
Abstract
Image colorization is one of the core issues in computer vision that has attracted significant attention in recent years. Colorization technique improves the human eye’s ability to recognize grayscale images and understand scenes, particularly in low-light-level (LLL) images. However, current colorization methods still face issues, such as semantic confusion, color bleeding, and loss of image details. To address these issues, a bi-stream feature extraction and multiscale attention generative adversarial network (BM-GAN) is proposed. The bi-stream feature extraction block combines global and local features extracted from two parallel encoders. This combination improves the ability of the network to extract deep features from images. The multiscale attention block enhances key features related to the colorization target across channels and spatial dimensions. This results in higher-quality color images. The proposed method is evaluated on ImageNet, Summer2winter validation set, and LLL images. Experimental results show that BM-GAN reduces the feature-aware evaluation metrics learned perceptual image patch similarity and Fréchet inception distance by 5.2% and 7.5%, respectively.
Introduction
Image colorization is the process of converting grayscale images into color images by assigning appropriate colors to each pixel (Maurya and Chand, 2022; Chen et al., 2023; Viswanathan et al., 2023). This process aims to restore or enhance the color information of an image, making it easier for individuals to comprehend and analyze. For grayscale images, especially low-light-level (LLL) images, the lack of color limits their visual effect and the ability of the human eye to extracting image details. Colorization not only improves image quality, but also improves the ability to recognize objects and scene details. It is essential in a range of applications, including LLL image colorization (Kong et al., 2020), restoration of old photos and movies (Chen et al., 2018), and medical image processing (Nida et al., 2016; Khan et al., 2017). In addition, the colorized LLL images are used in a wide range of applications in aerospace, military combat, military as well as civilian fields. However, current image colorization faces some key issues, such as semantic confusion (determining the appropriate color for each object in the image), color bleeding (where colors spill over object boundaries), edge ambiguity, and object intervention, among others.
Traditional colorization methods can be divided into two main categories: user-guided colorization and example-based colorization. The user-guided colorization requires users to manually add colors to grayscale images, which is labor-intensive and can lead to edge diffusion issues. Similarly, the example-based colorization involves selecting a color image similar to the grayscale image and transferring its colors. Although such methods reduce user involvement, they are heavily reliant on suitable reference images. These traditional methods are often inefficient and highly dependent on manual intervention.
In recent years, the rapid advancement and extensive adoption of deep learning have significantly impacted the field of image colorization (Pastor-Pellicer et al., 2019; Tu et al., 2017; Tang et al., 2022). These methods excel at extracting color patterns from vast datasets of colorized images and applying them to grayscale images. Deep learning methods have shown great potential for learning color patterns from a large dataset of ground truth color images and applying this knowledge to grayscale images. The initial deep learning methods for image colorization were primarily based on convolutional neural networks (CNNs). These methods take grayscale images as input and, through training, learn the color distribution and characteristics. By accurately extracting semantic information from the image, they are able to generate images that are both realistic and natural. As deep learning technology progresses, more sophisticated methods have been developed. A notable example is the generative adversarial network (GAN), which enhances colorization through adversarial training. Several GAN-based methods, including DualGAN (Yi et al., 2017), CycleGAN (Zhu et al., 2017), CUT (Park et al., 2020), InstaGAN (Mo et al., 2018), and Pix2pix (Isola et al., 2017), among others, are specifically tailored to address various challenges in image colorization. These advanced techniques leverage deep learning and adversarial training to generate high-quality colorized images. Despite enhancing image colorization, these methods have notable limitations. The training of GANs is intricate and can be unstable. For example, pattern collapse forces the generator to fixate on a single color scheme, which restricts its ability to create varied color outputs. The focus of the network on maximizing adversarial loss can result in color bleeding or loss of texture in the colorized images. This distortion can cause considerable differences between the colorized image and ground truth color image. Additionally, it may hinder the network from understanding the semantic content of the image, leading to semantic confusion or color mismatch. To address these issues, a bi-stream feature extraction and multiscale attention GAN (BM-GAN) is proposed. The complete architecture of the BM-GAN network is presented in Figure 1. Compared to current methods, the following contributions are presented:
A BM-GAN grayscale image colorization network is designed, which consists of two parallel encoders to enhance the effect of colorization. The network effectively combines global and local features while maintaining texture details. It enhances the ability of a network to extract detailed, scene-specific, and semantic features, and effectively mitigates color bleeding. A multiscale attention block (MSAB) is designed. It integrates channel attention with spatial attention in an effective manner to improve the accurate identification of various targets within the image. During the decoding phase, the introduction of an MSAB at skip connections allows the network to selectively fuse features from the encoder and decoder. The combination of information from the shallow encoding layers focuses on key features associated with colorized objects in specific channels and spatial regions. The colorization quality of the network is improved by reducing semantic confusion and loss of image details between the colorized targets. Several sets of LLL images in different scenarios are captured by the multipixel photon counter (MPPC) experimental platform in an LLL environment. The proposed colorization method, when applied to these LLL images, significantly enhances the visualization of LLL images in practical applications and facilitates better image information acquisition by the human eye.
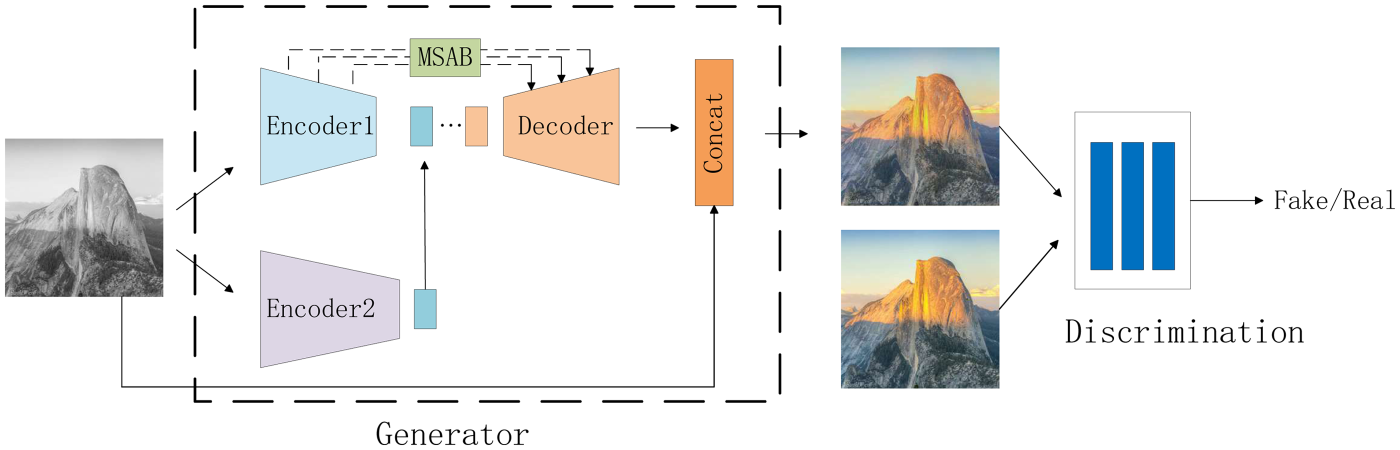
Overall architecture of the proposed image colorization network. The generator is composed of two parallel encoders that jointly learn the global and local features of the image, and introduce multiscale attention modules at skip connections.
