
Abstract
We evaluate the statistical and conceptual foundations of empirical tests for disparate impact. We begin by considering a recent, popular proposal in the economics literature that seeks to assess disparate impact via a comparison of error rates for the majority and the minority group. Building on past work, we show that this approach suffers from what is colloquially known as “the problem of inframarginality”, in turn putting it in direct conflict with legal understandings of discrimination. We then analyze two alternative proposals that quantify disparate impact either in terms of risk-adjusted disparities or by comparing existing disparities to those under a statistically optimized decision policy. Both approaches have differing, context-specific strengths and weaknesses, and we discuss how they relate to the individual elements in the legal test for disparate impact. We then turn towards assessing disparate impact of search decisions among approximately 1.5 million police stops recorded across California in 2022 pursuant to its Racial Identity and Profiling Act (RIPA). The results are suggestive of disparate impact against Black and Hispanic drivers for several large law enforcement agencies. We further propose alternative search strategies that more efficiently recover contraband while also exerting fewer racial disparities.
Introduction
Anti-discrimination law in the U.S. recognizes two distinct forms of discriminatory conduct. First, disparate treatment law aims at prohibiting decisions that intentionally condition on protected group status, either to harm minorities or as an intermediate step to further a different goal. This notion of discriminatory conduct is largely consistent with Becker’s popular model of discrimination, which defines as discriminatory those actions that are either motivated by animus (“taste-based discrimination”) or that use race as a proxy for an unobservable, decision-relevant factor (“statistical discrimination”) (Becker, 1957). But in many areas of life, such as employment and credit, U.S. law has long embraced a second definition of discrimination, significantly broadening its scope. This notion of discrimination is known as disparate impact. The doctrine of disparate impact renders illegal those policies that produce avoidable and unjustified excess disparities [Griggs v. Duke Power Co., 401 U.S. 424 (1971)]. In practice, disparate impact is often found if the plaintiff can demonstrate the existence of an alternative, feasible decision rule that is at least as good as the existing decision rule at achieving the stated policy goal while imposing fewer disparities. Although the law’s embrace of disparate impact doctrine can be traced back decades, empirical scholarship both in the law and in the social sciences at large has almost exclusively limited itself to the analysis of disparate treatment. It is only recently that the literature has made a systematic attempt to broaden its focus (Arnold et al., 2022; Ayres, 2005, 2010; Bartlett et al., 2021; Bohren et al., 2022; Cai et al., 2022; Elzayn et al., 2023; Grossman et al., 2024; Grunwald et al., 2022; Jung et al., 2023). In its wake, several statistical frameworks for the measurement of disparate impact have been proposed independently.
In this paper, we introduce, compare, and critically assess the three most prominent recent proposals: risk-adjusted disparities, disparities relative to statistically optimized decision policies, and error-rate disparities. We discuss their individual advantages and disadvantages, and examine how they relate to the legal doctrine of disparate impact as it has been developed by U.S. courts. We argue that the first two proposals speak to different legal elements of disparate impact doctrine, making both valuable empirical tools for assessing disparate impact in various situations, albeit with context-specific strengths and weaknesses. However, we further argue that the third proposal—error-rate disparities —is generally unsuitable for assessing disparate impact. To foreshadow our argument, consider a judge who makes detention decisions by balancing public safety with the individual rights of the defendants. Imagine the judge is able to perfectly distinguish between “risky” and “non-risky” defendants, and chooses to only detain risky defendants. Assuming further that detention decisions were generally subject to disparate impact law, 1 the judge’s decision practice would nonetheless not be considered to exert a disparate impact. After all, the judge is making decisions that optimally fulfill the goal of balancing public safety with the defendant’s interests, and any residual disparities that result would thus be considered justified. Yet, as we show below, in most scenarios a measure that relies on error rates would find that the judge’s decision practice is illegal, a result that can be reconciled neither with disparate impact doctrine nor with existing normative notions of discrimination. At a technical level, we illustrate that such error-rate-based measures suffer from what is known as the “problem of inframarginality” (Ayres, 2002; Hedden, 2021; Simoiu et al., 2017), an observation previously made in the technical literature in the context of algorithmic decisions (Corbett-Davies et al., 2017, 2023).
We utilize the insights obtained from our discussion and apply them to the concrete example of search decisions during vehicle and pedestrian stops conducted by police officers. To that end, we analyze a novel dataset of approximately 1.5 million stops recorded by police agencies across California in 2022. During this time period, officers could choose to search stopped pedestrians and drivers whom they perceived as sufficiently likely to be carrying contraband. Officers were, on average, more likely to search Black and Hispanic individuals than white individuals, providing prima facie evidence of disparate impact. Moving beyond this prima facie evidence, we then apply the proposals above to assess the evidence for disparate impact. Following the first proposal, we compute risk-adjusted disparities to determine whether the gap in search rates is justified by legitimate policy goals—namely, the recovery of contraband. To do so, we estimate the statistical likelihood that a stopped individual is carrying contraband, using all available recorded information. We find that search rates for stopped Black and Hispanic individuals are considerably larger than for stopped white individuals of comparable risk (i.e., the racial disparities persist even after accounting for risk). Next, following the second proposal, we compare the observed racial disparities to those achievable under a set of statistically optimized alternative search policies. We specifically consider a set of “threshold” policies, in which all individuals above a given level of estimated risk are searched. We find that there are indeed alternative policies that: (1) recover more contraband than the status quo; (2) require conducting fewer searches; and (3) impose fewer racial disparities. The existence of such policies provides additional evidence of disparate impact. We emphasize, however, that these results are primarily intended as an illustration of preferred approaches to measuring disparate impact. To conclusively demonstrate illegal disparate impact in a court setting, further scrutiny of policing practices is necessary.
Embracing a broader concept of anti-discrimination is vital to ensuring that empirical scholarship remains closely tied to legal realities. Our hope is that this study can contribute to that goal by serving as a guide to researchers interested in assessing the disparate impact of a policy or decision rule.
The Law of Disparate Treatment and Disparate Impact
Although our focus lies on disparate impact law, a brief primer on the legal concepts in U.S. anti-discrimination can serve as helpful background. For ease of exposition, we will focus on the law surrounding racial discrimination, although most of the content equally applies to other forms of discrimination based on legally protected features, such as gender.
Generally speaking, U.S. law recognizes two forms of discriminatory conduct: disparate treatment and disparate impact. Disparate treatment encapsulates the most intuitive notion of discrimination. It is aimed at outlawing decisions and policies that are motivated by race, making discriminatory intent the crucial element of disparate treatment [DeJung v. Superior Ct., 169 Cal. App. 4th 533 (2008); McDonnell Douglas Corp v. Green, 411 U.S. 792 (1973)]. The intent can take the form of explicit, racially conditioned decision making. But more commonly, disputes focus on facially neutral decisions or policies that are alleged to be—at least in part—racially motivated. Disparate treatment by public entities is governed by the Equal Protection Clause of the U.S. Constitution. Accordingly, if discriminatory intent is present and the discriminatory actor is a public entity or official, the decision is subjected to judicial review under a “strict scrutiny” standard [United States v. Carolene Prod. Co., 304 U.S. 144 (1938)]. 2 This standard is very difficult to meet and requires that the conduct in question is narrowly tailored to serve a compelling state interest. The only examples relevant today in which race-based decisions met this standard consist of affirmative action cases in a handful of domains, such as in government contracting [Rothe Dev., Inc v. United States Dep’t of Def., 836 F.3d 57 (D.C. Cir. 2016)] and—until recently—education [Fisher v. Univ. of Texas at Austin, 579 U.S. 365 (2016); Students for Fair Admissions, Inc v. President and Fellows of Harvard Coll., 143 S. Ct. 2141 (2023)]. In addition to the constitutional constraints imposed on public actors, disparate treatment by private actors is outlawed by federal and state laws in many public-facing contexts, 3 although relevant nuances may vary by context. 4
Although constitutional and statutory prohibitions against disparate treatment developed separately and employ differing evidentiary standards (Harris, 2014), they share a strong emphasis on the element of discriminatory intent. It is thus common to conceptualize disparate treatment as decisions made because of race.
