
Abstract
Introduction
Artificial intelligence (AI) has substantially influenced ophthalmology, augmenting diagnostic capabilities, improving disease monitoring, and enhancing patient outcomes through timely intervention and precision medicine approaches.1,2 Retinal diseases, such as diabetic retinopathy (DR), age-related macular degeneration (AMD), and glaucoma, are some of the leading causes of visual impairment globally.3–5 The effective diagnosis and management of these conditions frequently rely on multimodal imaging technologies and detailed clinical assessments, areas increasingly supported by AI.6,7
Large language models, advanced AI architectures designed to process and generate human-like text, have emerged as powerful tools in medicine, offering considerable potential to streamline diagnostic workflows and decision-making.8,9 Models such as GPT-4.o, Claude, and Gemini are distinguished by their capacity for multimodal integration, combining textual and visual data-processing capabilities, which is particularly relevant in the evaluation of retinal disease.10–12 Recent studies suggest that these advanced large language models could approach or even surpass human performance in specific medical assessments, such as the United States Medical Licensing Examination and board-style ophthalmology questions.13–15
Previous research into AI applications within ophthalmology has predominantly focused on image-based diagnostics, employing deep learning frameworks like convolutional neural networks for detecting conditions such as DR, glaucoma, and AMD.16,17 These models have shown high accuracy in clinical trials and real-world settings, highlighting their potential for improving diagnostic efficiency and accuracy.18,19 However, the integration of textual clinical information alongside imaging data remains relatively unexplored, representing a substantial opportunity for improvement in diagnostic precision and clinical decision-making.
Despite the rapidly expanding body of evidence supporting AI applications in ophthalmology, significant gaps persist in our understanding of how effectively multimodal large language models integrate complex clinical narratives with detailed imaging, particularly within retina-specific contexts. Specifically, the comparative effectiveness of multimodal large language models for retinal conditions using real-world data has been poorly characterized. Using a series of real-world retinal cases derived from the University of Iowa’s EyeRounds repository, the current study systematically evaluated and compared the diagnostic accuracy of 3 prominent multimodal large language models, GPT-4.o, Claude 3.7 Sonnet, and Google Gemini 2.5 Pro. 20 By examining each model’s capabilities in interpreting complex clinical narratives alongside detailed ophthalmic images, we strived to elucidate their respective strengths and limitations.
Methods
This study, carried out in March 2025, systematically evaluated and compared the diagnostic accuracy of 3 advanced multimodal large language models, GPT-4.o (OpenAI), Claude 3.7 Sonnet (Anthropic), and Google Gemini 2.5 Pro, on a curated dataset of retinal cases. All 40 retinal cases were included from the University of Iowa’s publicly available EyeRounds clinical repository, ensuring coverage of a diverse range of retinal disorders, including DR, AMD, retinal vascular disorders, and retinal detachments (RDs). 20 Each case included comprehensive clinical data encompassing detailed patient histories, thorough ophthalmic examination results, and multimodal imaging, such as fundus photographs, optical coherence tomography, and fluorescein angiography.
The selected EyeRounds cases were manually processed and organized into a structured Excel datasheet, categorizing each case by clinical history, examination details, imaging findings, and ancillary test results. Any explanatory commentary or educational annotation originally present in the repository was removed to prevent bias. The study involved publicly available, de-identified educational case data; therefore, it was exempt from institutional review board review. For evaluation purposes, the cases were presented to each large language model in 2 distinct formats. The first format, “full clinical context,” provided complete textual narratives, including patient history, examination data, descriptive annotations of imaging, and ancillary testing results. The second format, “image-only context,” presented raw imaging data exclusively without any accompanying textual descriptions, requiring the large language model to interpret the imaging findings independently.
