from sparse point clouds still requires further enhancement.VoxelNeXt (Chen et al., 2023) achieves efficient 3D object detection through fully sparse convolutional networks, avoiding the reliance on anchors, center points, and dense heads. However, its performance is relatively limited when handling small objects and low-density point clouds.
The development of pure point-cloud methods can be largely attributed to the introduction of PointNet (Qi et al., 2016) and PointNet++ (Qi et al., 2017), which enable 3D object detection networks to directly process point clouds, thus effectively avoiding information loss. The DF-SSD network (Zhai et al., 2020) enhances detection accuracy and reduces model parameters through feature fusion and DenseNet. However, it lacks low-level deep feature information, which leads to slower detection speeds. In contrast, TSKPD (Feng et al., 2024) employs multiframe point cloud image fusion to detect missing point clouds, significantly improving the robustness of keypoint detection. However, it has high computational demands and its performance in detecting small targets still requires improvement. The PointPillars network (Lang et al., 2019) processes point clouds by converting them into pillars, significantly enhancing runtime speed, but its detection accuracy still needs further enhancement. CenterPoint (Yin et al., 2021) simplifies the detection process by utilizing center point regression to predict 3D size, orientation, and velocity, which improves accuracy. Nevertheless, its performance in detecting small targets and objects with extreme aspect ratios remains limited. The PointRCNN network (Shi et al., 2019) excels in 3D object detection but faces challenges in detecting small targets. PillarNeXt (Li et al., 2023) focuses on a pillar-based feature extraction model, expanding the receptive field to capture richer features from the point cloud, thereby improving detection performance. However, its feature fusion between points and pillars still requires further refinement. To address these limitations, this paper proposes multifeature fusion small-target detection network (MF-Net), which is based on PointRCNN and integrates both point and pillar features. This approach improves the detection accuracy of small targets, such as pedestrians and cyclists, reduces false detection rates, and enhances target feature extraction capabilities, thereby improving performance in detecting small targets across varying levels of task difficulty.
Currently, deep learning-based algorithms for 3D small-target detection confront several challenges, including a restricted feature range, scarcity of available features, and complexities in feature extraction. To address these issues, common approaches include multiscale learning, optimized downsampling strategies, and data augmentation. Subsequent developments introduced local search, sparse convolution networks (Ke et al., 2025) and unsupervised training strategies (Cai et al., 2025), further enhancing the feature extraction capability of 3D small object detection algorithms. In 2D detection, while downsampling can effectively reduce the size of feature maps and computational complexity, excessive downsampling may lead to the loss of small-target feature information. Although two-stage detection algorithms generally achieve higher accuracy, they tend to be slower in real-time scenarios (Li et al., 2021). The channel enhancement feature pyramid network (CE-FPN) network (Luo et al., 2022) improves feature representation capability by utilizing rich channel information through sub-pixel convolution and channel attention mechanisms; however, its speed remains limited when processing large-scale point cloud data.
Lin et al. developed a top-down architecture with lateral connectivity, building upon the traditional feature pyramid network (FPN) (depicted in Figure 1). This enhanced FPN integrates features at the same level during the upsampling phase, thereby improving the detection accuracy of small targets through multiscale learning (Lin et al., 2017).
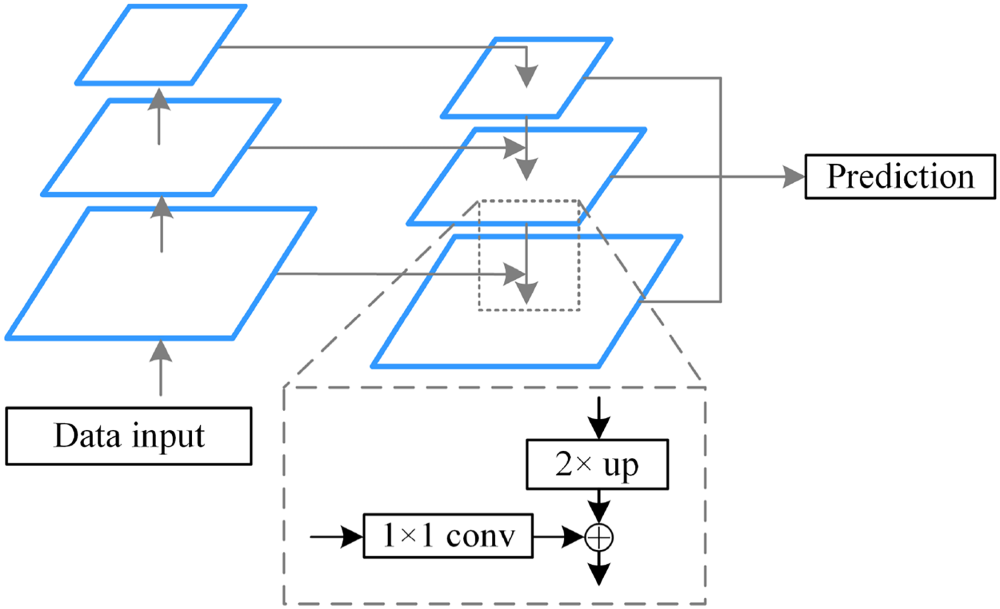
Feature pyramid network (FPN) structure.
Despite the capability of farthest point sampling based on Euclidean distance (D-FPS) to achieve uniform sampling, this process inevitably leads to the loss of substantial background point information (Zhu et al., 2024). Consequently, some researchers have refined downsampling strategies to better preserve small target point clouds. For instance, the 3DSSD network (Yang et al., 2020) integrates a feature distance-based sampling method with the D-FPS algorithm, effectively retaining small target point clouds; however, its operational speed remains low in large-scale point cloud scenarios. The IA-SSD network (Zhang et al., 2022) employs a downsampling strategy that combines category-aware and centroid-aware sampling to select foreground points, utilizing a single-stage detection approach to enhance detection speed. The DPA-RCNN network (Jiang et al., 2024) incorporates a center-aware feature extraction module to selectively retain points near the object center, while applying an edge segmentation-aware module for bounding box regression; however, its accuracy diminishes when detecting occluded objects. Additionally, the WS-SSD network (Li et al., 2024) improves pedestrian detection accuracy through weighted sampling and a unique network architecture, yet its performance in detecting small targets in complex scenes remains inadequate.
The advantages and disadvantages of different point cloud processing methods are presented in Table 1. Overall, deep-learning-based small-target detection algorithms can significantly enhance performance through multiscale learning and optimized downsampling strategies, particularly for small targets that lack distinct appearance features. However, in complex scenes, small targets are often affected by sparse and partially missing point clouds. Therefore, designing an efficient network to extract and utilize small-target feature information remains an important research topic in the current field.
Comparison of the Advantages and Disadvantages of Different Point Cloud Detection Methods.
