
Abstract
Except its two kana syllabaries and the Latin alphabet, the Japanese writing system is mainly based on Chinese characters and local, made-in-Japan characters. While the former, called kanji characters, are ubiquitous in Japanese, the latter, called kokuji characters, remain largely unknown and thus infrequently used. It is then meaningful and interesting to investigate these local characters, and that in a global manner, that is considering them as a whole rather than focusing on particular instances such as often done in previous works. To this end, in this paper we first conduct a formal, ontological discussion of the kokuji characters so as to identify common properties and patterns, and second we realise a quantitative analysis thereof according to several criteria. The obtained results clearly exhibit trends, which are subsequently discussed.
Keywords
Introduction
The Japanese writing system is based on different sets of characters: in addition to its syllabaries (the hiragana and katakana characters, simply called kana), it relies on Chinese characters (kanji) and local, made-in-Japan characters (kokuji, also known as wasei kanji). While the two character sorts kanji and kana are ubiquitous in any Japanese writing, this is not the case of the kokuji characters, whose vast majority is in fact rarely used. Not only are kokuji characters morphologically composed according to different patterns, and in general can be classified into several groups as detailed in the rest of this paper, they also have different historical backgrounds. The most ancient ones were introduced in order to fill semantical gaps that appeared when the Chinese characters were originally imported in Japan as the major part of the writing system therein. Such kokuji characters were typically created for Japanese words that had no corresponding Chinese character, for example natural species found in the Japanese isles but not in China at that time. Sample relevant dates are given next. Kokuji characters can be traced back to the Nara period (710–794), for instance in the Manyōshū poem compilation (poem no. 149: the character 蘰 “climbing plant”). The Edo period (1603–1869) saw the introduction of, for example, the 腺 “gland” kokuji character for the medical field (Sasahara 2017). More than a millennium after the first ones, kokuji characters were still being actively created: multiple were introduced during the Meiji period (1868–1912) to create characters that match the newly imported words from overseas, such as foreign measurement units (e.g. kilogram) and technologies (e.g. train). Besides, it can also be noted that local characters comparable to the kokuji characters of Japanese are found in other writing systems as well, for instance in Korean, these are the gukja characters, and in Vietnamese with the local characters of the Chữ nôm script.
Similar to an iceberg, the number of relatively used kokuji characters – the tip of the iceberg – is small compared to the total number, even approximated, of kokuji characters. It is thus insightful to study this particular set of largely unused characters. Etsuko Obata Reiman (1990) makes a well-documented analysis of kokuji characters and their usage, notably giving a geographical repartition. Hiroyuki Sasahara has been researching this subject for years (Sasahara 2007, and local characters in general in Sasahara 2020). For instance, the recent dictionary he prefaced (Sasahara 2017) classifies kokuji characters according to their fields of application (e.g. vegetation, animals, living), which is a rather conventional approach since also followed by Naokata Ban (18th–19th century). Other authors chose to separately discuss one or two kokuji characters rather than considering the whole (e.g. Nishii 2009). Xiaohong Liang (2021) discusses graphical specificities of Chinese (kanji) and kokuji characters in the case of Japanese. In this research, the author conducts a more formal analysis of the kokuji characters, notably by discussing the properties they share with characters of other sets and, more generally, how they can be classified, before conducting quantitative analyses thereof. This is in an attempt to expose in a Cartesian manner trends and reasons for the largely infrequent usage of the kokuji characters.
It is not always easy to state on the inclusion of characters of the Japanese writing system into this set of kokuji characters. In other words, the question “kanji or kokuji?” remains debated in some cases. Relatively old counts of kokuji characters are as follows: Hakuseki Arai (1760) gives 81 kokuji characters and Naokata Ban (18th–19th century) has 126. More recently, Etsuko Obata Reiman (1990) counts 641 of them, excluding variants. We give in this paper a new, up-to-date count.
The rest of this paper is organised as follows. Several basic definitions are recalled and introduced in Section 2. The ontological analysis of the kokuji characters is conducted in Section 3. Quantitative analyses are detailed in Section 4, including a discussion of the obtained results. Finally, this paper is concluded in Section 5.
Preliminaries
In preparation of the ontological discussion of the kokuji characters next conducted, the following character sets with respect to the Japanese writing system are defined.
Let J = C ∪ K with C the set of the Chinese characters used in Japanese (i.e. kanji) and K the set of the kokuji characters.
Note that the two sets C and K are disjoint (C ∩ K = ∅) even if, as explained in introduction, it may be difficult for a few characters to state whether they are in C or K.
Let A = H ∪ N with H the set of the hiragana characters and N that of the katakana characters.