GPT-4.o, Claude 3.7 Sonnet, and Google Gemini 2.5 Pro were assessed under both full clinical text and image-only conditions. Uniform prompts explicitly guided each model to identify relevant clinical signs and symptoms, generate appropriate differential diagnoses, determine the most likely primary diagnosis, and propose suitable treatment recommendations. All outputs from the models were collected verbatim without any postprocessing or alterations. Each EyeRounds case was presented independently to the models, and outputs were generated in a single interaction. No feedback, corrections, or case-to-case carryover occurred, ensuring that the model’s performance reflected their static capabilities at the time of evaluation, rather than iterative learning. Prompts were administered in a standardized manner using a structured spreadsheet containing complete case information. For the full clinical context condition, each row included the patient history, examination findings, and descriptive imaging annotations, which were uploaded and referenced directly in the model prompt (Figure 1). For the image-only condition, the raw clinical images were provided, in addition to patient history and examination findings that were not present in the clinical image. A researcher sequentially presented each case to the large language model, which was instructed to generate its diagnostic impression, differential diagnoses, signs and symptoms, and treatment recommendations. Models were not permitted to reference external resources or revisit previous cases.

Example of large language model input and output for determining the key signs and symptoms associated with Case 1 using GPT-4.o.
Each large language model’s response underwent independent evaluation by 2 trained reviewers using a standardized scoring protocol. Diagnostic accuracy was determined as a binary outcome, defined by whether the model’s primary diagnosis exactly matched the reference diagnosis provided by EyeRounds. Partial matches (eg, responses containing some correct features but not the correct final diagnosis) were not given partial credit. Accuracy in identifying clinical signs and symptoms, differential diagnoses, and recommended treatments was assessed based on the proportion of matches with the reference content, with class-level matches accepted for treatments (eg, if the reference was corticosteroids, a model response of ‘prednisone’ was counted as correct) (Table 1). For differential diagnoses, the proportion of matches listed by each model was recorded in comparison to the EyeRounds reference diagnoses. Additionally, in cases where the primary diagnosis was incorrect, performance was assessed based on whether the correct reference diagnosis appeared within the model’s differential list. The models were not prompted to provide descriptive explanations of findings; rather, they were evaluated solely on their ability to generate diagnostic outputs from the provided case materials.