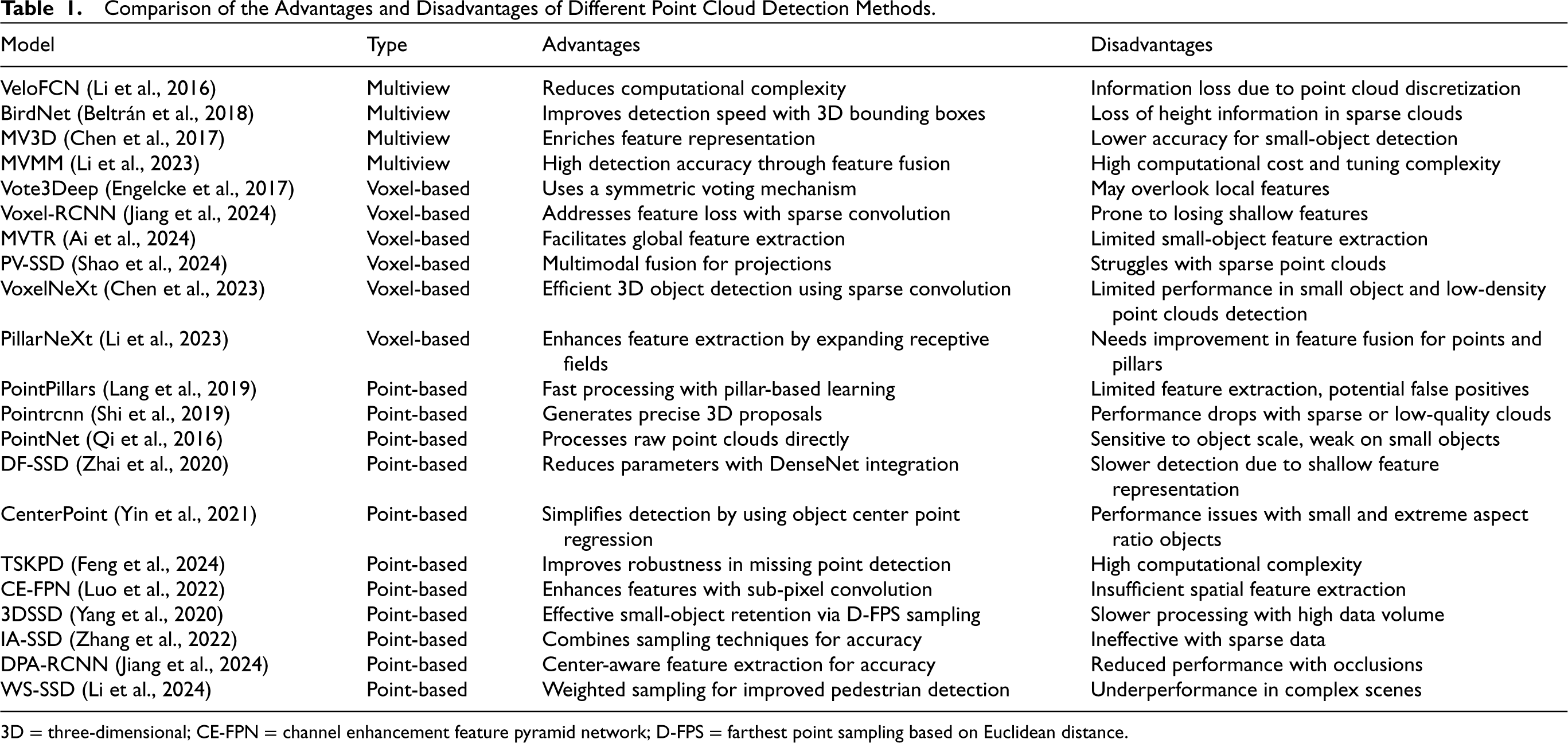
3D = three-dimensional; CE-FPN = channel enhancement feature pyramid network; D-FPS = farthest point sampling based on Euclidean distance.
PointNet++ point-set abstraction layer structure.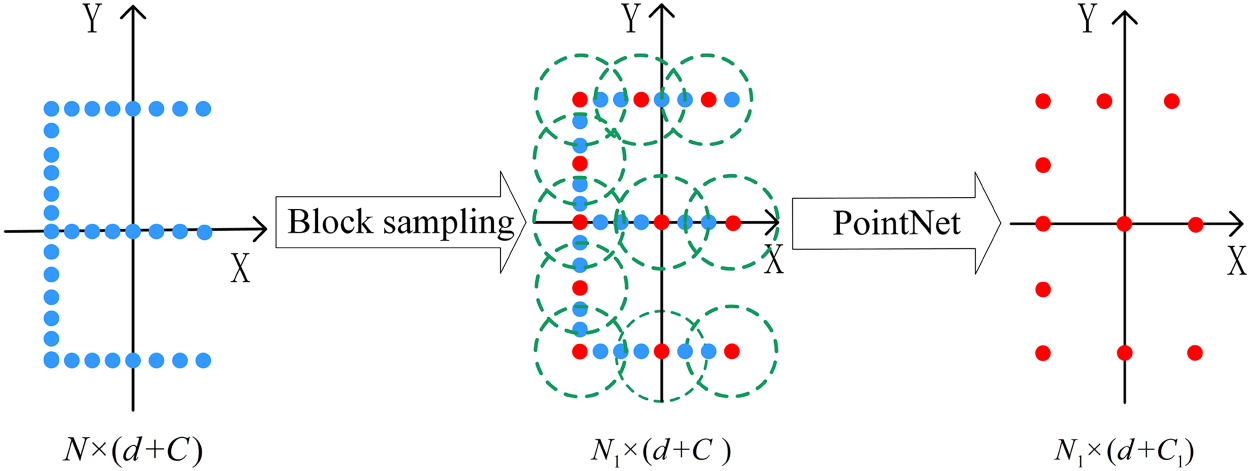
The main contributions and innovations of this paper are as follows:
A novel semantically controlled farthest-point sampling algorithm is proposed to mitigate the loss of point-cloud information for small targets during the downsampling process in the PointNet++ backbone of PointRCNN. A multisampling strategy is combined to ensure uniform sampling of the point set while effectively retaining small target points. A novel local feature aggregation (LFA) module is proposed to correct and encode the point-cloud echo intensity in the PointNet++ backbone network. By utilizing positional intensity encoding, the intensity features of small target point clouds are learned to reduce the misdetection of similar obstacles. A column feature branch is proposed to enhance the feature representation capabilities for small targets. 3D point cloud data are converted into pseudo-images, and then a FPN is adopted to enhance multiscale features learning for small targets. A multifeature concatenation module is utilized to obtain the fused features of point and column features to improve the detection accuracy for small targets.
The structure of this paper is organized as follows: a detailed analysis of the network structure of PointRCNN is provided and a MF-Net based on PointRCNN is proposed in Section 2. The experimental validation and discussion on the KITTI dataset are presented in Section 3. Finally, conclusions are presented in Section 4.
PointRCNN Network Structure Analysis
In this study, PointRCNN is optimized as the foundational network framework, with PointNet++ serving as the backbone network. This combination integrates bottom-up encoding branches and top-down decoding branches to acquire highly discriminative features. The multiscale learning approach allows PointRCNN to capture a richer and more comprehensive set of multiscale information. PointRCNN comprises several ensemble abstraction layers, including sampling, grouping, and PointNet layers, as illustrated in Figure 2. Each aggregate abstraction layer takes an
Sampling layer: The farthest-point sampling algorithm, which relies on Euclidean distance, is employed to uniformly select points from the point-cloud data. This process aims to characterize the original point set while effectively reducing the data volume. Grouping layer: We define PointNet layer: Receives a collection of points, specifically
PointRCNN encounters the following challenges in extracting small-target features:
When using PointNet++ to extract point features, it overlooks multivariate attributes such as voxels and columns, leading to a limited feature set that hinders the detection performance for small targets.
The point-set abstraction layer primarily relies on furthest point sampling, which tends to prioritize distant points to cover the space, potentially resulting in incomplete feature extraction for smaller targets.
Within the local neighborhood, PointNet relies solely on point coordinates to approximate information, which may not fully capture local details and fine-grained features. This limitation can lead to misdetections, especially for small targets with similar shapes. As illustrated in Figure 3, the echo intensity of obstacles varies significantly, and this additional information could be leveraged to effectively distinguish between similar obstacles.
