
Abstract
Cronbach’s α is the most widely reported metric of the reliability of psychological measures. Decisions about an observed α’s adequacy are often made using rule-of-thumb thresholds, such as α of at least .70. Such thresholds can put pressure on researchers to make their measures meet these criteria, similar to the pressure to meet the significance threshold with p values. We examined whether α values reported in the psychology literature are inflated at the rule-of-thumb thresholds (αs = .70, .80, .90) because of, for example, overfitting to in-sample data (α-hacking) or publication bias. We extracted reported α values from three very large data sets covering the general psychology literature (> 30,000 α values taken from > 74,000 published articles in American Psychological Association [APA] journals), the industrial and organizational (I/O) psychology literature (> 89,000 α values taken from > 14,000 published articles in I/O journals), and the APA’s PsycTests database, which aims to cover all psychological measures published since 1894 (> 67,000 α values taken from > 60,000 measures). The distributions of these values show robust evidence of excesses at the α = .70 rule-of-thumb threshold that cannot be explained by justifiable measurement practices. We discuss the scope, causes, and consequences of α-hacking and how increased transparency, preregistration of measurement strategy, and standardized protocols could mitigate this problem.
A measure’s reliability refers to the proportion of variance that is caused by the construct rather than noise (Allen & Yen, 2002, p. 73). Reliability places a limit on the measure’s validity (Murphy & Davidshofer, 2005), or put another way, reliability attenuates observable associations between scores on any two measures: The less reliably a given variable is measured, the lower the observable correlation is between the two variables. All else being equal, higher reliability therefore increases statistical power to detect associations.
Reliability can be quantified in different ways, but the most common metric by far is Cronbach’s (1951) α, which is based on inter-item correlations. Under certain assumptions (e.g., tau-equivalent items, independent error), it converges with reliability (i.e., of tau equivalence of items; Cortina, 1993). Although in practice, α is often incorrectly treated as being synonymous with reliability (Cortina, 1993; Schmitt, 1996), it remains to be the most commonly reported metric of it and indeed is typically the only metric of structural validity reported (Flake et al., 2017). There is a well-established literature debating the use and misuse of α, much of which focuses on the fact that many researchers inappropriately use it to test properties such as unidimensionality and homogeneity that are in fact assumed by α (i.e., it assumes rather than tests tau equivalence; Cortina, 1993). Alternatives to α with relaxed assumptions have been suggested (e.g., McDonald’s ω: McDonald, 1999) along with repeated calls to use them over α, although apparently without much success (Flake et al., 2017). This article adds to those concerns; we examine whether α values reported in the psychological literature show signs of inflation, for example, because of publication bias or hacking.
Rule-of-Thumb Thresholds
Cronbach’s α is commonly interpreted using well-known rule-of-thumb thresholds (e.g., α > .70). Nunnally and Bernstein (1994) recommended an α value of at least .70, and their book and its earlier 1967 and 1978 editions are frequently cited for this. However, these citations often omit the qualification that .70 was recommended for “early stages of research” (Lance et al., 2006). Nonetheless, their book remains a highly cited source for this threshold, with more than 8,000 citations at the time of writing. Many, if not most, contemporary undergraduate introductory textbooks on research methods include these rules of thumb and regard α > .70 as something “researchers are looking for” (Morling, 2017, p. 131), “satisfactory” (Howitt & Cramer, 2020, p. 241), or “a good measure of internal consistency” (McQueen & Knussen, 2013, p. 389; see also Breakwell et al., 2012, p. 149; Howitt & Cramer, 2020, p. 241). Psychologists have used α > .70 as a binary decision rule for scale development for decades. More than 30 years ago, Cortina (1993) observed that the “acceptance of α > .70 as adequate is implied by the fact that α > .70 usually goes uninterpreted. It is merely presented, and further scale modifications are seldom made” (p. 101). Although this threshold is the most common, previous work has demonstrated that a wide range of descriptive labels is used to describe an even wider range of α values. For example, Taber (2018) found that α values ranging from .45 to .98 have all been described as “acceptable” by authors. Thus, although α > .70 is a sufficiently common threshold for our analyses here, it is not as ubiquitous as an α level of .05 for p values and does not preclude authors from describing their α as “acceptable” (or other descriptors) in a looser everyday sense.
Publication Bias and Hacking
Similar to p values, when a rule of thumb becomes an important criterion for the publishability of findings, the pressure to meet the criterion mounts (Gigerenzer, 2018). This can be desirable if the criterion itself is an indicator of quality and the strategies scientists use to meet it increase the robustness of research, for example, increasing sample sizes to improve precision of estimates. However, if the metric can also be inflated illegitimately or “hacked,” some researchers will do so, wittingly or unwittingly. Provided such hacks are cost-efficient, they will spread at the expense of the qualities actually sought (Bakker et al., 2012; Smaldino & McElreath, 2016). One way in which hacking of metrics can become apparent is when the distribution of the aggregated metric deviates from plausible statistical distributions. For instance, Masicampo and Lalande (2012) observed, as they called it, “a peculiar prevalence of p values just below .05” in published research articles in three leading psychology journals. Hartgerink et al. (2016) provided additional evidence for an overabundance of barely significant p values in some journals and biased reporting of p values across all journals using a much larger sample of articles and journals (i.e., all articles published in American Psychological Association [APA] journals from 1985 to 2013). There has been debate about whether publication bias alone is a sufficient explanation of these overabundances (Lakens, 2015a, 2015b). Regardless of the specific cause or causes, distortions in the distributions of published estimates of any coefficient bias inferences or decisions made on the basis of them.
The use of α shares several similarities with p values: It and its rules of thumb appear to be used for decision-making purposes. The incentive structures in scientific publishing reward reporting some results over others, and references to pressure on researchers to obtain estimates that meet the threshold of .70 without further consideration of the implications of reliability date back at least 30 years (Cortina, 1993; Schmitt, 1996). When measures are altered ad hoc after seeing the results with the goal or effect of increasing in-sample α estimates, this conditions the analytic choices on the results and is likely to overfit to the in-sample data, making it less likely that these apparent increases in α will be reproduced in new samples. This is what we describe as α-hacking.
Anecdotal reports of α-hacking abound. Analogously to how analytic flexibility allows for p-hacking (Simmons et al., 2011), measurement flexibility may allow for α-hacking (Elson, 2019). Both flexibility and under-reporting have been argued to be prevalent issues (Flake & Fried, 2020). For example, Cortina et al. (2020) reported that out of 101 self-developed scales, only 25% reported any sort of scale-development process in detail. Self-developed, poorly validated, single-use scales are extremely common and appear to make up the majority of scales in psychology (Anvari et al., 2024; Elson et al., 2023), which increases the potential for α-hacking.