User-Guided Colorization
User-guided colorization method adds colors to grayscale images through user graffiti or specifying colors. This method allows users to intuitively intervene in the colorization process and customize it according to their creativity and preferences. Levin et al. (2004) utilized the Markov random field method to distribute colors by leveraging the similarity between adjacent pixels with similar intensities. Huang et al. (2005) proposed an adaptive edge detection algorithm aimed at preventing edge haloing in colored regions. The algorithm employs a high-threshold Sobel filter for initial edge detection, followed by color propagation to resolve color bleeding issues, particularly in cartoon images. Yatziv and Sapiro (2006) proposed a fast shading technique that utilizes luminance-weighted chrominance blending and weighted geodesic distance. Luan et al. (2007) studied a colorization approach that leverages texture similarity. The technique integrates texture matching with image segmentation to achieve more efficient color transfer. Sýkora et al. (2009) introduced a versatile tool for coloring hand-drawn comics that uses a graph cut-based approach to optimize colorization. This method is suitable for a wide range of artistic styles. Xu et al. (2013) utilized an appearance similarity method between user-defined pixels and other pixels, which is both time-efficient and memory-efficient. Paul et al. (2016) proposed a three-dimensional steerable pyramid method to deal with occlusions. These methods require users to have substantial expertise and involve significant manual effort, particularly when the input image contains complex content.
Example-Based Colorization
Example-based colorization method involves transferring color data from a reference image to a grayscale image. The reference image is typically a color image that shares a similar scene with the grayscale image. Techniques proposed by Reinhard et al. (2001), Tai et al. (2005), and Wu et al. (2013) are frequently used. Welsh et al. (2002) proposed a method to transfer color information between images by matching the luminance values of pixels in the color space. Charpiat et al. (2008) proposed a global optimization algorithm that handles multimodality by predicting the probability of possible colors at each pixel. He et al. (2018) utilized a colorization network to extract features that represent the statistical color distribution of a reference image. This method yields superior colorization results compared to pixel-level color matching. Li et al. (2019) developed a colorization method that first matches the reference image locally and then fuses it using a global optimization technique. The colorized image closely matches the reference image in terms of color, while also reducing the need for user guidance.
Fully Automatic Colorization
Recently, deep learning has gradually been applied to image colorization with the development of deep neural networks and datasets. By learning features from both the source and target domains, a color-mapping relationship is formed. Cheng et al. (2015) first employed CNNs to extract features from grayscale images. The image is colored based on features extracted from various patches and their respective regions within the image. Zhang et al. (2016) regarded image colorization as a self-supervised expression learning task and made progress in the domain of automatic colorization. They developed a method to address the multimodal challenges of colorization and investigated the diversity of possible color outcomes. Iizuka et al. (2016) pretrained a network with class labels for classification tasks on the ImageNet dataset. They extracted global semantic features that were later combined with intermediate features for color prediction. Su et al. (2020) proposed a hybrid learning method that combines instance branching and global branching features. It achieves fully automatic multiobjective colorization of instance-aware images.
GANs
In 2014, the GAN was proposed by Goodfellow et al. (2020) to generate data unsupervised and to have shown strong performance in computer vision tasks. The GAN framework consists of a generator and a discriminator. The generator generates synthetic data from random noise inputs, while the discriminator’s task is to differentiate between real and synthetic data. Adversarial training allows these two networks to continuously enhance their performance through mutual competition. The distinct architecture and training approach of GANs have driven their success in super-resolution reconstruction (Wang et al., 2018), image generation, image conversion, and style transfer (Andreini et al., 2020). GANs have been applied to tackle the challenge of image colorization. Yoo et al. (2019) introduced an enhanced memory network and leveraged GANs to achieve colorization for small sample sets. Isola et al. (2017) improved upon the GANs by enhancing both the objective function and network architecture. Additionally, they introduced constraints within the loss function to handle a variety of image transformation tasks. Vitoria et al. (2020) utilized semantic class distribution information in their ChromaGAN approach to direct image colorization. Zhao et al. (2020) proposed a composite colorization network that simultaneously predicts colorization and saliency mapping. Semantic confusion and color bleeding are effectively reduced.
Attention Mechanism
In recent years, attention mechanisms (Niu et al., 2021) have been widely applied in various deep learning tasks, such as image recognition, image generation, and 3D vision. The attention mechanism evaluates the importance of different features through weighted analysis to highlight relevant information and ignore irrelevant data. The attention mechanism model primarily includes the spatial attention model, channel attention model, and fusion attention model. The spatial attention model is designed to selectively capture spatial dependencies between positions to evaluate the importance of each point. The channel attention model amplifies or diminishes channels by concentrating on the significance of each channel. The fusion attention module is a prominent network that integrates both spatial and channel attention mechanisms.
LLL Images
In LLL environments, conventional visible-light cameras do not work properly under such conditions. MPPC (Li et al., 2021; Aull et al., 2014; Verghese et al., 2007), on the other hand, is able to accurately capture details in low-light environments without causing underexposure, and MPPC rely on avalanche effect imaging, which is capable of detecting images in very faint environments and has a great advantage in capturing LLL images. However, since the LLL images captured by MPPC are usually grayscale images lacking color information, resulting in the absence of many important details, this limits its visualization effect in practical applications and the degree of access to image information by the human eye. Therefore, colorization of LLL images is of great practical significance, especially in the military field, biomedicine, night-time automatic driving, ocean exploration, and so on (Deng et al., 2023). The colorization technique can convert the original low-contrast LLL images into colorful images that conform to, or approximate, the human visual perception, and improve their ability to discriminate targets.
Method
BM-GAN Architecture
The proposed BM-GAN architecture, shown in Figures 2 and 3, is divided into a generator and a discriminator. The generator network employs an encoder–decoder structure. It is composed of three main blocks: the bi-stream feature extraction block (BFEB), the main colorization network (MCN), and the MSAB. In BM-GAN, the generator takes a grayscale image of
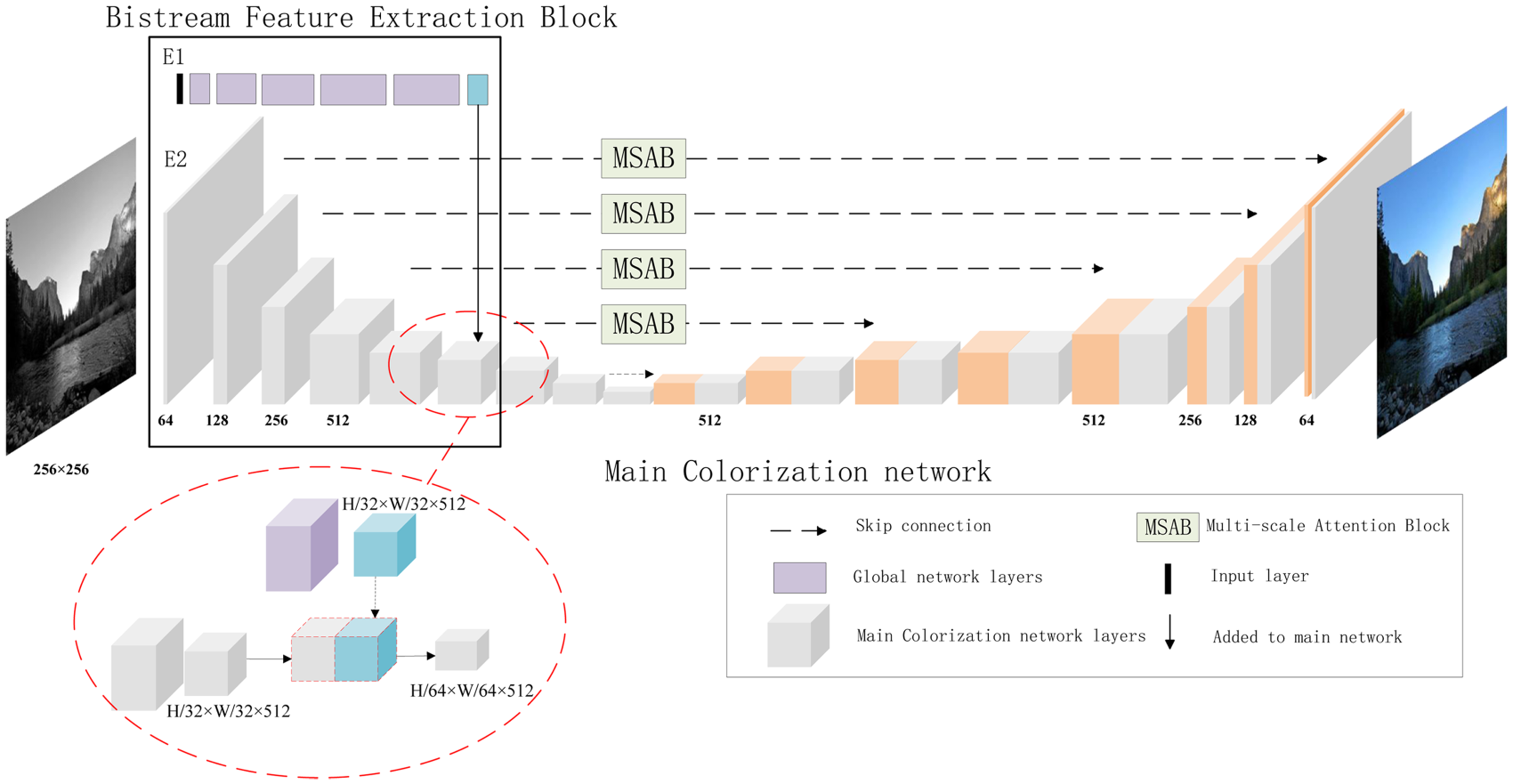
Architecture of the proposed BM-GAN generator. From left to right, the network consists of a BFEB, an MCN, and an MSAB. It receives grayscale images as input and predicts corresponding colorized images. Note. BM-GAN = bi-stream feature extraction and multiscale attention generative adversarial network; BFEB = bi-stream feature extraction block; MCN = main colorization network; MSAB = multiscale attention block.
