
Abstract
Since the text-to-image synthesis with non-stacked network structure only models the global features of the image and the semantic features of the text, it is easy to cause problems such as semantic inconsistency, loss of detail features, and incomplete main content in the generated images. To solve the above problems, this paper proposes a text-to-image generation method (cascaded structure and joint attention generative adversarial network (CSGAN)) that combines cascaded structure and joint attention. After encoding the text, this method utilizes a conditional enhancement module to process it, which enhances the expressive ability of the text features. In order to make the local area of the image better fit the text features, this method designs a joint attention module to solve the problem that the image generation process cannot fully reflect the local details of the text content. By using affine transform mapping visual features and cascade structure to fuse the features of different modules, the integrity of the whole content of the image is effectively guaranteed and the semantic consistency of the text image is improved. Experimental results on the CUB dataset show that compared with the current mainstream non-stacked network model DF-GAN model, the inception score index of the CSGAN model is improved by about 4.01%, and the Fréchet inception distance index is reduced by about 13.36%. These data indicators and visualization results fully demonstrate the effectiveness of the CSGAN model.
Keywords
Introduction
Text-to-image synthesis is a challenging cross-modal task in the fields of computer vision and natural language processing. Text-to-image synthesis has many beneficial applications in the development of art painting (Lei et al., 2021), image editing (Liu et al., 2021), and computer-aided design (Shi et al., 2021), and has therefore received great attention in the research field. The current text-to-image synthesis methods based on generative adversarial networks (GANs) mainly include two types: Stacked network structures and non-stacked network structures. The stacked network structure is usually a multi-stage refinement framework, which first generates a low-resolution initial image through text description, then gradually refines the image generated in the previous stage in each subsequent stage, and finally generates a high-resolution image (Qiao et al., 2019; Zhang et al., 2017, 2018, 2021). The stacked network structure solves the problem of low resolution of generated images. However, the stacked structure uses multiple generators, which causes mutual interference between generators and ultimately affects the quality of image generation. In addition, the generation results depend heavily on the quality of the initial images. If the images generated in the initial stage are of poor quality, it will be challenging to generate high-quality images in subsequent steps. To solve the above problems, DF-GAN (Tao et al., 2022) replaced the stacked backbone structure with a single-level backbone, and combined the hinge loss (Zhang et al., 2019) and residual network (He et al., 2016) techniques to directly generate high-resolution images. However, DF-GAN only relies on sentence-level information and ignores the guidance of word-level information, which reduces the consistency between generated images and text descriptions. Since the quality of the generated image is directly affected by the quality of the text features, each word has a non-negligible impact on the details of the image, especially in short text. If the local feature extraction of text is incomplete, the detail quality of the resulting image will be poor.
To solve these problems, this paper proposes a combining cascaded structure and joint attention generative adversarial network (CSGAN) based on DF-GAN, which combines cascade structure and joint attention. Different from the previous work (Tao et al., 2022; Xu et al., 2018), which directly encoded the text and embedded it to get the feature representation, the encoded text features are conditionally enhanced in this paper to generate more conditional variables for the generator, so as to improve the generalization ability of the network. Secondly, this paper designs a joint attention module combining the convolutional block attention module (CBAM) (Woo et al., 2018) and the bottleneck attention module (BAM) (Park et al., 2018) to improve the ability to focus on text nuances. In addition, this paper designs a cascade structure to deeply integrate the information of each up-sampling module, which solves the problem of incomplete content of the generated image. In summary, the main contributions of this paper are as follows:
In the feature extraction module, a conditional enhancement module (CEM) is added to generate more enhanced data when there are only a small number of text-image data pairs, thereby making the semantic space continuous and improving the robustness of small perturbations in the semantic space to achieve more accurate image generation effects. A joint attention module is designed to focus on the details of the text from both spatial and channel aspects, which helps the network to better learn the details from the text vector, improves the network performance, and ensures that the generated images can reflect the details of the text. A cascaded module is designed, which makes the low-dimensional semantic features and high-dimensional semantic features in the generator have a closer connection. It can effectively pass down the information of the current layer while accepting the information from the previous layer, which effectively ensures the integrity of the overall image content and improves the semantic consistency between text and image.
Related Work
Text-to-Image Generation Based on GANs
Reed et al. (2016) first used GANs to generate images with a resolution of 64
Text-Image Fusion
Xu et al. (2018) proposed AttnGAN, which repeatedly uses the attention mechanism to focus on the word-level information of the text during the image-generating process. Qiao et al. (2019) proposed MirrorGAN, which uses a global-local auxiliary attention module and mirroring method to generate high-quality images. Zhu et al. (2019) proposed DM-GAN to generate high-quality images, aiming to improve the impact of the initial generated images on subsequent work. Yin et al. (2019) proposed word-level and sentence-level conditioned batch normalization in SD-GAN to enhance visual semantic embedding in generated network feature maps.
