
Abstract
Deep learning has recently gained high interest in ophthalmology due to its ability to detect clinically significant features for diagnosis and prognosis. Despite these significant advances, little is known about the ability of various deep learning systems to be embedded within ophthalmic imaging devices, allowing automated image acquisition. In this work, we will review the existing and future directions for ‘active acquisition’–embedded deep learning, leading to as high-quality images with little intervention by the human operator. In clinical practice, the improved image quality should translate into more robust deep learning–based clinical diagnostics. Embedded deep learning will be enabled by the constantly improving hardware performance with low cost. We will briefly review possible computation methods in larger clinical systems. Briefly, they can be included in a three-layer framework composed of edge, fog, and cloud layers, the former being performed at a device level. Improved egde-layer performance via ‘active acquisition’ serves as an automatic data curation operator translating to better quality data in electronic health records, as well as on the cloud layer, for improved deep learning–based clinical data mining.
Keywords
Introduction
Recent years have seen an explosion in the use of deep learning algorithms for medical imaging,1–4 including ophthalmology.5–9 Deep learning has been very efficient in detecting clinically significant features for ophthalmic diagnosis9,10 and prognosis.11,12 Recently, Google Brain demonstrated how one can, surprisingly, predict subject’s cardiovascular risk, age, and sex from a fundus image, 13 a task impossible for an expert clinician.
Research effort has so far focused on the development of post hoc deep learning algorithms for already acquired data sets.9,10 There is, however, growing interest for embedding deep learning at the medical device level itself for real-time image quality optimization, with little or no operator expertise. Most of the clinically available fundus cameras and optical coherence tomography (OCT) devices require the involvement of a skilled operator in order to achieve satisfactory image quality, for clinical diagnosis. Ophthalmic images display inherent quality variability due to both technical limitations of the imaging devices and individual ocular characteristics. Recent studies in hospital settings have shown that 38% of nonmydriatic fundus images for diabetic screening, 14 and 42–43% of spectral domain (SD)-OCTs acquired for patients with multiple sclerosis 15 did not have acceptable image quality for clinical evaluation.
Desktop retinal cameras have been increasingly replaced by portable fundus cameras in standalone format16–18 or as smartphone add-ons, 19 making the retinal imaging less expensive and accessible to various populations. The main drawback of the current generation portable fundus camera is the lower image quality. Some imaging manufacturers have started to include image quality assessment algorithms to provide a feedback for the operator to either re-acquire the image or accept it. 20 To the best of our knowledge, no current commercial system is automatically reconstructing ‘the best possible image’ from multiframe image acquisitions.
Embedding of more advanced algorithms and high computation power at the camera level can be referred to as ‘smart camera architectures’, 21 with or without the use of deep learning. For example, Google launched its Clips camera, and Amazon Web Services (AWS) its DeepLens camera which are capable of running deep learning models within the camera itself without relying on external processing Verily, the life sciences research organization of Alphabet Inc., partnered with Nikon and Optos to integrate deep learning algorithms for fundus imaging and diabetic retinopathy screening (https://verily.com/projects/interventions/retinal-imaging/). Similar implementation of ‘intelligence’ at the device level is happening in various other medical fields, 22 including portable medical ultrasound imaging, with more of the traditional signal processing being accelerated graphics processing units (GPUs), 23 with the deep learning integrated at the device level. 24
There are various ways of distributing the signal processing from data acquisition to clinical diagnostics. For example, the use of fundus cameras in remote locations with no Internet access requires all the computations to be performed within the device itself, a system which has been implemented by SocialEyes, for retinal screening on GPU-accelerated tablets. 25 This computing paradigm, known as edge computing, 26 is based on locally performed computations, on the ‘edge’,27,28 as opposed to cloud computing in which the fundus image is transmitted over the Internet to a remote cloud GPU server, allowing subsequent image classification. In some situations, when there is a need for multilayer computational load distribution, additional nodes are inserted between the edge device and the cloud – a computation paradigm known as mist 29 or fog computing. 30 This situation applies typically to Internet-of-things (IoT) medical sensors, which often have very little computational capability. 31
The main aim of the current review is to summarize the current knowledge related to device-level (edge computing) deep learning. We will refer to this as ‘active acquisition’, for improved ophthalmic diagnosis via optimization of image quality (Figure 1). We will also overview various possibilities of computing platforms integrate into the typical clinical workflow with a focus on standard retinal imaging techniques (i.e. fundus photography and OCT).
