
Abstract
The CADE ATP System Competition (CASC) is the annual evaluation of fully automatic, classical logic, automated theorem proving (ATP) systems—the world championship for such systems. CASC-J12 was the 29th competition in the CASC series. Nineteen ATP systems competed in the various divisions. This paper presents an outline of the competition design and a commentated summary of the results.
Introduction
Automated theorem proving (ATP) deals with the task of proving theorems from axioms—the derivation of conclusions that follow inevitably from known facts (Robinson and Voronkov, 2001). The converse task of disproving conjectures is another facet of interest (Claessen and Sörensson, 2003; Blanchette and Nipkow, 2010). The axioms and conjectures are written in an appropriately expressive logic and the solutions (proofs and models) are often similarly written in logic (Sutcliffe, 2023). The CADE ATP system competition (CASC; Sutcliffe, 2016) is the annual evaluation of fully automatic, classical logic, ATP systems—the world championship for such systems. One purpose of CASC is to provide a public evaluation of the relative capabilities of ATP systems. Additionally, CASC aims to stimulate ATP research, motivate the development and implementation of robust ATP systems that can be easily and usefully deployed in applications, provide an inspiring environment for personal interaction between ATP researchers, and expose ATP systems within and beyond the ATP community. CASC evaluates the performance of the ATP systems in terms of the number of problems solved, the number of acceptable solutions output, and the average time taken for problems solved, in the context of a bounded number of eligible problems and specified time limits.
CASC is held at each of the International Conference on Automated Deduction (CADE) and the International Joint Conference on Automated Reasoning (IJCAR) conference—the major forums for the presentation of new research in all aspects of automated deduction. CASC-J12 was held on 4 July 2024, as part of the 12th IJCAR (IJCAR 2024), 1 in Nancy, France. It was the 29th competition in the CASC series; see Sutcliffe and Desharnais (2023) and citations therein, and the CASC website (https://tptp.org/CASC), for information about previous CASCs.
CASC-J12 was organized by Geoff Sutcliffe, and overseen by a panel consisting of Cláudia Nalon, Christoph Wernhard, and Christoph Weidenbach. The CASC panel has a few, but important, responsibilities:
Advise (by email) on contentious issues that arise before the competition, and that cannot be agreeably resolved by the organizers and entrants. With the help of the organizers, adjudicate the acceptability of the sample proofs and models that are submitted before the competition. If possible, be physically present at the start of the competition, so entrants can see who they are and raise any issues they are concerned about. Supply a seed digit for the random problem selection process. Be contactable during the competition to advise on contentious issues that arise and that cannot be agreeably resolved by the organizers and entrants. With the help of the organizers, adjudicate the acceptability of the winners’ proofs and models. If possible, be physically present at the end of the competition for resolving possible open issues, confirming the final system ranking in each division and assisting in winner announcements.
The competition was run on computers provided by the StarExec project (Stump et al., 2014) at the University of Miami. The CASC-J12 website provides access to all the resources used before, during, and after the event: https://tptp.org/CASC/J12.
The design and organization of CASC have evolved over the years to a sophisticated state. An outline of the CASC-J12 design and organization is provided here; the details are in Sutcliffe (2024) and on the CASC-J12 web site. Important changes for CASC-J12 were (for readers already familiar with the general design of CASC):
The FNT division went on hiatus. The ICU division was added.
The CASC rules, specifications, and deadlines are absolute. Only the panel has the right to make exceptions. It is assumed that all entrants have read the documentation related to the competition, and have complied with the competition rules. Noncompliance with the rules can lead to disqualification. A catch-all rule is used to deal with any unforeseen circumstances: No cheating is allowed. The panel is allowed to disqualify entrants due to unfairness and to adjust the competition rules in case of misuse.
The rest of this paper is organized as follows: Section 2 describes the competition divisions and the ATP systems that entered the various divisions. Sections 3 and 4 describe the competition infrastructure and the requirements for the ATP systems. Section 5 describes how the systems are evaluated. Section 6 provides a commentated summary of the results. Section 7 contains short descriptions of three of the ATP systems. Section 8 discusses ideas and plans for introducing proof and model verification into CASC. Section 9 concludes and discusses plans for future CASCs.
A Tense Note: Attentive readers will notice changes between the present and past tenses in this paper. Many parts of CASC are established and stable—they are described in the present tense (the rules are the rules). Aspects that were particular to CASC-J12 are described in the past tense so that they make sense when reading this after the event.
Divisions and Systems
CASC is divided into divisions according to problem and system characteristics, in a coarse version of the Thousands of Problems for Theorem Provers (TPTP) problem library’s Specialist Problem Classes (SPCs; Sutcliffe and Suttner, 2001). Each division uses problems that have certain logical, language, and syntactic characteristics, so that the systems that compete in a division are, in principle, able to attempt all the problems in the division. Some divisions are further divided into problem categories that make it possible to analyze, at a more fine-grained level, which systems work well for what types of problems. Table 1 catalogs the divisions and problem categories of CASC-J12. The example problems can be viewed online. 2 Sections 3.2 and 3.3 explain what problems are eligible for use in each division and category.
Divisions and Problem Categories.
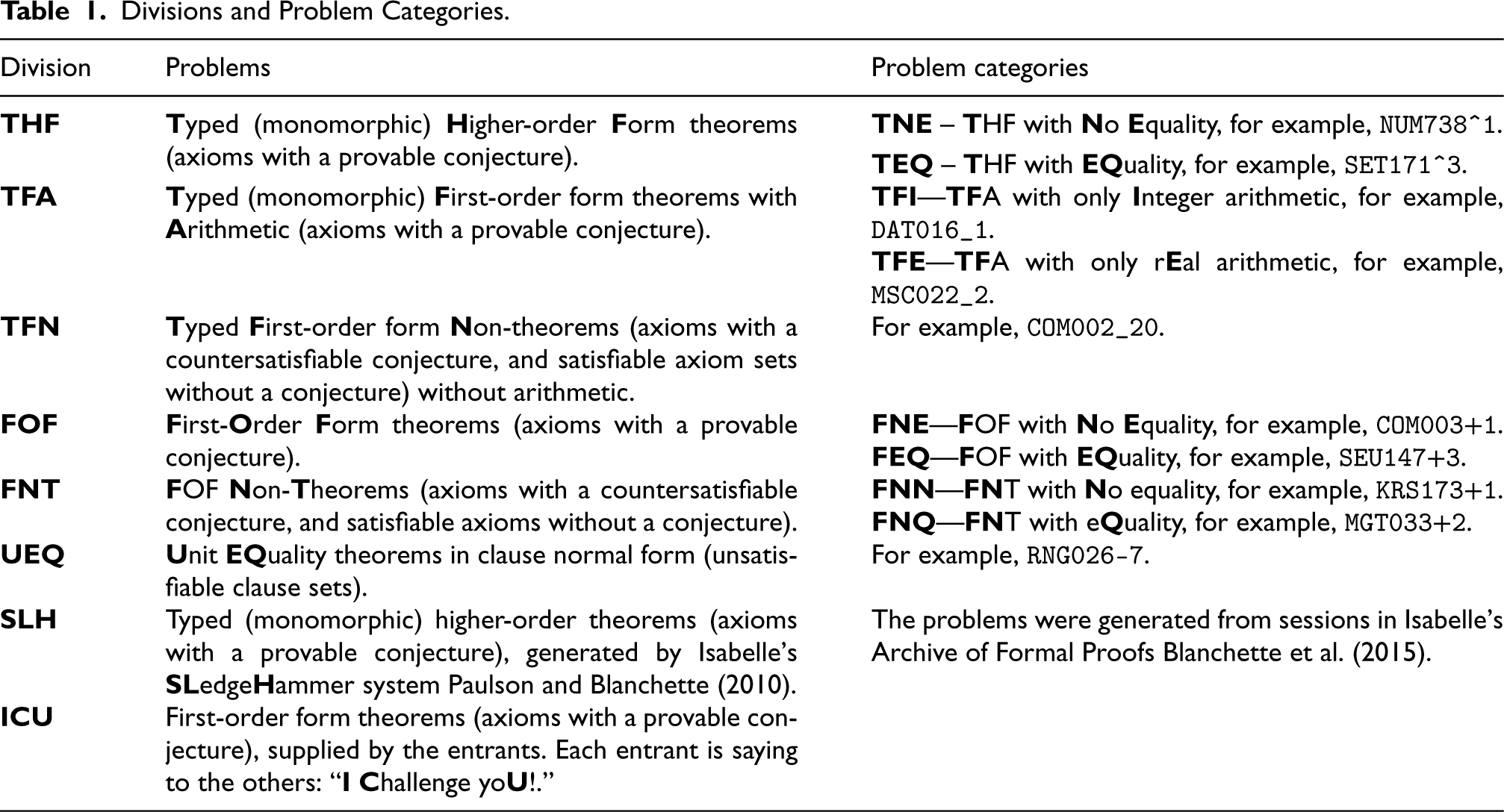
Divisions and Problem Categories.
