Abstract
Although neural-symbolic techniques for symbol grounding in sensory data have shown significant effectiveness, they still require substantial training. This article revisits symbolic-only approaches by introducing a new algorithm for creating hierarchical concept structures from spatial sensory data. The method is based on Bateson’s idea of difference as the fundamental element of concept formation. By leveraging this principle, the algorithm extracts atomic features from raw data through basic sequential comparisons within a stream of multivariate numerical values. Experiments carried out on a set of common objects indicate that the method can successfully discriminate and assimilate categories as needed without training. The results show that the model improves on the neural networks it has been tested against, which required more than 400 training examples for the same task. The results also show that the model can generate rich conceptual structures and human-like representations, which (i) facilitate high composability, (ii) support formal reasoning, (iii) inherently enable generalisation, and (iv) possess potential for generative behaviour. Consequently, this approach offers a compelling contribution to symbol grounding and neural-symbolic research by providing a seamless algorithm to bridge perception and conceptual knowledge.
Keywords
Introduction
The motivation behind this research is to investigate new symbolic methods capable of generating rich and composable conceptual representations of spatial objects. Humans possess remarkably sophisticated encodings of the world, characterised by their exceptional ability to differentiate and assimilate the realities they perceive. Even without extensive training, these encodings enable the formation of highly flexible and composable concept structures that support logical operations and exhibit generative capabilities. Additionally, these structures can be expressed semantically through symbols. Therefore, bridging the gap between sensory data and such internal models of the world is a pivotal challenge in artificial intelligence (AI). Symbolic or logic-based AI systems are often credited with replicating certain crucial aspects of human thought, such as compositionality, causality, and reasoning capacity (Newell, 1980; Simon, 1995). However, they face substantial hurdles when confronted with raw spatial data, including the symbol grounding problem (SGP) as formulated by Harnad (1990) (see Section 2.2), and a computational complexity bottleneck. In contrast, the connectionist approach, which emerged from the work of early cyberneticians Wiener (1948) and Pitts & McCulloch (1947), has proven exceptionally adept at handling this type of input, exemplified by pixel-based images. This proficiency has been firmly established through neural network paradigms, particularly deep learning (Lecun et al., 2015), which employ error optimisation as their core learning mechanism. However, those strengths featured by symbolic models turn out to be important limitations in connectionist methods.
In this context, the emergence of neural-symbolic models (NSMs) (Garcez et al., 2015) has drawn attention as a promising approach to address the limitations in both symbolic and connectionist AI paradigms. Indeed, the literature on NSMs has witnessed substantial growth in recent years (Hitzler et al., 2022; Sarker et al., 2021), although much earlier contributions can also be found (Fdez-Riverola & Corchado, 2003; Zhou et al., 2003). These hybrid models aim to overcome important shortcomings previously identified by prominent figures in AI research (Bengio, 2017; Cristianini, 2014; Lake et al., 2015; Xia et al., 2021). However, while NSMs are very promising, several challenges remain, particularly with regard to the SGP.
One of the primary challenges is the requirement for neural networks to be trained on labelled data, which introduces external symbolic information, potentially compromising the SGP’s objective of grounding symbols in sensory data. This is evident in the case of neural networks used for classification tasks, where labelled data is essential for training. In contrast, certain NSM approaches may appear to circumvent the reliance on external symbolic information. Notably, neural autoencoders can be harnessed to extract clusters from complex data in an unsupervised or self-supervised manner. Then, arbitrary symbols may be assigned to these clusters for further processing. However, a closer examination of some of these works (Section 3) suggests that they may not fully adhere to the zero semantical commitment condition (Z condition) proposed by Taddeo & Floridi (2005). The ‘Z condition’ asserts that an AI agent should autonomously elaborate its own semantics for the symbols it manipulates, without relying on external symbolic knowledge. Another important limitation of these methods is the need for large training sets, even when autoencoders are employed in a self-supervised fashion (and no labelling is required).
The method proposed in this article, BIGA (Bateson-inspired grounding algorithm), is primarily intended for the domain of real-world objects, restricted in this initial iteration of the method to multi-attribute one-dimensional entities. Nevertheless, it is envisioned that future work will extend this scope to incorporate higher dimensional and more complex data modalities (such as images, videos, audio, etc.). Examples include the trajectories of particles suspended in a fluid, or, more generally, any one-dimensional geometry that can be derived from, for instance, the spatial contours of material forms. Alternatively, more abstractly, a curve in space with varying width and colour (or any other set of properties) can also be considered. In all of these cases, objects can be fully represented as multivariate time series.
The algorithm employs a straightforward approach to extract symbols from a multivariate stream of numerical data using a basic feature extraction process. This operation occurs continuously as the sensor moves along an object, similar to sensing the shape of an object by swiping a finger along its contour. Thus, the act of sensing is always modelled as a dynamic sequential process, which is an essential aspect of this work. The method draws inspiration from Bateson’s concept that an idea is essentially a difference: ‘a difference that makes a difference’ (Bateson, 1999). Similarly to the approach presented by Cárdenas-García (2022) and Cárdenas-García & Ireland (2020), the proposed sensor generates qualitative information by encoding the quantitative aspects of continuous values through a comparator element. The fundamental features analysed in this method are whether two successive values
The work presented here hinges on the notion that sensing does not primarily grasp magnitudes, but rather, it discerns differences in magnitude. Humans exhibit remarkable proficiency in detecting variations and proportions, but fall short in assessing absolute magnitudes with precision. This inherent limitation has led to the development of tools for precise measurement. Biological neurons also follow a similar pattern, conveying signals not by their intensity but in an ‘all-or-none’ manner (firing or not firing) (Jr, 1994). While most connectionist machine learning models utilise floating point values as input and propagate their magnitudes through the network, Bateson’s differential ideas offer a promising foundation for constructing human-like cognitive models. The proposed model deviates from the connectionist error optimisation paradigm by simultaneously (i) eliminating the need for training to generate high-level concepts and, (ii) adhering to the all-or-none signal transmission nature of biological neurons. This novelty opens up the possibility of developing bio-inspired connectionist systems based on the firing scheme found in nature, capable of constructing rich conceptual representations without the need for training. An early sketch of ideas regarding the design of such system can be found by de Miguel Rodríguez (2023).
Regarding the SGP, it is not the aim of this study to propose a definitive solution, but to establish a foundation for future research by exploring alternative approaches. It is acknowledged that the method presented here does rely on external information, as it assigns semantic values to the tokens or symbols representing the atomic comparators and the sensor variables. And for this reason, it violates the Z condition introduced earlier. However, it is worth considering the possibility of leaving these semantic values unassigned, essentially rendering them unlabelled or anonymous. This could be achieved in an embodied implementation of the model, where these tokens are mapped to the system’s innate or ‘wired’ discretisation capacity. In this scenario, consensus on the meanings of these unspecified tokens could be established among a group of agents, employing mechanisms similar to those discussed by Taddeo & Floridi (2005). These mechanisms could involve schemes such as Vogt’s ‘guess game’ (Vogt, 2003) or later attempts by Taddeo & Floridi (2007). This approach shows two potential advantages:
Reduced complexity: The algorithm is based on the use of the minimum number of comparators that allow establishing a maximum differentiation between the values obtained by the sensors. For example, in the case of continuous attributes, three comparators Bottom-up emergence: The model possesses an inherent generative ability, stemming from its full symbolic traceability, from the sensor level to the highest levels of generated concepts. This generative capacity would enable producing outputs into the environment, representing aspects of the internal representations of objects. These outputs could then be perceived by other processes (agents), initiating a consensus-building loop of interactions. While the specifics of this multilateral agreement process remain unclear, there is potential for the emergence of a rudimentary language or alphabet without external interference, and it could hypothetically provide a path towards circumventing the SGP in future work.
The proposed method, based on the recursive computation of differences, might seem simplistic and potentially limited in its discriminative power at a first glance. However, the results demonstrate surprising potential for common objects, particularly when incorporating multisensory data. In this sense, for example, when perceiving a curve with a robotic or human arm, not only positional coordinates
Although the method may face limitations in certain domains, it holds promise for achieving satisfactory discrimination in others. Data domains where the patterns rely heavily on subtle signal magnitude structures will encounter limitations, including fields such as financial time-series analysis or machinery fault detection using sound or vibration spectra. Conversely, areas where patterns are better described conceptually or through relative values and proportions are ideal for this method. Examples include the field of design, handwritten text recognition, and the characterisation of spatial trajectories, which may involve speed and acceleration profiles among other attributes. In short, if the accuracy in distinguishing everyday objects proves to be sufficient, the model can leverage its inherent advantages to address several critical aspects of contemporary AI.
As a summary, the following items capture the spirit of the model, which:
Operates on qualitative differences rather than quantitative magnitudes, aligning with human cognition. Generates rich and composable representations without extensive training. Exhibits complete traceability, enabling clear links from sensor data to the highest-level concepts. Supports formal reasoning, allowing for logical manipulation of concepts. Is naturally equipped for generalisation, enabling the application of concepts to new situations and contexts. Generates human-like semantic concept structures, capturing the essence of human understanding. Provides multiple conceptual definitions of the same object, reflecting the flexibility of human cognition. Is inherently generative, allowing for the creation of new concepts and representations. Requires minimal external symbolic input, with only three comparator symbols and one symbol per sensor variable. This makes it conducive to future development of bio-inspired implementations and new avenues to tackle the SGP. Adopts a bottom-up approach, building complex concepts from basic atomic elements, mimicking the process of language acquisition. Utilises a straightforward algorithm, simplifying its implementation and making it easier to build upon for future challenges and applications.
In essence, the main contribution of the method is that it provides a simple algorithm to bridge perception and semantic conceptual structures seamlessly, without either (i) necessitating combining models from different AI paradigms as is the case of neural-symbolic models, or (ii) limiting the model’s ability to create vast conceptual richness by allowing it to generate its own ‘labels’ in a bottom-up approach.
Fundamentals
This work aims to generate conceptual structures from atomic features acquired from sensory data. The term ‘concept’ has many definitions across a wide number of disciplines (Goguen, 2005). In the realm of computer science, these definitions range from the notion of ‘universals’ introduced by the pioneer of cybernetics, Wiener (1948), to that of ‘patterns’ handled by connectionists. However, most approaches to concept learning come from symbolic AI, with a significant emphasis on semantics. An extensive review of these approaches can be found in the work of Goguen (2005), which includes the geometrical conceptual spaces of Gärdenfors (1990), the symbolic conceptual spaces of Fauconnier, the information flow of Barwise and Seligman, the formal concept analysis (FCA) of Wille (1982), the lattice of theories of Sowa (2005), and the conceptual integration of Fauconnier and Turner. While concepts in these theories can still be viewed as a form of ‘pattern’, they possess an intrinsic symbolic structure that facilitates compositionality, generality, semantics, reasoning, explainability, and generative capabilities. Thus, the term concept in AI encompasses not only patterns, but a more fundamental suite of human-like cognition abilities. Due to the strong resemblance between the conceptual structures targeted in this study and those found in FCA, the latter has been selected for the initial iteration of the method.
Formal Concept Analysis
FCA offers a robust engine for pattern learning, reasoning capabilities, and an organised hierarchy of concept networks represented as formal lattices (Wille, 1982).
FCA relies on the idea of a formal context, which consists of a collection of attributes, objects, and their relationships. Formally, a formal context
It is usual to represent a formal context through a binary table/matrix
A Simple Formal Context Example With Four Objects and Three Attributes.

A Simple Formal Context Example With Four Objects and Three Attributes.