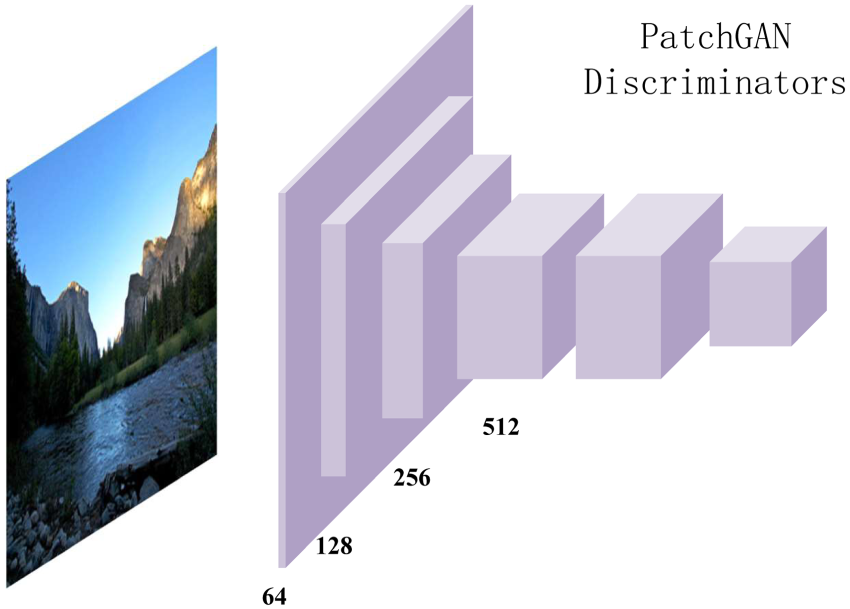
Architecture of the proposed BM-GAN discriminator. Note. BM-GAN = bi-stream feature extraction and multiscale attention generative adversarial network.
The discriminator adopts a
A BFEB is proposed to integrate global and local features to minimize semantic confusion and color bleeding. As illustrated in Figure 2, the MCN is based on the U-Net structure (Ronneberger et al., 2015). The skip connections between the encoder and decoder directly map feature details from the downsampling layer to the up-sampling layer. This structure effectively prevents gradient vanishing and speeds up network convergence.
Specifically, the BFEB consists of two parallel encoders (E1 and E2) in the BM-GAN. E1 extracts global features from the input image using the first 16 layers of the VGG19 network. E2, as part of the colorization network, extracts local features through the first five layers of the MCN. The global features extracted are merged with the local features to guide the image colorization.
The schematic diagram of the fusion layer is shown in the red dashed box in Figure 2. Owing to its small receptive field, the U-Net network primarily captures local features that highlight image details. By incorporating global features from the pretrained VGG19 network, the colorization network acquires richer image information. This integration allows the network to assign colors more accurately to objects in the image and effectively alleviates color bleeding.
Multiscale Attention Block
To achieve high-quality grayscale image colorization, MSABs are integrated into the network. These blocks enable the network to emphasize the channel and spatial information across varying scales of each feature map. The structure is shown in Figure 4. A spatial attention structure is incorporated into the generator. It assigns importance to different spatial positions, which focus on the most relevant areas of the image. Channel attention enables the network to automatically learn the dependencies of each feature channel. By introducing MSAB, the ability of the network to learn feature channel interdependencies and spatial correlations is strengthened.
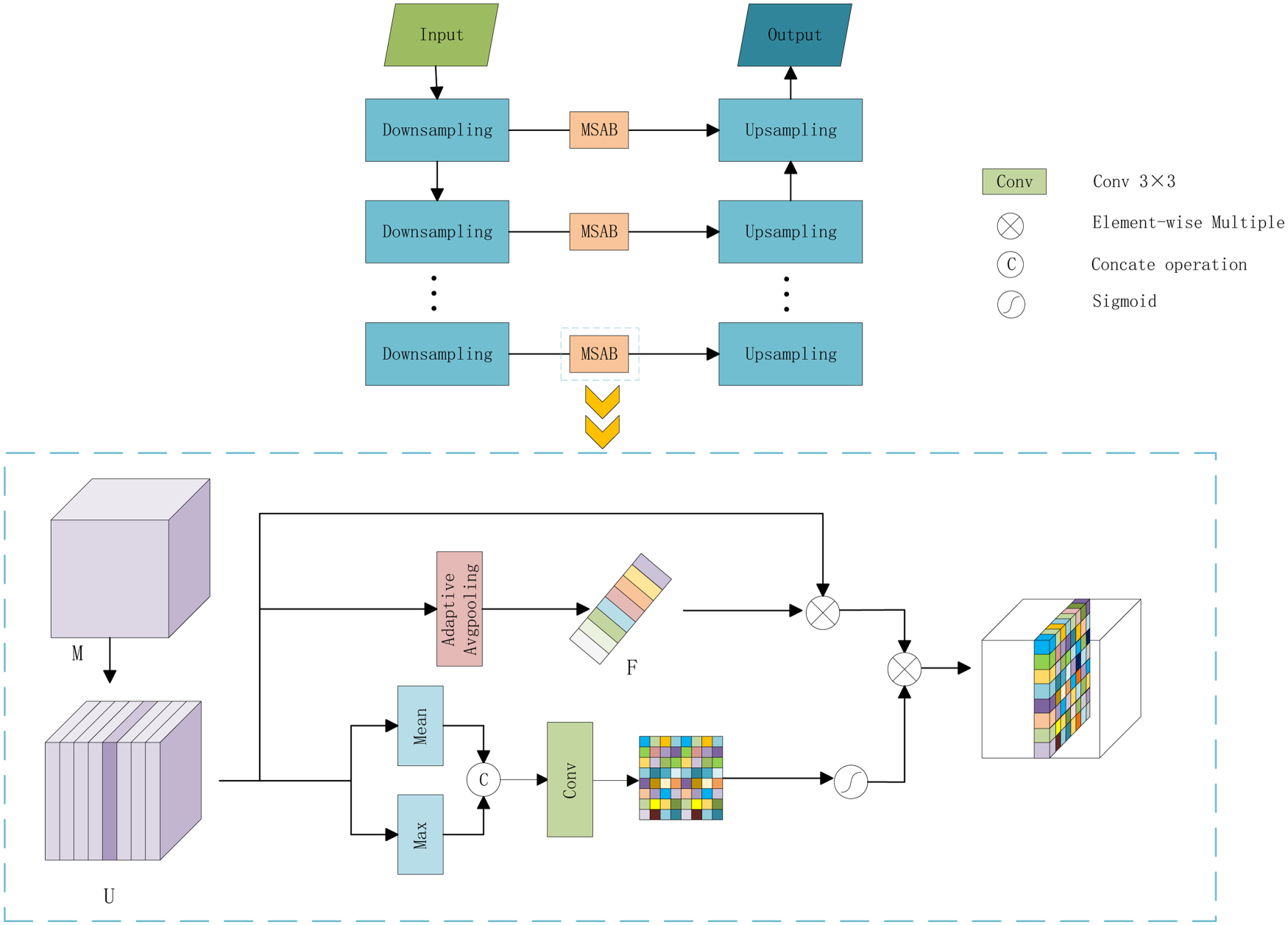
Architecture of the multiscale attention block.