The ATP Systems and Entrants.
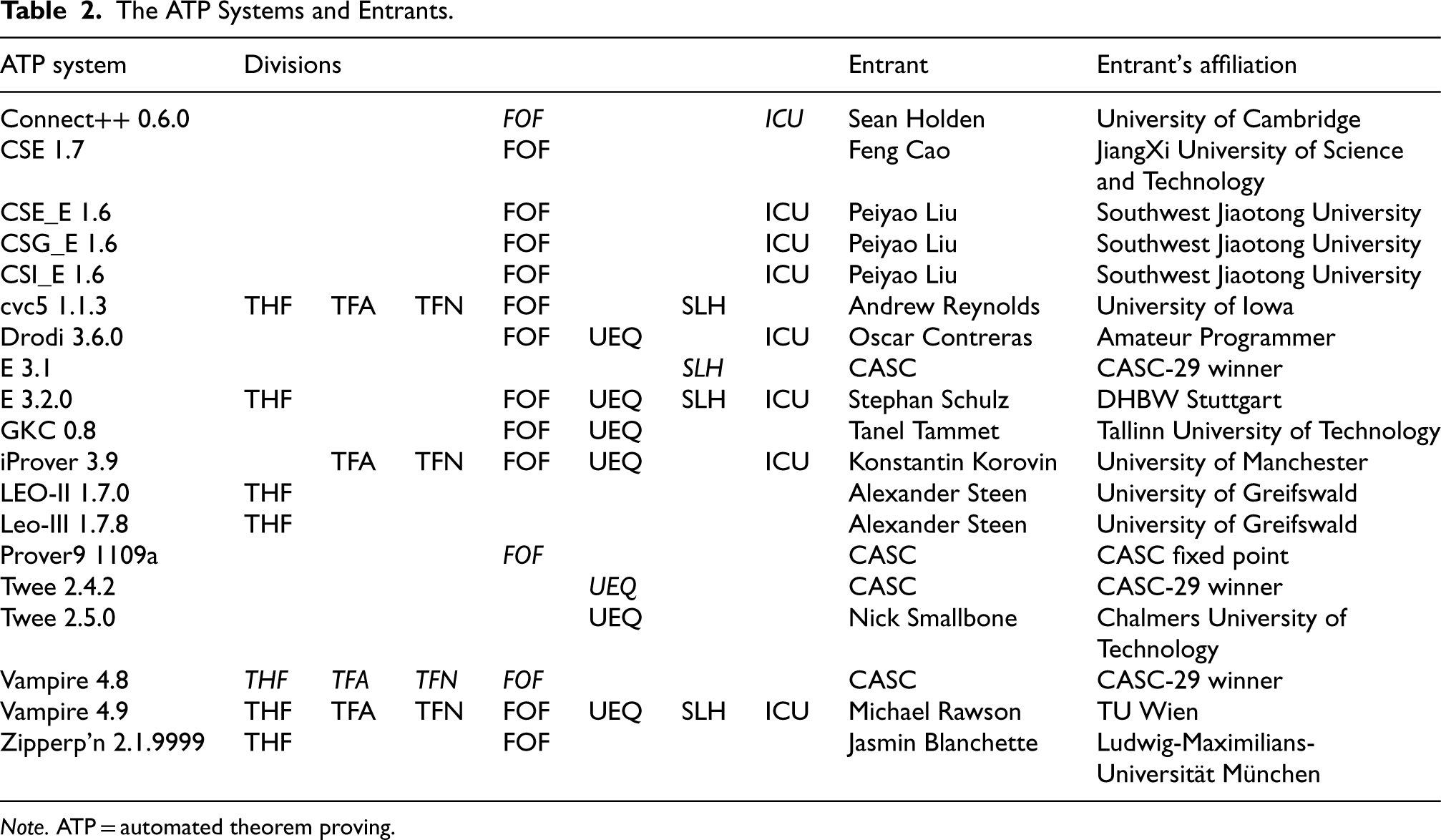
Note. ATP = automated theorem proving.
Systems that cannot be entered into the competition divisions (e.g., the system requires special hardware or the entrant is an organizer) can be entered into the demonstration division. The demonstration division uses the same problems as the competition divisions, and the entry specifies which competition divisions’ problems are to be used.
Nineteenth ATP systems competed in the various divisions of CASC-J12. The division winners from the previous CASC (CASC-29) and the Prover9 1109a system were automatically entered into the demonstration division, to provide benchmarks against which progress can be judged. The systems, the divisions in which they were entered, and their entrants, are listed in Table 2. A division acronym in italics indicates the system was in the demonstration division. System descriptions are in the competition proceedings (Sutcliffe, 2023) and on the CASC-J12 website.
Computers
The StarExec computers used for the competition have two octa-core Intel(R) Xeon(R) E5-2667 v4 CPUs running at 2.10 GHz, 256 GB memory, and the CentOS Linux release 7.4.1708 (Core) operating system Linux kernel 3.10.0-693.el7.x86_64. StarExec uses Linux’s
Systems can use all the cores on the CPU, which can be advantageous in divisions where a wall clock time limit is used (see Section 3.5). StarExec copies the systems and problems to the compute nodes before starting execution, so that there are no network delays. The StarExec computers used for CASC are the same as are publicly available to the TPTP community, which allows system developers to test and tune their systems in exactly the same environment as is used for the competition.
Demonstration division systems can run on the competition computers, or the computers can be supplied by the entrant. The CASC-J12 demonstration division systems all used the competition computers.
Problems for the TPTP-based Divisions
The problems for the THF, TFA, TFN, FOF, and UEQ divisions were taken from the TPTP problem library ( v9.0.0, Sutcliffe, 2017). The TPTP version used for CASC is released after the competition has started, so that new problems in the release have not been seen by the entrants. The problems have to meet certain criteria to be eligible for use:
The TPTP tags problems that are designed specifically to be suited or ill-suited to some ATP system, calculus, or control strategy as biased. They are excluded from the competition. The problems must be syntactically nonpropositional. The TPTP uses system performance data in the Thousands of Solutions from Theorem Provers (TSTP) solution library to compute problem difficulty ratings in the range 0.00 (easy) to 1.00 (unsolved; Sutcliffe and Suttner, 2001). Problems with ratings in the range of 0.21 to 0.99 are eligible—the upper bound of 0.99 excludes problems that cannot be solved by any system and thus don’t differentiate between systems; the lower bound of 0.21 was chosen (many years ago and it has worked successfully) to exclude problems that would be solved by most of the systems and thus don’t differentiate between systems. Problems of lesser and greater ratings are made eligible if there are not enough problems with ratings in that range. In the CASC-J12 TFN division 59 problems with a rating of 0.00–0.20 and 48 problems with a rating of 1.00 were made eligible, because there were only 55 eligible problems with a rating of 0.21 to 0.99. The organizer considered making these additional 107 problems eligible to be acceptably useful: solving easy problems would be encouraging for weaker systems, and solving hard problems would be encouraging for stronger systems. See Section 6.3 for the results on these additional problems. Systems can be submitted before the competition so that their performance data is used in computing the problem ratings—problems that are newly solved get a rating <1.00 and thus become eligible (until the rating drops below 0.21). The rating calculation also uses performance data from ATP systems that are not entered into the competition, which can produce ratings that make some problems eligible for selection but easy or unsolvable for the systems in the competition. Using problems that are solved by all or none of the competition systems does not affect the competition rankings, has the benefit of placing the systems’ performances in the context of the state-of-the-art in ATP, but does reduce the differentiation between the systems in the competition.
