
Abstract
In recent years, there has been a growing trend in utilizing deep learning techniques to solve various NP-hard combinatorial optimization problems, mostly using deep neural networks to generate the solutions directly. In this work, we address a famous combinatorial optimization problem on graphs, the graph coloring problem (GCP), and propose novel ways that train and utilize deep node embeddings to facilitate the problem’s solving. Specifically, we propose to use Transformer to learn the correlation between nodes in graphs. The Transformer learns the node embeddings (feature vectors) such that nodes that might be in the same color in (near-)optimal solutions have close embeddings. To generate the labels, we use a typical GCP heuristic called Tabucol to solve each small training instance multiple times. In this way, the labels are generated more efficiently and robustly as compared to using an exact solver. We then apply the learned embeddings to guide several construction and searching algorithms for the GCP, including Tabucol. Empirical results show that all the algorithms could be improved by utilizing the learned node embeddings, and our methods generalize well to graphs on much larger scales than the training graphs.
Introduction
The graph coloring problem (GCP) is a well-known NP-hard combinatorial optimization problem. It was featured in the second DIMACS implementation challenge 1 as one of the most representative NP-hard problems, alongside the maximum clique and satisfiability problems. Given an undirected graph, the GCP aims to color all nodes with the minimum number of colors, constraining that any two adjacent nodes are in different colors. Graph coloring methods can be applied to study other models such as independent sets (Paschos, 2001), cliques (Li et al., 2018), and relaxation cliques (Zhou et al., 2021), and can also be applied to many real-world applications such as timetabling (de Werra, 1985), allocation problems (Chow & Hennessy, 1990; Wang et al., 2014), and human subjects (Kearns et al., 2006).
Recently, the rise of deep learning has provided some new perspectives for solving combinatorial optimization problems, resulting in many innovative and distinctive methods (Bai et al., 2021; Ireland & Montana, 2022; Kool et al., 2019; Nazari et al., 2018; Paulus et al., 2021). Graph neural networks (GNNs) are a kind of popular network structure for combinatorial optimization problems over graphs (Awasthi et al., 2022; Chen et al., 2024; Hudson et al., 2022; Khalil et al., 2017; Prates et al., 2019), including the GCP (Lemos et al., 2019; Li et al., 2022; Schuetz et al., 2022; Wang et al., 2023). These methods for GCP all use GNNs for node embedding. That is, using the trained GNNs to calculate the embeddings, i.e., feature vectors, of nodes in the graph. Then, they further use the obtained embeddings to try to solve the GCP directly. More details about the related studies are referred to in Section 2.
In this paper, we argue that using deep neural networks (DNNs) to solve the complex NP-hard GCP directly is very difficult. The power of deep learning lies in fitting the learned experiences from a large amount of labeled data, while traditional algorithms are powerful in constructing and searching with well-designed logic. We believe that compared to using DNNs to directly solve the problem, using experiences learned from DNNs to guide traditional algorithms is more appropriate and effective.
We suggest some new ways to use deep node embedding to boost traditional GCP algorithms. We propose to use the encoder of Transformer (Vaswani et al., 2017), a very popular and powerful deep learning model, to learn a low-dimensional representation (i.e. embedding) for each node in a graph, making nodes that should be in the same color (i.e. might be in the same color in optimal or near-optimal solutions) have close embeddings. The embeddings are then used to guide and boost traditional algorithms rather than solve the problem directly, which can make the model concentrate on learning the correlation between nodes in graphs. Note that general GNNs are usually homogeneous, assigning similar embeddings to connected nodes. However, the GCP has heterogeneity, meaning that connected nodes should be in different colors. This is also our reason for selecting Transformer, not GNNs, and the experiments also demonstrate the advantages of Transformer over GNNs.
Our Transformer encoder model is trained in a supervised manner. For each training graph, we generate a label to distinguish whether two nodes should be in the same color. A straightforward method to distinguish whether two nodes should be in the same color is to see whether they are in the same color in the optimal solution of the GCP instance. However, such a method has some disadvantages. On the one hand, a GCP instance might have diverse optimal solutions. Two nodes that are in the same color in an optimal solution might be in different colors in other optimal solutions. On the other hand, obtaining the optimal solution for each training instance is expensive. To address these issues, we propose to use a famous heuristic GCP algorithm, Tabucol (Hertz & de Werra, 1987), to generate 100 diverse optimal or near-optimal solutions for each training graph and use the 100 solutions as the labels for model training. Intuitively, two nodes that are assigned to the same color in most of the 100 solutions are more likely to be in the same color in an optimal solution.
