
Abstract
Recent advances in deep learning-based super-resolution (SR) techniques for remote sensing images (RSIs) have shown significant promise. However, these performance improvements often come at a high computational cost, which limits their practical application. To address this issue, this paper proposes a dual-branch SR model (DBSR) that enhances both model performance and efficiency through primary and auxiliary branches. The primary branch integrates the advantages of channel recalibration, a separable swin transformer (SST), and a spatial refinement module to achieve fine-grained feature extraction. The SST serves as the core of the primary branch, employing hierarchical window attention calculations to facilitate lightweight and effective multiscale feature representation. Conversely, the auxiliary branch enhances shallow features through a global information enhancement module, which mitigates the misleading effects of directly upsampling these shallow features on the SR results. Comparative and ablation experiments conducted on four RSI datasets and five SR benchmark datasets demonstrate that our DBSR method effectively balances the number of parameters with performance, showcasing its potential for application in RSI processing.
Introduction
High-resolution remote sensing images (RSIs) are crucial for monitoring the environment, urban development, and changes caused by natural or human activities (Albiston, 2005). The spatial resolution of these images directly impacts the accuracy of analyses. However, obtaining high-resolution (HR) images is challenging due to limitations imposed by imaging equipment, observation distance, and viewing angles (Han et al., 2021). While enhancing the precision of charge-coupled device sensors is a direct method for acquiring HR images, it incurs significant costs. Super-resolution (SR) offers a cost-effective alternative by reconstructing HR images from low-resolution (LR) ones using efficient algorithms. Therefore, SR technology is an effective and economical approach for improving spatial resolution in remote sensing.
In recent years, deep learning techniques—particularly those utilizing convolutional neural networks (CNNs) and transformers—have emerged as the leading technologies for achieving HR RSIs (Wang et al., 2022; Huang & Liu, 2023). The introduction of CNNs into SR technology marked a paradigm shift (Wang et al., 2022). Initially, the focus was on simple network architectures, but development has progressed to complex networks capable of capturing intricate spatial details. Early research concentrated on single-scale CNN feature extraction (Dong et al., 2015; Song et al., 2021), but subsequent studies emphasized the importance of integrating multiscale features (Dong et al., 2016; Purohit et al., 2020) for processing remote sensing data. This led to the development of multiscale feature extraction methods (Ma et al., 2021; Huan et al., 2021) and efficient attention mechanisms (Huang et al., 2021; Wang et al., 2022), significantly improving the performance of CNN-based RSI SR. Additionally, building on features extracted from LR images, researchers have developed SR methods that use implicit functions to map these features to spatial coordinates, predicting pixel values at any given location and enabling arbitrary scaling factors. For instance, Local implicit image function (LIIF) (Chen et al., 2021a) proposed a network with a local implicit image function to achieve continuous image SR, using coordinates and nearby 2D features as inputs to predict the corresponding red–green–blue (RGB) values. However, due to its reliance on local features, LIIF may struggle with maintaining global consistency and handling complex structures. To address these limitations, FunSR (Chen et al., 2023) introduced a continuous SR framework that enhances global semantic consistency by facilitating contextual interactions within the implicit function space for continuous image representation.
While CNNs have been successful in addressing image SR tasks, they are constrained by the local receptive fields of convolutional kernels, which makes it difficult to capture the self-similarity present in RSIs (Liang et al., 2021). In contrast, transformer models, with their superior global information processing capabilities, have demonstrated distinct advantages in SR (Lei et al., 2024). The image processing transformer (IPT; Chen et al., 2021b) serves as an image restoration backbone network based on the standard transformer architecture, achieving multitask degraded image restoration. However, its impressive performance relies on 115.5 million parameters. Lei et al. (2021) introduced a transformer-enhanced network (TransENet) for SR in RSIs, leveraging the transformer’s feature extraction capabilities at different stages for multiscale fusion. Nonetheless, transformer-based SR models typically segment the input image into fixed-size patches, leading to boundary artifacts. Additionally, the extensive self-attention operations result in a considerable number of parameters, as evidenced by TransENet’s 37.3 million parameters. Consequently, these issues limit the applicability of transformer-based models in remote sensing.
To address the large parameter sizes in transformer-based SR models, we propose an innovative lightweight dual-branch SR (DBSR) model specifically designed for RSIs. Compared to existing lightweight SR networks, DBSR utilizes a carefully designed dual-branch structure that effectively combines the proposed separable swin transformer (SST) and global information enhancement module (GIEM) to achieve a deep fusion of local and global information. This design not only significantly enhances performance but also reduces computational burden. Unlike traditional lightweight models that directly upsample shallow features and add deep features, DBSR introduces an auxiliary branch that performs deep modeling of shallow features. This approach reduces the interference from redundant information during shallow feature upsampling, thereby improving reconstruction quality. Specifically, the main branch of DBSR consists of the channel recalibration (CRC), SST, and spatial refinement module (SRM). The CRC module dynamically adjusts channel feature responses to minimize channel redundancy. The SST module employs a hierarchical window attention design for parallel processing, effectively extracting multiscale window features while reducing the parameter count by 25% compared to the standard swin transformer (Liu et al., 2021). The SRM module further enhances pixel-level features. The auxiliary branch, utilizing the lightweight GIEM, refines shallow features, thereby strengthening the global feature modeling of the main branch. Finally, the interaction feature fusion (IFF) module effectively integrates and cross-weights features from both branches, emphasizing important features while suppressing redundancies. As shown in Figure 1, the dual-branch structure allows the DBSR model to achieve a parameter count of only 245K, delivering superior performance while maintaining a lightweight design.
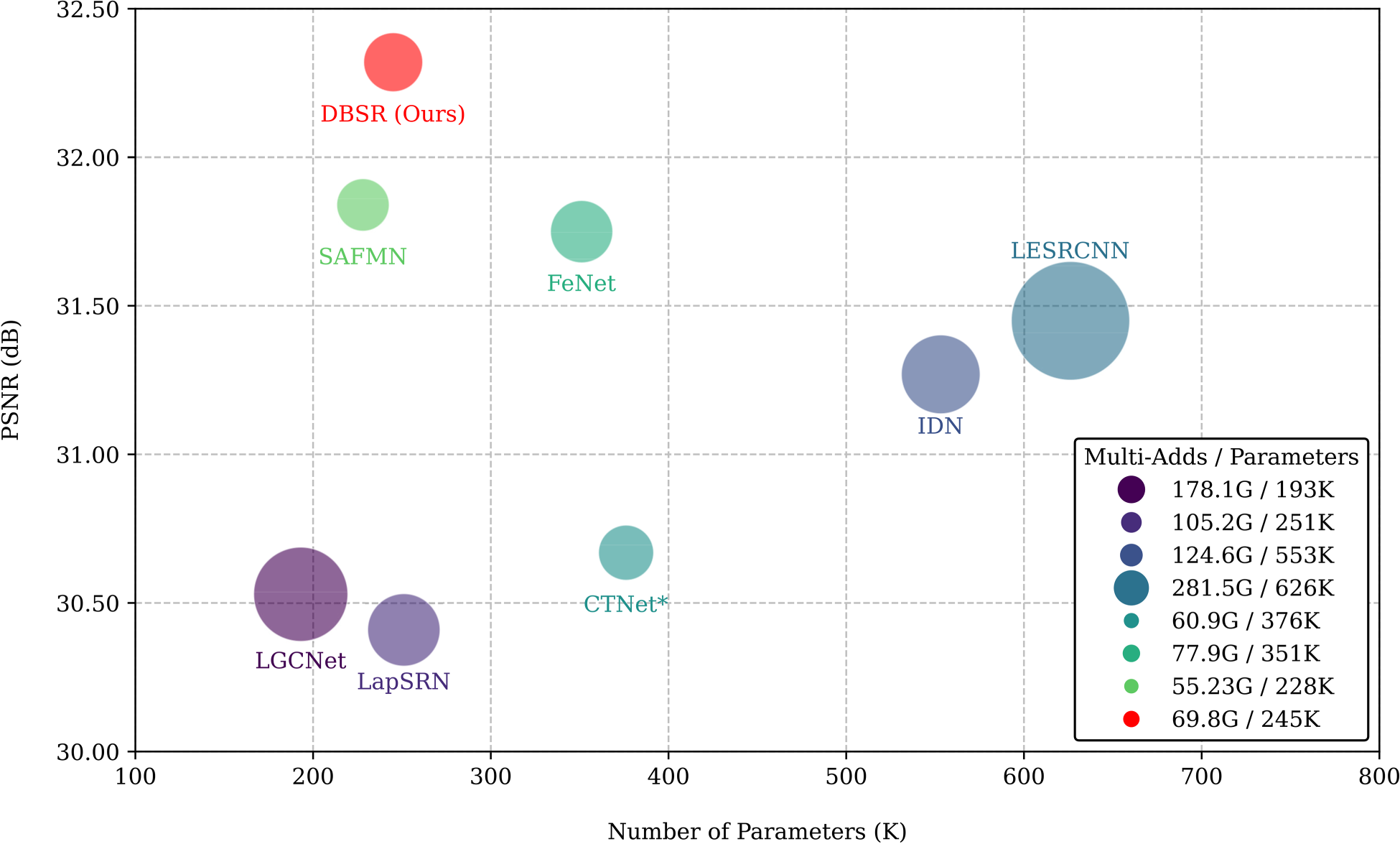
Performance comparison with other lightweight methods on the Ubran100 (
Constructing deep neural networks to directly learn the mapping from LR to HR images has become a mainstream approach in the field of SR. Rapid advancements in SR methods based on CNNs continue to push the boundaries of reconstruction quality. With the widespread adoption of transformers in visual tasks, transformer-based SR methods have opened new avenues for research in this area. Therefore, this section reviews the progress in SR technology from the perspectives of both CNN-based and transformer-based approaches.