In order to ensure that no system receives an advantage or disadvantage due to the specific presentation of the problems in the TPTP, the problems are obfuscated by stripping out all comment lines (in particular, the problem header), randomly reordering the formulae (
The numbers of problems used in each division and problem category are constrained by the number of eligible problems, the number of systems entered in the divisions, the number of CPUs available, the time limits, and the time available for running the competition live in one conference day, that is, in about 6 h. The numbers of problems used are set within these constraints according to the judgment of the organizer. The problems used are randomly selected from the eligible problems based on a seed supplied by the competition panel:
The selection is constrained so that no division or category contains an excessive number of very similar problems, according to the “very similar problems” (VSP) lists distributed with the TPTP problem library (Sutcliffe, 2000). For each problem category in each division, if the category is going to use In order to combat excessive tuning toward problems that were already in the preceding released TPTP version, the selection is biased to select problems that are new in the TPTP version used until 50% of the problems in each problem category have been selected or there are no more new problems to select, after which random selection from old and new problems continues. The number of new problems used depends on how many new problems are eligible and the limitation on very similar problems.
Table 3 gives the numbers of eligible problems, the maximal numbers that could be used after taking into account the limitation on very similar problems, and the number of problems used in each division and category. With the exception of the SLH division (which is a special case), nowhere near 50% new problems were selected. This is due to a slump in the contributions of new problems to the TPTP—nowhere near 50% new problems were available (see Section 9 for a plea to the community to submit problems).
Numbers of Eligible and Used Problems.

Numbers of Eligible and Used Problems.
The problems are given to the ATP systems in TPTP format, with include directives, in increasing order of TPTP difficulty rating.
For the SLH division of CASC-29 (the previous CASC), Isabelle’s Sledgehammer system was used to generate 8400 problems, of which 1000 appropriately difficult problems were selected based on performance data (Sutcliffe, 2023; Sutcliffe and Desharnais, 2024). For the SLH division of CASC-J12, the same problem set was used, but 1000 different problems were selected. The same CPU limit was imposed. This was announced in advance of CASC-J12, so that developers could tune their systems using the CASC-29 problems. Of the 1000 problems selected for CASC-J12, 401 had not been solved in the testing done before CASC-29. If many of them were solved in the competition, that would indicate progress. See Section 6.6 for results on these problems. The problems were given in a roughly estimated increasing order of difficulty.
Problems for the ICU Division
For the ICU division, each entrant had to submit 10 FOF theorems (axioms with a provable conjecture). The problems had to be provided in decreasing order of desired use in the division, that is, probably from hardest to easiest for other systems. The problems had to all be different, as assessed by the competition organizer. Problems from the TPTP problem library had their include directives expanded. The problems were given in reverse order of desired use, so that the “easier” problems were used before the “harder” ones.
It was expected that each entrant would submit problems that are easy enough for that entrant’s system, but difficult for the other entrants’ systems. Most of the entrants chose existing TPTP problems with high difficulty ratings—only the entrants of Drodi and E submitted non-TPTP problems: seven for Drodi and five for E. Fifteen of the 68 TPTP problems had a rating of 1.00, and another 36 had ratings above 0.80. Interestingly the entrant of the demonstration division system Connect++ chose problems all with a rating of 1.00, suggesting that he was setting a challenge for the other systems without having much hope of Connect++ solving the problems.
The design decision that “each entrant had to submit 10 FOF theorems” meant that any entrant or group that entered multiple systems would be able to submit problems in their collective interest. In CASC-J12 the entrants of CSE_E, CSG_G, and CSI_E were in this situation. Analysis of those systems’ results in Section 6.7 indicates that there was no collusion. To prevent possible collusion in the future there will be a limit on the number of problems submitted by individual entrants and their colleagues.
Time Limits
In the TPTP-based divisions, a time limit is imposed for each problem. The minimal time limit for each problem is 120 s. The maximal time limit for each problem is constrained by the same factors that constrain the number of problems that are used, taking into account the phenomenon that ATP systems solve most problems quickly and very few slowly (Sutcliffe and Suttner, 2001; Sutcliffe, 2024). This phenomenon is also evident in the performance plots from the competition, 3 and from the ratios of total times taken to solved times given in Section 3.1. The time limit is chosen value within the range allowed according to the judgment of the organizer and is announced at the competition. In CASC-J12, a 180 s wall clock time limit was imposed for each problem, and no CPU time limit was imposed (so that it could be advantageous to use all the cores on the CPU).
In the SLH division, a CPU time limit is imposed for each problem. The limit is between 15 and 90 s, which is the range of CPU time that can be usefully allocated for a proof attempt in the Sledgehammer context. 4 The time limit is chosen within the range allowed according to the judgment of the organizer and is announced at the competition. In CASC-J12, a 30 s CPU time limit was imposed for each problem.
In the ICU division, a wall clock time limit is imposed for each problem. The limit is between 300 and 600 s, which is a range that gives the systems sufficient time (4800 s CPU time on the octa-core CPUs) to attempt the difficult problems submitted. The time limit is chosen within the range allowed according to the judgment of the organizer and is announced at the competition. In CASC-J12, a 600 s wall clock time limit was imposed for each problem.
System Entry, Delivery, and Execution
Systems can be entered at only the division level and can be entered into more than one division. A system that is not entered into a division is assumed to perform worse than the entered systems, for that type of problem—wimping out is not an option. Entering many similar versions of the same system is deprecated, and entrants can be required to limit the number of system versions that they enter. Systems that rely essentially on running other ATP systems without adding value are deprecated; such systems might be disallowed or moved to the demonstration division.
The ATP systems entered into CASC are delivered to the competition organizer as StarExec installation packages, which the organizer installs and tests on StarExec. Source code is delivered separately, under the trusting assumption that the installation package corresponds to the source code. After the competition all competition division systems’ StarExec and source code packages are made available on the CASC web site. This allows anyone to use the systems on StarExec, and to examine the source code. An open source license is encouraged, to allow the systems to be freely used, modified, and shared. Many of the StarExec packages include statically linked binaries that provide further portability and longevity of the systems.
The ATP systems must be fully automatic. They are executed as black boxes, on one problem at a time. Any command line parameters have to be the same for all problems in each division. The ATP systems must be sound and are tested for soundness by submitting nontheorems to the systems in the THF, TFA, FOF, UEQ, SLH, and ICU divisions, and theorems to the systems in the TFN division. Claiming to have found a proof of a nontheorem or a disproof of a theorem indicates unsoundness. Happily, no systems were found to be unsound before CASC-J12.
System Evaluation
The ATP systems are ranked at the division level. For each ATP system, for each problem, four items of data are recorded: whether or not the problem was solved, the CPU and wall clock times taken (as measured by StarExec’s
In addition to the ranking data, three other performance measures are presented in the results: The state-of-the-art contribution (SotAC) quantifies the unique abilities of each system (excluding the previous year’s winners that are earlier versions of competing systems). For each problem solved by a system, its SotAC for the problem is the fraction of systems that do not solve the problem. A system’s overall SotAC is the average SotAC over the problems it solved but not solved by all the systems. The efficiency balances the number of problems solved with the time taken. It is the average solution rate over the problems solved multiplied by the fraction of problems solved (the solution rate for one problem is the reciprocal of the time taken to solve it). Efficiency is computed for both CPU time and wall clock time, to measure how efficiently the systems use one core and multiple cores, respectively. The core usage measures the extent to which the systems take advantage of multiple cores. The core usage is the ratio of CPU time to wall clock time used. Core usage below 1.0 is typically the result of the problem being solved in early (pre)processing before multicore search is started. The results present the average core usage and the number of problems solved with core usage >1.0. The competition ran on octa-core computers, thus the maximal core usage was 8.0. While high core usage can be seen as a strength of an ATP system, the ability to solve problems quickly before a multicore search is started is also a strength—the number of such problems is simply the difference between the number solved and the number solved with core usage >1.0.
The demonstration division results are presented along with the competition divisions’ results, but might not be comparable with those results. The demonstration division is not ranked.
Results
The result tables below give the number of problems solved with a solution output (with a “()” bracketed number of problems solved without a solution output), the average time taken over the problems solved, the SotAC, the (micro-) efficiency, the core usage/the number of problems solved with core usage >1.0, the number of new problems solved, and the number of problems solved in each problem category. In each table, the best value for each performance measure in the competition division is
The THF Division
Table 4 summarizes the results of the THF division. Vampire 4.9 won the division, with a significant improvement over Vampire 4.8. The main reason for the stronger performance was better optimization of the strategy schedules for the TPTP problems. A short system description of Vampire is provided in Section 7, further explaining the improvements.
THF Division Results.