Comparison of Claude, Gemini, and GPT-4.0 Responses for Retina Case #10 (Central Retina Artery Occlusion).
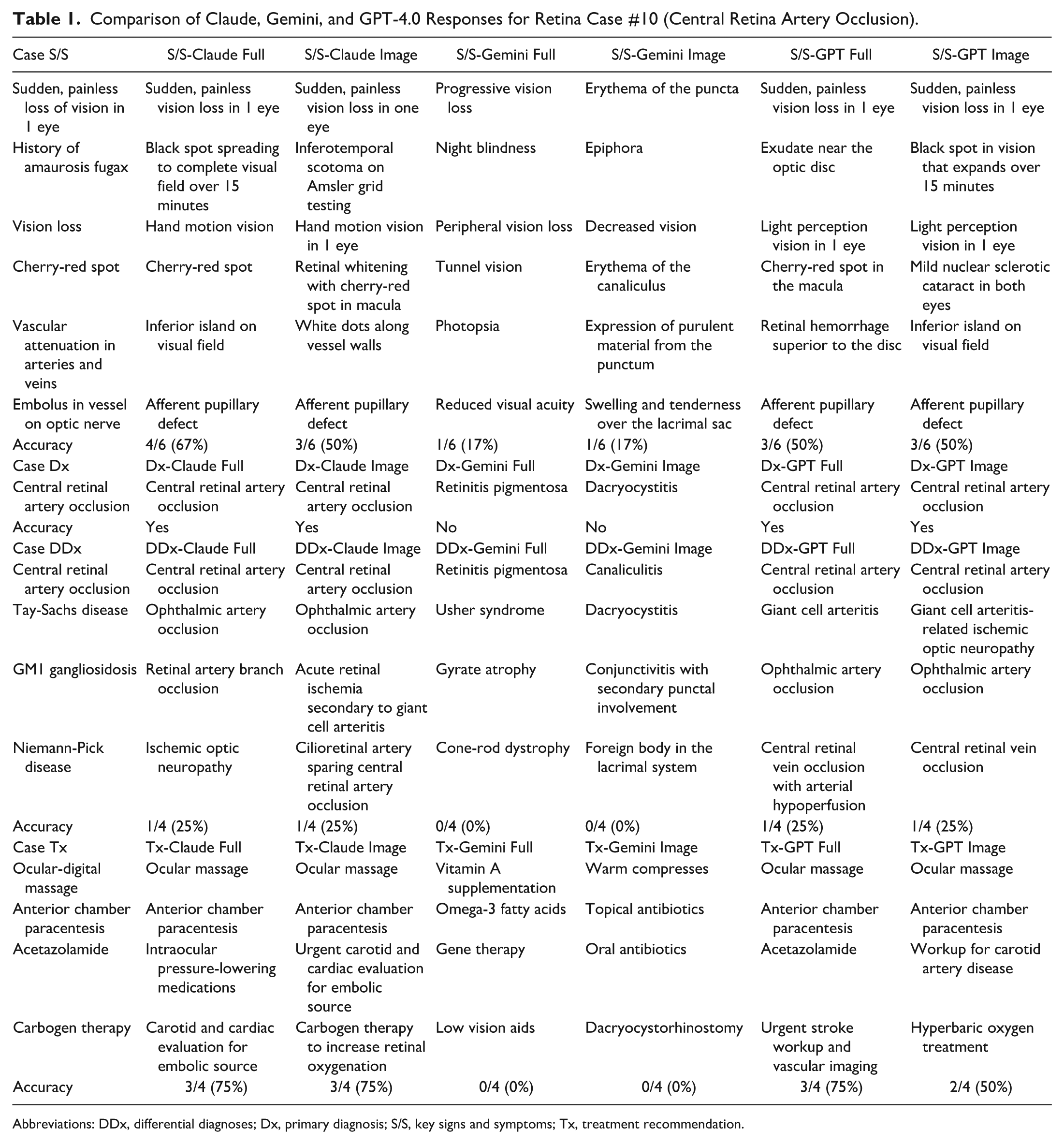
Abbreviations: DDx, differential diagnoses; Dx, primary diagnosis; S/S, key signs and symptoms; Tx, treatment recommendation.
All available retina cases within the Iowa EyeRounds were used in this multimodal clinical reasoning study. Statistical analysis was performed with SPSS (version 29, IBM Corp), with a significance level of α = 0.05. The primary diagnostic accuracy differences across the 3 models were assessed using Cochran Q test for related samples, followed by post-hoc pairwise comparisons using McNemar tests with Bonferroni correction for multiple comparisons. For continuous clinical reasoning performance metrics (signs/symptoms recognition, differential diagnosis generation, and treatment recommendations), repeated measure analysis of variance was used to compare model performance within each metric. Greenhouse-Geisser correction was applied when sphericity assumptions were violated. Within-model performance differences between full case and image-only conditions were evaluated using paired sample t test for continuous variables and McNemar test for dichotomous diagnostic outcomes. Wilcoxon signed rank tests were used when normality assumptions were violated. Effect size was calculated using Cohen d for significant differences. Interrater agreement between models and across modalities was assessed using Cohen kappa (κ) statistics with 95% CIs. With a sample size of 40 cases, the power analysis showed that paired t tests have 87.3% power to detect medium effects (d=0.5), repeated measures analysis of variance has 43.4% power for medium effects (η²=0.06), and correlations achieve 73.1% power for moderate associations (r=0.4). McNemar tests reach 49.1% power with 15 discordant pairs. The current study can reliably detect differences with 80% power when Cohen d ≥0.53 for paired comparisons, η² ≥0.13 for analysis of variance, and r ≥0.42 for correlations. This sample size should be adequate for detecting clinically meaningful differences in the diagnostic performance of large language models.
Results
Significant differences in primary diagnostic accuracy were identified among the models. With access to the full clinical context, GPT-4.o achieved the highest accuracy, at 78.4%, closely followed by Claude, at 73.0%; both significantly surpassed Gemini’s 29.7% accuracy (Cochran Q=24.33, P < .001) (Table 2, Figure 2). In the image-only condition, Claude demonstrated the highest accuracy, at 73.7%, significantly outperforming both the 63.2% accuracy of GPT-4.o and Gemini’s 31.6% (Cochran Q=21.90, P < .001, Figure 2).
