
Abstract
Research has long touted and recently confirmed the importance of intercultural communicative competence (ICC) — the ability to appropriately communicate with those from diverse sociocultural and linguistic backgrounds — in second language (L2) teaching and learning. Additionally, while multimodal course materials have contributed to learners’ ICC, the link between students’ embodied modes (gestures, facial expressions, body movements) and ICC remains under-explored. Building on ICC and the social semiotic theory of multimodality, this study blends multimodal transcription and conversation analysis to examine how 73 university undergraduate learners of L2 French used embodied modes in 188 asynchronous video reflections and how these modes accompanied demonstrations of ICC skills, knowledge, and attitudes. Findings indicate that gestures and facial expressions indicated students’ demonstrations of the ICC skills of observing, analyzing/interpreting, evaluating, relating, listening, questioning, researching, and problematizing. Further, embodied modes demonstrated students’ retrieval and communication of cultural and sociolinguistic knowledge. This study has implications for online language learning and enhancing ICC through virtual multimodal assignments.
Keywords
Introduction
Research in second language (L2) teaching and learning has examined the potential of video essays and digital storytelling to enhance linguistic and sociocultural learning. Multimodal composing has helped learners repair lexical and grammatical errors (e.g., Amgott, 2022; Mortensen, 2016), bolster motivation (e.g., Jiang and Luk, 2016), and express their multiple identities (e.g., Amgott and Gorham, 2022; Smith et al., 2017). The social semiotic theory of multimodality holds that students make meaning by combining modes such as image, color, motion, sound, layout, and text (Jewitt, 2009). As Kumagai et al., (2015: 142) note, multiple modes do “not merely assis [t] or replac [e] what students cannot communicate through language; the use of multimodality creates new meaning”. Nevertheless, embodied modes such as gesture and facial expression 1 have been underemphasized in L2 digital multimodal composing studies and are often considered “compensatory strateg [ies] [for] learners’ lack of verbal competence” (Belhiah, 2013: 113).
Given that embodied modes are communicative (Mondada, 2016) and exist in sociocultural context (Gao, 2006), they may be useful in illustrating L2 learners’ intercultural communicative competence (ICC), an increasingly critical objective of L2 teaching (McLaren, 2019). Additionally, given the explosion of online language teaching (Maican and Cocoradă, 2021), it is essential to understand how students’ embodied modes may demonstrate ICC while speaking the L2 in digital contexts. Grounded in multimodality (Kress, 2003, 2010), this study examines how 73 L2 French university students visually manifested ICC through embodied modes in 188 asynchronous video reflections and discusses the implications of multimodal analyses of ICC.
Literature review
Theoretical framework
Intercultural communicative competence
We recognize that there is no consensus definition of ICC (Chao, 2014; Deardorff, 2015, 2019). In fact, UNESCO (2013) summarized commonalities across various conceptualizations, concluding that ICC entails: “adequate knowledge about particular cultures, (...) general knowledge about… issues arising when members of different cultures interact, holding receptive attitudes that encourage establishing and maintaining contact with diverse others, as well as having the skills required (in) … interacting with others from different cultures.” (16, as cited in Deardorff, 2019: 4).
This definition stemmed from a plethora of terms used in research across diverse fields (Deardorff, 2019). For example, Bennett’s (1993, 2013) six stages of intercultural sensitivity (IS) — denial, defense, minimization, acceptance, adaptation, and integration — represent worldviews ranging from ethnocentrism to ethnorelativism. This framework has been criticized for suggesting linear IS development, which conflicts with contemporary understandings of cultural competencies as non-linear, which Bennett (2017) later acknowledged.
Among models that address cultural competencies instead of sensitivities, some use the term intercultural competence (IC) and other intercultural communicative competence (ICC). Compared to IC, ICC more explicitly emphasizes communicative modes — embodied and verbal — and their relationships to intercultural knowledge, attitudes, and skills (Acar, 2016). Both IC and ICC are widespread in L2 literature (Fantini, 2019), with frameworks including Byram’s (1997) ICC and Deardorff’s (2009) IC. Byram’s model (1997) argues that education rooted in intercultural communicative competence aims to cultivate 5 ‘savoirs’: (a.) savoir — knowledge of one’s own culture, (b.) savoir comprendre — relating to other cultures, (c.) savoir s’engager — critical sociocultural knowledge, (d.) savoir être — attitudes towards new and known cultures, and (e.) savoir faire/savoir apprendre — discovery of new cultural information.
