
Abstract
Advances in microscopy have increased output data volumes, and powerful image analysis methods are required to match. In particular, finding and characterizing nuclei from microscopy images, a core cytometry task, remains difficult to automate. While deep learning models have given encouraging results on this problem, the most powerful approaches have not yet been tested for attacking it. Here, we review and evaluate state-of-the-art very deep convolutional neural network architectures and training strategies for segmenting nuclei from brightfield cell images. We tested U-Net as a baseline model; considered U-Net++, Tiramisu, and DeepLabv3+ as latest instances of advanced families of segmentation models; and propose PPU-Net, a novel light-weight alternative. The deeper architectures outperformed standard U-Net and results from previous studies on the challenging brightfield images, with balanced pixel-wise accuracies of up to 86%. PPU-Net achieved this performance with 20-fold fewer parameters than the comparably accurate methods. All models perform better on larger nuclei and in sparser images. We further confirmed that in the absence of plentiful training data, augmentation and pretraining on other data improve performance. In particular, using only 16 images with data augmentation is enough to achieve a pixel-wise F1 score that is within 5% of the one achieved with a full data set for all models. The remaining segmentation errors are mainly due to missed nuclei in dense regions, overlapping cells, and imaging artifacts, indicating the major outstanding challenges.
Introduction
Microscopes collect images from scales of atoms and molecules to cells and tissues. While visual inspection can guide intuition, automated image processing is central for distilling understanding from the gathered data. Computational analysis approaches have evolved together with the instrumentation, with a plethora of methods developed to date.1,2 However, due to the high dimensionality, large data volumes, and complex signals in high-content microscopy, image analysis remains challenging to automate in general. 3 Perhaps the most important and most thoroughly studied task is identifying nuclei in cell microscopy images, 4 a common foundational step in many analysis workflows. As generating brightfield images is relatively quick and noninvasive, it would benefit many protocols to be able to segment nuclei directly from them. However, this rewarding task remains challenging 5 and is therefore the main focus of this work.
Over the last decade, deep learning-based approaches have advanced image classification, 6 object detection, 7 and segmentation. 8 The cell microscopy analysis community and the larger cytometry field in general have taken note and exapted the useful ideas.9–11 One of the earliest popular approaches that utilized convolutional neural networks for nuclear segmentation from fluorescence images was DeepCell. 12 Many more have been proposed since.13–20 U-Net, 21 later superseded by U-Net++, 22 has also been introduced as a plugin for ImageJ 23 to make the models accessible for biological image analysis. Overall, classical methods have been outperformed by deep learning techniques for nuclear segmentation, justifying the substantial interest in them. 4 However, while segmenting the more challenging brightfield cell images has also been attempted,5,24 there remains a performance gap compared with fluorescence segmentation.
The rapid development of deep learning has continuously provided new insights that could also impact practical solutions.8,22,25–27 The key advances in image segmentation have come from properly accounting for context. 28 The early approach was to use the features extracted in earlier layers as inputs into deeper ones,21,29 followed by considering a broader context for the segmented object.22,25,30,31 Training was further improved by data augmentation,32,33 and objects of different scales better handled with scale-robust architectures.30,31 These recent ideas and advanced networks could improve nuclear segmentation performance as well, but have not yet been utilized for this purpose.
Here, we tackle the nucleus segmentation problem in brightfield and fluorescence images with current state-of-the-art deep learning approaches. We evaluate the architectures of U-Net++, 22 Deeplabv3+, 30 Tiramisu, 25 and a modified version of U-Net, 5 as well as a novel streamlined PPU-Net architecture, for identifying nuclei. To gain a deeper understanding, we investigate the causes of variable performance across cell lines and images, the sources of error, and the data requirements for training successful segmentation models.
Materials and Methods
To evaluate modern deep learning methods for the nuclear segmentation task, we use two data sets containing a total of eight different cell lines, five alternative neural network architectures, and a unified training process that includes models with different amounts of training data, transfer learning, label smoothing, data augmentation, and multiple evaluation metrics (Box 1).
