
Abstract
Background
Multiple imputation is often used to reduce bias and gain efficiency when there is missing data. The most appropriate imputation method depends on the model the analyst is interested in fitting. We consolidate and compare the performance and ease of use for several commonly implemented imputation approaches.
Methods
Using 1000 simulations, each with 10,000 observations, under six data-generating mechanisms (DGM), we investigate the performance of four methods: (i) ’passive imputation’, (ii) ’just another variable’ (JAV), (iii) ’stratify-impute-append’ (SIA), and (iv) ’substantive model compatible fully conditional specification’ (SMCFCS). The application of each method is shown in an empirical example using England-based cancer registry data.
Results
SMCFCS and SIA showed the least biased estimate of the coefficients for the fully, and partially, observed variable and the interaction term. SMCFCS and SIA showed good coverage and low relative error for all DGMs. SMCFCS had a large bias when there was a low prevalence of the fully observed variable in the interaction. SIA performed poorly when the fully observed variable in the interaction had a continuous underlying form.
Conclusion
SMCFCS and SIA give consistent estimation and either can be used in most analyses. SMCFCS performed better than SIA when the fully observed variable in the interaction had an underlying continuous form. Researchers should be cautious when using SMCFCS when there is a low prevalence of the fully observed variable in the interaction.
Keywords
Introduction
Missing data is often a problem in medical research because it can cause biased and inefficient inference of parameter estimates when missing data are improperly handled, including when they are ignored (i.e., a complete case analysis), leading to reporting of incorrect conclusions. The validity of inference from incomplete data depends on the mechanism driving missingness; when used properly and assuming the correct missingness mechanism, multiple imputation is known to reduce bias and improve efficiency and is a common approach for handling missing data.1,2
Several approaches exist for performing multiple imputation when modelling a continuous, binary, or time-to-event outcome along with ways of incorporating non-linear and time-varying effects or effect modification. 2 Various studies have explored scenarios that involve partially observed outcomes, and/or covariates, and interactions between partially observed covariates.3,4 Commonly used imputation methods are passive imputation, just another variable (JAV), stratify-impute-append (SIA), and substantive model compatible fully conditional specification (SMCFCS). These approaches can be used in differing settings, with SMCFCS the most flexible of the approaches but, to our knowledge, there is no consolidated comparison of the performance of the approaches and their ease of implementation.
To compare the various imputation approaches, we first introduce a motivating example. Medical research often focuses on regressing a binary outcome Y on several covariates, one of which can be fully observed (henceforth referred as Z) or partially observed (X). Suppose one is constructing a logistic regression model, which is often built with an interaction XZ. For example, a model built to estimate the odds of death (Y) amongst a cohort of cancer patients might include an interaction between the cancer diagnostic stage (X) and a patient’s comorbidity status (Z). The model assumes the effect of comorbidity on mortality varies at different stages of cancer. In population-based cancer data sets, cancer diagnostic stage (X) is often poorly recorded, leading to studies requiring a suitable approach for multiple imputation. Suppose data were observed on a sample of individuals for a binary outcome (Y), an exposure (X), and an additional covariate (Z). Suppose also that the data in X was not fully observed (i.e., there is some missing data for some individuals). To ascertain the association between Y and X, adjusted for Z, one could perform a logistic regression analysis on only those individuals who have a complete (fully observed) set of X (i.e., complete case analysis). Assuming the missingness mechanism did not involve the outcome, e.g. if the data were missing completely at random, these results would not be biased but would be potentially inefficient. If the data were missing at random given the outcome, the complete case analysis would be biased, and inefficient, compared to results after performing multiple imputation.
In context of the motivating example, the simplest possible method is to passively impute the component of the interaction separately; this is known as passive imputation. Von Hippel et al (2009) showed that passive imputation will, in general, lead to bias and recommended another approach called ‘transform then impute’ (i.e., JAV), which considers the interaction as an independent variable in the imputation model. 3 Seaman et al (2014) demonstrated that unless JAV is used in special cases (i.e., for linear regression and where missing data are assumed missing completely at random) it can also lead to biased inference. 4 Seaman et al further showed that JAV will lead to biases in logistic regression models when imputing a partially observed variable that has a non-linear (e.g., quadratic) effect. However, while results are expected to be similar, it is not known how passive or JAV imputation approaches perform for logistic regression models containing an interaction with a partially observed variable (i.e., XZ). 4 Von Hippel et al also proposed another approach to impute X: ’stratify, then impute’ (we refer to this as Stratify-Impute-Append [SIA]). SIA imputes X within strata (i.e., Z = 1 and Z = 0) of the fully observed variable in the interaction. Using the example before, this is to impute the partially observed cancer diagnostic stage variable within strata of the fully observed binary comorbidity covariate Z. More recently, Bartlett et al (2014) developed an approach to perform multiple imputation by fully conditional specification (FCS) where the substantive model is a linear, logistic, or time-to-event model. 5 This approach accommodates complex terms in the substantive model (e.g., including interaction terms) whereby making the imputation model compatible with the substantive model: thus termed substantive model compatible fully conditional specification (SMCFCS).
In this article, we aim to consolidate and compare the commonly used imputation approaches for different model specifications. In the Methods section we formally describe the various imputation approaches, specify the simulations, and present results of the performance of the methods. Then we describe an empirical example using England-based cancer registry data of patients diagnosed with diffuse large B-cell lymphoma, we illustrate the application of each imputation method for this real-world setting and present the results from each imputation approach. Lastly, we discuss the performance and applicability of each imputation method.
Methods
Data-generating mechanisms
Let Y
i
, X
i
and
Let Z1 represent treatment (1 = treated, 0 = untreated), Z2 represents age (centred on the mean and rescaled by a factor of 10), Z3 represents sex (1 = female, 0 = male), Z4 is a unit increase in deprivation level (higher is more deprived), Z5 represents comorbidity (1 = comorbidity, 0 = no comorbidity), and X1 represents the cancer diagnostic stage (1 = late stage, 0 = early stage). These variables were simulated as Z1 ∼ Binomial(0.3), Z2 ∼ N(70, 10), Z3 ∼ Binomial(0.5), Z4 ∼ Beta(1, 1.2), Z5 ∼ Binomial(0.3), and X1 ∼ Binomial(0.4). The outcome Y was specified to mimick values estimated from real data and generated according to the following logistic regression model:
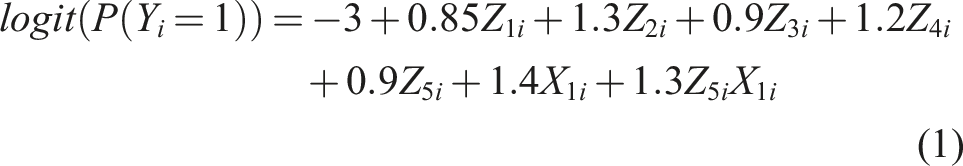
Missingness was imposed on X1 using a missing at random (MAR) missing data mechanism. The probability of observing X1 (i.e., R
i
= 1) was dependent on the variables in the substantive model (including the outcome) with parameters defined as:
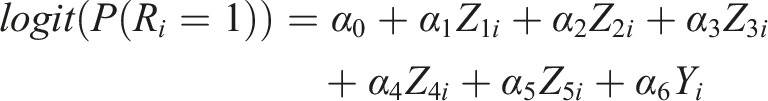
where each α k (k = 1, …, 6) was set to 1. The intercept (α0) was set to make the probability of observing X1 equal to 0.8 (i.e., 20% missing data in diagnostic stage).
Specifications of each data-generating mechanism.