Although some characters such as ニ ∈ N and 二 ∈ C look similar and might thus be considered the same, it is emphasised here that the two sets J and A are disjoint and that the two sets H and N are disjoint as well (J ∩ A = H ∩N = ∅). In other words and for example, it is recalled that the katakana character ニ is distinct from the kanji character 二 and that the hiragana character り is distinct from the katakana character リ. This distinction is natural, and indeed made by computer systems (i.e. encodings; see for instance Unicode 2020). This discussion is summarised in Figure 1. The character sets distinguished in this research and their inclusion relations.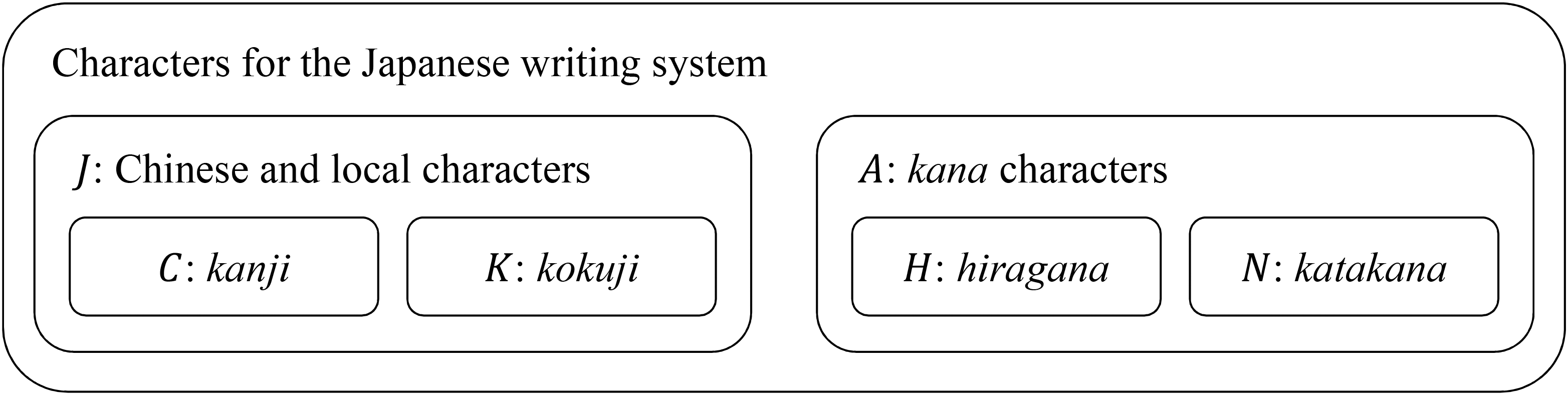
This part of the paper is focused on conducting an ontological analysis of kokuji characters, which is in continuation of previous works (Bossard 2018, 2020).
On variants, forms and styles
First and foremost, it is important to note that just as Chinese characters, kokuji characters can have variants and writing styles. The writing style of a character is simply about some “cosmetic” changes made to a character, for instance by lengthening some of its strokes (Fukawa and Koike 2001). Such light changes suffice not to induce a new character, that is a new variant.
A character can also have variants, in which case we say that such characters are in semantic relation. There are different sorts of variants: the ancient form, the original form, the orthodox form, the erroneous form, the vulgar (demotic) form and the alternative form are some examples (Bossard 2018). The name “alternative form” is used when there is no other suitable category or classification remains ambiguous. It is recalled that two characters in semantic relation share the same reading and the same meaning.
Any two characters of J are in semantic relation if and only if one is a variant of the other.
The binary relation s(c, c′) over J × J with c ≠ c′ holds if and only if the character c is in semantic relation with the character c′.
From Definition 3, the binary relation s is symmetric: s(c, c′) ⇔s(c′, c)holds.
For example, the relation s(観,觀), or equivalently the relation s(觀,観), is satisfied: the character 觀 is the old form of the character 観, and vice-versa the character 観 is the new form of the character 觀. These two characters are thus in semantic relation.
The binary relation a(c′, c) over J × J holds if and only if the character c'is an alternative form of the character c.
It is important to note that the binary relation a is not symmetric over J × J, but it is symmetric over K × K (it is recalled that K ⊂ J). For example, the character 嶋 ∈ C is an alternative form of the character 島 ∈ C, and thus the relation a(嶋, 島) holds, but the character 島 is the orthodox form of the character 嶋, and thus not an alternative form of 嶋. Hence, the relation a(島, 嶋) does not hold. Furthermore, just as the relation s, the relation a is irreflexive: for any character c ∈ J, the relation a(c, c) does not hold.
Both character variants and writing styles apply to kokuji characters. We give an example in Figure 2 with the kokuji character 饂 un which has at least two styles (Sasahara 2017) and one vulgar form (Ogawa et al. 2017). An illustration of character variants and writing styles with the kokuji character 饂 un.