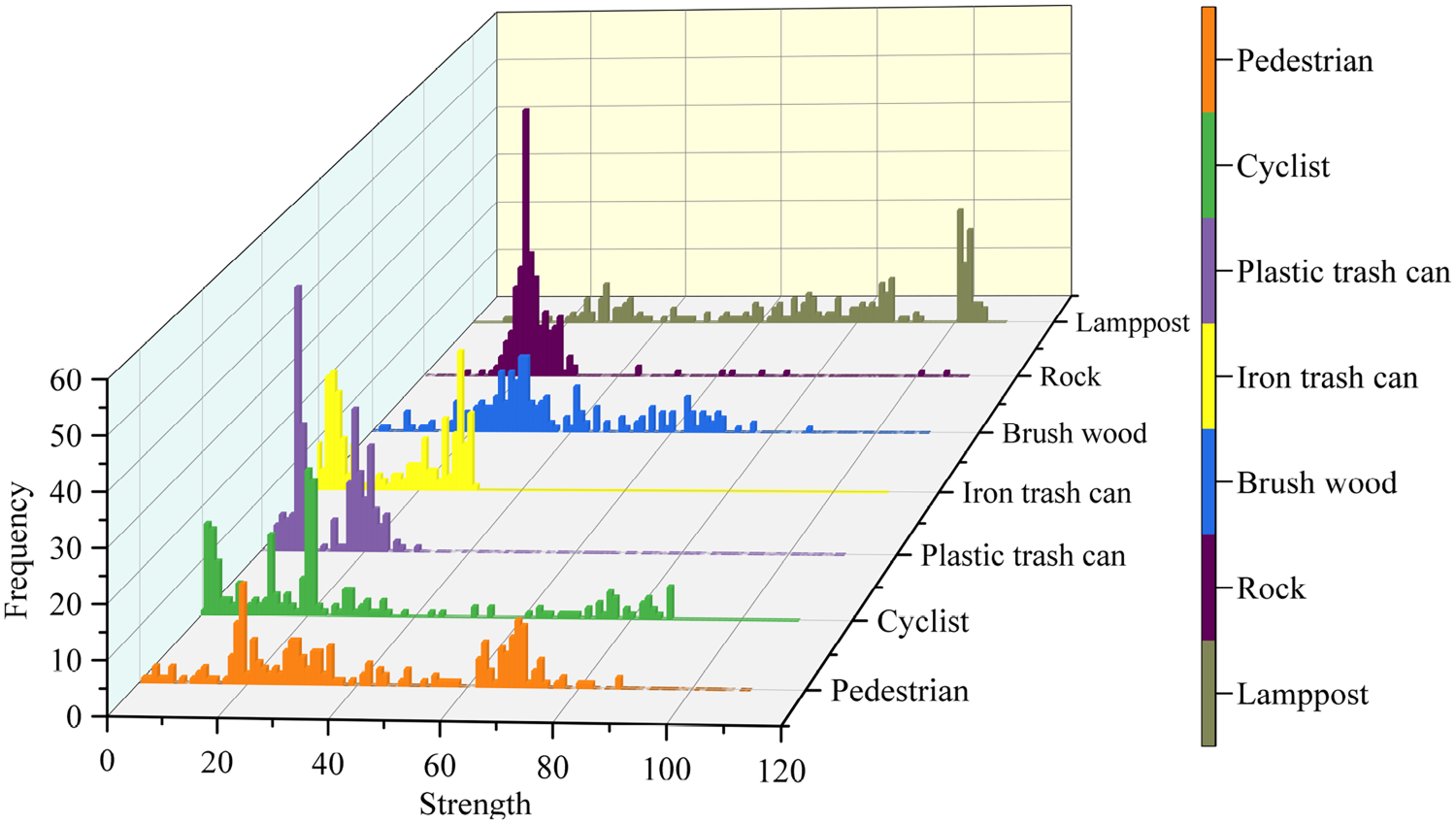
Histogram of echo intensity of different objects.
The MF-Net architecture is a two-stage detection network, as shown in Figure 4. The first stage consists of three key modules: Point feature extraction, column feature extraction, and feature fusion. In the point feature extraction branch, an enhanced PointNet++ backbone is used for encoding and decoding. This branch combines farthest-point sampling with semantically controlled farthest-point sampling and utilizes a LFA module to efficiently capture local features. Afterward, a series of inverse interpolation operations are applied to generate feature vectors for the points. The column feature extraction branch then refines the target’s positional and semantic information by using a FPN.In the second stage, the features obtained from the first stage undergo local pooling to further extract local features. Meanwhile, the bounding box features predicted in the first stage are processed using segmentation masks and passed through a multilayer perceptron (MLP) for dimensionality expansion. Then, these features are combined with the point cloud features and pillar features from the first stage to obtain both global semantic features and local features. Finally, the merged features are processed through PointNet for regression and classification, generating the final confidence scores and refined detection boxes.
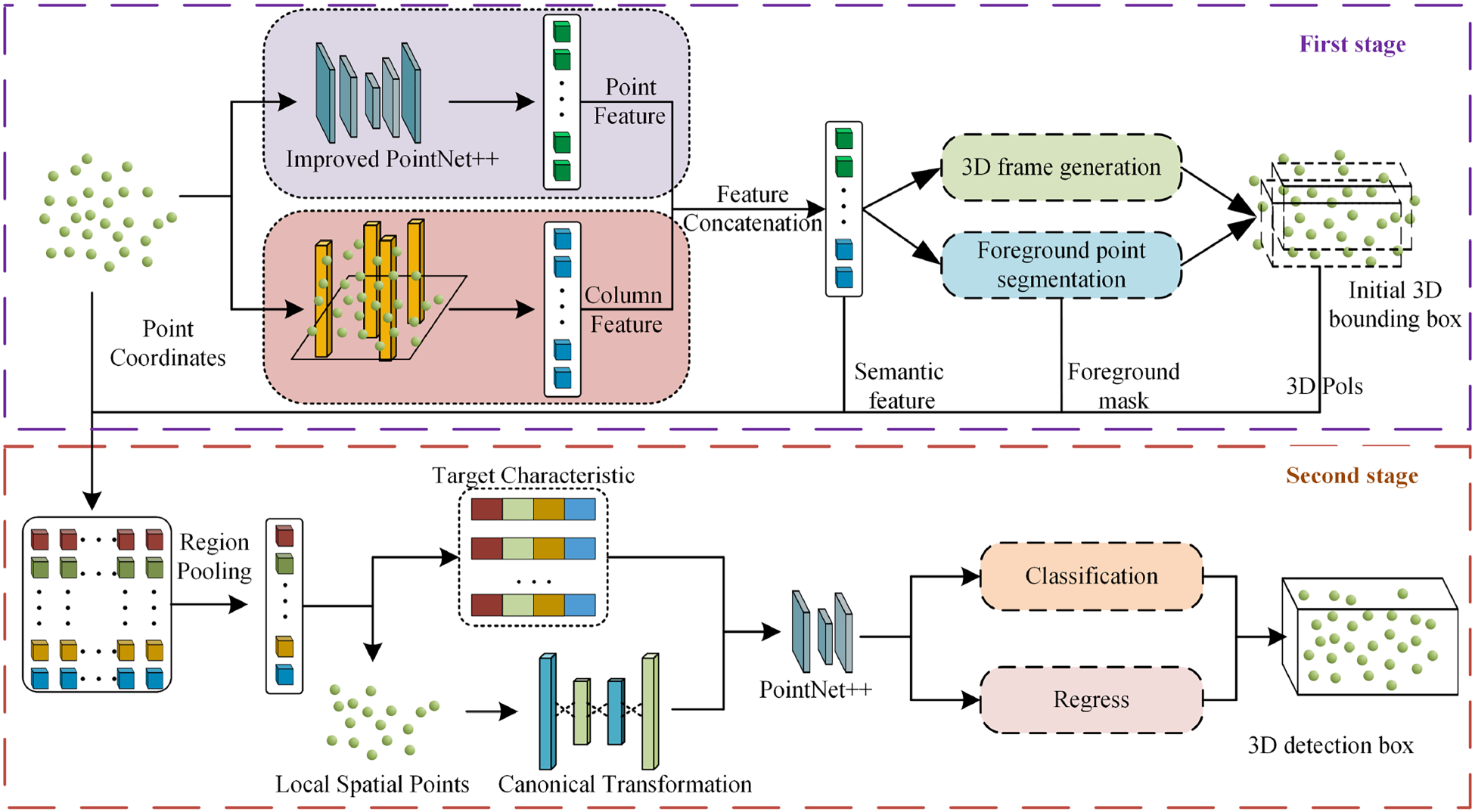
Network structure of multifeature fusion small-target detection network (MF-Net).
The point-feature extraction branch primarily uses an enhanced version of PointNet++ as the cornerstone of its network architecture. This enhanced PointNet++ incorporates a coding and decoding framework that consists of a point-set sampling (PS) module and a LFA module serving as the encoder, paired with a feature propagation (FP) layer functioning as the decoder. The comprehensive layout of the system is depicted in Figure 5.