Comparative Performance of Multimodal Large Language Models in Clinical Reasoning Match.
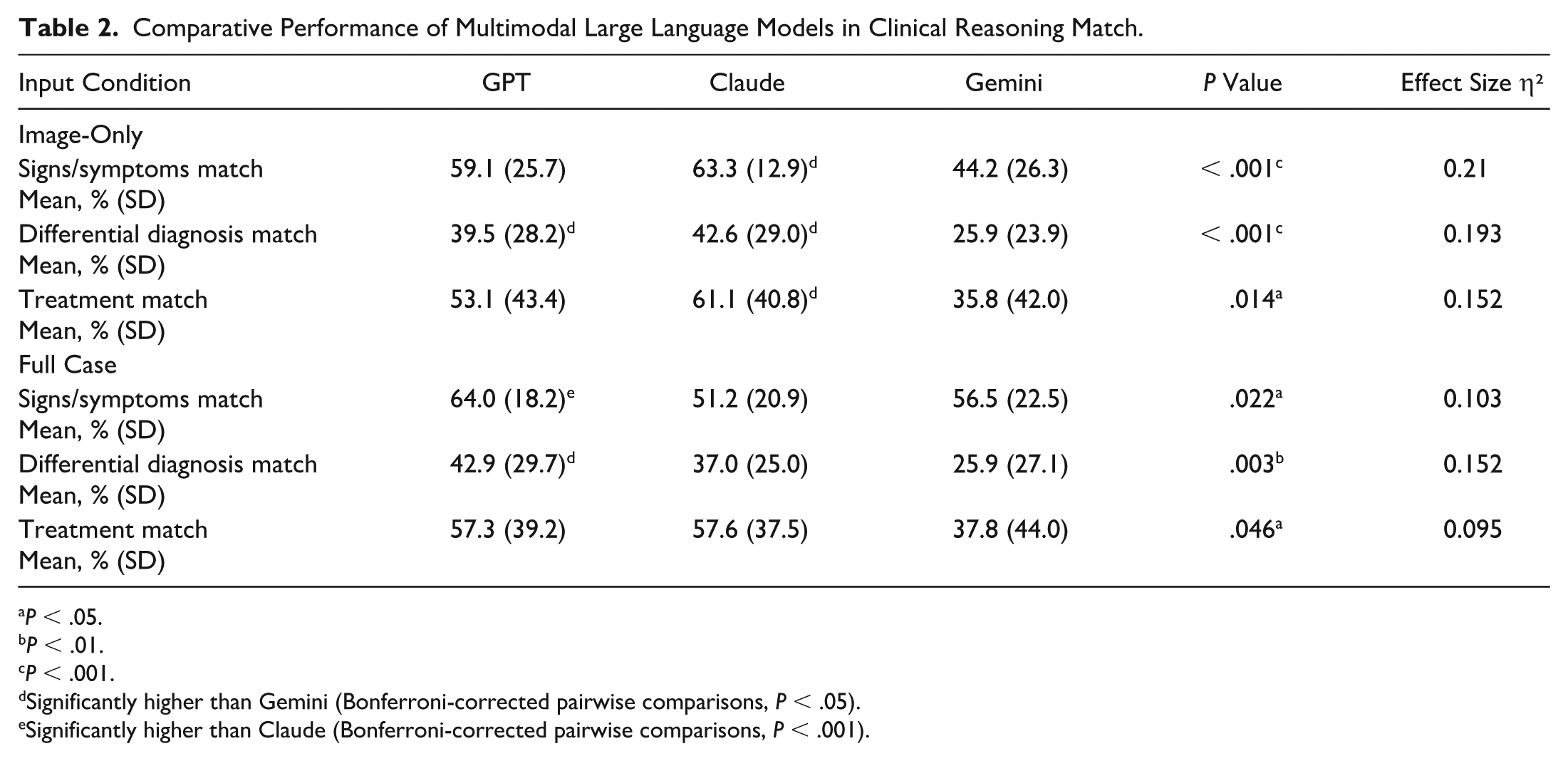
P < .05.
