
Abstract
Image compression is crucial for reducing storage and transmission costs, particularly in applications involving high-resolution and complex imagery. Traditional compression methods, such as JPEG, PNG, and newer lossless formats like JPEG XL and WebP, often suffer from suboptimal compression ratios (CRs) and image quality when handling modern high-definition content. To overcome these limitations, this paper proposes a novel deep learning-based lossless image compression method. The symmetrical transformer (STF) model is introduced, integrating transformer blocks in both the downsampling encoder and upsampling decoder to enhance the capture of local and global features. The model also includes a multivariate mixture distribution channel conditioning (MMCC) entropy model, which improves pixel dependency predictions by modeling complex relationships within image channels. Additionally, an automated searching of optimal kernel shapes (SOKS) is employed to dynamically configure kernel sizes, optimizing the convolutional layers for different image regions. The system also applies stripe-wise pruning (SWP), which selectively prunes unimportant features during compression, reducing computational complexity and memory usage without compromising image quality. Extensive evaluations on standard datasets, including Kodak, CLIC, and DIV2K, demonstrate the effectiveness of the proposed model. Specifically, the approach achieves significant compression efficiency, with bits-per-dimension (BPD) values of 3.06 on Kodak, 3.91 on CLIC, and 3.63 on DIV2K, outperforming traditional methods such as iVPF (3.20 BPD on Kodak), GOLLIC (3.15 BPD on Kodak), and MSPSM (3.12 BPD on Kodak). In addition to compression efficiency, the proposed method excels in inference speed, with encoding times as low as 7.80 ms per sample on Kodak, significantly faster than competing methods. These results demonstrate a substantial improvement in compression rates and image reconstruction quality, highlighting the model's potential for real-world applications, including medical imaging, remote sensing, and real-time streaming, offering a significant advancement in lossless image compression.
Introduction
Image compression refers to reducing the data needed to store a digital image. There are two primary approaches to image compression: lossless and lossy compression. Lossless compression aims to reduce the image's size without any loss of information, making it suitable for applications like medical imaging, scientific data, and cases where maintaining image quality is crucial. Lossy compression, on the other hand, sacrifices some image details to achieve greater compression, making it more versatile for various practical purposes (Wang et al., 2023). Traditional image compression approaches, including free lossless image format (FLIF) (Sneyers & Wuille, 2016), JPEG2000 Rabbani & Joshi, 2002), and WebP (WebP Image Format) use manually designed encoding and decoding techniques for capturing spatial correlations among pixels in an image. These methods have been effective in their own right.
In recent years, deep learning has advanced significantly, leading to learning-based image compression techniques that outperform traditional methods. Both traditional and learning-based lossless compression methods share the goal of approximating the true distribution of image data. Flow-based models, such as invertible volume preserving flow (iVPF), offer an advantage by enabling exact likelihood optimization through bijective mappings (Zhang et al., 2021). For example, iVPF introduced the modular affine transformation (MAT) algorithm, which achieves precise bijective mapping without numerical errors.
Other learning-based lossless compression methods, like L3C, have also demonstrated exceptional performance. L3C utilizes a fully parallel hierarchical probabilistic model and surpasses traditional compression formats like WebP, PNG, and JPEG2000. Similarly, RC utilizes BPG for lossy reconstruction and employs the RC (residual compressor) network for lossless compression (Mentzer et al., 2019, 2020). In a related approach, an end-to-end lossless image compression framework was proposed, building on prior work in lossy image compression (Lee et al., 2019). This framework, as detailed in Cheng et al. (2020), employs an autoregressive model for latent variables to enhance performance. It's worth noting that autoregressive models, while powerful, can be computationally intensive.
Neural coding, especially in the context of neural image compression (NIC), has gained significant attention from both the research community and industry. This emerging field has produced promising solutions for end-to-end image compression, outperforming traditional methods in terms of coding efficiency. NIC relies on autoencoders (AEs) to perform a non-linear transformation of the input signal into a compact representation (Ghorbel et al., 2023). This AE-based system consists of three main components: a transformation stage, quantization, and entropy coding. These components can be trained end-to-end with the aim of minimizing distortion among the source image and its reconstructed version while minimizing the data rate needed to transmit the latent representation bitstream.
This article introduces an optimal kernel transformer approach for learned lossless image compression. It represents a unique combination of architectural changes inspired by models like autoregressive models, SOKS, recurrent neural network (RNN) entropy coding, and Window-based attention transformer. The key contributions of this paper are outlined in the following sections.
To introduce channel-conditional (CC) models that efficiently capture pixel redundancies in image compression, addressing the time-consuming nature of autoregressive models. To enhance entropy modeling through the multivariate mixture distribution channel conditioning (MMCC) model, surpassing the performance of traditional Spatial Gaussian mixture (SGM)-based entropy models. To adopt a sequence-to-sequence RNN architecture for both compression and decompression, leveraging binary RNNs for entropy coding and binarization to improve compression ratios (CRs). To integrate shifted window-based self-attention modules, inspired by vision transformer (ViT) and Swin transformer architectures, for improved correlation capture among spatially adjacent elements in CNN and Transformer models. To implement the searching of optimal kernel shapes (SOKS) methodology, automating the search for optimal kernel shapes and enhancing network efficiency through stripe-wise pruning (SWP), reduces storage and computational demands.
In this article, the remaining sections are organized as follows: Section 2 presents the literature review, providing an overview of relevant prior work. Section 3 delves into the background of the research, offering contextual information for understanding the study. Section 4 outlines the proposed methodology, detailing the approach employed in the research. The experimental setup is elaborated upon in Section 5, describing how the experiments were conducted. Section 6 presents the results and discussion, analyzing the findings and their implications. Finally, the conclusion, summarizing the key findings and insights, is presented in Section 7.
Literature Survey
Image processing plays a major role in various areas and the processing steps there are various techniques have been applied in recent years that are existed. From those some of them are represented here like thresholding for segmentation with an optimization algorithm called African vultures optimization algorithm (AVOA) (Gharehchopogh & Ibrikci, 2024), classification of images for acute lymphoblastic leukemia diagnosis using convolutional neural network (CNN) (Özbay et al., 2023), detection of COVID-19 disease using interactive autodidactic school (IAS) algorithm (Gharehchopogh & Khargoush, 2023), Feature selection of biomedical data for COVID-19 disease using the discrete artificial gorilla troop optimization (DAGTO) (Piri et al., 2022). Also, there are some optimization algorithms that are applied for networking-based image processing. Those optimization algorithms are Harris Hawks optimization (HHO) for community detection (Gharehchopogh, 2023), whale optimization algorithm (WOA) (Shen et al., 2023), slime mould algorithm (SMA) (Gharehchopogh et al., 2023), and dynamic HHO (Gharehchopogh et al., 2023). From the above finding the compression turns of the image has a major role for clearly processing the image data to further proceeding. According to these findings, the methods that are applied for image compression that existed already are represented below.