CNN-Based SR
As CNN technology has evolved, it has demonstrated excellent performance in image SR tasks. Existing CNN-based SR methods can primarily be categorized into several types: residual dense connections, multiscale methods, attention mechanisms, and lightweight model architectures.
Residual learning has enabled the construction of deeper network structures, effectively mitigating the degradation issues associated with deep networks. For instance, very deep super-resolution (VDSR) (Kim et al., 2016) incorporates residual learning to build an SR network with 20 layers and a larger receptive field, enhancing the network’s reconstruction capabilities. Residual blocks have now become fundamental components of SR network architectures. However, simply increasing the number of layers does not efficiently transfer features across layers. To address this limitation, residual dense backprojection network (Pan et al., 2019) introduced a residual dense connection network, which combines residual learning with dense connections to fully utilize interlayer feature transfer and fusion, thereby significantly enhancing reconstruction accuracy. Despite the progress in feature utilization with residual dense connection methods, limitations still exist in fully capturing multiscale features to enhance SR effects.
Multiscale features are crucial in SR reconstruction. To better utilize multiscale feature information, Lu et al. (2019) proposed a multiscale residual neural network that significantly improves the preservation of high-frequency details by integrating multiscale residual information. Additionally, HSENet (Lei & Shi, 2021) leverages both single-scale and cross-scale self-similarity to enhance the model’s feature processing capabilities further. By extracting and integrating features across different scales, this model fully utilizes the hierarchical structure and detailed information of images, significantly improving CNN performance in SR tasks. However, multiscale methods may introduce redundant information when integrating details from different scales, potentially leading to detail blurring. Moreover, these methods may not effectively focus on key feature areas, limiting further improvements in reconstruction quality.
The attention mechanism aims to guide the network in focusing on key features. Recursive squeeze and excitation networks super resolution (Cheng et al., 2018) introduced a single-image SR method based on recursive compression and excitation networks, achieving remarkable reconstruction results. However, CNN convolutional operations typically struggle to capture contextual information beyond the local receptive field, meaning that information from distant areas may be highly relevant to the reconstruction objective. To address this issue, cross-scale non-local neural network (Mei et al., 2020) introduced a cross-scale nonlocal attention module that uncovers long-distance dependencies between LR features and HR blocks, significantly enhancing reconstruction quality. However, the design of complex attention mechanisms often incurs higher computational and storage costs, making them less suitable for deployment in resource-constrained real-world applications.
Consequently, limitations in computational resources and storage space have spurred the development of lightweight SR models. Hui et al. (2019) introduced an information multidistillation network (IMDN), combining contrast-aware attention with cascaded information multidistillation blocks. This approach reduces model complexity while preserving essential information. Despite IMDN’s success in achieving high-fidelity reconstruction, there remains room for improvement. To this end, deep residual feature distillation neural networks (Mardieva et al., 2024) optimized IMDN by using deep separable convolutions and multicore deep separable convolutions, resulting in higher-quality reconstruction. Additionally, FeNet (Wang et al., 2022) introduced the lightweight lightweight lattice block (LLB) module, which utilizes channel attention (CA) mechanisms for information exchange between upper and lower branches, enhancing channel feature expression capabilities while reducing model parameters. However, the introduction of nested networks in the LLB module is prone to generating redundant features during feature combinations. Although lightweight models strive to enhance performance while reducing complexity, there is still room for improvement in balancing model efficiency and reconstruction quality. Moreover, many lightweight architecture models follow a direct upscaling method that processes shallow features and outputs SR results using a cascaded structure. This approach can introduce noise and cause distortions in the SR output. To address these challenges, we designed an auxiliary branch focused on the refined processing of shallow features. This design significantly reduces the misleading effects of directly upscaling shallow features on the final results while effectively enhancing the model’s reconstruction accuracy and visual quality.
Transformer-Based SR
Transformer-based models have significantly enhanced single-image SR (SISR) tasks by effectively capturing both global and local dependencies. Researchers have broadened the applicability of transformers in low-level vision tasks through innovations ranging from large-scale pretrained models to efficient hybrid architectures. Currently, transformer-based SR approaches can be categorized into three primary types: those based on standard vision transformers, window-based approaches, and hybrid architectures that combine CNNs and transformers.
Standard vision transformers excel at capturing global information from images. For example, Chen et al. (2021b) introduced an IPT pretrained on a large dataset, incorporating contrastive learning tailored to various image processing tasks. After fine-tuning, the pretrained model can be effectively applied to specific tasks. However, IPT relies on extensive datasets and has a substantial parameter count (over 115.5 M), which significantly limits its applicability. TransENet (Lei et al., 2021) enhances multiscale information interaction through a multilevel augmentation based on the standard transformer, effectively addressing the challenge of perceiving key image content among similar pixels. Although standard transformer-based SR models achieve high-quality SR results, their redundant self-attention mechanisms result in an excessive number of parameters, limiting practical applications.
To address the issue of standard vision transformers losing boundary information when processing image blocks independently, SwinIR (Liang et al., 2021) partitions the image into windows, performs self-attention within each window, and enhances interwindow information exchange through sliding window operations. This approach effectively reduces computational complexity and captures local dependencies, thereby improving the quality of SISR tasks. However, SwinIR lacks direct interwindow interaction, resulting in a limited field of view across windows. To overcome this limitation, cross aggregation transformer (Chen et al., 2022) transforms square windows into rectangular ones and employs axial shift operations to expand the attention field without increasing complexity, achieving efficient cross-aggregation between windows. Additionally, to further improve window-based transformers, hybrid attention transformer (Chen et al., 2023) introduces an overlapping cross-attention module that enhances the interaction between window features, activating more pixel attention areas and improving the model’s ability to capture details.
The strength of CNNs lies in their ability to effectively extract local features through convolutional layers, which is crucial for understanding details such as textures, edges, and shapes within images. Conversely, transformers offer the advantage of a self-attention mechanism, which captures long-range dependencies or global information, aiding the model in comprehending complex relationships between different parts of an image. Combining these two technologies enables the model to possess both sensitivity to local visual details and a deep understanding of the global context. For instance, Restormer (Zamir et al., 2022) embeds CNNs within the transformer framework to perform multiscale local–global learning. This approach is not only suitable for processing large images but also effectively captures interactions among distant pixels, achieving a good balance between performance and efficiency. Similarly, dual transformer residual network (Sui et al., 2023) combines the strengths of CNNs and transformers to learn hierarchical features through global feature fusion, harmonizing global and local information. EHNet (Zhang et al., 2024) also utilizes CNNs and swin transformers within a U-Net-like architecture to capture multiscale features effectively. However, these hybrid architectures can lead to increased complexity in model structure, along with a rise in parameter and computational demands, making deployment in resource-constrained environments challenging. In response to this issue, this research adopts a hybrid architecture of CNNs and transformers, constructing a DBSR model that effectively integrates the advantages of both. This model also introduces SST based on the swin transformer, successfully reducing the parameter count by 25% while significantly enhancing SR accuracy. This innovative architecture demonstrates the considerable potential for achieving high efficiency and performance in complex image-processing tasks.
Network Architecture
In this section, we first provide an overview of the overall structure of the proposed DBSR. Following this, we detail the HCTF feature extraction module in the main branch and the GIEM and IFF components in the auxiliary branch.