5
Empirical legal research has translated this definition of disparate treatment into a “kitchen-sink” model (Gaebler et al., 2022). Under this approach, the investigator typically runs a regression of the form
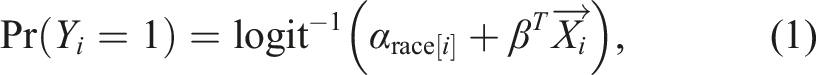
There are some problems with conceiving of disparate treatment in this way. Among others, it is our view that empirical researchers often define the set of covariates included in
In addition to disparate treatment, U.S. anti-discrimination laws sometimes render illegal a second form of discriminatory conduct, disparate impact. But unlike disparate treatment, there is no general prohibition of disparate impact under the U.S. Constitution. Instead, disparate impact is rendered illegal only through state and federal laws. The most prominent domains subject to disparate impact analysis include credit [15 U.S.C. §1691 et seq.], employment [42 U.S.C. §2000e et seq.] and housing [42 U.S.C. §3601 et seq.]. Although the fragmented nature requires a few generalizations, disparate impact laws aim to prevent policies and decisions that, while not necessarily racially motivated, nonetheless have an adverse impact on racial minorities that cannot be justified by a furtherance of the policy goals.
To illustrate, consider the case of a job posting by a tech company for the position of a software engineer. The posting requires applicants to have a computer science degree. The degree requirement impacts Black potential applicants more negatively than white potential applicants, given that the share of Black computer scientists is disproportionately low (Dillon Jr. et al., 2015). However, a computer science degree can reasonably be assumed to teach skills that software engineers benefit from, meaning that the degree requirement does not constitute disparate impact. But contrast this to the seminal case of Griggs v. Duke Power Co., where the Supreme Court examined an internal policy under which a high school diploma was required for certain promotions within Duke Power Company in North Carolina. Black employees were much less likely to hold a high school diploma than white employees, thus disproportionately excluding the Black minority from the positions. The Supreme Court found that, while it is principally permitted to impose job requirements that impact racial minorities disproportionately, a high school diploma did not indicate better job performance, thus rendering the requirement illegal.
More formally, legal tests of disparate impact typically have three elements. Those require that: (1) the minority group is disproportionately impacted by a policy (“adverse impact”) [New York City Env’t Just. All. v. Giuliani, 214 F.3d 65 (2d Cir. 2000)]; (2) that there is no legitimate justification for the policy [Texas Dep’t of Hous. and Cmty. Affs. v. Inclusive Communities Project, Inc, 576 U.S. 519 (2015)]; and (3) that an alternative policy with a lesser disproportionate impact is available and implementable [Elston v. Talladega Cnty. Bd. of Educ., 997 F.2d 1394 (11th Cir. 1993)]. The plaintiff is responsible for establishing that the defendant’s policy adversely impacts the minority group. The burden then shifts to the defendant, who must show that the adverse impact is justified by legitimate policy goals. Failing to do so would typically result in a finding of disparate impact. However, if the defendant does provide compelling justification for the disparities, the burden then shifts back to the plaintiff, who, to establish a finding of disparate impact, must show that there exists an equally efficient policy with less adverse impact than the status quo [see, e.g., 42 U.S. Code §2000e–2]. We describe these three elements in more detail below.
Adverse Impact
An adverse impact is typically defined as a difference in group-based selection rates [29 C.F.R §1607.16]. In the context of standardized tests for promotions, for instance, a court would compare the passage rate among white test takers to the passage rate among Black test takers. The test would demonstrate an adverse impact if the passage rate among Black test takers was substantially lower than that among white test takers. 7
No Justification
An adverse impact lacks a substantial justification if it is not demonstrably related to a significant, legitimate goal. At times, it is also held that the adverse impact needs to be a necessary condition to effectuate the policy goal. 8 How courts operationalize this requirement is highly context-specific [Clady v. Los Angeles Cnty., 770 F.2d 1421 (9th Cir. 1985); Smith v. Xerox Corp, 196 F.3d 358, 363 (2d Cir. 1999); Groves v. Alabama State Bd. of Educ., 776 F. Supp. 1518 (M.D. Ala. 1991)]. For instance, the strength of the evidence required may vary by the extent of the adverse impact, by the entity that makes the relevant decision, and by whether the decision-relevant factors that cause the disparity are innate or can be acquired.
No Less Discriminatory Alternative
Demonstrating the shortcomings of the current policy is not enough if there is no less discriminatory alternative [Elston v. Talladega Cnty. Bd. of Educ., 997 F.2d 1394 (11th Cir. 1993); Georgia State Conf. of Branches of NAACP v. State of Ga., 775 F.2d 1403 (11th Cir. 1985)]. In this way, disparate impact law is grounded within the realm of feasible policy choices: If the only way for an employer to mitigate adverse impact is to spend tens of thousands of dollars on each applicant to assess their suitability for the job, this is not something that anti-discrimination laws will ask of them. With the advent of algorithmic decision making, the requirement to have no less discriminatory alternative has received heightened relevance. Often, if a decision was based on these complex model estimates, it would both improve outcomes and decrease the adverse impact (Goel et al., 2016). However, it remains unclear in what contexts decision makers will be required to rely on these more complex estimation procedures. Does disparate impact law require employers to forego their traditional, interview-based hiring practices if it can be shown that algorithmic assessments of job performance are superior and impose fewer disparities (Hoffman et al., 2018)? To date, courts have shied away from providing a clear answer.
Statistical Formulations of Disparate Impact
Unlike for disparate treatment, there have been surprisingly few attempts to provide a statistical framework for the evaluation of disparate impact. Our goal in this section is to introduce and mediate between the different approaches. We focus on three statistical formulations, all of which are relatively recent.
Differences in Error Rates
One approach to measuring disparate impact is rooted in error rates. This approach deems discriminatory those decisions that lead to differences in error rates across the marginalized and the majority group, such as the false positive or the false negative rate. Conceiving of biases as error rates has a long tradition in the literature on algorithmic fairness in computer science and statistics (Buolamwini & Gebru, 2018; Chouldechova, 2017; Corbett-Davies et al., 2017; Dwork et al., 2012; Kleinberg et al., 2017), law (Chander, 2016; Huq, 2019; Mayson, 2019), medicine (Goodman et al., 2018; McCradden et al., 2020; Paulus & Kent, 2020), the social sciences (Berk et al., 2021; Imai et al., 2023; Kleinberg et al., 2018), and philosophy (Card & Smith, 2020; Hu & Kohler-Hausmann, 2020; Kasy & Abebe, 2021). This formulation of bias has not typically been tied to disparate impact law. But a recent contribution in the economics literature has proposed a measure based on error rates that is explicitly described as an estimand corresponding to the legal concept of disparate impact (Arnold et al., 2021, 2022; Baron et al., 2023). This estimand—and its associated, novel estimation method—have since attracted significant attention.
Arnold et al. (2022) illustrate their measure of disparate impact in a pretrial detention setting in which judges must decide whether or not to release defendants on bail. Each defendant has a latent “misconduct potential”, which takes on the value 1 if the defendant would violate the terms of release if released, and zero if not. Their measure of disparate impact, Δ, is based on a weighted sum of the difference in true negative rates and the difference in false negative rates across two groups of individuals, with weights defined by the overall violation rate across all individuals. Arnold et al. (2022) use the following mathematical formulation:
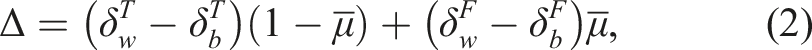
Drawing on past work in computer science (Corbett-Davies et al., 2023), we argue that any such measure of disparate impact (or “fairness,” for that matter) that is based on error rates is ill-suited to provide either legal or policy guidance. This is because these measures suffer from what is colloquially known as the “problem of inframarginality” (Ayres, 2002). Intuitively, the problem is that error rates do not only capture aspects of the decision rule, but also of the underlying risk distribution for each group (Simoiu et al., 2017). When defining disparate impact in such a way, an actor who does the best possible job to make decisions in furtherance of the stated policy goal can be found to discriminate simply due to differences in underlying risk distributions. In an attempt to avoid liability for disparate impact under this definition, the actor would then be required to make contra-indicated decisions, such as to search or jail people that, to the best of their knowledge, are of low risk.
