
Abstract
Amazon's Alexa has long been presented as a leading force in voice assistant technology, yet the rapid rise of large language models has raised new questions about innovation within the Amazon Alexa Platform. This article analyses Voice Assistant Development in the context of the Alexa Prize Competitions, Amazon's program that invites university teams to build conversational systems using its proprietary platform. Drawing on qualitative interviews with participants, the study examines how Amazon's Platform Governance structures shape the conditions of Third-Party Developer Innovation and influence the everyday work of developing for the Alexa ecosystem. Using theories of science, infrastructure and platform studies, the analysis shows that Amazon's emphasis on user satisfaction—and its use of Alexa's platform capabilities as a ranking mechanism—directs developer effort away from exploratory innovation and toward continuous maintenance and repair. These dynamics are reinforced by Amazon's organizational processes, which establish evaluation, support, and oversight in ways that further limit Third-Party Developer Innovation. The findings reveal how the company's Software Development Infrastructure simultaneously enables and constrains novelty, producing a culture of ‘good enoughness' that stands in tension with the competition's rhetoric of Silicon Valley exceptionalism. By situating the Alexa Prize Competitions within Amazon’s broader model of platform governance and third-party engagement, the article contributes to sociological research on infrastructure, platform companies, and innovation, demonstrating how corporate management and infrastructuralization shape the development of everyday voice assistant technologies.
Keywords
Introduction
Amazon's Alexa was portrayed as being at the bleeding edge of innovation for a decade. As one of the few dominant companies in the voice assistant industry, Amazon has taken a leading role in establishing and developing how people talk to smart devices. While platform technologies can be ephemeral and fragile, the companies behind them usually are credited to have some competent oversight of their products’ future (Edwards, 2021: 333). In recent years, however, this image could be painted from a different perspective, as Amazon seems to struggle with the introduction of large language models challenging Alexa's core functionalities (Strüver, 2025). Investigating the organizational and sociotechnical circumstances of Alexa development during these turbulent times can give insights into one of the largest technology companies’ development practices, showing how the work of software development and innovation for the Alexa platform is managed. Due to its material presence in smart homes, Alexa has played an important role in people's daily life as a speaker-borne voice assistant, assisting with small tasks like setting timers, turning on lights, or playing music when spoken to, making it an ‘infrastructuralized platform’ (Plantin et al., 2018). Further, Alexa integrates within Amazon's platform ecosystem (Strüver, 2023), placing the company in control of the interactions third-parties and users have with their technology (Ametowobla and Kirchner, 2023; Dolata and Schrape, 2023). Amazon, like other large platform companies, holds competitions to acquire new ideas from third-parties into their ecosystems (Hallinan and Striphas, 2016; Luitse et al., 2024; Seaver, 2022: 56–58), but also to garner publicity for a technology (Khan, 2020: 90). These openings are usually presented as opportunities for outsiders to work with coveted platform technologies and gain insights into cutting-edge industry processes (Hind et al., 2024), forming a ‘protective niche’ (Geels, 2005) to explore novelty within the boundaries of existing technology. Amazon has established the Alexa Prize Competitions (APCs), where teams of university researchers gain access to Alexa technologies for 1 year and compete to produce novelties for the voice assistant, connecting to the much-touted development culture of Silicon Valley (Fourcade and Healy, 2024: 12).
Against this background, the development practices within the APCs can be investigated to question how innovative work for Amazon Alexa truly is, while paying close attention to the effectiveness of platform affordances in innovation management and the implications of infrastructural conditions on software development work. Based on qualitative interviews with competition participants, the following arguments will be presented and investigated: how the platform conditions of working within Alexa under Amazon shape development; the consequences of the infrastructuralization of Alexa into the daily lives of smart home dwellers for software development; Amazon's limitations in organizing innovation through software development competitions will be traced, as participants navigate a complex competitive situation and question Amazon's sincerity; how Amazon's strict control over third-parties stymies innovation for Alexa; and how this is an emblematic organizational trait within the company. To stage this analysis, the next section will introduce the APCs as research objects and lay the theoretical groundwork for understanding software development within Amazon.
Alexa Prize Competitions as an innovation system
Competitions and challenges issued by large technology companies had significant cultural impact on the developing field of computer engineering (Hallinan and Striphas, 2016; Hind et al., 2024). Especially with the turn to artificial intelligence (AI), their institutionalization in the discipline can be seen within AI development as a normalized ‘sporting competition environment’ (Orr and Kang, 2024). The purpose of development prize competitions seems to be to drive innovation, recruit possible future employees, involve multiple stakeholders and organize development (Adamczyk et al., 2012: 346). Prize grantors often have sway over the outcomes and the competition-progression, but even with powerful platform actors, it is not predictable how big their contribution to innovation will be (Luitse et al., 2024; Seaver, 2022: 56–58). This claim of uncertain outcomes and efficacy is not limited to platformized competitions but holds true historically for various models of competitions (Khan, 2020: 385). Perhaps this is the reason for the APCs differing from archetypical competitions as means of crowd (and out-) sourcing development work, since Amazon closely supervises the APCs and invests significant resources into accompanying the participants throughout the process (Johnston et al., 2023). Platformized competitions like the APCs can be classified as ‘administered innovation systems’ (Khan, 2020: 69), where a singular actor is in control of making decisions about competition rewards and proceedings, which can create information and power asymmetries, emphasized by Amazon's increased involvement.
These competitions exist within the narratives of Silicon Valley's focus on constant innovation. They foster a culture of innovation at any cost, established through a multitude of narratives and beliefs repeated by companies and ‘thought leaders of capitalism’ (Fourcade and Healy, 2024: 30). Such narratives are the bedrock of Silicon Valley and a way of thinking about the world as a place to be improved with software development as a competitive sport. The drive to achieve excellence, efficiency and novelty are instilled into the workforce ‘to make software technology that is “disruptive”, “critical” or “important”’ (Bialski, 2024: 25). However, questioning pristine imaginaries produced by Silicon Valley and understanding them as a social process allows an investigation of software development work practices and helps reintroducing sociality into discussions of innovation and the resulting machine learning systems (e.g. Engdahl, 2024; Jaton, 2020; Seaver, 2022). Bialski (2024) shows how software work is fraught with idiosyncrasies, redundancies and slowdowns that are deeply social in their process, resulting in compromises and software versions that are ‘good enough’ for the moment, rather than perfect. Instead of disruptiveness, developers often involuntarily settle into an ‘incremental mode’ (Lindblom, 1965). While inherently not problematic, developing software in this incremental mode stands in contrast to what Silicon Valley ideology demands. This process of muddling through innovation in the face of the idealized demand for excellence created by structures typical to infrastructuralized platforms is the focal point of this paper, as it traces tensions in the APCs speaking to the state of innovation for Alexa.