From a semantic relation point of view, that is considering the semantic relations between kokuji characters and other character sets, we can distinguish the following four sorts of kokuji characters: A kokuji character that is not in semantic relation with a kanji character and there is no kokuji character that is an alternative form. In other words, the equivalence relation k ∈ K of type 1 ⇔ ∄ c ∈ C, s(k, c), ∄ k′ ∈ K, a(k′, k) is satisfied.For instance, the kokuji character 腺 sen has no alternative form and is not in semantic relation with a kanji character. A kokuji character that is not in semantic relation with a kanji character but there is at least one kokuji character that is an alternative form. In other words, the equivalence relation k ∈ K of type 2 ⇔ ∄ c ∈ C, s(k, c), ∃ k′ ∈ K, a(k′, k) is satisfied. For instance, the kokuji characters 凪 and 𣷓 nagi are two alternative forms which are not in semantic relation with a kanji character. A kokuji character that is in semantic relation with at least one kanji character and there is at least one kokuji character that is an alternative form. In other words, the equivalence relation k ∈ K of type 3 ⇔ ∃ c ∈ C, s(k, c), ∃ k′ ∈ K, a(k′, k) is satisfied. For instance, the kokuji characters 椙 and 𪳉 sugi are alternative forms which are in semantic relation with the kanji character 杉. Another example are the two kokuji characters 艝 and 轌 sori which are in semantic relation with the kanji character 橇. A kokuji character that is in semantic relation with at least one kanji character but there is no kokuji character that is an alternative form. In other words, the equivalence relation k ∈ K of type 4 ⇔ ∃ c ∈ C, s(k, c), ∄ k′ ∈ K, a(k′, k) is satisfied. For instance, the kokuji character 椥 nagi which has no alternative form is in semantic relation with the kanji character 梛.
This classification is essential in that it is directly related to the usage frequency of the kokuji character. For instance, it is obvious that a kokuji character that has no corresponding kanji character (i.e. a kokuji of type 1 or 2) is more likely to be used than one that has a corresponding kanji character (i.e. a kokuji of type 3 or 4).
Classification by reading
Just as Chinese characters in general when used in Japanese (i.e. kanji characters), the kokuji characters can have multiple readings, and of various sorts. The kun reading and on reading are the two main sorts of readings for both kanji characters and kokuji characters, the former being for Japanese readings and the latter for readings derived from Chinese.
Since kokuji characters are characters local to Japan as explained, most of them have no on reading. And for the few which have, like 腺 sen, there is no distinction between on reading sorts, unlike for kanji characters which can have a kan-on reading, a go-on reading or a tō-on reading (Sampson 2015).
In addition, and once again just as kanji characters, a kokuji character can be used to write a loanword – it is then said to be an ateji character – and can thus have a reading that is a phonetic loan (examples follow). As a result, we can distinguish the following four sorts of kokuji characters: A kokuji character that has only kun readings (one, typically, but not necessarily). For instance, 裃 kamishimo and 靏 tsuru. A kokuji character that has only on readings (one, typically). For instance, 腺 sen and 鋲 byō. (Although it can be noted that a few references give in addition suji as kun reading for the kokuji character 腺, we abide by the authoritative reference Daikanwa jiten (Morohashi et al., 2000) in addition to Ogawa et al. (2017) and Sasahara (2017), which conventionally list no kun reading for this character.) A kokuji character that has both a kun reading and an on reading. For instance, 働 hataraki (kun reading) and dō (on reading). A kokuji character that has an ateji reading. For instance, 籵 dekamētoru (decametre) and 瓩 kiroguramu (kilogram).
Here again, this classification depending on the reading sort of a kokuji character is directly related to its usage frequency: a kokuji character that has an ateji reading, that is which corresponds to a loanword, is more likely to be neglected in favour of the katakana syllabary, which is typically used for phonetic loans. For instance, instead of using the kokuji 瓩, Japanese people write キログラム kiroguramu or simply キロ kiro to denote a kilogram.
Classification by morphology
Chinese characters are conventionally classified according to the Six writings: pictograms, ideograms, phono-semantic compounds, compound ideographs, phonetic loans and derivative cognates (Coulmas 1989). These six character groups somehow apply to kokuji characters but, due to the younger age of the kokuji characters (they were, as explained and obviously, created after kanji characters were imported to Japan, so the pictogram class can be deemed irrelevant) and their mostly Japanese-only readings as explained previously, the Six writings apply to a much lesser extent to kokuji than to kanji characters, and are thus not a pertinent classification method in our case.
So, it is more meaningful to instead consider morphological properties that are characteristic of the kokuji characters. Hence, we can distinguish the following sorts of kokuji characters: A kokuji character that combines both parts (i.e. sub-characters, or the full character) and meanings of several kanji characters, typically two, and this possibly partially: the meaning of only one part may be reused. For instance, the kokuji character 鰯 “sardine”, which combines the character 魚 “fish” and 弱 “weak”. This example illustrates the combination of two (complete) Chinese characters. The kokuji character A kokuji character that combines two elements of the set N (i.e. katakana), and this possibly partially. For instance, the kokuji character A kokuji character that is an element of the set H (i.e. hiragana). For instance, the kokuji character ん nari, which has no direct English translation. It is used just as the Chinese character 也 to denote existence or state, and is thus somehow close to the English verb “to be”.
 densha “train” exemplifies the case of partial combination: this character combines the character 車 sha “wheel” and the lower part of the character 電 den “electricity”.
densha “train” exemplifies the case of partial combination: this character combines the character 車 sha “wheel” and the lower part of the character 電 den “electricity”.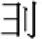 yori combines the two katakana characters ヨ yo and リ ri. As another example, the kokuji character
yori combines the two katakana characters ヨ yo and リ ri. As another example, the kokuji character 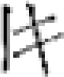 toki partially combines the two katakana characters ト to and キ ki.
toki partially combines the two katakana characters ト to and キ ki.
