
Abstract
Machine learning (ML) applications are increasing their footprint in underground mine planning, enabled by the gradual enrichment of research methods. Indeed, improvements in prediction results have been accelerated in areas such as mining dilution, stope stability, ore grade, and equipment availability, among others. In addition, the increasing deployment of equipment with digital technologies and rapid information retrieval sensor networks is resulting in the production of immense quantities of operational data. However, despite these favourable developments, optimisation studies on key input activities are still siloed, with minimal or no synergies towards the primary objective of optimising the production schedule. As such, the full potential of ML benefits is not realised. To explore the potential benefits, this study outlines primary input areas in production scheduling for reference and limits the scope to six key areas, covering dilution prediction, ore grade variability, geotechnical stability, ventilation, mineral commodity prices and data management. The study then delves into the literature of each before examining the limitations of existing common applications, including ML. Finally, conclusions with recommendations/solutions to enhance resilience, global optimality, and reliability of the production schedule through synergistic nexus with function-specific optimised input models are presented.
Introduction and motivation
The increasing world population and demand for technological devices exert tremendous pressure on the academic and professional communities to deploy ever more efficient techniques in extracting exhaustible mineral resources essential to support modern lifestyles (Hotelling, 1991). Naturally, sub-surface mineral resources amenable to surface mining methods tend to be exhausted first, while an increasingly deep-seated proportion of the resource is gradually deferred for extraction by complex, underground mining methods (Chung et al., 2022; Khaboushan and Osanloo, 2020). One of many challenges in underground mining is the limited flexibility imposed by excavation sizes, which are generally optimised for the type and size of mining equipment utilised in such activities. As such, the planning and scheduling of production for underground mining require a proactive and highly collaborative deployment of resources to realise optimum benefits. The digital era, already upon us, has set this in motion with the introduction of machine learning (ML) in various aspects of production planning in underground mining. To date, remarkable successes regarding the predictive potency of ML models in underground mining have opened a new window with a broader demagogic perspective and global view of process optimisation. This study leverages literature review to establish pertinent challenges in production scheduling activities and propose novel or emerging machine learning-based concepts and transferrable applications within the last decade to improve global optimisation of production schedules. To achieve this, the current study deliberately narrows the discussion scope by choosing six main scheduling activities commonly referred to in extant literature and proposes research questions that are then discussed with rigorous academic reference. Finally, conclusions with recommendations are provided to engineer flexibility and resilience into the processes, albeit with a strong inclination to support the overall production schedule optimisation. To that end, we propose the following questions which are specific to production planning and scheduling in underground mining operations to focus the current study and subsequent efforts to propose suitable solutions.
Items (1) to (6) require a comprehensive academic tete-a-tete with extant literature on current and emerging optimisation methods, their weaknesses or strengths, as well as the relevance and accuracy of input data for increased visibility on the level and extent of the magnitude and impact of the challenges, before an adaptive solution can be proposed. Items (7) and (8) are deeply rooted in the equipment selection, maintenance, availability, and utilisation space. A full discussion of these two areas without a detailed and robust case study will likely yield premature or inconclusive recommendations. As a matter of caution, this study has deferred these for concreteness and simplicity, but if they should prove to be of higher importance in related studies, the foregoing readily extends to cover them. Accordingly, items 1 to 6 bracket the scope of this paper.
Machine learning (ML) applications in underground mining are quite diverse, spanning across activities, such as drill and blast performance (Latif et al., 2023; Leonida, 2023), prediction of resistance in ventilation circuits (Wang et al., 2022), simulation of underground fires using mine ventilation circuits for fire training and risk mitigation controls (Xue et al., 2023), geotechnical prediction of rockbursts, seismicity and deteriorating ground conditions (He et al., 2021; Shirani and Taheri, 2019; Shirani et al., 2020; Shirani Faradonbeh et al., 2024), mining dilution prediction (Jang et al., 2015; Jorquera et al., 2023; Zhao and Jia’an, 2020) and ore grade estimation (Kaplan and Topal, 2020). However, despite the growing footprint of ML and its emerging favourable prediction strength over linear statistical methods in the underground mining space, the applications are still largely confined to discrete optimisation endeavours, with a tenuous link to the full scope optimisation of underground production plans and schedules (Chimunhu et al., 2022; Shreyas and Dey, 2019). As such, the full potential of ML capabilities is undersold, with minimal or no synergies drawn from these siloed applications towards optimising production schedules. Thus, the original contribution of this paper arises from recommendations to harness the full potential of current and emerging ML applications to address the identified problems and influence the trajectory of future, related studies.
For a clear roadmap to reader referencing, the paper is structured as follows: Sections ‘Dilution in underground mining’ to ‘Robustness of data for production planning and scheduling’ discuss the selected six research questions. Each section commences with a research question, followed by a brief literature review and challenges, which precede the current and emerging applications of ML in the area, concluding with machine learning-based recommendations to engineer resilience and flexibility into the schedule.
Dilution in underground mining
Control of dilution in underground mining is essential to optimise the business's resources on the fundamental tasks of extracting planned material economically, as dictated by the schedule, while maintaining the geotechnical design constraints, such as pillars and stope spans, intact to preserve regional stability for the safety of personnel and equipment working in the active areas (Erten et al., 2021; Papaioanou and Suorineni, 2016; Potvin, 1989). Furthermore, uncontrolled dilution may result in unplanned additional material that compromises the scheduled production forecasts, ore quality and tremendous cost pressures on material handling systems (Cordova et al., 2022; Henning and Mitri, 2008; Jang and Topal, 2013). Similarly, underbreak results in ore losses, leading to low metal output and underutilisation of resources (Jang et al., 2016). In fact, missed schedule forecasts and related cashflows are one of the biggest challenges in underground mining operations (Delentas et al., 2021; Hefni et al., 2020; MacLean, 2017).
The Mathews stability graph, first proposed by Mathews et al. (1980) and later refined by Potvin (1989) and subsequent scholars (Suorineni, 2010; Sutton, 1998), is foundational to early prediction of hanging wall instability and dilution in open stope underground mining. The method utilises geotechnical data, such as stress around an excavation, rockmass structure and strength, as well as the physical properties of the stopes (shape, size, orientation etc.) to determine an excavation's stable and unstable zones, through a graphical plot of the excavation's hydraulic radius and the stability number. While the method still has considerable application today, it is handicapped by its blurred definition of stability number factors and its different interpretations of stability zones, leading to data concerns in comparing its application for new or evolving mining environments (Chongchong et al., 2018; Suorineni, 2010). Further, the model is handicapped by limited scalability, as empirical modelling is best suited to the database of cases, which may lead to spurious results and conclusions in circumstances with scanty data (Erten et al., 2021; Suorineni, 2010). Furthermore, the method disregards blast-induced stress factors and is not appropriate for rockburst conditions (Jang et al., 2015). Fortunately, recent studies on dilution prediction in open stope mining using ML have occasioned a progressively positive trend in both accuracy and reliability of results, partially addressing the rigidity of the Stability Graph method through enhanced capabilities. This includes the ability to consider the relative importance of influencing variables and the ability to effectively handle outliers with minimal impairment to results, as noted in the application of the Random Forest (RF) model for hanging wall stability prediction by Chongchong et al. (2018). The two ML methods principally fronting these developments are the variants of the Neural Network (NN) and the Decision Tree (DT) models. While NN models have remarkable prediction capability, they generally require large volumes of data to produce an accurate model, otherwise a model produced with a small data set would tend to overfit. Further, NN models utilise hidden layers in their architecture, making it difficult to logically trace or understand the underlying decision rubric leading to the result (i.e. they have a black-box nature). On the contrary, the DT model and its variants exhibit a logically coherent decision framework, which lends greater clarity to users. Furthermore, the models can handle outliers and multimodal data, with minimum impact to prediction potency (Shirani et al., 2020). Importantly, the models require minimal data transformations to establish non-linear relationships in input data (Nilashi et al., 2021). Notably, its application in the recent study by Jorquera et al. (2023) has some striking results, reporting a precision score and prediction accuracy of 83.5% and 82.4%, respectively, for the Random Forest (Decision Tree) model, compared to the k-nearest neighbour (k-NN)'s 78% and 74.7%, respectively, based on a sample of 752 cases of pre-processed in-situ observations in stable zones from various open stope mines in Brazil, Chile and Argentina.
Given the foregoing, the study leverages the increasingly remarkable performance of DT models in this field to propose the application of DT model variants to address challenges peculiar to flawed or inaccurate mining dilution, such as poor schedule forecasts with significant variances to actual production. Specifically, a ML-based dilution prediction model is proposed to provide direct input feed to a production schedule optimisation model. The ML model scans the scheduled stopes and predicts the mining dilution, based on the stopes’ projected properties and prior learning acquired from modelled data. The ML dilution factor is then utilised to calculate the final mined tonnes for stopes in the production schedule optimisation process. For clarity, the proposed synergistic configuration is presented in Figure 1.