Given a set
A formal concept of
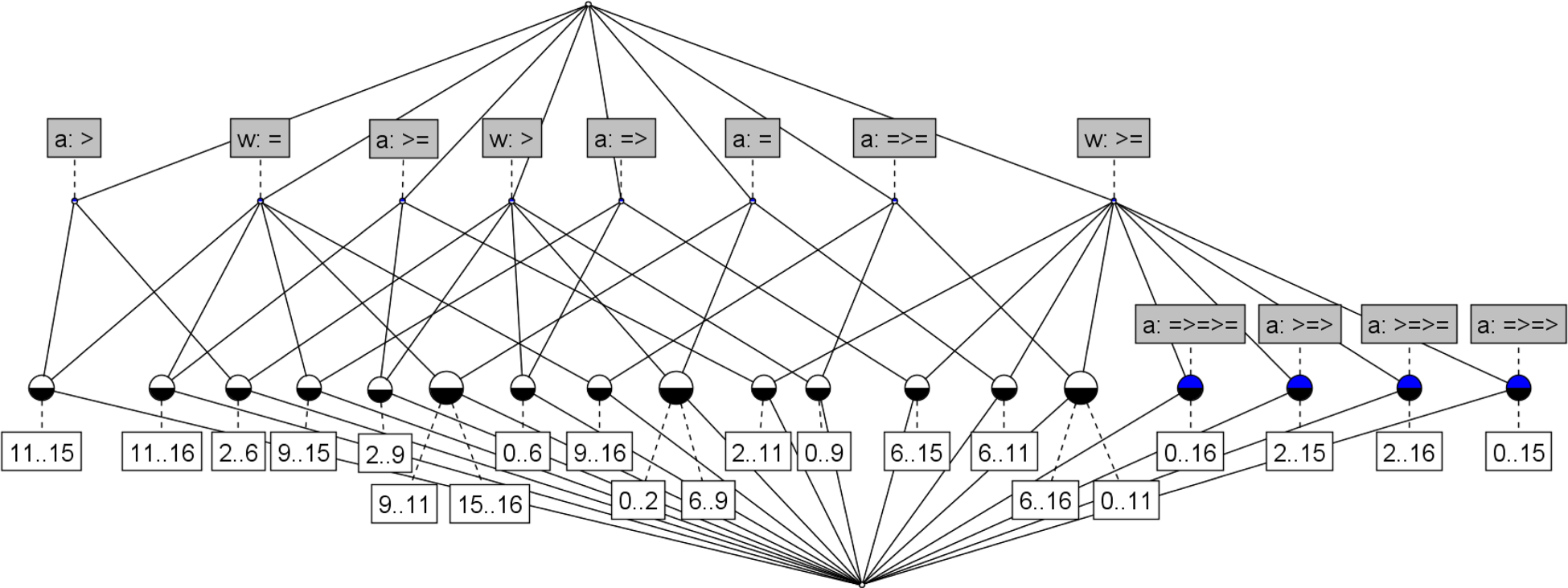
Given a formal context, FCA allows arriving at a concept lattice, which is a hierarchical network of relationships between the formal concepts obtained from the context (each node in the lattice is a concept): if
The concept lattice corresponding to the formal context in Table 1 is shown in Figure 1, where, for example, the node
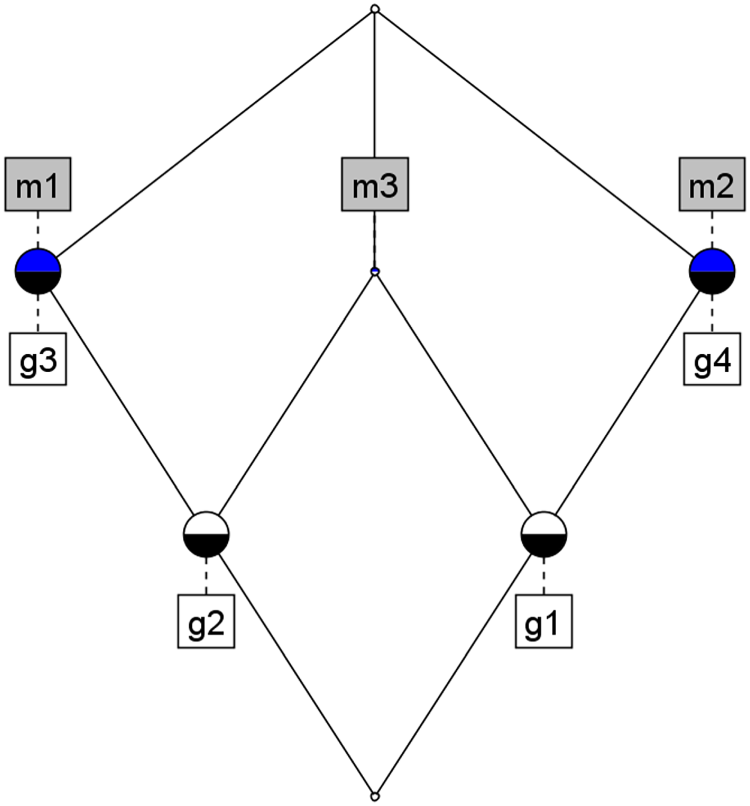
A simple formal concept lattice example.
Works like Borrego-Díaz & Páez (2022) have explored the potential of these models in the field of explainable AI. However, implementing FCA on detailed data (such as raw sensor data) has been a persistent challenge. Due to its combinatorial nature, applications often results in large and complex lattices that are computationally intensive and contain a large number of irrelevant concepts. Many studies have focused on complexity reduction to address this issue. Some of the first approaches in this regard were led by Bělohlávek exploring constraints based on the attribute dependency formulas (Belohlávek & Sklenár, 2005a), attribute equivalence (Belohlávek et al., 2004), hierarchically ordered attributes (Belohlavek et al., 2004), and the reduction of fuzzy lattices using hedges (Belohlávek & Vychodil, 2005). An important contribution to complexity reduction was the introduction of granular computing (Yao, 2000; Zadeh, 1979) to the realm of FCA (Belohlávek & Sklenár, 2005b; Wu et al., 2009), by handling floating-point values by relying on unsupervised machine learning techniques to automatically generate ‘granules’ or clusters according to the desired complexity level. Other strategies include variable threshold models (Zhang et al., 2007), Rough concept analysis (Kent, 1996; Saquer & Deogun, 1999), and Fuzzy concept analysis (Saquer & Deogun, 2001), which emerged as important contributions to the field and have been widely adopted today. Despite these proposals and more recent efforts to improve computing efficiency (Mouakher et al., 2021), enhance flexibility (Min & Kim, 2019), and reduce complexity in concept lattices (Aragón et al., 2021; Hao et al., 2021), research on FCA applied to complex sensor data remains limited, with only a few examples such as Boukhetta’s work Boukhetta et al. (2020), where FCA is used to extract sequential patterns from interval-based sequences.
In 1990, Harnad introduces the SGP (Harnad, 1990), expanding on Searle’s earlier ‘Chinese Room Argument’ (Searle, 1980). Harnad writes: ‘
Since the formulation of the SGP, there have been a number of attempts to develop models capable of addressing it. Many of these efforts were collected and discussed early on by Taddeo & Floridi (2005), where they introduced the notion of the zero semantical commitment condition (or Z condition) as a summary of the ultimate requirement for any valid solution to the SGP. In words of the authors, (i) ‘no semantic resources (some virtus semantica) should be presupposed as already pre-installed in the artificial agent’ and (ii) ‘no semantic resources should be uploaded from the ‘‘outside” by some deus ex machina already semantically-proficient’. The implications of this condition are far reaching: not only do symbols need to emerge from sensory data, but also, the artificial agent needs to learn autonomously how to identify those symbols as icons that have been assigned a certain perceptual reality and understand how to operate with them. Otherwise, there is the assumption that semantic capabilities are already present in the agent, thus failing the Z condition. In this context, the SGP might be crucial for comprehending how humans, thousands of years ago, developed a symbolic and semantic system purely from sensory inputs. Consequently, the SGP intersects various fields, including AI, linguistics, cognitive science, philosophy, among others. Recent studies are available by Nagoev et al. (2023), Dushkin & Stepankov (2023), Li (2022), and Chang et al. (2020).
Related Works
Recent advances in neural-symbolic research have witnessed a convergence of the strengths of neural and connectionist models with the benefits of symbolic and logic-based AI. SATNet Wang et al. (2019), a notable work in this domain, achieves logical reasoning within deep learning models by incorporating a differentiable maximum satisfiability solver (MAXSAT). The model transforms the task of learning a logical structure from data into the acquisition of a MAXSAT solution for a well-defined problem instance. This framework was further refined by Topan et al. (2021), where the task of classifying digits from the MNIST dataset was seamlessly integrated into SATNet. This was carried out without explicit supervision while simultaneously learning the rules of Sudoku and solving Sudoku boards. In doing so, the authors claim to have addressed the SGP, despite the intricate symbolic and logic knowledge required by the model to solve MAXSAT problems. In their study, the
A similar approach was adopted by Dai et al. (2019), where the authors proposed a neural network architecture to perceive pixel data from images and a logic-based reasoning engine to extract rules and knowledge from the former. To translate the patterns learned by the network into symbols that can be processed by the reasoning engine, the model assigns pseudo-labels to these patterns and then resolves a logic puzzle to determine the correct label assignment. As in the previous work discussed, this approach relies on a specific problem statement with a known solution. This puzzle-solving approach resembles the concept employed by Asai & Fukunaga (2017), where actual puzzles are solved. Another intriguing hybrid approach is presented by Garnelo et al. (2016), drawing inspiration from reinforcement learning. Their method also features a neural perception module and a symbolic reasoning engine. However, in their case, the interface between the two modules is a symbolic ontology tailored to the context of a learning agent. The ontology is explicitly uploaded to the agent based on the characteristics of its environment. This approach is particularly relevant to the work presented in the present article, since the emergent concept structures developed here could potentially serve as the ontology layer proposed in their work; thus, removing the necessity of prior ontology modelling.
In their insightful paper (Evans et al., 2021b), the authors explore the intricacies of ‘sense-making’ from a continuous stream of sensory input. They challenge the prevailing notion that prediction, retrodiction, and imputation of missing values alone are sufficient evidence for sense-making. Instead, they argue that the construction of a symbolic theory that explains the underlying patterns and relationships in the data, is the hallmark of genuine sense-making. This perspective is consistent with previous research suggesting that the ability to construct explanatory theories is a crucial element of human common sense. Building on this foundation, the authors explore a possible definition of the underlying mental model that emerges when one makes sense of sensory input, and show how this mental model implicitly enables predictive, retrodictive, and imputational abilities. However, the discrete nature and limited range of sensory data handled by the model in its current form are recognised as significant limitations. The examples provided to demonstrate the model’s capabilities, such as elementary cellular automata, drum rhythms, and other relatively simple data streams, underscore the need for a broader applicability. To address this shortcoming, the authors introduce neural networks into their subsequent work (Evans et al., 2021a), extending the reach of the model to more complex and continuous data domains. Although this integration of neural networks, requires training, it also promises to enhance the model’s ability to make sense of real-world sensory data streams. This paves the way for more sophisticated AI systems capable of true understanding.
A noteworthy aspect present in the NSMs above is their capacity to learn logic-based rules without extensive training. This constitutes a distinct advantage over traditional pattern recognition tasks that require massive supervision. Additionally, their inherent ability to extract knowledge from data without overfitting is particularly appealing, as it aligns with human learning processes and holds promise for more efficient and generalisable AI systems. The methodology presented in this article further exemplifies this trend, demonstrating how concept structures can be learned from real-world data without the need for vast sets of labelled examples. This facilitates the development of more robust and adaptable AI systems, capable of acquiring knowledge from the world without the burden of extensive labelling.
In a separate line of research, a notable study from 2015 Lake et al. (2015) explores two core questions: (i) How do humans acquire new concepts from a handful of examples? And (ii) How do humans develop such abstract, rich, and flexible representations? The first question sheds light on the realm of unsupervised or weakly supervised concept emergence and out-of-distribution learning, while the second addresses the crucial importance of natural compositionality in concept structures. Their method introduces the Bayesian programming learning framework, which learns simple stochastic programmes to represent concepts. These programs function as probabilistic generative submodels, and the model as a whole learns by fitting them to a background set of data using only a few samples per category. The implementation provided utilises the Omniglot dataset as its background set of data, encompassing both pixel and stroke data from handwritten characters. It is essential to note that in this model, the building blocks of concepts are predefined as subparts, parts, and spatial relations. Subparts represent strokes separated by brief pauses in the pen, while parts are defined by pen-down and pen-up events. Despite the general applicability of the methodology, its implementation is highly dependent on the specific nature of the dataset, provided in the form of a library rather than emerging from raw sensor data. Nevertheless, this approach shares several notable similarities with the methods presented here. A particularly interesting observation is that models capable of learning and evolving rich conceptual representations must simultaneously exhibit both generative and learning capabilities in a seamless manner. This bidirectional property is closely related to the central thesis of the present work.
Considerable research on extracting symbolic knowledge from sensory data has also focused specifically on concepts. A notable contribution is Bechberger (2021), which builds upon prior work on Conceptual Spaces (Bechberger & Kühnberger, 2018) as proposed by Gärdenfors. Their approach is supported by logic tensor networks, a type of neural network employing fuzzy membership functions. Conceptual spaces offer a vector representation of conceptual knowledge as regions within a feature space, providing a more natural approach to handle the grounding of sensory data. The combination of logic tensor networks and conceptual spaces results in a model that is capable of emerging concept structures directly from sensory data, while simultaneously leveraging the powerful learning engine provided by neural networks. The approach, then, relies on mapping symbolic knowledge into vector-based spaces. As a consequence, the extracted knowledge becomes somewhat more indirect and less semantically transparent. Finally, Nevens et al. (2020) specifically addressed the challenge of bridging the gap between continuous observations and symbolic concepts within the context of ‘grounded’ learning within the domain of classifying volumetric primitives from the CLEVR dataset (Johnson et al., 2017). Attributes such as the number of corners of shapes are extracted using computer vision libraries, including continuous-valued attributes such as colour, and other complex attributes such as the ratio between the area of the object region and the area of the rotated bounding box. Ultimately, the model is trained using both a weighted schema for concept relevance in a tutor-learner scenario.
Table 2 presents a schematic comparison of these works. It should be noted that this summary is merely a guide from the point of view of the authors, and should be taken rather loosely; most of the aspects indicated in the table are not ’black or white’, and long debates could be carried out considering the classification assigned to each work.