Let the input feature map be denoted as

In the spatial attention mechanism, the feature map
The final feature map is obtained by the dot product of the feature maps from the channel and spatial dimensions. This adaptive attention block can be formulated as follows:
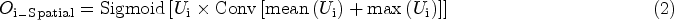


The loss function is an important reference for adjusting weights in the network. To better achieve accurate colorization of images, the loss function consists of two parts: generator loss and discriminator loss. The loss function of traditional GAN is represented as equations (5) and (6):


To enable the network model to generate high-resolution colorized images that closely resemble ground truth images, the

Therefore, to enhance the colorization effect of the network, a perceptual loss function is introduced. It helps align the colorized image more closely with the ground truth image in terms of visual appearance. In contrast to traditional pixel loss, perceptual loss relies on features extracted from a pretrained VGG19 network as a metric for loss. It measures the perceptual similarity of an image by comparing the differences in these extracted features. The perceptual loss function is as equation (8):

The total loss function of the generator includes equations (5), (7), and (8), and the expression for the new generator loss function is equation (9):

To enhance the convergence speed and stability of the network model, the gradient penalty (GP) term (Arjovsky et al., 2017) is used to constrain the discriminator’s gradient. It operates linear interpolation between real and generated samples, calculating the norm of the gradient of the discriminator at these points. This norm is then compared to the constant 1 (1-Lipschitz) and added as penalty terms to the loss function of the discriminator. The new discriminator loss function can be expressed as equation (10):
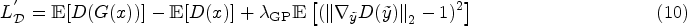
In this section, the Summer2winter and ImageNet datasets are first introduced and experimental parameter settings are explained. Then, comparative experiments are conducted to analyze the results obtained from each dataset. Finally, ablation studies are carried out on the loss functions and blocks to validate the effectiveness of the proposed method.
Datasets
Summer2winter
The Summer2winter dataset from CycleGAN was selected for the experiments (Shu et al., 2019). The dataset contains color red–green–blue images with a high resolution, which include 1231 in the test set and 309 in the training set.
ImageNet
To evaluate the colorization quality, 2000 images were randomly selected from the ImageNet dataset (Russakovsky et al., 2015) as the test set. The high-resolution images in the ImageNet dataset are particularly suitable for image colorization tasks.
Implementation Details
In the network architecture of BM-GAN, dropout is set to 0.5, and the normalization operation is set to instance normalization. During the training phase, the Adam optimizer is used with an initial learning rate of 0.0002. The batch size is 8, and the network is trained for 200 epochs, with
The network was implemented in Python 3.7 using the PyTorch framework. The discriminator and generator were trained alternately until the BM-GAN converged. The experiment was carried out on a Windows 11 operating system, equipped with an Intel (R) Core (TM) i5-13500X CPU @ 2.50 GHz, and an NVIDIA GeForce RTX 4060 graphics card. A GPU-based Python deep learning environment was set up for the training and experimentation.
Evaluation Metrics
To objectively reflect the performance of each colorization method on different datasets, peak signal-to-noise ratio (PSNR), structural similarity (SSIM), learned perceptual image patch similarity (LPIPS), Fréchet inception distance (FID), and information entropy (IE; Hore and Ziou, 2010; Wang et al., 2004; Tsai et al., 2008; Kumar et al., 2021) are chosen as evaluation indicators to quantitatively analyze the colorization results. PSNR is a commonly used objective measure for image evaluation. A larger PSNR value indicates smaller image distortion. The metric measures the difference between the generated image and the corresponding real image. It is frequently applied in quantitative assessments of image colorization, defogging, denoising, and related tasks. Given a clean image I and a noisy image K with dimensions
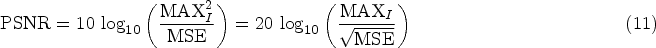
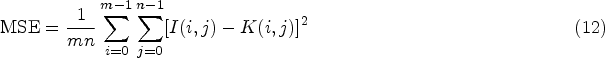
SSIM evaluates the quality of generated images based on brightness, contrast, and structural composition. The larger the value, the more similar the image structures are. If the images are exactly the same, the SSIM value equals 1. The formula for SSIM is as follows:
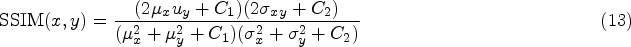
LPIPS is a learning-based metric for perceptual similarity that better matches human perception than traditional methods. The lower the value of LPIPS, the higher the degree of similarity. The formula for LPIPS is as follows:
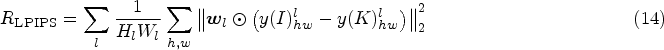
FID measures the quality of colorization by evaluating the difference between the feature distribution of the generated image and that of the real image. This metric reflects the similarity between the generated image and the real image. The formula for FID is as follows:
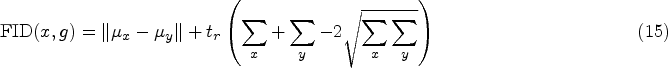
IE represents the average amount of information contained in an image and is a key indicator to measure the richness of image information. The greater the IE, the richer the image information and the better the image quality.
To verify the effectiveness and superiority of the proposed algorithm, it was compared to existing state-of-the-art methods (Iizuka et al., 2016; Yi et al., 2017; Larsson et al., 2016; Antic, 2019; Su et al., 2020; Lei and Chen, 2019; Vitoria et al., 2020; Kumar et al., 2021, 2023). All experiments were carried out in the same software and hardware environment. Each method was trained for 200 epochs on the Summer2winter and ImageNet datasets. The results are shown in Figures 5 and 6.

Comparison of colorization results of different methods on the Summer2winter dataset (the first and last columns represent input and ground truth images).

Comparison of colorization results of different methods on the ImageNet dataset (the first and last columns represent input and ground truth images).
Certainly, Figure 5 illustrates the qualitative outcomes of the proposed BM-GAN and other methods on the Summer2winter dataset. For example, in line 4, Zhang et al. and Larsson et al. produced grass colorization that does not match the ground truth image and exhibits color bleeding. DeOldify et al. and Su et al. proposed methods to obtain images with low color saturation. The proposed method prevents color bleeding. In line 2, other methods have the problem of missing color details, ignoring the color details of the grass in the lower left corner. There are also gaps in the colors of the mountains and sky compared to the real image. The proposed method not only restores the color details of the grass but also ensures that the overall color scheme is closer to the real image. From the above comparison, it is obvious that the proposed method can alleviate the problems of color bleeding and detail loss to a certain extent while preserving more color information.
Certainly, Figure 6 illustrates the qualitative outcomes of the proposed BM-GAN and other methods on the ImageNet dataset. For example, in line 3, the image produced by Zhang et al. and Vitoria et al. is closer to the real image, but there is a serious color bleeding problem. The method of Vitoria et al. mitigates the color bleeding but does not assign the correct color to the walls. The method in this paper ensures correct colorization without color bleeding. In lines 4, 5, and 7, the image obtained by Lei et al. is discontinuous and presents an unnatural colorization effect. Although the method by Su et al. performs better than those by Iizuka et al. and Zhang et al., it still does not fully match the real image. In contrast, the proposed method more accurately restores the colors of the puppy, grass, and buildings, achieving the highest similarity to the real image. In line 6, the image produced by Lei et al. and Vitoria et al. has obvious color bleeding. BM-GAN effectively captures detailed information and reduces the error distance between the generated and real images.