Deardorff’s (2009) “four factor” model of IC aims to be measurable and applicable to any language and claims that ICC consists of attitudes (openness, respect, tolerance of ambiguity), knowledge (cultural and sociolinguistic), comprehension (cultural and sociolinguistic), and skills (listening, observing, evaluating, analyzing, interpreting, and relating), which then contribute to internal and external IC outcomes (Figure 1). More recently, Fantini (2019, 2021) also conceptualizes ICC as being composed of attitudes, knowledge, comprehension, and skills. Visual summary of Deardorff’s (2006) four-factor model of intercultural competence.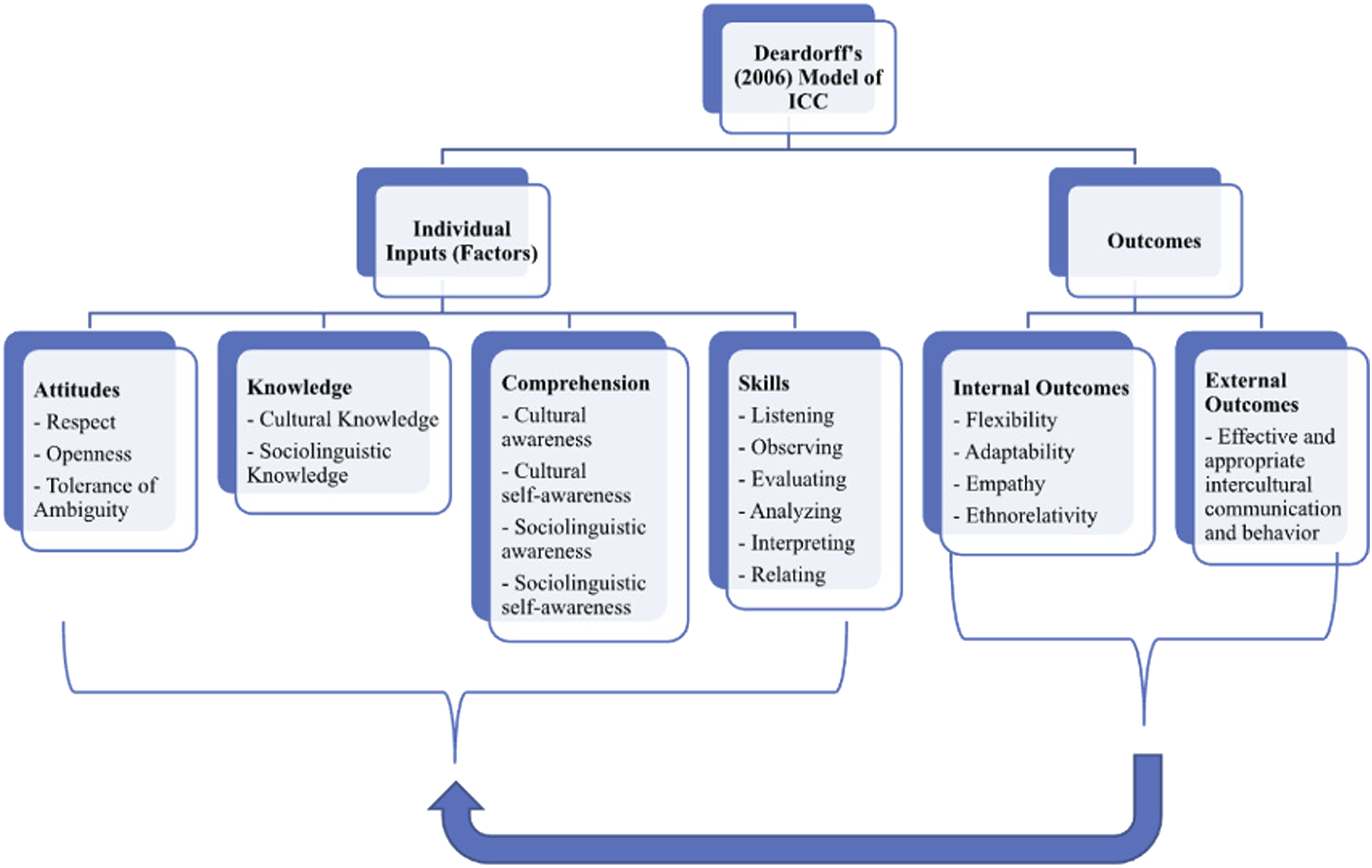
The detail of Deardorff’s (2009) model, which divides contributing factors into sub-categories, offers a succinct basis for qualitative analysis that incorporates the key components of other well-known models. We thus adopt this framework to inform our analysis for this study. Although Deardorff (2009) is less focused on the communicative element of intercultural competence, and thus employs the term IC rather than ICC, we use ICC when referring to our participants since we are examining their intercultural abilities in explicitly communicative contexts (i.e., students’ pre-recorded video reflections) 2 .
Finally, it is important to note that even the notion of interculturality as a set of competencies has been seen as problematic by scholars who argue that measuring or assessing interculturality promotes a touristic approach that is no longer focused on the respect and ethics of interaction with diverse others (Ferri, 2018). We recognize that no model perfectly captures the complexities of ICC and that assessing it can be problematic. We keep these difficulties in mind while responding to Deardorff’s (2015) call for additional work to shed more light on ICC, given the plethora of diverse and sometimes contradictory definitions and conceptualizations.
Multimodality
Next, we leverage the social semiotic theory of multimodality (Kress, 2003, 2010) to understand students’ embodied modes. Multimodality involves making meaning through a plurality of modes such as text, image, audio, color, and gestures. Multimodal perspectives are process-oriented, stressing that there is “an essential link between (…) social conditions and the ways in which these are modally instantiated” (Jewitt and Kress, 2010: 342). Individuals, therefore, design meaning based on perceived sociocultural nuances carried by each mode (Kress, 2003, 2010). In L2 research, multimodality is employed to analyze digital multimodal composing, or designing meaning by combining modes in mediums such as digital stories or vlogs (e.g., Xie et al., 2021).
Although proponents of multimodality emphasize the inseparability of modes (Jewitt, 2009; Kress, 2010), L2 teaching often situates modes on hierarchical planes of importance. Kimura and Canagarajah (2020), for instance, noted the “logocentric,” language-centered nature of L2 teaching, which Grapin (2019: 31) labeled “weak” multimodality, where nonlinguistic modes are positioned as superfluous scaffolds that help students produce written or spoken “language”. Instead, Grapin (2019: 31) argued for “strong” multimodality in which all modes are considered equally valuable for designing meaning and Kimura and Canagarajah (2020) proposed further investigating embodied modes.