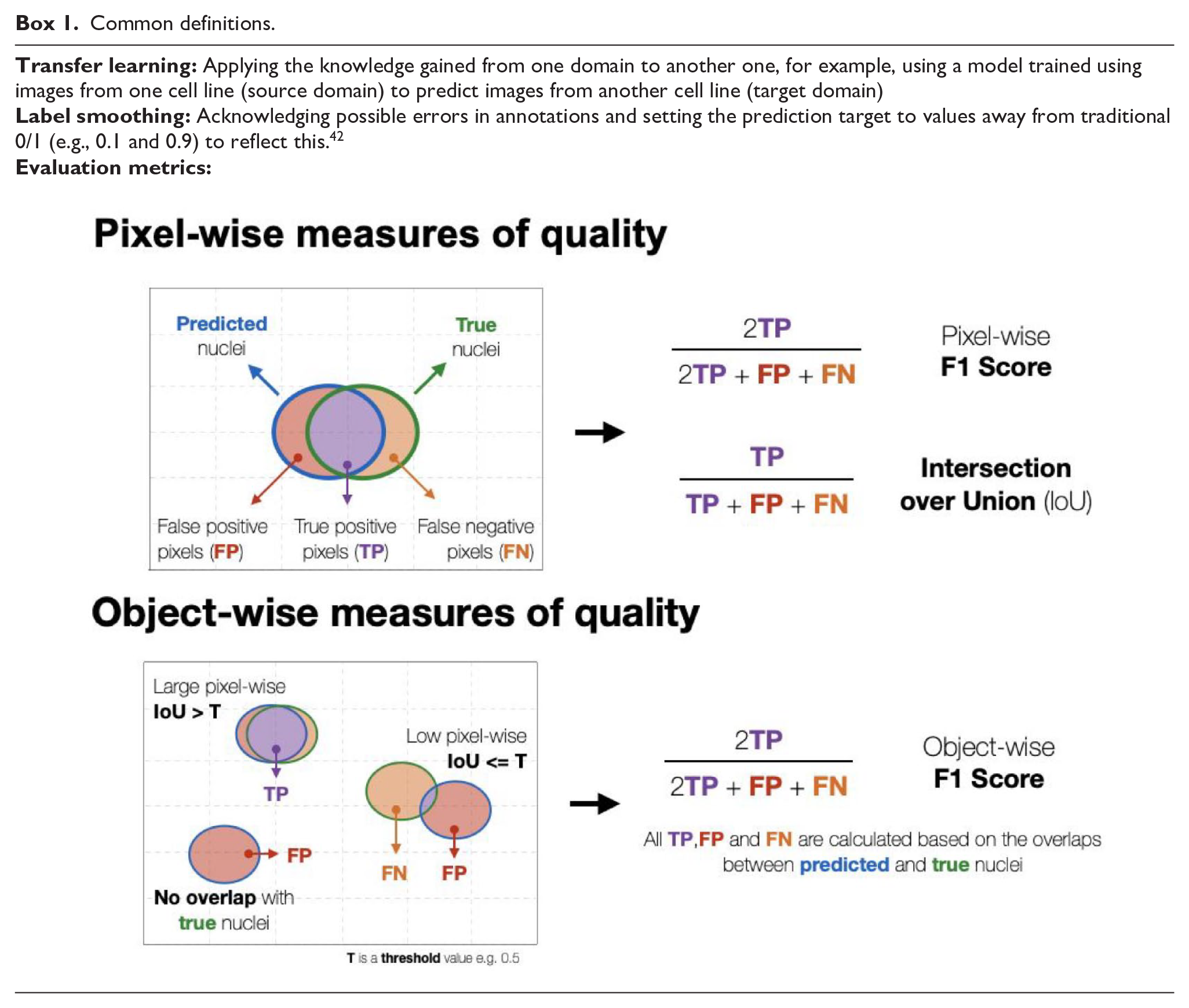
Common definitions.
Network Architectures
We evaluated four convolutional neural networks that cover the successful architectural features for image segmentation: skip connections, atrous convolution, pyramid pooling, and dense blocks. All models are end-to-end trained encoder–decoder networks with a downsampling contraction path, an upsampling expansion path, and a bottleneck to connect them. Inspired by the surveyed literature, we also propose a new architecture (PPU-Net) to strike a balance between model size and performance. We describe each of the models in detail below.
As a baseline, the successful U-Net
21
has already been adapted for brightfield nuclei segmentation.
5
The architecture has four main components: a contraction path, an expansion path, a bottleneck to connect them, and skip connections to enhance localization by transferring high-resolution features from the contraction to the expansion path (
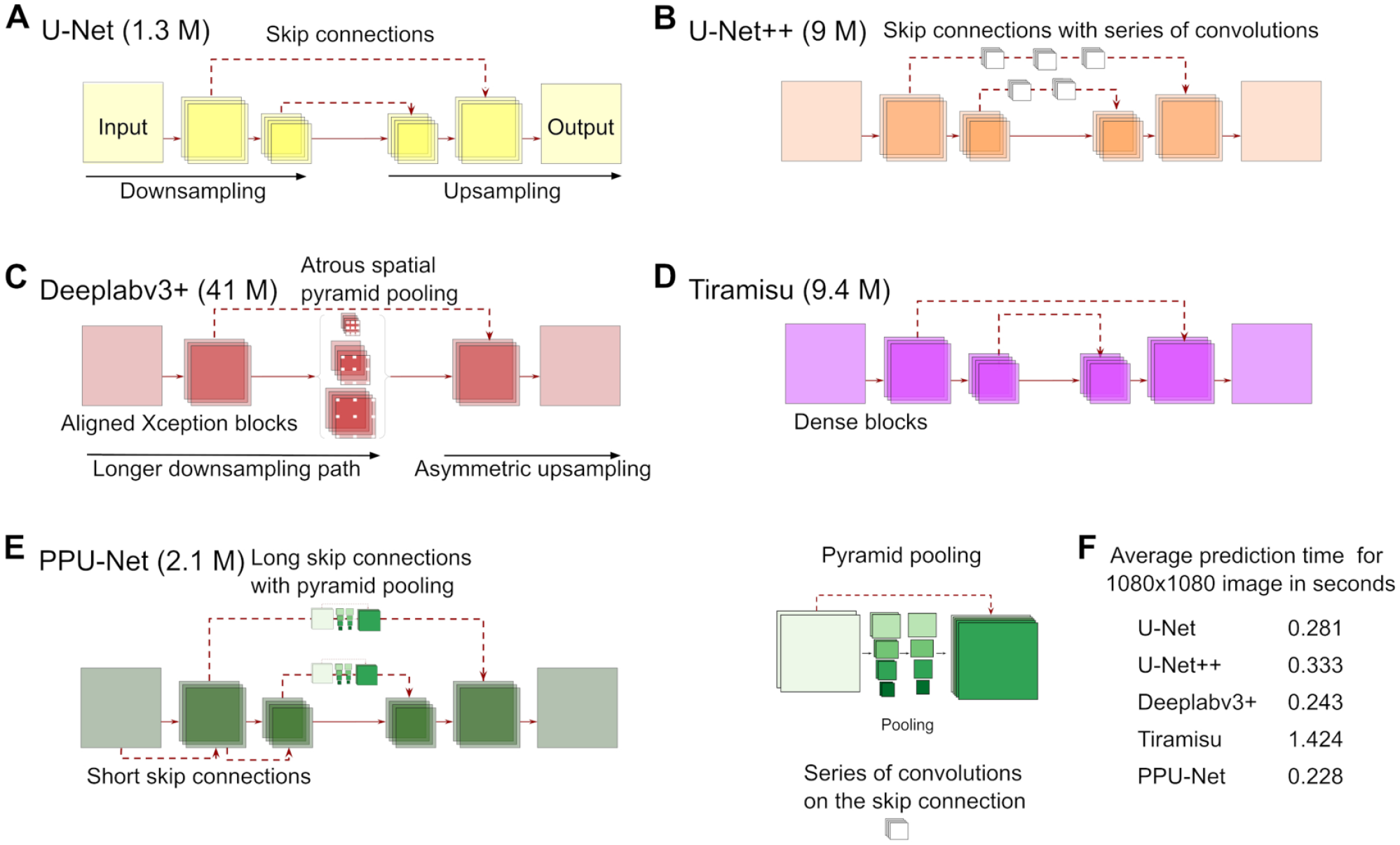
Convolutional neural network architectures. (
U-Net++
22
enriches the skip links between the contraction and expansion paths. To achieve this, a series of dense convolutions are added to the encoder feature maps, and their output concatenated to the decoder counterparts (
The Deeplab family of models has evolved to be some of the most sophisticated in the field8,26,27,30). Like the other considered models, its most recent member, Deeplabv3+, has the form of an encoder–decoder network, with the Xception backbone
35
for sharper boundaries of segmented objects. The published encoder module consists of four parts: entry flow, middle flow, exit flow, and atrous spatial pyramid pooling (
The Tiramisu architecture
25
uses dense blocks
37
for segmentation (
Inspired by the diversity of successful ideas in the field, we designed our own pyramid pooling U-Net architecture (PPU-Net) (
The PPU-Net consists of a contraction path, an expansion path, a bottleneck between them, and a skip pathway connection that link the features in the contraction path to the ones in the expansion path. There are 10 blocks in the contraction path, 10 blocks in the expansion path, and 2 blocks in the bottleneck between the paths. A block comprises two 3 × 3 convolutions, each of which is followed by batch normalization and ReLU activation layers. Each convolution layer in such a block has 64 filters. The contraction path block output is processed by the pyramid pooling module in the skip pathway, and concatenated to the input of the corresponding block in the expansion path. This module integrates