
Abstract
The current trend in recommendation services is prioritizing personalization to ensure accurate recommendations. This study aims to enhance the user-based collaborative filtering algorithm for cross-domain recommendations by exploiting the similarity in user cognition across multiple domains. The research suggests three steps: (i) gathering user feedback from various domains to represent their cognition, (ii) constructing a user cognition-based collaborative filtering model for multi-domain recommendations, and (iii) generating recommendations in the target domain. The experimental results demonstrate that the proposed model outperforms all baseline methods. In particular, the proposed method is better than the baselines, approximately 12% up to 16%, regarding mean average precision and normalized discounted cumulative gain metrics.
Introduction
In modern web applications, recommendation systems (RSs) are extensively utilized in various areas, such as video sharing on YouTube, e-commerce on Amazon, and social networking on Facebook, to address the issue of information overload (Ricci et al., 2010). Among the existing RS techniques, collaborative filtering (CF) is the most promising approach (Nguyen et al., 2020a, 2020b; Ricci et al., 2010; Vuong Nguyen et al., 2021). The fundamental principle of CF is to identify the most appropriate products for a specific user based on the preferences of other users with similar interests. Many effective RS techniques have been proposed in recent years, particularly those relying on CF (Nguyen et al., 2020c, 2021).
However, most real-world applications encounter the issue of data sparsity, as only a limited number of users provide ratings or reviews for items (Ricci et al., 2010). As a result, the accuracy of recommendations generated by CF algorithms is reduced. CF-based RSs face data sparsity problems to varying degrees (known as the cold-start problem), particularly for new users or products (Duan et al., 2022; Zhao et al., 2022). This issue can lead to over-fitting during CF model training, which can significantly impact the accuracy of recommendations. To address this problem, two approaches have been developed. The first method involves intelligently eliciting user preferences, while the second method involves inferring user preferences using other data. A promising solution under the second approach is the cross-domain recommendation, which uses user preferences and item features from different but related domains to make recommendations in the target domain (Yu et al., 2019; Zhu et al., 2020). Cross-domain RSs (CDRSs) have emerged to overcome data sparsity issues by utilizing relatively richer information, such as user/item information, thumbs-up, tags, reviews, and observed ratings, from the source domain to improve recommendation accuracy in the target domain (Berkovsky et al., 2007). For example, an RS can recommend books to users based on their movie reviews because a common user in multiple domains is likely to have similar preferences.
CDRSs are RSs that provide personalized recommendations by leveraging data from multiple domains or sources (Fernández-Tobías et al., 2019; Yu et al., 2019; Zhang et al., 2022). These systems aim to overcome the limitations of traditional RSs that are limited to a single domain. CDRSs are currently being studied in various domains for different purposes, such as cross-system personalization in user modeling (Hu et al., 2019; Yu et al., 2019; Yuan et al., 2019), practical applications of transfer learning techniques in machine learning (Fernández-Tobías et al., 2019; Li & Tuzhilin, 2020; Zhang et al., 2022), and alleviating the lack of user preference data in RSs. Cross-domain CF is a recommendation technique in a CDRS that leverages user and item data from multiple domains to make recommendations in a target domain. This method addresses the cold-start problem by utilizing the data from other domains where more user and item data are available. The basic idea behind CDCF (Liu et al., 2022) is to identify correlations and similarities between the different domains, which allows the algorithm to transfer knowledge from one domain to another. CDCF has been successfully applied in various domains, such as music, movies, and e-commerce. The main advantage of this approach is that it allows for better personalization, even for new users or items, by using information from other domains. However, challenges still need to be addressed, such as domain adaptation and feature selection, to ensure the effectiveness and efficiency of CDCF (Natarajan et al., 2022; Nguyen & Jung, 2023; Yu et al., 2022; Zhang et al., 2022).
This research aims to extend the CF algorithms to overcome the difficulties of CDRSs stated above. This requires transforming the CF problem into a multi-task learning problem, in which similarities between multiple domains are utilized to handle the issue (Krohn-Grimberghe et al., 2012; Singh & Gordon, 2008). Remarkably, multi-domain settings often exhibit significant similarities in online user behavior. For instance, similar products from book and fashion domains are recommended when users rate or like any item in the movie domain of the SABRE platform (Nguyen & Jung, 2020). Clicking on these recommended products implies that they are similar items in the auxiliary domains of users in the source domain, which helps gather cognitive similarity data of users across different domains. Hence, in multiple-domain scenarios, we can exploit the cognitive similarity between users across different domains to define the group of nearest neighbors for the target user. The idea is to represent the target user’s cognition with similar items by the set of similar neighbors, which can be obtained by combining the domain-specific and domain-shared cognitive similarities. This approach can help to overcome the data sparsity problem and improve the accuracy of recommendations in CDRS. To enhance the accuracy of the clustering method for similar users from multiple domains, the user cognition-based CF (UCCF) model is presented for a top-N cross-domain recommendation task. UCCF is based on the adaptive K-nearest-neighbor (KNN) framework, which identifies a set of nearest neighbors who are sufficiently similar to the active user based on cognitive similarity data across multiple domains. To collect this data, a crowdsourcing platform called SABRE is employed (Nguyen & Jung, 2020), where users can provide explicit and implicit feedback on similar items from various domains. In summary, the contributions of this research are as follows.