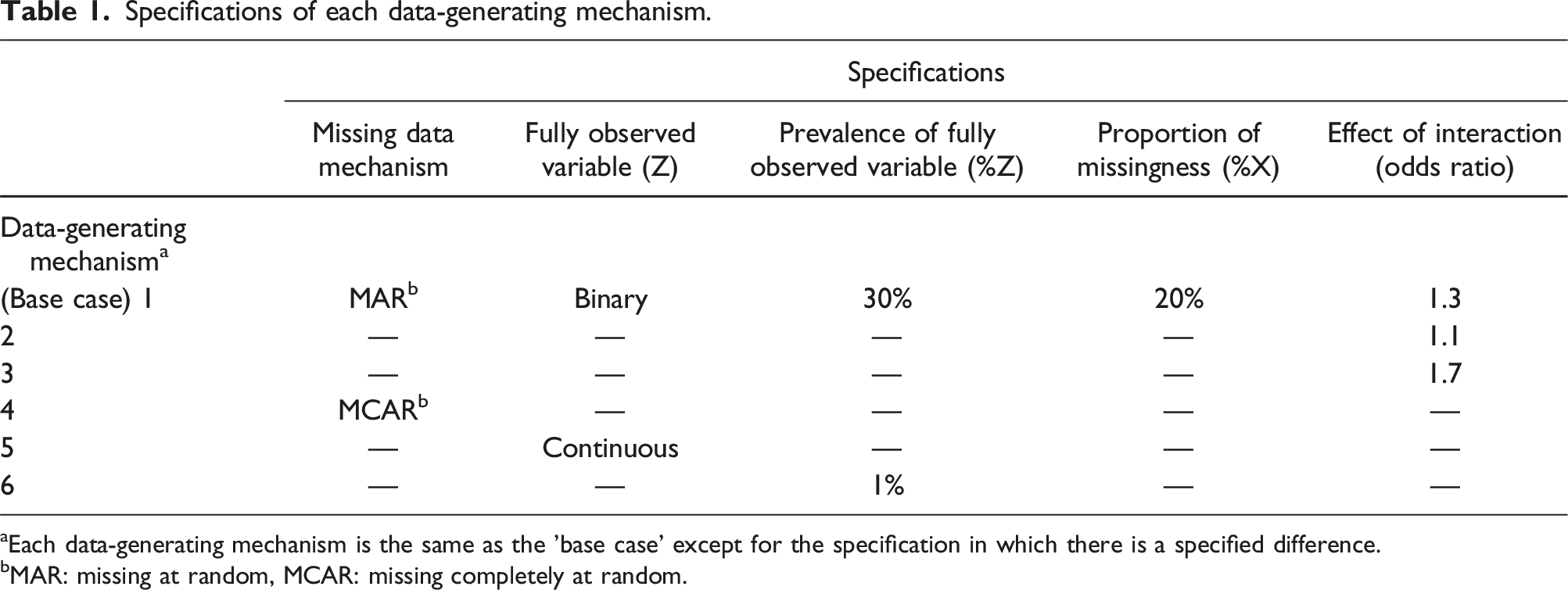
aEach data-generating mechanism is the same as the ’base case’ except for the specification in which there is a specified difference.
bMAR: missing at random, MCAR: missing completely at random.
We simulated 10,000 observations (n
obs
) containing data based on distributions found within real-world settings of cancer registry data on patients with diffuse large B-cell lymphoma in England.6–8 We chose a large enough sample of repetitions (n
sims
= 1000) such that we obtained a small enough Monte Carlo standard error without unfeasible computational time. The formula for the Monte-Carlo confidence interval around the mean estimate is:
9
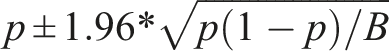
If we substitute p with the nominal coverage probability (i.e., 0.95) and B with the number of simulations (n sim = 1, 000), the estimated coverage (see Section 2.3) should fall between 93.6% and 96.4% (i.e., approximately 19 times out of 20).
The estimands are the exponential of the fixed effect parameter estimates (i.e., odds ratios) of the substantive logistic regression model (equation (1)) for (i) the fully observed variable (Z5), (ii) the partially observed variable (X1), and (iii) the interaction term (Z5X1).
Imputation approaches
For each simulated data set, and for each data-generating mechanism (DGM), we performed multiple imputation in the following manner: passive imputation, JAV, SIA, and finally SMC-FCS. We first briefly describe each approach.
In passive imputation the imputation model is specified by the distribution of X given Y and Z. Missing values in X are imputed from this distribution and the values for the interaction XZ are then calculated. Passive imputation ensures that the imputed values of XZ conform to the relationship between X and Z (i.e., that XZ = X × Z). On the other hand, JAV imputation does not ensure this relationship holds. JAV imputation ignores the relationship X and Z and imputes XZ as just another variable. This approach imputes missing values assuming that Y, X, Z, and XZ are separate variables. Therefore, imputed values of XZ will not always be consistent with X × Z (i.e., for an individual with Z = 1, X might be imputed as 1, giving XZ = 1, but XZ might be imputed as 0).
As an alternative to handle the interaction term, one could use Stratify-Impute-Append (SIA) This approach imputes values of X within levels of the Z. Imputing separately in levels of Z allows associations between X and Y to differ according to the level of Z. The three approaches mentioned thus far either ignore the compatibility between the imputation model and the substantive model (i.e., passive and JAV) or aim to by-pass the interaction term (i.e., SIA). The last approach, substantive model compatible full conditional specification (SMCFCS) ensures X is imputed using an imputation model that is compatible with the substantive model. The compatibility is achievable through rejection sampling, which involves drawing values from a proposal density (i.e., a function of the missing values in X given the other variables) and accepting the draw if it satisfies certain conditions based on a ratio of a target density to the proposal density. The target density incorporates the parameters from the substantive model, allowing for compatibility with the imputation model.
For DGM 1-4, and DGM six (i.e., not including DGM 5), firstly, missing values of X were passively imputed and values for the interaction (XZ) were calculated from the combination of the imputed X values and the observed Z values. Secondly, we imputed missing XY values using the ’just another variable’ (JAV) approach, as proposed by von Hippel,. 3 Thirdly, we performed Stratify-Impute-Append (SIA) imputation by initially stratifying the data by the groups of the fully observed variable (Z) within the interaction (XZ). We then imputed missing values in X, separately, for each stratified data set, and calculated the values for interaction (XZ). The stratified data sets were then appended for calculation of the estimands. Fourthly, we used SMC-FCS to impute missing values in X and XZ.
For DGM 5, the fully observed variable (Z) in the interaction (XZ) was of a continuous form, and passive imputation, JAV, and SMC-FCS were performed as in DGM 1-3 (and DGM 6). However, for SIA, the continuous form of Z was categorised using quintiles (i.e., creating five groups of equal sizes). SIA imputation for X was carried out in 5 separate data sets (i.e., one data set for each of the five groups), which were then combined. The odds ratios (i.e., estimands) were calculated assuming a linear distribution (i.e., continuous form) across the levels of the categorical variable Z.
As a comparison, we also include a “null scenario” where the substantive model does not include an interaction term (i.e., where the effect of the interaction has an odds ratio of 1).
For each imputation method we impute 10 data sets with 10 iterations between imputations. Estimates and confidence intervals (CI) were calculated using Rubin’s rules.10,1 We used R software for all analyses. The Passive, JAV, and SIA imputation methods were performed using the mice 11 package and SMCFCS was performed using the smcfcs 5 package.