Regarding type 1, it can be noted that when all the parts retain their respective meaning, this sort of kokuji character is somehow related to the compound ideograph group of the Six writings classification, and when only one out of the several parts retains its meaning, typically the radical, and the kokuji has an on reading (see Section 3.3), this sort of kokuji character could be linked to the phono-semantic compound group of the Six writings classification.
In addition, some works (e.g. Sasahara 2017) consider a few kanji as kokuji characters, seemingly when they are used in Japanese with a meaning that is unrelated to the original Chinese one. Yet, such characters correspond to what is called the kokkun readings, and since they are not characters local to Japan, we do not consider them as kokuji since this would be an infringement of the C ∩ K = Ø principle. For instance, the kanji character 厶 is such an element of C given as kokuji in Sasahara (2017).
Global overview
We illustrate in Figure 3 sample relations that have been defined previously: semantic types, morphology types and reading types. In this figure, the grey horizontal line separates kanji and kokuji characters. An illustration of sample relations and types that have been defined for the kokuji characters.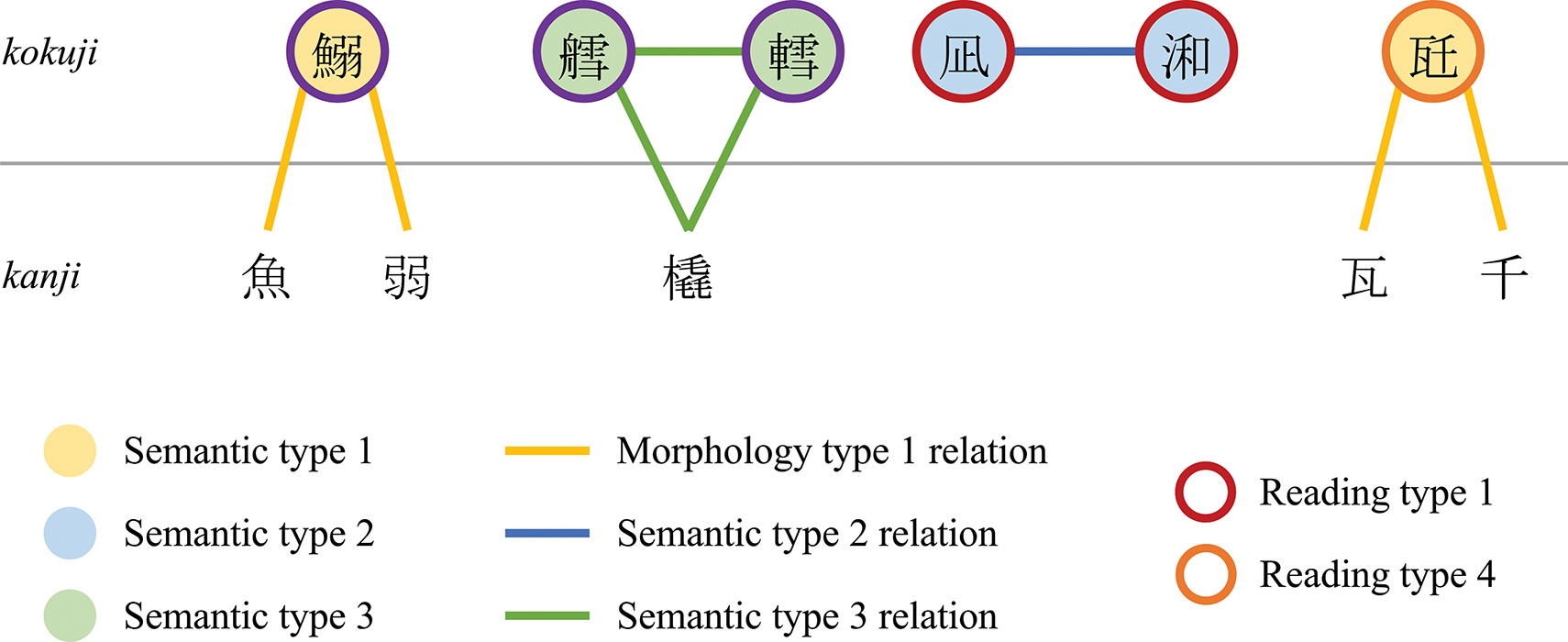
In this section, we conduct a quantitative analysis of the kokuji characters by measuring their distribution according to various properties. We recall that, as mentioned several times previously, it is sometimes unclear whether a character is a kanji or a kokuji. Therefore, our results completely abide by the very recent kokuji list given in Sasahara (2017), without stating on this kanji–kokuji classification issue, and thus not distinguishing between character variants such as 辻 and 辻. Because the number of occurrences of characters for which the kanji–kokuji distinction is unclear is low, this issue does not significantly impact our measurements and can thus be safely ignored: the obtained results retain generality.