Comparison of Main Related Works.
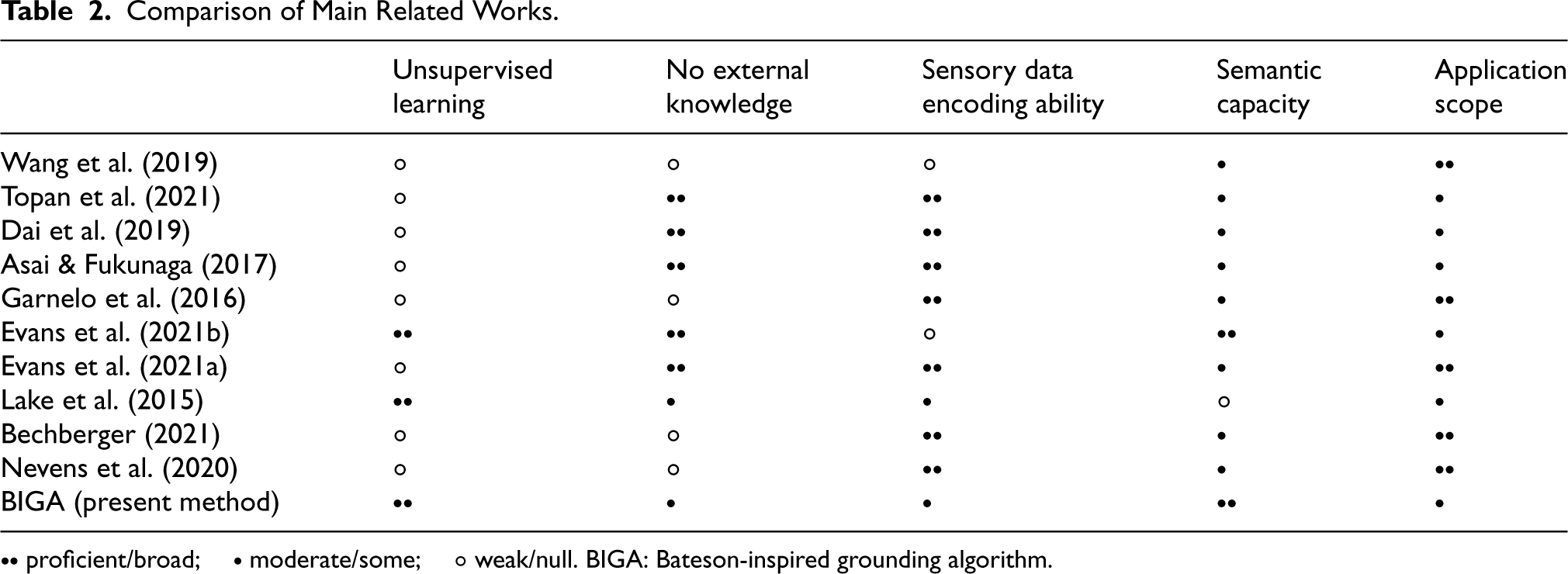
Comparison of Main Related Works.
The present study aims to extract symbolic features or patterns from multivariate time series without requiring a training process. Thus, it is essential to place it within the wider scope of time-series analysis. Several notable methods have emerged in this domain, including SAX (symbolic aggregate approximation) (Lin et al., 2003), where a combination of Gaussian normalisation and discretisation allows a symbolic representation to be extracted in a predetermined number of symbols. A key contribution of this work lies in the fact that distances in the symbolic space offer a lower-bound guarantee with respect to the original data.
Another notable contribution involves the incorporation of the Fourier transform into the latter approach, which establishes the symbolic Fourier approximation (SFA) method (Schäfer & Högqvist, 2012). The recent literature has focused primarily on variations or enhancements of SAX (Bountrogiannis et al., 2023; Imamura & Nakamura, 2021; Kloska & Rozinajova, 2021; Yu et al., 2023) and SFA (Li & Shen, 2022), including efforts in the field of explainable deep learning (Schwenke & Atzmueller, 2023). Additionally, alternative strategies have also emerged. For example, Nguyen & Ifrim (2023) used random symbolic sequences for efficient and accurate classification tasks. Zunino et al. (2022) developed a novel time-series representation strategy based on the concept of permutation entropy introduced by Bandt & Pompe (2002). While these works predominantly aim at providing efficient machine learning algorithms for time-series analysis, they differ from the central objective of the present study, which is to construct human-like conceptual and semantic structures from the data.
A closely related field of research that does share this same objective can be found in the area of linguistic summarisation of time series. Although, perhaps, not the most popular, it is definitely a well-established domain of research with origins in the broader field of data summarisation (Yager, 1982). Linguistic summarisation involves the extraction of relatively simple features from data streams (Aoki & Kobayashi, 2016; Aydogan, 2023; Castillo-Ortega et al., 2011; Kacprzyk et al., 2007; Özdogan et al., 2021), so that they can be expressed semantically in human-readable terms. In this context, it bears significant resemblance to the method described in this article. Nevertheless, there are two key distinctions: (i) the features extracted necessitate prior understanding of the relationships between variables (Baydogan & Runger, 2014), and (ii) the present model generates hierarchical structures of formal concepts from the features extracted, which is arguably more similar to the ways in which human knowledge is articulated.
In subsequent discussions, a segment will be represented as a named tuple in the form (
A curve or trajectory is represented as a sequence of segments sharing the same structure (identical attribute set). For instance, as will be elaborated in the subsequent subsection, a segment could be defined by the structure
In line with the focus on identifying changes in the curve’s progression, three possible comparators are naturally associated for each attribute. The choice of comparators depends on the attribute type; since numerical attributes are considered in this case, all attributes employ the same set of comparators. Specifically, the comparators (<, >,
The curve feature extraction algorithm operates on a curve
Preprocessing. For each The set of intervals with the above attributes will be denoted by Symbolic Comparison Scheme of the Nine Possible Basic Transition Combinations.
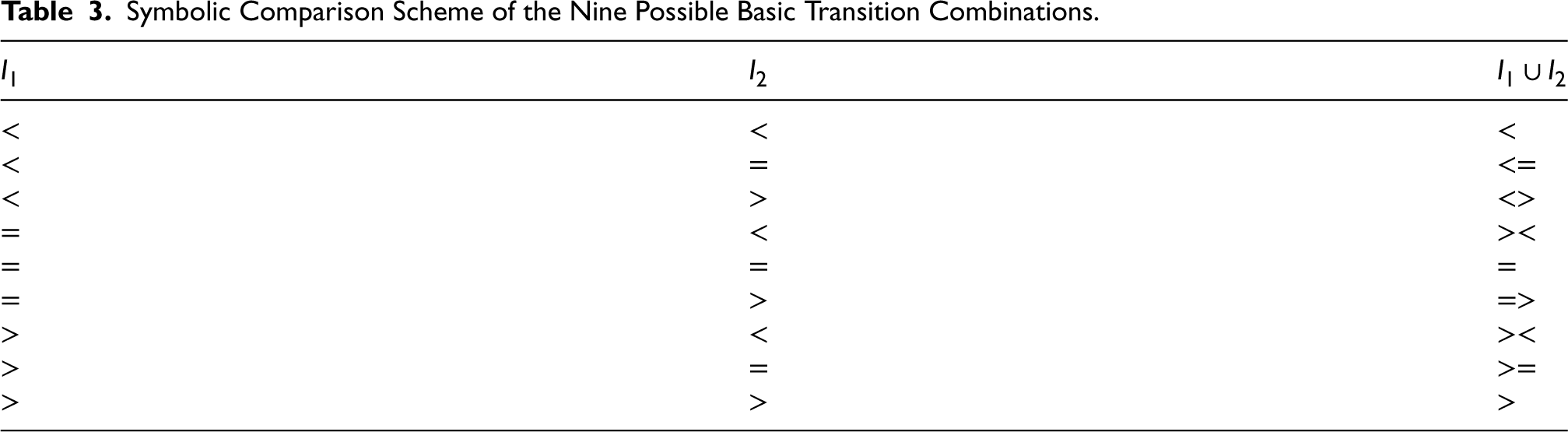
Remove redundancies. Information redundancy between contained intervals is checked. An interval
In this step, the intervals that are redundant with respect to another existing interval in the set of intervals shall be removed from the set. Thus, the set
Recursion.
If
If
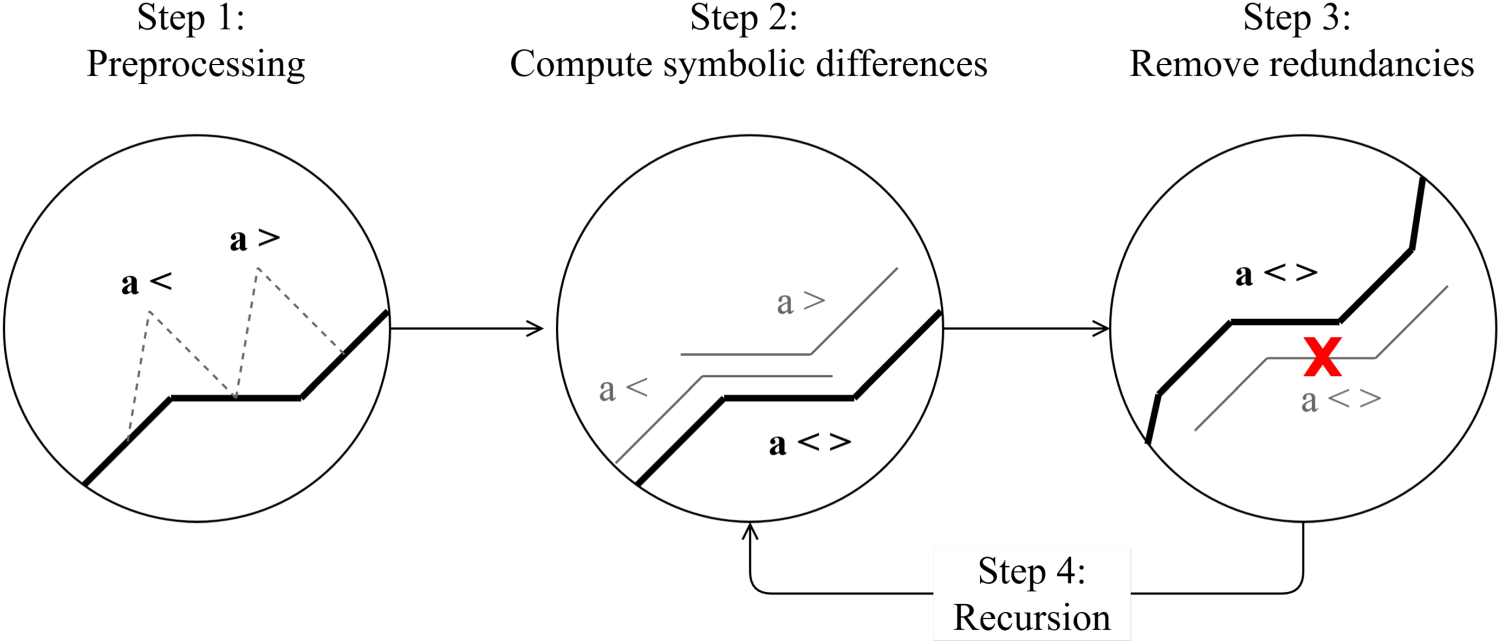
Flowchart of the proposed algorithm.
In this example, a curve is represented in Figure 3(a), with an axis line and variable thickness as illustrated by the grey shade around it. A sensor is reading the curve at regular intervals, as shown in Figure 3(b). For the sake of simplicity, these intervals have been fixed to generate as few segments as possible, thus the poor definition of the curved sections. However, in practise, these intervals would allow for a very smooth definition of the curve.
