
Abstract
When reporting results from randomized experiments, researchers often choose to present a per-protocol effect in addition to an intention-to-treat effect. However, these per-protocol effects are often described retrospectively, for example, comparing outcomes among individuals who adhered to their assigned treatment strategy throughout the study. This retrospective definition of a per-protocol effect is often confounded and cannot be interpreted causally because it encounters treatment-confounder feedback loops, where past confounders affect future treatment, and current treatment affects future confounders. Per-protocol effects estimated using this method are highly susceptible to the placebo paradox, also called the “healthy adherers” bias, where individuals who adhere to placebo appear to have better survival than those who don’t. This result is generally not due to a benefit of placebo, but rather is most often the result of uncontrolled confounding. Here, we aim to provide an overview to causal inference for survival outcomes with time-varying exposures for static interventions using inverse probability weighting. The basic concepts described here can also apply to other types of exposure strategies, although these may require additional design or analytic considerations. We provide a workshop guide with solutions manual, fully reproducible R, SAS, and Stata code, and a simulated dataset on a GitHub repository for the reader to explore.
Introduction
Typically, researchers draw causal inferences from survival analyses using experimental data (e.g., randomized clinical trials (RCTs) or pragmatic randomized trials), by estimating intention-to-treat (ITT) effects - the effect of being randomized to treatment on a time-to-event outcome, such as mortality.1–5 These effects are usually estimated using an unadjusted regression model, typically Kaplan-Meier, with the justification that the randomization process in these studies ensures no baseline confounding; or a regression model adjusted for baseline covariates, e.g. Cox proportional hazards.6–9 Here baseline confounding refers to preferential selection into a particular arm based on preexisting factors.
But, many RCTs specify treatment strategies that are longitudinal - participants may be asked to take pills daily over a course of one year, or to receive infusions of a novel drug every two weeks for 6 months.10,11 Often implementations of these longitudinal treatment strategies encounter issues with patients who are non-adherent to the treatment protocol. In these cases, the ITT effect does not capture the effect of treatment received on the outcome. 12 In these cases, researchers should also estimate a per-protocol effect: the effect of receiving treatment according to the trial protocol on the outcome.13,14 Per-protocol effects are patient-centered causal effects, and may be important for shared decision-making.15,16
That said, the definition and estimation of per-protocol effects are context-dependent – they change depending on the study design and available data. Randomized treatment assignment only protects against confounding at the time of randomization, so even in the controlled setting of an RCT the per-protocol effect is not guaranteed to be free from confounding. Therefore, our estimation procedure needs to thoughtfully consider post-randomization confounding for treatment adherence and/or loss to follow-up. 14
Common methods for estimating per-protocol effects in randomized trials with interventions that happen only once, such as instrumental variables or as-treated analyses, are generally not appropriate for trials with sustained or longitudinal treatment strategies, because of the structure of time-varying confounder adherence feedback and because future adherence can violate the exclusion restriction.12,14
Here, we present a complete example of the causal thinking and assumptions needed to estimate survival per-protocol effects from follow-up studies. A supplementary online repository 17 includes a workshop training guide and solutions manual, as well as software and a sample dataset. In this, we use directed acyclic graphs (DAGs) to visualize the causal assumptions, and present complete R, SAS, and Stata code to implement inverse probability weighting of a discrete-time hazard model to estimate per-protocol effects in simulated data. For pedagogical purposes, we first describe how to estimate several intention-to-treat effects: counterfactual survival curves standardized to baseline covariates, the average hazard ratio over follow-up, and the cumulative incidence difference and the cumulative incidence ratio by the end of follow-up. Then, we describe how to estimate the corresponding survival per-protocol effects using inverse probability weighting to adjust for treatment-confounder feedback. The simulated dataset is based on the Coronary Drug Project, an historic double-blind placebo-controlled randomized trial. 18
Motivating example: The Coronary Drug Project
The U.S. National Heart Blood and Lung Institute sponsored the Coronary Drug Project (CDP), a double-blind placebo-controlled randomized trial conducted between 1966–75, to determine the safety and efficacy of a set of drugs for secondary prevention of mortality among men with a history of myocardial infarction. 18 The trial initially compared 5 active treatments, but for simplicity we focus on the comparison between clofibrate and placebo. 19 Clofibrate (no longer available in the U.S.) was a lipid-lowering agent first created in 1966 that works to increase lipoprotein lipase activity to decrease high cholesterol and triglyceride levels. In the trial, patients were instructed to take 600 mg three times per day. The placebo was sugar pills, designed to look like clofibrate, and taken on the same schedule. Adherence to treatment in this trial was defined by the physician at each quarterly visit throughout follow-up, who visually inspected the bottle of pills to describe the adherence as “good” (≥80% empty) versus “poor” (<80% empty). Table 1 presents a description of the relevant parts of the CDP.