Deploy the SABRE
2
platform–the crowdsourcing platform that collects cognitive similarity data from users across multiple domains such as movies, books, tourism, fashion, etc. Proposing UCCF models for clustering users across multiple domains without considering the knowledge transfer between domains.
The organization of this paper is as follows. The subsequent section presents a literature review on CDRSs using CF and prior efforts to enhance the performance of the user-based CF approach. Section 3 outlines the cross-domain crowdsourcing platform for recommendation services based on user cognition. The experimental results and evaluation are presented in Section 4. In Section 5, we summarize the results of the study and propose future research directions.
Related Work
The earliest studies on CDCF were mentioned in several works such as Berkovsky et al. (2007), Li et al. (2009a), and Li et al. (2009b). These studies proposed various methods for aggregating rating vectors of users from different domains, which can be categorized into neighborhood-based models and latent factor models. The former assumes shared users or items in different domains, while the latter does not require shared users or items. One specific example of the neighborhood-based CDCF (N-CDCF) approach is introduced in Berkovsky et al. (2007), which estimates the similarity between users or items. N-CDCF can be divided into the user-based nearest neighbor (NCFU) and item-based nearest neighbor (NCFI) models. In this paper, we focus on improving the user-based method and provide a detailed review of the N-CDCF-U model. The following section will present a discussion of related works on CF CDRSs and existing studies on enhancing the performance of the user-based collaborative filtering approach. Additionally, we will introduce a cross-domain crowdsourcing platform for recommendation services based on user cognition and report the experimental results and evaluation in later sections.
The study in Berkovsky et al. (2007) presents the problem formulation for N-CDCF-U. The formulation involves
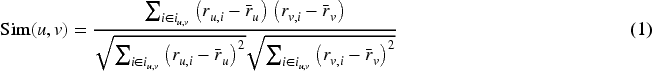
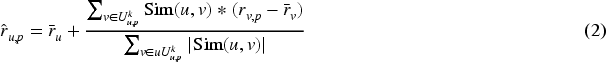
In addition to the aforementioned approach, the traditional matrix factorization (MF) model is also utilized for handling CDCF problems. In Koren et al. (2009), the Funk-SVD model is introduced as the most commonly used MF model for a single-domain collaborative filtering RS. The main idea of this model is to map users and items into a joint latent factor space of dimension

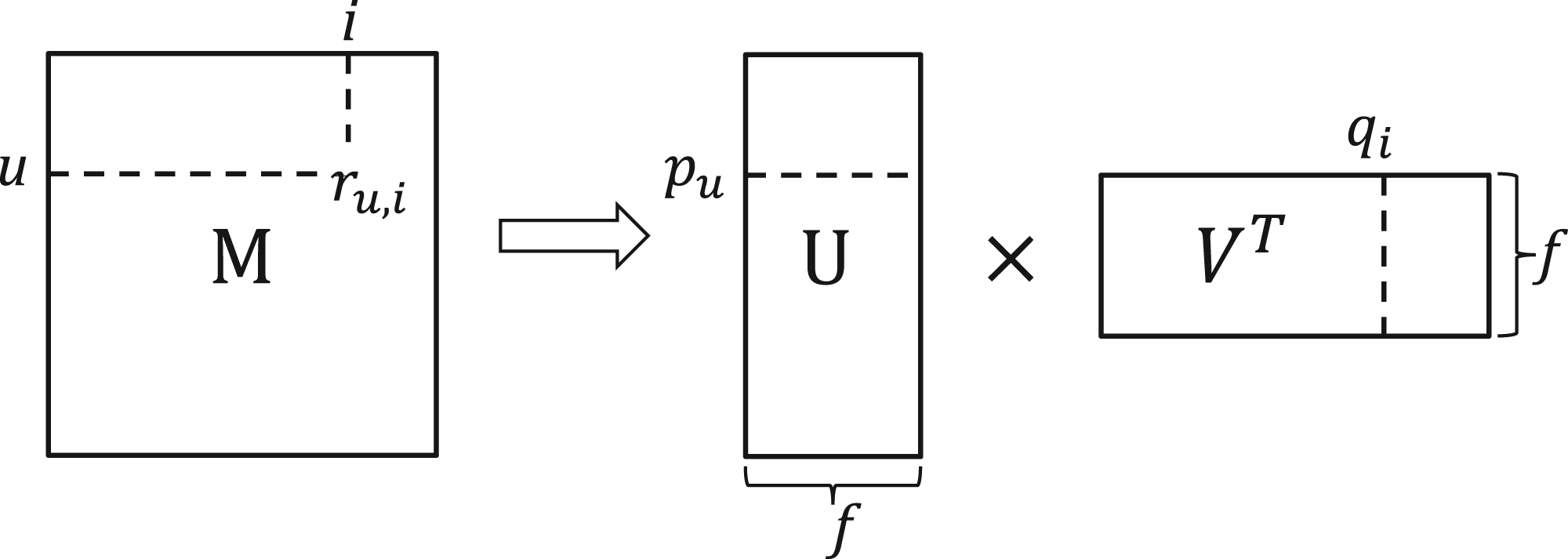
Illustrate the decomposition of the Funk-SVD model.
To learn the latent vectors, the Funk-SVD model minimizes the regularized squared error on the set of known ratings, which is expressed by the following equation:
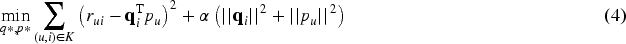

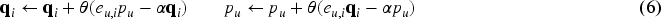
In a different study, the cross-domain triadic factorization model (Hu et al., 2013) was utilized, which considers the entire relationship between users, products, and domains to effectively capture user preferences for items across different domains. A three-order tensor is employed to represent the user–item–domain interactions, and a tensor factorization approach is used to factorize users, items, and domains into latent feature vectors. The user–item–domain rating is generated by taking the element-wise product of the latent factors for user, item, and domain. However, the temporal complexity of tensor factorization is exponential, with a computational cost of
The transfer by collective factorization (TCF) model presented in Pan et al. (2011) aims to address the issue of data sparsity in numerical ratings by leveraging knowledge from auxiliary domains. This model assumes that the latent feature matrices for user–item pairs are identical and uses both numerical rating data and binary like/dislike auxiliary data. Unlike the code book transfer model (Li et al., 2009a) and the rating matrix generative model model (Li et al., 2009b), which do not share latent features, the TCF model shares these features and analyzes data-dependent information using two inner matrices. However, this approach is only suitable for a single auxiliary domain and requires the alignment of users/items between the target matrix (rating) and the auxiliary binary matrix (like/dislike).
Assuming the set of
The research aims to provide personalized recommendations for users in each domain based on their preferences. The problem is formulated by introducing a model based on general similarity in a single domain. This model uses a function
In this user-based KNN problem, we set parameter


The idea of CDRS involves exploiting the similarity between common users, which are overlapping users interacting with different items across multiple domains, based on their cognition of comparable items. However, the primary challenge is establishing a group of nearest neighbors for the target user based on cognitive similarity across different domains. As a result, we can represent the cognition of the target user using a set of similar neighbors. In a single domain, personalized neighbors for each user are typically determined based on shared cognitive similarities, known as domain-specific cognitive similarities. However, in multiple-domain scenarios, we aim to merge domain-specific cognitive similarity with cognitive similarities shared between domains, referred to as domain-shared cognitive similarity. The proposed model is depicted in Figure 2 and formulated as follows:
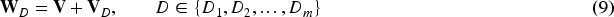
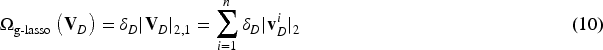

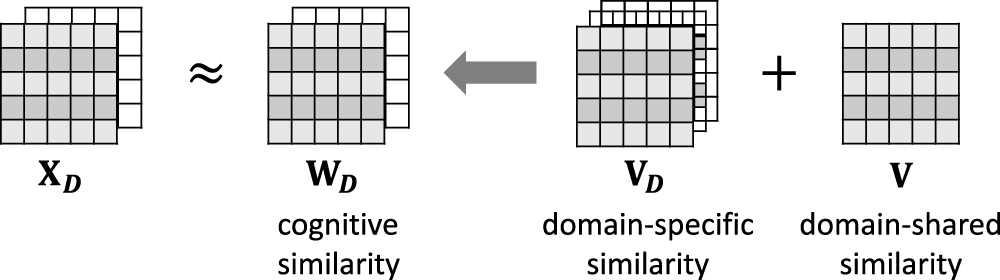
Ilustration of the user cognition-based collaborative filtering (UCCF) model.
Finally, the cognitive similarity can be integrated into a loss function with the least square loss, which is defined by the following equation:

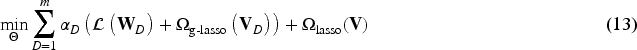
This section provides an overview of our feedback collection platform for our experiment. We outline the platform’s architecture and functionality, detailing how it efficiently gathers and processes user feedback to inform our analysis. The platform’s user interface, data handling capabilities, and integration with other experimental tools are thoroughly explained to illustrate its robustness and reliability. Following this, we detailed SABRE’s initial dataset, describing its composition, sources, and the preprocessing steps undertaken to ensure data quality and consistency. This includes information on the types of data collected and the specific features extracted for our study. We also present the dataset collected from SABRE during the experiment, highlighting the data’s dynamic aspects as it evolves with user interactions. Finally, we discuss the experimental results, presenting a thorough analysis of the data obtained through our feedback collection platform. We provide quantitative and qualitative evaluations to demonstrate UCCF’s performance.
