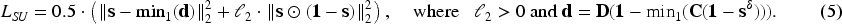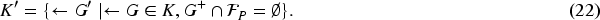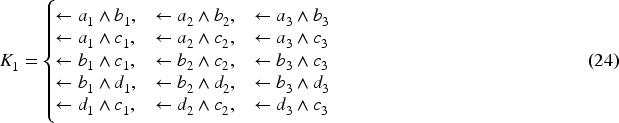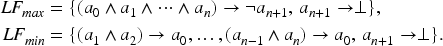We propose an end-to-end approach for Answer Set Programming (ASP) and linear algebraically compute stable models satisfying given constraints. The idea is to implement Lin-Zhao’s theorem together with constraints directly in vector spaces as numerical minimization of a cost function constructed from a matricized normal logic program, loop formulas in Lin-Zhao’s theorem and constraints, thereby no use of symbolic ASP or SAT solvers involved in our approach. We also propose precomputation that shrinks the program size and heuristics for loop formulas to reduce computational difficulty. We empirically test our approach with programming examples including the three-coloring and Hamiltonian cycle problems.
Computing stable model semantics (Gelfond & Lifshcitz, 1988) lies at the heart of Answer Set Programming (ASP) (Lifschitz, 2008; Marek & Truszczyński, 1999; Niemelä, 1999) and there have been a variety of approaches proposed so far. Early approaches such as smodels (Niemelä & Simons, 1997) used backtracking. Then the concept of loop formula was introduced and approaches that use a Boolean satisfiability problem (SAT) solver to compute stable models based on Lin-Zhao’s theorem (Lin & Zhao, 2004) were proposed. They include ASSAT (Lin & Zhao, 2004) and cmodels (Lierler, 2005) for example. Later more elaborated approaches such as clasp (Gebser et al., 2007, 2012) based on conflict-driven no good learning have been developed. While these symbolic approaches continue to predominate in ASP, there has been another trend towards differentiable methods. For example, differentiable ASP/SAT (Nickles, 2018) computes stable models by an ASP solver that utilizes derivatives of a cost function. More recently, NeurASP (Yang et al., 2020) and SLASH (Skryagin et al., 2022, 2023) combined deep learning and ASP. In their approaches, deep learning is not used in an end-to-end way to compute stable models, but used as a component to compute and learn probabilities represented by special atoms interfacing to ASP. Takemura and Inoue (2024) proposed a neurosymbolic learning pipeline that leverages differentiable computation of supported models. Although their method does not specifically address stable model computation, it bypasses the need for a symbolic solver and illustrates how differentiable computation facilitates integration with deep learning. A step towards end-to-end computation was taken by Aspis et al. (2020) and Takemura and Inoue (2022). They formulated the computation of supported models, a super class of stable models, entirely as fixedpoint computation in vector spaces, and obtain supported models represented by binary vectors. However, there still remains a gap between computing supported models and computing stable models.
In this article, we propose an end-to-end approach for ASP and compute stable models satisfying given constraints in vector spaces. The idea is simple; we implement Lin-Zhao’s theorem (Lin & Zhao, 2004) together with constraints directly in vector spaces as a cost minimization problem, thereby no use of symbolic ASP or SAT solvers involved. Since our approach is numerical and relies solely on vector and matrix operations, future work could explore the potential benefits of parallel computing technologies such as many-core CPUs and GPUs.
Technically, Lin-Zhao’s theorem (Lin & Zhao, 2004) states that a stable model of a ground normal logic program coincides with a supported model which satisfies “loop formulas” associated with the program. Loop formulas are propositional formulas indicating how to get out of infinite loops of top-down rule invocation. We formulate finding such a model as root finding in a vector space of a non-negative cost function represented in terms of the matricized program and loop formulas. The problem is that in whatever approach we may take, symbolic or non-symbolic, computing supported models is NP-hard (for example graph coloring is solved by computing supported models) and there can be exponentially many loop formulas to be satisfied (Lifschitz & Razborov, 2006). We reduce this computational difficulty in two ways. One is precomputation that removes atoms from the search space which are known to be false in any stable model and yields a smaller program. The other is to heuristically choose loop formulas to be satisfied. The latter would mean allowing non-stable model computation, and in our continuous approach, we modify the cost function to be affected only by these chosen loop formulas. The intuition behind this heuristic is that the modified cost function would assign higher cost to models that do not satisfy the chosen loop formulas, thus driving the search process away from them.
Our end-to-end computing framework differs from those by Aspis et al. (2020) and Takemura and Inoue (2022) in that they basically compute supported models and the computing process itself has no mechanism such as loop formulas to exclude non-stable models. In addition, any propositional normal logic program is acceptable in our framework, since we impose no restrictions on the syntax of programs like the multiple definition (MD) condition (Aspis et al., 2020) or the singly defined (SD) condition (Takemura & Inoue, 2022). More importantly, we incorporate the use of constraints, that is, rules with an empty head, which make ASP smooth and practical.
Hence, our contributions include as follows:
a proposal of end-to-end computing of stable models in vector spaces for propositional normal logic programs;
augmentation of the above by constraints;
introduction of precomputation and heuristics to reduce computational difficulty of stable model computation.
We add that since our primary purpose in this article is to establish theoretical feasibility of end-to-end ASP computing in vector spaces, programming examples are small and implementation is of preliminary nature. Furthermore, the main search algorithm we propose in this article is incomplete, in the sense that it does not guarantee reaching a global minimum if it exists, nor it cannot conclusively prove that no solution exists.
In what follows, after preliminaries in Section 2, we formulate the computation of supported models in vector spaces in Section 3 and that of stable models in Section 4. We then show programming examples in Section 5 including ASP programs for the three-coloring problem and the Hamiltonian cycle problem. We there compare performance of precomputation and loop formula heuristics. Section 6 contains related work and Section 7 is the conclusion.
Preliminaries
In this article, we mean by a program a propositional normal logic program which is a finite set of rules of the form , where is an atom called the head, is a conjunction of literals called the body of the rule, respectively. We equate propositional variables with atoms. A literal is an atom (positive literal) or its negation (negative literal). The logical connective in this article denotes negation as failure. We suppose is written in a given set of atoms but usually assume = atom(), that is, the set of atoms occurring in . We use and to denote the conjunction of positive and negative literals in , respectively. may be empty. The empty conjunction is always true. We call rule for . A rule with an empty head is called a constraint. Let be rules for in . When , put . When , that is, there is no rule for , put , where is a special symbol representing the empty disjunction which is always false. We call the completed rule for . The completion of, comp(), is defined as comp() = . For a finite set , we denote the number of elements in by . So is the number of rules in the program .