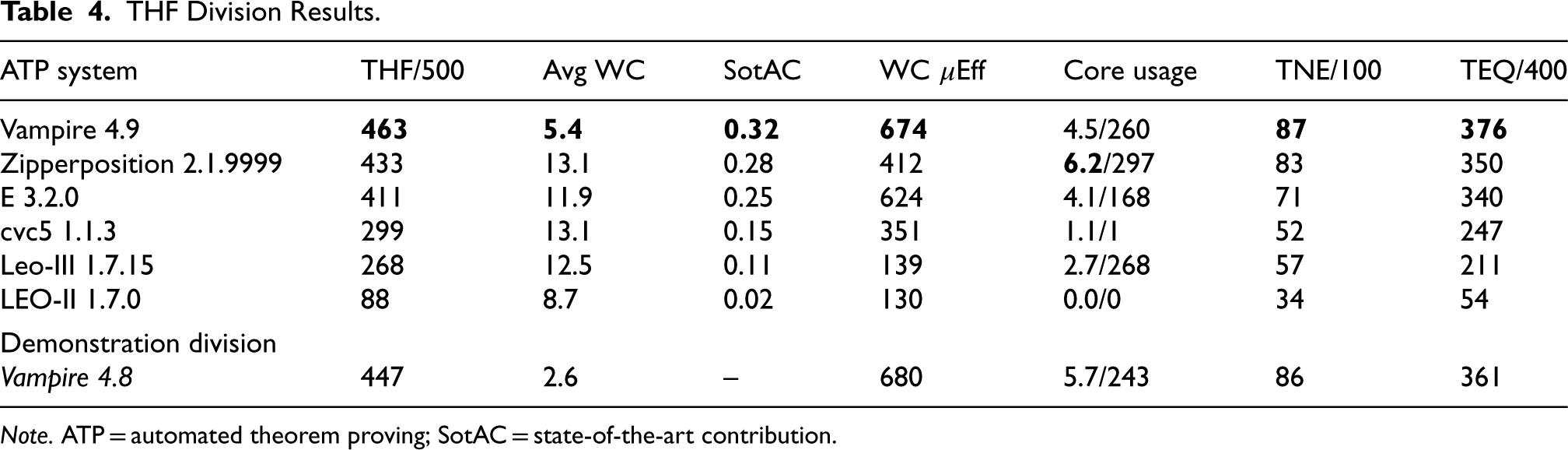
THF Division Results.
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
In addition to solving the most problems, Vampire had the lowest average time, highest SotAC and efficiency, solved 203 problems before starting to use multiple cores, and reasonable core usage for the other problems. E and cvc5 solved the most problems before starting to use multiple cores, but E had good average core usage while cvc5 did not try to use multiple cores (the data shows that cvc5 used more than one core for one problem, but that is not due to intentional parallelism). Zipperposition made the most use of the multiple cores. It was noticed that E solved 13 problems in the last second of wall clock time, but used less than a second of CPU time. The developer commented: “What is weird is that for many problems outside the SEV/SEU domain, this effect does not seem to happen. But from a process point of view, there should be no difference.” The category rankings are almost completely aligned with the overall ranking, which indicates that the systems are not particularly tuned to problems with or without equality.
Leo-III was experimentally configured for the competition with only E as a subsystem. The developer explained: “There is a tradeoff between more (orthogonal) provers and more time/instances per prover.” In CASC-29, Leo-III 1.7.8 included cvc4 as a subsystem, and solved 302 problems, with 110 (36% of 302) solved by the cvc4 subsystem and 130 (43% of 302) by the E subsystem. In CASC-J12, 203 problems (76% of 268) were solved by the lone E subsystem, indicating that using the single subsystem might be an effective configuration.
The individual problem results show that 10 problems were unsolved, 55 problems were solved by all the systems, and 29 problems were solved by only one system (12 problems were solved by only the two versions of Vampire, and are counted as unique solutions for Vampire 4.9). Of the 29 unique solutions, 15 were by Vampire 4.9, seven by E, five by Zipperposition, and two by cvc5. A portfolio (sharing the time between several systems) of these four systems, with 45 s allocated to each, would solve 484 problems.
Table 5 summarizes the results of the TFA division. The winner was Vampire 4.9, and as in the THF division, there was a significant improvement over Vampire 4.8. The ranking of the systems is the same as in CASC-29, with the Princess system missing from the bottom of the ranking. The SotAC, efficiency, and category rankings are aligned with the overall ranking. All the systems other than cvc5 made good use of the multiple cores.
TFA Division Results.
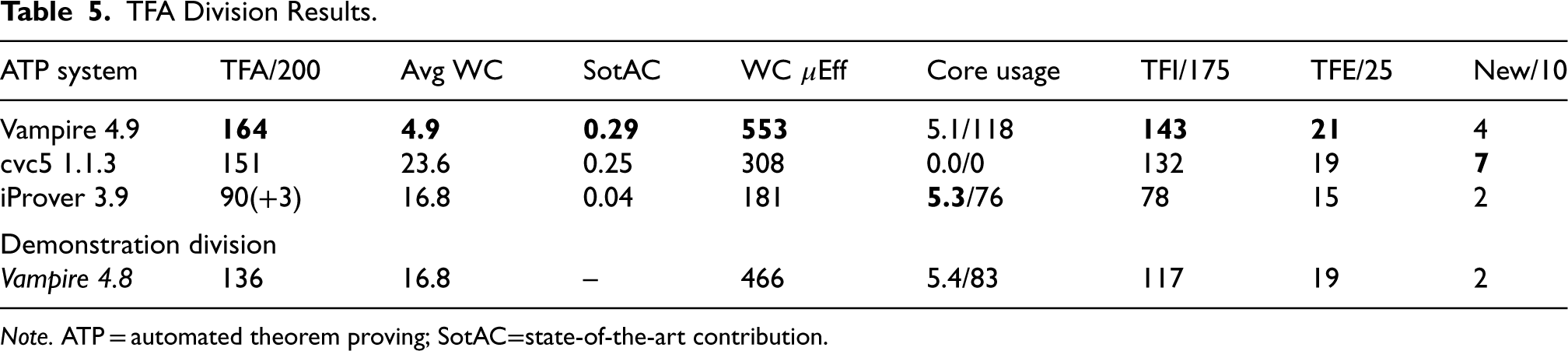
TFA Division Results.
Note. ATP = automated theorem proving; SotAC=state-of-the-art contribution.
There were 10 new problems in the division, all proving the equivalence of two syntactically different programs that generate the same sequence of integers Gauthier et al. (2023). cvc5 solved the majority of the new problems, which were challenging for the other systems. cvc5 also had an interesting performance plot 5 : 43 problems were solved very quickly, and another 37 problems were solved in 14–18 s. The 37 problems are all TFI software verification problems, generated by the Toccata system (Bobot et al., 2014), and the same cvc5 strategy solved 36 of them. This illustrates how a diverse strategy schedule can be useful, and that the order in which the strategies are used has a significant impact.
The individual problem results show that 12 problems were unsolved, 75 problems were solved by all the systems, and 43 problems were solved by only one system (14 problems were solved by only the two versions of Vampire, and are counted as unique solutions for Vampire 4.9). Of the 43 unique solutions, 22 were by Vampire 4.9, 18 by cvc5, and three by Vampire 4.8. A simple portfolio of Vampire 4.9 and cvc5 1.1.3, with 90 s allocated to each, would solve 183 problems. A more careful allocation of time, with 26 s allocated to Vampire 4.9, 124 s to cvc5 1.1.3, and 30 s to Vampire 4.8, would solve 187 problems.
Over the years, the TFA division has struggled to attract entrants, with the same few systems being entered each year—this was noted in the CASC-29 report (Sutcliffe and Desharnais, 2024). Theorem proving in typed first-order logic with arithmetic is an important area, with applications in areas such as mathematics (Korovin et al., 2023), software verification (Bobot et al., 2015), and interactive theorem proving (Paulson and Blanchette, 2010). CASC will continue to have a TFA division in order to encourage the development of ATP in this area. Conversations during IJCAR 2024 suggested that there is work in progress to add arithmetic capabilities to two of the other regular CASC entrants—fingers crossed for CASC-30.
TFN Division Results.