Framework View
We propose a dual-branch lightweight remote sensing SR network. As shown in Figure 2, the proposed DBSR model consists of three parts: shallow feature extraction, deep feature extraction, and reconstruction modules. To enrich the representation of image details, for an input image

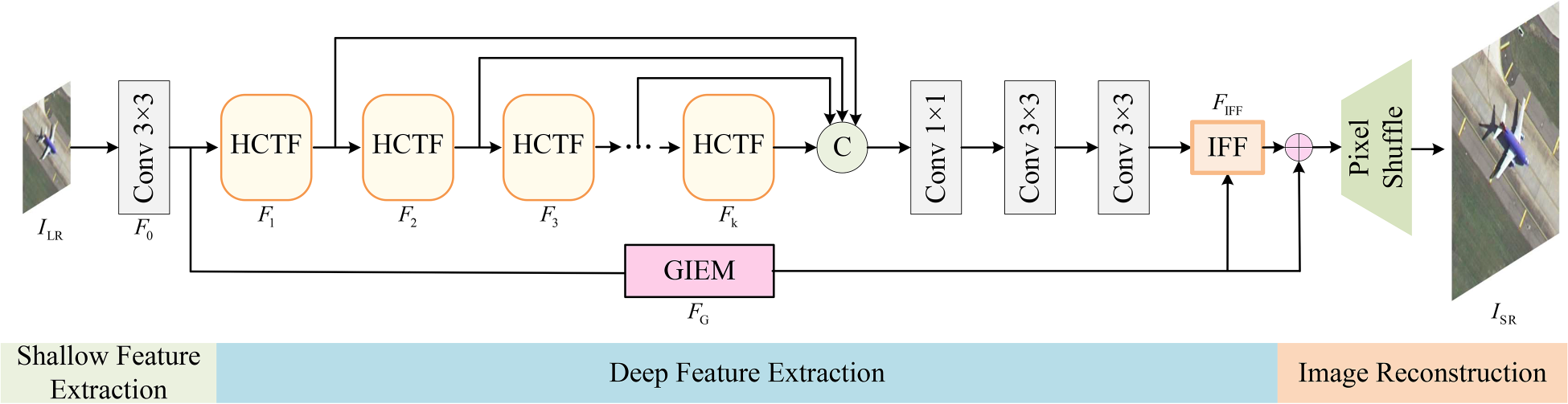
Architecture of the proposed dual-branch super-resolution (DBSR).
In the feature extraction part, the main branch refines features layer by layer through a cascaded HCTF, while the auxiliary branch enhances shallow features using the GIEM. Assuming the number of HCTFs is
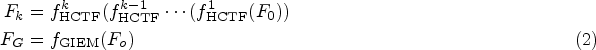
After obtaining the refined features from the main and auxiliary branches, we concatenate the features from different levels of the main branch with the features from the auxiliary branch and fuse them using IFF. The output of IFF can be expressed as:
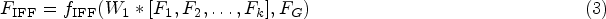
Finally, in the reconstruction part, the features are shuffled through a


To fully leverage the advantages of both CNN and transformer, we propose a feature extraction module, HCTF. This module combines CRC, SST, and SRM. Each component will be introduced in detail below.
Channel Recalibration (CRC)
In the CRC stage, as illustrated in Figure 3, the input shallow features
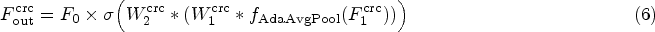

Structure of channel recalibration (CRC).
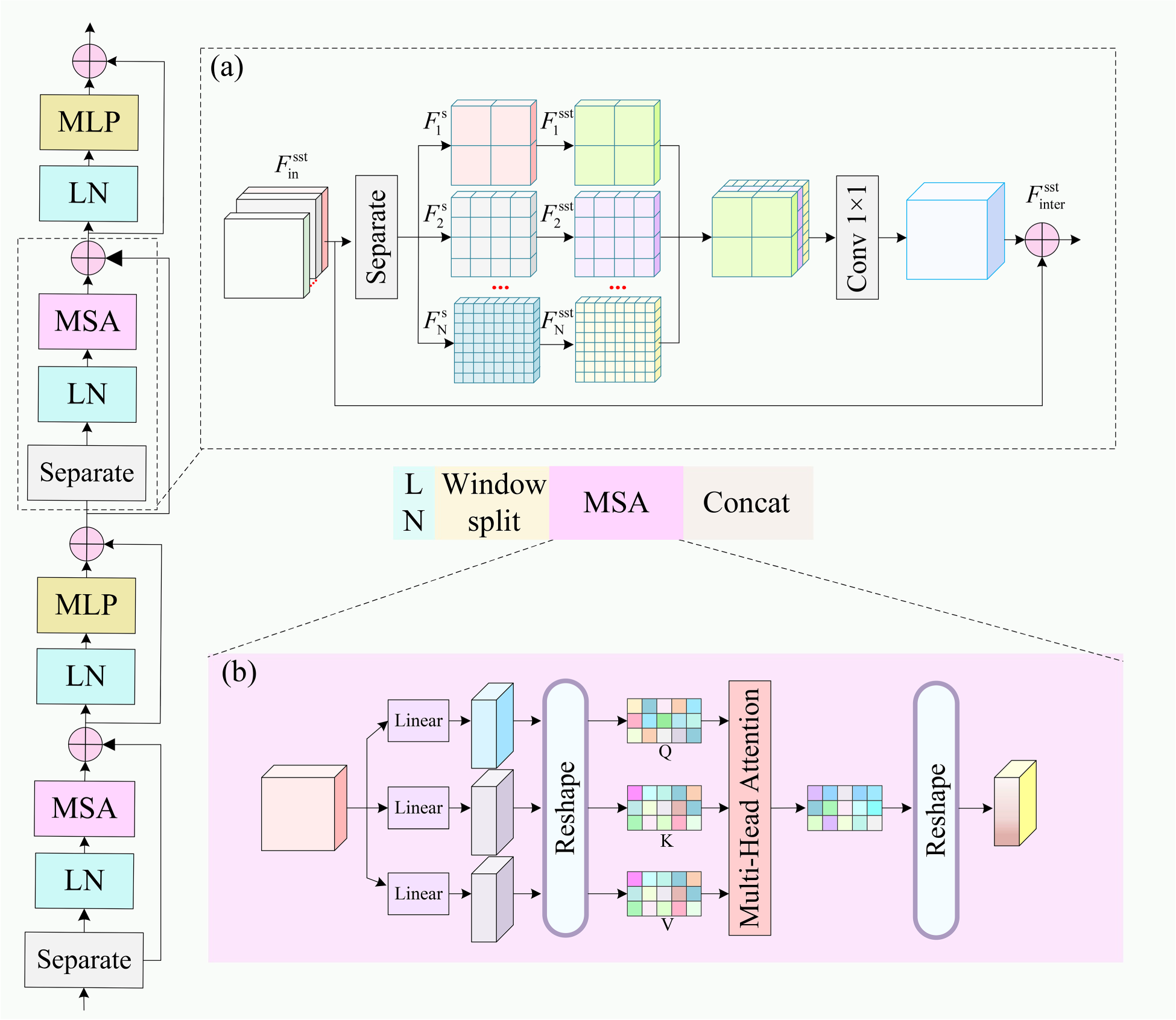
Network structure of sparable swin transformer: (a) Channel separation process and (b) structure of multihead self-attention (MSA).
Inspired by the window attention mechanism of the swin transformer, we designed an SST. As shown in Figure 4, for a given input
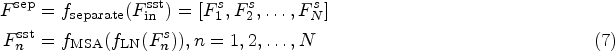
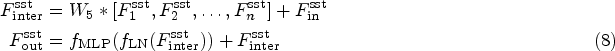
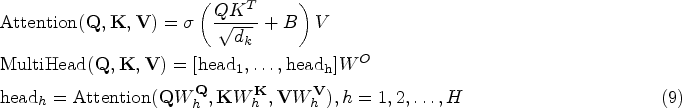
To further refine SST features, we constructed a SRM to enhance the expression of key features on a pixel-by-pixel basis. As shown in Figure 5, for the SST output features

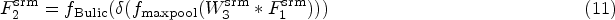
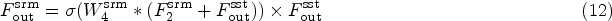
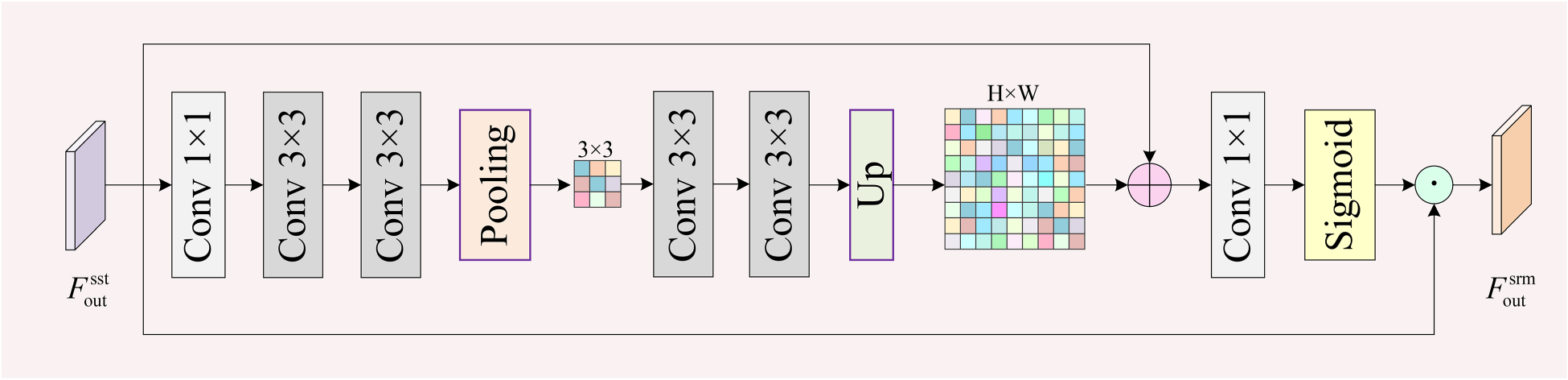
Structure of spatial refinement module (SRM).