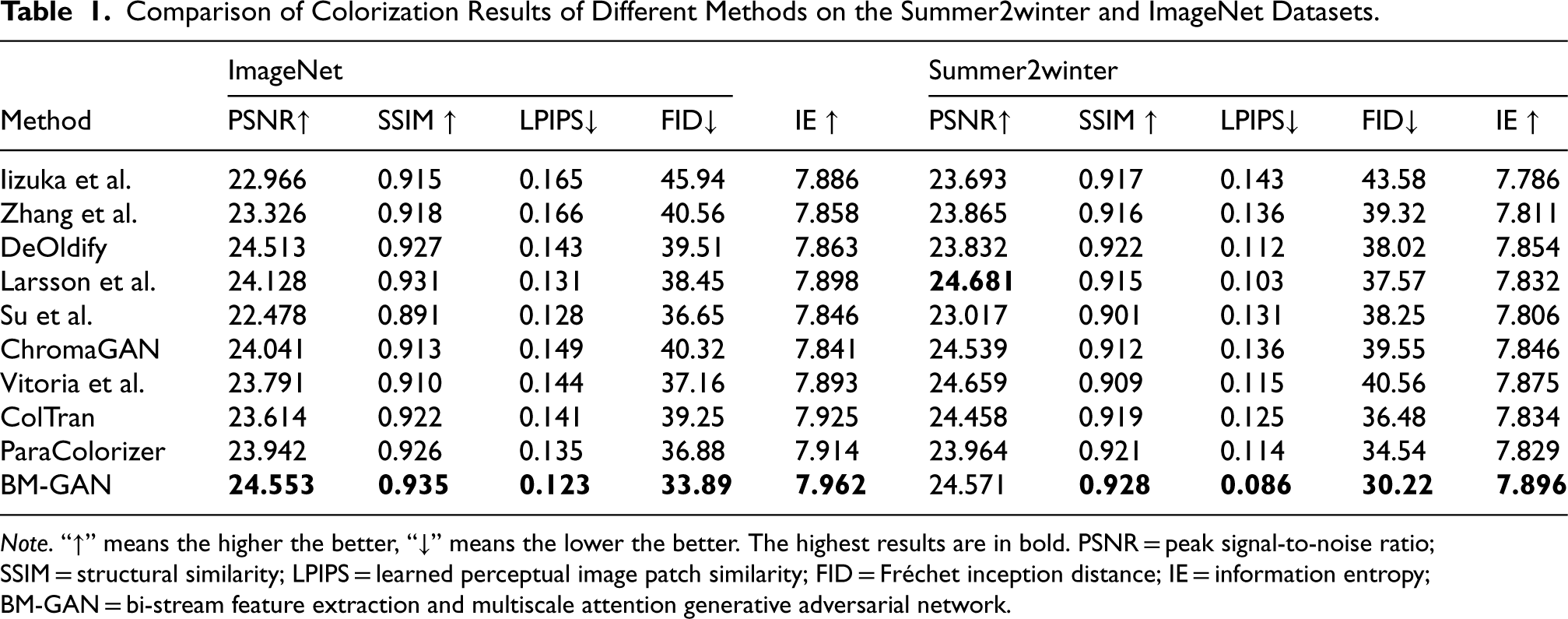
Quantitatively evaluate the results of image colorization methods using the four evaluation indicators introduced in Section 4.2, as shown in Table 1. It can be seen that the value of the PSNR reached 24.571, the value of the SSIM reached 0.928, the value of the LPIPS reached 0.086 and the value of the FID reached 30.22 on the Summer2winter dataset. On the ImageNet dataset, the value of the PSNR reached 24.553, the value of the SSIM reached 0.935, the value of the LPIPS reached 0.123, and the value of the FID reached 33.89. The PSNR of the proposed method is not the highest, which is expected given the weak correlation between PSNR and the human visual system. SSIM was introduced to evaluate structural similarity to address the limitation that PSNR does not fully capture the alignment between image quality and human visual perception (Wang et al., 2018). The SSIM index of BM-GAN is significantly better than other methods, and the generated image is closer to the real image. The method in this paper has the lowest LPIPS and the lower FID value indicates that the results in this paper are closer to the real image.
Comparison of Colorization Results of Different Methods on the Summer2winter and ImageNet Datasets.
Note. “
On both datasets, BM-GAN ranks first in SSIM metrics, which means that the system can accurately simulate the perceptual structure of the reconstructed image. The proposed method can generate results that are consistent with the real image. The IE value of BM-GAN is also higher than other methods, which indicates that the color distribution of the generated image is more diverse. The low IE means that the color distribution of the generated image is more concentrated and lacks diversity.
The above quantitative indicators indicate that for the same test image, BM-GAN not only produces authentic colors but also has a natural transition between them. Compared with other methods, the color image generated by BM-GAN has a better effect.
The validity of the proposed method is further validated by comparing the proposed method by Su et al. on the ImageNet test set (10k). The experimental results are shown in Figure 7. It can be seen that BM-GAN still performs better on the same test set. This is because the images obtained by the proposed method have clear boundaries and rich textures. The colorization results of BM-GAN are visually closer to the ground truth images, especially in the region containing sky and grass. In addition, the results of quantitative metrics are shown in Table 2. The proposed method is not only better than Su et al. in PSNR, SSIM, and LPIPS, but also the FID metric reaches 36.72.

Comparison of colorization results of Su et al. on the ImageNet test set (10k) (the first and last columns represent input and ground truth colorful image.
Comparison of Colorization Results of Different Methods on the ImageNet ctest 10k.
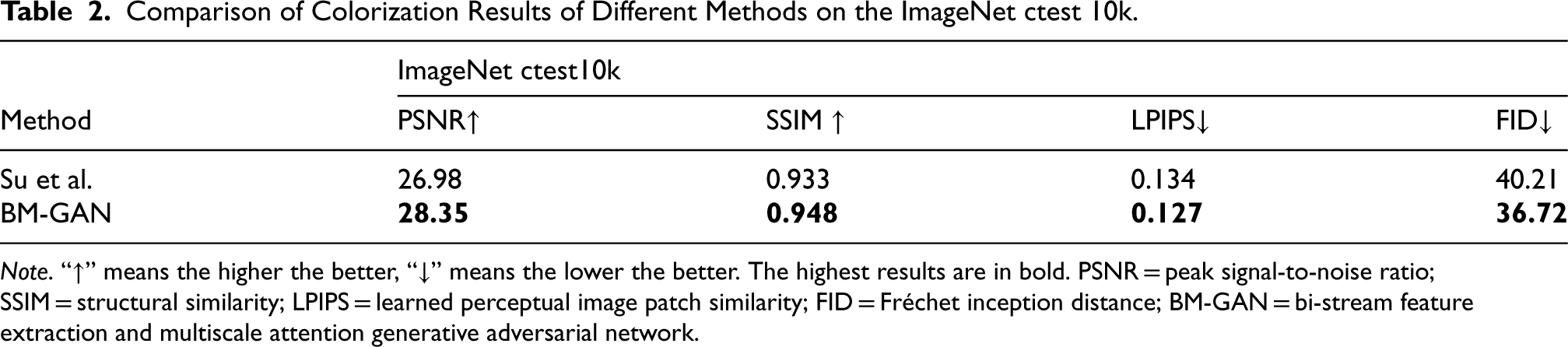
Note. “
Quantitative metrics are intended to objectively assess the quality of a method. But in image colorization, the goal is not to achieve fixed colors but to produce colors that are as realistic as possible. A method is considered effective when its colorization results offer rich color information that enhances the expressive quality of the image.
