
Abstract
Background
In meta-analysis, researchers often pool the results from a set of similar studies. A number of studies, however, often tend to report only the minimum and maximum values, median, and/or the first and third quartiles. Recently, many methods have been discussed for estimating the mean and standard deviation from those sample summaries. However, these methods may provide a substantially biased estimate of the inverse variance that is needed for the meta-analysis.
Research Design
We use Basu’s theorem to derive unbiased estimators for σ−2 from the most commonly used sample summaries from the normal distribution. While there are no closed formulas for these estimators, we use simulations to obtain simple approximations for the estimators.
Results
The proposed approximate estimators still show a little to no bias for normally distributed data and generally show smaller bias than the usual methods even for some non-normal distributions. The proposed estimators have lower mean squared error.
Conclusions
The proposed estimators are recommended for the purpose of obtaining inverse-variance weights, particularly in the context of meta-analyses.
Introduction
When one wishes to combine data from multiple independent studies, the sample mean and sample standard deviation are the essential quantities for the meta-analysis. 1 Some studies do not report either the mean or the standard deviation and report only the five-figure summary (including the sample median, the first and third quartiles, and the minimum and maximum values). Moreover, even the five-figure summary may not be fully reported; see, for example, Thatcher et al., 2 where only the median and range were reported or Monaco et al. 3 where only the median and the quartiles were reported. Rather than discarding the studies that do not report the sample mean and standard deviation directly, one can try to estimate these quantities from the reported summaries. While the work on this problem can be traced back all the way to Tippett, 4 the interest in the systematic research of the estimators resurfaced in Hozo et al. 5 and a significant body of literature soon followed;6–11 see also Weir et al. 12 and Walter et al. 13 where various methods have been discussed and compared.
Typically, three scenarios are investigated depending on the summaries being reported in addition to a sample size: 1. {a, m, b; n}, 2. {q1, m, q3; n}, or 3. {a, q1, m, q3, b},
