
Abstract
The mathematical methods developed so far for addressing truck dispatching problems in fleet management systems (FMSs) of open-pit mines fail to capture the autonomy and dynamicity demanded by Mining 4.0, having led to the popularity of reinforcement learning (RL) methods capable of capturing real-time operational changes. Nonetheless, this nascent field feels the absence of a comprehensive study to elicit the shortfalls of previous studies in favour of more mature future works. To fill the gap, the present study attempts to critically review previously published articles in RL-based mine FMSs through both developing a five-feature-class scale embedded with 29 widely used dispatching features and an insightful review of basics and trends in RL. Results show that 60% of those features were neglected in previous works and that the underlying algorithms have many potentials for improvement. This study also laid out future research directions, pertinent challenges and possible solutions.
Keywords
Introduction
To extract minerals from open-pit mines, various tasks are performed such as drilling, blasting, loading and hauling. Of these, the haulage operation is the most expensive, comprising half up to two-thirds of the total operational costs (Chaowasakoo et al., 2017b). Shovel–truck systems are a widely adopted hauling approach, particularly in large-scale open-pit mining operations (Czaplicki, 2008), with large dump trucks being the primary contributor to greenhouse gas (GHG) emissions during mining activities (Siami-Irdemoosa and Dindarloo, 2015). As a result, the mining sector finds it necessary to develop efficient fleet management systems (FMSs) in order to achieve reduced operational costs and environmental impacts. Since the 1970s, scholars have resorted to operations research techniques to deal with the truck allocation and dispatching problems in FMSs to such an extent that a good level of maturity is noticeable nowadays in these methods in terms of addressing multiple allocations and dispatching features required in a typical truck–shovel system. However, these mathematical methods demonstrate some weaknesses when it comes to acting autonomously in the dynamic environment of an open-pit mine. That is why machine learning methods, particularly reinforcement learning (RL), have gained attention as a viable solution for establishing the allocation and dispatching systems in line with Industry 4.0 or its translation in the mining domain known as Mining 4.0. The fourth industrial revolution in the mining sector demands attributes such as autonomy, dynamicity, visualisation and real-time control. Generally, financial/environmental motivations, the analytical models’ drawbacks, and the hype in Mining 4.0 have encouraged some scholars to incorporate RL-based algorithms into mine FMSs. However, the proposed frameworks are far from being adequate in addressing the essential multiple objectives required in a material handling operation, as will be evident in the remaining sections of the article. Therefore, it is imperative to review the published works with the aim of detecting their shortfalls and then setting the stage for less flawed intelligent dispatching systems in the future. Yet, characteristics of a well-structured intelligent dispatching system should be identified in advance to serve as comparison criteria. To this end, the present study initially examined a substantial number of previously published studies on operations-research-based FMSs in open-pit mines. This choice is motivated by the fact that analytical methods in this field have achieved a favourable degree of maturity in parameter settings. Subsequently, the most commonly addressed features (29 in number) in shovel–truck systems were categorised into five major classes such as production, shovel, truck, operation, and destinations, each assigned with a numerical code as seen in Table 1. For example, when a certain research work is said to lack code 27, it means the work has failed to address scheduled maintenance for shovels. These codes are applied as criteria to compare RL-based mine FMSs together and highlight their advantages and disadvantages. Apart from this technical review, an algorithmic scrutiny is also carried out to examine these systems through the lens of RL. For this purpose, a concise glance is taken at the fundamental theories and algorithms of RL to provide the readers with more insights into the basics of this promising field of artificial intelligence. Familiarised with both the comparison criteria and necessary concepts of RL, one can then weigh up the pros and cons of previous RL-based FMSs, resulting in developing more concrete works in the future. To recapitulate, the present article delivers the following contributions:
Proposing a five-feature-class scale for drawing distinctions among different intelligent FMSs in open-pit mines. Visualising thematic patterns among the main research works on intelligent FMSs. A concise review of fundamentals and trends in the RL world for less acquainted readers. A critical technical/algorithmic examination of RL-based FMSs developed so far to pinpoint their pertinent advantages and disadvantages. Defining research gaps and directions for future works on intelligent FMSs. A profound investigation into challenges encountered and possible solutions.
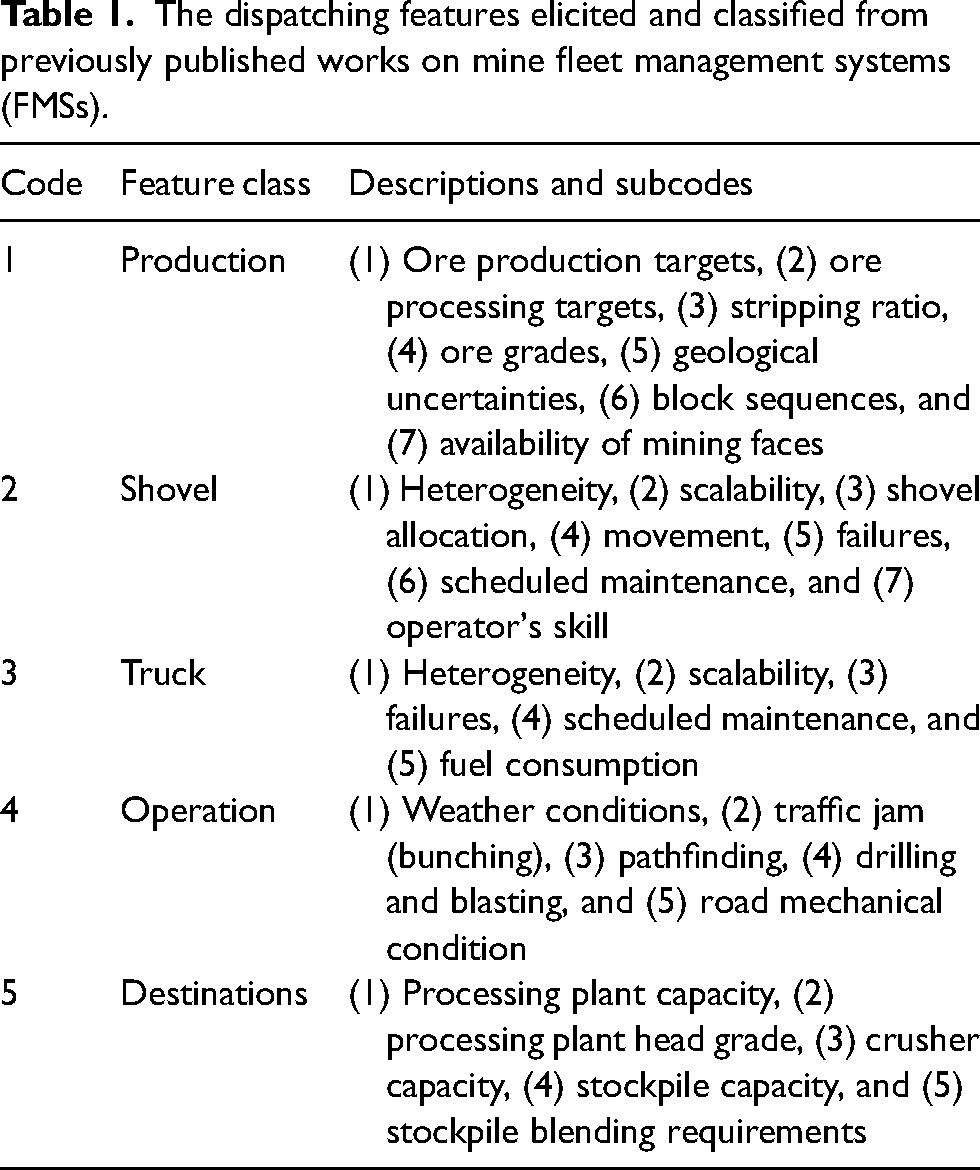
The dispatching features elicited and classified from previously published works on mine fleet management systems (FMSs).
The present paper is structured as follows: first, the most common classifications for mine FMSs are introduced before laying out the drawbacks associated with conventional mathematical dispatching models. Then, a bibliometric analysis is conducted on the previously published research works on a variety of intelligent solutions for mine FMSs in order to decipher tentative thematic patterns. Having established an outlook on this research domain, the basics in RL are explained and two chief categories of algorithms known as value-based and policy-based are reviewed. Since truck dispatching systems enjoy more than one agent in their architecture, a separate subsection is allotted to multi-agent algorithms. Next, the RL-based FMSs developed so far are critically reviewed to elicit their technical and algorithmic pros and cons. Finally, research directions and challenges are explored in discussion followed by conclusions.
Definition of conventional FMS
Truck dispatching refers to the act of determining the subsequent location for a haul truck following the dumping of its load. Having a nested link with FMSs, logistics and finally supply chain, the truck dispatching if managed efficiently can contribute to more than 15% improvement in ore production and truck waiting time (Moradi Afrapoli et al., 2021). FMSs are classifiable from various aspects. The crudest one is whether the truck is allocated to a certain shovel over a certain path during the whole shift (fixed or static allocation) or it frequently receives new assignments and path recommendations from the dispatching unit (flexible or dynamic allocation; White et al., 1993). Regarding the level of computer utilisation, three FMSs exist manual, semi-automated and fully automated (Lizotte and Bonates, 1987). The process of manual dispatching involves adhering to a predetermined heuristic method, in which a specific number of trucks are designated to a particular shovel for the entire shift, and the operation is managed by an in-field operator. Fully automated systems eliminate the need for any involvement by a human operator using telematics. In terms of solving stages, two main fleet management approaches are noticed in the literature such as the single-stage and the multistage approach (Alarie and Gamache, 2002). There are also some heuristic truck dispatching methods, namely minimising shovel waiting time, minimising truck cycle time, minimising truck waiting time, and minimising shovel saturation and coverage (Chaowasakoo et al., 2017b). These heuristic methods that assign trucks to shovels based on one or more criteria without taking into account any production targets or constraints are known as single-stage models, while the multistage models divide the dispatching problem into three sequential parts: (a) shortest path model, (b) truck allocation (the upper stage) and (c) truck dispatching (the lower stage; Moradi Afrapoli and Askari-Nasab, 2019). In another classification, fleet management strategies are designed as truck-centered, shovel-centred or a combination of both to get the right assignment for a truck. To put it differently, three dispatching strategies exist considering the interaction of the m forthcoming trucks and the n shovels in the field (Alarie and Gamache, 2002). In the 1-truck-for-n-shovels strategy, one of the heuristic methods is used to determine which shovel has the greatest potential, and then the truck is directed to that shovel. The m-trucks-for-1-shovel strategy considers the m next trucks and then dispatches the best truck (based on the selected heuristic method) to the neediest shovel (the shovel that is behind the production schedule the most). The m-trucks-for-n-shovels consider simultaneously the assignment of the m forthcoming trucks to n shovels. A comparison of these three strategies in a simulated mine indicated the production supremacy of the latter (Chaowasakoo et al., 2017a).
Viewing through mathematics of the decision-making, in essence, dispatching is a non-deterministic polynomial-time (NP)-hard combinatorial problem, such as the iconic knapsack problem, involving assigning trucks to shovels to achieve one or several specific objectives (e.g. production maximisation, equipment utility maximisation, and cost minimisation), while considering various restrictions (e.g. head grade and blending requirements, shovels’ digging rates, and crushers’ capacity; Bastos et al., 2011; Cohen and Coelho, 2021). It makes sense to recognise that a large number of FMSs introduced since the 1970s have included a wide array of mathematical models that have their origins in the field of operations research. Some prevalent models are exemplified as queueing theory (Ercelebi and Bascetin, 2009), transportation approach (Li, 1990), linear programming (Gurgur et al., 2011), non-linear programming (Soumis et al., 1989), integer programming (Zhang and Xia, 2015), mixed integer linear programming (Chang et al., 2015), goal programming (Temeng et al., 1998), and mixed integer linear goal programming (Upadhyay and Askari-Nasab, 2016). Pure mathematical optimisation methods not only complicate the problem, but also adopt a deterministic approach, whereas mining operations are characterised by uncertainties in terms of equipment cycle time, unexpected failures, rock characteristics, weather and road conditions, etc. (Ozdemir and Kumral, 2019). Consequently, another major research stream known as simulation-based optimisation emerged in order to incorporate the discrete event simulation (DES) paradigm into inherently discretised mining operations. This integration was accentuated in the last decade by the works of Nageshwaraniyer et al. (2013), Askari-Nasab et al. (2014), Moradi Afrapoli and Askari-Nasab (2020), and Mohtasham et al. (2022), to name a few. Typically, the structure of traditional optimisation methods is restricted by the requirement to rerun the model if there is any change made to the mining dynamics (De Carvalho and Dimitrakopoulos, 2021). Moreover, a large number of models developed so far are both offline and non-intelligent, while Mining 4.0 demands dynamicity and autonomy at all operational levels (Hazrathosseini and Moradi Afrapoli, 2023b). Machine learning as an imperative pillar of this revolution has shown impressive results in many domains and was predicted in 2017 to need 2 to 5 years to reach the plateau of productivity (Gartner Inc., 2017), and in 2023 that plateau seems to have been reached judging by the unprecedented prosperity received by machine learning techniques, particularly in chatbots and image/video/voice generators.
An intelligent solution
Initially coined by Arthur Samuel from IBM in 1959, machine learning is “a field of study that gives computers the ability to learn without being explicitly programmed” (Samuel, 1959). In other words, algorithms are not hard-coded but adaptive in order to evolve architecturally through training (El Naqa and Murphy, 2015). According to the nature of the training data, machine learning paradigms are categorised into supervised, unsupervised, and semi-supervised, whereas supervised, unsupervised, and RL are the categories when data availability matters (Lee and El Naqa, 2015). In a supervised learning model, the algorithm learns from a labelled dataset to obtain a function for mapping inputs to outputs in classification or regression problems. In contrast, an unsupervised model tries to infer the intrinsic pattern of inputs with no feedback received mainly for clustering purposes. In the event that the feeding dataset is missing, RL comes to the fore to train an agent from the interactions it makes with its surrounding environment. The agent ameliorates the actions it takes through the reinforcements (rewards or punishments) imposed by the environment. In a mine dispatching problem, the data on the best assignment in every possible dispatching situation is not completely available considering the variable number of equipment, dynamic changes and multiple optimisation goals. Therefore, a data-independent method such as RL best dovetails with the dispatching problem since it helps agents accumulate ample experience in the training phase for applications in various real-time dispatching situations. RL is the result of a convergence of animal psychology and optimal control in the late 1980s. RL's versatility and potential for wide-ranging applications are showcased in various domains such as robotics (Ibarz et al., 2021), board games (Silver et al., 2016), automated driving (An and Jung, 2019), vehicle routing (Zhao et al., 2020), and finance (Deng et al., 2016). Another RL-like approach exists that is called negotiable scheduling (Hazrathosseini & Moradi Afrapoli, 2023a). In negotiable scheduling, intelligent agents are employed to achieve production plan objectives with minimal expenses by collaboratively negotiating and generating schedules for each piece of equipment, potentially using mechanisms such as the Contract Net Protocol (CNP; Smith, 1980).
In the context of intelligent FMSs in open-pit mines, three main approaches are noticeable including supervised learning, negotiable scheduling and RL. Some researchers have taken advantage of different supervised learning algorithms including k-nearest neighbours (kNN), support vector machine (SVM), and random forest (RF) in the mine dispatching problem. Sun et al. (2018) delved into accurately predicting truck travel times in open-pit mines. The authors divided mine roads into two categories: fixed and temporary link roads. They explored the application of three distinct machine learning models, including kNN, SVM, and RF, for predicting the travel time on each type of road. SVM and RF-based models exhibited superior performance compared to the kNN model. Another study by Choi et al. (2021) explored the application of machine learning algorithms in predicting ore production in open-pit mines. They tested six different algorithms on data collected from a limestone open-pit mine and found that the SVM, neural networks, and RF models were particularly accurate, with SVM being the top predictor. In another effort, the authors introduced a combination of Harris Hawks optimisation and SVM to predict ore production with high accuracy (Choi et al., 2022). Choudhury and Naik (2022) endeavoured to enhance truck haulage system productivity by minimising dumper cycle times and optimising dumper allocation to shovels, reducing idle time. Machine learning models including kNN, SVM, and RF were employed to predict travel times under varying atmospheric conditions. Nobahar et al. (2022) applied linear regression, decision tree, kNN, RF, and gradient boosting algorithms for optimum fleet selection, with the latter being recognised as the most accurate. Specifically looking at negotiable scheduling methods, Icarte Ahumada et al. (2020) applied the CNP protocol in their multi-agent system in order to capture dynamicity in material handling systems in open-pit mines. Cohen and Coelho (2021) leveraged a similar negotiation approach for task allocation and pathfinding among trucks and shovels.
Nevertheless, the application of RL in material handling systems has an edge over supervised learning and negotiable scheduling. With respect to supervised learning, changes in fleet management policies will affect the future supply and demand, and supervised learning methods find it challenging to capture and represent these dynamic changes in real time (Lin et al., 2018). Moreover, compared to the mathematical approaches needing to resolve the model in case of changes in the mine configuration, an agent in an RL setting learns to make informed decisions in many complex situations after sufficient interactions within the environment, thereby generating real-time truck dispatching assignments (De Carvalho and Dimitrakopoulos, 2021). On the other hand, negotiable scheduling is not the optimal option due to the elevated solving time resulting from communication overhead during negotiations to determine the best schedule, especially as the truck fleet size expands (Hazrathosseini and Moradi Afrapoli, 2023a). Tersely, the RL paradigm lends itself to online applications such as mine FMSs, where a highly dynamic and stochastic environment governs. Furthermore, a well-trained set of agents following the RL approach can make knowledgeable decisions more swiftly. This has been a driving motivation for developing RL-based FMSs in open-pit mines by a number of researchers (Bastos et al., 2011; De Carvalho and Dimitrakopoulos, 2021; Huo et al., 2023; Zhang et al., 2020), the works of whom are exclusively discussed in the rest of the present study.
Examining and visualising the interrelationships among the aforementioned research on intelligent FMSs in terms of keywords offers valuable insights into patterns and connections. VOSviewer® is a useful software tool for constructing bibliometric networks, represented by nodes and links, through distance-based visualisations (Van Eck and Waltman, 2010). Node proximity indicates their relatedness, with larger nodes denoting a higher frequency of the labels they represent. In Figure 1, the network representing keywords found in the titles and abstracts of the previously mentioned research on intelligent FMSs in open-pit mines reveals four primary clusters. The blue cluster appears to be associated with RL, indicated by the keyword ‘q’, a popular RL algorithm. The node ‘Scheduling’ suggests that the green cluster pertains to negotiable scheduling methods, while the yellow cluster is likely connected to supervised learning algorithms. The red cluster appears to be a diverse group of keywords, with significant connections to both the blue and yellow clusters. Notably, the ‘open-pit mine’ node is the largest, highlighting that all the analyzed articles revolve around the theme of open-pit mines.
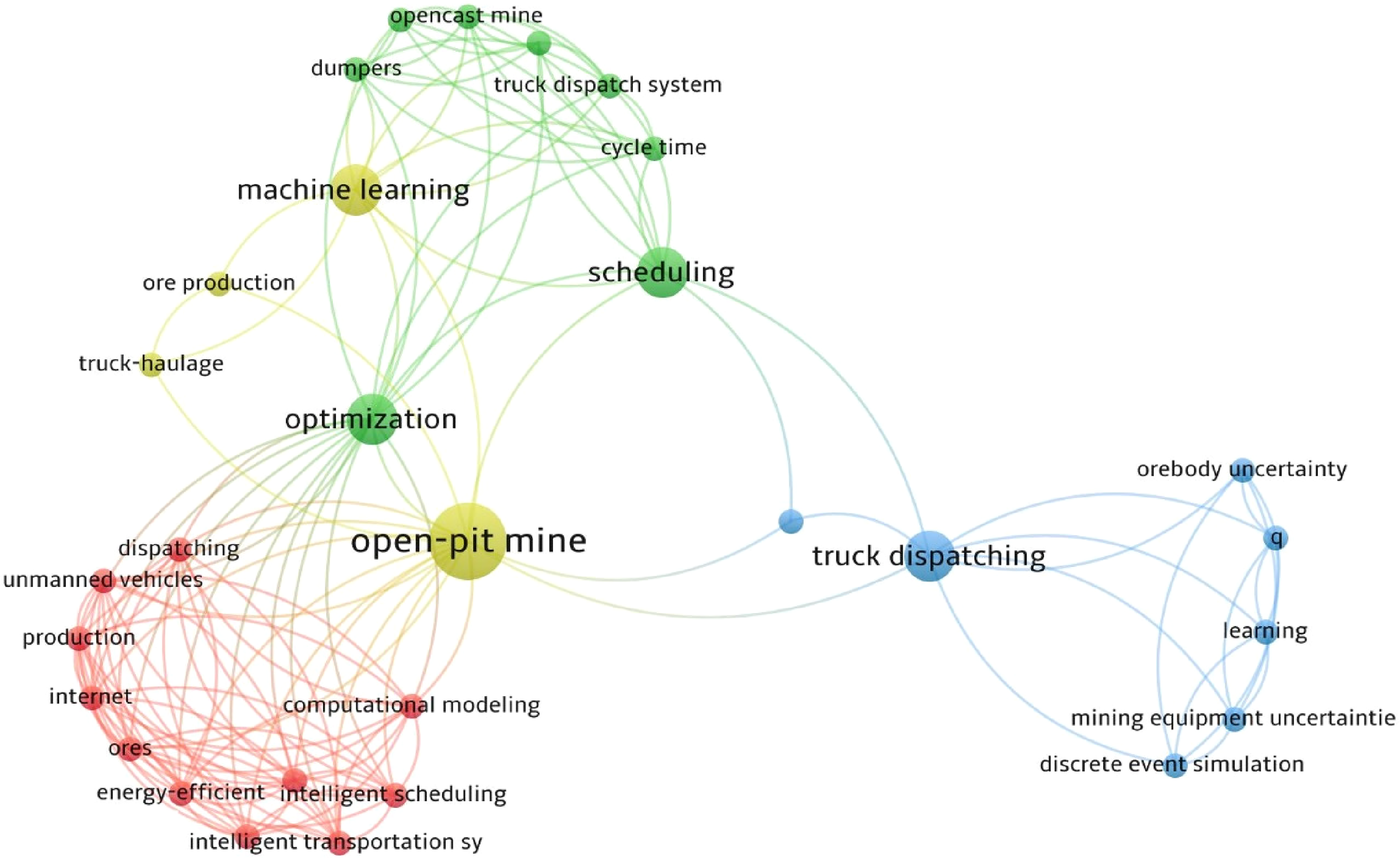
Network visualisation of keywords used in articles regarding intelligent fleet management systems (FMSs) in open-pit mines.
Having established the outlook of various intelligent methodologies, this research endeavours to focus specifically on RL-based FMSs. The goal is to not only assess the current state of knowledge in this field, but also to identify crucial research directions concerning algorithmic and mining-related aspects of this type of intelligent system. The next section introduces some foundational concepts of RL to provide a basis for a more in-depth examination of RL-based FMSs in open-pit mines.
Reinforcement learning (RL)
An RL problem is formulated using the Markov decision process (MDP) due to three main reasons: (a) real-world events show stochastic behaviours, (b) discretisation of continuous environments and treating them as Markovian processes simplify the solving procedure, and (c) MDP creates a framework to translate the problem into an understandable language for the agent (the computer). MDP assumes the Markov property, in which the capacity to anticipate the next state 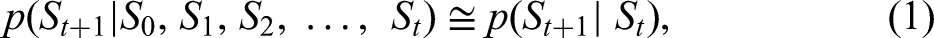
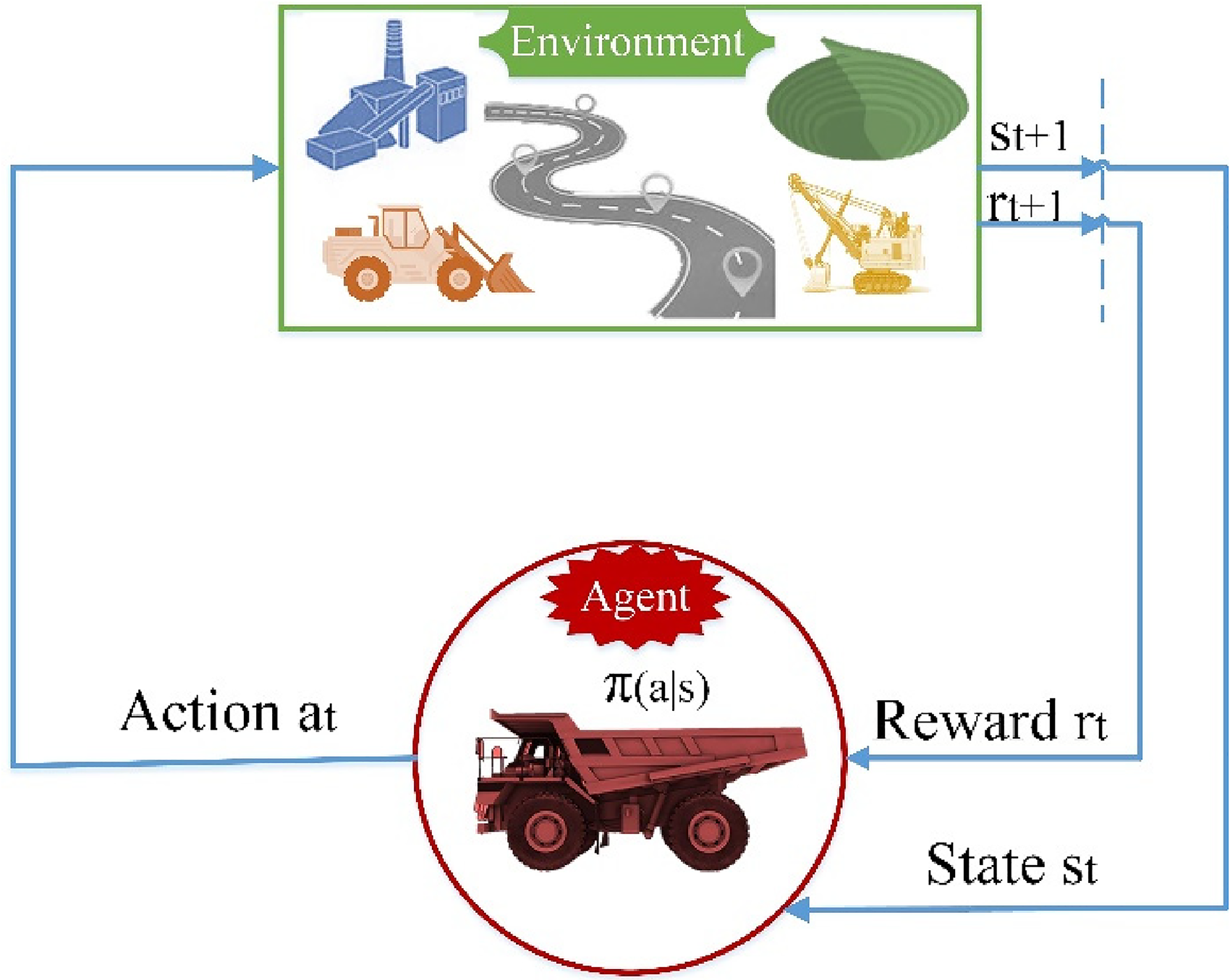
A single agent interacts within a mine environment (modified after Sutton and Barto, 2018).
Typical RL components
A typical RL setting is comprised of various components, namely an agent(s), an environment, states, actions, rewards, a policy, value functions and sometimes a model of the environment. The agent is the learner and decision-maker. The environment encompasses everything outside the agent that the agent interacts with. An environment has several properties including fully/partially observable, single-agent/multi-agent, deterministic/stochastic, episodic/sequential, static/dynamic, discrete/continuous and known/unknown (Russell and Norvig, 2010). Some of these features hinge on how the environment is defined. The environment's dynamics is denoted as 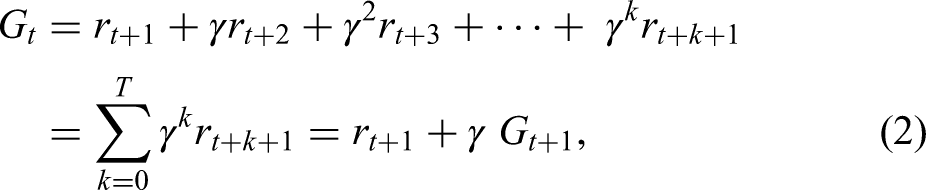
The state-value function 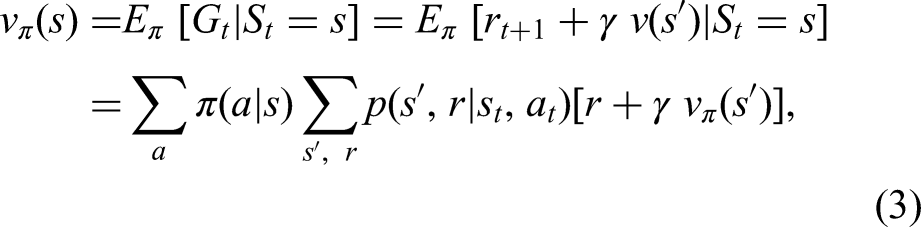
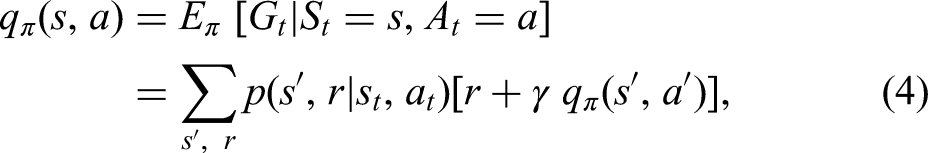
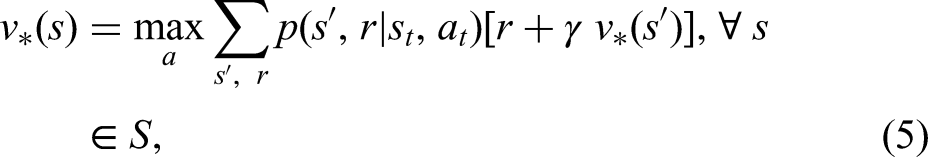
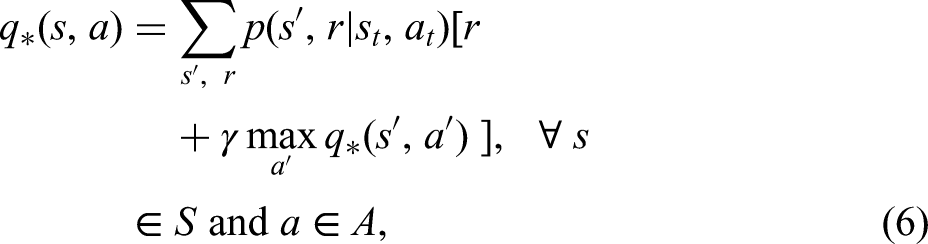
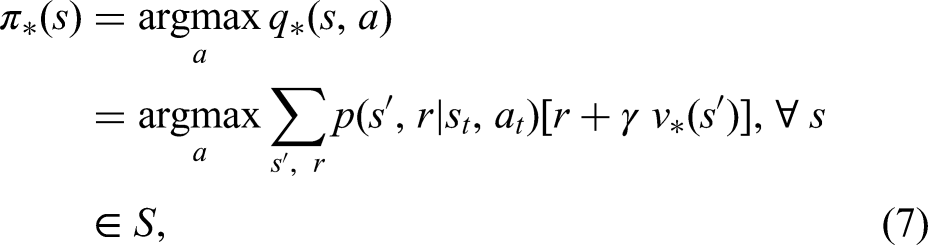
The environment that an agent is encountered with may be either known or unknown from its own perspective. This environmental knowledge is called “model” and underlies the classification of RL algorithms in two major categories: model-based algorithms and model-free algorithms. In model-based algorithms, since the dynamics of the environment (
Algorithms
Three main approaches including DP, MC and TD come to notice in the RL literature. Although capable of updating estimates of the values of states based on the previous estimates of the values of successor states (bootstrapping), DP methods (e.g. policy evaluation, policy improvement, policy iteration, and value iteration) require a complete model of the environment. MC methods are based on averaging sample returns, with the agent learning optimal behaviour directly from interactions with the environment, the dynamics of which is unknown. Nonetheless, the algorithm must wait until the end of an episode, while the conclusion of the episode may take an extended amount of time in certain applications, thereby decelerating the learning process. Formally expounded by Sutton (1988), TD is a hybrid method that combines the strengths of these two distinct techniques by being model-free such as MC, but simultaneously benefiting from bootstrapping such as DP. To put it differently, the sum of the immediate reward and the estimated reward for the next state known as the sample or the TD target (equation (8)) is based on updating the old estimate for the value function instead of calculating the expectation as previously seen in equation (3) (recall: 
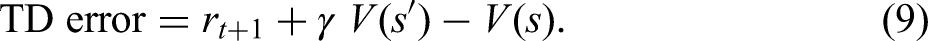
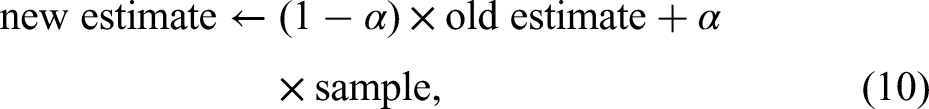
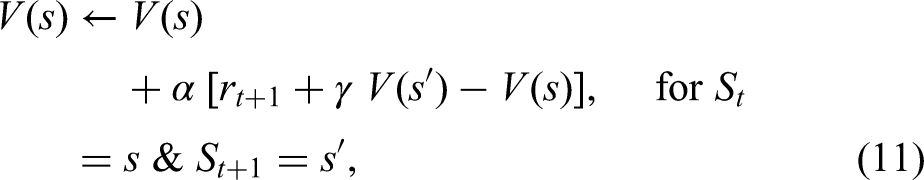
Value-based algorithms
In value-based algorithms, as the name implies, optimal value functions (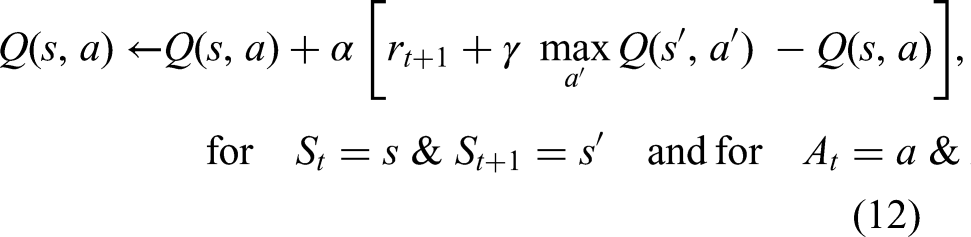
Nevertheless, the tabular Q-learning reaches an impasse in many real situations, where visiting all the state–action pairs and storing them in the memory are not a viable option. Deep RL is a valuable tool for improving representations of even simple games such as the old version of the Atari game Pong. With over 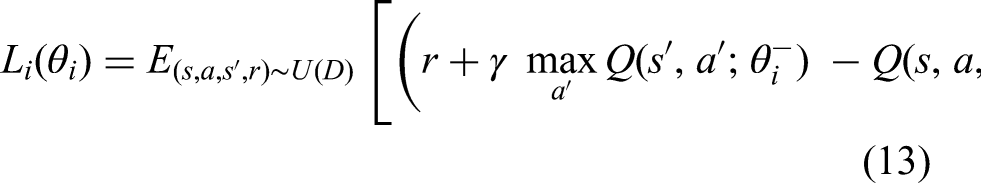
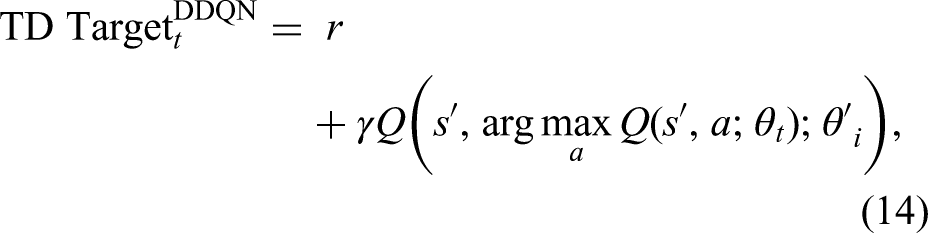
Policy-based algorithms
Policy-based methods do the contrary by searching for the optimal policy directly, which gives them an edge in high-dimensional continuous action spaces such as self-driving cars. The main concept involves using a differentiable parametric probability distribution 

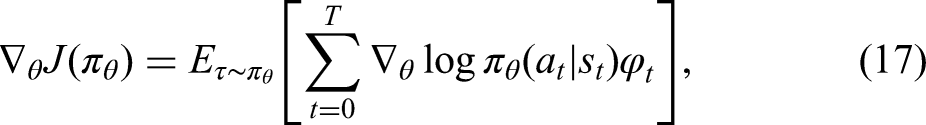
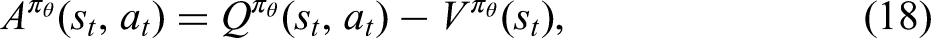
Multi-agent RL
In complex and large environments, it is not only advantageous for an individual agent to make intelligent decisions but also for a group of agents to engage in communication and collaboration. Consequently, the development and implementation of learning strategies for each agent becomes imperative to facilitate efficient coordination among multiple agents in such situations (Zhang and Zhang, 2020). This paradigm in RL is translated into multi-agent RL (MARL), in which several agents are involved in interacting with the environment and learning concurrently to enhance the proficiency of the whole system as time passes. Agents can either work independently or jointly (Claus and Boutilier, 1998). That is, independent learners lack awareness of other agents’ actions and rewards, whereas joint action learners learn the value of their own actions in relation to the actions of other agents so that a joint optimal policy (e.g. the Nash equilibrium) maximising all the agents’ rewards is reached. Based on the goal defined for each agent, the interaction among them can be cooperative, competitive or mixed (Buşoniu et al., 2010), reminding the strategic interactions in a game between a set of players in the game theory. Despite the single-agent RL, the MARL environment in which each agent operates is non-stationary (non-time homogeneous) as the transition probabilities are subject to change over time due to the fact that an agent tries to learn the other agents’ actions which are changing at the same time, rendering the environment non-Markovian, particularly for independent learners (Laurent et al., 2011). Instead, the environment is formulated as a generalised form of MDP known as a stochastic game or Markov game (Shapley, 1953). Markov games maintain the assumption that state transitions adhere to the Markov property; nonetheless, the probabilities of transitioning between states and the expected rewards are influenced by the joint actions of all participating agents. Generally, four inherent challenges exist in MARL (Wong et al., 2022): computational complexity, non-stationarity, partial observability, and credit assignment.
Agents involved in MARL can learn policies or value functions in three different architectures: decentralised, centralised, or mixed. In decentralised learning such as the independent Q-learning by Tan (1993), each agent is trained independently from others, which simplifies the system design; nevertheless, two issues occur: (a) since no information is shared, each state must be revisited by each agent to collect sufficient experience, (b) non-stationarity is extremely highlighted as the learning and exploration of one agent interferes with the learning and exploration of others (Busoniu et al., 2006). In other words, a separate network is assigned to each agent in decentralised learning, and agents have no knowledge about each other. In contrast, centralised learning involves agents sharing their observations and policies with a central controller, which then makes decisions on the optimal actions for each agent. To put it differently, only one central network exists making decisions for all agents, and agents are allowed to share experience. It might diminish non-stationarity and partial observability, but scaling becomes challenging as the joint action space expands exponentially with the increasing number of agents involved. A middle-ground approach is centralised training and decentralised execution, where each agent has a separate network and communication capability. This approach is divided into two groups: value-based methods, for example, Value-Decomposition Networks (VDN) (Sunehag et al., 2017) and Q-mix (Rashid et al., 2018), and policy-based methods, for example, multi-agent DDPG (Lowe et al., 2017) and Counterfactual Multi-Agent (COMA) (Foerster et al., 2018). However, Zhang et al. (2020) argued that original centralised training and decentralised execution methods are not satisfactory enough for the mine dispatching problem since the number of agents (trucks) is not fixed and that assigning a separate network to each truck is managerially challenging. Therefore, they employed a certain variant known as experience-sharing centralised learning and decentralised execution initially introduced by Foerster et al. (2016) in their developed dispatching system. The methodology employed involves utilising a shared network for all the agents (trucks), which receives the observation from each agent and independently produces the corresponding action for each agent. Khorasgani et al. (2021) criticised this approach because of failing to attain the optimal policy when an agent's optimal action is dependent on the actions of other agents. They suggested applying a weight-sharing K-nearest method to cope with the challenges of a variable number of agents, action dependency, model management, and non-stationarity.
MARL implementations are not limited to single-objective policy optimisation, but rather extend to multiple conflicting objectives in real-world problems such as mine dispatching. Despite the scalar reward in single-objective contexts, in multi-objective settings, the reward signal or the value function for each agent is represented as a vector, with each entry denoting the corresponding reward or value on each objective (Van Moffaert and Nowé, 2014). Two classes of algorithms are identified to cope with multi-objective tasks: single-policy and multiple-policy algorithms (Roijers et al., 2013). The former produces only one single optimal solution (policy), while offering the user a variety of solutions, which provides additional insights into the compromises that may be necessary among conflicting objectives (Vamplew et al., 2008). A multi-policy algorithm searches for a set of optimal solutions (e.g. Pareto coverage sets) to output the most feasible trade-offs among objectives. The value vector of objectives is merged into a scalar value using a scalarisation function to facilitate the comparison of different solutions. Among various ways of objective combination in multi-objective MARL, the vector elements are advised to be scalarised using a utility function definable jointly, separately, or based on the social choice theory for agents (Rădulescu et al., 2020). Despite the previously mentioned works in deep single-objective MARL, the development of methods addressing continuous or high-dimensional state/action spaces in multi-objective MARL has not been adequately attended. A recent promising work by Lu et al. (2022) incorporates a multi-objective multi-agent DQN into residential appliance energy management but with a discrete action space. This might be problematic in, for instance, robotics, where a high-dimensional action space exists; however, the action space in dispatching (i.e. moving towards shovels or destinations) is discrete. Multi-agent multi-objective RL formulation dovetails with FMSs’ requirements in open-pit mines as it can adapt to changing conditions, efficiently allocate resources, and optimise conflicting goals. In other words, in open-pit mining operations, numerous trucks operate simultaneously to satisfy multiple objectives including maximising ore production, minimising fuel consumption, and meeting the required head grade and feed rate of processing plants. Multi-agent multi-objective settings facilitate the synchronisation of these trucks to concurrently optimise multiple goals.
RL for FMSs in open-pit mines
A typical truck cycle (material transportation cycle) in an open-pit mine involves several stages, namely queuing at a shovel, spotting, loading, hauling, queuing, spotting, and dumping at destinations (e.g., crusher, stockpile, waste dump, dyke, etc.), asking for a new assignment, and empty travelling. To formulate a truck dispatching problem in an open-pit mine in the context of an RL setting, those previously discussed MDP components are required to be recognised first as follows.
Agent
The agent in a dispatching problem is a truck interacting within a mine environment improving its performance over time. The truck is associated with some attributes such as capacity, velocity, and cycle time. Trucks accumulate experience independently or collectively based on the learning scheme executed.
Environment
Anything outside a truck is defined as a part of the environment including shovels, destinations, roads, humans, and even other trucks in the decentralised learning scheme. Imitated in a DES tool, the environment in a mine dispatching problem is of the multi-agent type.
State
The quality of learning is greatly influenced by a precise and specific definition of the current state. The places that a truck can be located are considered as states such as shovels and destinations. Paths are not included in the state space to decrease the dimensionality. Numerous state representations exist mostly in the form of an attribute-based vector accommodating equipment capacities, distances, load type (ore or waste), queue lengths, and location to name a few.
Action
Any dispatching decision such as a shovel or destination assignment is defined as an action. Thus, the action space in the dispatching problem is finite and discrete contrary to domains such as robotics, implying the point that value-based algorithms such as DQN are appropriately applicable.
Reward
The reward function sends a positive or negative signal based on the quality of the dispatching action taken. Waiting time, carried tonnage and equipment maintenance are some examples of reward definitions, which are linearly or non-linearly combined in single-objective settings, whereas the reward signal is a vector with an entry for each objective in multi-objective problems.
Policy
Each agent, as a truck attempts to reach an optimal policy, in which the most rewarding dispatching decision is autonomously taken given the truck's state representation. Trucks learn this decision-making capability as a result of frequent interactions within the environment in the training phase in order to implement it in online applications.
Model
The mainstream in general RL publications try to apply model-free algorithms due to the benefits mentioned in previous sections, and mine dispatching texts are no exception in this regard.
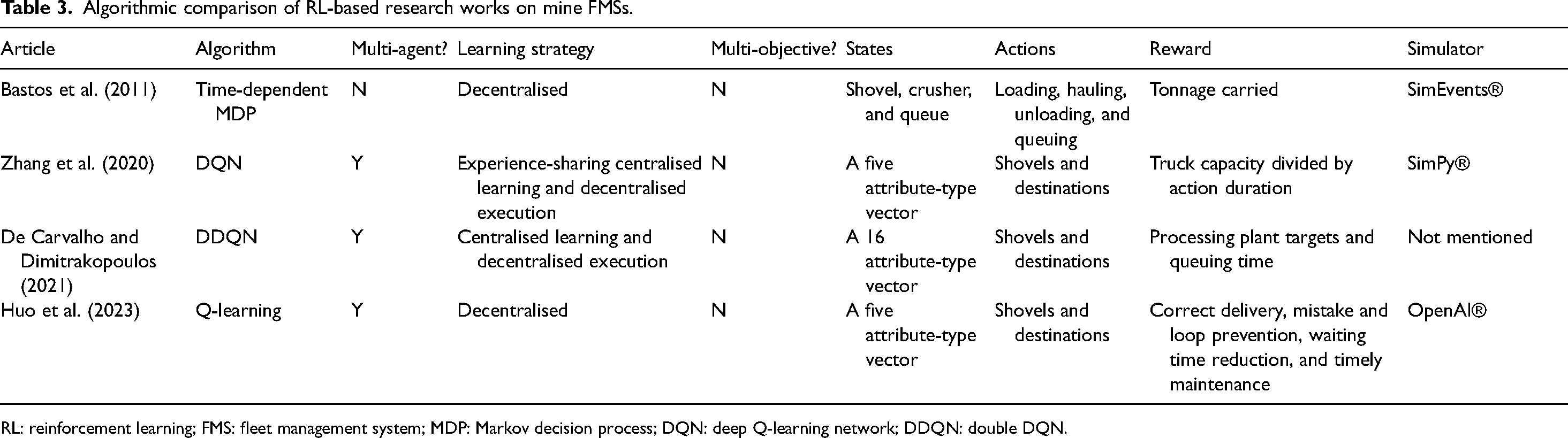
The advent of RL-based FMSs in open-pit mining dates back to more than a decade ago. Bastos et al. (2011) proposed a basic combinatorial formulation for truck dispatching modelled as a time-dependent MDP. Action durations are considered deterministic and stationary in the standard MDP, while the time-dependent MDP includes both stochastic state transitions and stochastic time-dependent action durations (Boyan and Littman, 2000), lending itself to the inherently uncertain mine environments. In the work by Bastos et al. (2011), the model's output will provide guidelines that specify the optimal action for the agent to take, considering its present time and state before being verified by a human dispatcher. To avoid the curse of dimensionality, they proposed the use of a single-dependent agent method, which simplifies a multi-agent issue into a single-agent problem for decentralised learning. In other words, an agent's decision is determined by the observation of its own state as well as the states of other agents involved. The reward function was defined as the amount of tonnage carried by a truck and yields rewards merely after unloading. Production maximisation was determined as the single objective of their medium-scale mine problem constrained by characteristics (e.g. velocity and capacity) of heterogeneous trucks and shovels. They assumed a scenario with three shovels, 15 trucks and one crusher. The crusher, shovels, and their queues were treated as states, while loading, empty travelling, loaded haulage, queuing, and unloading were considered actions. A two-phase framework was proposed including: (a) solving the MDP model (offline) and (b) executing the value iteration algorithm and then issuing the truck assignment. The offline phase is resolved prior to the mining shift, while the dispatching phase happens in real time. They simulated a 10-h shift of their hypothetical scenario in SimEvents® (MathWorks) and compared the total tonnage transported with that of two baselines, achieving a slightly higher production. As the authors admitted, dispatching decisions were not optimal enough. As mentioned in previous sections, the presence of several agents renders the environment non-stationary, questioning the conventional MDP assumptions. In fact, basic expansions of RL algorithms for multi-agent systems are not guaranteed to attain the optimal policy even in relatively simple environments (Kapetanakis and Kudenko, 2002). In addition, all the features mentioned in Table 1 for mine FMSs have not been addressed, except for the heterogeneity for shovels and trucks. Aside from the algorithmic and technical shortfalls, this pioneering article set the stage for developing more advanced frameworks for years to come. However, before reaching an acceptable level of maturity, the mainstream in truck dispatching was fed by operations research techniques, where a variety of linear, non-linear, integer, mixed integer, multi-objective, and stochastic programming methods were employed. This hype disengaged scholars from agent-based systems for a long period.
The study by Zhang et al. (2020) breathed new life into RL-enabled dispatching with the aid of a multi-agent system for dynamic operation of heterogeneous mining fleets at large scale. They employed a single network with shared parameters (experience-sharing, centralised learning, and decentralised execution) to accelerate the learning process and decrease the number of learned parameters as inspired by Foerster et al. (2016) but with two main differences: (a) applying the standard DQN instead of deep recurrent Q-networks with the aim of reducing computational overheads, while the latter more finely addresses partially observable settings (Hausknecht and Stone, 2015) and (b) as opposed to completely eliminating the experience replay, a subset of memory known as corrupted experience is removed using a memory tailoring algorithm to coordinate other trucks with those trucks dispatched later but arriving to the destination sooner. They allowed for heterogeneity of trucks treated each as an agent, yet shovels and dumps were assumed homogeneous. One of their novelties is representing a state as a vector of five attributes including truck capacity, expected wait time, total capacity of waiting trucks, activity time of delayed trucks, and capacity of delayed trucks, in order to realise two benefits: facilitating the centralised learning and relieving the state vector from dependence on the number of agents in order to adapt the algorithm to the trucks added or removed. The total vector size is dictated by the number of available shovels and dumps. The action space was set to accommodate each unique shovel and dump in the environment since the dispatch problem is all about finding the best destination. Contrary to the normal practice in MARL, the reward signal was defined independently for each agent as a function of truck capacity divided by the duration of the action taken. Their developed algorithm known as experience sharing and memory tailoring DQN mainly consists of two sequentially repeating modules: (a) memory generation, where an action (a destination) is selected for a needy truck using the ε-greedy strategy (see the “Typical RL components” section), and then executed in a simulator to obtain a reward and a new state. The whole transition is stored and then tailored for each truck during each simulation time and (b) network training, where a three-layer shared neural network is trained within numerous episodes using batches sampled from the memory buffer, and then optimising the loss function (equation (13)) to update network weights. A scenario involving three shovels, three dumps, and 50 trucks of three types was simulated in SimPy® (SimPy; Vignaux et al., 2007) over a 12-h shift in the first module. The framework was benchmarked against two basic dispatching heuristics rules in two different simulation settings including cycle-based and time-based heuristics over metrics such as production, cycle time, and match factor, achieving marginally superior results. Indeed, only a nearly 5% increase in production was achieved in comparison with a very basic heuristic, whereas operational-research-based works with more comprehensive algorithms report up to 11% production increase compared with not a basic heuristic, but with a currently in-the-market optimisation model (Moradi Afrapoli and Askari-Nasab, 2020). In addition, the model was initially trained for 50 trucks, and the production level decreased significantly with a change in the number of trucks. Another shortcoming relates to their too-straightforward reward shaping. Finally, yet importantly, only three dispatching features mentioned in Table 1 including truck heterogeneity, truck failures, and truck scalability are catered for. Overall, their research is inspiring in terms of innovations offered in state representation, memory tailoring and scalability.
De Carvalho and Dimitrakopoulos (2021) took intelligent dispatching to the next level by incorporating processing plant targets and geological uncertainties in the decision-making process. The workflow proposed consists of interactions between two main modules: a discrete event simulator and a neural network. The DES examines the key events of loading, hauling, dumping, and equipment breakdowns to mimic the operational interactions among shovels, trucks, and dumping sites within the mining area. The simulator operates under the assumption of a predetermined order for block extraction, allocation of shovels, a destination policy for each mining block, and predefined shortest routes among resources and destinations. The DES begins by situating all trucks at their designated shovels before moving on to the loading and hauling process. After the truck completes the dumping process, a new decision is made based on the network policy, and the DES simulates the ensuing operations that arise from this allocation, leading to reward and new state signals. In the second module, there exists a DDQN model receiving the agent's state representation as an input, evaluating it by the reward received from DES and outputting an action (dispatching decision). A vector that encodes all the pertinent attributes to define the current status of a mine serves as the state representation. These attributes number to 16 types and encompass properties of shovels, destinations, and trucks. The reward function for each agent was defined as the difference between the reward for accomplishing the mill's throughput target, and the penalty for spending time in queues. Yet, a part of the network training reward was set to be the sum of all individual rewards and then shared among agents to ensure all follow the same goal. This runs contrary to the work by Zhang et al. (2020), where the authors argued the process of reward sharing becomes computationally complex because the duration of activities can vary and rewards cannot be assigned immediately after an action. In the work by De Carvalho and Dimitrakopoulos (2021), based on how the reward function was defined earlier, the training objective was set as fulfilling production planning targets and minimising queue formation. Their algorithm works in a way that when a truck dumps its load and demands a new assignment, its state-representing vector is fed into the neural network. Then, the truck agent selects an action using the ε-greedy strategy before realising the resultant reward and the new state from the simulator. This experience is stored in a memory buffer in the form of a tuple in order to be uniformly sampled later for the TD target estimation. Having calculated the TD target, the algorithm updates weight parameters and takes action based on the updated policy. As a good initiative, the authors took geological uncertainties as a major concern in mining operations into account by considering the load's grade to be below the ore grade given in three different scenarios with probabilities of 10%, 50%, and 90%, respectively. The proposed system was put into operation at a copper–gold mining complex comprising two pits, four heterogeneous shovels, 12 heterogeneous trucks, a large waste dump, a mill with two crushers, and a leach pad with one crusher. In the training phase, each episode lasted three consecutive days in a simulation sense and the computational time for the whole training was 4 h. Two baselines (fixed allocation and needy shovels with the smallest queue sizes) were offered as a means of evaluating the effectiveness of their suggested method. During a five-day production simulation in the testing phase using the three-day trained network, the proposed model produced 12% to 16% more copper and 20% to 23% more gold. Truck failures were applied on the fourth and fifth day, bringing about a better performance for the DDQN model compared with the baselines. Overall, this framework is still one of the most full-fledged intelligent FMSs ever developed in terms of allowing for aspects such as the processing plants throughput, geological variations, comprehensive state representation, and preference of DDQN to the standard DQN. In other words, this work has considered many more dispatching features introduced in Table 1 than the previous works, namely ore processing targets, geological uncertainties, shovel heterogeneity, shovel failures, truck heterogeneity, truck scalability, truck failures, processing plant capacity (mill and leach pad), and crusher capacity. Algorithmically, the authors did not provide any explanations for their multi-agent network learning scheme (centralised, decentralised, or mixed) as well as a reason for the choice for it, while as seen in previous sections, this choice leaves a substantial impact on the learning performance in MARL. However, the learning scheme might be centralised learning and decentralised execution since all the rewards accumulated by each agent are summed together to train network parameters.
The emission reduction capability of an RL-based dispatching system in open-pit mining operations was assessed by Huo et al. (2023) through a combination of truck–shovel simulations and real-time estimations of GHG emissions from haulage fuel consumption. They applied the standard Q-learning algorithm, arguing that their model had limited state space. Every haul truck was viewed as an agent in a homogeneous fleet. A discrete set of locations was considered as the action space. Five attributes were defined in the state space including the current location of the agent, payload, the material's grade, queue length, and maintenance requirements. The reward function was shaped in a manner that it could address six aspects, namely the reward/penalty for correctly/incorrectly delivering ore or waste, the reward/penalty for avoiding/making mistakes in assigned tasks, the reward for timely maintenance, the penalty for missed maintenance, the penalty for waiting in a long queue, and finally the penalty for getting trapped in loops between two locations. As seen, the GHG emissions reduction goal is not directly embedded in the reward function, but rather as a calculation component in a simulation module. In fact, the time spent for empty travel, full haulage, and queuing by each truck is computed in the simulator, and then multiplied by known fuel consumption rates retrieved from Caterpillar® handbooks (Caterpillar Inc., 2010) in order to estimate the consumed literage of diesel. Next, the GHG emissions are calculated in terms of
Advantages and disadvantages of RL-based research work on mine FMSs.

RL: reinforcement learning; FMS: fleet management system.
Discussion
This section delves into the different avenues for future research on RL-oriented mine FMSs so that researchers can put forward more consummate algorithms. Nonetheless, there are numerous challenges related to these systems that require thorough investigation.
Research directions
To detect open research questions, the previously reviewed articles have been compared in Tables 3 and 4 in terms of RL-related and mine-specific aspects, respectively. Algorithmically, DDQN is the most advanced method used (Table 3). Most works have been formulated as a multi-agent problem, but none of them enjoys the multi-objective structure. Some works such as Huo et al. (2023) encompass three objectives in the reward function, yet the problem is still of single objective because the reward is not in a vector form. The learning scheme in half of these studies is decentralised learning; however, as discussed earlier, this strategy causes non-stationarity and non-convergence. Therefore, the centralised learning and decentralised execution strategy seems more apposite given the fact that it inherits the communication benefits of centralised learning and the large-state/action-space manageability of decentralised learning. Various state vectors embedded with up to 16 types of attributes have been defined for state representation. The vector set by De Carvalho and Dimitrakopoulos (2021) consists of 102 elements to be imported into their developed neural network. Action space is often structured to embrace all possible dispatching decisions towards unique destinations such as each shovel, waste dump, or plant. Reward shaping is the most critical part of an RL algorithm since it represents the user's objectives. Having treated the dispatching problem as single-objective, the authors in previous works were compelled to insert their desirable objectives into a reward function outputting only a single signal. Therefore, some reward functions such as the one developed by Huo et al. (2023) are long-notated to incorporate different goals. In contrast, Zhang et al. (2020) shaped their reward as a two-variable fraction, with the action duration placed in the denominator to be minimised.
Algorithmic comparison of RL-based research works on mine FMSs.
RL: reinforcement learning; FMS: fleet management system; MDP: Markov decision process; DQN: deep Q-learning network; DDQN: double DQN.
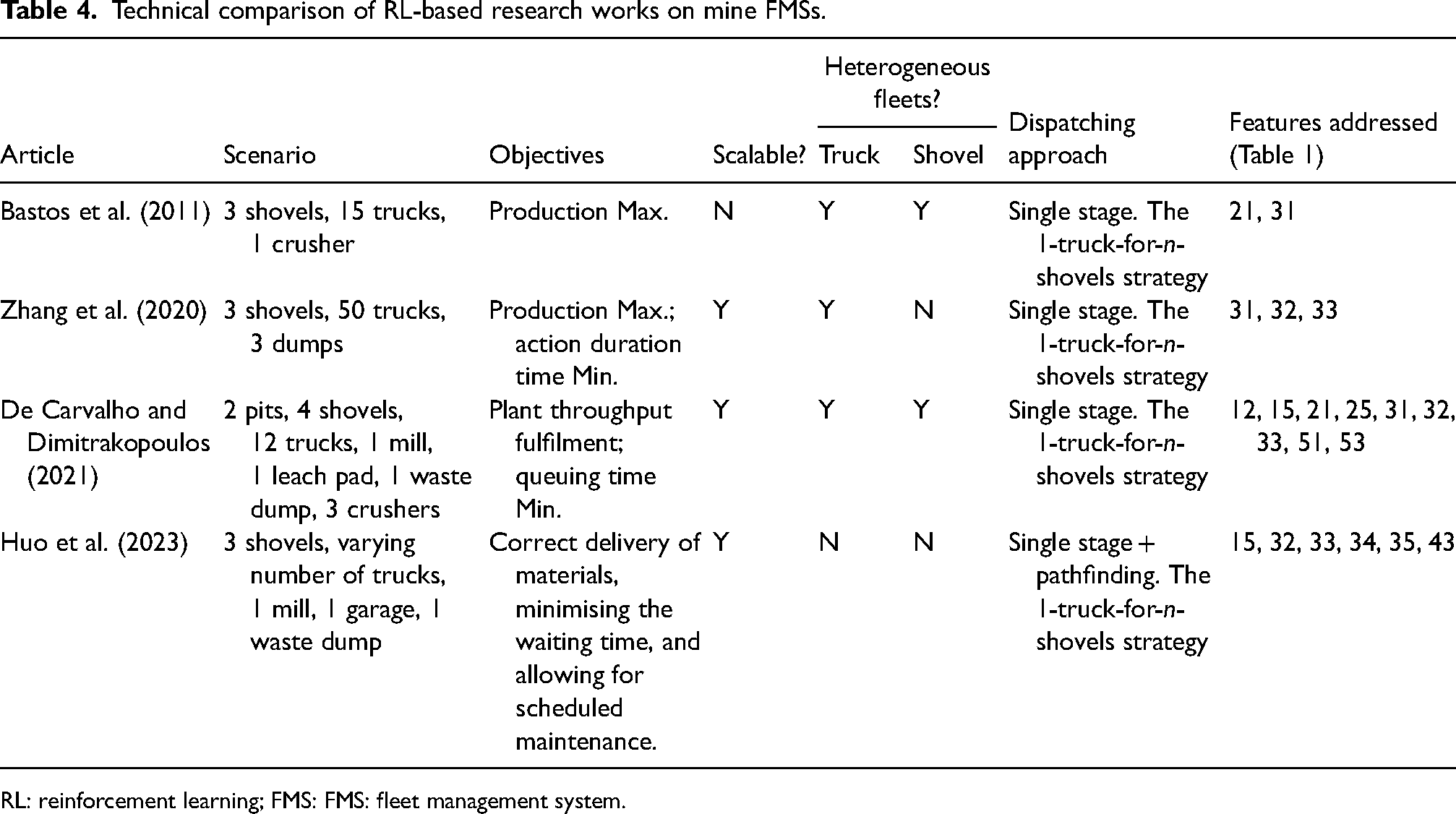
Technical comparison of RL-based research works on mine FMSs.
RL: reinforcement learning; FMS: FMS: fleet management system.
Training the agents within a real-world mine in a dynamic dispatching problem is not only costly but also irrational. Thus, different discrete event simulators are noticeable in these research works. Generally, simulators employed for the purpose of training a truck agent within a simulated mining environment can be categorised into two primary types: manually coded or externally provided. Manually coded simulators are crafted from scratch through programming languages, such as Python®, and supported by libraries such as SimPy®. Manual coding confers a high degree of control over the simulation environment, enabling tailored customisation to meet specific requirements. Nevertheless, this approach necessitates a more substantial development effort. Externally provided simulators, such as Simio®, come with pre-built simulation environments explicitly tailored for specific applications such as mine simulations. These tools often feature user-friendly interfaces for simulation creation and configuration. When opting for an external simulator such as Simio®, it is common practice to establish connectivity between the training code, written in Python® or another programming language, and the external simulator through an application programming interface. However, it is important to note that the use of external simulators may elongate the time needed for agent training due to the requirement for data exchange between the training script and the simulator. The choice between these simulator types is contingent on the desired level of customisation and the programming proficiency of the developer.
Based on what has been observed thus far, the action space in mine dispatching is finite and discrete compared to domains such as robotics. However, the state space can incorporate numerous attributes and vector entries depending on how the state of a truck is represented. Thus, the state space can show medium- to high-dimensional representations. The small action space accompanied by the large-state space lends itself to value-based methods, justifying the reason for leveraging these types of algorithms in the previous works reviewed here. However, more advanced methods such as DuDQN are overlooked. On the other hand, policy-based methods have shown incredible performance in real-world problems, which makes them worthy to be at least tested in the mining context. In fact, the whole dispatching problem is all about finding the right decision or policy in the RL terminology when a truck asks for an assignment. Therefore, the dispatching algorithm can search directly for the most possible dispatching policy instead of estimating the value functions. Judging from the recent five-year trends in the RL academic world, policy-based methods have witnessed more growth than value-based methods. It is possible that actor–critic algorithms will probably reach a maturity level to some extent that their computational costs might become negligible or even lower than value-based methods. In terms of the multi-agent learning strategy, innovative attempts come to notice in the literature such as the work by Khorasgani et al. (2021) on a weight-sharing K-nearest method for industrial applications such as mining with a variable number of agents and interdependencies among actions. Some operations-research-based works (Mohtasham et al., 2021; Moradi Afrapoli and Askari-Nasab, 2020; Moradi Afrapoli et al., 2019a, 2019b, 2022) enjoy multi-objective modelling to capture conflicting objectives seen in mine operational levels. However, this attitude has not been followed in the intelligent works reviewed here despite the fact that the RL literature offers some potential multi-objective multi-agent frameworks such as the model developed by Lu et al. (2022) to cope with this necessity. Finally, all the developed systems witness model-free algorithms in their RL settings, while their combination with model-based algorithms might bring more benefits. Overall, there are many opportunities for enhancement in the underlying algorithms used in these RL-enabled FMSs developed so far.
The reviewed articles demonstrate interesting characteristics in terms of technical aspects (Table 4). Most scenarios are hypothetical, except for the case study simulated by De Carvalho and Dimitrakopoulos (2021) as the most realistic and complex scenario. On the contrary, Zhang et al. (2020) experimented with the highest number of trucks (50) in their study. Productivity maximisation was set as the sole objective by Bastos et al. (2011), whereas Zhang et al. (2020) considered action duration time minimisation as well. The objective defined by De Carvalho and Dimitrakopoulos (2021) is unique in the sense that they paid attention to processing plant targets in addition to minimising the queuing time. Huo et al. (2023) employed the latter accompanied by the correct delivery of materials and allowing for scheduled/unscheduled maintenance. In dynamic dispatching, the count of accessible trucks and shovels can fluctuate unexpectedly. Scalability is essential for truck dispatching systems in mines as it enables efficient operations, cost savings, and flexibility in the face of changes in the equipment size. The majority of these research studies have, in one way or another tackled the issue of scalability. In terms of allowing for equipment heterogeneity, while Huo et al. (2023) assumed homogeneity for both shovels and trucks, Bastos et al. (2011), and De Carvalho and Dimitrakopoulos (2021) allowed for heterogeneous loading and hauling fleets. All these FMSs are categorised as single-stage systems judging by the fact that these models abstain from solving the upper-stage optimisation problem often seen in operations-research-based dispatching models. The one-truck-for-n-shovels strategy has been applied in all these research works, while it is not the best choice compared with the m-trucks-for-n-shovels strategy (Chaowasakoo et al., 2017a). Figure 3 depicts the dispatching features addressed by each of these research works, with codes 31 and 32 being the most attended features. The work by Bastos et al. (2011) addressed the least number of features compared with that by De Carvalho and Dimitrakopoulos (2021) as the least flawed, where processing plant targets and geological uncertainties were unprecedentedly considered as well as shovel failures and destinations’ capacities. The work by Huo et al. (2023) is distinctive in terms of recognising scheduled maintenance, fuel consumption, and pathfinding. In total, only 12 unique features have been addressed so far among those 29 items collected in Table 1, implying the statistics that 60% of the desirable features are neglected in the articles reviewed here. Moreover, the analysis shows that the operation feature class is widely missed, while weather conditions, bunching, pathfinding, drilling/blasting activities, and road mechanical conditions are typical operational issues in most open-pit mines. The linkage to strategic plans is of great importance since it ensures that the operational level of mining is in line with short-term, mid-term, and long-term planning horizons, and it should be included within the mine FMSs (Moradi Afrapoli and Askari-Nasab, 2019). Frequently, operations-research-based FMSs face criticism for not taking into account the impacts of downstream processes on the operation, causing deviation from plant feed rate targets (Moradi Afrapoli et al., 2019a, 2019b). The fulfilment of the plant head grade and blending requirements is also crucial to ensure a grade-consistent final product. Therefore, this feature class is essential to be adequately attended in an RL-based FMS. Shovel-related features such as shovel allocation, movement, and operator's skill demand more attention. Integrated shovel–truck allocation systems may lead to above 95% utilisation for shovels and less movement costs, and even plant utilisations above 99% and truck utilisations above 92% (Upadhyay and Askari-Nasab, 2016). The shovel operator's skill may seem trivial at first glance, but studies show that different shovel operators may demonstrate 11% to 50% variability in ore production (Patnayak et al., 2008; Vukotic and Kecojevic, 2014). The truck feature class has been generally addressed, even though sparsely by previous works. The two features of scheduled maintenance and fuel consumption are only included in the work by Huo et al. (2023). All things considered, the following research directions are imagined for future works on RL-based FMSs in open-pit mines:
Taking advantage of the state-of-the-art value-based algorithms including DuDQN as the underlying dispatching program. Applying more efficient multi-agent learning strategies such as the K-nearest method in the training phase of algorithms. Formulating the dispatching program as a multi-objective problem to address the various conflicting objectives present in mining operations. Feasibility study of leveraging the policy-based algorithms, particularly the actor–critic methods within FMS. Feasibility study of applying mixed model-free model-based algorithms. Developing full-fledged dispatching algorithms capable of addressing the essential features introduced in Table 1 in mining operations. Substituting the conventional simulation tools with digital twins to exploit the benefits that this technology trend offers.
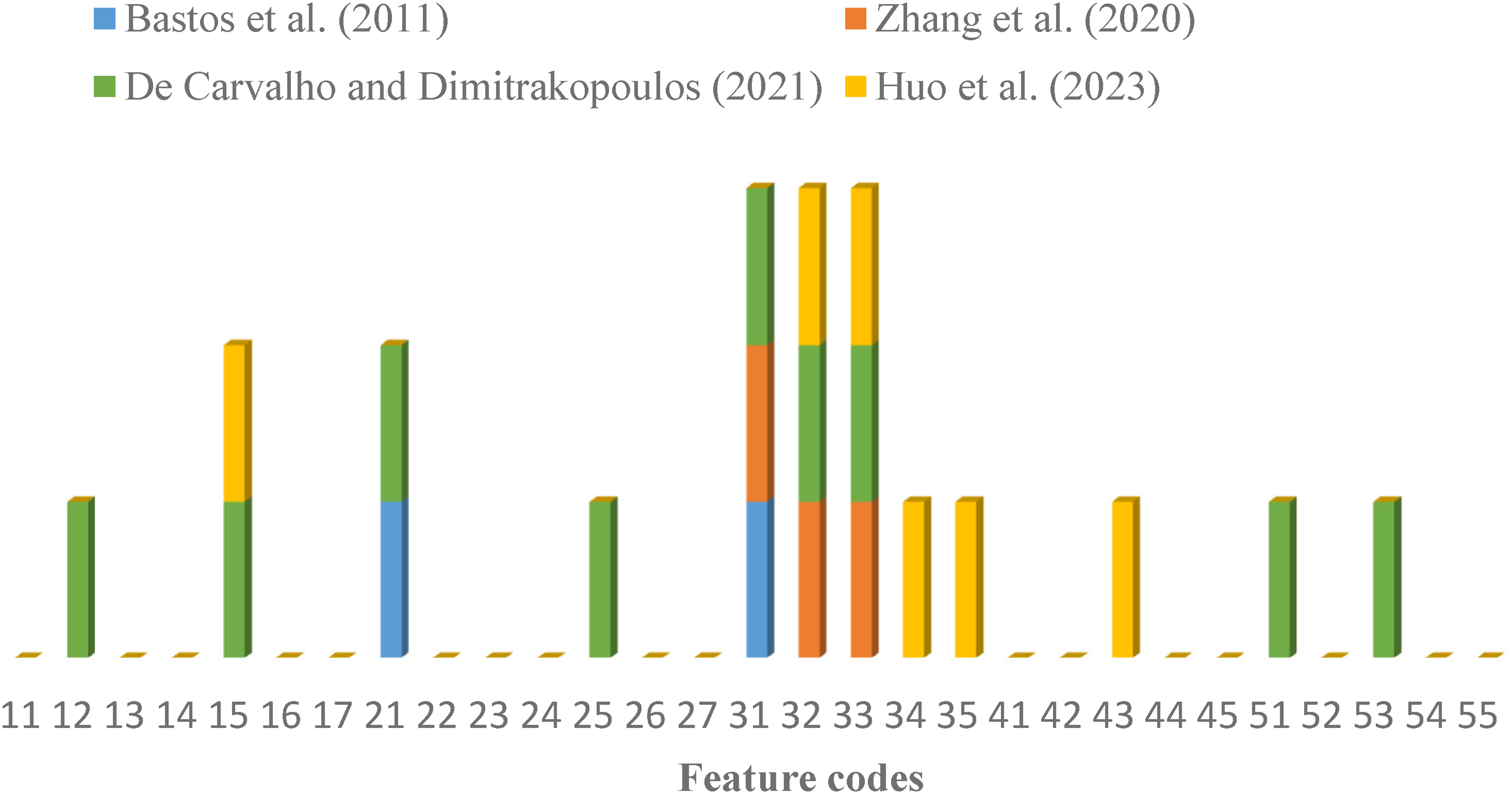
The dispatching features addressed by different authors in mine RL-based FMSs.
Challenges
RL shows significant potential to optimise the mine dynamic dispatching problem. Instead of resolving a mathematical model repeatedly upon every change occurred in the environment, agents learn how to make an optimal decision thanks to the experiences accumulated over numerous episodes. In that manner, the agent is capable of acting autonomously even when encountered with unseen decision-making situations. Moreover, the system can produce solutions of excellent quality within a short period of time given sufficient training. Nonetheless, certain difficulties appear, requiring much attention. Dulac-Arnold et al. (2021) enumerated a group of nine generally encountered challenges impeding the practical application of RL (Table 5).
Common challenges encountered when implementing reinforcement learning (RL) in real-world scenarios (Dulac-Arnold et al., 2021).

The process of learning necessitates a substantial number of samples to acquire an adequate policy, while this volume of samples on online applications such as dynamic dispatching is not available. This issue propels the RL practitioners to apply more sample-efficient learning approaches including meta-learning and transfer learning (e.g. reward shaping, learning from demonstrations, policy transfer, and representation transfer; Nagabandi et al., 2018; Zhu et al., 2020). Fast data collection for the state representation of trucks poses another challenge since sensors communicate via the Internet of Things, and some delays might occur, but tractable with the advent of affordable 5/6G wireless technology in the foreseeable future. It is worth noting that the implementation of wireless technology involves the intricate management of multiple layers, including technology, administration, and governance. These layers encompass diverse aspects such as upgrading network infrastructure, ensuring regulatory compliance, safeguarding data security, achieving interoperability, allocating resources, data governance, addressing environmental considerations, promoting user adoption, and developing policies and standards. Effective coordination of these layers is critical to harnessing the full potential of wireless technology and its positive impact across mine FMSs. Although agents in a dispatching system are associated with a finite action space, the state space can grow exponentially by the increasing number of trucks. However, the state space in the mine dispatching problem would not be as high-dimensional as that in autonomous vehicles provided that the state representation vector is carefully designed. As a result, the already developed algorithms such as DQN or its variants would suffice. Environmental constraints deal with safety issues such as crashes that are mostly case-specific in robotics and autonomous driving. In a typical mine, trucks are driven by human operators who eliminate the consequences of tentative aggressive driving behaviours imaginable in self-driving trucks. The next challenge is the dynamicity rooted in partial observability and non-stationarity. The first factor, partial observability, stems from our incomplete knowledge, for instance, about the environment's dynamics, the attitude of truck drivers, reliability of sensors, etc. Therefore, real-world environments are usually formulated as a partially observable MDP. The second factor, non-stationarity, is tractable by employing centralised-learning-oriented MARL and simulation tools up to some extent. Canese et al. (2021) have compared various variants of MARL algorithms with respect to partial observability, non-stationarity, and scalability. Their analysis shows that no algorithm exists to address all these three aspects simultaneously. Nguyen et al. (2020) proposed different value-based, policy-based, and actor–critic algorithms to cope with common challenges encountered in MARL, with multi-agent DDPG (Lowe et al., 2017) being suggested as a capable algorithm to address partial observability, non-stationarity, and multi-agent training scheme challenges (i.e. centralised or decentralised). Reward assignment has always been a concern for RL researchers and is usually nicknamed the credit assignment problem. This issue is even intensified in multi-objective systems, for agents who have no clue as to how to correlate a certain action to a certain reward. As algorithms grow in maturity on a daily basis, this aspect will be addressed by adding certain extensions to the thus-far-developed algorithms. A wise solution at present is letting agents accumulate as many experiences as possible within the environment. Real-time response as a must in dynamic dispatching is achievable through well-designed algorithms, minimised communication delays, and fast-processing hardware. Technological advancements in telematics show a promising trend in these scopes. Offline training is important in the sense that agents are trained in advance to decrease the need for exploration in applications with fewer available samples online. Fortunately, historical shovel–truck logs are usually available from mining operations to be used in simulators, enabling offline agent training for faster decision-making in real-time dispatching systems. Offering explainable policies to human operators is another challenge for an agent-based system. In other words, agents might render some suboptimal dispatching decisions that might be irrational from a human expert perspective. Therefore, rewards must be shaped properly to avoid such shortsighted behaviours. Two additional challenges were introduced by Khorasgani et al. (2020) a variable number of agents and variable goals in mine dynamic dispatching systems. The number of trucks is prone to fluctuate due to failures, maintenance, and operator absence. The multi-agent learning strategy plays a key role in the scalability of algorithms to varying numbers of trucks, and the methods developed by Zhang et al. (2020) and Khorasgani et al. (2021) seem effective. Dispatching systems attempt to train agents in order to fulfil different operational objectives. Nevertheless, abrupt changes in those objectives are challenging for agent-oriented systems in terms of timely retraining. As seen in the last section, the thus-far developed systems in open-pit mines have been formulated as a single-objective problem, while multi-objective multi-agent algorithms already exist in the literature, and consequently should be leveraged in order to fulfil diverse dispatching objectives. Transfer learning and Meta-learning algorithms can make a significant contribution to speeding up the multi-objective models' solving time, in addition to the abovementioned sample inefficiency. The summary of algorithmic challenges and recommended solutions in RL-based FMSs is illustrated in Figure 4.
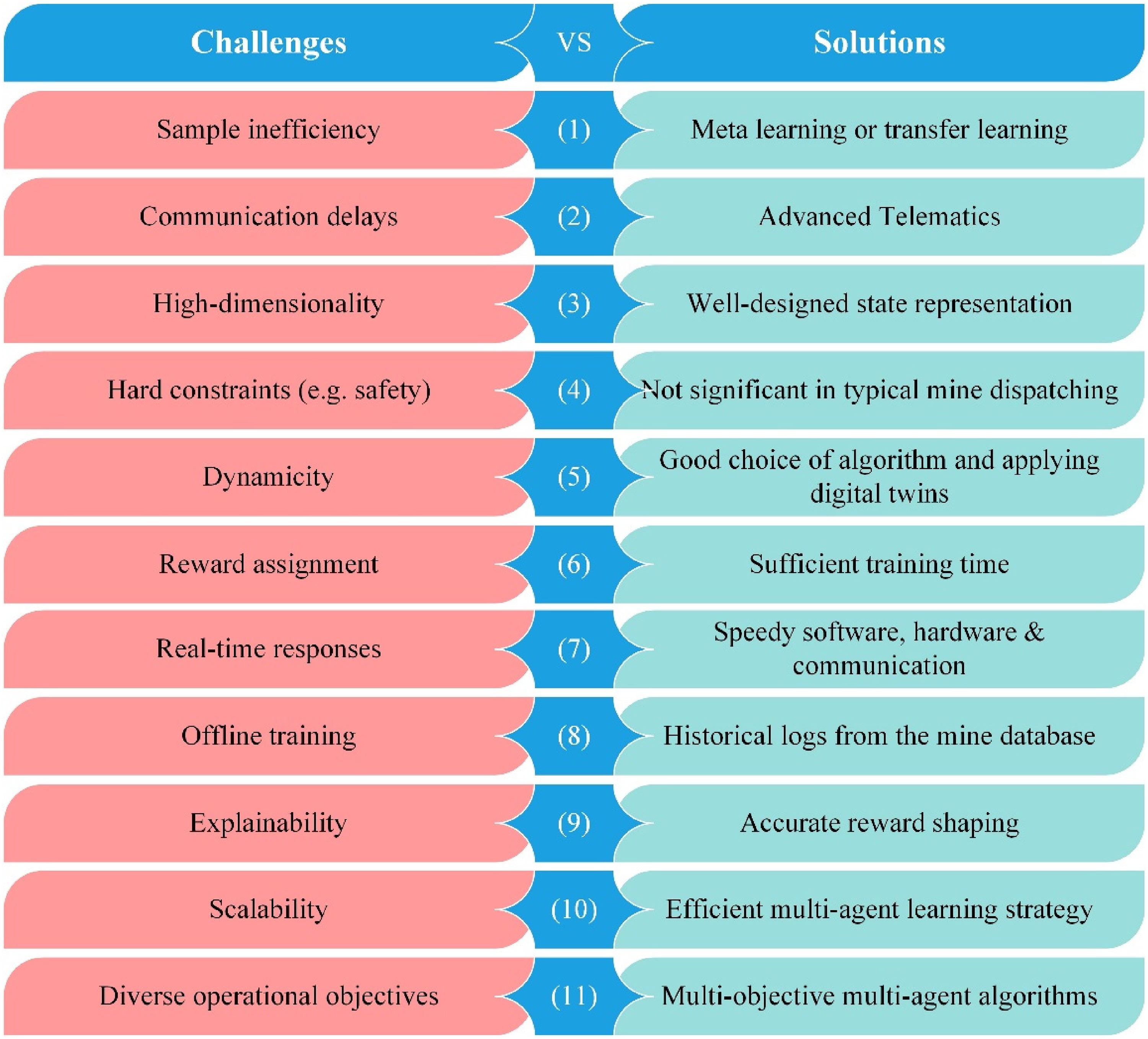
Algorithmic challenges and recommended solutions in RL-based mine FMSs.
Another major class of challenges is related to technical or mine-specific aspects. The features mentioned in Table 1 can be regarded as technical challenges that intelligent dispatching systems should capture. As seen in the previous subsection, around two-thirds of these features are ignored in the thus-far published RL-based dispatching systems. Thus, addressing the entire set of features is deemed as a mining-related challenge. Apart from the algorithmic and technical challenges discussed so far, there are also other types of difficulties, such as those related to infrastructure and attitude. Regarding the former, some troubles in terms of capital investment and workforce training may exist. The latter refers to the resistance of both managers at the highest level and employees at the lowest level against technological changes. Value chain analysis (Porter, 1985) functions as a robust tool for elucidating the influence of technological advancements, such as RL algorithms, on an organisation's value chain and profit margin, thereby motivating managerial support. As RL algorithms become integrated into the value chain, this analysis can illuminate critical facets, including cost minimisation and enhanced operational efficiency. It underscores the feasibility of RL adoption, emphasising its tangible impact on the mine's holistic financial performance rather than existing solely as a theoretical concept (Hazrathosseini & Moradi Afrapoli, 2024). Additionally, the more mature the RL theoretical backgrounds become in terms of addressing various algorithmic and technical challenges, the more the RL paradigm receives recognition, acceptance, and appreciation by the mining industry for financial and operational justifications. Intelligent dispatching in open-pit mines exhibits notable strengths, such as dynamicity, fast decision-making, generality (enabling choices in novel circumstances), and autonomy. These capabilities offer encouraging opportunities for various aspects, particularly in terms of economic efficiency, production optimisation, environmental impact, operational efficiency, safety enhancement, and workplace culture (Hazrathosseini & Moradi Afrapoli, 2023a). In general, as time passes, an increasing number of algorithms that capture a wider range of challenges are developed. Nevertheless, the ideality milestone might not be reached at present; thus, a trade-off should be forged so that all these challenges are satisfactorily addressed as much as possible.
Conclusion
The mining industry is on the verge of a substantial digital transformation, and mine FMSs can enjoy financial/environmental improvements, autonomy, and optimal efficiency by tapping into RL-based algorithms. Some seminal articles come to notice in the literature regarding RL-based dispatching systems in open-pit mines. However, the frameworks developed so far suffer from technical and algorithmic drawbacks. In this study, a 29-feature scale was proposed to be used as a base for comparing works towards intelligent FMSs. Results show that 17 features (60% of the entire scale), particularly the operation feature class, have not been addressed in the literature at all, while operations-research-based FMSs show more maturity from this perspective. As another aim for the present study, an algorithmic investigation into the selected articles was carried out after taking a concise glance at the fundamentals of RL, revealing the fact that there is ample opportunity for enhancement in the underlying algorithms of currently available intelligent open-pit FMSs. Consequently, seven research directions were drawn to promote well-established intelligent dispatching systems for years to come. Following that, different types of challenges were discussed, with 11 algorithmic challenges offered with possible solutions. Although daily technological advancements in both hardware and RL theoretical backgrounds pave the way for more applications of agent-based systems; however, at present, a general compromise should be considered to satisfy all the algorithmic and technical expectations to the furthest extent. As a final point, the future belongs to artificial intelligence, and mine managers should consider adopting RL in order to enhance their company's competitiveness and stay ahead of the curve in the competitive market of mining imposed by green regulations.
Footnotes
Author contributions
Arman Hazrathosseini: Conceptualisation, methodology, data curation, investigation, and writing – original draft. Ali Moradi Afrapoli: Conceptualisation, supervision, and writing – review and editing.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.