Performance measures
We assess the performance of each of the four imputation methods by comparing: (i) relative bias (i.e., the relative difference between the mean estimated coefficient, (ii) coverage (i.e., proportion of 95% confidence intervals that include the true coefficient) (iii) relative error is a comparison between the average model-based standard error (ModSE) and the empirical standard error (EmpSE),
12
and expresses how closely the model-based standard error approximates the empirical standard error (EmpSE):
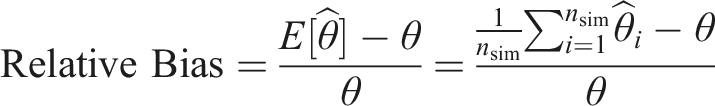
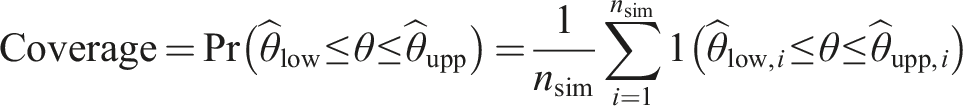
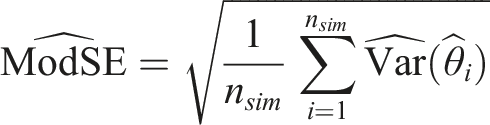
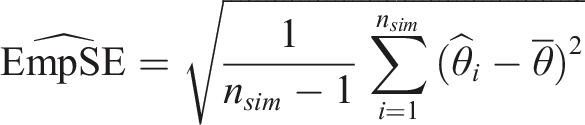
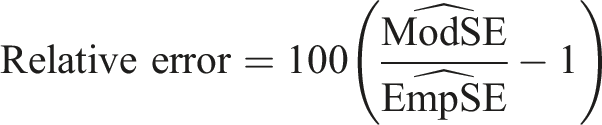
Simulation results
The results of the performance measures for each imputation approach are shown in the Figure 1 (and Appendix Table A1). Bias of each imputation method for each variable of interest across simulations (n = 1000) by data-generating mechanism.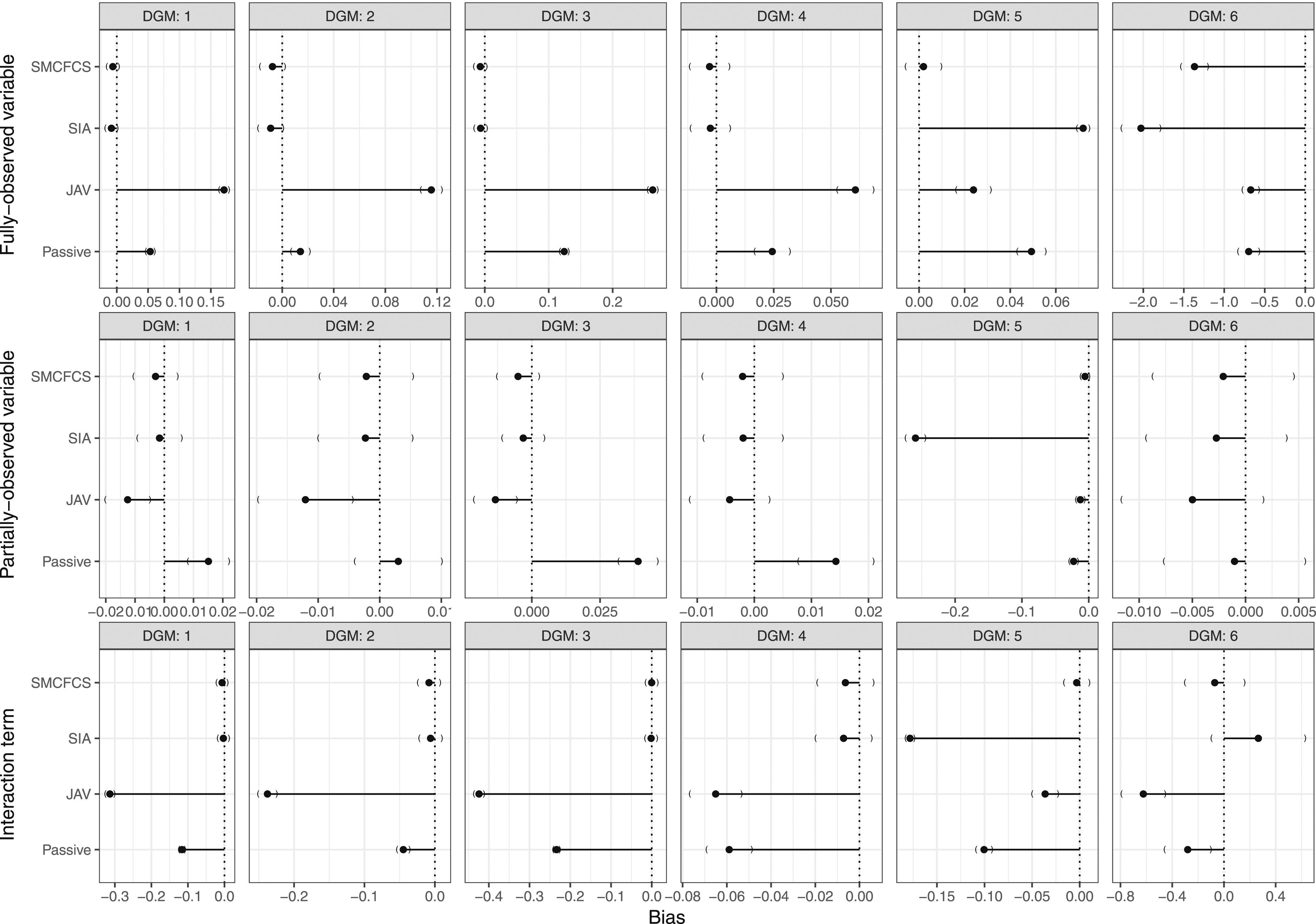
In the null scenario (i.e., no interaction), there was negligible bias, and optimal coverage, of the fully and partially observed variables for all imputation methods (Appendix Table A1). The relative error was similar across all four imputation methods for the fully observed variable but SMCFCS had the lowest relative error for the partially observed variable.
Bias (and relative bias)
Figure 1, row 1, shows the results of the bias for the coefficient of the fully observed variable for each imputation method. SIA and SMCFCS showed negligible bias for DGMs 1–5, but were the most biased for DGM 6. JAV consistently overestimated the effect of the fully observed variable in DGMs 1-4 but severely underestimated the effect in DGM 6.
Figure 1, row 2, shows bias for the coefficient of the partially observed variable for each imputation method. For all four imputation approaches, there was negligible bias, except for SIA, which severely underestimated the effect when the partially observed variable had an underlying continuous form (i.e., DGM 5). Passive imputation, was slightly biased in DGMs 1, 3, 4, and 5. JAV showed an underestimate of the partially observed variable in DGMs 1, 2, 3, and 4.
Figure 1, row 3, shows bias for the coefficient of the interaction for each imputation method, Appendix Table A1 shows the precise values. For DGMs 1-4, SIA and SMCFCS showed negligible bias, JAV was severely and the most biased, and passive imputation was biased for DGMs 1-4. In DGM 5 (continuous form of fully observed variable), SMCFCS showed negligible bias, SIA was the least accurate (most biased) followed by passive imputation, then JAV. In DGM 6, JAV had the largest bias, followed by passive imputation and SIA, and SMCFCS was the least biased.