An interpretation (assignment) over a set of atoms is a mapping which determines the truth value of each atom . Then the truth value of a formula is inductively defined by , and if becomes true evaluated by , we say satisfies , is true in , or is a model of and write . This notation is extended to a set by considering as a conjunction . For convenience, we always equate with , that is, the set of atoms true in . When satisfies all rules in the program , that is, , is said to be a model of . If no rule body contains negative literals, is said to be a definite program. In that case, always has the least model (in the sense of set inclusion) , that is, the set of atoms provable from .
A model of comp() is a supported model of (Apt et al., 1988; Marek & Subrahmanian, 1992). When is a definite program, there is at least one supported model, and its least model is also a supported model. In general, there can be multiple supported models for both definite and non-definite programs . Stable models are a subclass of supported models. They are defined as follows. Given a program and a model , remove all rules from whose body contains a negative literal false in , then remove all negative literals from the remaining rules. The resulting program, , is called the Gelfond-Lifschitz (GL) reduct of by or just the reduct of by . It is a definite program and has the least model. If this least model is identical to , is called a stable model of (Gelfond & Lifshcitz, 1988). may have zero or multiple stable models, as in the case of supported models. Since the existence of a stable model is NP-complete (Marek & Truszczyński, 1999) and so is a supported model, their computation is expected to be hard. Supported models and stable models of a propositional normal logic program coincide when the program is tight (no infinite call chain through positive goals) (Erdem & Lifschitz, 2003; Fages, 1994).
Let be a Boolean formula in variables (atoms) in disjunctive normal form (DNF), where each () is a conjunction of literals and called a disjunct of . When has no disjunct, is false.
A walk in a directed graph is a sequence () of vertices representing the corresponding non-zero sequence of edges . When , it is said to be closed. A cycle is a closed walk , where are all distinct. A Hamiltonian cycle (HC) is a cycle which visits every vertex exactly once. A path is a walk with no vertex repeated. A directed subgraph is called strongly connected if there are paths from to and from to for any pair of distinct vertices and . This “strongly connected” relation induces an equivalence relation over the set of vertices and an induced equivalence class is called a strongly connected component (SCC).
The positive dependency graph for a program is a directed graph where vertices are atoms occurring in and there is an edge from atom to atom if and only if (iff) there is a rule in such that is a positive literal in . is said to be tight (Erdem & Lifschitz, 2003; Fages, 1994)1 when is acyclic, that is, has no cycle. A loop in is a set of atoms where for any pair of atoms and in ( allowed), there is a path in from to and also from to . A singleton loop is induced by a self-referencing rule of the form where is possibly empty, that is, a self-loop . A support rule for relative to a loop is a rule such that . Given a loop and its external support rules , the (conjunctive) loop formula is the following implication: .
We denote vectors by bold lower case letters such as , where represents the -th element of . Vectors are column vectors by default. We use to stand for the inner product (dot product) of vectors and of the same dimension. and , respectively, denote the 1-norm and 2-norm of , where and . We use to denote an all-ones vector of appropriate dimension. An interpretation over a set of ordered atoms is equated with an -dimensional binary vector such that if is true in and otherwise (). is called the vectorized .
Bold upper case letters such as stand for a matrix. We use to denote the -th element of , the -th row of and the -th column of , respectively. We often consider one dimensional matrices as (row or column) vectors. denotes the Frobenius norm of , that is, . Let be matrices. denotes their Hadamard product, that is, for . designates the matrix of stacked onto . We implicitly assume that all dimensions of vectors and matrices in various expressions are compatible. We introduce a piece-wise linear function that returns the lesser of 1 and as an activation function which is related to the popular activation function by . denotes the result of component-wise application of to matrix . We also introduce thresholding notation. Suppose is a real number and an -dimensional vector. Then denotes a binary vector obtained by thresholding at where for , if and otherwise. is treated similarly. We extend thresholding to matrices. Thus means a matrix such that if and otherwise. For convenience, we generalize bit inversion to an -dimensional vector and use an expression to denote the -dimensional vector such that for . is treated similarly.
Computing Supported Models in Vector Spaces
In this section, we formulate the semantics of supported models in vector spaces and show how to compute it by cost minimization.
Matricized Programs
Matricized program
A program that has rules in atoms is numerically encoded as a pair of binary matrices and , which we call a matricized program .
represents rule bodies in . Suppose atoms are ordered like and similarly rules are ordered like . Then the -th row () encodes the -th conjunction of the -th rule . Write (). Then an element of is zero except for . combines these conjunctions as a disjunction (DNF) for each atom in . If the -th atom () has rules in , we put to represent a disjunction which is the right hand side of the completed rule for : . If has no rule, we put for all (). Thus the matricized can represent the completed program .
For concreteness, we explain by an example below.
Encoding a program
Suppose we are given a program below containing three rules in a set of atoms .
Assuming atoms are ordered as and correspondingly so are the rules as in (1), we encode as a pair of matrices . Here represents conjunctions (the bodies of ) and their disjunctions so that they jointly represent .
As can be seen, represents conjunctions in in such a way that , for example, represents the conjunction of the first rule in by setting , and so on. represents the disjunctions of rule bodies. So means the first atom in has two rules, the first rule and the second rule , representing a disjunction for .
Evaluation of Formulas and the Reduct of a Program in Vector Spaces
Here we explain how the propositional formulas and the reduct of a program are evaluated by a model in vector spaces. Let be a model over a set of atoms. Recall that is equated with a subset of . We inductively define the relation “a formula is true in ,” in notation, as follows. For an atom , iff . For a compound formula , iff . When is a disjunction (), iff there is some () s.t. . So the empty disjunction () is always false. We consider a conjunction as a syntax sugar for using De Morgan’s law. Consequently, the empty conjunction is always true. Let be a program having ordered rules in ordered atoms as before and the body of a rule in . By definition, ( is true in ) iff and . Also let be the completed rule for an atom in . We see iff .
Now we isomorphically embed the above symbolic evaluation to the one in vector spaces. Let be a model over ordered atoms . We first vectorize as a binary column vector such that if and () otherwise, and introduce the dualized written as by . is a vertical concatenation of and the bit inversion of .