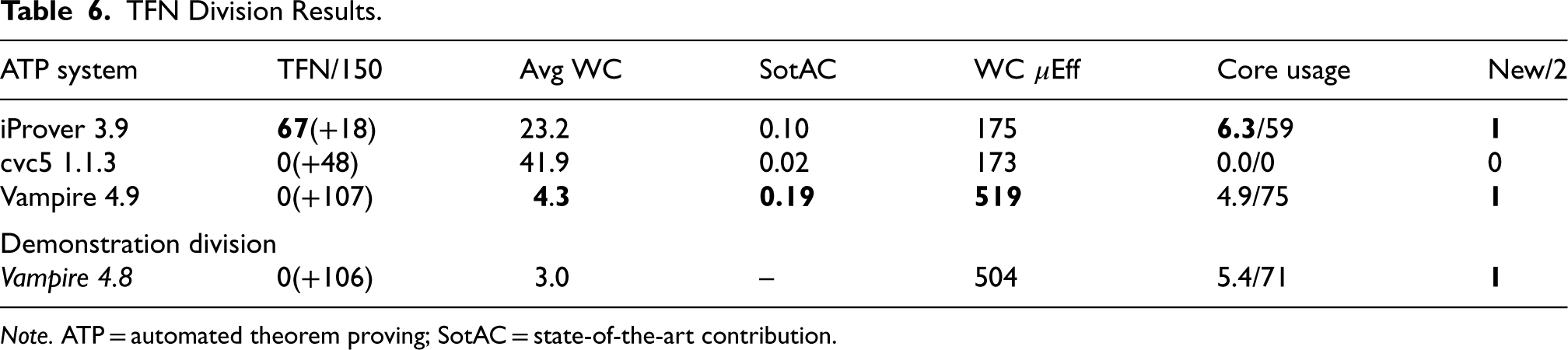
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
Table 6 summarizes the results of the TFN division. While the Vampires solved the most problems, neither output any acceptable models. In CASC-29, Vampire 4.8 produced empty saturations due to aggressive simplification in preprocessing. This was discussed by the panel after CASC-29, resulting in 18 saturations not being counted. Vampire 4.8 also produced some unsatisfiable models due to syntactic errors in the output, but the CASC-29 panel allowed those models to be counted. These errors were not fixed in Vampire 4.9, and the entrant conceded: “we failed to finish our satisfiability-certificates homework since last year,” and when told the models would not be counted in CASC-J12: “Given these two disqualifications span our entire non-theorem capability, Vampire will effectively be demonstration-only in the non-theorem divisions. This is fine by us.” cvc5 suffered the same fate because it outputs empty models in some cases, for example, when the ---mbqi strategy is used. The cvc5 developer accepted his fate: “Unfortunately [I] don’t have a lot of bandwidth to resolve the issues for this year’s CASC, so feel free to use cvc5 in a way you see fit.” In contrast, in CASC-29, iProver 3.8 had 34 models not counted: 18 empty saturations (it uses the same CNF conversion code as Vampire) and 26 Herbrand formulae for transformed problems with a signature different from that of the input problem. In CASC-J12, iProver 3.9 had turned off the aggressive simplification in the CNF conversion, and no longer produces empty saturations. However, in CASC-J12, some models were still for transformed problems, and these 18 models were not counted. The upshot is that iProver won the division.
As explained in Section 3.2, 59 problems with a rating of 0.00–0.21 and 48 problems with a rating of 1.00 were made eligible for the TFN division. Of those, 51 rated 0.00 and 44 rated 1.00 were selected. All the problems with a rating of 0.00 were solved (without model output) by both the Vampires, 5 were not solved by iProver, and 10 were not solved by cvc5. Of the 44 problems with a rating of 1.00 only one was solved by all the systems except cvc5. One might expect all the problems with a rating of 0.00 and none of the problems with a rating of 1.00 to be solved, but this is not the case because the ratings were calculated using earlier versions of the systems; clearly, progress is not monotonic.
The individual problem results (without requiring model output) show that 43 problems were unsolved, 40 problems were solved by all the systems, and 14 problems were solved by only one system (all 14 problems were solved by only the two versions of Vampire, and are counted as unique solutions for Vampire 4.9). A portfolio approach cannot improve the individual systems’ results.
The inability of the model-finding systems to output acceptable models is disappointing. The reason seems to be a lack of developer time, rather than a lack of motivation. The systems have the information they need to output a model when satisfiability is established, and “all” that is necessary is to output the model in an acceptable format. Section 8 summarizes some more formal specifications of an acceptable model that will be used in CASC-30. Hopefully, this step will motivate developers towards outputting models.
FOF Division Results.
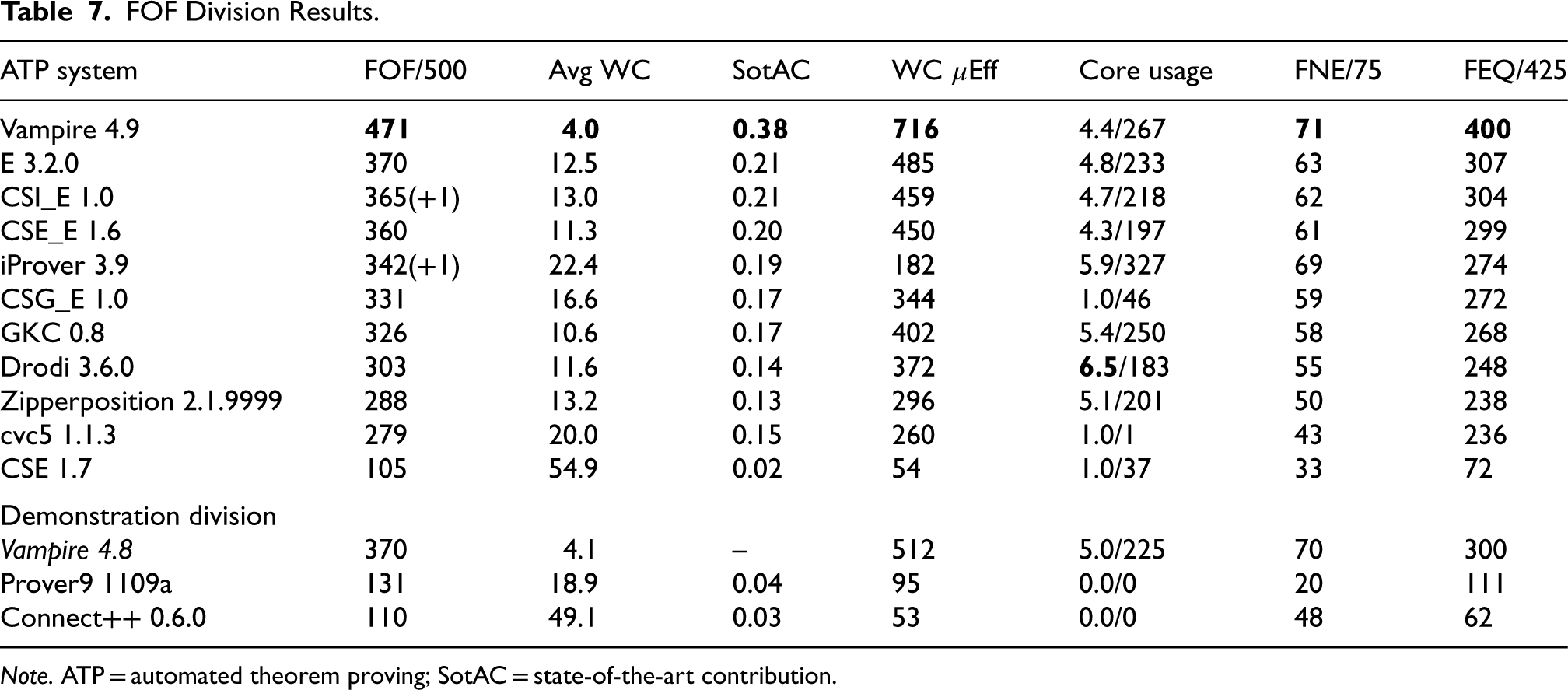
FOF Division Results.
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
Table 7 summarizes the results of the FOF division. The dominance of Vampire increased further compared to CASC-29: in CASC-29, Vampire 4.8 solved 451 problems, E 3.1 solved 393 problems, CSE_E 1.5 solved 346 problems, and iProver 3.8 solved 355 problems. The numbers of problems solved generally suggest that the CASC-J12 problems were harder than the CASC-29 problems, but Vampire 4.9 still solved more problems than Vampire 4.8 did in CASC-29. The main reasons for Vampire 4.9’s stronger performance were work tackling the problem of overfitting in strategy schedule construction (Bártek et al., 2024) and submitting the system in time for problem ranking (as discussed below).