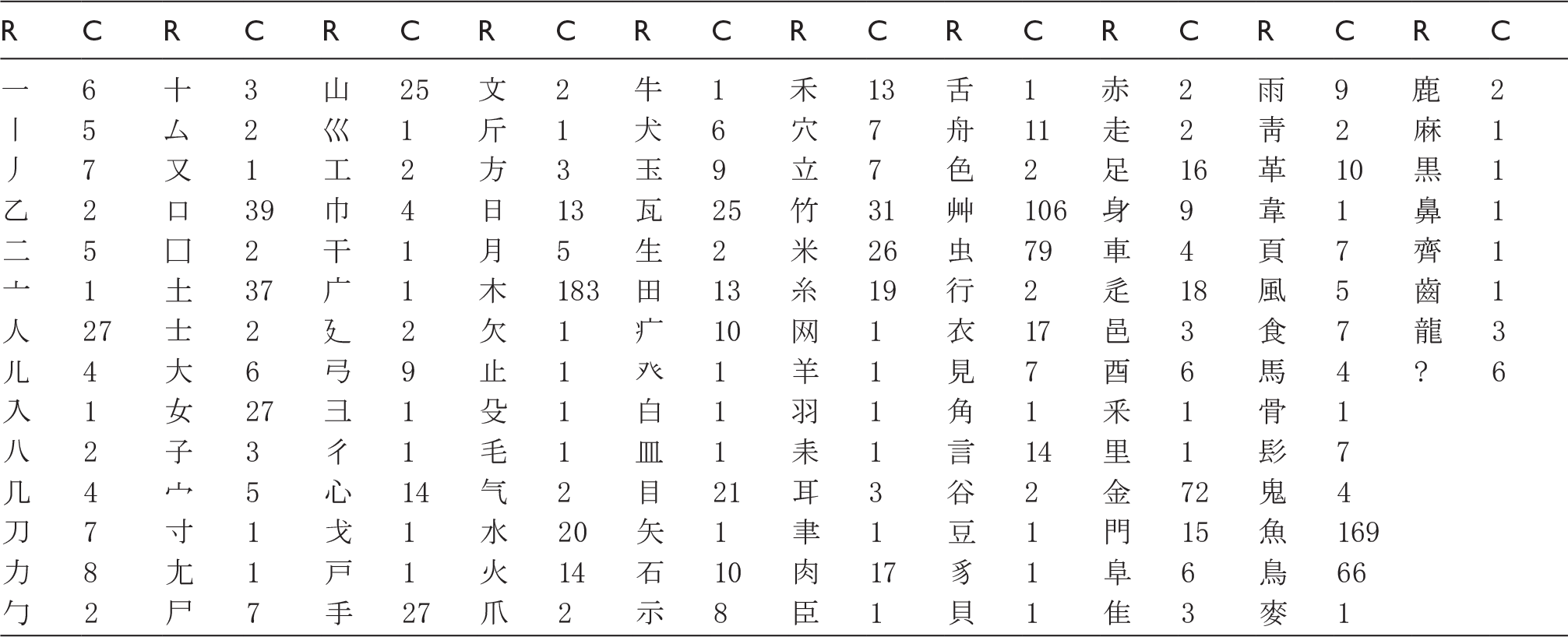
Distribution of the kokuji characters per radical
We start with a quantitative analysis of the kokuji characters by measuring their distribution according to the character radical. Radicals are a conventional character classification method, not only for kokuji but also kanji characters. It is recalled that the modern radical classification is based on 214 radicals (Bossard 2018).
Distribution of kokuji characters according to their radical; only the radicals with at least one kokuji character are included in this table.
Distribution of kokuji characters according to their radical; only the radicals with at least one kokuji character are included in this table.
Second, the radicals for which there are more than eight kokuji characters are emphasised in Figure 4. We chose eight as threshold value to sufficiently filter the radicals and thus better visualise the trend. Distribution of kokuji characters according to their radical emphasised on the radicals that have the most kokuji characters: only the radicals with more than eight occurrences are included in this figure.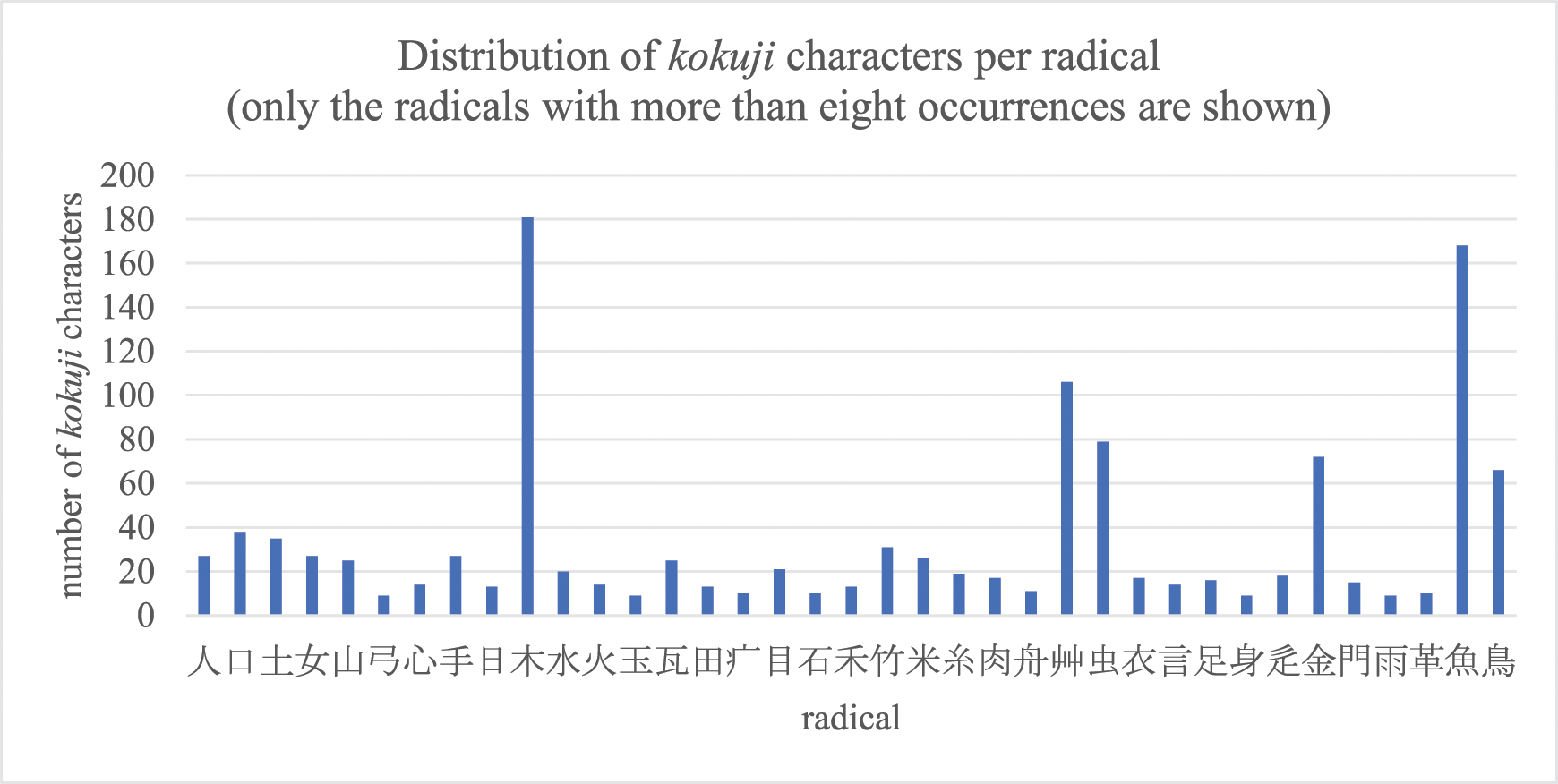