Consider a matricized program , and its -th rule having a body represented by . Compute which is the number of true literals in in and compare it with the number of literals 2 in . When holds, all literals in are true in and hence the body is true in . In this way, we can algebraically compute the truth value of each rule body, but since we consider a conjunction as a negated disjunction, we instead compute which is the number of false literals in . If this number is non-zero, have at least one literal false in , and hence is false in . The converse is also true. The existence of a false literal in is thus computed by which is if there is a false literal, and otherwise. Consequently, if there is no false literal in and vice versa. In other words, computes .
Now let be an enumeration of rules for and the disjunction of the rule bodies. is the number of rule bodies in that are true in . Noting if and otherwise by construction of in , we replace the summation by matrix multiplication and obtain . Introduce a column vector . We have = the number of rules for whose bodies are true in ().
In the case of in (1) having three rules , take a model over the ordered atom set , where and are true in but is false in . Then we have , , , and finally, . The last equation says that the rule bodies of , , and have, respectively, zero, one, and zero literal false in . Hence indicates that only the second rule body is false and the other two bodies are true in . So its bit inversion indicates that the second rule body is false in , while others are true in . Thus by combining these truth values in terms of disjunctions , we obtain . The elements in denote for each atom the number of rules for whose body is true in . For example, means that the first atom in has one rule () whose body () is true in . Likewise, means that the second atom has one rule () whose body (empty) is true in . indicates that the third atom has no such rule. Therefore, denotes the truth values of the right hand sides of the completed rules evaluated by .
Let be a matricized program in a set of atoms and a vectorized model over . Put . It holds that
Put . Suppose and write , the completed rule for an atom (), as (). We have . So if , , and hence , giving because is the number of rule bodies in that are true in . So holds. Otherwise, if , we have and . Consequently, none of the rule bodies are true in and we have . Putting the two together, we have . Since is arbitrary, we conclude , or equivalently . The converse is similarly proved.
Proposition 1 says that whether is a supported model of the program or not is determined by computing in vector spaces whose complexity is where is the number of rules in , that of atoms occurring in . In the case of with as in the aforementioned example, since holds, it follows from Proposition 1 that is a supported model of .
We next show how , the reduct of by , is dealt with in vector spaces. We assume has rules with a set of ordered atoms as before. We first show the evaluation of the reduct of the matricized program by a vectorized model . Write as , where (resp. ) is the left half (resp. the right half) of representing the positive literals (resp. negative literals) of each rule body in . Compute . It is an matrix (treated as a column vector here) such that if the body of contains a negative literal false in and otherwise (). Let be a rule with negative literals in the body deleted. We see that and is syntactically represented by , where with columns replaced by the zero column vector if (). denotes a rule set in for . We call the matricized reduct of by .
The matricized reduct is evaluated in vector spaces as follows. Compute . denotes the truth values of rule bodies in evaluated by . Thus () if is contained in and its body is true in . Otherwise and is not contained in or the body of is false in . Introduce . () is the number of rules in for the -th atom in whose bodies are true in .
Let be a matricized program in a set of ordered atoms and a model over . Write as above. Let be the vectorized model . Compute , , and . Also compute . Then, , , , and are all equivalent (proof in Appendix A.1).
From the viewpoint of end-to-end ASP, Proposition 2 means that we can obtain a supported model as a binary solution of the equation derived from or derived from the reduct . Either equation is possible and gives the same result but their computation will be different. This is because the former equation is piecewise linear w.r.t. , whereas the latter is piecewise quadratic w.r.t. .
Evaluation of a reduct
Now look at in (1) and a model again. is the reduct of by . has the least model that coincides with . So is a stable model of . To simulate the reduction process of in vector spaces, let be the matricized . We first decompose in (2) as , where is the positive part and the negative part of . They are
Let be the vectorized . We first compute to determine rules to be removed. Since , the second rule , indicated by , is removed from , giving . Using and shown in (3), we then compute and . The elements of denote the number of rule bodies in that are true in for each atom. Thus, since holds, is a supported model of by Proposition 2.
Cost Minimization for Supported Models
Having linear algebraically reformulated several concepts in logic programming, we tackle the problem computing supported models in vector spaces. Although there already exist approaches for this problem, we tackle it without assuming any condition on programs while allowing constraints. Aspis et al. formulated the problem as solving a non-linear equation containing a sigmoid function (Aspis et al., 2020). They encode normal logic programs differently from ours based on Sakama’s encoding (Sakama et al., 2017) and impose the MD condition on programs which is rather restrictive. No support is provided for constraints in their approach. Later Takemura and Inoue proposed another approach (Takemura & Inoue, 2022) which encodes a program in terms of a single matrix and evaluates conjunctions by the number of true literals. They compute supported models by minimizing a non-negative function, not solving an equation like (Aspis et al., 2020). Their programs are, however, restricted to those satisfying the SD condition and constraints are not considered.
Here we introduce an end-to-end way of computing supported models in vector spaces through cost minimization of a new cost function based on the evaluation of disjunction. We impose no syntactic restriction on programs and allow constraints. We believe that these two features make our end-to-end ASP approach more feasible.
We can base our supported model computation either on Proposition 1 or on Proposition 2. In the latter case, we have to compute GL reduction which requires complicated computation compared to the former case. So for the sake of simplicity, we explain the former. Then our task in vector spaces is to find a binary vector representing a supported model of a matricized program that satisfies , where . For this task, we relax to and introduce a non-negative cost function :
Let be defined from a program as above.
iff is a binary vector representing a supported model of .
Apparently if , we have and . The second equation means is binary (), and the first equation means this binary is a vector representing a supported model of by Proposition 1. The converse is obvious.
is piecewise differentiable and we can obtain a supported model of as a root of by minimizing to zero using Newton’s method. The Jacobian required for Newton’s method is derived as follows. We assume is written in ordered atoms and represents their continuous truth values, where is the continuous truth value for atom (). For the convenience of derivation, we introduce the dot product of matrices and and a one-hot vector which is a zero vector except for the -th element and . We note and hold (see Appendix B.1 for details).
Let be the matricized program and write . Introduce , , , , , and compute by
We then compute the Jacobian of as follows (full derivation in Appendix B.2):
Note that since is a vector, the Jacobian in this case is also a vector.