Succinct description of the Coronary Drug Project.

In 1980, the Coronary Drug Project team published an analysis comparing 5-year survival among individuals who did and did not adhere (at all quarterly visits) to placebo, and detected a large association between placebo adherence and survival. 20 The results of this study have been used to argue that adherence adjustment (and by extension, per-protocol effect estimation) cannot be done in a randomized trial. However, re-analyses of the Coronary Drug Project accounting for post-randomization confounding using inverse probability weighting showed that this association was spurious.21,22
The CDP contains protected health information, so sharing is restricted. Instead, we have created a simulated dataset,17 based on the relationships between a subset of the variables recorded in the CDP from the clofibrate and placebo arms. The data are in long format, so each row corresponds to one person-visit. A complete data dictionary is available in eTable 1. Although some individuals in the original trial were lost to follow-up, for simplicity we have chosen to simulate data with no loss to follow-up; all individuals either contribute the full 5 years of follow-up, or follow-up ends due to death. The methodology presented here is easily extendable to scenarios with other types of censoring.
Causal thinking
We are also interested in the per-protocol effect: the effect of adherence to assigned treatment strategy defined by the study protocol. Under perfect treatment strategy adherence by all trial participants, this effect is identical to the ITT. The interpretation of a per-protocol effect is therefore trial-specific, and more than one per-protocol effect definition is possible for a given trial. Researchers often estimate these effects in pragmatic trials because patients and providers want a measure of effectiveness that is not influenced by adherence. Examples of different kinds of per-protocol effects that can be estimated from survival analyses are given in Table 2.