In the auxiliary branch, we designed a GIEM to enhance primary features through global context modeling, supplementing the main branch with global information. As shown in Figure 6, for the input primary features, we first optimize the features using two layers of



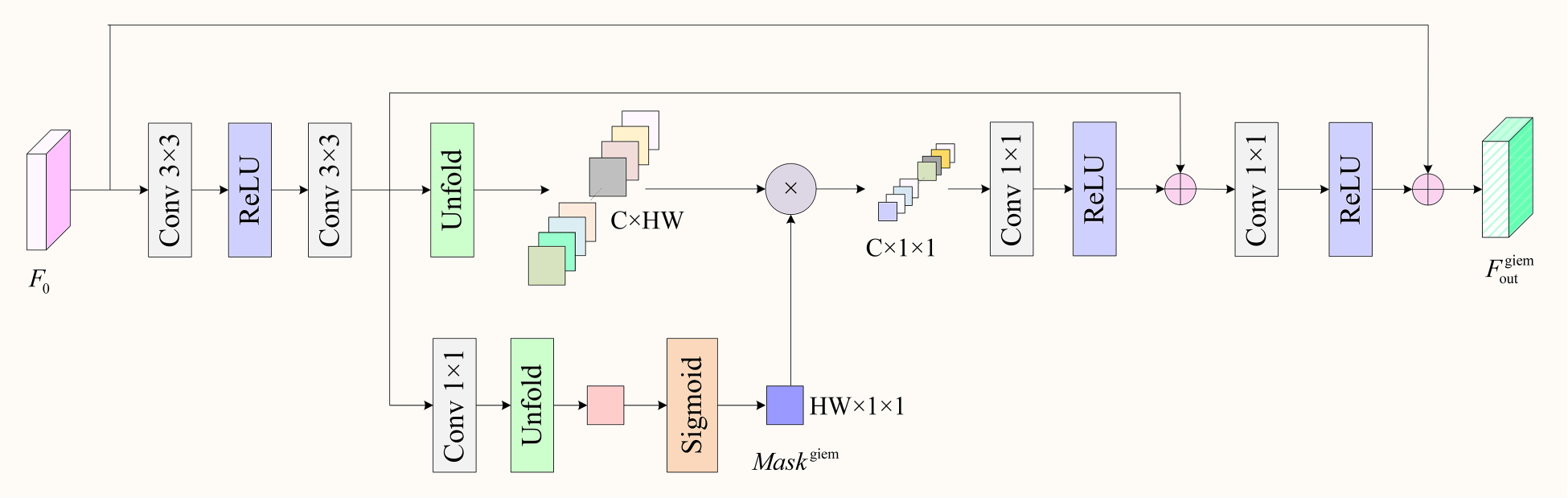
Structure of global information enhancement module (GIEM).
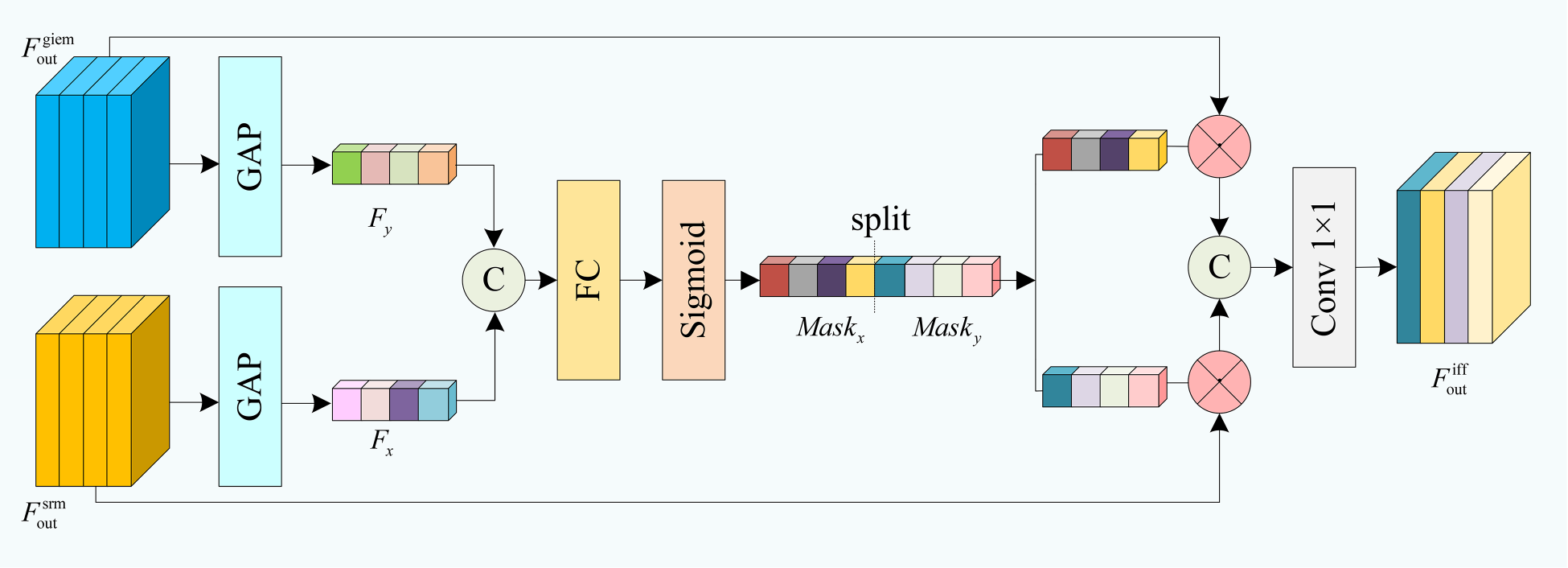
Structure of interaction feature fusion (IFF).
To effectively integrate the main and auxiliary branches, we constructed an IFF module to highlight important features and suppress secondary information. As shown in Figure 7, for the input main branch feature
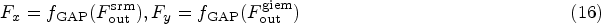

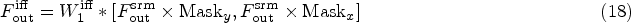
Datasets and Metrics
Following the experimental setups of previous studies (Hui et al., 2019; Wang et al., 2022), we optimized the DBSR model using 800 training images from the DIV2K dataset (Timofte et al., 2017). The model’s reconstruction performance was evaluated using publicly available two RSI datasets (RS-T1 and RS-T2; Wang et al., 2022) and real image data (images from the GaoFen-2 and Beijing-2 satellites). Additionally, to comprehensively validate the model’s performance, we tested it on five SR benchmark datasets of natural images: Set5 (Bevilacqua et al., 2012), Set14 (Zeyde et al., 2012), BSD100 (Martin et al., 2001), Urban100 (Huang et al., 2015), and Manga109 (Matsui et al., 2017). The SR results were evaluated on the Y channel in the YCbCr color space using the following metrics: average peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), learned perceptual image patch similarity (LPIPS), and no-reference image quality evaluator (NIQE). To evaluate the computational complexity of the network, we considered the number of model parameters and multi-adds (M-Adds) operations.
Implementation Details
To obtain LR training images, we applied bicubic interpolation to downscale HR images. To maximize the effectiveness of the training data, we employed data augmentation techniques such as random rotations (
Results on RSI Datasets
To validate the effectiveness of DBSR for remote sensing image super-resolution, we compared it with several lightweight models. These models include SRCNN (Dong et al., 2014), VDSR (Dong et al., 2015), LGCNet (Lei et al., 2017), LapSRN (Lai et al., 2017), IDN (Hui et al., 2018), LESRCNN (Tian et al., 2020), CTNet (Wang et al., 2021), FeNet (Wang et al., 2022), and SAFMN (Sun et al., 2023). All models were trained using the same DIV2K training set to ensure fairness.
Table 1 presents a quantitative comparison of these models and Figure 8 illustrates the SR results of image patches from two RSI datasets. The results indicate that DBSR outperformed all other models across all scaling factors on the RSI datasets. Notably, compared to the sota lightweight remote sensing SR model FeNet, DBSR reduced the number of parameters by 30% and improved PSNR by 0.25 to 0.35 dB. Additionally, DBSR displayed clearer contours and better visual perception than other methods.

Visual comparison of DBSR with other SR methods on RSI datasets (
Quantitative Results on RSI Datasets.
