
Abstract
Triangle meshes are a crucial and powerful data type for three-dimensional (3D) shapes, extensively studied in the fields of computer vision and computer graphics. In this paper, we delve into the challenge of analyzing deforming 3D triangle meshes using deep neural networks. While existing methods extend graph-based deep learning to 3D triangle meshes using graph convolution, the lack of effective graph convolutional structures and pooling operations limits the learning capacity of their networks. We propose a variational autoencoder structure that integrates graph convolutional residual blocks with multilayer pooling to explore the latent space of 3D shapes for generation. This framework introduces graph convolutional residual blocks to address the issue of gradient vanishing in deep networks. By employing multilayer pooling and unpooling structures based on triangle mesh simplification, gradually reducing the spatial dimensions of the input, the model can extract more general features. This enables it to handle denser mesh models effectively. Extensive experiments demonstrate that our generalized framework can learn reasonable representations of deformable shape collections with minimal training examples. It produces competitive results across various applications, including shape generation and interpolation, requiring fewer training samples and outperforming state-of-the-art techniques.
Introduction
With advancements in three-dimensional (3D) capture, modeling, and rendering, point clouds and triangular meshes have found widespread applications in augmented reality, virtual reality, gaming, and film production. Although point cloud data gives raw spatial position information, it does not capture the topological structure of 3D structures, limiting its applicability. Triangular meshes, on the other hand, as illustrated in Figure 1, are made up of a set of interconnected vertices, edges, and faces that are used to represent and define the geometric shape of 3D objects. As a result, an increasing number of academics prefer to examine triangular mesh data using neural networks, and this paper focuses on investigating deep neural networks in this sector. Triangular meshes, unlike photos, have complicated and irregular connections. Most existing works preserve mesh communication between layers, limiting the possibility of enhancing the receptive field when pooling techniques are used.
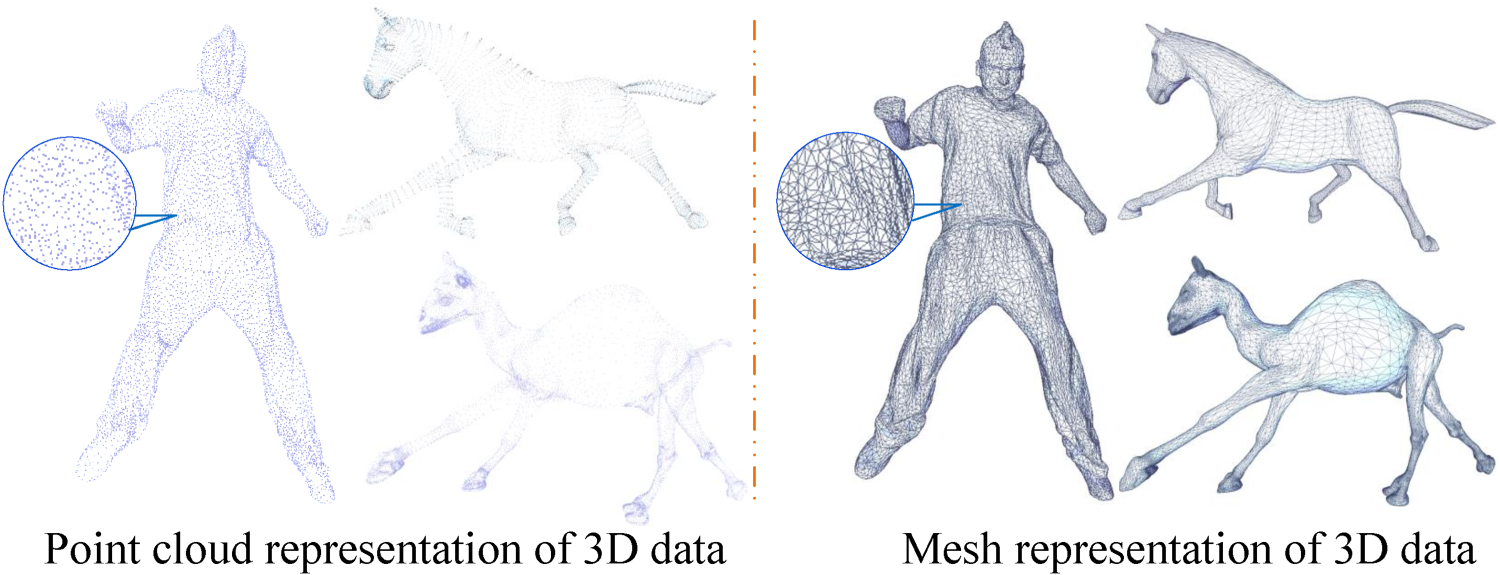
Different Representations of 3D Data. Note. 3D = three-dimensional.
Deep learning has significantly aided the advancement of domains such as image processing, natural language processing, speech recognition, and others. They have also become increasingly significant in 3D data analysis in recent years. ShapeNets (Wu et al., 2015) initially proposed using voxels for 3D volumetric representation of shapes, with each voxel recording whether the corresponding spatial position was occupied by an object. The network may learn representations that capture shape data in 3D space by introducing voxel representation and applying 3D convolutions. PointNet (Qi et al., 2017a) demonstrated good performance in 3D classification and segmentation tests using a deep learning architecture for managing 3D point clouds. PointNet++ (Qi et al., 2017b) added new sampling and grouping procedures to better gather local information. It efficiently handles the local structure of point clouds by sampling key points and assigning other points to their neighborhoods. PointCNN (Li et al., 2018) introduced the X-alter operation, which learns an adaptive transformation matrix to alter the coordinates of input point clouds. This improves the network’s resistance to transformations in the input point cloud. Furthermore, several recent methods (Feng et al., 2019; Hanocka et al., 2019; Hu et al., 2021) use grid topological information to improve the 3D data representation performance of neural networks. Despite these methods’ considerable gains in processing 3D point cloud data, there has been little advancement in the sector based on triangular meshes.
Recently, several significant studies have extended 3D mesh analysis methods. For example, TPNet (Li et al., 2023b) proposed a novel mesh analysis method that achieves a more accurate analysis of triangular meshes by preserving topology and enhancing perceptual capabilities. Additionally, MBA (Fan et al., 2023) explored backdoor attacks on 3D mesh classifiers, which is crucial for understanding and improving the robustness of deep learning models. Meanwhile, 3D reconstruction based on hierarchical reinforcement learning (Li et al., 2023a) demonstrated efficient transferability across different categories, indicating that task decomposition through hierarchical structures can enhance generalization in 3D reconstruction tasks.
Variational autoencoder (VAE; Kingma and Welling, 2014), a sort of generative network, has been widely used in a variety of applications, including two-dimensional (2D) image restoration and 3D activities such as triangular mesh generation and interpolation. Mesh VAE (Tan et al., 2018) initially explored the latent space of 3D meshes using fully connected operations, however, this model required a large number of parameters and had poor generalization capabilities. Although fully connected layers permit changes in mesh connectivity between layers, they cannot be applied directly to convolutional layers following irregular modifications. Litany et al. (2018) added a convolutional layer structure to the VAE model. However, such convolutional techniques cannot change the mesh’s connection. When executing mesh operations in neural networks, Ranjan et al. (2018) proposed sampling operations, but their sampling approach did not gather all local neighborhood information when reducing the number of vertices. To address the correspondence concerns between coarser and denser mesh structures in the hierarchical structure of network models, Yuan et al. (2020) suggested a VAE with edge contraction pooling based on Mesh VAE. Because the model has a single-layer pooling structure, excessive averaging of some local features may occur, resulting in the loss of important information. TetGAN (Gao et al., 2022) is a tetrahedral mesh generation convolutional generative adversarial network. This approach learns deep properties on each tetrahedron, encodes them as latent space vectors, and may be used to edit and synthesize shapes. While these methods are effective for 3D data processing, they have drawbacks such as the limited influence of graph convolution operations on connectivity, insufficient aggregation of local information in pooling processes, and the inability to establish deep networks.
We designed a framework for a Mesh VAE to investigate the latent space representation of triangular meshes in order to accommodate denser triangular mesh models and improve the network’s reconstruction capabilities. We used mesh simplification’s edge collapse procedures to build a hierarchical mesh structure with variable levels of detail, enabling efficient pooling by tracking mappings between coarse and fine-grained meshes. The network framework employs multilevel pooling procedures, which effectively aggregate local neighborhood information to reduce the number of mesh parameters. We created graph convolutional residual modules to address difficulties such as gradient vanishing in deep networks. To address issues such as gradient vanishing in deep networks, we designed graph convolutional residual modules. The model is easy to train, requiring only a small number of training samples for the encoder to map triangular mesh information to a latent space representation. This further facilitates the feasibility of interpolation in the latent space, enhancing the effectiveness of 3D shape manipulations.
This paper’s contributions can be summarized as follows:
We propose a Mesh VAE capable of learning a meaningful representation of deformable shape collections to investigate latent space operations. It produces competitive performance in a variety of applications, including shape generation, interpolation, and exploration. We create an effective and fast feature extraction mechanism that better captures structural correlation information in input data, avoids gradient vanishing in deep networks and improves precision. We adopt a multilayer mesh simplification-based pooling and unpooling structure that gradually reduces the spatial dimensions of the input. The model can progressively extract more general features, enhancing the generative model’s ability to generalize to different shapes and structures.