In addition to this, a large proportion of psychological scales contain few items and are therefore particularly vulnerable to α-hacking because each item modified post hoc (e.g., dropped, reverse-scored, moved to a different subscale) represents a larger proportion of the total items and therefore has greater potential to distort the in-sample reliability estimate and increase heterogeneity between studies purporting to use the same measure. For example, dropping an item from a 100-item scale would have less influence than dropping an item from a five-item scale. To understand the degree of vulnerability, we quantified the distribution of the number of items in psychological scales by extracting this information from the APA PsycTests database, which aims to cover all psychological measures published since 1894. Among scales created in the last 50 years, 15% have five items or fewer, 35% have 10 items or fewer, and 50% have 15 items or fewer. Fewer than 7% of measures have 50 items or more. Short scales that are quite susceptible to α-hacking therefore make up a substantial portion of scales in psychology research.
Although excellent measure development and refinement work is, of course, done by assessment specialists, it is an unfortunate fact that the majority of the primary research literature is produced by substantive researchers who are relatively less expert in measurement. Measurement choices in the primary literature often remain unreported or severely underreported (Flake et al., 2017; Flake & Fried, 2020; Hussey & Hughes, 2020), which undermines the ability to quantify their effects on test reliability and validity (Elson, 2019; Flake et al., 2022). It is therefore important to study not only measure development and refinement done by experts but also measurement as it occurs in the primary literature.
The Current Research
In light of this, all of the same ingredients that allowed for p-hacking are apparently also present for α-hacking: Publication bias and measurement flexibility provide opportunity, and the combination of rules of thumb and structural incentives in publishing provide motive. It is therefore reasonable to suspect that some degree of hacking or publication bias is taking place regarding Cronbach’s α coefficients. However, this hypothesis has not yet been directly tested. Analogously to the work on overabundances of barely significant p values (Hartgerink et al., 2016; Masicampo & Lalande, 2012), we tested the hypothesis that evidence of α-hacking is present in the literature by examining distortions in the empirical distribution of reported Cronbach’s α coefficients. This approach has also more recently been applied to examine excesses of area-under-the-curve values at rules-of-thumb cutoffs (White et al., 2023). We hypothesized that there would be an excess of α values at commonly used rule-of-thumb threshold values (αs = .70, .80, .90) relative to other values.
Method
Transparency statement
All code, processed data, and preregistration are available (osf.io/pe3t7) along with a supplementary materials document (osf.io/5xzy4).
Data sources
We examined α estimates in two different published literatures, one covering the psychology literature published in APA journals and one covering the industrial-organizational (I/O) literature (i.e., applied psychology, management). These data sets were mostly nonoverlapping (10.1% overlap in DOIs) and used very different extraction methods, providing us with convergent sources of evidence. In addition, we extracted data from a third data source: the APA’s proprietary PsycTests data set (APA, 2023), which is designed to be a comprehensive database of all psychological measures since 1896 and includes information about the source and use of each measure and empirical findings about its reliability and validity.
The analytic method was developed using the psychology data set. R code for the analysis was preregistered before obtaining the I/O data set. The analysis of the I/O data set therefore represents a stronger, confirmatory assessment of the hypotheses. Despite this movement from exploratory to confirmatory analytic strategies, we consider it useful to define the analysis of the I/O literature as an assessment of the generalizability of the effect to what is arguably a different population rather than a replication (i.e., a second sample drawn from the same population). The same analytic code was then used to analyze the PsycTests database. No formal preregistration was made, but the same hypotheses, tests, and code implementations of these tests were employed as in the preregistered analysis of the I/O data set. The substantive differences in the methods of extracting α estimates from the data sets represent an additional reason why the analyses may be better conceptualized as an assessment of generalizability.
Psychology data set
To assess distortions in the distribution of α values in the psychology literature, we made use of a data set of the full text of all articles published in APA journals between 1985 and 2013. The full data set contains 74,470 articles published in 81 journals covering all major areas of psychology research, including clinical, social, personality, cognitive, experimental, developmental, educational, and applied psychology. For a list of all journals included in the data set, see Table 1S in the Supplemental Material available online (or see osf.io/5xzy4). This data set was previously used to assess reporting errors using the statcheck program, and further details of this data set can be found in the original publication (Hartgerink, 2016).
I/O data set
Distortions in the distributions of α estimates in the I/O literature were assessed using the metaBUS database (Version 2018.09.09). In short, the metaBUS project (Bosco et al., 2017, 2020) seeks to curate (i.e., extract, classify, and make available) all zero-order effects from primary studies in I/O research (e.g., applied psychology and management) to facilitate future meta-analyses. More than 90% of zero-order effects reported in I/O are correlation coefficients, so the extracted values are highly representative of results reported in the field of I/O. Extraction of numerical values is semiautomated, but classification of the values into their constructs is fully manual. The metaBUS project covers 27 journal titles selected based on their impact factor in the areas of applied psychology and management according to ISI’s Web of Science Journal Citation Reports in the year the project began. Years of coverage vary by journal and range from 1980 to 2017. The full metaBUS data set contains data from 14,038 articles published in 27 journals between 1980 and 2017. For a list of all journals included in the data set, see Table 2S in the Supplemental Material. Full details of the data set’s curation and utility can be found in the original publications (Bosco et al., 2017, 2020).
Each row of the database represents one numerical value extracted from a correlation matrix in a published article. In general, correlation matrices report the zero-order correlations between a given number of variables. Most fields of psychology report only either the upper or lower triangle of correlations to avoid redundancy. Unlike some other fields of psychology, articles in the I/O field often also report reliability estimates in the diagonal of correlation matrices (e.g., in the correlation matrix, rather than leaving it blank, the element representing the association between a given measure and itself reports the Cronbach’s α for that measure). Entries in the metaBUS data set were extracted from correlation matrices reported in the I/O literature. To date, uses of the metaBUS data set have made use of the correlations reported in the nondiagonal elements. This study is the first to make use of the large number of reliability estimates reported in the diagonals of these matrices that are included in metaBUS. It is these values of Cronbach’s α estimates that were used in the present analyses. A variety of other metadata are available in the database, including each original study’s sample size, sample type, country of origin, publication year, and construct classification. For details on the metaBUS database architecture, see Bosco et al. (2017); for information about the method and reliability of extractions, see Bosco, Aguinis, et al. (2015) and Bosco, Steel, et al. (2015). Two journals were included in both the psychology data set (1985–2013) and the I/O data set (1980–2017): Journal of Applied Psychology and Journal of Occupational Health Psychology. We discuss this overlap later in the article.
APA PsycTests data set
Distortions in the distributions of α estimates across known psychological measures were assessed using the APA PsycTests database (version as of March 1, 2023). The full PsycTests data set contains data from 60,491 scales reported in 71,692 articles published in 3,159 journals between 1896 and 2023. Full details of the data set’s curation and contents can be found on the APA’s website (APA, 2023). Each entry in the database, which was provided in full by the APA, contains a text field that contains unstructured text information about reliability and validity information for the scale that was assembled and curated by APA staff members from the published literature. A variety of other metadata are available in the database, including language, publication year, item availability and contents, construct classification, and whether a given measure is an original measure or a translation or modification of an existing measure.