To evaluate the performance of the trained model, i.e. the embeddings learned, we apply the embeddings to improve two kinds of GCP heuristics. One is the construction heuristics (Graf, 2021; Tabakhi, 2016), which constructs a solution by sequentially coloring each node. We select the classical Greedy heuristic (Welsh & Powell, 1967) that is widely used in graph coloring tasks and the Fastcolor algorithm (Lin et al., 2017) that can efficiently color massive graphs. The other is a searching heuristic (Alexiadis & Refanidis, 2016; Hussain et al., 2016; Niu et al., 2018), which maintains one or more solutions and explores the solution space to find better solutions. We select the famous and classical Tabucol algorithm (Hertz & de Werra, 1987) because it is the algorithm to generate the training labels in our methods and, more importantly, the most recent effective searching heuristics (Goudet et al., 2022; Moalic & Gondran, 2018; Zhou et al., 2018) use Tabucol as their local search components. Experiments on GCP instances with up to 4,000 nodes show that both the construction and searching heuristics could be improved under the guidance of the embeddings. Note that the number of nodes in the training graphs ranges from 100 to 200, indicating that our model exhibits good generality.
The main contributions of this work are as follows.
We suggest novel ways of using deep learning to solve the NP-hard GCP. We make the model concentrate on the correlation between elements, i.e. the nodes, in the problem. The model aims to learn the embeddings of the nodes, leading nodes that should be in the same color to close embeddings. We propose to use a heuristic rather than exact solvers to calculate multiple times to generate labels for model training, which can avoid spending a lot of time running exact solvers and can handle the issue that an instance might have multiple optimal solutions. We suggest new ways to apply the learned node embeddings to guide some construction and searching GCP heuristics, including Tabucol, the algorithm for generating labels. Results show that they can all be improved by applying the node embeddings, indicating the excellent performance of our methods. Our training model has excellent generalization capability that can be generalized to instances with much larger scales (e.g., instances with 4,000 nodes) than the training instances with 100 to 200 nodes.
Related Work
This section reviews studies that use deep learning to solve the GCP, which can be divided into supervised and unsupervised learning. The GNN-GCP algorithm (Lemos et al., 2019) is trained in a supervised manner. It regards the GCP as a decision problem and uses the embeddings to predict whether a graph can be colored by a given number of colors. Such a prediction is not precise, and thus the reference value of their results is uncertain. Moreover, they generate the labels by calling an exact GCP solver to solve more than 60,000 training instances, which is very time-consuming. Another supervised learning model for the GCP is incorporated in the DLMCOL algorithm (Goudet et al., 2022). To the best of our knowledge, DLMCOL (Goudet et al., 2022) is the only algorithm that combines deep learning with traditional algorithms to solve the GCP in the literature. However, the model in DLMCOL is only used to judge whether a solution might be improved to be a better solution by local search. Thus, deep learning might play a minor role in DLMCOL.
Unsupervised learning models usually regard the GCP as a node classification task and use different GNN models to handle the task, such as graph discrimination network (Li et al., 2022), physics-inspired GNN (Schuetz et al., 2022), and GraphSAGE (Hamilton et al., 2017). These methods investigate the potential of GNNs for solving the GCP, resulting in some novel frameworks. However, their models are trained in an unsupervised manner with only the rule that connected nodes should be assigned to different colors, which we believe is not enough for the models to solve the problem. In other words, their models only know how to avoid conflict without knowing how to minimize the coloring number. Moreover, these unsupervised learning models cannot well handle the problems in the GCP that there might be many equivalent (symmetric) node pairs in each graph and multiple optimal solutions for each graph, making the models inaccurate when facing these kinds of graphs.
Compared to the existing deep learning-based methods, our method assigns a more suitable task for the deep learning model, making it concentrate on the correlation between components of the problem, and the combination of the deep learning model and traditional algorithm results in more practical and effective solving methods.
Methodology
This section first presents the overall framework of our methods, then introduces the components used in the framework, including how to generate the training data, the Transformer encoder structure, the loss function, and how to apply the learned embeddings to improve various GCP heuristics.
General Framework
The framework of our proposed methods is summarized in Figure 1, where Figure 1(a) illustrates the training scheme and Figure 1(b) shows how to use the trained model.