information from five different scale levels by average pooling the feature maps with pool sizes of 16 × 16, 8 × 8, 4 × 4, 2 × 2, and 1 × 1 and strides that equal the pool size. The output of each pooling level is processed by sixteen 1 × 1 convolutions, followed by batch normalization and ReLU activation layers. The output is rescaled bilinearly to match the input dimensions, and concatenated with the input again (
Data
Two data sets were used in this study with a total of eight different cell lines. Their provenance has been described previously,
5
and we briefly repeat this here. First, human cervical cancer cells (HeLa), epithelial cells from kidney tissue of adult dogs (MDCK), human hepatocellular carcinoma cells (HepG2), human breast cancer cells (MCF7), mouse embryonic fibroblast cells (NIH3T3), human alveolar basal epithelial cells (A549), and human fibrosarcoma (HT1080) were seeded into collagen type 1-coated CellCarrier-384 Ultra Microplates (PerkinElmer, Waltham, MA; cat. 6057700) using 48 wells for each. The cells were fixed in formaldehyde (Sigma, St. Louis, MO; cat. 252549) and stained with 10 µg/mL Hoechst 33342 (Thermo Fisher, Waltham, MA; cat. H3570). Images were acquired using a 20× water immersion objective on an Opera Phenix high-content screening system (PerkinElmer) in confocal mode for both brightfield and fluorescence modalities. A total of 3024 images of size 1080 × 1080 pixels (1 pixel = 0.59 µm) were acquired for each modality, with nine fields of view from each well (432 combined) for each of the seven cell lines, and 353 cells in each field of view, on average (
Second, human prostate adenocarcinoma (LNCaP, sourced from ATCC) cells were seeded into the 384 wells of a CellCarrier Ultra (PerkinElmer) microplate, fixed in formaldehyde, and stained using DRAQ5 fluor (Abcam, Cambridge, United Kingdom) to label nuclear DNA. A total of 784 images of 2556 × 2156 pixels (1 pixel = 0.325 µm) were acquired using a 20× objective in both confocal mode to capture fluorescence images and brightfield mode on a CellVoyager 7000 (Yokogawa, Tokyo, Japan) instrument, giving an average of 681 cells per image (
Harmony image analysis software (PerkinElmer) with expert quality control to optimize parameters was used to generate ground truth masks from fluorescence images of nuclear stains for the seven cell lines, as described in Fishman et al. 5 To establish ground truth fluorescence nuclear boundaries for LNCaP, we applied the U-Net++ model previously trained to segment fluorescence micrographs from the seven cell line images 5 on these data.
