
Abstract
The introduction of ChatGPT—an artificial-intelligence (AI) chatbot capable of text recognition and generation—has been transformative for numerous academic research communities, including psychology. We propose using ChatGPT to reduce researchers’ cognitive load and time spent creating text materials for psychological studies (e.g., vignettes). We present examples of ChatGPT-generated text materials for relationship-science (N = 60) and social-cognition (N = 67) studies and provide evidence of their effectiveness. Furthermore, we discuss ethical considerations and make recommendations related to using text materials generated by ChatGPT or similar AI tools. We end with a brief discussion of the importance of this work and encourage others to leverage AI in the field of psychology.
Keywords
Rapid advancements in artificial intelligence (AI), particularly in large language models (LLMs), have drastically altered how people use digital technologies. An extensive review of LLMs is out of the scope of this article and has been thoroughly discussed by others (e.g., see De Angelis et al., 2023; Demszky et al., 2023). However, a brief introduction of key features of LLMs and ChatGPT 1 specifically is relevant. LLMs are advanced and complex statistical systems with two key capabilities: natural language understanding and natural language processing (i.e., text recognition and generation; IBM, 2023). These capabilities are possible through a training process in which LLMs are exposed to diverse data sets of textual sources, such as books, articles, webpages, social media, and technical documents (Hua et al., 2024). Exposure to these textual sources allows LLMs to learn the nature of human language and statistically predict the next word in a sequence more accurately to produce coherent responses (Hua et al., 2024; IBM, 2023). LLMs are a diverse technological tool because they provide the foundational capabilities for a variety of applications rather than being specialized to do only one task (Hua et al., 2024; IBM, 2023). For instance, variations in the prompts given will result in variations of the tasks that it performs (Lin, 2024; Meyer et al., 2023). To illustrate, LLMs can perform a wide range of tasks, such as question answering, summarization, translations, and data analysis, to name a few (Demszky et al., 2023; Fraiwan & Khasawneh, 2023; Ke et al., 2024; Lund et al., 2023; Yenduri et al., 2024). ChatGPT specifically harnesses OpenAI’s advanced generative-pretrained-transformer (GPT) technology, which uses deep learning (i.e., neural networks that involve many hidden layers; IBM, 2023; LeCun et al., 2015). The greater the number of hidden layers is, the greater is the sophistication and complexity of inputs/outputs it can understand/produce (LeCun et al., 2015). It gives ChatGPT the ability to produce remarkably human-like text responses compared with other LLMs (for a detailed description of ChatGPT and its evolution, see Hua et al., 2024). Furthermore, among the available LLMs, ChatGPT is arguably the most user-friendly (De Angelis et al., 2023; Meyer et al., 2023). Therefore, even individuals without technical expertise can take advantage of this technology.
Multiple uses of LLMs have been proposed to increase productivity in and to advance psychological research. Among the proposed uses are conducting literature reviews, hypothesis generation, experimental design (e.g., stimuli generation), data analysis, academic writing, peer review, and practice (e.g., case management; Demszky et al., 2023; Ke et al., 2024). Although exploring these possibilities is exciting and valuable, there are numerous limitations that have been discussed regarding being able to achieve them using ChatGPT or any other LLMs. Specifically, some concerns involve hallucinations (i.e., errors), biases, plagiarism, copyright violations, privacy concerns, and many others (Hua et el., 2024; Khowaja et al., 2024; Wu et al., 2024; Yenduri et al., 2024). Nonetheless, many researchers have used LLMs to benefit their academic and research goals (Ke et al., 2024; Raman, 2025; Salah, Al Halbusi, & Abdelfattah, 2023).
We are particularly interested in the role of ChatGPT in generating experimental text stimuli. Although others have suggested using AI tools for stimuli generation, as mentioned earlier, we are one of the first to try it and evaluate its effectiveness. Many psychological-research studies use specific sets of text materials (e.g., vignettes) to test their hypotheses. Depending on the design of the study, creating the materials can be a tedious, time-consuming task. ChatGPT can reduce a researcher’s cognitive load and overall time spent on creating these materials. In this article, we discuss the utility and success of ChatGPT in generating experimental text stimuli for psychological research. We specifically selected ChatGPT because it is one of the LLMs at the forefront of this technological revolution and is easy to use. In the first part of this article, we present examples of GPT-4-generated text materials and empirical data testing their effectiveness. In the second part of this article, we discuss ethical considerations and make recommendations related to using text materials generated by ChatGPT or similar AI tools. In the last part of this article, we discuss the importance of this work and encourage others to leverage AI tools in the field of psychology.
Part 1
Two examples of materials created using GPT-4 will be discussed. Both sets of materials were created to mimic materials previously developed by a researcher for studies that have been conducted. These examples demonstrate and support our claim that GPT-4—with its current capabilities—can be used for this purpose. A brief description of each of the studies is provided to give context to what materials were required to test those research questions. Along with the description, our predictions will be detailed. Then, we address how the materials were generated using GPT-4. Finally, we present our findings. All studies discussed in this article were approved by the Institutional Review Board at The University of Texas at El Paso. Our predictions and methods were preregistered and are available on our OSF profile (https://osf.io/w7scm/?view_only=4b49de111fbe45bb916f96c13e149ab7). Our materials, data, and syntax are also available on our OSF profile (https://osf.io/kjtqx/?view_only=94b2c8a1939c48e1b2af9a7b3694cbc9). Any deviations from our preregistration are detailed in Table 1, as suggested by Willroth and Atherton (2024), to maintain transparency and increase credibility of research findings.
Preregistration Deviations

Note: TOST = two one-sided tests; AI = artificial intelligence.
Prompt tuning
The output generated by LLMs can be improved in multiple ways (Demszky et al., 2023). However, prompt tuning is one way of doing this without requiring changing the underlying model parameters (i.e., how it has been trained; Demszky et al., 2023). Although prompt engineering (i.e., developing effective instructions to request LLMs to generate output) also requires technical expertise, compared with other forms of fine-tuning LLMs, prompt engineering is more accessible. Some guidelines for prompt tuning have been put forward. Lin (2024) summarized different strategies for writing effective prompts for LLMs. These strategies include guiding the model to solutions (i.e., providing incremental instructions), adding relevant context, being explicit in the instructions, asking for multiple options, assigning characters (i.e., instructing the model to role-play), showing examples, declaring a preferred response format, and experimenting (i.e., making tweaks; Lin, 2024). The prompts entered to generate materials for the two studies presented here used multiple of these strategies.