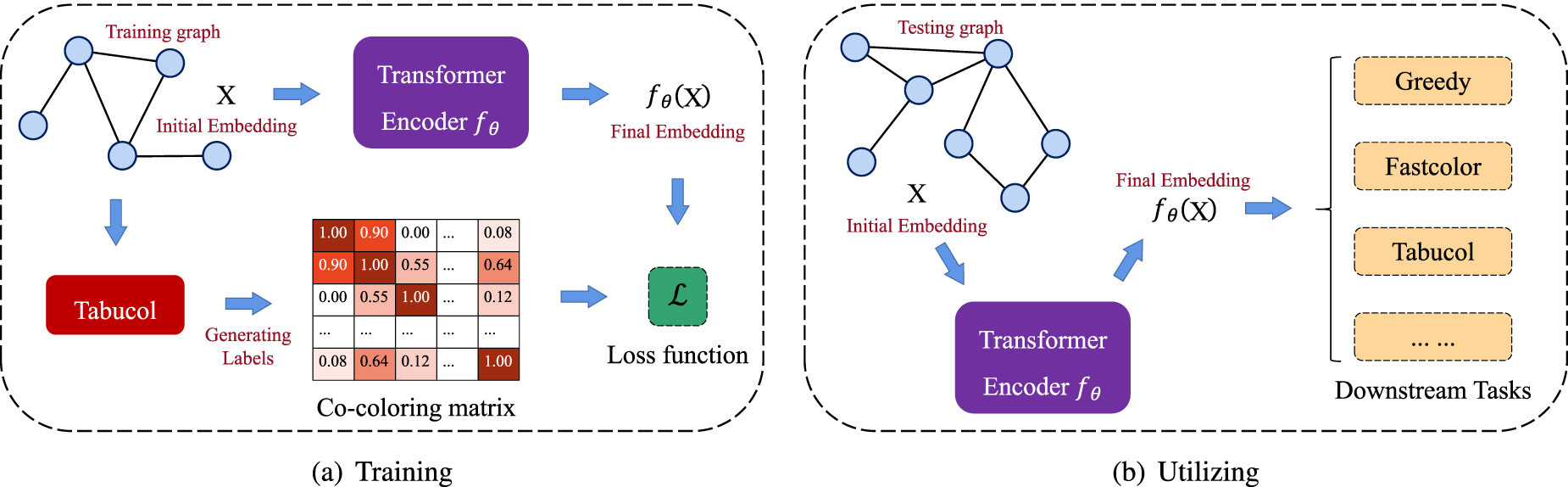
Overview of the proposed framework.
As shown in Figure 1(a), during the training process, the Transformer encoder receives an initial embedding matrix
As shown in Figure 1(b), we use the trained embedding network to obtain the node embeddings of a testing graph and use the embeddings to do downstream tasks, such as guiding or assisting the heuristic GCP algorithms (e.g., the Greedy, Fastcolor, and Tabucol algorithms in our experiments).
This subsection introduces the methods of generating the training instances and their initial embeddings.
Training Instances
Considering that the GCP instances might have various densities and how to learn the features of instances with different densities might be different, we randomly generate 10,000 graphs for each density
Generating the Initial Embeddings
The initial embedding is the only information and representation of each graph that inputs the encoder network. In other words, the encoder network can only distinguish the graphs by analyzing their initial embeddings. Therefore, we believe that the initial embedding of a graph should contain the information that is important for the GCP task, such as the structural information and the vertex degree information.
For each training graph, to embed the structural information, we use the DeepWalk (Perozzi et al., 2014) algorithm, a classic graph embedding method that preserves the topology information of nodes in the graph, to generate a feature vector
Transformer Encoder Structure
Due to the prevailing success of the Transformer in natural language processing and computer vision and its powerful encoding capability, we select the Transformer (Vaswani et al., 2017) as the embedding network in our model. Since the goal of our model is to learn the embeddings of nodes, we only need the encoder structure of the Transformer.
For an input graph
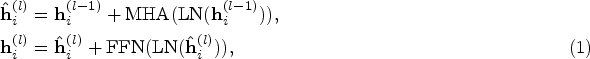
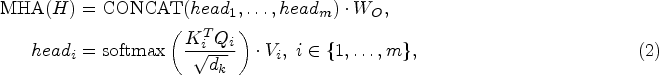
Before introducing the loss function in our model, we first provide some necessary definitions. Let
Intuitively, we wish
To address this issue, we set two bounds,
Based on the above definitions, we design two terms in the loss function. The first considers that the distance between
Then, the triple loss function
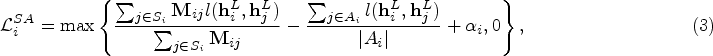
The second term in the loss function considers that the distance between
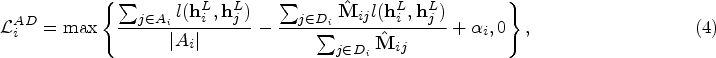
In the end, the entire loss function

Given a testing graph, our trained model can generate the embeddings for the nodes. The second problem we need to handle is how to use the node embeddings to improve various GCP algorithms. We propose to use the
For evaluation, we select some representative GCP heuristics, including construction algorithms, the classical Greedy algorithm (Welsh & Powell, 1967) and Fastcolor (Lin et al., 2017), as well as the Tabucol (Hertz & de Werra, 1987) local search algorithm. In the following, we first introduce the process of these heuristic baselines and then introduce how to use the embeddings to boost the algorithms.