First organized by Amazon in 2017, APCs consist of three different annual competitions (Figure 1), starting with the Socialbot Grand Challenge, where Amazon encourages 10 chosen university teams (composed of PhD students and a senior researcher acting as team leader) worldwide to build a conversational bot ‘that converses coherently and engagingly with humans on popular topics and news events for 20-min’ (Amazon, 2023). In 2021, Amazon added the TaskBot and SimBot Challenges with more practical and embodied goals. In TaskBot, users cooperatively complete a DIY project (e.g. cooking a recipe, or following an origami instruction) with Alexa, while in SimBot they use Alexa to, for example, verbally guide a robot to retrieve items in a virtual environment. According to Amazon, the goal of these competitions is to accelerate ‘the field of artificial intelligence’ and provide ‘novel engaging interactions’, to Alexa users ‘[t]hrough the innovative work of students’ (Amazon, 2022a). The competitions have a similar structure in time, incentive and supervision. Amazon provides an initial budget of US$250,000 and a certain amount of AWS-cloud credit for each team and up to US$250,000 prize money for the winners.

Alexa prize challenges (https://www.amazon.science/alexa-prize).
The competitions’ schedules (Figure 2) can be generally split into two overarching stages: In the initial stage, accepted teams develop their internal baseline bots with rudimentary functions, followed by a boot camp where Amazon employees establish a common understanding of Alexa's development infrastructure. The second overarching stage consists of releasing bot functions to the public, after they have been internally tested and given feedback by Amazon employees. In these ‘interaction periods’, Alexa users in the USA interact with an Alexa-app specific for the APC to talk to the teams’ bots, leaving a rating (1–5 stars) and written feedback. The combined rating of a bot is reflected on a daily-updated leaderboard, ranking the teams, allowing them to judge how changes made to the bots reflect on user ratings and revisit changes accordingly. This leaderboard eventually determines which teams remain for the ‘Finals Interaction Period’ and ultimately the placement of the winning teams and allocation of prize money. While the leaderboard is instrumental to determining winners, the APCs remain an administered corporate innovation system (Rikap, 2022; 2024), controlled by Amazon, which can create ‘inefficiencies such as unfair discrimination and arbitrary decisions’ (Khan, 2020: 70), which can affect the progression through the competition.
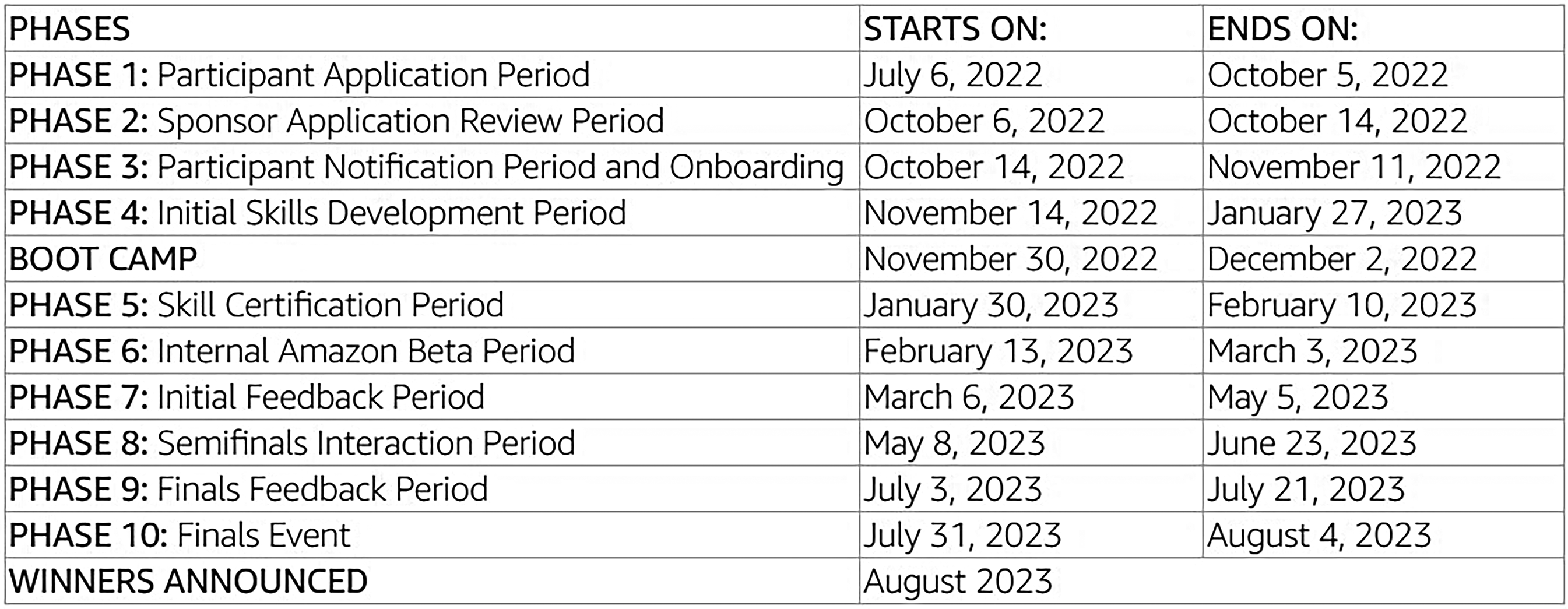
Schedule for the 5th social bot challenge (Amazon, 2022b).
Amazon scientists describe that the ‘competition enables university teams from around the world to test their innovations at scale with Alexa users’ (Johnston et al., 2023). While this is marketed as a unique selling point of the competition, it also means that in the second stage participants interface directly with Amazon's infrastructures that connect Alexa to users, transferring considerable importance onto tailoring development to Amazon's platforms. Studying the APCs from this perspective shows how innovation for Alexa is accomplished and managed through various technology relationships, continuing the investigation into Amazon's platform governance (e.g. Delfanti, 2021) and reliance on third-parties (e.g. Rowberry, 2022: 42; Weigel, 2023; Woodcock and Cant, 2023), often mediated by platform technologies. Platform technologies’ modularity allows adding applications, devices or services to them, making modern platforms connect various entities, such as companies, users, third-parties or advertisers (Van Dijck et al., 2018). Through relational and infrastructural connections, platforms offer various tools to control and delimit the realms of possible interactions with and within their domains (Gerlitz et al., 2019; Van der Vlist et al., 2022). This centre-periphery relationship represents a power asymmetry where platform organizations control others’ platform interactions (Ametowobla and Kirchner, 2023; Dolata and Schrape, 2023; Frenken and Fuenfschilling, 2020) and attempt to ‘orchestrate’ the ecosystem surrounding their technologies (Van der Vlist, 2022), aligning labour on it with their own interests (Nieborg et al., 2024; Rikap, 2022; Srnicek, 2022) in an act of platform governance (Gorwa, 2019).