We illustrate this argument by way of a specific example in the context using the Δ estimand proposed by Arnold et al. (2022), shown in Figure 1. For a more formal treatment that extends to a wider range of error-rate-based measures and also discusses the case of different thresholds for each group, see Corbett-Davies et al. (2023). Suppose there are two groups of pretrial defendants, each with 100 defendants. Each defendant has either a 10% likelihood of violating the terms of pretrial release if released (“low risk”) or a 40% likelihood (“high risk”).
9
Imagine 30% of defendants in Group 1 are of high risk, and 40% of defendants in Group 2 are of high risk. Further suppose that the presiding judge can perfectly estimate whether a defendant is of low risk or high risk, using only legally permissible factors. The judge decides whether to detain defendants based on a simple rule: high-risk defendants are detained, and low-risk defendants are released. Denote a true negative as an instance in which the judge releases a low-risk defendant, and denote a false negative as an instance in which the judge releases a high-risk defendant. Illustration of the problem of inframarginality when comparing error rates across groups with different underlying distributions of risk. Suppose there are two groups of pretrial defendants and two possible levels of pretrial risk. Each group has 100 defendants. If released pretrial, lower-risk defendants violate the terms of release 10% of the time, and higher-risk defendants violate 40% of the time. 30% of Group 1 defendants are higher risk, compared to 40% of Group 2 defendants. Suppose a judge can perfectly perceive pretrial risk. The judge imposes a unilateral risk threshold decision rule in deciding whom to release: lower-risk defendants are always released, and higher-risk defendants are always detained. In this scenario, the Δ measure of disparity from Arnold et al. (2022) is approximately .1, incorrectly suggesting that the decision rule disparately impacts Group 2 defendants. See main text for calculations.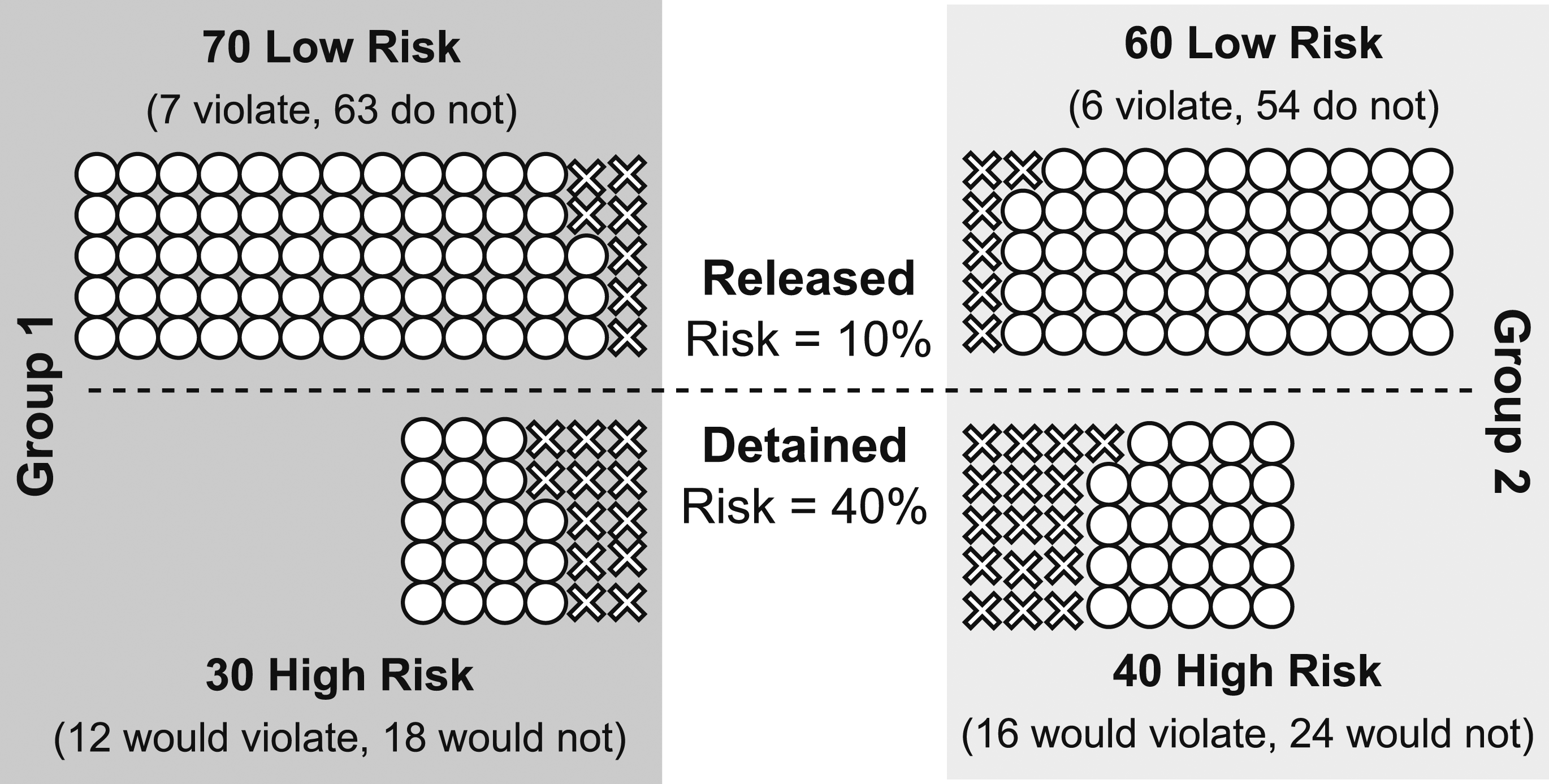
Although this decision rule treats similarly situated 10 defendants identically, the true negative rates and false negative rates among each group differ in expectation. In this example, the true negative rate is the proportion who are released, among those who would not violate if released. Here, 81 of the defendants in Group 1 would not violate if released (as indicated by the circles in the left-hand side of Figure 1). Further, 63 of these defendants are actually released—represented by the ○ symbols above the dotted line— resulting in a true negative rate of 63/81 = 78%. We can analogously compute the true negative rate for Group 2. In particular, among the 78 defendants from Group 2 who would not violate if released (the ○ symbols on the right-hand side of Figure 1), 54 are released (those above the dotted line), yielding a true negative rate of 54/78 = 69%. Importantly, the true negative rates differ across groups even though the same, risk-conditioned decision rule was applied to each group.
Similarly, the false negative rate is the proportion who are released, among the defendants who would violate if released. In Group 1, 19 defendants would violate if released (represented by the × symbols on the left-hand side of Figure 1). Among these defendants, 7 are released (the × symbols above the dashed line), resulting in a false negative rate of 7/19 = 37%. Moving to Group 2, 22 defendants would violate if released (indicated by the × symbols on the right-hand side of Figure 1). Among these 22 defendants, 6 are released (those above the dashed line), giving us a false negative rate of 6/22 = 27%.
Next, the calculation of Δ requires computing
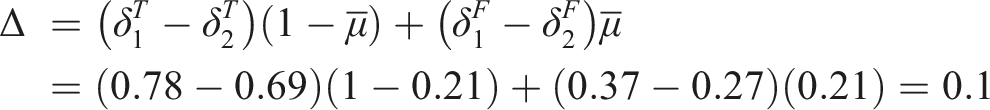
The resulting value of Δ = .1 suggests disparate impact to the disadvantage of defendants in Group 2. The only way for the judge to reduce Δ is to detain some low-risk defendants and/or release some high-risk defendants.