Research methods for L2 embodied modes
Research on embodied modes in L2 contexts has often employed conversation analysis (CA) —examining talk in interaction (Goodwin, 1986; ten Have, 2007) — as its primary means of analysis. Although CA transcription has attempted to capture gestures in (often textual) representations, it does not always display the simultaneous interaction of embodied modes with other modes (Mondada, 2016). CA recognizes the “artificiality of separating language and the body in action,” (Mondada, 2019: 49); however, it still produces static, asynchronous analyses through transcriptions that can be highly unreadable for the uninitiated. We posit that more multimodal analyses, blended with CA, can provide a better-integrated, diachronic landscape for interpreting how L2 students leverage their multimodal toolboxes when designing meaning. In the following section, we explore ICC, embodiment, and multimodality in L2 teaching and learning research.
Previous studies
ICC in L2 teaching and learning
Current ICC research builds on previous research on culture in language classrooms. Historically, L2 culture has been addressed stereotypically (Kramsch, 2013), a problem that grounds Hall’s (1976) iceberg model, which holds that the most visible culture (e.g., food, festivals, fashion) is only the tip of the iceberg and is influenced by invisible culture (e.g., values, attitudes, beliefs). ICC research aims to uncover how L2 learners acquire knowledge of less-visible deep culture (Hall, 1976) and integrate it with linguistic competence for effective intercultural communication. However, Bickley et al. (2014) pinpointed a key difficulty in cultivating L2 ICC; in their survey of 70 ESL instructors, 73% stated that they struggled to teach ICC due to the limitations of their textbooks and materials.
In response, researchers have proposed pedagogical activities focused on ICC. For example, Velasco’s (2017) ESL students watched a video on racism and completed activities describing the cultural aspects of the video. After the lesson, 87% of participants agreed that the activities augmented their intercultural understanding and helped them reflect on their personal biases. Similarly, Cai and Lv (2019) scaffolded ESL students’ ICC during a lesson on dating cultures and found that mean scores on Valette’s (1977) Cultural Test Instrument increased after the lesson.
Recent research has explored the use of educational technologies in L2 teaching and learning to enhance students’ ICC. Lin and Wang (2018) assessed 65 ESL students at a Taiwanese university who viewed TED Talks, finding an increase in their scores on the Intercultural Competence Scale (Chao, 2014) after the activity. In Lenkaitis et al. (2019) study, students from U.S. and Mexican universities participated in synchronous Zoom discussions in Spanish and English. The researchers analyzed the recordings for the “Communication” and “Cultural Self-Awareness/Understanding” components of ICC and concluded that both linguistic and intercultural development were demonstrated during telecollaboration. These studies suggest that digital, multimodal tools and assignments can help pedagogically cultivate ICC and facilitate students’ demonstration of their growing intercultural competencies.
Multimodality and embodied modes in L2 teaching/learning
Prior research has also revealed how using the entire modal repertoire can augment L2 learners’ motivation (e.g., Hafner and Miller, 2011; Jiang and Luk, 2016) and navigation of difficult communicative situations (e.g., Canals, 2021; Harrison et al., 2018; Matsumoto and Dobs, 2017). For example, a study on three eighth graders in an English class revealed how bilinguals “codemeshed,” or translanguaged by shuttling across language(s) and other modes in a “gyroscopic” fashion as they became more comfortable with digital multimodal composing (Smith et al., 2017: 14).
In L2 teaching, embodied modes have supported instructors in improving student pronunciation (e.g., Ilizuka et al., 2020; Smotrova, 2015), verb use (e.g., Jacknick, 2018; Matsumoto and Dobs, 2017; Ro, 2021), and vocabulary (e.g., Huang et al., 2018; Van Compernolle and Smotrova, 2017). These studies paint language teaching as “a fundamentally multimodal process” (Van Compernolle and Smotrova, 2017: 195) and describe how embodied practices help instructors provide feedback to students.
In addition to benefits for instructors, research has illuminated the advantages of embodied modes for L2 learners, including how they negotiate language-related episodes (LREs) — instances when students question their own or a peer’s language use (Swain and Lapkin, 1998). Although this field of research has demonstrated how embodied modes can portray understanding or miscommunication (Canals, 2021), by centering language-related episodes, these studies still represent verbal language as the ultimate means of communication. The focus on communicative breakdowns positions gestures as crutches that L2 learners use to communicate with language. Additionally, this research consists primarily of case studies, meaning that little is known about how large groups of L2 learners leverage their bodies while communicating in their L2.
Moreover, few studies have explicitly examined L2 embodiment as it relates to ICC. Although not directly focused on ICC, Salvato (2020) highlighted the intersectionality of L2 embodiment and cultural context by examining whether geographic location (Italy vs. Canada) played a role in gesture use and perception in L2 Italian courses. Findings illustrated that L2 students in Italy used more gestures when interacting with others, while in Canada, students used gestures more when thinking. This study paves the way for additional work on embodied modes in relation to culture, specifically in terms of how gestures are used and perceived by students within the vehicle of an L2 that is culturally situated within communities of speakers. Piazzoli (2016) further investigated L2 Italian teachers employing Total Physical Response (Asher, 1969) and drama pedagogy, an embodied approach, in a skit intended to encourage them to enact a day in the life of a resident of Venice. The semi-structured skit was paired with a multimodal brainstorming activity, visual glossaries, a detailed virtual map of Venice, a Total Physical Response activity to rehearse vocabulary, and choreography for an ‘acqua alta evacuation’ routine. Piazzoli (2016: 101) found that embodied drama helped students “experience” Italian culture in Venice, although no embodied modes were explicitly noted in the data analysis or results.