Therefore, to establish an image evaluation metric based on user evaluation, a certain number of color images were randomly selected from all color images generated by DeOldify et al. and BM-GAN. Without informing the users about the generation method, users were asked to subjectively select the image with better colorization. Fifty participants were invited, and seven pairs of images were randomly selected from the two methods for the experiment. Each participant viewed the same grayscale image produced by both methods and was given 5 s to choose the image they considered more natural and visually harmonious. After each selection, participants were not informed of the model used to generate the images.
The results of the user-based image quality assessment are presented in Figure 8. The subjective willingness scores from users show that the colorization effect generated by BM-GAN is more highly recognized compared to that of DeOldify et al. This indicates that the colorization achieved by the proposed method is superior and more consistent with the human visual experience.

Comparison of user evaluations of different method colorization experiments.
To further confirm the effectiveness of each block, experiments were conducted with various network structures to evaluate how each block influences the overall performance of the method.
Ablations of Different Blocks
Ablation experiments were conducted on the BFEB, the loss function and the MSAB.
Figures 9 and 10 show the results of ablation experiments on both datasets, demonstrating the clear benefits of the proposed method. The PSNR, SSIM, and LPIPS values of the test results on Summer2winter and ImageNet datasets are shown in Tables 3 and 4. Compared to the baseline network, the network with the addition of each block shows improvements across all metrics. The addition of each block significantly reduces miscoloring and color bleeding. The colorization effect is also more realistic and natural, contributing to greater overall color harmony. Removing the BFEB leads to inaccurate colorization with visible color bleeding, which has a considerable negative impact on the PSNR, LPIPS, and SSIM values. This demonstrates that the BFEB enhances the colorization effect. MSAB enables the fusion of channel and spatial information, which can help the network to better preserve the detailed features of the image. However, the removal of MSAB significantly degrades the performance of the colorized network. Moreover, the loss function allows the network to capture high-level semantic information, ensuring that the colorization remains consistent with the real image.

Comparison of results for different network architectures on the Summer2winter dataset.

Comparison of results for different network architectures on the ImageNet dataset.
Comparison of Ablation Experiments on the Summer2winter Dataset.
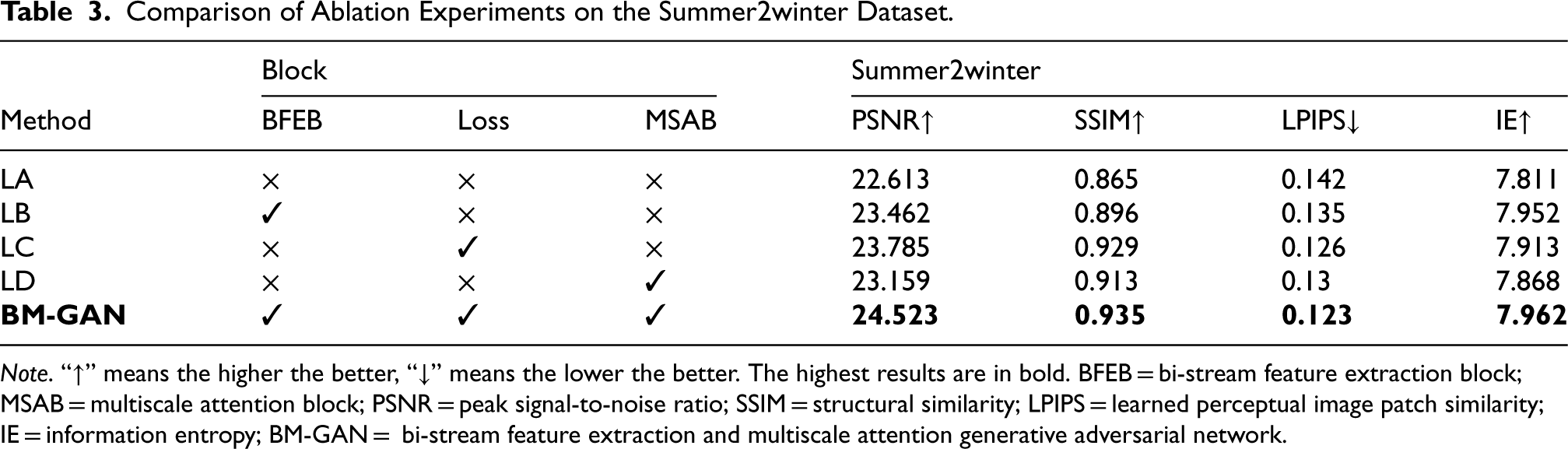
Note. “
Comparison of Ablation Experiments on the ImageNet Dataset.
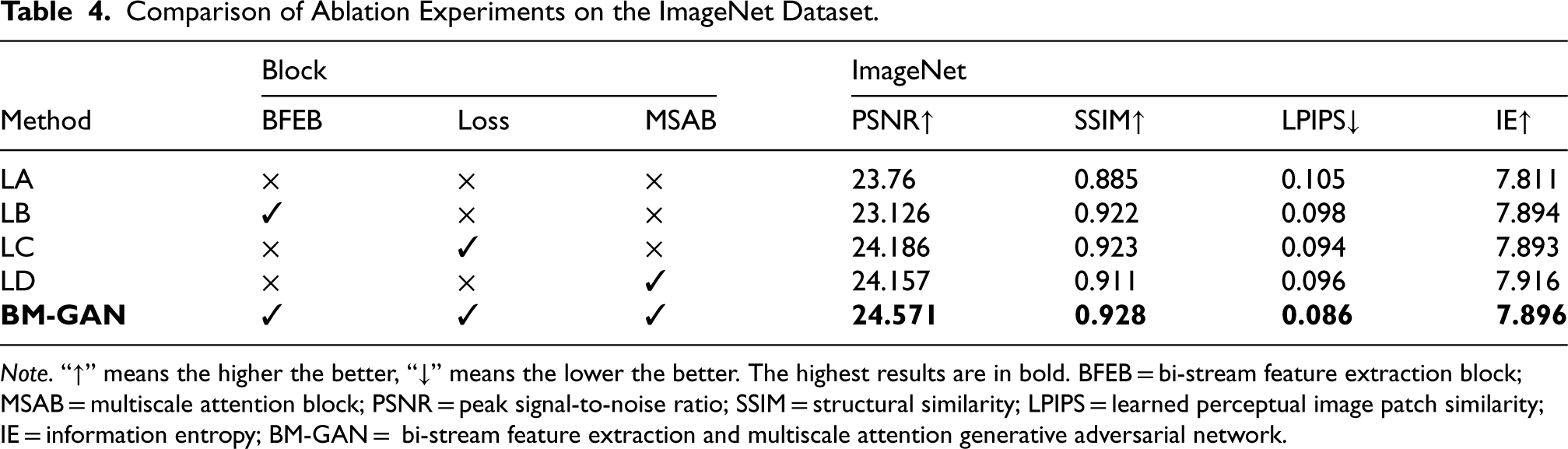
Note. “
The impact of each loss function is also discussed, and the comparison results are shown in Figure 11 and Table 5. The figure shows the colorization effect of different loss functions and the corresponding LPIPS mapping graphs. The change of color in the mapping graph corresponds to variations in LPIPS values, which reflects the perceived similarity between the generated image and the real image. A color closer to dark purple indicates a lower LPIPS value and a smaller difference between the generated and real images. Conversely, a color closer to yellow signifies a higher LPIPS value and a greater difference between the generated and real images. Visualizing the LPIPS provides an intuitive way to identify significant differences in features or structures between the generated and real images. This approach also makes it easier to observe the perceived similarity across various parts of the entire image.