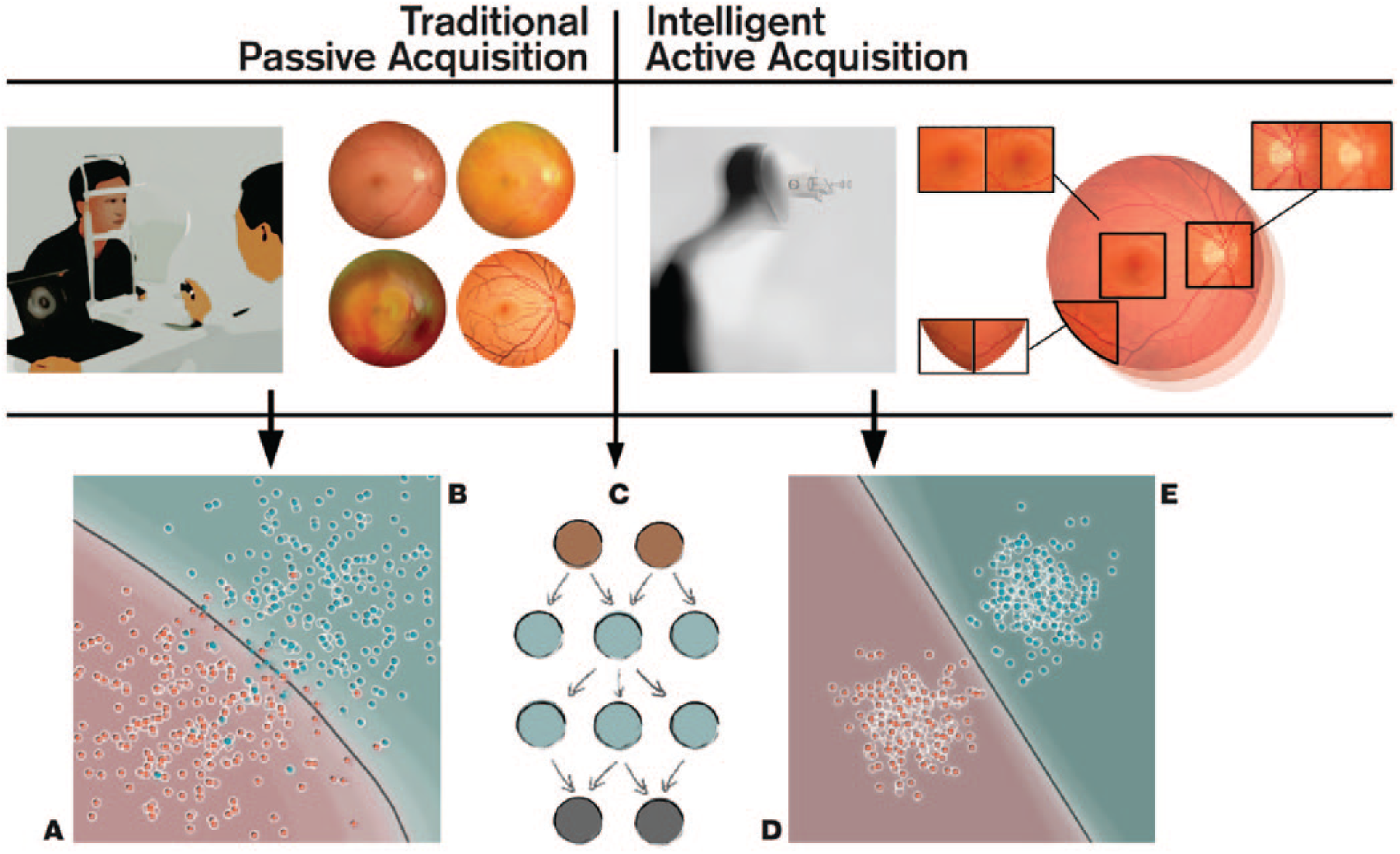
Comparison between traditional passive acquisition and intelligent active acquisition approaches for fundus imaging. (Top-left) In passive acquisition, the healthcare professional manually aligns the camera and decides the best moment for image acquisition. This acquisition has to be often repeated, especially if the patient is not compliant, if the pupils are not dilated, or if there are media opacities, that is, cornea scar, cataract, and so on. (Top-right) In an ‘intelligent’ active acquisition process, the device is able vary imaging parameters and iterates automatically frames until the deep learning is been able to reconstruct an image of satisfactory quality. (Bottom) This intelligent acquisition serves as automated data curation operator for diagnostic deep learning networks (C)9,10 leading to improved deep leading to better class separation (healthy D vs disease E). In traditional passive acquisition, the image quality is less consistent leading to many false positives [patient from disease population B (cyan) is classified as healthy A (red)] and negatives [patient from healthy population A (red) is classified as disease B (cyan)]. The gray line represents the decision boundary of the classifier, 32 and each point represents one patient.
Embedded ophthalmic devices
Emerging intelligent retinal imaging
The increased prevalence of ophthalmic conditions affecting the retinas and optic nerves of vulnerable populations prompts higher access to ophthalmic care both in developed 33 and developing countries. 34 This translates into an increased need of more efficient screening, diagnosis, and disease management technology, operated with no or little training in clinical settings or even at home. 16 Although paraprofessionals with technical training are currently able to acquire fundus images, a third of these images may not be of satisfactory quality, being nongradable, 35 due to reduced transparency of the ocular media.