Training
All the experiments were conducted using a Tesla V100-PCIE-16GB Graphics Processing Unit, and the architectures were built using the Keras framework with TensorFlow backend v1.14.0. 38
Model Comparison
The five models (U-Net, U-Net++, Deeplabv3+, Tiramisu, and PPU-Net) were trained on the seven cell line data set (separately on fluorescence and brightfield images), using 2016 images for training, 504 images for validation, and 504 for testing; and on LNCaP, using 628 images for training, 78 for validation, and 504 for testing. The Adam optimizer 39 was used to optimize binary cross-entropy loss. Each architecture was trained for up to 500 epochs with (10,000/batch size) iterations. The learning rate was selected as described below, and reduced by a factor of 10 once the validation loss was not improving for 10 consecutive epochs. Training was terminated completely if validation loss was not improving for 20 consecutive epochs. Batches of size 16, 8, 8, 4, and 8 images were used for U-Net, U-Net++, Deeplabv3+, Tiramisu, and PPU-Net networks, respectively, chosen based on the available processing budget.27,40 All networks have an input size of 288 × 288 pixels.
Learning Rate Selection
Learning rate is among the most critical hyperparameters for training neural networks.
41
We used the strategy introduced in Smith
40
to select it separately for each model. We monitored loss during training each model for a few epochs, while gradually increasing the learning rate from a very small value (1e-10) to a very large one (10). The candidate optimal learning rate was manually identified as the value that gives the largest change in loss (
Effect of Training Data Set Size
To simulate situations in which a data set of a few images is available, different models using an increasingly different number of images were trained. We randomly extracted 1, 2, 4, 8, 16, 32, 64, and 286 images of the A549 cells from the seven cell line data. Those data sets are used to train seven models from each network architecture. The same models are also trained two more times, once with label smoothing and another time with data augmented using five basic data augmentation techniques (horizontal flip, vertical flip, and rotations of 90°, 180°, and 270°). The models were evaluated using the A549 cell line held-out data.
Smoothing Factor Selection
In label smoothing, the cross-entropy loss is optimized against soft targets.
42
The targets were softened such that the positive label 1 is reduced by a smoothing factor and the negative label 0 is increased by the same factor. We selected the best smoothing factor by conducting a grid search on models trained using factors of 0.05, 0.10, 0.15, and 0.20; selected the best performing of each architecture; and evaluated them on held-out data (
Effect of Architecture Selection
To test the effect of making different selections for network architecture, we evaluated three aspects that distinguish U-Net from U-Net++. First, we doubled the number of U-Net pathway connections. Second, we added batch normalization 33 to the vanilla U-Net. Third, we increased the number of connections as well as introduced batch normalization, and further modified the number of filters in the convolution layers. We gradually increased the number of filters in the contraction path to be 64, 128, 256, and 512 filters while decreasing them symmetrically in the expansion path. Finally, we excluded half of the U-Net++ convolutions in the skip connection layers.
Transfer Learning
To evaluate the models’ performance across domains, we fine-tuned a model trained on a source domain (one data set) using images from the target domain (another data set), as well as using images from both source and target domains. In both cases, we used an increasing number of images (1, 2, 4, 8, 16, 32, 64, and 128) to fine-tune the model. When fine-tuning on images from multiple domains, the same number was picked from both domains. We examined two sets of source and target domains. First, we used six cell lines from the seven cell line data set as the source domain and the remaining cell line as the target domain, and repeated for each cell line, introducing a small domain shift of the different line, but still considering images from the same acquisition experiment. Second, we used the LNCaP data set as a source domain and the seven cell line data collected on another instrument as a target domain, introducing a large domain shift of the imaging instrumentation and laboratory undertaking the work. We conducted the experiments of this section on the lightest model (U-Net), as we expect domain shift, rather than model differences, to dominate quality.
Effect of Number of Training Focal Planes
The LNCaP data set was used to learn about the impact on segmentation performance with different numbers of unique focal planes as network input. To keep the model’s number of parameters constant, the number of input channels was fixed to nine, and the number of input focal planes was varied from nine copies of a single plane to nine different planes. The order in which to add planes was experimentally determined. First, we trained a different model for each plane and picked the best input plane based on evaluation. Then, we repeated the experiment to pick the next best plane out of eight possible variants in addition to the previously picked one.
Postprocessing and Evaluation
To evaluate models, we first postprocessed the image probability maps they produce. All results are based on pixel-level outputs binarized at a 0.5 cutoff unless detailed otherwise. Objects are detected by clustering the interconnected positive pixels into objects using measure.label from the skimage package. 43 We filtered out objects smaller than 25 pixels and filled out holes smaller than 25 pixels using remove_small_objects and remove_small_holes, respectively, from the same package.
We used both pixel-wise and object-wise metrics (Box 1) to quantify model performance. The accuracy and F1 score used for pixels are standard in machine learning. 5 To quantify object-level accuracy, we measure the intersection over union (number of pixels in intersection of two objects divided by number of pixels in their union [IoU]) for pairs of segmented and ground truth objects, and consider a ground truth object detected at an IoU threshold if there is a segmented object with an IoU value to it above the threshold. We report the F1 score for object detection across IoU thresholds ranging from 0.5 to 0.95 with a step of 0.05, as well as averaged over these thresholds (object-wise F1 score), as established earlier. 4 We also record the number of merges (more than one ground truth object overlaps a predicted one), splits (a single object in the ground truth overlaps multiple predicted objects), and missed objects (ground truth objects that are not detected). To detect splits and merges, which lead to a small object overlap by definition, we used an IoU threshold of 0.1. To detect missed objects, we used an IoU threshold of 0.6, which gives a good balance between strict overlap and not missing objects entirely.