Coverage
Figure 2 shows the results of the coverage of 95% confidence intervals for the interaction variable for each imputation method. Specific values are shown in Appendix Table A1. SMCFCS consistently showed an optimal coverage for DGMs 1-5, and was only affected by overcoverage for DGM 6. SIA had similar results, but for DG5, where it had severe undercoverage (35.6%). Coverage for the other two methods was instead inferior, with JAV undercovering in all scenarios but DGM six and passive imputation showing overcoverage for DGM two and 6, and undercoverage for DGM3. Coverage of 95% confidence intervals for the interaction term across simulations (n = 1000) by data-generating mechanism and for each imputation method.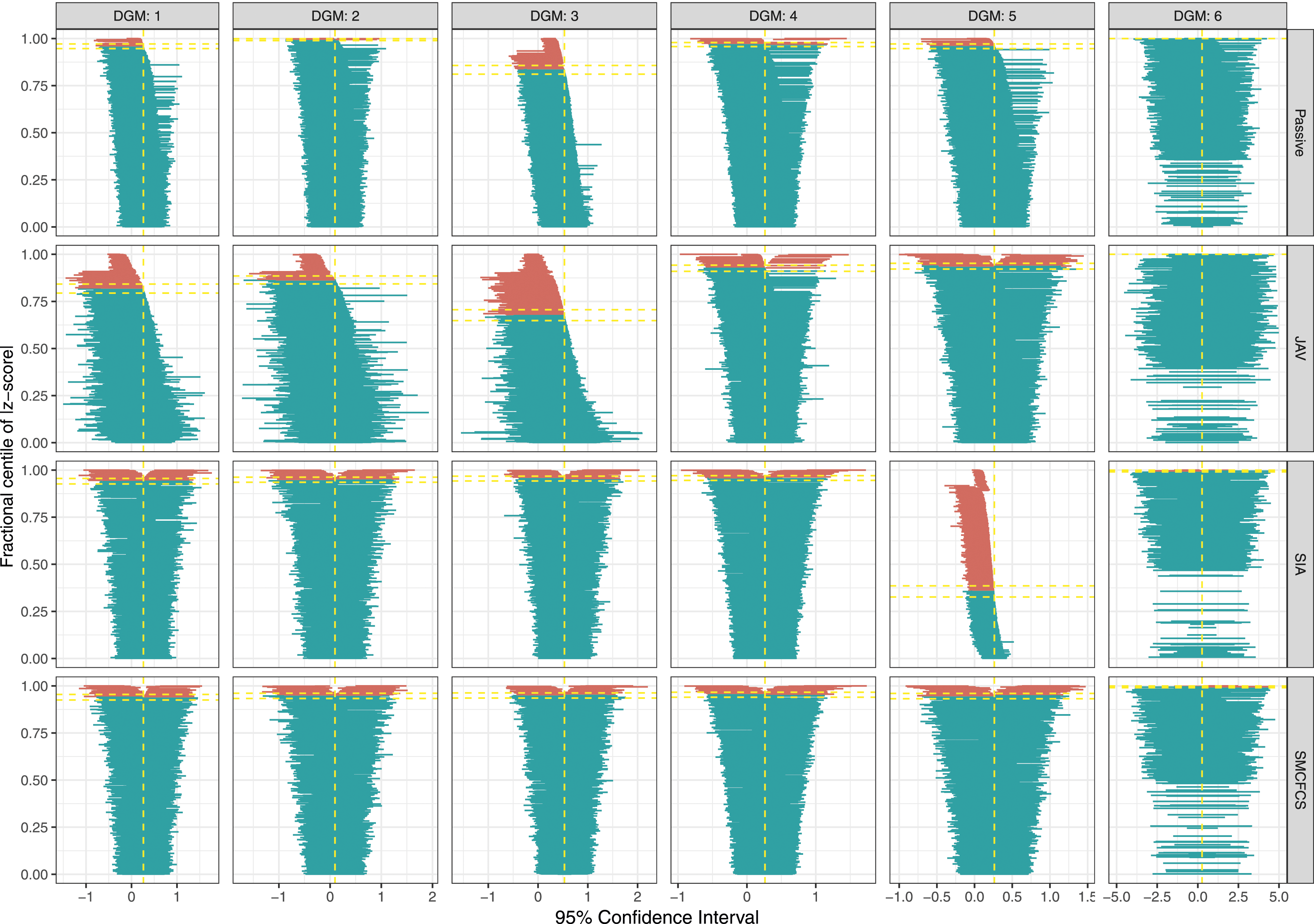
For the partially observed variable, all of the imputation approaches, except SIA in DGM 5, showed a similar coverage in the optimal range (93.6%–96.4%) (Figure 3). SIA had severe undercoverage (75.3%) when the fully observed variable had an underlying continuous form (i.e., DGM5). Coverage of 95% confidence intervals for the partially observed variable across simulations (n = 1000) by data-generating mechanism and for each imputation method.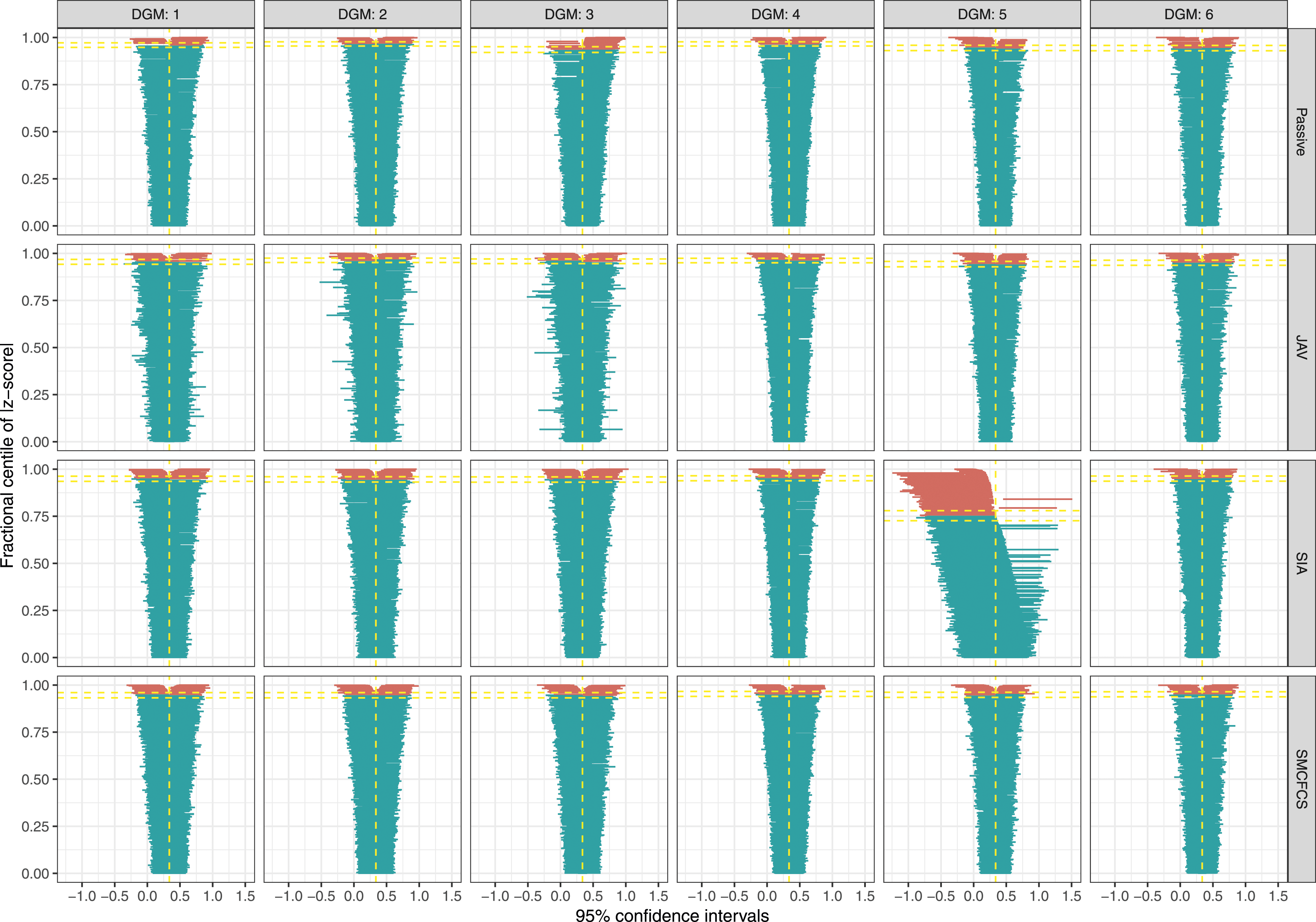