Greedy and Fastcolor
The coloring process of the Greedy and Fastcolor algorithms is similar. Both of them sequentially color a node in each step. The coloring orders of the nodes in the two algorithms are determined according to their degrees and saturation degrees, respectively. Each node is colored with the minimum possible color, i.e. the color with the minimum index. Since there exists randomness in finding the cliques and the reduction process in Fastcolor, it restarts the entire procedure once finishing coloring the graph to find better results until the cut-off time is reached.
To apply the embeddings to a construction GCP algorithm, we do not change the rule of ordering the coloring nodes but use the
Tabucol
In each round, Tabucol tries to color the graph with
To apply the embeddings to Tabucol, we increase the probability of selecting a move
In summary, the embeddings learned by our model are used to guide the GCP heuristics without changing their original frameworks and procedures. As a result, the heuristics can utilize the information of the learned embeddings to assign appropriate colors to the nodes. In particular, the embeddings can improve Tabucol, indicating that our model, which is trained by Tabucol, can surprisingly enhance the teacher. Moreover, we offer some ways of utilizing the learned embeddings. Actually, one can design appropriate methods to utilize the embeddings according to the tasks and situations.
Experiments
This section presents experiments to evaluate the performance of our model and performs ablation studies to evaluate the efficacy of the components in our model.
Experimental Setup
Testing
We test our model by using the output embeddings to guide some baseline GCP heuristics, including Greedy (Welsh & Powell, 1967), Fastcolor (Lin et al., 2017), and Tabucol
2
(Hertz & de Werra, 1987) (see details in Section 3.5). The experiments were run on a server using an Intel
The computational results contain two groups. The first presents a comparison with the state-of-the-art deep learning based algorithms, GDN (Li et al., 2022), PI-SAGE (Schuetz et al., 2022), and GNN-1N (Wang et al., 2023), all of them show better performance than the GNN-GCP algorithm (Lemos et al., 2019). The second group compares the heuristic baselines and their improved versions with the embeddings. The testing instances for this group consist of the 38 most difficult DIMACS coloring challenge benchmarks 3 for the GCP, which are the union of the GCP instances used in the best-performing GCP heuristics (Goudet et al., 2021; Moalic & Gondran, 2018). Their number of nodes ranges from 125 to 4,000, and densities range from 0.03 to 0.97. They are also widely used in some other GCP heuristics (Goudet et al., 2021, 2022; Zhou et al., 2018). The testing instances for this group contain some common and hard instances with up to 19,717 nodes used in the original paper (see Table 1).
Comparison Between Tabucol+Embed and Tabucol with Deep Learning Based Algorithms.
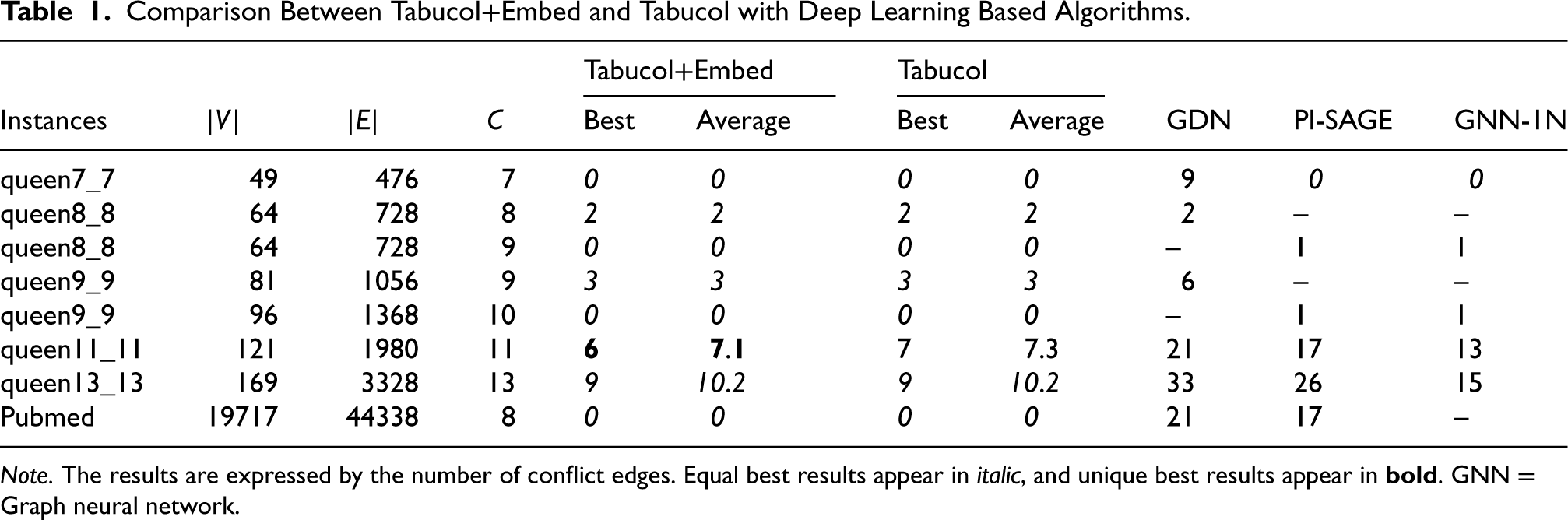
Comparison Between Tabucol+Embed and Tabucol with Deep Learning Based Algorithms.
Note. The results are expressed by the number of conflict edges. Equal best results appear in italic, and unique best results appear in
Our network has
As described in Section 3.5, we use the
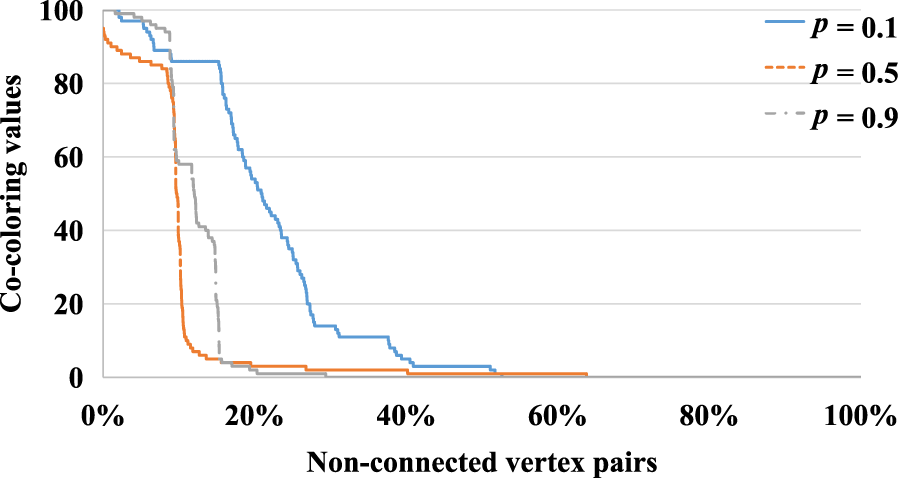
Distribution of the co-coloring values in sampled training graphs with various densities.
We denote the algorithms that use the embeddings to improve Greedy, Fastcolor, and Tabucol as Greedy+Embed, Fastcolor+Embed, and Tabucol+Embed, respectively. In the following, we first compare Greedy+Embed with Greedy, Fastcolor+Embed with Fastcolor, and Tabucol+Embed with Tabucol. For each instance, Greedy(+Embed) calculates once, and the other four algorithms with randomness in their searching process calculate 10 times with different seeds. Due to the difference between our machine and the machine used in Lin et al. (2017), we set the cut-off time to 90 seconds for Fastcolor(+Embed). We set the cut-off time to 5,000 seconds for Tabucol(+Embed).
The comparison results of Greedy vs. Greedy+Embed, Fastcolor vs. Fastcolor+Embed, and Tabucol vs. Tabucol+Embed are shown in Table 2. Note that for each pair of algorithms, equal best results appear in italic, and unique best results appear in
Comparison Between the Baselines and their Improved Algorithms Guided by the Embeddings.
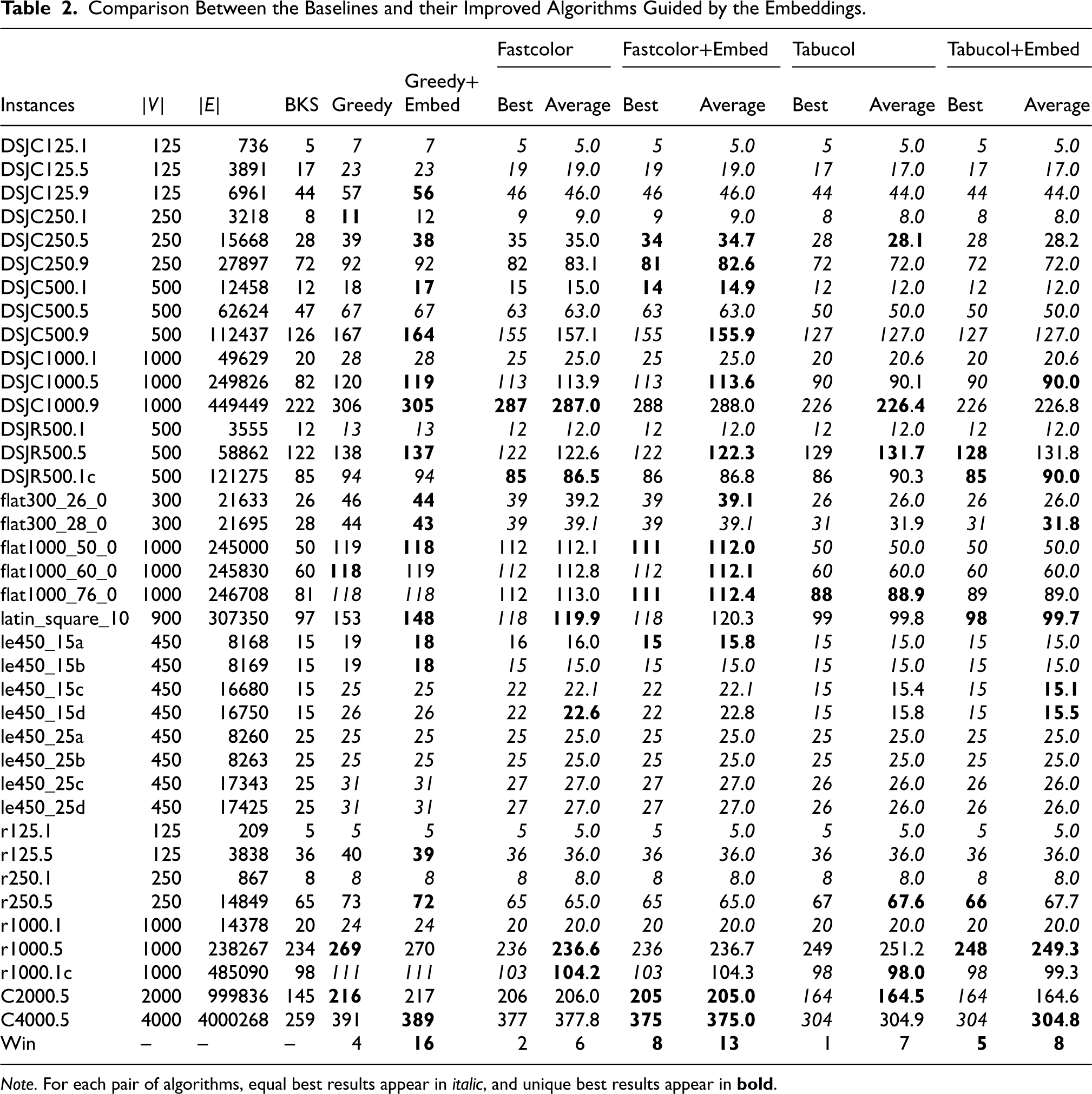
Comparison Between the Baselines and their Improved Algorithms Guided by the Embeddings.
Note. For each pair of algorithms, equal best results appear in italic, and unique best results appear in
From the results, we can observe that Greedy+Embed yields better (resp. worse) results than Greedy in solving 16 (resp. 4) instances. The best solutions of Fastcolor+Embed are better (resp. worse) than Fastcolor in solving 8 (resp. 2) instances. The best solutions of Tabucol+Embed are better (resp. worse) than Tabucol in solving 5 (resp. 1) instances. The average solutions of Fastcolor+Embed and Tabucol+Embed are also better than the baselines. The results indicate that both construction and searching GCP heuristics can be improved with the guidance of the embeddings. In particular, the embeddings can even boost Tabucol, helping it escape from local optima and find better results, indicating that the “student” can surprisingly improve the “teacher,” which is a really exciting result. Moreover, the embeddings work well in solving instances with much larger scales than the training instances, indicating the excellent generalization capability of our model.
Then, we compare Tabucol+Embed and Tabucol under a time limit of 5 minutes with deep learning based algorithms, GDN, PI-SAGE, and GNN-1N (their results are from the literature). The results are shown in Table 1, where column
Since the Greedy algorithm is fast and deterministic, we perform ablation studies based on this algorithm. We first analyze the performance of Greedy+Embed with different
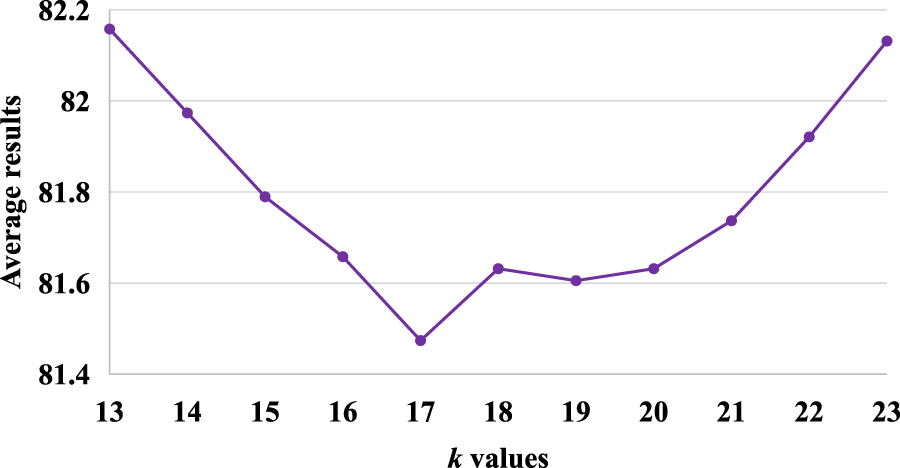
Average coloring results in 38 tested graph coloring problem (GCP) instances of Greedy+Embed with different
Then, we perform four ablation studies to analyze the components in our model in Figure 4. The first study aims to analyze the method of generating the initial embeddings by comparing Greedy+Embed and Greedy with two variants, Greedy-NoDegree and Greedy-Rand. Greedy-NoDegree only uses the features generated by Perozzi et al. (2014) as the initial embeddings without concatenating the degree features. Greedy-Rand randomly generates the initial embeddings. We use Greedy+Embed, Greedy-NoDegree, and Greedy-Rand to calculate the 38 testing instances with
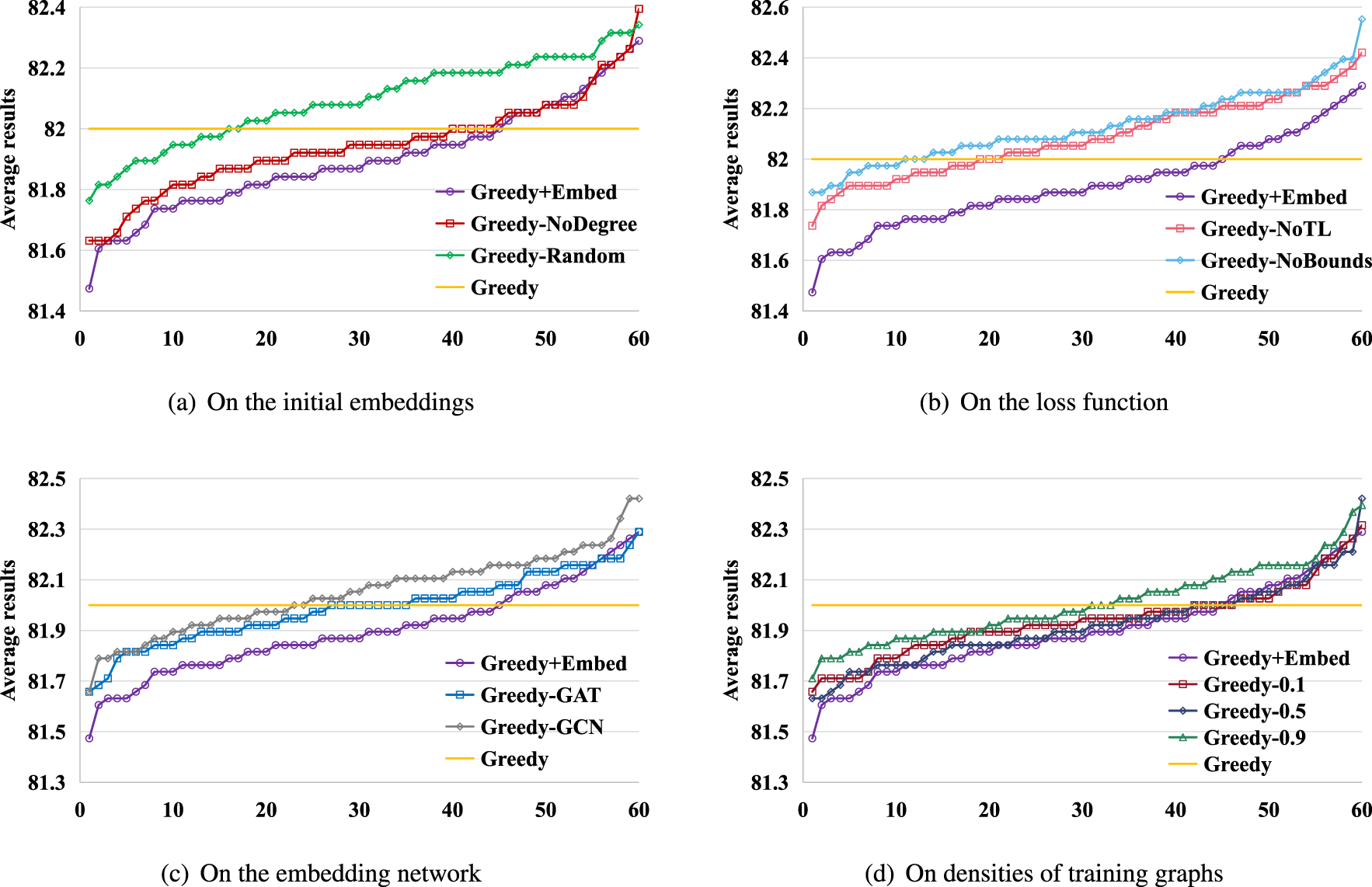
Ablation studies by comparing Greedy+Embed, Greedy, and their variants. The results are expressed by the average coloring results in 38 tested graph coloring problem (GCP) instances.
We use the same method to perform the other three groups of ablation studies. The second study aims to analyze the design of the loss function and also involves two variants, Greedy-NoTL and Greedy-NoBounds. Greedy-NoTL does not use triplet metric learning but only uses the co-coloring values to weight the distances of the node pairs with clear correlation, i.e.
The third study is to analyze the embedding network we choose, i.e. the Transformer encoder layer. We use the graph convolutional network (GCN) (Kipf & Welling, 2017) and graph attention network (GAT) (Velickovic et al., 2018) as the embedding network and obtain two variants, Greedy-GCN and Greedy-GAT. The comparison results of Greedy+Embed, Greedy-GAT, Greedy-GCN, and Greedy are shown in Figure 4(c). The results show that Greedy+Embed significantly outperforms Greedy-GAT and Greedy-GCN, which might be owing to the conflict between the homophily of GCN and GAT and the heterophily of the GCP. This is also the reason we did not choose GCN and GAT but the Transformer model.
The last study is to analyze the influence of the densities of training graphs on the performance of the model in solving the testing instances. We denote Greedy-0.1, Greedy-0.5, and Greedy-0.9 as variants of Greedy+Embed that only use the model trained on graphs with densities of 0.1, 0.5, and 0.9, respectively, to solve the testing instances. The comparison results of Greedy+Embed, Greedy-0.1, Greedy-0.5, Greedy-0.9, and Greedy are shown in Figure 4(d). We can observe that Greedy+Embed outperforms the three variants, and Greedy-0.9 shows the worst performance among the three variants. This is because the number of instances with densities close to 0.9 is the smallest among the 38 testing instances. The results indicate that training the model based on instances with different densities is effective.
Moreover, the results of Greedy+Embed and Greedy in the four groups of ablation studies show that with most
In this work, we propose to incorporate supervised deep learning methods to solve the NP-hard GCP. The GCP itself is very difficult, especially for DNNs. This paper provides some new perspectives for using DNNs to help solve the problem and obtains some empirical improvements.
We propose to focus the deep learning model on learning the correlation between nodes in each graph. The model aims to learn the node embeddings, making nodes that should be in the same color have close embeddings. Then, we propose to use a heuristic, Tabucol, to solve each training instance multiple times to obtain a co-coloring matrix that indicates the correlation between nodes. The co-coloring matrix is used as a label to train the model to distinguish what kind of node pairs should be in the same color. We use triplet metric learning to improve the robustness of our model. Finally, we suggest using the embeddings to guide and boost the GCP heuristics by applying the
In future work, we will continue to investigate the potential of deep node embeddings in solving other combinatorial optimization problems.
Footnotes
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation of China (62076105) and Microsoft Research Asia (100338928).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.