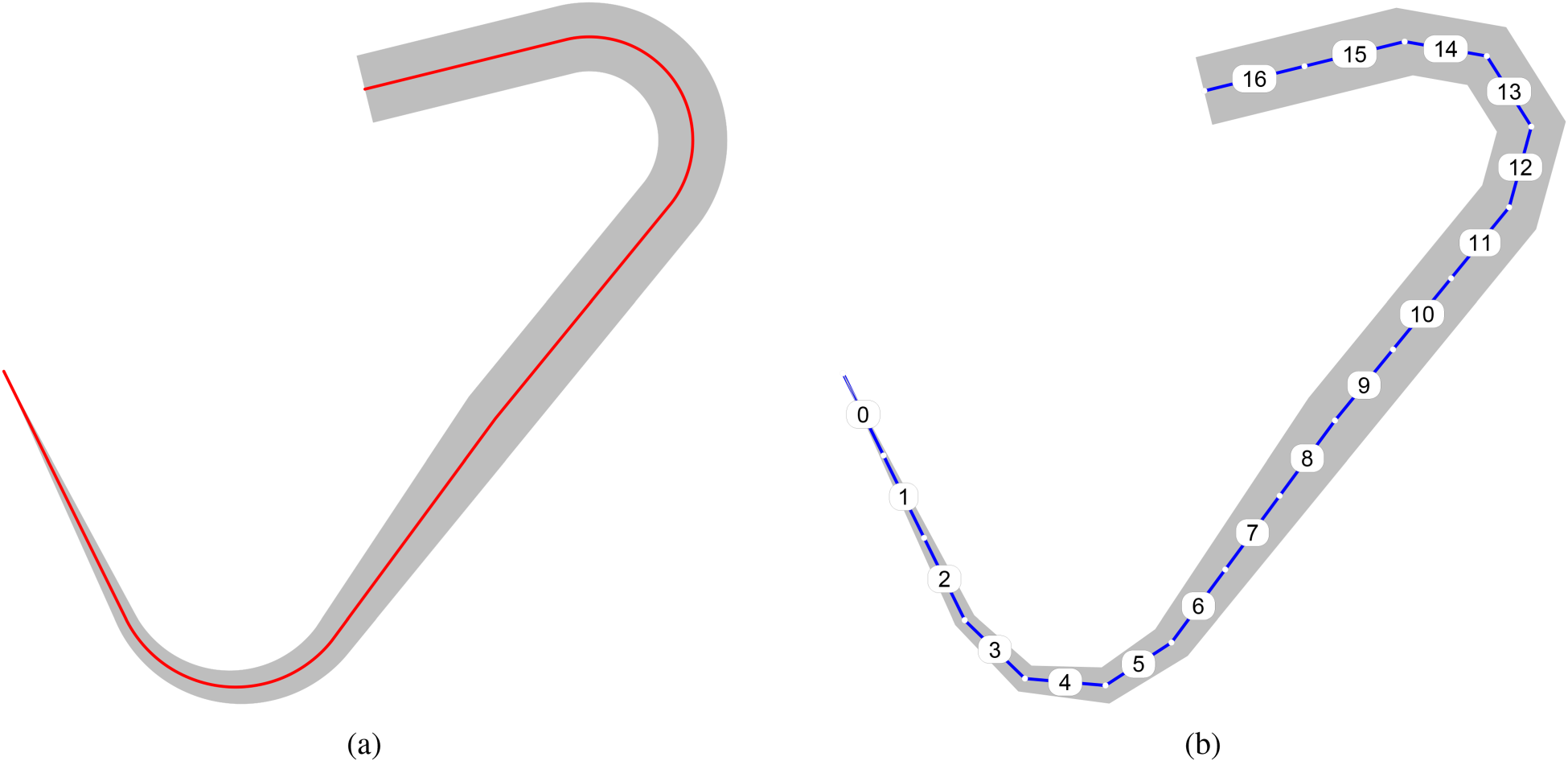
(a) Entity selected as example, and (b) breakdown into segments after sensor reading.
A time-series representation of the example curve, taking into account the angles and widths at each segment is provided in Table 4. It should be noted that the model does not operate with the specific values, but rather, it just needs to compare pairs of adjacent values and discriminate whether the values are equal or whether one value is larger or smaller than its peer.
Preprocessing. In the first step, value comparisons of sequential record pairs are performed to obtain symbolic properties. The first pair takes the first two segments ( Compare Time Series Representation of the Sample Entity. Formal Context Table Resulting From Step 1.

Resulting Concept Set After Step 1.

Visualisation of each concept’s extent after step 1.
Compare
Compare
Remove redundancies. At this point, each interval that is contained in any other interval is checked for redundancy: if the attributes of the shorter interval are the same as the attribute set of the larger interval, then the former is removed from the interval table. When an interval is removed from the table, it is no longer used in the process going forward. For example, the intervals
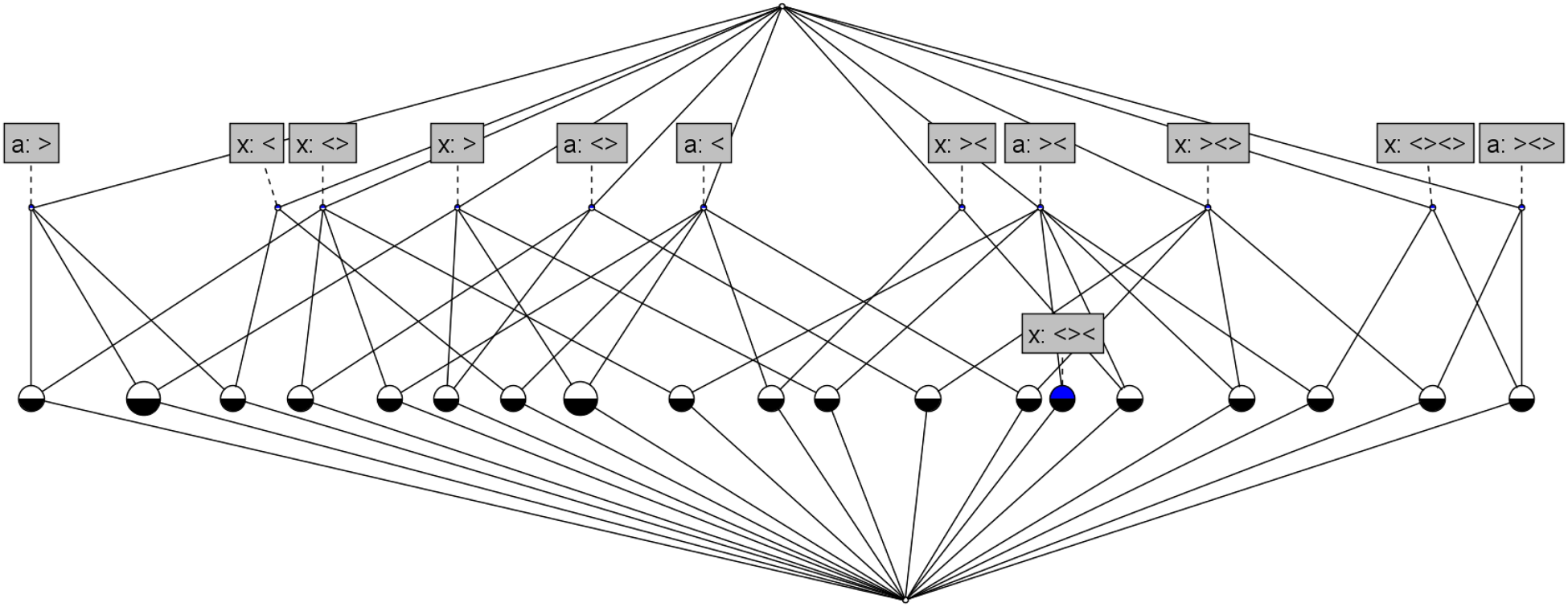
Recursion. Steps 2 and 3 are repeated recursively until the model generates no new information. This occurs in the present example after three iterations, resulting in the final formal context presented in Table 15 (Appendix). From this formal context, 28 concepts are calculated by the FCA algorithm, nine of which have already been obtained in Step 1 (
Resulting formal concept analysis (FCA) lattice of the example curve (
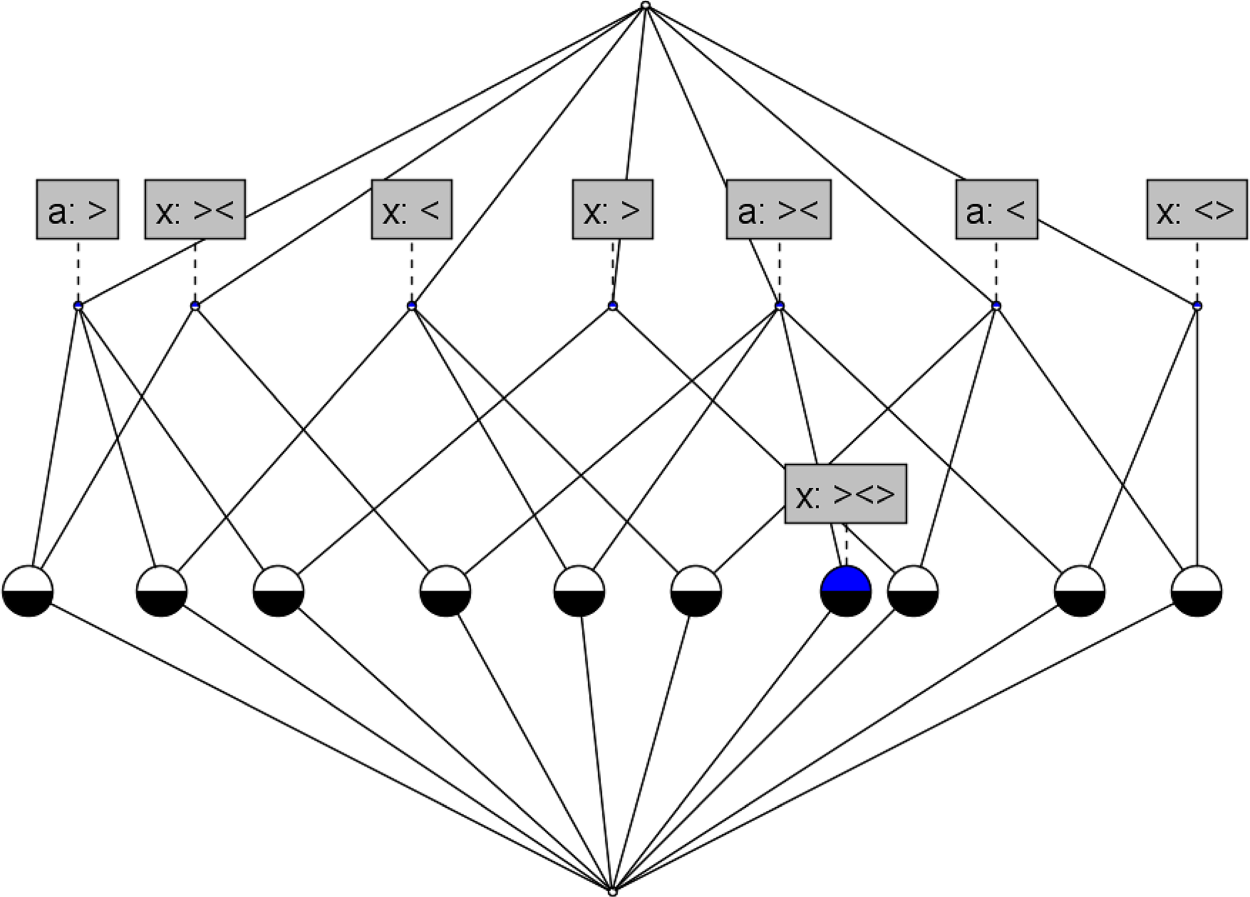
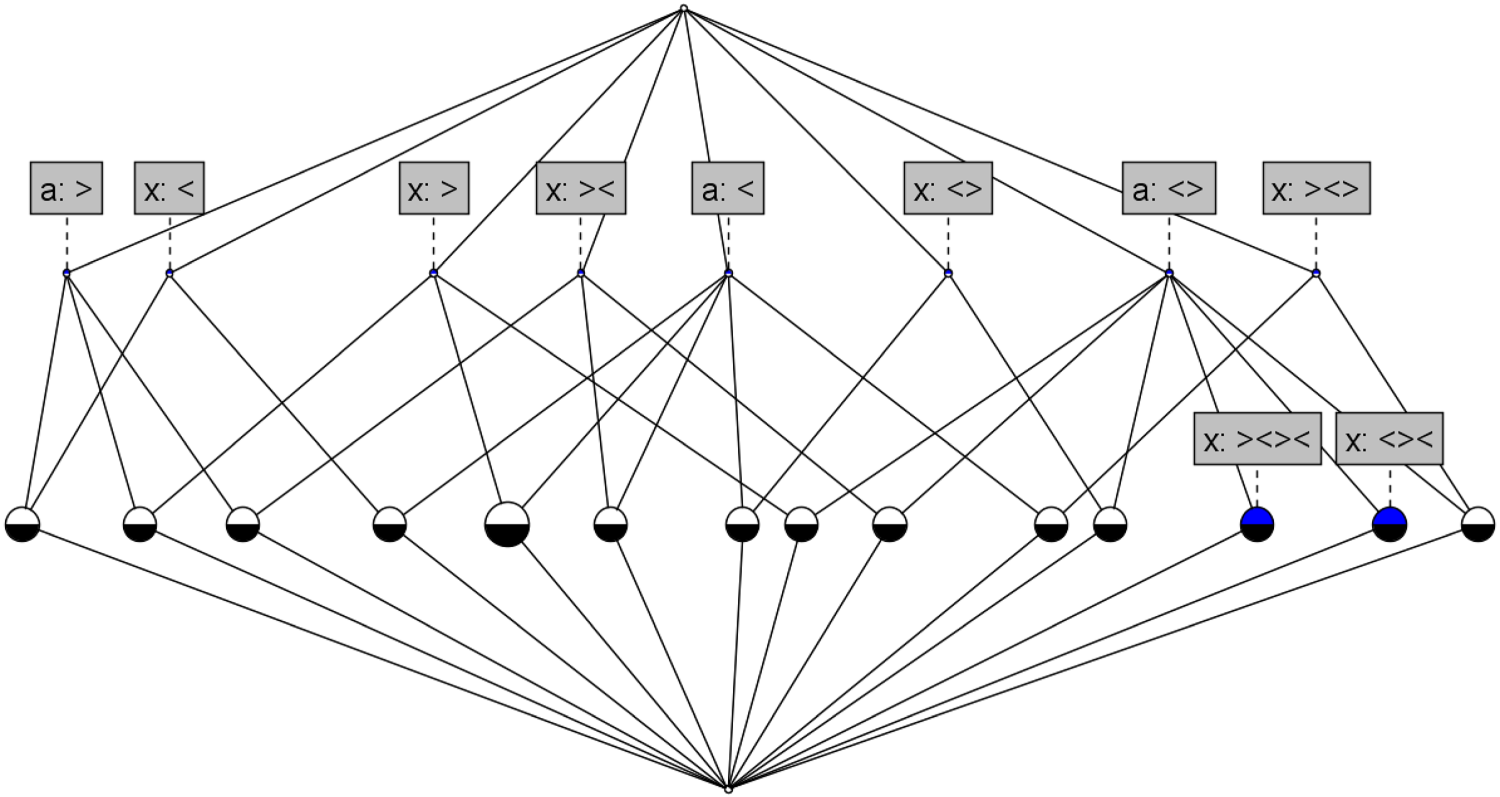
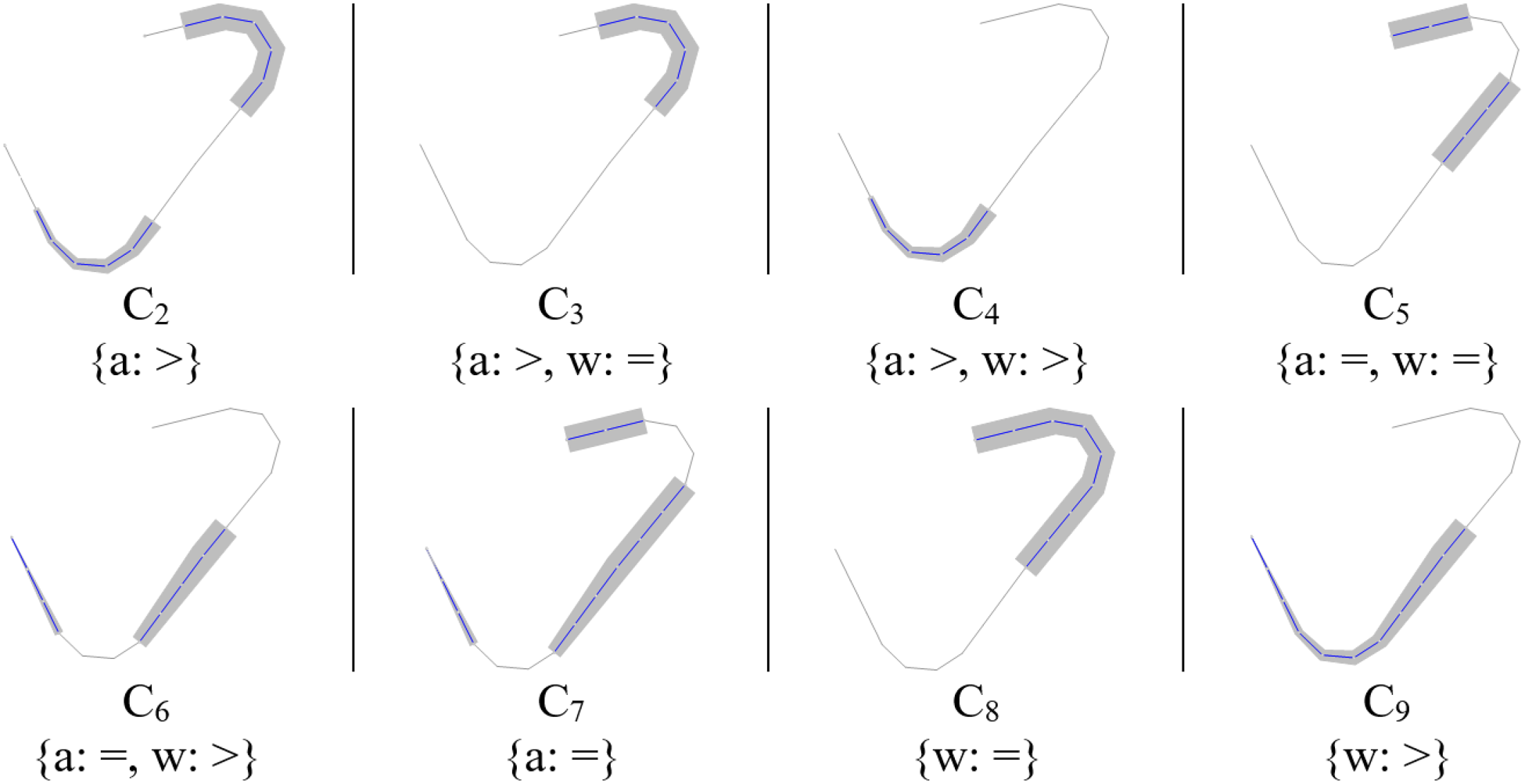
