
Abstract
Utilizing a comprehensive panel dataset spanning from 1900 to 2020, this study introduces an innovative methodology for the analysis and categorization of legal documents, specifically national constitutions. Contrary to the predominant reliance on unsupervised methods within the field, this research incorporates a supervised machine-learning approach, notably the SEMMS method, alongside traditional unsupervised algorithms. This dual approach facilitates a nuanced analysis of the human rights provisions contained within national constitutions, resulting in the identification of both traditional and novel constitutional groupings. Broadly speaking, the more traditional common law-civil law divide does not seem particularly relevant in this context. Furthermore, our methodology enables the examination of “switchers”—nations transitioning between groupings—thereby shedding light on critical moments of constitutional reclassification. By pinpointing the key variables that delineate these groupings and transitions, our findings not only complement previous scholarly insights but also unveil unique patterns of constitutional evolution. The implications of our research extend beyond constitutional studies, offering valuable insights and methodological advancements for the analysis of extensive legal corpora across various domains.
Keywords
Introduction
The classification of legal systems in comparative constitutional law has long been a subject of scholarly debate. For instance, La Porta et al. (2008) applied the conventional legal family framework across various areas of law, including constitutional law. Importantly, Law (2019), based on the preface of the constitutions, employed topic modeling to propose a new taxonomy of constitutional families. Although analyses sometimes correspond with the traditional legal families identified in comparative law, they often uncover novel configurations, particularly through the application of computational methods—for example Chang et al. (2021), Chang (2023), and Ho, Huang, and Chang (2024).
This study examines 937 “unique constitutions” that were operational between 1900 and 2020, alongside 736 instances of transition from one unique constitution to another, employing machine-learning algorithms for analysis. Utilizing hierarchical clustering, an unsupervised machine-learning algorithm, we are able to identify ten distinct constitutional families. Subsequently, this paper leverages the five primary groups as labels in a novel supervised machine-learning method known as SEMMS, developed by Bar et al. (2020). Bar et al. (2020) compare SEMMS performance with several well-known variable selection approaches, and SEMMS achieved the best or nearly the best results in different simulation settings. Consequently, SEMMS is a reliable variable selection methodology to find the human rights provisions that differentiate one group from another.
Concerning clusters or legal families, broadly speaking, the more traditional common law-civil law divide (La Porta et al., 2008; Mahoney, 2001) does not seem overwhelmingly relevant in this context. Concurrently, our approach also uncovers some unconventional groupings and proposes a deviation from the four families identified by Law (2019). This deviation is illustrated by focusing on human rights provisions, as done by Law and Versteeg (2012, 2013), which take a leading role in the comparative constitutional law literature (Chilton & Versteeg, 2016, 2020; Ho, Huang, Garoupa, et al., 2024). In fact, by emphasizing human rights provisions, our findings and methodologies invite evaluation and discussion within the context of the existing empirical literature.
Furthermore, our methodology enables the analysis of countries transitioning between different groupings. Unlike previous research, which often relies on static classifications, we introduce a dynamic framework for legal family classifications, allowing us to pinpoint pivotal moments of constitutional reclassification. By identifying the key variables that drive these groupings and transitions, our findings not only complement existing scholarship but also uncover distinct patterns of constitutional evolution.
More specifically, from the standpoint of comparative law scholarship, a legal family approach is about classifying a country into one group, ideally one-classification-fits-all-legal-areas. Legal origin has been conceptualized as exogenously determined and arguably still relevant to modern phenomenon (Anderson, 2018; Ayele et al., 2024; La Porta et al., 2008). However, we show that there are dynamic concerns since countries shift across groups and belong to different clusters in different periods of time.
From the perspective of constitutional law scholarship, we show that there is some discrepancy between our classification in 2020 and classifications based on waves of democracy and legal/colonial origins (Ginsburg, 2008; Law, 2005, 2016, 2019). These factors (waves, legal origin, and colonial origins) have influenced countries at some point as widely documented by previous scholarship, but later development pushed some countries away from the conventional classification (Chang et al., 2024). Moreover, our article is also the first to use an algorithm to select key human right provisions to classify constitutions into distinct groups. These selected provisions enable us to get a bird’s-eye view on the differences and evolutions of constitutional human rights over 121 years.
Overall speaking, our article contributes both substantively and methodologically to the discourse on constitutional comparative analysis. Our unsupervised machine learning method enables us to classify nearly one thousand unique constitutions over a century to groups, without inputs of human knowledge (or bias) of legal origins or other classifications. In combination of a Bayesian variable-selection method, we produce interpretable results for human experts to further explore the underlying mechanism of constitutional diffusion. Our findings once again challenge the conventional wisdom of legal origins and present a different picture of the evolution of human right provisions across time and country.
Nevertheless, it is important to acknowledge a limitation common to this body of literature: our analysis is confined to the textual content of constitutions rather than the actual practice (Elkins et al., 2009; Gutmann et al., 2024). The distinction between de jure and de facto rules in constitutional law has a long tradition; the literature on the expressive role of the law has debated the value of unenforced legal norms (McAdams, 2015). While our focus on textual analysis sheds light on the intentions of drafters and the ideologies they espouse, we do not claim that these texts invariably influence practical outcomes.
The next section presents a literature review about method and object. The data is introduced after the literature review and followed by a discussion of methods. A later section reports and discusses our findings. Final remarks close the article.
Literature Review of Legal Typology
Legal Traditions
Legal traditions and families, classifications, typologies, and taxonomies have long dominated scholarly discussions in comparative law (Pargendler, 2012), and more recently in law and economics (Garoupa & Pargendler, 2014).
The rise of the legal origins movement in development economics and law and finance (La Porta et al., 2008; Mahoney, 2001) has put the typology of legal traditions (mainly the distinction between the common law and the civil law traditions) at the heart of the academic and policy debate (Chang & Smith, 2012, p. 3) about causal mechanisms explaining financial markets and economic growth (Klerman et al., 2011). For example, within the legal origins movement, stronger checks and balances have been related to the common law—civil law divide (La Porta et al., 2004).
The expansion of empirical comparative law has inevitably improved quantitative methodologies and the overall quality of available data to scholars (Engel, 2021; Spamann, 2009, 2015). As a consequence, typologies have been under scrutiny; the appropriate way to divide these legal traditions is itself contested. While La Porta et al. (2008) divide countries into four groups, Klerman et al. (2011) divide countries into six groups, Chang et al. (2021), Chang (2023), and Ho, Huang, and Chang (2024) argue that countries can be divided into any number of groups, and Bradford et al. (2021) and Chang et al. (2024) suggest that the nature and usefulness of these groups is likely to vary across substantive legal questions.
Typologies have also been relevant in comparative politics, in particular when it comes to forms of government, separation of powers, electoral rules, or constitutional regimes (Colomer, 2006). However, this vast literature in political science has not focused on legal families, but rather on political traditions (democracy vs. authoritarianism, parliamentary vs. presidential, proportional vs. single-seat districts, party system, and so on).
Detecting, improving, and disagreeing over typologies of legal families or traditions are no stranger to comparative constitutional law. Based on the diffusion patterns around the world, scholars have classified constitutions according to waves (Ginsburg, 2008; Law, 2005, 2016). By now, an extensive qualitative literature focuses on explaining similarities and distinctions in constitutional law around the world (Skach, 2006; Suteu, 2021; e.g., Venter, 2001).
With the popularization of quantitative large-N studies in comparative constitutional law in the last decade, many possible taxonomies have emerged (Elkins & Ginsburg, 2021). For example, constitutional waves are not just chronologically relevant but reveal diverse textual borrowing trends (freedom of expression is a good illustration). Therefore, the three or four waves of constitutional design emphasize varying priorities across time and place in terms of separation of powers, civil liberties, socioeconomic rights, new environmental rights, and so on (Law & Versteeg, 2011, 2012). Additional typologies can reflect constitutional resilience and ability to endure (Elkins et al., 2009); constitutional provisions with a focus on social rights and their actual enforcement (Chilton & Versteeg, 2016, 2020); constitutional regulation of foreign relations law (Cope et al., 2022); or the interaction between domestic constitutional law and public international law (Elkins et al., 2013) and constitutional compliance (Law & Versteeg, 2013). Finally, cultural aspects of diffusion cannot be ignored (Rockmore et al., 2018).