Finally, we assigned a likely cause of error to mislabeled pixels. First, we assigned errors to noisy input data if at least four out of five models agree on the same prediction in a fluorescence image that is opposite to the ground truth label, and calculate the fraction of errors that these pixels account for. Second, to quantify the error contributed by imaging artifacts, we manually annotated artifacts in 20 images and recalculated performance outside those anomalous regions to derive a difference in error that can then be ascribed to the artifacts.
Results
We assessed the performance of four state-of-the-art and one novel segmentation model on the seven cell line and LNCaP data sets (
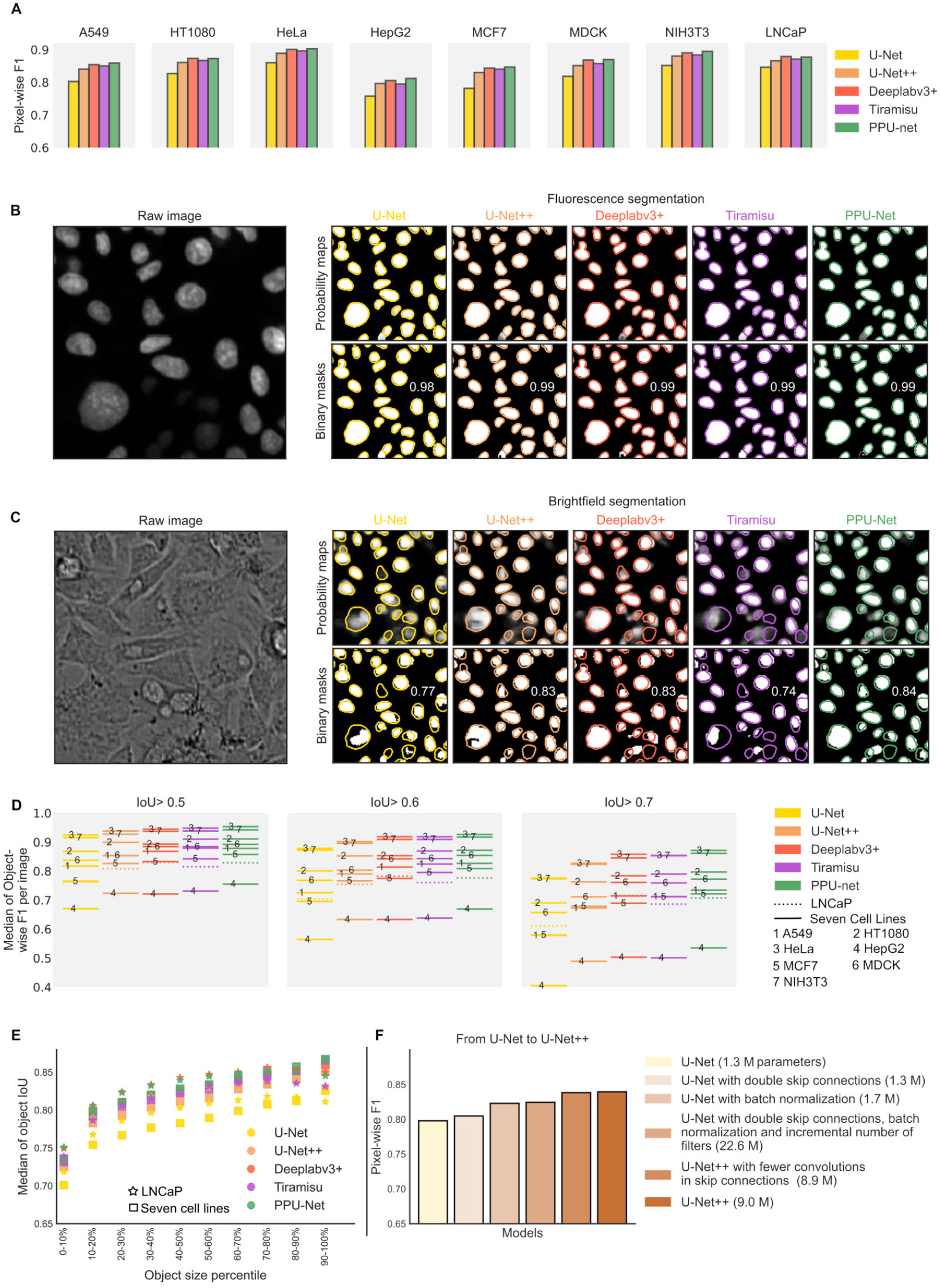
Comparison of models’ performance. (
Model Performance on Brightfield Images
Unlike for fluorescence images, models’ performances on brightfield images have a wider range. The methods achieved pixel-wise F1 scores of 81.3%, 85.0%, 86.2%, 85.6%, and 86.5% for U-Net, U-Net++, Deeplabv3+, Tiramisu, and PPU-Net, respectively (
Next, we assessed object segmentation performance, using the area intersection over union (“IoU,” Materials and Methods, Box 1
4
) to identify correctly segmented nuclei. In line with pixel-wise results, PPU-Net slightly outperformed other models in the seven cell lines and was on a par with Deeplabv3+ in the LNCaP data set. Classical U-Net was inferior (object-wise F1 scores of 48.8%, 55.4%, 58.1%, 58.2%, and 59.8% for U-Net, U-Net++, Deeplabv3+, Tiramisu, and PPU-Net, respectively, for seven cell lines; and 45.2%, 51.0%, 54.9%, 51.4%, and 54.6% for the LNCaP data set) (
Data Set and Architecture Properties Influencing Performance
It is important to understand when brightfield segmentation can be expected to be successful and what the quality determining factors are. We first tested whether cell density influences segmentation performance and found a negative correlation between the number of cells per image and the pixel-wise F1 score (Pearson’s R = −0.65, −0.66, −0.69, −0.67, and −0.70 for U-Net, U-Net++, Deeplabv3+, Tiramisu, and PPU-Net in seven cell line data, respectively; and Pearson’s R = −0.39, −0.39, −0.46, −16, and −0.40 for the same respective models in the LNCap data). This trend held across all data, as well as within images from individual cell lines (
Next, we considered whether the size of nuclei impacts the accuracy of prediction. We observed that larger objects are segmented more accurately by all models in the complete data set (