For the compression of lossless images within a short period the recent approaches perform the encoding in a total unit or subimages. In compressed image reconstruction, the approaches of the image prior play a major role. The usage of independent quantization of Discrete Cosine Transform (DCT) coefficients at the low bit rates the block transform coded images were generally affected by irritating artifacts. To overcome this problem Mu et al. (2020) devised a graph-based non-convex low rank regularization model to surrogate the matrix patch. In both the perceptual and objective qualities this approach achieved highly accurate reconstruction. An image compression approach based on CNN was developed to maintain the accuracy of decoded images. Moreover, optimization depending on the PSNR causes degradation in the image having low quality and low bit rates. To overcome this issue a regularization method was developed by Kudo et al. (2019) for subjective image quality. This approach helps to develop the image compression model that might compress the structural changes between the original and the compressed image. For a high resolution image compression entropy model becomes a major element to get better performance. But this approach still unexplored the dependencies in the spatio channel in the field of latents and also in the execution of context adaptivity. The adaptive characters in the transformer were encouraged the Koyuncu et al. (2022) to introduce a new method called context transformer. It is a transformer-based context model that normalizes spatio channel attention from the de facto stable attention model. This method achieved a higher rate of distortion performance and it was not able to lower a gap among real time operations. For better image security depending on the joint compression and encryption the compressive sensing (CS) was used simultaneously. Certain approaches mostly have the minimum CR and they might be faulty during the process of compression. Considering this as a drawback, Song et al. (2019) designed a compression mechanism to maintain the CR. The introduced mechanism was joint image compression and encryption by applying entropy coding and CS. This method accomplished better reconstruction performance in the compression and encryption.
In the task of generic video compression, it was hard to perform the interpolation between the phase of encoding and the decoding. In various compressions, it was not parallel to maintain the speed of the code. It was hard to generalize well while applying different datasets to a large range of various types of videos. To overcome this problem, Liu et al. (2020) formulated a video compression approach called conditional entropy coding. This approach helps in modifying the correlation among every frame code and also it carries the internal learning for every frame code while interference. In the learned image compression, the variational auto encoders (VAEs) had a large area application. Based on the principal algorithm certain approaches may apply only for lossless compression, and while compressing various images concurrently they accomplished a very small efficiency. For compressing a unique image few approaches become ineffective. Considering the above issues, Flamich et al. (2020) presented a latent representation with relative entropy coding for compressing images by encoding. For a single image, this approach was capable of encoding the latent representation directly by codelength nearer to relative entropy. The drawback observed in this approach was compression speed. For lossless image compression, the widely used approach was dependent on the detection due to their simplicity and also it assures an exact retrieval of data. A few methods of image compression had precious spectral data that was unable to be detected by the human eye and required high accuracy. However, the scientific value might be lost due to the information loss. To defeat those problem statements, Chang et al. (2019) developed adaptive prediction, context modeling, and entropy coding for lossless image compression. The entropy coding model helps to remove the statistical redundancy.
The existing methods for image compression, both traditional and learning-based, exhibit various limitations that hinder their effectiveness in achieving optimal compression efficiency while maintaining high-quality image reconstruction. Traditional methods like JPEG2000 and WebP rely on manually designed encoding techniques, which often fail to fully exploit spatial correlations among pixels, resulting in artifacts and quality degradation, especially at low bit rates. Learning-based approaches, while showing promise, suffer from computational inefficiency and over parameterization, leading to excessive computational demands and redundancy in parameters. Additionally, current CNN-based methods struggle to preserve fine details and non-repetitive textures, impacting reconstruction quality. The proposed Optimal Kernel Transformer approach addresses these limitations by integrating innovative strategies such as CC models, MMCC entropy modeling, and RNN-based compression to efficiently capture pixel redundancies and improve CRs without sacrificing image quality. By leveraging advanced transformer techniques and automating the search for optimal kernel shapes, this model enhances representation power while optimizing computational efficiency, providing a robust solution for high-performance lossless image compression. Table 1 presents the comparative table for the related work on lossless image compression.
Comparative Table for Lossless Image Compression.
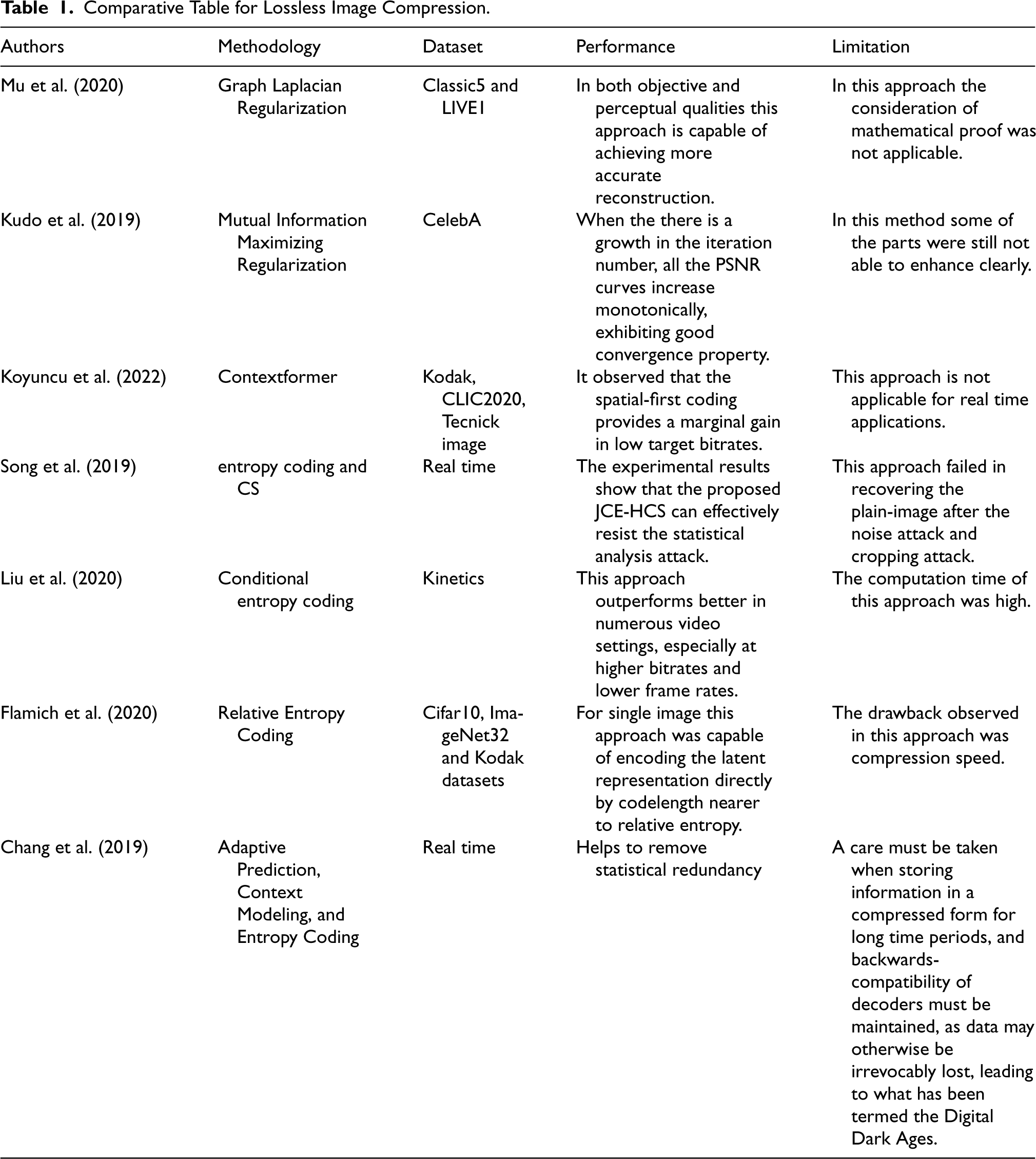
Comparative Table for Lossless Image Compression.