In terms of identifying and explaining legal families, Law (2019) used automated content analysis on 615 constitutional texts to uncover an important classification: British colonialism, French colonialism, Spanish colonialism, and socialism. Law (2019) suggested an association with a distinctive genre, dialect, and constitutional language. He concluded that changes over time in the popularity of these categories merely reflected the rise and fall of competing empires. In addition, Rockmore et al. (2018) used topic modeling to analyze 591 constitutions and uncovered systemic variation in the patterns of borrowing from ancestral constitutional texts. As another example, Ramdas et al. (2024) use document term matrix, a natural language processing approach, to assess the impact of 13 core and iconic constitutions on 572 new constitutions adopted in 1900–2020.
Constitutional Diffusion
Since our article provides a dynamic approach to classification of legal families, it also relates to the study of constitutional diffusion and transplantation, albeit only indirectly. For example, in an earlier study, Law and Versteeg (2011) empirically demonstrated both ideological convergence and polarization in constitutional design, identifying a trend where constitutions diverge into two distinct families—libertarian and statist.
Further, Law and Versteeg (2012) showed that countries are increasingly unlikely to model their rights-related or structural constitutional provisions on the U.S. Constitution. Analyzing sixty years of data, they revealed a growing “generic” component in global constitutionalism, where a set of rights provisions appears in nearly all constitutions. This trend highlighted the increasing divergence of the U.S. Constitution from global norms, a finding echoed by Elkins et al. (2009), who documented the declining similarity between the U.S. Constitution and those of other nations. Rockmore et al. (2018) similarly used topic modeling and concepts from cultural evolution to trace the sequential influence of certain constitutional texts on their successors.
Shifting focus to constitutional review, Ginsburg and Versteeg (2014) explored its diffusion, finding that domestic electoral politics, such as political insurance or hegemonic preservation, play a significant role in its adoption. In contrast, they found little evidence to support ideational factors, federalism, or international norm diffusion as major drivers.
Ginsburg et al. (2008) examined how constitutions incorporate international law, showing that democracies often use it as a tool to solidify policies, build trust in state regimes, and enhance global reputations.
Later, Goderis and Versteeg (2014) identified four mechanisms driving the spread of constitutional provisions: coercion, economic competition, learning, and acculturation. Their analysis showed that a nation’s decision to adopt a right often correlates with adoptions by former colonizers, nations with shared legal origins or religious traditions, and aid donors, particularly when adopting a first constitution.
In addition to this quantitative-oriented empirical work, a vast qualitative literature also explores borrowing and diffusion across comparative constitutional law, as seen in works by Jackson (2010) and Perju (2012), among many others.
Data
Our data on human-right provisions in the constitutions come from the Comparative Constitutions Project (CCP), which contains constitutions from more than 200 countries since 1789. As of 2020, CCP contains constitutions from 194 countries, but in total, our analysis (shown in Figure B.1) contains 201 countries. The dataset is compiled by one of the co-authors (Ginsburg) and is available online. 1 However, some information utilized by this article has not yet been released publicly, as we refined the coding for several specific questions. Appendix A describes how we deal with missing information in the CCP and to describes our method in transforming non-categorical variables in CCP into dummy variables. The rest of this part explains how we define “unique constitutions” and “transitions” which are the unit of observations in our quantitative analysis.
As relatively few constitutions existed before 1900, we arbitrarily pick 1900 as the cutoff year and study only constitutions in the period 1900–2020. After cleaning the data set, we picked out each “unique constitution” which differs from the effective constitution in the same country in the previous year.
2
In most years in each country, the human rights provisions remain the same. Hence, only a new constitution or a new constitutional amendment regarding human rights is considered a unique observation (at this stage, no constitutions have missing values). Suppose Country X enacted its first constitution in 1920 and expanded its bill of rights in 1975. Only the 1920 and 1975 constitutions (but not those in 1921–1974) are defined as unique constitutions, and these two unique constitutions are included in our analysis as two observations. Constitutions in other years are omitted from further analysis, even if there were amendments, so long as those amendments did not affect our variables of interest. A unique constitution is marked with a square (□) in Figures 1–6 and Figure B.4. In total, there are 937 unique constitutions in terms of the 135 human rights provisions in 1900–2020. 823 out of 937 unique constitutions are classified as “amendment” or “new” in the CCP dataset.
3
Among the 736 transitions, on average 15.9% of the human rights provisions were changed (added or removed). The minimum and maximum numbers of changes are 1 and 78, respectively. The 25, 50, 75 percentiles of the number of human rights provisions changes are 3, 20, and 33, respectively. For countries which enacted a constitution before 1900, their constitution as of 1900 is marked as a unique constitution, even though it went into effect before 1900. Note that no country happened to adopt a constitution in 1900. A country’s year of political independence is marked with a black dot in Figures 1–6 and Figure B.4. Some countries’ constitutions were established before they gained political independence. Finally, Figures 1–6 and Figure B.4 show a country-year matrix. A cell is blank when either the country and its constitution did not exist in that year or there is no coding of the constitution in the CCP database.
4
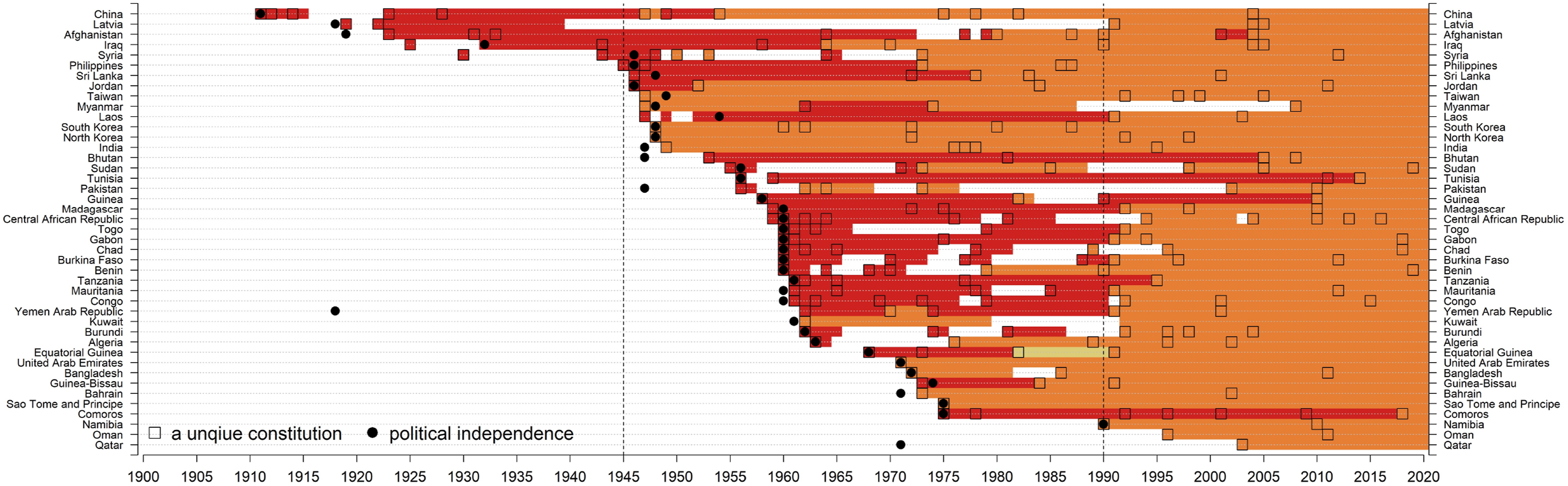
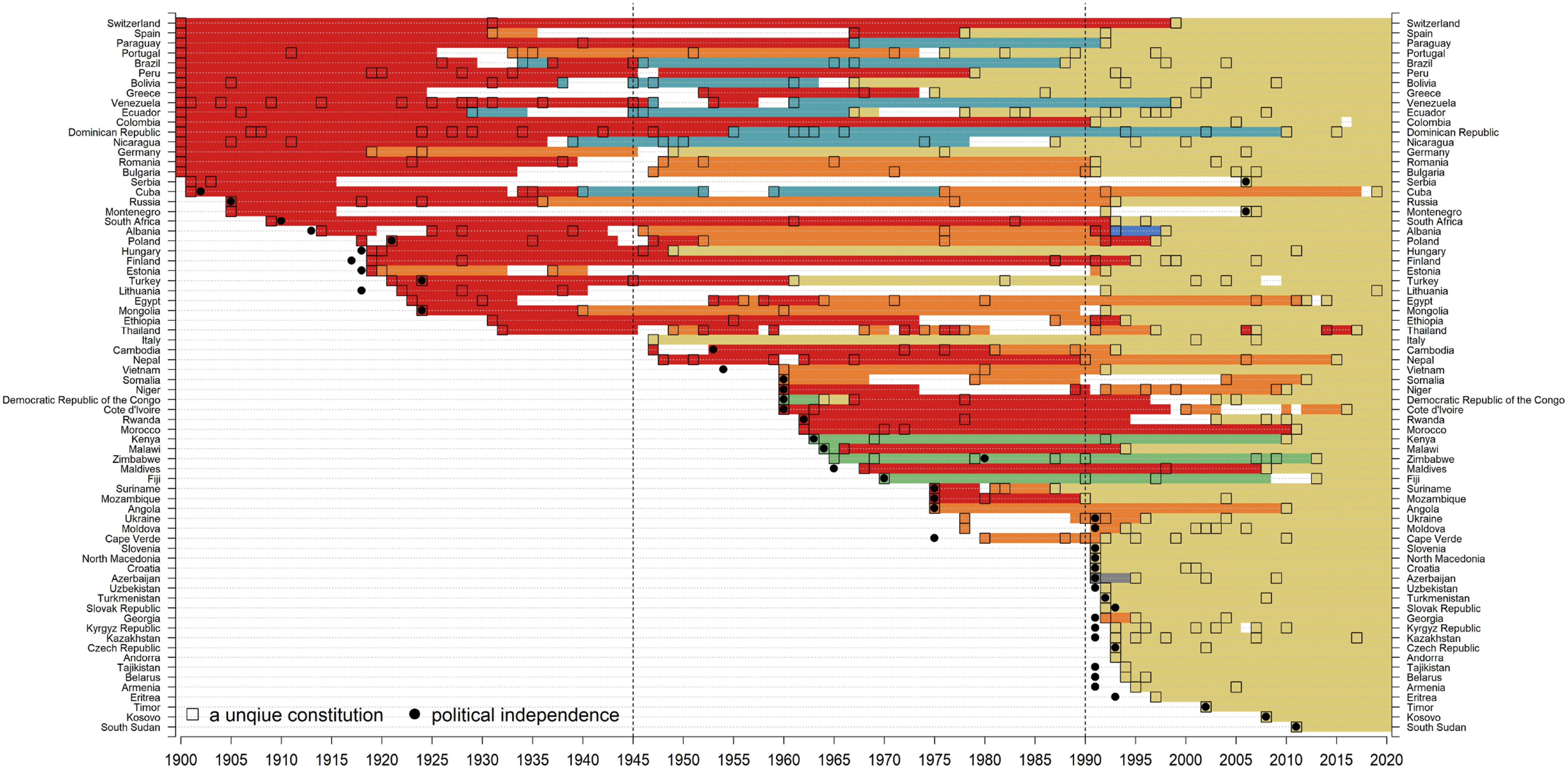
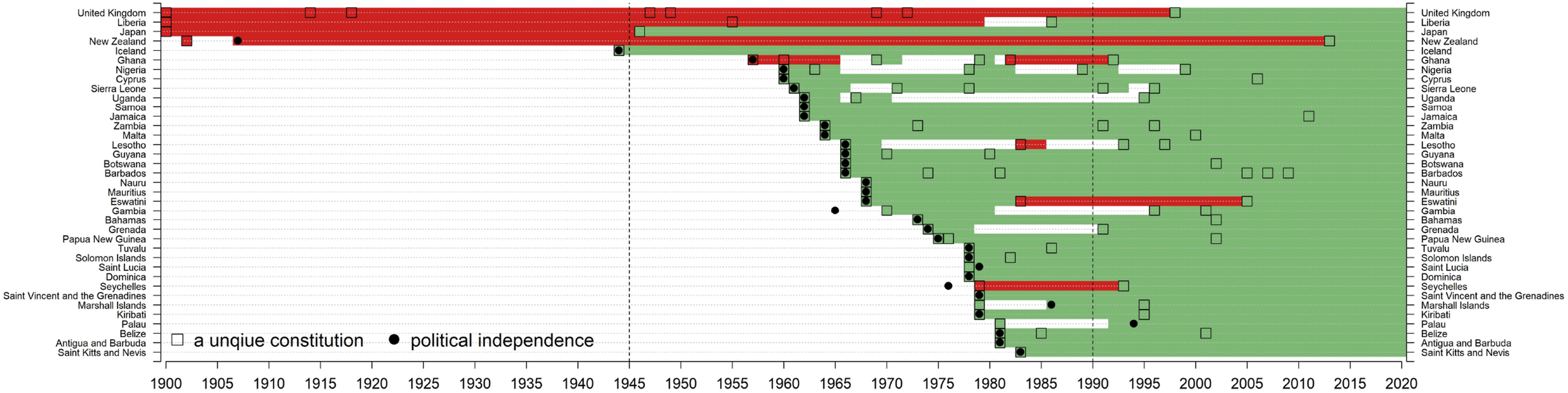
Countries with red-group constitutions in 2020. Notes. N = 113 unique constitutions. Note that not all red unique constitutions are included in this figure. A country is classified as a red group based on its 2020 constitution. 29 countries are contained in this figure. Each square represents a unique constitution. No country adopted a unique constitution in 1900, but for graphical presentation purposes, the squares were placed in 1900 for those constitutions in effect that were enacted before 1900. The black solid dot indicates the year a country gained political independence. The countries in this figure are first sorted by the year of unique constitutions in or after 1900, and then sorted according to countries’ first ever constitutions. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0. Countries with orange-group constitutions in 2020. Notes. N = 222 unique constitutions. 43 countries are contained in this figure. See also notes to Figure 1. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0. Countries with yellow-group constitutions in 2020. Notes. N = 390 unique constitutions. 72 countries are contained in this figure. See also notes to Figure 1. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0. Countries with green-group constitutions in 2020. Notes. N = 95 unique constitutions. 37 countries are contained in this figure. See also notes to Figure 1. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0. Countries with blue-group constitutions in 2020. Notes. N = 74 unique constitutions. 10 countries are contained in this figure. See also notes to Figure 1. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0. Countries not belonging to the five major groups in 2020. Notes. N = 43 unique constitutions. 10 countries are contained in this figure. See also notes to Figure 1. All the 16 purple unique constitutions are from Mexico. High-resolution file of this figure can be downloaded at https://www.dropbox.com/scl/fo/uvw09ursj6ch6kom91aaa/AIAA1hNAyeTb4xDUUMhAgMQ?rlkey=vdus5zrbl4dweurcyav5fmssr&st=eg4jiipa&dl=0.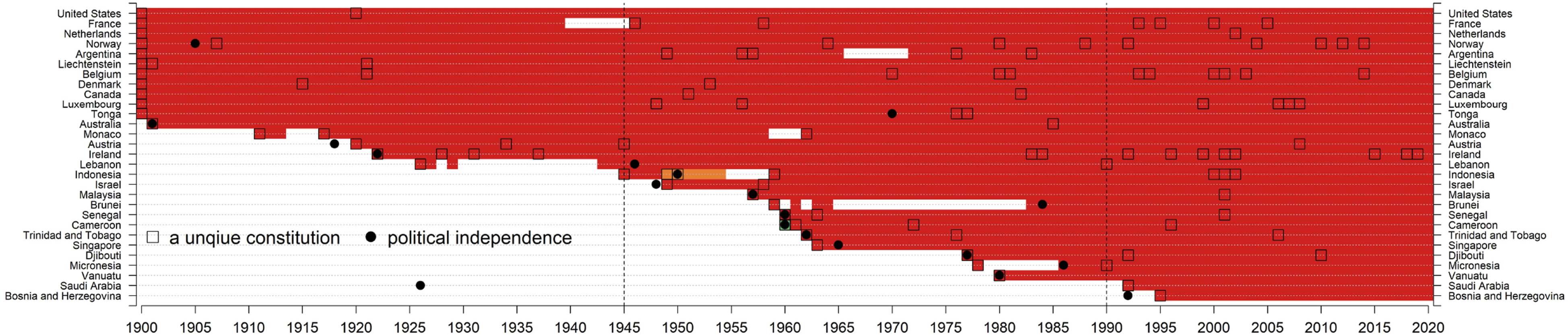


A country that has more than one unique constitution (again, only human rights provisions are considered) in 1900–2020 has at least one constitutional “transition.” One transition in our data set stands for the switch from the previous unique constitution to the next. In total, there are 736 transitions in terms of human rights provisions in 1900–2020.
Methods
In this part, we lay out our three-step methodological architecture. Section A describes how we use hierarchical clustering, an unsupervised learning method that does not require any pre-existing labelling or reference of countries or constitutions, to divide the unique constitutions into five large groups and four small groups. Section B introduces SEMMS, a new variable selection method that enables us to find, given the groups identified by the hierarchical clustering, the most distinctive characteristic of each cluster; that is, which human rights provisions drive the classification. Section C uses Firth logistic regressions to empirically assess how well the sparser model provided by SEMMS relates to the “true” model in terms of consistency; that is, whether the human rights provisions selected by SEMMS do turn out to be statistically significant in a regression framework. We also compare our methods with other prominent methods.
Such a three-step approach is not strictly necessary for our purposes. We could have stopped in Step 2 (SEMMS) and reported the key human right provisions found for each group identified in the first step (hierarchical clustering). Fitting a separate model again after variable selection is always doable in practice. Yet, some people stick with the results of variable selections, thinking the p-values in a separate regression are invalid, because the outcome-based variable selection had already been performed (data snooping), while others do re-run the analyses, as if no variable selection had happened, especially when there are control variables. We chose to carry out the post-SEMMS (Firth) logistic regressions because we would like to gain additional empirical insight. As long as SEMMS selects relevant predictors, we expect that most, if not all, of the selected variables to be significant in a traditional statistical approach (and indeed they do). Step 3 uses Firth logistic regression models rather than the conventional logistic regression models to consider the possible “near-complete separation” and the bias of MLE due to the imbalance of outcome, both of which commonly occur in binary dependent variables with rare events.
Step 2 is the key step dealing with the issue that few, if any, existing empirical legal studies have dealt with. As SEMMS is “cast as a classification problem” (Bar et al., 2020, p. 536), input data must include already labelled data (i.e., classified into groups). Such labels can be provided by human experts among the authors, pre-existing literature, or another algorithm. We could have skipped Step 1 if existing grouping in the literature or grouping by human experts is accepted as the ground truth. Whatever the bases of given classes are, there are as many possible partitions as there are many notions of similarity and discrepancy. That being so, it is natural in the attempts to identify unknown homogenous subgroups among unique constitutions with unsupervised learning according to the features. Hence, we decided to defer to the hierarchical clustering algorithm, a standard unsupervised learning method, forming the distinct classes by 135 human rights provisions themselves, to come up with the labels.
Finding groups of unique constitutions that are similar with respect to 135 human rights features via a clustering algorithm without prior knowledge about class membership, or whether there are distinct classes, is our goal here in Step 1. The exercise of clustering tends to be more subjective without a relatively simple purpose, in contrast to the use of labelled data to build a classifier to make predictions as almost the only goal of supervised learning. Therefore, supervised machine learning methods, even with a similar tree-like visual representation, do not fit our purposes in Step 1.
Hierarchical Clustering
In a hierarchical clustering analysis, the distance of each pair of countries is calculated. Hastie et al. (2009) provide a rigorous treatment of clustering techniques and outline a process related to hierarchical clustering, coupled with broader clustering insights. Hastie et al. (2009) stress that substantive expertise is essential at all stages of the clustering process. The systematic process described underscores the balance between mathematical rigor and practical application for hierarchical clustering workflows.
The first step is the data preprocessing, followed by selecting a distance/proximity measure. As our data set contains only binary variables, the Euclidian distance cannot be used. Following Chang et al. (2021) and Chang (2023), we use Gower distance, which is essentially the percentage of disagreement. 5 The next major choice is choosing a linkage method with different linkage criteria (e.g., single, complete, or average), resulting in different cluster shapes and structures. The single-linkage measures the shortest distance between groups; the complete-linkage measures the longest distance between groups; and the average-linkage calculates the average distance of all countries in one group with all countries in the other group. This article uses average-linkage (as did Chang et al., 2021), which, as it is more stable (Ho, Huang, & Chang, 2024). The hierarchical clustering analysis is agglomerative, under which every unique constitution starts as its own cluster. Then, two unique constitutions separated by the shortest distance (the least dissimilar) are merged forming a small cluster with two members. In each iteration, one cluster (with one or more members) is merged into another, until all clusters are connected.
The next step is constructing the dendrogram using the chosen distance metric and linkage method. The dendrogram visually represents cluster merges, helping identify natural breakpoints. The result of any hierarchical clustering method is often presented in a dendrogram; 6 see Figure B.3. At the bottom (the left side) of the dendrogram, each jurisdiction is considered its own cluster. The horizontal axis (the scale at the top) of the dendrogram indicates the Gower dissimilar coefficients. The “height” of the nodes (or joining points), visualized as vertical line in Figure B.3, thus represents the Gower dissimilar coefficients when two clusters merge. As we move up the tree (from left to right), the groupings of merged countries become more dissimilar (James et al., 2021, pp. 522–524). Groupings continue until, at the far right of the dendrogram, all observations appear in a single supercluster.
The next critical decision is deciding the number of clusters. Hastie et al. (2009) suggest a visual inspection of the dendrogram that looks for large gaps in the height of merges, as these indicate natural splits in the data. In this inspection, one assesses the trade-off between the number of clusters and within-cluster variance; an “elbow” point indicates diminishing returns for additional clusters. This visual inspection is carried out within the context of the substantive problem under study. We decided to categorize the 937 unique constitutions into nine groups. For the purpose of graphical presentation, we call them the red, orange, yellow, green, blue, purple, dark blue, pink, and grey group. As shown in Table B.1, the purple (N = 16), dark blue (N = 1), pink (N = 1), and grey (N = 1) groups are very small and thus cannot be included in the further regression analysis.
The next critical step is validating and interpreting the clusters. Here, we assessed cluster stability, that is, how stable the clusters are under variations in data or parameters (e.g., by bootstrapping). We assessed an external validation using domain knowledge to evaluate whether clusters align with meaningful real-world categories and an internal validation to evaluate the intra-cluster distance and inter-cluster distance. 7 There are many clustering algorithms because different datasets and problems have unique characteristics, and no single algorithm performs optimally in all situations. The variety of algorithms arises from the need to address different types of data structures, scales, and objectives. We use the hierarchical clustering algorithm because it is standard, model-free, and simple to understand and to visualize. The attractive tree-based representation highlights the advantage that one single dendrogram can be used to obtain any number of clusters, and then we determine a sensible number of clusters without specifying in advance the number of clusters as in the centroid-based clustering. In our study, we do not want to impose such a constraint, as there is no strong theory that suggests how many groups we should divide the unique constitutions into, nor do we find very suitable centroid-based clustering methods for our binary data to apply. Even though we may use the validation method to find the best value of the number of clusters, however, a centroid-based clustering method such as k-means performs better if clusters are more spherical and roughly equal in size and density, which may not be the case in our data, because some small groups or outlier constitutions can be expected. As for other possible partitional clustering methods, the density-based clustering is indeed able to identify non-spherical clusters of different diameters and outlying cases; nevertheless, it works better in continuous data. The model-based clustering might be promising. However, our longitudinal binary data structurally needs more temporal modeling considerations than just fitting mixtures of multivariate Bernoulli distributions under existing methods.
The final step in the cluster analysis is an iterative refinement based on the stability analysis. At this point, the constitutional scholars interpreted the validation results and concluded that further analysis. Given the results of the validation study, it was determined that five clusters contain a substantial number of unique constitutions, and the four other groups will not be used in further analysis.
Variable Selection
While categorization of the unique constitutions in itself is interesting, it does not readily inform us the driving factors. In our context, we are interested in the key human rights provisions (a small set of the 135 provisions) that distinguish the groups of unique constitutions, and we thus apply a variable selection procedure that deals with sparsity in the high-dimensional setting where p >> n. The Scalable EMpirical Bayes Model Selection (SEMMS) approach, developed by Bar et al. (2020), is a principled variable selection method. Modern model selection methods, such as SEMMS, Lasso (Tibshirani, 1996), SCAD (Fan & Li, 2001), and MCP (Zhang, 2010) automatically select a subset of relevant predictor variables while shrinking the coefficients deemed not significant to zero. Information-based model selection criteria, such as AIC, BIC, and Cp (Boisbunon et al., 2014), penalize models with excessive parameters but do not enforce coefficient shrinkage to zero. In contrast, thresholding methods impose stricter constraints on feature selection by explicitly setting some coefficients to zero. As a result, thresholding approaches are more aggressive in feature selection compared to information-based criteria. Both techniques are widely used in empirical research. 8
SEMMS is an objective and data-driven approach to variable selection, relying on mathematical criteria to determine variable importance. This approach can help prevent overfitting by reducing the number of variables in the model, which can lead to better generalization and is especially useful when dealing with many potential predictor variables. The advantage of using SEMMS is that SEMMS carries out the variable selection and inference simultaneously and preserves the proper significance levels, even though the sample sizes in our individual regressions are no less than the number of predictors (Bar et al., 2020). 9
SEMMS takes an empirical Bayes approach and models that the effects predictors have on the expectation of outcome can be either positive, negative, or have no effect at all. Mathematically, the SEMMS approach uses a three-component mixture in which the magnitudes of the non-null predictors are assumed to follow normal distributions. The three-component mixture of normal priors is flexible enough to be applied to variable selection in the generalized linear models framework (McCullagh & Nelder, 1989), which includes normal, binomial, and Poisson distributions and censored survival data as well. The detailed simulation study in Bar et al. (2020) showed that SEMMS has the best or nearly the best selection results and control of false positive errors than penalization methods such as the Lasso, SCAD, and MCP. 10
We note here the methodological differences between Step 2 here and a recent article by Cope et al. (2022) in a different legal context. Cope et al. (2022) use an estimation procedure called ideal-point estimation to identify and describe the principal ways in which states’ relationship to international law in their domestic legal order can vary over time. An ideal point or policy point represents the set of policies an actor thinks is ideal, that is, which it prefers over all other alternatives. The word “ideal” has nothing to do with the quality of the statistical estimation procedure. Cope et al. (2022) use principal-component analysis (PCA) on 31 subjectively selected variables (traits) to establish that two combinations of issues divide states in their foreign relations law choices for these thirty-one traits. Cope et al. (2022) use two dimensions, and then fit an item response theory (IRT) model to calculate discrimination parameters in the two dimensions to explain the latent dimensions. 11 The discrimination parameters indicate which “votes” best explain the variation for each dimension. Once their dimensions are fixed and the IRT parameters are calculated, country clusters are investigated. The approach of Cope et al. (2022) is different from ours, as we first cluster the constitutions (the basic observations) in Step 1 and then select variables that explain those groupings in Step 2 without a dimension reduction step.
Our approach also differs from the optimal classification method used by Law and Versteeg (2011), which applied Poole (2000), based on a singular value decomposition. Law and Versteeg (2011, p. 1205) discuss some of the drawbacks of Poole (2000); an important point is that “one cannot identify precise ideal points,” which may lead to difficulty interpreting the results. Our two-step method, with hierarchical clustering plus sparse model approach, provides an interpretable methodology.
As SEMMS can only be used in one-against-one comparison, we conduct a number of pair-wise comparison among the five groups with enough unique constitutions. 12 More specifically, two types of comparison are done. The first approach, comparing member constitutions in two groups, is intuitive. Unique constitutions in, say, the red group are compared with those in, say, the orange group. SEMMS will select human rights provisions that best separate the red versus orange group. Put differently, the SEMMS-selected provisions inform us the key differences between the two groups.
The second approach studies the transitions versus the lack of transitions. As shown in Figures 1–6, when a country adopts a new unique constitution, sometimes it remains in the original group, and sometimes it switches to a new group. The second approach compares, say, red-to-orange unique constitutions with red-to-red unique constitutions (i.e., the latter includes countries that remain in the same group). Table B.2 summarizes the number of transitions. To operationalize, we subtract the values of the dummy variable (with values 0 or 1) in the previous unique constitution from those in the later unique constitution. As a result, each post-subtraction human right variable could take three values: −1, 0, or 1; that is, at this stage, each human right variable is categorical. Intuitively, 0 means the provision of interest remains unchanged, while both −1 and 1 imply a change regarding the variable with the sign meaning the direction of change. As in a conventional linear regression with independent categorical variables, each of the categorical variables is converted into using two dummy variables. For instance, a binary “Variable X: Add” takes the value of 1 if the original categorical variable X equals 1 and takes the value of 0 if the original categorical variable X equals 0 or −1. Similarly, a “Binary Variable X: Remove” takes the value of 1 if the original categorical variable X equals −1 and takes the value of 0 if the original categorical variable X equals 0 or 1. We then ran SEMMS. Most SEMMS-selected variables are of the “add” type, partly because most variables are framed as affirmative rights for which removal is rare. When SEMMS selects only the dummy variable “Variable X: Add,” (i.e., only this first indicator variable is statistically significant), we also include “Variable X: Remove” (and vice versa) in the later Firth logistic regressions. (Table B.3 shows whether it is the “add” variable or the “remove” variable was originally selected by SEMMS.) Including the other related indicator variable (usually the one indicating removal of a human rights provision) in the Firth logistic regressions enable us to more intuitively interpret the coefficient of the “Variable X: Add” variable.
The SEMMS algorithm modifies at most one parameter estimate in each iteration because changing more than one variable may introduce multicollinearity. Consequently, even though each single variable may increase the likelihood, changing a set of highly correlated variables may cause the log-likelihood to decrease (and it may even approach infinity because it involves the logarithm of the precision matrix). Consequently, as pointed out in Bar et al. (2020, p. Section 1 of Supplemental Material), the SEMMS algorithm automatically prevents selecting models with extremely highly correlated predictors. The SEMMS algorithm keeps track of predictors that are correlated with ones selected to be in the model since they are likely to be related to the outcome as well. Given the binary nature of our data, one would expect groups of variables to be highly correlated. SEMMS algorithm, by design, guards against selecting groups that are very highly correlated which is not the case with LASSO, SCAD, and MCP. Multicollinearity exacerbates the complete separation issue in logistic regressions. The Firth logit approach (explained below) is the proper feasible approach in dealing with quasi-complete separation in the context of reducing first-order bias of ordinary maximum likelihood logistic regressions.
Firth Logistics Regressions
The dependent variables in all models are binary; thus, it is natural to fit with logistic regression. However, due to the nature of our data, the responses and non-responses can be near perfectly separated by a single covariate or a linear combination of covariates. The near-separation problem is an issue of the possible non-existence of the maximum likelihood estimate under a particular configuration of the sample. In addition, the imbalance of the binary outcomes tends to increase the first order bias of MLE as well. A solution to both problem is to regularize the likelihood using the natural logarithm of the Jefferys’ invariant prior, one-half times the log of the determinant of the Fisher information matrix (denoted by I), ½ln|I| (Firth, 1993). The choice of penalization has been extensively discussed (Greenland & Mansournia, 2015). The standard errors for Firth-corrected logistic regression produced by Stata and SAS differ. SAS uses the unpenalized inverse information I−1 in Newton-Raphson iterations to maximize the penalized likelihood, taking the final I−1 as the estimated covariance matrix (Firth, 1993; Heinze & Puhr, 2010), whereas Stata uses the penalized inverse information I*−1 (the negative Hessian of the penalized likelihood). The difference is theoretically minor, but Greenland and Mansournia (2015) point out that the covariance estimate I*−1 may suffer from higher-order bias. Therefore, we have adopted the fitting approach used in SAS.
With a subset of human rights provisions selected by SEMMS as the more important variables in distinguishing the multiple groups, we further put these selected variables in regressions to gauge the magnitude of their impacts and their statistical significance. For each inter-group comparison, we ran four regressions. The first two regressions adopt the first approach (say, red vs. orange), whereas the latter two regressions adopt the second approach (say, red-to-red vs. red-to-orange). Model (1) uses SEMMS-selected variables for, say, red versus orange. Model (3) uses SEMMS-selected variables for, say, red-to-red versus red-to-orange. The variables SEMMS selects for (1) and (3) are not always the same, which is reasonable since the models have different dependent variables. Models (2) and (4) use independent variables that are the union of the variables under (1) and (3), so the variables used in Models (2) and (4) are the same. 13 Models (1)–(4) are Firth-corrected logistic regressions introduced above.
Some SEMMS-selected variables were dropped from the final reported regression results. 14 Sometimes, including all the SEMMS-selected variables in the models produce convergence failures due to “complete separation,” which implies that the Jefferys’ invariant prior penalized maximum likelihood estimates do not exist. 15 We dropped one or more variables (marked in Table C.1) until the model converges. Moreover, sometimes, even when the model converges, one or more variables were dropped due to high multicollinearity. We identified high multicollinearity among independent variables if the overall model is statistically significant (as suggested by the large likelihood ratio chi-square statistic) while individual variables are statistically insignificant. More specifically, we ran an OLS on the specified variables to check the VIFs and checked the conditional indices from output of the COLLIN option in SAS’ PROC REG to tease out which variables are highly correlated. We dropped the variable one at a time with VIF>2.5 or the variables whose value of “proportion of variation” is 0.5 or greater (indicating major contribution to the collinearity) when the conditional index is large and re-ran the Firth models. The process is repeated until there was no unacceptably high multicollinearity. The detailed working process was recorded and is available upon request.
Findings and Discussions
Nine Groups of Constitutions
A hierarchical clustering analysis can produce an arbitrary number of groups, and we use nine groups to demonstrate the results. Members in those groups are unique constitutions, not countries. The full clustering results are contained in Figure B.4. Five groups contain a substantial number of unique constitutions, and they are conveniently labeled red, orange, yellow, green, and blue. The four tiny groups are labeled purple, dark blue, pink, and grey. The unique constitutions that belong to four other tiny groups will not be used in further analysis. The number of unique constitutions contained in each group is shown in Table B.1.
To make the visual results more legible, the classification results must be presented in several figures instead of one. We put countries in Figures 1–5 based on the affiliation of its unique constitution in effect in 2020. The countries whose effective constitution in 2020 are in the, say, red group are referred to as “red-group countries” for ease of reference. (Recall, again, that it is the unique constitutions, not countries, that are classified by our machine-learning algorithm). Figure 6 contains the remaining countries, including those that extinguished before 2020, as well as the idiosyncratic Mexico.
The red group countries include those whose constitutions have been stable during the entire period of our analysis. These countries have the most stable and oldest constitutions in the world, including the United States, the Netherlands, Norway, Belgium, and Tonga. These are among the handful of countries whose constitutions have lasted more than a century, including the first constitution in the data which is that of the United States. The younger countries which have joined this group include several in which the constitutional text is not consolidated into a single document, such as Saudi Arabia, Israel, and Canada. Finally, a small number the former British colonies are found in the group.
The orange group countries are numerous and include a diverse range of postcolonial countries. Most of these countries gained independence after 1945, and in no case does membership in the orange group precede that year. India seems to play a vital role in the network, perhaps because it was a model for other states in the Global South. Many of the postcolonial states are in Francophone or Lusophone Africa or were former British colonies in the Middle East. The Middle Eastern group includes Iraq, Bahrain, Kuwait, the UAE, Oman, and Qatar. This is an interesting finding of similarity across colonial origins, but also suggests regional proximity as a driver of text, as earlier scholars have found (Ginsburg, 2014). Membership in the orange group consolidates around 1990.
The yellow group emerges and consolidates around 1990, as there were relatively few yellow group constitutions before that point. Many yellow group countries switched from other groups. Some of them, such as the Dominican Republic, Paraguay, and Portugal, have gone through multiple groups in constitutional evolution. This indicates a good deal of constitutional experimentation. Countries that became independent after 1990, such as those in the Balkans or central Asia, as well as the world’s youngest country of South Sudan, are uniformly in this group. It seems to represent a set of very right-heavy countries, including those in Latin America, whose text were influenced by their drafting during the “third wave” of democracy.
Membership in the green group is largely composed of countries that became independent after 1960, particularly in sub-Saharan Africa and the Caribbean. The majority are former British colonies, consistent with the finding of Law (2019) that these constitutions were very similar. But it also includes other countries, such as Japan’s 1947 constitution, which may have served as an unobserved model for the drafting of later post-colonial texts. What these countries seem to have in common is great stability, with a relatively small number of switchers.
The blue group countries and the miscellaneous set of countries in Figure 6 are diverse. Seven of the 10 countries in the blue group are in Latin America, and another is nearby Haiti which, suggesting again some regional convergence. These are all older countries with long and turbulent constitutional histories, that switched out of the red group at various times between the early 1930s in the late 1970s. Iran, which of course experienced a dramatic regime change in 1979, is also in the group.
To present the evolution of constitutional typology, in Figures B.5–B.10, we show a series of world maps with countries color-coded according to the groups they belong to in 1900, 1925, 1950, 1975, 2000, and 2020. 1900 and 2020 are the first and last years of the data we use. The 1950 map shows the changes World War II already made. 16 The 1975 map reflects the post-colonization changes started in 1960s. The 2000 map describes the world in the aftermath of the Soviet fall. A video that shows the evolution of group changes from 1900 to 2020, year by year, is available at https://youtu.be/k4Ez_TI953w.
Finally, the dendrogram of the 937 unique constitutions (Figure B.3) shows that in terms of Gower distance (i.e., the percentage of disagreement), the red group is closest to the orange group, and the red and orange groups are closer to the green group than the remaining groups. Red, orange, and green, along with dark blue, pink, and grey, form a supercluster, whereas yellow, blue, and purple form another supercluster.
Driving Factors
Summary of Firth Regression Results.
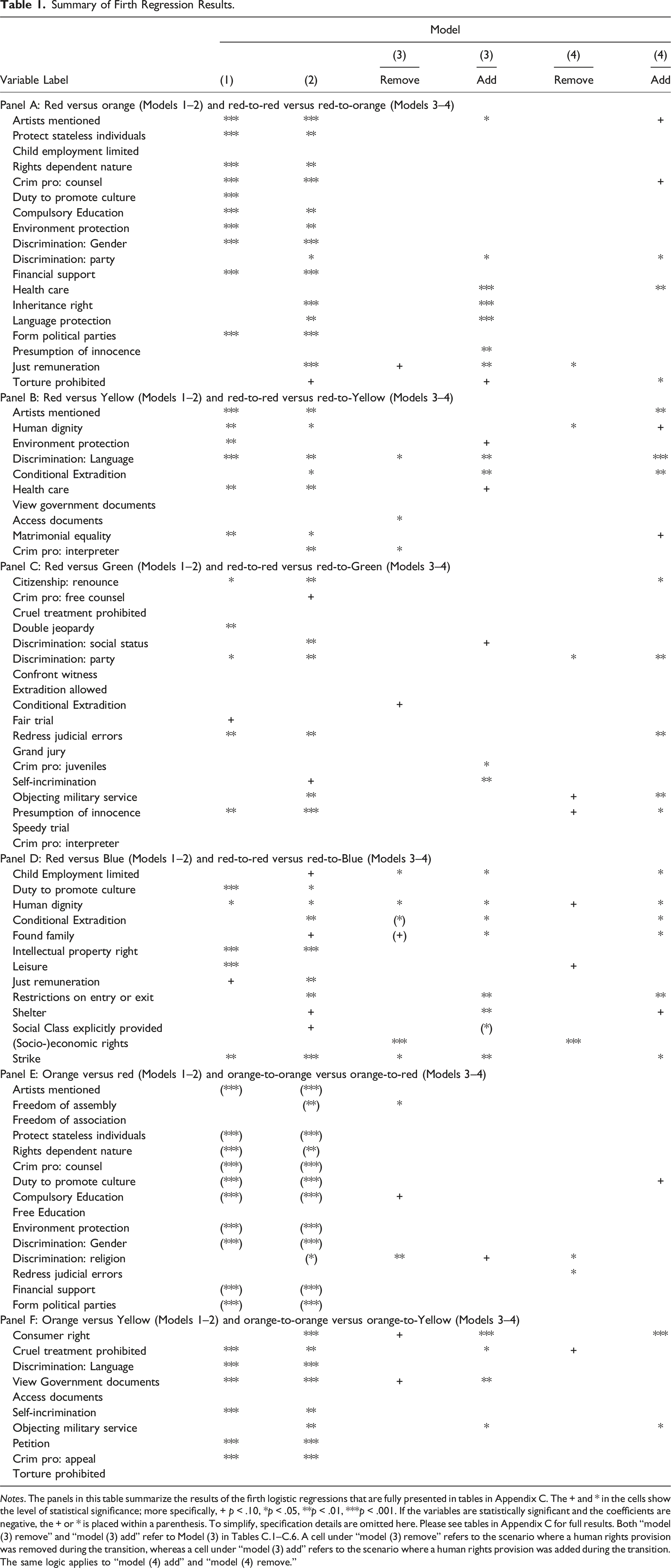
Notes. The panels in this table summarize the results of the firth logistic regressions that are fully presented in tables in Appendix C. The + and * in the cells show the level of statistical significance; more specifically, + p < .10, *p < .05, **p < .01, ***p < .001. If the variables are statistically significant and the coefficients are negative, the + or * is placed within a parenthesis. To simplify, specification details are omitted here. Please see tables in Appendix C for full results. Both “model (3) remove” and “model (3) add” refer to Model (3) in Tables C.1–C.6. A cell under “model (3) remove” refers to the scenario where a human rights provision was removed during the transition, whereas a cell under “model (3) add” refers to the scenario where a human rights provision was added during the transition. The same logic applies to “model (4) add” and “model (4) remove.”
Based on Figures 1 to 6, we find five major groups plus four minor groups. As of 2020, only the five major groups plus the idiosyncratic Mexican and Libyan constitutions (purple and pink, respectively) remained. The red group, including the U.S. and most pre-20th century constitutions, seems to have the “conventional”, sort of “minimalist”, and stable constitutions. The other four major groups capture different waves and emphases. From Table 1, we can infer that these four major groups seem to be distinct from the “minimalist” stable red by expanding constitutional law in different directions. Broadly speaking, the main directions seem to be: (i) Orange group – education, culture, and gender rights; (ii) Yellow group – language, environment, family (marriage), and health rights; (iii) Green group – criminal justice and civil justice (including discrimination) provisions; (iv) Blue group – culture and labor rights.
While some jurisdictions seem to be resilient to change within the red group, others have evolved in different directions. It naturally follows that jurisdictions value distinct economic and social rights quite differently, thus generating diverse groups—this is consistent with previous scholarship by Law and Versteeg (2011), Rockmore et al. (2018), and Chilton and Versteeg (2020).
Averages of Color-Ness in the Five Groups.
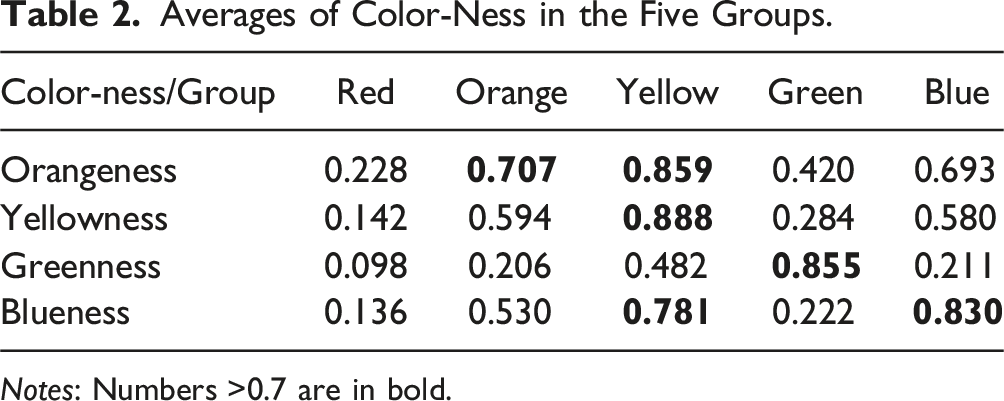
Notes: Numbers >0.7 are in bold.
Common Law – Civil Law Divide
One thing that stands out is that the more conventional distinction between common law and civil law countries does not map onto the groupings we have found. There are common law and civil law jurisdictions in the four largest groups, namely, red, orange, yellow, and green. However, common law jurisdictions are overwhelming in the green group, with a minority in the other three groups. If one takes a crude measure based on the observation that common law jurisdictions are about 1/3 and civil law jurisdictions are about 2/3 of standard classifications (Klerman et al., 2011; La Porta et al., 2008), our findings suggest that common law jurisdictions are overrepresented in the green group and probably underrepresented in the other four main groups. But as noted above, the green group includes prominent countries squarely in the civil law tradition, such as Japan (which could merely reflect the influence on the United States in the Japanese constitution). The idea that the traditional common law relies more on judicial lawmaking than civil law applies more directly to the red group (which includes the United States). However, one should note that both common law and civil law countries in the red group tend to have older codified constitutions, thus inevitably relying on landmark court decisions to enhance and enforce constitutional rights. As to the specific case of the United Kingdom, the move from the red to the green group reflects the statutory change made possible by the Human Rights Act 1998 (which incorporates the rights set out in the European Convention on Human Rights into domestic law).
Grouping and Legal Origin.
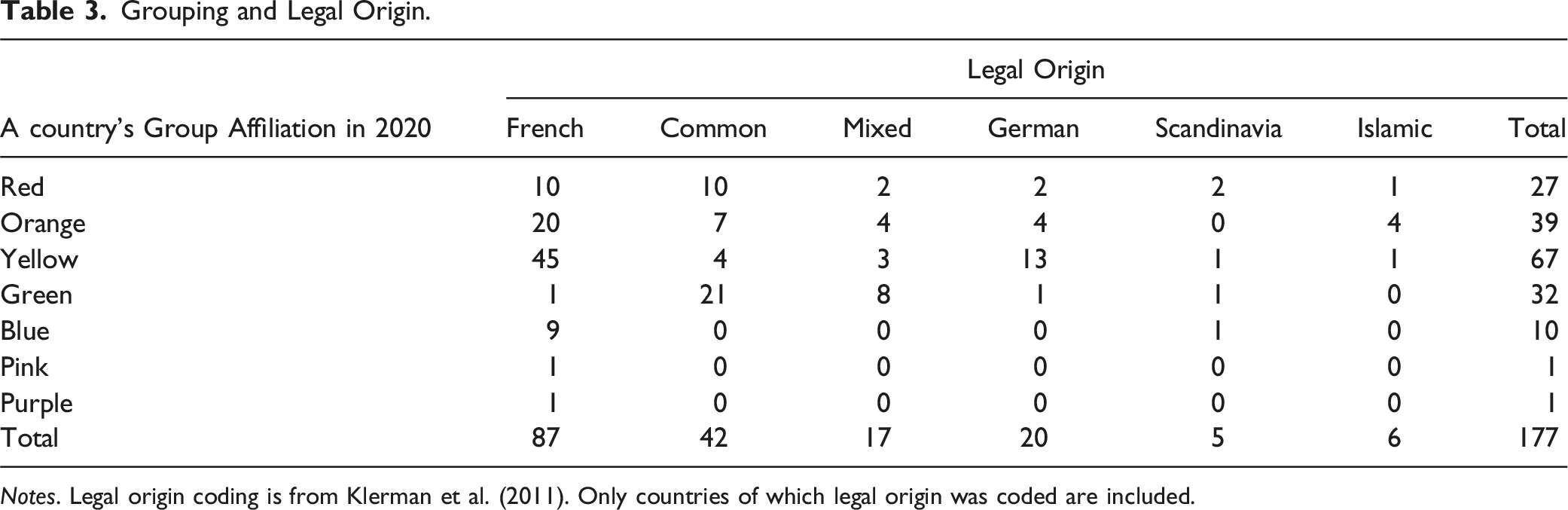
Notes. Legal origin coding is from Klerman et al. (2011). Only countries of which legal origin was coded are included.
Grouping and Colonial History.
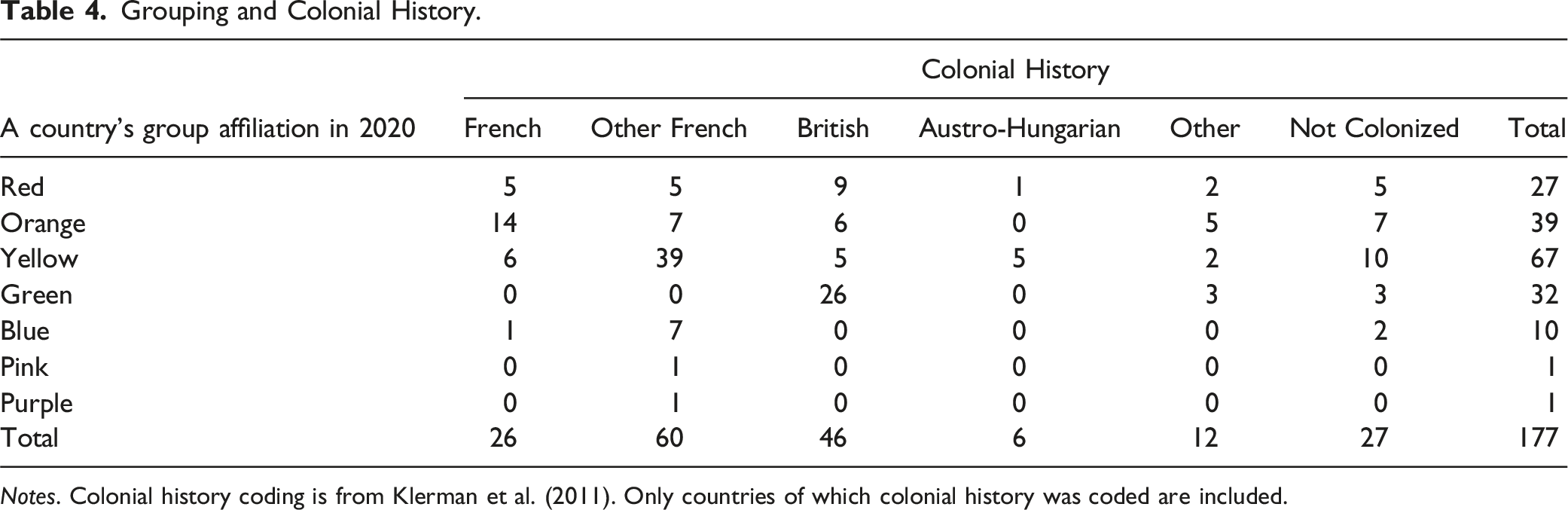
Notes. Colonial history coding is from Klerman et al. (2011). Only countries of which colonial history was coded are included.
Our approach offers a more nuanced comparison of jurisdictions that have not traditionally been considered close counterparts. For instance, Germany and the Dominican Republic are both included in the yellow group, while Japan and the UK appear together in the green group (notably, Japan, often seen as influenced by the United States, aligns with the UK group in our study). Similarly, Sweden and Costa Rica are clustered in the blue group, India and South Korea in the orange group, and Denmark and Singapore in the red group. These diverse pairings underscore the influence of specific human rights provisions (as outlined in Table 1), which drive the clustering within these color-coded groups. However, such granular similarities in human rights provisions are often overlooked in traditional comparative constitutional law, which tends to focus on broader categorizations, as illustrated in Tables 3 and 4.
It is important to note that standard accounts of conventional legal families and colonial influence (Chang et al., 2024; Klerman et al., 2011; La Porta et al., 2008) generally assume a stable classification of jurisdictions over time. These origins were determined by some historical process (conquest, colonization, trade, etc.) and arguably determine legal systems for a long period of time up to the present. However, Figures 1 through 6 illustrate significant changes across these groups, while Table 1 summarizes the key driving factors behind these shifts. Such changes challenge the view of an enduring common law–civil law divide that remained a stable institutional framework for over two centuries.
Other Classifications
The color groups do have some post-colonial flavor, with the green group being more British, and the blue, yellow, and orange are more of a mix of former French, Spanish, Portuguese colonies, and other countries. It suggests that the findings by Law (2019) are broadly valid but more nuanced than anticipated. On the one hand, as emphasized above, former British colonies are mostly represented (but not exclusively) in the green group. On the other hand, however, for example, Spanish speaking-countries and former Spanish colonies can be found in several groups – orange, yellow, and blue. As to Portuguese-speaking and French-speaking jurisdictions, we find them present in two groups – orange and yellow (and Haiti in the blue group). In particular, the French colonial origin countries make up the majority of those in the yellow group, while many French-speaking countries are also yellow. The most we can say is that these traditions have at best a conditional relevance: they may matter at the moment of decolonization but then adjustments may be made thereafter, at least in some regions.
Concerning the four waves of constitutional models (Ginsburg, 2008; Law, 2005, 2016), our findings suggest a more subtle approach. The red group can be understood as representing the first wave, as it generally aligns with older constitutions. However, the subsequent waves do not correspond as neatly to the color groupings. For instance, the blue group includes countries with long and turbulent constitutional histories that transitioned out of the red group at various times between the early 1930s and late 1970s. This means it does not perfectly align with the second wave (post-World War II). The green group largely clusters around the 1960s and consists mostly of former British colonies. It appears to sit between the traditional second wave (post-World War II) and the third wave (marked by democratization after the 1970s). The yellow group captures constitutional shifts predominantly after the 1990s, though some cases trace back to the 1970s, encompassing both the third wave (democratization after the 1970s) and fourth wave (late 20th and early 21st centuries). The orange group is even more mixed in terms of constitutional waves. Although most members of this group consolidated around 1990, aligning with the fourth wave, many countries within it have constitutional histories dating back to 1945, consistent with the second wave. As such, the orange group appears to draw on constitutional models from all three waves.
In an earlier study, Law and Versteeg (2011) identified two distinct constitutional families—libertarian and statist. Our classification does not find any direct connection according to the color groups in that regard. The same conclusion applies to classifications based on separation of powers’ metrics (Colomer, 2006). These discrepancies may just reflect a significantly diverse methodological focus.
Conclusion
The classification of constitutional law families has been widely discussed. By making use of machine learning, we identify five major types of domestic constitutions and four minor groups, allowing us to identify changes in the overall character of constitutions and their shifts among groups. These groups reflect different trends in terms of social rights and specific constitutional provisions, in line with previous work in the field. Although the groups have a post-colonial flavor, they do not follow canonical legal families (the traditional common law – civil law distinction) and colonial influence, strictly speaking.
Change, rather than continuity, plays a central role in understanding constitutional development. Our approach allows for the analysis of countries’ transitioning between different legal classification groupings, emphasizing the fluidity of these shifts. This perspective challenges the reliance on static classifications that have largely dominated previous legal scholarship’s grouping, both in comparative law and in constitutional law.
By introducing a dynamic framework for analyzing legal families, we are able to pinpoint pivotal moments of constitutional reclassification. Identifying the key variables driving these transitions, our findings not only complement and reinforce existing scholarly conclusions but also reveal distinct patterns of constitutional evolution. In essence, according to our analysis, machine learning makes it possible to test the conventional wisdom about legal families, which turns out to be at best partially supported.
Supplemental Material
Supplemental Material - Machine-Learning Human Rights
Supplemental Material for Machine-Learning Human Rights by Han-wei Ho, Patrick Huang, Nuno Garoupa, Martin T. Wells, Yun-chien Chang, and Tom Ginsburg in Journal of Law & Empirical Analysis
Footnotes
Author Notes
Draft of this article has been presented at the 2023 CELS at the University of Chicago Law School, 2023. ALEA at Boston University, Faculty Workshop at Max-Plank Institute for Research on the Collective Goods, 2022 CELS in Asia, Methodology of Social Sciences Workshop at the Institute of Social Science of the University of Tokyo, Faculty Workshop at Cornell Law School, Institutum Iurisprudentiae and the Institute of Economics, Academia Sinica, Taiwan, and the Sixth Conference on Data Legal Studies held in Beijing, China in December 2023.
Acknowledgments
We thank three anonymous referees, the editor in charge, Christoph Engel, and Liz Anker, Emad Atiq, Sandra Babcock, Roy Baharad, Haim Bar, Li-Kung Chen, Wen-Tsong Chiou, Dawn Chutkow, Angela Cornell, Kevin Davis, Alexander Egberts, Liangcong Fan, Miguel de Figueiredo, Mike Dorf, Josh Fischman, Takeshi FUJITANI, Hanjo Hamann, Valerie Hans, Michael Heise, Eric Helland, Thomas Holzhausen, Jimmy Chia-Shin Hsu, Masaki Iwasaki, Riley Keenan, Mahdi Khesali, Masahiko KINOSHITA, Dan Klerman, Mitch Lasser, Pascal Langenbach, Chien-Chih Lin, Adi Leibovitch, Chao Ma, Kenneth Mori McElwain, Hatsuru Morita, Ed Morrison, Frank Pasquale, Chun Peng, Jeff Rachlinski, Rima-Maria Rahal, Kyle Rozema, Hiroharu SAITO, Hans-Bernd Schaefer, Jed Stiglitz, Masayuki TAMARUYA, Yingmao Tang, Paul Vaaler, Pham Hoang Van, Eleanor Wilking, Tzung-Mou Wu, Yiwei Xia, Moulin Xiong, Ya-Wen Yang and Todd Zywicki for helpful comments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.