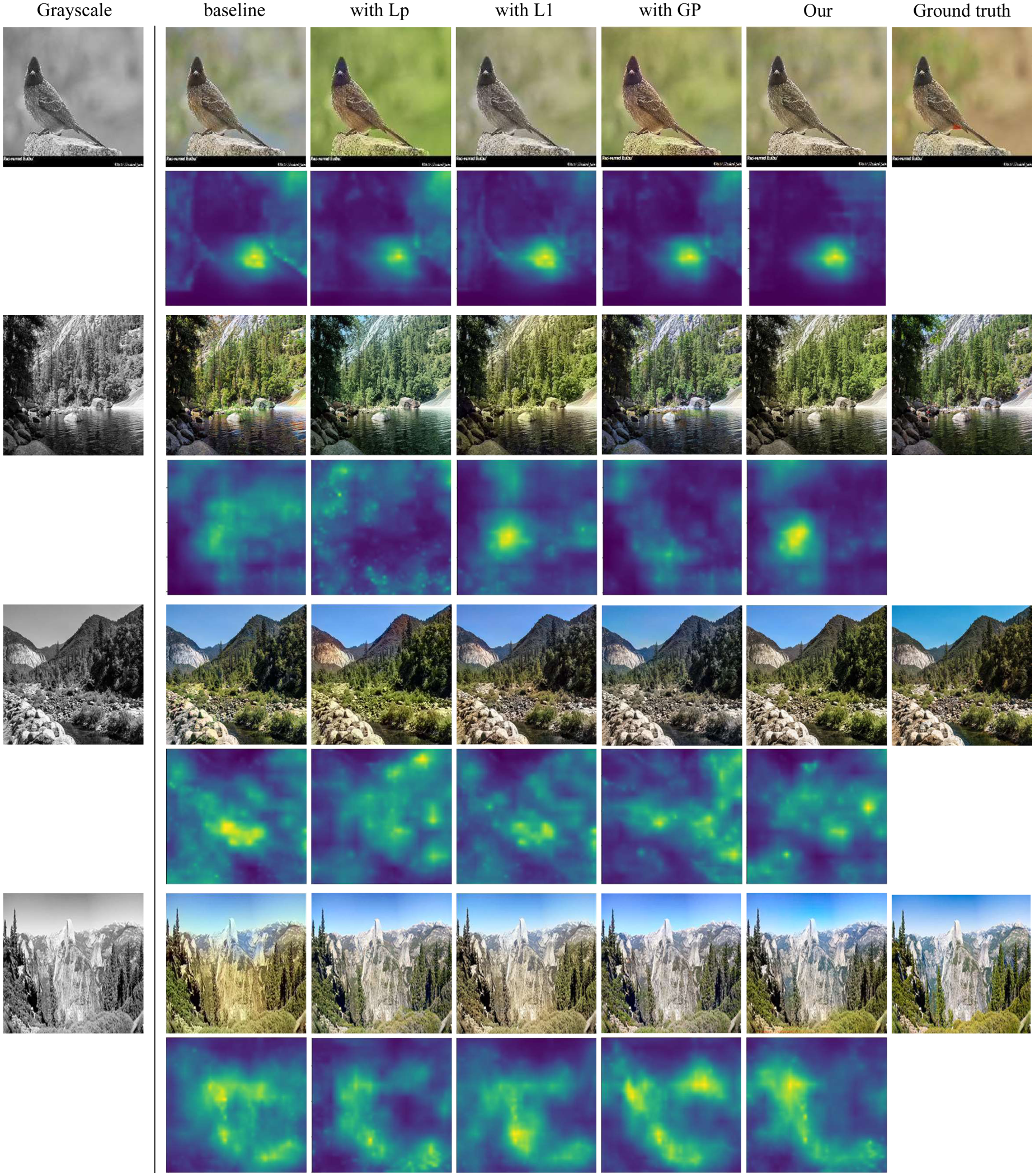
Comparison of results for different loss function on the Summer2winter and ImageNet datasets.
Comparison of Ablations of Different Loss Functions Experiments on the Summer2winter and ImageNet Datasets.
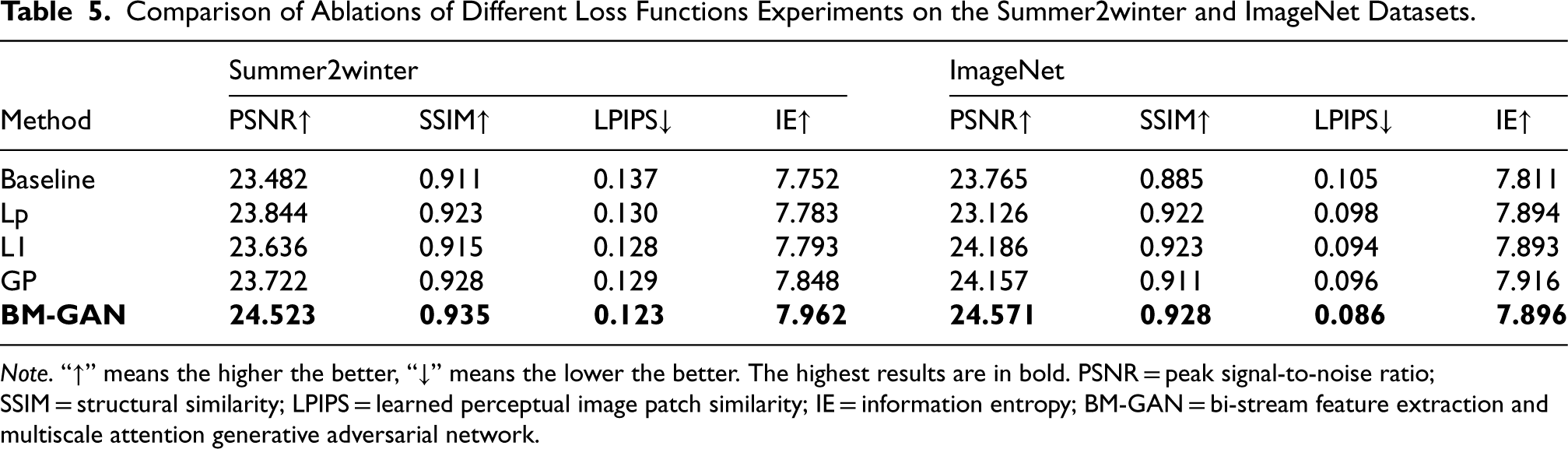
Note. “
Compared to the baseline network, the addition of perceptual loss enhances the alignment of the generated image with the real image in terms of color, texture, and structure. The
To verify the advancement of the proposed BM-GAN in practical applications, BM-GAN was used to colorize the LLL images. Based on the MPPC LLL experiment platform, several sets of LLL images were captured in an LLL environment. The LLL experiment platform mainly consists of the MPPC detector, two-dimensional guide, lens hood, computers, optical fibers, and cables connecting various devices. The schematic block diagram is shown in Figure 12. Firstly, a small amount of light reflected from the target object is refracted through an optical lens and converges at the rear of the lens to form a two-dimensional image plane. Subsequently, a two-dimensional guide directs the MPPC detector to scan the image plane point by point and captures the photon count value at each point. Finally, the captured data is transmitted to the computer via optical fiber and restored to an LLL image by image restoration. Unlike traditional paired techniques, LLL image colorization takes low signal-to-noise ratio images as input. Therefore, utilizing an attention mechanism to improve the adaptability of a network to handle low signal-to-noise ratios and uneven brightness is essential for LLL image colorization. The color accuracy of the generated images may not fully match that of paired techniques, but they offer valuable information under extreme conditions. The core idea of LLL image colorization is to apply convolution and multiple downsampling to the input grayscale image to obtain its high-level features. These features are then used to infer the color information in the a and b channels, which are then combined with the L channel to generate the final image. Figure 13 shows the difference between the conventional paired technique and the LLL image colorization technique.
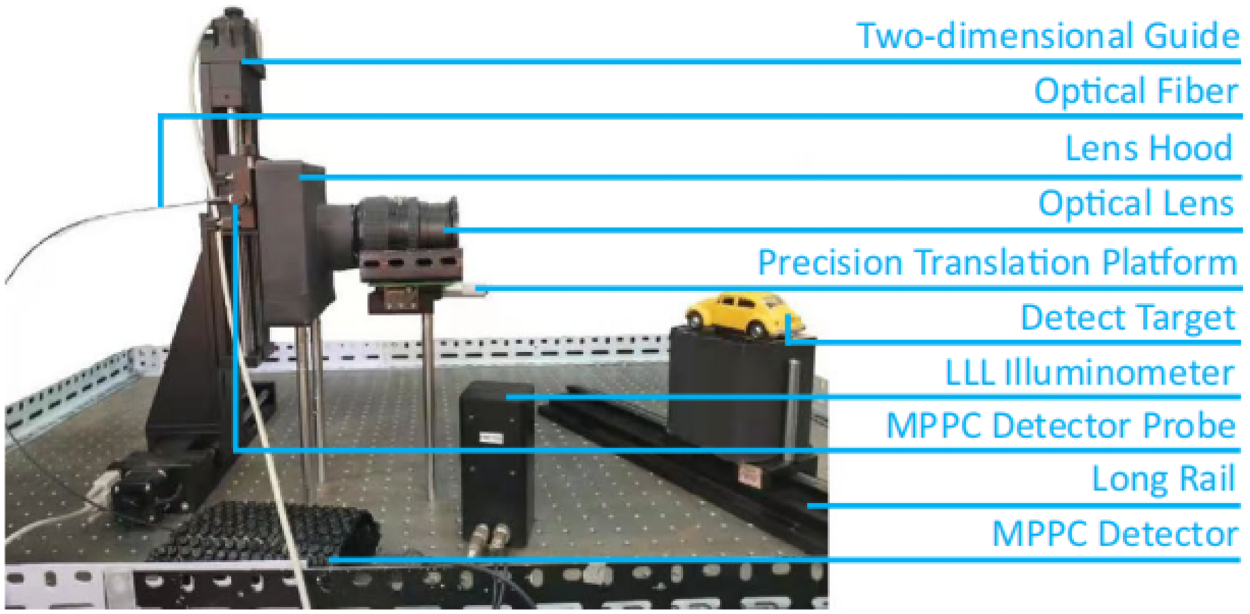
MPPC platform. Note. MPPC = multipixel photon counter.
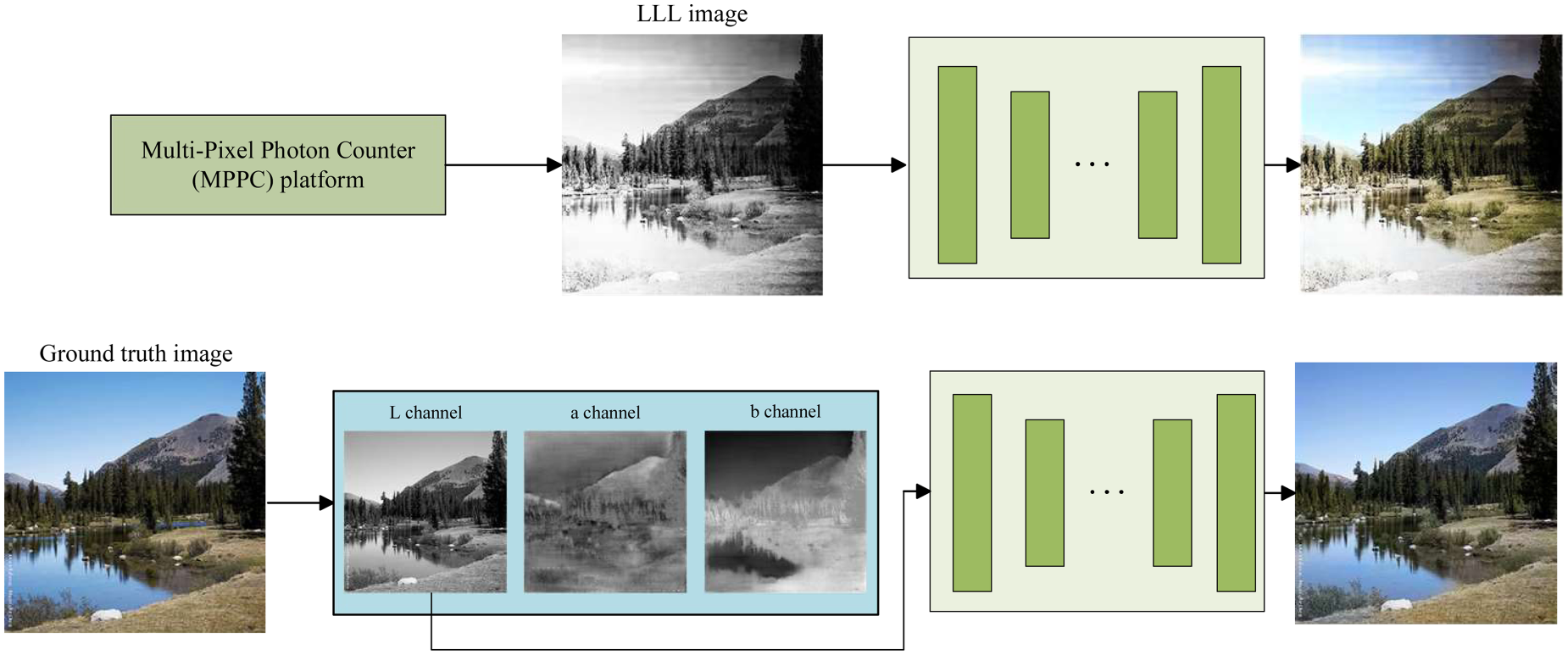
The difference between the conventional paired technique and the LLL image colorization technique. Note. LLL = low-light-level.
Colorization experiments are performed on the LLL images and compared to existing state-of-the-art methods. Usually, to achieve a better LLL image colorization effect, the network model training should use an LLL image and a corresponding color image. However, due to the condition limitation, a grayscale image and corresponding color image from the dataset were adopted as the training set to train the network model. Although the LLL image also belongs to the grayscale image, there is a certain difference with the grayscale image from the dataset. If a neural network model trained on grayscale images from the dataset can successfully colorize LLL images, it further validates the advancement of BM-GAN. The LLL image colorization effect is shown in Figure 14.

Comparison of colorization results of different algorithms on LLL images. Note. LLL = low-light-level.
The colorized LLL image provides a more visually comfortable experience and makes the contained information easier to discern. In addition, the colorization results show that BM-GAN is well-adapted and of high practical value.
To further validate the performance of the BM-GAN, colorization validation was performed on SAR images from LS-SSDD-v1.0 dataset (Xu et al., 2022a, 2022b, 2022c; Zhang et al., 2021; Zhang et al., 2020). Some of the results are shown in Figure 15. While SAR images are used in remote sensing due to their powerful ground imaging capabilities, their visual analysis and interpretation are often constrained because they are typically presented in grayscale. The features and color details emphasized in SAR images differ from those in the training set utilized in this study. Nonetheless, BM-GAN is capable of producing more realistic colors, which reflects the strong fitting ability of BM-GAN and consistent performance across various image datasets. The conversion between SAR and optical images offers observers detailed structural and scene information to enhance SAR image visualization.

Comparison of colorization results of different algorithms on SAR images. Note. SAR = synthetic aperature radar.
This paper proposes an innovative colorization method for grayscale images called BM-GAN. The network enhances its feature extraction capabilities by leveraging a BFEB to integrate both global and local features. Additionally, an MSAB is employed to highlight features related to colorized objects in both channel and spatial domains. The block improves the ability of the network to perceive texture and color. A composite loss function is constructed for training, which reduces the gap between generated and real images. BM-GAN is applied to LLL and SAR images to improve human target recognition and scene interpretation. Experiments demonstrate that BM-GAN effectively addresses issues such as semantic confusion, color bleeding, inaccurate colorization, and loss of image details. Nevertheless, certain limitations exist. In images with blurred edges, the colorization results may deviate from the real image.
Footnotes
Author Contributions
Xiaoning Gao contributed to conceptualization, methodology, software, writing, reviewing, and editing. Liju Yin contributed to visualization, investigation, and supervision. Yulin Deng contributed to data curation, software, and validation. Feng Wang contributed to writing—original draft preparation. Yiming Qin and Meng Zhang contributed to software.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Shandong Province, China (ZR2020MF127).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.