The MMCC model and the autoregressive image were applied for the compression of the raw image. This model helps to minimize the code length and thus it improves the performance.
Formulation of Lossless Image Compression
The lossless image compression carries two elements such as the hyper path and the main path. The main path is expressed in the form of



The latent representation is signified by v, is created by feeding the original images u into the encoder
The hyperprior path carries of hyper decoder 


The MMCC approach plays a vital role in analyzing the parameters in the features. The procedure of the MMCC is expressed below. The input of MMCC carries the elements created by the hyper decoder and quantized latent v. Beside the dimension of the channel the latent
The slices in MMCC follow a consecutive dependence while the process of encoding and decoding takes place. Depending on the hyperprior the primary slice 





Figure 1 illustrates the architectural diagram of the proposed optimal kernel transformer approach for image compression, consisting of two primary components: the major path and the hyper path. In the major path, the compression process begins with the original image being divided into patches. These patches are then processed through transformer-based encoders that employ a window attention mechanism. This mechanism downsamples the feature resolution while increasing the feature channels, enabling the model to effectively capture and represent the image details. Following this, the transformer decoder reverses the process by splitting the patches into layers and de-embedding them to reconstruct the image from the compressed representation. Throughout this process, a conditional probabilistic model is integrated, utilizing a binary RNN to manage the compression and decompression tasks, ensuring efficient data encoding and retrieval.
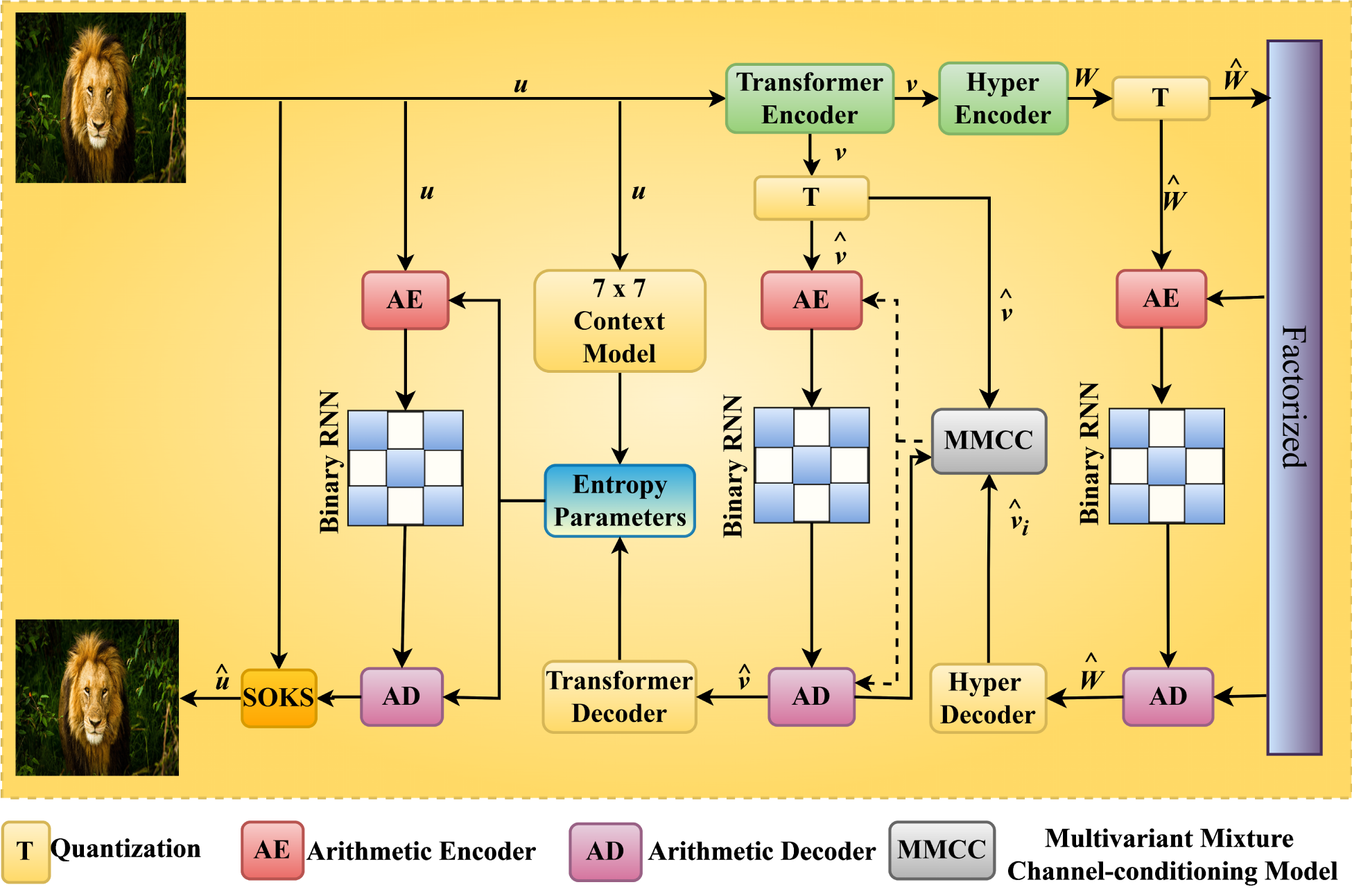
Architectural diagram of the proposed optimal kernel transformer approach for image compression.
The hyper path employs the MMCC framework to analyze feature parameters based on sequential dependencies, which enhances the overall model performance. The MMCC operates in parallel with the major path to refine the compression process. Regularization is performed using the SOKS method, which includes three types of regularization: sparse regularization, direction-wise regularization, and group-wise regularization. These regularization techniques help in optimizing the network by reducing computational complexity and improving efficiency. Finally, the SWP method is applied to prune irregular shapes, ensuring the kernels achieve optimal shapes for better compression performance. This combination of advanced techniques in both the major and hyper paths ensures a high level of compression efficiency and image quality preservation.
The block diagram for the transformer block is shown in Figure 2. In the transformer block the local attention supports to arrange bits sequentially and maintain the performance of Rate Distortion (RD). The benefits of this transformer block it gives attention to the spatially neighboring patches during sequentially increasing the receptive area, by acceptable computational complexity. Here the normalization coefficient Layer Normalization (LN) is generally applied in transformer. The LN is applied default in this transformer block and it have an issue in LN is that it may ruin the Gaussian distributions of the network's components by rescaling the responses of linear filters with the same rescaling factor over all spatial locations in order to maintain the network within a tolerable functioning range. For rescaling the response range the LN is necessary during computation of attention map. Comparing to the original CNN approach the MLP achieve a better outcome (Sneyers & Wuille, 2016). The Window-based multi-head self-attention (MHSA) is signified as W-MSA. It is a MHSA module carrying regular windows and the shifted window-MHSA is denoted as the SW-MSA. It is a MHSA module carrying shifted windows (Liu et al., 2021).
