
Abstract
Unplanned dilution in underground mining is detrimental to the business, as imprecise dilution factors may impair production forecasts for existing operations or the economic evaluation and viability of brownfield expansions and greenfield projects. While high prediction accuracy of over 90% has been achieved using machine learning algorithms, particularly artificial neural networks (ANNs), the studies mostly predicted the overall dilution of stopes or included performance-subjective determinants, such as drill and blast factors. These factors compromise the models’ reproducibility for extensional application to cover new mining projects that do not have historical drill and blast input. To address this, the study explores gene expression programming (GEP) and ANN with backpropagation (BPNN) to predict dilution on a per-stope granularity based on geotechnical and design data. A 138-stope sample from a sublevel open stoping gold mine operation in Western Australia was used to generate predictive models. Model and infield results showed that the GEP model performed better, with a coefficient of determination, R2, of 0.740 with a root mean square error (RMSE) of 0.361 compared to BPNN's 0.681 and 0.409, respectively. Accordingly, the GEP model is recommended for dilution prediction for mine planning and production scheduling at the prescribed level of accuracy.
Keywords
Preliminaries and motivation
Predictive machine learning (ML) algorithms are increasingly being deployed to infer underground mining performance metrics such as mining dilution, improving the robustness of performance forecasts and enabling the upfront establishment of appropriate mitigatory controls (Nanda, 2020; Chimunhu et al., 2024b). Various underground mining methods exist, with the open stoping method being the most commonly used, particularly for narrow to medium-width orebodies. The method is preferred for its simplicity in execution and retreat methodology, which minimises personnel exposure to mined voids. Input assumptions such as mining dilution and recovery are essential in estimating the mining efficiency of planned mining blocks, called stopes. In particular, dilution accounts for the additional percentage of subeconomic or waste material mined in the course of extraction of the planned stope and is dependent, to a large extent, on rockmass quality, stope geometry and design, amongst other factors (Henning, 2007; Henning and Mitri, 2008; Mathews et al., 1980; Sutton, 1998). Figure 1 provides a simplistic overview of planned and unplanned dilution for a stope in open stope mining. The mining dilution factor is one of the underlying key input assumptions used in generating production schedules that forecast quantities (tonnes) and quality (grades) of metal to be mined per period (usually monthly) over the remaining life of the business. The schedules’ production forecasts are then used to project the business cash flows and assess the sustainability of operating projects or the economic viability of brownfield expansions (i.e. near-mine extensions where geological/geotechnical continuity is not confirmed but may be assumed based on their proximity to existing areas) and greenfield projects (i.e. new mining projects planned and mostly rely on transferable methodologies established elsewhere to establish suitable project-specific assumptions).
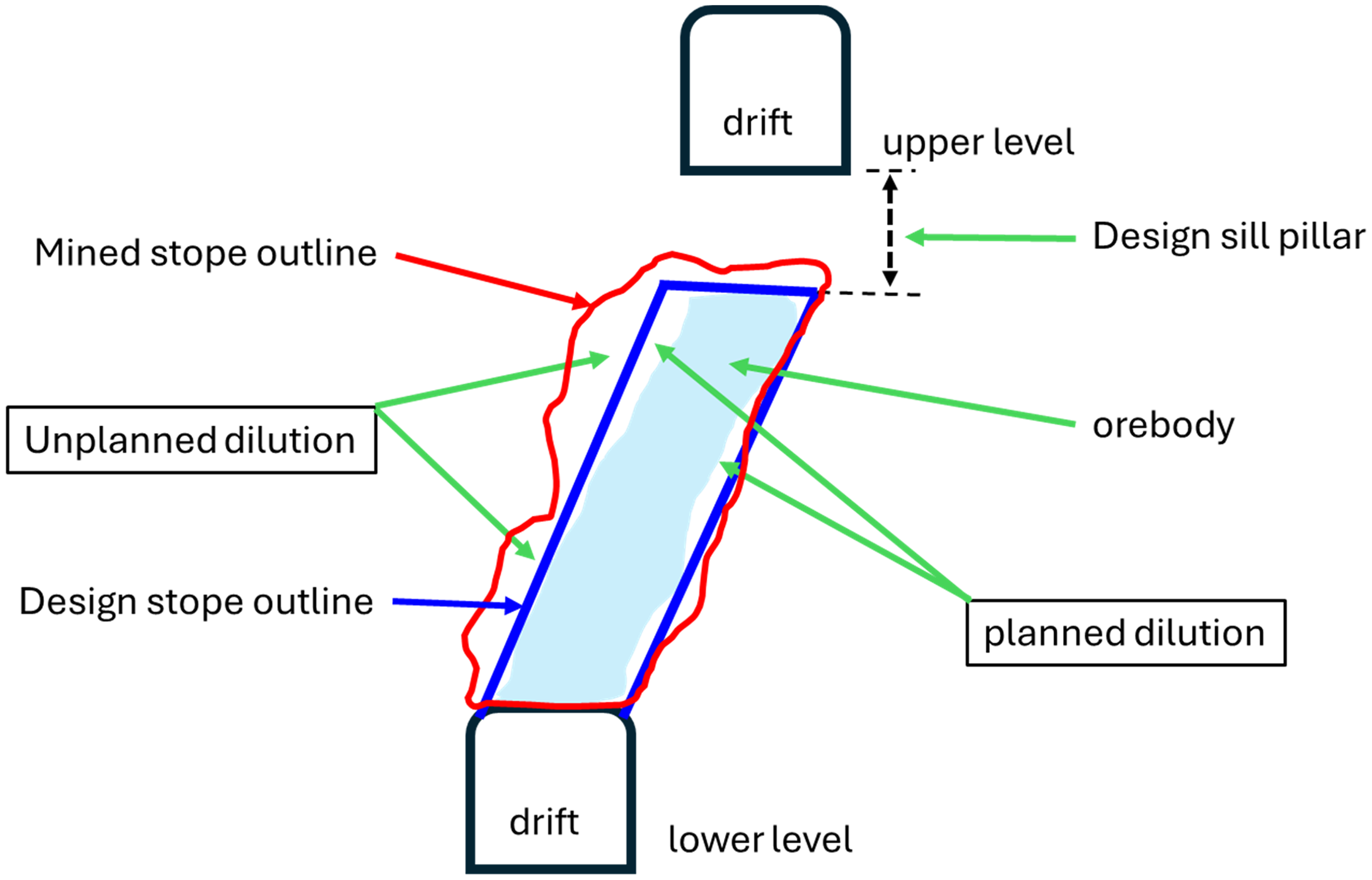
Planned and unplanned mining dilution in open stope mining.
Evidently, a robust dilution estimate is crucial in production forecasting as an underestimate/overestimate affects projected production volumes with serious ramifications to the project's financial performance (Planeta et al., 1990). Yet, despite this glaring fundamental, the common practice in mine planning uses a flat dilution factor for all stopes, in existing mine areas or brownfields and greenfield extensions. The adopted flat factor is usually derived from the historical stope performance data on prior mined stopes, whose performance may not adequately reflect future performance due to differences in the transitional degree of interactions amongst the causative factors as ground conditions and design attributes evolve (Chimunhu et al., 2024a). As a result, opportunities to implement targeted controls on potential high-dilution stopes or optimise production schedules based on a granular prediction of individual stope performance are lost. Further, as production schedules are usually developed years ahead of actual mining to inform high-level economic viability and business sustainability and related decisions, it is prudent that robust dilution factors are established based on stope-specific data available at the early stages of stope design and schedule generation. While prefeasibility data may be limited and crude, its application for dilution prediction provides fundamental insights on the phenomenon, unbiased by human-induced factors such as drill and blast performance, enhancing the generalisation of findings and transferability of concepts to new mining projects.
The stope's geotechnical properties, such as the rock quality designation (RQD), modified stability number (

The Mathews stability graph, proposed by Mathews (Mathews et al., 1980), and later modified by Potvin (Potvin, 1989) and other scholars, is one of the most widely used empirical methods for predicting hanging wall stability and dilution in underground mining. The method predicts hanging wall stability through graphical delineation of zones of stability and instability based on the modified stability number (N′) and hydraulic radius (HR) of a mined void (Sutton, 1998; Suorineni, 2010). The relationship between the modified stability number, N′ and


Summary of key studies on dilution prediction in underground mining and tunnelling.
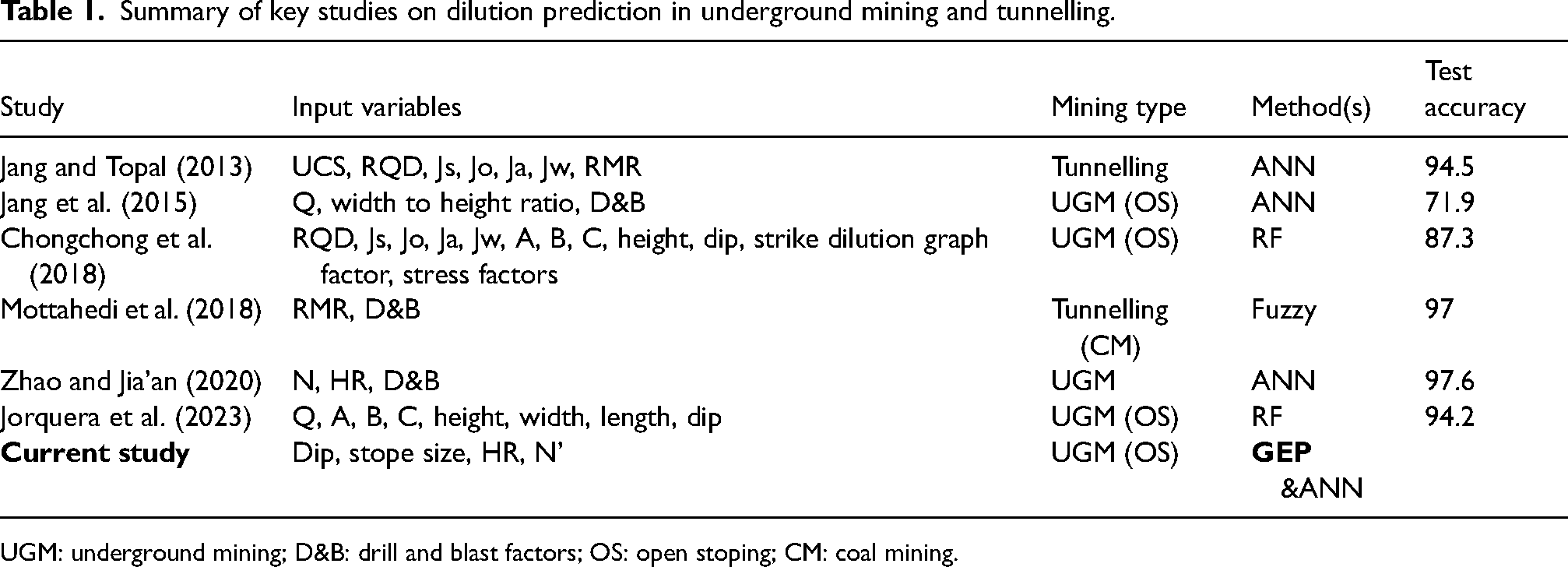
UGM: underground mining; D&B: drill and blast factors; OS: open stoping; CM: coal mining.