where a is the minimum, q1 is the first quartile, m is the median, q3 is the third quartile, b is the maximum and n is the sample size.
Walter et al.
13
showed that a naïve method for estimating σ−2 in Scenario 1 by estimating σ first and then raising that estimate to power −2 can result in substantial bias, particularly for small samples. This is true even for the state-of-the-art methods presented in Shi et al.
14
and Balakrishnan et al.;
15
see Figure 1. Therefore, Walter et al.
13
used a Taylor series approximation to provide a better estimate for σ−2 when only the sample range is available. They showed that the approximation by the polynomial of fourth degree yields good results even for small sample sizes. Bias and mean square error (MSE) of estimating σ−2 by first estimating σ using the best methods for the appropriate scenario from Shi et al.
14
and Balakrishnan et al.
15
and then raising the estimate to power −2. Results from 105 simulations for data from N(0, 1) are shown; however, the bias and MSE is the same regardless of the mean and the variance of the normal distribution. (a) Bias. (b) MSE.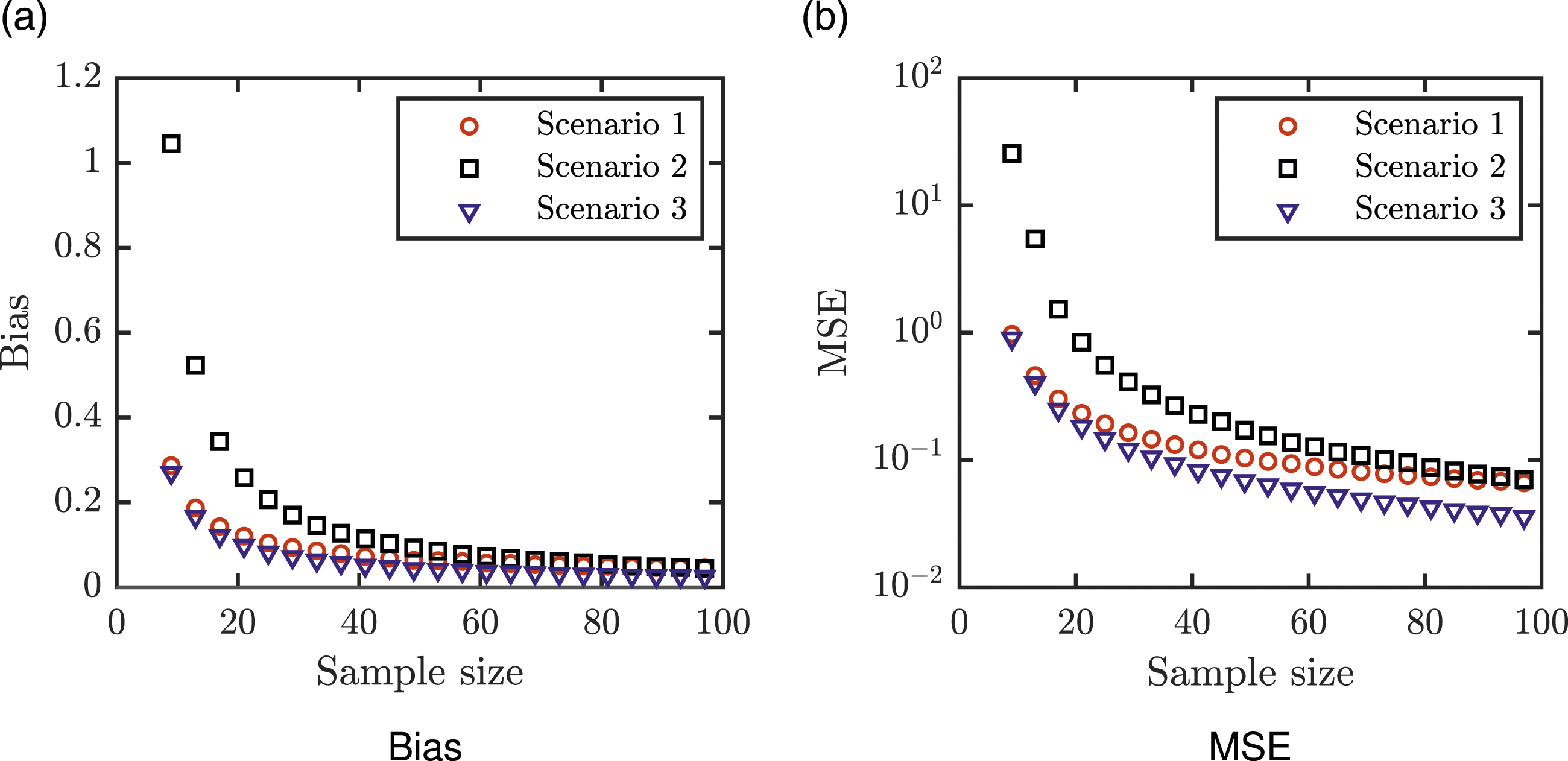
In this paper, we significantly simplify the method developed in Walter et al. 13 and propose unbiased estimators of σ−2 from normally distributed data. The estimators can incorporate the knowledge of the interquartile range as well. Unfortunately, there are no closed formulas for those estimators, and so we searched for and obtained simple-to-use approximations that still show a little to no bias.
Methods
Scenario 1, {a, m, b; n}
Let us write
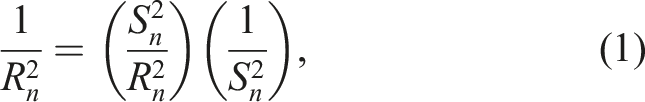
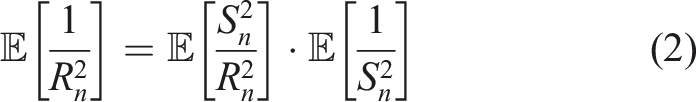
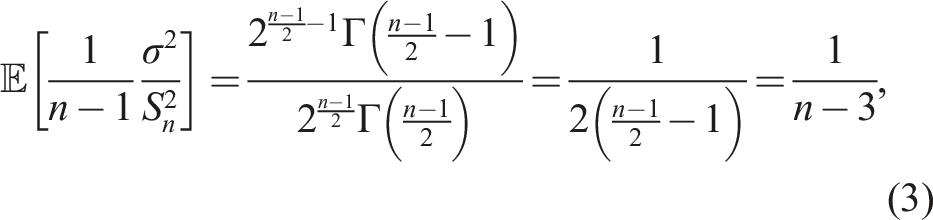
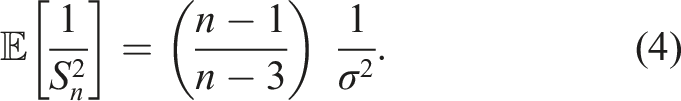
Let us denote
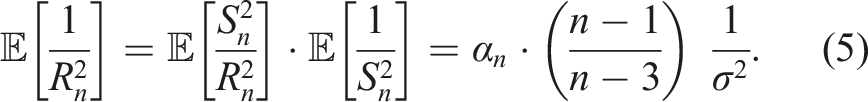
Thus, when we set
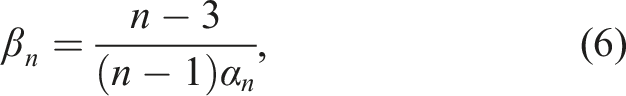
We note that there is no closed-form formula for β
n
. However, as
Scenario 2, {q1, m, q3; n}
As in scenario 1, let I
n
= q3 − q1 be the interquartile range and let
Scenario 3 {a, q 1 , m, q 3 , b; n}
As in Shi et al., 14 we will get an unbiased estimator of σ−2 if we take any linear combination of the two estimators presented above for Scenarios 1 and 2. We need to find the weights that yield the smallest variance.