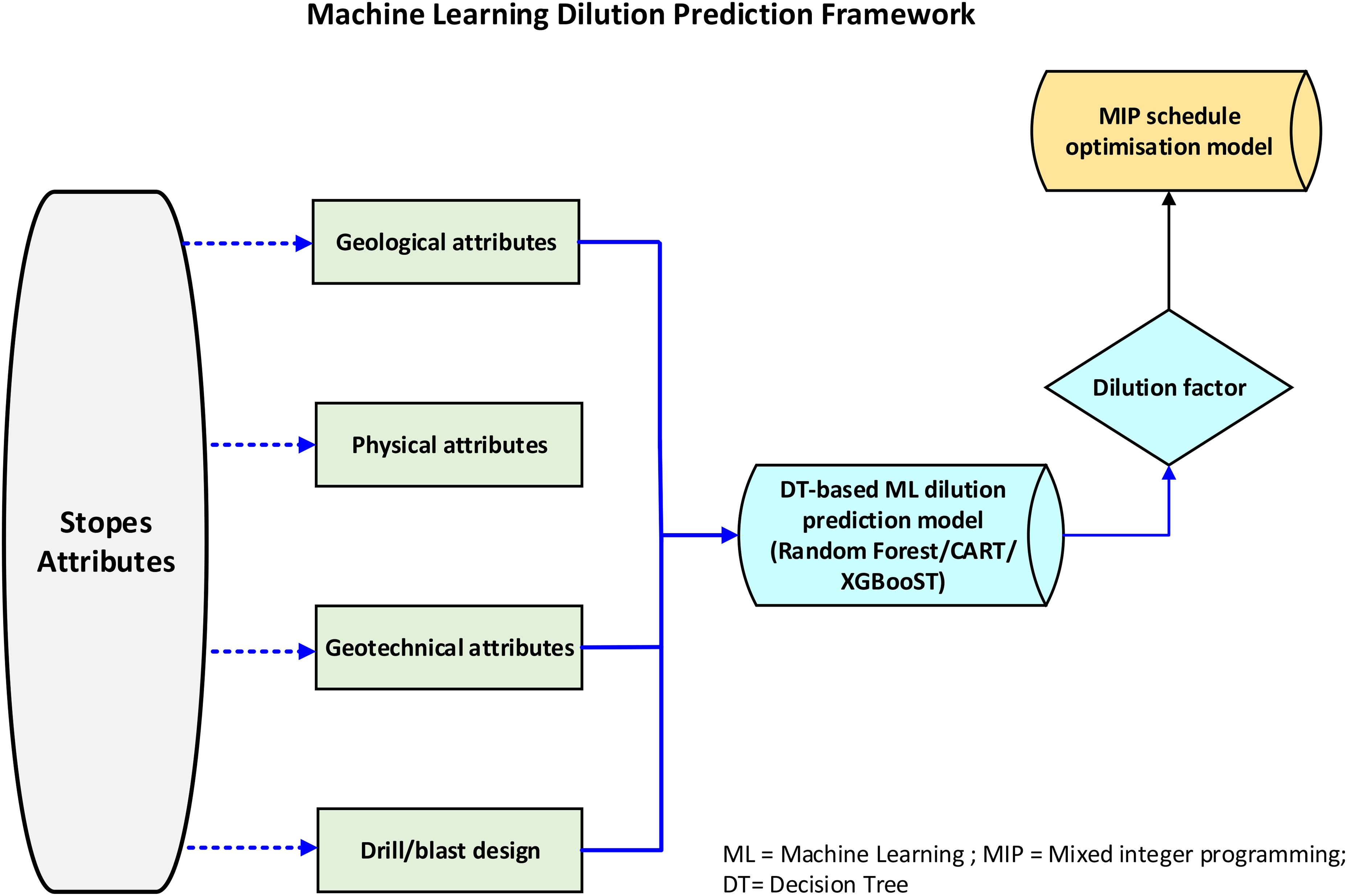
ML dilution prediction framework for mixed integer programming (MIP) schedule optimisation model.
The model utilises data on geological, geotechnical, and physical attributes, as well as drill and blast performance to establish patterns in overbreak and underbreak and therefore, dilution. The dilution predicted factor is then used to determine the actual tonnes and grade mined in the MIP schedule optimiser model. The proposed ML dilution model provides dynamic dilution factors with sufficient rapidity that reflects the changing landscapes as the schedule is executed.
Ore grade variability
Mineral grade uncertainties, particularly ore grade variability within an orebody, remain among the biggest challenges in production scheduling and forecasting. This is mainly because geological block models commonly used for mine planning are modelled using discrete field data, but the interpretation assumes the grade fields in the model are continuous (Smith and Dimitrakopoulos, 1999). Further, drilling the orebody densely to improve grade continuity interpretation is costly and practically infeasible. As such, the mineral resource is generally defined based on a minimum drill density pattern and a set confidence level. This conundrum has been addressed in part, by complex geostatistical mathematical computation methods, such as Kriging (Vann and Guibal, 1998), inverse distance weighting (Zhang et al., 2017), simulation (Dagasan et al., 2019; Dowd and Dare-Bryan, 2004; Maleki and Emery, 2015; Tercan and Akcan, 2004; Vallejo and Dimitrakopoulos, 2019) and stochastic modelling (Benndorf and Dimitrakopoulos, 2013; Lillah and Boisvert, 2013), to infer the radius of influence of the drill holes concerning the magnitude and level of continuity of the ore grade. The set confidence level facilitates standardisation of resource classification to commonly referred categories of inferred, indicated, and measured in increasing confidence level (JORC, 2012). Typically, an inferred resource has few drill holes but is short of the minimum required drill density for the resource evaluation to meet the indicated standard classification benchmark for production planning purposes. Without loss of generality, production scheduling mostly utilises the indicated resource, underpinned by its confidence level to justify ‘reasonable prospects for eventual economic extraction’ (JORC, 2012; Stephenson, 2001). The measured confidence category is largely theoretical because such a level of confidence can rarely be achieved, requiring a very high drill density that is costly and may render the eventual extraction of the resource uneconomic due to excessive drilling requirements.
Despite the rigours of mathematical computation involved, a monotonous chorus of geostatisticians has persistently pointed out the limitations of Kriging, such as the requirement for sufficient sample data to achieve reliable results and, in particular, the linear inference of data on blocks that are smaller than the geostatistical selective mining unit, vehemently arguing this practice distorts the grade-tonnage curves (De-Vitry et al., 2010; Tahmasebi and Hezarkhani, 2012). To circumvent this limitation, variants of Kriging have been developed, eventually leading to multiple-point geostatistics and sequential Gaussian simulation methods as alternatives to improve prediction of the spatial complexity of the orebody, thereby improving grade prediction (Dimitrakopoulos and Jewbali, 2013; Paithankar and Chatterjee, 2018; Song et al., 2019; Vallejo and Dimitrakopoulos, 2019). While these efforts gradually yielded some positive improvements in grade prediction, the problems remain, albeit with an increasing clarity on the magnitude and impact unearthed from ongoing scholarly and professional efforts. The increasing computing capabilities industrywide, spurred by the fourth industrial revolution, are gradually expanding the perspectives and options for ore grade prediction, with the inclusion of applications such as soft computing and ML methods (Dumakor-Dupey and Arya, 2021). Notably, the works of Kaplan and Topal (2020) reveal some interesting results in their ore grade estimation study for a gold deposit, using a combination of k-nearest neighbour (k-NN) and Multi-layer feed-forward neural network ML models. They formulated a grade prediction model based on ore lithology, level of ore alteration and sample coordinates to establish a pattern and reported a model coefficient of determination (R2) of 0.528. A similar study by Kaplan et al. (2021) on ore grade estimation using gradient boosting-based ML models reported a prediction accuracy of 72.8% against ordinary Kriging accuracy of 65.1% based on 1882 samples from 29 drill holes for a gold deposit. Interestingly, these findings were also complimented by Tsae et al. (2023), who reported a similar R2 value of 0.584, on their Neural Network grade prediction model based on a sample of 14,294 from Jaguar Copper Mine in Australia. Further interest is drawn to the recent research by Prior et al. (2021), who developed a Gaussian simulation algorithm to improve ore grade prediction by first updating the geological grade control model for an underground operation in near real-time using sensors installed near the mining face and on ore transfer conveyors. The results confirmed the superiority of models that were constantly being updated using ML prediction over the original unaltered geological models on grade prediction for short-term production planning purposes. In view of this, it is increasingly evident that the challenges of ore grade variation are immense, requiring higher-order mathematical computation and prediction capabilities to improve visibility into the phenomenon. When enhanced visibility is achieved, it essentially catalyses the efforts towards attaining appropriate solutions and mitigation strategies. In this regard, ML methods would provide better solutions especially for complex, non-stationary, and non-linear datasets as the ML methods assume the data is independent and has identical distribution. Given above, it can implicitly be concluded that the traditional geostatistical methods, such as Kriging, Inverse Distance Weighting (IDW), multiple-point geostatistics, Simulation, stochastic modelling and variants thereof, fall short in addressing these tremendous impediments. The same appears to be true for ML models, based on existing literature. However, comparatively better results are emerging from ongoing grade prediction studies using ML models or ensembles, yet ML applications in this field are still in their early years, suggesting the current and emerging ML methodologies may hold the key to unravelling the regularities essential for reliable ore grade prediction within an orebody. In the interim, the study leverages the literature to propose an ensemble ML model that utilises known geological data, with provision for short-term updating, based on learning inferred from new field data from activities such as development drilling, sampling activity, production drilling etc., thereby improving the geological database for short term functional needs. Because the reach of ML applications is not yet mature in this field of study, a surrogate (auxiliary/subordinate) mathematical model will still be required to cross-validate the results and ensure they fall within range.