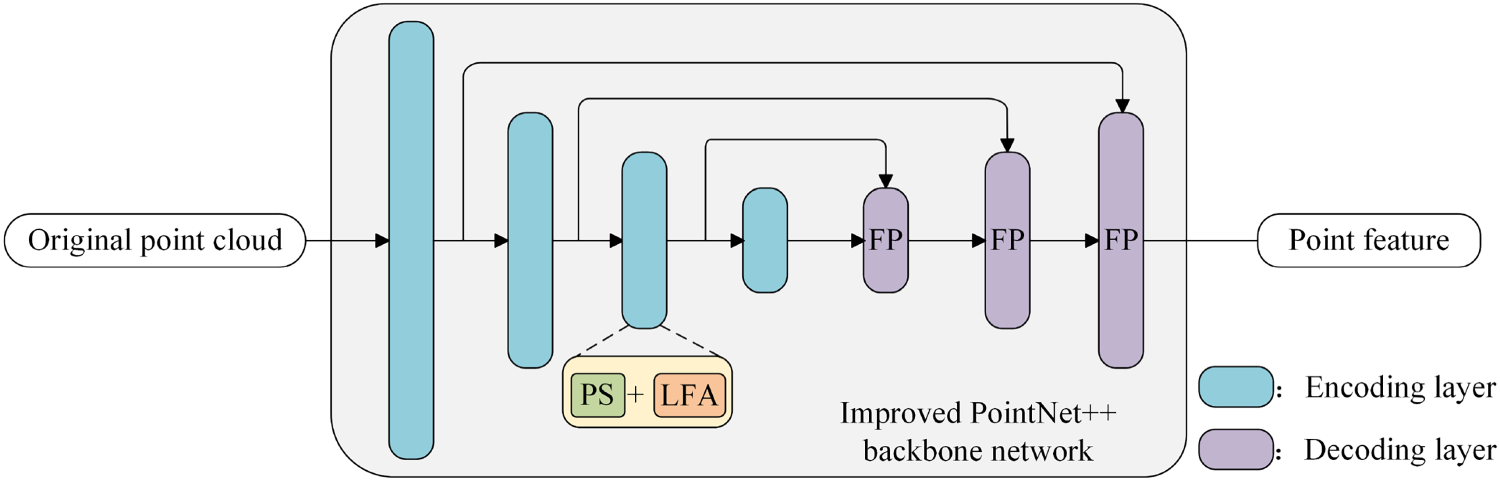
Branch structure of point-feature extraction.
The original point cloud is input into the enhanced PointNet++ backbone network, where feature extraction is carried out by an encoder composed of a PS module and a LFA module. The decoding process involves the stacked inverse interpolation operation in PointNet++ to obtain the point features within the region. In this study, our primary focus is on improving the coding layer of the PointNet++ network. We offer a comprehensive explanation of the two modules within the coding layer: The PS module and the LFA module.
(1) Point set sampling module.
The original point cloud may contain a disproportionately high number of background points and larger target points compared to smaller target points. When using a single farthest-point sampling method, this disparity can result in the loss of critical small target points. To broaden the global sensing scope of the point cloud and ensure the retention of more small target points, this paper introduces a semantically controlled farthest-point sampling algorithm that integrates multiple sampling techniques, akin to a heuristic feature search optimizer. In the hierarchical downsampling process, the initial layer applies the traditional farthest-point sampling algorithm (D-FPS), whereas the subsequent three layers utilize the proposed semantically controlled farthest-point sampling algorithm (SC-FPS). This methodology not only broadens the global sensing range of the point cloud but also successfully retains a higher proportion of small target points, as demonstrated in Figure 6.
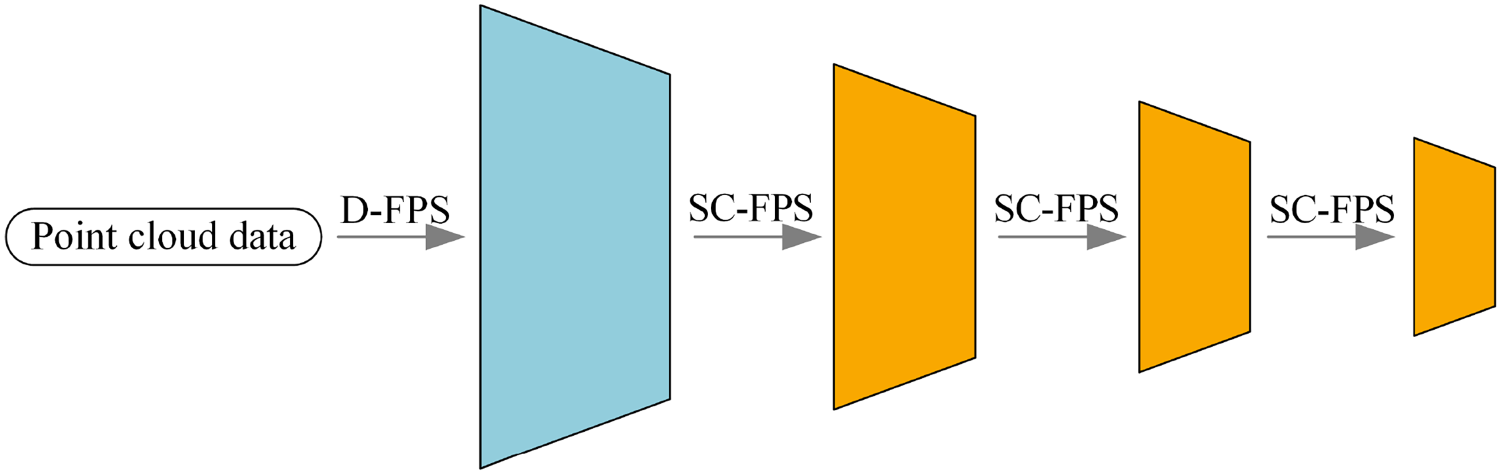
Layer level downsampling structure in encoder.
The SC-FPS algorithm introduced in this study incorporates semantic weights into the farthest-point sampling process, minimizing redundancy within large target point clouds while ensuring that small target point clouds, despite their smaller quantity, are not overlooked. This strategy helps provide more small target points for subsequent feature extraction tasks. The detailed process of the SC-FPS algorithm is outlined as follows:
Firstly, the frames per second (FPS) rate is computed. Subsequently, point-wise features 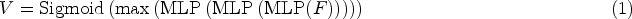
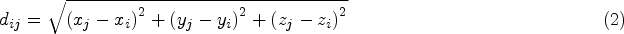

In the process of determining the sampled point set, the initial point with the highest semantic score is first selected based on the semantically weighted distance and added to the sampling point set. Subsequently, the system iteratively calculates the points that are the farthest from the current sampling point set and adds them to the final point set until the preset number is reached. Parameter
(2) Local feature enhancement module.
In this study, we propose a local feature enhancement method that integrates echo intensity and positional data to capture the geometric configuration and intensity variations within a small-target point cloud. This is achieved by introducing spatial position intensity coding. The architecture of the LFA module is depicted in Figure 7.
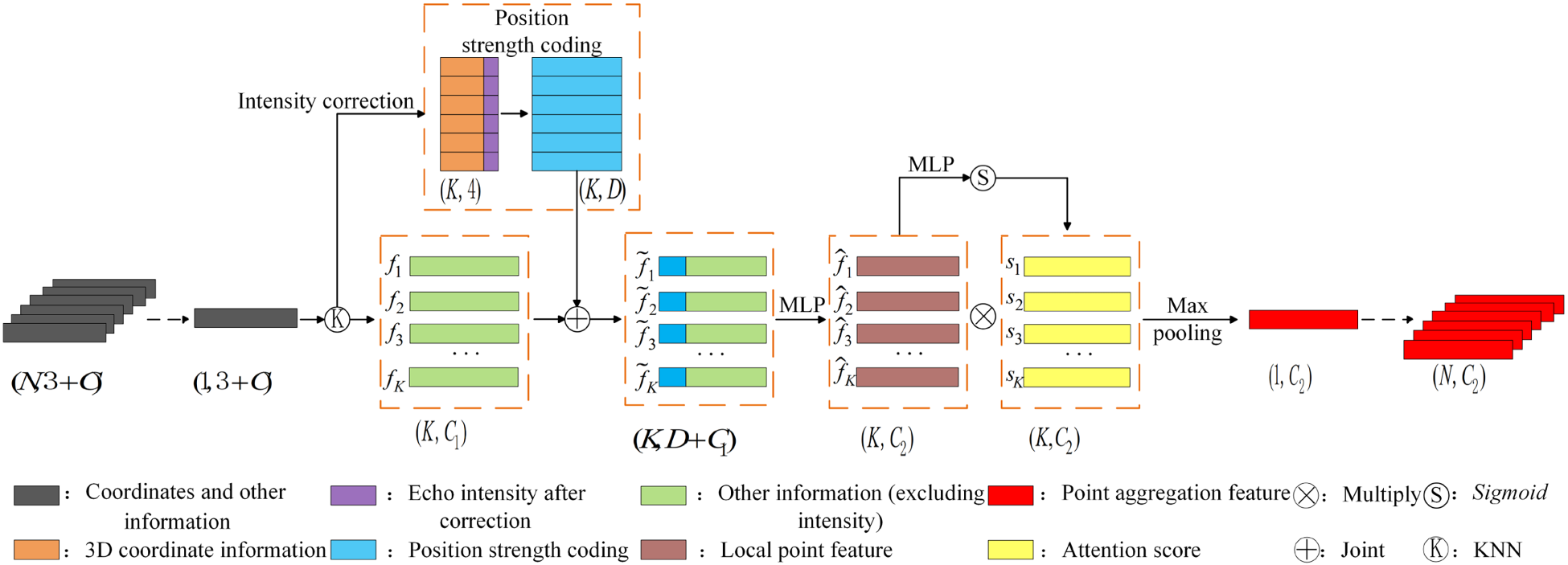
Local feature enhancement module.