Types of per-protocol effects comparing two longitudinal treatment strategies,

These effects are defined in the absence of censoring, but can be extended to that situation.
In order to estimate the per-protocol effect, researchers first need to define the protocol of interest. For simplicity, we will specify the static protocol: “continuously adhere to the assigned treatment arm, i.e., take at least 80% of assigned pills,” to answer the question “What is the causal effect of clofibrate versus placebo on mortality over 5 years?” As such, we are contrasting the counterfactual world where everyone took clofibrate, Causal assumptions for per-protocol effects. 1. Consistency. For all 2. Conditional exchangeability (or sequential randomization). For all 3. Positivity. If 4. No interference. Each individual’s treatment assignment does not affect the counterfactual outcome of others, For complete discussions of these assumptions, please see.23,30,38
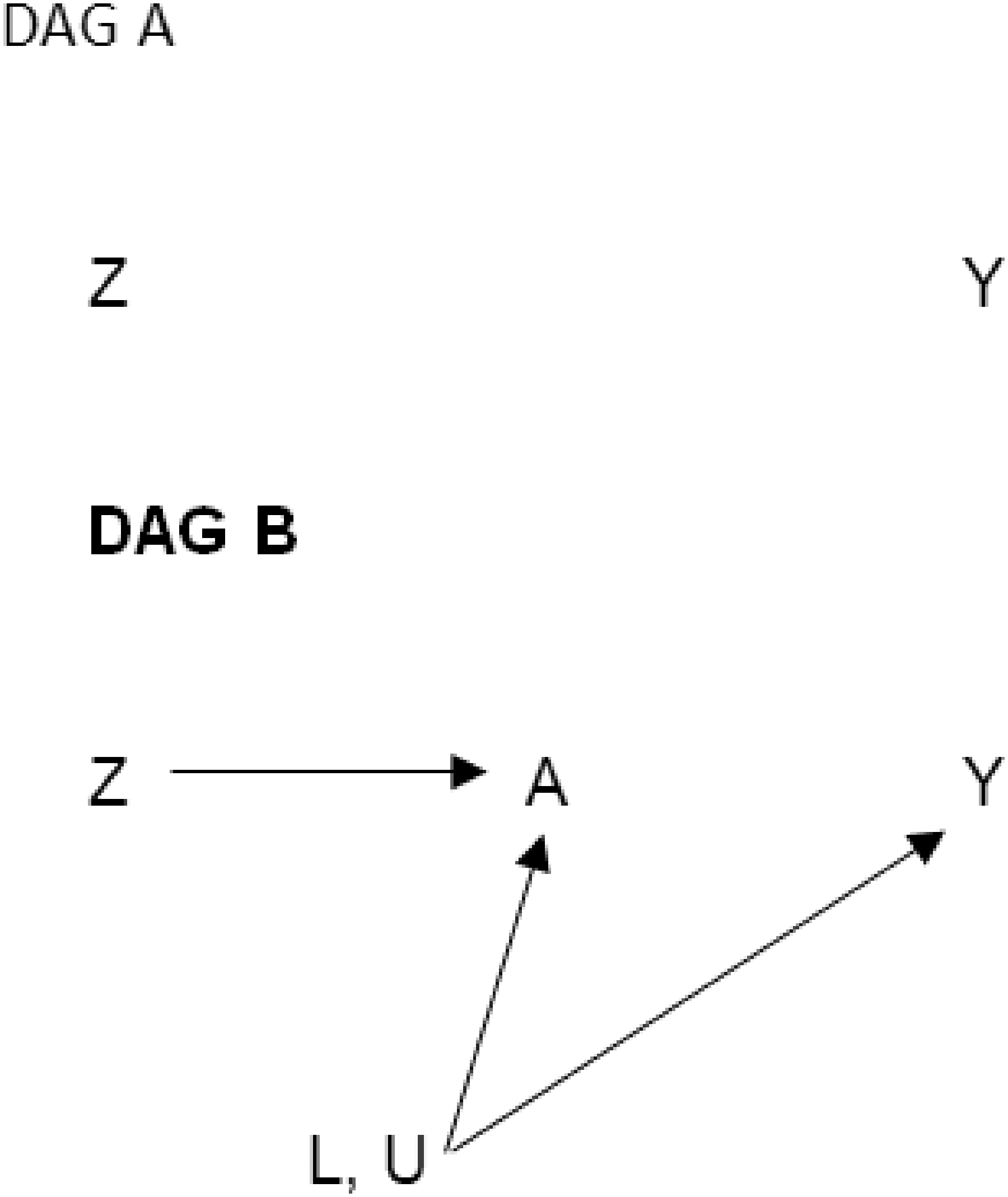
Directed acyclic graphs representing simple scenarios for estimating the intention-to-treat effect in a randomized trial. DAG A includes only Z and Y because the effect of randomization (Z) on the outcome (Y) is unconfounded by design. DAG B shows the mechanism by which the intention-to-treat effect operates. Common causes of A and Y could be measured (L) or unmeasured (U). We do not include a direct arrow from randomization (Z) to the outcome (Y) because we believe random assignment affects the outcome only through receiving treatment (A).