For any w ∈ [0, 1], consider an estimator
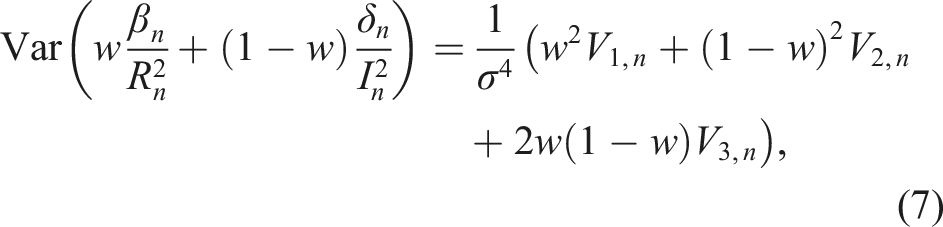
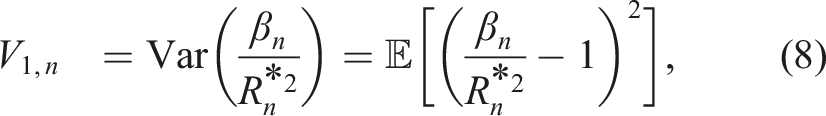
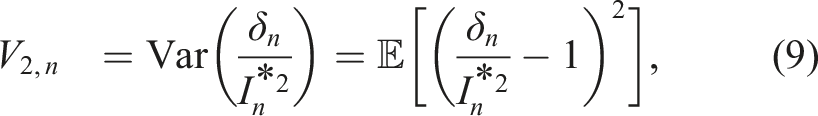
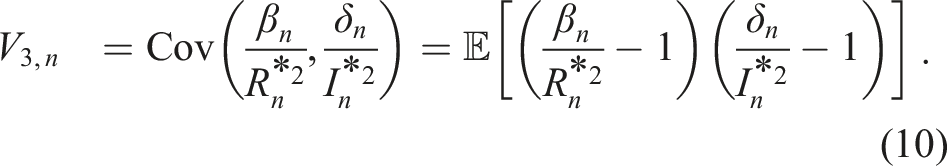
Minimizing (7) with respect to w ∈ (−∞, ∞), we get the equation
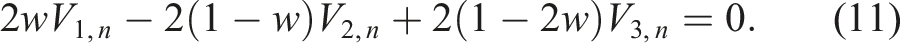
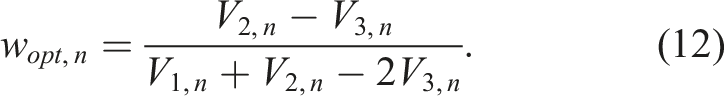
As before, while we could not obtain closed formulas for V1,n, V2,n and V3,n, we can obtain their approximate values from the simulations. This in turn gives an approximate value of the optimal weight wopt,n in (12). Moreover, the simulations yield wopt,n ∈ (0, 1); if we had wopt,n < 0 then we would have to use 0 as the optimal weight and, similarly, if wopt,n > 1, we would have to use 1.
Numerical simulations
For every n ∈ {9, 13, 17, …, 97} = {4k + 1; k = 2, 3, …, 24}, we generated 105 random samples of size n from N(0, 1). We restricted ourselves to n < 100 since, as seen in Figure 1, the indirect approximation has the highest bias and MSE for n < 50.
For each sample, we calculated the sample standard deviation S
