
Abstract
Vehicle detection using computer vision plays a crucial role in accurately recognizing and responding to various road conditions, targets, and signals, particularly within autonomous driving technology. However, traditional vehicle detection algorithms suffer from slow detection speed, low accuracy, and poor robustness. To address these challenges, this paper proposes the simple attention mechanism-you only look once (SAM-YOLO) algorithm. SAM-YOLO incorporates the simple attention mechanism into the YOLOv7 network, allowing for the capture of more detailed information without introducing additional parameters. In this study, we experimentally redesigned the backbone network of SAM-YOLO by replacing the redundant part of the network layer with the C3 module, resulting in improved model performance while maintaining accuracy. The experimental results show that the SAM-YOLO algorithm performs excellently in several evaluation metrics under conventional conditions, especially outperforming other algorithms in accuracy and mean average precision values. In tests on the ExLight dataset facing extreme lighting conditions, SAM-YOLO similarly demonstrated optimal detection capabilities, especially in terms of robustness when dealing with complex lighting variations. These findings emphasize the potential of the SAM-YOLO algorithm for real-time and accurate target detection tasks, especially in environments with highly variable lighting conditions.
Introduction
In recent years, substantial advancements in autonomous driving technology have occurred, motivated by the pursuit of scientific and technological innovation, as well as the increasing demand for convenient travel (Grigorescu et al., 2020; Kiran et al., 2022). Autonomous driving technology empowers vehicles to perceive and comprehend their surroundings, formulate navigation plans, and regulate their movements without human intervention (Yurtsever et al., 2020). To accomplish this, a car must possess the capability to detect objects in its vicinity, discern road conditions, and make informed decisions regarding its trajectory (Petit & Shladover, 2014). Hence, achieving precise detection and recognition of vehicles and road environments is crucial for fully exploiting the capabilities of autonomous driving technology (Gupta et al., 2021). In this context, the development of machine learning models for vehicle visual detection has emerged as a crucial research area with substantial practical implications (Liu et al., 2021a).
Traditional machine learning algorithms commonly used for object detection rely on manual feature engineering, including predefined feature extraction (Outay et al., 2020; Shi et al., 2019; Wang et al., 2019), sliding windows (Chen & Huang, 2019; Chen et al., 2014; Song et al., 2019), and statistical learning (Alotibi & Abdelhakim, 2021; Cucchiara et al., 2000; Sun et al., 2006; Wang & Lien, 2008). These algorithms extract features from input images and utilize machine learning techniques to ascertain the presence of objects at each location (Liu et al., 2019). The final detection outcome is obtained by aggregating multiple detection results using suppression rules. However, these algorithms face limitations when dealing with complex scenes (Wang et al., 2023), primarily due to the diverse shapes and viewpoints of detected objects, resulting in high computational complexity, low accuracy, and poor robustness (Srivastava et al., 2021). Various factors such as different driving poses, changes in lighting conditions, occlusion by surrounding objects, and interference from cluttered backgrounds pose challenges to traditional machine learning object detection algorithms. The advent of deep learning has attracted significant attention in the field of artificial intelligence, particularly in the development and application of deep learning-based object detection algorithms (Srivastava et al., 2021).
You only look once (YOLO) is an object detection algorithm based on convolution neural networks that was proposed by Redmon et al. (2016). In contrast to two-stage object detection methods (Law & Deng, 2019; Liu et al., 2016; Long et al., 2015; Wang et al., 2021), YOLO can precisely predict the bounding box and object probabilities of the entire image in a single evaluation using a single neural network. This property makes YOLO an efficient approach for object detection since the entire detection process is contained within a single neural network, featuring a single end-to-end architecture that encompasses all processing steps from image input to output. The high effectiveness and efficiency of YOLO have contributed to its popularity as an algorithm in the field of computer vision, where it has found applications in various areas including autonomous driving, surveillance, and robotics (Li et al., 2022).
YOLOv7 is a part of the YOLO family of object detection models (Wang et al., 2022a). It represents an enhancement over YOLOv5 (Jocher et al., 2022). Like the YOLO algorithm, YOLOv7 employs a single neural network to conduct an overall prediction for the entire image within one evaluation. As a conventional neural network model, YOLOv7 comprises four primary components: the input network, backbone network, neck network, and head network. These components collaborate harmoniously to efficiently and precisely identify objects in images, making YOLOv7 a versatile tool applicable to a broad range of computer vision tasks.
Despite exhibiting exceptional performance in object detection tasks, the YOLO algorithm has high rates of missed detections and false alarms for detecting small objects (Hu et al., 2021; Jiang et al., 2022a; Li & Shen, 2023). Researchers have proposed various methods to address this issue (Liu et al., 2021b), such as multi-scale feature representation (Hong et al., 2016; Najibi et al., 2017, 2019; Newell et al., 2016; Wu et al., 2018), additional detection heads (Deng et al., 2022; Zhu et al., 2021), image enhancement (Rabbi et al., 2020), super-resolution techniques, and attention mechanisms.
For instance, Hsu and lin (2021) proposed a multi-scale feature representation that combines length and width information, alleviating image distortion after resizing and integrating complementary data from multiple sub-images. Carrasco et al. (2023) integrated features extracted from local images at different scales into the YOLOv5 Backbone network, effectively reducing the number of trainable parameters and floating-point operations per second (Carrasco et al., 2023). As a result, both inference speed and accuracy were improved.
Zhu et al. (2020) presented a multi-sensor multi-level improved convolution network model that incorporates an improved reasoning head and feature fusion method, integrating radar data. Additionally, Zhao et al. (2023) introduced a prediction head to YOLOv7 and utilized the simple attention mechanism (SimAM) module to enhance the detection of small objects or individuals.
Enhancing image information is also a prevalent approach in recent studies. Liu et al. (2022) employed the Flip-Mosaic algorithm to enhance the network’s capability in detecting small targets and mitigating the false detection rate of occluded vehicle targets. Likewise, Jiang et al. (2022b) incorporated the attention mechanism and merged the infrared image with the image enhancement algorithm and the global attention mechanism, resulting in enhanced accuracy for small target detection. The method proposed by Shen et al. (2023b) is based on multiple information perception and attention modules, including five processes: information preprocessing, information collection, information interaction, feature fusion, and attention generation.
Thus, this paper proposes an improved YOLOv7 object detection algorithm called simple attention mechanism-YOLO (SAM-YOLO) that improves the accuracy of object positioning and recognition, while preserving the original excellent features of the YOLOv7 network. The contributions of this paper on-road road-vehicle visual detection can be summarized as follows:
The SAM-YOLO algorithm introduces an SimAM that integrates both channel-level and spatial-level information to model multidimensional dependencies, structural information, and global insights. This attention mechanism focuses selectively on critical regions within the image, thereby enhancing the precision of small object detection. By effectively capturing essential features within the two-dimensional space of images, it addresses information loss and improves the accuracy of behavior recognition. The SAM-YOLO algorithm’s network layer has been reduced based on the concept of model lightweight design. This reduction significantly alleviates the computational burden caused by the multi-layer propagation of information during the inference process, thereby enhancing recognition speed and achieving high computational efficiency. Consequently, it becomes well-suited for fast image processing and rendering, making it suitable for real-time applications. Moreover, it facilitates the deployment of the algorithm on low-power vehicle terminals. We propose a new application of the SAM-YOLO algorithm specifically for detecting moving vehicles on the road. Our findings demonstrate that the SAM-YOLO algorithm offers advantages in performance when compared to existing YOLO and other algorithms.