Adding Constraints
A rule which has no head like is called a constraint. We oftentimes need supported models which satisfy constraints. Since constraints are just rules without a head, we encode constraints as rule bodies in a program using a binary matrix . We call constraint matrix. We introduce , a non-negative function of and ’s Jacobian as follows (derivation in Appendix B.3):
The meaning of and is clear when is binary. Note that any binary is considered as a model over a set of ordered atoms in an obvious way. Suppose constraints are given to be satisfied. Then is a binary matrix and is a matrix. () is the number of literals falsified by in a conjunction of the -th constraint . So , or equivalently implies has no false literal, that is, , and vice versa. Hence equals the number of violated constraints. Consequently, when is binary, we can say that iff all constraints are satisfied by .
When is not binary but just a real vector , and are thought to be a continuous approximation to their binary counterparts. Since is a piecewise differentiable non-negative function of , the approximation error can be minimized to zero by Newton’s method using in (9).
An Algorithm for Computing Supported Models With Constraints
Here we present a minimization algorithm for computing supported models of the matricized program which satisfy constraints represented by a constraint matrix . We first combine and into using .
The next proposition is immediate from Proposition 3.
iff represents a supported model of satisfying a constraint matrix .
We compute in by (6) and by (8), and their Jacobians and by (7) and by (9), respectively. We minimize the non-negative to zero by Newton’s method using Algorithm 1. It finds a solution of which represents a supported model of satisfying constraint matrix . The updating formula is derived from the first-order Taylor expansion of and by solving w.r.t. . The updating formula with a learning rate is thus defined as follows:
Algorithm 1 is a double-loop algorithm where the inner -loop updates repeatedly to minimize while thresholding into a binary solution candidate for . The outer -loop is for retry when the inner loop fails to find a solution. The initialization at line 3 is carried out by sampling () where is the standard normal distribution. Lines 6 to 8 collectively perform thresholding of into a binary . As the inner loop repeats, becomes smaller and smaller and so do and in . being small means is close to a supported model of while being small means each element of is close to . So binarization with an appropriate threshold 3 has a good chance of yielding a binary representing a supported model of satisfying constraints represented by . It may happen that the inner loop fails to find a solution. In such a case, we retry another -loop with perturbated at line 12. There is perturbated by where before the next -loop.
Computing Stable Models in Vector Spaces
Loop Formulas and Stable Models
Let be a matricized program in a set of atoms having rules , where and . We assume atoms and rules are ordered as indicated.
Computing a supported model of is equivalent to computing any binary fixedpoint such that in vector spaces and in this sense, it is conceptually simple (though NP-hard). Contrastingly since stable models are a proper subclass of supported models, if one wishes to obtain precisely stable models through fixedpoint computation, the exclusion of non-stable models is necessary. Lin-Zhao’s theorem (Lin & Zhao, 2004) states that is a stable model of iff is a supported model of and satisfies a set of formulas called loop formulas associated with .
Let be a loop in . Recall that is a set of atoms which are strongly connected in the positive dependency graph of .4 A support rule for with respect to is a rule such that . is called a support body for . Introduce a (conjunctive) loop formula for by
Then define loop formulas associated with as , which is treated as the conjunction of its elements. We note that in the original form (Lin & Zhao, 2004), the antecedent of is a disjunction . Later it was shown that the disjunctive and conjunctive loop formulas are equivalent (Ferraris et al., 2006), and we choose to use the conjunctive form of as it is easier to satisfy using our method. We evaluate by a real vector . Introduce an external support matrix by if there is a support rule for , else (). Suppose there are loops in . Introduce a loop matrix such that if the -th loop has as a support body for , else ().
Encoding loop formulas
Suppose we are given a program :
This program contains two loops: and . In this case, only has an external support body . Thus, the external support matrix and the loop matrix for this program are as follows:
We then introduce a loss function , which is a non-negative piecewise linear function of .
Let be defined as above. When is a binary vector representing a model over , it holds that iff .
Suppose and is binary. A summand in (17) corresponds to the -th loop and is non-negative. Consider as a disjunction . Then implies , or equivalently . Consequently, as is binary, we have or . The former means . The latter, , means . This is because the element is the number of support rules for whose bodies are true in (), and hence means some support body () for is true in . So in either case . Since is arbitrary, we have . The converse is straightforward and omitted.
The Jacobian of is computed as follows (derivation in Appendix B.4):
Now introduce a new cost function by (19) that incorporates and compute its Jacobian by (11).
By combining Propositions 4, 5, and Lin-Zhao’s theorem (Lin & Zhao, 2004), the following is obvious.
is a stable model of satisfying constraints represented by iff is a root of .
We compute such by Newton’s method using Algorithm 1 with a modified update rule (12) such that and are replaced by and , respectively.
When a program is tight (Fages, 1994), for example, when rules have no positive literal in their bodies, has no loop and hence is empty. In such a case, we directly minimize instead of using with the empty .
LF Heuristics
Minimizing is a general way of computing stable models under constraints. It is applicable to any program and gives us a theoretical framework for computing stable models in an end-to-end way without depending on symbolic systems. However, there can be exponentially many loops and they make the computation of (17) extremely difficult or practically impossible. To mitigate this seemingly insurmountable difficulty, we propose two heuristics which use a subset of loop formulas.
The first heuristic is . We consider only a set of loop formulas associated with SCCs in the positive dependency graph of a program . In the case of a singleton SCC , must have a self-loop in . We compute SCCs in time by Tarjan’s algorithm (Tarjan, 1972).
In this heuristic, instead of SCCs (maximal strongly connected subgraphs), we choose minimal strongly connected subgraphs, that is, cycle graphs. Denote by the set of loop formulas associated with cycle graphs in . We use an enumeration algorithm described by Liu and Wang (2006) to enumerate cycles and construct due to its simplicity.
We remark that although and can exclude some of non-stable models, they do not necessarily exclude all of non-stable models. However, the role of loop formulas in our framework is entirely different from the one in symbolic ASP. Namely, the role of LF in our framework is not to logically reject non-stable models but to guide the search process by their gradient information in the continuous search space. Hence, we expect, as actually observed in experiments in the next section, some loop formulas have the power of guiding the search process to a root of .
Precomputation
We introduce here precomputation. The idea is to remove atoms from the search space which are false in every stable model. It downsizes the program and realizes faster model computation.