Neural Networks Based on Multiview, Point Clouds, and Voxels
Following the successful application of deep learning to 2D photos, many academics (Hanocka et al., 2019; Maturana and Scherer, 2015; Qi et al., 2017a) have begun to investigate how neural networks may be used for 3D geometric knowledge. 3D data contains more representations than 2D data, including multiview pictures, point clouds, voxels, meshes, and more (Xiao et al., 2020). Researchers are gradually applying neural networks directly to 3D objects (Qi et al., 2017a, 2017b; Wu et al., 2015) as neural networks improve. Point clouds, unlike images, are unstructured and unordered. A straightforward way (Maturana and Scherer, 2015; Riegler et al., 2017; Wu et al., 2015) for using point clouds in 3D convolutional neural networks is to turn the input into a structured voxel representation. Although such representations are extensively employed in the processing of 2D pictures, as the number of voxels increases in 3D, the computing and storage needs grow. To eliminate duplicate computations, Graham et al. (2018) used sparse convolution. Wang et al. (2021) also improved on this method by using a patch-guided partitioning scheme and output-guided skip connections.
Due to the higher computational costs associated with using voxels, other studies (Qi et al., 2017a, 2017b; Wang et al., 2018) have begun to directly explore methods utilizing point clouds. PointCNN Qi et al. (2017a) developed point cloud convolution operators, which enhanced the nonstructural character of point clouds via feature modification matrices. PointNet (Qi et al., 2017a) used multilayer perceptrons and max pooling to overcome the lack of structure in point clouds, while PointNet++ (Qi et al., 2017b) improved point-based network performance by taking hierarchical structures and set abstraction into account. PointCNN (Li et al., 2018) developed point cloud convolution operators, which improved the nonstructural nature of point clouds via feature transformation matrices, while KPConv (Thomas et al., 2019) improved point cloud network performance even further by suggesting deformable convolutions. Additionally, Zhao et al. (2021) built a self-attention network that used attention mechanisms to improve point cloud processing results. These methods offer a versatile and strong paradigm for dealing with 3D geometric data, offering new opportunities for a variety of application scenarios.
Neural Networks Based on Triangular Meshes and Graphs
Some methods (Dong et al., 2023; Feng et al., 2019; Hanocka et al., 2019; Liang et al., 2022) have begun to apply neural networks to meshes due to high computing costs or a lack of topological information. The researchers (Haim et al., 2019; Maron et al., 2017) do this by employing parametric methods to translate geometric information onto mesh structures, allowing the mesh to be used with 2D convolutions. TangentConv (Tatarchenko et al., 2018) pioneered the notion of tangent convolution, which enables neural networks to handle large-scale meshes. Through a parallel framework, PFCNN (Yang et al., 2020) improves the neural network’s surface processing capabilities even further.
However, these methods often come with relatively high computational costs. As a result, many researchers (Hanocka et al., 2019; Monti et al., 2017) regard meshes as graphs and employ graph convolutional networks. Mesh Net (Feng et al., 2019) performs surface convolution directly using mesh adjacency connections, however, unlike neural networks on images, it does not generate a hierarchical structure for pooling. DiffusionNet (Sharp et al., 2022) and HodgeNet (Smirnov and Solomon, 2021) investigate the use of spectral algorithms on meshes to learn geometric properties. Some research uses mesh simplification to create a hierarchical structure in order to increase network performance (Feng et al., 2019; Hanocka et al., 2019; Hu et al., 2021). Other research looks into novel ways to build hierarchical structures, such as random walks (RWs; Lahav and Tal, 2020), loop subdivision (Hu et al., 2022), parallel vertex clustering, and adaptive edge contraction (Hanocka et al., 2019). However, due to the lack of a precise mapping, these simplification methods cannot guarantee a consistent receptive field for the network. Subdivision-based (Hu et al., 2022) approaches place substantial demands on the mesh, restricting the application of mesh networks.
Despite the fact that pooling operations are commonly employed in deep networks for image processing, some existing mesh-based deep learning models either do not support pooling (Litany et al., 2018; Tan et al., 2018) or use simple sampling processes (Ranjan et al., 2018) that fail to aggregate all local neighborhood information. Rather, we use multilayered pooling techniques based on mesh simplification to assist the network in learning hierarchical features. The network may gradually capture both global and local features on the mesh, augmenting the learned 3D feature representation. This is especially important when dealing with large-scale mesh data since it can boost computational efficiency. Multilayered pooling can preserve important global structural information by aggregating information from neighboring nodes, aiding in preventing overfitting and enhancing the model’s generalization ability.
Representation and Applications of Deformable Meshes
To better represent a triangular mesh, a direct approach is to use its vertex coordinates. However, vertex coordinates lack both translational and rotational invariance, posing challenges for learning large-scale deformations. Instead, we employ a recent method for representing triangular mesh shapes (Gao et al., 2021), which involves recording deformations at the vertices, making graph convolution and pooling operations easier to implement.
In the beginning, Kingma and Welling (2014) proposed the VAE model, which effectively blends variational Bayesian approaches and deep neural networks, making it a classic deep generative model. In contrast to standard autoencoder models, VAE injects noise into the latent space, causing it to follow a specific distribution, hence increasing the latent space’s expressive potential and enabling the model to create data. VAE can be utilized in mesh creation to learn the latent representation of 3D objects and generate new mesh models. Shape generation and interpolation are common applications of mesh data. Leveraging the VAE structure, Mesh VAE (Tan et al., 2018) can generate more deformable mesh shapes, and the method proposed by Ranjan et al. (2018) can generate vividly expressive 3D faces from latent space. In fact, these VAE-based methods can also be used for shape interpolation. However, Tan et al. (2018) cannot handle shapes with too many vertices, limiting the resolution of the generated mesh shapes. Although the method by Ranjan et al. (2018) performs well on facial shapes, it lacks generality. Our work is based on the VAE architecture, which has a rich latent space expressive capacity. By training the model to capture the latent patterns in the data, we can naturally apply it to shape generation and interpolation in triangular meshes, with improved generalization capabilities.
Method
This paper introduces a novel VAE architecture specifically tailored for triangular mesh generation, as illustrated in Figure 2. Our approach integrates several advanced techniques, including residual blocks, graph convolution, and a triangular mesh simplification algorithm, to create a flexible and effective framework. The residual blocks are designed to enhance the network’s expressive capacity, enabling it to capture complex relationships between local features and graph structures. To facilitate multiscale feature extraction, we employ a hierarchical structure where pooling is achieved by carefully tracking the mapping between coarse and fine meshes. The entire residual block, combined with pooling operations based on a triangular mesh simplification algorithm, forms a hierarchical feature extraction structure, further enhancing the network’s ability to perceive multiscale features.
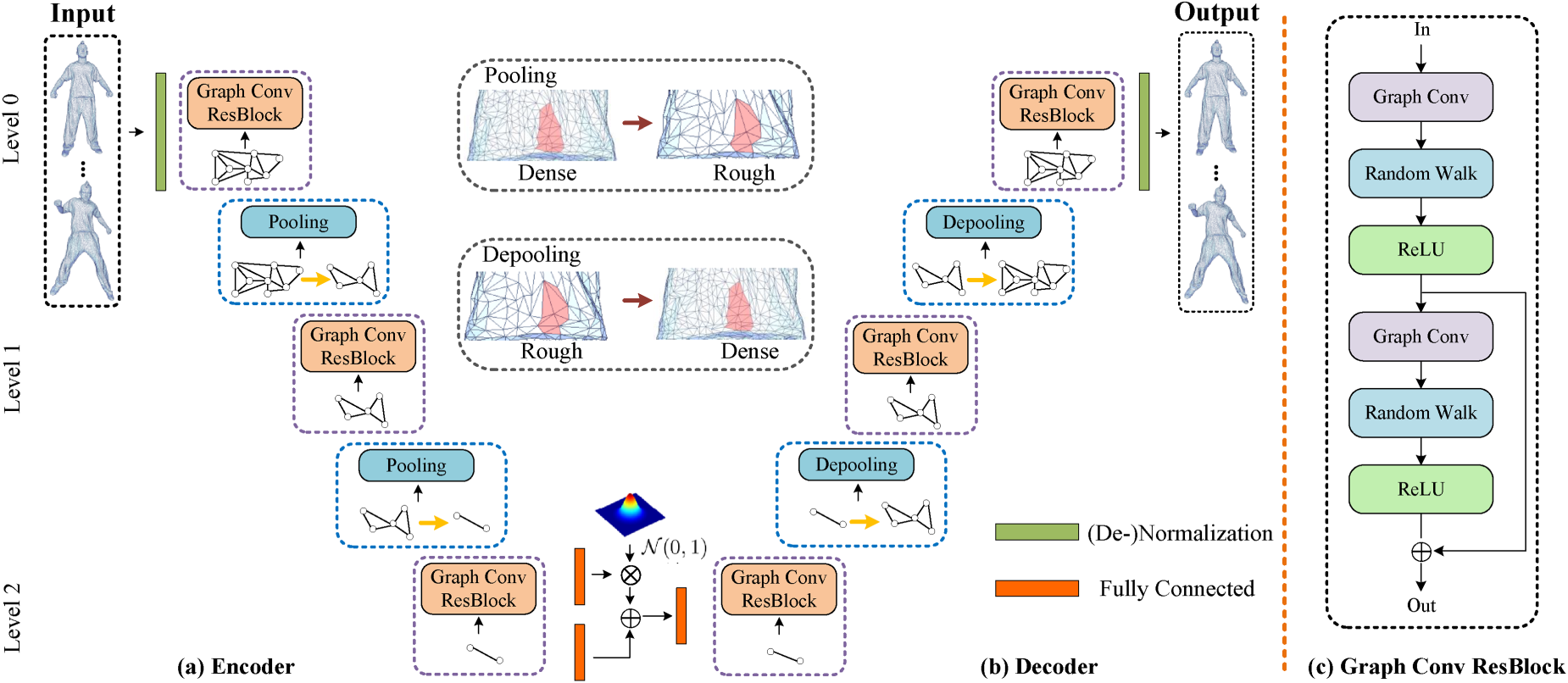
Our network architecture.