First, after the sampling stage is concluded, the center point resulting from the downsampling process is designated as the center of a circle. Subsequently,
Secondly, before encoding the positional intensity of the
Once the corrected echo intensity values are obtained, the 3D coordinates of each point in the point cloud, along with their corresponding corrected echo intensities, are introduced. To effectively encode the spatial coordinates while preserving the geometric structure of the point cloud, this study employs a method of spatial position coding, as detailed in equation below


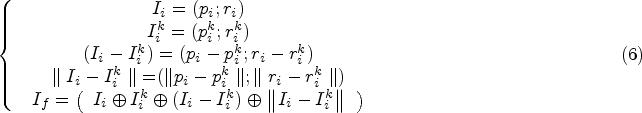
After the positional intensity encoding module, the encoded features and remaining point features 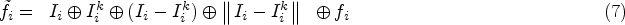
To enrich the feature expression and achieve good accuracy and fast inference at the same time, this paper introduces the column feature extraction branch, which mainly includes the column feature network under the point pillars and the 2D convolutional neural network (CNN) based on the FPN. The structure of the column feature extraction branch is shown in Figure 8.
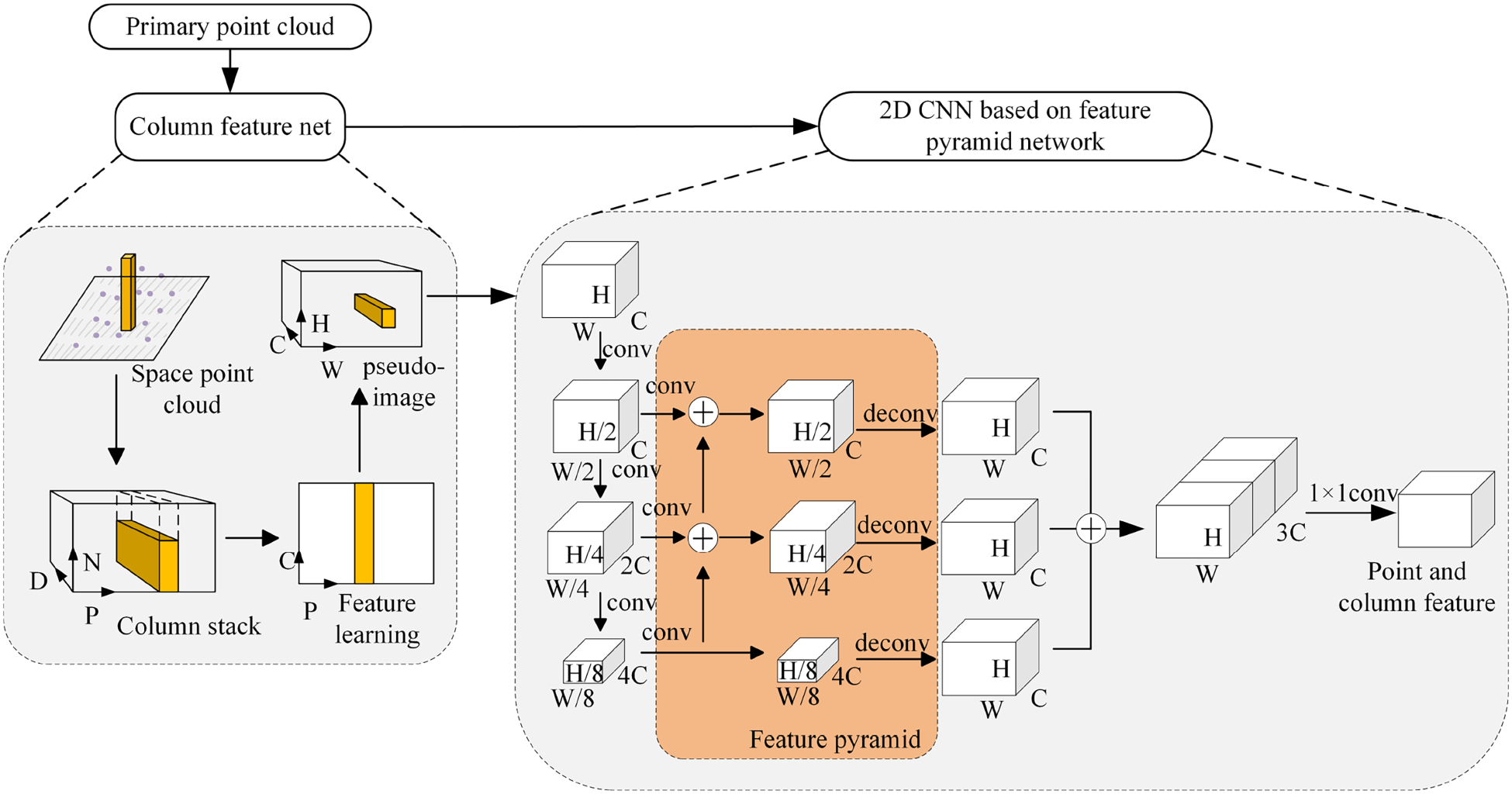
Structure of pillar feature extraction branch.

Schematic diagram of multifeature splicing.
(1) Pillar feature network.
The point cloud space is first divided into column cells; each cell can contain up to
(2) 2D CNN backbone network based on feature pyramid.
In this study, a feature pyramid-based network is used to capture semantic and location information at different scales to improve detection accuracy. The spatial resolution of the pseudo-image is gradually reduced using three sets of convolutions in the top-down branch, whereas the bottom-up branch outputs deep features with strong semantic but weak spatial information. In horizontal concatenation, the dimensionality is first reduced by a
After the point-cloud data has traversed both the Column and Point-Feature Extraction branches, it is necessary to integrate these two branches. The point features are derived through an enhanced PointNet++ encoding and decoding process, which encapsulates the coordinate information of each point. Meanwhile, in the column feature extraction branch, the column feature mesh documents the point coordinates associated with each column. This information is utilized to facilitate the fusion of features, as illustrated in Figure 9.

Partial image data from the KITTI dataset and the nuScenes dataset.
Furthermore, it is crucial to adjust the number of channels in the subsequent classification and regression branches to match the number of channels after concatenation. This ensures compatibility and allows for seamless reuse within the subsequent detection network of the PointRCNN framework.
Experimental Setup
The performance of deep learning models typically depends on the scale and diversity of the training dataset. Commonly used datasets include ONCE Dataset (Mao et al., 2021), nuScenes (Caesar et al., 2020), DAIR-V2X (Yu et al., 2022), and KITTI (Geiger et al., 2012). To evaluate small object detection capabilities, this study selects the KITTI 3D detection dataset and the nuScenes dataset for experimental validation and analysis. The KITTI dataset covers a variety of road environments and target categories, making it suitable for training and testing small object detection algorithms. The nuScenes dataset provides high-quality sensor data, making it particularly suitable for evaluating small object detection in complex urban environments. Figure 10 demonstrates the diversity of image data from these two datasets, allowing MF-Net to rigorously assess its small object detection capabilities.
This study uses the KITTI dataset, which consists of 7,481 training samples and 7,518 test samples. Detection tasks are classified into easy, medium, and difficult categories based on the extent of target occlusion and truncation. To bolster the robustness of the model and mitigate the risk of overfitting, various data augmentation techniques are employed. These include random flipping, scaling, rotating, and the addition of non-overlapping small-target ground truth boxes. These operations emulate targets from diverse viewpoints, scales, and rotational states, thereby enhancing sample diversity and improving the model’s generalization capability. The precise environmental setup for the experiment is outlined in Table 1.