When a program in a set = atom() is given, we transform to a definite program by removing all negative literals from the rule bodies in . Since holds as a set of rules for any model , we have , where denotes the least model of a definite program . When is a stable model, holds and we have . By taking the complements of both sides, we can say that if an atom is outside of , that is, if is false in , so is in any stable model of . Thus, by precomputing the least model , we can remove a set of atoms from our consideration as they are known to be false in any stable model. We call stable false atoms. Of course, this precomputation needs additional computation of but it can be done in linear time proportional to the size of , that is, the total number of occurrences of atoms in (Dowling & Gallier, 1984).5 Accordingly precomputing the least model makes sense if the benefit of removing stable false atoms from the search space outweighs linear time computation for , which is likely to happen when we deal with programs with positive literals in the rule bodies.
More concretely, given a program and a set of constraints , we can obtain downsized ones, and , as follows.
Compute the least model and the set of stable false atoms .
Define
Let and be, respectively, the program (21) and constraints (22). Also let be a model over atom(). Expand to a model over atom() by assuming every atom in is false in . Then
is a stable model of satisfying constraints iff is a stable model of satisfying constraints .
We prove first is a stable model of iff is a stable model of . To prove it, we prove as set.
Let be an arbitrary rule in . Correspondingly there is a rule in such that . So there is a rule in such that and . implies by construction of from . So is contained in , which means is contained in because (recall that and and have the same set of positive literals). Thus since is an arbitrary rule, we conclude , and hence .
Now consider . There is a selective linear definite clause (SLD) derivation for from . Let be a rule used in the derivation which is derived from the rule such that . Since , we have and hence , that is, contains no stable false atom. So and because every atom in the SLD derivation must belong in . Accordingly . On the other hand, implies . So is in and is in . Therefore is in because . Thus every rule used in the derivation for from is also a rule contained in , which means . Since is arbitrary, it follows that . By putting and together, we conclude .
Then, if is a stable model of , we have as set. Since as set, we have as set, which means is a stable model of . Likewise when is a stable model of , we have and as set. So as set and is a stable model of .
As for the constraints, consider a constraint in . We consider two cases, where occurs positively and negatively in and . In the former case, the body remains the same between and , thus if then and vice versa. In the latter case, because always evaluates to true, the negative occurrence in the body of the constraint will not change the result of the conjunction . Thus, combining the two cases and since the constraint is arbitrary, we conclude that iff .
Programming Examples
In this section, we apply our ASP approach to examples as a proof of concept and examine the effectiveness of precomputation and heuristics. Since large scale computing is out of scope in this article, the program size is mostly small.6
The Three-Coloring Problem
We first deal with the three-coloring problem. Suppose we are given a graph . The task is to color the vertices of the graph blue, red, and green so that no two adjacent vertices have the same color like (b) as shown in Figure 1.
Three-coloring problem: (a) graph and (b) three-coloring.
There are four nodes in the graph . We assign a set of three color atoms (Boolean variables) to each node to represent their color. For example, node is assigned three color atoms . We need to represent two facts by these atoms.
Each node has a unique color chosen from . So color atoms assigned to each node are in an XOR relation. We represent this fact by a tight program below containing three rules for each node.
Two nodes connected by an edge must have a different color. We represent this fact in terms of constraints.
Assuming an ordering of atoms , the normal logic program shown in (23) is matricized to , where is a binary identity matrix (because there are 12 atoms and each atom has just one rule) and is a binary matrix shown in (25). Constraints listed in (24) are a matricized to a () constraint matrix (26). In (25) and (26), , for example, stands for a triple and for .
We run Algorithm 1 on program with constraints to find a supported model (solution) of satisfying .7
To measure time to find a model, we conduct 10 trials8 of running Algorithm 1 with , , and take the average. The result is 0.104 s (0.070)9 on average. Also to check the ability of finding different solutions, we perform 10 trials of Algorithm 110 and count the number of different solutions in the returned solutions. #solutions in Table 1 is the average of 10 such measurements. Considering there are six solutions and the naive implementation, the number of different solutions found by the algorithm, which was 5.2 on average, seems rather high.
Time and the Number of Solutions.
Time(s)
# solutions
6.7 (0.7)
5.2 (0.9)
Next we check the scalability of our approach by a simple problem. We consider the three-coloring of a cycle graph like (a) in Figure 2. In general, given a cycle graph that has nodes, we encode its three-coloring problem as in the previous example by a matricized program and a constraint matrix , where is an identity matrix and and represent, respectively, rules and constraints. There are solutions () in possible assignments for atoms.11 So the problem will be exponentially difficult as goes up.
Convergence and scalability: (a) cycle graph, (b) minimization of with retry, and (c) scalability.
The graph (b) in Figure 2 is an example of convergence curve of by Algorithm 1 with , , and . The curve tells us that in the first cycle of -loop, the inner for loop of Algorithm 1, no solution is found after iterations of update of continuous assignment vector . Then perturbation is given to which causes a small jump of at and the second cycle of -loop starts and this time a solution is found after dozens of updates by thresholding to a binary vector .
The graph (c) in Figure 2 shows the scalability of computation time to find a solution up to 10,000. We set , and plot the average of 10 measurements of time to find a solution. The graph seems to indicate good linearity w.r.t. up to 10,000.
The HC Problem, Precomputation, and Another Solution Constraint
A HC is a cycle in a graph that visits every vertex exactly once and the HC problem is to determine if an HC exists in a given graph. It is an NP-complete problem and has been used as a programming example since the early days of ASP. Initially, it is encoded by a non-tight program containing positive recursion (Niemelä, 1999). Later a way of encoding by a program that is not tight but tight on its completion models is proposed (Lin & Zhao, 2003). We here introduce yet another encoding by a tight ground program inspired by SAT encoding proposed by Zhou (2020), where Zhou showed that the problem is solvable by translating six conditions listed in Figure 3 into a SAT problem.12
Conditions for Boolean satisfiability problem (SAT) encoding of a Hamiltonian cycle problem.
In what follows, we assume vertices are numbered from to = the number of vertices in a graph. We use to denote an edge from vertex to vertex and to indicate there exists an edge from to in an HC. means vertex is visited at time () and means that one of is true. We translate these conditions into a program and constraints . To be more precise, the first condition is translated into a tight program just like a program (23). The conditions constitute a tight definite program. Constraints are encoded as a set of implications of the form , where are literals. A set of atoms contained in a stable model of satisfying gives an HC.