Acquisition of such images may be even more difficult in nonophthalmic settings, such as emergency departments. 36 Recent attempts have aimed to automate retinal imaging processing using a clinical robotic platform InTouch Lite (InTouch Technologies, Inc., Santa Barbara, CA, USA) 37 or by integrating a motor to the fundus camera for automated pupil tracking (Nexy; Next Sight, Prodenone, Italy). 38 These approaches have not been validated clinically and are based on relatively slow motors, possibly not adapted to clinically challenging situations. Automated acquisition becomes even more important with the recent surge of many smartphone-based fundus imagers. 39 Due to the pervasiveness of smartphones, this approach would represent a perfect tool for non-eye specialists. 40
Similar to fundus imaging, OCT systems are getting more portable and inexpensive and would benefit from easier and robust image acquisition.17,18,41 Kim and colleagues 41 developed a low-cost experimental OCT system at a cost of US$ 7200 using a microelectromechanical system (MEMS) mirror 42 with a tunable variable focus liquid lens to simplify the design of scanning optics, with inexpensive Arduino Uno microcontroller 43 and GPU-accelerated mini PC handling the image processing. The increased computing power from GPUs enables some of the hardware design compromises to be offset through computational techniques.44,45 For example, Tang and colleagues 46 employed three GPU units for real-time computational adaptive optics (AO) system, and recently Maloca and colleagues 47 employed GPUs for volumetric OCT in virtual reality environment for enhanced visualization in medical education.
Active data acquisition
The computationally heavier algorithms made possible by the increased hardware performance can be roughly divided into two categories: (1) ‘passive’ single-frame processing and (2) ‘active’ multiframe processing. In our nomenclature, the ‘passive’ techniques refer to the standard way of acquiring ophthalmic images in which an operator takes an image, which is subsequently subjected to various image enhancement algorithms either before being analyzed by clinician or graded automatically by an algorithm. 48 In ‘active’ image acquisition, multiple frames of the same structure are obtained either with automatic reconstruction or with interactive operator-assisted reconstruction of the image. In this review, we will focus on the ‘active’ paradigm, where clinically meaningful images would be reconstructed automatically from multiple acquisitions with varying image quality.
One example for the active acquisition in retinal imaging is the ‘Lucky imaging’ approach,49,50 in which multiple frames are acquired in quick succession assuming that at least some of the frames are of good quality. In magnetic resonance imaging (MRI), a ‘prospective gating scheme’ is proposed for acquiring because motion-free image acquisition is possible between the cardiovascular and respiration artifacts, iterating the imaging until satisfactory result is achieved. 51 For three-dimensional (3D) computed tomography (CT), an active reinforcement learning-based algorithm was used to detect missing anatomical structures from incomplete volume data 52 and trying to re-acquire the missing parts instead of relying just on postacquisition inpainting. 53 In other words, the active acquisition paradigms have some level of knowledge of acquisition completeness or uncertainty based on ideal images, for example, via ‘active learning’ framework 54 or via recently proposed Generative Query Networks (GQNs). 55
To implement active data acquisition on an ophthalmic imaging device, we need to define a loss function (error term for the deep learning network to minimize) to quantify the ‘goodness’ of the image either directly from the image or using some auxiliary sensors and actuators, to drive the automatic reconstruction process. For example, eye movement artifacts during acquisition of OCT can significantly degrade the image quality, 56 and we would like to quantify the retinal motion either from the acquired frames itself 57 or using auxiliary sensors such as digital micromirror device (DMD). 58 The latter approach has also been applied for correction of light scatter by opaque media. 59 Due to the scanning nature of OCT, one can re-acquire the same retinal volume and merge only the subvolumes that were sampled without artifacts.60,61
Deep learning–based retinal image processing
Traditional single-frame OCT signal processing pipelines have employed GPUs allowing real-time signal processing.62,63 GPUs have been increasingly used in medical image processing even before the recent popularity of deep learning. 64 The GPUs are becoming essentially obligatory with contemporary high-speed OCT systems. 65 The traditional image restoration pipelines employ the intrinsic characteristics of the image in tasks such as denoising 66 and deblurring 67 without considering image statistics of a larger data set.
Traditionally, these multiframe reconstruction algorithms have been applied after the acquisition without real-time consideration of the image quality of the individual frames. Retinal multiframe acquisition such as fundus videography can exploit the redundant information across the consecutive frames and improve the image degradation model over single-frame acquisition.68,69 Köhler and colleagues 70 demonstrated how a multiframe super-resolution framework can be used to reconstruct a single high-resolution image from sequential low-resolution video frames. Stankiewicz and colleagues 71 implemented a similar framework for reconstructing super-resolved volumetric OCT stacks from several low-quality volumetric OCT scans. Neither of these approaches, however, applied the reconstruction in real time.
In practice, all of the traditional image processing algorithms can be updated for deep learning framework (Figure 2). The ‘passive’ approaches using input–output pairs to learn image processing operators range from updating individual processing blocks, 74 to joint optimization of multiple processing blocks,75,76 or training an end-to-end network such as DeepISP (ISP, Image Signal Processor) to handle image pipeline from raw image toward the final edited image. 77 The DeepISP network was developed as offline algorithm, 77 with no real-time optimization of camera parameters during acquisition. Sitzmann and colleagues 78 extended the idea even further by jointly optimizing the imaging optics and the image processing for extended depth of field and super-resolution.

