
Abstract
A critical challenge for urban planners lies in estimating the potential impacts of planning interventions before their implementation. Current approaches to urban planning intervention effect estimation encounter notable constraints. Association modelling approaches, while effective at capturing complex relationships between interventions and outcomes in observed cases, fail to estimate causal effects, making them unreliable for counterfactual predictions. Operational modelling approaches frequently set up structural causal models to transform interventions into outcomes based on subjective assumptions about simplified causal relationships. These approaches, while achieving a clear representation of causality, compromise the ability to accurately model the dynamic and intricate nature of cities and human behaviour. This paper introduces the Causal Generative Network for Planning Intervention Effect estimation (CGNet-PIE), a lightweight yet robust approach that directly estimates causal effects from observed data without the need for fully articulated causal interaction models. By integrating generative deep learning with the Rubin Causal Model, CGNet-PIE effectively captures non-linear relationships and enhances causal inference for reliable and generalizable counterfactual predictions. Experiments on synthetic, semi-synthetic, and real-world datasets demonstrate CGNet-PIE’s superior accuracy and generalization compared to baseline models. CGNet-PIE offers a powerful tool for planners to improve decision-making for informed policymaking and optimal resource allocation.
Keywords
Highlight
Introduces the concept of the Rubin Causal Model (RCM) from statistics to urban planning for intervention effect estimation.
Integrates deep generative models with the RCM paradigm, enhancing accuracy, and generalization in counterfactual analysis.
Facilitates practical utility in urban planning, offering a powerful tool for improving decision-making in complex urban systems.
Introduction
With over half of the global population currently residing in cities, and projections indicating an increase to 62.5% by 2035, urban areas are confronted with unprecedented challenges in managing population growth and promoting sustainable development (Un-Habitat, 2020). In countries such as China, urbanization has already reached 65% as of 2023, and the rate of expansion has begun to decelerate (Yao et al., 2024). The focus of urban planning has shifted from expanding capacity to improving the quality and efficiency of urban services and infrastructure (He et al., 2024). One of the central challenges for urban planners and policymakers is accurately estimating the potential impacts of various planning policies and interventions before their implementation. Quantifying the effects of different planning interventions in advance allows practitioners to make informed comparisons between alternative scenarios, thereby facilitating adjustments that ensure optimal resource allocation to meet the dynamic demands of urban development (Jin et al., 2013, 2017; Yang, 2020).
Traditional approaches to estimating the effects of planning interventions primarily rely on association-based models. These models utilize large datasets to uncover relationships between intervention strategies—such as location and settings of facilities, infrastructure investments, or policy changes—and observed outcomes, including citizen behaviour or urban system performance. (Debrezion et al., 2011; Li et al., 2022; Zhu et al., 2020). With the advent of advanced machine learning techniques, particularly deep learning, there has been a shift from classic linear regression models to more sophisticated, data-driven approaches capable of modelling non-linear relationships within complex urban systems and diverse human behaviours (Simini et al., 2021). Unlike traditional linear approaches, deep learning architectures use layers of neurons—each applying linear transformations followed by non-linear activation functions—to model complex, high-dimensional patterns. This layered structure allows deep neural networks to simulate intricate, non-linear interactions among a diverse range of factors, ultimately providing richer predictive insights into urban systems. Additionally, modern interpretability methods, such as Shapley Additive Explanations (SHAP), help illuminate the contribution of each input variable to the predictions of complex deep learning models, making it easier to understand how and why deep learning models differ from simpler, linear forms of analysis (Lundberg & Lee, 2017). Yet, despite the enhanced representational power and interpretability afforded by deep learning and related tools, current models remain predominantly association-based. They excel at capturing patterns in observational data but offer limited guidance for predicting outcomes under entirely hypothetical or counterfactual scenarios. A key limitation of association models is their inability to capture causal relationships. While association methods can identify patterns in historical data, they cannot distinguish between associations and cause-and-effect dynamics. This shortcoming becomes particularly problematic in the context of urban planning, where the goal is often to estimate the impact of hypothetical interventions—scenarios where planners ask “what if” questions about future actions (Yang et al., 2021). Without a clear understanding of causal mechanisms, planners cannot reliably predict the effects of their decisions in unobserved conditions, potentially leading to suboptimal or even counterproductive outcomes.
Recognizing these limitations, some scholars have turned their focus to operational modelling approaches to map out the complex network of cause-and-effect relationships in urban systems. These approaches facilitate predictive analysis by explicitly modelling interactions among interventions, intermediate variables, and outcomes (Batty & Milton, 2021; Jin et al., 2013; Waddell, 2002; Wegener, 1994). However, the application of operational modelling approaches in urban planning presents significant challenges. Urban systems are highly complex, with innumerable variables interacting in dynamic and often unpredictable ways. Fully uncovering all causal relationships for any given planning task is practically infeasible. Moreover, even with a complete operational model with comprehensive causal structure, obtaining the necessary data for all relevant variables for given tasks in a specific study area can be extremely challenging. These challenges make operational modelling approaches less practical options for many applications, despite their theoretical promise (Yang et al., 2022).
A central question remains: How can the concept of causality be integrated into planning intervention effect estimation using observable data without requiring a fully discovered network of cause-and-effect relationships? This paper aims to address this gap by proposing a novel method that integrates generative deep learning algorithms with the Rubin Causal Model (RCM) for causal inference, to estimate the effects of planning interventions (Rosenbaum & Rubin, 1983; Rubin, 1974, 1997). Our approach builds on the state-of-the-art deep learning-based RCM model for causal inference, VCNet, and introduces two key modifications that transform the model into a generative system (Nie et al., 2021). First, we employ a non-linear mapping network to map the input planning intervention data—represented by both continuous and discrete features—into a latent space, enabling effective feature fusion. To reinforce the intervention information throughout the system, we integrate these latent features at multiple stages of the model. Second, we enhance the base model by incorporating a Variational AutoEncoder (VAE) structure, enabling representation learning without the need for per-datapoint optimization, which reduces overfitting and improves the model’s generalization capabilities on non-observed cases (i.e., counterfactual scenarios) (Kingma, 2013).
The performance of the proposed model is evaluated using both synthetic and semi-synthetic datasets, which are widely recognized as benchmarks for assessing the efficacy of deep learning-based RCM models in causal inference for both observed and counterfactual cases. In addition, we apply our model to a real-world dataset by predicting student visitation to the university canteen at various locations. This serves as a test case for estimating the effects of planning interventions in urban settings.