In the experimental setup, the OpenPCDet object detection framework was utilized, and the training process was conducted in a PyTorch environment, as shown in Table 2. The training parameters were configured with a batch size of 8, a learning rate of 0.02, a learning rate decay factor of 0.1, and a weight decay coefficient of 0.01 to reduce the risk of overfitting. The momentum parameter was selected within a range of 0.95–0.85, with the specific value of 0.9 being chosen for this study. A weight decay of 0.1 was applied, and the Adam optimizer was utilized with the loss function as the objective to minimize, with the training process lasting for a total of 80 epochs. During the training process, an intersection over union (IoU) threshold of 0.7 was established for cars, whereas for pedestrians and cyclists, the IoU threshold was set at 0.5. The definitions of the 3D bounding boxes were as follows: car [3.9, 1.6, 1.56], pedestrian [0.8, 0.6, 1.73], and cyclist [1.76, 0.6, 1.73]. Figure 11 depicts the trends of various loss functions throughout the training process, encompassing the total loss, classification loss, corner loss, and regression loss.
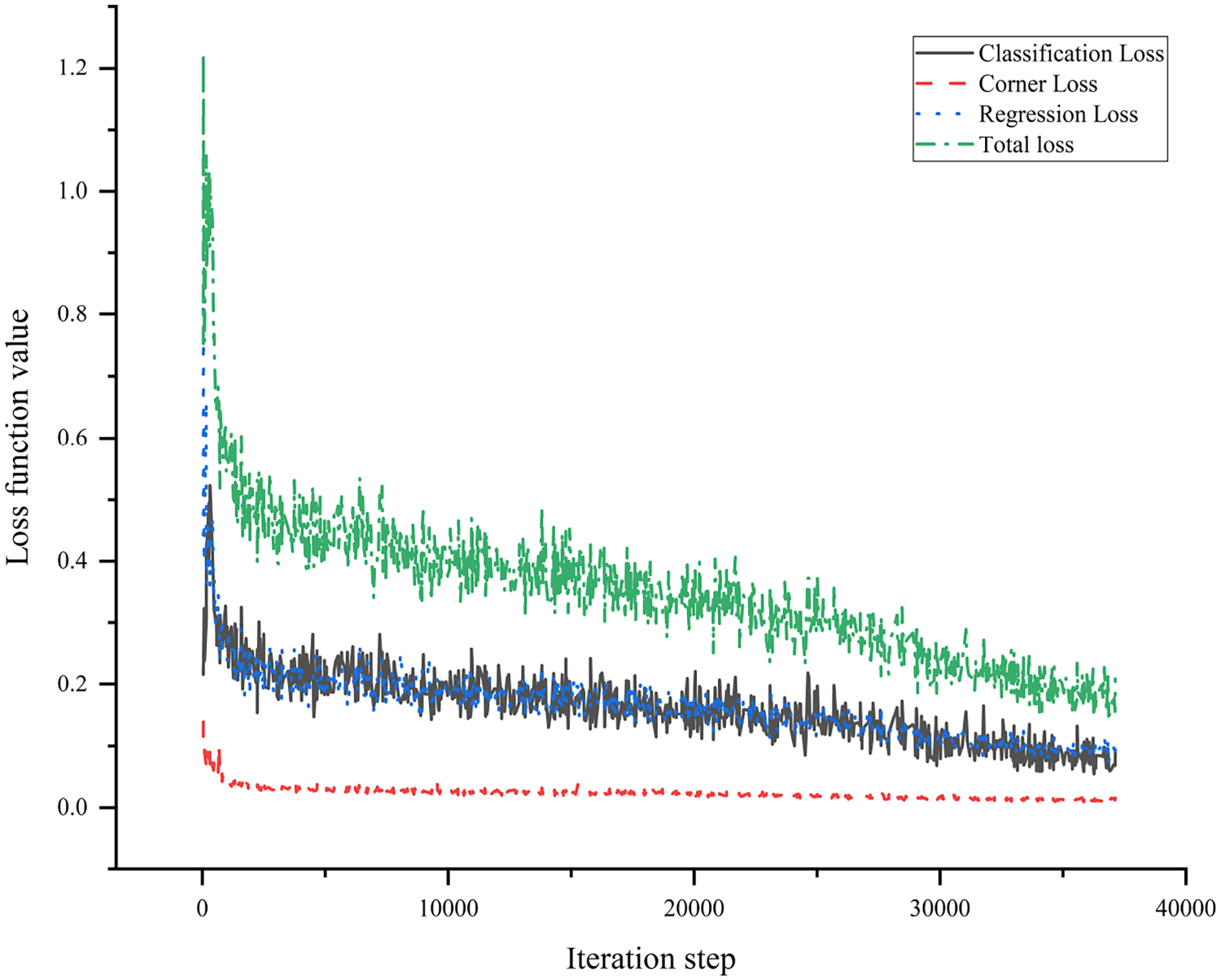
The trend graph of various loss function values during the training process with respect to the number of iterations.
Experimental Environment Configuration.
In this study, we utilize average precision (AP) and mean Average Precision (mAP) in 3D space as evaluation metrics to quantify the accuracy of single-class detection and overall detection performance, respectively. Furthermore, the IoU threshold is determined by calculating the overlap volume between the detected target’s bounding box and the ground truth bounding box in 3D space.
In this study, we examined PointPillars (Lang et al., 2019), PointRCNN (Shi et al., 2019), STD (Yang et al., 2019), SECOND (Yan et al., 2018), and IA-SSD (Zhang et al., 2022), which are renowned for their high accuracy and speed in detecting small targets. Comparison experiments were conducted using the MF-Net proposed in this study on the KITTI test set. To ensure a fair comparison of each network’s performance, we adhered to common evaluation criteria and set the IoU thresholds for pedestrians and cyclists to 0.5 for calculating the AP and mAP metrics of the detection results. The 3D target detection results of MF-Net and the other networks are presented in Table 3.
Three-dimensional Mode Detection Results of Small Targets in KITTI test(%).
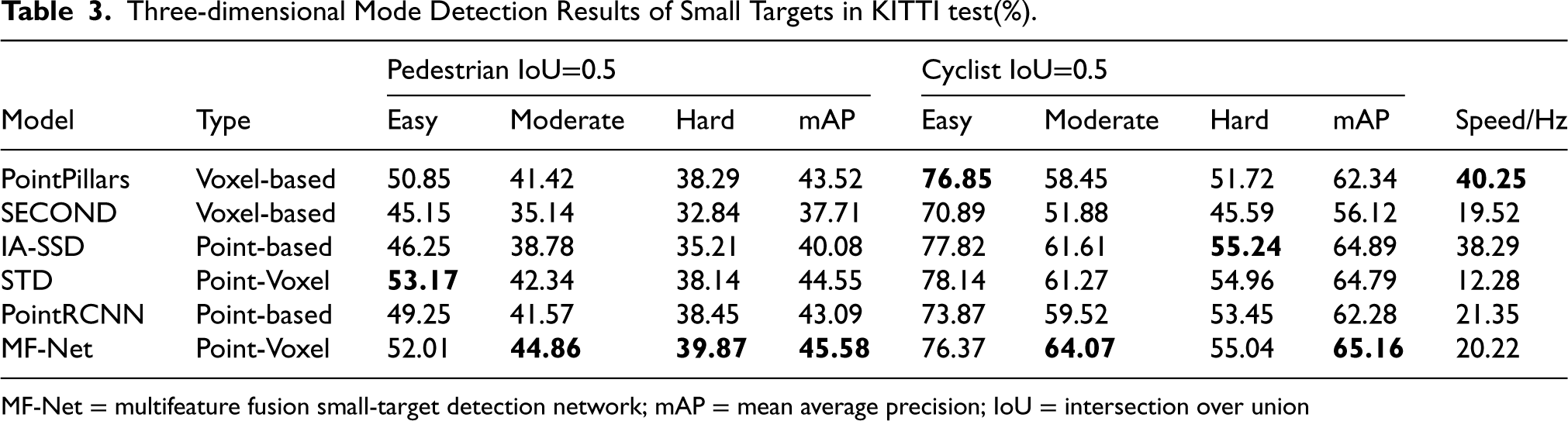
MF-Net = multifeature fusion small-target detection network; mAP = mean average precision; IoU = intersection over union
As shown in Table 3 and Figure 12, MF-Net generally demonstrated higher detection accuracy for small pedestrian and cyclist targets compared to other networks. Specifically, MF-Net achieved a 2.49% improvement in the mAP value for pedestrian detection and a 2.88% improvement for cyclist detection relative to PointRCNN, leveraging its multifeature fusion strategy. This performance enhancement was evident across all three difficulty levels, particularly notable in the easy (52.01%) and moderate (44.86%) categories, while improvements for severely occluded targets were more limited (39.87%). In terms of real-time performance, MF-Net operated at a speed of 20.22 Hz, slightly slower than PointRCNN (21.35 Hz) but still outperforming other networks, notably those like STD, which operated at only 12.28 Hz. Overall, MF-Net exhibits significant advantages in both the accuracy and speed of small-target detection, highlighting its potential value in practical applications.