Further, the studies also reveal that a high prediction accuracy of over 90% observed in ANN models is achieved mostly in the tunnelling environment or when additional factors, such as the human-influenced drill and blast performance, are considered.
However, Jang et al. (2016) established that rock quality, stope width, mining depth and the horizontal to vertical stress ratio were key dilution causative factors, with drill and blast factors ranked as secondary causatives in their investigatory study on the relative importance of 10 dilution causative factors. Further, these findings were also complimented by Chongchong et al. (2018), who concluded that the stope design method, RQD, stope height, dip, strike and joints data were primary drivers of dilution in underground mining based on 13 influencing variables analysed from a sample of 115 hanging wall cases for sub-level open stoping (SLOS) operations using the RF algorithm. A recent study on dilution for open stoping operations by Cadenillas (2023) also confirmed that stope height, length, width, hydraulic radius and dip angle significantly influenced dilution based on 29 causative variables for underground mining. This suggests that while there are numerous causative variables, variables related to rockmass quality and stope geometry are principal predictors that significantly influence prediction accuracy. Further, human-influenced factors such as drill and blast performance have improved prediction accuracy, albeit as secondary determinants. Therefore, the omission of such in other studies that still managed to achieve prediction accuracy of over 70% strongly suggests their influence is minimal, considering the bias they potentially introduce arising from subjectivity on human performance and potential human errors. This perspective is supported by Urli (2015), who asserts that rockmass quality (as measured by the modified stability number, N′) and stope spans (HR) are chief causes of dilution and proposes ore-skin design options, which minimise hanging wall disturbance or dilution by not extending blast holes to hanging wall contact. Further, Mateo et al. (2024) also proposed and successfully demonstrated the variability of drill- and blast-related dilution through the application of presplitting blasting techniques at Pique mine in the El Oro province of Ecuador, suggesting that the influence of drill and blast factors on dilution can be considered and handled at a localised scale based on site-specific mining standards and experience. On a similar note, Delentas et al. (2021) argue that optimising the design features of the stopes at the early design stage (stope geometry) is one of the most effective control mechanisms for dilution in underground mining based on the results of their study on stability conditions and dilution in open stoping operations. Such initiatives include optimal placement of drives relative to the reef to minimise footwall trenching dilution when it comes to stope production, control of production drill hole deviation using drill-mounted azimuth aligners and a plethora of other drill and blast controls that are being made possible by an increasing realisation of the possibility of ML augmented capabilities in underground mining (Chimunhu et al., 2024b). As such, drill- and blast-induced variations are expected to be small to moderate, well within reach of the capacity of modern mining standards.
Soft computing methods have also been used to predict dilution in related tunnelling studies, with a prediction accuracy of over 84% reported (Mottahedi et al., 2018). However, these methods have not been sufficiently extended to cover underground mining operations such as open stoping. In the past decade, evolutionary ML models such as genetic algorithms (GAs) have shown a continued and stable application in prediction and forecasting studies, as ANN models are usually not the first models of choice due to their black-box nature in their prediction architecture. In particular, gene expression programming (GEP), a sibling of genetic programming algorithms inspired by the Darwinian evolutionary theory of ‘Survival of the Fittest’ (Roohollah Shirani et al., 2017; Shirani et al., 2024), is increasingly being used to develop mathematical predictive models. The model was first introduced by Ferreira et al. (2002), leveraging the merits and overcoming the limitations of the pioneering works of Koza (1994) and Sampson (1976). In its simplest form, the GEP model, like the GA, utilises a randomly generated sample population (chromosomes) as the initial population. This population is then improved multiple times (evolution) through activation by a group of genetic operators (mutation, crossover, reproduction, etc.). The dominant characteristic genes of the surviving population then represent the model's solution, encoded in strings called chromosomes. The solution is expressed in a branch-like structure linked by genetic operators that describe the multiple relationships between the leaves. In its mathematical presentation, the model's ability to generate clear and structured mathematical representations of complex systems and phenomena through its mutational architecture offers increased visibility to underlying relations for modelling complicated relationships often handled by neural networks in a black-box architecture. Further, its successful application in related mining studies, such as the prediction of rockbursts (Shirani Faradonbeh et al., 2022; Shirani et al., 2024), blast-induced ground vibrations (Faradonbeh and Monjezi, 2017; Shirani Faradonbeh et al., 2016) and more recently, hanging wall stability in underground mining (Amirkiyaei et al., 2023; Jalilian et al., 2024), lends its credibility in offering potential solutions to extensional studies such as overbreak prediction (dilution) in underground mining as proposed in this study.
This study aims to establish a dilution prediction model for individual stopes based on geological/geotechnical and geometrical (design) attributes and generate a mathematical equation of the model to facilitate the optimisation of production schedules through granular predictions on stope performance. The study also aims to establish a dilution prediction model that is not influenced by human performance factors such as drill and blast performance and, therefore, is generalisable for extensional applications in open stoping operations at the strategic level of detail. When that is achieved, the novel contribution of this study to existing literature emanates from using a unique set of data available at the early stages of mine planning to predict dilution on a per-stope basis. Further, the study's significance lies in its pioneering incubation of a GEP-based methodology for dilution prediction in underground open stope mining operations, where currently, to the authors’ knowledge, no known studies have explored its application. While the crudeness of the input data at the early stages of mine planning and production schedule generation points to potential challenges in achieving high prediction accuracy, this study seeks to harness the merits of the increasing ability to use reduced data inputs and still generate more insights, utilising the computing power of modern-day computing systems coupled with emerging ML applications as proposed by Chimunhu et al. (2022, 2024c) and Buaba (2023). While the deliberate omission of drill and blast input may result in a lower prediction than when included, the prediction is not impaired by the subjectivity of human performance that comes with its inclusion. Further, if modelling and prediction with fewer data achieve a considerably high prediction accuracy, this may save on the additional time and costs that would have been required to generate more data and, more importantly, will likely bring production schedules and cash flows forward with an earlier start in production.
In a nutshell, the chronological progression of studies on mining dilution largely shows an increasing inclination to include drill and blast factors to improve prediction accuracy. However, including drill and blast factors requires that a reasonably large number of stopes are mined first to create the relevant database. As such, the results will be limited in application scope, particularly when planning for brownfields extension or greenfield projects where no drill and blast and related databases exist. Few studies that have not considered drill- and blast-related factors continue to face challenges in achieving relatively high prediction, particularly for prediction on a per-stope basis. This study leverages literature to explore different input variables, riding on the merits of emerging ML applications such as gene expression programming, which has not been used extensively in previous related studies.
Data collection and preparation
Parametric and geotechnical data for 167 stopes was collected from an anonymised multireef narrow to medium-width orebody open stope mining operation in Western Australia. Parametric data focused on stope size (T), dip (A) and dimensions to calculate hydraulic radius, HR, while geotechnical data comprised additional random checks on rock quality measures to verify stope stability numbers (N) acquired from the geotechnical database. The equivalent linear overbreak slough (ELOS) measurement method was used to convert measured dilution values from percentage form to metres for a linearised transformation of the values to improve dimensional consistency with other variables. The dilution proxy, equivalent ELOS, was back-calculated from percentage form and converted to ELOS classification system as per equation (4):
This transformation was essential for comparing dilution on stopes with different widths, as percentage dilution factors do not reflect the comparative magnitude of hanging wall overbreak (dilution) when assessing stopes with different widths. The resultant ELOS equivalent dilution proxy will later be reconverted back to percentage form for production scheduling purposes. ELOS values above 3 m were discarded as such magnitude of overbreak is generally regarded as a failure criterion and not overbreak (Brady et al., 2005). A desurvey of the mine's exploration drill hole database was conducted to randomly check some of the drill hole intercepts on the sample stopes and use the borehole data to check the core samples and logged geological and geotechnical data for any obvious discrepancies. Further, a correlation matrix was used to assess any interference amongst the variables that could lead to redundancies or poor model calibration and performance (Figure 2).