Apart from these studies, little is known about how L2 students’ embodiment may accompany ICC development. By investigating the juncture of embodiment and ICC, we may explore how students leverage embodied modes when navigating discussions about cultural products (e.g., videos, texts, and other media) and experiences in the L2. Thus, this study is guided by the following research question: How, if at all, do students’ embodied modes accompany or illustrate components of ICC portrayed through asynchronous video reflections in the L2?
Methodology
Setting and participants
This study was conducted from Spring 2018 to Summer 2019 in the French department of a large, public university in the Southwestern United States. 73 undergraduate students participated; 54 were enrolled only in fourth-semester French and 19 were enrolled first in fourth-semester French and then in the university’s 6-week summer study abroad program in Paris, where they took fifth- and sixth-semester French courses. These courses were included in the study for their use of multiliteracies curricula and video discussions, which were not used in the institution’s other courses.
The participants ranged in age from 17 to 44 years (M = 21.1). 63.0% self-identified as female, 26.0% as male, and 11.0% as non-binary. 48.0% identified as white, 16.4% as multiracial, 12.3% as Hispanic/LatinX, 12.3% as Asian, and 11.0% as black. 27.4% had declared a French major or minor; 72.6% had not. 80.8% reported speaking only English at home while 19.2% spoke another language instead of or in addition to English including Spanish, Korean, Mandarin, Yoruba, Lingala, Arabic, Haitian Creole, and Portuguese.
Data collection
Participants were recruited via classroom visits, emails, and announcements. They were offered extra credit to incentivize participation; in accordance with institutional review board (IRB) protocol, alternative extra credit was available for those electing not to participate.
Video reflection prompts by course and semester.
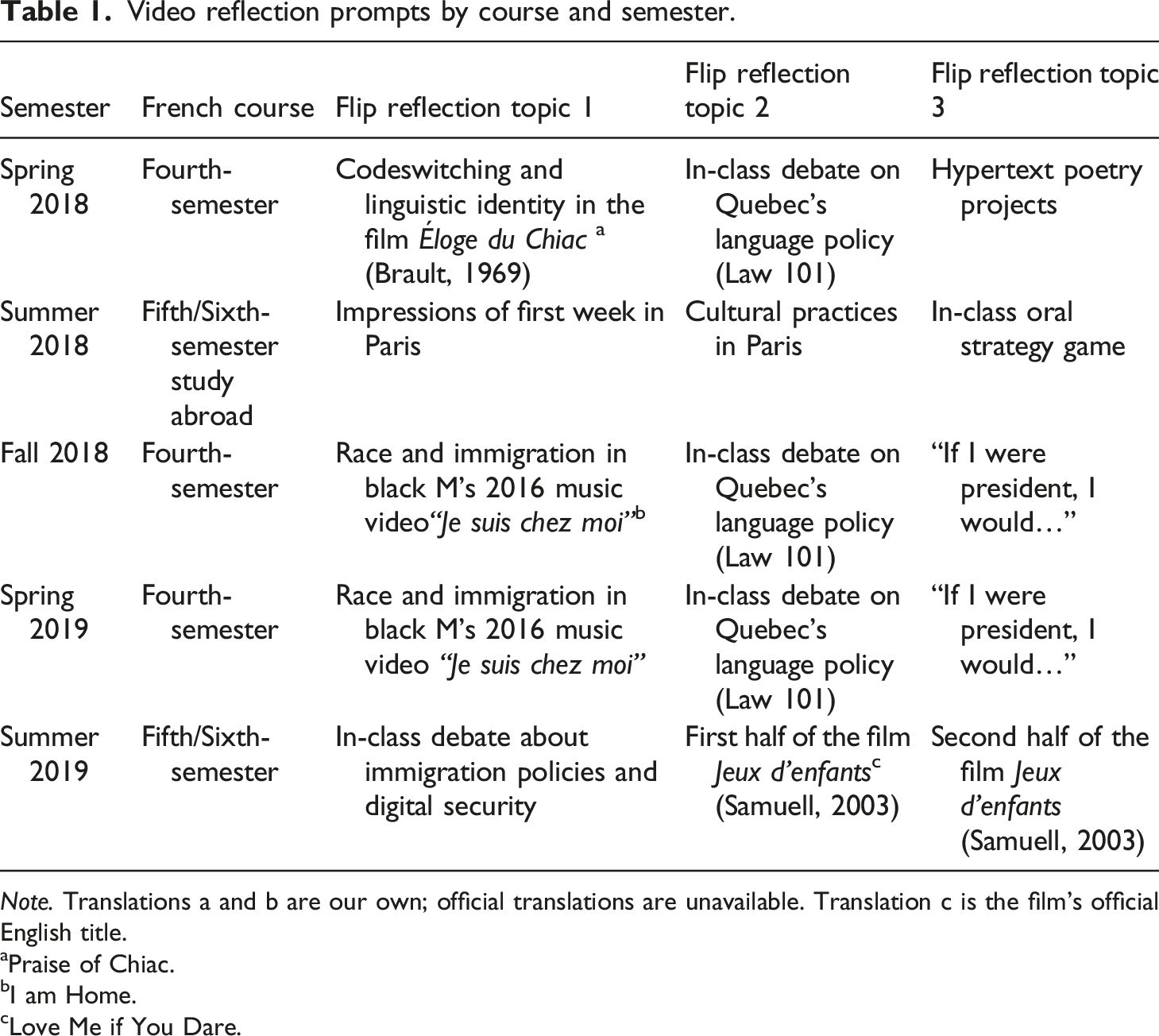
Note. Translations a and b are our own; official translations are unavailable. Translation c is the film’s official English title.
aPraise of Chiac.
bI am Home.
cLove Me if You Dare.