For the fully observed variable (Figure 4), results were broadly in line with those for the interaction parameter. Coverage of 95% confidence intervals for the fully observed variable across simulations (n = 1000) by data-generating mechanism and for each imputation method.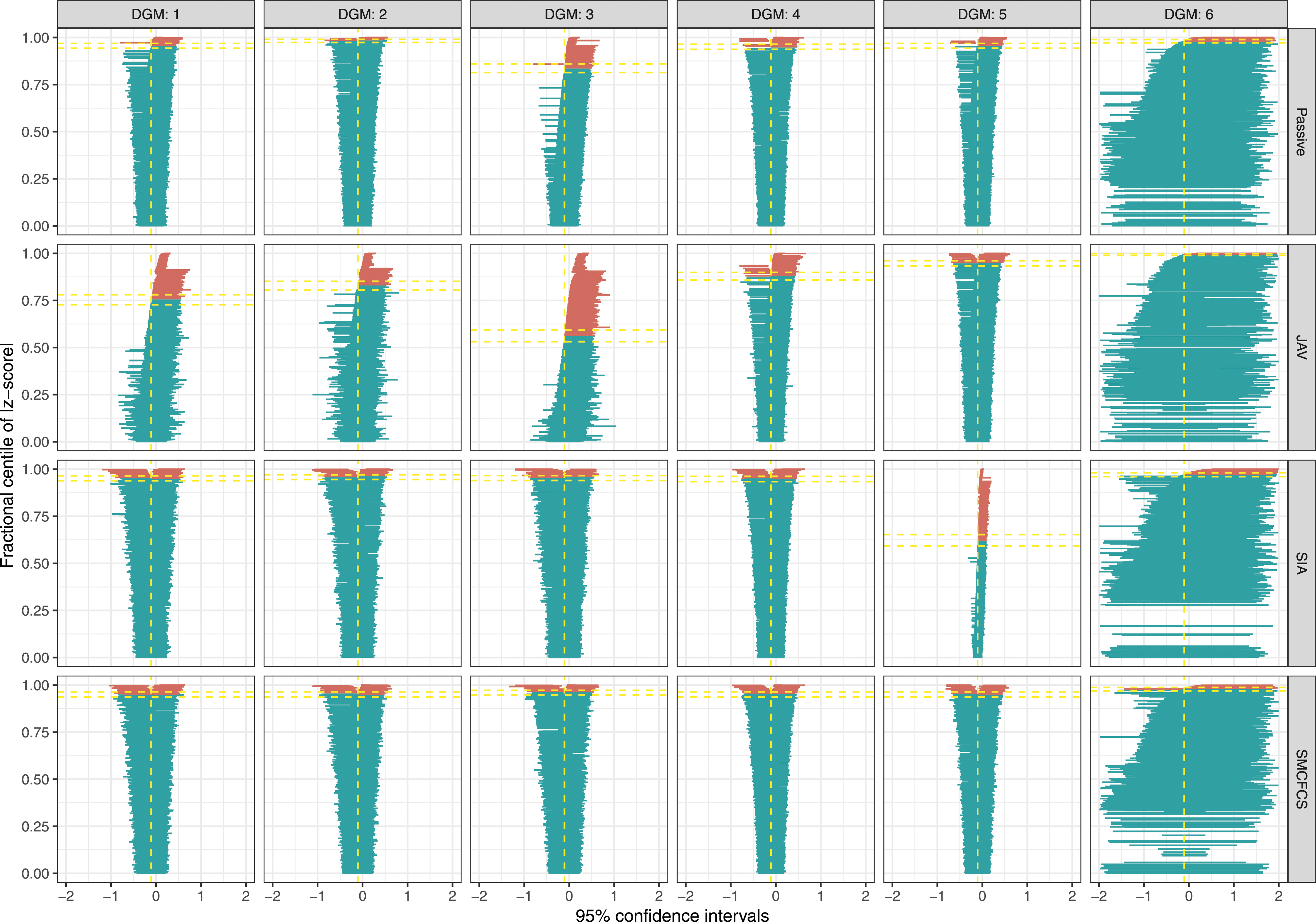
Relative error
For the fully observed variable (Figure 5, row 1), SMCFCS and SIA showed negligible relative error for DGMs 1-4, a larger relative error for DGM 5, and a very large relative error for DGM 6. JAV showed a large relative error for DGMs 1-3, a slightly larger ModSE for DGMs four and 5, and a very large relative error for DGM 6. Passive imputation showed a large relative error for all DGMs. Relative error for the variable of interest across simulations (n = 1000) by data-generating mechanism and for each imputation method.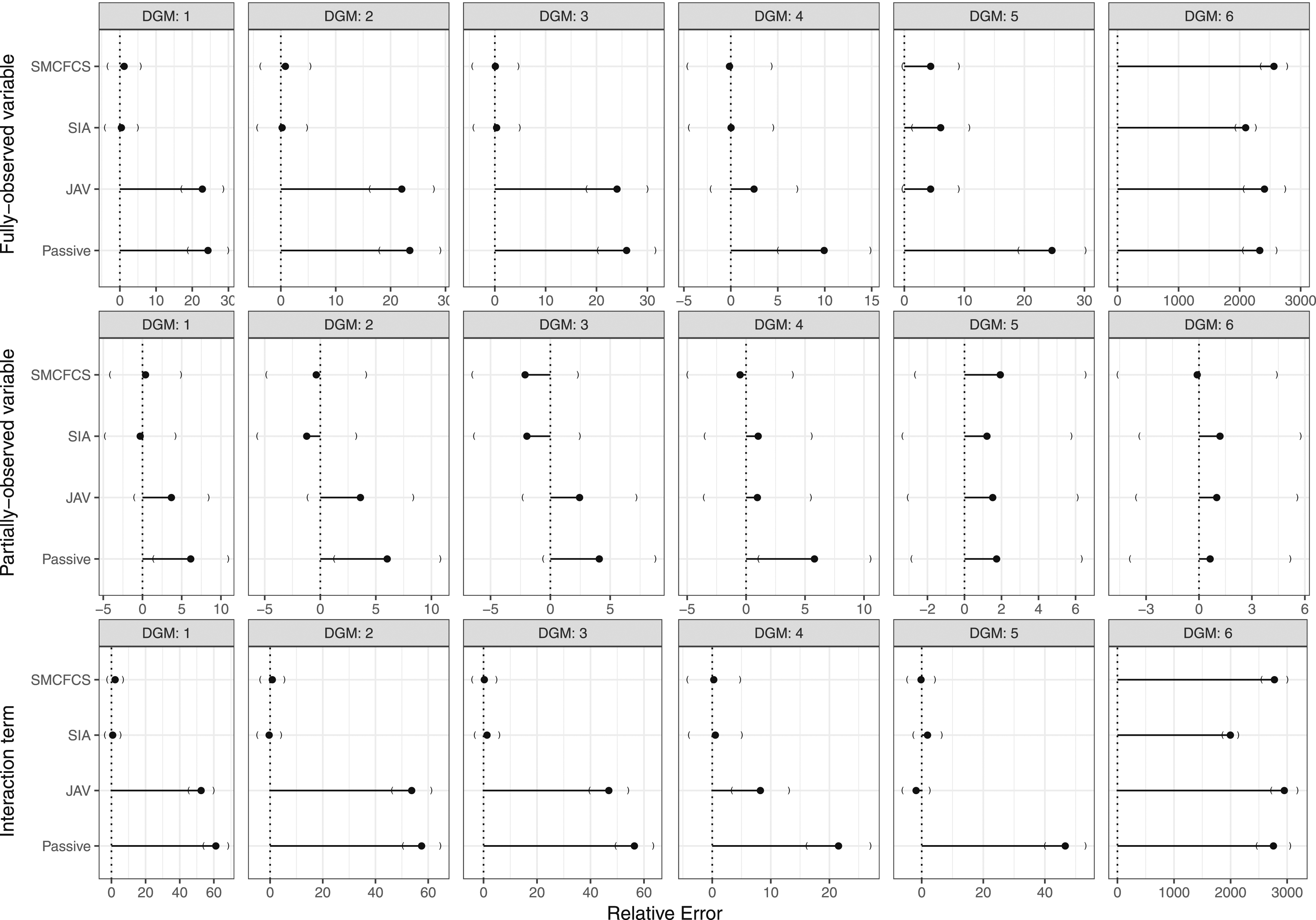
For the partially observed variable (Figure 5, row 2), SMCFCS, SIA and JAV showed a relative error that was within the expected range (i.e., within MCSE confidence intervals) for all DGMs. Passive imputation showed a slightly larger relative error than expected (i.e., outside the MCSE confidence intervals) for DGMs 1, 2, and 4, but was within MCSE confidence intervals for DGMS 3, 5, and 6.