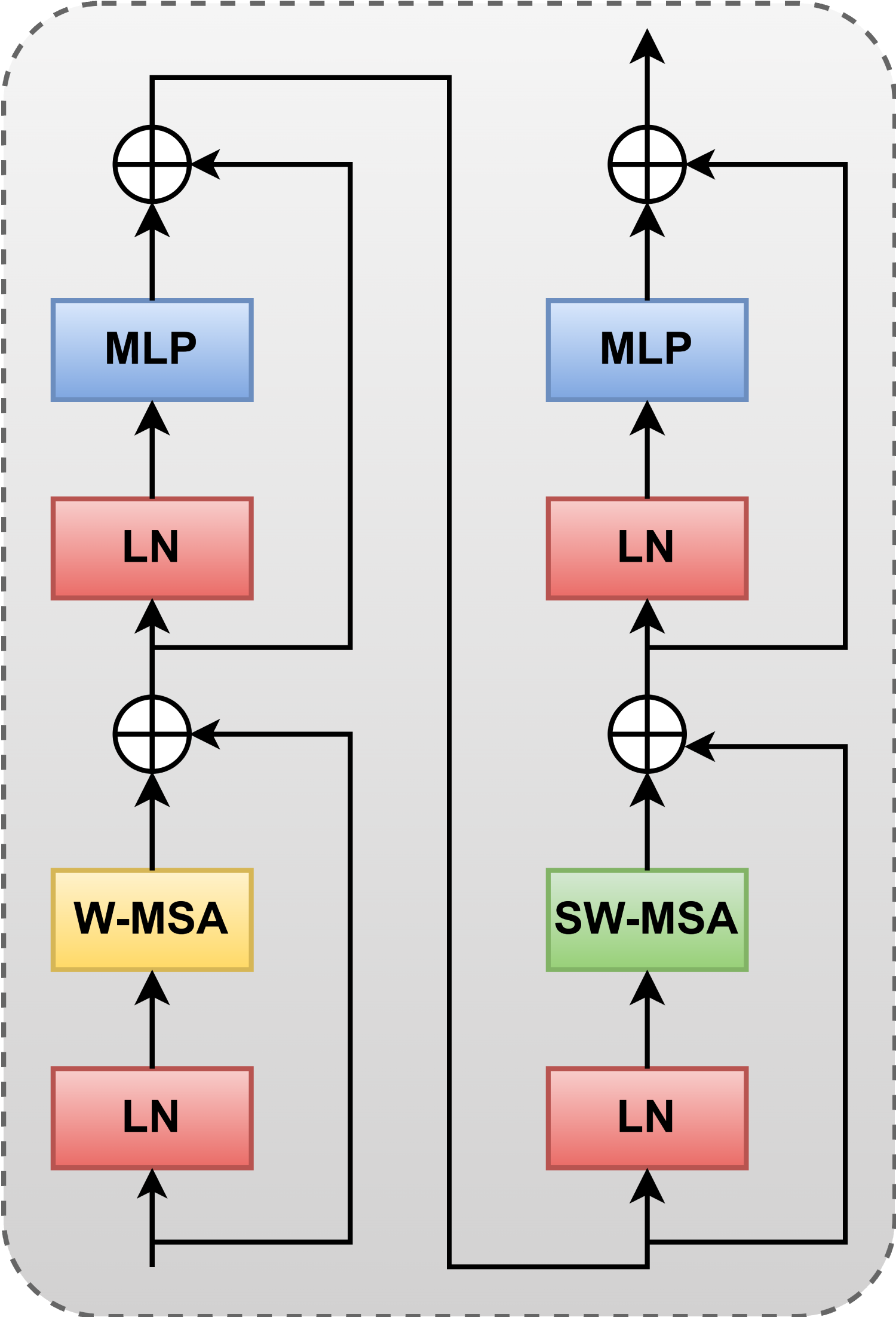
Block diagram of the transformer block.
It divides the original image
Transformer-Based Decoder
It develops a balanced decoder carrying various de-embedding layers, patch splitting layers and transformer blocks. To reconstruct the image
Entropy Coding
The entropy of codes created while interference is not high due to inexplicitly modeled network for increasing the entropy in its codes. This approach did not essentially accomplish redundancy along a big spatial range. Summation of another entropy coding may develop the CR. These usually happen in the standard image compression codecs. Here, image encoder is provided and applied as a binary code. The structure of the binary RNN entropy coding is represented in Figure 3.
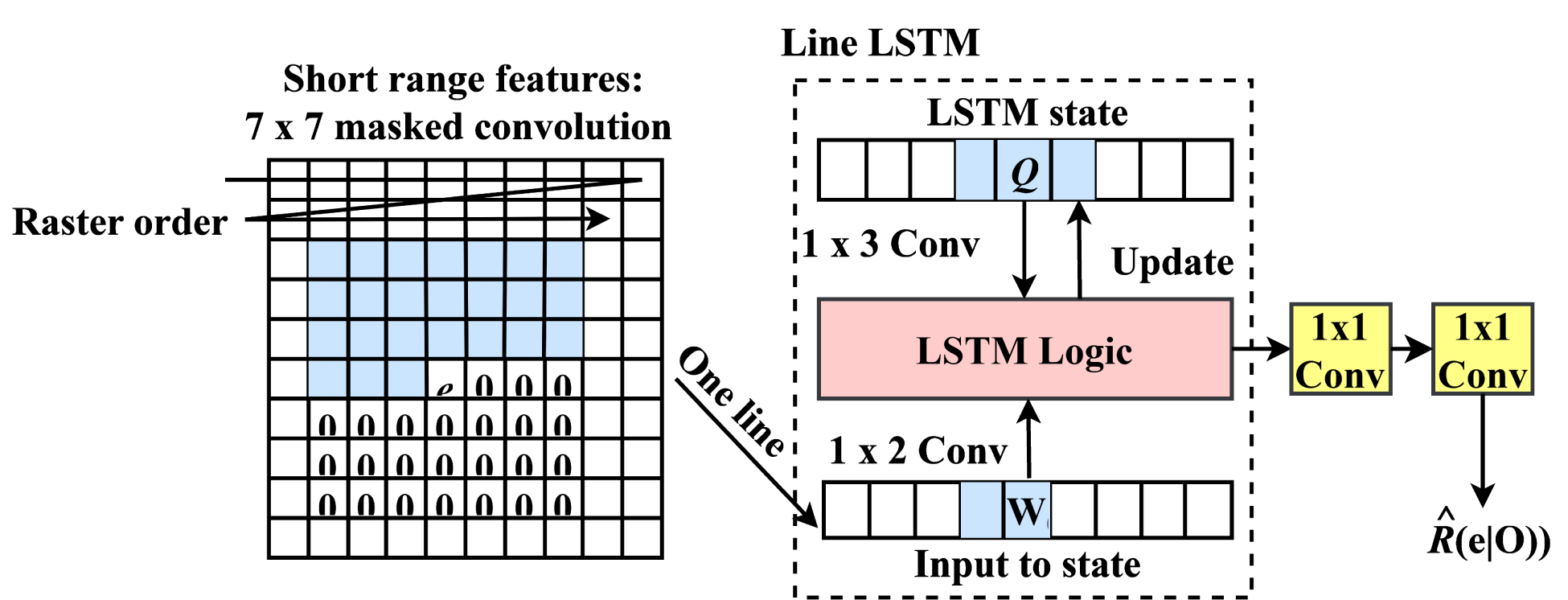
Structural representation of binary RNN entropy coding.