Example 1
Description of research study
One of the purposes of this research study was to test how the level of inclusion of other in the self is associated with disregarding red flags (i.e., an indicator that a person is potentially bad for one’s mental and physical well-being) in romantic partners. This research question was tested by using online dating profiles that incorporate an inclusion-of-other-in-the-self manipulation and reveal a transgression committed by a potential romantic partner.
In this investigation, we tested and compared only the effectiveness of an inclusion-of-other-in-the-self manipulation using human-generated and AI-generated (i.e., GPT-4) materials. It was predicted that inclusion of other in the self would be greater in the high (vs. low) self-disclosure condition for both the human-generated and AI-generated stimuli. It was also predicted that the effectiveness of human-generated and AI-generated stimuli would be equivalent. Finally, it was predicted that participants would indicate low confidence in their ability to distinguish between human-generated and AI-generated stimuli and would demonstrate this inability.
Method
Inclusion-of-other-in-the-self manipulation
The level of inclusion of other in the self (i.e., overlap in identities; Aron et al., 1992) was manipulated by controlling the level of self-disclosure to six question prompts included in the online dating profiles. The question prompts differ in the level of intimacy (i.e., low, moderate, and high), and they were selected from an interpersonal closeness-generating task (Aron et al., 1997). Higher levels of self-disclosure are associated with higher levels of inclusion of other in the self (Aron et al., 1997). Therefore, online dating profiles with high (low) self-disclosure answers are high (low) on inclusion of other in the self. First, we entered the following in the chat box: Imagine that you are a college student who is creating an online dating profile. Create an online dating profile answering only the questions prompts below and create responses that are low in self-disclosure. Question Prompt #1: For what in your life do you feel the most grateful? Question Prompt #2: If you could wake up tomorrow having gained any one quality or ability, what would it be? Question Prompt #3: What is your most terrible memory? Question Prompt #4: If you knew that in one year you would die suddenly, would you change anything about the way you are now living? Why? Question Prompt #5: Complete this sentence: “I wish I had someone with whom I could share . . . ” Question Prompt #6: If you were to die this evening with no opportunity to communicate with anyone, what would you most regret not having told someone? Why haven’t you told them yet?
Here is an example of an online dating profile with answers that are low in self-disclosure.
For what in your life do you feel most grateful? That I am still alive. If you could wake up tomorrow having gained any one quality or ability, what would it be? I would like the ability to fly or have super strength. What is your most terrible memory? I don’t feel comfortable sharing this. Sorry. If you knew that in one year you would die suddenly, would you change anything about the way you are now living? Why? No. I like how it is. Complete this sentence: “I wish I had someone with whom I could share . . . ” My Food. I think it’s delicious and I always make extra. If you were to die this evening with no opportunity to communicate with anyone, what would you most regret not having told someone? Why haven’t you told them yet? My deepest secret. I haven’t told people because it is a secret. Avoid repetitiveness between the answers in the profile that is generated and the answers in the profile that was provided as an example.
After its first iteration of output, GPT-4 was told the following: Recreate the profile. Keep the same answers but make them less expressive of personality and interests.
For GPT-4’s response to this final request, see Table 2 (OpenAI, 2024). Then, we entered the same prompt but changed our request to create responses that are high in self-disclosure and to make them different than the response it generated for low self-disclosure.
Imagine that you are a college student who is creating an online dating profile. Now, create an online dating profile answering only the questions prompts below and create responses that are high in self-disclosure. Question Prompt #1: For what in your life do you feel the most grateful? Question Prompt #2: If you could wake up tomorrow having gained any one quality or ability, what would it be? Question Prompt #3: What is your most terrible memory? Question Prompt #4: If you knew that in one year you would die suddenly, would you change anything about the way you are now living? Why? Question Prompt #5: Complete this sentence: “I wish I had someone with whom I could share . . . ” Question Prompt #6: If you were to die this evening with no opportunity to communicate with anyone, what would you most regret not having told someone? Why haven’t you told them yet?
Artificial-Intelligence-Generated Online Dating Profiles

Here is an example of an online dating profile with answers that are high in self-disclosure.
For what in your life do you feel most grateful? I am grateful for having a family who loves and cares about me. I am also grateful for the love and endless support I receive from my friends. They have become my second family. I can’t imagine going through life without them. If you could wake up tomorrow having gained any one quality or ability, what would it be? I would like the ability to teleport myself anywhere I want. Teleporting would give me the opportunity to travel around the world, see the beauty that this world has to offer, and experience new cultures. What is your most terrible memory? My most terrible memory is receiving a call from a family member to inform me that my mother had died. For months, I felt anxious every time I received a call. I was always worried that someone would call me to tell me something bad had happened again. If you knew that in one year you would die suddenly, would you change anything about the way you are now living? Why? I would attempt to experience life more. I would try to do the things that I keep saying I will but had been reluctant to do like traveling on my own. I would also reconsider my priorities. I would spend more time making memories with my loved ones. Complete this sentence: “I wish I had someone with whom I could share . . . ” My life. I want to find someone with whom I can share my successes and struggles and someone that feels they can do the same with me. If you were to die this evening with no opportunity to communicate with anyone, what would you most regret not having told someone? Why haven’t you told them yet? My biggest regret would be not telling my family and friends how much I love them and how much better my life is because of them. I think I assume that they already know, but I should express my feelings to them more often. Avoid repetitiveness between the answers in the profile that is generated and the answers in the profile that was provided as an example.
For GPT-4’s response to this request, see Table 2 (OpenAI, 2024). Our human-generated online dating profiles were the examples in our prompts to create the AI-generated profiles.