The second quantitative analysis of the kokuji characters measures their distribution according to the character reading. Precisely, we show the repartition of the kokuji characters that have an ateji reading as introduced in the first part of this paper.
Distribution based on radicals of the kokuji characters that have an ateji reading. Only the radicals that include at least one kokuji character with an ateji reading are listed.
Distribution based on radicals of the kokuji characters that have an ateji reading. Only the radicals that include at least one kokuji character with an ateji reading are listed.
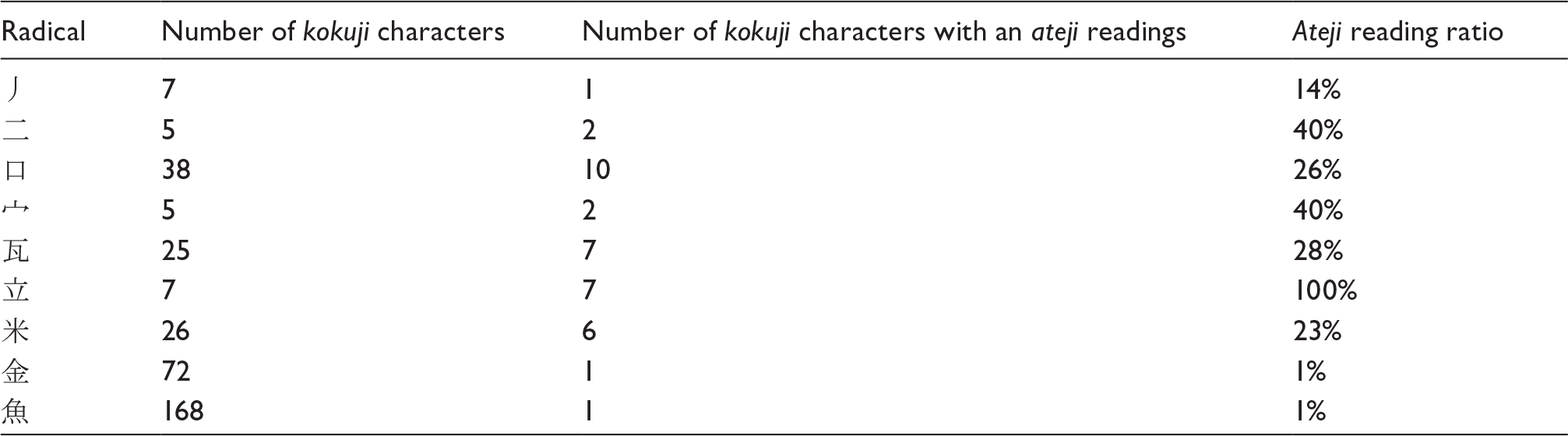
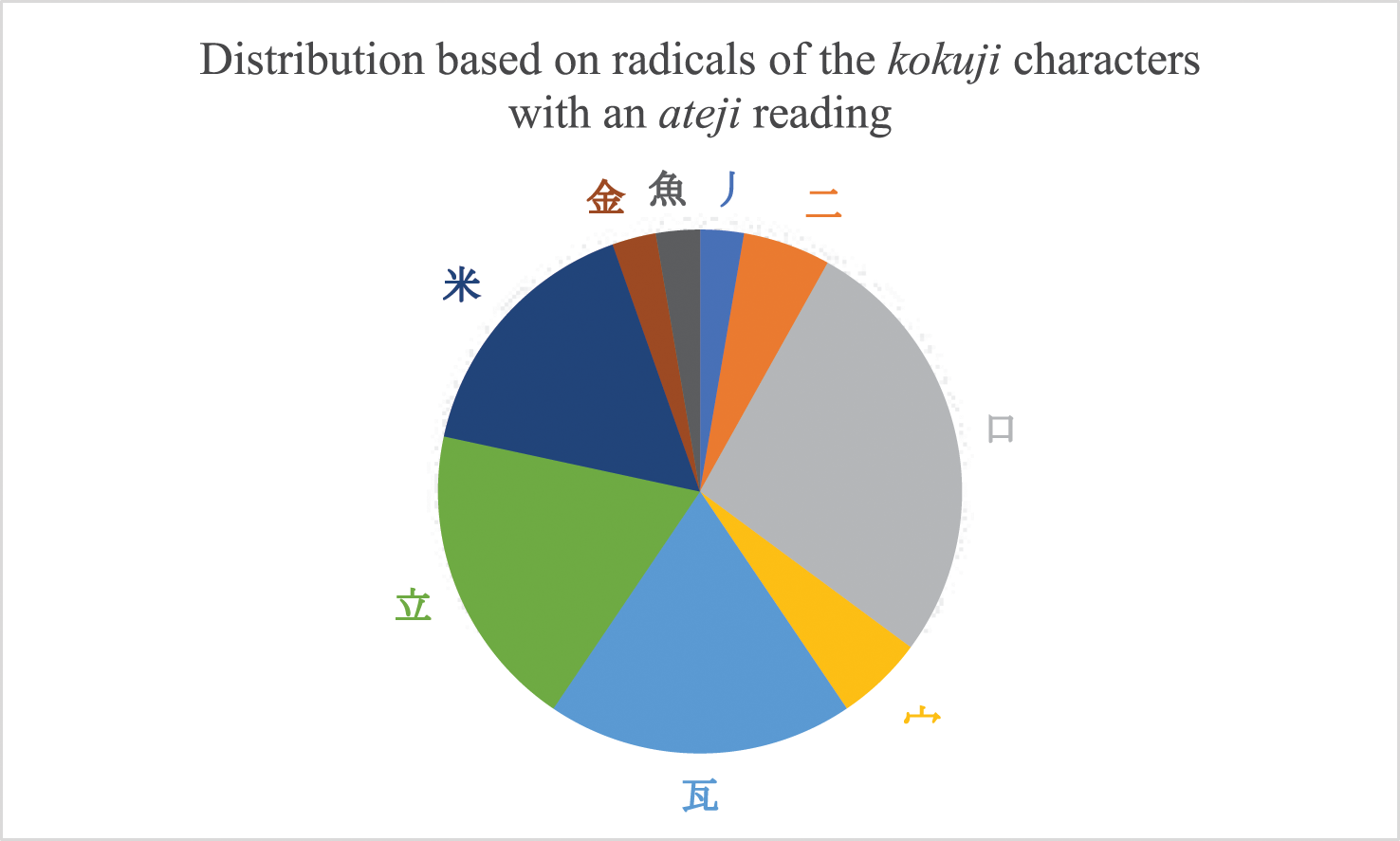
Distribution based on radicals of the kokuji characters that have an ateji reading.
We start by discussing the results of the first analysis: the distribution of the kokuji characters based on their radical. Out of the 214 character radicals, 133 (62%) include at least one kokuji character and there are in total 1499 kokuji characters. It is interesting to note that the radicals for which there are the highest numbers of kokuji characters are related to natural elements. The reason for this trend has been recalled in introduction and details can be found for instance in Bossard (2018): while most original Japanese words (i.e. yamatokotoba: early spoken Japanese) could be matched to (at least) one Chinese character when the latter were imported into Japan as writing system, some could not. For those, new characters, kokuji, were introduced according to several patterns as detailed in the first part of this article.
Considering the ancient time when this happened, it is easy to understand that such unmatched original Japanese words were first and foremost related to natural species native to Japan. Hence, the radicals for which the number of kokuji characters is highest are 木 “tree” (183 occurrences), 艸 “plant” (106), 虫 “insect” (79), 魚 “fish” (168), 鳥 “bird” (66), for natural species, and those account for more than 40% of the total number of kokuji characters (1499), and 金 “metal” (72) for kokuji characters related to arts such as those for tools and craft (approximately 5% of the total kokuji characters). In terms of number of kokuji characters, the other radicals are nowhere near those six dominant ones.