The lossless entropy coding approaches obtained here are wholly convolutional, they proceed the binary code continuous order and also for a provided encoding iteration in the sequence of raster-scan. Every image encoder architecture creates binary code in the form of
In a single layer it controls the Pixel RNN architecture and applies same architecture for the suppression of the binary codes. Here, the analysis of conditional code probability for line x based on few neighboring codes still it is not direct on early decoded binary codes along a line of states Q with size
The end to end probability valuation carries 3 steps. Initially, the primary convolution of size
It is essential to lower the amount of bits applied after entropy coding that may generally cause a cross-entropy loss. Due to the binary codes of 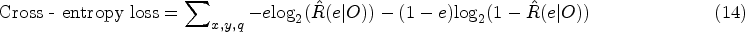
While handling many repetitions, if the iteration repeats then the single iteration entropy coder might be reflected by the unit repetition entropy coder. Each and every repetition has its own LSTM. Moreover, the architecture might not capture the redundancy among repetitions. This may augment the data they are accepted for the iteration of line LSTM by certain information from the early layers. The line LSTM just not receive single iteration similar to
SOKS
SOKS is a framework that search for the optimal kernel shapes. The SOKS had two phases such as the searching phase and the retraining phase.
Framework for SOKS
To predict the significant position in the convolution kernels the coefficient matrices forced by various regularization terms are created. 
To know more about optimal Kernel Shapes, before convolution it takes the product between weights of the filter z and coefficient matrix 
In that case noticing that it may either use diverse coefficient matrices for every channel or convert every channel to share one matrix. Hence, it divides these k filters to
For a CNN approach having I convolution layers to be suppressed, it gathers every 2-D coefficient matrices and get
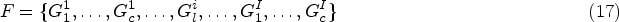
Every component in the F are set to 1 and while training various regularization limitations are established. In training after several repetition the network parameter containing F may converge, and then for predicting main position of kernel F is applied, these are stored to procedure the shapes of optimal kernel. After considering the shapes of the optimal kernel, for every convolution layers pruning based on strip was happened. To get larger accuracy in the stage of retraining the suppressed approach is trained through scratch (Liu et al., 2022).
For image classification the tradition loss function may be equated in the form of

To accomplish spontaneous SOKSs, it include few regularization constraints 
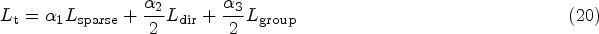
The partial derivative of the sparse regularization 
Based on the chain rule, the partial derivative of the direction wise regularization 
Depending on chain rule the partial derivative of the group wise regularization 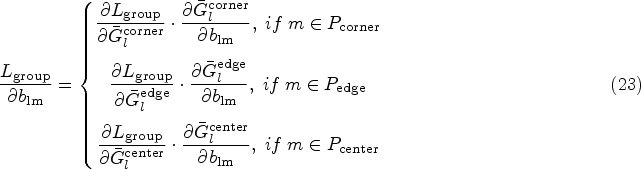
For pruning here the SWP model is applied. In SWP kernel stripes corresponding to unimportant positions are removed and the calculation order of convolution is modified for efficient inference of the pruned network.
Every coefficient matrix
In dissimilar coefficient matrices it can differ highly due to consideration of proper value of the elements. It identifies a threshold
To get the SWP the unimportant kernel parameters may be removed after the optimal kernel shapes are taken. By applying the binary search algorithm the preferred suppression rate is accomplished. Then the pruned approach is trained from scratch to get better outcome. By changing the input information the training and interference of the irregular convolution kernels are executed (Liu et al., 2022).
Experimental Setup
To evaluate the introduced Optimal Kernel Transformer approach it was trained by using three different datasets and it was executed by applying a python tool. This approach is compared with the existing model metrics.
Dataset Description
The introduced Optimal Kernel Transformer approach for lossless image compression applies three different image datasets to achieve better outcomes and also it is compared with the developed method. The different datasets used here are the Kodak dataset, challenge on learned image compression (CLIC) professional validation dataset The CLIC dataset, and the DIV2K dataset.
The Kodak dataset carries 24 uncompressed images with the resolution of
The CLIC carries 41 high quality images with high resolutions from the cameras of DSLR by professionals. Many of the images in the CLIC dataset are 2k resolution however few of them are low resolution as far as
DIV2K dataset is a widely-used high-resolution image dataset. It is divided into 800 training data and 100 validation data. It uses all 800 training data for training. For evaluation (encoding/decoding), it use DIV2K original validation dataset and the randomly cropped version of DIV2K validation dataset (denoted as DIV2K (crop)). The crop size is set to 512 × 512 for the fair comparison to L3C.
Training Details
The model architecture is derived from Cheng et al.'s work in 2020 (Cheng et al., 2020) and implemented within the Compress AI platform (Bégaint et al., 2020). Particularly, the output channel configuration of
Image Compression Performance Comparison.
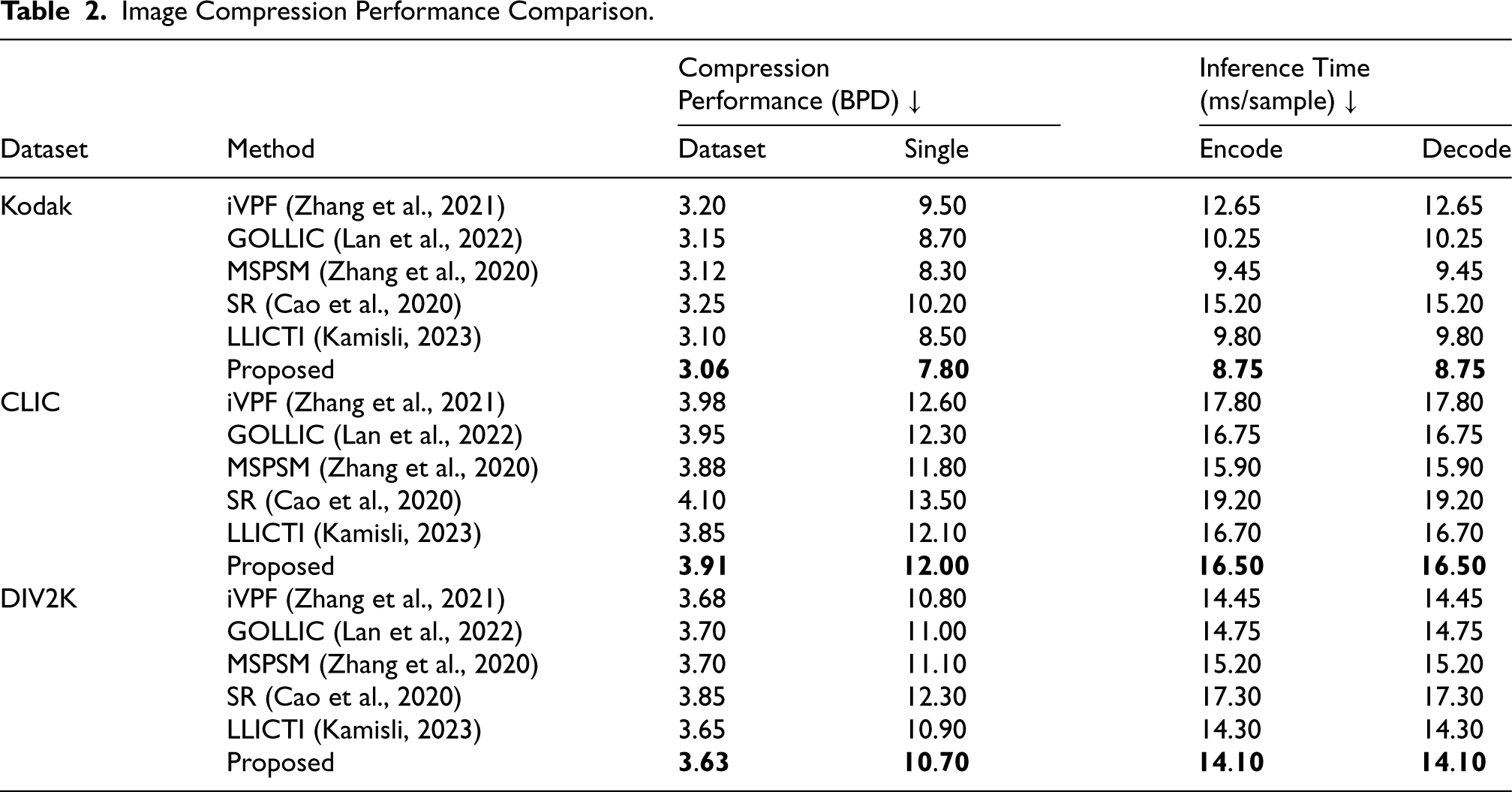
Image Compression Performance Comparison.