This research makes three key contributions. First, it introduces the RCM framework for treatment effect estimation to the field of urban planning, addressing the limitations of existing association-based modelling approaches and demonstrating how causality can be incorporated into planning intervention effect estimation. Second, it proposes a causal generative model that enhances the performance of state-of-the-art deep learning-based RCM models by incorporating deep generative components, improving its ability to handle complex task settings for better predictive accuracy and generalization across both observable and counterfactual cases. Third, results from extensive experimentation demonstrate the model’s superiority over baseline approaches across multiple challenging datasets, showcasing its potential applicability in a wide range of urban planning scenarios.
The remainder of this paper is organized as follows: the next section provides an overview of related work, followed by an introduction to the research background and problem setup. We then present the proposed Causal Generative Network for Planning Intervention Effect estimation (CGNet-PIE), followed by experiments, results with discussions, and finally a conclusion.
Literature review
Urban planning interventions range from large-scale infrastructure projects, such as transportation networks, to neighbourhood-level changes like facility location adjustments. These interventions—whether policy-driven or physical developments—can be conceptualized as treatments applied to urban systems, leading to emotional and behavioural responses among citizens, which can be defined as associated effects. Accurately predicting these effects before the implementation of interventions is crucial for policymakers and planners to make informed decisions by integrating potential outcomes into the planning process.
However, modelling different planning interventions and quantifying their effects involve varying degrees of data availability, system complexity, and causal inference challenges. At the macro scale, interventions like new transportation corridors or regional economic policies typically involve large datasets, but they also present significant difficulties in capturing the dynamic interactions among multiple urban systems and agents across various spatial scales. In contrast, smaller-scale interventions, such as adjustments to local or neighbourhood facilities, require highly granular data, which is often sparse or difficult to collect due to privacy concerns. The quantification of the causal effects of such changes is even more challenging because of diverse individual behavioural characteristics. Given the complexity of urban environments—which include socio-economic, environmental, and human behavioural factors—accurately forecasting how interventions will reshape cities is essential but difficult.
Association modelling approaches
A broad range of studies has employed association modelling approaches—such as ordinary least squares (OLS), geographically weighted regression (GWR), and deep learning—to formulate relationships between planning interventions, context factors, and observed outcomes. Through parameter calibration using historical data, the calibrated association model can be used to predict potential future outcomes under different intervention and context settings. Jiang et al. (2024) employed OLS and GWR to quantify the effects of government interventions on redevelopment activities in Shenzhen, China. Zhu et al. (2020) identified the negative impacts of rapid urbanization on habitat quality in Hangzhou through an analysis of longitudinal cross-sectional data. In transport planning, models like the gravity model have been widely used to estimate mobility flows that may be generated as effects under given Origin-Destination settings, drawing parallels with Newton’s law of gravitation (Schläpfer et al., 2021; Simini et al., 2012).
In addition to the classic regression-based association approach, deep learning has emerged as a more advanced form of association modelling, capable of capturing complex, non-linear patterns in observed data. However, despite its increased capability, deep learning still primarily focuses on fitting observational data patterns, which share a key limitation with the classic association modelling approaches: a focus on associative rather than causal relationships (Liu et al., 2020; Simini et al., 2021). Even with deep learning algorithms, association-based modelling approaches struggle particularly when tasked with predicting the impacts of interventions that have not yet been observed or applied. This is a significant shortcoming when addressing the kinds of hypothetical or counterfactual scenarios often encountered. Therefore, while association models can provide valuable insights and have been an effective tool for knowledge discovery, their inability to infer causality limits their usefulness in planning intervention effect estimation, where understanding cause-and-effect relationships for counterfactual analysis is essential.
Operational modelling approaches
Urban systems are inherently complex, with interdependent economic, social, and environmental dimensions that interact in non-linear ways (Batty, 2009). To account for these complexities, urban planning researchers have increasingly turned to operational modelling approaches that attempt to identify and model the underlying cause-and-effect relationships, which is essential for predicting counterfactual scenarios—something that association modelling approaches often fail to achieve. System dynamics models, originally developed in systems science and later adapted by Forrester to simulate urban processes, are frequently used to capture socio-economic dynamics over time (Forrester, 2007). These models employ causal loops and feedback mechanisms to simulate urban behaviour and evolution, thereby aiding researchers and policymakers in understanding the potential impacts of various planning interventions and allowing for more dynamic predictions of how interventions might play out.
Land Use and Transport Interaction (LUTI) models have similarly gained prominence. LUTI models simulate the interactions between land use, economic activities, and transportation systems, incorporating feedback loops to capture the effects of urban policy interventions. Prominent models such as TRANUS (De la Barra, 1989; De la Barra & Rickaby, 1982), MEPLAN(Anas, 2013), and UrbanSim (Waddell, 2002) employ these approaches to predict how interventions in transportation or land use influence urban development patterns.
These models have been successfully applied at regional and national levels to evaluate how infrastructure and policy decisions ripple through urban systems over time. Jin’s model, applied to the Greater Beijing region, demonstrated the utility of Spatial Equilibrium (SE) models for counterfactual analysis by using recursive calibration and validation with historical data (Jin et al., 2013, 2017; Ma & Jin, 2019a, 2019b). Tianren Yang further applied SE models to explore land value uplift resulting from infrastructure investments in regions such as the UK and the Yangtze River Delta. Through counterfactual analysis, they assessed the impact of these planning interventions on land values, providing valuable insights into the long-term policy effects on urban development (Yang, 2020).
Although operational modelling approaches provide a more theoretically grounded approach to understanding the causal relationships in urban systems, which can effectively support counterfactual planning intervention effect estimation, they are not without limitations. These models often involve subjective decisions in their construction, such as selecting variables, defining causal loops, and making assumptions about how urban systems operate. This subjectivity can introduce inconsistencies or lead to overly complex models that are difficult to calibrate and deploy in practice (Yang, 2022). The extreme complexity of urban systems, combined with the diversity of human behaviours, makes it almost impossible to fully capture all the intricate interaction mechanisms required to construct a causal loop for accurate effect estimation of planning interventions based solely on established theories and rules. Even with a fully formulated model, obtaining all the necessary data for the variables involved is often impractical. These challenges have limited their application to simplified, large-scale, strategic urban development decisions, and they are rarely deployed for finer-grained analyses, such as neighbourhood- or street-level interventions—where understanding local human responses to planning changes is critical.
Summary
While association models are effective at recognizing data patterns, their inability to infer causality limits their applicability for counterfactual analyses in planning intervention effect estimation. Operational models address this gap by focusing on cause-and-effect relationships but are constrained by their data requirements, subjective assumptions, and practical difficulties in model calibration, particularly for localized or fine-grained interventions. These limitations highlight the need for a more lightweight and robust method to estimate the effects of planning interventions—one that can infer causality for counterfactual analysis directly from observed data, without the need for fully articulated causal interaction models.