P < .01.
P < .001.
Significantly higher than Gemini (Bonferroni-corrected pairwise comparisons, P < .05).
Significantly higher than Claude (Bonferroni-corrected pairwise comparisons, P < .001).
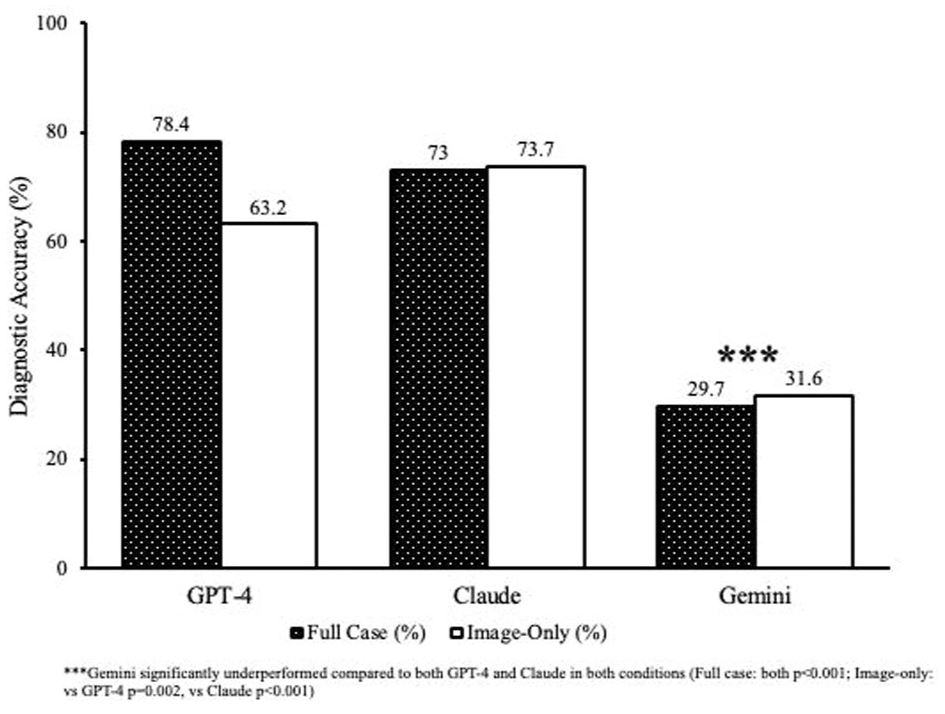
Primary diagnostic accuracy of the large language model and condition.
When analyzing recognition of signs and symptoms, GPT-4.o’s 64.0% accuracy significantly outperformed Claude’s 51.2% under the full clinical context condition (P < .001). Gemini demonstrated intermediate performance, at 56.5%. Conversely, Claude excelled in the image-only condition, achieving 63.3% accuracy, which was significantly better than Gemini’s 44.2% (P = .002); GPT-4.o displayed intermediate performance, at 59.1%. Notably, Claude significantly improved diagnostic accuracy from 51.2% in the full clinical context to 63.3% in the image-only condition (Cohen d=−0.663, P < .001), highlighting its unique visual diagnostic capability.
Differential diagnosis accuracy presented a notable challenge for all large language models, but GPT-4.o (42.9%) and Claude (37.0%) consistently and significantly outperformed Gemini (25.9%) (P ≤ .011) across both evaluation modalities. Regarding treatment recommendations, Claude achieved the highest accuracy in the image-only condition (61.1%), while GPT-4.o provided superior treatment accuracy in the full clinical context (57.3%). Both models significantly exceeded Gemini’s 35.8% accuracy (P < .05).