In this section, the methodology presented above will be assessed in terms of its capability to both discriminate and assimilate among a family of curves. Figure 6 shows the set of curves (or trajectories) that will be considered. All curves feature variable thickness or width and flow from left to right. It can be observed that there are four pairs of visually similar curves
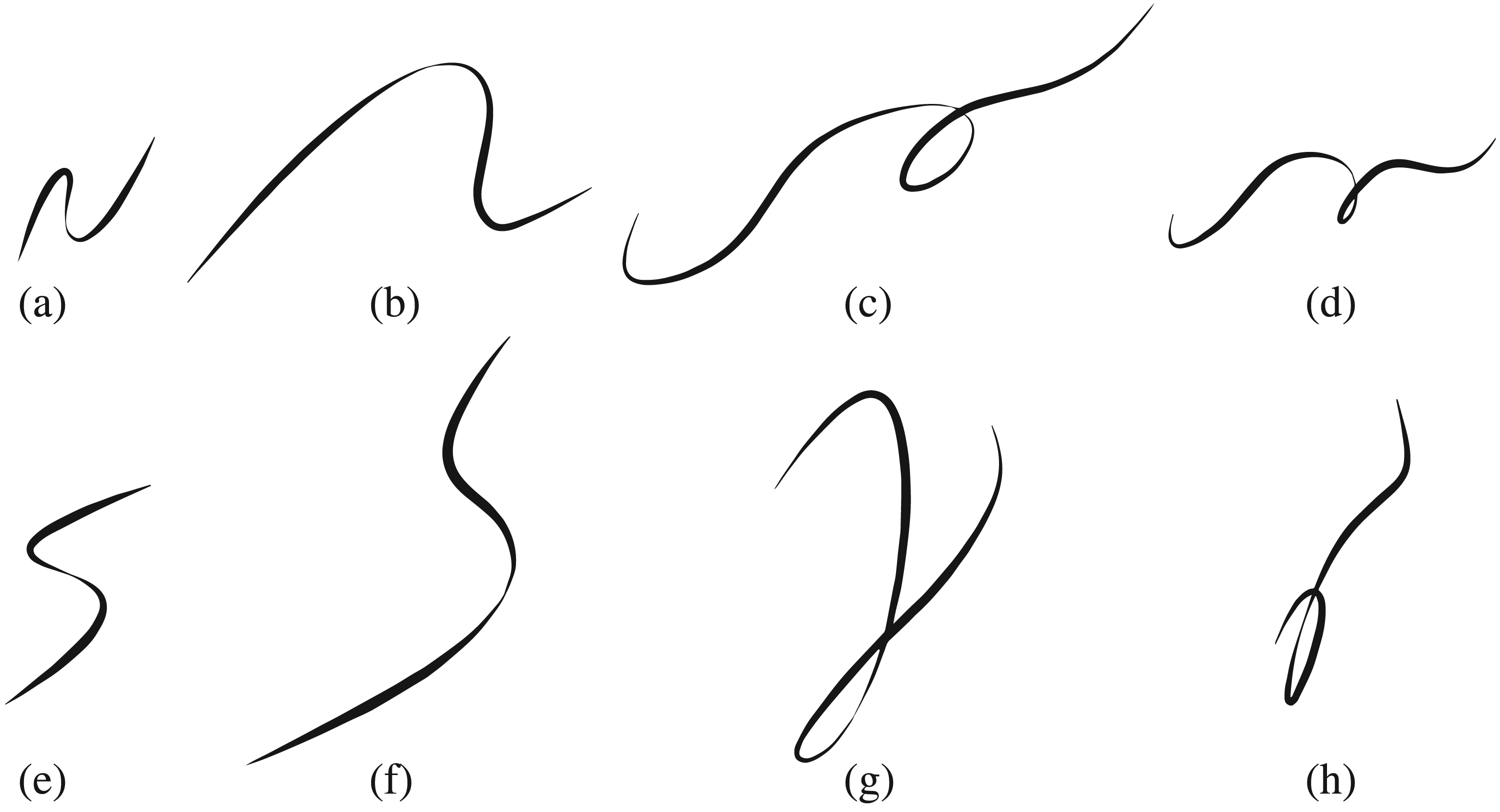
Curves setup for experimentation.
The experiments focused on providing answers to three questions: (i) Can the model generate concepts that capture common patterns among the curves? (ii) Is there a concept (or set of concepts) that uniquely characterises each pair of visually-similar curves?, And (iii) Within each pair, can the model generate a concept that discriminates each individual curve? The results of these questions are presented in the subsections below.
Although this first task is perhaps rather trivial, it allows further showcasing the features of the model. There are, of course, a great number of concepts that capture common patterns across the curves. However, for the sake of simplicity, only those concepts that are common to all samples are presented (Table 9). A list of concepts has been provided for four different combinations of sensor parameters as follows:
Apart from the concepts provided, this list can be extended to include any subconcepts that can be extracted from them. For example, if the intent of the concept
Extent of concept intent
Concepts (Intent) Present Across All Curves in the Sample-Set.

For each curve, the model provides the corresponding set of concepts according to the methodology presented in this article. Various sets of concepts have been obtained for the following sensor combinations for segments:
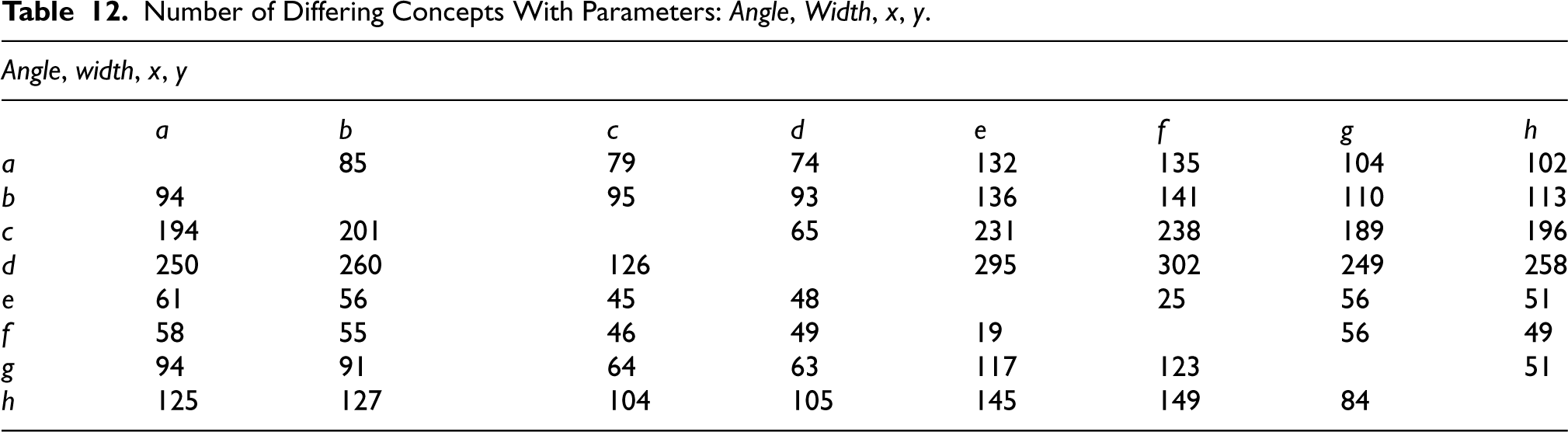
Number of Differing Concepts With Parameters:
.