The field of statistics, to handle a related task—causal effect estimation using observational data—has developed a series of methods that have been successfully applied in various domains, for example, understanding the effects of drugs (Alaa & van der Schaar, 2017), verifying which factor causes a certain disease (Höfler, 2005), and estimating the effects of pollution on the weather (Hannart et al., 2016). 1 Meanwhile, in the field of artificial intelligence, recent advancements in conditional deep generative models also show great potential in handling similar tasks. Generative models have demonstrated their ability to translate data across conditions without requiring paired examples. CycleGAN can learn to translate an image in style A into a target style B without training on paired image samples—an approach conceptually similar to generating “counterfactual intervention-conditioned” outcomes by learning from factual data (Zhu et al., 2017).
Inspired by these advancements, this paper proposes a novel method that fully utilizes deep learning’s ability to model complex, non-linear relationships while integrating RCM for causal inference and generative algorithms to achieve more robust and reliable estimation of planning intervention effects in counterfactual scenarios. To implement this integration within a deep learning framework, we adopt VCNet as the base model (Nie et al., 2021). 2 By enhancing VCNet with deep generative components, we introduce a new model, CGNet-PIE, as a practical and efficient tool for improved predictive performance in estimating the effects of planning interventions, particularly on counterfactual cases and using observational data.
Preliminaries
We formulate the problem following the RCM paradigm and as follows: the problem is the prediction of the potential responses of various individuals under specific contextual environments to different planning interventions. The prediction is made based on given
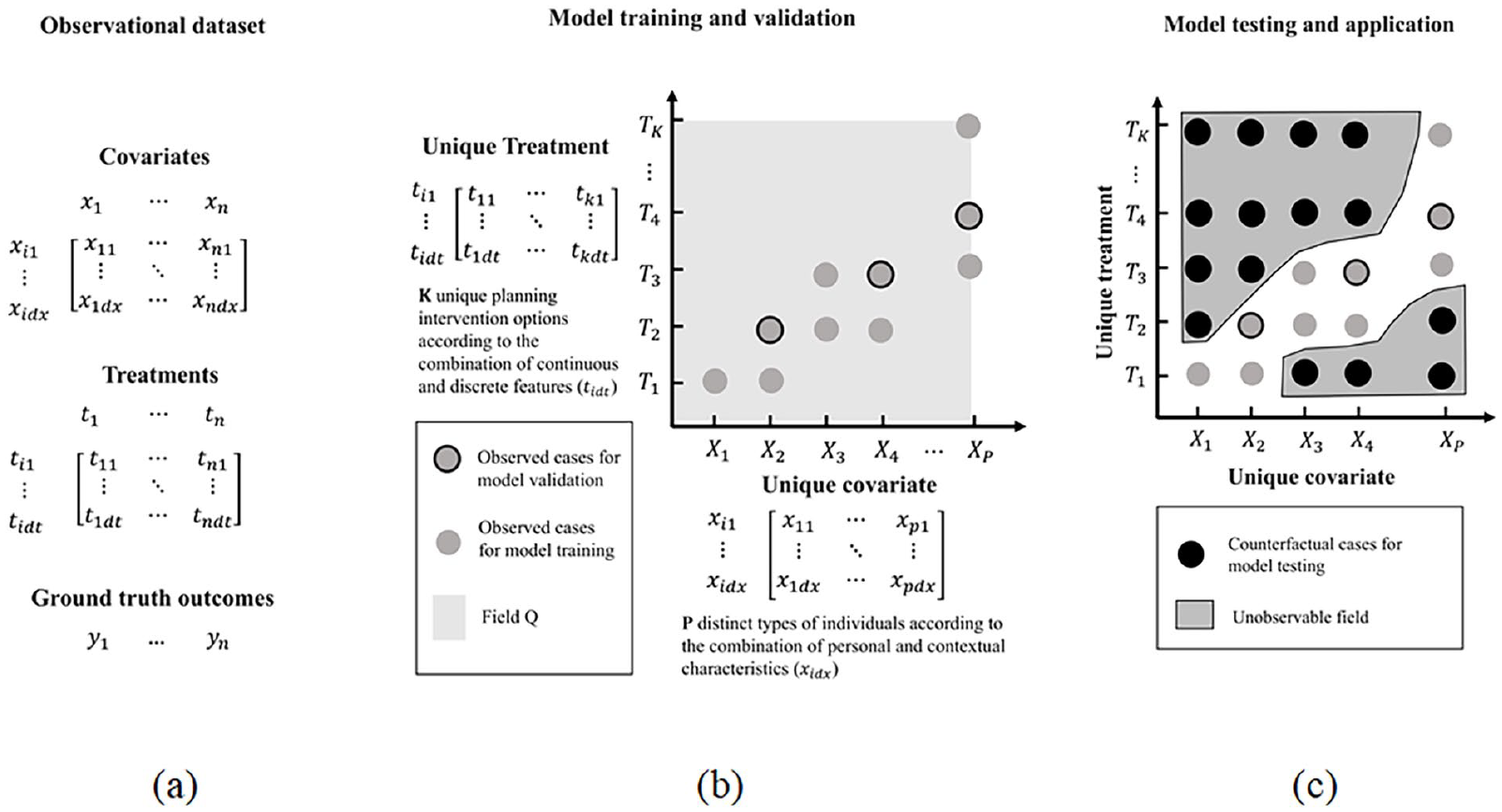
Diagrammatic representation of the problem setting.