Typical image processing operators used in retinal image processing that are illustrated with 2D fundus images for simplicity. (a) Multiple frames are acquired in a quick succession, which are then registered (aligned) with semantic segmentation for clinically meaningful structures such as vasculature (in blue) and optic disc (in green). (b) Region-of-interest (ROI) zoom on optic disc of the registered image. The image is denoised with shape priors from the semantic segmentation to help the denoising to keep sharp edges. The noise residual is normalized for visualization showing some removal of structural information. The denoised image is decomposed 72 into base that contain the texture-free structure (edge-aware smoothing) and the detail that contains the residual texture without the vasculature and optic disc. (c) An example of how the decomposed parts can be edited ‘layer-wise’ 73 and combined to detail enhanced image, in order to allow for optimized visualization of the features of interest.
With deep learning, many deep image restoration networks have been proposed to replace traditional algorithms. These networks are typically trained with input versus synthetic corruption image pairs, with the goodness of the restoration measured as the network’s capability to correct this synthetic degradation. Plötz and Roth 79 demonstrated that the synthetic degradation model had significant limitation, and traditional state-of-the art denoising algorithm BM3D 80 was still shown to outperform many deep denoising networks, when the synthetic noise was replaced with real photographic noise. This highlights the need of creating multiframe database of multiple modalities from multiple device manufacturers for realistic evaluation of image restoration networks in general, as was done by Mayer and colleagues 81 by providing a freely available multiframe OCT data set obtained from ex vivo pig eyes.
Image restoration
Most of the literature on multiframe–based deep learning has focused on super-resolution and denoising. Super-resolution algorithms aim to improve the spatial resolution of the reconstructed image beyond what could be obtained from a single input frame. 82 Tao and colleagues 83 implemented a deep learning ‘subpixel motion compensation’ network for video input capable of learning the inter-frame alignment (i.e. image registration) and motion compensation needed for video super-resolution. In retinal imaging, especially with OCT, typical problems for efficient super-resolution are the retinal motion, lateral resolution limits set by the optical media, and image noise. Wang and colleagues 84 demonstrated using photographic video that motion compensation can be learned from the data, simplifying data set acquisition for retinal deep learning training.
Deblurring (or deconvolution), close to denoising, allows the computational removal of static and movement blur from acquired images. In most cases, the exact blurring point spread function (PSF) is not known and has to be estimated (blind deconvolution) from an acquired image 85 or sequential images. 86 In retinal imaging, the most common source for image deblurring is retinal motion, 56 scattering caused by ocular media opacities, 87 and optical aberrations caused by the optical characteristics of the human eye itself. 88 This estimation problem falls under the umbrella term inverse problems that have been solved with deep learning recently. 89
Physical estimation and correction of the image degradation
Efficient PSF estimation retinal imaging can be augmented with auxiliary sensors trying to measure the factors causing retina to move during acquisition. Retinal vessel pulsations due to pressure fluctuations during the cardiac cycle can impact the quality. Gating allows imaging during diastole, when pressure remains almost stable. 90 Optical methods exist for measuring retinal movement directly using, for example, DMDs 58 and AO systems measuring the dynamic wavefront aberrations as caused, for instance, by tear film fluctuations. 88
All these existing physical methods can be combined with deep learning, providing the measured movements as intermediate targets for the network to optimize. 91 Examples of such approaches are the works by Bollepalli and colleagues, 92 who provided training of the network for robust heartbeat detection, and Li and colleagues, 93 who have estimated the blur PSF of light scattered through a glass diffuser simulating the degradation caused by cataract for retinal imaging.
Fei and colleagues 94 used pairs of uncorrected and AO-corrected scanning laser ophthalmoscopic (AOSLO) images for learning a ‘digital AO’ correction. This type of AO-driven network training in practice might be very useful, providing a cost-effective version of super-resolution imaging. For example, Jian and colleagues 95 proposed to replace deformable mirrors with waveform-correcting lens lowering the cost and simplifying the optical design, 95 Carpentras and Moser 96 demonstrated a see-through scanning ophthalmoscope without AO correction, and very recently a handheld AOSLO imager based on the use of miniature MEMS mirrors was demonstrated by DuBose and colleagues. 97
In practice, all the discussed hardware and software corrections are not applied simultaneously, that is, joint image restoration with image classification. 75 Thus, the aim of these operations is to achieve image restoration without loss of clinical information.