Substantial intermodel agreement was noted between GPT-4.o and Claude for image-based diagnoses (κ=0.658, P < .001) (Table 3). In contrast, Gemini demonstrated minimal agreement with both GPT-4.o and Claude (κ≤0.196), emphasizing fundamental performance differences among these multimodal large language models.
Cohen’s Kappa Analysis of Large Language Model Diagnostic Agreement.
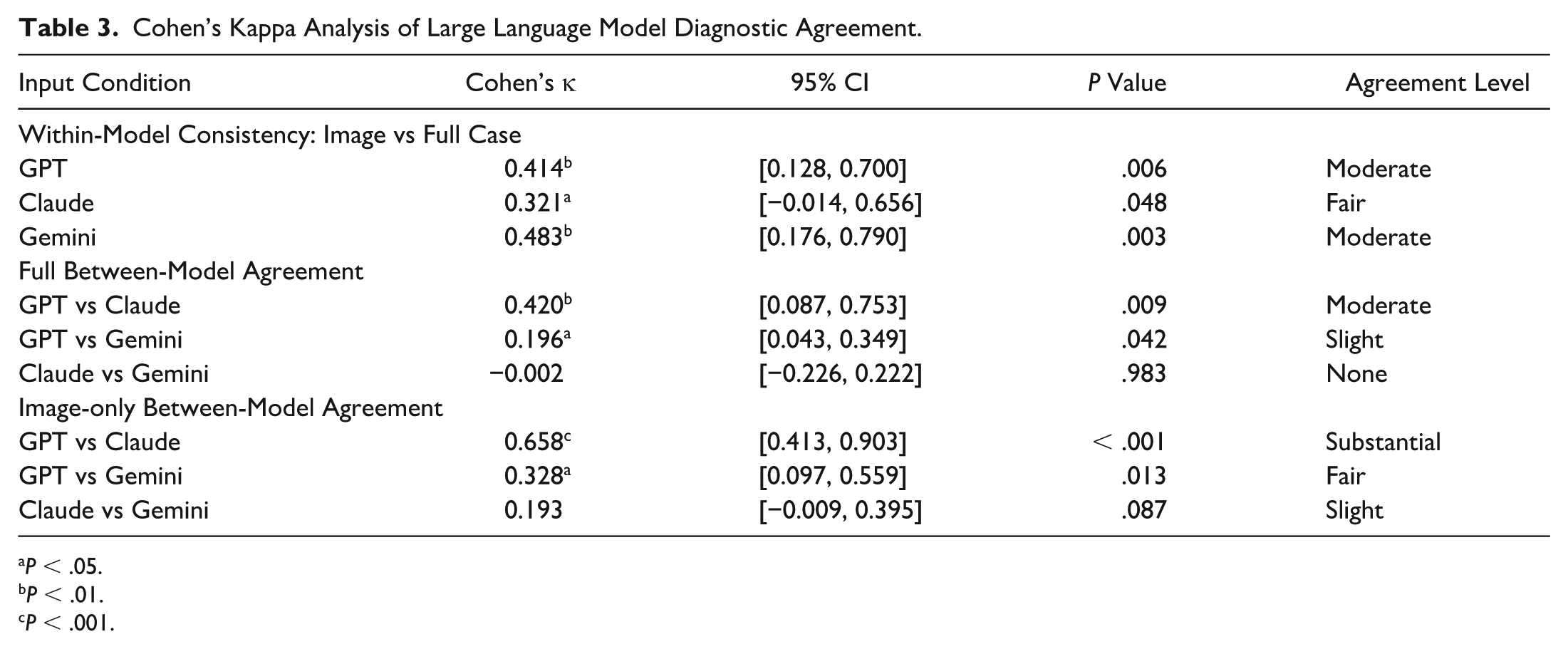
P < .05.
P < .01.
P < .001.