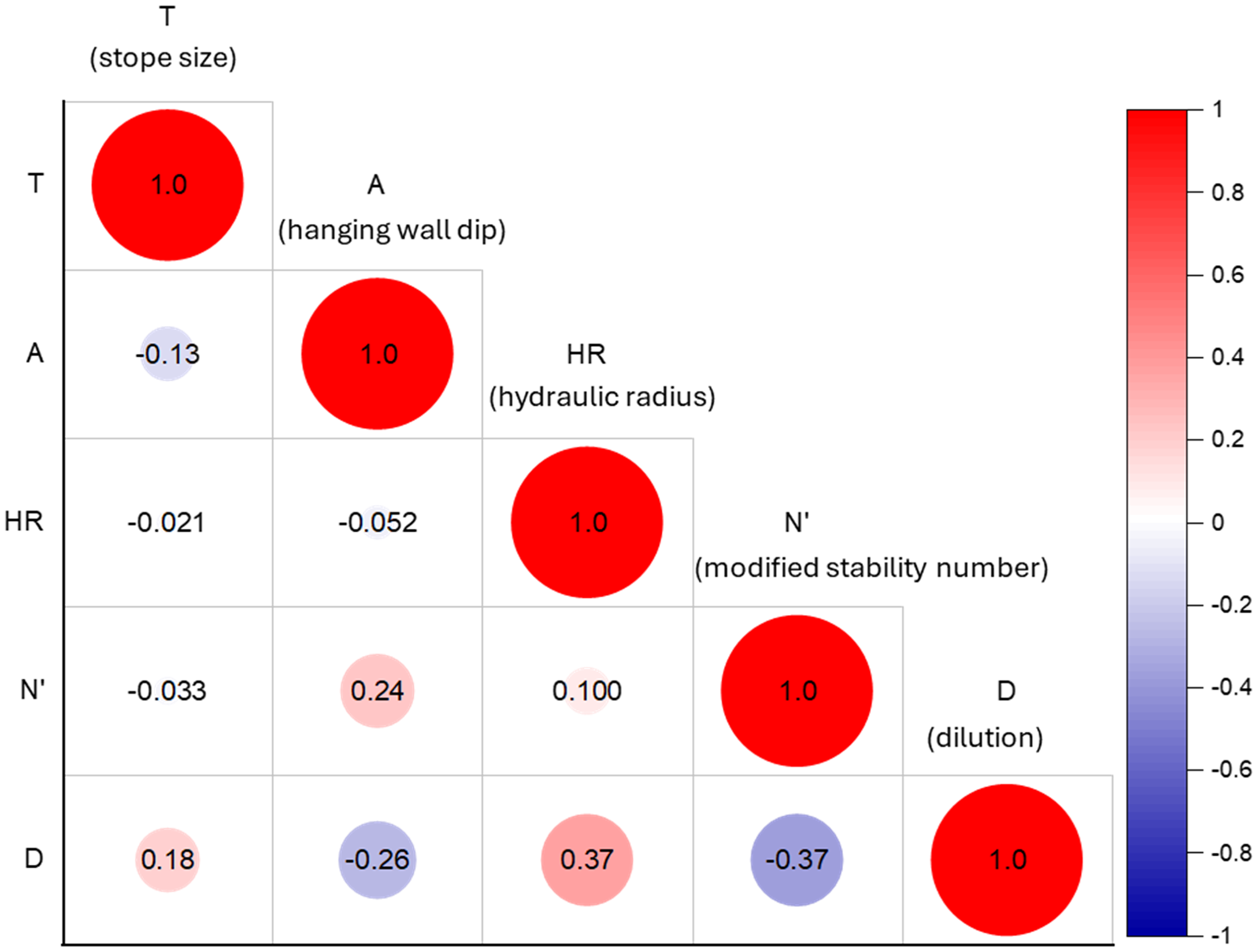
Correlation matrix for the dependent and independent variables.
Histogram plots for the dependent variables showed that the distributions were largely asymmetrical as the stopes were from different reefs with dissimilar wide-ranging geometrical and geotechnical attributes. As such, a data contextualisation approach was adopted to ensure that the observed asymmetry was not error-driven, but represented inherent variability of data and a legitimate population of stopes that the model will still encounter and expected to predict dilution on. This approach involved additional checks and validations on the primary data sources, such as borehole logging and stope design data, to deal with outliers and noted anomalies. Further, these checks were critical to ensure the models would be trained on a realistic data profile that would enhance the models’ projective capability and generalisability. Measurements outside the data’s interquartile bounds, Q1 − 3(Q3 − Q1) and Q3 + 3(Q3 − Q1), where Q1 and Q3 represent the data's first and third quartiles, are generally regarded as extreme outliers that require to be removed to avoid skewing of data (Faradonbeh and Monjezi, 2017). A total of 29 cases were removed from the original data set following the completion of the data processing phase (i.e. missing values, outliers and unvalidated discrepancies), and 138 cases were kept for the study. A summary of the descriptive statistics for the final data set is presented in Table 2, and an overview of the distribution is presented graphically in the form of histograms in Figure 3.
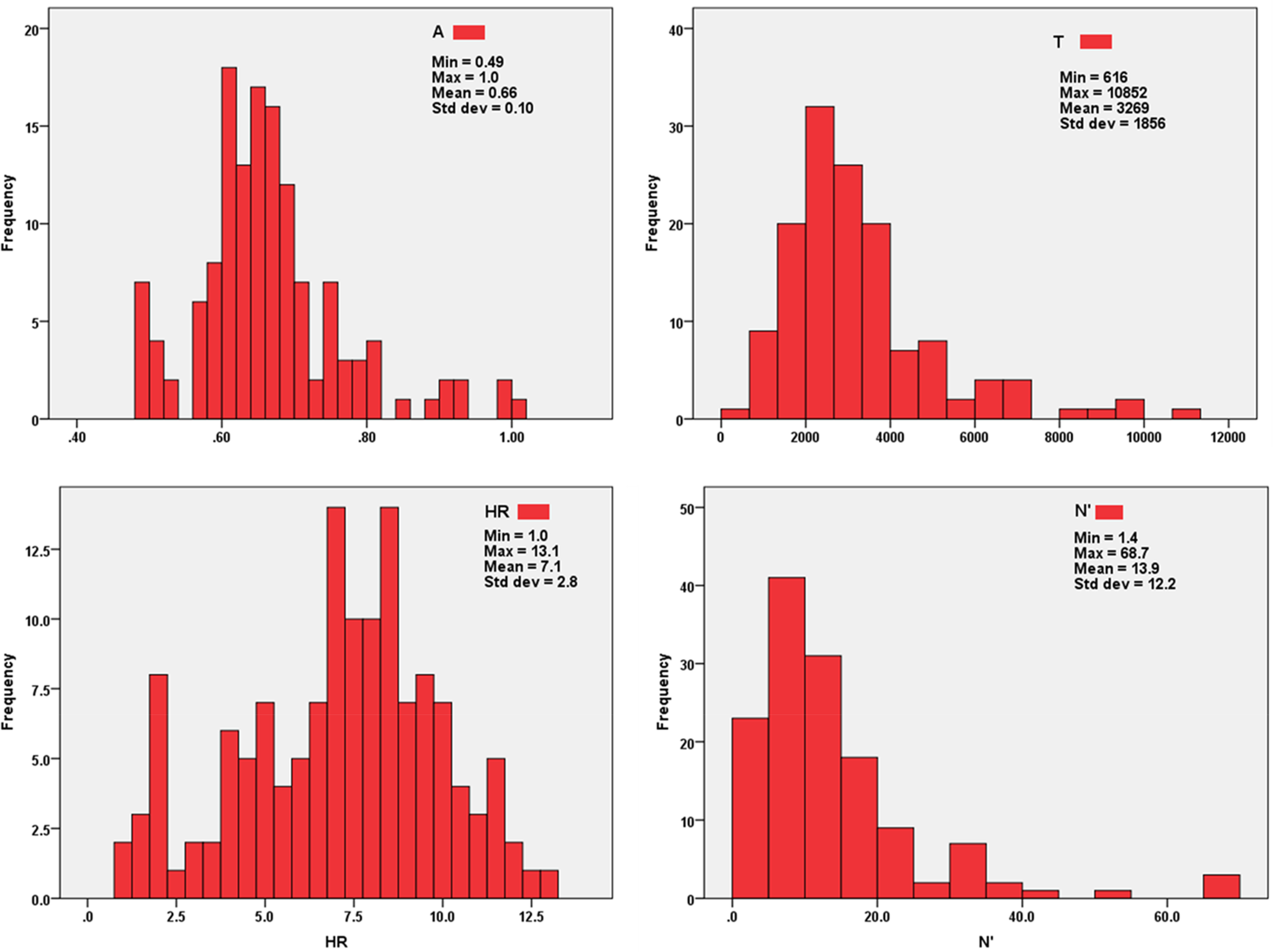
Histograms showing the statistical distribution of input data.
Stope variables considered for this study.

The sample data was then randomly shuffled several times before splitting it using the 80/20 rule for the training and validation or training and test sets. Accordingly, 115 samples from the shuffled data set were used as a training and validation set, and the remaining 23 samples were held out as a test set.
Methods and model development
Figure 4 presents a conceptual framework for the dilution prediction model construction followed in this study. It shows the generalised relationships between input variables, key processes and the independent variable. This framework sets the overarching philosophy to which all the proposed models will generally relate.