APC participants establish connections to Amazon services and cloud infrastructures in the competition's first stage and are introduced to more platformized development tools in the boot camp. Thus, it is clear how Amazon expects participants’ development to interact with its own vast set of infrastructures without friction. Correspondingly, these development infrastructures and platforms turn into standard pathways for parts of the internet (Van Dijck, 2021), becoming infrastructuralized (Plantin et al., 2018). This is illustrated by the second stage of the APCs when participants’ projects become part of users’ Alexa interactions and therefore need to continually hold certain standards for which platformized development functionalities are critical. This emphasizes the infrastructural backbone for internal and third-party platform development, as they ensure the platform's function and its alignment with the companies’ interests. They can range from contracts, to (technologically mediated) rules, application programming interfaces, software development kits or more loosely communicated ideals and goals (Dolata and Schrape, 2023: 12). The notion of infrastructure helps to understand how the ‘subtending’ (Slota and Bowker, 2017: 540) platform acts as an infrastructure that does not have to be actively re-considered in action by actors and supports daily work. This also highlights the hierarchical organization of platform development carried out by different actors on different scales. Software development in the APCs is situated within Amazon's platformized infrastructures of development which implicitly emphasize the need to interface well with the Amazon ecosystem.
This study is based on 12 1 h video interviews conducted in early 2024 with participants of all three versions of the 2022/2023 APCs. Participants, nine from the USA and three from Europe, came from 10 different university teams (see Table 1). Seven participants were PhD students, two MSc students and three professors in faculty and team-leading positions; the average age was 29. Final ranking placement of the teams whose members were interviewed was not slanted in any direction. Like the skewed gender representation in the field of computer sciences, there were only two women in the sample of interviewees. To elicit narratives from the interviewees describing their experience throughout the competition, the guiding qualitative interview questions were equal parts narrative and expert interview (Bogner et al., 2018). Narrative components ensured a more personal conversation, evoking statements beyond factual retellings. With signed consent, interviews were anonymized and analysed according to thematic qualitative analysis (Kuckartz, 2014: 70). Interviewees’ quotes are referenced by pseudonyms using neutral pronouns for further anonymization. When a sentiment was shared multiple times between different interviewees, it is paraphrased and indicated in single quotation marks. As the interviews were conducted at the start of 2024 with participants who had competed in the 2022/23 APCs, which ended in 2023's autumn, limitations of recency apply. Further, participants were under non-disclosure agreements with Amazon (Amazon, 2022b) making some information vague. A previous study (Strüver, 2025) utilizing the same data focusses on engineering artificial intelligence capabilities for Alexa within the competitions and differs from the present study, which investigates the APCs’ organizational embeddings. Despite changes in the Alexa team in the wake of large language models, the study at hand can show how Amazon innovates (on Alexa) and how they conduct themselves in their relationships with third-parties. Furthermore, this facilitates underpinning the sociotechnical analysis of voice assistants, which have been studied from a multitude of perspectives and are globally prevalent (Habscheid et al., 2025). Contributing to the body of research that questions their platformized technological foundations (e.g. Goulden, 2019; Pridmore and Mols, 2020; Sadowski et al., 2021), qualitative inquiry of APC-procedures illuminates the sociotechnical mechanisms subtending Alexa. The APCs will now be contextualized to establish a thorough understanding of platform work in the competition for the subsequent sections.
Interview participants’ demographics.

Live user ratings as a faulty but glorified metric
To the outside world, Amazon portrays a brand narrative of having a ‘customer obsession’ in its media endeavours. West (2022: 57) argues how Amazon specifically cares about touch points customers have with their brand. Accordingly, Alexa acts as the prime touch point for the smart home (Strüver, 2023: 113). This becomes a fundamental constraint for innovation in Alexa, as the device consistently needs to function well enough to assure users’ satisfaction with it. In the APCs this manifests in the judgement of participants through a daily-updated leaderboard. Participants’ placements are determined by users’ interactions with the teams’ bots, which they rate on a scale from one to five stars. This form of ‘human voting-based benchmark’ is a standard when evaluating machine learning models, as ‘models should ultimately align with human values’ (Singh et al., 2025: 30) and are therefore easiest judged by users. Reportedly, the daily ranking became the participants’ main indicator for quality and consequently their focus. They emphasized that code had to be ‘tested stable’, as ‘it was delivered to end-customers. And there was quite a high bar for the quality of code’ (Centis). Alexa users are implicated in the process and success of the teams, emphasizing the importance of the ratings leaderboard. The institutionalized focus on competition (Orr and Kang, 2024) and the drive for excellency in software development (Bialski, 2024: 25) become evident in this. Modern platform technologies afford the capture of live user feedback, making it an easy choice for the platform company to facilitate the ranking of competitors and testing their work (Dolata and Schrape, 2023: 13). While most of the developers eventually figure out a way to test their code internally before publishing it to the general user base – for more detail on testing, see Strüver (2025: 390) – this focus on ratings underscores the ‘pressure-conditions’ under which developers are working. Considering how central star ratings are to the competitions, their accuracy and efficacy were reported to be questionable by multiple developers, who described the ratings as ‘useless, repeating, coarse grained, not reliable, not constructive, unpredictable’, or ‘noisy’. The main cause for these assessments is that developers considered the ratings inconsistent with their perceived performance of their own code, as some thought ‘it wasn't a fair assessment of any of the capabilities of our system’ (Erwin). It seemed like some users would have a good interaction with Alexa and leave a bad rating or vice versa. Due to the critical position user ratings have, some developers found this ‘troublesome’ (Raju). The active feedback users give in the form of short comments was regarded similarly inconsistent. Effective assessments were gained through conversational log analysis, using the ratings and written user feedback as merely a ‘mood-barometer’ that is ‘just good to see if what we are doing is helping or not’ (Dart). They could then reverse engineer based on code changes made. Seeing how user feedback is skewed from what developers expect shows a lack of alignment between the involved parties in development (Engdahl, 2024).
While drawing complex evaluations of labour back to one singular performance metric is a staple for Amazon (Delfanti, 2021), developers pointed out that in earlier competition phases, there is qualitative feedback from Alexa employees, which is more nuanced and conducive to qualitative improvement. Qualitative professional criticism expands on abstract user ratings, which is especially important in the beginning, as Amazon is organizationally highly interested in cooperation to succeed since they are onboarding future potential and ‘achiev[ing] lots of innovative results in a quick turnaround with less resources spent’ (Gardé). User scores can be an automation attempt for this, as Amazon engineers providing extensive feedback can be expensive. Khan (2020: 187) points out how in administered innovation competitions the costs of administering typically exceed the prizemoney payout. Partly automating the work of judging and organizing the competition through the platform infrastructure is a way to reduce costs. This ties the competition to the leaderboard with user satisfaction as a metric for quality of innovation, making user satisfaction an important aspect in development. Alexa, as a prime contact point between users and Amazon's brand in the smart home, further stresses the importance of infrastructural stability and reliability.