The input to our network encoder is preprocessed as-consistent-as-possible features (Gao et al., 2021) with a size of
We present a novel graph convolutional residual block as part of a VAE model for producing triangular meshes. This architecture seeks to better capture structural information and correlations in incoming data, hence improving the algorithm’s power for representation learning. One of the important components of our model is the integration of an RW (Lahav and Tal, 2020) process within the graph convolutional layer, which enhances the model’s ability to capture complex local geometric relationships.
As shown in Figure 2(c), this graph convolutional residual block integrates numerous critical components, such as graph convolutional layers (Pei et al., 2019), RW procedures, and ReLU activation functions, to provide a strong and efficient feature extraction approach. With this design, our model can not only extract local features from the input triangular meshes and capture correlations between nodes, but it can also introduce some randomness into the network structure exploration by incorporating RWs, which aids in the capture of global features and trends.
Specifically, the graph convolutional layer allows the model to extract local features from the input triangular mesh and capture node relationships. Assume

Then, applying the RW transition matrix

By introducing the RW process, the residual block can better adapt to different triangular mesh topologies, enhancing the model’s generalization capability. In terms of activation functions, ReLU is employed to introduce nonlinearity, allowing the model to better adapt to complex data distributions. By further processing

For mesh simplification, we introduce an edge contraction algorithm to aid in mesh simplification (Yuan et al., 2020). This technique not only generates a multilevel mesh structure to accommodate varying degrees of complexity, but it also assures consistency across coarser and finer meshes. Edge contraction procedures are iteratively applied and optimized based on a shape change measure using standard edge contraction methods. However, to achieve more effective pooling, it is crucial to ensure that each vertex in the coarser mesh represents a region of similar area or volume in the original mesh.
Since edge length is a crucial metric throughout the simplification process, it is used as one of the criteria for sorting edges to be contracted, helping to prevent the formation of overly long edges during contraction. We adopt the edge contraction algorithm based on the quadric error metrics as introduced by Garland and Heckbert (1997). In this approach, the error at a vertex
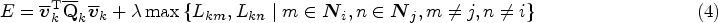
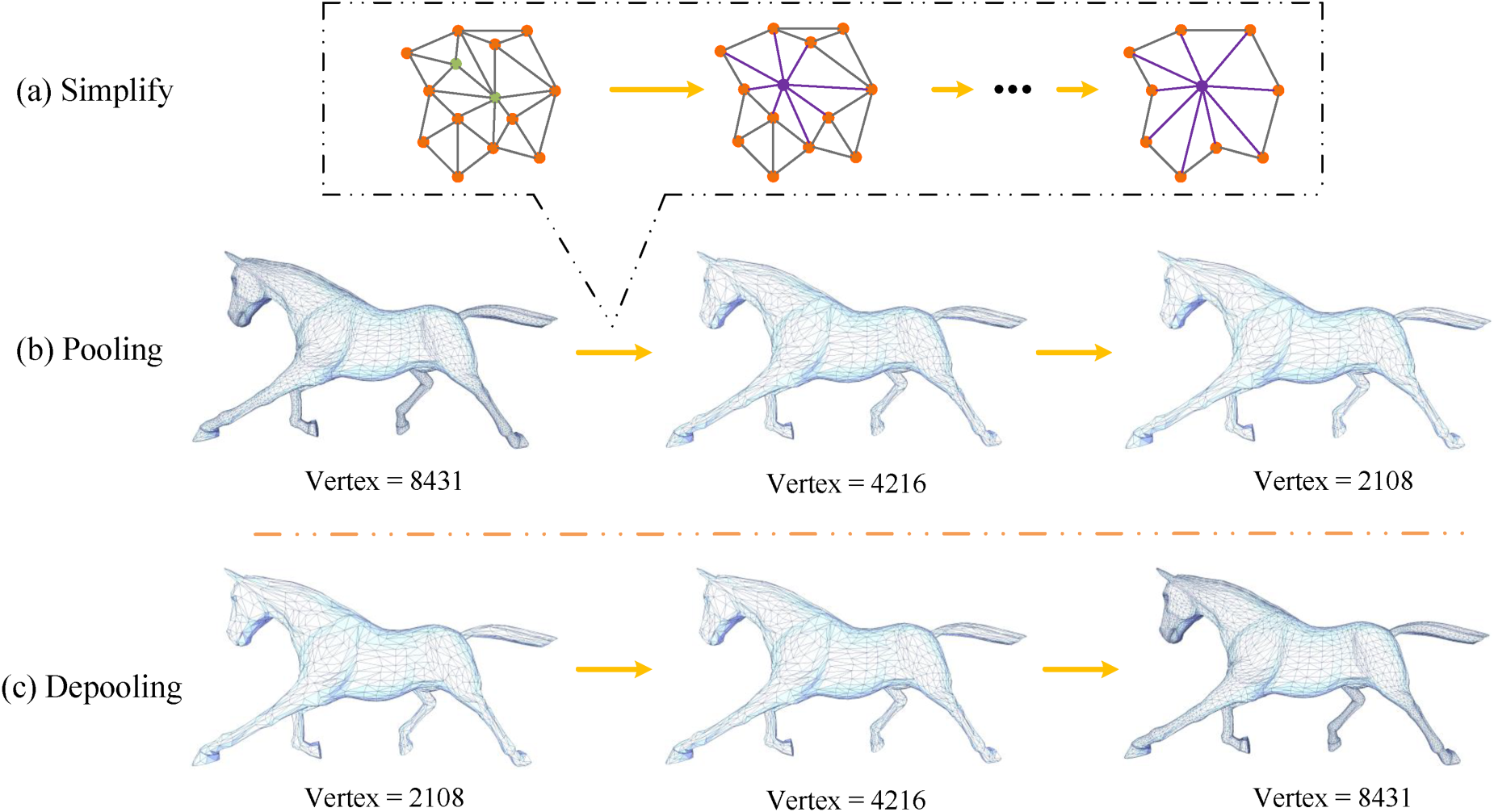
Pooling and depooling based on triangular grid simplification.
Mesh simplification is accomplished by combining two nearby vertices into a new vertex through repeated edge contraction procedures. This procedure is used to define mesh pooling operations in our network framework. The characteristics of the new vertex are specified as the average features of the contracted vertices following the edge contraction phase, guaranteeing the efficacy of pooling operations in the relevant simplified region. This retains the correct topology, allowing numerous layers of convolution or pooling to be supported while producing a well-defined receptive field.
As the VAE network has a decoder structure, it is crucial to properly define the unpooling operation. Here, we utilize the vertex relationships recorded during the simplification process and define unpooling as the inverse of edge contraction: the features of vertices on the simplified mesh are evenly redistributed to the corresponding contracted vertices on the dense mesh. This process ensures the accurate restoration of the original mesh details during the network decoding phase. Specifically, during the simplification operation, each edge contraction records the information of the corresponding vertex pairs and their connections. In the unpooling operation, based on these records, we accurately restore which vertices were transformed into edges after
When synthesizing a new 3D shape, it is often desired to control the type of shape generated, especially when the training dataset contains different shapes. In our improved VAE-based network training, we utilize mean-squared error (MSE) loss and Kullback-Leibler (KL) divergence loss (Tan et al., 2018; Van Erven and Harremos, 2014).
MSE loss is primarily used to measure the positional reconstruction error between the generated mesh model and the target shape. By calculating the squared differences between the vertex positions of the generated mesh and the corresponding vertex positions of the target shape, the network is encouraged to learn to generate vertex positions as close as possible to the input shape. This ensures that the created mesh has vertices positioned similarly to those in the target shape, thereby optimizing the positional accuracy of the generated shape. However, it is important to note that MSE loss focuses on vertex positions and does not directly measure the preservation of the overall geometric structure. This approach is effective as our network maintains the topology of the mesh, ensuring that the overall geometric structure remains consistent during the generation.