For the interaction term (Figure 5, row 3), SMCFCS and SIA showed an optimal relative error (i.e., within the confidence intervals of the MCSE) for DGMs 1-5, but had a very large relative error for DGM 6 (low prevalence of the fully observed variable). JAV’s average model-based standard error overestimated the empirical standard error (i.e., large relative error) within DGMs 1-3. JAV showed an optimal relative error for DGM four and DGM 5, and severely overestimted the relative error in DGM 6. Passive imputation showed the largest overestimate of the relative error for all DGMs.
Cancer registry data example
Description of the data
The National Cancer Registry and Analysis Service (NCRAS), run by Public Health England (PHE), is responsible for cancer registration in England and supports cancer epidemiology, public health, service monitoring and research. Information on patients diagnosed with cancer is essential for assessing the public health system’s ability to care for these patients. In England, 17,345 patients were diagnosed with diffuse large B-cell lymphoma between 1st January 2014 and 31st December 2017. Information was available on the patient’s age at diagnosis, sex, socioeconomic status, comorbidity status, and cancer stage at diagnosis.
A patient’s comorbidity status is based on the Charlson comorbidity index 13 and was defined as “the existence of disorders, in addition to a primary disease of interest, which are causally unrelated to the primary disease”.14,15 Comorbidities were coded within Hospital Episode Statistics 16 data according to the International Classification of Diseases, 10th revision. 17 Patients with any previous malignancy were removed. For each patient, we defined a time window of 6–24 months prior to cancer diagnosis for a comorbidity to be recorded. A patient’s comorbidity status was determined using an algorithm developed by Maringe et al. 18
It is known that the presence of comorbidity symptoms can delay or hasten the cancer diagnostic stage. 19 For example, comorbidity symptoms similar to the cancer might hide the cancer symptoms, whereas dissimilar symptoms might highlight the differing diagnoses (particularly if the patient is frequently attending routine health appointments for their underlying comorbid condition). For patients with DLBCL, it has been shown that comorbidities are associated with diagnostic delay.6,8,20 It would be natural to assume that a statistical model included an interaction between comorbidity and cancer diagnostic stage when investigating the probability of short-term mortality.
Patient characteristics and crude odds ratios of death within 90 days after diagnosis of diffue large B-cell lymphoma amongst 17,345 patients diagnosed in England between 2014 and 2017.
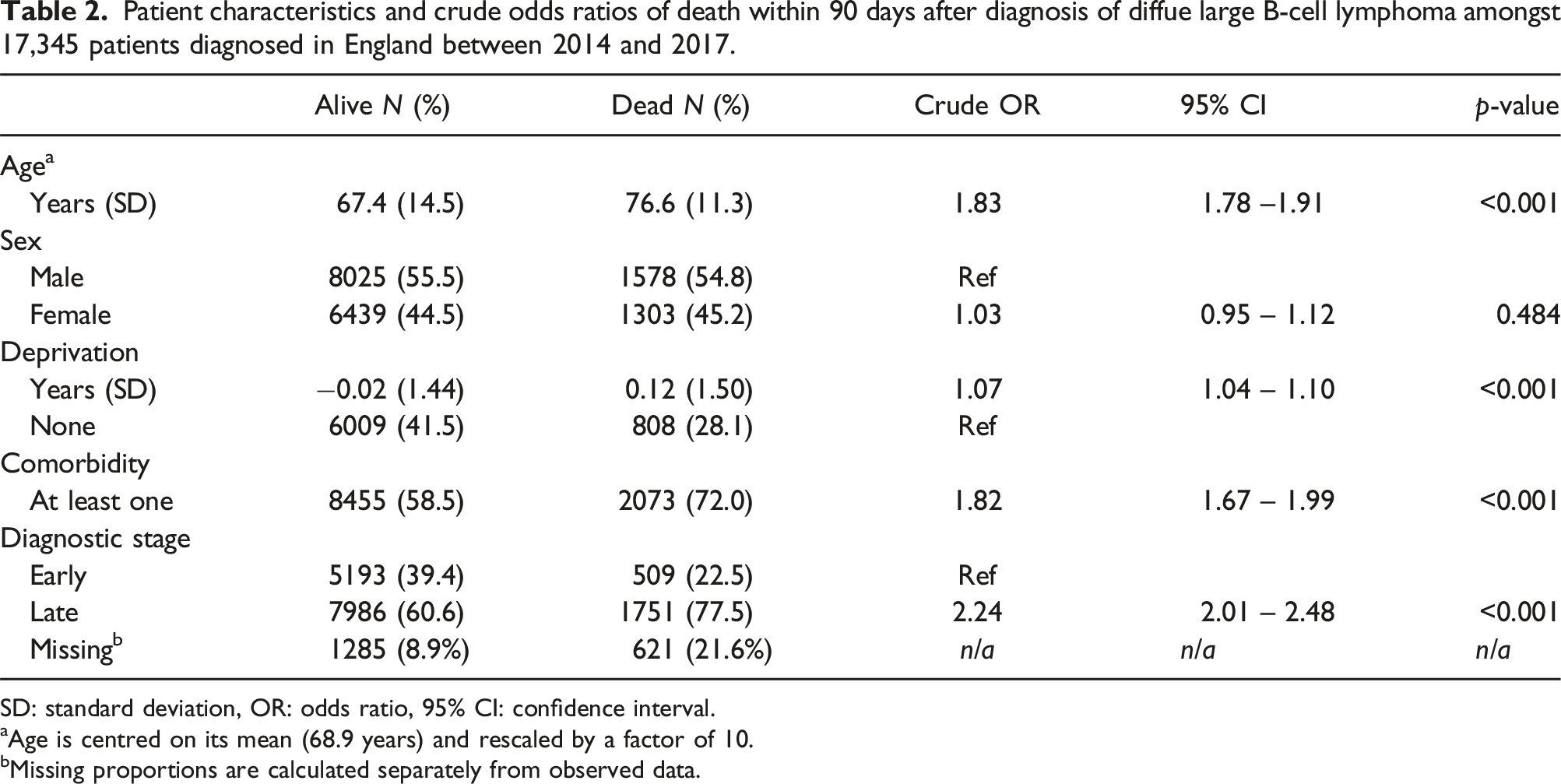
SD: standard deviation, OR: odds ratio, 95% CI: confidence interval.
aAge is centred on its mean (68.9 years) and rescaled by a factor of 10.
bMissing proportions are calculated separately from observed data.