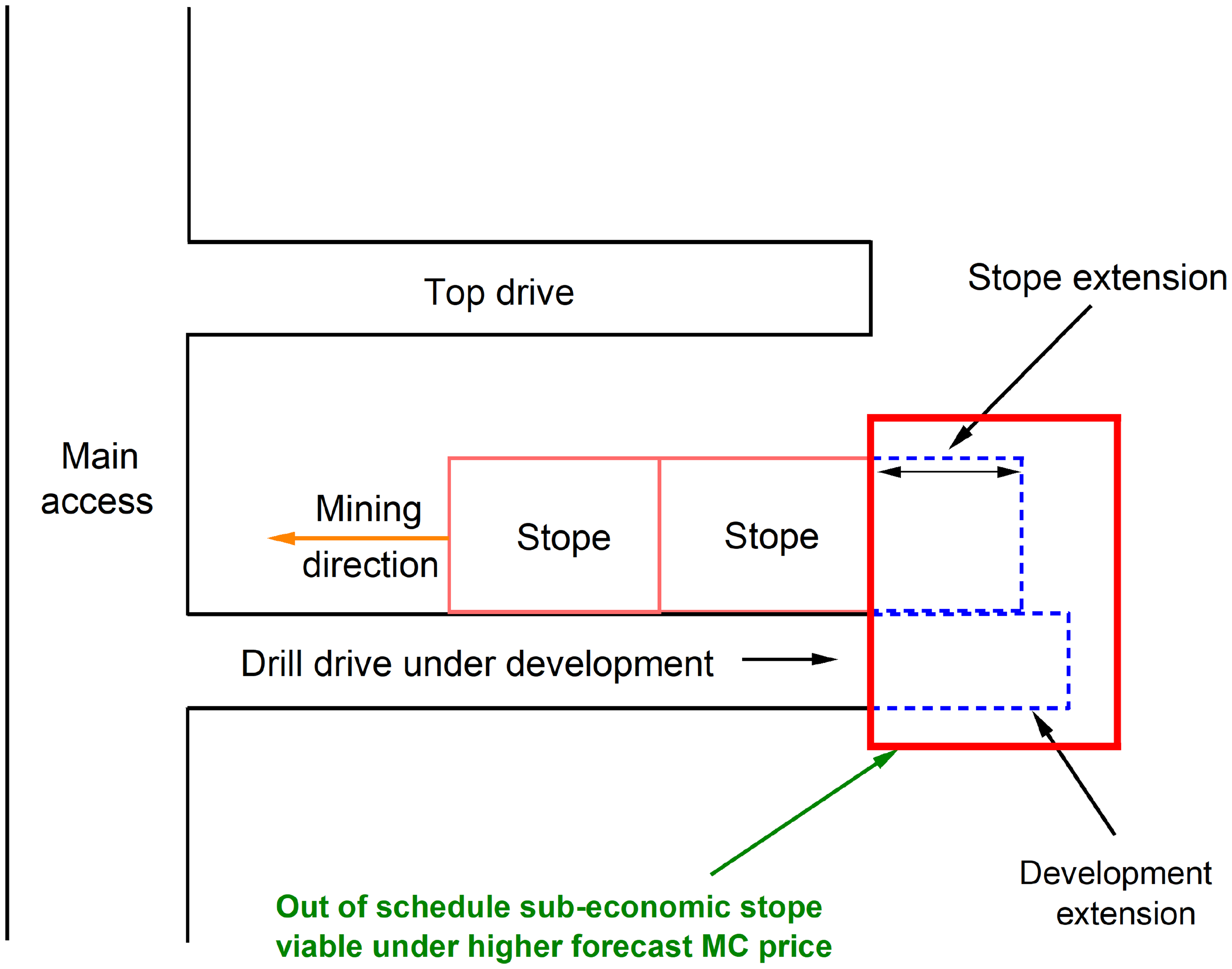
Fundamentally, this proposal seeks to mitigate ore grade variability in a production schedule in two ways. First, the immediate review and application of the latest ore grade data provides opportunities for short term potential stope extensions beyond pre-established limits from the conventional model. For illustrative purposes, a drift under development for a sublevel open stope is considered, where a ML model being updated with the latest data suggests the orebody extends by a few metres beyond previously established limits according to a conventional model (Figure 2). Assuming an extension of 1 m to the ore drive development, with a projected average stope grade of 4 g/t of gold, a similar stope height of 20 m as for the adjacent stopes, an average width of 3 m and material-specific gravity of 2.75, the extension stope will potentially contribute an additional 165t @ 4.0 g/t or 21 troy ounces. Financially, this is worth approximately $USD 42,000 of revenue for the in-situ tonnes (excludes recovery, mining, and processing costs) per extensional metre, assuming a gold price of $USD 2000 per troy ounce. Evidently, such short-term decisions have the capacity to progressively build resilience to the production schedule through gains that incrementally build up to mitigate losses when ore grade unexpectedly falls below plan. A key success factor for this proposal is the ‘immediate’ application of the ore grade data to make prompt decisions, without waiting for periodic model updates, as the wait time will cause schedule slip that outweighs the incremental benefit from stope extensions. Further, additional value may also be generated from such extensional opportunities by rapidly reassessing the potential (stope) extension's economics under the prevailing economic environment at the time of extraction. Thus, the value is in the immediate extraction and monetisation of the extensions at present value instead of a period in the future when the model is updated, potentially requiring the generated cashflows to be discounted. For example, if the metal price spikes temporarily, there could be short term opportunities to extend the development and stope boundaries slightly and recover supplementary metal ounces for a rainy day, adding robustness to schedule forecasts in the long term.
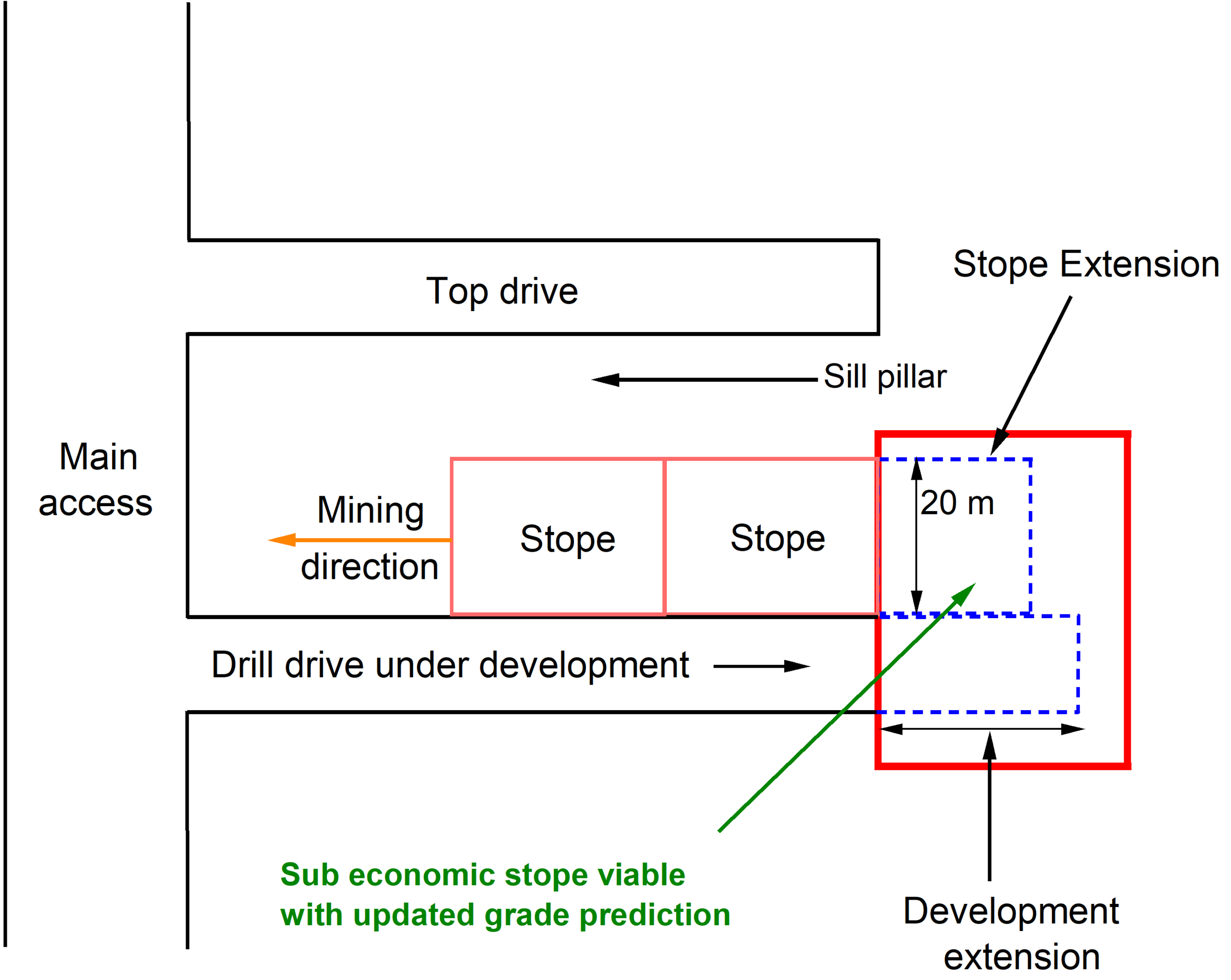
Development and stope extensions from machine learning grade prediction.