The remaining sections of this paper are organized as follows. In Section 2, a restatement of the problem is provided, followed by the details of the SAM-YOLO algorithm in Section 3. The experimental results and effectiveness evaluation of the approach are presented in Section 4. Finally, the findings are summarized, and potential avenues for future research are discussed in Section 5.
Restatement of the Problem
Object detection, or object recognition, is a fundamental problem in computer vision that involves identifying and localizing objects within images or video sequences. The task requires the model to predict both the presence and category of objects, as well as draw bounding boxes around detected objects to indicate their locations. This problem combines elements of classification and localization and poses challenges due to variations in object appearance, scale, occlusion, and environmental conditions.
The YOLOv7 algorithm is widely applied in diverse object detection scenarios, and its network model is predominantly composed of input, backbone, neck, and head components, as shown in Figure 1. More specifically, the input layer consists of preprocessed and normalized image inputs, and the backbone network is responsible for extracting features from input images. The head layer in YOLOv7 is a CSPSPP layer, so it is merged into the neck layer in the image.
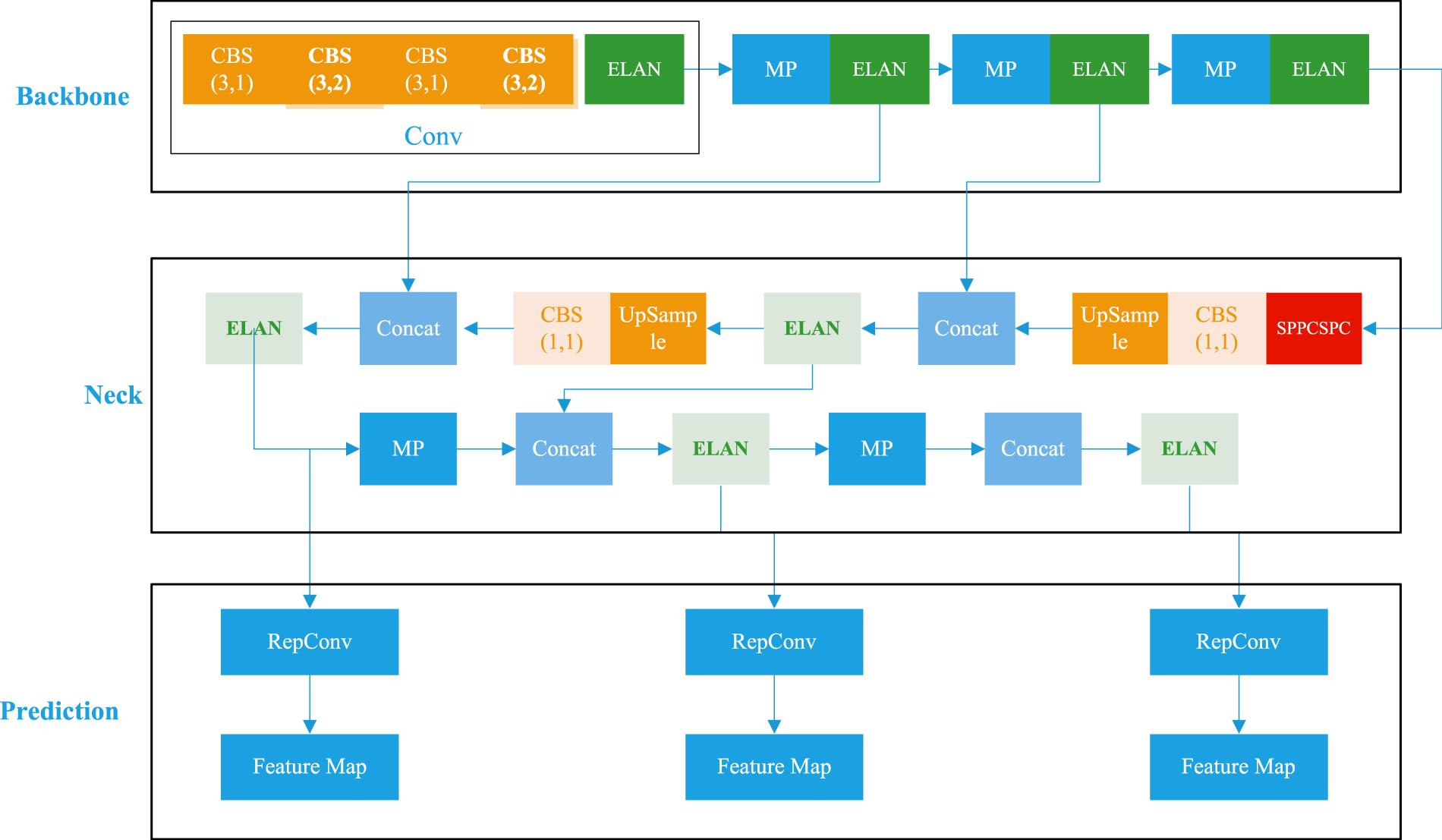
The architecture of YOLOv7.
The multi-layer efficient layer aggregation networks (ELAN) structure is designed to enhance computational efficiency and strengthen feature fusion capabilities. This structure employs complex layer aggregation strategies to significantly improve feature extraction performance, making it more suitable for object detection tasks. Specifically, the ELAN architecture consists of basic units made up of multiple convolutional layers, activation functions (such as rectified linear unit [ReLU] or Leaky ReLU), and normalization layers (such as batch normalization), which are further combined into higher-level groups. ELAN achieves parallel feature processing by aggregating outputs from multiple convolution paths at specific nodes, thereby enriching feature expression diversity. At the same time, ELAN emphasizes multi-scale feature aggregation, integrating information from different layers through feature fusion, and it alleviates the vanishing gradient problem with skip connections similar to those in ResNet, thus enhancing training stability and efficiency.
However, the original multi-layer ELAN structure in YOLOv7 results in substantial inter-layer information exchange, thereby decelerating the algorithm’s training speed. Additionally, the utilization of fixed anchor sizes in YOLOv7 confines its effectiveness in discerning and detecting objects with various scales, particularly in demanding scenarios. These demanding scenarios can include conditions such as poor lighting, occlusion, or objects in high-speed motion, which complicate the detection process.
In object detection, another major challenge is the limitation of the YOLO algorithm in detecting small targets, especially in complex traffic environments. Due to the small size of these targets and their low pixel resolution, they often contain limited information in the image, making them susceptible to interference or occlusion from the background.
It is widely recognized that increasing the number of parameters and utilizing more intricate networks can partially enhance the accuracy of algorithmic detection. However, concerning detection accuracy, the effectiveness of improving training time and model size is restricted. Moreover, in engineering applications, the use of complex networks and a high volume of parameters is non-ideal owing to the computational constraints at the application level. Therefore, the presented algorithm strives to enhance the efficiency of the network layers instead of further augmenting the complexity of the YOLOv7 base model.