For the adjusted analysis, the substantive model adjusted for age, sex, deprivation, comorbidity, diagnostic stage, and an interaction between comorbidity and diagnostic stage. Multiple imputation was performed using the four imputation methods (i.e., passive imputation, JAV, SIA, and SMCFCS). We used 10 imputation with 10 iterations and combined results using Rubin’s rules. We tabulate the results of each imputation method in the results section along with the results from a complete case analysis (i.e., ignoring missing data).
Results
Odds of mortality within 90 days from diagnosis of patients diagnosed with diffuse large B-cell lymphoma in England between 2014 and 2017. JAV: Just-Another Variable. SIA: Stratify-Impute-Append. SMCFCS: substantive model compatible fully conditional specification.
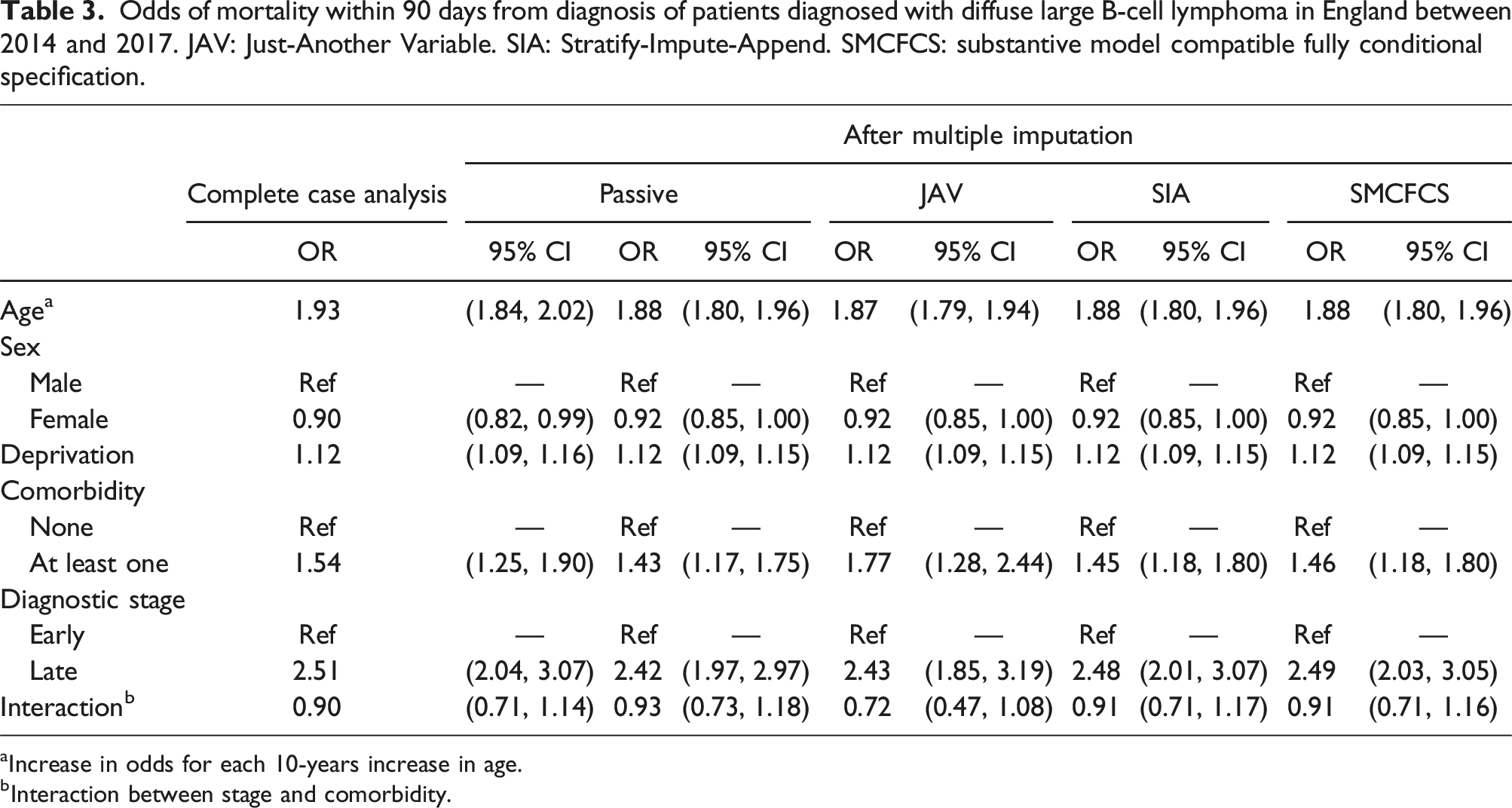
aIncrease in odds for each 10-years increase in age.
bInteraction between stage and comorbidity.
The data from this example compares most closely with DGM two from the simulation study. The missing data in stage is assumed to be missing at random, the fully observed variable is of binary form, the prevalence of the fully observed variable is not small (i.e., 60.7%), and there is a small effect of the interaction between comorbidity and diagnostic stage on the probability of death.
For the interaction term, SIA and SMCFCS showed very similar coefficients and confidence intervals, differing only by at most 2 decimal places. Passive imputation showed a slightly weaker effect of the interaction. JAV showed a strong protective effect (OR 0.73, 95% CI 0.47 - 1.08) of the interaction term. The coefficient for the partially observed variable (diagnostic stage) was similar between SMCFCS and SIA, which differed from a similar result between JAV and passive imputation. The coefficient, and confidence intervals, for the fully observed variable (comorbidity status) was again similar between SIA and SMCFCS, but also similar to passive imputation. JAV showed a much larger harmful effect of comorbidity (OR 1.77, 95% CI 1.28 - 2.44) compared to the other imputation approaches and the complete case analysis.
There was negligible difference between the imputation approaches for the odds of death, and the confidence intervals (CI), for age, sex and deprivation and the substantial conclusions remained the same irrespective of the methods used.
Discussion
We assessed the performance of four imputation approaches when handling missing data before fitting a logistic regression model with an interaction that contains a partially observed variable. We assessed their performance on the coefficients for (i) the interaction term, (ii) the partially observed variable, and (iii) the fully observed variable in the interaction. SMCFCS imputation consistently provided the least biased estimate of the three coefficients, except when there was a low prevalence of the fully observed variable in which case Just Another Variable (JAV) and passive imputation approaches showed the least bias. The Stratify-Impute-Append (SIA) approach also provided the least biased estimate for the three coefficients of interest, except when the fully observed variable had an underlying continuous form.