Deep Attentional Multi-modal Similarity Model Loss
The deep attentional multi-modal similarity model (DAMSM) (Wu et al., 2022) loss is a loss function used in image generation and vision-language tasks. The model maps image sub-regions and words in the text into the same semantic space to evaluate the text-image similarity at the word level. Wherein, the image encoder uses the middle layer to learn the local feature matrix

First, we calculate the similarity between image subregions and words:


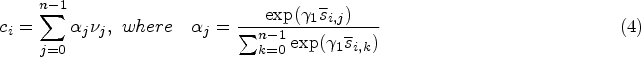
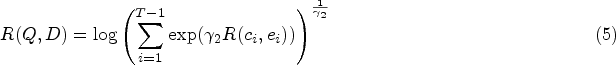
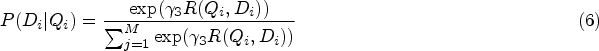



The overall framework of the CSGAN network proposed in this paper is shown in Figure 1. The CSGAN network is mainly composed of a text feature extraction module, a generator, and a discriminator. The feature extraction module takes text features and random noise as input, the generator takes the original noise and the text features of the text feature extraction module as input, and the discriminator takes the image generated by the generator and the text features extracted by the feature extraction module as input.
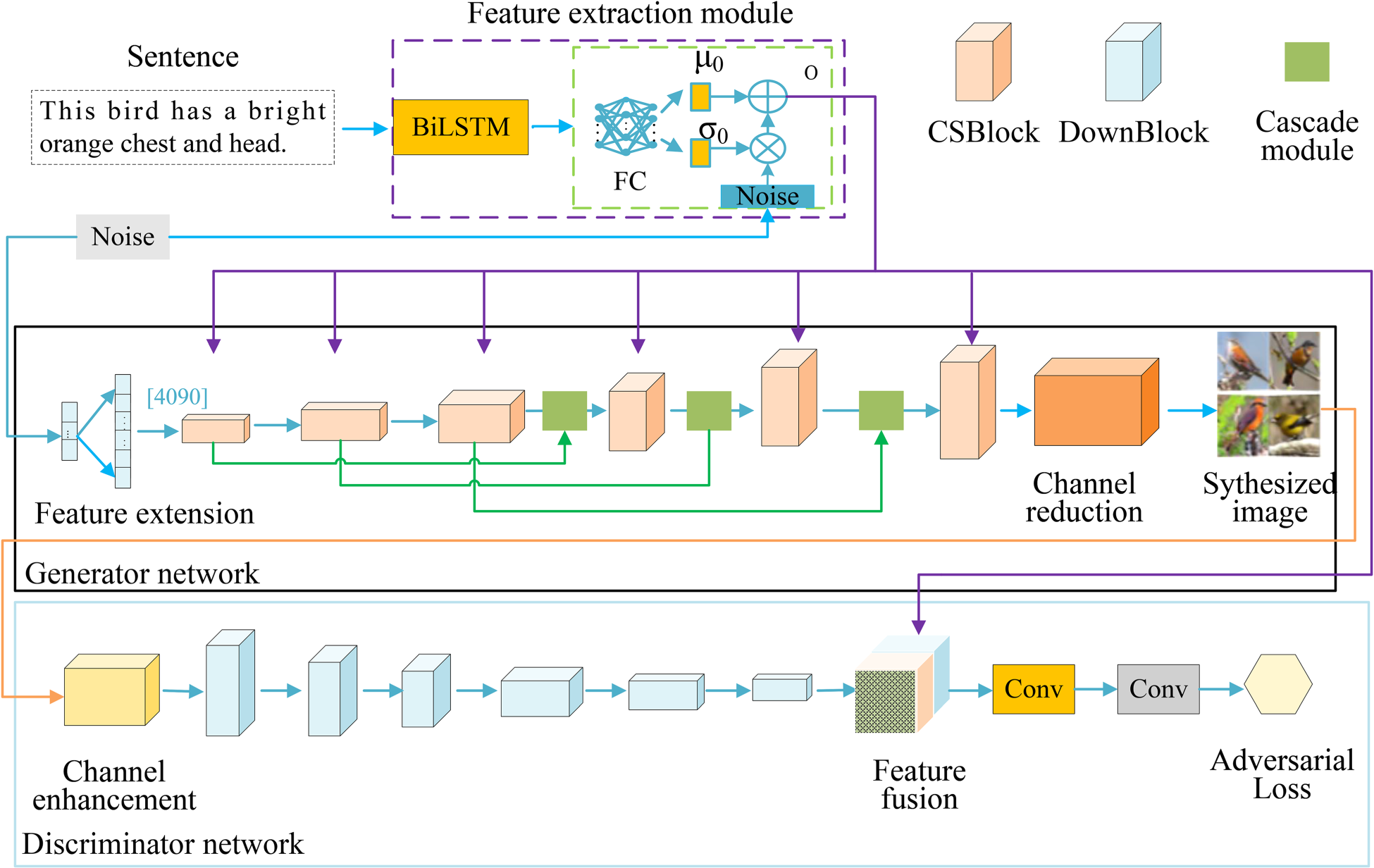
The network structure of cascaded structure and joint attention generative adversarial network (CSGAN). It has a pair of generators-discriminators. The generator consists of a feature extraction module, six CSBlock modules, three cascade modules and a channel dimension reduction module.