The performance plots for the FOF division 6 clearly separate the systems into three groups: Vampire 4.9, the “hoi polloi,” and the “also rans” (two of which were demonstration systems). In the middle group, E and the CS?_E systems stand out with better performances. The CS?_E systems have a unique architecture. CS? and E are applied to the given problem sequentially. If either prover solves the problem, then the proof process completes. If neither CS? nor E can solve the problem then some clauses with no more than two literals, especially unit clauses, inferred by CS? are fed to E as lemmas along with the original clauses for further proof search. CSE_E solved 14 problems that E did not, two by the CSE part, and 12 by the E part using lemmas generated by the CSE part. CSG_E solved nine problems that E did not, all by E using lemmas generated by the CSG part. CSI_E solved two problems that E did not. All the problems that the CS?_E systems solved but the E didn’t are hard problems. The 14 by CSE_E have ratings from 0.55 to 0.97 with an average of 0.80; the nine by CSG_E have ratings from 0.41 to 0.97 with an average of 0.72; and the two solved by CSI_E have TPTP difficulty ratings 0.85 and 0.94. The CS? parts use the SCS inference rule (Xu et al., 2018) that can have very many parents—in one proof there is an inference step with 636 parents! The ability of the CS?_E systems to solve hard problems has been a focus of the developers’ research (Liu et al., 2023). A short system description of the CS?_E systems is provided in Section 7.
CSI_E and iProver each solved one problem close to the time limit, but did not finish proof output by the time limit.
The top-performing systems had the best SotACs and efficiencies. CSG_E solved the most problems before starting to use multiple cores and seldom used multiple cores. The highest core usages came from Drodi, iProver, and GKC. The performances in the two problem categories are well aligned with the overall performance.
The individual problem results show that 18 problems were unsolved, 24 problems were solved by all the systems, and 41 problems were solved by only one system (nine problems were solved by only the two versions of Vampire, and are counted as unique solutions for Vampire 4.9). Of the 41 unique solutions, 37 were by Vampire 4.9, three by cvc5 1.1.3, and one by Vampire 8.8. Not much could be gained by a portfolio: with 35 s allocated to Vampire 4.9, 36 s to Vampire 4.8, and 109 s to E, 475 problems would be solved.
To assess the extent to which Vampire benefited from: “submitting the system in time for problem ranking,” the TSTP data used for computing the problem ratings has been examined. Note that the system versions used to obtain the data (and referred to here) were in some cases the same as used in the competition and in some cases a preceding version; the TSTP had been updated with the latest versions of the systems available by the system submission for problem rating—1 May 2024. In particular, the Vampire version used for problem rating was a special prerelease of the version used in the competition. Of the 500 problems used in the competition, the prerelease of Vampire was the only system to have solved 74 of them, and six problems had not been solved by Vampire but had been solved by one of the other systems in the division. In the competition, Vampire 4.9 solved 60 of the 74 and one of the six problems. The runner-up, E, solved 11 of the 74 and three of the six. Those numbers give Vampire a net advantage of 47 problems over E, that is, around 10%, which is a significant advantage. The converse numbers gave E no net advantage over Vampire. This clearly shows the benefit of submitting a system before the competition so that its performance data is used in computing the problem ratings. However, there were clearly other improvements in Vampire that contributed to its strong performance. 7 A short system description of Vampire is provided in Section 7, further explaining the improvements.
Connect++ was the only newcomer in CASC-J12, and met the developer’s expectation in the online system description: “It is not expected at this stage to be competitive.’. On the flip side, entering CASC had a positive impact on the development of Connect++, and a short system description of Connect++ is provided in Section 7. The CASC rules explicitly state: “A system that is not entered into a division is assumed to perform worse than the entered systems,” that is, Connect++ is assumed to be better than known ATP systems (that were not entered). There is one well-known FUNny ATP system that has been absent from CASC for many years, and the developer has been threatening to enter again if the EPR division is brought back from hiatus (see Section 9).
The UEQ Division
Table 8 summarizes the results of the UEQ division. After many years of effort and hope, Vampire finally ascended to the UEQ throne, thus deposing “King Nicholas of Twee,” who had succeeded the Waldmeister in 2021 (Sutcliffe and Desharnais, 2022). As reported in Sutcliffe and Desharnais (2024), the original Vampire developer had made some bold statements during and after the running of CASC-29 about winning the division in CASC-J12 …his claims were justified! The new techniques used for UEQ in Vampire 4.9 are described in the short system description in Section 7. Twee 2.5.0 improved slightly over the CASC-29 winning version. Twee’s missing proof was caused by an
UEQ Division Results.
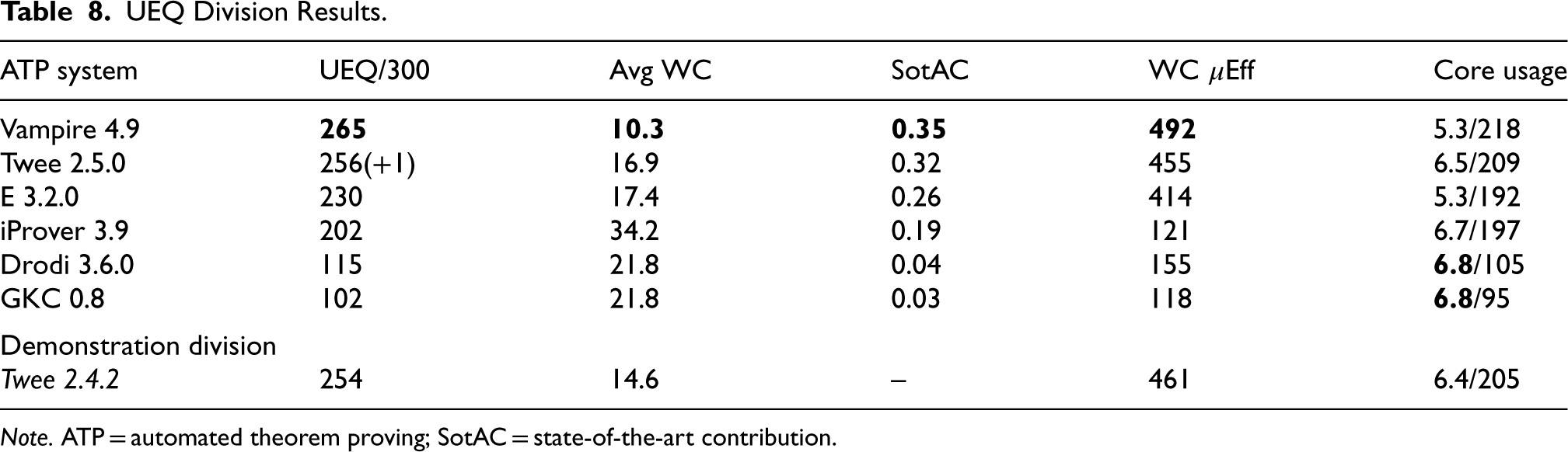
UEQ Division Results.
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
The SotAC and efficiency values were mostly aligned with the division ranking, with the exception of Drodi whose higher efficiency resulted from very few solutions with a high time taken—only 26 solutions (23% of 115) took more than 20s. This is in contrast to iProver which solved 112 problems (55% of 202) in more than the 20s, with a corresponding low efficiency. Vampire and Twee 2.5.0 solved the most problems before starting to use multiple cores and had good core usage during multicore search. iProver, Drodi, and GKC solved very few problems before starting to use multiple cores and thus had the highest core usage.
The individual problem results show that nine problems were unsolved, 77 problems were solved by all the systems, and 22 problems were solved by only one system (four problems were solved by only the two versions of Twee, and are counted as unique solutions for Twee 2.5.0). Of the 22 unique solutions, nine were by Vampire, eight by E, and five by Twee 2.5.0. A simple portfolio of these three systems, with 60 s allocated to each, would solve 283 problems.
Table 9 summarizes the results of the SLH division. Vampire’s improved performance on higher-order problems (see Section 6.1) is shown again here. The problems were apparently harder in CASC-J12 compared to CASC-29: in CASC-29 E 3.1 solved 467 problems. As noted in Section 3.3, 401 of the 1000 problems had not been solved in the testing done before CASC-29, and if many of them were solved in CASC-J12 that would indicate progress in the field. Of the 401 problems, 19 were solved in CASC-J12, 13 by cvc5, five by Vampire, and 1 by E 3.2.0 (i.e., none were solved by more than one system). That possibly indicates progress, but at best slow progress.
SLH Division Results.