n
, sample range
We calculated bias of the estimates as the average of
Finally, as in Wan et al., 8 we study the performance of the proposed estimators relative to the naïve methods using the state of the art estimators of σ from Shi et al. 14 for various distributions, specifically (a) normal distribution with μ = 50 and σ = 17, (b) log-normal distribution with μ = 4 and σ = 0.3, (c) beta distribution with α = 9 and β = 4, (d) exponential distribution with λ = 10, and (e) Weibull distribution with a = 2 and b = 35.
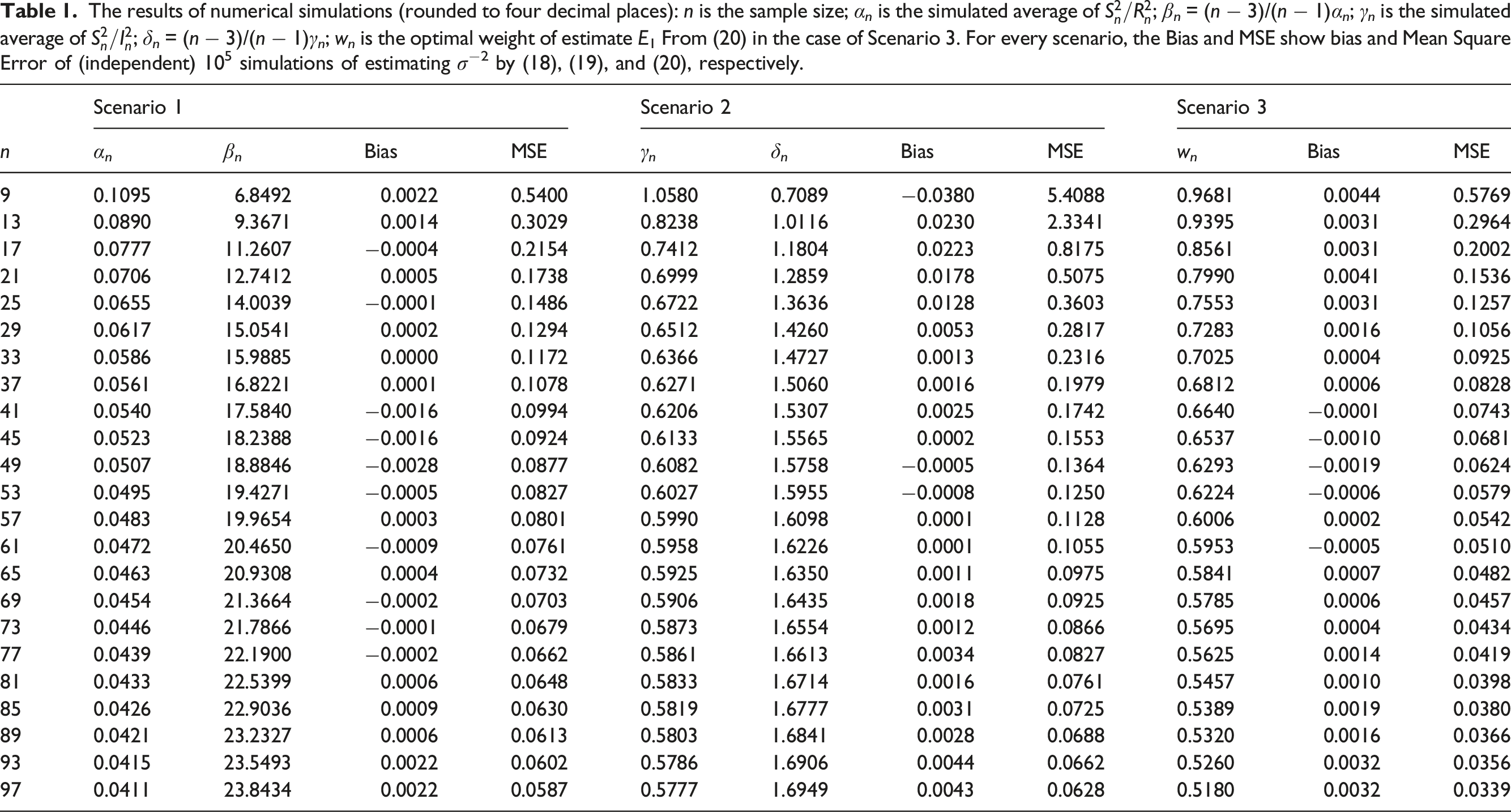
Results
The results of numerical simulations (rounded to four decimal places): n is the sample size; α
n
is the simulated average of
By trial and error, we discovered that 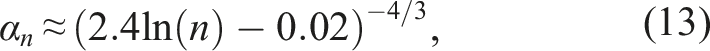
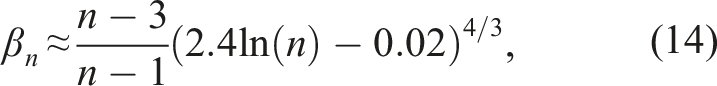
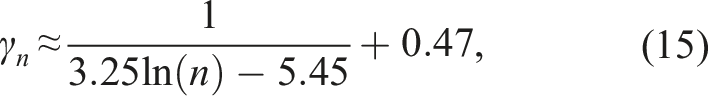
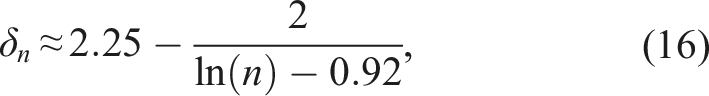
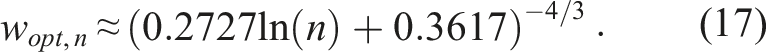
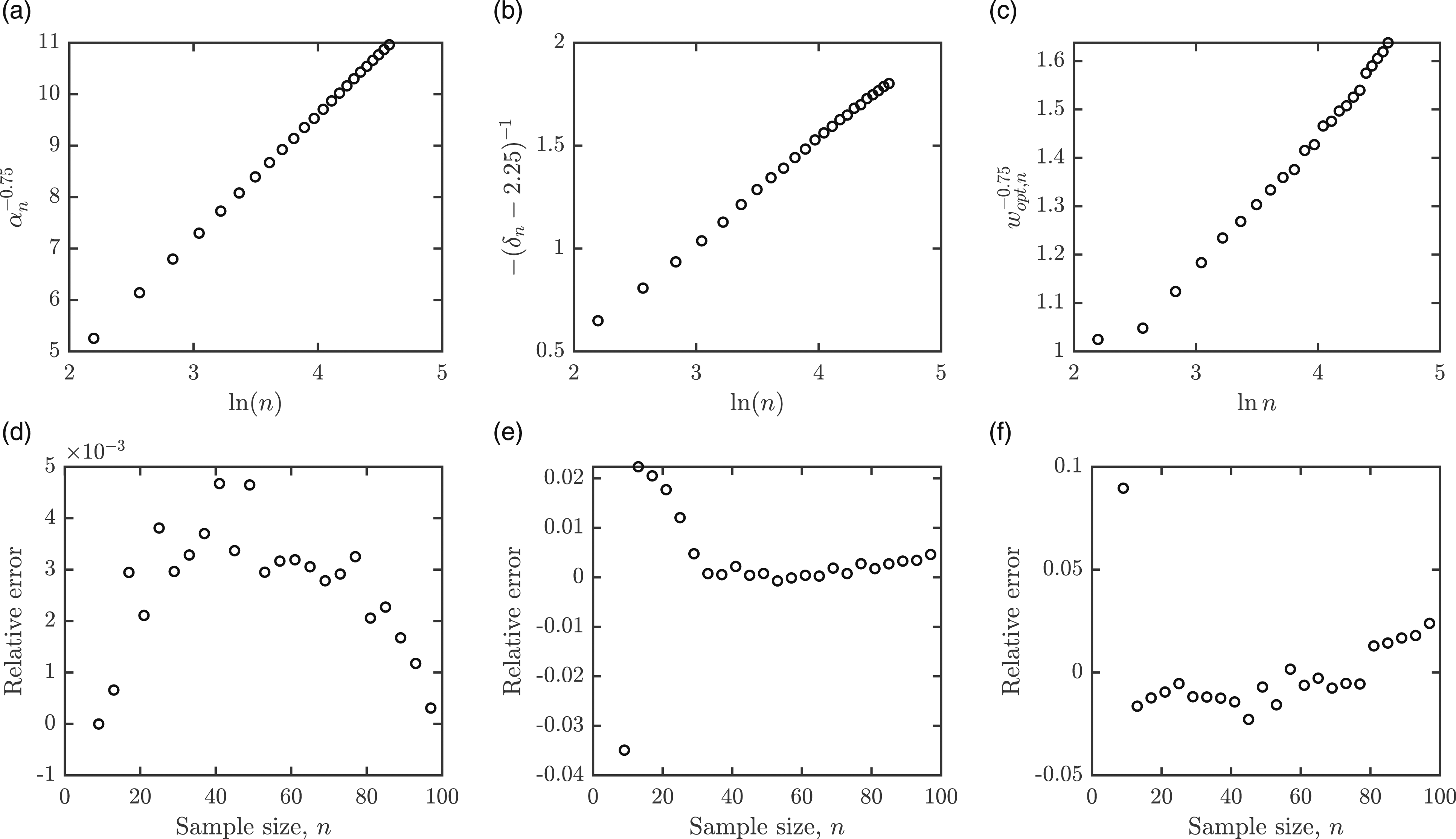