The feature extraction module consists of a bidirectional long short-term memory (BiLSTM) network (Schuster & Paliwal, 1997) and a CEM. BiLSTM obtains text features and introduces the CEM to enable it to have better representation capabilities for text.
Bidirectional Long Short-term Memory
BiLSTM includes two independent long short-term memory (LSTM) networks, which can process the forward and reverse text information in parallel, so as to dig the context information in the text sequence more deeply. Its network structure is shown in Figure 2. Given the input text information
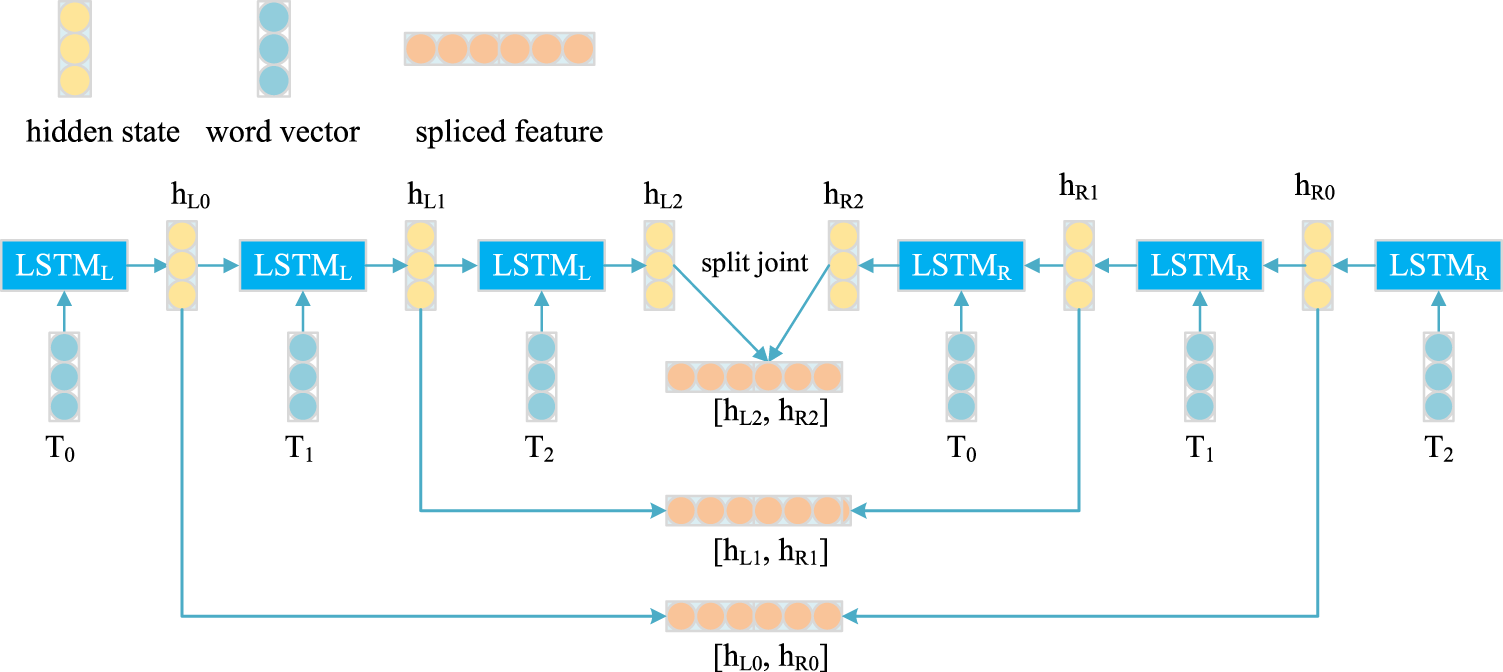
The network structure of bidirectional long short-term memory network (BiLSTM). It can not only obtain the previous information, but also the future information at a certain point in the sequence.