Ideals clashing with platformized management
Socialized with a mindset bent on innovation and a culture that idealizes invention, it is not surprising that many developers’ teams wanted to work independently. They valued independence from each other, but especially from Amazon, as some of them expressed not wanting it to have insight into their work processes: ‘we do a lot of our work offline and that did not make Amazon very happy. Because they were doing stat-checks on our working directories on their cloud servers, and were like: “Why haven't you made any updates this month?”’ (Erwin). This is reminiscent of Agre's (1994) concept of computational data capture, which, as an operation of power, monitors labour but also imposes structure onto the captured work processes. Eluding this capture undermines Amazon's workplace surveillance efforts and is therefore sanctioned with continuous reminders to adapt to Amazon's ‘synchronous workflow’. Adding to weekly meetings with Amazon, where teams would demonstrate their work and discuss weaknesses and future aims for their bot, this highlights the ‘push-and-pull struggle over the control of their work organization’ (Bialski, 2024: 114). These industry standard meetings are identified as a core problem of the APCs by the participants, who complain about having to ‘spend a lot of time on those meetings’ (Dart). This echoes Forsythe's (2001: 25–26) finding that software developers only consider time spent on coding work time, classifying these meetings as superfluous ‘non-work’. Participants perceived constant surveillance and management strategies as innovation inhibitors, as they constantly want to tell Amazon ‘“we are doing something big, and you can just wait for our update.” […] But they [Amazon] are looking for small progress over time’ (Longwei). Expressions of desire for self-determination underscore the tension between idealistic group identity and managerial capture. However, in ‘instinctively’ disregarding the work of aligning themselves (Engdahl, 2024: 5) with Amazon's organizational practices and wanting to focus on ‘decontextualized problem-solving’ (Forsythe, 2001: 33–34), it is hardly surprising that their built systems brush up against Alexa's sociotechnical environment.
This tension highlights the self-expectations that APC participants have: Participants wanted to be ‘the best in the competitions’, appreciated ‘the room for creativity’, to pursue idealistic concepts with ‘very high ambitions’. Which, given the nature of a competition, might be unsurprising, as prizes ‘are positional goods, whose worth lies in their relative scarcity’ (Khan, 2020: 72), making a high placement in the finals an aspiration. Although all participants stated that the APC was not the only project they were working on, time constraints went unreflected with regard to their performance expectations, despite being prompted about worktime allocation. Exploring this internalized drive for innovation and competition is vital to understanding the limitations that developing for Alexa inherently places upon the participants, as Alexa is a platformized social environment for the APC where Amazon sets constraints and conditions for the competition. Having high expectations can cause tensions when the surrounding labour conditions are not conducive to achieving the self-formulated goals, as they move through the competition phases (Figure 2):
During the first stage, developers are tasked with establishing an infrastructural code basis and engage in ideation, setting plans for the kind of research they are trying to focus on. Many report that their work was unrestricted, enabling them to work creatively within the known realms and processes of academic work: ‘there was no struggling with the system. It's more “do you have improvement ideas?”, instead of “how to solve this or that kind of issue?”’ (Chen). In this stage, they were permitted to achieve a high level of closeness to their work and code by having ‘time to focus on these moments, to zone in and just build software’ (Bialski, 2024: 62), as the teams could formulate goals and plans to begin laying the foundation for their bot as a group. This is perceived as a privilege: a state of absolution from commercial viability and strict managerial oversight. From a conceptual standpoint, an outsider would expect innovation competitions to be such an ideal environment, as it engages highly motivated and skilled academics in programming. The Amazon-organized onboarding event called a boot camp sets the ironic marker of change for the competition, as all participants describe it as a genuinely positive social experience that brought their teams together as they were introduced to Amazon scientists, the other teams and the infrastructures they would be working with in the coming months. These convention-like events strengthen the closeness to the code (Bialski, 2024: 62) and team cohesion, while simultaneously marking the beginning of having to orient more towards engineering work. In the second stage, the bots were first beta tested by Amazon employees, then connected to the live Alexa system and judged by the user ratings. Participants describe the beta testing phase as ‘helping Amazon debug the system’, where they claim being treated like ‘testers and not researchers’: ‘They changed their software infrastructure so rapidly that a lot of your performance in the competition was just: “how quickly you adapted to what they were doing?”’ (Erwin). For the live connected part, participants felt that it is not enticing for researchers to enter the competition, because engineering and debugging and not academic research is the main focus, some calling it ‘barely a research competition’.
The perceived dichotomy between development and engineering is nothing new, as software is often about maintenance work and fixing upcoming issues, which the APC developers classify as ‘engineering work’. However, this type of work does not leave space for the focus on innovation the groups established in the first stage, where they were absolved from oversight and could focus on creative work: this trajectory was what they had signed up for, not being skilled engineer testers for Amazon's systems. Within the second stage, the innovation-driven spirit prevalent in the first and bootcamp stages becomes less important, as different forms of oversight are introduced. This makes teams less self-sufficient and highlights the ‘struggle to maintain control over the labor process’ (Bialski, 2024: 105) ongoing in the APCs, as developers attempt to uphold their intrinsically high expectations for innovation and excellence while contending with the conditions of the competitions. Paying attention to this clash can deepen the understanding of the emergence of new technologies, as actors learn to balance expectations of governance and self-interest (Stilgoe, 2018: 28). The importance and simultaneous inaccuracy of user metrics adds to this line of tension, as developers are frustrated by the platform environment and clash with Amazon's interests. The focus can now turn to the strains that the live system places upon development in the second stage.
Sociotechnical implications of being infrastructural
In the second part of the APC, teams get ‘to test their innovations at scale with Alexa users’ (Johnston et al., 2023). This claim is central to the competition from a marketing perspective and for understanding innovation on a platform like Alexa, as it is this feature that allows insights into the development of wide-spread platforms. When platforms become infrastructures for daily practices of many people, there is an expectation for them to be robust, reliable and stable (Plantin et al., 2018: 304–307). When platform companies act as institutional basis (Dolata and Schrape, 2023: 5), they assemble an ecosystem of various elements that warrants stability as not to tarnish the company's image. Aspects of robustness, reliability and their ‘maintenance’ (Denis and Pontille, 2023) are critical for understanding the second stage. To ensure that contestants’ bots do not make Alexa say egregious or harmful things (like giving financial, legal or medical advice), there is a multitude of protocols for developers to follow. They learn what Alexa can ‘appropriately’ discuss and how to implement certain ‘safeguard-template-answers’ with satisfactory detection modules for user statements. Upon compliance with these rules, Amazon certifies the bots to go live on the user base, as Pak explains: For the second part of the competition, we were working with a live system that's connected to Alexa 24/7. We had to maintain a server that is running 24/7. […] We had to also get approved by Amazon and meet some kind of tech-check. I guess it's all due to the fact that we were connected to a live system.