To tackle the challenges of detecting small targets in complex scenes, this paper proposes an improved YOLOv7 object detection algorithm based on the YOLOv7 network. The algorithm enhances the accuracy of target localization and recognition while retaining the fundamental features of the YOLOv7 network. This model differs from existing methods in that it does not require multi-scale feature fusion. Instead, it introduces the SimAM, which enables the network to learn and emphasize important aspects of the targets without introducing additional parameters. Additionally, the algorithm improves efficiency while maintaining detection accuracy by redesigning the original backbone network. By replacing the loss function used in the YOLOv7 algorithm, its recognition capability is enhanced, improving both parallelism and stability. Experimental results demonstrate that the improved YOLOv7 algorithm performs exceptionally well in handling complex scenes and small targets, effectively overcoming the aforementioned challenges.
SAM-YOLO is an improved target detector based on the YOLOv7 architecture. The algorithm focuses on the challenges of small target detection in complex scenarios and improves the accuracy of target localization and identification while retaining the basic features of the YOLOv7 network while minimizing the potential degradation of target detection accuracy and recall. In addition, SAM-YOLO effectively reduces the number of parameters required for the model and speeds up the inference of the model. The network structure is shown in Figure 3, and the main improvements are as follows:
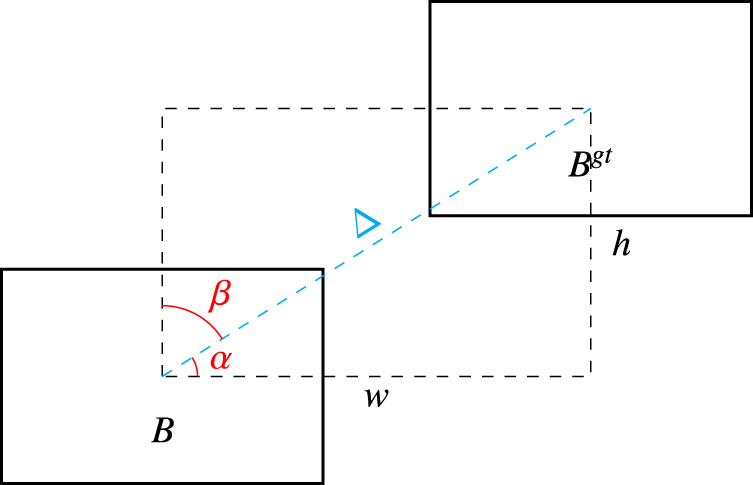
The schematic diagram of SIoU loss function. Notes. SIoU = SCYLLA intersection over union.
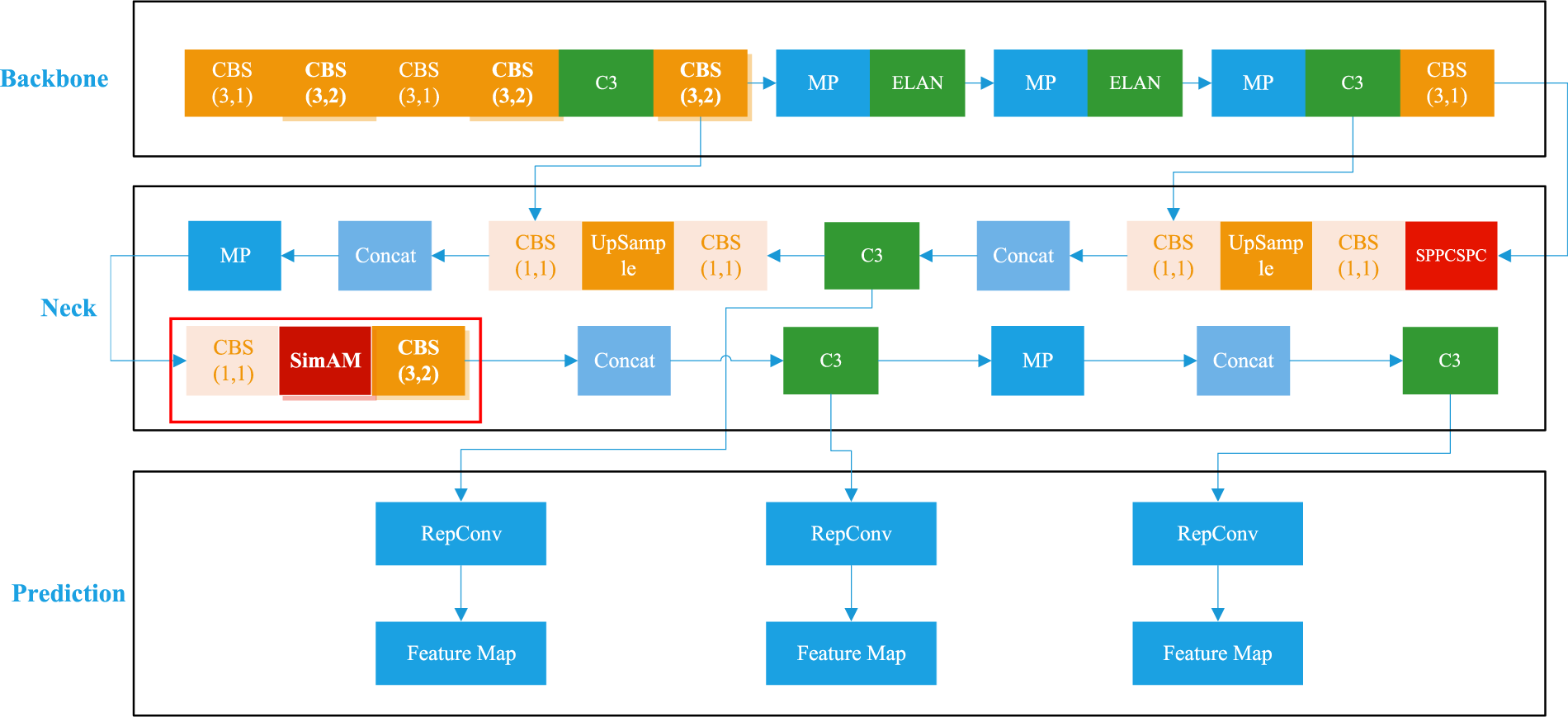
The architecture of the improved algorithm.
Incorporating the SimAM into the backbone network by designing experiments. Redesigning the backbone network of the model. Replacing part of the original structure with the more lightweight C3 module. Redesigning the loss function of the model.
The attention mechanism is a widely used technique in the fields of machine learning and deep learning. It aims to simulate the human attention mechanism, selectively focusing on important parts of the input data. The attention mechanism has been extensively studied and applied in various tasks, including natural language processing, computer vision, and speech recognition. By introducing the attention mechanism, models can pay more attention to the parts that are more important for the current task when processing large amounts of information. The core idea of this mechanism is to determine the importance of each element in the input data through learning weight allocation. In the attention mechanism, each element can be assigned a weight or attention score, which reflects the model’s degree of attention to each element. The model can adaptively adjust these weights based on the characteristics of different tasks and input data, thereby making more accurate predictions and processing.
The application of attention mechanisms in the fields of machine learning and deep learning is very extensive, including several important attention mechanisms such as convolutional block attention module (CBAM), channel attention (CA), squeeze-and-excitation (SE), and SimAM (Cheng et al., 2024; Jia et al., 2023; Mahaadevan et al., 2023; Shen et al., 2023a; Wu & Dong, 2023).