High-dynamic-range ophthalmic imaging
In ophthalmic applications requiring absolute or relative pixel intensity values for quantitative analysis, as in fundus densitometry, 98 or Purkinje imaging for crystalline lens absorption measurements, 99 it is desirable to extend the intensity dynamic range from multiple differently exposed frames using an approach called high-dynamic-range (HDR) imaging. 100 OCT modalities requiring phase information, such as motion measurement, can benefit from higher bit depths. 101 Even in simple fundus photography, the boundaries between optic disc and cup can sometimes be hard to delineate in some cases due to overexposed optic disc compared with surrounding tissue, illustrated by Köhler and colleagues 70 in their multiframe reconstruction pipeline. Recent feasibility study by Ittarat and colleagues 102 showed that HDR acquisition with tone mapping 100 of fundus images, visualized on standard displays, increased the sensitivity but reduced specificity for glaucoma detection in glaucoma experts. In multimodal or multispectral acquisition, visible light range acquisition can be enhanced by high-intensity near-infrared (NIR) strobe 103 if the visible light spectral bands do not provide sufficient illumination for motion-free exposure. The vasculature can be imaged clearly with NIR strobe for estimating the motion blur between successive visible light frames. 104
Customized spectral filter arrays
Another operation handled by the ISP is demosaicing 105 which involves interpolation of the color channels. Most color RGB (red-green-blue) cameras, including fundus cameras, include sensors with a filter grid called Bayer array that is composed of a 2 × 2 pixel grid with two green, one blue, and one red filter. In fundus imaging, the red channel has very little contrast, and hypothetically custom demosaicing algorithms for fundus ISPs may allow for better visualization of clinically relevant ocular structures. Furthermore, the network training could be supervised by custom illumination based on light-emitting diodes (LEDs) for pathology-specific imaging. Bartczak and colleagues 106 showed that with pathology-optimized illumination, the contrast of diabetic lesions is enhanced by 30–70% compared with traditional red-free illumination imaging.
Recently, commercial sensors with more than three color channels have been released, Omnivision (Santa Clara, CA, USA) OV4682, for example, replaced one green filter of the Bayer array with an NIR filter. In practice, one could acquire continuous fundus video without pupil constriction using just the NIR channel for the video illumination and capturing fundus snapshot simultaneously with a flash of visible light in addition to the NIR.
The number of spectral bands on the filter array of the sensor was extended up 32 bands by Imec (Leuven, Belgium). This enables snapshot multispectral fundus imaging for retinal oximetry. 107 These additional spectral bands or custom illuminants could also be used to aid the image processing itself before clinical diagnostics. 108 For example, segmenting the macular region becomes easier with a spectral band around blue 460 nm, as the macular pigment absorbs strongly at that wavelength and appears darker than its background on this band. 109
Depth-resolved fundus photography
Traditionally, depth-resolved fundus photography has been done via stereo illumination of the posterior pole that involves either dual path optics increasing the design complexity or operator skill to take a picture with just one camera. 110 There are alternatives for depth-resolved fundus camera in a compact form factor such as plenoptic fundus imaging that was shown to provide higher degree of stereopsis than traditional stereo fundus photography using an off-the-shelf Lytro Illum (acquired by Google, Mountain View, CA, USA) consumer light field camera. 111 Plenoptic cameras, however, trade spatial resolution for angular resolution, for example, Lytro Illum has over 40 million pixels, but the final fundus spatial resolution consists of 635 × 433 pixels. Simpler optical arrangement for depth imaging with no spatial resolution trade-off is possible with depth-from-focus algorithms 112 that can reconstruct depth map from a sequence of images of different focus distances (z-stack). This rapid switching of focus distances can be achieved in practice, for example, using variable-focus liquid lenses, as demonstrated for retinal OCT imaging by Cua and colleagues. 113
Compressed sensing
Especially with OCT imaging, and scanning-based imaging techniques in general, there is a possibility to use compressed sensing to speed up the acquisition and reduce the data rate. 114 Compressed sensing is based on the assumption that the sampled signal is sparse in some domain, and thus it can be undersampled and reconstructed to have a matching resolution for the dense grid. Most of the work on combined compressed sensing and deep learning has been on MRI brain scans. 115 OCT angiography (OCTA) is a special variant of OCT imaging that acquires volumetric images of the retinal and choroidal vasculature through motion contrast imaging. OCTA acquisition is very sensitive to motion and would benefit from sparse sampling with optimized scan pattern. 116
Defining cost functions
The design of proper cost function used to define suboptimal parts of an image is not trivial at all. Early retinal processing work by Köhler and colleagues
117
used the retinal vessel contrast as a proxy measure for image quality, which was implemented later as fast real-time algorithm by Bendaoudi and colleagues.
118
Saha and colleagues
119
developed a structure-agnostic data-driven deep learning network for flagging fundus images either as acceptable for diabetic retinopathy screening or as to be recaptured. In practice, however, the cost function used for deep learning training can be defined in multiple ways as reviewed by Zhao and colleagues.
120
They compared different loss functions for image restoration and showed that the most commonly used
Physics-based ground truths
The unrealistic performance of image restoration networks with synthetic noise and the lack of proper real noise benchmark data sets are major limitations at the moment. Plötz and Roth 79 created their noise benchmark test by varying the ISO setting of the camera and taking the lowest ISO setting as the ground truth ‘noise-free’ image. In retinal imaging, construction of good-quality ground truth requires some special effort. Mayer and colleagues 81 acquired multiple OCT frames of ex vivo pig eyes to avoid motion artifacts between acquisitions for speckle denoising.