Whenever developers talk about the stability of their system, they reference the rating system and the high bar for code quality it enforced. They also describe how ‘there was always something that was not working’ (Centis) in need of swift repair, as they don’t want to be ‘offline for a long period of time’ (Dart), as this would hurt ratings, putting them in maintenance mode, oscillating ‘between the regularity of planned operations and the permanent surprise of unpredictable deterioration that must be dealt with on the spot’ (Denis and Pontille, 2023: 220). The repetitive nature of maintenance enmeshes developers in a constant fixing of bugs and dealing with users’ creative ways of talking to Alexa, leaving less time for innovation. New solutions would often slow down Alexa's response rate, which is detrimental to the rating, meaning that sometimes innovative functionalities had to be postponed or dismissed before they could be optimized. However, it is important to point out that most of the teams still tried to be innovative, constantly introducing new features with the potential for breakdowns as a state of normality as part of ‘the work required to keep algorithms doing what they do’ (Jaton, 2020: 7). To manage this volatility, they act as maintainers of a relatively stable system on whose basis they can innovate, reminiscent of the notion of good enough software (Bialski, 2024: 171), with developers often distracted from innovation to attend to maintenance work (Russell and Vinsel, 2018). The robustness required for success in the innovation-oriented APCs, therefore, presents itself as virtue and issue simultaneously.
Despite Amazon advertising exactly for these types of situations, which consistently require participants to handle large amounts of interactions with their system, interviewees’ descriptions of surprise when first faced with the stress of handling Alexa interactions evidences how it seemed hard to anticipate the requirements. Multiple developers report they were not prepared for the increase in user numbers during the last weeks of the competition. The first step after the ‘Internal Amazon Beta Period’ meant a 10-fold increase in data influx as the bots went live for the general audience for the ‘Semifinals Interaction Period’. Furthermore, as the ‘Finals’ approach, there were progressively less teams while Amazon increased advertisement for the competition. According to developers, ‘the traffic was too much to handle’ as they were ‘not prepared for that scale’ (Dart). They acknowledged Amazon had communicated its intention to increase advertising but had not anticipated the resulting strain on their systems. This sentiment was consistent across all competitions and might indicate how participants were not adequately prepared for the scale of interactions with Alexa. This highlights how volatile engagement with Alexa can be, resulting in the underlying infrastructure needing to be robust for these contingencies. Further, this shows how the epistemic (Knorr-Cetina, 1999) and office culture (Seaver, 2022: 83) of self-confidence in computer scientists and therefore their ‘tacit beliefs’ (Forsythe, 2001: 33) become visible in the bots, when they do not plan for system strain being higher (than they are used to) when working on Amazon's scale. Breen, at multiple points in the interview, conveys that high user numbers induced ‘panic’ into the team as they were ‘trying to get new functionalities, so it's very difficult to take some time out and prioritize this infrastructure effectively’, while also admitting that the data they received was more than they could handle, as they consequentially ‘didn't have that infrastructure to be able to find meaningful patterns’, which ultimately stymied their potential for innovation. Inspired by the competitions’ outset goals of innovation, they can find the requirements of maintaining a permanently live system to stunt their aspirations, as potential slow or faulty interactions reflect badly on their ratings, preventing them from pursuing innovation as intended.
The need to reinvent the wheel
Amazon has reportedly provided many tools for ‘shielding complexity from the bot’ (Scott) for the teams not to spend too much time on ‘mundane matters of infrastructure’ (Pak). Providing tools like this is typically touted by big tech companies as a democratization of software development (Burrell and Fourcade, 2021: 214) and an opening of proprietary systems to science (Van Dijck et al., 2018: 154). While systems like this make development more predictable and efficient, especially younger developers can tend to dismiss them, as they seem overburdened, outdated or limiting (Bialski, 2024: 88; 146). Scott reminisces that using more of Amazon's tools would have been beneficial, even though their team oftentimes complained that: ‘it doesn't make sense to do things that way’. Because when you want to do things at Amazon-scale, you need to allow for seven different kinds of use cases for each thing. And as a team, we know we're only going to really care about the first use case, right? So, we can simplify our code significantly.
This conflict is situated within the larger tension between developers and Amazon's competition management and organization: The focus on a live system with user ratings foregrounds how infrastructural requirements are put upon the participants despite the advertised focus on innovation. It would not be unreasonable to expect a competition of this nature to produce hack-driven solutions – characterized by a ‘messy, creative, improvisational state of coding’ that ‘can lead to interesting design ideas’ (Bialski, 2024: 85) – which could later be consolidated into robust code. Many developers quoted the generation of novel ideas as the raison d’être of the competition. Still, it seems that Amazon's focus on ratings dissuades precisely this, as it emphasizes long-term stability, favouring less ambitious code. Administered prize competitions frequently lead to ‘inefficiencies’ (Khan, 2020: 70), as a singular body governs the competitions’ course and, in this case, sets diverging goals and rules. If innovation is the APCs’ goal, it can be argued that the emphasis on infrastructural soundness undermines it, as maintenance becomes both a virtue and a constraint on innovation in Alexa. This too calls into question Amazon's customer focus, as the live system requires user satisfaction but strains developers whose wishes and needs can fall out of focus when focusing on users’ satisfaction. The next section will therefore investigate if the teams follow the path of reliability set by Amazon.
Incrementalism on the bleeding edge of innovation
Hind et al. (2024: 9) argue that incremental progress is the norm for coding competitions, as the competitive structure encourages participants to aspire to develop algorithms that surpass benchmark numbers for specific tasks. While the APC has benchmarks (e.g. average bot response time), these technical standards do not serve in judging the full quality of the bots. APCs aim to judge the quality of user interactions, which resist straightforward quantification, unlike, for example, image recognition algorithms. Amazon acknowledges this complexity by keeping mission statements vague. Benchmark development ‘involves adherence to agreements or standards that necessitate diverse alignment efforts’ (Engdahl, 2024: 10) and functions as a transparent measure of performance; in the APCs, however, the absence of benchmarks engenders vagueness and a ‘lack of accountability for decisions and outcomes’ (Khan, 2020: 394). This ambivalent environment of diffuse goals may encourage incrementalism – which might be a source of tension when deemed insufficient by Amazon. Therefore, this section will investigate the competition management in regard to incrementalism and innovation.