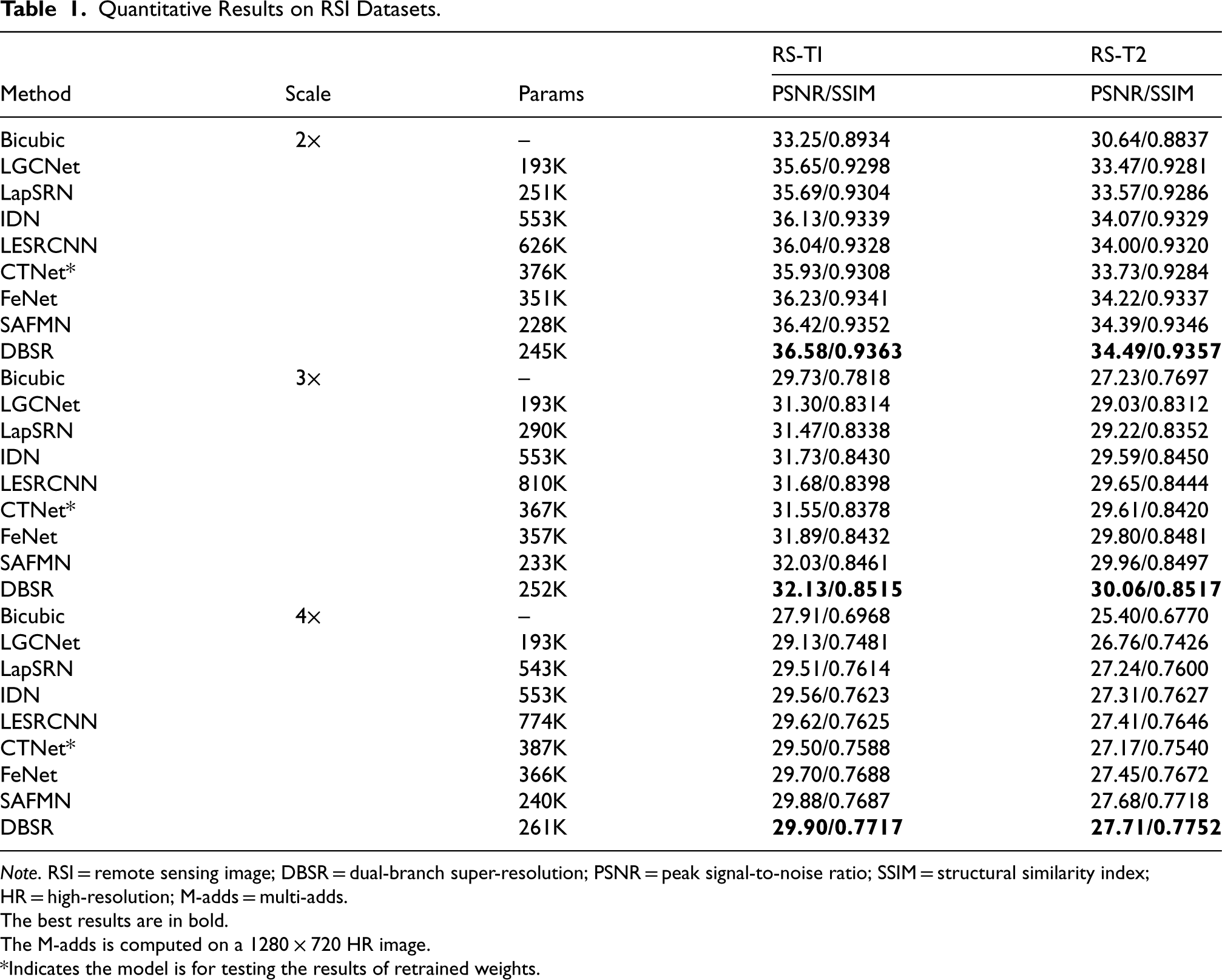
Note. RSI = remote sensing image; DBSR = dual-branch super-resolution; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index; HR = high-resolution; M-adds = multi-adds.
The best results are in bold.
The M-adds is computed on a
*Indicates the model is for testing the results of retrained weights.
To comprehensively assess the robustness of the DBSR model under varying conditions, we introduced the RSSCN7 (Zou et al., 2015) dataset and adjusted brightness factors to 0.5, 0.6, and 0.7 using the Pillow.ImageEnhance.Brightness module. This process constructed three low-light scene datasets, named RSSCN7-0.5, RSSCN7-0.6, and RSSCN7-0.7, respectively. From each dataset, we randomly selected three images and used LGCNet, CTNet, FeNet, and SAFMN as comparative models. After upscaling the images by a factor of three, we conducted a comparative analysis, and visual comparisons for the three datasets are presented in Figure 9. DBSR exhibited superior performance in reconstructing details and textures, providing significantly better visual quality than other methods. Additionally, DBSR achieved lower values for the LPIPS and NIQE metrics, indicating that its super-resolved image quality is closer to that of real images.
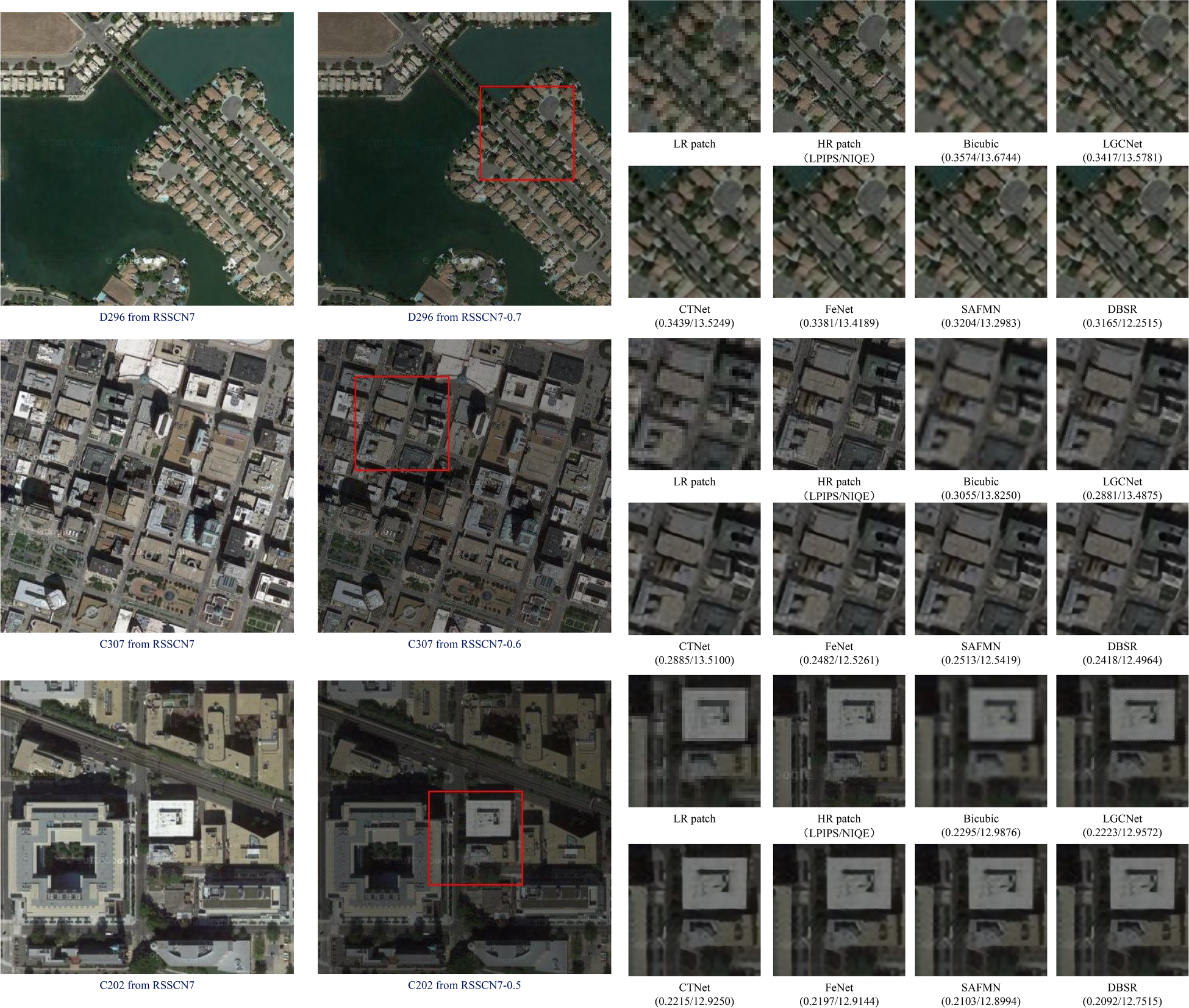
Visual comparison of DBSR with other SR methods on RSSCN7-0.5, RSSCN7-0.6, and RSSCN7-0.7 (
To thoroughly evaluate the potential application of the DBSR model in real-world projects, we collected 1576 landslide RSIs with a resolution of

Visual comparison of dual-band super-resolution (DBSR) with other super-resolution methods in landslide object detection (
DBSR also exhibits excellent reconstruction performance across various remote sensing datasets and practical applications. Due to factors such as long distances and complex imaging equipment, RSIs often suffer from LR, which can hinder tasks such as urban planning and disaster management. HR RSIs, however, contain more details that can improve the efficiency of downstream applications. To address this issue, the DBSR model can be utilized for real-time SR reconstruction of LR images received during satellite data transmission and processing, thereby enhancing spatial resolution and detail. This real-time processing can be implemented on satellite edge-computing units or high-performance computing platforms at ground stations. Through these approaches, DBSR can provide robust support for the real-time analysis and application of remote sensing data.