The difference between the generated latent space distribution and the standard normal distribution is measured using the KL divergence loss. By introducing KL divergence, it forces representations in the latent space to be more regular, assisting in the production of more continuous and interpretable shapes. Its formula is as follows:

Finally, the loss function

Mesh Dataset
We used several deforming shape datasets, including the SCAPE dataset (Anguelov et al., 2005), Swing dataset (Vlasic et al., 2008), Camel dataset, Horse dataset (Sumner and Popović, 2004), Dense dataset, and Dyna dataset samples (Pons-Moll et al., 2015). Unless otherwise specified, each dataset was divided into two sections for training and testing at random. This splitting strategy aids in evaluating the network’s reconstruction performance on geometries not seen during training. We normalized the mesh models of the same category to ensure fairness in error comparison. Specifically, each model was normalized based on the proportion of the length of its bounding box diagonal, allowing for geometric error comparison among models of the same category. This approach effectively eliminates size differences within the same category, making the error calculation more reasonable. We calculated the reconstruction error, root MSE (RMSE), and geodesic distance to assess the network’s performance on the test set. The geodesic distance (Bouttier et al., 2003) was calculated using the following formula:

The experiments were conducted on a machine equipped with an Intel Xeon(R) CPU E5-2620 v4 @ 2.10 GHz (16 cores), an NVIDIA GTX 1080Ti GPU, 16 GB of RAM, and 2 TB of solid-state drive storage. The deep learning framework used for the experiments was PyTorch. Additionally, the operating system was Ubuntu 20.04, with CUDA Toolkit 11.0 installed to enable integration with PyTorch, optimizing the training speed and performance of neural networks.
In this paper’s trials, we set the hyperparameters in the graph convolution at
Generated Mesh RMSE Values for Different
Values.
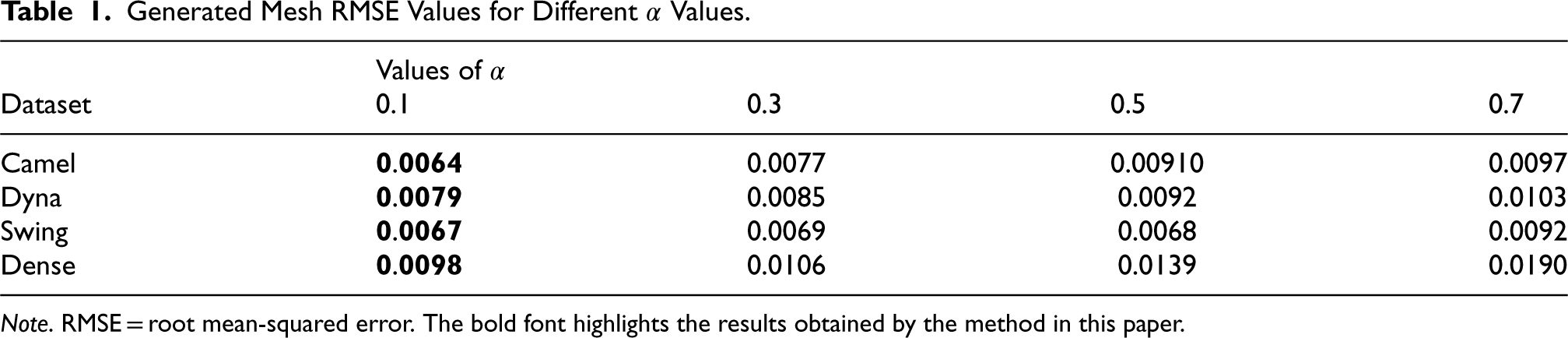
Generated Mesh RMSE Values for Different
Note. RMSE = root mean-squared error. The bold font highlights the results obtained by the method in this paper.
Because our mesh generation model uses both MSE and KL divergence as loss functions, we incorporate a regularization factor
RMSE and Geodesic Distance Values of Grids Generated by Different Methods.
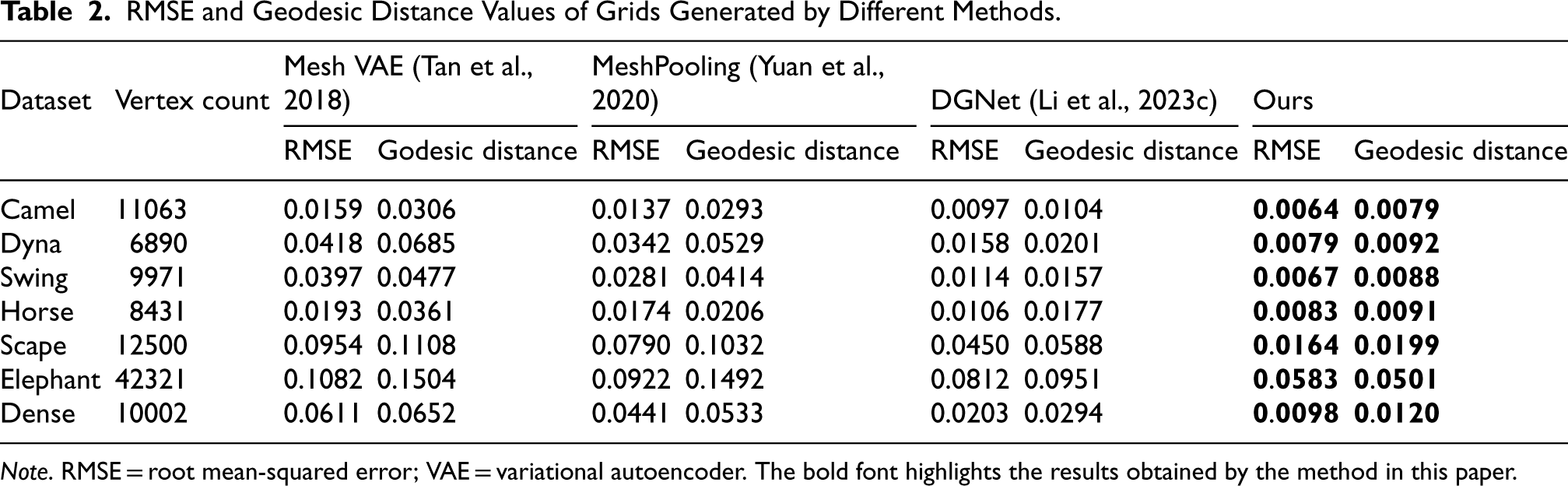
Note. RMSE = root mean-squared error; VAE = variational autoencoder. The bold font highlights the results obtained by the method in this paper.
We developed a unique mesh generation technique and conducted comparative experiments with existing approaches in this paper. We compared our method against the baseline network Mesh VAE (Tan et al., 2018), MeshPooling (Yuan et al., 2020), and DGNet (Li et al., 2023c) based on reconstruction error RMSE and geodesic distance. As demonstrated in Table 2, our framework consistently achieved better outcomes in terms of both reconstruction error and geodesic distance across multiple datasets. These results highlight our algorithm’s exceptional ability to accurately reconstruct the original mesh structure, effectively capturing complex geometries and subtle features. Our method not only outperforms previous approaches on overall dataset performance but also excels in preserving intricate details and complex structures, making it superior in both quantitative measures.
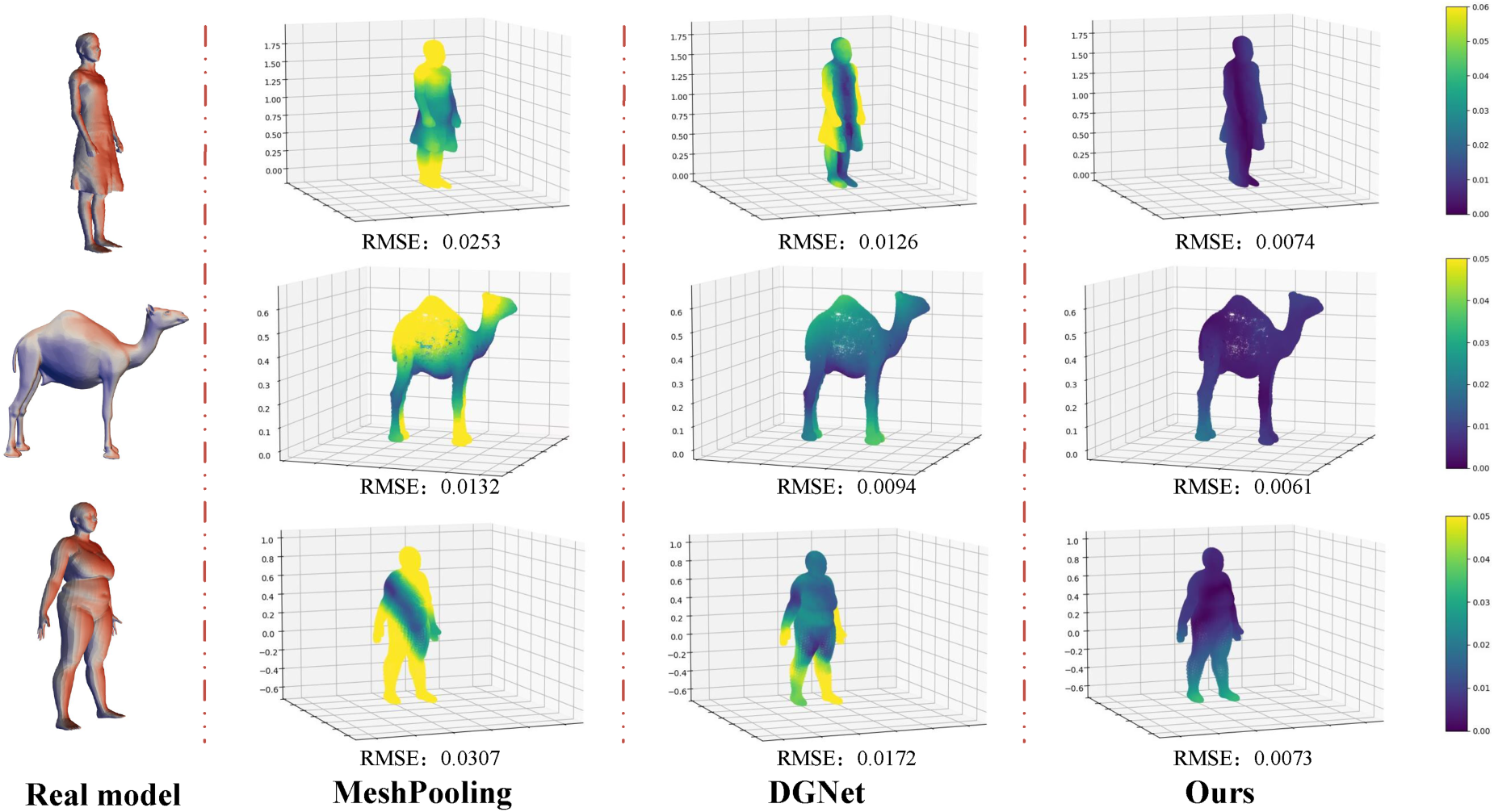
The heatmap visualization of the reconstruction results in the comparison of methods.