SMCFCS showed good or optimal coverage for all scenarios. SIA performed similarly to SMCFCS, except when the fully observed variable had an underlying continuous form. JAV consistently showed large undercoverage for the coefficients of the fully observed variable and the interaction. This is most likely driven by the previously noted large bias, which leads to the severe type II error. 12 For the relative error, SMCFCS consistently provided a close approximation between the average model-based standard error and the empirical standard error, except when there was a low prevalence of the fully observed variable. In this case, SIA approach had the smallest relative error of the four imputation approaches but this was still very large.
Careful consideration should be given to which parameter is of interest to the study when using JAV imputation. Although all four imputation approaches have similar bias when estimating the coefficient of the partially observed variable, JAV imputation will not only be biased for the interaction term but will also introduce bias into the coefficient for the fully observed variable that is included in the interaction. If the coefficient of the partially observed variable is the primary parameter of interest and the interaction term (and the coefficient of the fully observed variable) is a nuisance parameter, then any of the four methods are appropriate. However, if all three parameters are of interest, as is most often the case, SIA and SMCFCS should be used because they will give the least biased estimates of the slope parameters for X, Z, and XZ.
Seaman et al (2012) had previously showed that JAV imputation should not be used for logistic regression models with a quadratic term. 4 Our results are consistent with their conclusions and extend the implications to the case of logistic regression models that include an interaction term. Passive imputation performed better than JAV in our settings, except when the fully observed variable in the interaction had an underlying continuous form, but we have shown that even in the simplest of specifications for a logistic regression model with interactions, both passive or JAV imputation should best be avoided. The only exception was that JAV performed almost as well as SMCFCS when the fully observed variable in the interaction has an underlying continuous form. However, this is a rare and specific example, and other imputation approaches may, more often, perform better.
SMCFCS is possibly the best option for most analyses but SIA is also a suitable alternative, particularly in situations where the model being fit is not available in the SMCFCS package (e.g., excess hazard models in survival analysis). SIA allows one to remove the complexity of the interaction term and impute the missing data within levels of the categorical variable. SIA can be used when the fully observed variable is a categorical variable but only when there is a large enough number of observations for each level (i.e., avoiding perfect prediction). However, SIA is difficult to use if the fully observed variable in the interaction has a continuous underlying form and one would need to carefully consider how to categorise the continuous variable so that it appropriately captures the patterns observed in the variable; an approach could incorporate machine learning techniques such as classification and regression trees. Moreover, SIA cannot be used when both variables in the interaction contain missing values but SMCFCS can be used (passive and JAV can also be used but might provide biased results). We focused on multiple imputation because it is the most widely used approach for dealing with missing data, other methods such as inverse probability weighting (IPW) were not considered.21,22
We considered the simple scenario where the only complex covariate was an interaction. Seaman et al (2012) investigated the performance of imputation approaches for logistic regression that included a quadratic term as the only complex covariate. 4 They found that, under MAR assumption, passive imputation produced biased estimates of the quadratic term and predictive mean matching (PMM) was unbiased with correct coverage. Since the SIA approach performs imputation within strata of the fully observed variable (i.e., removing the interaction and imputing only the partially observed covariate), it is possible that SIA can be used for more complex substantive models. For example, a logistic regression model with both a quadratic term (X2 and an interaction (XZ) could be handled by using predictive mean matching within strata of the fully observed variable of the interaction. The logistic regression of the form Y = β0 + β1Z + β2C + β3C2 + β4X + β5XZ, where C is a continuous variable with a quadratic effect on Y, then X and C could be imputed using PMM within strata of Z, yielding unbiased estimates for a complex logistic regression model. This hybrid approach would combine PMM and SIA, which we refer to as ”stratified predictive mean matching”. The performance of this hybrid approach, and in comparison to SMCFCS, requires further investigation.
SMCFCS performed poorly for the bias and coverage of the coefficient of the fully observed variable (i.e., Z5) in the interaction when there was a low prevalence (i.e., 1%) of this fully observed variable. In this scenario (i.e., DGM 6), the average number of observations for which Z5 = 1 was 100, and the average number of observations for which Z5 = 0 was 9900, in the simulated study. The low prevalence of this variable could lead to perfect prediction for the interaction term if there are low numbers for those with both Z5 = 1 and X1 = 1. Since the prevalence of X1 = 1 was simulated to be 40%, the approximate number of observations for Z5 = 1 and X1 = 1 in this scenario would be 40. SMCFCS could be adapted in this scenario with a data augmentation scheme where a few additional carefully crafted observations are added before the imputation model is fitted. 23 Another approach could be to use Firth’s bias correction approach, which modifies the maximum likelihood procedure by removing its first order finite sample bias.24,25 We also simulated 100,000 observations to specifically assess the performance of SMCFCS in a larger sample, we found SMCFCS performed better with larger samples (results not shown). Further studies are required to assess the performance of these adaptations in various scenarios, particularly for low prevalence of the fully, or partially, observed variables.
We compared the results of the four imputation methods using a real-world cancer data set on patients diagnosed with diffuse large B-cell lymphoma in England. As expected, SIA and SMCFCS showed very similar estimates for the effect (and confidence intervals) of diagnostic stage on mortality with 90 days since diagnosis. Passive imputation produced similar results to the complete case analysis, SIA, and SMCFCS approaches; however, as shown in the simulations, passive imputation is expected to be biased for the interaction term and the coefficient of the fully observed variable. In the simulations, JAV imputation showed markedly different (and poorer) results for the interaction term and the coefficient of the fully observed variable, which was also reflected in the cancer data analysis and would explain the large bias (away from the null) for these two parameters.
Stage at diagnosis is often considered a categorical variable (i.e., stages I, II, III, and IV). We used a binary form for diagnostic stage (i.e., early vs late stage) for two reasons. Firstly, treatment, such as combination immunochemotherapy, for patients with diffuse large B-cell lymphoma is allocated based on an international prognostic index (IPI). 26 One criteria of the DLBCL-IPI is whether the cancer is late stage (i.e., stage III or IV) or early stage (i.e., stage I or II). Secondly, for simplicity of the simulation study, a categorical form for diagnostic stage would be handled similarly to a binary variable (i.e., impute within levels of the fully observed variable: comorbidity) and we anticipate this would not change the conclusions of our results.
We assumed that missing data in diagnostic stage was missing at random. In real-world settings, over the past 5 years, the proportion of missing diagnostic stage has reduced. The proportion of patients with a late diagnostic stage has either plateaued or increased at the same rate as the decrease in missing diagnostic stage, possibly indicating the two are related. Thus, the probability of observing cancer stage at diagnosis could be associated with the actual value of the cancer stage. This could potentially be true even after conditioning on all the observed covariates. Thus, the missing cancer diagnostic stage in our real-world study could be missing not at random (MNAR), requiring alternative approaches to multiple imputation. Since the MNAR assumption is never testable with observed data, the standard approach is to perform sensitivity analyses to different missingness mechanisms.27,2
SIA and SMCFCS imputation approaches give consistent estimation for logistic regression models with an interaction term when data are MAR, and either can be used in most analyses. SMCFCS performed better than SIA when the fully observed variable in the interaction has an underlying continuous form. Passive imputation performed better than JAV imputation but these approaches should only be used (instead of SMCFCS or SIA) when the coefficient of interest is the fully observed variable that has a low prevalence.
Footnotes
Author contributions
MJS, ENN and MQ developed the concept. MJS and MQ designed the first draft of the article and the computing code. All authors interpreted and reviewed the code and the data, and drafted and revised the article. All authors read and approved the final version of the article. MJS is the guarantor of the article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Cancer Research UK (Reference C7923/A18525). Funders had no role in the study design, data collection, data analysis, data interpretation, or writing of the report.