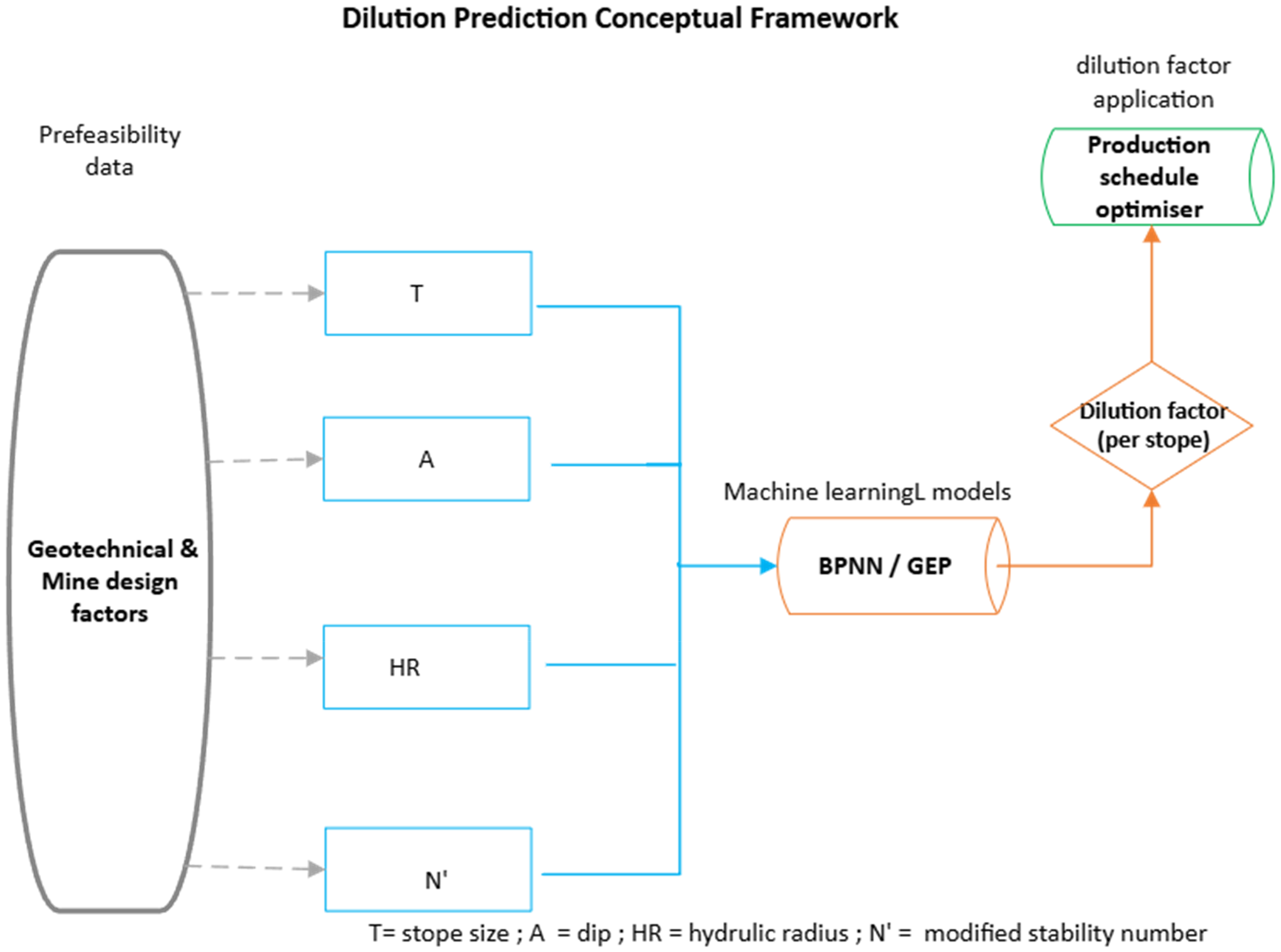
A generalised conceptual framework of the study.
Backpropagation artificial neural network (BPNN) algorithm
The three-layer structure backpropagation neural network has been shown to have strong approximation abilities for non-linear relationships in related mining studies (Lawal, 2020; Zhao and Jia’an, 2020). The model architecture comprises three layers: the input, hidden and output. A summary of the model's design and prediction is provided. However, the reader is directed to Li et al. (2021) and Zheng et al. (2022) for more comprehensive information on the algorithm's design. In the backpropagation algorithm, input data is processed through a transfer function through the hidden layer in a forward pass to the output layer. The output is compared to the measured target value, and the error variance is relayed back to the network in a backward pass to adjust synaptic weights, triggering an update to the model's input weights to reduce the output error to within set limits (Greenwood, 1991). Thus, ANN prediction optimisation fundamentally involves establishing optimum weights for inputs to achieve convergence below minimum set error limits. The input weights and bias of the optimised model are then used to establish a mathematical equation that represents the relationships between the inputs and the outputs.
BPNN model construction
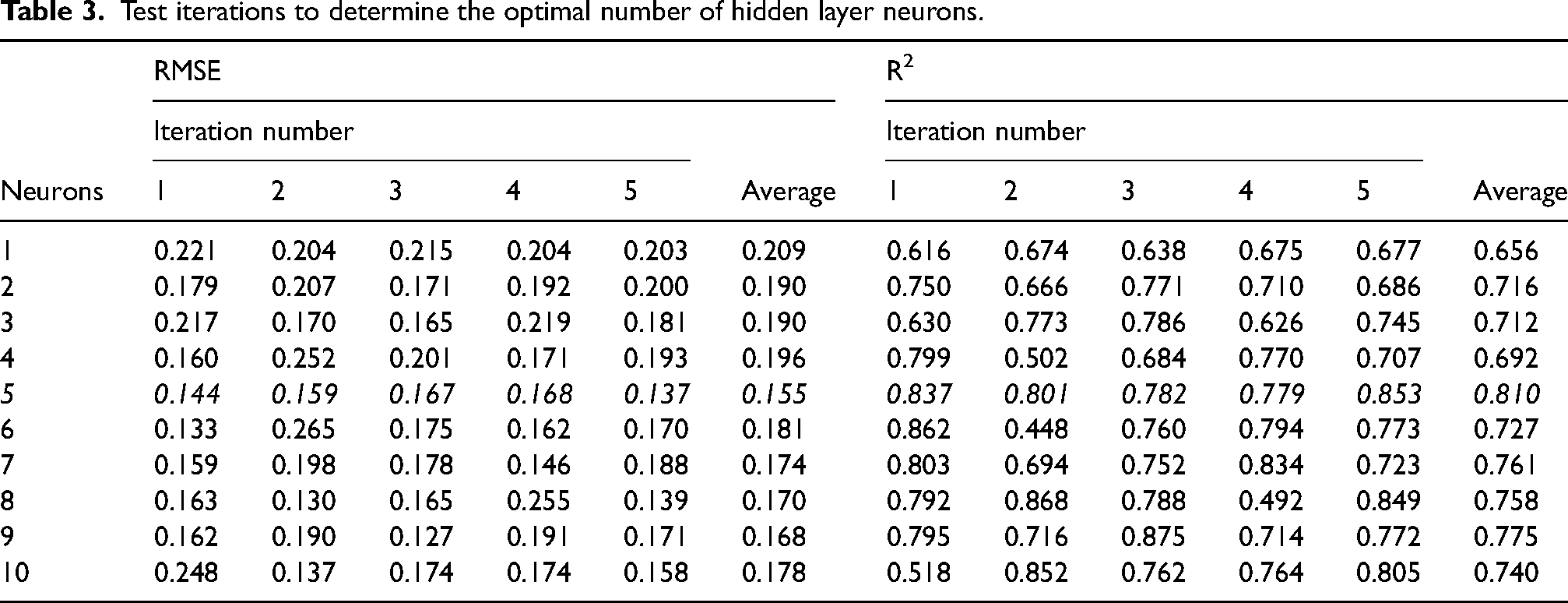
Extant literature on ANN model development has no universally prescribed method for determining the optimal number of neurons for the hidden layer. However, one widely used method is the trial and error approach, and this was adopted for this study. This involved iterative test runs to test various configurations as proposed by Gorman and Sejnowski (1988). MATLAB® was used to determine the number of hidden neurons for a range of 1–10 neurons by performing test runs in an iterative loop and assessing performance, seeking to establish a neuron architecture with the least RMSE. The lowest RMSE value was achieved with five neurons in the hidden layer (Table 3).
Test iterations to determine the optimal number of hidden layer neurons.
Accordingly, a five-neuron configuration for the hidden layer was adopted as the optimal neuron architecture for the BPNN model (Figure 5). The input layer has four neurons corresponding to the study's proposed input variables. The output layer has one neuron representing the output, i.e. ELOS equivalent dilution (D). K-fold cross-validation (CV) was used to split the data into subsets (k-folds) on which the model was then trained and validated ‘k’ times instead of a single run. Cross-validation was essential to avoid overfitting the model and ensure that the model's performance could be generalised on unseen data and, therefore, appropriate for prediction purposes. Specifically, a five-fold CV was applied to split the training set into five subtraining sets (five-folds). In each iteration, data from four folds (80% of the training set) was trained and then validated on unseen data from the remaining fold (20%). A low learning rate of 0.001, a target error threshold of 10−2, a maximum number of training epochs without change of 100 and maximum training iterations of 10,000 were used to ensure effective model training. Further, the model's independent variables were also normalised to the [0,1] range to improve the dimensional consistency of inputs and ensure compatibility with the selected activation function.