A set of qualitative studies were conducted to thoroughly evaluate our mesh generation method. Figure 4 illustrates the reconstruction errors, while Figure 5 displays the geodesic distances, comparing our approach to existing mesh-generation methods. As shown in Figures 4 and 5, our technique consistently achieves lower reconstruction error values and geodesic distances across multiple datasets, indicating that the generated meshes more effectively preserve the integrity of the original structures. The alignment between our technique and the actual mesh structure is clearly demonstrated through simple heatmap visualizations, where our method consistently highlights regions of minimal distortion and better captures fine details compared to other methods.
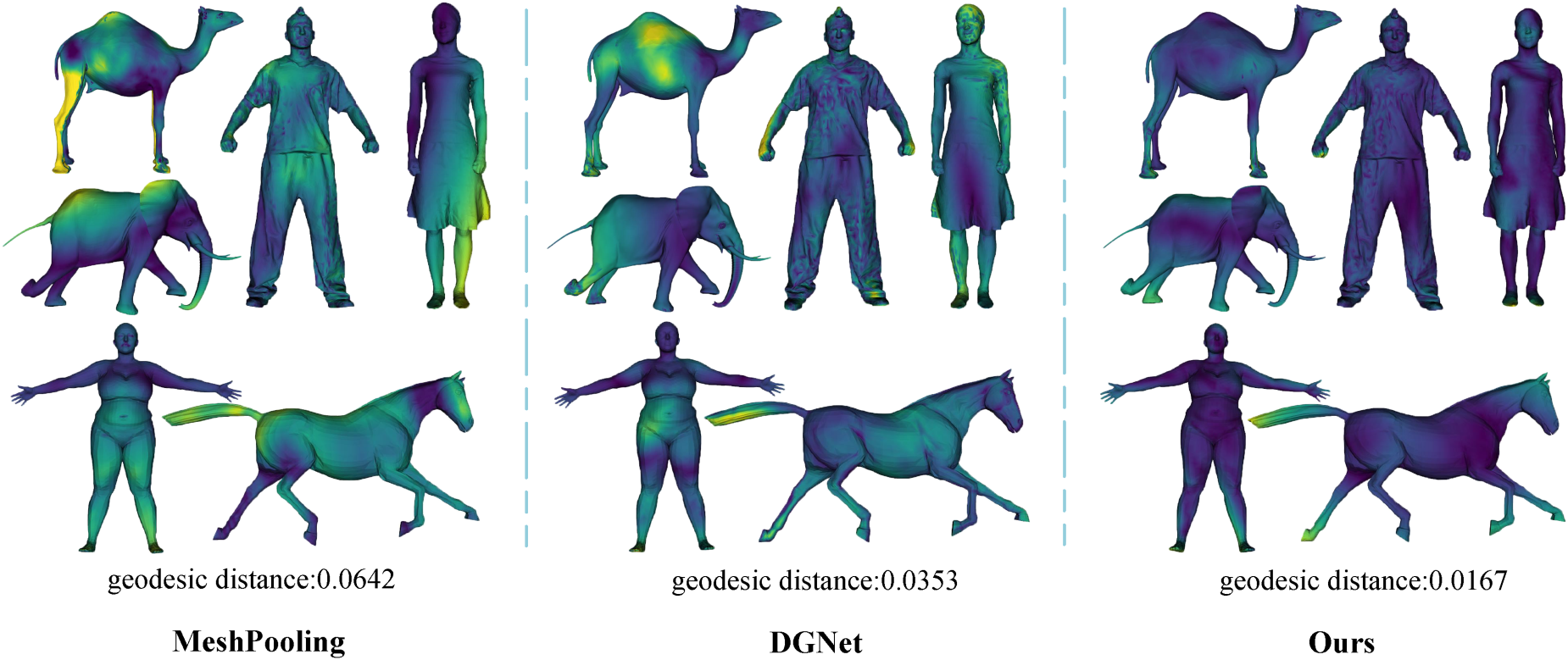
Visualization comparison of geodesic distances across different methods.
For a detailed comparison of reconstruction details, we chose the DGNet (Li et al., 2023c) algorithm for visual contrast in the generated results. Figure 6 shows that the mesh structure formed by DGNet within the orange circles has some visible flaws, particularly in the intricate sections of the face, indicating information loss. These qualitative experiments illustrate our method’s exceptional performance in the field of mesh production. We not only improved quantitative indicators significantly, but also provided compelling visual outcomes. The combined findings of quantitative and qualitative testing show that our suggested method outperforms current state-of-the-art methods in creating mesh details.
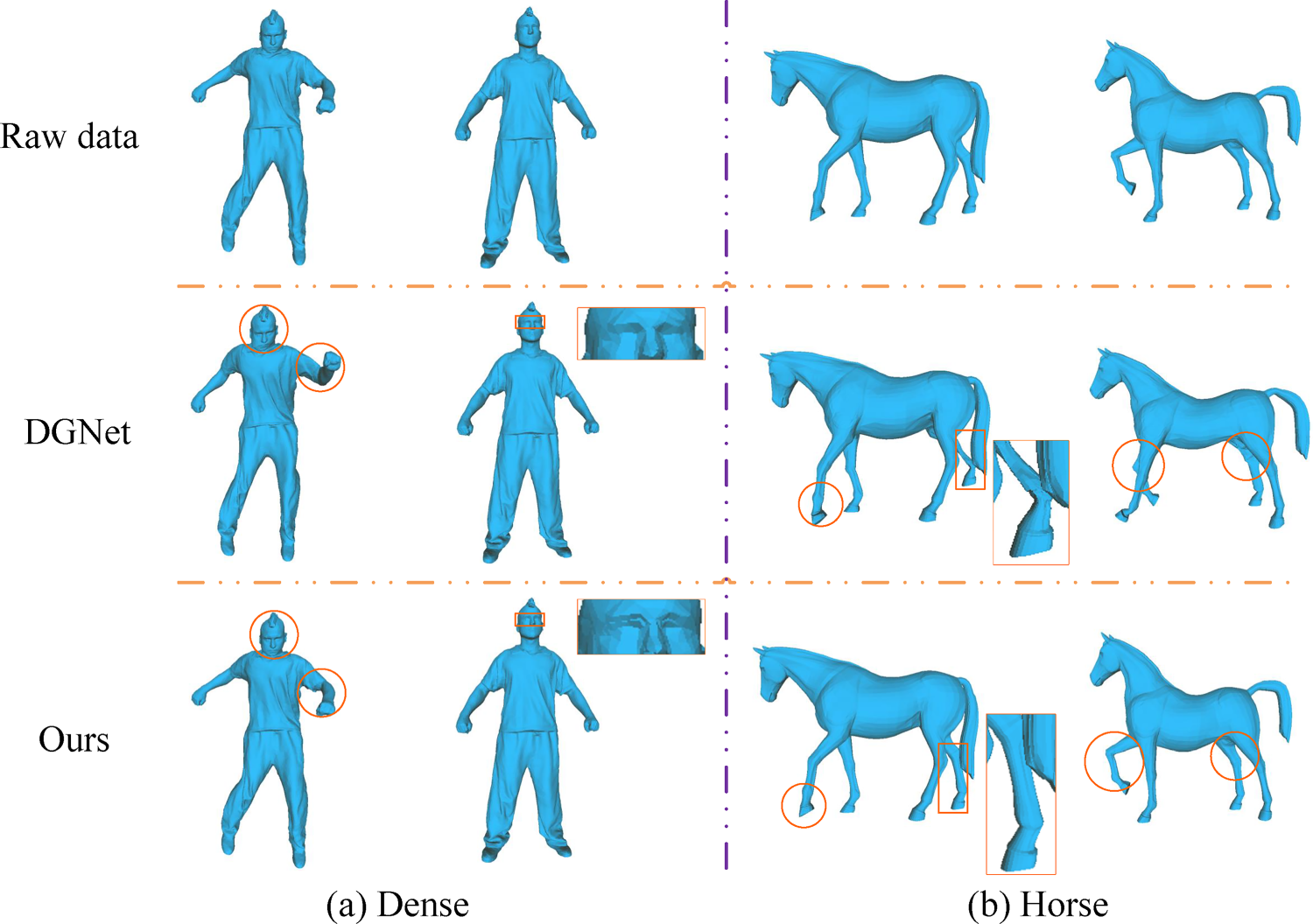
The visualization of reconstruction outcomes with the DGNet (Li et al., 2023c) approach was compared.