Causal Generative Network for Planning Intervention Effect estimation
Model structure
We built the proposed Causal Generative Network for Planning Intervention Effect estimation (CGNet-PIE) model using a multi-headed deep learning model architecture that has been widely adopted in existing deep learning-based RCM: one predicts the planning intervention, and the other predicts the response of individuals based on their characteristics and the intervention applied. We use an encoding network (E) to produce a representation layer
Specifically, we developed our model based on a state-of-the-art model in the field of causal inference for the problem of estimating the average dose-response curve (ADRF) for continuous treatments, VCNet (Nie et al., 2021). We improved it by enhancing the encoding network (E) within the system. By introducing the concept of generative deep learning using Variational AutoEncoder (VAE) for representation learning, the modified model avoids a per-datapoint optimization loop (Kingma, 2013). As shown in Figure 2, our proposed encoding network (E) learns stochastic mappings between input
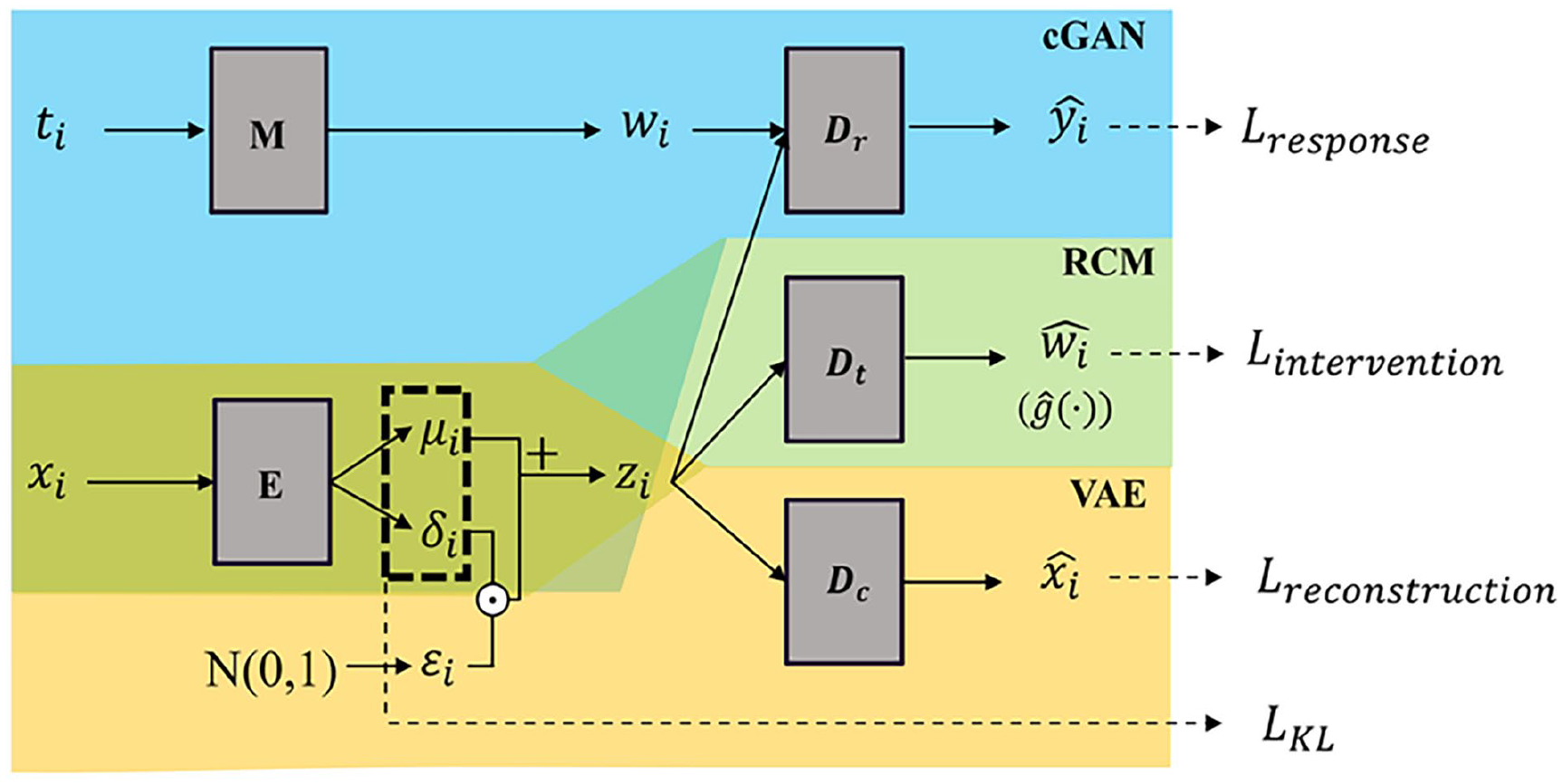
Overall framework of proposed CGNet-PIE.
To handle the mixture of continuous and discrete features in the planning interventions, we introduce a non-linear mapping network (M) to map the input planning intervention information to a continuous intermediate latent space W, which then serves as the given conditions for Dr to predict response. To prevent the intervention information from being lost in the latent representation through the decoding process, we repeatedly attach these latent features at multiple layers of Dr. These techniques have been verified for their effectiveness in conditional generative modelling and have been widely applied as fundamental components in state-of-the-art generative models (Karras et al., 2019, 2020).
Finally, to deal with planning interventions represented by the continuous feature vector w in intermediate latent space W and to preserve the continuity of ADRF in prediction, we designed the Dr model as the varying coefficient model following VCNet. The varying coefficient component can allow the weight of the prediction head to be a continuous functions of the planning intervention features. With the non-linear activation function defined by the neural network depending on the varying intervention, the mapping defined by the network can automatically adapt accordingly and produce continuous ADRF estimation.
Loss function
Four types of loss, namely intervention prediction loss, response prediction loss, covariate reconstruction loss, and Kullback–Leibler divergence loss, are jointly minimized respectively to train the proposed CGNet-PIE by iteratively updating the parameters embedded in the model. The joint use of intervention prediction loss and response prediction loss allows the adversarial training of the model to learn a trade-off between predictive accuracy and the propensity-score representation. Meanwhile, the introduction of covariate reconstruction loss and Kullback–Leibler divergence loss into the total loss function turns the deep learning-based RCM framework into a VAE-based generative system, improving its generalization capability. The total loss function is defined as:
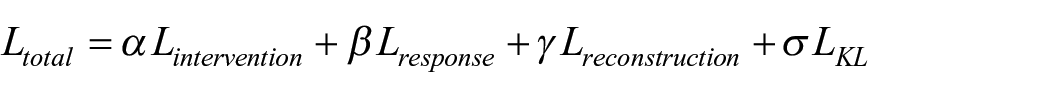
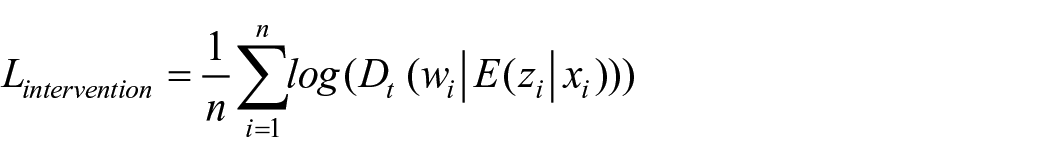
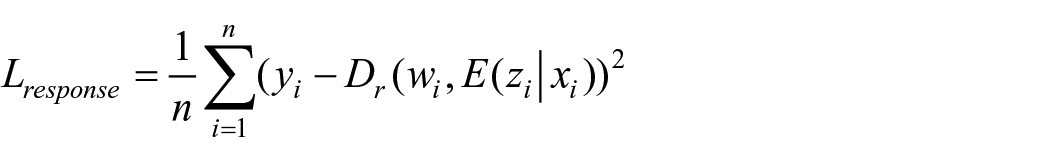
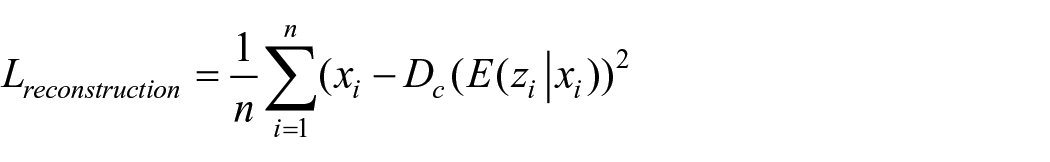
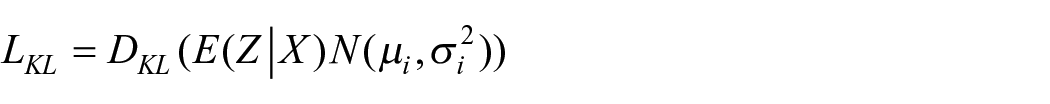
where α, β, γ, and σ are hyperparameters adopted to weigh the four losses.