We performed further comparisons of DBSR with the mentioned state-of-the-art SR methods. Quantitative results are shown in Table 2. For three scaling factors, DBSR achieves the best results across all test datasets. Moreover, compared to SAFMN, DBSR has better performance for a similar parameter count, especially on the Urban100 dataset, where PSNR improves by over 0.25 dB for each scaling factor.
Quantitative Results on SR Benchmark Datasets.
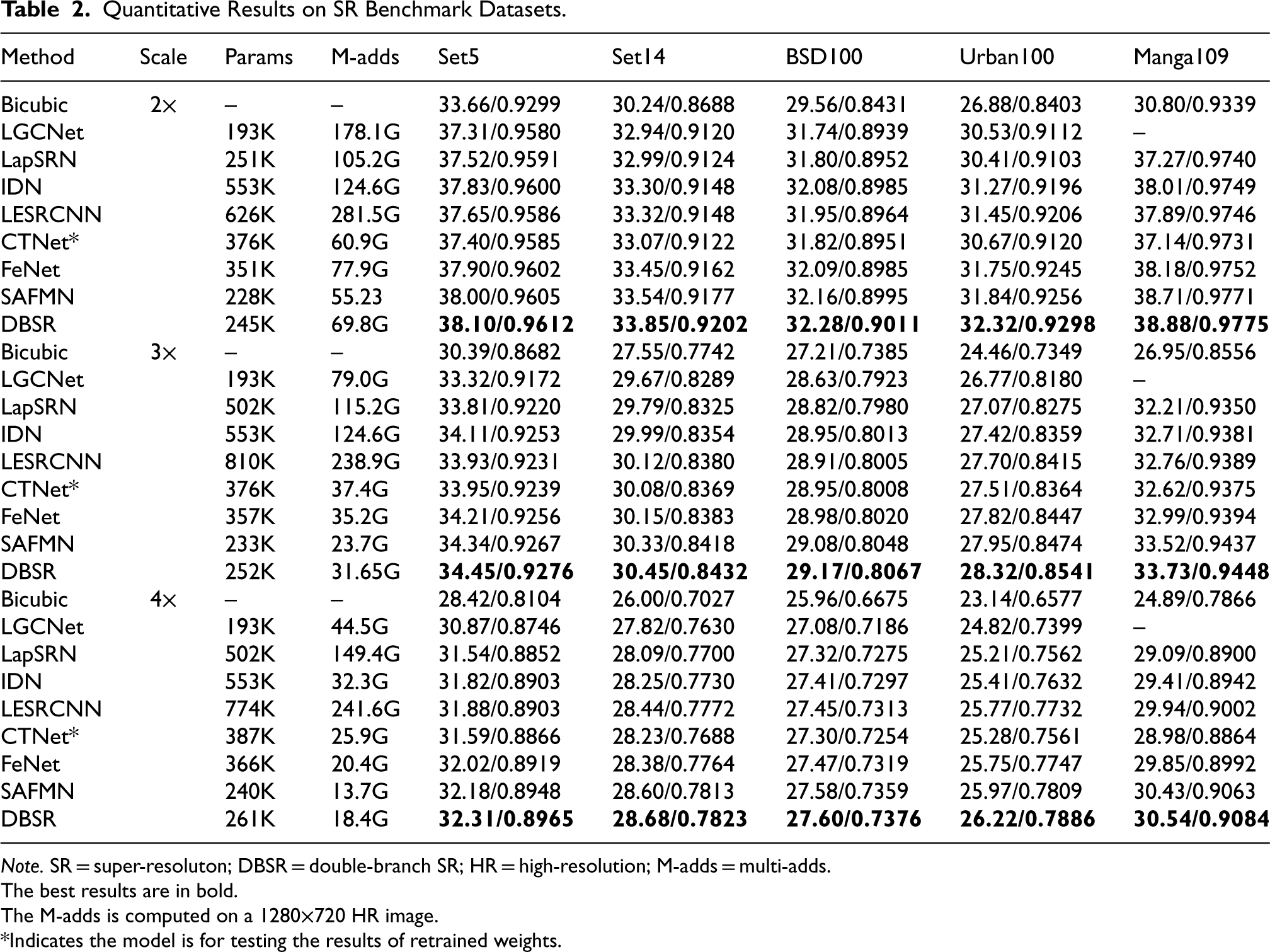
Quantitative Results on SR Benchmark Datasets.
Note. SR = super-resoluton; DBSR = double-branch SR; HR = high-resolution; M-adds = multi-adds.
The best results are in bold.
The M-adds is computed on a 1280
*Indicates the model is for testing the results of retrained weights.
To evaluate perceptual quality, we present three SR results of the models on the Urban100 datasets in Figure 11. The DBSR model produced excellent image clarity and texture detail, outperforming the other models. The success of DBSR is attributed to the enhancement of shallow features by the auxiliary branch: in traditional bilinear interpolation, although the original pixel values are not altered, directly interpolating between pixels often results in image blurring and artifacts. For instance, “img098” in Figure 11 shows prominent artifacts between steel frames when upsampled using bilinear interpolation. In the comparison model, adding the model output to the shallow feature bilinear interpolation result introduces erroneous details. Consequently, this leads to display errors, such as showing only three steel frames in an image where there should be four. In contrast, DBSR, through its dual-branch design advantage, especially with the fine processing of shallow features with GIEM, successfully recovers accurate images, avoiding disturbances caused by the direct upsampling of shallow features.

Visual comparison of DBSR with other SR methods on Urban100 datasets (
The lightweight SR model is designed to achieve efficient image processing through reduced computational complexity and faster inference speeds. To comprehensively evaluate the operational efficiency of our proposed method, we compared it with four representative lightweight SR methods, including IDN, CTNet, and FeNet. Experiments were conducted on two datasets: RS-T1 and DIV2K. We extracted 100 images from each dataset with resolutions of
The comparative results of model inference efficiency are displayed in Table 3. Compared to the most advanced methods, our DBSR model demonstrates significant advantages across multiple key metrics. With its carefully designed lightweight dual-branch structure, DBSR reduces GPU memory consumption by approximately 8%–10% compared to FeNet and outperforms FeNet in runtime on both GPU and CPU. Additionally, although DBSR’s runtime is comparable to that of IDN, its Multi-Adds are reduced by more than 30% on both datasets. These results indicate that DBSR achieves a favorable balance between inference speed, model complexity, and reconstruction performance. Combined with the experimental results from both datasets, DBSR not only enhances SR reconstruction performance but also surpasses existing cutting-edge methods in inference efficiency and resource utilization, demonstrating its practical value. The model has significant advantages in real-world applications, making it particularly suitable for scenarios with limited resources and offering superior overall performance compared to existing state-of-the-art methods.
Quantify the Model’s Lightweight Performance Across Different Resolutions.
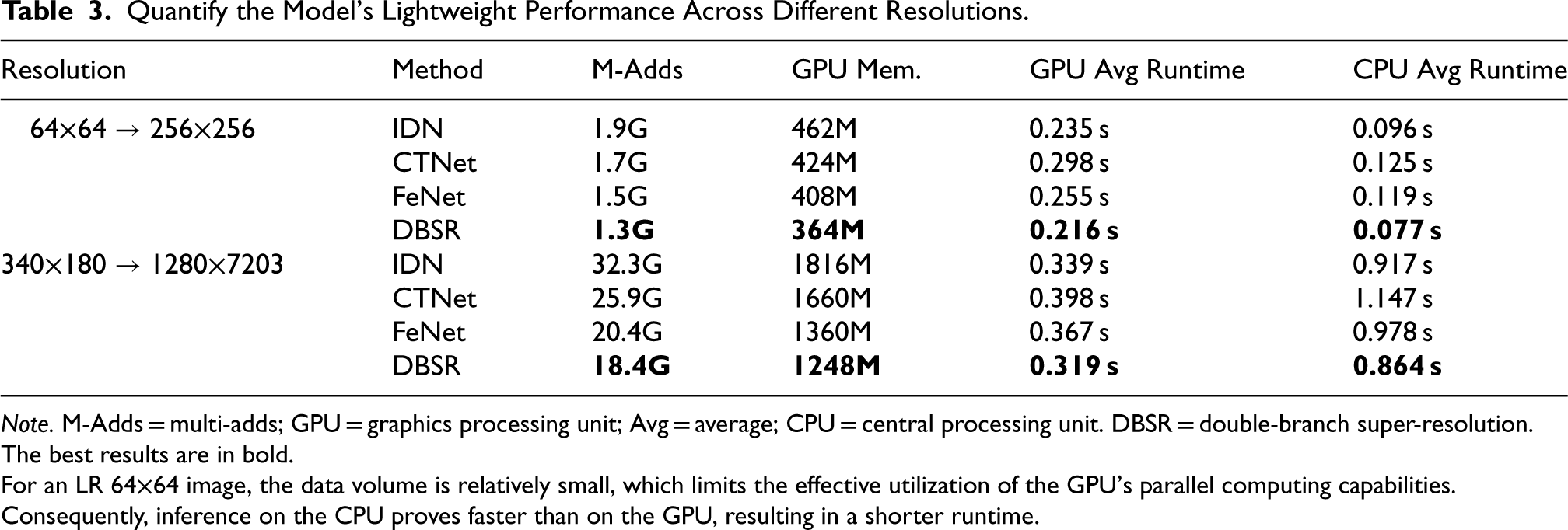
Quantify the Model’s Lightweight Performance Across Different Resolutions.