Figure 2 extends the example in Figure 1 to a range of similar scenarios in which a judge only detains high-risk defendants. The scenario in Figure 1, in which 30% of Group 1 defendants and 40% of Group 2 defendants are high risk, is denoted by the × symbol in the fourth panel of Figure 2. Appendix Figure A1 further extends this example to continuous distributions of risk. Extension of the scenario in Figure 1 to different discrete distributions of risk and different violation probabilities. The × symbol panel denotes the scenario from Figure 1. When risk distributions are identical, the Δ (Delta) measure of disparity correctly indicates no disparate impact, as indicated by the white diagonal in each panel. The leftmost panel shows that the Δ measure correctly indicates no disparate impact when low-risk defendants never violate and high-risk defendants always violate. However, as the violation probabilities of low- and high-risk defendants move away from the extremes, differences in the underlying distributions of risk result in non-zero values of Δ, incorrectly indicating evidence of disparate impact.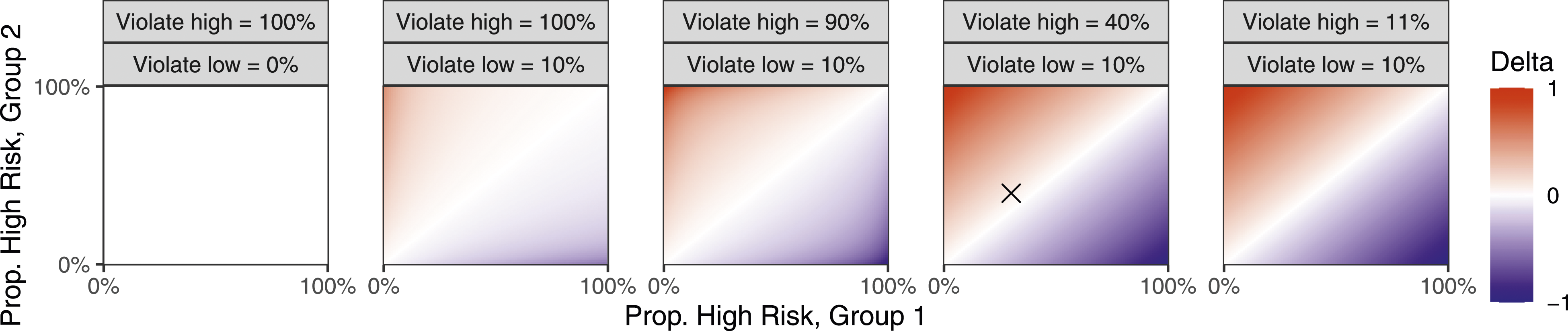
Overall, these results illustrate the problem of infra-marginality that plagues error rates: Error rates change as a function of the underlying group-specific risk distributions, even if the decision rule remains the same. Hence, in these simulations, the Δ measure correctly indicates the absence of disparate impact in only two scenarios: (i) when risk is perfectly predictive, such that high risk defendants always carry contraband and low-risk defendants never do; or (ii) when the risk distributions between the groups are identical. In all other cases, the Δ measure indicates disparate impact on Group 2 if Group 2 defendants are, on average, riskier than Group 1 defendants, and vice versa. As the violation probabilities for low-risk and high-risk defendants move from the extremes, the Δ measure of disparate impact is more sensitive to differences in the distribution of risk across groups. Because the measure does not allow us to draw accurate inferences about the decision rule, we believe it is ill-suited to capture disparate impact. Indeed, it is our view that this and other estimands based on error rates are not appropriate to accurately capture notions of fairness, calling into question their utility (Chohlas-Wood et al., 2023; Corbett-Davies et al., 2023; Hedden, 2021; Simoiu et al., 2017).
Alternative Interpretations of Error Rate Differences
One interpretation of error rates is that they are a direct measure of disparate impact (Arnold et al., 2022). An alternative understanding of error rate discrepancies is that they merely provide a first signal that is neither necessary nor sufficient to establish disparate impact, but should give reason for further investigation. For instance, despite inframarginality issues, Hellman (2020) suggests that “[a] lack of error ratio parity between a previously disadvantaged group and its counterpart (blacks and whites, for example) is suggestive of unfairness and provides a normative reason to engage in further investigation and for caution.” (Hellman, 2020, pp. 845–846). One could think of this conceptualization of error rate discrepancies as replacing the first element in a disparate impact analysis, thereby shifting the burden of proof to justify the disparities towards the decision maker. If that decision maker then showed that the discrepancies arise from differences in the underlying risk distribution, they would be justified.
Although not subject to the same statistical problems, we similarly believe this conceptualization of error rates not to be fruitful. “Adverse impact” as the burden-shifting element, although not free of significant limitations, has the virtue of at least being simple to understand and easy to form statistically accurate intuitions about. For error rates, this is not so. Imagine an audit that finds detention rates among Black defendants to be 10% higher than for white defendants. It is quite intuitive to determine that this discrepancy alone is insufficient to establish the existence of a discriminatory decision making process (Ayres, 2010; Heaton et al., 2017). This is because it is easily understood how risk-relevant differences between the groups may cause the identified discrepancies. However, if that same audit found the error rates for Black defendants to be 10% higher than for white defendants, those without empirical training would have trouble understanding whether or not this is definitive evidence for discrimination. After all, appreciating the problem of inframarginality requires at least some familiarity with statistics, which is often lacking among the relevant legal actors. As such, there is a concern that shifting from easily understood statistics like selection rates to more complex statistics like error rates could convolute the assessment. And because neither selection nor error rate differences alone provide strong evidence for disparate impact, we don’t believe that shift would come with a tangible benefit that would justify the costs. In addition, differences in selection rates are a burden-shifting element that is firmly established in the relevant case law. Again, we see no reason to break with this significant precedent without a clear benefit on the other side. Last but not least, to the extent that error rates are not viewed as a replacement of adverse impact, but simply as an additional diagnostic tool to identify normatively problematic differences between two groups, we note that there are several more informative proxies. For instance, if it is believed that differences in risk distributions themselves point towards larger systematic discriminatory practices (e.g., overpolicing) (Hellman, 2020, p. 840), a simple solution would be to analyze these risk distributions directly, rather than to rely on error rates.
Risk-Adjusted Disparities
An alternative approach to the measure of disparate impact is risk-adjusted regression (Jung et al., 2023). The approach consists of two steps. First, the analyst uses all available data to create a risk-model of the form

In the second step, the analyst fits a model of the following (or similar) form:
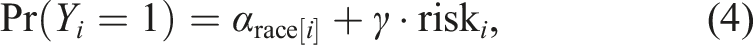
Consider how this approach connects to the legal definition of disparate impact. Assuming that g is sufficiently flexible, the first model reflects the analyst’s best attempt to capture an individual’s probability that the relevant outcome (e.g., weapon recovery, recidivism or satisfactory job performance) will occur. If the actual decisions made were fully explainable by the individual’s risk, the coefficient on
Optimized Decision Making
In a scenario where risk or qualification can be estimated for every individual, the utility-maximizing decision rule is one where a unilateral threshold dictates decision making (cf. Corbett-Davies et al., 2023). In other words, individuals with estimated risk or qualification above the threshold are selected, and individuals below are not. Among others, this approach has been used by Elzayn et al. (2023) to measure adverse impact under hypothetical risk thresholds. Similar to risk-adjusted regression, the first step consists of estimating a risk model of the form

After risk has been estimated, individuals are sorted based on their estimated risk. A threshold is drawn such that everyone above the threshold receives the costs/benefits and anyone below the threshold does not. After defining the threshold, adverse impact is assessed by comparing the group-specific probability of receiving the cost/benefit.
How exactly the threshold is drawn is a matter of policy, and typically reflects some type of constraint. For instance, in defining a reference policy for the auditing practices of the IRS, Elzayn et al. (2023) pick the threshold such that the number of people audited are the same as under current IRS practices. Other possibilities are to draw a threshold such that the risk to public safety or the amount of loans given out are the same as under a current policy. For example, suppose a law enforcement agency seeks to assess potential disparate impact in its decisions to search stopped drivers. Using historical data, the agency estimates that they could have recovered the same amount of contraband had they searched all stopped drivers with a perceived risk of carrying contraband greater than 10%. Under this hypothetical policy, suppose that 15% of white drivers would have been searched, compared to 20% of stopped Black drivers (i.e., 1.33 times more often). Suppose that under the agency’s actual policy, 25% of Black drivers were searched, compared to 10% of white drivers (i.e., 2.5 times more often). The existence of an implementable and equally-efficient policy with lower adverse impact suggests possible disparate impact in search practices.
Consider how this statistical approach relates to disparate impact law. Disparate impact law requires a showing of a feasible, alternative policy that has fewer disparities while achieving the stated policy goal at least as effectively as the current policy. If such a policy exists, it implies that the (greater) disparities under the current decision rule are avoidable. In this way, disparate impact law can be understood as a search over the policy space for policies that fulfill the before-mentioned criteria. This approach is equivalent to assessing a subset of the policy space for whether it provides less disparate alternatives. Importantly, threshold rules are not a random subset of decision rules. Instead, as Corbett-Davies et al. (2023) and others have shown, threshold decision rules are uniquely optimal among all policies, given estimated risk.