We conducted a series of ablation experiments to conduct a complete comparison of different network architectures and settings, as well as to comprehensively assess the aspects that significantly effect the performance of encoding and decoding outcomes. These investigations intended to validate the contributions of the method’s constituent components to overall performance.
The Ablation Experiment of Pooling Layer Based on Triangle Mesh Simplification
Our model incorporates pooling operations based on triangular mesh simplification. To further validate the impact of various pooling methods on the network, we investigated the cases of no pooling, single-layer pooling, and double-layer pooling. Table 3 compares the reconstruction errors under these three conditions. According to the findings, multilayer pooling and unpooling processes have a considerable advantage in increasing model performance and the network’s ability to reconstruct unseen forms. Multilayer pooling aids in the learning of more complicated form structures and the capture of more features, and is especially beneficial for mesh models with hierarchical structures.
Ablation Experiment of Pooling Layer.

Ablation Experiment of Pooling Layer.
The bold font highlights the results obtained by the method in this paper.
We expanded the experimental design even more by including an error comparison heatmap for scenarios without pooling, single-layer pooling, and the proposed multilayer pooling model. The heatmap evaluates the performance of several pooling techniques in various shape reconstruction tasks visually. Figure 7 shows that when no pooling is applied, the model’s error in form reconstruction tasks is relatively significant. The use of single-layer pooling improves performance slightly, whereas our suggested multilayer pooling model excels in all tasks, achieving reduced error values. This further verifies the multilayer pooling model’s great benefit in enhancing shape reconstruction performance.
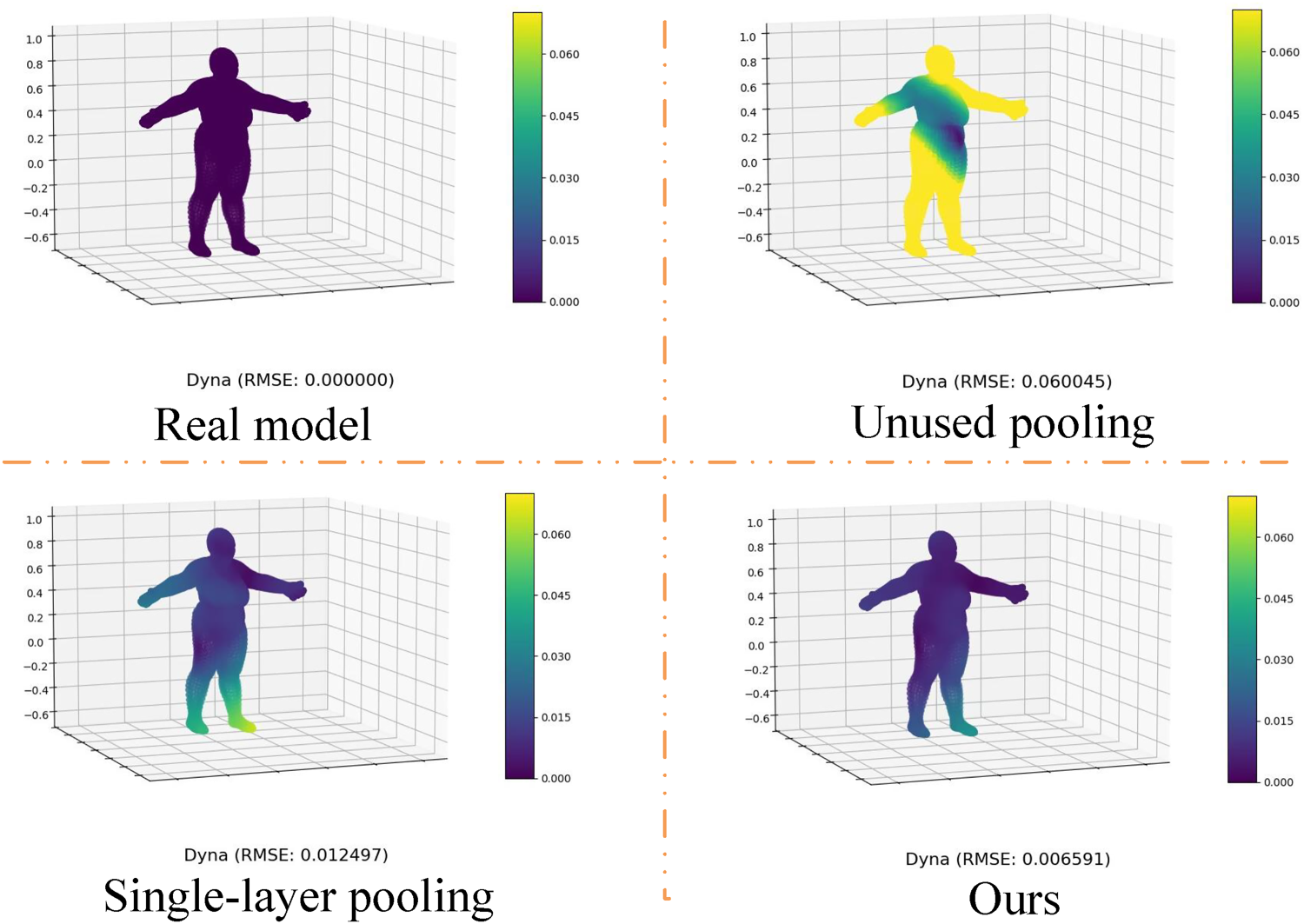
Visualization of ablation experiments on the pooling layer based on triangle mesh simplification.
The goal of the ablation experiment on the graph convolutional residual block was to obtain a better understanding of how each component of this module contributes to overall model performance. First, we created a baseline model that included the entire graph convolutional residual block and measured its performance on the dataset. Following that, we retrained the model and evaluated performance metrics by removing the graph convolutional residual block and replacing it with graph convolution, as well as removing RWs and replacing them with batch normalization.
Table 4 shows the outcomes of this set of ablation tests. According to a careful study of the experimental data, incorporating graph convolutional residual blocks into the model structure greatly enhanced reconstruction performance. When compared to other ablation circumstances, the model with extra graph convolutional residual blocks had the lowest reconstruction error. In comparison to other experimental settings, the model with extra RWs also displayed comparatively low reconstruction error, demonstrating its critical role in enhancing model performance and accuracy. The experimental results of RWs indicate that they bring significant improvements to the network model when dealing with graph data.
Ablation Experiments on Graph Residual Blocks and Random Walks.

Ablation Experiments on Graph Residual Blocks and Random Walks.
The bold font highlights the results obtained by the method in this paper.
We conducted an ablation experiment to investigate the effect of graph convolutional residual blocks on training cycles. At different training cycles, we compared the reconstruction errors of two models, one containing graph convolutional residual blocks and one without. The experiment was carried out using the Dense dataset, and the results are given in Figure 8. At the same training cycles, the model with graph convolutional residual blocks has a much lower reconstruction error than the case without them.
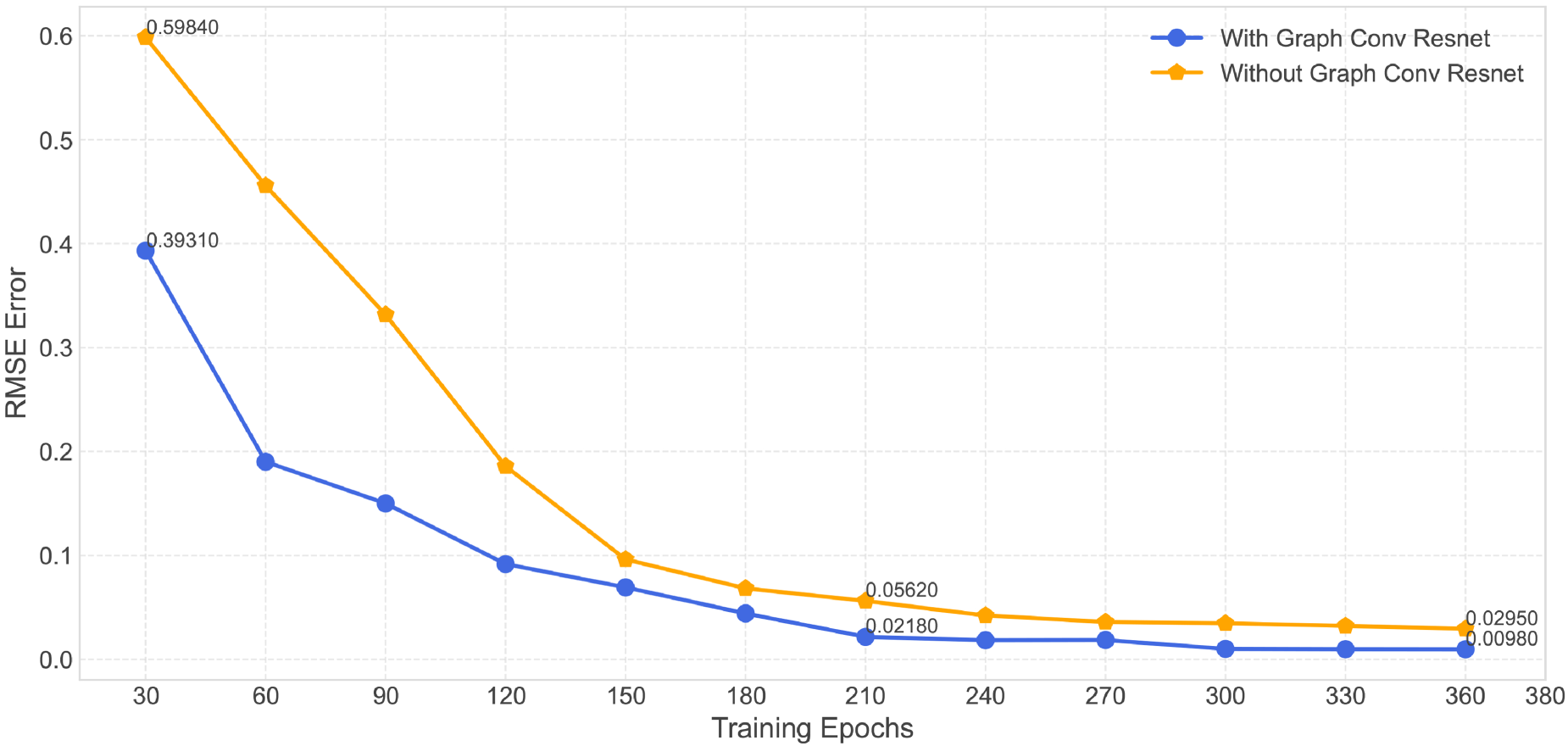
The impact of graph convolutional residual blocks on the training epochs.