As we found models to have a range of performances, we attempted to understand which model features are responsible for the differences. We suspected that the lower performance of U-Net could be ascribed to the model representation capacity (e.g., number of trainable parameters) and training approach. To test this, we evaluated three aspects that distinguish it from the otherwise similar U-Net++ architecture. First, we doubled the U-Net pathway connections, and this improved the pixel-wise F1 score by 0.006 (
Common Errors in Segmentation
The results of the second-generation deep learning models for brightfield nuclei detection were better than earlier reports,4,5 but errors still occurred. We next visually inspected output segmentations and found that the errors are mainly due to four effects. First, some samples were contaminated (
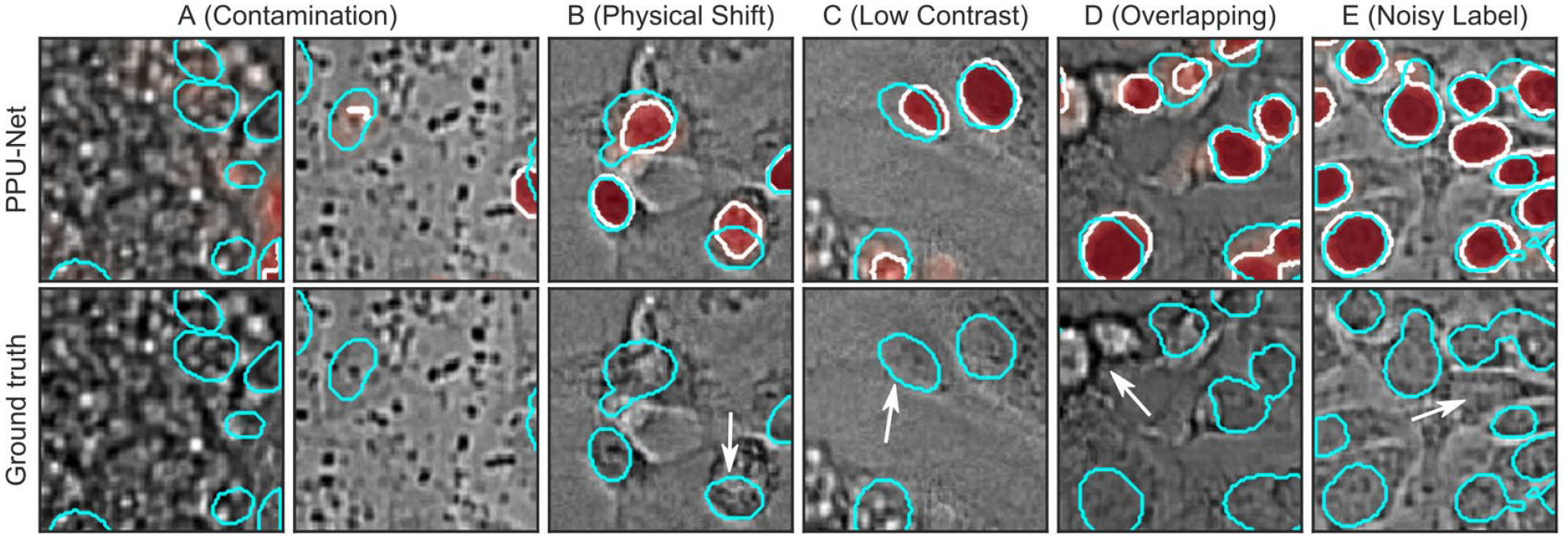
Examples of errors from visual inspection. Cyan, ground truth contour; white, prediction contour; red, prediction probability maps; white arrows, error. Top images: Ground truth and PPU-net model predictions. Bottom images: Ground truth only. (
We next attempted to quantify the relative contribution of the various errors. To do so, we first picked 20 images with evidence of sample contamination and recalculated performance outside of manually annotated anomalous regions only. An average of 10.7% (range, 9.3%–11.8%) of misclassified pixels were caused by those anomalies, and filtering out the anomalous regions improved the pixel-wise F1 score by 1.6%–1.9% per image. This suggests that artifacts are a substantial but not the major source of remaining pixel errors in segmentation. Second, we found that 53%–61% of errors are due to false-negative pixels, consistent with either underprediction at object boundaries or missing entire objects, contributing more errors compared with false-positive pixels. Finally, we estimate 3%–5% of misclassified pixels to be due to noise in the ground truth labels (
Next, we considered object-level errors of splits, merges, and missing nuclei at a range of pixel classification thresholds (Materials and Methods). Compared with other advanced models, Tiramisu had the smallest number of total merges (5376 in seven cell lines, 4182 in LNCaP) and splits (4271 in seven cell lines, 3088 in LNCaP), on average, considering 176,946 and 53,828 objects in the seven cell line and LNCaP data sets, respectively (
Training Choices Influencing Performance
The results so far were obtained on a large training data set that has thousands of annotated images. In practice, annotation is expensive, and a limited number of annotated images are available. Hence, an important practical question, especially for advanced architectures with millions of parameters, is how many training images are sufficient for optimal performance. Predictably, the model performance improves with more annotated images (