Procedure
Our final sample consisted of 60 college students from a Hispanic-Serving Institution who participated in this study in exchange for class credit (38.33% female, 58.33% male, 3.33% nonbinary; 3.33% African American, 8.33% White, 1.67% Asian, 85% Hispanic, 1.67% other; age: range = 18–27, M = 20.28 years, SD = 1.96). Participant responses were excluded from data analyses if they were not single (n = 3) or did not reconsent after being debriefed (n = 3). No participant responses were excluded for extreme responses (i.e., 2.5 SD above or below the mean on outcome variables). Participants first completed an online dating profile by answering the same question prompts in the four online dating profiles they reviewed. Half of the online dating profiles were human-generated (i.e., created by a researcher), and the other half were AI-generated (i.e., created by GPT-4). In addition, each set of online dating profiles had one profile high on inclusion of other in the self and one low on inclusion of other in the self. Participants were randomly presented with the online dating profiles, and they rated each online dating profile on various attributes using a 7-point Likert scale. Specifically, for each online dating profile, participants rated the perceived level of self-disclosure (“Please rate the level of self-disclosure for [NAME]”), the expected level of inclusion of other in the self (“Please select the set of circles that best represent how close you anticipate feeling towards the person in this dating profile”), and the likelihood that this was created by a human versus AI (“Please rate the likelihood that this was created by a human versus being generated by artificial intelligence”). At the end of the study, participants rated their overall confidence in distinguishing between human- and AI-generated materials (“Overall, how confident do you feel in your ability to distinguish between content created by humans and content generated by artificial intelligence”). Finally, participants were debriefed and thanked for their participation.
Results and discussion
Data analytical plan
First, the effectiveness of our materials was tested separately by source (i.e., human-generated vs. AI-generated). Then, two-one-sided-tests (TOST) procedures were used to test the equivalence between the effect sizes for human-generated and AI-generated materials (Lakens et al., 2018) using the TOSTER R package (Lakens & Caldwell, 2025). The equivalence bounds were set at Cohen’s d = ±0.15, representing the smallest effect size of interest. This effect size was selected based on a recent meta-analysis, which calculated the average small (d = 0.15), medium (d = 0.36), and large (d = 0.65) effect sizes in social psychology (Lovakov & Agadullina, 2021). Finally, a Bonferroni correction was used to adjust for multiple tests (i.e., nine statistical tests) using the same sample. The alpha level was adjusted to .006, and all interpretations of significance were based on this threshold. When we compared human-generated and AI-generated materials, our interpretation was based on the results of both null hypothesis significant testing (NHST) and TOST (i.e., lower and upper bounds; Lakens et al., 2018). Equivalence was concluded when both one-sided tests were significant, indicating that differences (if any) were within the bounds of the determined smallest effect size of interest. Nonequivalence was concluded when the NHST was significant and one or both TOST were nonsignificant, indicating that mean differences corresponded to differences in performance. Results were considered inconclusive when the NHST and one or both TOST were nonsignificant, indicating that there was no sufficient evidence to distinguish between equivalence and nonequivalence.
Human-generated online dating profiles
A paired samples t test indicated that levels of inclusion of other in the self were higher for potential romantic partners paired with high self-disclosure responses (M = 4.62, SD = 1.91) than for potential romantic partners paired with low self-disclosure responses (M = 2.68, SD = 1.89), t(59) = 5.95, p < .001, Hedges’s g = 1.02. Therefore, the manipulation was effective.
AI-generated online dating profiles
A paired samples t test indicated that levels of inclusion of other in the self were higher for potential romantic partners paired with high self-disclosure responses (M = 3.75, SD = 1.86) than for potential romantic partners paired with low self-disclosure responses (M = 2.38, SD = 1.79), t(59) = 5.06, p < .001, Hedges’s g = 0.75. Therefore, the manipulation was effective.
Comparing human-generated and AI-generated online dating profiles
A paired samples t test (NHST) indicated that the human-generated online dating profile (M = 4.62, SD = 1.91) performed better than the AI-generated online dating profile (M = 3.75, SD = 1.86), t(59) = 3.53, p < .001, Hedges’s g = 0.45, when manipulating high levels of inclusion of other in the self. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .006) was nonsignificant, t(59) = 4.69, p < .001 (lower bound), t(59) = 2.37, p = .989 (upper bound), 98.8% confidence interval [CI] = [0.23, 1.51]. This test indicated a notable difference in the strength of manipulation for high inclusion of other in the self between human-generated and AI-generated profiles favoring the human-generated materials. Another paired samples t test (NHST) indicated no difference between the human-generated online dating profile (M = 2.68, SD = 1.89) and the AI-generated online dating profile (M = 2.38, SD = 1.79) for low levels of inclusion of other in the self, t(59) = 1.23, p = .224, Hedges’s g = 0.16. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .006) was also nonsignificant, t(59) = 2.39, p = .010 (lower bound), t(59) = .07, p = .527 (upper bound), 98.8% CI = [−0.33, 0.93]. Therefore, there is no sufficient evidence to distinguish between a significant difference and equivalence in the strength of manipulation for low inclusion of other in the self between human-generated and AI-generated materials.
Confidence and ability to distinguish source
Overall confidence in the ability to distinguish between human-generated and AI-generated content was closer to a neutral point (M = 4.15, SD = 1.61). A paired samples t test (NHST) indicated no difference between the ratings of perceived source (human-generated vs. AI-generated) between the human-generated (M = 5.02, SD = 1.37) and AI-generated online dating profiles (M = 4.73, SD = 1.32), t(59) = 1.64, p = .106, Hedges’s g = 0.21. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .006) was also nonsignificant, t(59) = 2.80, p = .003 (lower bound), t(59) = .48, p = .683 (upper bound), 98.8% CI = [−0.17, 0.75]. Therefore, there is no sufficient evidence to distinguish between a significant difference and equivalence in the ability to discern between human-generated and AI-generated materials.
Our findings provide partial support for our predictions. Our manipulation was effective regardless of the source (i.e., human-generated vs. AI-generated) of the online dating profiles. In addition, participants lacked the confidence to distinguish between human-generated and AI-generated materials. However, our data were insufficient to properly distinguish between a significant difference and equivalence for the low inclusion-of-other-in-the-self online dating profiles and for participants’ ability to discern between sources. Based on our one interpretable comparison, human-generated materials were superior to AI-generated materials, but this result should be carefully considered.
Example 2
Description of research study
One of the purposes of this research study was to test the influence of stereotypes on spontaneous trait inferences (i.e., traits inferred from observable behavior; Bray, 2019). This research question was tested using a recognition-probe paradigm in which participants read sentences and identified whether a word (i.e., a probe) was present or absent from the sentence. Slower reaction times to words that were implied but not present in the sentence demonstrate the occurrence of a spontaneous trait inference.