These experimental results show that the graph convolutional residual block has a good impact on the training process. For starters, this module helps to accelerate the model’s convergence speed, allowing it to learn the data representation faster. Second, the graph convolutional residual block’s architecture improves the model’s stability by decreasing fluctuations throughout the training process, pushing the model to attain greater performance in shorter training periods.
Model Complexity and Parameter Comparison With Baseline Networks.

Note. Mesh VAE = Mesh variational autoencoder; RMSE = root mean-squared error. The bold font highlights the results obtained by the method in this paper.
To further evaluate the differences in model complexity between our proposed method and the baseline methods (Mesh VAE; Tan et al., 2018), we conducted a detailed analysis of model parameters. Although our model has significantly more parameters than the baseline networks (as shown in Table 5), this increase endows the model with greater representation capacity, enabling it to achieve higher accuracy and generalization ability when handling complex mesh data. For example, in reconstruction tasks, despite the higher model complexity, our method is better at capturing subtle geometric features and performs excellently in generating new mesh instances. Additionally, the increase in parameters enhances the model’s expressiveness in the latent space, allowing our method to excel in shape interpolation and generation tasks. In contrast, the baseline networks do not utilize residual modules and employ only a single-layer pooling structure, which limits their ability to handle complex meshes. Although our model requires longer training time than the baseline networks, this additional time cost is offset by the significantly lower RMSE and geodesic distance, making our method more competitive in practical applications.
Framework Evaluation
We validated our framework’s design choices and effectively demonstrated the efficacy of residual blocks and the triangular mesh simplification pooling layer by comparing outcomes under varied parameter settings and input conditions.
Latent Space Vector Dimensions
We compared the reconstruction errors (i.e., the RMSE of position for each vertex) of created meshes with varied latent vector dimensions. The experimental results, as given in Table 6, suggest that utilizing 128 dimensions effectively enhances reconstruction quality. Lower dimensions do not capture enough information, whereas greater dimensions do not appreciably improve the results and may potentially lead to overfitting.
Mesh RMSE Values for Different Latent Space Vector Dimensions.
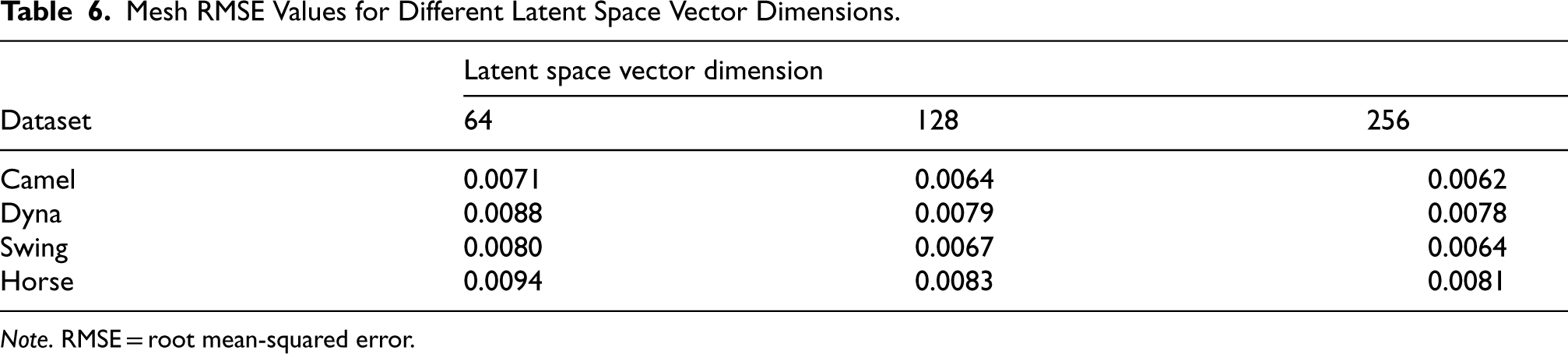
Mesh RMSE Values for Different Latent Space Vector Dimensions.
Note. RMSE = root mean-squared error.
Impact of Dataset Size on Reconstruction Error
We also ran mesh generation tests on the Dyna and Swing datasets, producing line graphs of the resulting RMSE versus dataset size. The findings, as shown in Figure 9, show that our proposed technique works extraordinarily well on various datasets, demonstrating its great advantage in generative tasks. It is worth noting that even with a smaller dataset, our technique delivers excellent generation outcomes, as evidenced by relatively low RMSE values. This property is critical for small-scale data scenarios in practical applications, emphasizing our method’s robustness and efficiency under low data conditions. These experimental results corroborate our approach’s excellent generalization performance in addressing mesh generation difficulties, giving strong support for its viability in real-world applications.
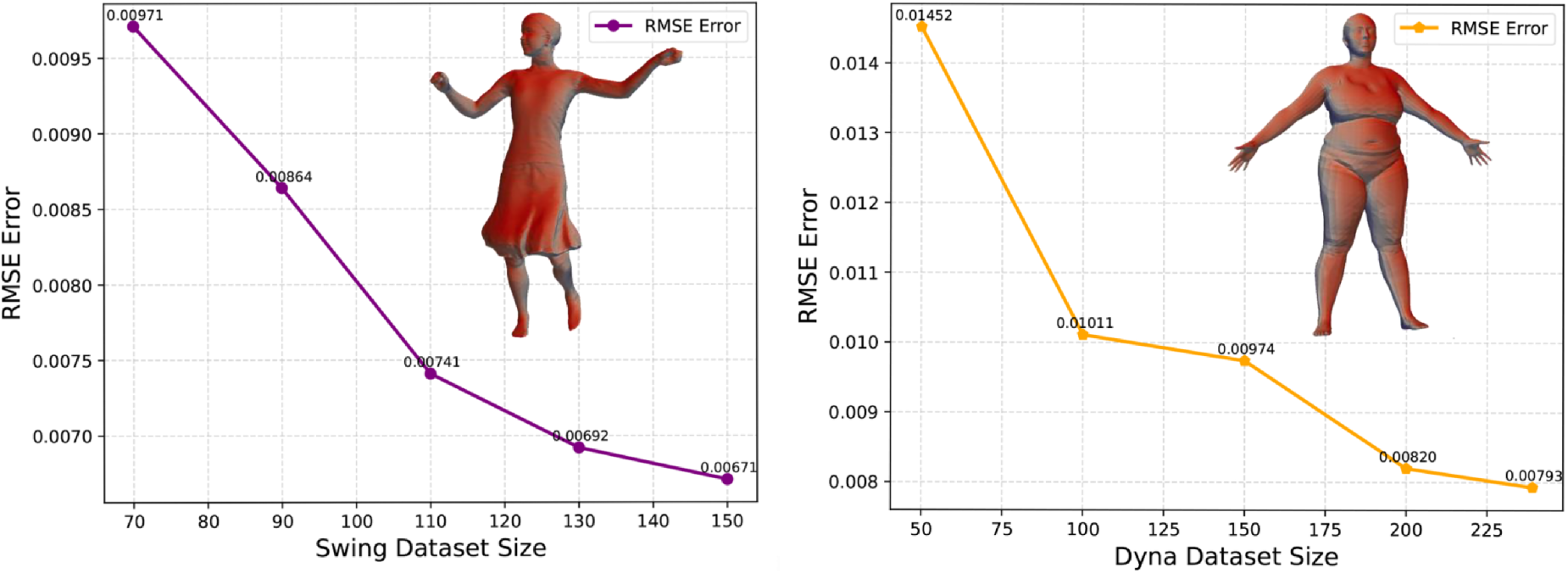
The effect of various dataset sizes on reconstruction error (RMSE). Note. RMSE = root mean-squared error.
These experimental results further validate the exceptional generalization performance of our approach in addressing mesh generation problems, providing strong support for its feasibility in real-world applications.