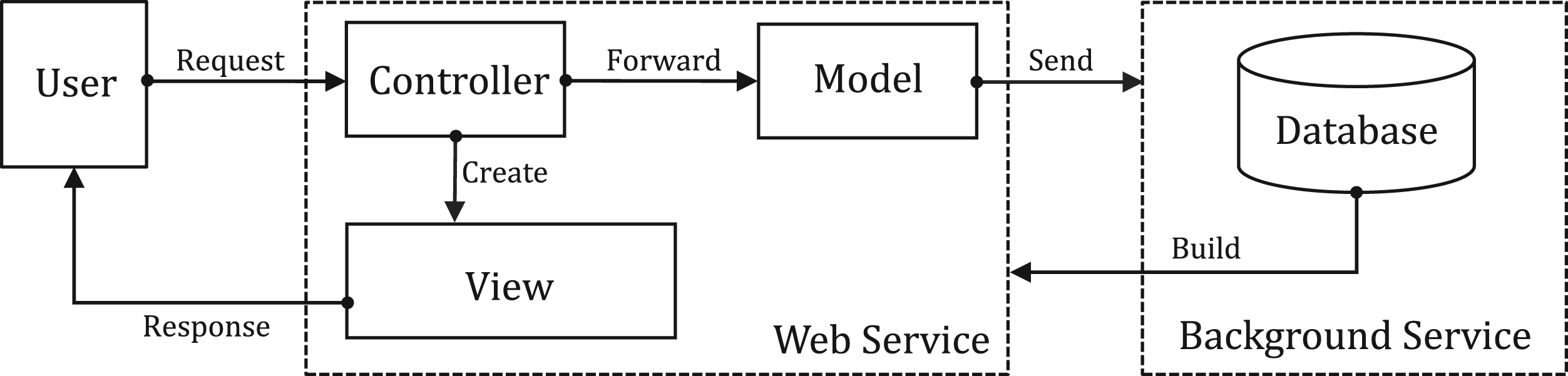
Architecture of SABRE crowdsourcing platform.
The SABRE platform was created using Java 8 and the Spring framework. Its architecture follows the MVC model, which includes both web and background services. On the web service side, we use Tomcat 11, while MySQL is used for the background service. All user data is collected and stored in the MySQL database and then extracted into CSV files for our experiments. A SABRE platform’s architecture diagram can be found in Figure 3. Our goal with the SABRE platform is to gather user cognition effectively, so we prioritized designing a user-friendly interface that individuals with varying skill levels could use. To achieve this, we consulted the essential guide for user-interface design outlined in Galitz (2007). Interact with SABRE, users only need to remember URLs rather than a predefined sequence, and the platform offers alerts and roll-back methods in case of errors. Additionally, users can quickly resume their work if they need to stop abruptly. The simplicity of SABRE was our primary strategy in its design. Hence, we applied three golden rules to achieve this and described them as follows.
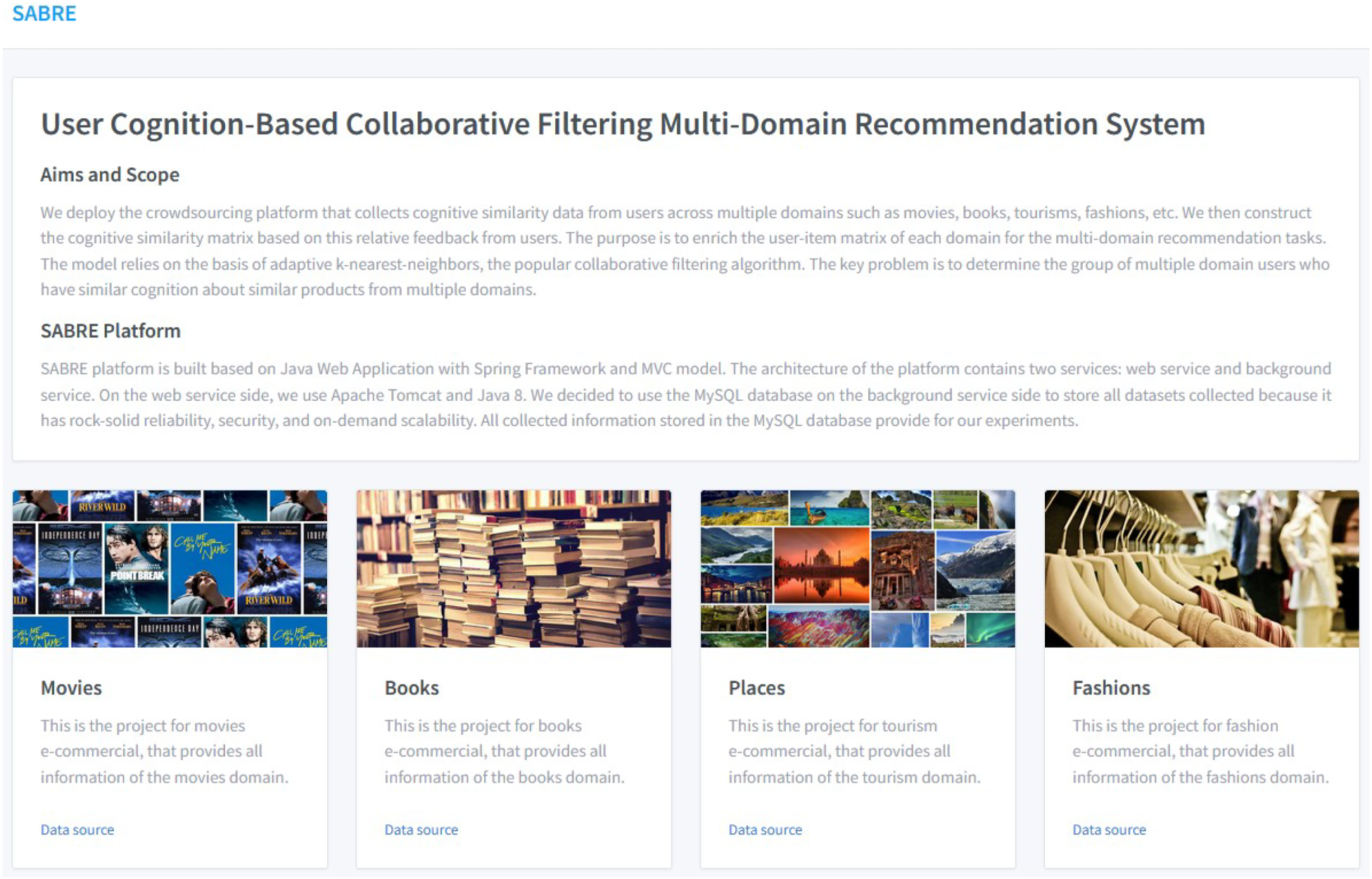
The homepage of the SABRE cross-domain crowdsourcing platform.
An example in the movie domain of the SABRE platform with the variant of pagination technique, called Infinite Scrolling.
In order to assess the efficacy of the proposed approach, we utilized a dataset obtained from SABRE. Initially, we imported data from Kaggle and IMDB to the SABRE platform as an initial dataset, consisting of user, item, and rating of the Movie, 3 Book, 4 and Fashion 5 domains. Table 1 displays the detailed initial dataset. Cognitive similarity data for users was gathered on the SABRE platform by allowing them to provide implicit feedback, such as clicking on suggested products or similar products. An illustration of user interaction on SABRE is presented in Figure 6. To ensure a reliable evaluation, we removed all user data containing less than 10 feedbacks. The final dataset collected from SABRE contained around 7,000 interactions from 3,210 users.
Evaluation
To evaluate the effectiveness of our proposed model, we compared the top recommendations with the actual behavior of users (i.e., clicking on similar products). Our experiments were assessed using two metrics, namely, mean average precision (MAP) and normalized discounted cumulative gain (NDCG), with
Description of Datasets.

Description of Datasets.