Data extraction
Psychology data set
The α estimates were extracted from the psychology data set using regular expressions, which are sequences of characters that specify search patterns in text and are commonly used for searching unstructured text data. These were implemented using the R package stringr (Wickham & RStudio, 2022). Our approach was therefore similar to that employed by Nuijten et al. (2016) and Hartgerink (2016) in their original extraction of p values and test statistics from the data set, although our exclusion criteria were necessarily more conservative because of the less standardized way in which α values are reported.
The general strategy was as follows. First, we defined multiple patterns of interest (e.g., variations of “Cronbach’s α”). Variations included but were not limited to whether an apostrophe was used, the use of “α/a/alpha,” and reference to “Cronbach’s α” versus “Coefficient α.” Second, we searched the full text of all articles in the data set for occurrences of these patterns. Third, for each occurrence found, we extracted the text 50 characters before the occurrence and 50 characters after it. This provided a much smaller data set of character strings, each of which may or may not contain an α estimate. Fourth, we extracted potential α estimates from each character string such that it must follow one of several variations of “α = .XX,” where at least two numerical characters were reported. We did not extract α values reported to just one decimal place because they could too easily be affected by (questionably appropriate) rounding (e.g., observing α = .65, rounding and reporting this as α = .7). We, however, noted that it was very uncommon to observe α values reported to only one decimal place. Nevertheless, this choice of selecting only α values reported to at least two decimal places can pick up on inappropriate rounding followed by inappropriate reporting of trailing zeros (e.g., observing α = .65, rounding this to α = .7, and then reporting as α = .70). This is a feature rather than a bug: Such forms of rounding followed by inappropriate reporting of trailing zeros would represent a clear form of α-hacking that we would want to detect, agnostic to whether it was accidental or intentional. Only the first apparent α estimate was extracted from each instance of a character string to avoid duplication, although multiple character strings could be detected and extracted from each article. Thus, there were dependencies among the extracted α estimates. Fifth, we applied a large number of exclusion criteria to each character string to exclude everything other than α estimates.
These exclusions prioritized specificity over sensitivity: That is, we prioritized excluding all non-α estimates and accepted that some valid α estimates would be excluded as a result of this. Some of the most important of these exclusions ensured that references to threshold values were excluded and not mistaken for occurrences of α estimates, for example, “According to Nunnally (1967), a Cronbach’s α of 0.70 is seen as acceptable for . . . ”. Threshold criteria included but were not limited to references to any mention of variations of the phrase “cutoff criteria,” comparisons (words such as “exceeded”), ranges (“between”), plurals (e.g., “αs for the subscales ranged from 0.5 to 0.8”), the presence of p values (which would suggest the α value was not Cronbach’s α but the α value associated with a hypothesis test), and other metrics of reliability (κ, ω, etc.). These exclusion criteria were refined and added to through an iterative approach involving rounds of manual inspection of the extracted strings and α estimates. Two researchers inspected (a) every text string from which an α estimate at one of the thresholds was extracted (.70, .80, .90) and (b) a random sample of 100 text strings from noncutoff estimates to exclude nonvalid or incorrectly extracted α estimates. If any nonvalid extractions were found, the implementation of the exclusion criteria was updated to cover similar cases, and a new round of manual inspections was conducted. All regular expressions for exclusions can be found in the R code (osf.io/pe3t7). Of the original 60,153 instances, 26,744 were excluded. In all, 33,409 α estimates were extracted that were deemed to be valid; 16.1% of articles in the data set produced at least one α estimate.
I/O data set
The metaBUS data set already included the extraction of α values via a different method to that used in the psychology data set: semiautomated extraction of estimates from correlation tables reported in articles. In the I/O literature, reliability estimates are often reported in the diagonal of correlation tables, and it is these extracted estimates that we made use of in our analyses. In its entirety, the metaBUS data set also includes the correlations reported in correlation tables. In the original creation of the metaBUS data set, all extracted estimates were inspected by trained graduate student raters, who also manually coded other details (e.g., whether the reliability estimates were Cronbach’s α or another reliability metric, taxonomization of the constructs measured). Approximately 10% of each coder’s entries were checked on a weekly basis by a supervisor. For a full description of the curation of the metaBUS data set, see Bosco et al. (2017).
To prepare for our analyses, only a subset of the metaBUS data set was used: those rows of the database that referred to reliability values reported in the diagonals of correlation tables. In all, 92,725 reliability values were extracted and sent to us. Of them, 89,926 (97.0%) were of the coefficient α type. Only α estimates from psychometric scales relating to psychological constructs, subjective reports, performance measures, behaviors, and attitudes were employed in the current analyses (i.e., but not for demographic variables or other nonpsychological constructs). Finally, 282 rows were removed because of erroneous or missing data as identified by the metaBUS curators. This resulted in an analyzable data set of 89,644 α values.
APA PsycTests data set
The α estimates were extracted from the PsycTests data set in an almost identical manner to the psychology data set given that both involved searching unstructured text for α estimates using regular expressions. The field for reliability and validity information for each measure in the PsycTests database reliability was shorter than the full-article texts searched in the psychology data set. In addition to this, the field often reported multiple α estimates in a given sentence. We therefore made one modification to the search strategy compared with the psychology data set: The code was modified to be able to extract multiple α estimates from a single candidate string of text. Like those from the psychology data set, these extractions prioritized specificity over sensitivity. The implementation of the exclusion criteria was again refined and supplemented through an iterative approach involving rounds of manual inspection of the extracted strings and α estimates to maintain their specificity (i.e., we observed and had to exclude new patterns that represent non-α estimates). Rather than exhaustively searching the extracted estimates, we employed a random-sampling method. Two researchers inspected 1,005 randomly sampled reliability estimates and their surrounding text to ensure that they represented α estimates. Six hundred fifteen of these values were sampled from threshold values (α = .70, .80, or .90), and 390 were sampled from nonthreshold values. In cases in which non-α estimates were observed, additional exclusion rules were implemented to exclude all similar patterns. That is, we drew random samples of varying sizes, manually searched for incorrectly extracted non-α values in these samples, and if non-α values were found, updated the exclusion rules to cover these cases before drawing another sample. The sizes of the samples we drew were based on our expectation of the prevalence of non-α estimates based on the previous round of inspections. Using a sample-size calculator implemented in the R package epiR (Stevenson et al., 2023), we started with smaller samples (< 100), reflecting our uncertainty regarding the expected false-positive rates. Because we modified the Regex code to exclude more sources of false positives, we entered increasingly precise expected prevalences when calculating sample sizes. Our final two samples, for example, were 243 (α estimates at the thresholds) and 188 (nonthreshold estimates) large, reflecting expected prevalences of 0% to 3% and 0% to 4%, respectively. The false-positive rate in the last sample we inspected at the thresholds in the nonthreshold sample was 1.6%, 95% confidence interval = [0.5%, 4.3%]. The false-positive rate in the analytic sample was likely lower than this, again thanks to the final round of Regex modifications. Out of the original 106,397 instances, 38,885 were excluded. The 67,512 α estimates were extracted that were deemed to be valid; 70.1% of DOIs in the database produced at least one α estimate.
Analytic strategy
Although the distribution of single α values is known (van Zyl et al., 2000), the distribution of multiple α values that are derived from measures that differ in their sample sizes and number of items in unknown ways is not. Thus, we employed a data-driven approach. The logic of our analysis was therefore that there is, at minimum, reason to believe that a large sample of α values should follow a smooth (albeit unknown) distribution. Deflections from such a distribution, especially at a small number of a priori points (i.e., commonly used thresholds), would represent evidence that reported α values are being influenced by some other variable (e.g., α-hacking). On the basis that previous work examining the prevalence of barely significant p values employed caliper tests, we also report them as robustness tests (e.g., Hartgerink et al., 2016). Only the kernel-smoothing approach in the I/O data set was preregistered.
Results
Kernel smoothing and residuals
We applied kernel smoothing to the extracted α estimates to estimate their distribution and quantify the excess of α values at the thresholds. Kernel smoothing was selected over other modeling approaches because it involves relatively fewer assumptions and demonstrated better fit to the observed αs than alternatives. For results of an exploratory beta regression model that was fit to the psychology data set, see Note 1S and Figure 1S in the Supplemental Material.
The extracted α estimates were rounded to two decimal places (using the half-up method and the R package janitor; Firke et al., 2021). The rounded α estimates were then converted to counts for each value of α. Density was estimated at 99 equally spaced bins in the interval (i.e., from .01 to .99). We opted for the default options in R’s density function: gaussian kernels with a smoothing bandwidth set using Silverman’s rule of thumb (Silverman, 1986; i.e., the settings kernel = gaussian, and bw = nrd0). All other options for kernels that are available in R’s density function were explored in the psychology data set. However, as expected with large sample sizes (Sheather, 2004), the choice of kernel did not have a noticeable impact on the resulting density distribution in the psychology data set. The bandwidth was chosen based on Silverman’s rule of thumb (Silverman, 1986), which seemed to provide the best fit to the data because it yielded a relatively narrow bandwidth, which is appropriate for large sample sizes (Trosset, 2009, p. 172). These analytic choices and the code implementing them were explored in the psychology data set and then preregistered for the analysis of the I/O data set. In the case of the bandwidth, we preregistered the actual bandwidth returned in the psychology data set for use in the I/O data set (i.e., bw = 0.01). That is, we preregistered the bandwidth to be used rather than the bandwidth-determination method. The observed counts and fitted smoothed curves for each data set can be found in Figures 1 through 3 (top), respectively.

Observed counts of α values with (top) kernel smoothing and (bottom) residuals in the psychology data set (33,409 α values). Bins corresponding to the rule-of-thumb thresholds for which we hypothesized that excesses would be found are colored in blue, and nonthresholds are in gray.

Observed counts of α values with (top) kernel smoothing and (bottom) residuals in the industrial-organizational data set (89,644 α values). Bins corresponding to the rule-of-thumb thresholds for which we hypothesized that excesses would be found are colored in blue, and nonthresholds are in gray.

Observed counts of α values with (top) kernel smoothing and (bottom) residuals in the PsycTests data set (67,512 α values). Bins corresponding to the rule-of-thumb thresholds for which we hypothesized that excesses would be found are colored in blue, and nonthresholds are in gray.
In each data set, residuals were calculated for each of the bins. That is, we calculated the excess or deficit of the observed count of each bin (Figs. 1–3, top, in gray or blue) relative to its predicted value according to the smoothed curve (Figs. 1–3, top, in black). These residuals are plotted by themselves in Figures 1 through 3 (bottom).
Two nested hypotheses were tested regarding excesses at .70 (Hypothesis 1) and excesses at .70, .80, or .90 (Hypothesis 2) on the basis that .70 is the single most commonly employed rule-of-thumb threshold but .70, .80, and .90 are all common. These hypotheses were tested using independence permutation tests implemented using the R package coin (Hothorn et al., 2021). The magnitude of the excesses or deficits (i.e., the residuals) was quantified by converting the observed and predicted counts to proportions.
Tests of the first hypothesis in each data set compared the .70 bin against all other bins. In the psychology data set, a 14% excess of α values of .70 relative to other values was found, z = 3.15, p = .01042. 1 Tests of the second hypothesis in each data set compared the .70, .80, and .90 bins against all other bins. The hypothesized excesses were found across the three bins, z = 3.94, p = .00035, with an excess at .80 = 3% and at .90 = 3%.
Both of these effects were found to generalize to the I/O data set, for which we preregistered verbal hypotheses and the code implementations of their inference tests. The test of the first hypothesis found a 14% excess of α values of .70, z = 5.01, p < .00001. The test of the second hypothesis found excesses across the three bins, z = 4.53, p = .00016, with an excess at .80 = 2% and excess at .90 = 1%. We therefore rejected the null hypothesis that there was no evidence of excesses of α values at common rule-of-thumb thresholds.
At the time of preregistration, the two data sets were understood to be nonoverlapping. Upon obtaining the I/O data set, we discovered that two APA psychology journals were included in both data sets (Journal of Applied Psychology and Journal of Occupational Health Psychology; see Tables 1S and 2S in the Supplemental Material), albeit using a wider range of years and a very different extraction method in the I/O data set. We elected not to deviate from our preregistered analyses of the I/O data set. As a robustness test, we report the results of the same analyses applied to a nonoverlapping data set (i.e., removing all DOIs from the I/O data set that were already present in the psychology data set) in the Supplemental Material. The conclusions of the preregistered analyses in the I/O data set were not affected by the removal of these articles: The proportion of excess α values differed by ≤ 1% between analyses (14% excess at .70, z = 4.68, p = .00007; excesses across the three bins: z = 4.84, p < .00001, 3% excess at .80, 1% excess at .90). See Figure 2S in the Supplemental Material.
These effects were also found to generalize to the PsycTests data set. The test of the first hypothesis found a 13% excess of α values of .70, z = 4.675, p = .0006. The test of the second hypothesis found excesses across the three bins, z = 4.57, p < .00001, with an excess at .80 = 5% but no excess at .90 (0%). We therefore rejected the null hypothesis that there was no evidence of excesses of α values at common rule-of-thumb thresholds. The excesses at the thresholds across all three data sets are illustrated in Figure 4.

Excesses (residuals) of α values at the thresholds across the three data sets.
Influence of construct frequency
We considered it plausible that α-hacking might be especially common with newly created ad hoc measures than frequently used ones that may have more well-established items, scoring strategies, and so on. It was possible to explore this in the I/O data set because the metaBUS extraction process included manually labeling the construct that each α estimate came from using a taxonomy (see Bosco et al., 2020). We performed exploratory subgroup analyses in measures of constructs that (a) occurred only once in the data set (i.e., ad hoc measures that were not reused in future studies; N = 34,778 α values), (b) appeared more than once (i.e., non-ad hoc measures reused in future studies; N = 43,662 α values), and (c) appeared more than 100 times (i.e., frequently employed measures whose cutoff was chosen based on the distribution of frequencies; N = 11,204 α values; for the distribution of the frequency of use of measures, see Figure 3S in the Supplemental Material). In each subgroup, we applied kernel smoothing using the same method as previously described and calculated the residuals at α = .70. Statistically significant excesses were found in each subgroup, all ps < .013, indicating that α-hacking was present in ad hoc measures, reused measures, and highly reused measures. Descriptively, the excesses were of similar magnitudes across subsets (i.e., 12%–15%), perhaps suggesting that α-hacking was not more prevalent in ad hoc measures. However, the equivalence of excesses between the subsets could not be tested directly (i.e., no statistical method of doing so was known to us), and so this must be interpreted with caution as a descriptive comparison. Unfortunately, the sample size also did not allow for any meaningful analysis of changes in excesses over time.
Influence of measure revision and translation
We considered it plausible that the frequency of α-hacking might differ between original measures relative to revisions and translations of existing measures. It was possible to explore this in the PsycTests data set, which included information about whether a given measure was original versus a revision or translation of an existing one. We performed exploratory subgroup analyses in (a) original measures (N = 38,774 α values) versus (b) revisions and translations (N = 19,633 α values) using the same analytic strategy as above (see Figures 4S and 5S in the Supplemental Material). Statistically significant excesses were found in both subgroups at α = .70 (all ps < .00001), indicating that α-hacking was present in both original measures and revised and translated measures. Descriptively, excesses were of similar magnitudes in both subsets (i.e., 12%–15%). As with the previous section, this was a descriptive comparison that must be interpreted with caution, and no meaningful analysis of changes in excesses over time was possible.
Caliper tests
Previous research on the overabundance of barely significant p values has employed caliper tests, which count the number of estimates in two bins of equal width on either side of a cutoff (Hartgerink et al., 2016). We judged these tests to be less suitable than the kernel-smoothing method above on the basis that there are plausible distributional differences between adjacent bins (i.e., the distribution of α values is nonuniform, see Figs. 1–3). Of course, this was also the case when this analysis was applied to p values and is not specific to our analyses (i.e., in the presence of nonzero effects, the distribution of p values is also nonuniform). Regardless of whether they are applied to p values or α values, the logic of the caliper ratio test is the same: (a) In the absence of any distortions in the distributions, caliper ratios should not be expected to be zero; (b) nonetheless, substantial deviations from zero can be usefully interpreted as evidence of distortions. The caliper tests retain utility here because we calculate a caliper ratio for each bin (e.g., .70 vs. .69, .69 vs. .68). Although we cannot expect any ratio to be exactly zero given a nonuniform distribution of α values, it is still useful to ask whether the ratios at threshold values are larger than nonthreshold values. Permutation tests were therefore used to test this, similar to the residuals from the kernel-smoothing method. For the sake of comparability with previous work on distortions in the distributions of p values and as a secondary test to assess robustness to the analytic method, we therefore also implemented caliper tests. See Note 2S and Figures 6S through 12S in the Supplemental Material. In summary, the pattern of excesses at α = .70 was robust to the choice of analytic method (.69 vs. .70 caliper ratios: psychology = 1.71, I/O = 1.64, PsycTests = 1.60). The collective excesses at all three thresholds were robust in the psychology data set but not the I/O or PsycTests data sets (.79 vs. .80 caliper ratios: psychology = 1.16, I/O = 1.13, PsycTests = 1.19; .89 vs. .90 caliper ratios: psychology = 1.02, I/O = 0.96, PsycTests = 0.98).
Discussion
This study provides a test of the hypothesis that published α values are hacked or biased in some way. Results clearly suggest that they are. Across three very large data sets covering tens of thousands of measures and publications in psychology and I/O, we observed excesses in the proportions of α values at a commonly used threshold criterion (α = .70). These excesses were observed in both the psychology and I/O literatures and the measures covered by the APA’s PsycTests database. When estimated using kernel density smoothing, the magnitudes of the excesses of α values of .70 were found to be in a consistent range between the data sets and subset (all 12%–15%). When using caliper ratios, the method used in previous work on the excess of significant p values (e.g., Hartgerink et al., 2016), the magnitude of the counts of α = .70 versus .69 was also large (caliper ratios from 1.60 to 1.71). Excesses at other thresholds (α = .80 and .90) were smaller and less robust to the choice of analytic method.
Possible explanations
It is useful to first set aside some potential explanations of our results as implausible or impossible. First, we must consider whether these apparently distorted α values are due to some desirable process of measure refinement. For example, dropping an item from a translated scale that, on reflection, may have performed poorly may serve to increase α. Although there may be good reasons to modify a measure after data collection (e.g., dropping items, changing the scoring method), there is no reason to assume that all such changes are conducted exclusively under such circumstances. Numerous sources of evidence show that questionable research practices are prevalent in psychology (for a review, see Lakens, 2022, Section 15.1), and there is no reason to believe that α estimates are somehow uniquely immune to such practices. Indeed, Flake and Fried (2020) argued that more generally, questionable measurement practices are prevalent and concerning. Critically, well-justified changes to measures cannot explain the excesses of α values at the .70 threshold that we observed: Improvements because of post hoc changes to measures would raise α values generally, not specifically to .70.
One other explanation that we believe should be dismissed is that psychologists are just exceptionally good at precisely calibrating their study design and data-collection efforts to exactly meet this reliability threshold. We believe precise calibration to this value is extremely implausible because at typical sample sizes (i.e., 50–500) and number of items (i.e., 3–50, based on our analysis of the PsycTests database), the standard error of Cronbach’s α ranges from .02 to .08 (see Table 3S and Note 3S in the Supplemental Material; van Zyl et al., 2000). This precludes effective calibration as an explanation for the combination of a dearth of α values at .69 and excess at .70 because estimates in typical studies are not estimated precisely enough for a researcher to reliably make this distinction. In this sense, the distributions of αs are suspicious, much like a player in Blackjack who gets exactly 21 too often—or indeed, a series of studies with p values mostly between .025 and .049 (Simonsohn et al., 2014).
Publication bias is a more plausible explanation. For example, authors, editors, and reviewers may be less inclined to publish studies if included scales do not meet the .70 criterion. Publication bias is less obviously problematic for α values than for p values. The field does not want the scientific literature to be filtered by statistical significance but might desire a literature filtered for measures with high reliability. However, the estimation precision of α noted above precludes a purely benign or even desirable review process that selects for high population reliability. Publication bias would also act on stochastic variation of the in-sample estimates and would imply a general increase in the proportion of measures with reliabilities above the thresholds. In addition to this, we observed an excess at .70 for well-established measures (i.e., those used more than 100 times). In such cases, it is clear that publication bias would inflate our impression of the reliability of these scales.
Another important aspect is also at odds with an explanation for this pattern of results that is entirely benign, in the sense of it being produced solely by a publication process that strives for reliable measures. If publication bias for minimum α exists, this also exerts pressure on researchers to increase their α values in accordance with Goodhart’s law: the cutoff criterion becomes a target to be met, and its utility is undermined to some degree (Strathern, 1997, p. 308). If researchers can take shortcuts to do so, some are likely to engage in legitimate measurement refinement but also in questionable measurement practices (Flake et al., 2022). One piece of indirect evidence for such hacking was the noticeable deficit of values at .69 in each data set (see Figs. 1–3) because it seems implausible that editors and reviewers would discriminate against .69 more than .68.
We believe α-hacking is therefore a likely explanation for at least some of the observed distortions in the distribution of α values. The counterfactual that no α-hacking occurs in the literature is relatively harder to imagine given the presence of incentives that may lead at least some researchers to do so. As with p-hacking, field norms may be partially unclear on which practices are problematic. Clearly, rounding up α values to one decimal place is inappropriate (e.g., reporting α = .66 as α = .7 to imply that α > .70 has been met 2 ). But, for example, there is more debate about whether other practices that can be benign or even helpful in some contexts can be abused in others. For example, although practices such as item dropping, alterations to reverse-scoring, and subscale redefinition might all be legitimate and necessary forms of scale improvement in some contexts, these practices can also be abused to artificially increase in-sample α (i.e., ways that overfit on the data at hand, without producing increases in reliability that would be reproduced in new samples). The line between legitimate and problematic use of these methods can be a very fine one, and this situation is sometimes not helped by their unthinking use. For example, when calculating α, many common statistics packages, including SPSS, the popular R package psych (Revelle, 2018), and the open-source programs JASP (JASP Team, 2024) and jamovi (The jamovi Project, 2024), all also provide suggestions for what α would instead be if items were dropped. The presentation of this information may serve as a cue that increases the probability that a researcher drops one or more items post hoc without necessarily providing deeper engagement with the relative performance of the items or the appropriateness of doing so.
Researchers’ willingness to engage in various questionable measurement practices is likely influenced by existing incentives (e.g., to report high-reliability coefficients, especially those exceeding common thresholds). 3 Of course, α-hacking and publication bias are not mutually exclusive, and we suspect both play a role. There have been comparable debates about the causes of excesses of barely significant p values (see Hartgerink et al., 2016). This debate does not need to be entirely settled for our results to be important. Just as with p values, knowing there are meaningful distortions in the literature is enough to motivate us as a field to examine and more importantly, take steps to prevent both potential sources in the future so that we produce a less biased or distorted cumulative science.
Early work on p-hacking quickly sought to determine what forms it might take to guard against these specific questionable research practices. It may be similarly useful for future research to attempt to catalog forms of questionable measurement practices (Flake & Fried, 2020) that may constitute or give rise to α-hacking. We are at present agnostic as to the prevalence of different forms of α-hacking, but it may be useful to look at the ways in which authors report modifying scales (before or after data collection) to understand what types of flexibility may be present and therefore potentially exploitable. For example, Cortina et al. (2020) observed that the most common form of pre-data-collection self-report-scale modification is item dropping, which could also be applied post hoc as a form of α-hacking. Several other forms of scale modification identified by Cortina et al. could also be exploited post hoc for α-hacking, including creating composite scores, dichotomizing scores, opportunistically reverse-coding items, or otherwise altering the scoring strategy. Of course, the form and prevalence of such practices may differ substantially from those that are transparently reported in the literature given that such problematic practices are defined in part by their lack of transparent reporting (Flake & Fried, 2020). Other potential methods of α-hacking could come from direct analogs with p-hacking methods, such as inappropriate rounding, double rounding, selective reporting (either simply not reporting α values, selectively reporting whole-scale vs. subscale estimates, selectively reporting among multiple measures, or selectively reporting some reliability metrics and not others), outlier exclusion to increase apparent reliability, favorable imputation, or subgroup analysis (see Stefan & Schönbrodt, 2023). It is likely many other forms are possible, too, such as selectively reporting the in-sample α estimate (e.g., “reliability was found to be adequate in our sample”) or estimates from previously published research (e.g., “the measure has been demonstrated to be reliable in previous research”).
Prevalence of α-hacking
It is worth considering whether our results can speak to the prevalence of α-hacking to the degree that it may be contributing to the observed results. To this end, it is important to bear in mind that our analytic strategy can detect distortions only in α values that produce an α at the thresholds (i.e., .70, .80, or .90) but not other values. For example, if a researcher hypothetically used one or more forms of α-hacking (i.e., to reiterate, methods that would not be likely to produce legitimate improvements in the scale’s reliability that would be reproducible in new samples) to change their observed α value of .65 to create an apparent α of .73, this could represent a problematic distortion of the measures’ true reliability, and yet it would not be detectable by this analytic approach. Our results therefore represent an extreme lower bound of the actual occurrence of α-hacking, likely just the tip of the iceberg. Future research is needed to estimate the prevalence of α-hacking. For example, comparisons could be made between α values reported in the published literature and in bias-resistant methods such as Registered Reports, as has been done with p values (Scheel, Schijen, & Lakens, 2021). There are again useful links with the literature on biases in reported p values here: Significant methodological investment has produced multiple methods by which the field can detect and even partially correct for p-hacking and publication bias under certain assumptions, but the understanding of whether those assumptions hold up in real life is still limited (Carter et al., 2019; Renkewitz & Keiner, 2019).
Magnitude and consequences of α-hacking
We suspect that questionable measurement practices (Flake & Fried, 2020), including α-hacking, are currently perceived by most to be just as permissible as some p-hacking practices were before the publication of Simmons et al.’s (2011) seminal article “False-Positive Psychology.” However, ad hoc measures and ad hoc modifications to existing measures in the service of boosting apparent α may have more pernicious and further-ranging consequences than expected. Many readers of Simmons et al. were at the time surprised that various forms of p-hacking could alter the apparent in-sample p value so much. It took several years for the field to provide more comprehensive catalogs of the different forms that p-hacking can take and understand the relative degree of distortion they can cause (e.g., Stefan & Schönbrodt, 2023). We suggest that similar efforts are needed to collate the different forms that α-hacking can take and furthermore to understand the relative impact of its different form on reliability estimates. Like p-hacking, there is also no guarantee that changes to the in-sample estimate bear any relation to a true increase in reliability. And as with p-hacking, it is exceptionally easy to fool oneself or to use methods unthinkingly. Without replication in new samples, how can researchers know if, for example, a given item was genuinely performing poorly and should be dropped or if they are simply conditioning analyses on their own results? We return to this point below when making recommendations for future research.
In addition to inflating the perceived reliability of our measures, α-hacking has multiple problematic downstream consequences. That is, reliability is not merely important in and of itself but because of the relationship between reliability and other properties. For example, the maximum correlation that can be observed between two variables (x and y) is a function of not only the true correlation between the variables (ρ) but also the reliability of the measures of x and y (i.e.,
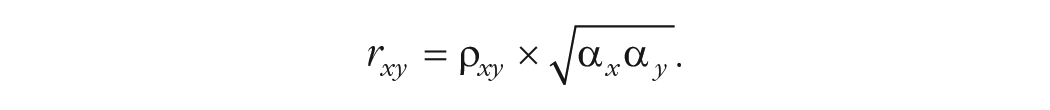
For example, when the true association between two variables is large (ρ = .50) and each variable is measured by a scale with α = .70, the maximum observable correlation (in the long run of highly powered samples) is r = .35. This has a direct bearing on the validity of statistical power analyses, which must specify an effect size (e.g., an expectation of the true effect size or their smallest effect size of interest; Lakens et al., 2018). Although they typically do not explicitly involve quantifying the reliability of the measures used, power analyses are nonetheless dependent on accurate and stable estimates of it (Heo et al., 2015; Parsons, 2018). For example, imagine a researcher accurately judged the true association between the variables to be of large size (ρ = .50) but the estimates of the reliability of both measures had been α-hacked. Assume that one or more forms of α-hacking had artificially increased the α of both scales in previous studies from .60 to an apparent α = .70. Even though the true population effect size has not changed, the observable effect size is actually r = .30 because of the lower than expected reliability of both measures. Our hypothetical researcher collected data from 62 participants, expecting that this would provide 80% power to detect a true observable correlation of r = .35. However, because of the prior α-hacking constraining the observable correlation more than the researcher realized, these 62 participants provide only 66% power. If more severe α-hacking were to occur, even more substantial reductions in power would result. Thus, although it is distinct from p-hacking, there are good mathematical reasons to believe that α-hacking could contribute to lower replicability and therefore weaken the credibility of the field’s claims in a similar fashion. This is not limited to primary research. Several types of meta-analysis, such as psychometric meta-analyses (Schmidt & Hunter, 2015; Wiernik & Dahlke, 2020), adjust effect sizes for the reliability of their measures (i.e., disattenuate for reliability). As a result, α-hacking would also bias the results of such meta-analyses.
Specific forms of α-hacking, were they to occur, would likely have other detrimental consequences for the literature beyond inflating Type I error rates. To take just one example, item dropping can exacerbate issues of measurement (non)invariance and in doing so, distort the homogeneity or heterogeneity of research findings. For example, imagine a seven-item scale that is used in two studies to test the same hypothesis. If researchers from each study dropped two items in their analysis, then as few as three items would overlap between studies. This may introduce “jingle” issues, in which measures share identical names but measure different things (see Elson et al., 2023). In this hypothetical, both studies state that they used the same scale and measured the same construct, but the overlap in the actual items is low: in this case, as little as 42% of the original items. To what degree are the two studies measuring the same construct anymore? And to what extent can conflicting results of the two studies be attributed to differences in implementing what is supposed to be the same scale? Perhaps these questions can be meaningfully answered when the scales in question are already well validated and there is reason to believe that the items measure the same construct, but this information is frequently not available given that most measures are used very few times and therefore are often poorly validated (Anvari et al., 2024; Elson et al., 2023).
These questions are not merely hypothetical: Recent work has also shown that replication studies often involve poorly validated measures and underappreciated degrees of modifications to their measures. This undermines the degree to which the original and replication study can be directly compared and the degree to which either validly tests the hypothesis of interest (Flake et al., 2022; for further discussion of this general problem caused by flexible measures, see also Elson, 2019).
Other plausible forms of α-hacking, such as undisclosed alterations to the scoring strategy, can also exacerbate the jingle problem by leaving what are, in effect, different measures. There is some evidence that behavioral tasks are particularly prone to heterogeneity in scoring, and measurement flexibility among some tasks therefore represents a substantial vulnerability to many forms of hacking (Elson, 2019; Lilienfeld & Strother, 2020). Future research is needed to quantify the degree of measurement flexibility in other commonly used measures through metamethods reviews to understand which measures and literatures are vulnerable to the downstream consequences of such flexibility. Separately, simulation studies are needed to examine the degree to which various plausible α-hacking strategies, measurement flexibility, and publication can bias in-sample α values, analogous to what has been done to understand the impact of different p-hacking strategies on the false-positive rate of p values (Stefan & Schönbrodt, 2023).
Limitations
Because our analyses are limited to distortions at the thresholds, we can say little about the true distribution of the reliability of measures in these literatures. Although the distribution of individual α values is known to be a function of sample size and the number of items (van Zyl et al., 2000), the distribution of multiple α values from the population of scales is not known because of unknown and likely heterogeneous methods of selection of these scales and their resulting α values. Perhaps some features of the observed distributions are due to the legitimate selection and refinement of scales with high α values (causing its left skew) or the shortening of scales with very high α because of perceived item redundancy (causing few values above .95).
The validity of the analyses of the psychology and PsycTests data sets are bounded by the validity of our extraction of α estimates and exclusion of all non-α estimates. Our extraction method therefore prioritized specificity over sensitivity at the level of individual estimates. Although, separately, we note that our approach cannot distinguish between multiple estimates taken from the same sample (e.g., α calculated using the full scale and then after dropping an item). On the one hand, this could result in unmodeled dependencies among the data. On the other hand, if items were dropped (or other post hoc modifications were made to the scale) to increase α to meet the rule-of-thumb thresholds, this would nonetheless be appropriately captured by our analyses (e.g., excesses at the thresholds because of α-hacking). This approach was additionally limited by the lack of standardized reporting practices for α in comparison to p values. Although we have high confidence that only valid estimates of α were included in the final data sets, this was at the sacrifice of sensitivity. Many potentially valid but unclear or difficult-to-extract α values were excluded from the psychology and PsycTests data sets. It is possible that this extraction method was biased in some way. Inferences about the true distribution of α values in the psychology and PsycTests data sets should therefore be made with much caution. However, the I/O data set does not suffer from this issue because of its very different extraction method and the more standardized nature of α reporting in those journals (i.e., in the diagonals of correlation tables). The fact that evidence of α-hacking was found in both databases, which used very different extraction methods, increases our confidence in the results.
It is important to acknowledge that we studied reported α values, which may not represent the full range of reliability estimates from the measures employed in the component studies. The reported values may be distorted in ways other than α-hacking around the thresholds, for example, (a) not calculating reliability estimates, which is more common in stimulus-response laboratory tasks than self-report scales and can hide very low reliability (Lilienfeld & Strother, 2020); (b) under-reporting of α values (Flake et al., 2017); or (c) opportunistically switching to other metrics of reliability (e.g., McDonald’s ω, intraclass correlation coefficient, or split-half reliability).
Finally, we use the term “α-hacking,” which should not be misunderstood as connoting intentional deception. Comparable discussions about researchers’ intentions in specific cases have been had in the p-hacking literature and are generally an unproductive distraction (Nelson et al., 2018). We use the term “hacking” to make clear that plausible explanations for the effect we observed here attribute them to researchers’ behaviors, which serve to modify an index in a way that overfits on the data at hand or analytic choices are conditioned on their results rather than some passive effect of the system (as with publication bias).
Recommendations
There are many circumstances under which it is appropriate and important to modify a measure. Measure development, translation, and use in new populations all require an ongoing process of validation. However, when measure development and measure use are conducted within the same data set, for example, by dropping an apparently poorly performing item that lowered α, it is extremely difficult to know whether one has either (a) appropriately refined the measure or (b) overfit on the data at hand. Even with the best of intentions, researchers may be overfitting more than they realize given that item dropping increases the apparent (in-sample) α by a large degree. This risk is compounded by the fact that 43% of psychological measures are used just once, and indeed, 80% of measures are used 10 times or less (Anvari et al., 2024; Elson et al., 2023). With no or limited reuses in new samples, it is exceptionally difficult to avoid overfitting a measure on the data at hand, maximizing apparent α without knowing whether this represents a genuine increase in the reliability of the scale. Equally, when a scale has been reused many times and accumulated more validity evidence, it is difficult to justify modifying it because this introduces measurement flexibility and heterogeneity into the literature. To balance the need to continually validate and refine measures with the risks of overfitting measurement choices, we argue that our field must move away from ad hoc changes to measures done within primary research, that it must conduct more systematic measurement development and refinement that is done outside of primary research and that proposed alterations are verified in new samples, and that it should move toward centralized measure repositories and versioned measurement standards (see Elson et al., 2023).
Just as the understanding of the risks of p-hacking led to a greater distinction being made between exploratory and confirmatory research (e.g., Munafò et al., 2017), we believe that the risk of α-hacking and other questionable measurement practices require researchers to make a greater and more explicit separation between measure development and measure use in primary and substantive research. That is, modifications to measures should not be made post hoc, any proposed changes should be confirmed in new samples, and the details of measures should be fixed in preregistrations along with other elements of the design and analysis. Put another way, suggested modifications to scales based on a given data set should not have those modifications be applied to that same data set because this is conditioning decisions on results. Instead, suggestions for modifications should be confirmed in new samples and then applied consistently in the future. The timing and rationale for such choices is only knowable with increased transparency (e.g., through preregistration). Of course, as with p-hacking, increased transparency through preregistration and a clear separation of exploratory and confirmatory research (aka, measure development and use with regard to α-hacking) can increase the detectability of hacking but will not automatically prevent it. Increased transparency about the nature and timing of decisions is necessary but not sufficient to prevent hacking. These and other suggested changes to measurement practices, how authors comply with them, and how editors and reviewers may enforce them are discussed in greater detail in the Standardisation Of BEhavior Research (SOBER) guidelines (Elson et al., 2023). There are many differences between p-hacking and α-hacking, although the cure may often be the same: increased transparency about which researcher choices were planned (e.g., through preregistration) and which were data-dependent.
Just as with hypothesis tests, preregistration is a plan, not a prison. Preregistering details of a measure does not preclude making post hoc or data-informed decisions about that measure, such as whether to drop a truly badly performing item; it merely makes the timing of this decision visible to others. Deviations from preregistration should be clearly labeled, and the preregistered analyses using data from the unmodified measures should be reported in addition to any exploratory analyses with modified measures.
Construct validation is difficult and often neglected (Schimmack, 2021). Hard questions, such as the trade-offs between internal consistency (which when high, can represent a form of redundancy), participant time, and construct breadth, are important and should be explicitly investigated, and the resulting measures should be validated in independent data. For such work to become more commonplace, field norms likely need to change. Currently, the incentive structures in academic psychology tend to reward primary research that attempts to test hypotheses over validation of measures even when the ability to test those hypotheses relies on valid measurement (Scheel, Tiokhin, et al., 2021).
Conclusion
The distributions of Cronbach’s α values in large samples from three different data sets examining the published psychology literature show excesses of α values at the commonly used threshold of .70. Features of the distributions suggest that these excesses cannot be explained solely by benign selection for high true reliability but are more likely to be biased by publication bias and α-hacking (i.e., questionable measurement practices). These excesses at the thresholds may be only the tip of the iceberg of biases in reported α values. Just like p-hacking, α-hacking occurs when researchers overfit to in-sample data by exploiting researcher degrees of freedom, wittingly or not. Also like p-hacking, α-hacking could be reduced through more transparent research practices, tailored to target the specific forms of overfitting, flexibility, and under-reporting that give rise to it. Whereas p-hacking has played an important role in the replication crisis in psychology, α-hacking may contribute to a growing measurement crisis (Flake & Fried, 2020; Lilienfeld & Strother, 2020).
Previous research has discussed at length the misuse of α and the issues of using thresholds for decision-making, all with very limited impact on the continued (mis)use of α (e.g., Cortina, 1993; Schmitt, 1996; Sijtsma, 2009). We are agnostic as to whether α and indeed cutoffs should or should not be used. α-hacking, in the sense of overfitting to in-sample data, is a different and potentially more pressing problem. However, expediting increased transparency in scale development could, at the same time, lead to more informed choices of reliability coefficients and a less problematic impact of thresholds.
Therefore, in the future, researchers should more precisely preregister and fully report not only their analytic strategy but also their measurement strategy. We echo similar calls for greater transparency made by Flake and Fried (2020). This includes the content and implementation of measures (Heycke & Spitzer, 2019), their scoring, any changes made to them relative to previous studies (e.g., item dropping, rewording, scoring), the methods of quantifying reliability (and other measurement properties), all decision-making rules, and any ad hoc modifications. Of course, such full reporting is much easier if a standardized protocol can simply be cited. Indeed, we believe increased requirements for measurement transparency will also entail increased measurement standardization and thus help psychology mature to become a more integrated science.
Supplemental Material
sj-docx-1-amp-10.1177_25152459241287123 – Supplemental material for An Aberrant Abundance of Cronbach’s Alpha Values at .70
Supplemental material, sj-docx-1-amp-10.1177_25152459241287123 for An Aberrant Abundance of Cronbach’s Alpha Values at .70 by Ian Hussey, Taym Alsalti, Frank Bosco, Malte Elson and Ruben Arslan in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We thank the American Psychological Association for its support and for providing access to the American Psychological Association PsycTests database. We thank Michèle Nuijten for helping us understand why the results of our permuted z tests do not pass statcheck despite being correct (i.e., because the z values of permuted tests are approximated rather than exact, causing statcheck to return false positives). We also thank Annika Külpmann for her assistance with validating the regular expressions’ extractions.
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contributions
M. Elson and R. Arslan are joint last author.