This yields the following unbiased estimators of 1/σ2: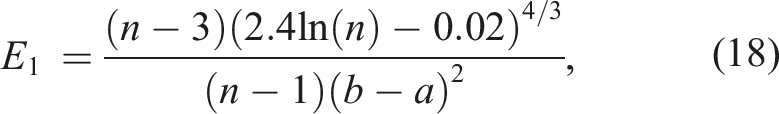
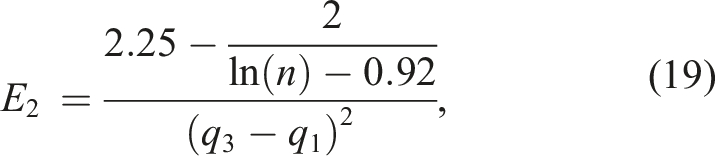
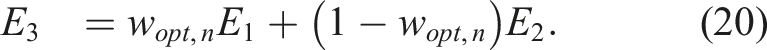
The estimator E
i
is used in scenario i. The illustration that the estimators are unbiased and their mean square errors are shown in Figure 3.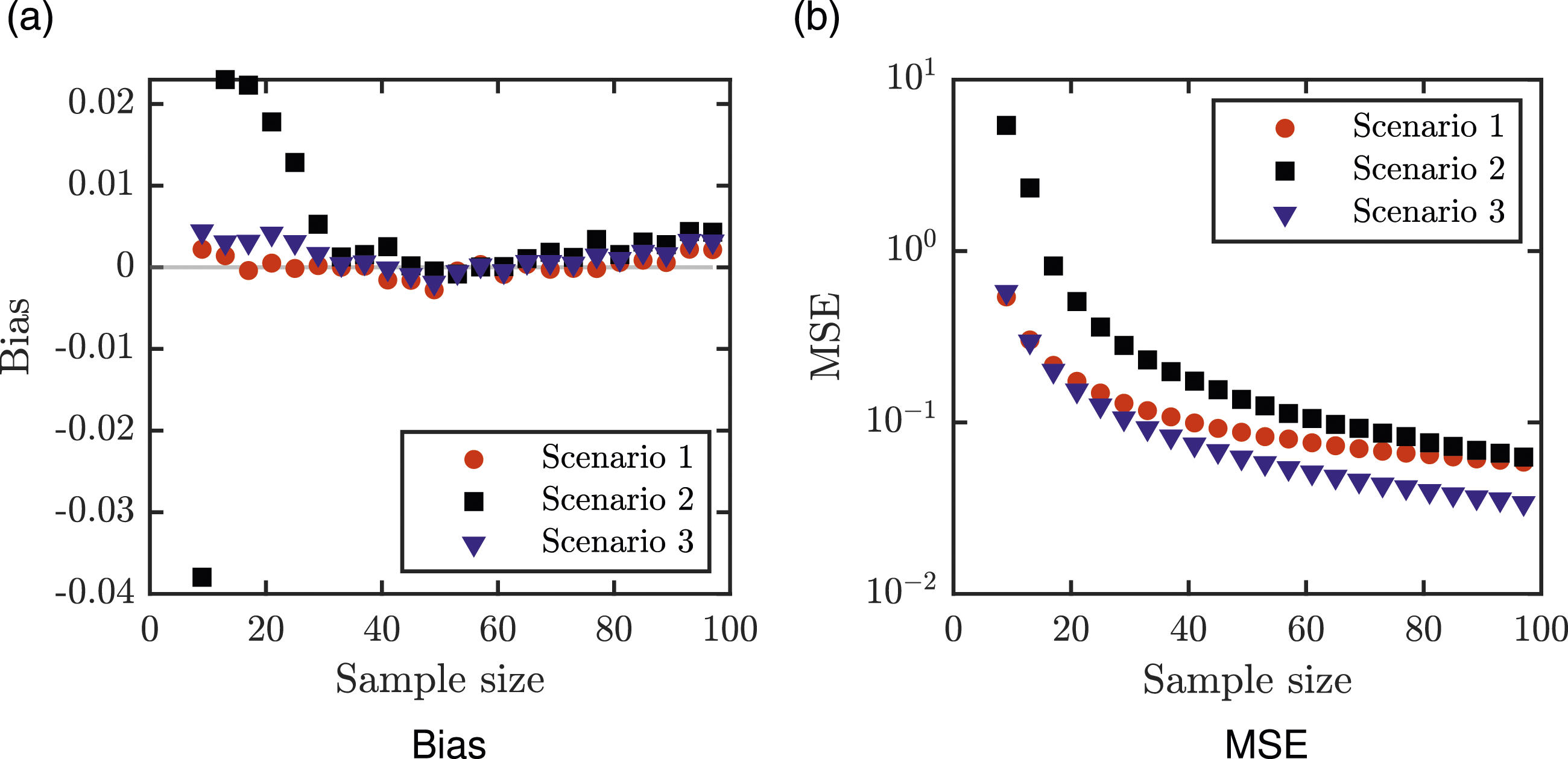
The performance of the proposed estimators for non-normal distributions is illustrated in Figures 4 and 5. We see that, in terms of MSE and generally also in terms of bias, the proposed estimators outperform the naïve method of estimating the standard deviation first and then raising it to power −2. The notable exception when bias is slightly smaller for the naïve methods are for n > 20 in Scenario 2 for beta distribution. The proposed methods also slightly underperform, in terms of bias, in Scenario 1 for n > 80 and log-normal or Weibull distributions. Bias of estimating σ−2 by the newly proposed estimators (full markers) against the bias of the naïve method using the state of the art estimators from Shi et al.