CBAM is an attention mechanism based on convolutional neural networks. It enhances model performance by capturing both CA and spatial attention. CA is used to determine the importance of each channel in the input feature map, thereby weighting the channels. Spatial attention, on the other hand, determines the importance of each spatial position in the feature map, thus weighting the elements at different spatial positions. By combining CA and spatial attention, the CBAM attention mechanism enables the model to more accurately focus on the important parts of the input data.
The CA mechanism focuses to determine the importance of each channel in the feature map. By utilizing global average pooling and fully connected layers, the CA model can compute and allocate weights for each channel to better capture the feature representations of different channels. The CA mechanism performs well in computationally intensive tasks and helps the model differentiate the importance of each channel more effectively.
The SE attention mechanism is a lightweight attention model that enhances the representation capability of the model efficiently. The core idea of the SE attention model is to dynamically adjust the weights of each channel by utilizing global contextual information. By introducing the “squeeze” and “excitation” stages, the SE attention mechanism can adaptively learn the importance of each channel and re-weight the features accordingly. The SE attention mechanism has achieved good results in many image classification and object detection tasks.
Yang et al. (2021) propose a module that efficiently generates true three-dimensional weights in SimAM. Specifically, it estimates the importance of individual neurons by taking into account the phenomenon in neurology where over-excited neurons usually inhibit surrounding neurons. This phenomenon suggests that neurons with spatial inhibition effects should be assigned higher weights in visual processing. The importance of each neuron is determined based on its linear separation from other neurons using the formula defined as equation (1):

Computationally,

Variance
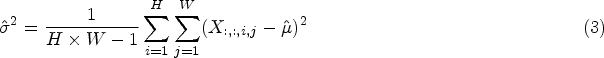
Neuron energy

To determine the impact of the SimAM module on different parts of YOLOv7, we conducted a series of experiments to evaluate the architecture of the SimAM module that has the greatest positive impact on evaluation indicators. Specifically, we integrated the SimAM module into the input network, backbone network, neck network, and head network of YOLOv7 by replacing certain layers within the original architecture. We then compared the model performance before and after the SimAM module’s integration. The experimental results show that the SimAM module has the greatest impact on the neck network of YOLOv7. After introducing the SimAM module, the performance of the backbone network of YOLOv7 has significantly improved. Tables 1 and 2 shows detailed experimental results on our collected datasets.
Test Result on Different Attention Mechanism.
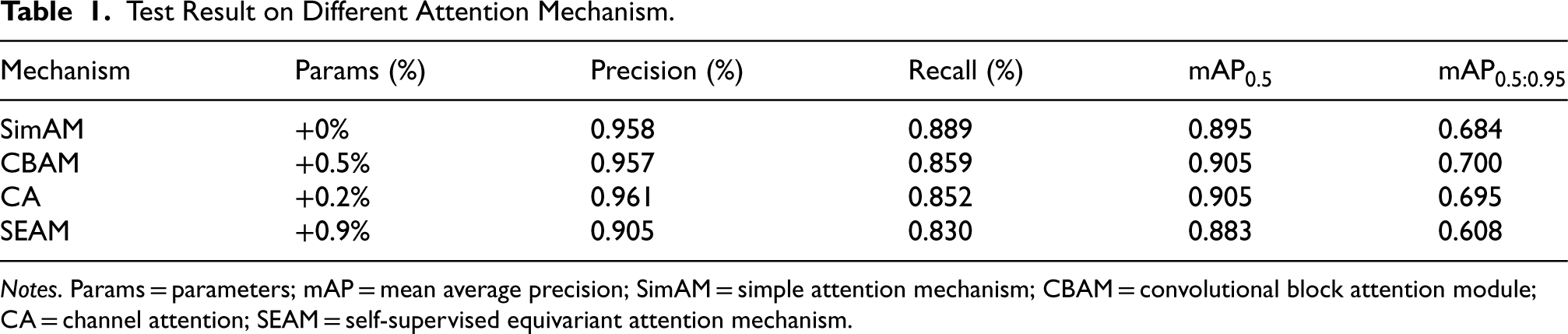
Notes. Params = parameters; mAP = mean average precision; SimAM = simple attention mechanism; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism.
The Impact of SimAM Module on YOLOv7.

Notes. SimAM = simple attention mechanism; mAP = mean average precision.
In the SAM-YOLO model, the SimAM substitutes a segment of the ELAN structure within the neck layer. More precisely, the SimAM module replaces the initial six convolutional layers, featuring 1, 1 as the step size parameter and 3, 1 as the convolution kernel size parameter. During forward propagation, SimAM evaluates the neurons and activates them based on Equation (4).
In machine learning, the loss function serves as a metric for evaluating the discrepancy between the predicted and actual values of a model. By continuously adjusting its parameters to minimize this discrepancy, the model’s performance can be improved, leading to better detection and prediction accuracy.
Meanwhile, during object detection, the algorithm generates multiple bounding boxes with high confidence around the target object. However, only one bounding box can accurately represent the target. To address this redundancy, a non-maximum suppression algorithm is implemented, which ensures that only the most appropriate bounding box is selected. The algorithm starts by sorting all bounding boxes and then calculates the intersection over union (IoU) of the highest-confidence bounding box with the remaining boxes. If the IoU of a bounding box exceeds a predefined threshold, it is discarded.
To evaluate the performance of object detection models, the IoU metric is commonly employed. This metric quantifies the degree of overlap between predicted and ground truth boxes, thereby assessing the accuracy of predictions made by the model.



The SIoU loss function assigns different weights to object detection at various scales, giving more attention to objects with smaller scales during training. By introducing additional variables, such as shape loss, the SIoU function not only provides a better measure of symmetry between the predicted box and the true box but also addresses the imbalance problem found in other IoU variants. Additionally, it facilitates faster convergence to the optimal solution and reduces training time. Moreover, it possesses greater sensitivity in detecting small target objects, thereby reflecting the effectiveness of the target detection model more accurately.
In the SAM-YOLO algorithm, YOLOv7 is adopted as the basic network architecture, and the C3 module is incorporated. The number of layers and parameters in the network is reduced through this module, accelerating the model’s inference and training speed.
Furthermore, the SimAM is introduced into the neck network. This parameterless attention algorithm proposes an energy function based on mathematical methods to determine the importance of each neuron. Inspired by concepts in neurology, this approach avoids expending excessive energy on adjusting and enhancing the structure. Figure 3 illustrates the improved architecture of the algorithm.
Experiment and Analysis
The Dataset
To ensure the applicability of the vehicle recognition model on highways and urban roads, we collected a substantial number of authentic road videos captured by vehicle dashcams or built-in cameras near Xiangyang City, China, on highways and urban roads. The videos were captured from the driver’s front-facing perspective encompassing diverse road and driving scenarios, including clear weather conditions on two-way four-lane roads, dimly lit rural road scenes, capturing traffic signs, vehicles, pedestrians, traffic lights, and road markings while vehicles are in motion. Figure 4(a) to (c) displays images from the training set, capturing different types of vehicles from various angles, road segments, and lighting conditions to enhance the dataset diversity. Figure 4(a) displays images captured in clear weather conditions, Figure 4(b) displays images captured in cloudy weather conditions, and Figure 4(c) displays images captured at night or in tunnels.

Images from the training set. (a) Clear weather condition; (b) cloudy weather condition; (c) night or tunnel condition.