The performance of the proposed optimal kernel transformer model is evaluated against several existing models including iVPF (Zhang et al., 2021), GOLLIC (Lan et al., 2022), multi-scale progressive statistical model (MSPSM) (Zhang et al., 2020), super resolution (SR) (Cao et al., 2020), and learned lossless image compression through interpolation (LLICTI) (Kamisli, 2023). Each model is assessed across three datasets: Kodak dataset, CLIC professional validation dataset, and DIV2K dataset. The evaluation focuses on metrics such as compression performance (bits-per-dimension [BPD]) and inference time (ms/sample), providing insights into the efficacy of the proposed approach compared to established methods in lossless image compression.
Experimental Outcomes
Here the performance analysis is carried out among the evaluation measures and the existing approaches. The introduced approach is compared with five existing models namely iVPF (Zhang et al., 2021), GOLLIC (Lan et al., 2022), MSPSM (Zhang et al., 2020), SR (Cao et al., 2020), LLICTI (Kamisli, 2023), and proposed optimal kernel transformer model with three distinct datasets namely Kodak dataset, CLIC professional validation dataset, and DIV2K dataset. Table 2 illustrates a comprehensive comparison of image compression performance among several methods, focusing on Compression Performance (BPD) and Inference Time (ms/sample) for encoding and decoding across three datasets: Kodak, CLIC, and DIV2K. The methods evaluated include iVPF (Zhang et al., 2021), GOLLIC (Lan et al., 2022), MSPSM (Zhang et al., 2020), SR (Cao et al., 2020), LLICTI (Kamisli, 2023), and the proposed method. The results demonstrate that the proposed method excels in both compression efficiency and speed. In terms of Compression Performance, the proposed method consistently achieves the lowest BPD values across all datasets. For instance, in the Kodak dataset, it achieves a BPD of 3.06, outperforming LLICTI (Kamisli, 2023), which has a BPD of 3.10. This indicates that the proposed method can more effectively reduce the amount of data required to represent an image without losing any information. Additionally, the proposed method shows superior Inference Time for both encoding and decoding. Thus, the table underscores that the proposed method not only achieves better compression performance but also operates more efficiently in terms of speed. This makes it the best choice among the evaluated methods, particularly when considering the balance between compression effectiveness and processing time.
Table 3 shows how varying the regularization coefficient vector k influences key performance metrics such as the number of parameters, FLOPs, latency, and accuracy of the model. The k values in this context refer to the regularization coefficients applied to different regions of the convolutional kernel, with k in the format l-m-n, where, l is the coefficient applied to the corners of the filter, m is applied to the edges, and n is applied to the center.
Impact of k on the Model Performance.
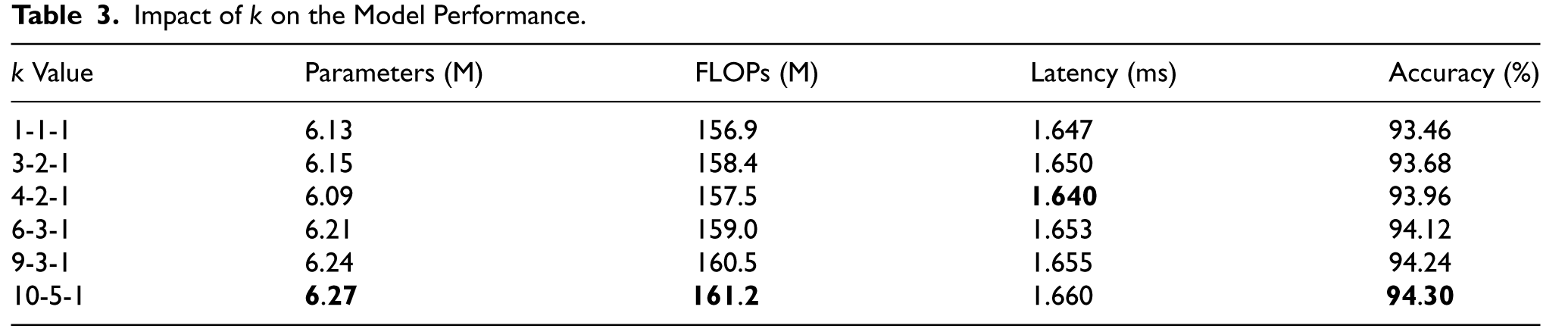
Impact of k on the Model Performance.
The proposed approach optimizes these coefficients to focus on key regions of the filter kernel, thereby enhancing the model's ability to capture important features while imposing appropriate sparsity. The table shows that as the value of k changes, the model's accuracy improves progressively. The baseline configuration of k = 1-1-1 (equal sparsity across all regions) yields an accuracy of 93.46%. As k becomes more sophisticated (e.g., with greater emphasis on the edges and center), accuracy increases. The configuration of k = 4-2-1, where more emphasis is placed on the corners and center, improves accuracy to 93.96%. Further increases in k (e.g., 6-3-1, 9-3-1, and 10-5-1) yield even better results, with the best accuracy of 94.30% achieved with k = 10-5-1. This result demonstrates that by applying different regularization across various parts of the convolutional kernel, the proposed method can effectively capture spatial features more efficiently, leading to better classification performance. The trade-off between computational complexity and accuracy is well-managed, as the number of parameters, FLOPs, and latency increase slightly with larger k values, but the performance improvements justify the added complexity. This solves the problem of uniform sparsity across the kernel, which might overlook the significance of different spatial regions in the filter.
Table 4 illustrates the impact of the number of filter groups (c) on model performance, focusing on parameters, FLOPs, latency, and accuracy. The filter groups partition the convolutional filters into different sets, influencing the model's ability to extract features efficiently. Adjusting c directly impacts the trade-off between computational cost and model performance. As observed, setting c to 2 achieves the best overall performance, with 94.80% accuracy. This configuration has the fewest parameters (6.06 M) and lower FLOPs (134.5 M) compared to c = 1, where FLOPs increase to 152.3 M, leading to reduced accuracy (94.15%). The latency remains consistent across all configurations, with marginal variations (from 1.640 ms to 1.649 ms), indicating that the choice of c mainly affects computational efficiency and accuracy rather than inference speed. Increasing c to 4 further reduces the FLOPs (115.7 M) but at the expense of a slight accuracy drop (94.42%). This suggests diminishing returns as c increases beyond a certain point, where additional filter groups no longer provide meaningful gains in feature extraction and instead lead to underutilization of model capacity. The proposed approach optimally utilizes the configuration c = 2, providing a balance between accuracy and computational efficiency. By reducing the number of FLOPs while maintaining a high accuracy rate, this approach addresses common challenges such as overfitting with too few filter groups or inefficiency with too many groups. The choice of c = 2 minimizes computational complexity without sacrificing performance, demonstrating its effectiveness in resource-constrained environments or large-scale applications requiring both high accuracy and low computational cost.