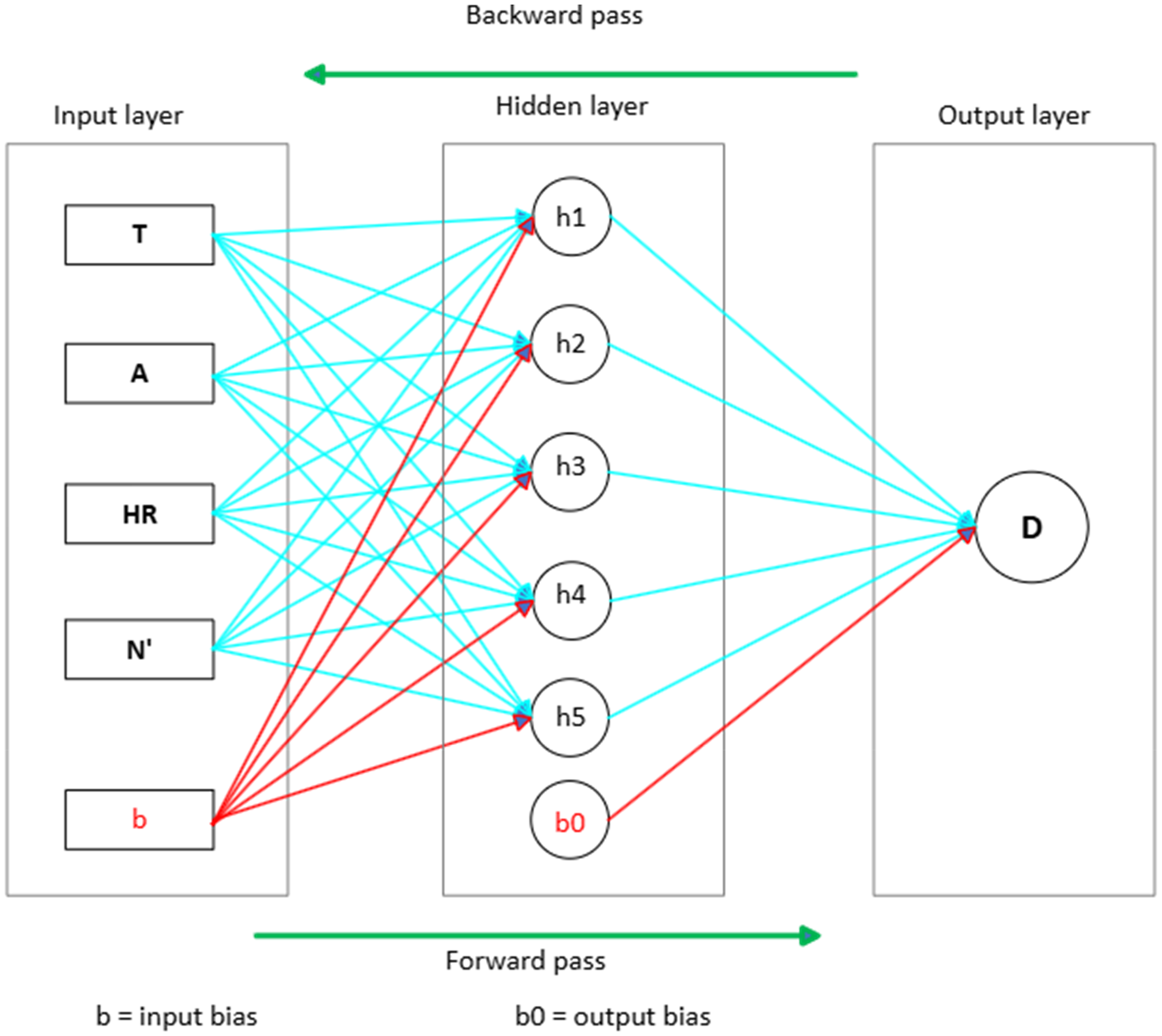
ANN model architecture showing the layers, neurons and dual propagation directions.
The network model was built using the Origin Lab® software. The software has a simplified user interface with a wide range of optionalities on input data settings and output display, providing great flexibility in training neural network models. A key feature of the software is its default capability to normalise or standardise inputs in the background for network training but still keep the output (predictions) in their original, unscaled form. As such, the formulated proxy regression equation will also be in the same format to effectively simulate the training environment for optimum performance. Model tuning was conducted by trialling different activation functions (logistic, identity, hyperbolic tangent and rectified linear unit) and assessing the model's performance. The best training and validation performance was achieved using the logistic activation function (the sigmoid function), with an average
Summary of the models’ training results for five-fold cross-validation and the final model.

The sigmoid activation function, which is defined mathematically as
Logistic (x) = 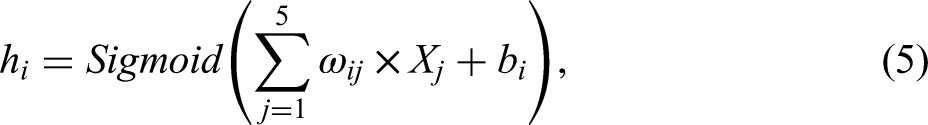
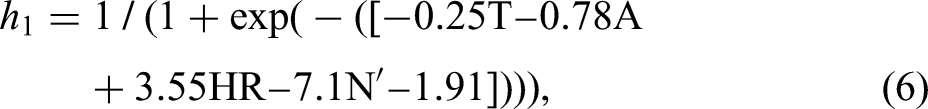

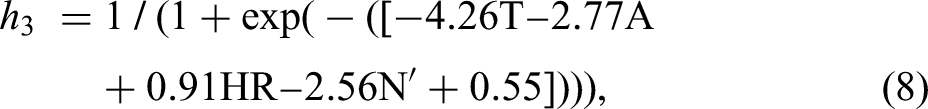
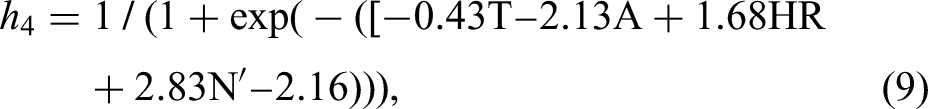

The output from the hidden layer (i.e. predictions) is calculated using the formula below: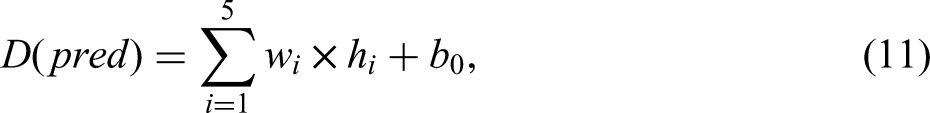
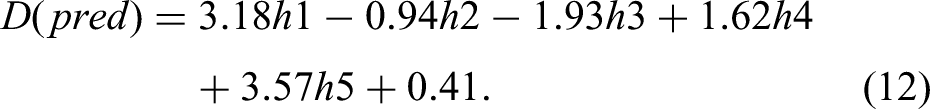
If required to calculate dilution with the original unnormalised inputs, then equation (12) will need to be back-transformed by replacing the normalised values in equations (6) to (10) with the actual values using equation (13):
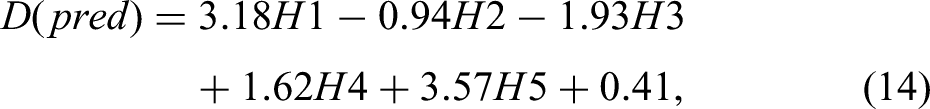
Gene expression programming algorithm
Gene expression programming (GEP) is a genome–phenome nature-inspired genetic algorithm that integrates the simplicity of the legacy genetic algorithms and the proficiencies of genetic programming (Roohollah Shirani et al., 2017) to decipher relationships between variables and use the acquired knowledge to explain the relationships (Ferreira et al., 2002). The model allows user-defined fitness functions to evaluate the initial randomly generated population of linear-coded fixed-length strings of different sizes (chromosomes) that use the Karva code language to interpret and express coded programs. The chromosomes comprise genes with a head and a tail and can also be presented as expression trees (ETs). Terminals (input variables and constants) and functions (mathematical functions) in the head instantiate chromosome modification through processes such as mutation, inversion or transposition (Mohammadpour, 2017). These modifications to the selected population generate a new population with new characteristics. Preference for reproduction is accorded to the fittest chromosomes. This process repeats on the new population until a suitable solution is achieved or stopping criteria are met. A concise description of the key stages of GEP is presented; however, for a detailed scope, the reader is directed to the comprehensive treatise by Ferreira et al. (2002). The GEP algorithm has six key steps, as outlined below and graphically presented in Figure 6.
Establishment of the functions and terminals that govern the formation of chromosomes Selection of a fitness function for model performance evaluation (the Random generation of the initial population using functions and terminals Evaluation of the chromosomes’ fitness using the selected fitness function (RMSE) Selection and retention of best chromosomes for replication in the next generation The modification of chromosomes through genetic operators and their rates (mutation, inversion, transposition, recombination) and combining reproduced chromosomes with retained best chromosomes to create the next generation of chromosomes
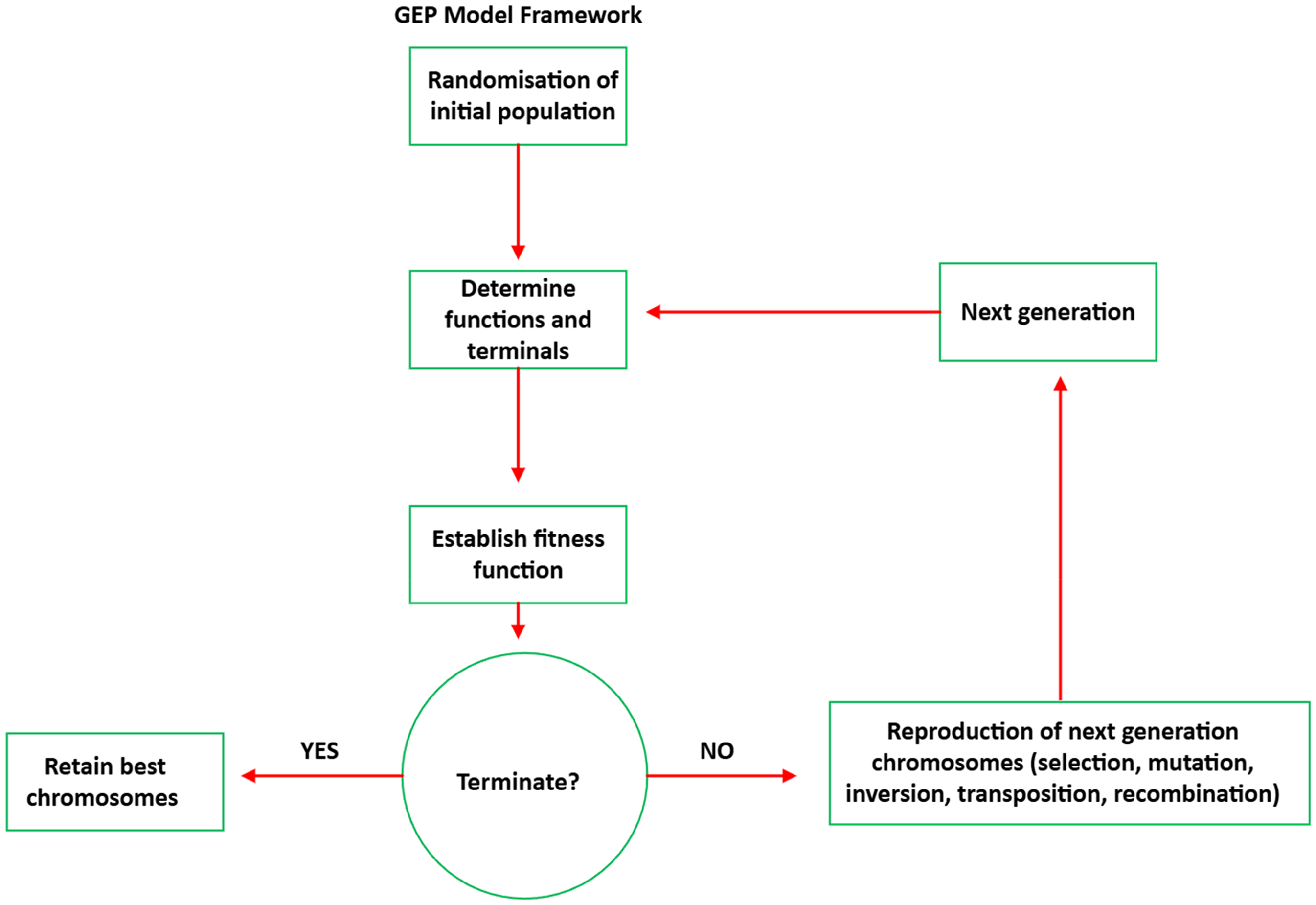
Generalised schematic of the GEP model framework.