Segments with a high number of vehicles and clear video quality were meticulously selected, and one image sample was extracted for every 25 frames. Ultimately, a dataset of 16,008 images with vehicle information was obtained, encompassing various vehicle categories such as cars, trucks, taxis, and tankers. To ensure proper evaluation, the dataset was divided into training, validation, and test sets in a ratio of
Videos captured by dashcams or in-vehicle cameras, while partially representative of real road scenarios are influenced by various factors. Challenges such as image blurring from camera focus issues, underexposed or overexposed objects due to high contrast, and video noise from lighting conditions introduce recognition noise to the captured images. These issues hinder the training effectiveness of machine learning models.
To address this, we implement data augmentation during model training to enhance model robustness. Our augmentation techniques include:
Rotation: Images are randomly rotated between Shear: Horizontal and vertical shearing by Brightness adjustment: Variation in image illumination by Blur: A blur effect of up to 2 pixels approximates the out-of-focus images. Noise addition: Introducing noise to up to
Additional challenges include motion-induced blur from the movement of objects and the camera’s distance, often resulting in out-of-focus images. Gaussian blur, a linear smoothing filter, is utilized to reduce this blur while preserving edge information. The Gaussian kernel is defined as follows:
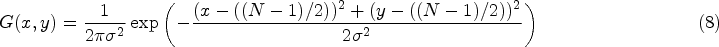
Additionally, low-light conditions can introduce random image noise, which mere camera adjustments cannot correct. In this context, Poisson noise—a statistical distribution that models random events such as photon counting—effectively simulates noise under low light. This approach helps to replicate realistic imaging conditions, further improving the model’s robustness.
The experimental environment utilized in this study is summarized in Table 3.
Experimental Environment.

Experimental Environment.
The training parameters utilized in this experiment are presented in Table 4.
Training Parameters.

Performance evaluation of the SAM-YOLO algorithm involves the utilization of multiple metrics to assess the model’s quality. For this study, the evaluation metrics employed include precision rate (P), recall rate (R), mAP with an IoU recognition threshold of 0.5 (
Precision represents the probability of correctly predicting a positive sample, whereas recall denotes the probability of accurately identifying a positive sample from the original sample.
In equations (9) and (10), which establish the function
In equations (11) and (12), TP represents the number of true positives, FP represents the number of false positives, and FN represents the number of false negatives (Tables 5 and 6).




Comparison of Evaluation Indicators Results.

Notes. mAP = mean average precision; GFLOPS = gigaflops; FPS = frames per second; SAM-YOLO = simple attention mechanisim-you only look once.
Comparison of Detection Category Results.
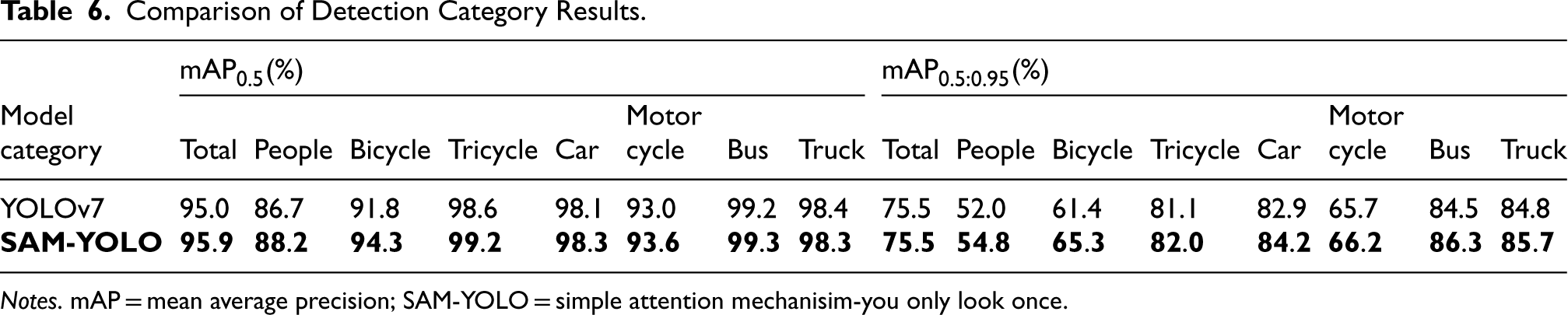
Notes. mAP = mean average precision; SAM-YOLO = simple attention mechanisim-you only look once.
The effectiveness of the proposed method was evaluated through extensive experiments conducted on a benchmark dataset in this study. The experimental results indicate that the proposed SAM-YOLO algorithm achieves higher accuracy and recall rates compared to the original YOLOv7 algorithm. Additionally, there is a 3% improvement in the accuracy of
It can be observed from Figure 5 that the SAM-YOLO algorithm exhibits characteristics of missed detection rate and false detection rate across all detection categories, and demonstrates high accuracy in detecting small targets.
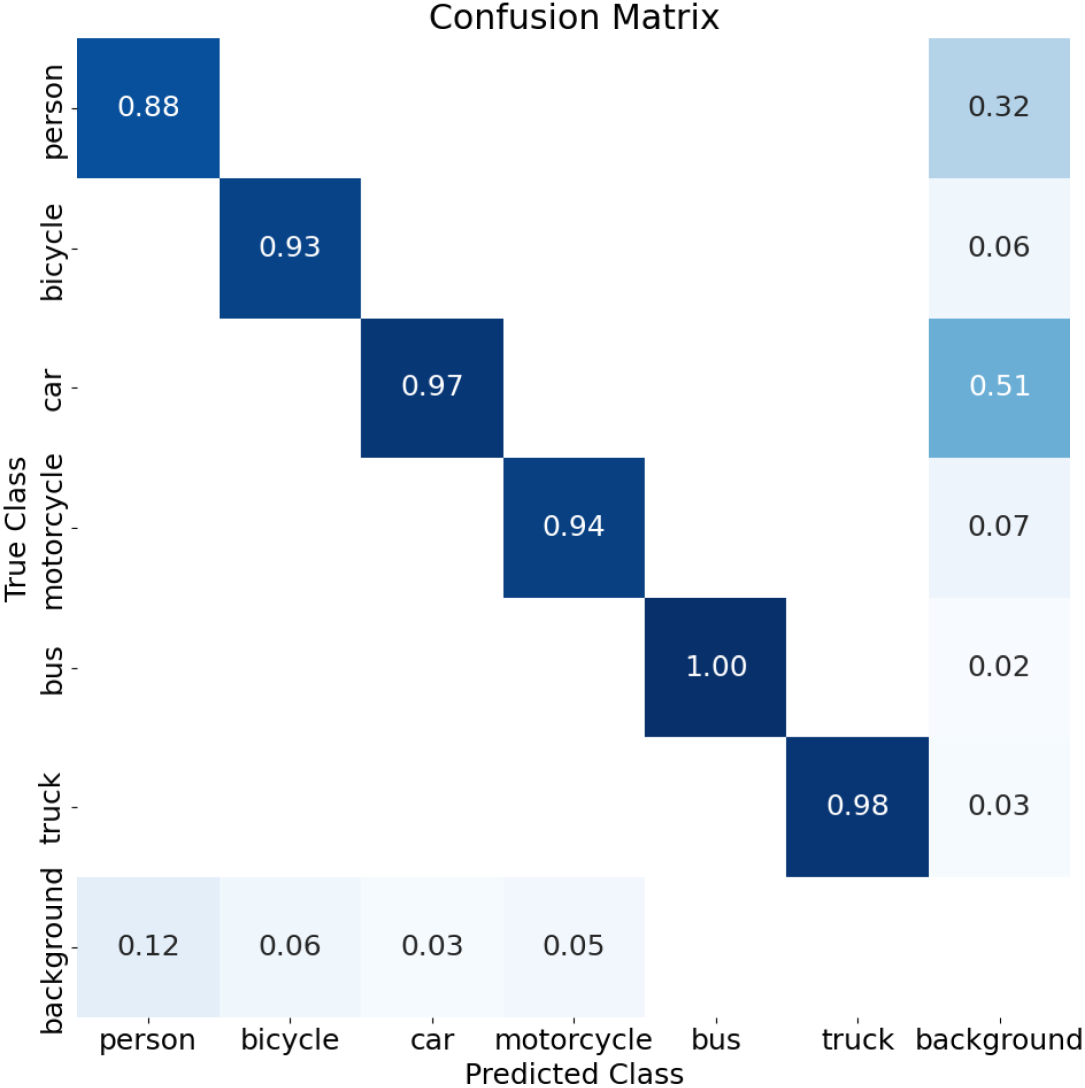
Confusion matrix of the SAM-YOLO Algorithm. Notes. SAM-YOLO = segment anything model-you only look once.