Participants and videos by course and semester.

Positionality
Both authors taught and designed the multiliteracies-based curriculum used in these courses, holding hybrid roles as curriculum designers, teachers, and researchers. They mitigated potential bias by collecting more than one hundred videos, conducting rigorous qualitative coding, and engaging in blind cross-coding to ensure inter-rater reliability.
Data analysis
First, the 188 Flip video reflections were downloaded and participants were pseudonymed. To examine students’ embodied modes and demonstrations of ICC, data analysis was guided by multimodal transcription (Flewitt et al., 2014) followed by three rounds of qualitative thematic analysis (Clarke et al., 2015).
Multimodal transcription
Multimodal transcription (Flewitt et al., 2014) was blended with CA (Mondada, 2019) to make the video transcription process more empirical and multimodal than in previous studies of gesture, which have often used conversation or discourse analysis alone (Mondada, 2016). The 188 Flip videos were transcribed in Google Sheets using one column each for a screenshot of the relevant image, timestamp, French transcription, and embodied modes. Transcripts were divided into rows based on verbal and embodied utterances, with divisions occurring when participants paused their speaking and embodied movements (Figure 2). Adapted from CA conventions (Goodwin, 1986; ten Have, 2007), double parentheses in transcriptions temporally and spatially indicated where embodied modes occurred in an utterance. Underlines indicated original emphasis, double backslashes indicated false starts or restarts, commas indicated rising intonation, and periods indicated falling intonation. “R” and “L” indicated right and left directions from the participant's perspective. Capital letters indicated non-standard pronunciations. Multimodal transcription and open coding.
Thematic analysis
Our rigorous qualitative coding was informed by thematic analysis, which aims to uncover and interpret key patterns in the data (Clarke et al., 2015) regarding how, if at all, gestures interacted with students’ ICC. We conducted three rounds of analysis to establish, revise, and consolidate codes and themes. The key unit of analysis was each row of the transcript (image, transcription, and gestures); gestures and their accompanying image and transcription were coded thematically if they related to the demonstration of ICC. Because we did not have interview data to further probe participants’ cultural competencies and interpretations, it was important that we examine a large quantity of videos (N = 188) and conduct inter-rater reliability calculations to interpret the demonstrations of ICC that we perceived and ensure the trustworthiness of our analysis (Lincoln and Guba, 1985).
First round
A starting code list was created based on Deardorff’s (2009) process model of ICC using the four inputs — attitudes, knowledge, comprehension, and skills — as parent codes and subcategories as child codes. Each author applied these codes to individually analyze the same 18.1% of the data (34 videos). Since imposing a pre-existing code set on the data can be problematic, each author also noted additional codes that recurred in the data and were not encapsulated by the initial categories. Both authors made a preliminary codebook before meeting to condense, expand, and refine the codes.
Second round
Next, each author independently re-coded the same 34 videos using the shared codebook (last column of Figure 2). We conducted rigorous inter-rater reliability calculations to ensure that the pre-existing codes that were applied were indeed present in the data. Inter-rater reliability was 91.2%; all discrepancies were discussed and resolved. The authors divided the remaining 154 videos and each coded half of the data using the revised codebook.
Third round
Coding process.

Note. Bolded codes are parent codes, followed by child codes.
Findings
Overview
Data analysis revealed that students’ embodied modes illustrated three elements of ICC development: communicative and analytical skills, intercultural knowledge, and intercultural attitudes. In this section, we briefly overview each manifestation of embodied modes.
In the 188 Flip videos, there were 1836 occurrences of embodied modes accompanying ICC. 65.04% of embodied modes co-occurred with the communicative and analytical skills of observing, analyzing/interpreting, evaluating, relating, questioning, listening, researching, and problematizing. Although separate in Deardorff’s framework (2006, 2009), analyzing and interpreting were difficult to distinguish because they often overlapped during the coding process; they were thus grouped together. Next, 24.18% of gestures demonstrated knowledge of Francophone cultures, sociolinguistics, politics, race 3 , class, gender, and/or religion. Similar to analyzing and interpreting, Deardorff’s categories of knowledge, comprehension, awareness, and self-awareness were difficult to consistently differentiate and were coded together. Lastly, attitudinal gestures comprised 8.77% of the corpus and illustrated students’ cultural openness, respect, tolerance of ambiguity, and counter-ICC attitudes.
Of the 1836 codes in the data, 330 comprised co-occurring codes when two or more codes occurred at once for the same embodied mode. For instance, if a participant raised their eyebrows both when problematizing one group or viewpoint and when conveying respect to another, the instance was coded once for ‘problematizing’ and once for ‘respect’, resulting in 1506 unique embodied modes in the Flip videos. We present examples of co-occurrences when unpacking each finding below. Equally important, specific gestures (i.e., nodding, headshaking, sweeping hand motions) were not correlated with any one specific ICC category. Rather, the same embodied mode could have different roles based on the combination of embodied and linguistic modes.
Embodying communicative and analytical skills
First, participants’ embodied modes and co-occurring verbalizations accompanied communicative and analytical skills associated with ICC. Five skills prevalent in the corpus of Flip videos matched those communicative and analytical skills identified by Deardorff (2009) — listening, observing, analyzing/interpreting, evaluating, and relating — whereas three skills — problematizing, questioning, and researching — were not mentioned by Deardorff (2009), but emerged from our data.