Impact of the Number of Filter Groups c on the Model Performance.

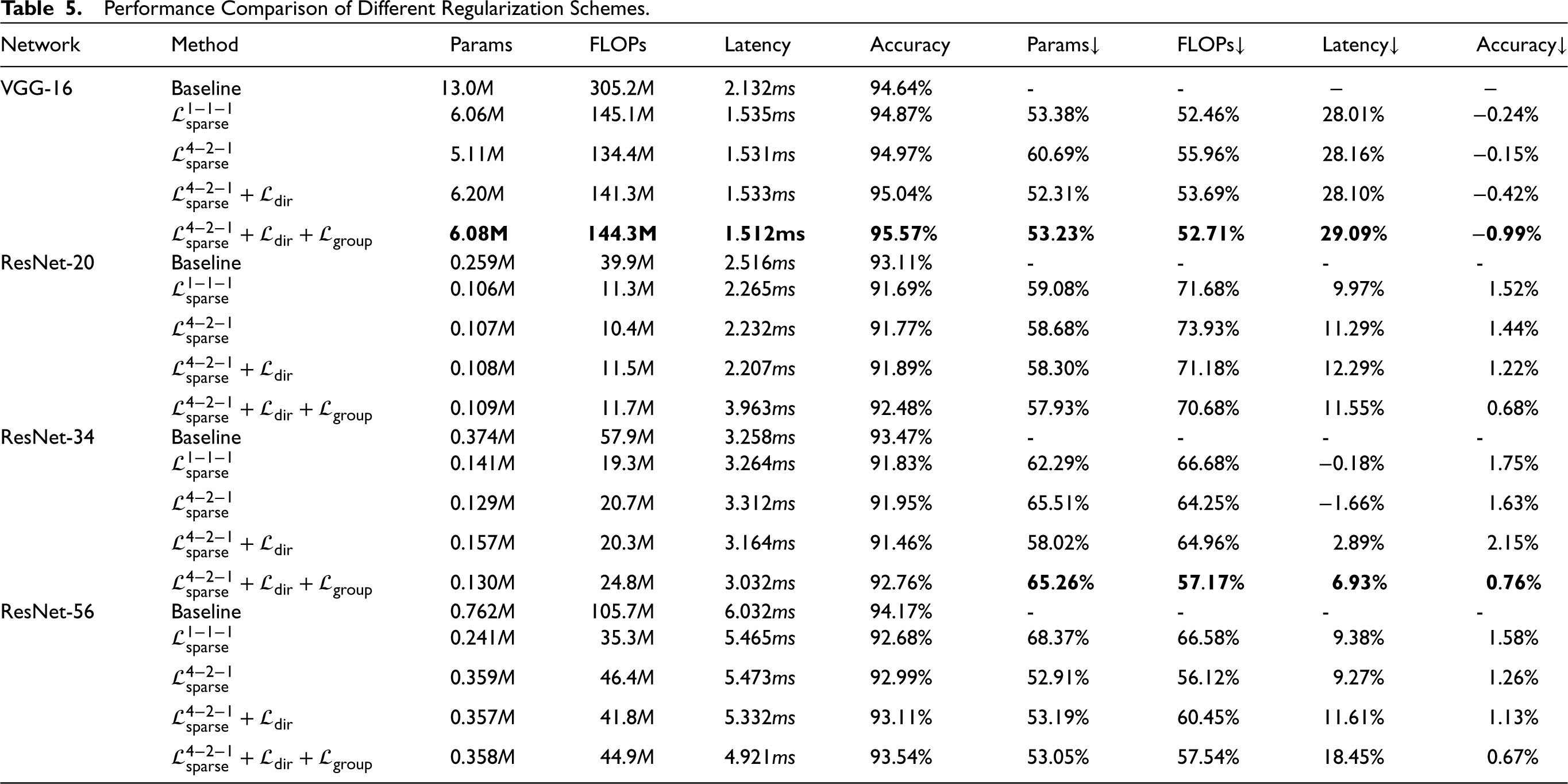
Performance Comparison of Different Regularization Schemes.
Implementation Outcome for Different Dataset.
The experiments are conducted on ResNets, and the results are summarized in Table 5. In all cases, the specific parameters are used, namely c = 2, Performance comparison for computational efficiency and scalability. Ablation Study on Various Model Performances.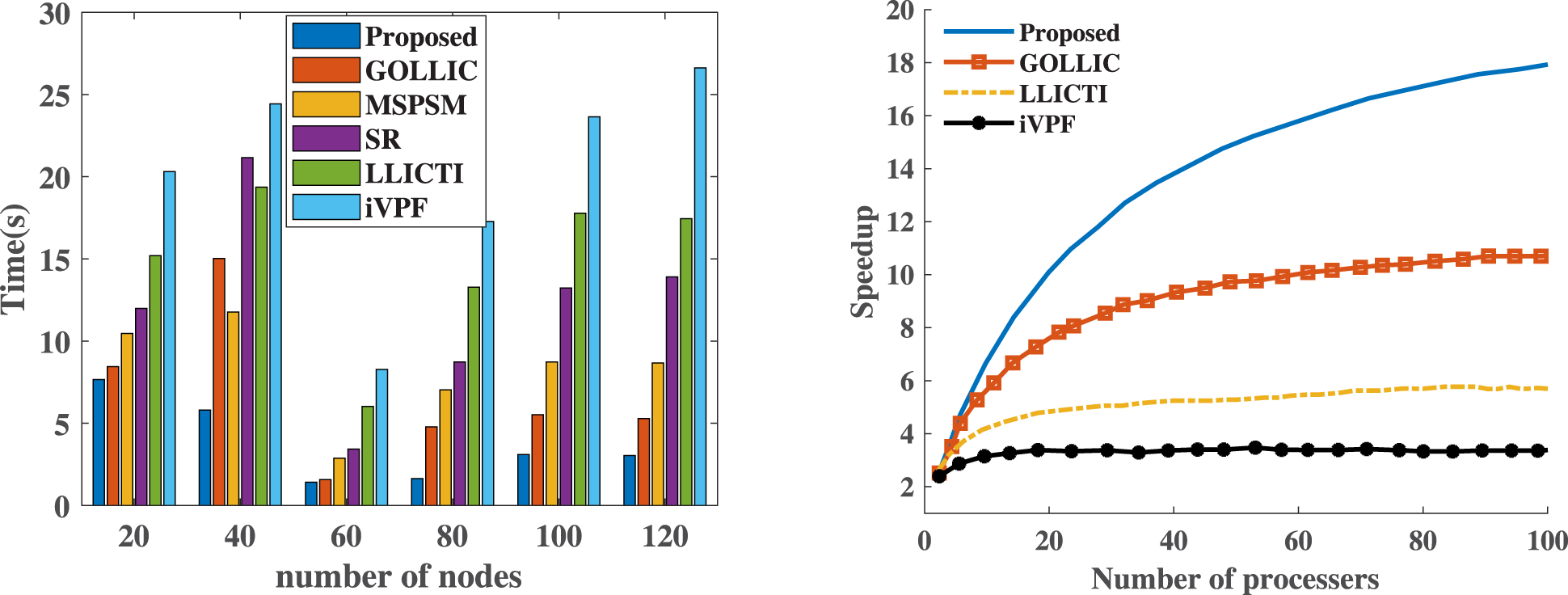

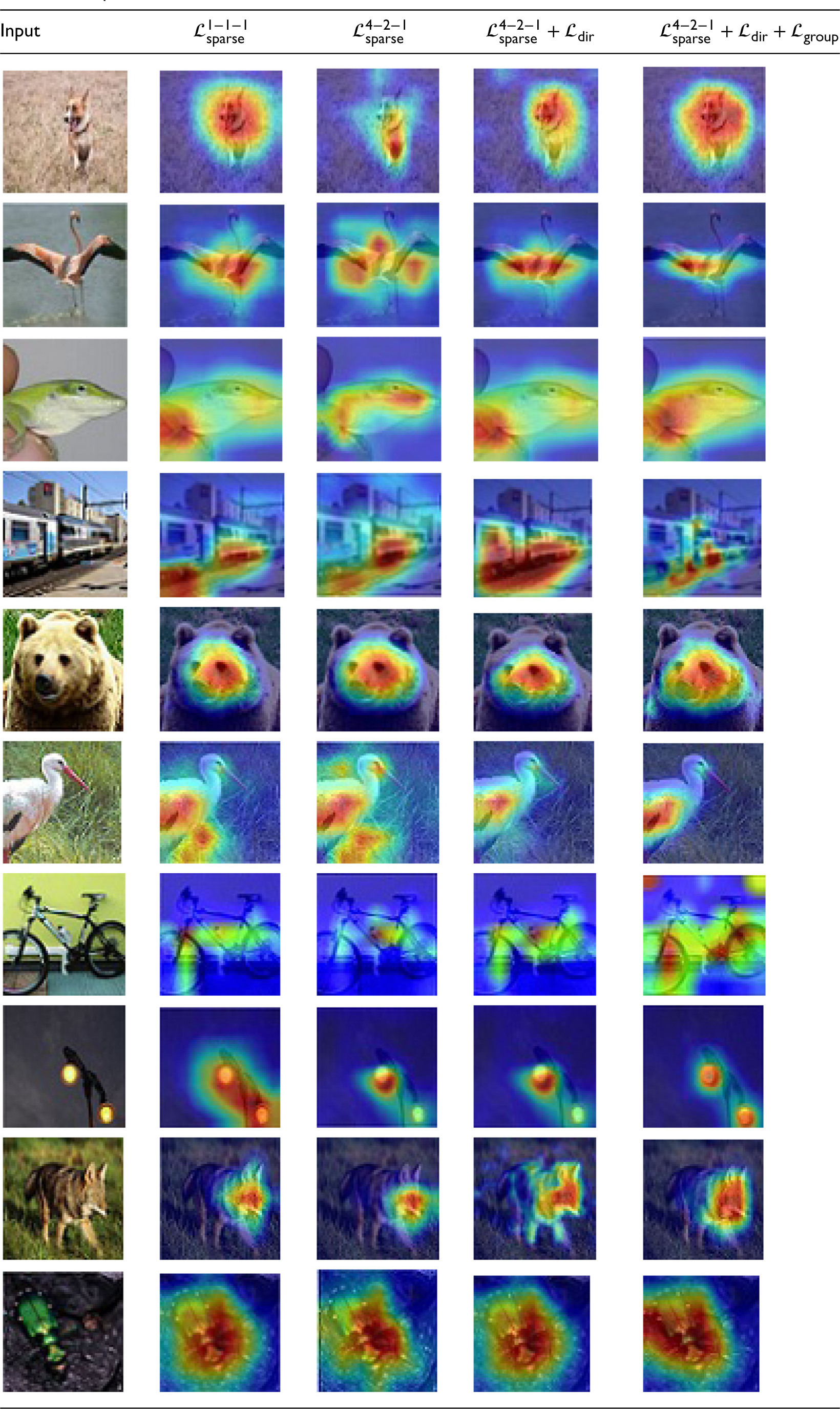
Table 6 represents the implementation result for different dataset compared with different image format. For obtaining better knowledge about every regularizer it apply a GradCAM (Selvaraju et al., 2017) for illustrating the discriminative areas by applying a searching method ResNet-20. It chooses one image from every category in the test setoff the given datasets. By the availability of noise in the background can disturb the outcome in the
Figure 4 represents the performance analysis based on the computational efficiency and the scalability of the proposed model. In the image compression task it shows that how the Optimal Kernel Transformer performs in image compression when compared with other models. For the computational efficiency it has the ability to compress and decompress images with less computational overhead. Thus the proposed approach minimizes the need of the resources like processing time and the computational overhead when compared with the existing approaches. Also for the scalability it analyses the ability of the model to maintain the performance of the model when the resolution of the image or the dataset increases. Thus it represents how the Optimal Kernel Transformer scales up while handling large amount of without any significant price drops. Thus the performance analysis highlights that the proposed model achieves high performance interms of scalability and computation efficiency.
Table 7 provides a comprehensive technical comparison of various compression models, focusing on the impact of integrating an additional autoregressive model specifically designed for the variable x. The evaluation metric utilized is bits per sub-pixel (bpsp) (Luo et al., 2023), which measures the average number of bits required to encode each pixel in the compressed images. Lower bpsp values indicate more efficient compression. The table demonstrates that augmenting the compression model with an extra autoregressive model specifically designed for x significantly enhances compression efficiency. The proposed model, integrating MMCC and the additional autoregressive component, outperforms both the baseline model and the enhanced baseline model across all evaluated datasets. This underscores the effectiveness of the proposed approach in achieving superior compression performance.