Text features are crucial for image generation, the same sentence may correspond to objects with different postures and appearances. In order to better obtain text features, the CEM is introduced to generate more conditional variables for the generator and enhance the robustness of the network, thereby solving the problem of overfitting when the number of image-text pairs is limited and the text data conditions are fixed. At the same time, the CEM also solves the problem that the text vector dimension obtained after the text description passes through the text encoder is too large, which may cause the text semantic space to be sparse, resulting in the lack of necessary features in the main body of the generated image.
Its network structure is shown in Figure 3. Given the text description T, the text encoder BiLSTM generates a sentence feature vector

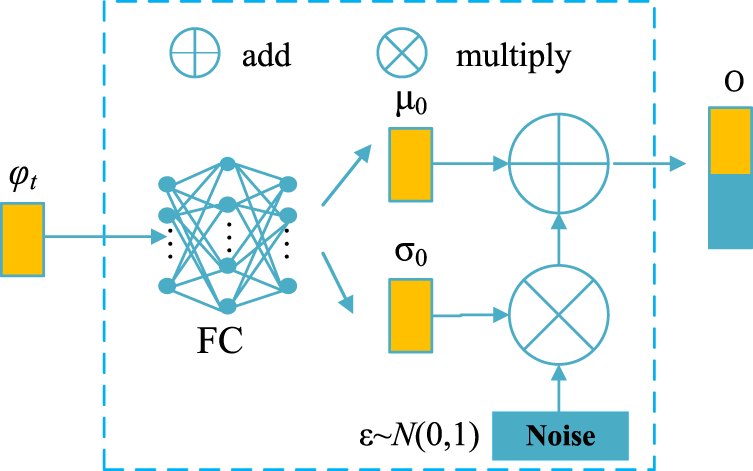
The network structure of conditional enhancement module (CEM). It can increase the representation ability of text coding and enhance the ability to capture important text content.
where
The generator mainly includes a feature expansion module, six CSBlock modules, three cascade modules and a channel dimension reduction module. The feature expansion module performs feature expansion on input noise, the CSBlock module deeply merges text features and noise features step by step to achieve further enhancement of text features, the cascade module strengthens the connection between CSBlock modules, the channel dimension reduction module performs channel dimension reduction operations on the feature map to obtain images with a resolution of 256
CSBlock
The CSBlock consists of an up-sampling module, multiple Affine layers, multiple activation layers, and two joint attention modules (FABlocks), as shown in Figure 4. The feature vector dimensions of each CSBlock are different, as shown in Table 1. The main function of the up-sampling module is to improve the resolution of the feature map. Through the cooperation of multiple Affine layers and Relu functions, the visual features based on natural language description can be better mapped to the image. By designing two FABlocks, the network structure can better integrate spatial attention and channel attention, which can not only enhance text features more deeply and effectively, but also improve the robustness of the network, enabling it to more effectively adapt to different types of input noise. The CSBlock receives text features multiple times to enhance and retain the details of text features, so that the generated image can better integrate text features and fit the text content.
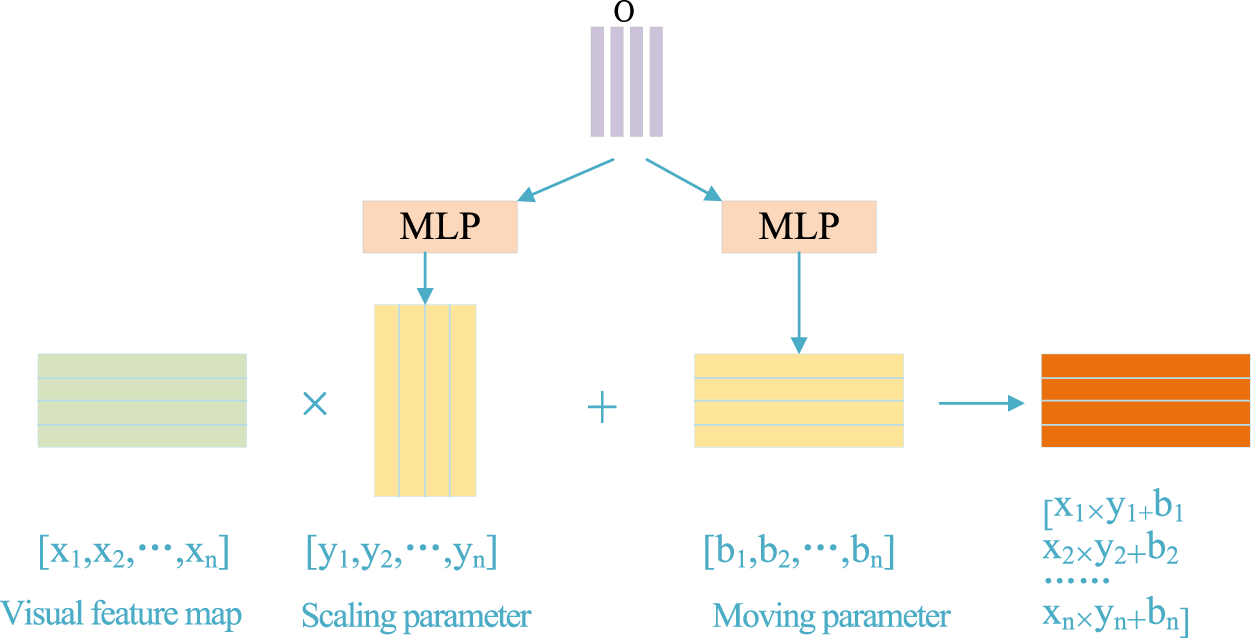
Affine layer
The network structure of CSBlock. Affine layers and FABlocks make better extraction of text content information. CSBlock Feature Vector Dimensions. FABlock
The network structure of Affine layer. Through channel-wise scaling and shifting, the generator can capture the semantic information in text description and synthesize realistic images matching with given text descriptions. In order to better enhance text features and obtain more feature details, a FABlock is designed, and its network structure is shown in Figure 6. This module consists of convolutional layers, CBAM, and BAM, which enables the network to better focus on the fine-grained information in text features. The CBAM connects the channel attention module and the spatial attention module to apply the weight information to the input feature information step by step, so that the network can better focus on text features. In order to further focus on the details of the text, the BAM module is added, and the number of channels in CBAM and BAM are spliced, so that the network can extract more complete features from complex text information. The network can pay attention to the content of the feature map as well as its details because of the combination of the two attention modules, the generated image’s primary content is more comprehensive and its details are more comprehensible.
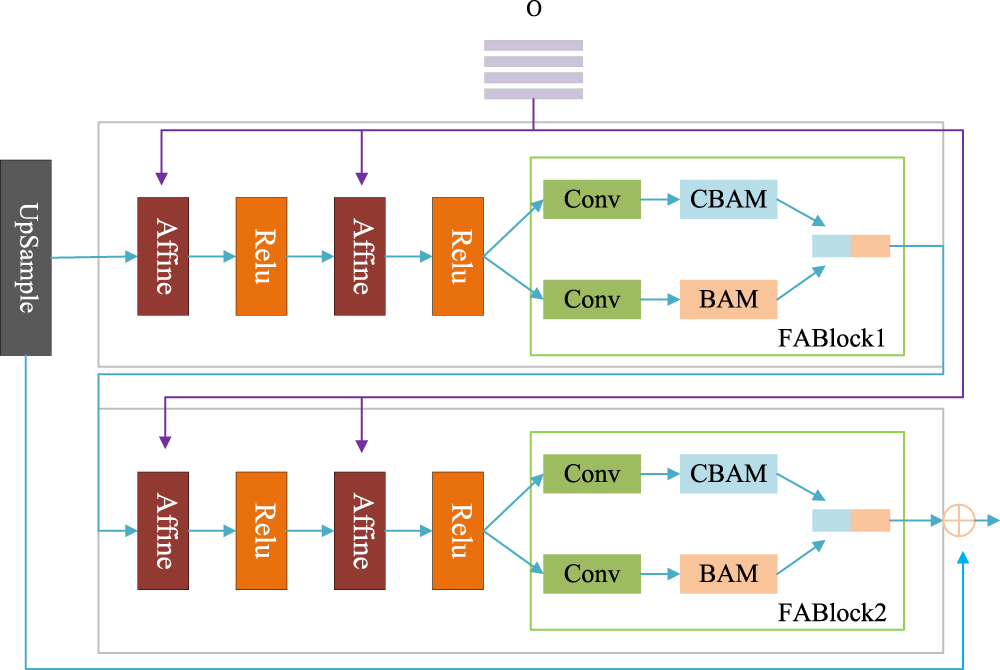


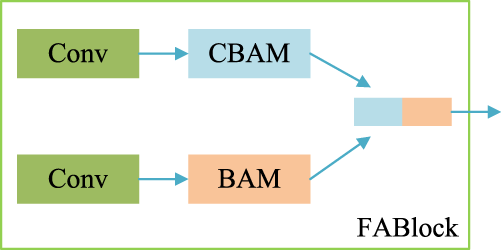
The network structure of FABlock. It effectively combines the advantages of CBAM and BAM, and deeply extracts the content of text information. CBAM = convolutional block attention module; BAM = bottleneck attention module.
In the past, the connection between each module in text generated images was not close, making it difficult to ensure the accuracy of the spatial position of main body of the generated image. Therefore, three cascade modules were designed, which fused the output features of the first CSBlock and the third CSBlock, the second CSBlock and the fourth CSBlock, and the third and fifth CSBlock step by step, establishing a close connection between multiple modules. Each cascade module is mainly composed of up-sampling and convolutional layers, and its structure is shown in Figure 7. In the
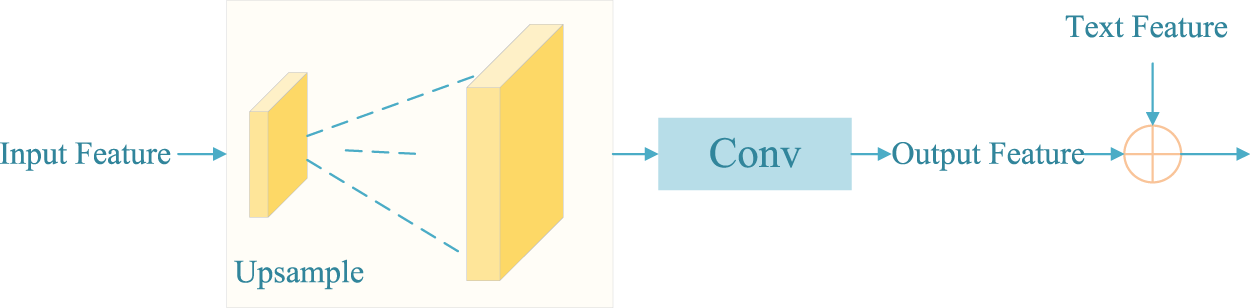
The network structure of cascade module. It effectively connects low-dimensional features and high-dimensional features, and better retains important information in the process of text information transmission.
The loss function used in the generator of the baseline network is shown in Formula (13), where 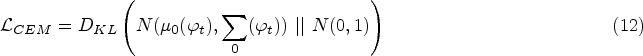

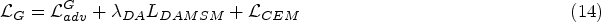
A channel dimension-raising module, six DownBlock modules, and two convolution modules make up the discriminator. The channel dimension-raising module converts the image output by the generator into features, extracts features from the feature map step by step through six DownBlock modules, and fuses the obtained features with the text features output by the CEM. Each DownBlock module has different feature vector dimensions, as shown in Table 2. The fused features undergo two convolution operations to calculate the loss function, optimize the generator, and generate high-quality images.
DownBlock Feature Vector Dimension.

DownBlock Feature Vector Dimension.
By calculating the confrontation loss function. The loss function of the discriminator is shown in formula (15), where 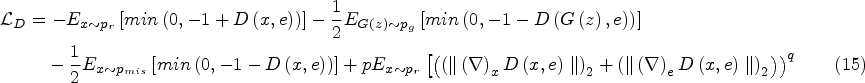
Data Sets and Parameter Settings
The CUB dataset (Wah et al., 2011) contains 200 bird species and 11,788 images, each with 10 language descriptions. A total of 8,855 images from 150 bird species are used as the training set, and 2,933 images from 50 bird species are used as the testing set.
Adam was used to optimize the network parameters,
Evaluating Indicator
In this paper, inception score (IS) (Salimans et al., 2016) and Fréchet inception distance (FID) (Heusel et al., 2017) are selected to evaluate network performance. The IS index evaluates the effectiveness of CSGAN generated images through clarity and diversity. The larger the IS value, the clearer and more diverse the generated image. FID is another evaluation index with more universal applicability, which represents performance by calculating the distance between the real sample and the generated sample in the feature space. The smaller the FID value, the closer the samples are and the better the model performance.
In addition, contrastive language-image pretraining (CLIP) is used to measure image-text alignment. CLIP model encodes images and texts by feature extractors to obtain image features and text features respectively, and calculates their cosine similarity, and then measures the matching degree between images and texts. The higher the value of CLIP mean, the higher the similarity between text and image.
Quantitative Evaluation
This paper compares the proposed method with many cutting-edge methods, including AttnGAN, MirrorGAN, DM-GAN, ITSC-GAN, and DF-GAN. Compared with other models, the CSGAN proposed in this paper achieves the highest IS and the lowest FID. Since DF-GAN has been compared with several state-of-the-art methods such as AttnGAN, MirrorGAN, and DM-GAN in comparative experiments, and the generated effects and data indicators are significantly better than them. In order to ensure the accuracy of the comparative experiment and strictly follow the single variable principle, this paper tests DF-GAN under completely consistent hardware and software configuration environments, and the experimental data is shown as DF-GAN*.
As shown in Table 3, compared with DF-GAN*, the IS index of CSGAN proposed in this paper on the CUB dataset increased from 4.73
Data Comparison of Each Model.
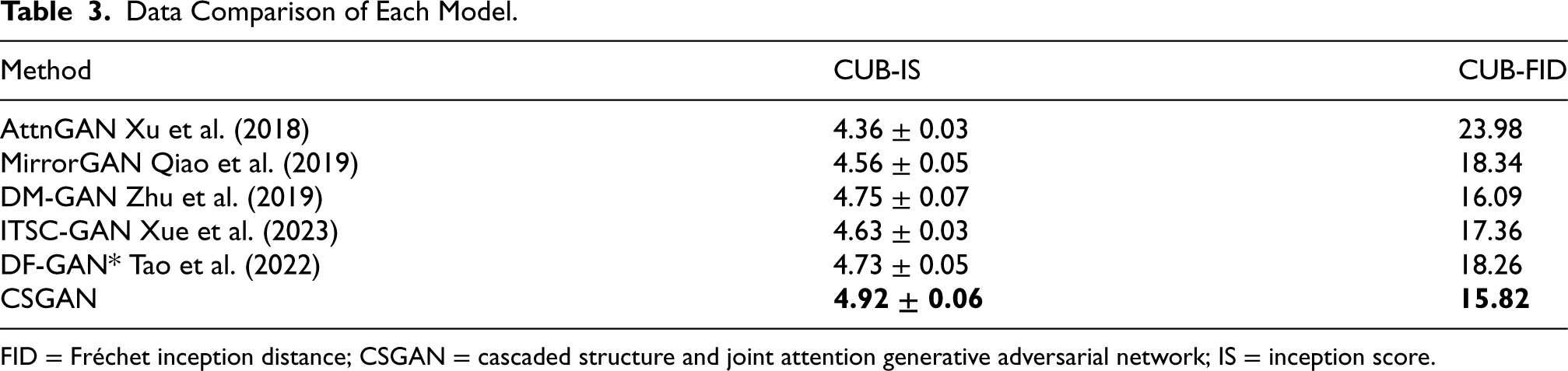
Data Comparison of Each Model.
FID = Fréchet inception distance; CSGAN = cascaded structure and joint attention generative adversarial network; IS = inception score.
At the same time, this paper selects a certain amount of text and the corresponding images generated by each model to evaluate the image-text alignment with CLIP model. The experimental results are shown in Table 4. It is worth noting that although AttnGAN has the highest CLIP mean, there are obvious defects in its generated images, such as incomplete main content and unclear reconstruction of details, as shown in Figures 8 to 10 (In Section 4.4). In contrast, the CLIP mean of CSGAN is 0.2472, which is slightly lower than AttnGAN, but it shows a significant advantage in image generation quality. The images generated by CSGAN not only have more complete main content, but also clearer image details. In addition, in comparison with DF-GAN (CLIP mean 0.2461) and DM-GAN (CLIP mean 0.2377), CSGAN showed certain competitiveness and demonstrated strong image text alignment ability.

Compared to AttnGAN, DM-GAN, and DF-GAN, cascaded structure and joint attention generative adversarial network (CSGAN) has a more complete main content and clearer details.

Using semantically consistent text to test models, the model in this article performs best.

When there is different noise in the agreed text content, the image generated by cascaded structure and joint attention generative adversarial network (CSGAN) performs better.
CLIP Mean for Each Model.

CLIP = contrastive language-image pretraining; CSGAN = cascaded structure and joint attention generative adversarial network.
In order to evaluate the performance of CSGAN more intuitively, this paper visually compares the images generated by the model with those generated by AttnGAN, DM-GAN, and DF-GAN* models. The comparison results are shown in Figure 8. From the figure, it can be seen that the main body of the first and second columns of AttnGAN is unclear, and important information such as the bird’s beak of the image in the third column is not reflected in the image. The boundaries of the images in the first and second columns of DM-GAN are unclear, resulting in the fusion of the main body and scene, resulting in low image quality. The generation of wings and claws in the first column of DF-GAN* is inaccurate, and the fusion of bird beak information and background in the generated images in the second column cannot be recognized. Compared to this, the CSGAN generated images in this paper have higher integrity of the main content and clearer detailed features of the images.
In the dataset, there are different language expressions for the same scene. In order to analyze the quality of images generated by the model from different text information in the same scene, this paper conducted corresponding experiments, and the results are shown in Figure 9. In the images generated by AttnGAN, the feather color of the bird’s belly in the third column of the image is inconsistent, which cannot accurately reflect the semantic information of “brown bell.” The main content in the images generated by DM-GAN is incomplete, especially in the third column where the bird’s legs are not reflected. There is a significant difference in the size of the main body in the images generated by DF-GAN*. Relatively speaking, CSGAN can ensure semantic consistency while ensuring the completeness of the main content, proving the reliability of CSGAN.
In the image generation process, for the same text, if the initial input noise is different, the generated image content may be biased. To this end, an experimental analysis of the impact of different types of noise on model performance was carried out, and the results are shown in Figure 10. In the case of the same text but different noises, there is a significant head generation error in the first and third columns of AttnGAN, and an image reconstruction error in the bird leg part in the second column. The first and third columns of DM-GAN also show reconstruction errors for the head of the main body of image, while the second column shows incomplete reconstruction for head details and legs. The reconstruction of details such as the beak and legs of the main body of the image in DF-GAN* is not clear. Compared to AttnGAN, DM-GAN, and DF-GAN*, CSGAN performs better in reconstructing details of the main body of the image such as bird beaks and eyes.
Ablation Experiment
Based on the baseline network, this paper completed three optimization tasks. First, in order to more accurately extract word-level features in text information, the CEM, DAMSM loss function, and KL loss function were introduced. Second, in order to address the problems of incomplete main content and weakened semantic consistency, cascade structure is designed to strengthen the internal connection between modules and improve the semantic consistency of text images. Third, in the process of generating features, in order to continuously enhance text features and ensure the integrity of text detail features, FABlock is designed to make the details of the generated image clearer. In order to demonstrate the impact of each module proposed in this paper on network performance, the following ablation experiment was performed on the CUB dataset. The results are shown in Table 4.
As can be seen from Tables 4 and 5, this paper adds the CEM and DAMSM loss function, to the basic model, the IS is improved by about 2.74% and the FID is reduced by about 1.25%; on this basis, only the cascade structure is added, which makes the model improve about 2.95% in the IS index and reduce about 3.45% in the FID index; on this basis, only the FABlock is added, which makes the model improve about 3.17% in the IS index and reduce 6.13% in the FID; finally, CSGAN improves about 4.01% in the IS index and reduces about 13.36% in the FID index. By analyzing the experimental results above, we can see that the cascade structure effectively combines the connections between the various modules in the generator, making the feature space of the generated image more consistent with the feature space of the real image, and improving the semantic consistency of the text image. The FABlock can deeply enhance the text detail features in the feature map, and at the same time can extract richer semantic features and improve the details of the final generated image, which proves the innovation and effectiveness of the model proposed in this paper.
Ablation Experiment.
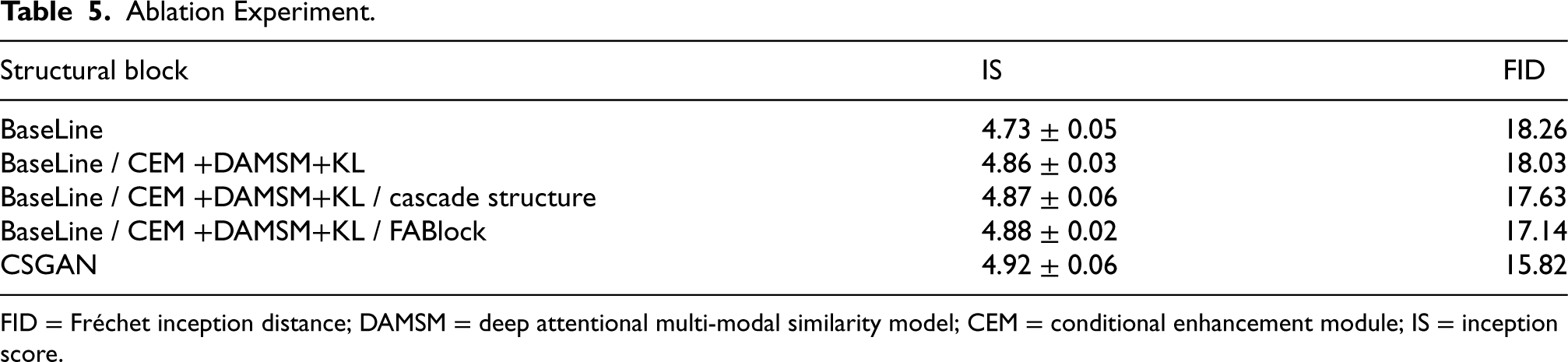
Ablation Experiment.
FID = Fréchet inception distance; DAMSM = deep attentional multi-modal similarity model; CEM = conditional enhancement module; IS = inception score.
This paper proposes a text-to-image model CSGAN that combines cascade structure and joint attention. In the feature extraction module, the CEM is added to enrich the text features and strengthen the full integration of text features and image features. The cascade structure strengthens the connection between modules in the generator, enhances the integrity of the main content of the generated image, and makes the image generated by the non-stacked structure better fit the text content. The joint attention module makes the details of the image such as edges and textures more realistic.This model will be further optimized, for example: in order to obtain text features with higher representation strength, use a better text encoder. In order to improve performance while minimizing additional network additions, further refine the loss function.
Footnotes
Acknowledgements
This work was supported by Nature Science Foundation of Jilin Province, No. 20230101179JC, China.
Funding
The authors received the following financial support for the research, authorship and/or publication of this article. This work was supported by Nature Science Foundation of Jilin Province, No. 20230101179JC, China.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.