Model training
The concatenation of
Training of our proposed model.

In summary, the proposed CGNet-PIE model builds on the state-of-the-art VCNet with two key enhancements: a non-linear mapping and encoding network for effective feature fusion, and a VAE structure for robust representation learning and improved generalization. These advancements, along with the varying coefficient model component from VCNet for continuous Average Dose-Response Function (ADRF) predictions, enhance the model’s adaptability to both continuous and discrete inputs and outputs, while improving accuracy in both factual and counterfactual analyses. In the next section, we validate CGNet-PIE on synthetic, semi-synthetic, and real-world datasets to demonstrate its performance and applicability.
Experiment design and results
Like treatment effect estimation tasks in the field of causal inference, evaluating model performance for planning intervention effect estimation is more difficult than many machine learning tasks, since we only have observed planning intervention and associated effects to train and test the model and rarely have access to the ground truth responses to the counterfactual intervention scenarios. Existing literature in treatment effect estimation mostly deals with this in two ways. One is by using synthetic datasets, where the treatment setting, assignment, and outcome are calculated based on manually predefined functions, thus all the treatment scenarios and outcomes are fully known. The other is using a semi-synthetic dataset, where the original dataset is created based on observed cases and then extended its specification using synthetic outcome functions to enable the simulation of all potential treatment scenarios (Shalit et al., 2017).
In this research, we performed experiments on one synthetic and one semi-synthetic dataset that have been widely applied to evaluate causal estimation procedures to benchmark our proposed CGNet-PIE with benchmark models. To further demonstrate the feasibility of applying the proposed CGNet-PIE model in an urban planning context, we include a real-world case study on planning intervention effect analysis. Specifically, we construct a real-world dataset derived from a large-scale facility visitation survey conducted at a typical university in Beijing, China. Using CGNet-PIE, we predicted students’ visitation frequencies under various location configurations for university canteens. With this real-world case study, we aim to demonstrate:
How the proposed CGNet-PIE model can be utilized to quantify the effects of planning interventions.
How the results produced by the CGNet-PIE model can be interpreted within the urban planning context and applied to support real-world decision-making.
Datasets
Dataset 1: Synthetic dataset
Following the dataset creation scheme introduced with VCNet (Nie et al., 2021), we set up the synthetic dataset that contains 500 randomly generated data pairs as observation cases to train and validate the model and 200 grid-sampled data pairs as testing cases to evaluate the performance of the model on factual and counterfactual cases. Each of the data pairs is composed of covariates
To generate data pairs for model training and validation, we randomly pick
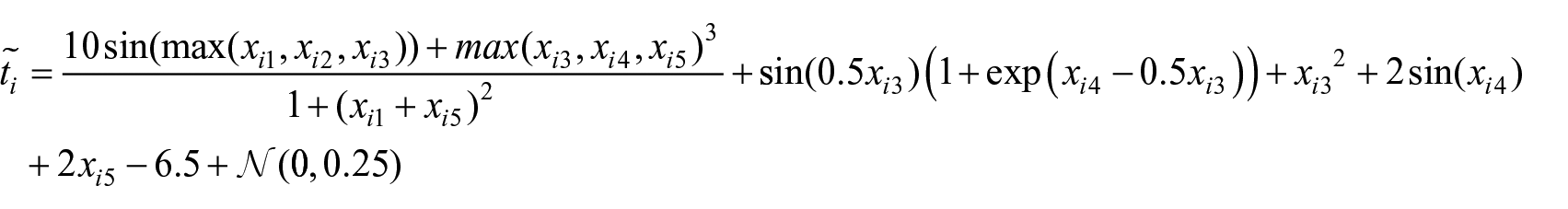

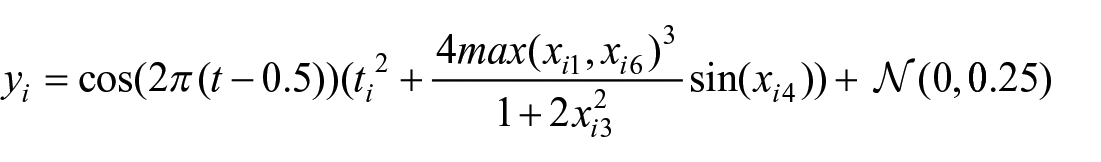
It is worth noting that the derivation of
The grid-sampled data pairs for model testing are derived using
Dataset 2: Semi-synthetic dataset
In addition to the synthetic dataset, we also include a semi-synthetic dataset to perform the experiment. The adopted semi-synthetic dataset is introduced in Hill (2011) for treatment effect estimation based on the Infant Health and Development Program (IHDP). This dataset is created using covariates coming from a randomized experiment investigating the effect of home visits by specialists on future cognitive test scores. The treatment groups have been made imbalanced by removing a biased subset of the treated population. The dataset comprises 747 units (139 treated, 608 control) and 25 covariates measuring aspects of children and their mothers. To enable the simulation of both factual and counterfactual cases under continuous
Dataset 3: Real-world dataset
To demonstrate the feasibility of applying the proposed CGNet-PIE in the urban planning context and to further evaluate model performance in real-world cases, we establish a real-world dataset based on a large-scale facility visitation survey at a typical university in Beijing, China. Through the survey, we obtained 1,972 valid university canteen visit frequency records covering all grades of undergraduate and graduate students from various departments. We first identified the spatial distribution of university canteens for the students and then inquired about students’ basic information and their visiting frequency to these canteens in the questionnaire.