In humans, commercially available laser speckle reducers can be used to acquire image pairs with two different levels of speckle noise122,123 (Figure 3). Similar pair for deblurring network training could be acquired with and without AO correction 125 (see Figure 3). In phase-sensitive OCT application such as elastography, angiography, and vibrometry, a dual beam setup could be used with a highly phase-stable laser as the ground truth and ‘ordinary’ laser as the input to be enhanced. 126

High-level schematic representation of an adaptive optics retinal imaging system. The wavefront from (a) retina is distorted mainly by (b) the cornea and crystalline lens, which is corrected in our example by (c) lens-based actuator designed for compact imaging systems. 95 (d) The imaging optical system 88 is illustrated with a single lens for simplicity. The corrected wavefront on (e) the image sensor is a (h) sharper version of the image that would be of (f) lower quality without (c) the waveform correction. The ‘digital adaptive optics’ (g) universal function approximator maps the distorted image (f) to corrected image (h), and the network (g) is the network that was trained with the image pairs (uncorrected and corrected). For simplicity, we have omitted the wavefront sensor from the schematic and estimated the distortion in a sensorless fashion. 88
Emerging multimodal techniques, such as combined OCT and SLO, 127 and OCT with photoacoustic microscopy (PAM), optical Doppler tomography (ODT), 128 and fluorescence microscopy, 129 enable interesting joint training from complementary modalities with each of them having different strengths. For example, in practice, the lower quality but inexpensive modality could be computationally enhanced. 130
Inter-vendor differences could be further addressed by repeating each measurement with different OCT machines as taken into account with clinical diagnosis network by De Fauw and colleagues. 9 All these hardware-driven signal restorations could be further combined with existing traditional filters and the filter output could be used as targets for so-called ‘copycat’ filters that can estimate existing filters. 131
Quantifying uncertainty
Within the automatic ‘active acquisition’ scheme, it is important to be able to localize the quality problems in an image or in a volume.132,133 Leibig and colleagues 134 investigated the commonly used Monte Carlo dropout method 132 for estimating the uncertainty in fundus images for diabetic retinopathy screening and its effect on clinical referral decision quality. The Monte Carlo dropout method improved the identification of substandard images that were either unusable or had large uncertainty on the model classification boundaries. Such an approach should allow rapid identification of patients with suboptimal fundus images for further clinical evaluation by an ophthalmologist.
Similar approach was taken per-patch uncertainty estimation in 3D super-resolution 135 and in voxel-wise segmentation uncertainty. 136 Cobb and colleagues 137 demonstrated an interesting extension to this termed ‘loss-calibrated approximate inference’ that allowed the incorporation of utility function to the network. This utility function was used to model the asymmetric clinical implications between prediction of false negatives and false positives.
The financial and quality-of-life cost of an uncertain patch in an image leading to false-negative decision might be a lot larger than false-positive that might just lead to an additional checkup by an ophthalmologist.The same utility function could be expanded to cover disease prevalence 138 ; enabling end-to-end screening performance to be modeled for diseases such as glaucoma with low prevalence needs very high performance in order to be cost-efficient to screen. 139
The regional uncertainty can then be exploited during active acquisition by guiding the acquisition iteration to only that area containing the uncertainty. For example, some CMOS sensors (e.g. Sony IMX250) allow readout from only a part of the image, faster than one could do for the full frame. One scenario for smarter fundus imaging could, for example, involve initial imaging with the whole field of view (FOV) of the device, followed by multiframe acquisition of only the optic disc area to ensure that the cup and disc are well distinguishable, and that the depth information is of good quality (Figure 4). Similar active acquisition paradigm is in use, for example, in drone-based operator-free photogrammetry. In that application, the drone can autonomously reconstruct a 3D building model from multiple views recognizing where it has not scanned yet and fly to that location to scan more. 141

(a) Example of re-acquisition using a region of interest (ROI) defined from the initial acquisition (the full frame). The ROI has 9% of the pixels of the full frame making the ROI acquisition a lot faster if the image sensor allows ROI-based readout. (b) Multiframe ROI re-acquisition is illustrated with three low-dynamic range (8-bit LDR) with simulated low-quality camera intensity compression. The underexposed frame (b, left) exposes optic disc correctly with less details visible on darker regions of the image as illustrated by the clipped dark values in histogram (c, left, clipped values at 0), whereas the overexposed frame (c, right) exposes dark vasculature with detail while overexposing (c, right, clipped values at 255) the bright regions such as the optic disc. The normal exposure frame (b, center) is a compromise (c, center) between these two extreme exposures. (d) When the three LDR frames are combined together using a exposure fusion technique 140 into a high-dynamic range (HDR) image, all the relevant clinical features are exposed to correct possibly improving diagnostics. 102
Distributing the computational load
In typical postacquisition disease classification studies with deep learning, 10 the network training has been done on large GPU clusters either locally or using cloud-based GPU servers. However, when embedding deep learning within devices, different design trade-offs need to be taken into account. Both in hospital and remote healthcare settings, proper Internet connection might be lacking due to technical infrastructure or institutional policy limitations. Often, the latency requirements are very different for real-time processing of signals making the use of cloud services impossible. 142 For example, a lag due to poor Internet connection is unacceptable at intensive care units (ICUs) as those seconds can affect human lives, and the computing hardware needs to placed next to the sensing device. 143
Edge computing
In recent years, the concept of edge computing (Figure 5) has emerged as a complementary or alternative to the cloud computing, in which computations are done centrally, that is, away from the ‘edge’. The main driving factor for edge computing is the various IoT applications 145 or Internet of Medical Things (IoMT). 146 Gartner analyst Thomas Bittman has predicted that the market for processing at the edge will expand to similar or increased levels than the current cloud processing. 147 Another market research study by Grand View Research, Inc. 148 projected edge computing segment for healthcare and life sciences to exceed US$ 326 million by 2025. Specifically, the edge computing is seen as the key enabler of wearables to become a reliable tool for long-term health monitoring.149,150

Separation of computations to three different layers. (1) Edge layer – the computations done at the device level which in active acquisition ocular imaging (top) require significant computational power, for example, in the form of an embedded GPU. With wearable intraocular measurement, the contact lens can house only a very low-power microcontroller (MCU), and it needs to let the (2) Fog layer to handle most of the signal cleaning, whereas for ocular imaging, the fog device mainly just relays the acquired image to (3) Cloud layer. The standardization of the data structure is ensured through FHIR (Fast Healthcare Interoperability Resources) API (application programming interface) 144 before being stored on secure cloud server. This imaging data along with other clinical information can then be accessed via healthcare professionals, patients, and research community.