In the ablation experiments conducted, by selectively adding or removing the SimAM, SIoU, and C3 modules, we were able to gain a deeper understanding of the specific impact of these components on the overall performance of the model. The addition or removal of each module provided us with unique insights, which in turn allowed us to meticulously evaluate their respective values and roles. The results of the ablation experiments show that when the SimAM, SIoU, and C3 modules are enabled simultaneously, the model can achieve the highest precision (0.961%), recall (0.930%),
Ablation Experiment Results.
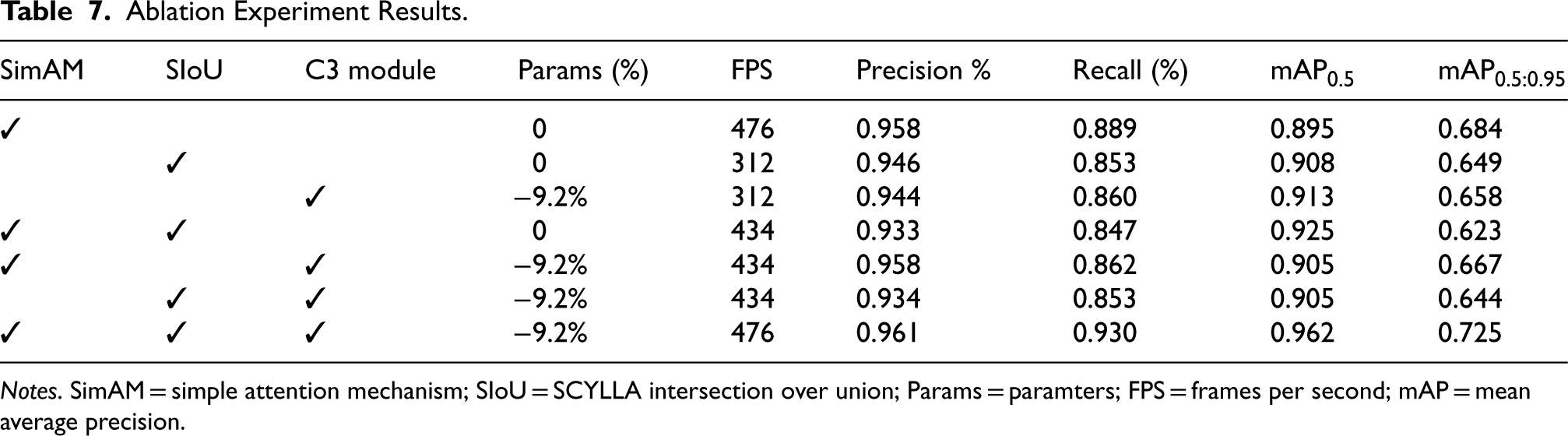
Ablation Experiment Results.
Notes. SimAM = simple attention mechanism; SIoU = SCYLLA intersection over union; Params = paramters; FPS = frames per second; mAP = mean average precision.
In this study, we compare and analyze the performance of multiple target detection algorithms in different contexts, including YOLOv7, SAM-YOLO, CBAM-YOLO, CA-YOLO, SEAM-YOLO, SSD, RetinaNet, and Faster-RCNN. We evaluate the performance of multiple target detection algorithms based on the number of parameters, frames per second (FPS), precision, recall, and different mAP metrics were comprehensively evaluated. All algorithms use ELAN or ResNet-50 as the underlying skeleton to ensure consistency and fairness in the evaluation.
In terms of overall performance, SAM-YOLO performs best in several metrics, especially in
In the
In contrast, the performance of SSD, RetinaNet, and Faster-RCNN is relatively weak, especially in the
Comparison of Detection Results.
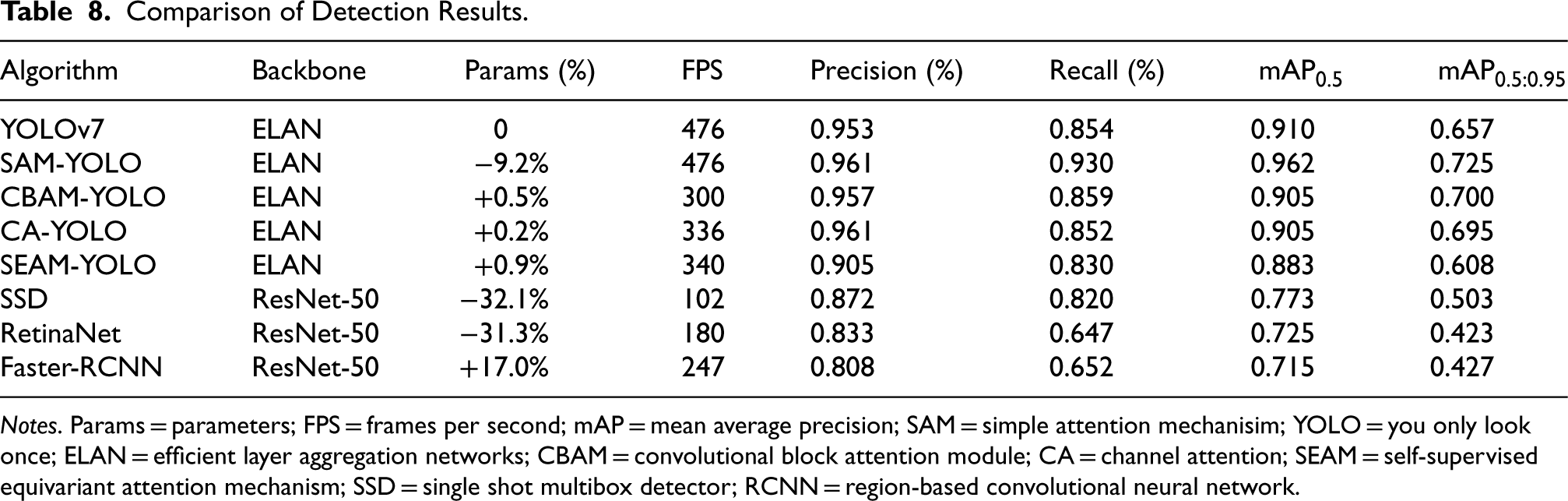
Comparison of Detection Results.