Illustrating observing, analyzing/interpreting, and evaluating with gesture
Observing, analyzing/interpreting, and evaluating were skills frequently associated with gestures and facial expressions in participants’ Flip videos. Observing (20.86% of all coded modes) occurred when embodied modes accompanied a participant’s general spoken observations about the course content. Analyzing/interpreting (12.91%) was coded when embodied modes co-occurred with linguistic attempts to make sense of the content, and evaluating (12.31%) when embodied modes occurred alongside verbal value judgments. These three skills thus appeared to represent a hierarchy of meaning-making from observing to analyzing to evaluating that closely parallels not only Deardorff’s framework (2009), but also Bloom’s taxonomy of learning, which involves “understanding” before then “analyzing” and “evaluating” learning materials (Anderson et al., 2001).
Common gestures during observing, analyzing, and evaluating included headshaking or eyebrow-raising. For example, Vakul said that he would not want to be president even if he were qualified. He raised his eyebrows when observing that political experience is important for a president, which he set apart from an evaluation about the toxicity of the office with a headshake and downward gaze (Figure 3). Through these embodied modes, Vakul added importance and order to his statements about the U.S. political system. Vakul demonstrates observing and evaluating. Note. To view the video, click here: https://www.youtube.com/watch?v=x7wcM9cxCK8.
Embodied listening and relating
Additionally, gestures appeared alongside the skills of listening (2.89% of all coded modes) and relating (8.22%). Listening was coded when a participant used embodied modes and speech to describe listening to a peer and relating when students connected the course material to personal experiences.
For example, Kimberly leaned forward and raised her eyebrows while reflecting on the potential of digital facial recognition technology to perpetuate xenophobia, emphasizing her personal experiences with discrimination as the daughter of a Lebanese immigrant (Excerpt 1). [In my life, since my dad is from Lebanon, um, I always see the prejudice against Muslims and, and I see the [unintelligible audio] in public. Um, I am still afraid that migrants could be targeted, um, by the government and could lose their freedom to have a private life.] ∼Kimberly, reflection on in-class debate
Embodiment representing problematizing, questioning, and researching
Finally, participants used embodied modes while problematizing (2.29% of all coded modes), questioning (3.00%), and researching (2.56%). When problematizing, participants’ gestures and speech often corresponded with their identification of problematic, or unjust, viewpoints or approaches. Students also used embodied modes when questioning to convey uncertainty about their own stance, and when researching information about culturally-specific products, practices, or situations.
Problematizing and questioning often involved embodied modes like squinting, shoulder shrugging, and diverting gaze. Karlie, for instance, looked up and down as she reflected on Black M’s music video “Je suis chez moi”, analyzing its implications for immigrants in France (Figure 4). While repeatedly shifting her gaze, she illustrated her discomfort with the racial discrimination in the video. Similar gestures also appeared as participants questioned their own viewpoints. For example, Raina looked left, gestured with her hand, and nodded while mentioning that she was unsure whether she would speak Chiac if she lived in New Brunswick, Canada, where this variety is spoken (Figure 5). These embodied modes co-occurred with her linguistic expression of uncertainty. Karlie problematizes a French music video. Note. To view the video, click here: https://www.youtube.com/watch?v=OCYMc3FhVKU. Raina’s hand gestures accompany her processes of exploring and questioning viewpoints.

Finally, participants’ embodied modes accompanied descriptions of their research processes while investigating concepts tied to class content. For example, Maya looked up and raised her eyebrows as she discussed looking online for information on Amnesty International while preparing for the in-class debate (Figure 6). While gesturing, she noted similarities between immigration in her hometown and Europe based on her research. Maya Researches Amnesty International. Note. To view the video, click here: https://www.youtube.com/watch?v=CODiai7VpKs
These findings corroborate Velasco (2017) and Cai and Lv (2019), who hold that ICC can be exhibited in pedagogical contexts, and findings by Lin and Wang (2018) that multimodal course materials – such as the Flip videos in this study – are often associated with the demonstration of ICC skills. Similarly, the embodied modes magnified students’ ICC skills and their multimodal conveyal of these skills to their peer audience. This suggests that multimodal composing assignments such as those used in this study can be harnessed to magnify and physically capture students’ burgeoning ICC skills, which then can be viewed by their classmates, who can apply the various levels of Bloom’s taxonomy of learning (specifically analyzing and evaluating) to interpret the culturally-situated meanings of embodied modes used by their peers (Anderson et al., 2001). In this way, the richness of embodied modes in multimodal assignments can help scaffold both linguistic and intercultural learning, helping students progress from individual demonstration of ICC skills to collective reflective analysis and discussion. Students could also be asked to re-watch their own recordings and reflections to critically examine their own perspectives and viewpoints, as well as how these are conveyed through their gestures and facial expressions. They could then consider how these embodied and verbal modes may be perceived by other audiences.
Gestures and cultural knowledge
Embodied modes also accompanied participants’ discussions of their cultural and sociolinguistic knowledge.