The MAP measure takes into account the relative order of the relevant items in the recommendation ranking by generating the precision score after each one is discovered as follows:
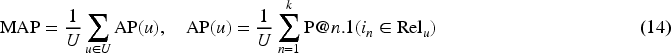

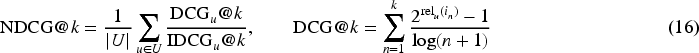
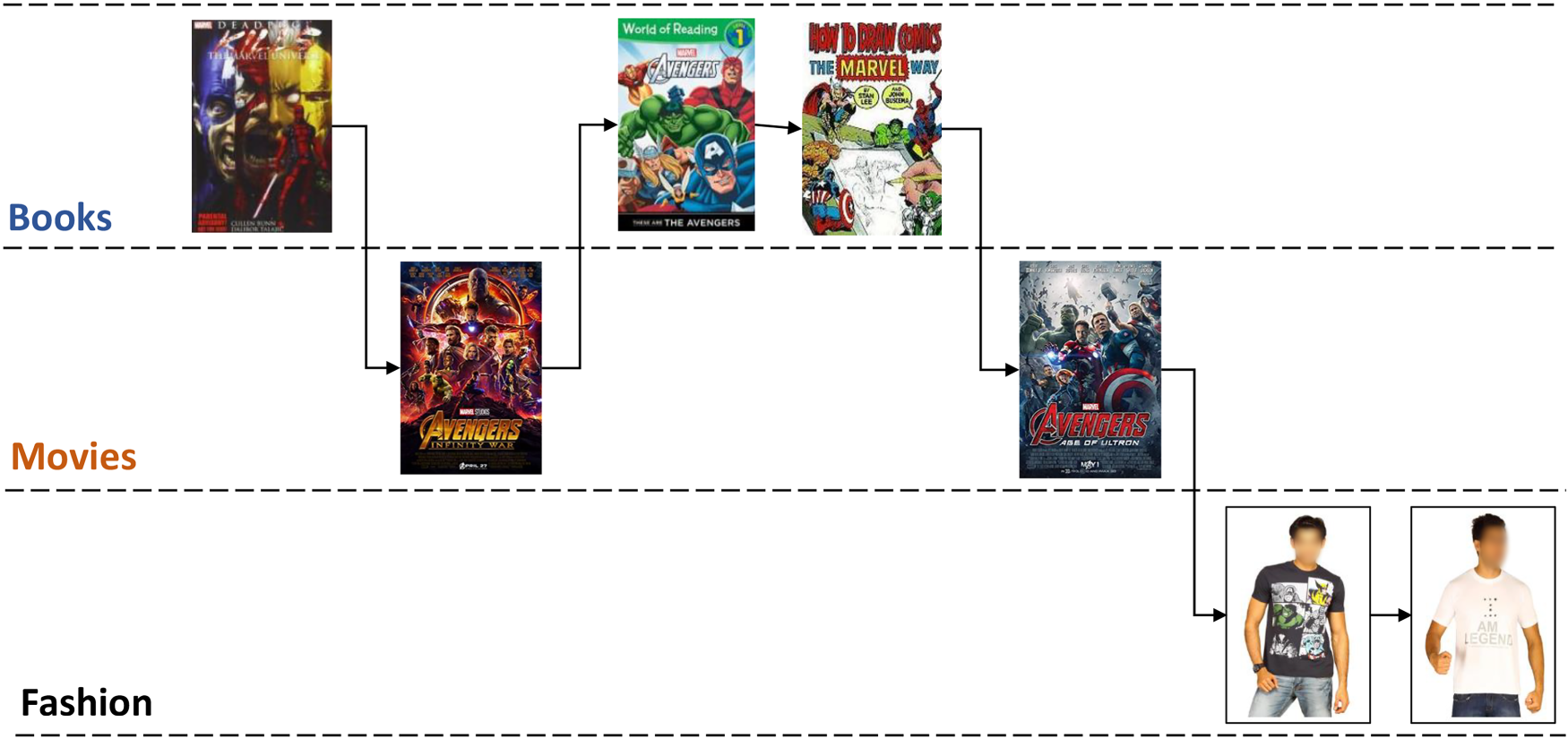
An example of interactions of users across multiple domains in the SABRE platform.
The Prediction Performance of the Proposed Model (UCCF) and mrSLIM, mrBPR, PopRank, NCDCF-U on Three Domains. The Best Results are in the Bold Text.
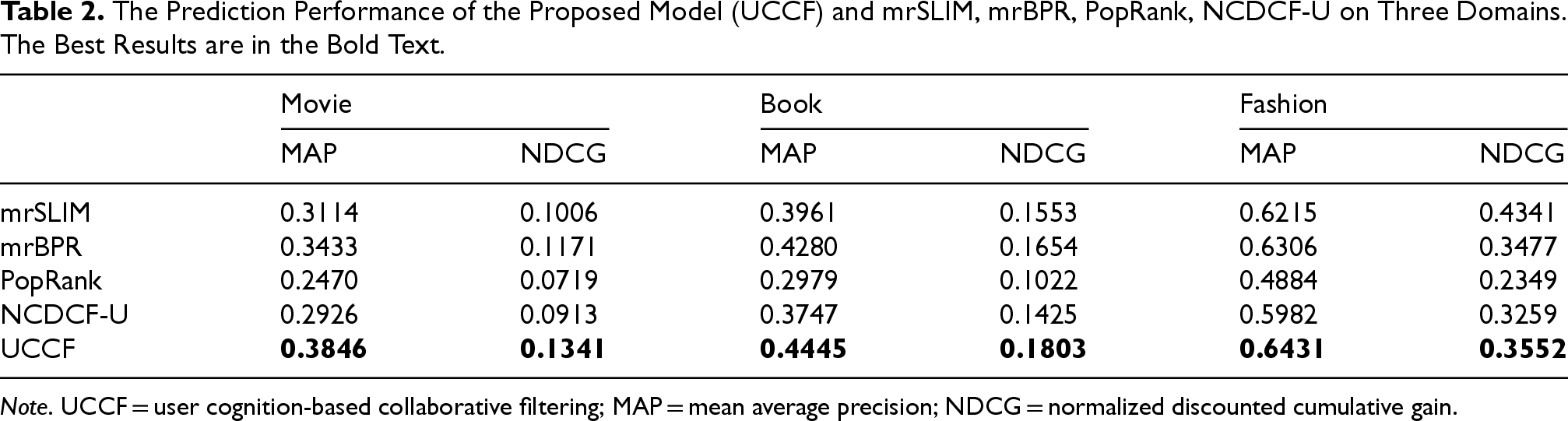
Note. UCCF = user cognition-based collaborative filtering; MAP = mean average precision; NDCG = normalized discounted cumulative gain.