As the network gradually learns the latent representation of the data during the training phase, this study is eventually able to use the learned latent space and decoder to generate new forms in an original manner. We can see the network’s good generating capability by feeding a sample from the standard normal distribution
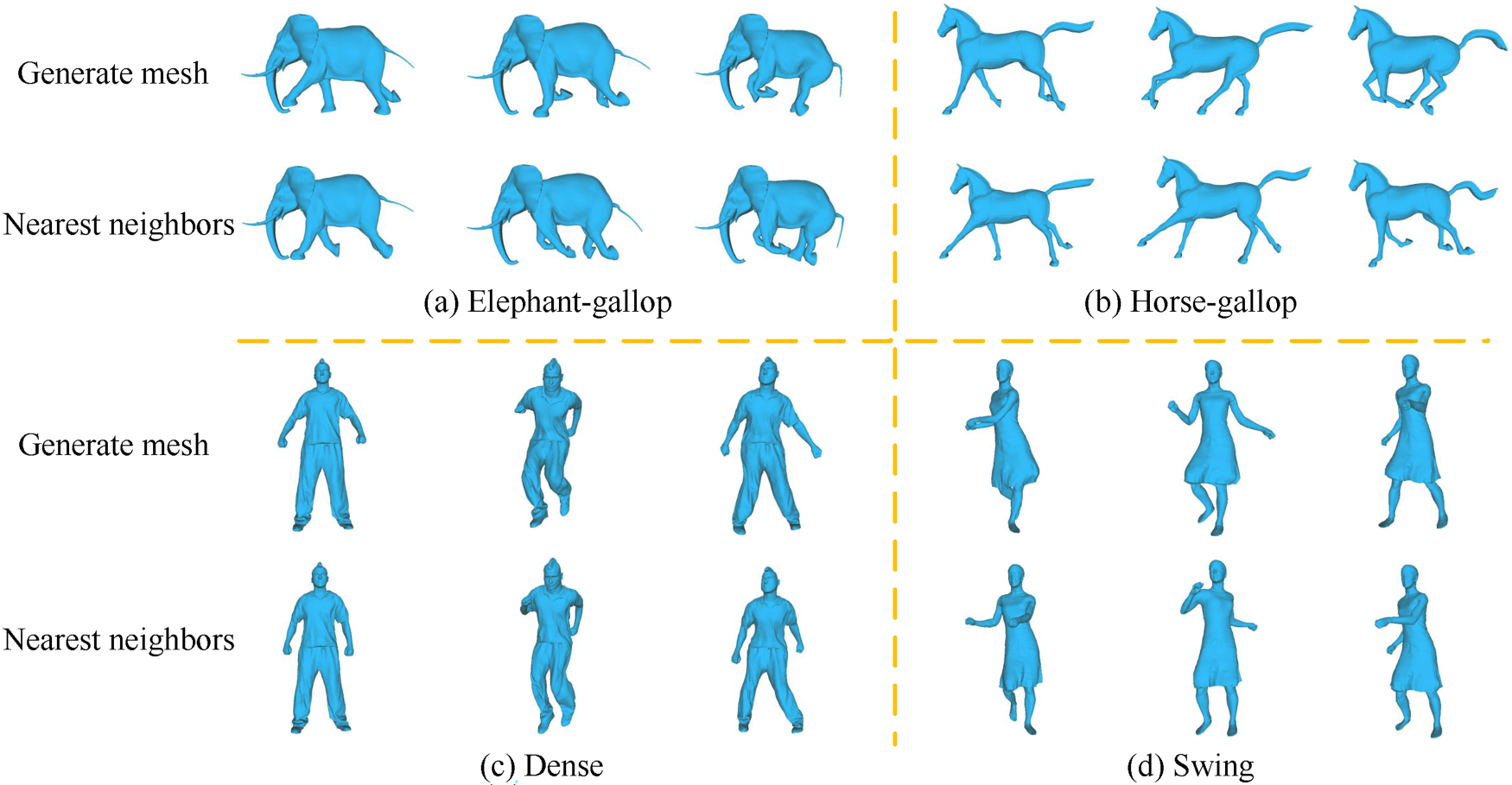
The system generates new shapes at random from the original collection, as well as their nearest neighbors.
We used an intuitive way to determine whether the created shapes differed from those previously present in the training dataset. We performed a visual comparison by computing the average Euclidean distance between vertices and identifying the sample in the training dataset that is closest to the created shape, that is, the nearest neighbor mesh model shown in Figure 10. The comparison results clearly illustrate that the generated shapes are architecturally distinct from any shapes in the training dataset.
We ran shape interpolation experiments on the Dense dataset to explore deeper into the shape space created by the model. We obtained a sequence of intermediate shapes by picking two alternative shape representations in the latent space, as shown in the orange box on the left side of Figure 11, and gradually interpolating along their continuous route. We layered the generated varied shapes at the same time, as illustrated on the right side of Figure 11, indicating its potential for achieving animation effects. The goal of this experiment is to show the continuity and smoothness of our proposed model in shape generation, as well as how well the model transitions between shapes in the learned latent space. The experimental results will be critical in gaining a more complete grasp of the model’s generative capabilities.
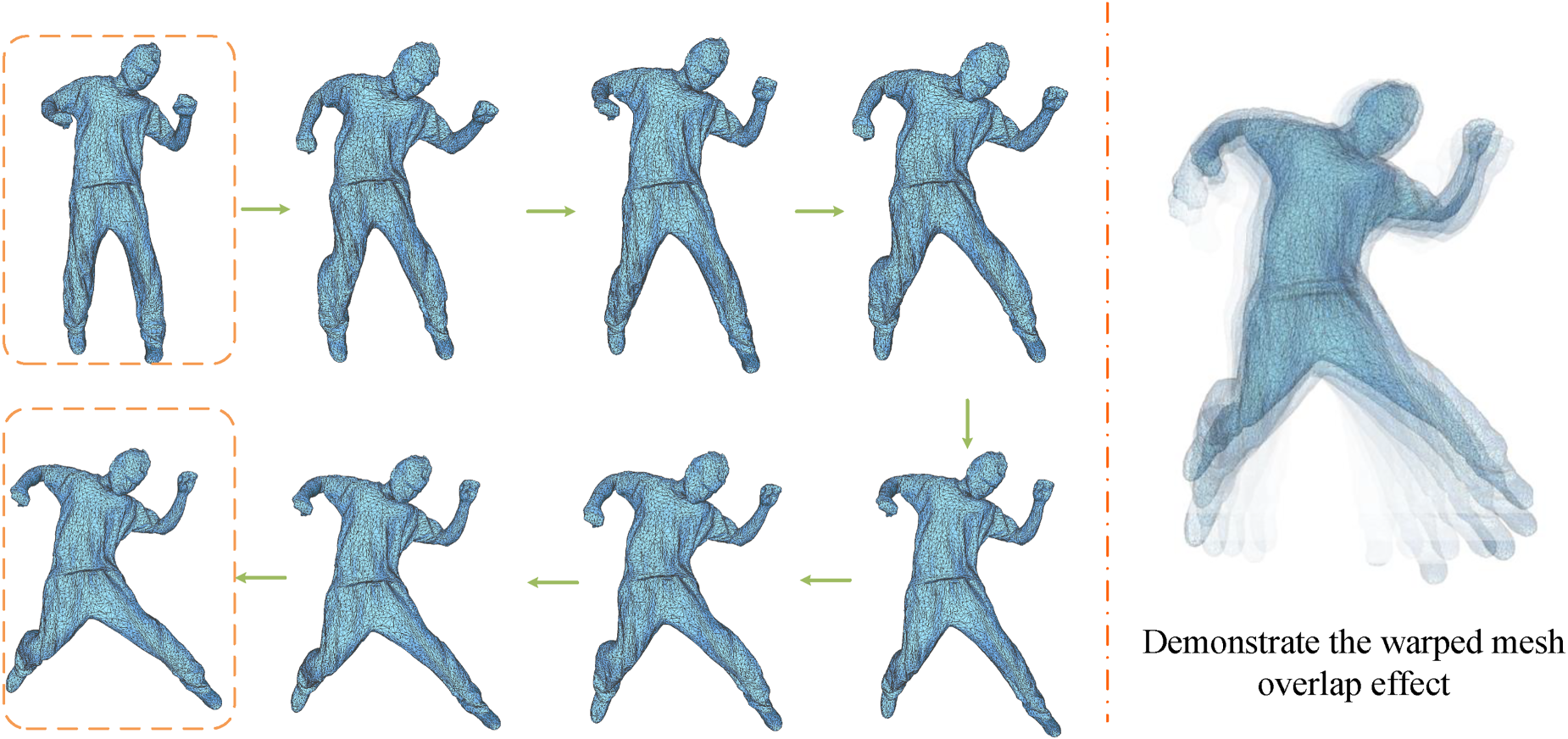
The outcomes of our frame shape interpolation.
In this paper, we present a unique framework for the Mesh VAE that efficiently overcomes the obstacles posed by dealing with triangular meshes’ complexity and irregularity. We improved the network’s generalization capability by employing multilayered pooling operations based on a triangular mesh simplification algorithm and graph convolution residual modules, further mitigating the issue of deep network gradient vanishing and achieving rapid convergence, thereby improving triangular mesh reconstruction accuracy. Furthermore, experimental results show that our framework outperforms others in handling deformable shape collections, which includes applications such as shape generation and interpolation across several domains. The drawback of our mesh-generating model is that it can only handle homogenous meshes. As a future endeavor, a framework capable of processing shapes with diverse topologies as input or generating a sequence of deformed data through data augmentation is required.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Key R&D Program of China (grant no. 2020YFB1709200).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.