The process repeats through a closed-loop iteration between steps iv, v and vi until the circuit is broken by achieving the set fitness condition, or a number of generations. At this point, the optimal solution is reached.
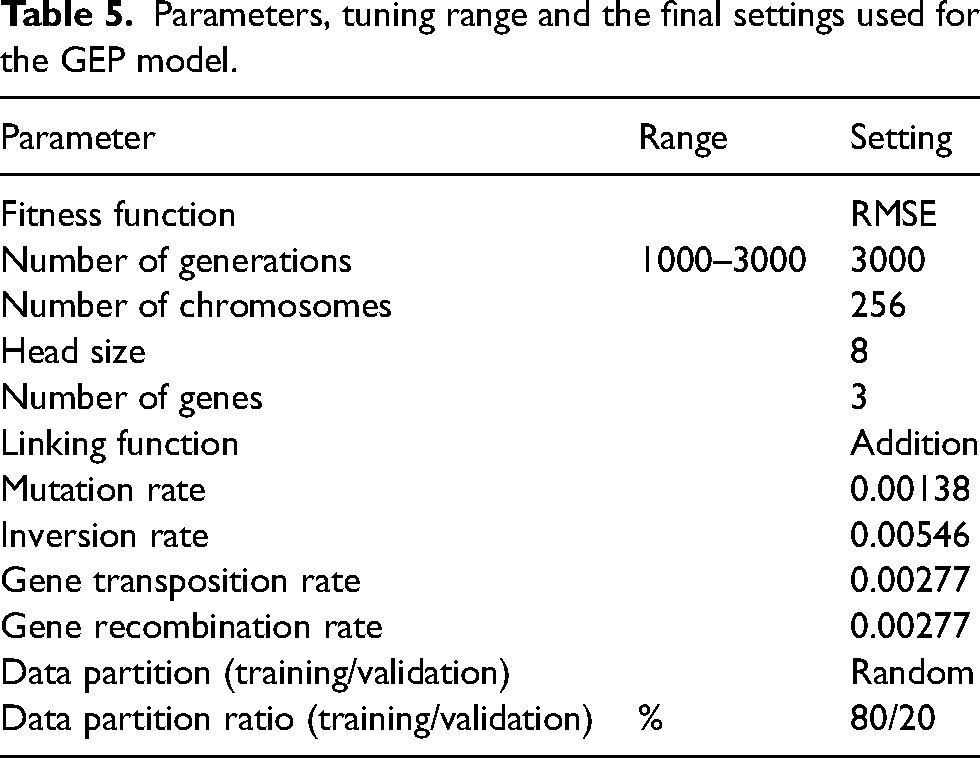
GeneXproTools software version 5.0 was used to build the model. The software is a powerful tool with exceptionally high flexibility in modelling functions and optionality that can quickly generate prediction models once the data is processed and provided in the required format. Several iterations were conducted using different genetic linking functions (i.e. ×, /, +, −) as part of model tuning, and finally, the addition (+) linking function was selected based on comparative performance results. The maximum generation was set at 3000 to avoid overtraining, which could result in overfitting the model. Further, model performance trial runs conducted using either the actual or normalised inputs yielded similar results, leading to conclude that input data transformation was not necessary. Random shuffling was used based on the 80/20 rule for subsplitting the original training set (115 samples) into a training (92 samples) and validation set (23 samples). After establishing the model's optimal settings, the parameters and settings eventually adopted are presented in Table 5.
Parameters, tuning range and the final settings used for the GEP model.
Five consecutive runs were conducted on these settings, with a random split of the entire training data set of 115 samples using the 80/20 rule to split it into a subset of a new training and validation set with 92 (80%) and 23 (20%) samples, respectively. The results of the consecutive training iterations are summarised in Table 6.
Summary of the GEP models’ training and validation results.
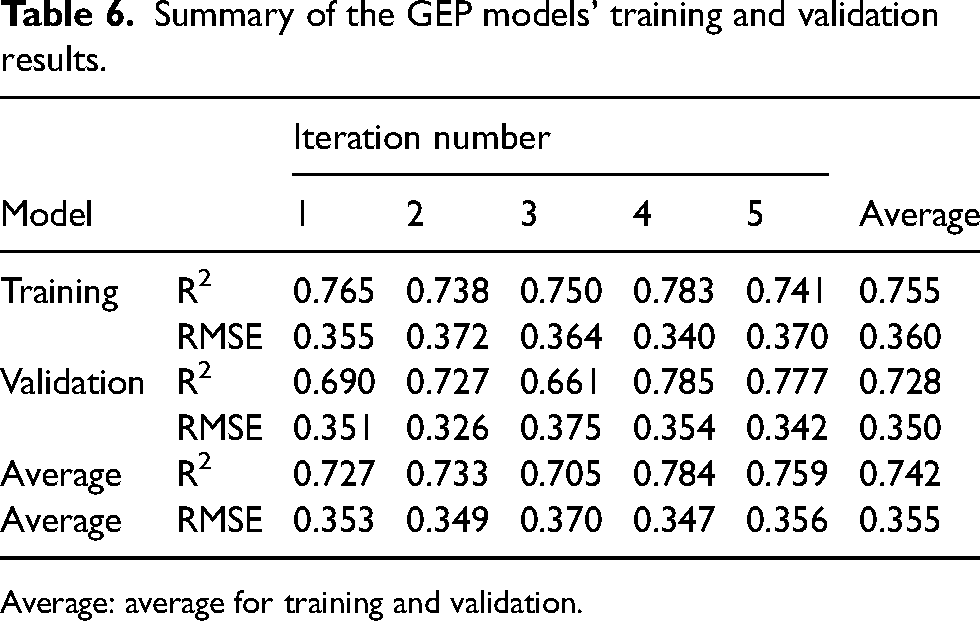
Average: average for training and validation.
It is clear that model 4 has the best performance based on the highest R2 across both the training and validation set and its MSE values that are broadly in line with the model's average. Also, the average performance for training and validation shows that model 4 has the highest average R2 and the least RMSE. Accordingly, model 4 was selected for further analysis.
The best GEP-based solution (model 4) resulted in a chromosome with three sub-ETs (genes), as shown in Figure 7. The values T, A, HR and N′ represent the model's inputs, and the numbers in the leaf nodes are constants generated by the model to enhance effective modelling of relationships between genes.