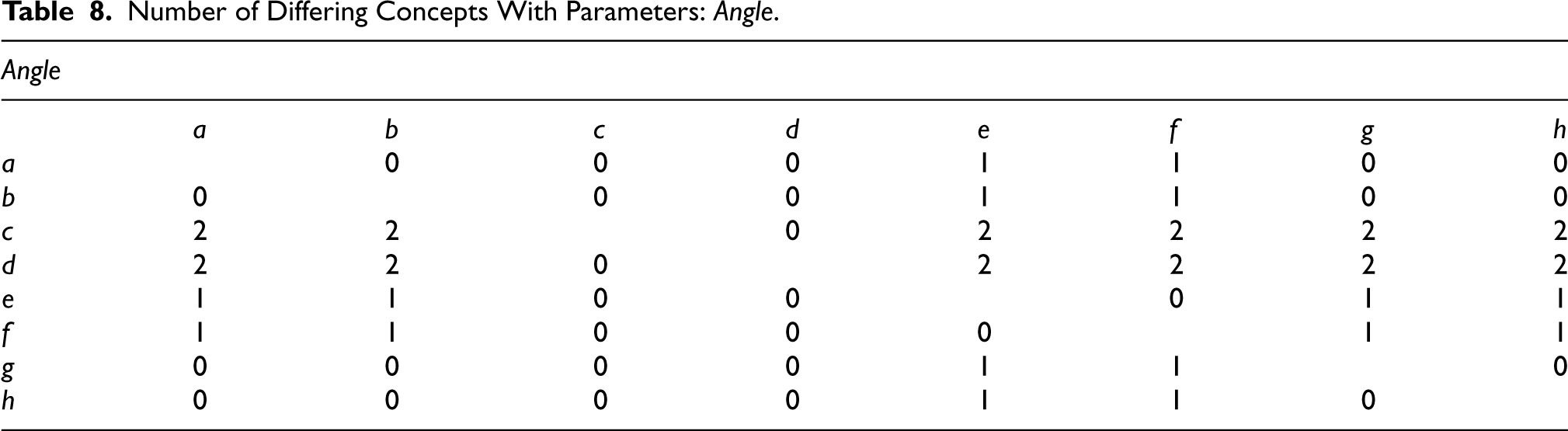
Number of Differing Concepts With Parameters:
Number of Differing Concepts With Parameters:
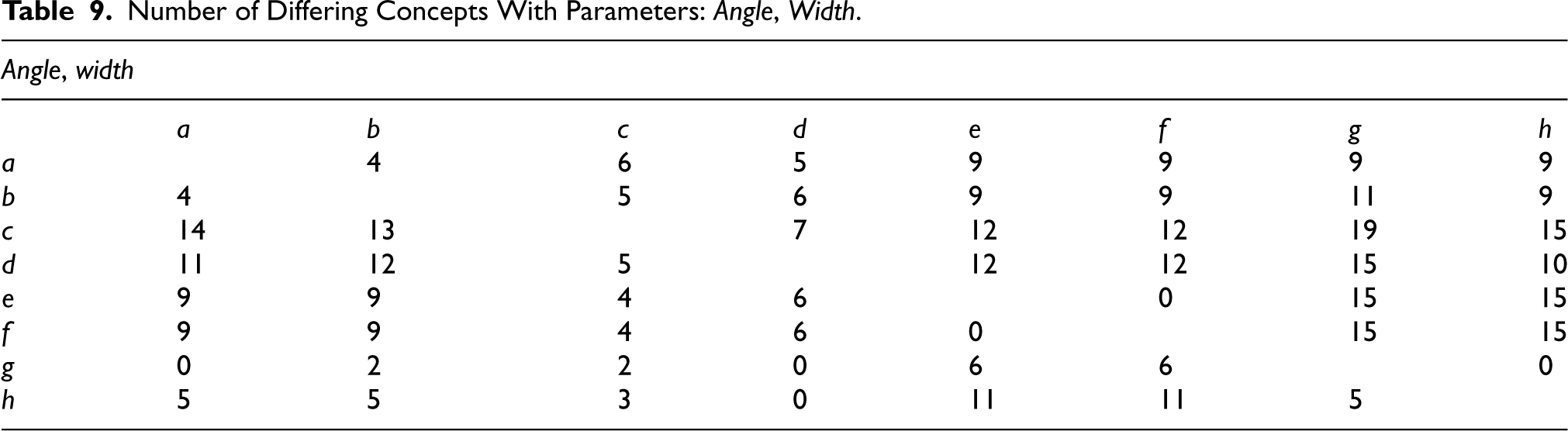
Number of Differing Concepts With Parameters:
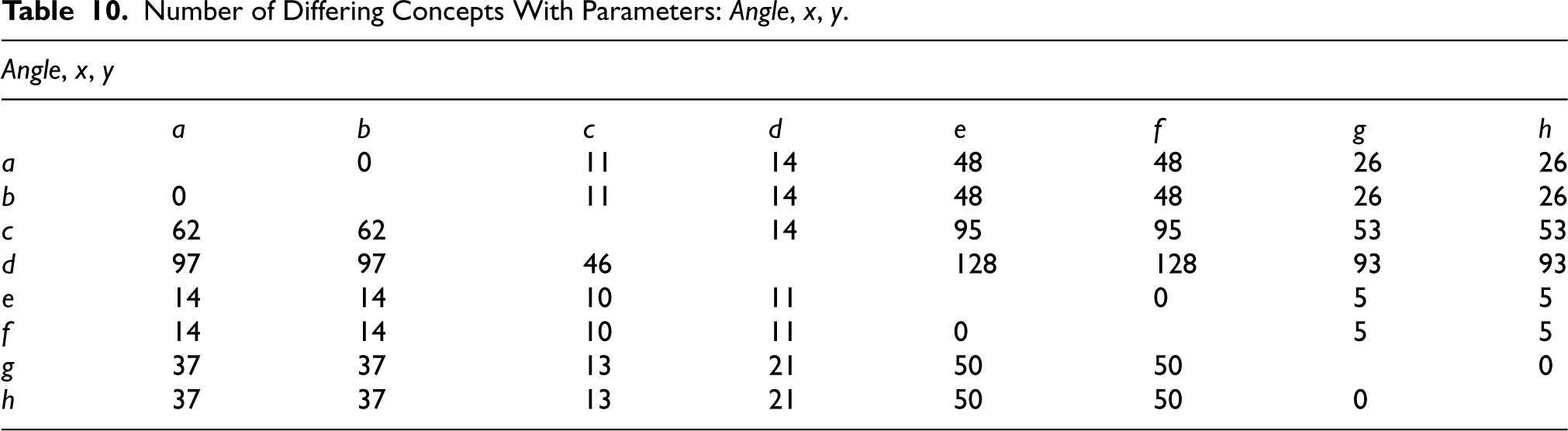
Number of Differing Concepts With Parameters:
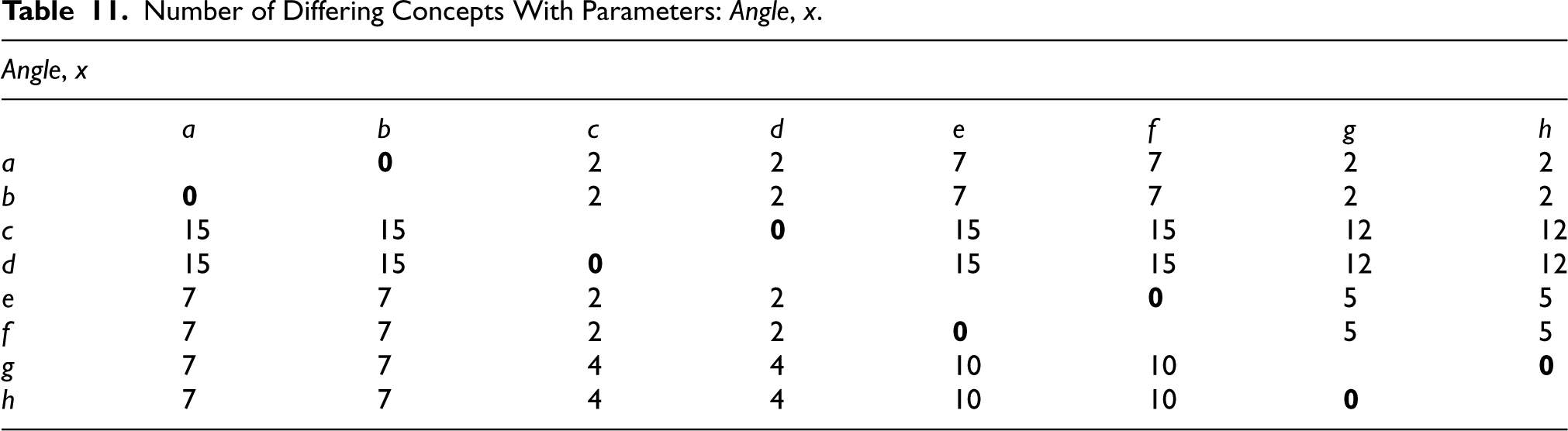
It should be noted that since the concepts of the curves are also sets in themselves, and not simple elements, the comparison between the obtained lattices can have different interpretations depending on how the concepts of two curves are compared to each other. However, there was no qualitative difference if this comparison was made strictly (two concepts must be exactly the same), or if a more relaxed version that takes into account the containment between them was used. After performing these calculations, the difference matrices remained essentially the same.
As can be observed in Table 11, the number of differing concepts between the visually similar curves
For all the curves to be uniquely characterised by a set of concepts that is also not a subset of that of any other curve, the matrix containing all the number of differing concepts should not contain any zeros. For the sensor combinations presented in the above subsection, there is no matrix that fulfils this condition; there are conceptual differences among most of the curves but not between all of them. For example, with the sensor combination
Number of Differing Concepts With Parameters:
,
,
,
.
Number of Differing Concepts With Parameters:
In order to provide a baseline for comparison, the last two experiments have also been tested with a neural network approach. Because of the similarities of the curves in the sample-set with the ‘curves’ in the MNIST dataset (Deng, 2012), a neural network model that excels at the MNIST challenge has been selected. The specific model has been taken from the resources available in the Keras library (Chollet, 2015). It achieves a test accuracy above 99% when classifying the
In order to apply this neural model to the sample-set used in this work, two operations are required. The first one is to convert the curves to images, and the second, to augment the sample-set of eight curves to a much larger dataset. This augmentation has been carried out through (i) random displacements, and (ii) random horizontal and vertical deformations. To avoid incurring in unfair conditions for the neural model, no rotations have been involved in the data augmentation process. The total sample space of possible variations enabled by the augmentation scheme is well above 1 million unique instances. Following this procedure, a dataset of 80,000 curve-images has been generated (10,000 variations of each original curve). An example of the instances obtained can be found in Figure 8

Example of random variations used for data augmentation (curve
The criteria to compare the neural model with the model proposed in this article was established in terms of the number of examples each one required to perform successfully. As it has been already demonstrated, BIGA required only one example per category to correctly discriminate and assimilate the curves. In contrast, the neural model necessitates a much larger number. According to Figure 9, the accuracy of the network in discriminating single curves decreases dramatically when ‘only’
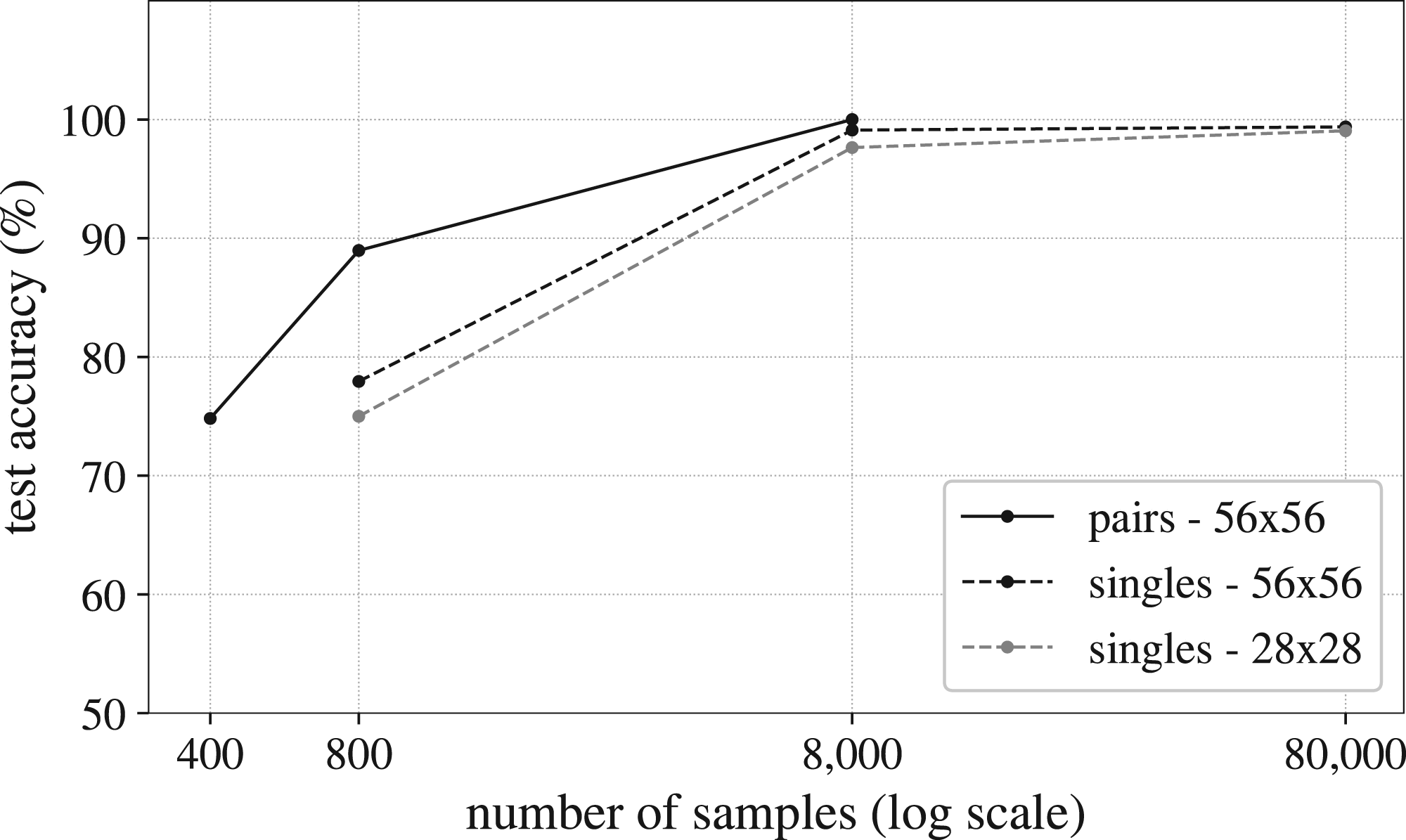
Test accuracy results for the two neural network models used as the baseline for comparison.