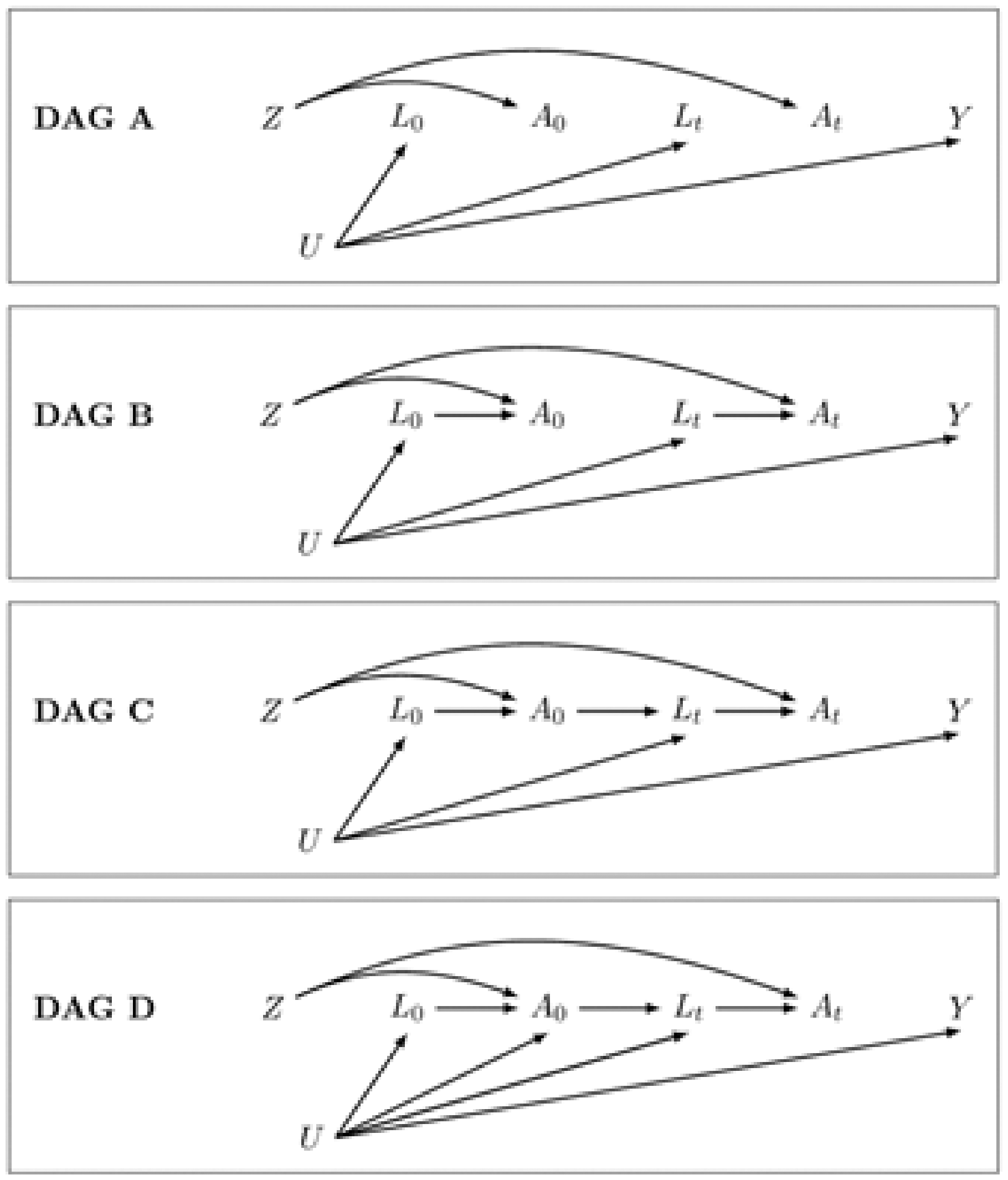
Directed acyclic graphs representing simple scenarios for estimating the per-protocol effect in a randomized trial. DAG A is drawn under the (simplistic and unrealistic) assumption that adherence is random and therefore there are no arrows from either measured or unmeasured covariates to treatment; there is no confounding or potential selection bias for the effect of treatment on the outcome, so we can use classic regression methods to estimate the per-protocol effect. DAG B imposes the assumption that the measured confounders affect adherence at each time point. In this scenario we do have time-varying confounding, but we can adjust using any statistical method (for example, adjusting for the
Estimating the intention-to-treat effect
Descriptions of how to estimate unadjusted intention-to-treat hazard ratios and conditional intention-to-treat hazard ratios adjusted for baseline variables are ubiquitous in the literature. Here, we describe how to estimate standardized average counterfactual survival curves and how to use these estimates to calculate average causal effects on the hazard ratio, cumulative incidence difference, and cumulative incidence ratio scales. We outline the following six steps, also described by Hernán and Robins.
23
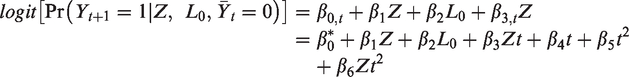
For an explanation of when and why the parameters of a pooled logistic model can be used to approximate the parameters of a Cox proportional hazards model, see Box 2. In the following steps, we will use the model’s predicted hazards p at each visit t for each value of Z and L0:
2. 3. 4. 5. 6.
Cox proportional hazards regression versus pooled logistic regression.