Conclusions
This study underscores the robust diagnostic performance of multimodal large language models in interpreting real-world retinal cases, particularly highlighting the capabilities of GPT-4.o and Claude 3.7 Sonnet. GPT-4.o demonstrated superior diagnostic accuracy (78.4%) when provided with comprehensive clinical narratives, aligning closely with previous research that emphasized its strong capabilities in complex clinical reasoning and integration of detailed patient histories.10,21,22 Claude notably excelled in the image-only condition, achieving a diagnostic accuracy of 73.7%, consistent with previous studies using deep learning algorithms that reported similarly high accuracy levels (>70%) for retinal conditions such as DR and AMD.6,16,17
Intermodel agreement analyses revealed substantial consistency between GPT-4.o and Claude in image-based diagnostic decisions (κ=0.658). However, minimal agreement involving Gemini (κ≤0.196) highlighted fundamental differences in model diagnostic approaches. Such discrepancies underscore the necessity for rigorously selecting and validating AI tools tailored specifically to ophthalmic clinical tasks before their deployment, ensuring alignment with clinical needs and expectations.23,24
Moreover, Gemini consistently demonstrated significantly lower diagnostic performance across all evaluation metrics, achieving only 29.7% accuracy in the full-context condition and 31.6% in the image-only condition. Such limitations suggest intrinsic weaknesses within Gemini’s model architecture or potential deficits in ophthalmology-specific training data. Similarly, previous studies have reported Gemini’s substantial performance challenges in medical contexts. For instance, Pal and Sankarasubbu 25 found that Gemini achieved significantly lower accuracy (approximately 61%) compared with the 88% achieved by GPT-4V (GPT4.o with additional pretrained vision capabilities), with notable reasoning errors and hallucinations in multimodal medical assessments. Furthermore, Yan et al 26 documented Gemini’s performance as below random chance in specialized medical visual question-answering tasks, underscoring the model’s inherent reliability concerns. Additionally, Carlà et al found that Gemini correctly suggested surgical approaches for RD cases in only 70% of instances compared with the 84% achieved by ChatGPT-4. Notably, Gemini failed to generate any surgical plan in 10% of the evaluated cases. In addition, Gemini also demonstrated significantly lower Global Quality Scores (mean, 3.5) relative to ChatGPT-4 (mean, 4.2), underscoring its limitations in handling complex ophthalmic imaging and planning scenarios. 27
Claude’s unique improvement from full-context (51.2%) to image-only conditions (63.3%) highlights its specific strength in visual interpretation, suggesting potential use in telemedicine and remote ophthalmic screening, particularly in underserved settings. The superior performance with image-only inputs has profound implications for teleophthalmology and remote screening programs, areas increasingly critical for early detection and management in underserved populations or regions lacking specialist access. This modality-specific strength aligns with landmark studies demonstrating the effectiveness of AI-driven retinal imaging analyses in screening for DR and other retinal diseases.3,6,16,17 Claude’s superior performance may stem from its advanced vision transformer architecture or alignment strategies, which emphasize carefully curated multimodal training datasets and reinforced learning from human feedback, optimizing its ability to accurately interpret ophthalmic images even in the absence of textual context.28,29
In the current study, superior diagnostic performance was demonstrated by Claude compared with GPT models, achieving 73.7% accuracy in image-only scenarios for retinal disease diagnostics. In contrast, Jiao et al 30 reported GPT-4.o as the best-performing model for corneal diseases, with an accuracy of 80.0%, while Claude achieved slightly lower accuracy, at 70.0%. The divergent outcomes between the current retina-focused study and Jiao et al’s cornea-focused research highlight important modality-specific strengths among large language models. Particularly, Claude’s unique improvement when processing image-only cases suggests a pronounced capability in interpreting ophthalmic images, such as fundus photographs, which are more routinely used in retina practice. In contrast, corneal diagnostics rely more heavily on slitlamp photography, which is less common and might not be as effectively represented in Claude’s training corpus. Thus, Claude’s performance advantage may be attributed to the greater prevalence and clarity of retinal imaging data, enhancing its image-processing proficiency. Understanding these nuances is crucial for selecting and optimizing AI models tailored to specific clinical ophthalmologic applications, thus offering the potential to improve patient outcomes with enhanced diagnostic accuracy.