In this investigation, we tested and compared only the effectiveness of sentences in implying a trait through the description of behavior. It was predicted that the effectiveness of human-generated and AI-generated stimuli would be equivalent. Finally, it was predicted that participants would indicate low confidence in their ability to distinguish between human-generated and AI-generated stimuli and would demonstrate this inability.
Method
Spontaneous-trait-inference sentences
Sentences for spontaneous trait inferences must describe a behavior that indicates a trait without explicitly saying what the trait is. A total of 24 traits (12 positive, 12 negative) were used to create the sentences. We entered the following in the chat box: Create a short sentence for each of the following traits: Caring, Smart, Helpful, Polite, Honest, Loyal, Lazy, Selfish, Jealous, Rude, Mean, Annoying, Considerate, Ambitious, Friendly, Brave, Respectful, Creative, Impolite, Nosy, Stubborn, Bossy, Stupid, Clumsy. Each sentence should imply the trait through observable behavior. The sentences should not explicitly mention the trait that it is implying. Here is an example. The sentence below implies the trait of caring through the description of behavior without explicitly mentioning the trait of caring. Helped the elderly lady pack her groceries into the car. Here is a second example. The sentence below implies the trait of smart through the description of behavior without explicitly mentioning the trait of smart. Aced the neuroscience project for their psychology class.
For GPT-4’s response to this request, see Table 3 (OpenAI, 2024). Our human-generated sentences are also presented in Table 3.
Spontaneous-Trait-Inference Sentences

Procedure
Sixty-seven college students from a Hispanic-Serving Institution participated in this study in exchange for class credit (56.70% female, 37.31% male, 2.99% nonbinary; 5.97% African American, 17.91% White, 1.49% Asian, 74.63% Hispanic; age: range = 18–46, M = 20.99 years, SD = 4.17). There were no inclusion criteria, and no participant responses were excluded from data analyses based on failure of attention checks or extreme responses (i.e., 2.5 SD above or below the mean on outcome variables). Participants rated 48 spontaneous-trait-inference sentences presented in a random order. Half of the sentences were human-generated (i.e., created by a researcher), and the other half were AI-generated (i.e., created by GPT-4). Participants rated each sentence on various attributes using a 7-point Likert scale. Specifically, after each sentence, participants rated the valence (“How good/bad do you think this behavior is?”), the trait agreement (“How well does the trait [TRAIT] describe this behavior?”), and the likelihood that this was created by a human versus AI (“Please rate the likelihood that this was created by a human versus being generated by artificial intelligence”). At the end of the study, participants rated their overall confidence in distinguishing between human- and AI-generated materials (“Overall, how confident do you feel in your ability to distinguish between content created by humans and content generated by artificial intelligence”). Finally, participants were debriefed and thanked for their participation.
Results and discussion
Data analytical plan
We used the same approach as in Example 1. However, our alpha level was adjusted to .013 based on the multiple tests conducted using this sample (i.e., four statistical tests). All interpretations of significance were based on this threshold and when relevant, on the alignment between the results of the NHST and TOSTs.
Trait-agreement and -valence ratings
Effective sentences based on trait-agreement ratings must demonstrate higher ratings for positive and negative traits. For a summary of the descriptive information for each sentence across sources, see Table 4. All sentences, irrespective of source, strongly implied the traits. The only exception was stupid, in which the AI-generated sentence did not reach a trait rating above a neutral score. A paired samples t test (NHST) indicated no difference between average trait ratings for human-generated (M = 6.16, SD = 0.49) and AI-generated (M = 6.04, SD = 0.48) sentences, t(66) = 2.00, p = .049, Hedges’s g = 0.24. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .013) was also nonsignificant, t(66) = 3.23, p < .001 (lower bound), t(66) = .78, p = .78 (upper bound), 97.4% CI = [−0.02, 0.26]. Therefore, there is no sufficient evidence to distinguish between a significant difference and equivalence in mean trait ratings between human-generated and AI-generated sentences.
Descriptive Information for Spontaneous-Trait-Inferencing Sentences Across Sources of Materials

Effective sentences based on valence ratings must demonstrate higher ratings for positive traits and lower ratings for negative traits. As shown in Table 4, behaviors described in the sentences were indeed rated as positive when the implied trait was positive and negative when the implied trait was negative irrespective of source. A paired samples t test (NHST) indicated no difference between average valence ratings for human-generated (M = 6.23, SD = 0.56) and AI-generated (M = 6.23, SD = 0.54) sentences for positive traits, t(66) = 0.00, p = 1.00, Hedges’s g = 0.00. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .013) was also nonsignificant, t(66) = 1.23, p = .112 (lower bound), t (66) = −1.23, p = .112 (upper bound), 97.4% CI = [−0.16, 0.16]. Therefore, there is no sufficient evidence to distinguish between a significant difference and equivalence in mean valence ratings for positive traits between human-generated and AI-generated sentences. Another paired samples t test (NHST) indicated that human-generated sentences (M = 2.17, SD = 0.47) performed better than AI-generated sentences (M = 2.60, SD = 0.48) at conveying behaviors that implied negative traits, t(66) = −7.49, p < .001, Hedges’s g = −0.90. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .013) was nonsignificant, t(66) = −6.26, p = 1.00 (lower bound), t(66) = −8.72, p < .001 (upper bound), 97.4% CI = [−0.56, −0.30]. Therefore, there was a meaningful difference in mean valence ratings for negative traits between human-generated and AI-generated sentences favoring the human-generated sentences.
Confidence and ability to distinguish source
Overall confidence in the ability to distinguish between human-generated and AI-generated content was lower than a neutral point (M = 3.25, SD = 1.85). A paired samples t test (NHST) indicated no difference between the ratings of perceived source (human-generated vs. AI-generated) between the human-generated (M = 5.07, SD = 1.00) and AI-generated sentences (M = 5.02, SD = 1.00), t(66) = 0.41, p = .684, Hedges’s g = 0.05. Furthermore, a TOST equivalence test (equivalence bounds = ±.15, α = .013) was also nonsignificant, t(66) = 1.64, p = .053 (lower bound), t(66) = −0.82, p = .208 (upper bound), 97.4% CI = [−0.23 0.33]. Therefore, there is no sufficient evidence to distinguish between a significant difference and equivalence in the ability to discern between human-generated and AI-generated materials.