Demonstrating cultural knowledge with embodiment
Students leveraged embodied modes such as eyebrow-raising, nodding, and hand gestures when demonstrating general cultural knowledge (8.33% of all coded modes), knowledge of political structures (2.40%), race (2.07%), social class (1.03%), gender (0.38%), and religion (0.11%). The knowledge types associated with these embodied modes varied according to the Flip prompts. For example, in considering Black M’s music video “Je suis chez moi”, on race and immigration, Alicia interpreted the lyrics, “Je suis noir, je suis beur
4
, je suis jaune5, je suis blanc”/[I am black, I am North-African, I am Asian, I am white] and “Je suis chez moi”/[I am at home] as a response to Marine Le Pen, a French politician with anti-immigration views (Excerpt 2). Alicia recited the lyrics while nodding her head rhythmically, then shifted her gaze and discussed Le Pen’s politics and their implications for people of color in France. Ultimately, Alicia’s embodied modes accompanied her efforts to scaffold multiple knowledges regarding race and politics, linking them together for herself and her peer audience. [Um, the song is against the policies of Marine Le Pen, and the song embraced [both] the French identity and other racial identities. Like the singer says, he is black, he is North African, he is white.] ∼Alicia, Reflection on Black M’s “Je suis chez moi” Music Video
Similarly, the prompt content influenced the cultural knowledge types associated with embodied modes in Brooklynn’s reflection on the in-class debate about digital facial recognition (Figure 7). In discussing contexts that use digital facial recognition technology, she waved her hand across the screen to visually locate the Uyghur region of China, explaining that this area is predominantly Muslim and suggesting the potential of facial recognition technologies to perpetuate discrimination. Thus, Brooklynn’s embodied modes allowed her to demonstrate and visualize her cultural knowledge of religion and connect it to the class debate regarding the possible implementation of digital facial recognition in Paris metros. Instructors can thus encourage students to use their entire multimodal repertoire – including embodied modes – to communicate knowledge that may be quite linguistically complex. Classmates can also be encouraged to attune to their peers’ gestures and facial expressions in order to boost the overall amount of information they get out of the discussion. Brooklynn’s gestures localize her cultural knowledge.
Illustrating sociolinguistic knowledge
Next, sociolinguistic knowledge was also accompanied by embodied modes, notably in response to Flip prompts explicitly encouraging sociolinguistic reflection, such as varieties of French spoken in Canada or the evaluation of peers’ poem projects. Ethan, for instance, explained a wordplay in a classmate’s poem involving a lion and an iris, both of which historically appeared in the Canadian coat of arms, evoking power and nobility (Excerpt 3). Looking up and to the left, Ethan applied his sociolinguistic knowledge to the poem: [Um [classmate] talked about/about Canadian culture, and um, his military service and also he used wordplay with the lion and the iris, and it was interesting.] ∼Ethan, Reflection on Class Poem Project
Overall, students’ use of embodied modes to illustrate cultural and sociolinguistic knowledge supported Canals’ (2021) conclusion that gestures and facial expressions play a role in conveying cultural understanding and comprehension. Our findings build on these functions of embodied modes, suggesting that full communication of cultural knowledge is “a fundamentally multimodal process” (Van Compernolle and Smotrova, 2017: 195) dependent on many modes rather than verbal language alone. Therefore, it may be advantageous for teachers to consider the limitations of traditional (monomodal) assignments requiring the expression of complex sociocultural and cultural knowledge and opt for multimodal alternatives when communication of such knowledge is a key objective. In so doing, they may help encourage students to convey more elaborate and sophisticated thought processes than may have been possible through verbal language alone.
Portraying attitudes with gesture
Students’ embodied modes further demonstrated attitudes of respect (4.74% of all coded modes), openness (2.29%), general affect (2.01%), and counter-ICC (1.69%). Affect and counter-ICC emerged as novel categories not originally included by Deardorff (2009). There was only one occurrence of an embodied mode associated with Deardorff’s (2009) tolerance of ambiguity, indicating a lack of connection between embodied modes and tolerance of ambiguity in this corpus, which may be partly attributable to the academic nature of the Flip assignments, where students are traditionally expected to demonstrate knowledge, rather than uncertainty (Paesani et al., 2016).
Representing respect and offering openness
First, several participants expressed respect and openness with their bodies. Students demonstrated these attitudes with sweeping gestures, throwing their hands sideways or waving their arms when recognizing the validity of other cultural perspectives. As authors, we interpreted these gestures by drawing on our positionality as teacher-researchers and our personal knowledge of our students as individuals, as well as the content of the speech that accompanied students’ embodied modes. Many students, such as Isabella, accompanied spoken respectful attitudes with embodied modes in their reflections on code-switching in Chiac (Figure 8). Isabella’s hand gestures accompany respectful language attitudes.
Isabella performed respect as she embodied the “switch” in code-switching by snaking her hand from one side of her chest to the other and holding up two fingers to indicate a second language. Her emphatic finger flexing while discussing bilinguals, a group with which she later identified (as a Spanish-English bilingual), indicated her simultaneous belonging to and respect for bilinguals. This unique combination of verbal and embodied modes illustrates the importance of encouraging students to interpret gestures and facial expressions in juxtaposition with all other modes present, since the combination of modes produces a meaning that is beyond the sum of its parts (Jewitt, 2009). Students could practice such analyses with videos and films, in addition to interpersonal communicative contexts.
Actualizing affect
Although not mentioned by Deardorff (2006, 2009), affect emerged as an ensemble of attitudes that participants expressed by looking up, nodding, moving eyebrows, and headshaking. In the data, affect involved attitudes and emotions not captured by Deardorff’s categories. For instance, Raina gestured while communicating her “strong” emotional connection with her classmate’s poem (Excerpt 4). [Um, I like poetry that is um sad or really dark. Um, I like poetry. I like poetry with feelings, the/bodies, um the head, everything that/that is very strong. Very strong. ] ∼Raina, Reflection on Class Poem Project
As a multilingual user of English, Spanish, French, and Russian communicating with an audience of several classmates who used Spanish daily in the U.S. Southwest, Raina translanguaged (Canagarajah, 2011), using “oscure” like the Spanish word oscuro (dark) and shrugged, perhaps conveying that she had approximated the form for her intended meaning. Raina’s headshaking and nodding underlined the importance that she gave to finding emotion and “body” in a poem, as well as the emotions that such poems evoked in her.