Note. M-Adds = multi-adds; GPU = graphics processing unit; Avg = average; CPU = central processing unit. DBSR = double-branch super-resolution.
The best results are in bold.
For an LR 64
In this section, we conduct a series of ablation experiments. First, we independently verify the effectiveness of the DBSR module and its auxiliary branch design. Next, we analyze the impact of the number of layers in the HCTF module and the separation layers in the SST on model performance. Finally, we validate the feature refinement capability of HCTF through feature map visualization.
Validation of DBSR Module Design
To validate the effectiveness of the modules designed in the DBSR framework, we used DBSR as a baseline and sequentially removed the CRC, SST, SRM, and GIEM. These modules were replaced with CA, spatial attention (SA), and swin transformer layer (STL) to construct nine variant models. These models were evaluated on the RS-T1 and RS-T2 datasets. Table 4 displays the quantitative results of these nine variants.
Ablation Experiments of DBSR Module Design on RSI Datasets (
).
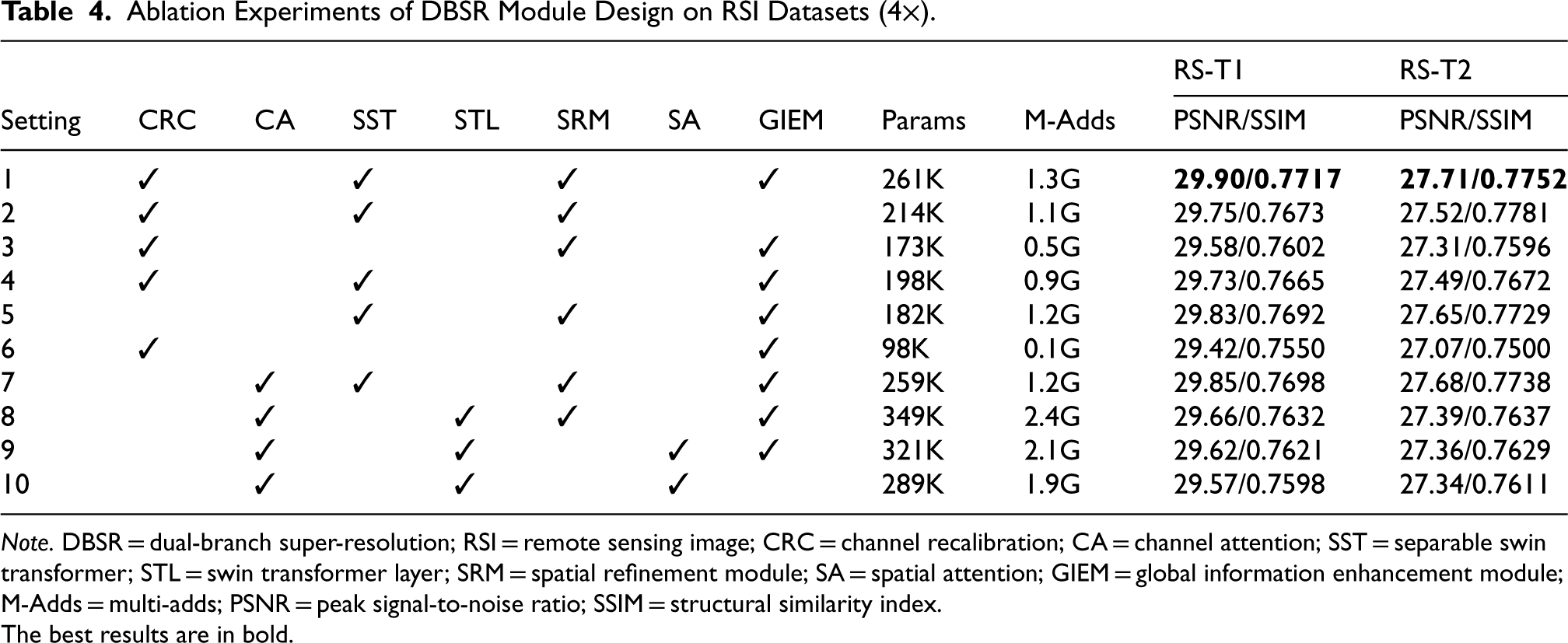
Ablation Experiments of DBSR Module Design on RSI Datasets (
Note. DBSR = dual-branch super-resolution; RSI = remote sensing image; CRC = channel recalibration; CA = channel attention; SST = separable swin transformer; STL = swin transformer layer; SRM = spatial refinement module; SA = spatial attention; GIEM = global information enhancement module; M-Adds = multi-adds; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
The best results are in bold.
In Variant Model 1, the combination of CRC, STL, SRM, and GIEM demonstrated the best PSNR and SSIM performance, particularly on the RS-T1 dataset with a PSNR of 29.90 dB and an SSIM of 0.7717, and on the RS-T2 dataset, achieving a PSNR of 27.71 dB and an SSIM of 0.7752. Compared to other model variants, this combination showed significant improvements in reconstruction performance while maintaining a reasonable balance between parameter count (261K) and computational cost (1.3G M-Adds). This indicates that the joint functionality of the CRC, STL, SRM, and GIEM effectively enhances image reconstruction precision, thereby delivering superior performance in SR tasks. In Variants 3 and 8, the removal of the SST module resulted in a noticeable decline in PSNR and SSIM. Variant 3 saw a decrease of 0.32 dB on RS-T1 and 0.4 dB on RS-T2, while Variant 8 experienced a PSNR drop of 0.3 dB on RS-T1, even with the STL replacement and a 25% increase in parameter count. This confirms the importance of the multiscale window parallel computation designed in the SST module, which facilitates multiscale window information interaction and enhances reconstruction quality and efficiency.
Furthermore, in Variant Models 7, 9, and 10, replacing the CRC and SRM with CA and SA did not achieve performance equivalent to the original DBSR modules, showing a decrease in PSNR and SSIM on both the RS-T1 and RS-T2 datasets. This further underscores the critical role of DBSR module design in SR tasks, demonstrating that DBSR’s uniquely tailored modules are better suited to the demands of SR detail and multiscale feature requirements compared to conventional attention mechanisms. Overall, the combination of CRC, SST, SRM, and GIEM in the DBSR model exhibits significant superiority in balancing parameter volume, computational expense, and reconstruction quality, with these uniquely designed modules playing a crucial role in enhancing SR performance.
To validate the performance of the auxiliary branch design, we used the HCTF as the baseline model. This baseline model follows previous methods by directly adding the bilinearly interpolated shallow features to the SR result. We then replaced this with the GIEM and IFF modules for testing on the RSI datasets. As shown in Table 5, the lightweight intervention of the auxiliary branch significantly improves model performance. This improvement is mainly due to the precise processing of shallow features by the designed GIEM and the further refinement of primary and auxiliary features through the interactive feature fusion of the IFF module. The results in Figure 11 further confirm that our designed auxiliary branch significantly outperforms the traditional method of directly upsampling shallow features.
Ablation Experiments of Auxiliary Branch Design on RSI Datasets (
).
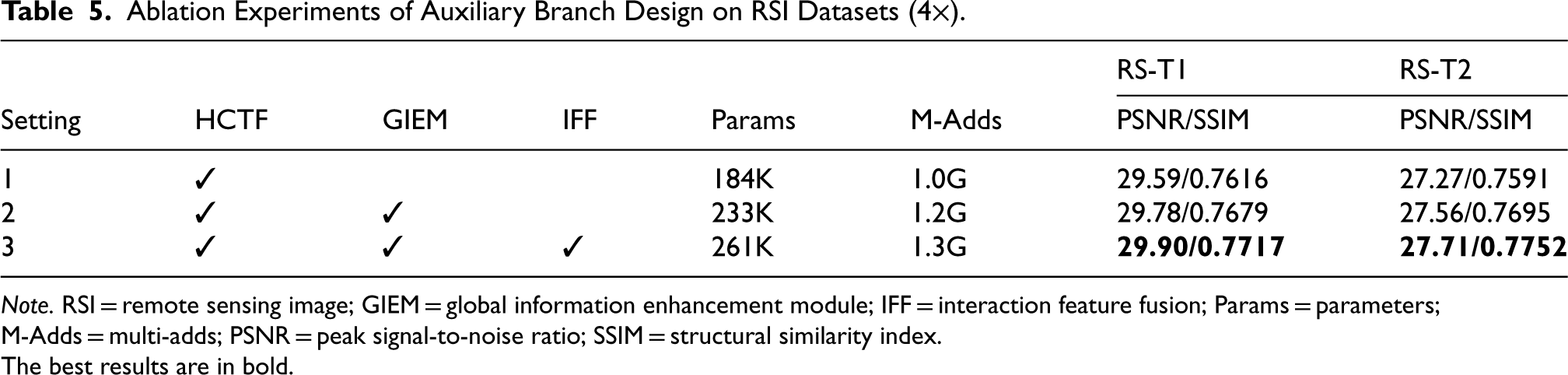
Ablation Experiments of Auxiliary Branch Design on RSI Datasets (
Note. RSI = remote sensing image; GIEM = global information enhancement module; IFF = interaction feature fusion; Params = parameters; M-Adds = multi-adds; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
The best results are in bold.