Notes. Params = parameters; FPS = frames per second; mAP = mean average precision; SAM = simple attention mechanisim; YOLO = you only look once; ELAN = efficient layer aggregation networks; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism; SSD = single shot multibox detector; RCNN = region-based convolutional neural network.
Comparison of Detection Results on
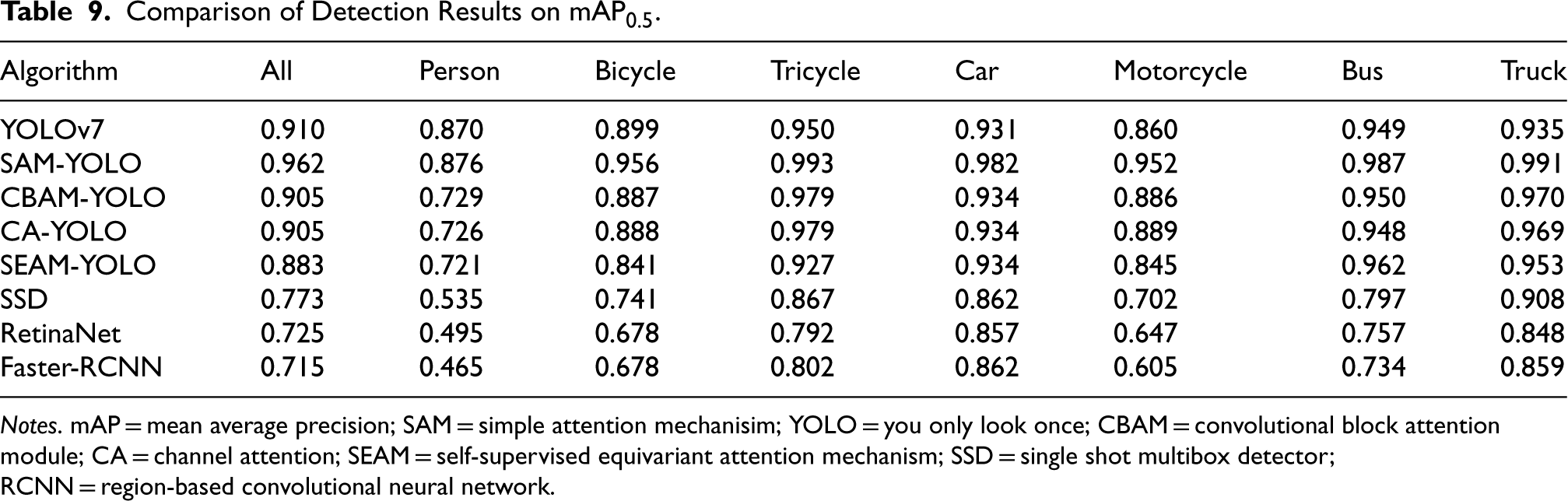
Notes. mAP = mean average precision; SAM = simple attention mechanisim; YOLO = you only look once; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism; SSD = single shot multibox detector; RCNN = region-based convolutional neural network.
The experimental results show that SAM-YOLO and YOLOv7 are the optimal choices for target detection tasks with high speed and high accuracy. They are not only able to accurately detect various types of targets in complex scenes but also maintain high processing speed to meet the demands of real-time applications. Future research can further explore the optimization and adaptation of these algorithms in specific application scenarios to achieve higher performance and better adaptability (see Figure 6 and Table 10).

(a) Original image; (b) simple attention mechanisim-you only look once (SAM-YOLO).
Comparison of Detection Results on
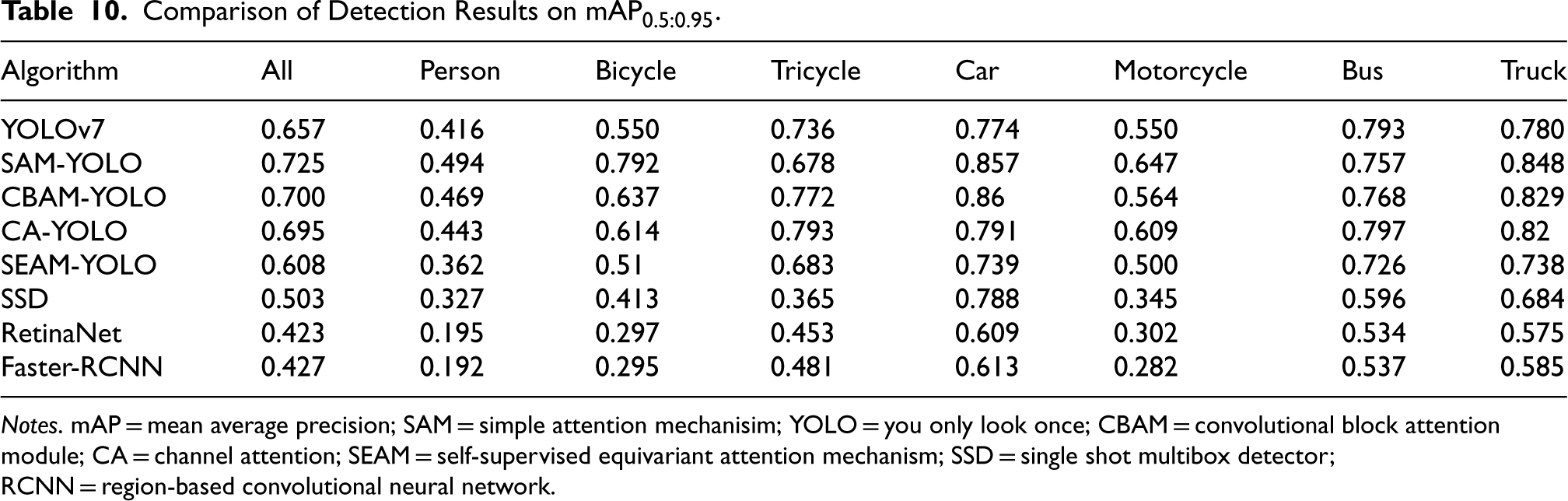
Notes. mAP = mean average precision; SAM = simple attention mechanisim; YOLO = you only look once; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism; SSD = single shot multibox detector; RCNN = region-based convolutional neural network.
This section analyzes the target detection results on the ExDark dataset (Loh & Chan, 2019), which is designed to evaluate the performance of target detection algorithms under extreme lighting conditions. The analysis covers several algorithms including YOLOv7, SAM-YOLO, CBAM-YOLO, CA-YOLO, SEAM-YOLO, SSD, RetinaNet, and Faster-RCNN. By comparing the performance of each algorithm under two main metrics,
Comparison of Detection Results on ExDark Dataset
.