Although this recommendation may serve to improve ore grade prediction and production planning flexibility proximately, on-going work and encouraging results regarding the predictive potency of ML suggests the course is right, and a tenable ML driven solution is within reach, as ML applications continue to extend their breadth and depth for a comprehensive and unified understanding of ore grade variability.
Mine ventilation
The increasing depth of operations for underground mining also present corresponding difficulties on continued provision of sufficient ventilation for the health and wellbeing of personnel, as well as meeting increasingly stringent minimum regulatory requirements. Furthermore, as mines extend laterally and deeper, the strain on installed ventilation capacity increases, requiring upgrades, including, but not limited to, fans, ventilation control devices, ventilation circuits, ventilation equipment and software. These upgrades are not cheap, considering the potential disruption to production when an active area is taken offline or impacted by adjacent areas during upgrades. For a long time, the design, control and monitoring of ventilation for underground mining, particularly hard rock open stoping operations, have largely been driven by mathematical modelling, supported by commonly used ventilation models, such as Ventsim (Bascompta et al., 2020; Carter, 2018). Key considerations focused on monitoring and controlling climatic data, such as humidity, heat, noxious fumes, and air quality, to ensure the safety of personnel is not compromised by adverse effects of exposure to such elements. In response to the increasing demand for ventilation, as mines go deeper, a number of mines shifted to the Ventilation on Demand (VoD) supply system, which essentially regulates the mine's ventilation infrastructure to provide just enough ventilation as and when required thereby saving power, running costs and improving on the utilisation of available ventilation utilities (Costa and da Silva, 2020; Shriwas and Pritchard, 2020). However, key challenges recurrent in extant literature include, but are not limited to, monitoring of manual ventilation control devices such as ventilation doors, reliable prediction of atmospheric conditions (temperature, humidity, noxious fumes, respirable dust, diesel particulate matter etc.) between sensors or established ventilation stations, resulting in data gaps (Shriwas and Pritchard, 2020). Thankfully, recent studies on mine ventilation modelling, using Artificial Neural Network models to predict the presence and concentration of nitrous fumes in underground mines, yielded some encouraging results, with remarkable prediction accuracies of more than 90% (Buaba, 2023; Karagianni and Benardos, 2023; Ray et al., 2023). These results suggest that ML methodologies have the prediction capability to mitigate some of the recurrent problems. Importantly, the study by Buaba (2023) demonstrates the impact of heat associated with auto compression, geothermal gradient and mining equipment in an underground sublevel open stoping operation to production planning. The results of production schedule scenarios subjected to heat showed that production schedules that were ‘heat constrained’, based on ML predicted heat levels, were more realistic than schedules that did not incorporate heat restrictions. With this emerging trend, the study proposes a basic surrogate model for the prediction of specific climatic data or atmospheric conditions for mine planning guidance. The climatic data will be overlain on the schedule (Figure 3), showing zones of low to high concentration for the climatic data element of interest. This will provide a global view of the element's potential interaction with the schedule at a glance, facilitating prompt assessment of the schedule's integrity in light of the predicted environmental conditions.
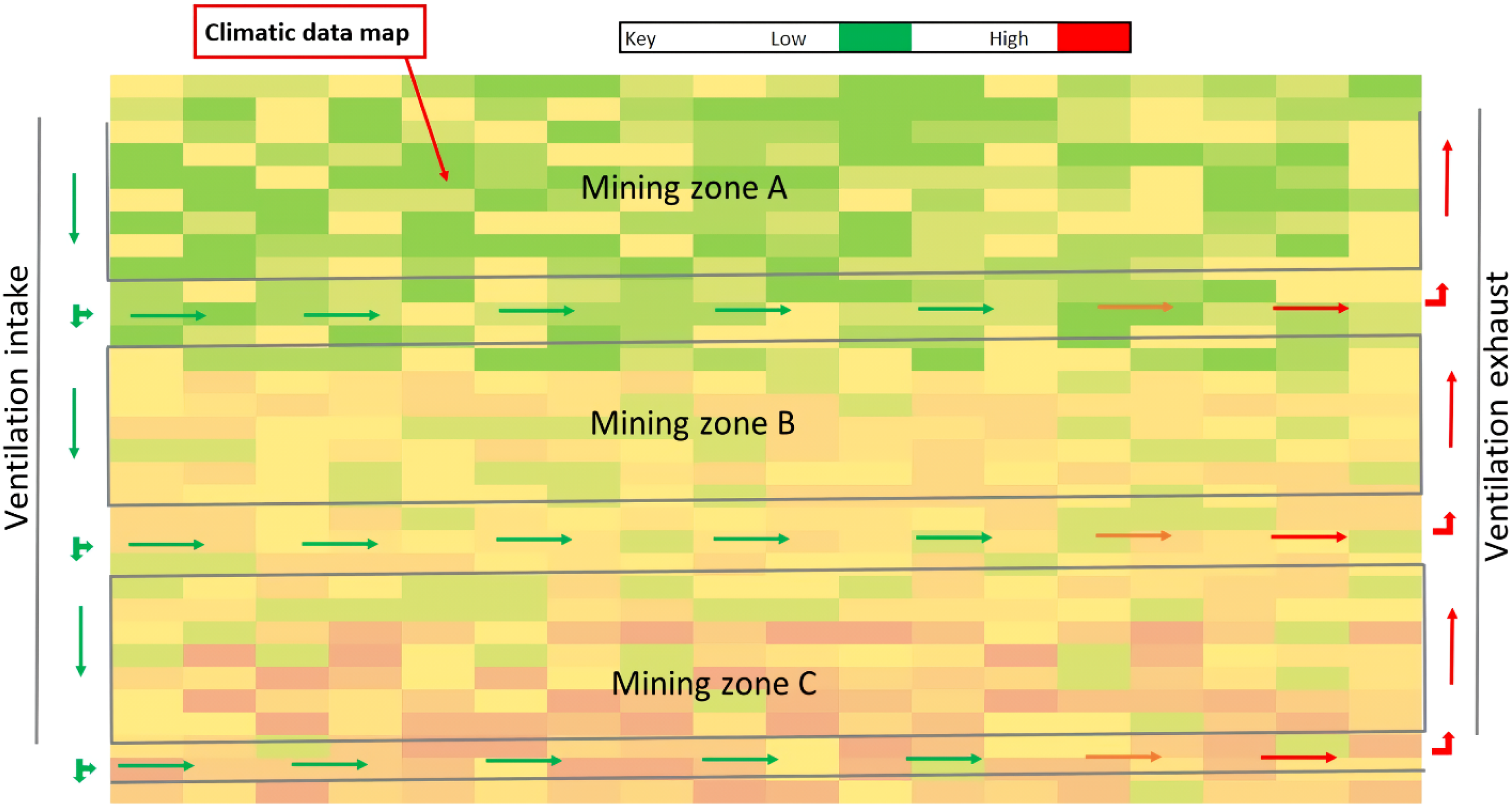
Machine learning generated climatic data map, overlain on sections of the mine showing zones of low to high concentration for the selected climatic data element.
The model may be restricted to focus on one or two key elements based on the risk weighting of such elements to the overall health and safety of personnel, and the gravity of potential production loss attributable to such risks. Thus, the atmospheric elements of interest will be site-specific and based on risk assessments, requiring tailored construction and prediction configurations to meet the needs. As before, such a basic ventilation model will improve ventilation risk awareness and stimulate constructive debate and interchange of ideas across the engineering teams by creating a wider platform for production risk consideration and mitigation, leading to robust and flexible production schedules.
Geotechnical conditions
The stability graph, initially proposed by Mathews et al. (1980) and later modified by Potvin (1989), and other scholars Suorineni (2010), is foundational to stope stability assessment and prediction of geotechnical conditions in underground open stope mining and design. The graph plots the stability number against the stability radius of a design surface (Figure 4), where the stability number is a function of the rockmass quality (Q).
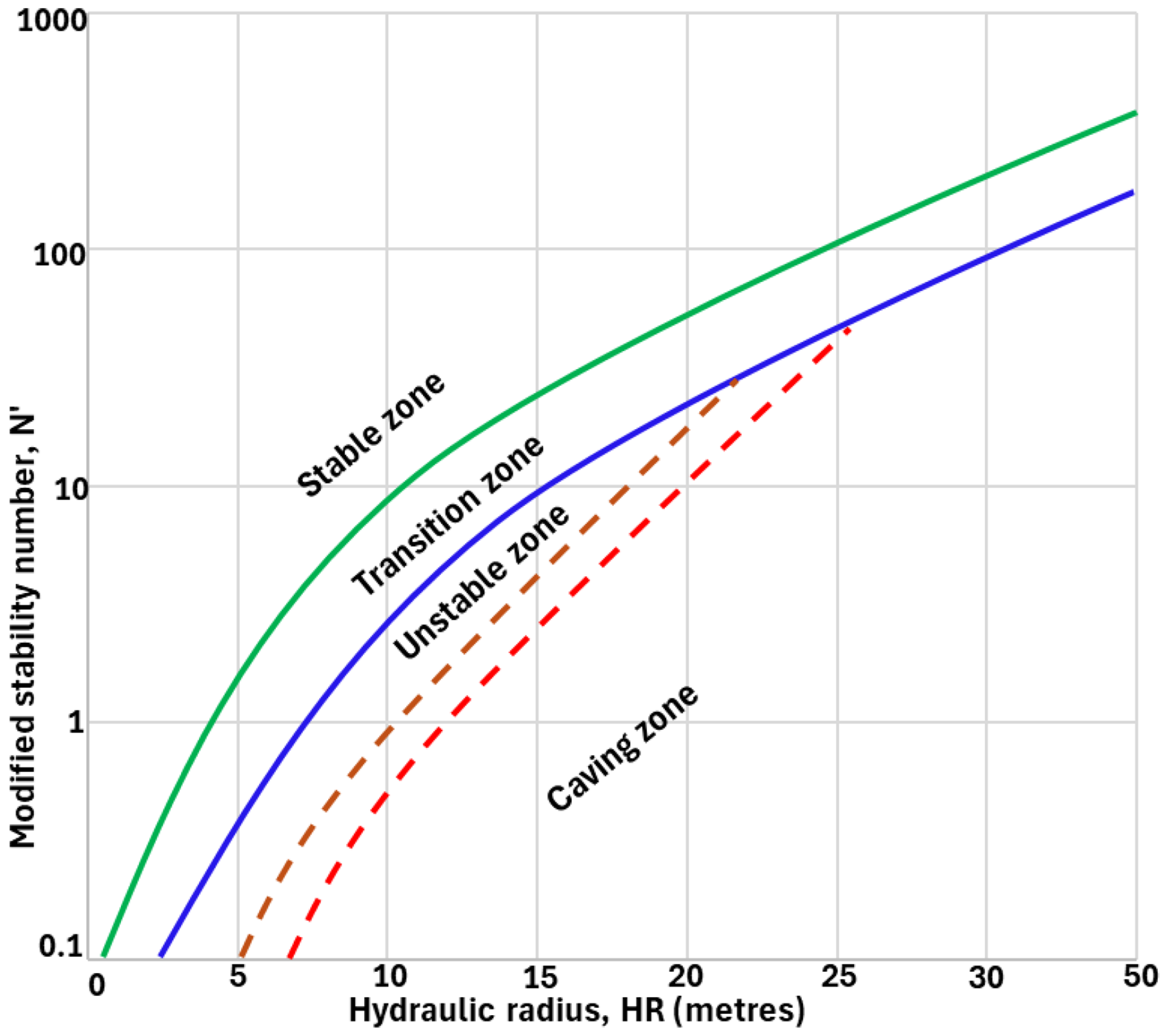
Stability graph.
Despite its successful application to date, its limited capacity to predict rockburst conditions is a major handicap in deep underground mining (Jang et al., 2015). Rockbursts and blast-induced seismicity in underground mining are increasingly showing their disruptive potential to production activities. As most of the mines are going deeper into zones of high in-situ stress and seismic activity, so does the likelihood of rockburst and seismic rockmass mass failures (Dong et al., 2013). Crudely, seismicity can be classified as induced or triggered, where induced seismicity occurs in close proximity to the stimulus (e.g. blast activity), and, therefore, migrative. On the other hand, triggered seismicity occurs distant to the stimulus but rather tends to be localised around rock mass failure processes and incitants such as faults, shears, dykes and yield pillars (Brown, 2021). Rockburst phenomena are an abrupt failure of over-stressed rock due to spontaneous release of accumulated strain energy, resulting in damage to equipment or infrastructure, injury to personnel, and possibly cause project discontinuance due to ground instability (Shirani and Taheri, 2019). Causes of rockbursts include, but not limited to, the existence of faults, shearing, rock stress/strain configurations due to pillar sizes, and external disturbances, such as blasting, caving, and adjacent development of drifts. The most common forms are strainburst rockbursts which occur during excavation, and impact-induced rockbursts, occurring post excavation (Keneti and Sainsbury, 2018). The level and extent of the ramifications are devastating, as extreme cases of loss of life and project abortion or malfunctioning from rockburst and seismic activity are possible, as noted in the unfortunate seismic event that resulted in the collapse of a 3 km long drift at the Deep Mill Level Zone Mine in Indonesia in 2013, leading to a six-month cessation of operations (Profera, 2022). Similarly devastating effects were noted in May 1994 when a 2.1-magnitude seismic event resulted in the violent failure of a peninsular remnant at depths of approximately 2300 m at an underground mine in the Carletonville Goldfield, South Africa (Durrheim et al., 1998). Researchers have applied numerous theories, such as the stiffness theory, bifurcation theory, strength theory, burst liability theory, chaos theory and energy theory, as well as various numerical analyses to predict rockburst and seismicity phenomena (Ma et al., 2016; Tang et al., 2010; Wiles, 2005; Zhou et al., 2012). Despite a plethora of detailed literature on the prediction of rockburst and seismicity phenomena, the lack of consensus on a key criterion for selecting key determinant parametric data inevitably points to the enormous modelling and prediction complexity for the phenomena. The challenges are aggravated by limited data on the phenomena, with several studies using shared databases, posing data validity concerns (Papadopoulos and Benardos, 2021). Indeed, most studies on rockburst and seismicity have explicitly pointed out that this phenomenon is poorly understood and remains one of the most pervasive risks in underground mining (Deng and Gu, 2018; Dong et al., 2013). In fact, despite this being a subject of numerous hypotheses, there is no consensus yet on what denotes a rockburst. Further, a number of open questions regarding rockburst occurrence and seismic propagation are still being met with dichotomous views from scholars, which suggests a lot more work is required for a unified and stable position on this phenomenon. While numerical and mathematical methods have been used for rockburst prediction (Deng and Gu, 2018; He et al., 2018; Wiles, 2005), recent studies show an increasing footprint of ML applications in this space (Dong et al., 2013; Waqar et al., 2023). Again, we note the application of various ML methodologies (Table 1), such as genetic algorithms (Li et al., 2017; Zhou et al., 2012), neural networks (Shirani and Taheri, 2019; Zhou et al., 2020), and decision trees (Dong et al., 2013; Papadopoulos and Benardos, 2023; Pu et al., 2018; Shirani and Taheri, 2019), with progressive improvements reported. Particularly interesting from the study results is the increasing consensus on certain causalities, such as mining depth, the magnitude of inducement/mining-induced disturbances, the existence of geological intensifiers (faults, shear zones, discontinuities, dykes), excavation geometry, excavation size, and the spatial location of yield pillars, among other factors. Additionally, there is an increasing realisation and acceptance that rockbursts are stochastic, due to variability in geotechnical and geomechanical conditions imposed by non-uniform distribution of geological structures (Kadkhodaei et al., 2022), which are the catalytic or transfer medium of stresses and deformation. This convergence of perspectives is crucial as it sets in motion a clearer pathway for the development of ‘basic’, yet robust geotechnical models that may be useful for different levels of production planning work. According to Profera (2022), there's growing consensus for the underground mining industry to consider more efficient models for rockburst and seismicity prediction to minimise potential significant production disruptions from these phenomena.
Representative studies for rockburst prediction using ML methods.
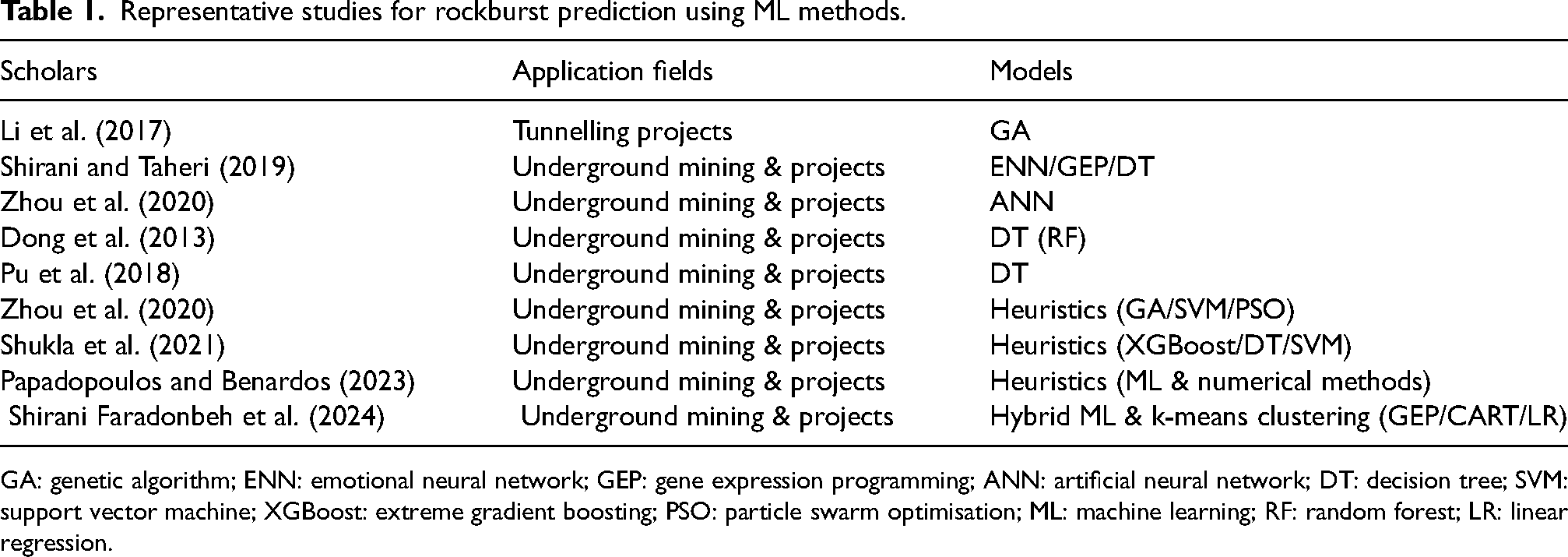
GA: genetic algorithm; ENN: emotional neural network; GEP: gene expression programming; ANN: artificial neural network; DT: decision tree; SVM: support vector machine; XGBoost: extreme gradient boosting; PSO: particle swarm optimisation; ML: machine learning; RF: random forest; LR: linear regression.
Meanwhile, the underground mining industry's lagging pace on rockburst and seismicity prediction, encumbered by the prevalence of outdated prediction and monitoring methods currently in use despite their glaringly inadequate predictive capability to keep pace with changes in the environment, was the subject of intense debate in 2022 at the 10th Rockburst Conference held in Tucson, Arizona, USA (Profera, 2022). This clearly points to an increasing awareness on the disruptive impact of these phenomena on production and the urgency to mitigate the concomitant risks.
Reflecting on the foregoing, the study leverages the existing knowledge to propose the inclusion of a basic geotechnical model that feeds selected input data into the mine planning and scheduling functional database. The analysis consciously refers to this model as ‘basic’ as this is a functional, specific model to support production scheduling needs, while the full model for expansive use remains available for deep diving into the specifics, if required. Based on current mining activity data, the basic geotechnical model will include core rockburst and seismicity cartographic data for mining areas, including their rockburst and seismicity proneness. Calibrated and validated models may be used to generate synthetic data where such data is limited, thereby minimising concerns with imbalanced data sets as proposed by Papadopoulos and Benardos (2021). The proposed model ensures that the visibility of potential risks and opportunities to production and scheduling is extended to the mining engineers and other disparate stakeholders in the mine planning and scheduling functions. For practical application simplicity, the basic geotechnical model may be superimposed on the mine plan or production schedule, similar to the ventilation model discussed earlier (Figure 3). Overlaying the model on the mine plan will facilitate a global view of the scheduled areas and their proneness to rockburst and seismicity. Provision of such basic models to disparate stakeholders is likely to accelerate the disintegration of departmental silos and facilitate collaborative engagements between Geotechnical and Mining engineering teams. When this occurs, production schedule optimisation endeavours benefit from increased stakeholder participation and catholicity, awareness, and constructive feedback, leading to robust schedules. Further, the increased visibility of such basic geotechnical tools facilitates early discussions on opportunities and threats peculiar to production planning and scheduling, to be embedded into the schedule at the shop floor level, increasing risk awareness for managerial consideration and mitigation.
Mineral commodity prices
A candid analysis of the economics of exhaustible resources by Hotelling (1991) posed some key questions regarding the value of a mine's worth, based on the potential production and cashflows redeemable from the investment. More confronting is the credibility and robustness of the mineral price values adduced to any such forecasts, when a plethora of factors are clearly involved in influencing the mineral commodities’ supply and demand, and therefore, prices (Chen, 2016; Cortez et al., 2018a; Cortez et al., 2018b; Shafiee and Topal, 2010) The dynamic evolution of needs, spanning across the financial, technological, geopolitical and psychological spheres, add to the complex web of mineral commodity (MC) price drivers (Gargano and Timmermann, 2014). The intricacy of price forecasting is further compounded when the already complicated relationship of price drivers, is considered relative to time.
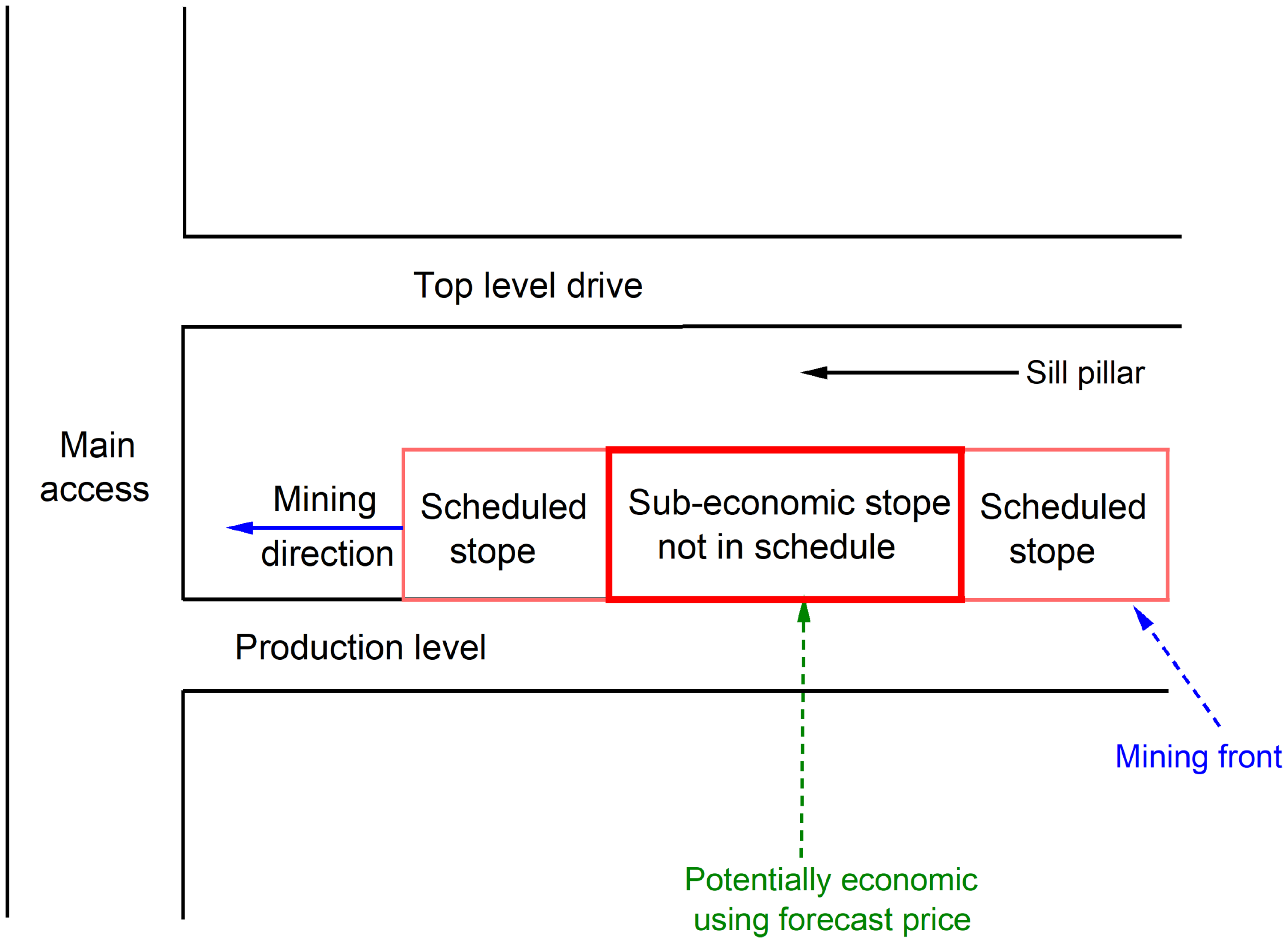
The diversity of businesses on financial risk matters necessitates the development of different and unique hedging strategies to curtail company-specific risks (Ali et al., 2022). As such, robust enterprise risk management strategies may be developed in advance based on insights from MC price forecasts (Hiransha et al., 2018). In underground mine planning, an intimate knowledge of the key determinant variables to MC price forecasts, spot, and future MC price movements, underpins the mine planning and scheduling core objectives of maximising shareholder value and meeting market supply obligations, among others. Furthermore, MC price assumptions are central to the determination of the economic viability, life of mine tenure and profitability margins for a mining operation. Indeed, MC prices are central to industrial and socioeconomic developments that we continue to witness, globally. As such, cost-sensitive production scheduling optimisation endeavours become imperative to maximise shareholder value, navigating threats and optimising on opportunities in the markets. To that end, the previous example discussed in the section ‘Ore grade variability’ (Figure 2) perfectly demonstrates the immediate benefits of robust MC price forecasts in the short-term planning horizon by facilitating rapid re-assessment of economic viability of marginal stopes using price forecast data. If viable, development drifts and stopes may be extended slightly beyond their initial delineations, allowing more economic material than planned to be extracted as shown in Figure 5.
Development and stope extensions based on re-evaluations using MC price forecasts.
Early studies on MC price forecasting mostly utilised correlational relationships between certain mineral commodities such as oil, or macroeconomic changes in global economy, to infer corresponding price changes to the mineral commodity of interest (Shafiee and Topal, 2010; Watkins and McAleer, 2004). Traditionally, spot and future MC price forecasting has been dominated by econometric, stochastic and time series models (Cortez et al., 2018a; Watkins and McAleer, 2004). However, while econometric models can handle multiple correlational relationships among variables, they notionally use static data, rendering them weak in handling uncertainties induced by variability within the variables (Cortez et al., 2018a). While stochastic models can mitigate this handicap by accounting for uncertainty in their architecture, they suffer from limited capabilities in handling the large volume of input data that is typically required for effective prediction. This conundrum has inclined scholars to pursue variants of these traditional models, including ensembles, to improve MC price forecasting capabilities, as noted in the recent work by Madziwa et al. (2022) in their forecasting of long-term gold prices using data for a 16-year period, from 2000 to 2016. The authors used multivariate stochastic models and reported a superior prediction result, measured by a mean absolute deviation error of 0.653, compared to the Mean Reverting, and the Autoregressive Integrative Averages (ARIMA) methods, which had mean absolute deviations of 2.127 and 2.489, respectively.
As ML applications gradually penetrated into various facets of the industry in recent years, its predictive potency drew interest from scholars in MC price forecasting as noted in the research by Cortez et al. (2018b) who proposed a combination of chaos theory and ML techniques to improve MC price forecasts. The authors argued that chaos theory models can recognise sensitivity to original conditions and can establish the time lags and other inherent causalities in the system and, therefore, better placed to handle the chaotic behaviour of MC prices. They further argue that ML can derive patterns from input data to recreate future behaviour. This opinion has been extended to propose the inclusion of entropy theory in MC price forecasting, as well as the use of intelligent long short-term memory (LSTM) models, with simulated annealing, in studies of long-term annual forecasts of copper prices (Hiransha et al., 2018; Tapia et al., 2020). Perhaps the recent attempt to forecast the prices of gold, silver, copper, platinum and palladium on daily and monthly fidelities using the particle swarm optimisation (PSO) model shows the capacity for agility inherent in ML models when it comes to handling multi-objective optimisations simultaneously (Cohen, 2022).
It is increasingly evident from the foregoing that, despite the complexity involved in MC price forecasting, the predictive potency of ML models is gradually coming into view. Further, ML models’ capabilities in easily handling large volumes of data lend them greater suitability to the challenging task. Furthermore, ML models can easily detect patterns and projective properties in data, facilitating better predictions in such instances. However, chaotic environments are difficult to model and simulate with ML and therefore, still require the heavy artillery of econometric models to handle. Further, the sensitive nature of financial indices, such as MC prices, naturally lends them to great scrutiny, particularly the underlying assumptions and decision rubric that underpins the forecast indices. As such, ML models that use hidden layers in their architecture (e.g. neural networks) easily lose appeal and convincingness to users despite their high predictive potency, as the predictand lacks a logical trace to the source variables. For this and other reasons, the study proposes developing a MC price forecasting ensemble model that utilises a combination of econometric and ML techniques for price forecasts on monthly fidelities. It is further proposed that the model output be accompanied by a business-specific commentary, as an adjunct to qualify the forecast’ underlying factors in broad terms. At this juncture, monthly fidelities on forecasts are preferred in order to keep the realism of MC forecasts closely in check, allowing extensional short-term mining opportunities to be extracted while ensuring a rapid change of course can be implemented should detrimental unexpected price spikes occur. Figure 6 illustrates an example of such a scenario for an underground sublevel open stope operation.
Stope extensions from machine learning MC price forecasting.
Specifically, the MC price forecast model allows extraction to occur using spot or near spot prices instead of the reserve prices, potentially presenting opportunities for short term extensions to be extracted viably at higher MC prices obtaining within a month's price forecast. The prediction of short-term price movements on a weekly or monthly fidelity may facilitate dynamic updates to production schedules, ensuring opportunities are not missed and threats are adequately mitigated in synchronous response to the peaks and troughs of changes in the operating environment (Figure 7). Sub-economic stopes left out of the schedule mainly on economic reasons may be reconsidered for inclusion into the schedule and eventual extraction if re-evaluation using favourable MC price forecasts shows a positive economic case.
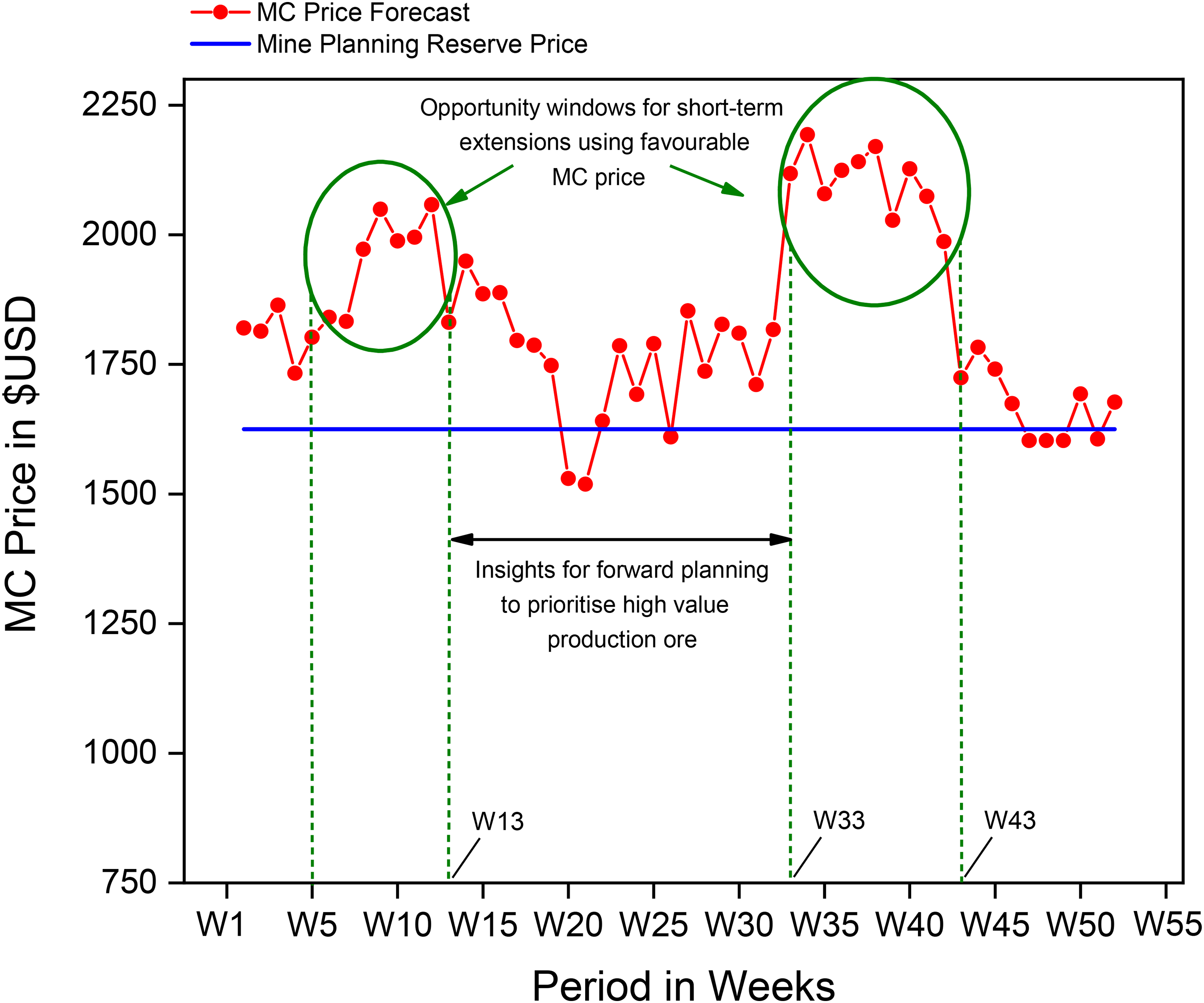
Mc price forecast showing opportunity windows for re-optimisation of mine plans.
Thus, this proposal adds flexibility to the mine plan by triggering prompts for production schedule review and related optimisation needs. For clarity, this proposal should not be interpreted as an attempt to establish a global prediction model of some sort, but rather, an internal, fit for purpose model, with architecture and inputs tailored to reflect the specific, yet diverse, needs of the business, in its quest to deliver maximum shareholder value.
Robustness of data for production planning and scheduling
Mathematical optimisation of production schedules in underground mining is approaching maturity after decades of gradual enrichment of models and optimisation philosophy from successive studies (Campeau and Gamache, 2020; Little et al., 2013; Musingwini, 2016; Nehring et al., 2012; Topal, 2003; Topal, 2008; Trout, 1995; Sandanayake et al., 2015; Sotoudeh et al., 2020). However, recurring challenges of significant variances between schedule forecasts and actual production prevail largely due to flawed inputs that may have become obsolete, lagging or no longer suitable, due to changes in the operating environment (Topal, 2019). Specifically, the currency of schedule inputs and their flexibility to remain intimately related to the mining processes as the schedule progresses through crests and troughs of a dynamic environment are a fundamental condition that underpins production scheduling effectiveness (Chimunhu et al., 2024; Harjunkoski et al., 2020). Typically, the common practice of using fixed parametric data sets in generating schedules, even when there is evident volatility in the environment to suggest otherwise, marks the tangent of a discrepancy between schedule forecasts and outcomes. This situation is further exacerbated by the uncertainty inherent in other key production inputs, such as ore grade variability or the magnitude of mining dilution (Sotoudeh et al., 2020). Building upon the foregoing discussions from sections ‘Dilution in underground mining’ to ‘Mineral commodity prices’, it is evident that the volume of data utilised in production planning and scheduling is undoubtedly immense. Further, the ubiquitous adoption of the mining industry into the digital world, through a rapid expansion of digital platforms on modern mining equipment and processes, is generating massive data into the business's servers and storage facilities at alarming rates.
Fortunately, a possible pathway to mitigate this obstacle is proposed for industrial production environments by Valdez-Navarro and Ricardez-Sandoval (2019) and Dias and Ierapetritou (2020), who both provide comprehensive proposals on the integration of design and control, with surrogate models proposed to improve quantification of uncertainty. Additionally, Li (2011) contributes to the early discussions on the application of ML, providing some practical recommendations for efficient data storage, retrieval and use, with a specific focus on feature selection and reduction of data for functional specifications, using the MapReduce data processing model. Similar ML applications are noted in Kadhum et al. (2019), who also use MapReduce and a ML subsystem built on user requirements to enhance feature selection and data partitioning for tailored use. With vast amounts of data now readily available from mining processes, data preprocessing and validation are crucial to minimise impairment of results of subsequent activities and processes that rely on such data as input. Thankfully, ML models are steadily proving their enhanced capability in preprocessing of such large volumes of data, enabled through function specific configurations for data processing, which include but are not limited to, detection and replacement of missing values, generic or domain-specific outlier imputation based on specific rules, ascription/supplanting missing data based on most probable worth as determined by available data as well as attribute reduction to remove noisy features and retain a subset of relevant data (Venkata and Narsimha, 2021).
Now, when the existing literature on mathematical optimisation of production schedules in underground mining is examined, it is silent on the level of accuracy of input data parsed onto the optimisation model. While there are several attempts and ways to mitigate this handicap, such as including stochastic processes in the optimisation methodology (Dimitrakopoulos and Jewbali, 2013), the scarcity of discussion on this issue in mathematical model applications represents a significant blind spot that warrants serious consideration. Addressing this oversight in the model inputs will undoubtedly minimise the impairment of optimal solutions, attributable to the use of flawed or inaccurate inputs. Moreover, optimisation of mining processes, such as drilling and blasting (Leonida, 2023), rockburst prediction (Waqar et al., 2023), and equipment availability (Nehring et al., 2010; Patil et al., 2021), are mostly isolated, with no direct connection to the ultimate objective, that is, supporting the optimisation of the production schedule. Consequently, the full potential from these isolated improvements in prediction may not be transferred for full realisation in the schedule.
Given the increasingly large volume of data being generated from modern mining equipment and product embedded systems such as information retrieval sensors and equipment performance monitoring modules, along with manual data systems, the complexity of establishing a robust mine planning database should not be underestimated. Indeed, robust data management and processing are pivotal to optimisation endeavours, requiring a high level of responsibility, and therefore, should not be delegated or relegated to inexperienced or junior personnel. For this reason, specialist data management personnel should be tasked with this responsibility, ensuring input data is frequently validated against in-field measurements. Further, the study proposes establishment of a central information sphere, where structured data for the schedule and other functional purposes can be precipitated without having to chase for it from departmental silos (Figure 8).
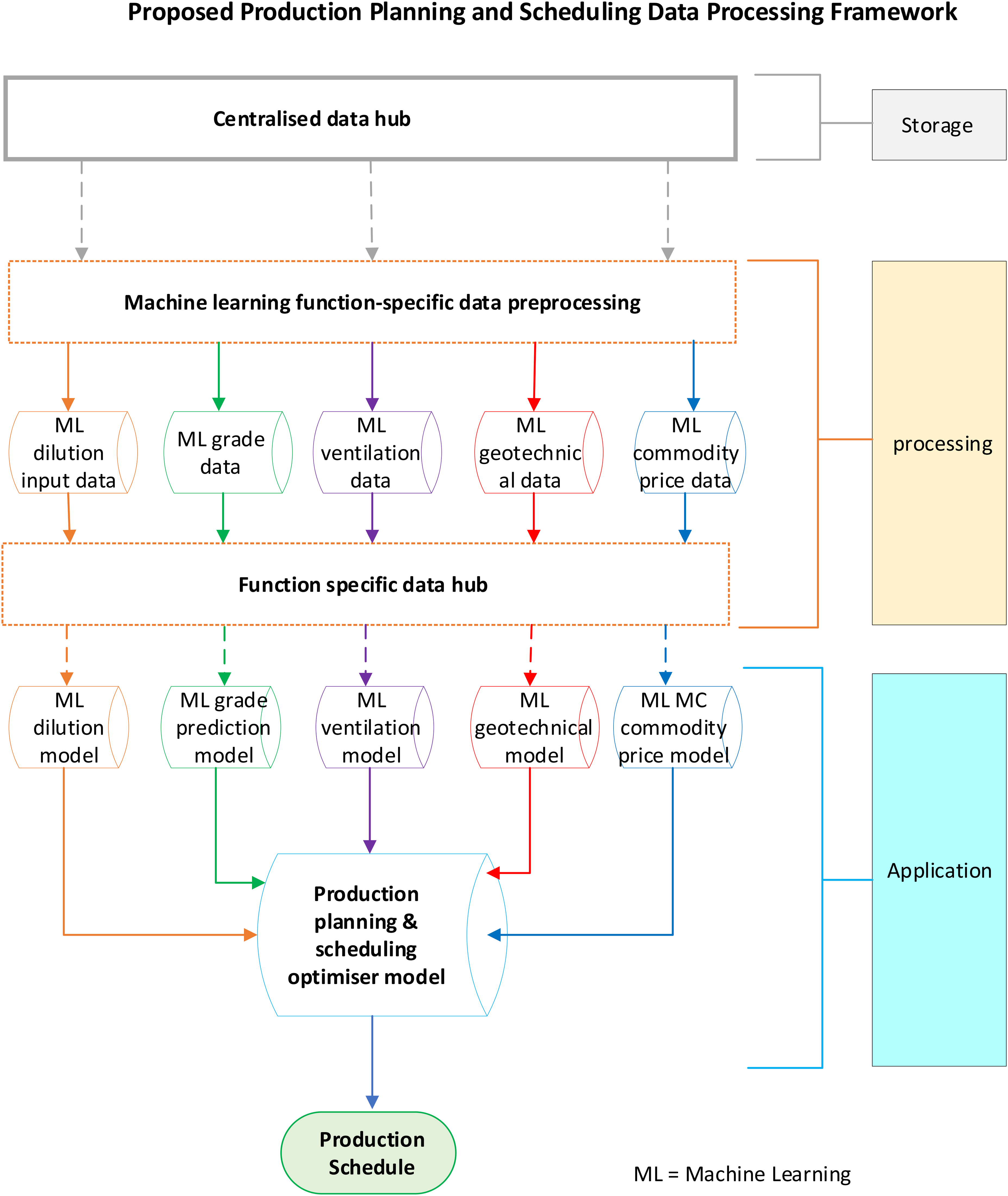
Machine learning dilution prediction framework for MIP schedule optimisation.
This data hub will include basic, function-specific models to enable the scheduling engineers to lead the process, seeking detailed information from departmental subject matter experts only in instances where detailed information is warranted. When data capture, processing and storage is improved, additional opportunities are presented through enhanced data analytics and ML capabilities. Structured data for function specific requirements improves simulation capabilities of optimisation models and their components, thereby improving efficiencies. As a result, huge financial rewards may be realised in the form of lower consumption on resources, leading to reduced waste generation and carbon emissions. Carbon footprint reduction is increasingly becoming a key business KPI, in line with the global push on reducing carbon emissions from the industry (Tost et al., 2018).
Thus, additional robustness will be embedded in the schedule, internally in terms of synergistic optimisations of schedule inputs, and externally in terms of machine learning enhanced data mining, processing and integrated systems. As a matter of caution, vestiges of the past epoch, characterised by the perennial problem of computing hardware and software that meets the needs, are still existent, although, benign. As such, the recommended architecture may not see the light of day if leading-edge infrastructural updates and computing systems are not deployed to refute the subtler fallacies of intractable computing challenges. Finally, the study also resonates with the monotonous chorus by geo-statisticians and mine planning engineers to incorporate geo-metallurgical modelling into geological block models for a global optimisation of the total system measures, such as the net smelter return (NSR) (Dominy et al., 2018; Dowd et al., 2016) and carbon emissions (Azadi et al., 2020; Dominy et al., 2018). This will minimise wasted efforts in piecemeal optimisations, which can only reveal at the back end of the process that a seemingly viable solution may not be viable when geo-metallurgical considerations are layered on.
Conclusions
The increasing footprint of ML in underground mine planning is reviewed with a focus on mining dilution, ore grade variability, geotechnical stability concerning rockburst and seismicity prediction, ventilation requirements, mineral commodity price forecasts and lastly, management of data for mine planning and scheduling. Despite an increasing deployment of ML applications and the remarkable predictive potency emerging from ML models, the full potential is barely realised in the global optimisation of production schedules because the studies are orphaned, with a tenuous link to the production schedule optimisation process. Cardinally, a central data repository is proposed for data storage. Function-specific, surrogate ML models are proposed for the prediction of mining dilution, ore grade variability, atmospheric conditions, mineral commodity prices, rockburst and seismicity. The proposed models derive function-specific data from the central database to produce a more accurate input feed to the primary mathematical schedule optimiser model. Further research work is recommended to examine similar opportunities in other mining activities such as production rates and equipment availability as previously noted in the section ‘Introduction and motivation’ (items 7 and 8). Future studies are also recommended to explore the full integration of ML subsystems of surrogate models with direct connectivity to the production schedule, spurred by the increasing maturity of ML applications and computing capabilities.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.