This trend thus brings indications on the comparatively low usage of kokuji characters: regarding natural species, the recent decades have seen an increasing usage of the katakana syllabary in Japanese when it comes to writing the names of such species (on the evolution of the scripts used in Japanese, see for instance Tomoda (2005), although not directly related to natural species, and Masuji (2018) for exhaustive classification), hence kanji characters have lost ground in this field, but in proportion (see Figure 4) kokuji characters have been even more impacted: it is a dramatical reduction of their possible usage scenarios. It could be suggested that a fortiori for original Japanese words that have no Chinese character equivalent, Japanese people tend to naturally avoid the artificiality of using one, even if it would be a kokuji and thus not a Chinese character per se, relying instead on the Japanese syllabaries (katakana, typically).
Finally, it is also interesting to note from the obtained results that the character that holds the greatest number of strokes amongst both kanji and kokuji characters is a kokuji character: 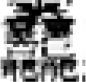 (it vertically combines 䨺 and 龘, and it is read taito or otodo) which has 84 strokes and two variants. It is of radical 龍 “dragon”.
(it vertically combines 䨺 and 龘, and it is read taito or otodo) which has 84 strokes and two variants. It is of radical 龍 “dragon”.
Next, we discuss the second analysis: the kokuji characters that have an ateji reading. Out of the 1499 kokuji characters, 37 (approximately 2.5%) have an ateji reading. Furthermore, out of the 133 radicals that have at least one kokuji character, 9 (approximately 6.8%) have at least one kokuji character that has an ateji reading.
Then, it is insightful to note that the entirety (100%) of the kokuji characters of radical 立 have an ateji reading. The ateji reading ratio for the other radicals is nowhere near this value. The corresponding characters are used to denote litre units (e.g. decalitre, decilitre). The reason can be rather safely deduced: the character 立 can be read ritsu in Japanese, thus close to the reading of “litre” in English, and even closer in French, especially when pronounced by a Japanese native speaker of earlier times, that is, not accustomed yet to foreign, here European, pronunciation. A comparable explanation can be given for the other two largely represented radicals in this ateji reading analysis: the radicals 米 mai for meter units and 瓦 kawara for gram units, whose readings are phonetically relatively close to the corresponding English words.
The fourth and last major group of such particular kokuji characters are those of the 口 “mouth” radical. Unlike the three previous groups (i.e. induced by the radicals 立, 米 and 瓦), this one is far less homogenous: it includes kokuji characters with an ateji reading for monetary units (e.g. dollar), distance units (e.g. mile, foot, inch), volume units (e.g. gallon), weight units (e.g. ounce, ton) and others (e.g. dozen). In Japanese, the character 口 can be used as quantifier, for instance to count humans, just as, for example, in French.
Lastly, the two kokuji characters with an ateji reading which are of radical 二 “two”, namely  and
and  , are for surface units (e.g. hectare); although it could here be suggested that the meaning of the radical, “two”, corresponds to the “square” (2) with which are denoted surface units, the author thinks that, simply, the character part 亜 (亞 is another form) – included in both kokuji characters – from which derives the radical 二 is read a ([a] in IPA notation), thus close to the English reading, and even closer to the French reading, of the surface unit “are” as in “hectare”. Interestingly, the two kokuji characters with an ateji reading of the radical 宀 are for the same surface units (e.g. centiare). One of the meanings of this radical being “roof”, the relation to surface units is rather clear.
, are for surface units (e.g. hectare); although it could here be suggested that the meaning of the radical, “two”, corresponds to the “square” (2) with which are denoted surface units, the author thinks that, simply, the character part 亜 (亞 is another form) – included in both kokuji characters – from which derives the radical 二 is read a ([a] in IPA notation), thus close to the English reading, and even closer to the French reading, of the surface unit “are” as in “hectare”. Interestingly, the two kokuji characters with an ateji reading of the radical 宀 are for the same surface units (e.g. centiare). One of the meanings of this radical being “roof”, the relation to surface units is rather clear.
Conclusions
The Japanese writing system is peculiar in that it is based on several distinct character sets: the kana syllabaries, the Chinese characters (kanji) and the kokuji characters. Whereas the first two sorts of characters are omnipresent in any Japanese text, it is not the case of kokuji characters. While previous works usually focus on a few selected kokuji characters, we have in this paper conducted an ontological analysis of the kokuji character group in order to formally understand the nature of these “unloved” characters, and second we have realised quantitative analyses thereof, notably measuring the distribution of kokuji characters according to character radicals and of those with an ateji reading (typically for loanwords), in an attempt to confirm trends and exhibit reasons for their generally low adoption.
One major issue with the kokuji characters is the appalling lack of support by computer systems: extremely few kokuji characters can be represented (i.e. input, output) on such devices (which is why several kokuji characters of this article had to be inserted as images). So, further investigations in this field, for instance considering the UCEJ method (Bossard 2019), are a meaningful future work.
Footnotes
Acknowledgements
The author is sincerely grateful towards the reviewers for their insightful comments and suggestions which helped to correct and improve this paper. Several characters included in this article are rendered with the “Mojikyo” font by the Mojikyo Institute and courtesy of AI-NET Corporation.