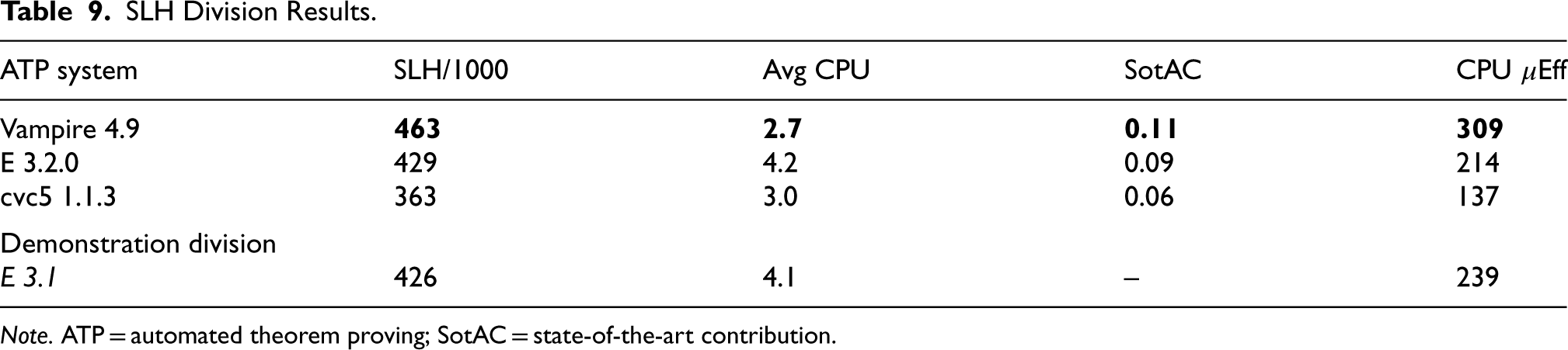
SLH Division Results.
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
The individual problem results show that 446 problems were unsolved, 258 problems were solved by all the systems, and 110 problems were solved by only one system (30 problems were solved by only the two versions of E, and are counted as unique solutions for E 3.2.0). Of the 110 unique solutions, 39 were by each of Vampire and cvc5, 31 by E 3.2.0, and one by E 310. A portfolio approach works well here—a portfolio of cvc5, E 3.2.0, and Vampire, with 10 s allocated to each, would solve 524 problems.
One of the goals of the SLH division is to encourage system developers to tune their systems to the needs of Sledgehammer users. As noted in Section 3.3, the problems were from the same problem set as for CASC-29 (but different problems were selected), so that developers could tune their systems using the CASC-29 problems. After CASC-J12 the developers were asked if they had done that tuning. One answered: “I’ve not done any tuning over the last two years, being too busy working on finalising the integration of higher-order logic,” and another (who had claimed after CASC-29 that: “We will be ready for SLH @ CASC-J12 in two months from now”) answered: “The schedule(s)
The use of Sledgehammer problems for testing and evaluating ATP systems has led to a practical development whereby Sledgehammer will provide its ATP subsystems with persistent storage associated with streams of homogeneous problems. This will allow the ATP systems to save search data between invocations, and use that data to incrementally improve their performance on the stream of problems. This approach was exploited by Vampire 4.7’s dynamic strategy weighting in the LTB division of CASC-J11 (Sutcliffe and Desharnais, 2023), and is used in the incremental strategy merging approach developed for E (McKeown and Sutcliffe, 2024).
The ICU division was created in response to evidence of CASC being a possible cause of incremental development of ATP systems (Sutcliffe and Desharnais, 2024), which in itself might be contributing to a slowing of progress in ATP (Sutcliffe et al., 2024). The new division also supports CASC’s goal of stimulating ATP research by providing a new type of challenge that could lead to some of the development effort being moved from breadth to depth (Sutcliffe and Desharnais, 2024). It certainly produced some rather interesting competition and results.
ICU Division Results.
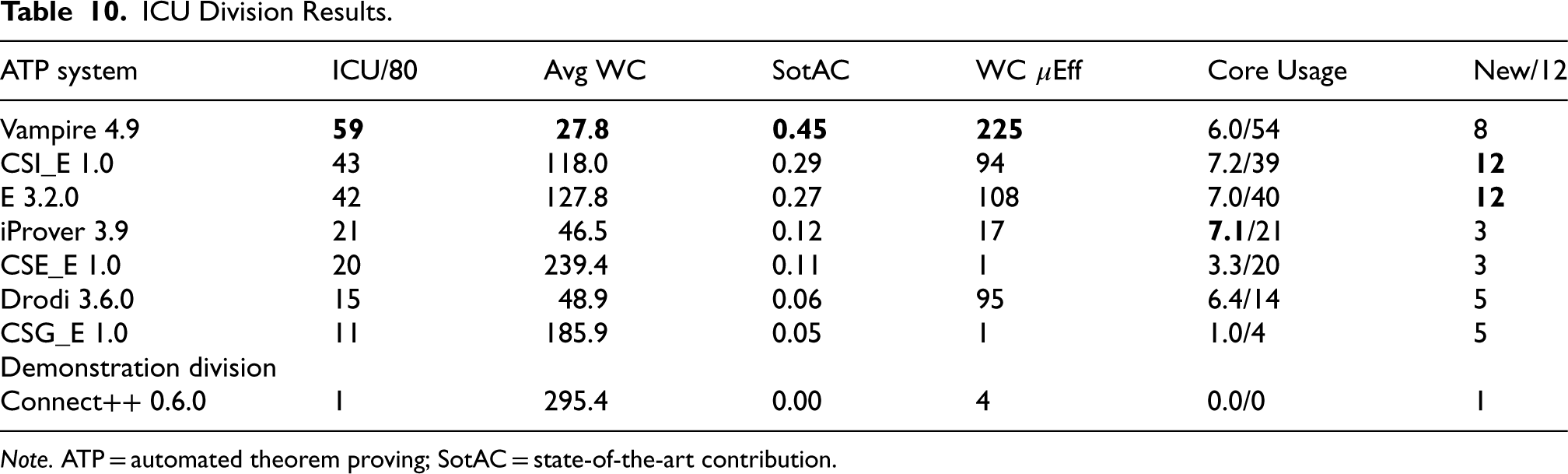
ICU Division Results.
Note. ATP = automated theorem proving; SotAC = state-of-the-art contribution.
ICU Matrix.
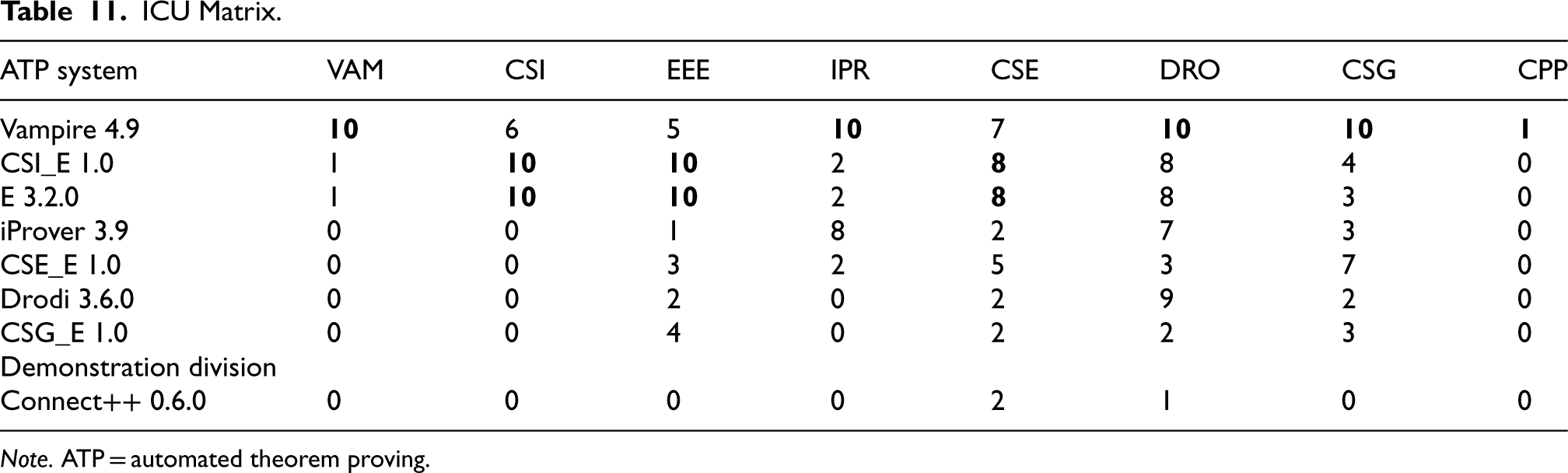
Note. ATP = automated theorem proving.