Both risk-adjusted regression and the search for risk-based alternative policies require an estimation of risk, reflected in g. As noted, due to the predictive nature of risk estimation, g can be arbitrarily flexible and can take an arbitrarily large set of covariates X as input. However, as detailed above, disparate impact law requires the plaintiff to propose alternative policies that are feasible and implementable. Depending on the context, it may be argued that such feasibility requires the imposition of constraints, both on g and on X. Take, for instance, the decision to search a stopped pedestrian, which is often a split-second choice that is made in the moment. If g takes a complex functional form such as a neural network, the model will uncover statistical associations that a police officer who is patrolling the beat might not be able to uncover themselves. Thus, the only way for the officer to meet the standard implicitly set by the use of g would be for them to use the risk model themself, e.g., by feeding a feature vector for the potential suspect into the model and obtaining the prediction. This is not always realistic, and so we may want to confine g to resemble decision making rules that the officer can quickly employ while on patrol. Such concerns are of less relevance, however, if well-resourced actors are making decisions without imminent time constraints. Indeed, some entities are already using complex algorithms, as is the case when the IRS makes its auditing decisions (Elzayn et al., 2023). Allowing g to be flexible in such contexts is merely akin to a requirement that they use the best available algorithm, which can often be achieved with relative ease. In the next section, we discuss the implementability of threshold rules in more detail. 12
Measuring Disparate Impact in Policing
To illustrate the discussed approaches, we next focus on a novel dataset of approximately 1.5 million stops to estimate disparate impact in search decisions of law enforcement agencies across California. In doing so, we highlight that the liability of law enforcement agencies under existing disparate impact laws is, as a legal matter, highly theoretical and contested (Tiwari, 2019). However, legal irrelevance does not imply policy or normative irrelevance, and we believe that disparate impact analysis can contribute significantly to better policymaking, irrespective of the specific, statutory context. This is for at least two reasons: First, a showing of disparate impact entails the proposal of an alternative, equally efficient yet less disparate policy. As such, it provides a concrete and practical way to make better policy. Second, and relatedly, a finding of unjustified disparities can exert pressure to examine an existing, presumably harmful policy.
The California State Legislature passed the Racial Identity and Profiling Act (RIPA) in 2015. RIPA requires that officers record detailed information following every stop of a pedestrian or driver, including information on race, ethnicity, and other protected characteristics. 13 We limit our analysis to 1,604,926 stops conducted in 2022 by the 50 agencies in California recording the most stops that year. 14 Among this initial set of stops, we exclude those for which the officers often conduct non-discretionary searches. Specifically, we exclude stops for which the stated stop reason was either (1) knowledge of parole/probation/postrelease community supervision (PRCS)/mandatory supervision or (2) knowledge of arrest warrant. 15 We additionally exclude consensual encounters, since only a subset of these interactions are recorded in our data, namely those that resulted in a search. Finally, we exclude stops initiated for suspected truancy or other educational policy, as the threshold for conducting searches in an educational context can often be lower [People v. William G. (1985) 40 Cal.3d 550]. This filtering results in 1,516,316 stops for our primary analysis. Next, for this set of stops, we consider a “search” to have taken place if, and only if, it appears that officers exercised discretion in determining whether to search the individual. In particular, we do not consider a stop to have resulted in a “search” if the exclusive recorded reasons for the search were limited to: (1) search warrant, (2) condition of parole/probation/PRCS/mandatory supervision, (3) incident to arrest, or (4) vehicle inventory.
Summary Statistics for the 1.5 Million RIPA Stops Included in the Analysis. The First Block of Statistics Shows Racial Demographics and Stop Reasons. Most Individuals Were Stopped Because of a Moving Violation. Black Individuals Were More Likely to Be Stopped for Suspected Criminal Activity Than all Other Groups, While Black and Hispanic Individuals Were the Most Likely to Be Stopped for an Equipment Violation. The Second Block Shows the Proportion of Stopped Individuals Who Were Searched, and the Proportion of Searches That Resulted in Contraband Recovery (“Hit Rate”), With Separate Statistics for Discretionary Searches. Stopped Black and Hispanic Individuals Were More Likely to Be Searched Than Stopped White Individuals, and Stops of White Individuals Were the Most Likely to Result in a Contraband Recovery. The Final Block Shows the Prevalence of Each Recorded Search Basis Among Stopped Individuals Who Were Also Searched. The Most Common Search Bases Were Non-discretionary, Such as an Outstanding Arrest Warrant or a Condition of Parole. The Most Common Discretionary Bases Were Consent of the Stopped Individual and Officer Concern for Their Own Safety or the Safety of Others.
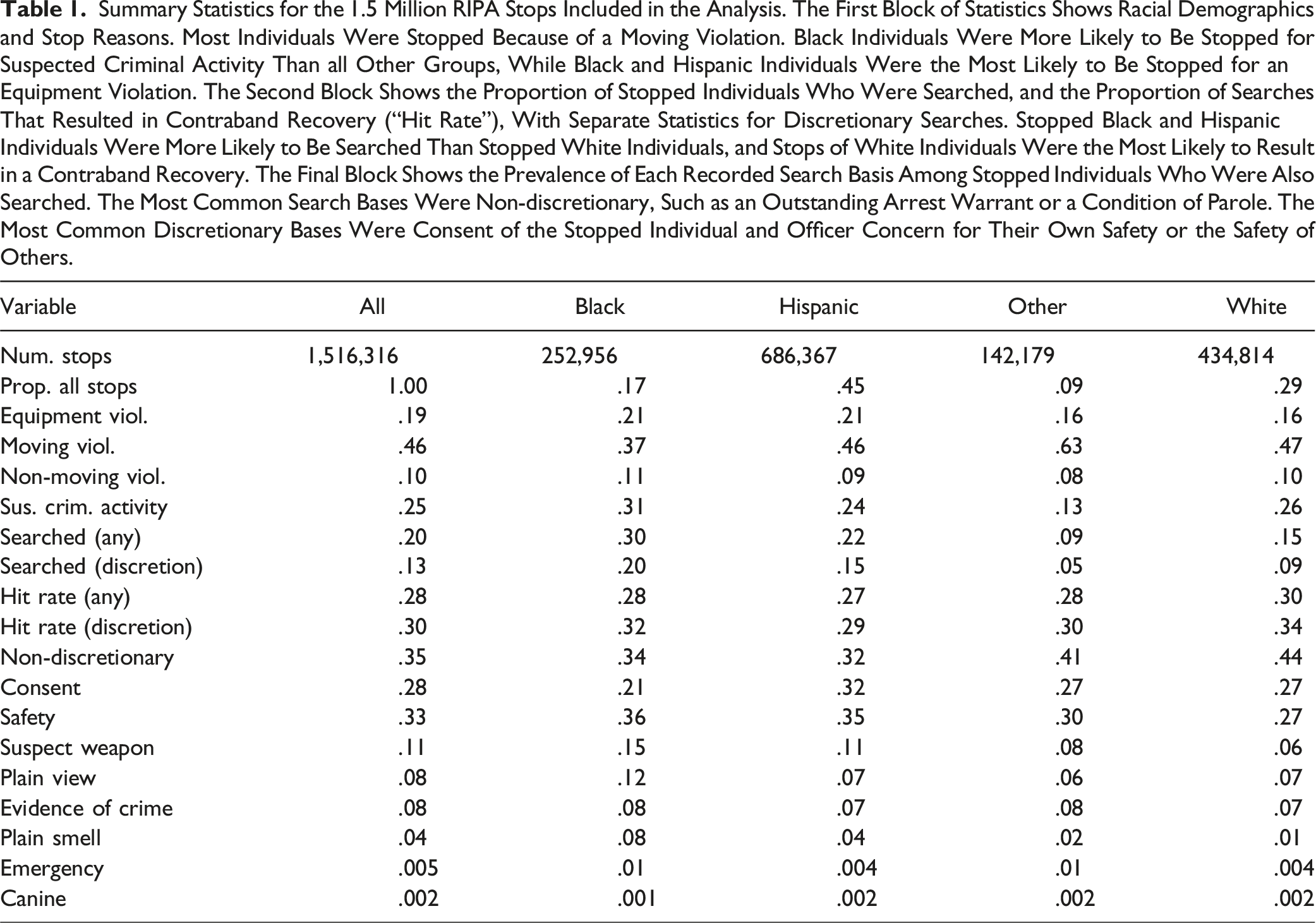
Table A1 separately reports adverse impact for the California law enforcement agencies with the most stops recorded in 2022 (henceforth the “largest” agencies). For many agencies, Black and Hispanic individuals were searched at substantially higher rates than white individuals. For expositional purposes, we focus the main analysis on the 10 largest agencies: the Los Angeles Police Department, the Los Angeles County Sheriff, the San Diego Police Department, the San Bernardino County Sheriff, the Riverside County Sheriff, the San Jose Police Department, the Orange County Sheriff, the Sacramento Police Department, the Sacramento County Sheriff, and the Anaheim Police Department. We include expanded results for the 50 largest agencies in the Appendix.