Our findings provide partial support for our predictions. Our materials were effective regardless of the source (i.e., human-generated vs. AI-generated) of the sentences. In addition, participants lacked the confidence to distinguish between human-generated and AI-generated materials. However, our data were insufficient to properly distinguish between a significant difference and equivalence across multiple comparisons of our materials and participants’ ability to discern between sources. Based on our one interpretable comparison, human-generated materials were superior to AI-generated materials, but this result should be carefully considered.
Part 2
The increased interest in AI tools has generated discussions about the ethics of their use. Nonetheless, these discussions have primarily focused on simply listing and describing various ethical concerns. Even when recommendations to address these ethical concerns are provided, these recommendations are too broad or too narrow. Some recommendations simply encourage researchers to follow AI guidelines and policies without necessarily specifying what those guidelines and policies are and/or where these can be found (Behrend & Landers, 2025; Ghandour et al., 2024; Haque & Li, 2025; Salah, Al Halbusi, & Abdelfattah, 2023; Tawfeeq et al., 2023; van Berlo et al., 2024; Zhou et al., 2024). On the other hand, some recommendations focus on addressing specific ethical concerns (Calderon & Herrera, 2025; Dehbozorgi et al., 2025; Farmer et al., 2025; Haltaufderheide & Ranisch, 2024; Youssef et al., 2025). For instance, a recent systematic review on the ethical discourse of ChatGPT concluded that the use of this AI tool in academic writing (i.e., authorship) is at the forefront of these ethical concerns (Stahl & Eke, 2024). Considering the array of AI tools and their possible applications, it is reasonable that as ethical guidelines and policies are developed, they will be focused on specific uses, such as academic writing. However, it is important to extend our ethical discourse beyond academic writing (Stahl & Eke, 2024). Currently, little to no discussion exists about the ethics of using output generated by this technology in other contexts, such as part of an experimental design. Even less, no guidelines have been proposed for using the generated output ethically. We start with a brief discussion on concerns related to plagiarism and copyright, which are the most closely related to whether and how ChatGPT output can be used. Then, we propose a few recommendations on how to use these AI-generated materials.
Plagiarism
Most definitions of plagiarism involve the accidental or purposeful appropriation of someone else’s work or ideas as one’s own (Merriam-Webster, n.d.). A primary concern in the usage of ChatGPT or similar AI tools and plagiarism is whether the generated text plagiarizes other people’s work or ideas. One major argument related to this concern, specifically to ChatGPT, is that the generated text is a combination of multiple corpora of text to which ChatGPT has been exposed (Brown et al., 2020; Henderson et al., 2023; Vincent, 2022). Therefore, ChatGPT’s generated text is arguably original and does not infringe on anyone’s intellectual property (Meyer et al., 2023). In the education field, for instance, when ChatGPT’s generated text has been submitted to popular plagiarism checkers (e.g., Turnitin), the content is not found to be plagiarized (Gao et al., 2023; Khalil & Er, 2023). When asked, ChatGPT does warn that its generated text can “resemble existing content” and potentially infringe copyrights, our next point of discussion.
Copyright
Intellectual property and creativity in many forms of work (e.g., photographs, music, videos, text) can be protected by copyright laws (U.S. Copyright Office, n.d.). Copyright gives the owners exclusive rights to their work (e.g., distribute copies) and thus limits how others can use this work. If someone exerts usage of copyrighted work without formal permission from the owners, they would be infringing on the owners’ rights over their work. There is concern that AI tools—including ChatGPT—were trained using text that includes copyrighted work (Epstein et al., 2023; Henderson et al., 2023; Sag, 2024). Some discussions related to this particular concern mention “fair use” to justify the potential use of copyrighted work for the training of this technology (e.g., Henderson et al., 2023). Fair use is an exception to copyright laws that allow the limited usage of copyrighted work without legal retributions. In general, four factors are considered when evaluating whether the unlicensed usage of copyrighted work is fair use. According to the U.S. Copyright Office (2023b), these factors are (1) purpose and character of the use, including whether the use is of a commercial nature or is for nonprofit educational purposes; (2) nature of the copyrighted work; (3) amount and substantiality of the portion used in relation to the copyrighted work as a whole; and (4) effect of the use on the potential market for or value of the copyrighted work. For a detailed discussion on how training for AI tools meets these criteria, see Henderson et al. (2023). Our primary focus is to discuss how fair use applies to the usage of generated output by ChatGPT and similar AI tools.
Experimental text stimuli created to be used in psychological research with ChatGPT or similar AI tools would most likely meet the requirements detailed in these factors. First, fair use applies when the content is being used for educational and research purposes (Factor 1). Second, fair use applies when the content that is being used is more technical and factual than creative (Factor 2). Experimental stimuli is an important part of scientific research, and it serves as a tool rather than expressing creativity, thus meeting these two first requirements. Third, fair use applies when the amount of copyrighted content that is being used is small (Factor 3). The amount of copyrighted content used is likely to be minimal because ChatGPT’s generated responses are a combination of multiple corporals of text, thus meeting this requirement. Finally, fair use applies when the original work is not negatively affected by the usage of some of its content (Factor 4). The usage of experimental stimuli is limited to scientific research and seen only by a specific audience (i.e., participants, researchers), thus not affecting the marketability of the original work and meeting this last requirement.
Although fair use can potentially legally protect the usage of materials created with ChatGPT and similar AI tools, note that courts decide fair use on a case-by-case basis, and it is dependent on the interpretation of the four factors mentioned above (U.S. Copyright Office, 2023b). The U.S. Copyright Office has created an index with a quick summary of all fair-use cases (https://www.copyright.gov/fair-use/fair-index.html). Closely related to this, guidelines have now been created for the registration of materials generated with AI tools, such as ChatGPT, to be protected by copyright regulations. Materials generated with AI tools are not eligible to be registered, but the changes made to the materials can potentially be protected by copyright regulations (U.S. Copyright Office, 2023a).