Teams feel that Amazon envisioned a mode of development where they would ‘quickly develop a basic idea to iterate upon for the rest of the competition’ (Erwin). Some teams reported that the maintenance workflow did not leave ‘a way of working on the big changes that they wanted to make, while still working in parallel on the incremental changes that needed to happen for getting research into place’ (Breen). This was in some cases exacerbated by the fact that Amazon kept developing the platform environment that the teams were supposed to use incrementally, leading to ‘cascading effects’ as developers needed to change their own software in order to still interface correctly with Amazon's ‘subtending’ (Slota and Bowker, 2017: 540) platform infrastructure. In these cases, developers complained that adapting to the frequent changes became strenuous to the point of impeding research: ‘it wasn't something [where] you could just sit down and focus on your own research’ (Erwin). This highlights how the conditions for software development in the APC seem unwieldy for participants, making long-term planning for big goals harder, as they adjust momentarily to Amazon's incremental changes. Innovation processes (in machine learning) typically depend on well defined ‘solvable problems’ (Stilgoe, 2018: 31) that align specific actors around shared objectives (Adamczyk et al., 2012: 350). By contrast, the shifting competition format with vague goals impedes such definition, producing ‘partisan mutual adjustment’ (Lindblom, 1965: 25–32), in which actors incrementally adapt to perceived conditions and anticipated responses. While this may be adequate for a complex decision-making environment with different interests and rationales, this dynamic constrains developers, particularly where unevenly distributed information and hierarchical structures shape the competition. This highlights how Amazon's management sets conditions for development in the APCs that require an incremental approach, inhibiting large ambitious projects. Assuming this goes against their interest, it can be questioned why the aims, rules and tools for the competition were not clear at the start of all competitions, but rather developed along the way, seemingly, Amazon is ‘muddling through’ the APCs.
Developers reported that Amazon appeared to lack a coherent strategic vision in all competitions, manifesting in contradictory statements, ambiguous regulations, frequent clarification of rules and unexplained changes to bot evaluation criteria. Participants of the SimBot and TaskBot challenges complained about evolving competition software. The SocialBot challenge appeared to lack guidance, as Amazon did not seem to know what outcomes to expect as the introduction of ChatGPT moved the goalpost for conversations with AI agents (Strüver, 2025). This adaptive changing of competition rationales reflects on Amazon's limited organizational rationality for Alexa development, leading some participants to question Amazon's commitment to the competitions. This uncertain environment was detrimental especially for ambitious teams, whose style of parallel development needed time to fully develop all different systems before connecting them. This means that a lot of development ‘will not be immediately visible to both the Amazon people and also the users’ (Longwei), clashing with Amazon's demand for incremental (visible) changes instead of one large update. As Breen points out, this is hardly surprising due to Alexa's scale: ‘when you say: “You're putting this code in production”, it's suddenly available on every Amazon [Alexa] device in the world [USA]. So, it's not surprising that there's some overhead associated with that’. This shows the tension between researchers who want to establish long-term projects that can be volatile and Amazon's encouragement for robust software development on a large scale. Adopting an incrementalist ‘policy of small steps’ (Lindblom, 1965: 144) is a strategy to reduce the risk of failure, as it makes unintended consequences less likely, lowers the cost of errors and increases certainty in the development trajectory, simultaneously constraining design space by introducing path dependencies. While the prize grantor defers risk and decision – a hallmark of prize competitions (Khan, 2020: 69) – this specific logic contradicts the APCs’ mission statement, as Pak remarks: ‘Alexa branded this as a research competition, but it's more engineering work to be specific, to fit their platform.’
Innovation on an uncertain treadmill
While incremental innovation may not be inherently unfavourable, this invites the question if incremental progress is the intended outcome of innovation competitions or whether it is ‘deemed sufficient by Big Tech firms financing the research and hinging their future growth on AI breakthroughs’ (Hind et al., 2024: 9). Chen recounts that their team decided to invest heavily in solutions that emphasize hard-coded rules over novel machine learning, which they identify as the reason for Amazon not valuing their bot highly: ‘I think they think our project is more engineer-oriented instead of research. They didn't say that explicitly, but we can feel why the other team got the first place’. This is perhaps the clearest example of a ‘lack of accountability for decisions and outcomes’ (Khan, 2020: 394) in the APCs, as ‘arbitrary decisions’ based on ‘reputation’, or ‘the identity of mentors’ (Khan, 2020: 70) can be made by Amazon as the final judge of prize allocation. Further, this shows that Amazon is looking for some degree of ambitiousness and innovation: maintenance is in fact not glorious, nor is it rewarded in the APCs. By acts of maintenance, care can be expressed (Denis and Pontille, 2023: 222), which Amazon pursues for their users. However, this product-oriented perspective ‘neglects the people providing services’ (Bialski, 2024: 101–104). Choosing to do repair and maintenance work is political (Henke and Sims, 2020: 22) and if developers decide to deprioritize repair and care for the user, they can exercise their power to advance other interests. To satisfy scientific aspirations and keep group cohesion intact under management constraints, participants adopt good enough software development methodologies. Lowering their maintenance and competitive ambitions, they ‘satisfice’ (March and Simon, 1958: 140) user requirements with good enough bot versions that enable pursuit of research objectives: ‘they [Breen's team] got to a certain point and they really hadn't implemented a research-oriented contribution. They were just on a treadmill. At some point you have to stop and say: “if I'm gonna do anything new, I'm gonna have to deprioritize some of this basic stuff”’ (Breen). This could manifest in knowingly ignoring issues in the bot that could have been ‘more polished but weren’t’ (Centis); leaving something good enough, which ‘absolve[s] the software developer of the pressure to strive for perfection’ (Bialski, 2024: 173). By adhering to good enoughness, they escape the infrastructural requirements of the live-rated system to reinstate their team's agency over the labour process. Rikap (2022: 154) describes the predatory nature of asymmetric relationships between companies like Amazon and universities – what she elsewhere calls ‘corporate-dominated innovation systems’ (Rikap, 2024: 1736) – showing how third-parties (e.g. universities) are deprived of the possibility to further mobilize and advance the knowledge gained in those cooperations. However, this reclamation of agency shows precisely how third-party actors can pursue their own interests when they have sufficient institutional and social embeddings – like a university working group, which might not apply to e.g. start-ups. As Pak explains, their goal as a group was ‘to make a good agent that can be impactful in science’, an important factor in their team's social relationship which was subdued by the platform's infrastructural weight. By adopting a good enough approach that absolves them of Amazon's exceptionalism, they could reinvigorate their own ambitions: ‘We did something that's unrelated to improving the ratings on Amazon. […] I guess you just have to not commit to this a hundred percent. […] Frankly, we just didn't follow Amazon; we just did our own thing’ (Pak). While platform and competition conditions set by Amazon are uncertain albeit unrelenting in their expectations, their intrinsic interest in academic excellency presents a fallback rationale for participants. Often results from prize competitions ‘cannot readily be transferred to other projects’ (Khan, 2020: 398); this, however, shows how academic knowledge can be transferred by shifting priorities.
Nonetheless, most participants described feeling some form of pressure to ‘produce results’ (Dart) coming from Amazon's corporate logics, amounting to the normality of producing software under the necessity of being profitable in capitalism. Under these conditions, Scott questions whether expecting them to build infrastructurally sound software is the right use of the competition: You can’t expect a bunch of people who haven't spent a lot of time in industry to be able to build something scalable. Does that mean they can't build something novel? No, they can build something novel. But the novelty is much more likely to be in the language model AI-layer, than in the infrastructure.
This failure to create an environment where the interests of all parties are met is emblematic, as Amazon routinely expects third-parties to adapt to its interests (Weigel, 2023). Breen's analogy of the APC as a treadmill illustrates how developers constantly need to repair and maintain Alexa for good user ratings while navigating the uncertainties of changes in platform and competition conditions that Amazon confronts them with. Similar to the ‘long now of technology infrastructure’ (Ribes and Finholt, 2009), whose development is never accomplished and remains an idealized aspirational state, the uncertain treadmill symbolizes work on an infrastructuralized platform for third-parties, as they adjust to the conditions and structures given with little foresight. However, APC developers are not strictly economically dependent on Amazon and have the choice to step off the treadmill to divert labour and care to their own interests. Instead of following a mode of repair, maintaining Alexa, they can choose to follow their own agenda.
Discussion
Even though research competitions are likely not intended to produce radical innovation, they can still be conceptualized as a protected niche (Geels, 2005), which the APCs’ infrastructural requirements for innovation open up. Rather than focusing on explorative research, participants are incentivized to focus on engineering solutions to fix performance issues, leading them to feel lacking sovereignty over their work. Seeking absolution from the need to be infrastructurally robust, to take bigger scientific leaps, some teams abandoned Amazon's competition goals and deprioritized user ratings. However, because they still had to maintain software that performed adequately for user-facing tasks and leaderboard standings, they were ultimately unable to fully dedicate themselves to research. Maintaining bots to a good enough-degree (Bialski, 2024: 173) was a constant task and negotiation of time, resources and care. This resulted in an incrementalist approach of small steps in both research and engineering, making participants doubt the ‘intellectual importance’ of contributions. This contradicts the purported purpose of innovation competitions to integrate multiple stakeholders in generating innovative solutions (Adamczyk et al., 2012: 346–347), pointing towards ‘governance problems’ (Khan, 2020: 393) typical in administered competitions.
Platformized isomorphism and innovation potential
Investigating how platform mechanisms lend themselves to organizing innovation showed how Amazon operationalizes its interest in user satisfaction through the automatic capture of users’ ratings as the competition's main success metric. Furthermore, the software development tools and environment provided by Amazon remained under active development throughout the course of the competition, making participants disregard tools and question the competition. This symbolizes Amazon's wish to control the platform ecosystem and its third-party contributors. By emphasizing its focus on user satisfaction as platformized performance metrics and haphazard tool development for third-party orchestration, Amazon failed to create an effective innovation niche. This aligns with Amazon's broader treatment of independent affiliations, typically subject to strict control via various sociotechnical platform elements (Rowberry, 2022; Weigel, 2023). In that sense it can be seen how the competition does not ask for researchers to fill a design space to improve a service for Alexa users, but rather to chase user ratings in preventing them from breaking functionalities. What ‘is incentivized by leaderboards and what is valued by practitioners’ (Ethayarajh and Jurafsky, 2021: 5) differed highly in the APCs. While Bialski (2024: 168) speculates that the interaction with users makes developers imagine them and their wishes, Amazon's platform processes operationalize users into star ratings, turning them invisible. This ‘commodification of user behavior’ (Dolata and Schrape, 2023: 14) appears to be a standard for evaluating machine learning models (Singh et al., 2025: 30) but changes the quality of the competition's key claim for participants: ‘to test their innovations at scale with Alexa users’ (Johnston et al., 2023). Reading this claim as a mark of distinction from other community-driven leaderboards that crowdsource evaluations for machine learning model content (Singh et al., 2025), the reality of the APCs fails to set itself apart. This might stem from the use of opaque and irreproducible performance metrics to capture data and assess labour – an instance of ‘augmented despotism’ (Delfanti, 2021) – which constitutes an established organizational process across Amazon's businesses, where Amazon typically utilizes ‘amalgamated statistics and calculations on performance and productivity’ (Beverungen, 2021: 190). In the APCs, contrary to Amazon's claimed user obsession, users are made invisible as an infrastructure and resource for Alexa development, minimizing expenses for qualitative expert feedback. The qualitative professional guidance provided in the earlier stages differs from Amazon's usual management style and highlights the difference in hierarchy in the relationship between Amazon and the universities (compared to warehouse workers), since Amazon is organizationally highly interested in this cooperation's success as participants are potential future employees, as acquiring talent from universities is a core endeavour for companies like Amazon (Rikap, 2024: 1752). In that sense, it is worthwhile considering what Weigel (2023: 34) states about third-party sellers on Amazon.com, who ‘described how succeeding on Amazon required them to behave like miniature Amazons’. This platformized isomorphism as a reaction to uncertainty (Caplan and boyd, 2018) is prevalent in the APCs, as Amazon incentivizes adoption of their development style for Alexa under infrastructural conditions, where stability is rewarded, volatility deterred and innovation strictly managed. By drawing parallels to warehouse and e-commerce, it can be seen how strictly managing working conditions through platformized management tools is a deliberate systemic organizational device within Amazon. In that sense, universities as third-parties are no different to other contractors, as their working conditions are moved to Amazon's platforms, their success is contingent on adapting to the set conditions, and their payment does not reflect the level of control that Amazon exercises (Woodcock and Cant, 2023).