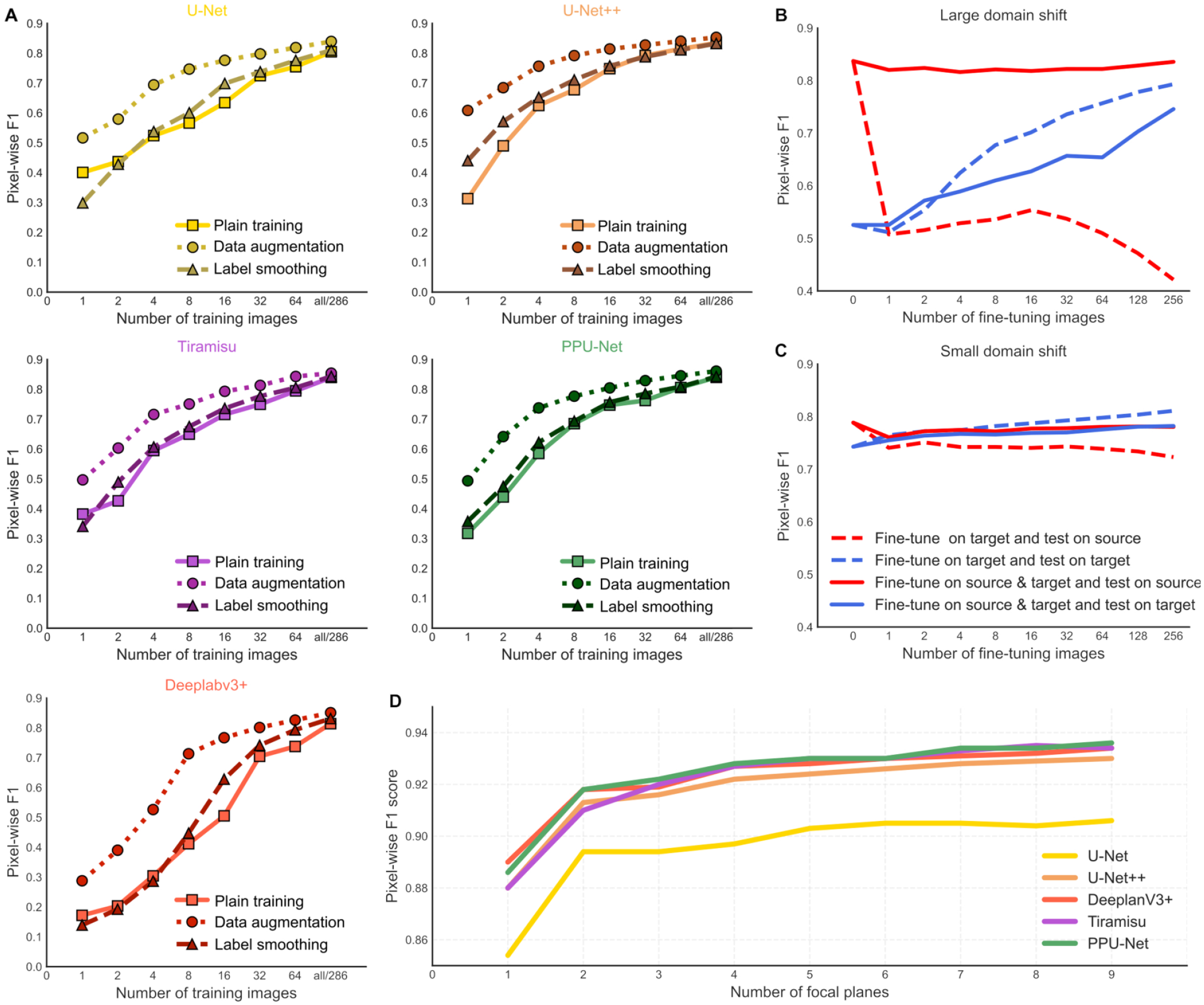
More training data from a relevant domain improves accuracy. (
We tested whether label smoothing (using soft targets in ground truth masks, for example, 0.1 and 0.9 instead of 0 and 1
42
) and data augmentation improve performance under limited training data. We found that nearly all models performed better using each of those strategies compared with training models without any of them (
Next, we considered transfer learning to deal with limited training data. First, we used a model that was trained on one data set (source domain) and to segment images in another (target domain). Intuitively, the performance then indicates how distant the target and source domains are. None of the transferred models perform near the optimum in another domain, and the domain shift is most marked for cells from another imaging experiment on different instrumentation (31% performance gap when source and target domains are LNCaP and seven cell lines, respectively) (
Next, we used an increasing number of images from the target domain to fine-tune the model. Fine-tuning improves performance on the target domain but degrades performance on the source domain (
Finally, we asked whether increasing the number of focal planes that are used in training improves segmentation performance. We found that adding one additional plane increased the pixel-wise F1 score by 3.3% on average, ranging from 4% in U-Net to 2.8% in DeeplabV3+ (
Discussion
We have surveyed the literature for developments in deep learning for segmentation and evaluated most advanced examples of multiple model families for their ability to identify nuclei in fluorescence and brightfield cell images. We found that models range from moderately performing (U-Net) to well-performing (Tiramisu, U-Net++, and Deeplabv3+) ones, and proposed PPU-Net, a novel architecture for this task. PPU-Net segments nuclei as accurately as the comparable alternative models while featuring smaller size, shorter training time, and quicker prediction. We noticed that the performance of complex models like Deeplabv3+ degrades when the amount of training data is small. We identified the number of focal planes, cell density, and nuclear size (but not its variability across cells), to influence segmentation quality, and established that a small number of ground truth images combined with substantial augmentation is sufficient for training a well-performing model. To our knowledge, these are the first experiments to segment nuclei from brightfield cell microscopy images with very deep neural networks, novel insights into their performance, and the most accurate segmentations presented to date.