Although the proposed method is quite straightforward in its current form, the three questions posed in the experimentation section have been successfully addressed. However, these tests were conducted on a limited sample-set and, therefore, these results should be interpreted as a proof of concept rather than as generalisable findings. Further experimentation should be performed with larger datasets, such as Omniglot (Lake et al., 2015), to allow rigorous benchmarking and establish the performance of the model.
The first experiment demonstrated the ability of the model to identify common concepts across the curves, as presented in Table 7. These concepts, expressed in natural language, showcase the model’s pattern recognition capabilities. Figure 7 provides a visual illustration of one such concept (intent:
The second experiment aimed to establish unique conceptual definitions for each pair of similar curves. These definitions were identified for the sensor combination
Another crucial observation is that the identification of specific sensor combinations that yield unique characterisations for curves has been conducted manually. This process should be further formalised in future endeavours by developing a supervised learning methodology. For example, when dealing with large category sets, the lattice-building process may benefit from graph-based cluster detection techniques and their corresponding optimisation algorithms (Gharehchopogh, 2023).
In the instances presented here, only two samples are provided for each category and a single sensor combination is employed for the entire curve. However, engaging with rich datasets might pose a challenge. To address this, one possibility is to dynamically adapt the combination of sensor parameters for distinct sections of the curves as a training parameter. This approach could potentially provide a viable solution to this challenge, analogous to the strategies employed by Imamura & Nakamura (2021) and Imani & Keogh (2019), where semantic sequences are matched by discarding some portions of information in the middle of these sequences (‘don’t care’ regions). Other options include feature selection methods as by Ayar et al. (2022).
Alternatively, BIGA could also be used as a feature extraction engine to guide a later training process within a different model in what is known as knowledge-guided training (Dattani & Bramer, 1996; Díaz-Rodríguez et al., 2022; He et al., 2018). This guidance can improve the performance and explainability of these models while also reducing the size of the required training data. However, it should be noted that in this workflow between the symbolic model and the neural engine, training would imply deviating from the ‘firing scheme found in nature’ (as referred to previously in this text). Overall, regardless of the training strategy, a direct advantage of the approach presented in this paper lies in its ability to handle as few training samples as necessary.
The third experiment was aimed at distinguishing all the curves from each other. This was accomplished using a combination of sensors that included all parameters Strategy 1: Arithmetic operations. The model could perform arithmetic operations on the sensor values to extract symbolic properties. For instance, it could aggregate values like segment count, total length, average thickness, etc. from intervals of a concept’s extent. If a concept contains multiple intervals with distinct aggregated values, they could be unfolded into separate concepts. Alternatively, these aggregated values could be integrated into the model’s standard comparisons, resulting in concept intents like Strategy 2: Comparison spaces. The model could create comparison spaces between objects and extract new sensory data from their relative differences. When studying the movement of vehicles for example, it could track the distance between two vehicle trajectories over time and use that distance as an additional sensor parameter. In the case of static curves, these could be positioned next to each other in various relative arrangements, similar to how children interact with toy shapes to observe the effects of different spatial configurations. Then, a distance parameter flowing along the curves could be incorporated into the sensor. This strategy would enable the model to generate concepts that directly express differences between initially similar curves. Furthermore, this approach could be extended to compare more than two curves simultaneously. Strategy 3: Memory. The model could implement a memory to store specific values. These stored values could be compared retrospectively, beyond the scope of pairwise comparisons employed in the current method. However, this approach might deviate slightly from the model’s core principles. Humans excel at grasping proportions and ratios rather than absolute magnitudes. Therefore, approaches that prioritise relative magnitudes over absolute ones might align better with the ideas presented in this article.
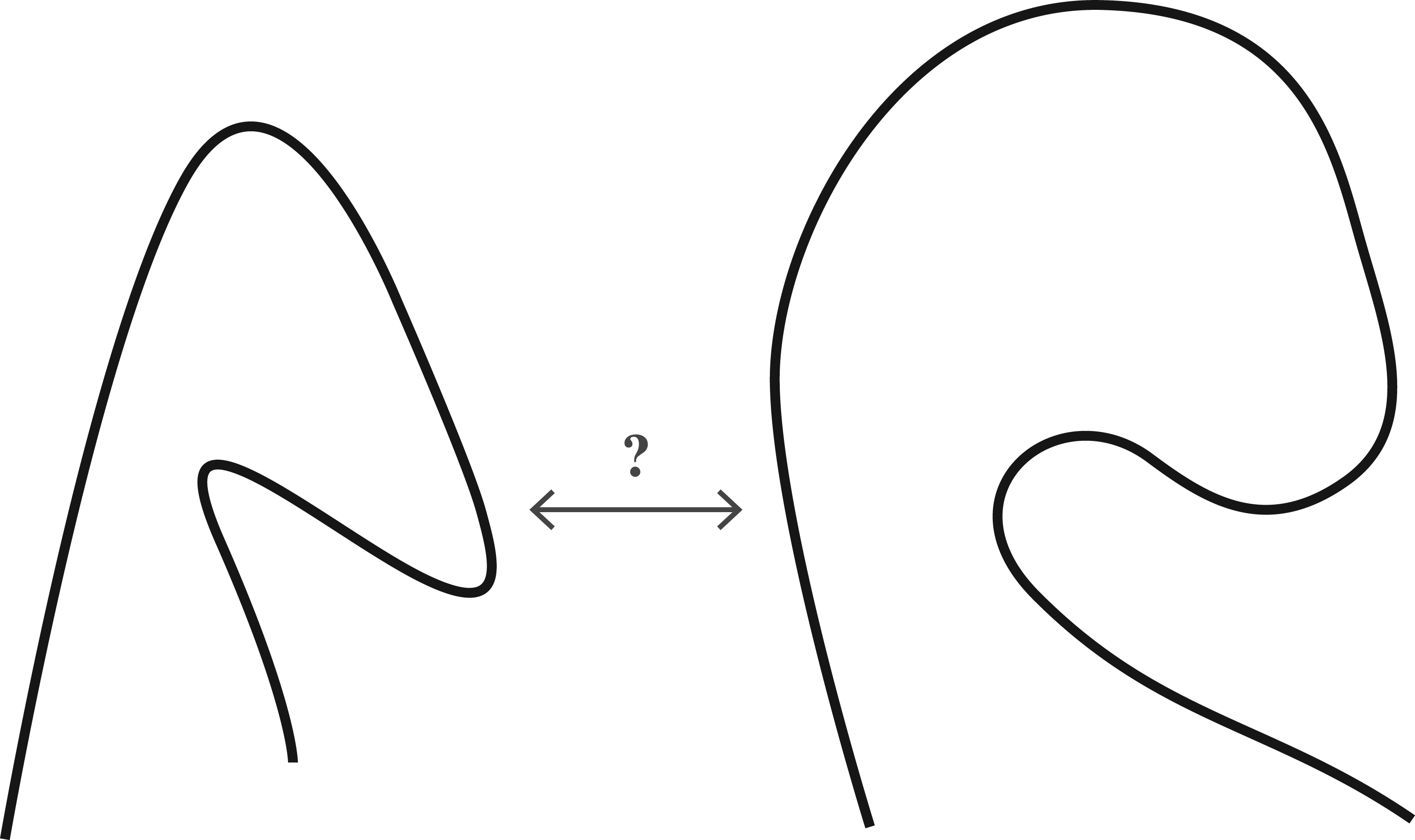
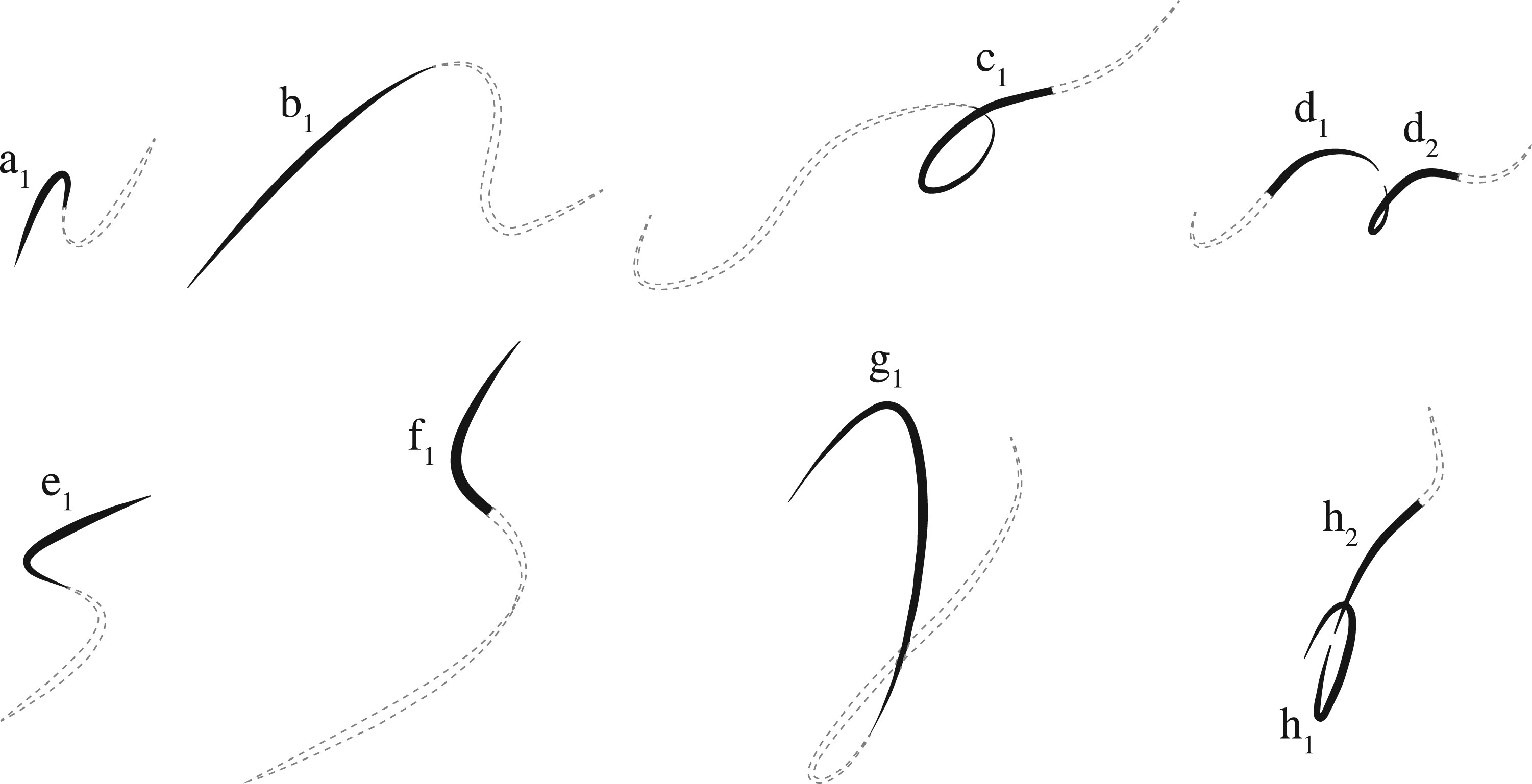
Two similar curves with tangible differences in angle variation that are not captured by the model.