Recommendations
The developers of ChatGPT warn that the responsibility to avoid plagiarism and violations of copyright is adopted by the users when they generate text using this tool. To date, there are no detailed guidelines on how to approach this. Consequently, the development of standardized guidelines to facilitate the ethical usage of AI tools while maintaining academic integrity has been encouraged by others (Abdelhafiz et al., 2024; Guleria et al., 2023; Malik et al., 2025; Raman, 2025; Rupp, 2024). Below is a summary of existing guidelines for the usage of ChatGPT and similar AI tools specifically in scientific publications, followed by our recommendations on how to ethically use the text generated by ChatGPT as experimental stimuli. We invite experts in psychology and other fields to join the conversation.
Existing guidelines for the usage of AI tools
Currently, existing guidelines for the usage of ChatGPT and similar AI tools are mostly focused on the role of these tools in the creation and publication of scientific articles. For a summary of the positions taken by multiple professional societies and journals on the usage of AI tools, see Table 5. The consensus among these entities is that AI tools cannot be given authorship (American Geophysical Union [AGU], n.d.; American Psychological Association [APA], 2023; Committee on Publication Ethics [COPE], 2023; “Science Journals: Editorial Policies,”n.d.; “Tools Such as ChatGPT Threaten Transparent Science,”2023; U.S. Copyright Office, 2023a; “World Scientific’s Position Statement on Authorship and AI Tools,”n.d.; Zielinski et al., 2023). The main argument made is that authors commit to taking responsibility for the materials and ideas being presented in the article, which is something that an AI tool cannot do. There is also a consensus that the usage of AI tools in any capacity (e.g., editing writing) should be made transparent in the methods section or any other relevant section (AGU, n.d.; APA, 2023; COPE, 2023; “Science Journals: Editorial Policies,”n.d.; “Tools Such as ChatGPT Threaten Transparent Science,”2023; U.S. Copyright Office, 2023a; “World Scientific’s Position Statement on Authorship and AI Tools,”n.d.; Zielinski et al., 2023). Between these entities, there are organizations specifically responsible for the creation of writing guidelines (e.g., COPE), organizations that are recognized and read by multiple disciplines (e.g., Nature), and organizations that are field-specific (e.g., AGU). Therefore, these guidelines represent the perspective of a wide range of academics regarding the usage of AI tools. These guidelines, however, apply largely to the drift of using AI tools to summarize and generate text for different sections of a scientific article (e.g., literature review). Next, we offer recommendations on how to ethically use the text generated by ChatGPT as experimental stimuli.
Guidelines for the Usage of ChatGPT According to Various Entities
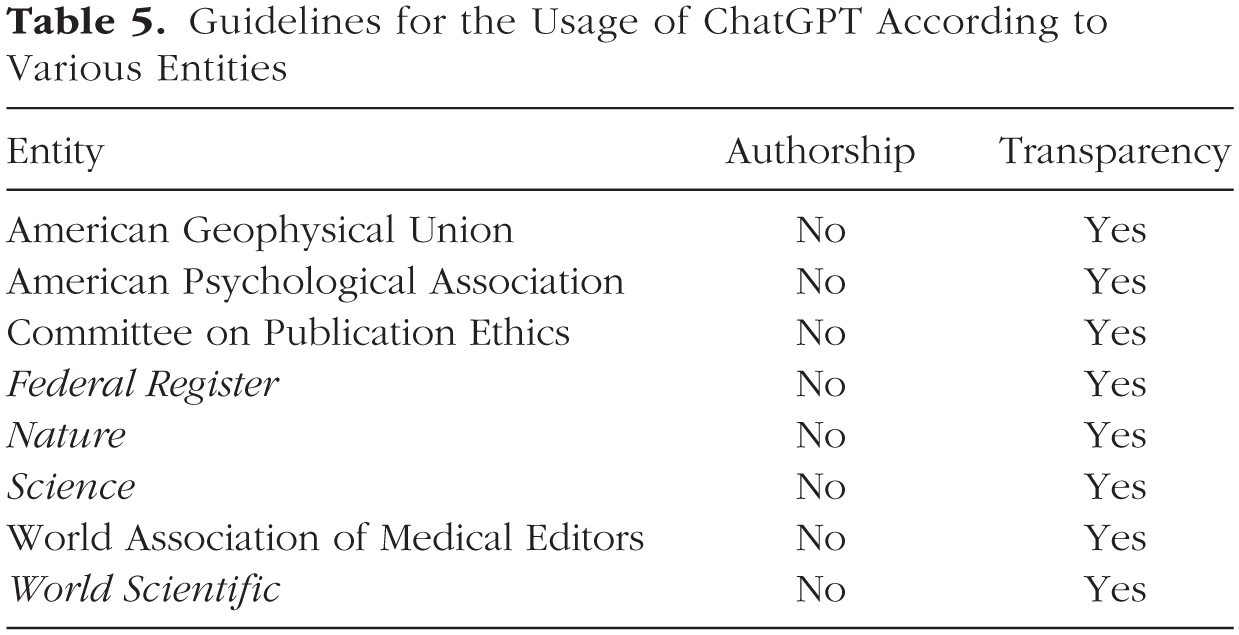
Proposed guidelines for the usage of experimental stimuli generated by ChatGPT
Referencing/citing
The most effective way to avoid plagiarism is to properly credit the original authors for their work. Unfortunately, ChatGPT cannot disclose its sources because it is considered proprietary knowledge or when it provides its sources, it does it inaccurately. Future iterations of this technology should consider making ChatGPT able to provide accurate references/citations for the corpora of text it uses for its output. Until then, although ChatGPT cannot be credited as an author for the materials it creates, ChatGPT can and should be cited as a tool (see Table 5). Furthermore, researchers should cite any other work that might have been used to inspire the materials created with ChatGPT. For instance, to create the online dating profiles in Example 1, ChatGPT was asked to answer six question prompts. Those question prompts were previously published by Aron et al. (1997). Therefore, Aron et al. should be credited along with ChatGPT as a tool.