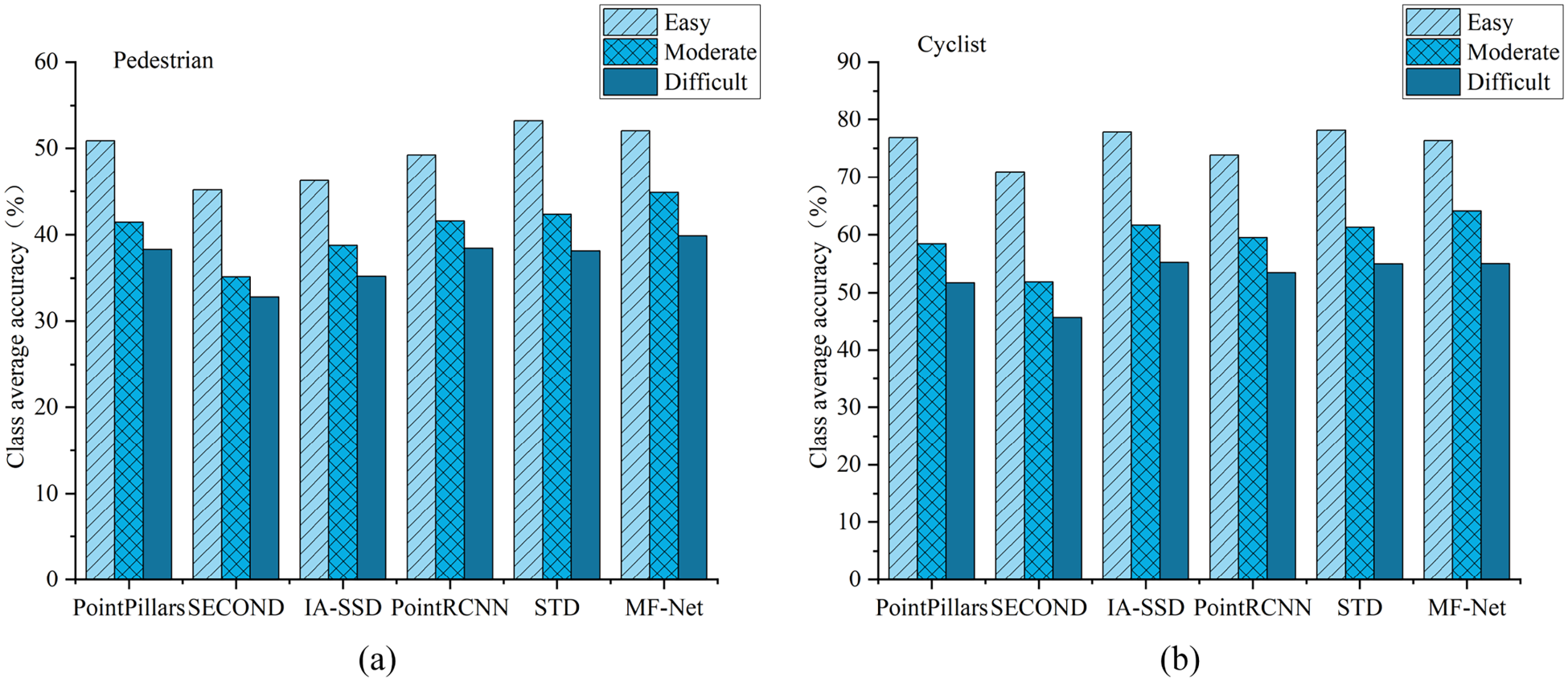
Comparing the detection accuracy of different networks for pedestrians and cyclists under different tasks. (a) Class average detection accuracy of pedestrians; (b) Class average detection accuracy of cyclists.
As illustrated in Figure 12, the detection accuracy of MF-Net for pedestrians and cyclists diminishes as the difficulty level increases. However, the rate of decline is notably slower compared to other models, indicating that MF-Net possesses a robust detection capability and strong scale adaptability for small targets. This advantage stems from MF-Net’s innovative approach of integrating point and column features, which enhances the feature representation of small targets.
To evaluate the effectiveness of the PS module, LFA module, and column feature extraction branch in the MF-Net network for small-target detection, we conducted ablation experiments on the KITTI test set, with results detailed in Table 4. The baseline model achieved an mAP of 43.09% for pedestrian detection and 62.28% for cyclist detection. After introducing only the PS module, the mAP increased to 43.95% for pedestrians and 63.23% for cyclists. Adding the LFA module further improved the mAP to 45.10% for pedestrians and 64.50% for cyclists. Finally, the model that combined the column feature extraction branch achieved the highest mAP of 45.58% for pedestrians and 65.16% for cyclists. These results clearly indicate that each proposed module significantly contributes to improving detection accuracy, confirming their effectiveness in enhancing small-target detection capabilities.
Results of Ablation Experiments (%).

mAP = mean average precision; PS = point-set sampling; LFA = local feature aggregation.
The experimental results demonstrate that each module enhancement in MF-Net contributes to improving the detection performance for small targets. Notably, the LFA module significantly boosts the detection accuracy of pedestrians and cyclists while reducing false detections by encoding echo strength feature information. The PS module, which combines D-FPS and SC-FPS, effectively retains small-target points and alleviates data imbalance. Additionally, the FPN extracts multiscale features of small targets to further enhance detection accuracy. To validate the effectiveness of MF-Net in detecting small targets, we utilize Open3D to visualize the KITTI test set data. As shown in Figure 13, MF-Net’s detection accuracy for pedestrians and cyclists decreases as detection difficulty increases, but this decrease is less pronounced than in other models. This suggests that MF-Net maintains stable detection capabilities and demonstrates strong adaptability to varying scales, especially for small targets. This robustness likely comes from MF-Net’s unique approach of combining point and column features, which enriches the feature representation for smaller objects. Figure 14 illustrates MF-Net’s detection results, with 3D bounding boxes marking detections: green for vehicles, blue for pedestrians, and yellow for cyclists, each labeled to show the target’s orientation. The side of each frame marked with crossed lines indicates the direction the target is facing.