This paper has provided reasons to believe that this control might have been an inappropriate choice for the APCs. Participants’ observations of Amazon's lack of a clear vision, coupled with tight third-party control, raises questions about the competition design, akin to Hind et al.'s (2024: 9) questioning whether small incremental steps will be deemed sufficient competition outcomes. In the APCs, Amazon's platformized approach produces said incrementalism. While this is nothing to be critiqued or questioned, it might be the sign of a missed chance for Amazon to foster an environment which could provide fresh perspectives and is therefore consistent with Khan's (2020: 385) finding that prize competitions often lack tangible results. Historically, prize competitions needed to make efforts to motivate sufficient high-quality contenders (Leimeister et al., 2009), almost the reverse is true for the APCs, as participants are highly motivated but let down by the competition management and ineffective communication strategies (Schäfer et al., 2017: 41). Many enter such collaborations in the hopes of working on groundbreaking innovations in cooperation with Amazon. When these expectations are not met, it creates a sense of disillusionment, as the APC takes place in the headspace of Silicon Valley, providing the antithesis to mediocrity. And yet, by placing participants on an uncertain treadmill, Amazon fosters good enoughness instead of excellence due to (and not despite a lack of) the company's extensive support and an ostensibly open-ended mission statement. The APCs diverge from comparable prize competitions through Amazon's dual role as both platform host and competition convener. Whereas platform-based competitions often leverage crowdsourcing mechanisms that enhance competition transparency (Orr and Kang, 2024; Singh et al., 2025), Luitse et al. (2024: 1751) show that competition hosts generally exert significant influence over organization and outcomes. In the APCs, this influence is intensified: Amazon's consolidation of roles curtails transparency, while ambiguous benchmarks for success further weaken accountability (Engdahl, 2024: 10) in choice of winners. While the APCs are administered prize competitions, which inherently have less accountability for decisions (Khan, 2020: 394), Amazon's incremental adjustments to rules and platform conditions embed the APCs within its wider platform governance (Gorwa, 2019; Delfanti, 2021), steering them even further away from the traditional innovation-oriented goals of such contests (Adamczyk et al., 2012: 346).
Amazon's third-party relations
This places participants in a position where they depend on Amazon's third-party conduct. Despite the many issues pointed out here, it would be inappropriate to equate their struggles with those of traditional third-party workers that interface with Amazon. Demographically, study participants were pursuing or holding degrees from prestigious universities, making them beholden to different privileges, affording them the choice to turn away from the competition and prioritize their own interest. Their difference from other platform workers becomes evident when comparing to Amazon's Mechanical Turk platform, where software development is crowd sourced through microtasks. These microworkers typically yield agency and are controlled ‘almost totally’ (Molina et al., 2023: 10) by the platform. The ‘Turkers’ are a largely isolated group with no pathway to sociality with their coworkers and, therefore, their founding of means to organize and be social is a form or rebellion (Woodcock and Cant, 2023: 159). The APC participants in contrast can leverage precisely their university-based sociality to organize resistance in pursuing their own goals in the competitions. In that sense, the APCs show a path to resistance against the loss of ‘innovation autonomy’ (Rikap, 2024: 1738) that can be entailed in cooperation with Amazon. However, they recognize that they would not want to be in a bad relationship with Amazon for the future, as Amazon provided money for the teams (besides the prize money) and is a prospective employer; requiring compromises between research for Amazon and academia. This introduces the question of openness of science, as the scientists engaging in the APCs are inherently in an asymmetric power relationship with Amazon. These private–public innovation relationships therefore deepen the gap of publicly versus privately available research data and options to conduct research. Ultimately the intellectual property of the teams’ bots remains with them; however, Amazon gains full rights to access and licence all technologies developed (Amazon, 2022b), making researchers turn ‘public resources into proprietary assets’ (Van Dijck et al., 2018: 154) – in the APCs this even includes an American company garnering insights from European universities in a ‘globalized innovation system’ (Rikap, 2024). This weighs particularly heavy when considering how the competitions are set up to encourage incrementalism (Lindblom, 1965) and platformized isomorphism (Caplan and boyd, 2018), steering technology development towards easy implementation into Alexa, rather than being novel, benefiting Amazon more than the competitors. Consequently, while prize competitions are typically linked to patent acquisition, the APCs – like other Big Tech-run contests – primarily function as opportunities for learning, visibility and enhanced career prospects (Khan, 2020: 69–73, 396–97), as such competitions ‘attract attention from major industry actors’ (Luitse et al., 2024: 1751). Further, Amazon offers only piecemeal insights into the Alexa team specifically to outsiders, who in turn do not gain an understanding of ‘what other internal teams are doing’ (Rikap, 2024: 1752), leaving them unable to know about the recombination of their work in conjunction with other Amazon technologies which might be patented. This points towards the fact that AI competitions colonize the university, giving credit to Srnicek's (2022: 244) observation that big tech companies are the gatekeepers to development of cutting-edge AI technologies.
Reading these assertions against the lines of conflict worked out through this article; however, it is possible to see how Amazon is not an omniscient actor that organizes labour to its own benefit (Edwards, 2021: 333), offering an in-depth insight into technology critique on a microscale. This serves to illuminate and give nuance to a more macro-level technology critique of companies like Amazon. Often, they appear to be highly competent actors, who leverage planning capacities and structures in their innovation systems to coordinate subordinate actors like universities and advance their business interests, (Rikap, 2024). While this may be overall true – especially when accounting for intangible and self-perpetuating knowledge advantages they hold over competitors and the public (Rikap, 2022: 149–152) – limits to these actors’ organizing capacities have been shown throughout this article. Despite being limited by participants’ selective self-descriptions of their work processes, the provided analysis of organizational conflicts is supported by the fact that the APCs have been discontinued in the following year, without an announcement; which is common for failed prize competitions (Khan, 2020: 72). In acting like a custodian of an infrastructure, focusing on efficiency and robustness, rather than asking participants to re-envision innovation for Alexa, Amazon shows its limited rationality, as custodianship for an infrastructure is warranted but less so in a space dedicated for innovation. This shows how path dependencies have made it hard for Amazon to relinquish the hold over their platform properties, even when they control the conditions for third-party innovation, placing participants on an uncertain treadmill, leading towards dissatisfactory small steps instead of harnessing the drive for novelty within participants through the established format of prize competitions. Finally, this hints at a certain rigidity in organizational culture (Seaver, 2022: 83) in Amazon's Alexa department, which overprioritizes following established logics to govern software development and innovation, which ultimately stymies innovation and calls into question Amazon's capability to steer their technologies into the future successfully.
Footnotes
Acknowledgements
I want to thank the participants of the study for sharing their experiences with me. Further, I would like to thank the various colleagues and friends who have helped shape this article at different stages with thoughtful comments or revisions. Finally, I want to thank the anonymous reviewers and the journal's editor for their kind and deeply engaged comments, which gave a lot of clarity and depth to the article.
Ethical considerations
To protect the participant's identities a strong concept of anonymization has been developed.
Consent to participate
All participants’ verbal informed consent for participation was gathered.
Consent for publication
All participants’ written informed consent for publication was gathered.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 262513311 – SFB 1187.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Due to the sensitivity of data, no sharing of the data was agreed upon.