Limit the usage of AI tools to low-complexity, low-creativity tasks
One of the main problems with the proposed uses of AI tools is that these tasks (e.g., writing scientific articles) require a level of sophistication that AI tools cannot completely fulfill. For instance, it has been established that ChatGPT’s output can include false and inaccurate information (Abdelhafiz et al., 2024; Guleria et al., 2023). It has also been established that to produce content with the required quality to accomplish specific goals (e.g., create accurate medical cases for educational purposes), human intervention is necessary (Beghetto et al., 2025; Ghaffari et al., 2025). Nonetheless, asking for AI tools to generate materials that are low in complexity and creativity is a better option. Low-complexity, low-creativity tasks refer to tasks that do not demand accuracy, advance problem-solving, or original thinking. For instance, in Example 1, the responses generated to the question prompts are not based on information that can be evaluated as correct or incorrect. Furthermore, these responses are broad descriptions of experiences or thoughts that many people undergo and do not necessarily infringe on other people’s ideas or work. A cautionary note for researchers is that ChatGPT learns from users’ input and this information is considered public knowledge. Therefore, any information included in a prompt is stored and used to produce better responses for that specific user and others. Because this information is stored and potentially shared with others, it is advised against entering information in the prompts or using ChatGPT to generate text materials intended to be copyrighted (e.g., psychometric assessment).
Transparency and accessibility
If materials are created using AI tools, such as ChatGPT, researchers should disclose this information. This is not different than what has been suggested when using AI tools to write sections of a scientific article (see Table 5). Lin (2025) proposed specific guidelines for documenting the usage of AI in research with the three (out of seven) most important attributes being to include the exact version of the AI tool used, indicate which parts were generated or influenced by AI, and specify the prompt entered or additional training data used. The AI-generated materials should also be made accessible for others to review and use. These AI-generated materials can be made accessible to others through personal websites or platforms such as GitHub or OSF, which are platforms that are already being used to increase transparency in psychological research. Furthermore, when posting these materials online, researchers should select a license that provides full access and gives permission to others to use them. Researchers should not claim ownership of output generated by AI tools unless requirements are met and proper steps are taken to copyright the changes made to these materials (U.S. Copyright Office, 2023a). In those cases, researchers can opt to select a license that restricts usage without permission. However, it is highly encouraged that whenever reasonable, no restrictions are placed on AI-generated materials. Researchers who then make use of these available AI-generated materials should cite both the original author and the AI tool (i.e., as cited by original author). Finally, transparency also involves creating awareness among research participants that they will be/have been exposed to AI-generated materials during the informed consent (e.g., “If you agree to be part of this study, you will be exposed to content generated using an artificial intelligence tool”) and/or debriefing process (e.g., “Some [or all] of the content used in this study were generated using an artificial intelligence tool”). Depending on the research design, these suggested statements may be expanded to address any nuances. For instance, if there was a manipulation, the nature of the manipulation can be explained (e.g., “This artificial intelligence tool was used to [describe the nature of the manipulation]”), or if deception was used about being exposed to AI content, then an explanation should be provided (e.g., “The usage of content generated by artificial intelligence was not disclosed to maintain the integrity of this research study. Specifically, [describe the reason why this information was not previously disclosed]”). The debriefing process could also be taken as an opportunity to promote AI literacy by suggesting sources of information or workshops (e.g., Google AI skills program).
Make an intellectual contribution
There are multiple ways in which researchers can add their own intellectual contribution to the materials created using AI tools. An intellectual contribution can be made by creating the criteria used to write the prompt entered in AI to generate a specific set of materials. For instance, in Example 1, deciding which question prompts to include and manipulating the level of self-disclosure is an example of this type of contribution. An intellectual contribution can also be made by editing or building up AI’s generated work. Finally, an intellectual contribution can also be made after AI’s generated work has been edited. For instance, researchers can test the materials to get relevant descriptive information or if the materials are used as a manipulation, that the manipulation is effective. Any of these contributions should be made explicit when writing an article, and products should be made available to others. The usage of AI tools and predetermined intellectual contributions can be included as part of open-science practices (e.g., preregistration) when relevant.
General Discussion
We proposed using ChatGPT to reduce researchers’ cognitive load and time spent creating text materials for psychological studies. As expected, across two studies, we found evidence that AI-generated materials (i.e., created by GTP-4) can successfully manipulate (Study 1) or imply (Study 2) psychological constructs. This is consistent with other work that underscores the ability of ChatGPT to understand psychological constructs as demonstrated by its use to assist in the development of psychological instruments (Beghetto et al., 2025; Schlegel et al., 2025), its ability to predict human emotion (Santavirta et al., 2025), and its ability to generate visual stimuli to show emotions (Lu et al., 2025). Furthermore, we found in our studies that participants lacked the confidence to distinguish between human-generated and AI-generated materials, which also supported our predictions. Similar findings have been noted in prior work that demonstrated that people make an appreciable number of errors when asked to distinguish between human-generated and AI-generated scientific abstracts (Gao et al., 2023). In most cases, our data were insufficient to properly test equivalence between the quality of human-generated and AI-generated materials because most of these results were considered inconclusive. In the cases in which our data were sufficient to test for equivalence, human-generated materials outperformed AI-generated materials. This is consistent with prior work that has also found human-generated materials to have an advantage over AI-generated materials (Grassini & Koivisto, 2025; Schlegel et al., 2025). Yet others have provided support for the superiority of AI-generated materials (Gherheş et al., 2024), and others have provided support for comparable performance (Alzahrani, 2025). Although our data are not well positioned to provide support for our hypotheses on equivalence, our data do provide evidence that irrespective of which set of materials performed better (i.e., human-generated vs. AI-generated), both were effective in achieving their intended purpose. Overall, ChatGPT indeed facilitated the creation of experimental text stimuli for psychological research and replicated the effects (i.e., although not necessarily the strength of the effect) of human-generated stimuli.
Implications
We are one of the first to provide empirical evidence that AI’s generation of human-like text can be used to facilitate the study of psychological phenomena. Although prior work has provided support for this, most of these studies have been focused on linguistic stimuli (Alzahrani, 2025; Duan et al., 2025) or psychometric-item generation (Beghetto et al., 2025; Schlegel et al., 2025). Our work is innovative in showing the utility of AI tools, specifically ChatGPT, in the creation of stimuli for other domains of psychology, such as relationship science and social cognition. There are multiple strengths in this to emphasize. First, it can be useful in speeding up the development of new research studies that advance or fill in the gaps across different fields. Although human expertise is fundamental for the effectiveness and quality of AI-generated content, AI tools facilitate this process by generating content instantly (Beghetto et al., 2025; Ghaffari et al., 2025). Second, it can help avoid the overuse of the same stimuli among psychological studies. For instance, the Chicago Face Database (Ma et al., 2015) is a widely used photography database in many psychological-research studies; the most recent citation count indicated that approximately 2,300 researchers have referenced this database. This is particularly important in recruitment platforms (e.g., MTurk, Prolific) that tend to have a fixed pool of participants who might be continuously being exposed to the same stimuli, which could bias the results of those studies. Finally, carefully developed prompts for AI-generated stimuli can eliminate biases related to having preconceived expectations on what the findings should be when testing specific hypotheses (Tomaino et al., 2025).