To evaluate the proposed model, we compared the UCCF with several popular baseline methods discussed above, such as sparse linear methods for Top-N recommender systems (SLIM; Ning & Karypis, 2011), popularity-based recommendation (PopRank), the user-based neighborhood method integrating user’s multiple types of behavior (NCDCF-U; Yuan et al., 2014), and the Bayesian personalized ranking (Krohn-Grimberghe et al., 2012).
The feedback dataset was separated into two parts, with 80% used for training and 20% for testing. This process was repeated 10 times, with randomly selected samples. The weights for the three domains in the UCCF model were set, respectively, as
Table 2 presents the results of our experiments, which show that the proposed UCCF model outperforms other baseline methods. PopRank, which recommends popular items, is inferior to all other methods, highlighting the importance of personalization in RSs. We also observed that generating movie recommendations is relatively easy, as all methods except PopRank perform well in the movie domain. This suggests that leveraging knowledge from the movie domain as an auxiliary domain to transfer information to other domains (e.g., book and fashion) could be beneficial. However, NCDCF-U, with
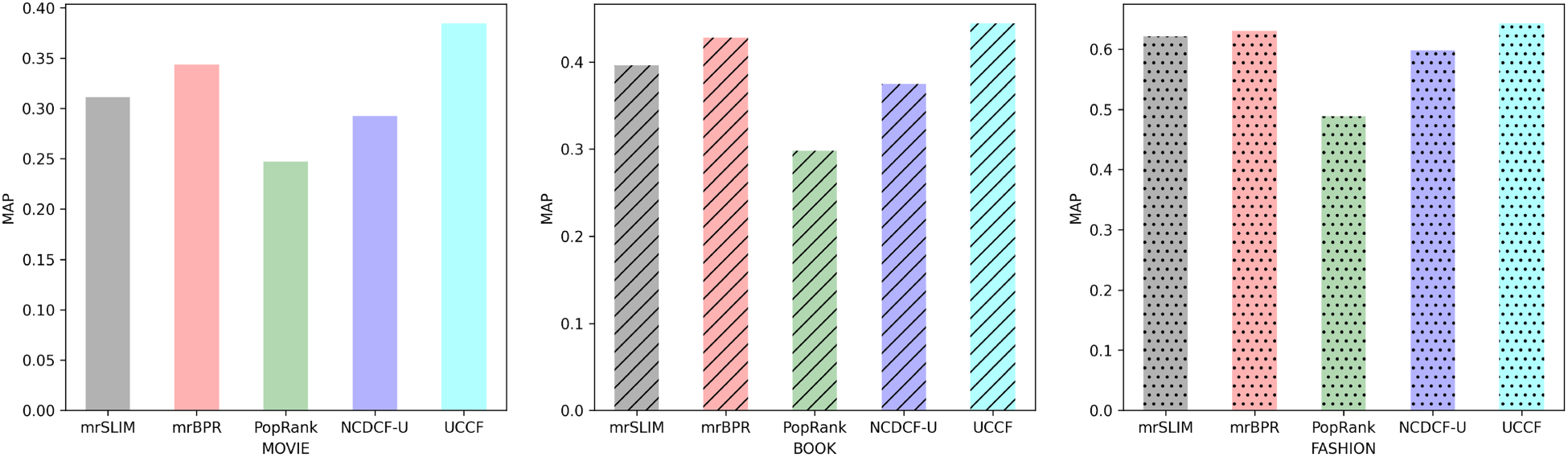
Comparision of the prediction performance between UCCF, mrSLIM, mrBPR, PopRank, and NCDCF-U with MAP metric in three domains. Note. UCCF = user cognition-based collaborative filtering; MAP = mean average precision.
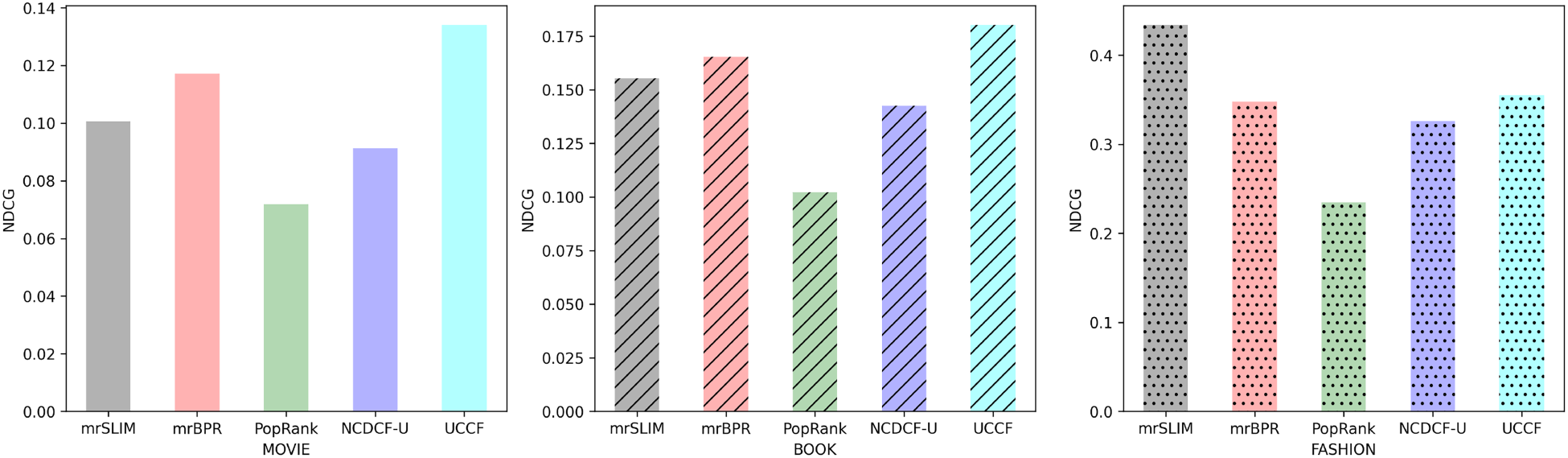
Comparision of the prediction performance between UCCF, mrSLIM, mrBPR, PopRank, and NCDCF-U with NCDG metric in three domains. Note. UCCF = user cognition-based collaborative filtering; NCDG = normalized discounted cumulative gain.
Moreover, we aimed to investigate whether the prediction performance of our proposed model can be further enhanced with more domains. Thus, we conducted experiments on three scenarios of overlapping datasets: Movie-Book, Movie-Fashion, and Fashion-Book. We evaluated the prediction performance of our UCCF model in each overlapping scenario and compared it with the same baselines and settings used in the previous experiments. The results are presented in Table 3, which demonstrate that the UCCF model consistently outperforms the baselines in all three scenarios. Specifically, our proposed method achieved better prediction performance in terms of MAP metric in all scenarios, indicating the effectiveness of our method in multi-domain RSs.
Comparison of the Prediction Performance Between Proposed and Baseline Methods (MAP Metric). The Best Results are in the Bold Text.

Note. MAP = mean average precision; UCCF = user cognition-based collaborative filtering.
However, the performance of UCCF itself is not better in the scenarios that use three domains. Especially in the case of generating Top-N recommendations in the Movie domain, the proposed model when using three domains gets very good performance in comparison with other scenarios using two domains. We also measure the prediction performance of the proposed method, UCCF, by using the normalized discounted cumulative gain (NCDG) metric. The results of the comparison of the prediction performance between proposed and baseline methods in terms of NCDG metrics are shown in Table. 4
Comparison of the Prediction Performance Between Proposed and Baseline Methods (NCDG Metric). The Best Results are in the Bold Text.

Note. NCDG = normalized discounted cumulative gain; UCCF = user cognition-based collaborative filtering.
This study introduces a new approach for cross-domain recommendation called the UCCF model. It incorporates both user cognition and personalization to construct a collective similarity parameter. To achieve this, an online crowdsourcing platform was utilized to gather cognitive similarity data of items from users across multiple domains. By utilizing the similarity between users based on their cognitive similarity data across various domains, the cognitive similarity data of active users can be predicted through optimized neighbors. The experiments conducted on cross-domain datasets illustrate the effectiveness of the proposed UCCF model in generating top-N recommendations compared to other existing methods.
However, there are some limitations to the cognitive similarity dataset. Specifically, only three datasets in the movie, book, and fashion domains were selected for the experiments. This led to the scope of the experiments being reduced and maybe not adapting to many more domains. Besides, the number of actual users who can express their feedback on the crowdsourcing platform is increasing slowly is one of the limitations of our approach. We aim to focus on growing the number of actual users as fast as possible to ensure the cognitive similarity data is more extensive for future research on user cognition-based approaches to solving the problems of RSs. Because of these limitations, our future work aims to deploy the experiments on many datasets of different domains. To do so, we keep collecting cognitive similarity data from our online crowdsourcing platform with more domains. In addition, we will select other methods and metrics to evaluate the proposed model in terms of multiple aspects of recommendation quality, namely accuracy, novelty, diversity, and coverage.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Chung-Ang University Research Scholarship Grants in 2023.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.