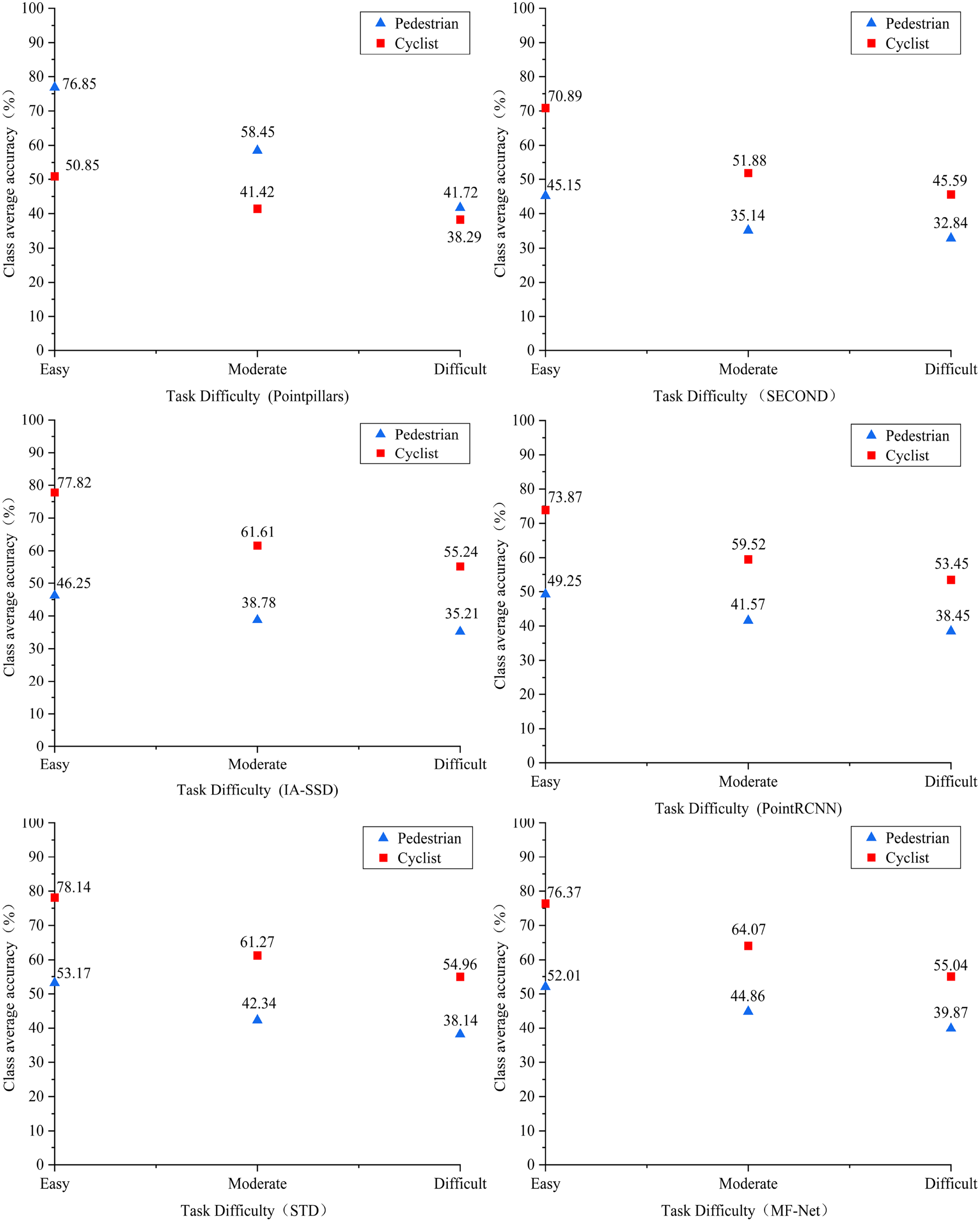
Detection accuracy of different networks under varying task difficulties. The red line represents the average detection accuracy of the cyclist while the blue line depicts the average detection accuracy of the pedestrian.

MF-Net detection results. (a) 2D image data under the current frame; (b) Corresponding point-cloud data. MF-Net = multifeature fusion small-target detection network; 2D = two-dimensional.
In this paper, the optimal detection models of MF-Net and the baseline network are used to detect the test set. The detection results of the two models are visualized, and the samples in three different scenes as shown in Figure 15 , Sample 1, Sample 2, and Sample 3 are selected, Sub-figure (a) is the scene graph of the current frame, sub-figure (b) is the effect graph of the PointRCNN network model detection, and sub-figure (c) is the effect graph of the effect image of MF-Net network model detection. Because pure point-cloud data were used and the relevant information could not be represented visually, the current frame scene graph captured by the front-view camera was used to compare the LIDAR detection results.

Comparison of visualization results of different samples.(a) Scene graph of the current frame; (b) Effect graph of PointRCNN network model detection; (c) Effect graph of MF-Net network model detection. MF-Net = multifeature fusion small-target detection network
In Sample 1, both models struggled to detect a heavily occluded and distant pedestrian within the orange circle. However, MF-Net demonstrated its superiority by successfully detecting two other pedestrians at long distances and accurately determining their motion directions. In contrast, PointRCNN missed these pedestrians due to the sparsity of the point cloud. Furthermore, PointRCNN incorrectly identified walls as pedestrians, while MF-Net avoided such misdetections.
In Sample 2, MF-Net successfully detected the partially occluded pedestrian target within the red elliptical box and accurately determined its direction of motion, whereas PointRCNN failed to detect the target. Furthermore, PointRCNN exhibited an over-reliance on geometric information and neglected echo strength information, leading to misidentifications. Specifically, it incorrectly classified the cylindrical iron obstacle and railing within the red elliptical box as pedestrians and vehicles, respectively, and overlooked the detection of two vehicles. In contrast, MF-Net avoided these errors.
In Sample 3, PointRCNN encounters significant challenges in detecting small targets, particularly pedestrians at long distances or under occlusion. The two pedestrians within the orange elliptical box have sparse point-cloud data due to their distance or severe occlusion, resulting in PointRCNN missing the detection and falsely identifying walls as pedestrians. Additionally, in the red elliptical box, the significant movement of a pedestrian causes its point cloud to merge with obstacles, deforming the contour and leading PointRCNN to mistakenly classify it as a cyclist. In contrast, MF-Net demonstrates its capability to accurately detect small targets and correctly determine their direction of movement.
To further validate the model’s effectiveness, a visualization analysis was conducted on the nuScenes dataset, as shown in Figure 16. In sample 1, the model successfully identified a pedestrian with occlusion; in sample 2, a pedestrian in front of a car on the left side was accurately detected; and in sample 3, despite the cyclist being partially occluded by a traffic light on the right side, the model was still able to effectively recognize the individual. These results further confirm the superiority of MF-Net in small object detection.

Visualization results under the nuScenes dataset. (a) Scene graph of the current frame; (b) Detection effect of the multifeature fusion small-target detection network (MF-Net) network model.
MF-Net integrates a multisampling strategy that combines SC-FPS and D-FPS, successfully retaining more small-target point clouds while effectively reducing false detections through LFA. Its multifeature fusion strategy enhances feature extraction capabilities and demonstrates excellent performance in detecting occluded targets. Although the model demonstrates promises, further optimization is necessary for effectively detecting small targets in sparse point clouds within complex scenes, and future work could optimize the feature extraction process using metaheuristic optimization algorithms. Overall, compared to PointRCNN, MF-Net shows higher accuracy and real-time performance in small-target detection, exhibiting greater robustness and adaptability.
A small-target detection network MF-Net is proposed to effectively reduce false and missed detection rates of small targets in deep learning by fusing point and column features. A semantically controlled farthest-point sampling algorithm, combined with a multisampling strategy, is introduced to uniformly sample the point set, thereby retaining a higher proportion of small-target points and significantly enhancing detection capabilities. The LFA module further refines the echo intensity of the point cloud and encodes the spatial position intensity, leading to a substantial reduction in false detections of similar obstacles. Furthermore, MF-Net incorporates a column extraction branch that transforms 3D point clouds into pseudo-images, employing a 2D CNN to capture small-target features across multiple scales. This enables the integration of point and column features via a multifeature splicing module, thereby enhancing the overall feature representation. Experimental results demonstrate that MF-Net achieves mAP values that are 2.49% and 2.88% higher than the baseline network PointRCNN for the pedestrian and cyclist categories, respectively, signifying a notable enhancement in detection accuracy.
In conclusion, MF-Net proposes a novel framework for small-target detection by integrating point cloud and pillar features, combined with innovative sampling strategies and the LFA module, effectively enhancing detection rates. However, although the model improves point feature extraction through an enhanced backbone network, its feature extraction performance is still less significant compared to pillar features. Additionally, in the feature fusion stage, the model simply combines point cloud and pillar features without fully considering their relative contributions, which limits its ability to detect small targets in sparse point clouds within complex scenes. Future work could incorporate attention mechanisms to assign adaptive weights to different features during the fusion process, thereby optimizing feature integration and further improving detection rates and robustness. Ultimately, we expect MF-Net to make a significant contribution to future vehicle-mounted LiDAR detection applications.
Footnotes
Funding
The author(s) received the following financial support for the research, authorship, and/or publication of this article: This study was funded by the Shandong Province Major Science and Technology Innovation Project (grant no. 2023CXGC010111) and the Small and Medium-sized Enterprise Innovation Capability Improvement Project (grant no. 2022TSGC2277).
Conflicts Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.