We apply the above encoding to a simple HC problem for a graph in Figure 4.13 There are six vertices and six HCs.14 To solve this HC problem, we matricize and . There are 36 atoms () and 36 atoms (). So there are 72 atoms in total. contains 197 rules in these 72 atoms and we translate into a pair of matrices , where is a binary matrix for disjunctions15 and is a matrix for conjunctions (rule bodies). Likewise is translated into a constraint matrix which is a binary matrix. A more detailed description of the encoding is available in the appendix (Appendix C). Then our task is to find a root of (10) constructed from these , , and in a 72 dimensional vector space by minimizing to zero.
A Hamiltonian cycle (HC) problem: (a) graph and (b) time and the number of different solutions.
We apply precomputation in the previous section to and to reduce program size. It takes 2.3 ms and detects 32 false stable atoms. It outputs a precomputed program and a constraint matrix of size , , and , respectively, which is or of the original size. So precomputation removes of atoms from the search space and returns much smaller matrices.
We run Algorithm 1 on with (no precomputation) and also on with (precomputation) using , , and and measure time to find a solution, that is, stable model satisfying constraints. The result is shown in Table (b) in Figure 4 as time(s), where time(s) is an average of 10 trials. The figures in the table, 2.08 s versus 0.66 s,16 clearly demonstrate the usefulness of precomputation.
In addition to computation time, we examine the search power of different solutions in our approach by measuring the number of obtainable solutions. More concretely, we run Algorithm 1 seven times, and each time a stable model is obtained as a conjunction of literals, we add a new constraint to previous constraints, thereby forcibly computing a new stable model in next trial. We call such use of constraint another solution constraint. Since there are at most six solutions, the number of solutions obtained by seven trials is at most six. We repeat a batch of seven trials 10 times and take the average of the number of solutions obtained by each batch. The average is denoted as #solutions in Table (b) which indicates that 5.7 solutions out of 6, almost all solutions, are obtained by seven trials using another solution constraint.
Summing up, the figures in Table (b) exemplify the effectiveness of precomputation which significantly reduces computation time and returns a more variety of solutions when combined with another solution constraint.
LF Heuristics and Precomputation on Loopy Programs
So far we have been dealing with tight programs which have no loop and hence have no loop formulas. We here deal with non-tight programs containing loops and examine how LF heuristics, and , introduced in the previous section work. We use an artificial non-tight program (with no constraint) shown below that has exponentially many loops.
We here consider an even , then program has atoms , supported models and one stable model . There are minimal loops and a maximal loop . The set of loop formulas for LF heuristics are computed as follows:
Note that although there are supported models, there is only one stable model. So and are expected to exclude supported models.
After translating into a matricized program , where is a binary matrix and is a binary matrix, respectively, we compute a stable model of for various by Algorithm 1 that minimizes (19) with coefficient for the constraint term (because of no use of constraints) using Jacobian (11).
Below is an example of the program , where .
This program has three minimal loops , and a maximal loop . There are 11 rules and six atoms, so is a binary matrix.
Since all supported models of except for one stable model are non-stable, even if and are used to guide the search process towards a stable model, Algorithm 1 is likely to return a non-stable model. We can avoid such a situation by the use of another solution constraint.
To verify it, we examine the pure effect of another solution constraint that guides the search process to compute a model different from previous ones. Without using or heuristics, we repeatedly run Algorithm 1 with/without another solution constraint for trials with , , , and measure time to find a stable model and count the number of trials until then. We repeat this experiment 10 times and take the average. The result is shown in Table 2.
The Effect of Another Solution Constraint.
Another solution constraint
Time(s)
# trials
Not used
11.46 (0.41)
Used
0.09 (0.13)
3.5 (1.6)
The figure in Table 2 in the case of no use of another solution constraint means Algorithm 1 always exhausts trials without finding a stable model (due to implicit bias in Algorithm 1). When another solution constraint is used, however, it finds a stable model in 0.09 s after 3.5 trials on average. Thus Table 2 demonstrates the necessity and effectiveness of another solution constraint to efficiently explore the search space.
We next compare the effectiveness of LF heuristics and that of precomputation under another solution constraint. For , we repeatedly run Algorithm 1 using with on matricized (and no constraint matrix) to compute supported (stable) models. Coefficients in are set to . To be more precise, for each and each case of , , precomputation (without ) and no , we run Algorithm 1 at most 100 trials to measure time to find a stable model and count the number of supported models computed till then. We repeat this computation 10 times and take the average and obtain graphs in Figure 5.
The effect of loop formula (LF) heuristics and precomputation on program : (a) time to find a stable model and (b) #computed models.
In Figure 5, no_LF means no use of heuristics. Also no_LF_pre means no_LF is applied to precomputed .17
We can see from graph (a) in Figure 5 that computation time is . This means that using LF heuristics is not necessarily a good policy. They might cause extra computation to reach the same model. Concerning the number of non-stable models computed redundantly, graph (b) in Figure 5 tells us that allows computing redundant non-stable models but the rest, , no_LF, and no_LF_pre, return a stable model without computing redundant non-stable models. This shows first that works correctly to suppress the computation of non-stable models and second that the heuristics works adversely, that is, guiding the search process away from the stable model. This somewhat unexpected result indicates the need of (empirical) choice of LF heuristics.
Finally, to examine the effectiveness of precomputation more precisely, we apply precomputation to a more complex program . It is a modification of by adding self-loops of atoms as illustrated by (a) in Figure 6. The addition of self-loop causes the choice of () being true or being false in the search process. has supported models but has just one stable model .
Precomputation applied to program : (a) a non-tight program and (b) scalability of precomputation w.r.t. .
We compute a stable model by running Algorithm 1 on precomputed without using LF heuristics up to . When precomputation is applied to , where , it detects false stable atoms and downsizes the matrices in from to and from to . Thus precomputed is downsized to 1/3 of the original .
We run Algorithm 1 on with and , at most 100 trials to measure time to find a stable model ten times for each and take the average. At the same time, we also run clingo (version 5.6.2) on and similarly measure time. Graph (b) in Figure 6 is the result. It shows that as far as computing a stable model of is concerned, our approach comes close to clingo. However, this is due to a very specific situation that precomputation removes all false atoms in the stable model of and Algorithm 1 run on the precomputed detects the stable model only by thresholding before starting any update of . So what graph (b) really suggests seems to be the importance of optimization of a program like precomputation, which is to be developed further in our approach.