The second generation of deep learning models for brightfield nuclei detection were superior to the initial tests on the same data, 5 but not yet as accurate as fluorescence-based segmentation approaches. Part of this improvement can be ascribed to advances in methodology, where the network size, qualitative features, and training approaches all had an effect on the outcome quality. In concordance with prior work, we observed modality-specific error sources, such as low contrast, likely physical shifts, and noisy ground truth labels. Some of these, such as physical shift, are systematic and unlikely to be improved by more complex models. Others, like out-of-focus cells, could be optimized by dedicated data acquisition and training. Upon inspecting the errors, we believe that there is room for further improvement to the current models, mainly by avoiding anomalous regions, having noisy labels in training data, and better segmentation of smaller objects.
As expected, and observed before (e.g., Caicedo et al. 4 and Fishman et al. 5 ), providing more training data improves the ability to accurately identify nuclei. While data acquisition is not limiting, annotating ground truth in brightfield modality can be a substantial bottleneck, even when fluorescence-guided nuclear segmentation is available. Various data augmentation techniques, such as signal-preserving orthogonal rotations and reflections, as well as lossy general rotations and scalings, can all help bootstrap additional signal for the same data, and thereby improve training for models that do not take these invariants into account. Soft labeling, or intuitively allowing false-positive and false-negative rates in the ground truth, also improves outcomes. Therefore, when compute time and cost are not limiting, but data set sizes are, we recommend augmenting the training data.
Our new segmentation architecture, PPU-Net, is arguably the most practical. While the U-Net model is the smallest, its performance was dominated by the larger models with additional features. For example, it has been demonstrated that the residual connections, as employed in Tiramisu and shown in Drozdzal et al., 32 give a substantial performance boost and stable training. Inspired by these networks, PPU-Net similarly employs simple light residual connections and achieves good performance in both brightfield and fluorescence modalities. Its smaller size and faster speed make PPU-Net more suitable to use in large-scale experiments.
Performance was variable across objects of different size and density. The large nuclei were well segmented in general. This could be due to technical reasons (they have more pixels, and therefore a smaller fraction of the area close to the more variable border), additional signal (more photons inform of their location), or a simpler context (larger nuclei also have larger cells, separating them from neighboring nuclei by a bigger distance). Conversely, the most difficult nuclei to segment were small and densely packed, in particular, for the HepG2 cell line. The dense packing problem is a general standing issue in instance segmentation. Dedicated object delineation models and bespoke data sets outside the scope of this work are needed to establish the best way of attacking this in cell microscopy.
The quality of brightfield cell nucleus segmentations is such that they are useful in practice. A major future direction is to expand this approach to segment entire cells, which would aid cytometry applications, especially in cases of relatively dense cultures. Substantial additional training data, as well as innovation in handling dense and overlapping objects, are required to make progress in this direction.
Supplemental Material
sj-pdf-1-jbx-10.1177_24725552211023214 – Supplemental material for Evaluating Very Deep Convolutional Neural Networks for Nucleus Segmentation from Brightfield Cell Microscopy Images
Supplemental material, sj-pdf-1-jbx-10.1177_24725552211023214 for Evaluating Very Deep Convolutional Neural Networks for Nucleus Segmentation from Brightfield Cell Microscopy Images by Mohammed A. S. Ali, Oleg Misko, Sten-Oliver Salumaa, Mikhail Papkov, Kaupo Palo, Dmytro Fishman and Leopold Parts in SLAS Discovery
Footnotes
Acknowledgements
M.A.S.A., M.P., D.F., and S.-O.S. were supported by the Estonian Research Council (IUT34-4) and the Estonian Centre of Excellence in IT (EXCITE) (TK148). L.P. was supported by Wellcome (206194), the Estonian Research Council (IUT34-4), and the Estonian Centre of Excellence in IT (EXCITE) (TK148). K.P. was supported by PerkinElmer Cellular Technologies. We thank the High-Performance Computing Center of the Institute of Computer Science at the University of Tartu for providing the computation power.
Supplemental material is available online with this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: M.A.S.A., M.P., D.F., and S.-O.S. were supported by Estonian Research Council grants (PRG1095, PSG59), Project No. 2014-2020.4.01.16-0271, and the Estonian Centre of Excellence in IT (EXCITE) (TK148). D.F. was also supported by an Estonian Research Council grant (ERA-NET TRANSCAN-2 [BioEndoCar]). L.P. was supported by Wellcome (206194), the Estonian Research Council (IUT34-4), and the Estonian Centre of Excellence in IT (EXCITE) (TK148). K.P. was supported by PerkinElmer Cellular Technologies.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.