Conceptual difference. Cox proportional hazard regression is a semi-parametric modeling approach – we assume that the hazard ratio is constant over follow-up and in return we do not need to make any assumptions about the functional form of the baseline hazards. If your target parameter is a conditional hazard ratio, Cox proportional hazards regression makes the fewest assumptions while giving an estimate of the hazard ratio.
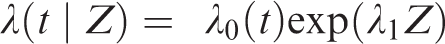
Pooled logistic regression is a parametric modeling approach –we need to make assumptions about the functional form the baseline hazard and about whether the hazard ratio is constant or time-varying. In return, we can use the results of this model to estimate not only the hazard ratio but also the survival, cumulative incidence (risk) difference, and cumulative incidence (risk) ratio. The pooled logistic regression model estimates the discrete time hazard, so one important caveat is that we need the outcome to be rare (<10%) in each time interval.
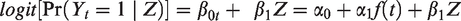
Implementation. To estimate the hazard ratio from a Cox proportional hazards model, we only need to know the amount of follow-up time and vital status at the end of follow-up for each individual. We also need to specify how to handle ties (individuals with events at the same time). Common methods are Breslow (used here), Efron, and exact.
To estimate the hazard ratio from a pooled logistic regression model, we need to use data in long (person-time) format. Time will be included as a covariate in our model to specify a functional form for the baseline hazard. We want to allow time to be included in a very flexible manner (e.g. polynomials, splines, categorical), as the pooled logistic regression model assumes that the baseline hazard is correctly specified. We can choose to include interaction terms between the treatment variable and time, which would relax the assumption that the treatment effect is constant over time. Moreover, the standard error estimates need to be adjusted to reflect the correlated observations. This can be achieved in two ways: (i) using a robust “sandwich” estimator, which gives valid but conservative estimates, or (ii) bootstrapping individuals to get valid, non-conservative intervals.
Estimating the per-protocol effect
Given a study protocol, there are two main approaches we can use to estimate the per-protocol effect: a censoring approach and a dose-response approach. Either determines:
whether each individual is adherent or not at baseline and then artificially censors them if and when they stop adhering, or whether each individual is adherent or not at every time point and models adherence as a continuous variable.
Here, we use approach (a); for an example of the second approach, see. 22
To estimate our per-protocol effect, we need to control for baseline and time-varying (post-randomization) confounding of adherence and mortality. Since many of the confounders may also be affected by prior adherence, we need to use g-methods to ensure that our adjustment does not introduce additional bias.30 Here, we will use an inverse probability of adherence weighted marginal structural model, outlined in the following steps:
Unstabilized weights, 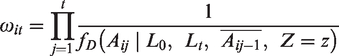
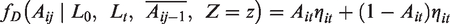
Stabilized weights are similar to unstabilized weights but have as a numerator the predicted probability of an individual having the adherence (or exposure) history they actually received, conditional on their baseline covariates. Stabilization ensures the weighting scheme is based only on the time-varying covariates.
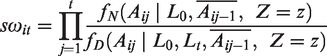
In this example we will use truncated stabilized weights – that is, stabilized weights which are truncated to prevent extreme values.
Also, note that in other settings, we may want to include adherence history in different forms in the weight models. For simplicity here, we have simply included baseline adherence (
It is best practice to check the weight distribution – while unstabilized weights can have a mean much higher than 1, stabilized weights should have a mean of approximately 1. Truncation should reduce the mean and narrow the range of the weights.