Related Work
The most closely related work is Aspis et al. (2020) and Takemura and Inoue (2022). As mentioned in Section 1, our approach differs from them in three points: (1) theoretically, the exclusion of non-stable models by loop formulas, (2) syntactically, no restriction on acceptable programs, and (3) practically, incorporation of constraints. Concerning performance, they happen to use the same -negative loops program which consists of copies (alphabetic variants) of a program . According to Aspis et al. (2020), the success rate w.r.t. of returning a supported model goes from one initially to almost zero at by Aspis et al. (2020), while it keeps one till by Takemura and Inoue (2022). We tested the same program with , , and observed that the success rate keeps one till 10,000.
Although our approach is non-probabilistic, that is, purely linear algebraic, there are probabilistic differentiable approaches for ASP. Differentiable ASP/SAT (Nickles, 2018) iteratively samples a stable model by an ASP solver a la ASSAT (Lin & Zhao, 2004). The solver decides the next decision literal based on the derivatives of a cost function which is the MSE between the target probabilities and predicted probabilities computed from the sampled stable models via parameters associated with “parameter atoms” in a program.
NeurASP (Yang et al., 2020) uses an ASP solver to obtain stable models including “neural atoms” for a program. They are associated with probabilities learned by deep learning and the likelihood of an observation (a set of ASP constraints) is computed from them. The whole learning is carried out by backpropagating the likelihood to neural atoms to parameters in a neural network.
Similarly to NeurASP, SLASH (Skryagin et al., 2023, 2022) uses an ASP solver to compute stable models for a program containing “neural probabilistic predicates.” Their probabilities are dealt with by neural networks and probabilistic circuits. The latter makes it possible to compute a joint distribution of the class category and data. Both NeurASP and SLASH are examples of symbolic ASP solver-based neuro-symbolic systems, where they include a neural frontend to process the perception part of the problem, and a symbolic backend which typically is the ASP solver. Therefore, the neural frontend does not need to be involved in the computational details and problems associated with computing stable models (Section 4).
Independently of ASP solver-based approaches mentioned above, Sato and Kojima proposed a differentiable approach to sampling supported models of (non-propositional) probabilistic normal logic programs (Sato & Kojima, 2019, 2020). They encode programs by matrices and formulate the problem of sampling supported models as repeatedly computing a fixedpoint of some differentiable equations. They solve the equations in vector spaces by minimizing a non-negative cost function defined by Frobenius norm. More recently, Takemura and Inoue (2024) proposed a neuro-symbolic learning pipeline for distant supervision tasks, which leverages differentiable computation of supported models. Similarly to this work, they encode normal logic programs into matrices and define a differentiable loss function which is based on the supported model semantics.
As for the non-differentiable linear-algebraic approaches to logic programming, Nguyen et al. adopted matrix encoding for propositional normal logic programs based on Sakama et al. (2017) and proposed to compute stable models in vector spaces by a generate-and-test approach using sparse representation (Nguyen et al., 2022).
Connection to Neural Network Computation
At this point, it is quite interesting to see the connection of our approach to neural network computation. In (6), we compute and . We point out that the computation of this is nothing but the output of a forward process of a single layer ReLU network from an input vector . Consider the computation of . We rewrite this using to
So is the output of a ReLU network having a weight matrix and a bias vector . Then is the output of a ReLU network with a single hidden layer and a linear output layer represented by having as activation function. Also when we compute a supported model , we minimize (6) which contains an MSE error term using (11). This is precisely back propagation from learning data .
Thus we may say that our approach is an integration of ASP semantics and neural computation and provides a neuro-symbolic (Sarker et al., 2021) way of ASP computation. Nonetheless, there is a big difference. In standard neural network architecture, a weight matrix and a bias vector are independent. In our setting, they are interdependent and they faithfully reflect the logical structure of a program.
Conclusion
We proposed an end-to-end approach for computing stable models satisfying given constraints. We matricized a program and constraints and formulated stable model computation as a minimization problem in vector spaces of a non-negative cost function. We obtain a stable model satisfying constraints as a root the cost function by Newton’s method.
By incorporating all loop formula constraints introduced in Lin-Zhao’s theorem (Lin & Zhao, 2004) into the cost function to be minimized, we can prevent redundant computation of non-stable models, at the cost of processing exponentially many loop formulas. Hence, we introduced precomputation which downsizes a program while preserving stable model semantics and also two heuristics that selectively use loop formulas. Then we confirmed the effectiveness of our approach including precomputation and loop formula heuristics by simple examples.
Future work could focus on improving the integration of neural networks with this proposed end-to-end approach to tackle neuro-symbolic benchmark tasks that require both perception and reasoning. We also aim to improve the optimization techniques, such as precomputation, to enhance efficiency and scalability.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by JSPS KAKENHI Grant Numbers JP21H04905, JP25K03190 and JST CREST Grant Number JPMJCR22D3.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
ORCID iDs
Taisuke Sato
Akihiro Takemura
Katsumi Inoue
Notes
Appendix A. Proofs
Appendix B. Derivations
Appendix C. Encoding the Hamiltonian Cycle Problem
This section describes the encoding and program used in solving the Hamiltonian cycle problem (Section 5.2).
Firstly, looking at the graph (Figure 4a), it is evident that there are six vertices. We use an atom to indicate there exists an edge from vertices to in an HC. Then there are 36 atoms . We also use an atom to indicate that the vertex is visited at time . Then there are 36 atoms . Thus, in total, there are 72 atoms consisting of and .
References
1.
AptK. R.BlairH. A.WalkerA. (1988). Towards a theory of declarative knowledge. In J. Minker (Ed.), Foundations of deductive databases and logic programming (pp. 89–148). Morgan Kaufmann.
2.
AspisY.BrodaK.RussoA.LoboJ. (2020). Stable and supported semantics in continuous vector spaces. In D. Calvanese, E. Erdem, & M. Thielscher (Eds.), Proceedings of the 17th international conference on principles of knowledge representation and reasoning, KR 2020, Rhodes, Greece, September 12–18, 2020 (pp. 59–68).
3.
DowlingW. F.GallierJ. H. (1984). Linear-time algorithms for testing the satisfiability of propositional Horn formula. Journal of Logic Programming, 3, 267–284.
4.
ErdemE.LifschitzV. (2003). Tight logic programs. Theory and Practice of Logic Programming (TPLP), 3(4–5), 499–518.
5.
FagesF. (1994). Consistency of Clark’s completion and existence of stable models. Journal of Methods of Logic in Computer Science, 1, 51–60.
6.
FerrarisP.LeeJ.LifschitzV. (2006). A generalization of the Lin-Zhao theorem. Annals of Mathematics and Artificial Intelligence, 47, 79–101.
7.