To balance the parameters and performance of the HCTF model, we considered different layer settings. Data in Table 6 show that increasing the number of layers improves SR performance. Notably, even a single-layer model outperforms FeNet on the Set5 and Set14 datasets. To maintain a lightweight model, we set the number of HCTF layers to three.
Ablation Analysis of the Number of HCTF Modules on Set5 and Set14 Datasets (
).

Ablation Analysis of the Number of HCTF Modules on Set5 and Set14 Datasets (
Note. Params = parameters; M-Adds = multi-adds; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
The best results are in bold.
To choose the optimal number of SST separation layers, we conducted comparative experiments with the number of SST separation layers set to 1, 2, 3, and 4, with one layer being the standard swin transformer. As shown in Table 7, the best performance was achieved with four layers. However, the window size of
Ablation Analysis of the Number of SST Separation Layers on Set5 and Set14 Datasets (
).
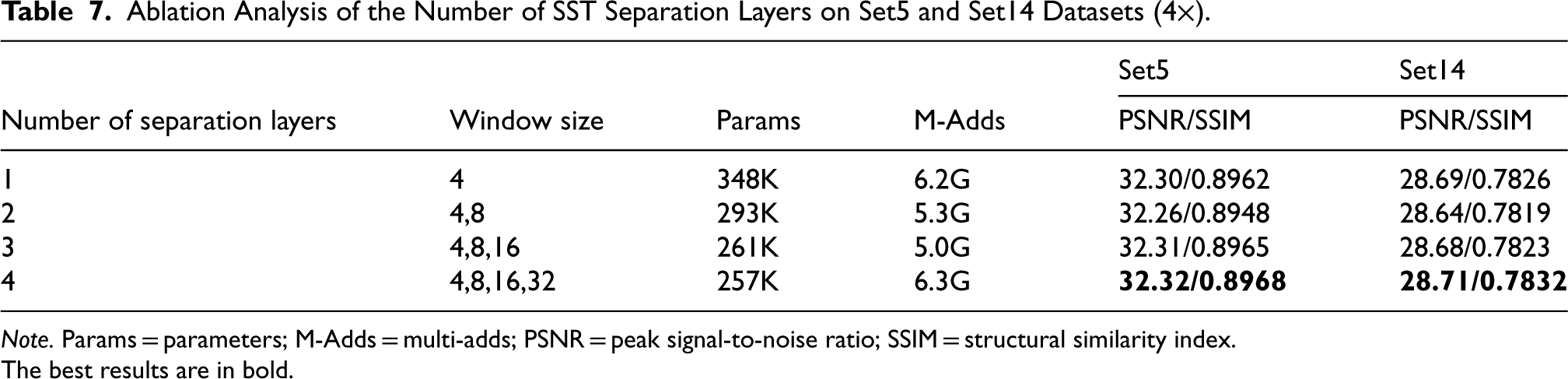
Ablation Analysis of the Number of SST Separation Layers on Set5 and Set14 Datasets (
Note. Params = parameters; M-Adds = multi-adds; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
The best results are in bold.
To visually demonstrate the effectiveness of the proposed HCTF in mitigating detail loss during the cascade CNN feature extraction process, we conducted a feature visualization analysis of HCTF during the DBSR inference process. As shown in Figure 12, the features exhibit a more refined trend as the HCTF module deepens.
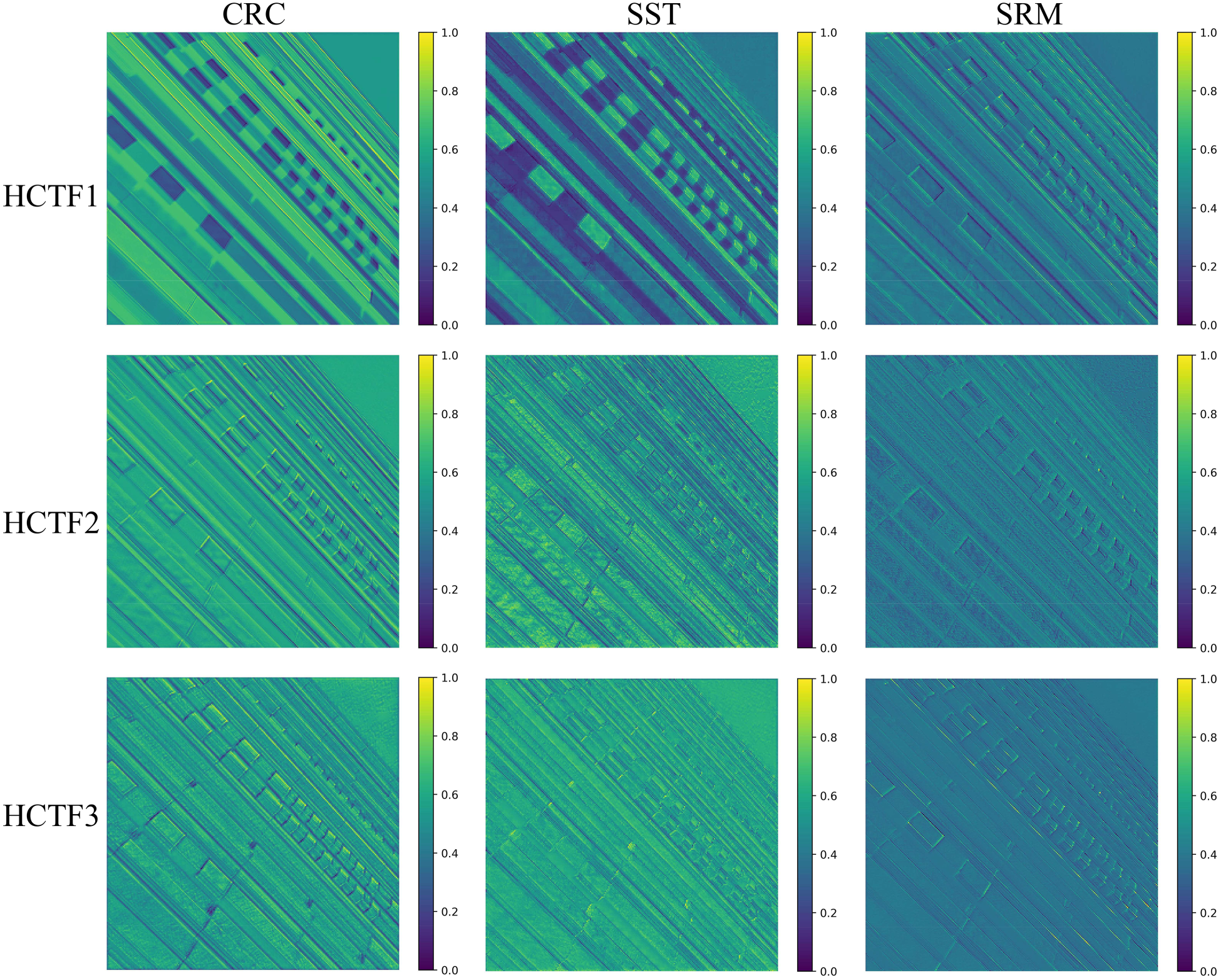
Average feature maps of HCTF blocks. HCTF1, HCTF2, and HCTF3 represent the intermediate features in the three-layer cascaded HCTF structure.
This study introduces a lightweight DBSR method that effectively combines the advantages of CNNs and SSTs. The dual-branch architecture maintains a total parameter count of just 245 K. The main branch utilizes CRC to dynamically adjust channel feature responses, thereby reducing channel redundancy. Additionally, we developed an SST that reduces the number of parameters while facilitating the parallel extraction of multiscale window features. The SRM further refines the features at the pixel level. The auxiliary branch enhances the global context of shallow features through a GIEM. Finally, the feature interaction fusion module integrates the main and auxiliary branches, creating high-quality feature representations. Comparative experimental results indicate that the DBSR network performs exceptionally well on four RSI datasets and five SR benchmark datasets. Furthermore, extensive ablation experiments confirm the effectiveness of each module, further demonstrating the superior capabilities of the DBSR model.
In the future, we intend to employ distributed computing and sparse representation techniques to handle datasets with higher resolutions and larger scales, thereby enhancing the scalability of lightweight SR models. Additionally, we plan to incorporate generative adversarial networks to improve the model’s robustness when addressing complex RSI transformations. We will also explore cross-modal learning to enable generalization across different sensor types, expanding the model’s adaptability to remote sensing applications involving multiple sensors.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Chongqing Municipal Education Commission through the Scientific and Technological Research Program (grant no. KJQN202304015).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.