The clinical implications of these findings are significant, particularly for retinal practice. Retinal diseases, including DR, AMD, and RD, often require prompt diagnosis and accurate monitoring to preserve visual function and prevent irreversible blindness.16,17 The demonstrated capability of GPT-4.o to effectively synthesize detailed clinical narratives makes it a powerful adjunct tool for comprehensive patient assessments, especially in complex cases where nuanced clinical histories are essential.
The reliability of these large language models must be carefully assessed, given the documented risks of AI-generated hallucinations, outputs that are plausible yet clinically inaccurate and which could potentially harm patient care. 31 Transparency in model limitations and careful clinician oversight remain essential to prevent overreliance on these tools, particularly in cases where AI systems are tasked with interpreting complex multimodal clinical inputs without adequate human verification. Therefore, to ensure accuracy, reliability, and patient safety in ophthalmic practice, ongoing education and structured integration of AI into clinical workflows are imperative.
Despite promising primary diagnostic accuracy, making a differential diagnosis, which inherently requires nuanced clinical reasoning and the simultaneous consideration of multiple potential conditions, remained challenging for all 3 models (GPT-4.o: 42.9%, Claude: 37.0%, Gemini: 25.9%). These findings are consistent with previous research that similarly identified challenges for AI models in generating comprehensive differentials, especially in ophthalmology.7,21
This study has several limitations that should be acknowledged. First, the relatively modest sample size may limit the generalizability of the findings, particularly given the broad spectrum of retinal pathologies encountered clinically. Larger studies using more diverse and extensive datasets are necessary to confirm these results. This study was also conducted at a time when GPT-4.o and Claude 3.7 represented the most advanced large language models available. Since then, newer versions, such as GPT-5.o and Sonnet 4.1, have been released. Although these updates offer incremental performance improvements, they do not fundamentally alter the core capabilities under evaluation, namely the first generation of multimodal models capable of processing both ophthalmic images and clinical text. Future studies evaluating these newer models will be important to determine whether these improvements translate into meaningful differences in ophthalmic performance. In addition, the complexity and variability of real-world clinical decision-making may not be fully captured by our study’s retrospective and standardized experimental design. Prospective validation studies using larger, diverse datasets are essential to comprehensively validate these findings and assess these models’ practical use in clinical settings.32,33
Another limitation involves potential previous exposure of the publicly available EyeRounds cases during model training, which could inflate the observed diagnostic accuracies. Future studies should explicitly address and mitigate dataset overlap to ensure genuine model evaluation. Additionally, this study did not stratify diagnostic performance by retinal disease subtype (eg, DR, AMD, RD, vascular occlusions). Although the dataset encompassed a broad spectrum of cases, the number of examples within each category was insufficient to permit meaningful subgroup analyses. Future studies with larger and more diverse datasets will be necessary to determine whether model performance varies systematically across different categories of retinal diseases. Lastly, the structured prompts and high-quality imaging provided in this controlled setting might not reflect typical clinical variability, possibly leading to an overestimation of real-world performance. Further investigation into AI-related inaccuracies, patient safety implications, and clinician acceptance will be essential before widespread clinical implementation.
In conclusion, this study highlights the diagnostic capabilities of GPT-4.o, Claude, and Gemini for retinal diseases, with each model demonstrating distinct modality-specific strengths. GPT-4.o excels with comprehensive clinical narratives, while Claude shows superior performance with image-only data. These findings emphasize the necessity of thoughtful selection and integration of multimodal AI tools in clinical ophthalmology. Future advancements should prioritize enhancing visual reasoning and differential diagnosis capabilities in retinal disease management to maximize clinical effectiveness and improve patient care.
Footnotes
Acknowledgements
Odum Institute for Research in Social Science, University of North Carolina at Chapel Hill, Chapel Hill, NC, USA.
Ethical Approval
This study was deemed exempt from institutional review board review, as it involved the use of publicly available, de-identified clinical cases from the University of Iowa’s EyeRounds repository.
Statement of Informed Consent
No human subjects were directly involved, and no identifiable patient data were used.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.