To create the real-world dataset, we collected students’ basic information (e.g., gender, monthly expense level) as covariates and used the spatial placement of university canteens as a planning intervention, with the goal of promoting on-campus dining and reducing food delivery. To quantitively represent the intervention, we used the walking distance from each respondent’s accommodation or office to the two nearest canteens as features. This choice reflects a hypothesis inspired by the revealed universal visitation law of human mobility: the number of visitors to any location decreases as the inverse square of the product of their visiting frequency and travel distance (Schläpfer et al., 2021). By focusing on the two nearest canteens for each student, we aimed to simulate the collaborative and competitive dynamics of facility placement while maintaining a manageable level of complexity.
The covariates and planning intervention features composed the input for the model, and students’ weekly university canteen visitation frequency, obtained from the survey, served as the ground truth labels for assessing the effects of different canteen location settings. The details of all input features and ground truth outputs are provided in Table S1 in the Supplementary Material. The real-world dataset combined the inputs and ground truth labels into data pairs for model development. A total of 67% of the randomly selected samples from the dataset were used to train and validate the models, while the remaining 33% were reserved for evaluating model performance and facilitating model comparison.
Under this setting, the CGNet-PIE model is designed to establish the relationship between students’ basic information (covariates), walking distances to canteens (interventions), and visitation frequencies (effects) based on the survey records. With the trained model, we can estimate and simulate the potential aggregate canteen visitation flow as the effect of various hypothetical canteen placement scenarios by multiplying the predicted visitation frequencies with population distributions. These simulations provide insights for estimating canteen capacity needs, guiding facility design, and optimizing canteen locations to maximize visitation and reduce food delivery, thereby contributing to carbon reduction goals.
Models
To evaluate the performance of the proposed CGNet-PIE on the above three datasets, we employ three different deep learning-based RCM models developed for treatment effect estimation as benchmarks. We compare our model against Dragonnet (Shi et al., 2019), DRNet (Schwab et al., 2020), and VCNet (Nie et al., 2021). Following the baselines and experiment settings introduced in Nie et al. (2021), we (1) set up separate prediction heads for T in different blocks for Dragonnet, (2) add a conditional density estimation head for DRNet, and (3) adopt truncated polynomial basis with degree 2 and two knots at {1/3,2/3}. Given the verified effectiveness of targeted regularization (TR) in improving deep learning-based models on treatment effect estimation tasks, we implemented two versions, the original version and the TR version, for all three benchmark models. Thus, in all, we considered a total of six benchmark models as baselines in the experiments using the three datasets to facilitate comprehensive model evaluation and comparison.
For CGNet-PIE, we adopted the original version of VCNet as the base model maintaining the network structure and hyperparameter settings of the encoding network (E) and decoding network
Evaluation metrics
For the experiments using synthetic and semi-synthetic datasets, we use the average mean squared error (AMSE) between the observed ground truth y and the model predicted
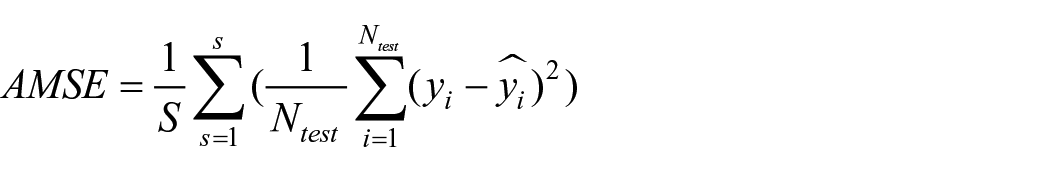
It is worth noting that the test sets for the synthetic and semi-synthetic datasets consist of grid-sampled data pairs, derived using uniformly enumerated covariates and treatments to cover all possible covariate-treatment pairings. Following previous research, we use the average mean squared error (AMSE) metric on synthetic and semi-synthetic datasets to benchmark the performance of our proposed CGNet-PIE model against existing models for regression tasks, where continuous outcomes
In the experiment using the real-world dataset, we adopt Top-1 and Top-2 Accuracy Metrics to evaluate the model’s ability to predict students’ canteen visitation frequencies. The use of Top-N accuracy metrics in the real-world case study is justified for the following reasons:
Align with survey question settings: Survey respondents typically provide preference-based answers to multiple-choice questions rather than absolute numeric values. In our case, students indicated their canteen visitation frequency by selecting predefined levels: “Never,” “1-2 times per week,” or “3-5 times per week.” Top-N accuracy metrics evaluate how well the model captures these discrete-choice preferences, making them particularly appropriate for the real-world dataset.
Complement metrics for classification tasks: The use of Top-N accuracy for the real-world dataset complements the AMSE metric used for regression tasks on synthetic and semi-synthetic datasets. This combination verifies CGNet-PIE’s ability to handle both discrete-choice and continuous-value scenarios, demonstrating its versatility across regression and classification tasks.