GebserM.KaufmannB.NeumannA.SchaubT. (2007). clasp: A conflict-driven answer set solver. In LPNMR. Lecture Notes in Computer Science, Vol. 4483 (pp. 260–265). Springer.
8.
GebserM.KaufmannB.SchaubT. (2012). Conflict-driven answer set solving: From theory to practice. Artificial Intelligence, 187, 52–89.
9.
GelfondM.LifshcitzV. (1988). The stable model semantics for logic programming. In ICLP/SLP 1988, pp. 1070–1080. MIT Press.
10.
LierlerY. (2005). CMODELS: SAT-based disjunctive answer set solver. In Proceedings of the 8th international conference on logic programming and nonmonotonic reasoning, LPNMR’05 (pp. 447–451). Springer-Verlag.
11.
LifschitzV. (2008). What is answer set programming? In Proceedings of the 23rd national conference on artificial intelligence, Vol. 3, AAAI’08 (pp. 1594–1597). AAAI Press.
12.
LifschitzV.RazborovA. (2006). Why are there so many loop formulas?ACM Transactions on Computational Logic, 7(2), 261–268.
13.
LinF.ZhaoJ. (2003). On tight logic programs and yet another translation from normal logic programs to propositional logic. In Proceedings of the 18th international joint conference on artificial intelligence (IJCAI’03) (pp. 853–858). Morgan Kaufmann Publishers Inc.
14.
LinF.ZhaoY. (2004). ASSAT: Computing answer sets of a logic program by SAT solvers. Artificial Intelligence, 157(1), 115–137.
15.
LiuH.WangJ. (2006). A new way to enumerate cycles in graph. In Advanced int’l conference on telecommunications and int’l conference on internet and web applications and services (AICT-ICIW’06) (pp. 57–59). IEEE Computer Society.
16.
MarekV. W.TruszczyńskiM. (1999). Stable models and an alternative logic programming paradigm. In K. R. Apt, V. W. Marek, M. Truszczynski, & D. S. Warren (Eds.), The logic programming paradigm: A 25-year perspective (pp. 375–398). Springer Berlin Heidelberg. doi:10.1007/978-3-642-60085-2_17
17.
MarekW.SubrahmanianV. S. (1992). The relationship between stable, supported, default and autoepistemic semantics for general logic programs. Theoretical Computer Science, 103(2), 365–386.
18.
NguyenT. Q.InoueK.SakamaC. (2022). Enhancing linear algebraic computation of logic programs using sparse representation. New Generation Computers, 40(1), 225–254. doi:10.1007/s00354-021-00142-2
19.
NicklesM. (2018). Differentiable SAT/ASP. In Proceedings of the 5th international workshop on probabilistic logic programming, PLP 2018 (pp. 62–74). CEUR-WS.org.
20.
NiemeläI. (1999). Logic programs with stable model semantics as a constraint programming paradigm. Annals of Mathematics and Artificial Intelligence, 25(3–4), 241–273.
21.
NiemeläI.SimonsP. (1997). Smodels—An implementation of the stable model and well-founded semantics for normal logic programs. In J. Dix, U. Furbach, & A. Nerode (Eds.), Logic programming and nonmonotonic reasoning (pp. 420–429). Springer Berlin Heidelberg.
22.
SakamaC.InoueK.SatoT. (2017). Linear algebraic characterization of logic programs. In Proceedings of the 10th international conference on knowledge science, engineering and management (KSEM2017), LNAI 10412 (pp. 520–533). Springer-Verlag.
23.
SarkerM. K.ZhouL.EberhartA.HitzlerP. (2021). Neuro-symbolic artificial intelligence: Current trends. The European Journal on Artificial Intelligence, 34(3), 197–209. doi:https://doi.org/10.3233/AIC-210084
24.
SatoT.KojimaR. (2019). Logical inference as cost minimization in vector spaces. In Proceedings of the fourth international workshop on declarative learning based programming (DeLBP’19). https://delbp.github.io/
25.
SatoT.KojimaR. (2020). In A. E. F. Seghrouchni & D. Sarne (Eds.), Artificial intelligence IJCAI 2019 international workshops, revised selected best papers. Lecture Notes in Computer Science, Vol. 12158 (pp. 239–252). Springer. doi:10.1007/978-3-030-56150-5
26.
SkryaginA.OchsD.DhamiD. S.KerstingK. (2023). Scalable neural-probabilistic answer set programming. Journal of Artificial Intelligence Research, 78, 579–617.
27.
SkryaginA.StammerW.OchsD.DhamiD. S.KerstingK. (2022). Neural-probabilistic answer set programming. In Proceedings of the 19th international conference on principles of knowledge representation and reasoning (pp. 463–473). IJCAI Organization.
28.
TakemuraA.InoueK. (2022). Gradient-based supported model computation in vector spaces. In G. Gottlob, D. Inclezan, & M. Maratea (Eds.), Logic programming and nonmonotonic reasoning - 16th international conference, LPNMR 2022, Genova, Italy, September 5–9, 2022, Proceedings (pp. 336–349). Lecture Notes in Computer Science, Vol. 13416. Springer.
29.
TakemuraA.InoueK. (2024). Differentiable logic programming for distant supervision. In U. Endriss, F. S. Melo, K. Bach, A. J. Bugarín Diz, J. M. Alonso-Moral, S. Barro, & F. Heintz (Eds.), ECAI 2024 - 27th European conference on artificial intelligence, Santiago de Compostela, Spain – Including 13th conference on prestigious applications of intelligent systems (PAIS 2024). Frontiers in Artificial Intelligence and Applications (Vol. 392, pp. 1301–1308). IOS Press. doi:10.3233/FAIA240628.
30.
TarjanR. E. (1972). Depth-first search and linear graph algorithms. SIAM Journal on Computing, 1(2), 146–160.
31.
WestD. B. (2001). Introduction to graph theory. Prentice Hall.
32.
YangZ.IshayA.LeeJ. (2020). NeurASP: Embracing neural networks into answer set programming. In C. Bessiere (Ed.), Proceedings of the twenty-ninth international joint conference on artificial intelligence, IJCAI-20, Yokohama, Japan (pp. 1755–1762). IJCAI Organization.
33.
ZhouN.-F. (2020). In pursuit of an efficient SAT encoding for the Hamiltonian cycle problem. In Proceeding of the principles and practice of constraint programming: 26th international conference (CP 2020) (pp. 585–602). Springer-Verlag.