14
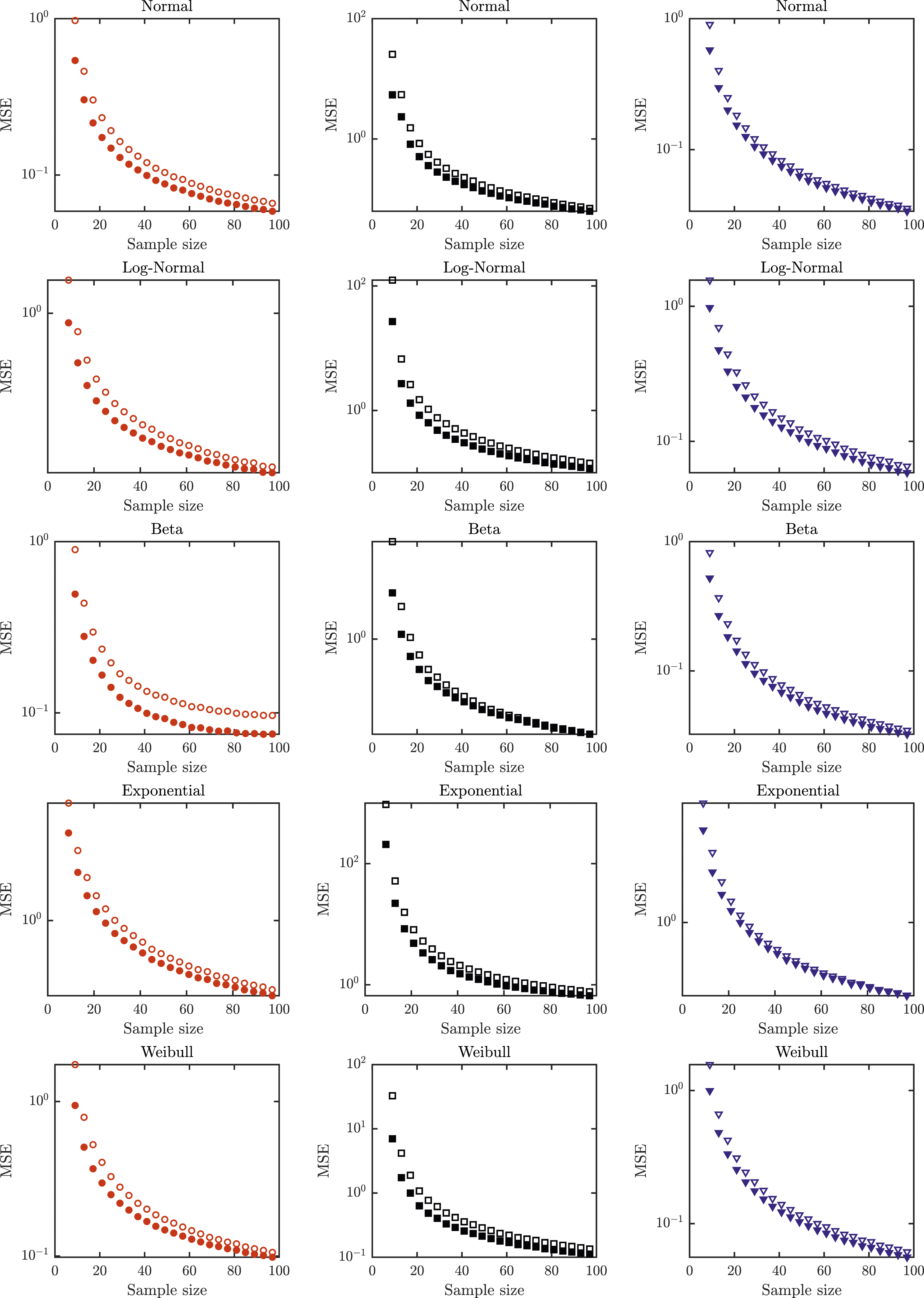
(empty markers) for Normal distribution (first row), Log-normal distribution (second row), Beta distribution (third row), Exponential distribution (fourth row) and Weibull distribution (fifth row) and scenario 1 (left column), scenario 2 (middle column) and scenario 3 (right column). MSE (on a logarithmic scale) of estimating σ−2 by the newly proposed estimators (full markers) against the MSE of the state of the art estimators from Shi et al.