Implementation detail
Our models for all designed experiments were trained with Python v3.11.8, on an Intel i9-13900KF CPU with a single NVIDIA GeForce 2080Ti GPU, using Adam as optimizer with the learning rate of 1e-4 for 2000 epochs. The entire training procedure for each repeat run within a experiment took roughly 55 sec. Our model evaluation and test were conducted on the same device with same batch size of 256 as model training. The data and codes that support the findings of this study are also available. 3
Results
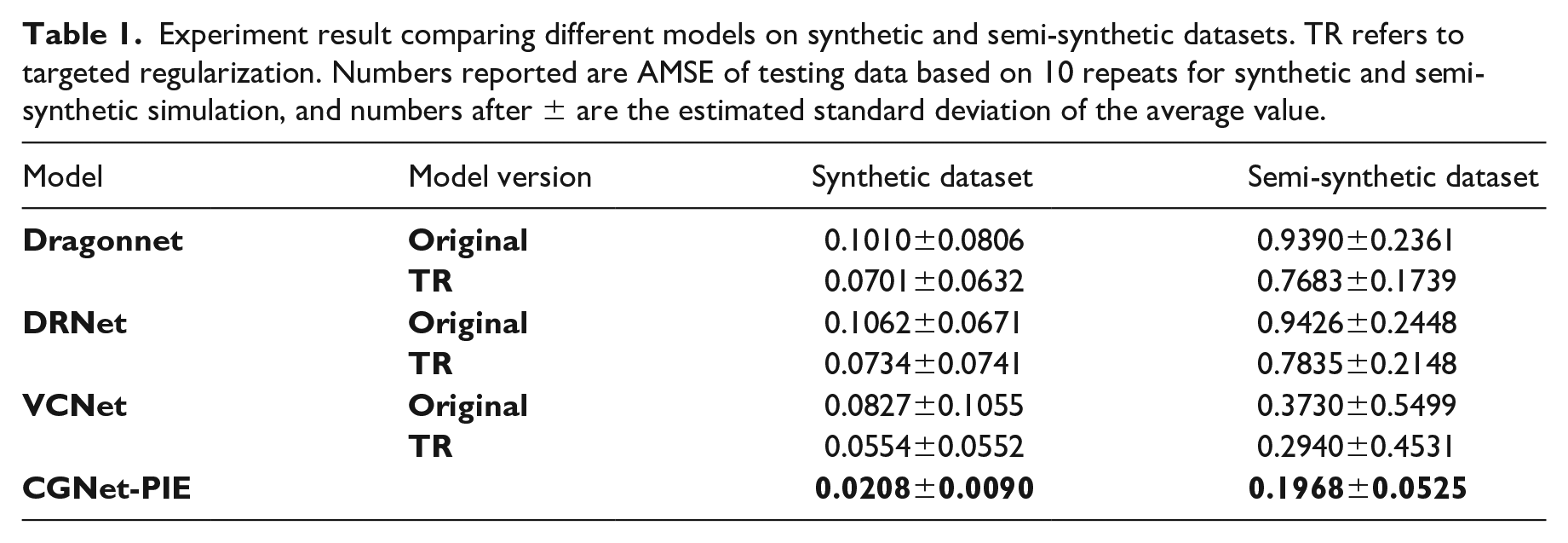
In this research, each model was run 10 times, with the average results and their performance variations across the multiple runs reported. Table 1 compares the predictive performance of all the baseline models alongside the newly proposed casual generative model, CGNet-PIE, on the synthetic and semi-synthetic datasets. Table 2 presents the predictive accuracy of all models on the real-world dataset.
Experiment result comparing different models on synthetic and semi-synthetic datasets. TR refers to targeted regularization. Numbers reported are AMSE of testing data based on 10 repeats for synthetic and semi-synthetic simulation, and numbers after ± are the estimated standard deviation of the average value.
Comparison of CGNet-PIE against based baselines on real-world cases. TR refers to targeted regularization. Reported Top-1 and Top-2 accuracy are averaged over 10 repeat runs using the real-world datasets. Numbers after ± are estimated standard deviation of the average accuracy.
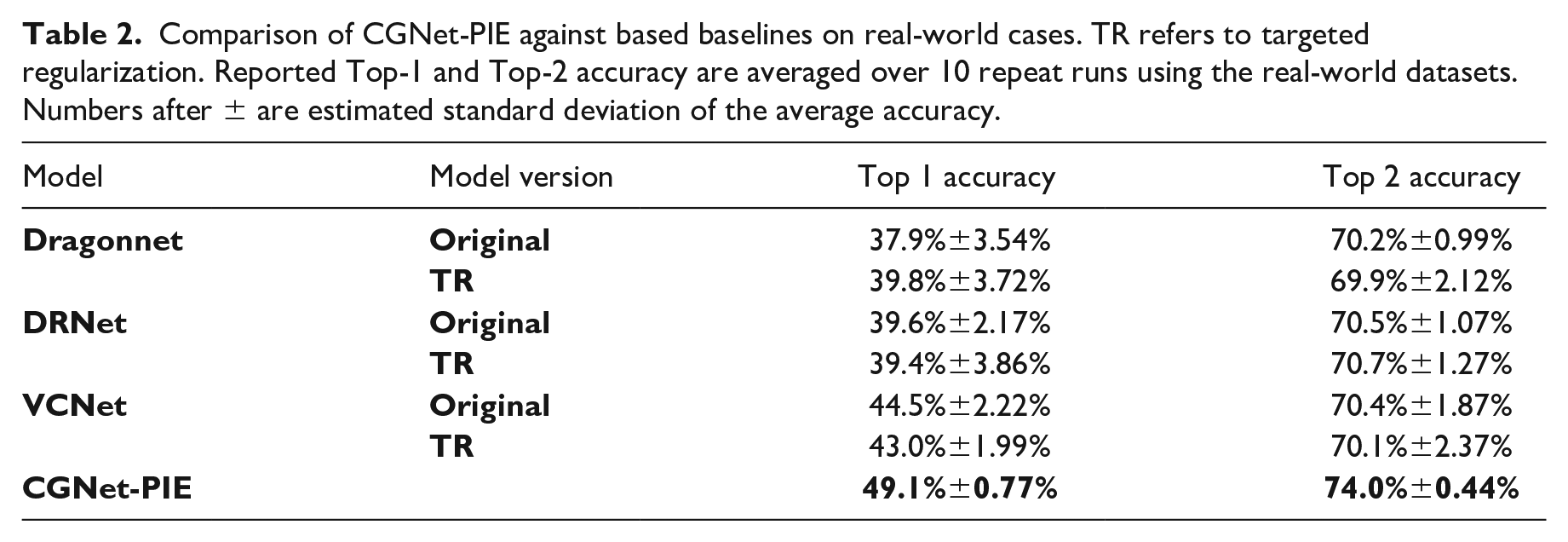
Comparing results in Table 1, we found that all baseline models that adopted additional targeted regularization strategy outperformed their original version, demonstrating the effectiveness of TR for treatment effect estimation when using deep learning approaches. We also found that CGNet-PIE outperformed all baseline models, including both the original and TR versions in terms of AMSE on both synthetic and semi-synthetic datasets. By comparing the performance of CGNet-PIE and original VCNet, which can be seen as CGNet-PIE with the additional generative components being removed, we can conclude that the proposed generative components empower CGNet-PIE achieving a better predictive performance.
To discover the model performance in the urban planning context, we compare results in Table 2 and observe that baseline models in the TR version do not consistently outperform their original version. This indicates that adherence to the targeted regularization strategy does not consistently yield superior performance across all datasets. However, CGNet-PIE demonstrates better performance compared to all baseline models in both the original and TR versions on real-world datasets. This further showcases its effectiveness in estimating the impacts of planning interventions in the urban context. With its improved performance in predicting students’ visitation frequencies to university canteens, CGNet-PIE helps planners achieve more accurate estimations of potential visitation flow, thereby guiding facility design and informing canteen capacity needs.