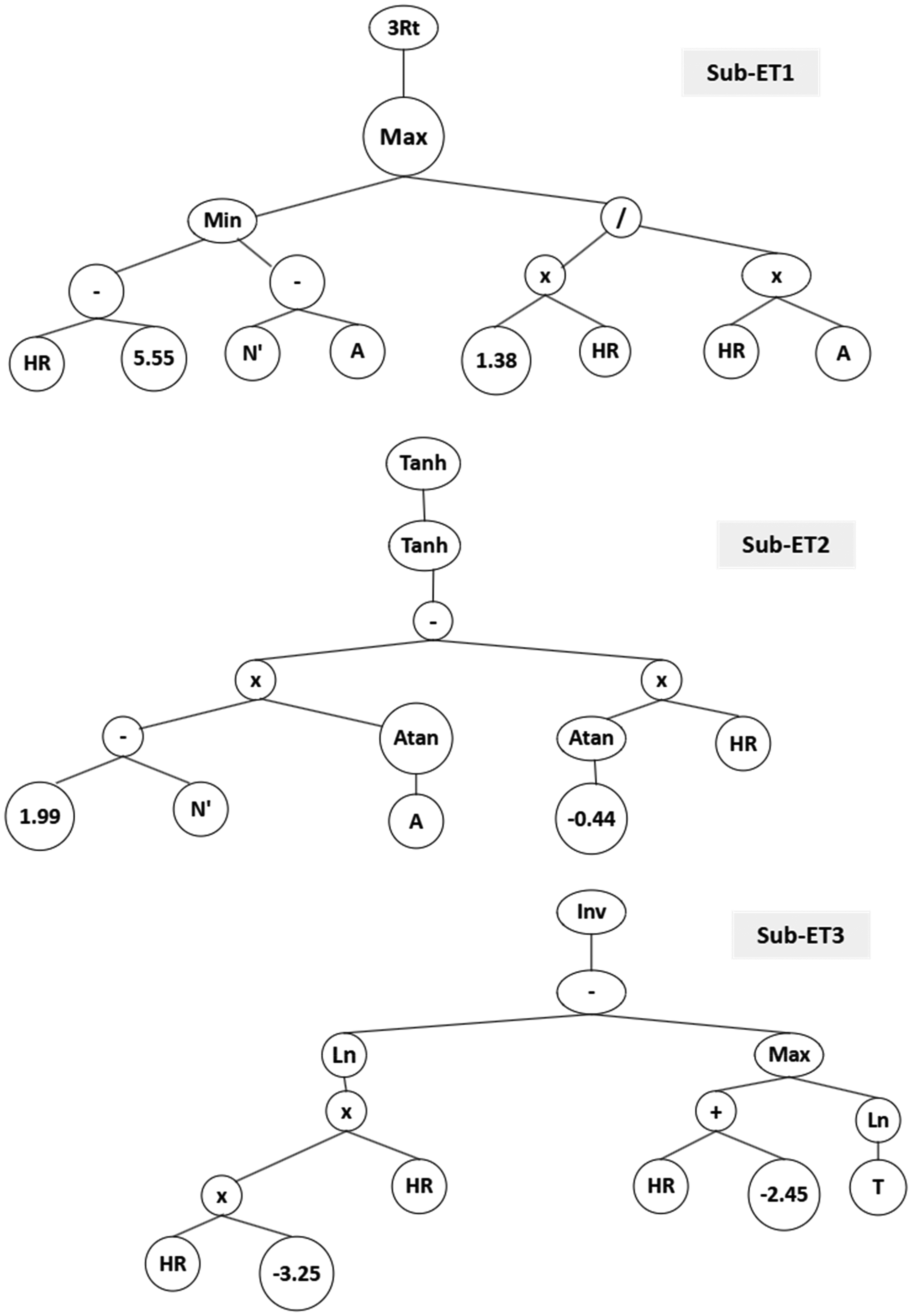
Expression tree (ET) for the GEP model.
The mathematical equations for the three genes (sub-ETs) were then extracted and summed up (as per the addition linking function) to get the output using equation (15):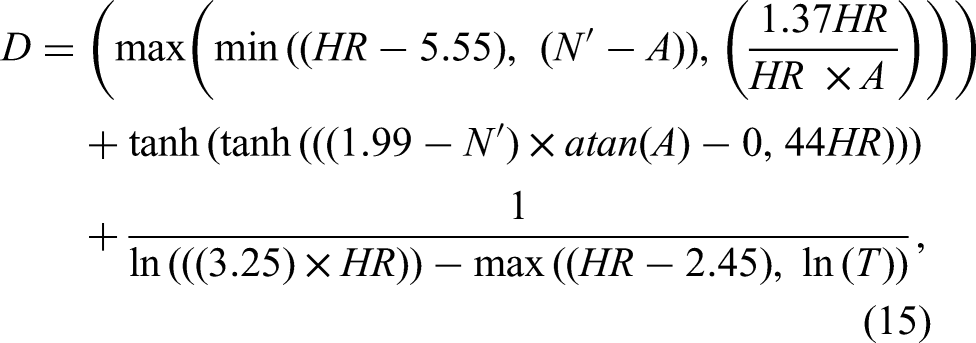
subject to
The expression tree (ET) displays how the inputs are combined with different mathematical functions to visually depict the construction of the non-linear equation that predicts the output for a given set of inputs. This simplifies an otherwise black-box operation, allowing the prediction process to be visually conceived from the expression tree, as in decision tree models’ architecture. In an actual mining scenario, this can facilitate easier analysis of complex interdependencies amongst the models’ input variables, thereby enhancing rapid assessment of the sensitivity of the predicted value to the inputs.
The extracted equation was then tested on the test set, and the results were compared with the actual model. The results are discussed in the next section.
Results and discussion
The root mean square Error
Summary of performance results for all models.
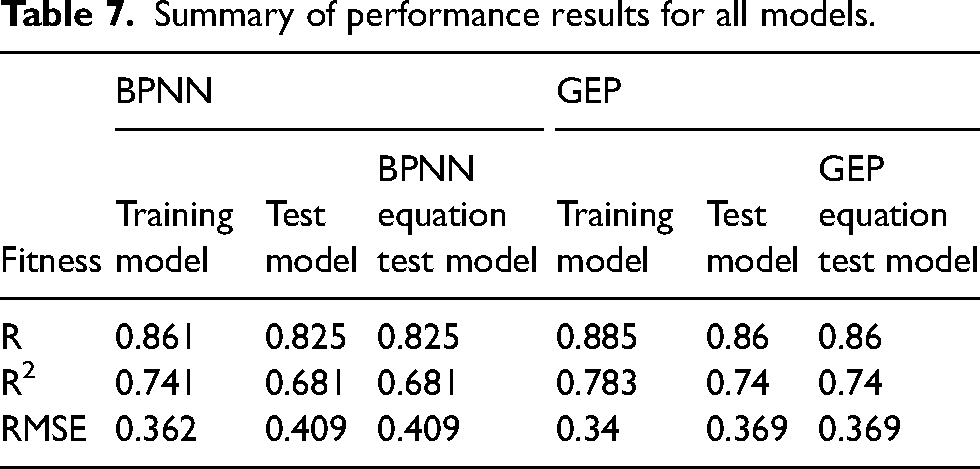
The summary results show a correlation coefficient between 82% and 88% for ELOS for both BPNN and GEP dilution prediction. These findings generally align with previous related studies (Chongchong et al., 2018; Jang et al., 2015), even though this study considered fewer variables than previous studies. Thus, the improved results provide alternative means for establishing robust, generalisable dilution estimates for production planning and scheduling devoid of bias from drill and blast inputs or other related metrics.
The mathematical proxy models’ prediction results perfectly match those obtained by the models on the test data (Table 7), confirming the successful mathematical simulation of both the BPNN and GEP models. The models’ mathematical proxies bring to view a crystallised perspective of the computations and complex relationship, which are often buried in the actual models’ complex architectures, commonly referred to as ‘black box’ due to their complexity. Indeed, this perspective is shared by Hotelling (1991), who argues that mathematics systematically unpacks the relationships, and nothing has a richer profusion of application or traverses the whole domain of human knowledge as does mathematics. Model configuration to mathematical proxies provides improved clarity and visualisation of the interlinked relationships, allowing engineers and operators to understand the key drivers of dilution better and, therefore, focus early on secondary controls for minimising the deviation of production schedules downstream at the mining stage.
The BPNN and GEP proxy models’ predicted dilution values on the test data set were plotted against the measured values for each stope to explore further insights on the model's predictions. Figure 8 overviews the model's predictions on a per-stope fidelity.
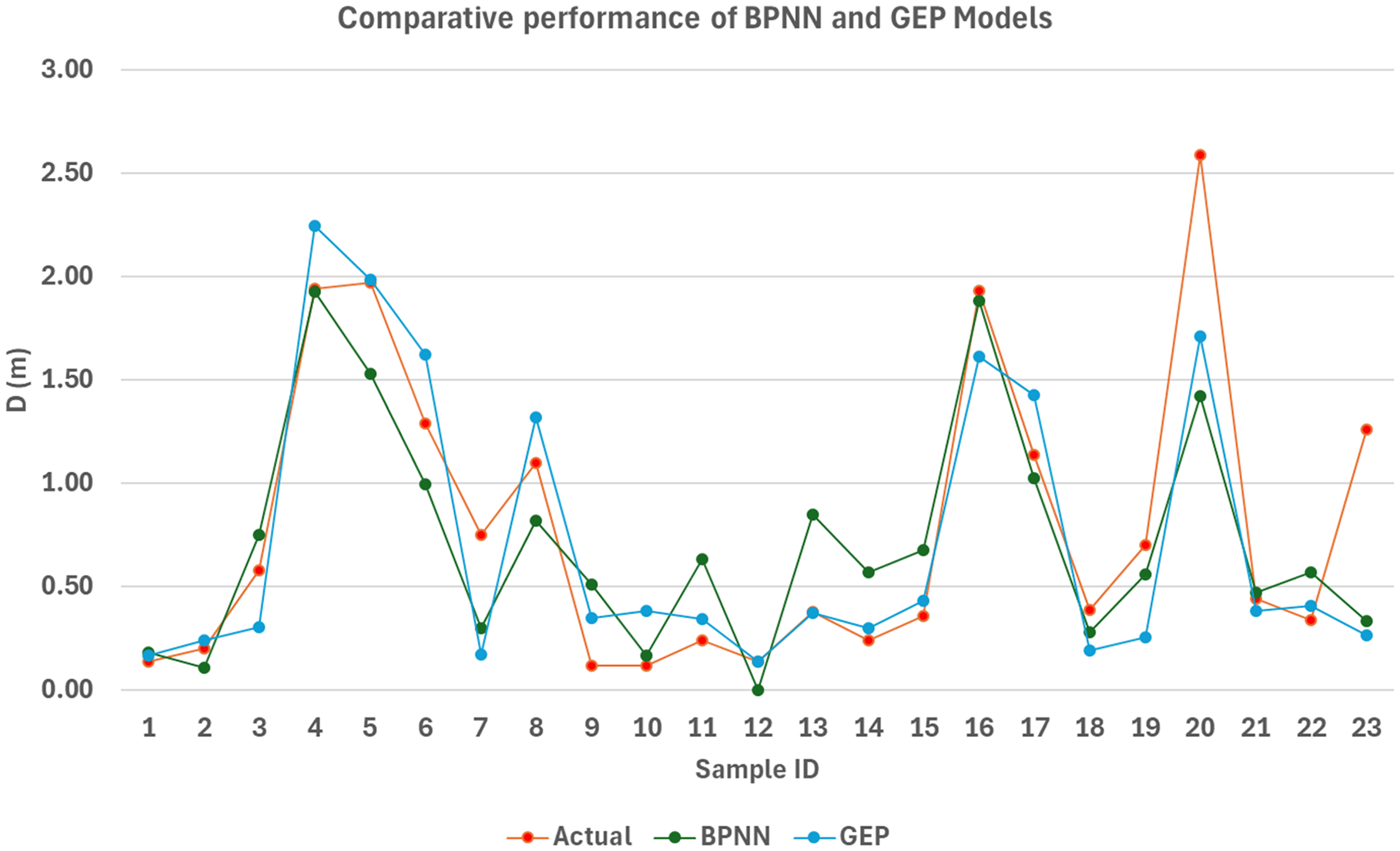
BPNN and GEP models’ predictions against the measured values on the test data set.