We will censor individuals when they deviate from their assigned protocol – that is, individuals assigned to the placebo arm are censored if and when they no longer take at least 80% of their assigned placebo pills and individuals assigned to the treatment arm are censored if and when they no longer take at least 80% of their assigned treatment pills. We then use a weighted pooled logistic regression model for the outcome. The model is the same as the model described in the ITT section above, except that it is restricted to the uncensored person-time:
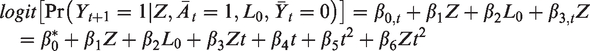
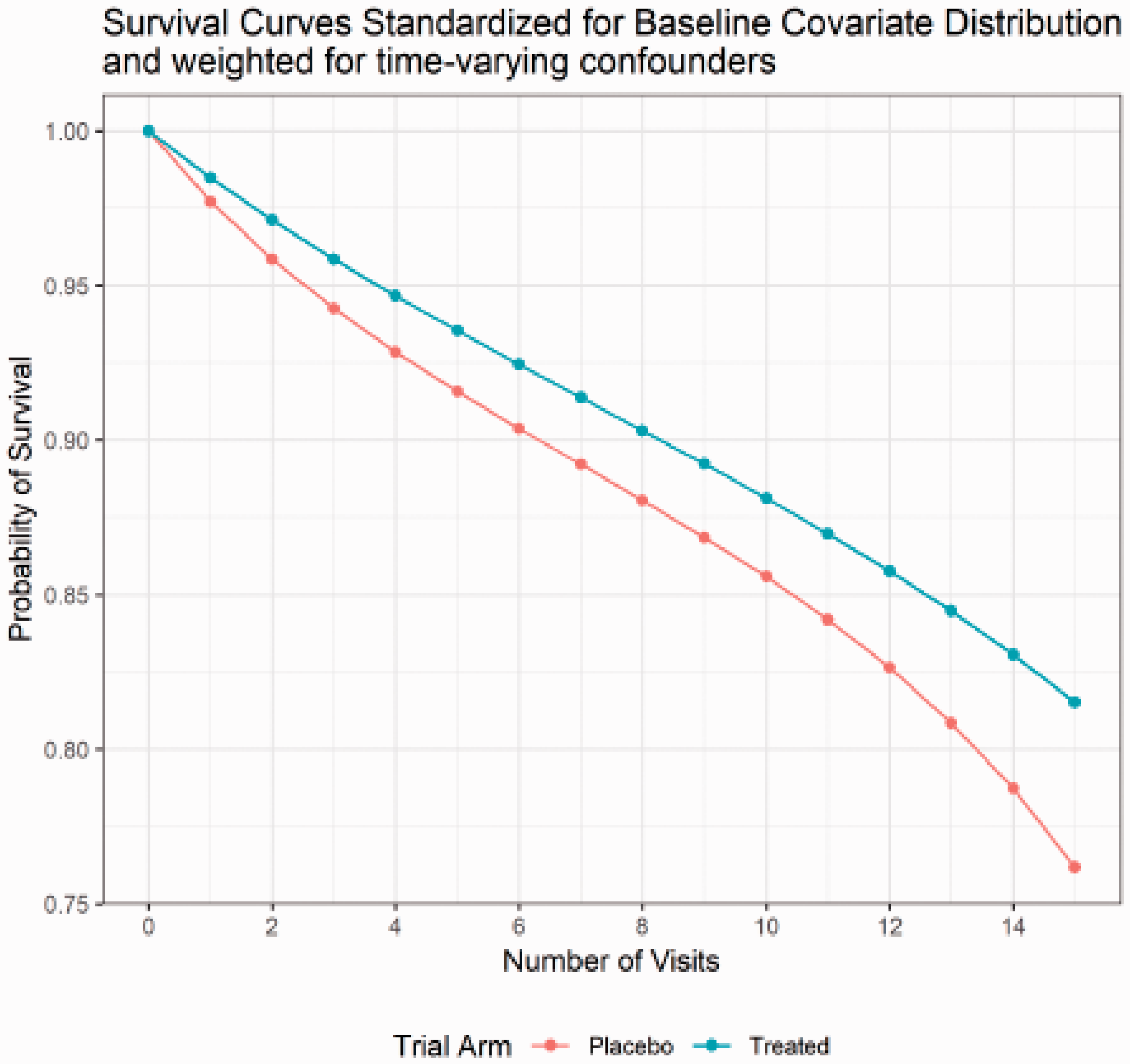
Counterfactual per-protocol survival curves standardized for baseline covariate distribution and weighted for time-varying confounders in simulated dataset.
Per-protocol causal effects on the hazard ratio (HR), cumulative incidence (risk) difference (RD), and cumulative incidence ratio (CIR) scales.