The results reported in Tables 1 and 2 also include performance variability (± values) observed across 10 independent runs for each model on different datasets, indicating the consistency of the results across scenarios. For CGNet-PIE, the variability in AMSE (e.g., ±0.0090 on synthetic datasets and ±0.0525 on semi-synthetic datasets) was significantly smaller than that of the baseline models. On real-world datasets, CGNet-PIE also achieved the highest Top-1 accuracy (49.1% ± 0.77%), with remarkably low variance compared to other models. This suggests that CGNet-PIE not only delivers better mean performance but is also more stable across multiple runs.
The reduced variability in CGNet-PIE’s performance across runs can be attributed to its generative modelling components. The adopted VAE structure and non-linear mapping module learn structured latent representations that effectively capture underlying data distributions, reducing the system’s sensitivity to noise and randomness. This leads to greater consistency and robustness during model training and testing. The consistent superiority of CGNet-PIE over VCNet (its base architecture without generative components) further confirms that the integration of generative components not only improves predictive accuracy but also enhances model stability. The low variability across multiple runs and scenarios underscores its practical utility in urban planning interventions, where reliability is critical for decision-making.
Conclusion
This paper presents the development of the CGNet-PIE as a novel approach for estimating the effects of urban planning interventions with observed cases, addressing critical limitations in existing models that either rely primarily on data-driven association mechanisms or manually constructed operational models. By leveraging a deep learning-based RCM model structure enhanced with generative techniques, CGNet-PIE contributes to more robust modelling of how planning interventions affect individual behaviours. Compared to traditional methods, such as propensity score matching or tree-based causal inference, CGNet-PIE offers significant advantages. Its deep learning foundation enables the handling of high-dimensional data and the modelling of complex, non-linear relationships among covariates, interventions, and outcomes. Furthermore, its adoption of the RCM for causal inference and generative components ensures robust predictions across both observational and counterfactual scenarios, making it uniquely suited for complex urban planning tasks.
Through a comprehensive series of experiments, we tested CGNet-PIE on synthetic, semi-synthetic, and real-world datasets. Compared against baseline models (Dragonnet, DRNet, VCNet), CGNet-PIE demonstrated superior performance for intervention effect estimation across both observational and counterfactual cases. The experimental results highlight the strengths of causal inference with generative modelling in three key aspects:
Improved accuracy: The generative components integrated into CGNet-PIE significantly contributed to its superior predictive performance compared to all baseline models, including the original and TR versions of VCNet. This improvement is evident in terms of AMSE on synthetic and semi-synthetic datasets, as well as predictive accuracy on the real-world dataset.
Improved stability: The inclusion of generative components, such as VAE, enables the model to learn structured latent spaces, ensuring consistent results even under noisy conditions. This improved stability in CGNet-PIE is evidenced by the lower performance variability observed across experiments compared to all baseline models.
Improved interpretability: Since the CGNet-PIE model is developed based on VCNet, which is rooted in the RCM paradigm, it can effectively decouple the influence of planning interventions on predicted outcomes from covariates. The contribution of interventions to the predicted outcomes can be directly quantified using the model. The interpretability of CGNet-PIE can be further enhanced by techniques like SHAP, which allow for the visualization of how covariates influence predicted outcomes, facilitating better understanding and trust in the predictions. These features make CGNet-PIE particularly suitable for urban planning scenarios, where decision-making demands both reliable and interpretable insights.
The implications of this research are significant for urban planners and policymakers. CGNet-PIE provides a reliable tool for estimating the effects of planning interventions, enabling decision-makers to explore “what if” scenarios and make better-informed choices about resource allocation and policymaking. The utility of CGNet-PIE is illustrated through its application to real-world urban planning scenarios. In the real-world case study, the CGNet-PIE model effectively captures the relationship between students’ demographic information (covariates), walking distances to canteens (interventions), and their visitation frequencies (effects) based on survey data. Using the developed model, we can simulate and estimate potential aggregate canteen visitation flows under various hypothetical canteen placement scenarios by integrating predicted visitation frequencies with population distributions. These simulations provide valuable insights for optimizing canteen placements to achieve desired visitation rates and for guiding facility design. Beyond this facility placement case, CGNet-PIE can also be applied to other planning intervention scenarios, including transportation planning—simulating the effects of new bus routes on commuter behaviour—or estimating the impact of policy changes on residential distribution. As long as the three key components—covariates, interventions, and effects—can be identified and represented using discrete or continuous features, CGNet-PIE can be adapted to practical applications.
While CGNet-PIE has shown significant promise in addressing the limitations of existing approaches and demonstrates great potential for widespread application in solving planning intervention effect estimation tasks across various domains, there are still areas that warrant further exploration. One key limitation of the current model is its focus on estimating the response of individual units (such as citizens) to single, isolated planning interventions. CGNet-PIE, as currently structured, is not capable of capturing the complex interactions between individual units within an urban system. It cannot represent the intricate relationships between supply and demand, competition and cooperation among multiple simultaneous interventions.
Future work should aim to extend CGNet-PIE’s capabilities by developing methods that can model the interactions among individuals and across various systems within the urban context. This includes exploring how multiple interventions might jointly affect different population segments, and how these effects are mediated and eventually influence urban system performance. Further research should also focus on modelling the dynamic feedback loops that emerge as cities respond to evolving market forces and policy shifts over time. Incorporating these complexities will be essential for creating more realistic and powerful models that better reflect the interconnected and dynamic nature of urban development.
Supplemental Material
sj-docx-1-tus-10.1177_27541231251318348 – Supplemental material for CGNet-PIE: A causal generative approach for urban planning intervention effect estimation
Supplemental material, sj-docx-1-tus-10.1177_27541231251318348 for CGNet-PIE: A causal generative approach for urban planning intervention effect estimation by Zhou Fang, Qianmu Zheng, Shuwen Zheng and Liang Zhao in Transactions in Urban Data, Science, and Technology
Footnotes
Acknowledgements
Zhou Fang appreciates the support from Tsinghua University via Shuimu Tsinghua Scholar Program and China Postdoctoral Science Foundation via the International Postdoctoral Exchange Fellowship Program. Zhou Fang also wishes to acknowledge funding support from National Natural Science Foundation of China (52308068) and China Postdoctoral Science Foundation (2023M731958). Liang Zhao wishes to thank funding support from the Tsinghua University Initiative Scientific Research Program via the Tsinghua–Cambridge research collaboration (20223080047).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.