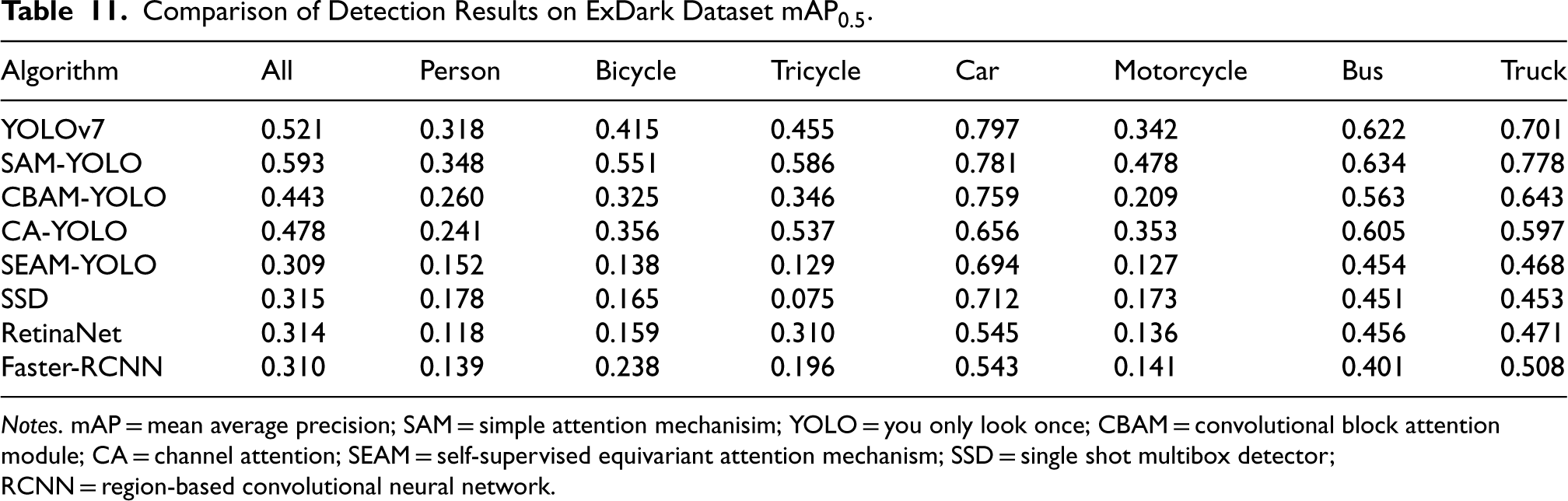
Comparison of Detection Results on ExDark Dataset
Notes. mAP = mean average precision; SAM = simple attention mechanisim; YOLO = you only look once; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism; SSD = single shot multibox detector; RCNN = region-based convolutional neural network.
In the
On the more stringent
By analyzing the test results on the ExDark dataset, we can conclude that the SAM-YOLO algorithm not only performs well under regular lighting conditions but also maintains a high detection performance under extreme lighting conditions. This ability makes it the preferred algorithm for high-precision target detection in complex lighting environments. However, the performance degradation of other algorithms under extreme lighting conditions suggests that improving the robustness of the algorithm to changes in lighting remains an important direction for future research (Table 12).
Comparison of Detection Results on ExDark Dataset
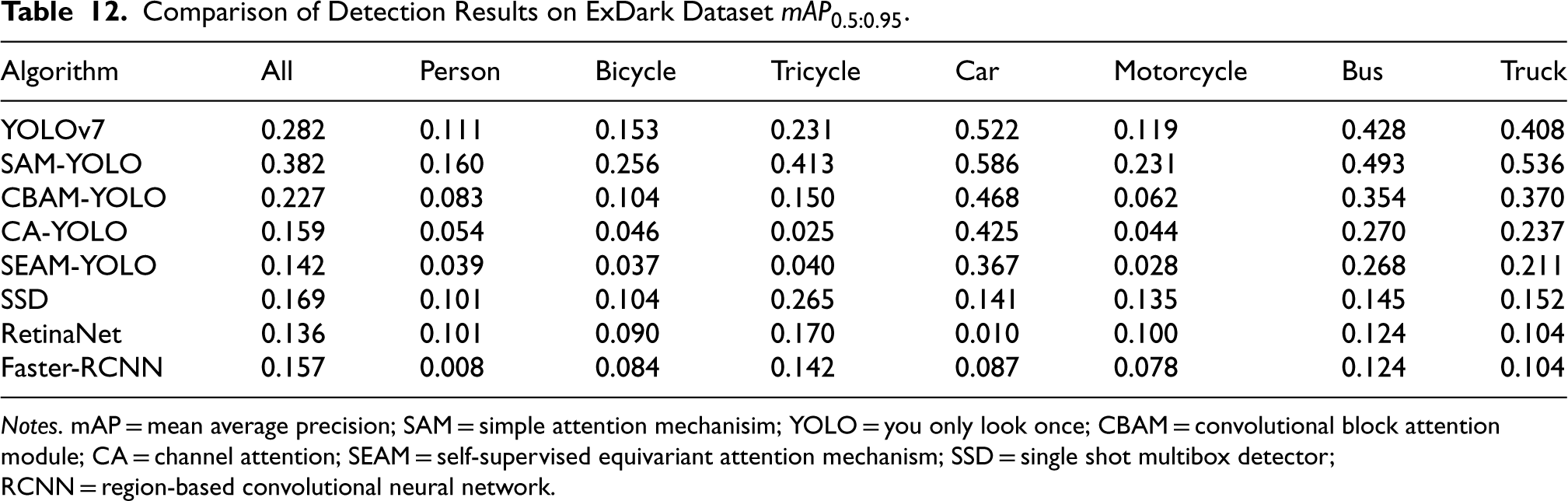
Notes. mAP = mean average precision; SAM = simple attention mechanisim; YOLO = you only look once; CBAM = convolutional block attention module; CA = channel attention; SEAM = self-supervised equivariant attention mechanism; SSD = single shot multibox detector; RCNN = region-based convolutional neural network.
In this paper, an improved YOLOv7 algorithm that incorporates a SimAM into the neck network was proposed, replaces the CIoU function of YOLOv7 with the SIoU function and simplifies the model architecture to accelerate model training and reduce the number of parameters. This approach enhances the model’s generalization ability, improves the learning of spatial features, and enhances computational efficiency. The results reveal that the SAM-YOLO algorithm outperforms other algorithms in terms of comprehensive performance, especially in terms of accuracy and mAP metrics, both in standard test environments and under extreme lighting conditions. This demonstrates the potential of SAM-YOLO in realizing high-speed and high-accuracy target detection, especially for real-world application scenarios with variable lighting conditions.
Regarding model training, the training set comprises real road videos with a fixed perspective effect, and the proportion of vehicles on the road varies. Consequently, the model training may result in bias. To mitigate this limitation, future studies should enhance the original dataset to alleviate the impact of issues related to data collection on the performance of the model. Furthermore, during the data collection process, non-conventional shooting perspectives such as reverse and left-right angles should be introduced to enhance the capability of detecting vehicles in various angles and environments.
Additionally, our findings point to a general decrease in the performance of target detection algorithms under extreme lighting conditions, highlighting the importance of improving the robustness of algorithms to lighting changes. While SAM-YOLO performed the best in these tests, the performance degradation of the other algorithms hints at the need for future work, especially in optimizing the algorithms to better adapt to extreme lighting conditions.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Natural Science Foundation of Hubei Province (No. 2024AFB147), Xiangyang Science & Technology Plan (High-tech field, No. 2022ABH006596), Innovation and Entrepreneurship Education Special Project (No. CX2023003).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.