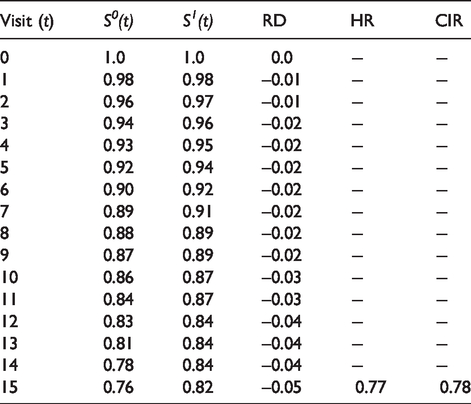
Inference
When we use inverse probability weighting, we again need to calculate robust standard errors or use bootstrapping to get valid confidence intervals. Robust standard errors will provide conservative estimates of the confidence intervals (higher than 95% coverage), as they treat the weights as true fixed population values. Bootstrapping the entire procedure (steps 1–3) will treat the weights as estimated, providing valid confidence intervals. The procedure presented here is singly robust – that is, unbiased inference depends on the assumption that the weight model is correct. Doubly robust procedures, where either the weight model or the outcome model is correct, are available, but implementation is not so straightforward.40,41
Extensions to observational studies
The main difference between causal survival analysis in RCTs or other experiments compared to observational studies is baseline confounding. Here we derived our example from a real randomized trial. However, the reader may be interested in implementing these ideas to study the effect of an exposure on a time-to-event outcome in observational data. There are two additional challenges to consider in causal survival analysis from observational studies: identification of time zero, and well-defined interventions. In RCTs, we know both when follow-up begins (time zero) and exactly which treatments are being compared because we assign individuals to treatment. However, in observational studies exposure is not assigned, leading to issues with time zero and the consistency assumption from causal inference. The target trial framework provides guidance for designing a study and analysis where the potential for bias in the choice of time zero and ambiguity in interpretation because of a lack of well-defined interventions is minimized.42–44 Briefly, the target trial framework requires us to imagine a hypothetical randomized trial to answer our scientific question, and use this to design our observational study. Using this methodology, we can frame scientific questions regarding the effect of a longitudinal exposure on a time-to-event outcome arising from observational data.
Conclusion
Randomized clinical trials are an ideal tool for estimating the causal effect of a potentially beneficial intervention. However, whenever any participants do not adhere perfectly to their treatment assignment, the interpretation of these trials can be complicated. With this tutorial, we hope to provide practical guidance on how to use modern causal inference techniques to estimate the per-protocol effect of a longitudinal treatment on a survival outcome.
All attempts to estimate causal effects require strong assumptions – even the ITT effect. In the case of the ITT, the most commonly violated assumption is that of no informative loss to follow-up. In RCTs with loss to follow-up, a similar approach to that described here for adjusting for non-adherence can be used to adjust for informative loss to follow-up, but only when predictors of loss to follow-up that are also prognostic for the outcome have been measured in trial participants.
When the per-protocol effect is of interest, we encourage trialists to also consider conducting and presenting a range of sensitivity analyses. When the comparator treatment is placebo and if experts agree that the placebo truly has no effect on the outcome of interest, one useful sensitivity analysis is to compare adherers to non-adherers in the placebo arm using the methods described above for estimating the per-protocol effect, but replacing randomization status with adherence status.21,22,27,28 Although such an analysis cannot guarantee that the required causal inference assumptions are met, it can be used to detect situations in which the required assumptions are clearly violated.
In this tutorial, we focused on explaining the estimation of the per-protocol effect in a simple case, where the longitudinal treatment has a single approved dose, adherence is measured as a binary variable, treatment cessation is not allowed for any reason, and there is no loss to follow-up and no competing events. Methods exist to address all of these complexities, but are beyond the scope of the current tutorial. For an overview of the conceptual approaches to dealing with those challenges, we encourage readers to refer to. 14
Footnotes
Authors’ contributions
We wrote this article to disseminate and facilitate the implementation of modern causal inference methods for survival analysis to a general public health practitioner audience. E.J.M., E.C.C., and L.C.P. developed the concept and wrote the article. E.J.M. wrote the SAS and Stata code. L.C.P. and E.J.M. wrote the R code. All authors drafted and revised the both manuscript and the code. All authors read and approved the final version of the manuscript. E.J.M. and L.C.P. are the guarantors of the article.
Acknowledgments
We thank Roger W Logan for his help creating the simulated dataset. We thank Miguel Hernán for helpful feedback on an earlier version of this work.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.