On analyzing the results it is found that the proposed Optimal Kernel Transformer approach for learned lossless image compression offers several strengths that distinguish it from existing methods. By introducing CC models, MMCC entropy modeling, and RNN-based compression, it efficiently captures pixel redundancies and achieves superior CRs without compromising image quality. The integration of shifted window-based self-attention modules inspired by ViT and Swin Transformer architectures enhances correlation capture among spatially adjacent elements, improving overall compression performance. Additionally, the methodology automates the search for optimal kernel shapes using the SOKS framework, further optimizing network efficiency through SWP to reduce storage and computational demands. These innovations collectively contribute to the model's ability to achieve state-of-the-art compression efficiency while maintaining high-quality image reconstruction, positioning it as a promising solution for real-world image compression applications.
This article introduces a novel approach to lossless image compression using the Optimal Kernel Transformer, addressing key challenges in traditional methods while utilizing deep learning and neural coding techniques for improved performance. The approach includes the use of CC models to mitigate the time-intensive nature of autoregressive models, the introduction of the MMCC framework to better model complex data distributions, and the application of a sequence-to-sequence RNN model for entropy coding. Symmetrical Transformer architecture is employed to optimize downsampling and upsampling processes, while techniques like Symmetrical Optimized Kernel Sampling and Sliding Window Processing further enhance network efficiency and reduce computational overhead, minimizing complexity. The proposed model outperforms existing methods such as iVPF, GOLLIC, MSPSM, SR, and LLICTI on the Kodak, CLIC, and DIV2K datasets, achieving the lowest BPD values (3.06, 3.91, and 3.63, respectively) and demonstrating superior compression efficiency. Additionally, it achieves faster inference times (7.80 ms for encoding on Kodak) compared to competing models, making it the most effective choice for lossless image compression in terms of both performance and speed. With an accuracy of 94.80%, the model strikes an optimal balance between precision and computational efficiency. Future work will explore optimizing the Optimal Kernel Transformer for efficient video compression applications.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.