Fog computing
In many cases, an intermediate layer called fog or mist computing layer (Figure 5) is introduced between the edge device and the cloud layer to distribute the computing load.31,151–153 At simplest level, this three-layer architecture could constitute of simple low-power IoT sensor (edge device) with some computing power. 154 This IoT device could be, for example, an inertial measurement unit (IMU)-based actigraph that sends data real time to user’s smartphone (fog device) which contains more computing power than the edge device for gesture recognition. 155 The gesture recognition model could be used to detect the falls in elderly or send corrective feedback back to edge device which could also contain some actuators or a display. An example of such actuator could be a tactile buzzer for neurorehabilitation applications 156 or a motorized stage for aligning a fundus camera relative to the patient’s eye. 157 The smartphone subsequently sends the relevant data to the cloud for analyzing long-term patterns at both individual and population levels.16,158 Alternatively, the sensor itself could do some data cleaning and have the fog node to handle the sensor fusion of typical clinical one-dimensional (1D) biosignal. An illustration of this concept is the fusion of depth and thermal cameras for hand hygiene monitoring, 159 including indoor position tracking sensors to monitor healthcare processes at a hospital level.
Balancing edge and fog computations
For the hardware used in each node, multiple options exist, and in the literature, very heterogeneous architectures are described for the whole system.31,160 For example, in the SocialEyes project, 25 the diagnostic tests of MARVIN (for mobile autonomous retinal evaluation) are implemented on GPU-powered Android tablet (NVIDIA SHIELD). In their rural visual testing application, the device needs to be transportable and adapted to the limited infrastructure. In this scenario, most of the computations are already done at the tablet level, and the fog device could, for example, be a low-cost community smartphone/Wi-Fi link. The data can then be submitted to the cloud holding the centralized electronic health records (EHRs). 161 If the local computations required are not very heavy, both the edge and fog functionalities could be combined into one low-cost Raspberry Pi board computer. 162 In hospital settings with large patient volumes, it would be preferable to explore different task-specific data compression algorithms at the cloud level to reduce storage and bandwidth requirements. In a teleophthalmology setting, the compression could be done already at the edge level before cloud transmission. 163
In the case of fundus imaging, most of that real-time optimization would be happening at the device level, with multiple different hardware acceleration options.164,165 One could rely on a low-cost computer such as Raspberry Pi 166 and allow for limited computations. 167 This can be extended if additional computation power is provided at the cloud level. In many embedded medical applications, GPU options such as the NVIDIA’s Tegra/Jetson platform 168 have been increasingly used. The embedded GPU platforms in practice offer a good compromise between ease-of-use and computational power of Raspberry Pi and desktop GPUs, respectively.
In some cases, the general-purpose GPU (GPGPU) option might not be able to provide the energy efficiency needed for the required computation performance. In this case, field-programmable gate arrays (FPGAs) 169 may be used as an alternative to embedded GPU, as demonstrated for retinal image analysis 170 and real-time video restoration. 171 FPGA implementation may, however, be problematic due to increased implementation complexity. Custom-designed accelerator chips 172 and Application-Specific Integrated Circuit (ASIC) 173 offer even higher performance but at even higher implementation complexity.
In ophthalmology, there are only a limited number of wearable devices, allowing for continuous data acquisition. Although the continuous assessment of intraocular pressure (IOP) is difficult to achieve, or even controversial, 174 commercial products by Triggerfish® (Sensimed AG, Lausanne, Switzerland) and EYEMATE® (Implandata Ophthalmic Products GmbH, Hannover, Germany) have been cleared by the Food and Drug Administration (FDA) for clinical use.
Interesting future direction for this monitoring platform is an integrated MEMS/microfluidics system 175 that could simultaneously monitor the IOP and has a passive artificial drainage system for the treatment of glaucoma. 176 The continuous IOP measurement could be integrated with ‘point structure + function measures’ for individualized deep learning–driven management of glaucoma as suggested for the management of age-related macular degeneration (AMD). 11
In addition to pure computational restraints, the size and the general acceptability of the device by the patients can represent a limiting factor, requiring a more patient-friendly approach. For example, devices analyzing eye movements177,178 or pupillary light responses 179 can be better accepted and implemented when using more practical portable devices rather than bulky research lab systems. For example, Zhu and colleagues 180 have designed an embedded hardware accelerator for deep learning inference from image sensors of the augmented/mixed reality (AR/MR) glasses.
This could be in future integrated with MEMS-based camera-free eye tracker chip developed by University of Waterloo spin-off company AdHawk Microsystems (Kitchener, ON, Canada) 181 for functional diagnostics or to quantify retinal motion. In this example of eye movement diagnostics, most of the computations might be performed at the device level (edge), but the patient could carry a smartphone or a dedicated Raspberry Pi for further postprocessing and transmission to cloud services.
Cloud computing
The cloud layer (Figure 5) is used for centralized data storage, allowing both the healthcare professional and patients to access the EHRs, for example, via the FHIR (Fast Healthcare Interoperability Resources) API (application programming interface). 144 Research groups can analyze the records as already demonstrated for deep learning for retinopathy diagnosis.9,10 Detailed analysis of different technical options in the cloud layer is beyond the scope of this article, and interested readers are referred to the following clinically relevant reviews.182,183
Discussion
Here, we have reviewed the possible applications of deep learning, introduced at the ophthalmic imaging device level. This extends well-known application of deep learning for clinical diagnostics.9,10,48 Such an ‘active acquisition’ aims for automatic optimization of imaging parameters, resulting in improved image quality and reduced variability. 8 This active approach can be added to the existing hardware or can be combined with novel hardware designs.
The main aim of an embedded intelligent deep learning system is to favor acquisition of a high-quality image or recording, without the intervention of a highly skilled operator, in various environments. There are various healthcare delivery models, in which embedded deep learning could be used in future routine eye examination: (1) patients could self-screen themselves, using a shared device located either in a community clinic or at the supermarket, requiring no human supervision; (2) the patients could be imaged by a technician in a ‘virtual clinic’, 184 in a hospital waiting room before an ophthalmologist appointment, or at the optician (https://www.aop.org.uk/ot/industry/high-street/2017/05/22/oct-rollout-in-every-specsavers-announced); (3) patients could be scanned in remote areas by a mobile general healthcare practitioner 185 ; and (4) the patients themselves could do continuous home monitoring for disease progression.16,186 Most of the fundus camera and OCT devices come already with some quality metrics probing the operator to re-take the image, but so far no commercial device is offering sufficient automatic reconstruction, for example, in presence of ocular media opacities and poorly compliant patients.
Healthcare systems experiencing shortage of manpower may benefit from modern automated imaging. Putting more intelligence at the device level will relieve the healthcare professionals from clerical care for actual patient care. 187 With the increased use of artificial intelligence (AI), the role of the clinician will evolve from the medical paternalism of the 19th century and evidence-based medicine of the 20th century to (big) data-driven clinician working more closely with intelligent machines and the patients. 188 The practical-level interaction with AI is not just near-future science fiction, but very much a reality as the recent paper on ‘augmented intelligence’ in radiology demonstrated. 189 A synergy between clinicians and AI system resulted in improved diagnostic accuracy, compared with clinicians’, and was better than AI system’s own performance.
At healthcare systems level, intelligent data acquisition will provide an additional automated data quality verification, resulting in improved management of data volumes. This is required because size of data is reported to double every 12–14 months, 190 addressing the ‘garbage in–garbage out’ problem.190,191 Improved data quality will also allow more efficient EHR mining, 192 enabling the healthcare systems to get closer to the long-term goal of learning healthcare systems 193 leveraging on prior clinical experience in structured data/evidence-based sense along with expert clinical knowledge.188,194
Despite the recent developments of deep learning in ophthalmology, very few prospective clinical trials per se have evaluated its performance in real, everyday life situations. IDx-DR has recently been approved as the first fully autonomous AI-based FDA-approved diagnostic system for diabetic retinopathy, 48 but the direct benefit of patients, in terms of visual outcome, is still unclear. 195 Future innovations emerging from tech startups, academia, or from established companies will hopefully improve the quality of the data, through cross-disciplinary collaboration of designers, engineers, and clinicians,196,197 resulting in improved outcomes of patients with ophthalmic conditions.
Footnotes
Acknowledgements
The authors would like to acknowledge Professor Stephen Burns (Indiana University) for providing images to illustrate the adaptive optics deep learning correction.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Health Innovation Centre Singapore Innovation to Develop (I2D) Grant (NHIC I2D) (NHIC-I2D-1708181).
Conflict of interest statement
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.