14
(empty markers) for Normal distribution (first row), Log-normal distribution (second row), Beta distribution (third row), Exponential distribution (fourth row) and Weibull distribution (fifth row) and scenario 1 (left column), scenario 2 (middle column) and scenario 3 (right column).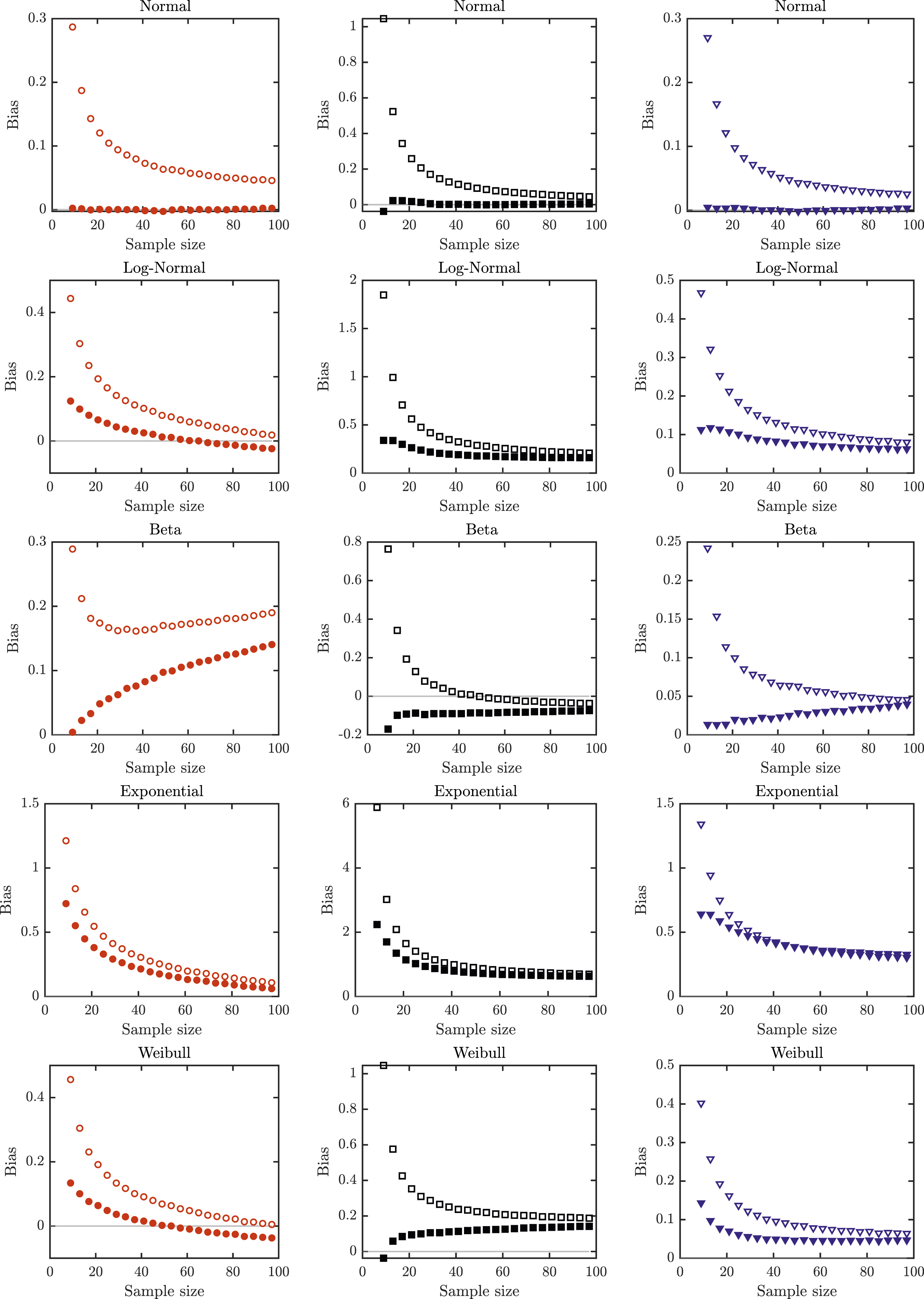
Real data example
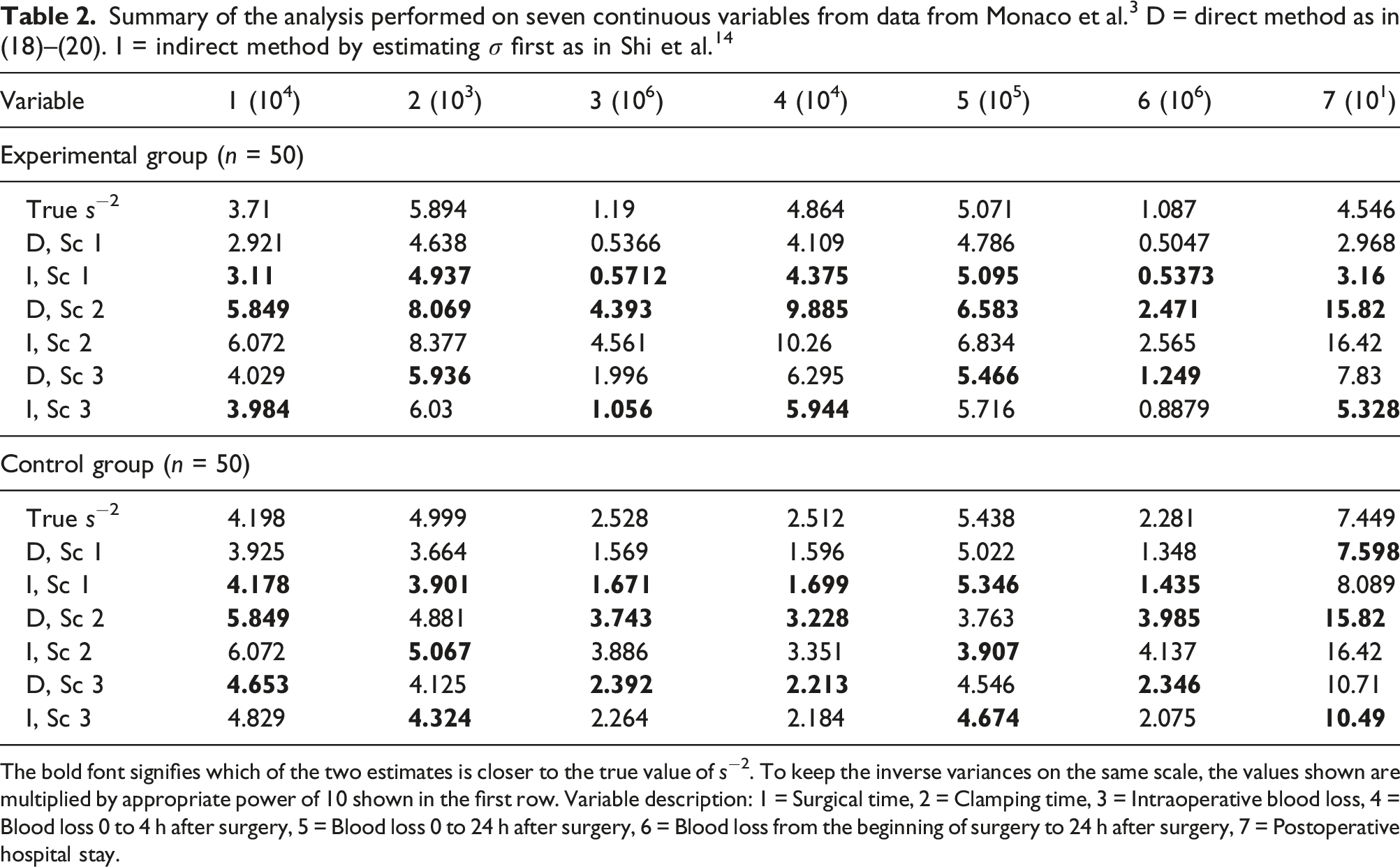
The bold font signifies which of the two estimates is closer to the true value of s−2. To keep the inverse variances on the same scale, the values shown are multiplied by appropriate power of 10 shown in the first row. Variable description: 1 = Surgical time, 2 = Clamping time, 3 = Intraoperative blood loss, 4 = Blood loss 0 to 4 h after surgery, 5 = Blood loss 0 to 24 h after surgery, 6 = Blood loss from the beginning of surgery to 24 h after surgery, 7 = Postoperative hospital stay.
The summary is presented in Table 2. The data published in Monaco et al. 3 contained only the quartile values, so this corresponds to our Scenario 2. The proposed direct methods in Scenario 2 always outperform the indirect method in the experimental group and mostly (5 out 7) outperforms the indirect method in the control group. However, in this Scenario, both methods also yield the worst errors among the methods we considered. The estimated values are closer to s−2 in Scenario 1 (when the indirect methods outperform the proposed method) and Scenario 3 (when the estimates are closest to the true value and the results are mixed). The goodness of the approximation is consistent with Figures 1 and 3 which show that, for n < 100, the MSEs in Scenario 3 are smaller than in Scenario 1 which are smaller than in Scenario 2.
Conclusions and discussion