We are also one of the first to recommend guidelines for using the output generated by AI tools. There have been efforts put forward to guide researchers in how to best approach developing high-quality experimental stimuli using AI tools (Duan et al., 2025; Li et al., 2025; Lu et al., 2025; van Berlo et al., 2024) and how to integrate AI tools as part of the research-design process (Behrend & Landers, 2025; El-Bassel et al., 2025; Gong et al., 2024; Lehr et al., 2024). However, there is still a need for recommendations on how to move forward once those materials have been created. A lack of guiding principles in using AI tools creates fear and hesitation among researchers in using AI irrespective of recognizing the value of such tools (Abdelhafiz et al., 2024). Likewise, perceived social acceptance of the usage of AI has been associated with a greater intention to use AI tools (Gado et al., 2022). Ease of use is a predictor of willingness to use AI tools among faculty (Cambra-Fierro et al., 2025) and students (Rodriguez-Saavedra et al., 2025). However, the anxiety involved with uncertainty of how to best approach these tools can reduce that perceive ease (Cambra-Fierro et al., 2025; Mohamed et al., 2025). Therefore, the existence of guidelines can decrease the hesitation to use AI and popularize the overall usage of these tools. Given the incremental interest in capitalizing on this technology—paired with a lack of guiding principles to adhere to—our recommendations are valuable in providing structure and direction. Nonetheless, our recommendations are not intended to be definitive.
Limitations and future directions
We have shown ChatGPT’s ability to create effective materials for research studies on different topics (e.g., interpersonal relationships, social cognition). One of the limitations of this article is that we focused on text materials because GPT-4 was best equipped to generate text at the time of preparation for this article. Nonetheless, ChatGPT and other AI tools can generate visual stimuli. The usage of other AI modalities can be capitalized in similar ways to advance psychological research. However, researchers opting to use those tools will have to investigate how to better use them to generate visual materials and the ethics of using the materials generated with those tools. The ethical considerations discussed in this article for ChatGPT are not necessarily applicable to all AI tools or modalities. Future directions include testing the effectiveness of generating stimuli using other modalities and initiating a conversation about ethics specific to those. For instance, van Berlo et al. (2024) recently put forward a summary on best practices to create visual experimental stimuli, and Li et al. (2025) put forward a summary of strategies to create multimodal stimuli. Closely related to this limitation is that our human-generated materials do not represent the “gold standard” (i.e., widely accepted and used by others) in their respective fields. Although these sets of stimuli have been successfully used in multiple replications, their success is still limited to their respective research labs. Future directions include comparing AI-generated materials with human-generated materials that have been thoroughly validated.
Another of the limitations of using AI tools to generate experimental stimuli is that it will generate only what it is asked to generate. AI tools will be helpful to the extent that researchers’ creativity can think of ways to use AI-generated materials to test their research questions and hypotheses. AI–human collaboration is likely to become the norm in the near future. Guidelines on how to approach AI–human collaborations for idea generation (Gong et al., 2024), stimuli generation (Behrend & Landers, 2025; Duan et al., 2025), and research-design implementation (Behrend & Landers, 2025; El-Bassel et al., 2025) have been proposed. However, it is important to consider the nuances in the generation of experimental stimuli. For instance, the level of specificity in the prompt entered to an AI tool to generate experimental stimuli can influence the generalizability of findings by introducing or eliminating biases (Tomaino et al., 2025). Furthermore, depending on the research question, AI-generated content can be perceived as untrustworthy compared with human-generated content, such as when asking for recommendations related to experience-based products (Jin & Zhang, 2025). Finally, the effectiveness of AI-generated stimuli has also been shown to be dependent on the language it was created on (Alzahrani, 2025). Future directions should include identifying the different context in which AI-generated stimuli is the best fit and effective.
Finally, another limitation of using AI tools to generate experimental stimuli is that it is proprietary technology and can have a subscription cost (e.g., GPT-4 subscription cost was approximately $20) that might increase with future iterations. Depending on the cost, it may lead to disparities of access to this technology. Similar concerns have been raised by others who have used AI platforms to develop a clinical-psychology chatbot and fear that the platform will become unavailable or require numerous updates to keep up with iterations of this technology (Siddig & Hines, 2019; Stahl & Eke, 2024). Lack of access to AI technology can be problematic given that others have underscored the importance of integrating this technology into daily tasks (Haque & Li, 2025; Kooli, 2023; Salah, Abdelfattah, et al., 2023). For this reason, developing AI literacy and competency should be objectives integrated into the curriculum of future scholars (Gong et al., 2024; Mohamed et al., 2025; Rupp, 2024). It is to be expected that AI literacy will be a desirable skill in the job market (Rupp, 2024), such as having a strong quantitative background. Future directions should include identifying the best methods to encourage human-AI collaboration and effective methods to teach these skills. Current efforts to address this gap include identifying predictors for intention to use AI tools (Cambra-Fierro et al., 2025; Gado et al., 2022; Rodriguez-Saavedra et al., 2025) and how to decrease AI anxiety (i.e., fear associated with the rapid advancement of AI technologies; Kim et al., 2025; Mohamed et al., 2025).
Conclusion
We proposed in this article how to use ChatGPT for the advancement of psychological research. Specifically, we proposed and provided examples of how to use GPT-4 to reduce the cognitive load and time invested in the creation of materials used in research studies. Furthermore, we made recommendations on how to move forward by using the materials created or inspired by ChatGPT-generated text. We hope to start a thorough discussion in the field about the potential ways in which ChatGPT and similar AI tools can be used to streamline psychological research without risking the quality and integrity of researchers’ work.
Footnotes
Acknowledgements
We gratefully acknowledge Jessica R. Bray for providing the human-generated spontaneous-trait-inference sentences.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions