
Abstract
Making scientific information machine-readable greatly facilitates its reuse. Many scientific articles have the goal to test a hypothesis, so making the tests of statistical predictions easier to find and access could be very beneficial. We propose an approach that can be used to make hypothesis tests machine-readable. We believe there are two benefits to specifying a hypothesis test in such a way that a computer can evaluate whether the statistical prediction is corroborated or not. First, hypothesis tests become more transparent, falsifiable, and rigorous. Second, scientists benefit if information related to hypothesis tests in scientific articles is easily findable and reusable, for example, to perform meta-analyses, conduct peer review, and examine metascientific research questions. We examine what a machine-readable hypothesis test should look like and demonstrate the feasibility of machine-readable hypothesis tests in a real-life example using the fully operational prototype R package scienceverse.
In many scientific fields, researchers rely on hypothesis tests to determine whether empirical observations corroborate predictions. In a well-specified hypothesis test, a hypothesis is used to derive predictions, which are operationalized during the design of a specific study and translated into a testable statistical hypothesis. Data are collected, and the statistical hypothesis is corroborated or not. Although this process sounds relatively straightforward, hypothesis tests are performed rather poorly in practice. First, statistical hypotheses are stated verbally, but these verbal descriptions rarely sufficiently constrain flexibility in the data analysis. Second, in articles, there is a lack of transparency about which statistical tests in the results section are related to the predictions in the introduction section, and which pattern of results should be observed to conclude that a prediction is corroborated. Finally, researchers typically implicitly specify only what would lead them to act as if their prediction is confirmed (i.e., typically a p value smaller than .05), and rarely specify what would lead them to act as if their prediction is falsified. Currently, it is often possible to infer the authors’ decision criteria only indirectly, which leads to disagreement about whether new patterns of results from replications should be considered to support or refute the hypothesis.
By contrast, a well-specified hypothesis test states the statistical hypothesis for each prediction in a way that eliminates flexible implementations, clearly links predictions derived from the theoretical hypothesis to statistical tests, and gives unambiguous criteria to conclude that the prediction is corroborated, the prediction is falsified, or the results are inconclusive. When we refer to falsifiability, we limit ourselves to the falsification of statistical predictions, not entire theories. A specific operationalization of a theoretical prediction always requires auxiliary hypotheses, and if a statistical hypothesis is falsified, it remains unclear whether the problem lies with the theory or the auxiliaries (Meehl, 1990). Additionally, although a well-specified hypothesis test is no guarantee that a hypothesis test is logically or statistically free from error, it provides reviewers and readers a way to unambiguously assess whether it is, avoiding problems of interpretation.
We propose that the gold standard for well-specified hypothesis tests should be a statistical prediction that is machine-readable. This means that a computer can evaluate whether a statistical prediction is corroborated (or not) on the basis of clearly articulated evaluation criteria and the observed data. Computers do not handle ambiguity well, and making a hypothesis test machine-readable guarantees that it is specified precisely. Although some of the improvements we suggest could also be achieved through careful verbal descriptions of mutually exclusive and exhaustive decision criteria in manuscripts and preregistrations, we believe that there are two broad arguments for a move to machine-readable hypothesis tests. The first argument is that when hypothesis tests are specified in a format that can be read and evaluated by a machine, tests of statistical predictions and the conclusions derived from these tests will become more transparent, statistically falsifiable, and rigorous. This provides a first step to improve the currently poor practices scientists use to test hypotheses. The second argument is that the benefits of making data FAIR (findable, accessible, interoperable, and reusable; Wilkinson et al., 2016) also apply to statistical predictions. If all aspects required to evaluate the test of a statistical prediction are machine-readable, researchers can easily reuse this information (e.g., when performing a z-curve analysis, effect-size meta-analysis, or p-curve analysis), and find and access this information (e.g., to answer metascientific questions about the proportion of statistical results in the scientific literature that corroborate the prediction). Although achieving all benefits of machine-readable hypothesis tests might take many decades, and will require extensive collaboration, coordination, and standardization, we believe machine-readable hypothesis tests as they can be implemented based on the approach and R package outlined in this article can already lead to immediate improvements in research practices.
Poor Practices in Testing Predictions
For a concrete example of a typical hypothesis test in the published literature, we use a study by DeBruine (2002), who posited the theoretical prediction that people would exhibit higher levels of prosocial behavior toward those who physically resemble them, which follows from the idea that actions are influenced by an implicit evaluation of relatedness based on phenotypic similarity. Physical resemblance was manipulated by morphing face photographs with either the participant’s own face (self morphs) or another person’s face (other morphs). There were two versions of this manipulation: Faces were morphed in shape only (n = 11) or in both shape and color (n = 13). Prosocial behavior was measured as the choice to trust or reciprocate trust in a monetary trust game in which the first player could decide whether to trust the second player to split money and the second player, if trusted, could decide whether to reciprocate this trust by splitting the money equally or selfishly. The theoretical hypothesis was operationalized, and the operationalized prediction stated that people playing a trust game would trust and reciprocate more when playing with a person who was represented by a self morph rather than by an other morph. The statistical prediction was tested by counting the number of trusting and reciprocating responses participants made to self and other morphs and then performing t tests on these counts, one for the shape morphs and one for the shape-color morphs. The statistical results indicated that participants made more trust responses to self morphs than to other morphs for both morph types. However, there were no differences in how often they reciprocated their partners’ trust. The conclusion drawn from this study was that these results show that facial resemblance can increase prosocial behavior. It was noted that the fact that an effect was observed for the trust measure, but not for the reciprocation measure, could perhaps be explained by the different payoff structures for trust and reciprocation in this particular game.
The first problem we can identify in this example is that it is not clear whether the operationalized prediction was confirmed only if an effect was observed on both the trust measure and the reciprocation measure, or if it was confirmed if an effect was observed on just one of the two measures. From the conclusion the author drew, one can infer that the statistical prediction would be considered corroborated if the morphing manipulation had an effect on the trust measure, the reciprocation measure, or both. However, even if the decision rule can be inferred from the discussion, it is still not clear which patterns would be considered corroboration or falsification in future replications that might find similar but not identical patterns of results.
The second problem is that it is not clearly specified what would corroborate the hypothesis and what would statistically falsify the hypothesis. Although it is never explicitly stated, one can infer that the prediction would be corroborated if either of the two tests is significant at an alpha level of .05, without correction for multiple comparisons. Furthermore, one can infer that a nonsignificant p value would be interpreted as the absence of any meaningful effect (even though this is a formally incorrect interpretation of a null-hypothesis test).
The third problem is that there is a range of options available for analyzing the data (e.g., pooling the two types of morphs in one analysis or reporting a separate analysis for each morph version). As is often the case when testing statistical predictions, no unique analysis strategy follows unequivocally from the introduction and methods section, which can lead to flexibility in the data analysis.
What Does a Formalized Test of a Prediction Look Like?
To make a hypothesis test machine-readable, one needs to capture all essential aspects of the test in a machine-readable data structure. A hypothesis test is a methodological procedure to evaluate a prediction that can be described on a conceptual level (e.g., people exhibit higher levels of prosocial behavior toward those who physically resemble them), an operationalized level (e.g., people playing a trust game make more trusting decisions when the person they play against is a self morph rather than an other morph), and a statistical level (e.g., the average number of trust moves is statistically larger for games against self morphs than for games against other morphs in a dependent-samples t test).
When researchers evaluate the result of a statistical prediction, they need to perform a statistical test, retrieve the relevant test result, and compare this with one or more criterion values. For example, researchers’ statistical prediction might be that they will observe a positive difference in the means between two measurements, which will be examined in a dependent-samples t test, from which they will determine the lower and upper bounds of a 97.5% confidence interval around the mean difference, which they will compare against a value of 0. Statistical hypotheses are probabilistic, and probabilistic hypotheses can be made falsifiable “by specifying certain rejection rules which may render statistically interpreted evidence ‘inconsistent’ with the probabilistic theory” (Lakatos, 1978, p. 25). A hypothesis test thus requires researchers to specify when the observed results of a statistical test will lead them to act as if their prediction is consistent with the data, inconsistent with the data, or inconclusive (Neyman & Pearson, 1933).
As highlighted above, one limitation of current practice in testing hypotheses is that researchers often do not explicitly state what would corroborate or falsify their prediction. To be able to unambiguously evaluate a hypothesis, researchers need to specify the rules they will use to evaluate whether statistical results corroborate a prediction, falsify it, or are inconclusive. For example, in a 2 × 2 design, many different patterns of means across the four cells could be predicted (e.g., one of two main effects or a specific pattern of the observed interaction effect), but the full pattern of possible results that would corroborate or falsify a prediction is seldom made explicit.
There are different approaches that can be used to statistically conclude that the prediction made in a study is falsified. In practice, corroborating or falsifying a statistical prediction in a single study is rarely sufficient to draw strong conclusions about a theory (Lakatos, 1978), and one should always keep random variation in mind when interpreting statistical results. One approach to conclude that a prediction is falsified is known as equivalence testing (Lakens et al., 2018). An equivalence test requires researchers to specify a smallest effect size of interest and tests if the presence of an effect that is large enough to be deemed interesting can be statistically rejected.
Continuing our example, we might conclude that the study’s prediction is corroborated when we can statistically conclude that the observed mean difference for at least one measure is both greater than 0 and not smaller than the smallest effect size of interest (SESOI). The prediction is falsified if both effects are smaller than the SESOI. Any other pattern of results, such as both effects being neither significantly larger than 0 nor smaller than the SESOI, is inconclusive. If our statistical test is a dependent-samples t test, our test result is the upper and lower bounds of a 97.5% confidence interval (i.e., a hypothesis test with a Bonferroni-corrected alpha level of 2.5%), and our smallest effect size of interest is 0.2, we can conclude that we have corroborated our prediction if at least one of our 97.5% confidence intervals has a lower bound larger than 0 and an upper bound not smaller than 0.2. We can decide that our prediction is falsified if the upper bounds of both 97.5% confidence intervals are smaller than 0.2, and our data are inconclusive in all other situations.
Computationally Evaluating Hypotheses
If a prediction is machine-readable, it is possible to automatically determine if it is corroborated by the data. Although computational reproducibility is becoming increasingly popular as user-friendly tools are continuously being developed, there are no existing solutions that make hypothesis tests machine-readable and reusable. We envision machine-readable hypothesis tests as part of a completely reproducible workflow. Computer scripts load the raw data and, if needed, create the analytic data from the raw data (e.g., outlier removal, transformations, computation of sum scores according to prespecified rules). The statistical tests are automatically performed on the analytic data, and the relevant test statistics are retrieved. These test statistics are compared against prespecified criteria, based on decision rules that evaluate whether the prediction is corroborated, falsified, or inconclusive. All the information that is required to perform these operations is stored in a structured metadata file.
We have provided a vignette for a Quick Demo (https://scienceverse.github.io/scienceverse/articles/demo.html) with a concrete example of a machine-readable statistical prediction for the study by DeBruine (2002) described above. It is written using the fully operational prototype we have implemented in the R package scienceverse (https://github.com/scienceverse/scienceverse/) and produces a JSON (JavaScript Object Notation) file that can be used to transmit data. Because JSON is an open-standard file format, the file can easily be converted into any other open-data file format (e.g., the Journal Article Tag Suite). In essence, open-data file formats are all nested lists. It can also be converted to a human-readable report that summarizes the study with verbal descriptions and a list containing the conclusion for each statistical prediction.
In summary, to make statistical hypotheses machine-readable, one needs to identify the individual components that make it possible to evaluate a hypothesis test. Our example relies on a statistical hypothesis that is tested in an analysis that takes data as input and returns test results. Some of these tests results will be compared against criteria, used in the evaluation of those test results. The sections below describe how each component can be specified in a machine-readable format, using the study by DeBruine (2002) as an example.
This example and supplemental materials available at GitHub (https://scienceverse.github.io/scienceverse/) use the following open-source research software: R (R Core Team, 2019), tidyverse (Wickham, 2017), Zcurve (Bartoš & Schimmack, 2020), metafor (Viechtbauer, 2010), faux (DeBruine, 2020), papaja (Aust & Barth, 2018), and scienceverse (DeBruine & Lakens, 2020).
Setting up a study
The top-level list (Box 1) contains components describing different aspects of the study, such as authors, hypotheses, methods, data, and analyses. In the future, researchers might be able to describe all metadata pointing to information in a scientific article that they would like to be able to retrieve, but here we focus on the aspects of the study that are required to make statistical predictions machine-readable. To achieve this, we need a metadata file that specifies the hypotheses, the analyses, and the evaluation criteria for each prediction.
The Top-Level Structure of the Machine-Readable Study Description

The metadata file is structured as a JSON object, which is a list of keys and values. Each key is separated from the corresponding values by a colon. The list items are separated by commas, and the list is surrounded by curly brackets (see Box 1). The basic structure requires keys for the study name, general study information (info), authors, hypotheses, methods, data, and analyses. All values (except the name) default to an empty array, “
Hypotheses
A study could contain multiple hypotheses, but our example contains only one. Each hypothesis (Box 2) consists of an
The Hypothesis Component of the Machine-Readable Study Description
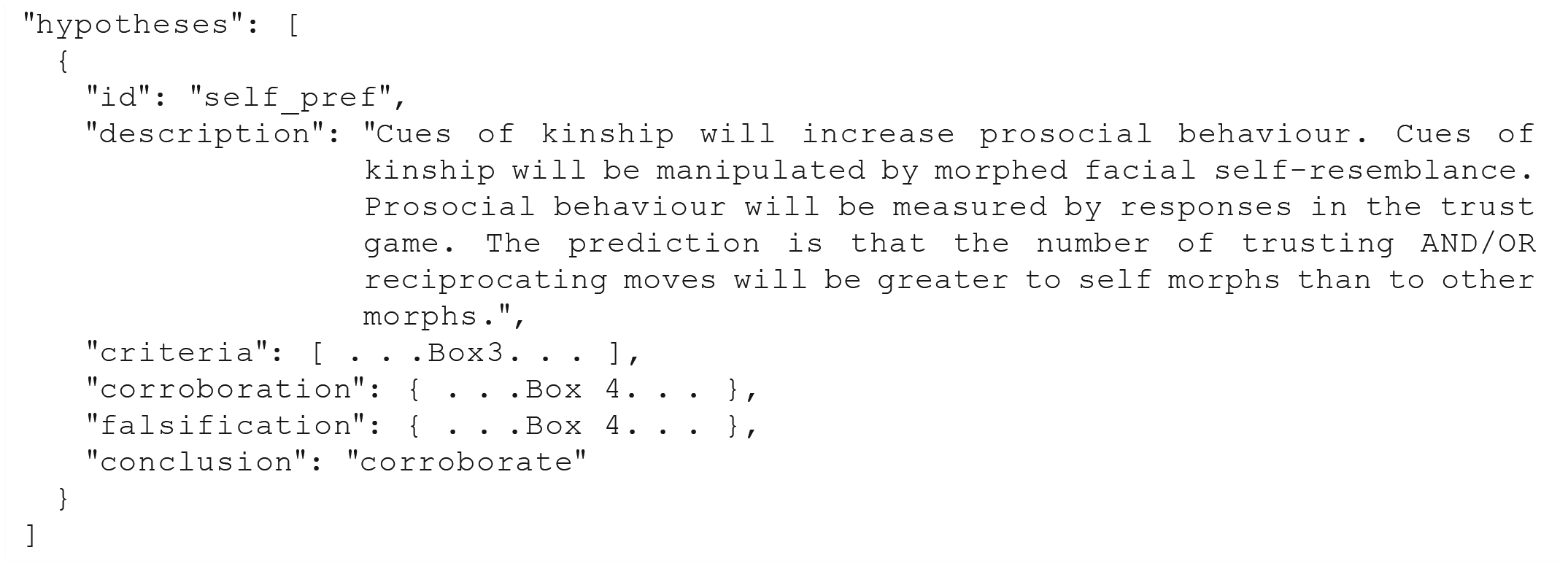
Criteria
Each criterion (Box 3) needs an
Criteria for Evaluation of the Hypothesis Tests in the Machine-Readable Study Description

Hypothesis evaluation
The
Corroboration and Falsification Rules in the Machine-Readable Study Description

Analyses
Each analysis is specified in the
The Analysis Component of the Machine-Readable Study Description

Data
Each data set can be specified in the
The Data Component in the Machine-Readable Study Description

Box 6 contains a data component with a codebook created by scienceverse using the Psych-DS 0.1.0 format, which is currently still in development. The descriptors for the columns can be arbitrarily detailed or follow other metadata formats. For other software that helps researchers to create and share machine-readable codebooks, see Arslan (2019).
Automatic evaluation
Now that the prediction is specified in a machine-readable format, it is possible for the statistical prediction to be evaluated automatically. Automatic evaluation of machine-readable hypotheses has at least two useful functions during the peer-review process. First, we foresee a future in which researchers are required to submit fully computationally reproducible analysis scripts with their submissions. This will require an editorial assistant or reviewer to check the computational reproducibility of the results reported in a manuscript. Machine-readable hypothesis tests would make this check a matter of running a single function. The scienceverse R package can do this for code written in R, and a machine-readable format makes it straightforward to create scripts that automatically run analyses in other languages.
Using the information specified in the analyses, criteria, and data components, the
After the

Example of machine-readable output generated by scienceverse that shows the results and evaluation of the hypotheses in our example.
Benefits of Machine Readability
The example we have described uses the coding language R to specify analyses, and our supplemental materials (https://scienceverse.github.io/scienceverse/) provide examples that use our R package, scienceverse. However, the use of R specifically, or of any coding language, is not essential to the general idea of machine-readable hypotheses. Much as the Brain Imaging Data Structure format does (Gorgolewski et al., 2016), the proposed open format makes it possible to create data-processing pipelines in any language. One can even create a JSON-formatted text file by hand in a text editor and specify the result values manually. This could be a useful way to make the information in existing archives machine-readable, even if one does not have access to the original data or code. Currently, implementing machine-readable hypothesis tests requires some effort, both in learning to specify explicit criteria for corroboration and falsification and in acquiring programming knowledge to enter the metadata. Future work should focus on making this process as easy as possible by providing detailed examples that users can follow and by developing online forms that guide researchers through the creation of a scienceverse-compatible JSON file.
We believe that the benefits of making statistical predictions machine-readable are worth the extra effort. First, machine-readable hypotheses remove ambiguity about what researchers predict and which criteria must be met to conclude that a statistical hypothesis is corroborated. Predictions are explicitly linked to the tests that are performed to evaluate if the predictions are corroborated or not. The exact tests are specified, which prevents flexibility in the data analysis. Furthermore, specifying the criteria for corroboration or falsification explicitly prevents future researchers who will replicate the study from having to infer which results would corroborate or falsify the original finding. Although machine-readable hypotheses might feel extremely rigid, it is possible to specify a range of sensitivity analyses across which a prediction should hold.
Another benefit of making statistical hypotheses machine-readable is that many important aspects of the hypothesis tests become accessible, findable, and usable. This will benefit researchers in the future. We can imagine a utopian future in which metadata files such as the example in Boxes 1 to 6 are accessible by browsing to a URL that consists of the DOI appended by “/meta” (e.g., https://doi.org/10.1098/rspb.2002.2034/meta). Researchers will be able to access these files to load all the available information about statistical predictions. For example, when a completely reproducible workflow is used, and data can be accessed as part of the metadata file, the metadata file should be sufficient to easily calculate or access effect sizes from the statistical tests performed for meta-analyses.
Although making hypothesis tests machine-readable obviously cannot ensure that statistical predictions are sensible or logically coherent, the process of writing a machine-readable statistical prediction could have a secondary benefit of providing a well-structured framework for thinking through and specifying all important aspects of a statistical prediction. This might not be easy. Researchers might find it difficult to specify all required components in advance or to specify the ranges of results that would corroborate or falsify a prediction. Sometimes a research idea is not yet well specified enough to be tested in a confirmatory hypothesis test. Hypothesis testing is an extremely formalized procedure to make a decision regarding whether a prediction is corroborated or not. If researchers realize that they are actually not yet ready to make a falsifiable statistical prediction when they are creating a machine-readable hypothesis test, we would consider this a benefit as well (Scheel et al., 2020). Researchers might then decide to estimate the population effect size instead of testing a falsifiable prediction. Alternatively, they might decide to perform additional studies that allow them to make a more falsifiable prediction. Specifying exploratory analyses in a machine-readable way still has benefits, such as clarifying the source of statistical values in a manuscript and providing values for meta-analysis.
Use Cases
Registered Reports
We realize that several aspects of our proposal to make hypothesis tests machine-readable sound futuristic. At the same time, we believe that immediate use cases for machine-readable hypothesis tests already exist in the form of the Registered Report publication format (Chambers, 2019). Registered Reports require researchers to clearly specify their statistical prediction and are developed to reduce flexibility in the statistical analyses. After Stage 1 review based on the introduction, methods, and analysis plan, researchers can receive an “in principle acceptance.” They then collect the data and submit a Stage 2 Registered Report that includes the results and conclusion. This should make it relatively easy for reviewers to compare planned and reported analyses. Peer reviewers might not always have the time to carefully check whether each reported analysis in the manuscript matches the planned analysis in the preregistration and whether the conclusions in the manuscript follow from the test results. A machine-readable hypothesis test can automatically generate reports that facilitate peer review.