Another limitation of the model (implicit in the experiments) is its inability to handle nested concepts effectively. For instance, the model fails to recognise a large S-shaped curve that is formed by smaller S-shaped sub-curves (as depicted in Figure 11). This limitation stems from the model’s reliance on purely symbolic representations, which can struggle to capture complex spatial relationships involving multiple scales. To address this issue, more embodied approaches could be explored. In this line, a potential solution may involve the design of a sensor system comprising a primary arm and a secondary arm (or hand). The primary arm would operate on a broader scale, providing a global overview of the curve, while the secondary arm or hand would focus on finer details, including noise and subtle patterns. This hierarchical approach could help the model better discern nested concepts and extract meaningful information from both macro- and micro-levels of observation.

An overarching S-shape comprised of smaller nested S-shapes.
The last set of experiments, the comparison of results, aimed to evaluate the performance of the model against a neural network baseline. The tests showed that even a powerful convolutional architecture requires more than 400 and 800 training samples to achieve an accuracy level above
An interesting avenue of research, in relation to the comparison with neural networks, would be to use a method from the class activation method family in order to obtain which regions of the image were determinant to the model’s classification (Chattopadhay et al., 2018; Selvaraju et al., 2019; Zhou et al., 2015). These regions, along with the features extracted by the convolutional layers, could then be compared to the concepts obtained by BIGA. Ultimately, such explorations may lead to relevant results regarding the explainability of AI models.
Another important point suggested by the experimental results is that the proposed model possesses generative capabilities; its radical composability enables the formation of novel concepts or features that have not been directly perceived by the sensor by combining those acquired from prior experience. Moreover, due to the fully tractable path from sensor data to the concepts generated by the model, these unseen new features can be propagated or decoded back to the sensor level. This decoding process would facilitate the generation of the corresponding curves for these unseen concepts. However, since each concept in the model exhibits a high degree of generalisation, there are an infinite number of potential outputs for each new concept. Therefore, a heuristic framework would be necessary to determine the final output (extent) for a given concept.
Furthermore, the fact that all concepts can be readily expressed in natural language suggests two crucial points:
Semantic encoding of sensor data: The model efficiently encodes sensory data, both static (nouns) and dynamic (verbs), from the real world into human-readable language. This ability bridges the gap between the physical world and natural language representation. Generative and creative output: By combining existing concepts into new ones through natural language queries, the model can generate novel objects, broadening its repertoire of representations. This opens up the possibility of imagining and creating novel sensory experiences.
Building on these insights, further research could delve into the potential of this model as the foundation for a natural language engine for sensory data, capable of interpreting and generating human-understandable descriptions of the world around us. Such an engine could play a significant role in multi-agent and human-agent ensembles, improving communication and collaboration between intelligent systems and humans (Black et al., 2022; Lemon, 2022). Recent advances in large language models further emphasise the potential of this approach to improve the way machines interact with and comprehend the world through language.
This article has introduced BIGA, a model that extracts human-relatable concepts from spatial sensor data. Inspired by Bateson’s idea of difference as the fundamental building block of a concept, the model utilises atomic value comparisons (
As outlined in the methodology, the proposed model is designed inherently for generalisation and composability. It also possesses reasoning and potentially generative capabilities, fuelled by formal concept analysis. Three experiments have been carried out upon a sample-set of eight curves of variable thickness. Within the set, every curve is visually-similar to one other, forming four pairs in total. The first experiment aimed at assessing the ability of the model to find common patterns among all curves in the sample-set. The model found a total of nine common concepts that were present in all the curves, corresponding to a total of four sensor combinations tested (see Table 7). The second experiment aimed at exploring the capacity of the model to assimilate objects that are similar, yet different. This was tested by determining whether or not the model was able to generate a unique conceptual representation for each pair of visually-similar curves. The goal was achieved by using the sensor combination
The comparison of results showed that a powerful neural model requires more than 400 samples to perform at the same level as what is achieved here with only one or two samples per category. Overall, the results demonstrate the ability of the method to generate ‘fairly’ rich representations of the data. These representations effectively discriminate and assimilate objects as needed. Additionally, the model can elaborate multiple representations of the same object with remarkable ease, which is one of the five pillars of creative behaviour proposed by Rowe & Partridge (1993). Optionally, training processes can be incorporated to further refine these operations. This flexibility enables the model to adapt to various data sets and tasks, making it a versatile tool for extracting meaningful concepts from spatial sensor data.
The proposed model aligns with the aspirations driving the recent surge in neural-symbolic developments. Neural-symbolic research aims to address the shortcomings of purely symbolic models, which excel in generalisation and composability but struggle to extract meaningful representations from complex data. Connectionist approaches, particularly deep learning, have demonstrated remarkable success in this regard. By combining neural and symbolic methods, researchers are creating ML models that exhibit superior generalisation, enhanced out-of-distribution learning capabilities, greater composability than their early deep learning counterparts, and the ability to generate extremely rich representations. However, these models typically require extensive training and the labelling of data samples remains a significant challenge for industry applications. In contrast, the method presented in this article eliminates the need for extensive training. It generates comprehensive conceptual representations from a minimal set of individual features. Moreover, these representations can be readily expressed in natural language without the need for feature labelling. Furthermore, every concept can be traced back to its underlying atomic comparisons, providing full explainability of the model’s reasoning process in natural language.
As discussed earlier, the concepts generated by this method can be static or dynamic, encompassing both object- and movement-related concepts (nouns and verbs). The ability to trace back each concept to its underlying atomic comparisons not only enhances explainability but also suggests the potential to build a basic language from primitive tokens such as sensor parameter identifiers and comparators (
In light of these promising aspects, the methodology presented here has the potential to make a significant impact in the field of machine learning. The main contribution is that it offers a straightforward algorithm to seamlessly integrate perception with semantic conceptual structures. This integration is achieved without the need to combine models from different AI paradigms, unlike NSMs, and without limiting the model’s ability to create extensive conceptual richness. While the current implementation may not match the granularity of representations achieved in more advanced neural-symbolic approaches, the experimentation section does demonstrate promising results. However, it is imperative to formally assess the model’s performance through rigorous benchmarking against well-established datasets. With continued research efforts within the scientific community, the gap between the proposed method and current NSMs could be significantly narrowed.
In conclusion, the proposed methodology based on the Bateson’s principle for generating concepts from sensor data calls for further attention and exploration. If this approach can demonstrate the ability to produce sufficiently rich representations, it may unlock the full potential of symbolic models without relying solely on neural networks for data acquisition and processing.
Future Work
Throughout this article, there have been a number of suggestions for future work; either in the form limitations of the model, or directly expressed as potential next developments. Although many of them have been already elaborated upon, a brief summary of all the items is listed below for clarity. They have been grouped in two sections: (i) general research avenues and (ii) specific improvements of the model.
1. General research avenues:
Researching the SGP and autonomous language emergence through AI agents and consensus-building. Developing bio-inspired connectionist implementations of the model. Expanding the model to higher dimensions beyond curves or trajectories (including pixel-based data such as images and spatio-temporal data such as video). Exploring the generative capacities of the model. Integrating the model with other neural-symbolic methods discussed in this article, such as (Evans et al., 2021a, 2021b; Garnelo et al., 2016). Improving the explainability of AI models by exploring comparisons of concepts obtained by the model with the regions and features extracted by methods from the CAM family. Training: Developing a training method upon the concept structures extracted by the algorithm is an important next step. Such a method would allow leveraging the model’s unsupervised learning capabilities, also, for supervised learning. Benchmarking: It is essential to formally evaluate the model’s performance by conducting rigorous benchmarking against well-established datasets (e.g., Omniglot for curves). If a training method is implemented as indicated in the item above, then it would be possible to carry out this important endeavour. Handling non-numerical values as input (e.g. symbolic input): This, for instance, would enable expressions of the sort ‘transition from no-sensing to sensing’ and vice versa. Such encodings are important for example, when handling disconnected curves. This is the case when the objects being sensed comprise multiple curves that are not necessarily sequentially connected to each other (e.g. the letter ‘X’, but not the letter ‘U’). Magnitudes: As shown in Figure 10, a significant challenge for this model is the generation of concepts that quantify changes in sensor variables. The core difficulty is to achieve this without introducing more external symbolic information into the model. Three strategies have been proposed earlier to address this limitation; they are listed here as the next three items. Arithmetic operations: The model can be fitted to perform arithmetic operations on sensor values to derive symbolic properties from them. For example, it can aggregate metrics such as segment count, total length, average thickness, and other attributes from intervals within the extent of a concept. Comparison spaces: The model can generate comparison spaces between objects and derive new sensor data from their relative differences. For instance, when analysing vehicle movement, it can monitor the distance between two vehicle trajectories over time and use this distance as an additional sensor parameter. Memory: The model could incorporate a memory module to store specific values and concepts, allowing for retrospective comparisons that extend beyond the pairwise comparisons used in the current method. Noise and overarching concepts: As shown in Figure 11, the model fails to detect overarching concepts in the presence of smaller, nested ones. A viable strategy to address this limitation could be to embrace a more embodied approach, as discussed previously in the paper.
2. Specific improvements of the model:
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A
Concepts Concept lattice representation for curves (c) and (d) considering variables 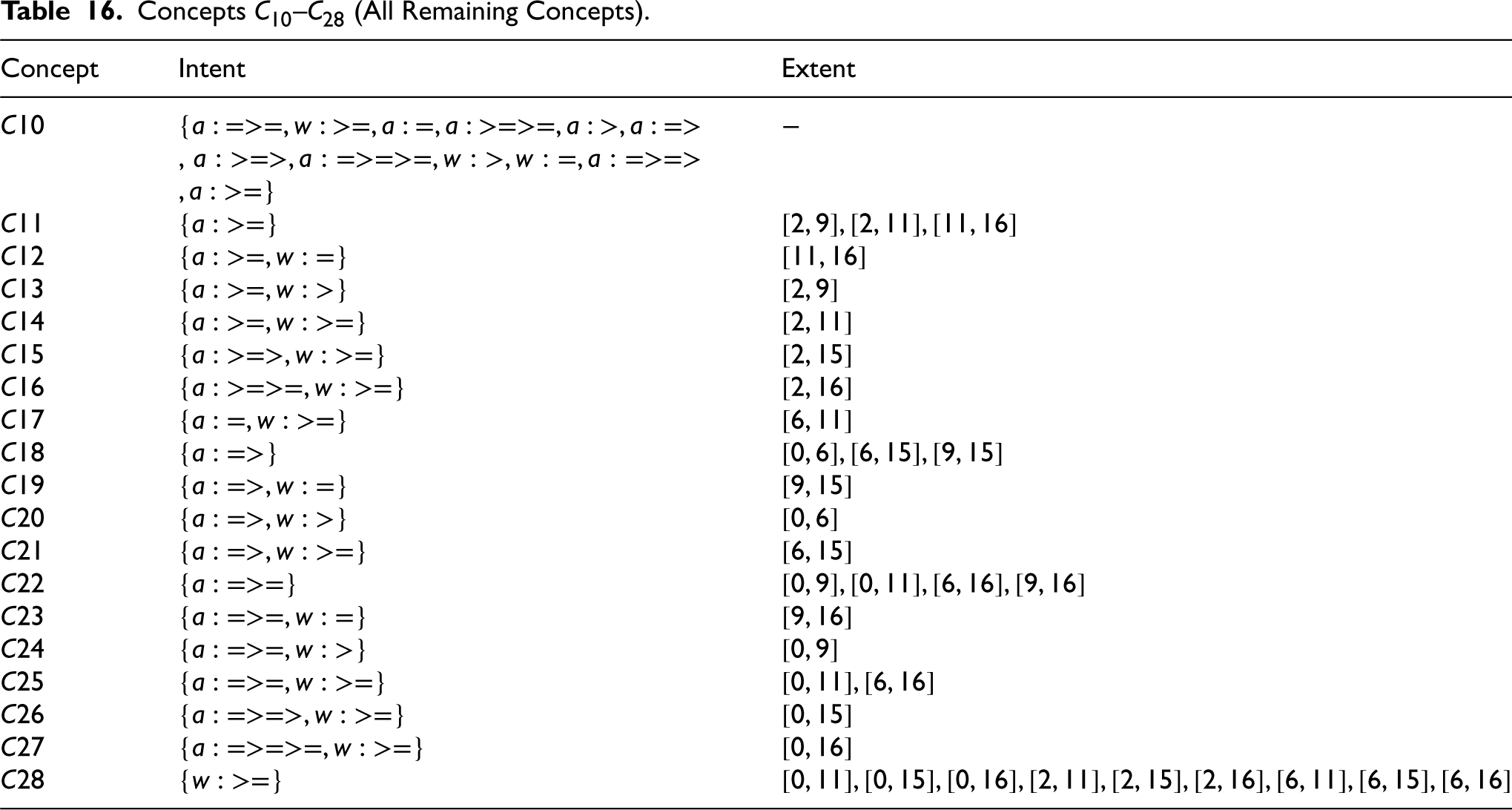
Concept
Intent
Extent
Concept lattice representation for curves (e) and (f) considering variables Concept lattice representation for curves (g) and (h) considering variables