The problem of estimating an unreported standard deviation from reported data summaries is an important problem in meta-analysis. Recently, unbiased methods with least MSE have been developed in Shi et al. 14 and Balakrishnan et al. 15 developed a unified approach that works for any reported summaries. However, even these optimal methods possess bias when used to estimate the inverse variance.
In this paper, we have developed a simple and efficient method for estimating the inverse variance directly. We have proved analytically that the proposed estimators are unbiased for normally distributed data. We obtained numerical values of the estimators through Monte Carlo simulations using which we have found simple-to-use approximations.
The proposed estimators were developed under the assumption that the data is normally distributed. Under this assumption, the proposed estimators outperform the naïve methods and even the best estimators from Shi et al. 14 and Balakrishnan et al. 15 both in terms of bias and MSE. However, the data distribution is typically not known and it thus important to estimate the robustness of the proposed method. We saw that the proposed estimators also improve MSE, and almost always (except for the exponential distribution and large n) possess lower bias, over the naïve methods even for data that are not normally distributed.
Therefore, when the inverse variance is the true quantity of interest, for pooling purposes, for example, one should estimate it directly using the estimators presented in this paper.
Footnotes
Acknowledgements
We thank Dr. Landoni (IRCCS San Raffaele Scientific Institute and Vita-Salute San Raffaele University, Milan, Italy) for providing the original study data used in the example.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by the Natural Sciences and Engineering Research Council of Canada RGPIN-2020-06733 and RGPIN-2016-03670. The funding agency had no input in study design, analysis and interpretation of data, in the writing of the report, nor in the decision to submit the article for publication.