Furthermore, whereas submission guidelines for Registered Reports require researchers to specify their analyses, researchers are typically not required to explain in advance when they would consider their hypotheses corroborated or falsified, though doing so would make it easier for reviewers to evaluate the severity of a statistical test (Lakens, 2019). In Registered Replication Reports published in this journal, authors are asked to explicitly specify when a replication corroborates the original finding. For example, in the analysis plan of the Registered Replication Report on Fischer et al. (2003) by Colling et al. (2020), available at https://osf.io/6a2ny/, a clear decision rule for corroboration is specified: If the congruency effect is positive and statistically significantly different from zero in the 500 ms and 750 ms delay conditions but not statistically significantly different from zero in the 250 ms and 1000 ms delay conditions, we will consider the findings of Fischer et al. (2003) to be replicated within the limits they propose. (p. 6)
The scienceverse package illustrates one possible workflow in which, after the hypotheses are specified in a Stage 1 submission, a machine-readable report can be produced. This report looks similar to Figure 1, without any of the lines containing color-coded “true” or “false” evaluations of the predictions. When the data are collected, they can be added to the metadata file generated at Stage 1, the preregistered analyses can then be run, and a human-readable report can be generated as in Figure 1. This should make it relatively easy for reviewers to compare planned and reported analyses.
Power analyses
To check the code in a preregistration, the scienceverse package has a function to simulate data sets by specifying the data structure for factorial designs (using the R package faux; DeBruine, 2020). Another function generates a specified number of simulations, runs the analyses using the automatic evaluation procedure described above, and reports the total number of simulations for which each hypothesis was corroborated, falsified, or inconclusive. In the supplemental files at https://scienceverse.github.io/scienceverse/, we have provided an R script with an extended example of the trust study discussed above that includes a power analysis.
Meta-analyses
Researchers face several challenges when they want to examine lines of research with meta-analytic techniques such as effect-size meta-analysis, p-curve analysis (Simonsohn et al., 2014), or z-curve analysis (Brunner & Schimmack, 2020). First, many scientific articles do not report the results of statistical tests in sufficient detail for the reported studies to be included in a meta-analysis. Effect sizes are often not computed, and although researchers performing a meta-analysis can attempt to manually calculate effect sizes, this requires access to the means, standard deviations, correlations for within comparisons, and exact sample size for each condition, which are also often missing. Effect sizes can sometimes still be approximated from test statistics, but these are often not reported for nonsignificant results. The second problem a researcher performing a meta-analysis faces is a lack of transparency about which statistical test in the results section is related to the theoretical predictions in the introduction section. This can make it difficult to select the appropriate test to include in a meta-analysis.
The structured metastudy files we propose solve both these problems, as long as researchers (a) include the raw data in the metastudy file and (b) specify for each hypothesis which statistical test result (or results) will corroborate or falsify the predictions. In the online vignettes (https://scienceverse.github.io/scienceverse/), we demonstrate how z-curve and p-curve analyses can easily be performed on the basis of the p values stored in the results section of the metastudy file, and how the raw data in metastudy files can be used to identify variables shared across data sets and to compute and analyze effect sizes in a meta-analysis. As meta-analyses will almost always include data from published articles that have no metadata available, unless a concerted effort is made to catalogue all published studies (for a noteworthy example, see Bosco et al., 2020), these benefits will at best apply to a subset of the studies included in a meta-analysis.
Conclusions
Technological innovation makes it possible to communicate scientific findings in digital formats that allow for much easier reuse of scientific information than is possible with traditional journal articles. As science moves toward a time when researchers are expected to share their data in a way that is FAIR (findable, accessible, interoperable, and reusable; Wilkinson et al., 2016), we believe it is feasible and beneficial to make the rest of research machine-readable as well. We see machine-readable hypothesis tests as a logical development, with immediate benefits for the rigor of hypothesis tests. Increasing the accessibility of essential information related to hypothesis tests in scientific reports will also facilitate peer review, especially of Registered Reports, and facilitate metascientific research. Making statistical predictions machine-readable will be an important next step toward a scientific literature that can be accessed not just visually, but also computationally.
Footnotes
Acknowledgements
We would like to thank Leo Tiokhin and Peder Isager for feedback on an earlier draft of this manuscript and attendants of a hackathon at the 2019 annual meeting of the Society for the Improvement of Psychological Science for their enthusiastic reception of the ideas behind machine-readable hypotheses.
Transparency
Action Editor: Daniel J. Simons
Editor: Daniel J. Simons
Author Contributions
The two authors contributed equally to the manuscript. First authorship was determined by a Great League trainer battle between the authors in Pokemon Go. Both authors conceptualized the main idea, L. M. DeBruine wrote the scienceverse software, and both authors wrote and revised this manuscript.