Application of Risk-Adjusted Regression
To determine whether the observed adverse impact in search rates across agencies may be justified, we first measure risk-adjusted disparities in search rates. Then, we attempt to construct alternative search policies with lower adverse impact and the same or greater efficiency than the status quo search policies. Under both approaches, we find suggestive evidence that search practices in many California law enforcement agencies may have imposed a disparate impact on Black and Hispanic individuals. As emphasized in the introduction, these results are not conclusive evidence of illegal disparate impact within particular California law enforcement agencies. 18
To generate risk estimates required for both risk-adjusted regression and risk-thresholded decision rules, we fit, separately for each agency, a model estimating the likelihood that a discretionary search of a stopped individual recovers contraband. 19 For the purpose of this analysis, we assume that contraband recovery is the sole motivation for conducting a discretionary search. After subsetting to individuals who were searched for a discretionary reason, such as evidence of a crime or the smell of contraband, 20 we fit a random forest model predicting contraband recovery based on all recorded factors that an officer could reasonably account for in their decision to search, irrespective of legality. 21 These covariates include the traffic violation or suspected criminal offense that prompted the stop and the basis or bases for conducting the search (e.g., “evidence of a crime” and “contraband in plain view”). In our main analysis, we also include gender and race under the rationale that the stop decision may be affected by additional, risk-relevant and legally permissible factors for which gender and race serve as a proxy, such as socioeconomics. But because this inclusion may raise concerns for disparate treatment violations, in Figure A12, we include an analysis in which we estimate risk without the use of gender and race. 22 The results are substantively similar.
For each stopped individual, we use the fitted risk model to estimate the probability of recovering contraband from a search—regardless of whether a search was actually conducted. 23 Of course, contraband recovery from searches is only observed among individuals who were actually searched, so it is impossible to verify the accuracy of the risk model among individuals who were not searched. If there exists an unobserved variable that is correlated with both the search decision and the likelihood of carrying contraband, then our risk estimates will suffer from omitted variable bias (Angrist & Pischke, 2008). For the purposes of illustration, we proceed under the assumption of no omitted variable bias. In other words, we assume that the decision to search is ignorable: conditional on observed covariates, the search decision is independent of carrying contraband. As a robustness check, Figures A13, A14, and A15 show the results of a sensitivity analysis as proposed in Jung et al. (2023). For several agencies, we find that estimates of disparate impact are robust to a degree of omitted variable bias comparable to blinding the risk models to the motivating offense of each stop.
Figure 3 shows, for stopped individuals in each agency, the observed probability of being searched, conditional on the estimated risk of carrying contraband. For the majority of the largest agencies, Black and Hispanic individuals were substantially more likely to be searched than white individuals of similar estimated risk. A risk-adjusted regression fit to each agency’s data confirms the visual pattern in Figure 3: conditional on estimated risk, both Black and Hispanic individuals were significantly more likely to be searched than white individuals in the majority of agencies (Figure 4). The results of the risk-adjusted regression suggest that the observed adverse impact of searches (see Table A1) is not fully explained by the estimated risk of recovering contraband, which we assume is the primary justification for conducting a search. For individuals stopped by the 10 largest agencies, the probability of being searched as a function of the estimated probability of carrying contraband (i.e., a “hit”), with 95% confidence bands. Hit probability is estimated via a random forest model. In the majority of agencies, Black and Hispanic individuals are substantially more likely to be searched than white individuals with similar estimated risk. Figure A10 expands this figure to include the 50 largest agencies. Coefficients on the race and ethnicity terms from risk-adjusted regression models fit separately to each of the 10 largest agencies, with 95% confidence intervals. In the majority of agencies, both stopped Black and stopped Hispanic individuals are significantly more likely to be searched than stopped white individuals of similar estimated risk, suggesting that the observed adverse impact of searches (see Table A1) is not explained by the risk of carrying contraband. Figure A11 shows the same coefficients for the 50 largest agencies.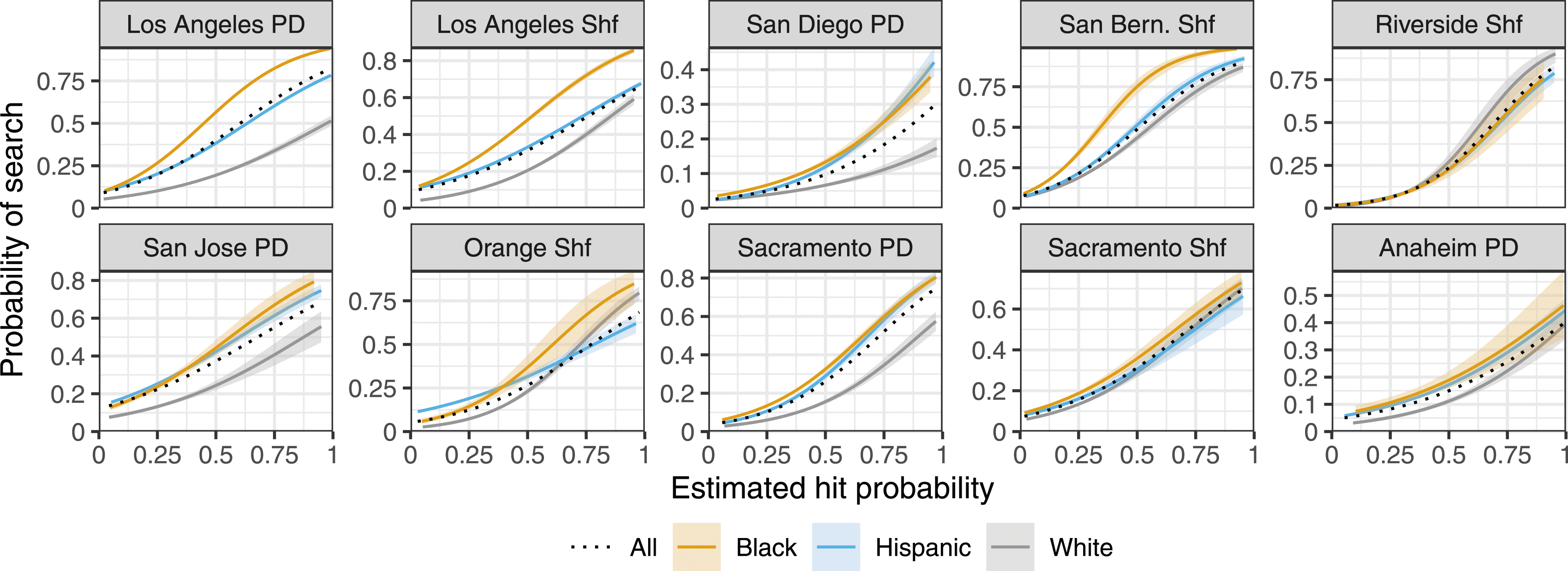
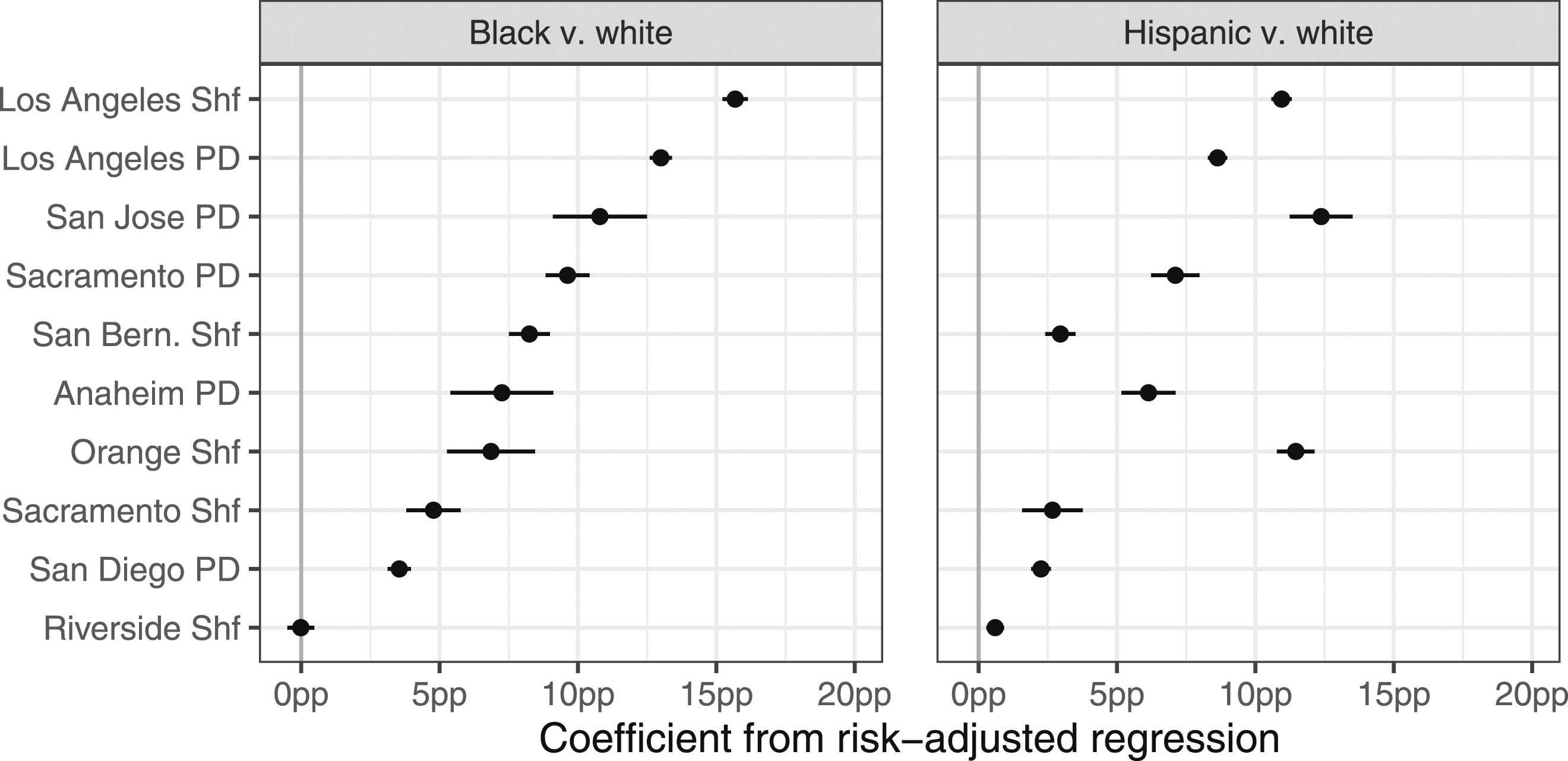
For completeness, in the Appendix, we contrast the results from our risk-adjusted regression to measures of disparate impact as obtained through the estimator suggested in Arnold et al. (2021, 2022). We observe that estimates are broadly consistent across agencies (Figure A16). We hypothesize that this is because risk distributions across groups are observably similar in most jurisdictions, thus removing concerns arising from inframarginality (Figure A17). There are notable exceptions, however. For instance, whereas risk-adjusted regression estimates suggest unjustified disparities in stops of Hispanic drivers of the Fairfield Police Department, the estimator proposed by Arnold et al. (2021, 2022) does not show similar disparities. Consistent with this divergence, we find that risk distributions in that jurisdiction differ markedly across groups.
Identifying Alternative Policies
The coefficients of the risk-adjusted regression models suggest that the adverse impact imposed by search decisions is not justified by the estimated risk of carrying contraband. In a last step, we turn to the question of whether there exist implementable alternative search policies that have lower adverse impact and are at least as efficient as the status quo search policy. Although there is not an agreed-upon definition of efficiency with respect to search decisions, for the purpose of this analysis we define a search policy as efficient if it results in the same number of contraband recoveries, in expectation, as the status quo policy without increasing the total number of searches. To guarantee officers are not required to do additional work under any of our proposals, we restrict ourselves to policies that do not increase the total number of searches. It is possible, however, that police agencies and courts might deem it acceptable to increase the space of policies to consider in order to find one that imposes less adverse impact.
To identify efficient threshold policies, we sort all n stopped individuals in descending order by their estimated risk. We then iterate through possible risk thresholds, where the k individuals above each risk threshold t are assumed to be searched, and the n − k remaining individuals are not. We measure the adverse impact of the search policy defined by each risk threshold as the ratio of the resulting per capita search rates for Black and white individuals. At each iteration, we also calculate the expected number of contraband recoveries. 24 We iterate over lower values of t until k is approximately the same as the total number of individuals searched by the status quo policy.
One might, however, argue that these threshold decision rules—which involve complex risk estimation using a random forest model—are not practically implementable. To address this concern, we follow Goel et al. (2016) and construct more readily implementable decision rules (See “Constructing the simple rule” in the Appendix for the rule construction process). These simple rules account only for the traffic violation or suspected offense that motivated the stop, the city in which the stop occurred, whether contraband is in plain view, and whether there is evidence of a crime. To use these simple rules, officers would only need to add up two small integers, and compare the result to a threshold unique to each combination of city and traffic violation or suspected offense.
Disparate impact law stipulates that the benchmark against which one should measure decision rates consists of those affected by the decision, or those who could be affected by a change in the way the decision is determined [Carpenter v. Boeing Co., 456 F.3d 1183 (10th Cir. 2006); Hous. Invs., Inc v. City of Clanton, Ala., 68 F. Supp. 2d 1287 (M.D. Ala. 1999)]. Following these guidelines, we calculate adverse impact using two reasonable benchmark populations. First, we calculate the ratio of per capita search rates, which are computed by dividing the number of searches for a given race or ethnicity by the entire population of that group within the jurisdiction patrolled by the agency. 25 This population-level benchmark is intended to be representative of all individuals who could have been searched by law enforcement agencies. Second, we also compute adverse impact as the ratio of stop-level search rates, which are computed by dividing the total number of searched individuals in each group by the total number of stopped individuals in each group. The second benchmark follows from a narrower perspective of disparate impact in search decisions where the affected group consists of just those who were stopped. 26 The main results use the ratio of per capita search rates, with results based on the ratio of stop-level search rates in the appendix (Figure A21).
Figure 5 shows the adverse impact resulting from the threshold policies derived from the iterative process outlined above. The dotted line in each panel represents policies where search decisions are determined by the simple rule.
27
The dotted line begins at the threshold where the expected number of contraband recoveries is the same as the actual number of contraband recoveries. This is the policy with the highest threshold that is arguably as efficient as the status quo policy, so we do not show policies with higher thresholds (i.e., fewer searches). Analogously, we do not show policies with lower thresholds than the policy that searches the same number of individuals as the status quo, which corresponds to the far right end of each dotted line. As we sweep across smaller thresholds, the total number of allowed searches increases. For the 10 largest agencies, estimated adverse impact under hypothetical threshold policies that, compared to the status quo, recover at least as much contraband and result in no additional searches. Adverse impact is measured as the ratio of per capita search rates. Contraband recovery risk is estimated via a simple rule. For the majority of agencies, there exist threshold policies (dotted lines) with lower adverse impact on stopped Black individuals and Hispanic individuals. Figure A19 show the same results for the 50 largest agencies.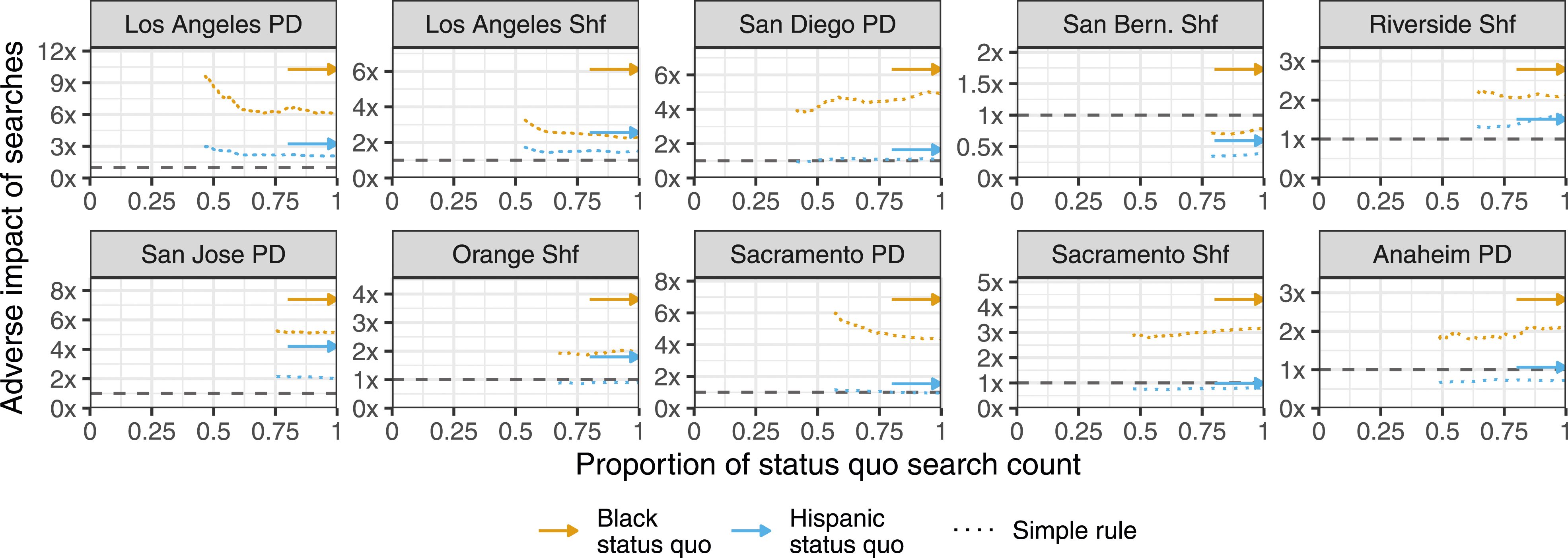
The x-axis shows, for each policy, the number of searches conducted (k) divided by the total number of searches observed in the real data (n). Finally, for comparison, the solid arrow on the right side of each panel indicates the adverse impact observed under the status quo search policy, measured as the ratio of per capita search rates among each minority group and white individuals (see Table A1). 28 For the majority of agencies, there exists a simple rule threshold policy with lower adverse impact on stopped Black individuals and Hispanic individuals than the status quo. Further, all of these policies are able to recover at least as many weapons as the status quo, in expectation, with fewer searches. These results show the existence of an equally efficient policy with lower adverse impact, arguably meeting the plaintiff’s burden under the third step of a disparate impact claim.
Discussion
In practice, risk-based approaches to disparate impact are only applicable in certain settings. First, there must be a measurable indicator of a successful decision. As an example, consider the pretrial setting. In most jurisdictions, the primary justification for pretrial detention is minimizing the risk of failing to appear or committing new criminal activity. The existence of a pretrial violation is a concrete way to assess whether a release decision is “successful”. In other domains, such as college admissions, it is not immediately clear how to denote a successful decision. Second, one must be able to estimate risk accurately. This typically means that decision rates must be high enough such that there exists a sufficient number of individuals from which to estimate risk. Additionally, as accurate risk estimation often rests on the strength of the ignorability assumption, the fitted risk model should incorporate as many of the variables observed by the decision maker as possible. If there are unobservable variables that are highly predictive of both the decision itself and the success of the decision, the risk model may suffer from severe omitted variable bias. Finally, the proposed risk-based alternative policies must be implementable. For example, the decision to search a pedestrian may be made in a matter of seconds, so even a simple rule could be deemed as impossible to realistically implement. For less time-constrained decisions, such as pretrial detention or tax auditing, risk estimates can be generated well in advance of decisions.
In addition, we note that, in this study, we take disparate impact law as given 29 and consider empirical strategies in relation to current legal analysis. But we believe the current law on disparate impact has many shortcomings itself. Among others, disparate impact law’s focus on raw disparities can lead decision makers to forego policies that are ultimately favorable to the minority group. For instance, a policy that is strictly beneficial to both the minority and the majority group, but that benefits the majority group more than the minority group, would not need to be enacted under disparate impact law because it increases the disparities between the groups.
To illustrate with a numeric example, consider a hypothetical scenario under which the current policy has police officers search pedestrians if they made ‘furtive movements.’ Under this policy, the officer stops 100 of 10,000 Black citizens a year, and 1000 of 100,000 white citizens. An analysis shows that, although officers do not act with discriminatory intent, ‘furtive movements’ are not predictive of weapon recovery. Removing this requirement would thus reduce the number of Black citizens stopped by 50, and the number of white citizens stopped by 600, without meaningfully affecting the weapon recovery rate. In this scenario, the current policy has a search rate of 1% for both Black and white citizens. Under the new policy, the search rate is reduced to .5% for Black citizens and .4% for white citizens. But although the new policy decreases the absolute number of both Black and white citizens who are searched, it increases the relative disparity between Black and white citizens from .0 to .1 percentage points. Under disparate impact law, the new policy need not be implemented, given that it does not decrease the disparities between the two groups.
The example helps clarify the focus of disparate impact law, and how it might differ from other welfare perspectives on fairness. Disparate impact law is primarily concerned with unjustified, differential treatment between the majority and the minority group. However, it is not a mandate to improve the welfare of the minority group, even if that can be done in a costless way. From a welfarist perspective, this might seem problematic, especially in settings where there is no budget constraint.
Additionally, the reference population from which action rates are calculated should, in theory, consist of those who are subjected to the practice in question [Carpenter v. Boeing Co., 456 F.3d 1183 (10th Cir. 2006); Hous. Invs., Inc v. City of Clanton, Ala., 68 F. Supp. 2d 1287 (M.D. Ala. 1999)]. In practice, though, it is often unclear what the relevant reference population should be. Furthermore, data for certain reference populations may be inaccessible. For example, in the case of lending, one might propose a reference population of all eligible individuals who applied for a loan from the institution in question. However, it appears to us that a more suitable population would be all individuals who would have been eligible for a loan, regardless of whether they actually applied. But, the size of this larger group may not be estimable, in which case the smaller group would be an appropriate reference population so long as it is sufficiently representative of the affected individuals [Frazier v. Consol. Rail Corp, 851 F.2d 1447 (D.C. Cir. 1988)]. Courts have also permitted reference populations that subsume the affected population, once again so long as the larger population is sufficiently representative [E.E.O.C. v. Joint Apprenticeship Comm. of Joint Indus. Bd. of Elec. Indus., 186 F.3d 110 (2d Cir. 1999)].
Conclusion
In this paper, we have discussed statistical approaches for assessing disparate impact. Our analysis suggests that recent estimators centered on error rates capture neither legal nor normative notions of disparate impact. While risk-adjusted regression can help document the existence of unjustified disparities, a concrete, optimal alternative policy can be derived by sorting individuals based on their estimated risk and defining a decision threshold. As we have shown for the example of search decisions by California law enforcement agencies in 2022, this approach relies on analysts to formulate alternative, less disparate, implementable policies even in scenarios where decision makers have constrained information or time. We hope that this research will positively contribute towards a current trend to broaden conceptions of discrimination in empirical research.
Supplemental Material
Supplemental Material - Reconciling Legal and Empirical Conceptions of Disparate Impact: An Analysis of Police Stops Across California
Supplemental Material for Reconciling Legal and Empirical Conceptions of Disparate Impact: An Analysis of Police Stops Across California by Joshua Grossman, Julian Nyarko, and Sharad Goel in Journal of Law and Empirical Analysis
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.