Countering ICC
An additional attitude unidentified by Deardorff (2009) comprised “counter-ICC,” or the manifestation of counterproductive attitudes towards ICC. Although a small percentage of the corpus (1.69%), we deem it critical to unpack situations in which students overtly expressed counter-ICC attitudes, including negative preferences for diversity, inclusion, and belonging-related themes that had been introduced in class (i.e., translanguaging).
For example, Ethan squinted while stating that he would not speak Chiac because he expressed wanting to avoid “language mixing” (Figure 9). He raised his eyebrows and acknowledged that “mixing languages” may sometimes be useful, before squinting and shaking his head to conclude that he preferred not to mix languages. Although he recognized translanguaging’s utility in his speech, his embodied modes emphasized that he did not want to use translanguaging in his own life. Ethan demonstrates counter ICC attitudes on translanguaging. Note. To view the video, click here: https://www.youtube.com/watch?v=1ehHTKpAiQs.
Despite a variety of course materials on translanguaging, Ethan used his body to convey doubt about minoritized language varieties, questioning the notion that the bilingual is “an integrated whole, a unique and specific speaker-hearer, and not the sum of two monolinguals” (Grosjean, 1989: 6). While stating a preference for using one language at a time instead of language “mixing” in French, he ironically leveraged his full semiotic repertoire to make meaning using the English word “fluent.” These practices demonstrated how translanguaging can accompany other multimodal elements in asynchronous video communication, as has been found for synchronous L2 video communication (Canals, 2021). However, while Canals characterized “translanguaging” and “multimodality” as distinct, we assert that the two practices are inseparable within an individual’s semiotic repertoire (Brown and Allmond, 2021; Wei, 2018), as multilingual learners “constantly translanguage and use their full linguistic repertoires to make meaning in the world” (Pacheco et al., 2019: 2).
Overall, students used their bodies to illustrate openness, respect, general affect, and counter-ICC, often while translanguaging and/or expressing sociopolitical attitudes.
Implications and conclusions
This study addressed the lack of research on embodied modes in multimodal and ICC research, examining how students illustrated ICC skills, knowledge, comprehension, and attitudes through embodiment in asynchronous L2 video reflections. Pedagogically, our findings echo the importance of process over product in multimodality (Jewitt and Kress, 2010) and ICC (Deardorff, 2006; 2009) in that we treat how students make meaning in the moment rather than simply the verbal content of their videos. To help students better manifest their ICC development, instructors can explicitly encourage them to use their bodies, translanguaging, and other modes to reach their audience(s) (Canagarajah, 2018; Canals, 2021). Simultaneously, instructors should provide examples to raise learners’ awareness of their own context-dependent meanings behind gestures and facial expressions. To address moments where students’ embodied modes demonstrate resistance to themes related to ICC – as Ethan did in this study –, educators can foster conversations and analyze potentially harmful meanings. Like Kimura and Kazik (2017), we call for educators to integrate gestures more consciously as communicative assets; however, we also propose a shift to centering the ways in which students gesture while communicating their thoughts on sociocultural topics such as those addressed by the various assignments students completed for this study.
Additionally, this study advanced L2 embodiment and ICC research beyond case studies or focus episodes (Belhiah, 2013; Lee et al., 2019; Matsumoto and Dobs, 2017; Van Compernolle and Smotrova, 2017) to analyze patterns across a large group of students. A fusion of multimodal transcription (Flewitt et al., 2014) and conversation analysis (CA) (Goodwin, 1986; ten Have, 2007) facilitated the creation of a corpus of embodied and linguistic modes and visualizations through dynamic Powtoons rather than static text or images alone. By integrating multimodal techniques, L2 embodiment research can highlight the process-oriented nature of multimodality and push for dynamic data representations in publications.
There are several limitations of the current study. Notably, IRB protocol for this institution did not allow showing student faces in data representations, meaning that facial expressions were portrayed through CA transcriptions (Mondada, 2019) and Powtoons. Although Powtoon’s affordances are growing, there are still only so many gestures available in Powtoon’s current (2023) version and it is not yet possible to completely synchronize the audio and gestures. We are confident that revised versions of technology will continue to enhance CA analysis especially when including data with embodied modes. Additionally, this study only showed associations, or relationships, between embodied modes and ICC; it does not claim causality. We acknowledge the critiques raised due to the existence of a myriad of ICC models and that culture can not be understood as a given without investigating the context at hand. For this reason, we call for further research on how different ICC models can handle the analysis of embodied modes, as well as for how embodied ICC research can incorporate more critical stances vis-à-vis the definition, discussion, and assessment of intercultural competencies. Further, it is important to emphasize that we did not collect perspective data in the form of interviewing participants. Our analyses represent interpretation from the audience perspective, which is inherently interpretive.
Future studies should compare students’ embodied modes across online synchronous, asynchronous, and face-to-face contexts to assess potential differences in ICC demonstration. Exploring how L2 students use their bodies when discussing cultural topics (e.g., immigration, translanguaging, and facial recognition as presented in this study) may also contribute to the growing field of virtual reality and language learning (Legault et al., 2019). Lastly, research is needed to understand which assignments and topics may promote the embodied manifestation of ICC more effectively than others.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.