Table 10 summarizes the results of the ICU division and Table 11 shows how many of the problems submitted by each system’s developer were solved by each system (the columns correspond to the problem submissions from the corresponding system row). As might have been expected, Vampire was dominant, solving all 10 of its own problems and also all 10 of the iProver, Drodi, and CSG problems. Only CSI_E and E managed to solve a Vampire problem, but in turn Vampire solved six and five of the CSI_E and E problems. As noted in Section 3.4, Connect++ was not expected to solve the problems it submitted, and indeed only Vampire managed to solve one. The problems submitted by CSI_E were most effective as being solvable by itself but unsolvable by other systems—itself and E solved them all, and Vampire was the only other system that solved any of them. The standalone E solved 42 of the 43 problems that CSI_E solved, suggesting that CSI_E’s solutions are largely thanks to the E component. The contribution of the E component to the performance of CSI_E is undoubted, but an examination of the proofs reveals that seven of CSI_E’s proofs are different from the standalone E proofs, that is, the CSI component of CSI_E helps the E component find proofs. The three CS?_E systems solved different numbers of each other’s problems: CSI_E solved five of its own problems, eight CSE_E problems, and 10 CSG_E problems; CSE_E solved five of its own problems, seven CSI_E problems, and no CSG_E problems; CSG_E solved none of its own problems (!), three CSI_E problems, and three CSE_E problems.
The SotAC values align with the division ranking, but the efficiency values are markedly unaligned. The performance plots for the ICU division 8 show the different numbers of problems solved quickly, resulting in this misalignment. The core usage numbers show that multicore search was used for most problems, and the core usage was high for most of the systems.
The individual problem results show that nine problems were unsolved, one problem was solved by all the systems, and 14 problems were solved by only one system. All 14 unique solutions were by Vampire. A portfolio approach works well here—a combination of CSI_E and Vampire, with 300 s allocated to each, would solve 71 problems.
This was the first ICU division, and only two entrants submitted non-TPTP problems—Drodi and E (see Section 3.4). CSI_E and E were most effective on the non-TPTP problems submitted. In E’s case, the strategy of submitting non-TPTP problems was effective, but as is evident from Table 11 CSI_E strategy of submitting carefully selected TPTP problems was also effective. In order to choose problems that are solvable by one system and not solvable by other systems requires some effort from entrants, to understand the other systems and test other systems on candidate problems. Making that effort has benefits beyond CASC, as it leads to an understanding of other systems’ techniques that work well for certain types of problems, which might subsequently lead to an integration of those techniques into the entrant’s own system.
Each year the competition report features short system descriptions of systems that stand out in some way. For CASC-J12, the salient systems are Vampire 4.9 for its strong overall performance and particularly its improved performance in the THF, TFN, FOF, and UEQ divisions; the CS?_E family of systems for generally strong performance, particularly from CSI_E; and Connect++ for being an interesting new development. These short descriptions of the systems were written by their entrants.
Proof and Model Verification
Over the years it has often been suggested that CASC should have a “verified track,” in which solutions are counted only if they have been approved by an independent verifier. Many other communities’ competitions include such tracks, for example, the SAT competition since 2016 (Balyo et al., 2017), the Confluence competition since its inception in 2012 (Middledorp et al., 2021), and the Termination competition’s certified category since 2007 (Giesl et al., 2019). To date, CASC has not tried to have a certified track, because there has not been an adequate proof or model format that system developers have commonly adopted and adhere to.
Empirical testing, as is done by most ATP system developers in their preparations for CASC, provides a weak assurance of soundness. The soundness testing done in CASC is also empirical (see Section 4), and this has been effective in detecting occasional instances of unsoundness, for example, Sutcliffe and Desharnais (2023, 2022)). However, there remains a need to verify the logical correctness of solutions in CASC. In addition to logical verification, the utility of solutions for users in their applications should be considered. Solutions must be well-formed so they can be parsed and verified, and comprehensible to the applications (including humans) that need to use the solutions. In the light of these observations, verification can be incrementally imposed in CASC:
Solutions must be written in an agreed language. For CASC, the language must be a TPTP language (Sutcliffe, 2023). A parser based on the BNF definition of the TPTP languages (Van Gelder and Sutcliffe, 2006) can be used to check conformance. Solutions must be written in an agreed-upon concrete format. For derivations, the established TPTP format (Sutcliffe et al., 2006) has already been adopted by many ATP systems. For models, the existing format for finite models (Sutcliffe et al., 2006) has been adopted by many ATP systems, but the forthcoming new format for interpretations (Steen et al., 2023) will support a broader range of model types. Solutions must be structurally correct. For proofs, the parents of the inferred formula must be documented and exist in the derivation, the derivation must be acyclic, refutations must have false roots, assumptions must be discharged, etc. The GDV derivation verifier (Sutcliffe, 2006) can be used to check conformance. For models, the domains must be specified (either explicitly or implicitly as is the case for Herbrand interpretations), and symbol mappings must be provided (either explicitly or implicitly). The AGMV model verifier can help (Steen et al., 2023). Solutions must be for the given problem. For proofs, the leaves of a derivation must come from the problem. This can be checked by treating leaves of the derivation as inferred from the problem and proceeding to step (5). For models, symbol mappings must be provided for all the symbols in the problem. Symbol mappings may additionally be provided for symbols added in the derivation, e.g., definitions, Skolem functions, etc. This can be done by comparing the signatures of the problem and model. Solutions must be logically correct. This is where most attention has been paid (possibly at the expense of the preceding requirements that are simply assumed) in proof verification (e.g., McCune and Shumsky-Matlin, 2000; Wetzler et al., 2014; Andreotti et al., 2023). There are several proof verification systems that can be used, including GDV (Sutcliffe, 2006), Dedukti (Dowek, 2022), and GAPT (Ebner et al., 2016). Verification of the logical properties of models has not received adequate attention, but tools such as AGMV and Dolmen Bury and Bobot (2023) are available.
For CASC-30, proofs will have pass checking for the first three items above, that is, they must be written in the TPTP language and format, and pass structural testing. Models will have to be written in the new TPTP format, but given the recency of the new format only the first two items above will be checked. Logical verification is left for CASCs beyond that. A long-range plan is emerging to run CASC only at CADE conferences, and have competitions based on other ATP-related topics at the IJCAR conferences. In particular, a proof verifier/verifiability competition (the “ProoVer” competition) is being planned for IJCAR in 2027. ProoVer will evaluate the capabilities of proof verifiers, and the extent to which ATP systems’ proofs can be verified.
CASC-J12 was the 29th annual evaluation of fully automatic, classical logic, ATP systems. CASC-J12 fulfilled its objectives by evaluating the relative capabilities of ATP systems, and stimulating development and interest in ATP. The highlights of CASC-J12 were: significant improvement in Vampire, the ability of the CS?_E systems to solve hard problems, continued weakness in model outputs, and interesting competition in the new ICU division.
While the design of CASC is mature and stable, each year’s experiences lead to ideas for changes and improvements. Changes being planned for CASC-30 are:
Proofs will have to be in TPTP format and pass parsing and structural verification tests. Models will have to be in the new TPTP format and pass parsing tests. The ICU division will limit the number of different problems submitted by individual entrants and their colleagues.
CASC-30 will be run either on the StarExec Miami cluster (which will be maintained, unlike the StarExec Iowa cluster that will be shutting down), or on StarExec-ARC that runs in Amazon’s EKS Kubernetes environment (Fuenmayor et al., 2024).
CASC’s evaluation is principally based on ATP systems’ abilities to solve problems. Evaluation of other performance measures would also be interesting (Sutcliffe et al., 2024). These include measures such as resource usage, stability modulo perturbations of the input, and verifiability of proofs/models (see Section 8). Evaluation of nonperformance measures is often ignored, but for users might be just as important. These include measures such as the range of logics covered, ease of building and deploying, portability to different hardware and operating system environments, an easy-to-access API, availability of source code, quality of source code and its documentation, licensing that permits a required level of use or modification, availability of user documentation, and (maybe most importantly!) developer support. These are possible topics for other future competitions.
As always, the ongoing success and utility of CASC depends on ongoing contributions of problems to the TPTP. The automated reasoning community is encouraged to continue making contributions to all types of problems.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.