The analysis of the model's prediction on a per-stope basis showed that both models’ sensitivity was generally low in the regions towards the extreme values, i.e. when ELOS values approach the minimum or maximum values of the ELOS dilution spectrum used for the study (i.e. 0.0 and 2.87). However, this is considered inconsequential in practical application because ELOS dilution in the lower spectrum is generally classified as minimal dilution that may not be avoidable due to blast damage. Similarly, ELOS dilution values approaching the higher end of the spectrum are considered extreme cases, with an ELOS above 2 also generally regarded as a failure criterion rather than mining dilution. Further, this observation is consistent with extant literature findings on dilution, confirming that the relationship between dilution and stability parameters such as the stability number and hanging wall radius is best modelled by a logistic function. To clarify this behaviour, Figure 9 offers an overview of the general form of the logistic function, showing the insensitive regions towards the low- and high-end values of the spectrum range.
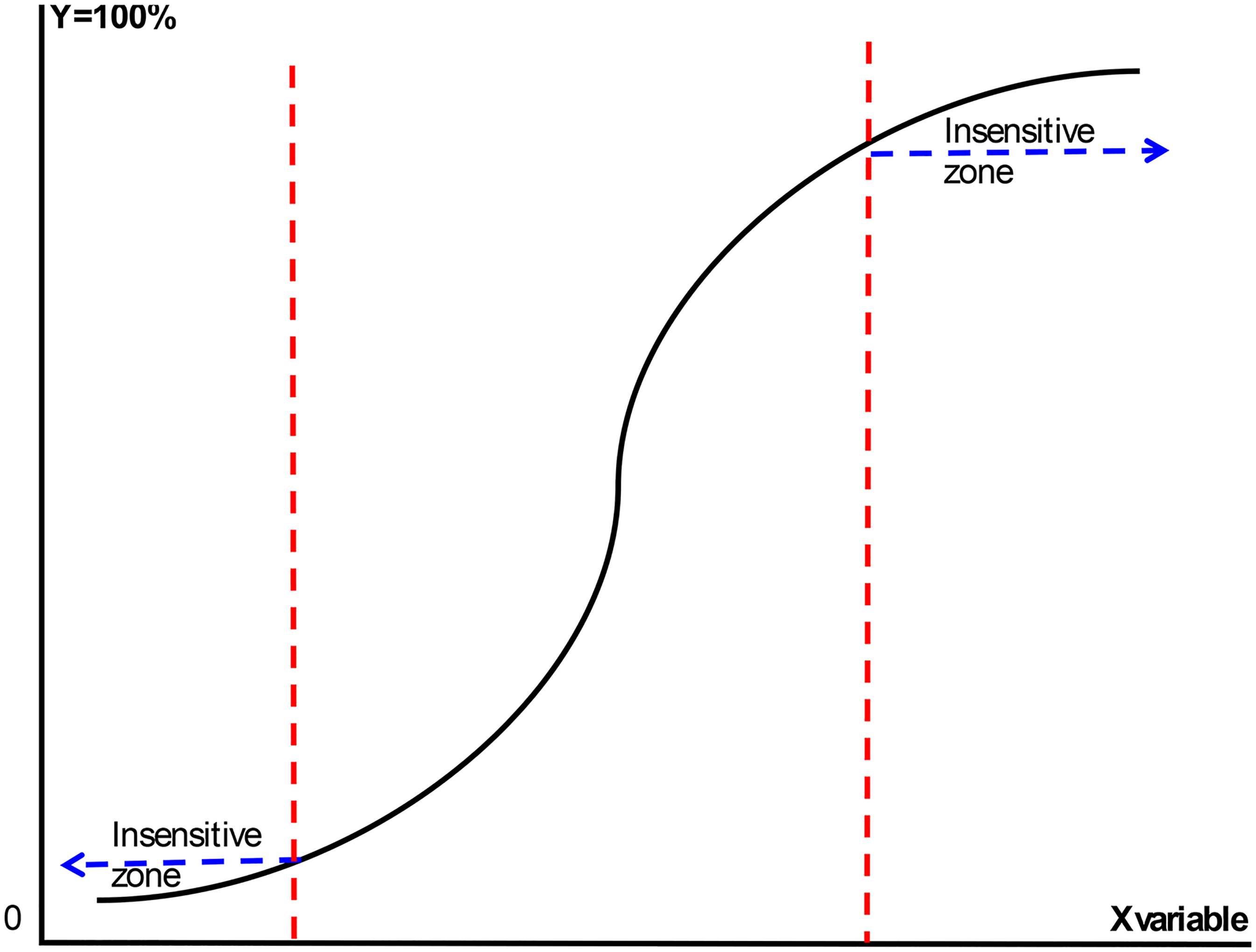
Generalised logistic regression graph showing low sensitivity at lower and upper bounds.
While stability is generally defined in terms of short-term stability, in a sense, it is mostly influenced by the mining methods that, by their nature, are of short-term duration. Thus, the failure criterion, which represents stope hanging wall failure and unstable ground conditions where it is deemed unsafe to conduct mining activities (Brady et al., 2005), does not pass the litmus for stable mining conditions, a fundamental assumption that must be met for mining operations. Thus, while the models are less sensitive in these regions, the predictands achieved are deemed sufficient to provide an indicative estimate for mine planning and production scheduling purposes.
These results also point to the difficulty in predicting the actual ground conditions in the mining zone, which may compromise the prediction accuracy of the models. As such, the models must be updated often to mitigate this as new data is generated. Overall, while there might appear to be a blurred distinction between the models’ performance on the test set as the results were considerably at par, the GEP model has exceptionally high flexibility on model inputs and similar prediction results obtained using actual and normalised input data are a testimony to that fact. Based on the foregoing, the GEP model was recommended for deployment based on its superior prediction accuracy, better generalisation capability and minimal data transformation requirements.
Infield application and further validation of the GEP proxy model
To further assess the performance of the GEP proxy model (i.e. the GEP model's mathematical equation), the model was tested on a sample of three recently completed stopes in the same mining area where the training and test data were extracted. The test stopes’ parameters and the proxy model's prediction results are summarised in Table 8.
GEP proxy model's prediction results on test stopes.

The preliminary test results show that the model's predictions were within a 10–30% relative error margin, consistent with the model's prediction accuracy range established in the model testing and validation phases.
GEP model field deployment and preliminary results
Having selected the GEP model as the best model, the model was deployed for further tests on an additional sample of 64 stopes acquired from another section of the mine where mining occurs on a different orebody of similar dimensions using the open stoping mining method. The summary statics details of the sample data are provided in Table 9.
Summary statistics for the GEP field sample.

The model's performance on the additional sample showed an R and
Merits and limitations of the models
The simplicity of the GEP model's output interpretation in a tree structure form, coupled with its high performance, speed, accuracy and minimal data transformation requirements, renders itself a preferred model of choice over other models with complex black-box architecture. Notwithstanding their comparative performance and the black-box nature of the actual models, the ability to extract proxy equations brings unparalleled convenience for users to deploy the models to Excel spreadsheets for use as an everyday tool. Further, these proxy models may also be linked as an input model to other optimisation models, such as production scheduling, enabling a seamless integration of optimisation processes.
However, although the models’ performance may be regarded as sufficient for mine planning at the strategic level of detail and accuracy, the model's performance will still be limited to the range of input parameters used to develop the models. Additionally, it may be worthwhile for future studies to include drill and blast factors and assess if the model's prediction accuracy can be further enhanced without compromising the model's generalisability. Furthermore, the stopes’ geology and geotechnical databases at the case study site were mature, with sufficient data points for most of the stopes; hence, it may be difficult to achieve high prediction accuracy in new areas with low data density.
Conclusions
Two predictive ML models, namely, artificial neural network with backpropagation (BPNN) and gene expression programming (GEP), were developed to predict mining dilution on a per-stope basis based on geotechnical and geometrical stope design data. The test results showed that the GEP performed better, recording a coefficient of determination, R2, of 0.740 with a root mean square error (RMSE) of 0.361 compared to BPNN's 0.681 and 0.409, respectively. The models were mathematically simulated to establish mathematical equations that were then used as proxy models. The proxy models were first tested on the test data, and the results obtained were similar to those achieved by the original respective models, confirming that the mathematically simulated proxies were as robust and effective for dilution prediction as the original software-run models. Further, preliminary results for field deployment of the GEP model showed that model performance was broadly consistent with the test results. Accordingly, the GEP model is recommended for dilution prediction for medium- to long-term production scheduling at the prescribed level of accuracy. The comparatively better performance of GEP models points to its growing maturity for mining-related applications, suggesting that it is well suited to handle prediction for similar and related studies. Importantly, the novel application of GEP for dilution prediction in open stoping operations enriches the existing literature on dilution prediction studies, marks another shift in revolutionising the conceptualisation of dilution prediction and sets the stage for future related studies. Future studies are also recommended to explore ways to improve prediction accuracy by harnessing the merits of improved data capturing, analysis and processing using emerging ML technologies in mining processes to enhance the granularity of model inputs.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.