
Abstract
Travel, as one way to relax oneself, has become the first choice for people to enjoy their body and mind in modern society. However, while facing lots of information, how to help users make better decisions on their next travel goals through their historical interest spots is a direction that needs further research in big data recommendation systems. In this thesis, we proposed the deep convolution and multi-head self-attention position network model. First, it extracts the user’s historical interest point feature information by convolutional neural network method, and then performs horizontal and vertical filtering. Next, it interacts the obtained information with the candidate attraction information, and extracts the location information of the historical interest sequence by the multi-head self-attention mechanism. Finally, the model does the attention mechanism of the candidate attraction by fusing the feature information of the location information. The final model achieves a deep fusion of user sequence interest and location feature information. We conducted detailed comparison experiments with the very popular models in the industry on different public datasets, and the results showed that our deep convolution and multi-head self-attention position network model has good performance.
Keywords
Introduction
In recent years, with the development of the economy, people’s material life has been greatly enriched and they gradually begin to pursue the satisfaction and enjoyment of spiritual life. At the same time, with the gradual improvement of transportation facilities and the development of social media, people are prone to yearn for attractions thousands of miles away. 1 Although the Internet is very advanced and users can find reviews about any tourist attractions they want to visit on many websites such as Ctrip, Mafengwo, and Xiaohongshu, there are too many choices for users. This is precisely the shortcoming that causes the phenomenon of “information overload.” That is to say, the process of filtering useful information from many reviews before making a decision is very time-consuming. 2
The recommendation system has been developed for many years, and it can be divided into two aspects: recall and sorting. Recall refers to the selection of hundreds or thousands of candidates that users may like from tens of thousands or hundreds of millions of items, while sorting is the selection of the top candidates that are most likely to be interacted with among the recalled items. It has huge applications in industry as well as in advertising systems. Applying a good click-through rate prediction model to commercialized systems in industry can not only enhance a good experience for users, but also bring huge revenue to businesses. 3
Click-through rate prediction model development is mainly divided into two categories: feature interaction and prediction based on temporal type. The classical models of base and feature interaction such as FM 4 mainly extract feature combinations by the hidden variable inner product between features. FFM 5 is based on the extension of FM. It adds the concept of field including the calculation of intra-field features and inter-field features, and others including AFM, 6 DeepFM, 7 and so on, are all extensions based on feature interaction. The earliest models based on sequence information mining include recurrent neural network (RNN) 8 and gating mechanism GRU, 9 and so on. The Deep Interest Network (DIN) 10 model, which emerged later, makes full use of the information and mines the historical user behavior data. Compared with the base model, it calculates the weight information of each historical item and candidate item to better predict the next item that is likely to be interacted with. It is widely used to realize the application in the business scenario of e-commerce advertising recommendation.
The RNN model is often used for capturing sequential relationships, but the dependency of capturing user behavior is very dependent on the previous behavioral action. However, the upper and lower proximity information in user behavior sequences is not strongly correlated in real life. For example, after a tourist browsed Disneyland, one history of behavior records generated. Then he browsed the Chenshan Botanical Garden, which is only because the user likes natural plants but that does not necessarily mean that there is a relationship between Disneyland and Chenshan Botanical Garden. In order to effectively extract the sequence relationship of the user’s history, the article draws on the features of the Caser 11 model. The model learns the relevant features mainly by using convolutional neural networks (CNNs). The extraction of important preferences in the whole sequence is achieved by improving the horizontal filter, and then the vertical filter is retained to do aggregation of the user’s historical behavior sequence. What is more, it learns the long-term general preferences of the user to prepare for the continuous recommendation, and introduces the sequence features as well as attention weights of target items. It achieves the extraction of feature information with different weights at three levels of important preferences, general importance, and associative similarity of sequence features. Second, the model needs to make prediction for tourist attraction information, because the location information of the attraction in the historical sequence is also very important for the next attraction information to be predicted. This thesis proposes to extract the location information in the historical attraction sequence first, and feed the location information into the multi-head self-attention mechanism to get the contextual information related to the whole sequence. Next, adding and fusing it with the original historical attraction sequence information, and then doing it in weight interaction with the candidate attraction afterwards. In addition, considering that for attraction recommendations, not all visited attractions may be liked by users, there exist those that have been visited but not highly rated and poorly experienced. Therefore, the article divides the goods browsed by users into positive and negative samples according to the criteria of user scoring to achieve better results. What is more, the model can also be used in any click prediction field such as the scenario of display advertising in the e-commerce industry with rich user behavior data. Due to the interest and location extraction layers, the model is suitable for recommendation scenarios with fused location information. For example, in the textile industry in the clothing recommendation scenario, the model considers the clothing-related data that users have clicked on historically, and can recommend more suitable clothing to users by extracting the position relationship between sequence data through multi-head self-attention.
In general, the main work of the thesis is as follows:
The deep convolution and multi-head self-attention position network (DCMPN) model proposed in the article introduces the learning method of CNN to achieve the in-depth extraction of users’ historical interests, mainly including the important preference degree and general preference information of user sequences.
Based on making full use of the interest information in historical sequences, we extract the location information of user sequences and use the multi-head self-attention mechanism to do interaction between sequence locations to achieve the fusion of location information and inter-sequence information.
For the preprocessing method, the positive and negative sample lists are divided by the scores, and the user feedback on the historical records is integrated.
Related Work
Traditional recommendation methods mainly include collaborative filtering algorithm and matrix decomposition algorithm, and the more representative ones are CF 12 and MF. The so-called collaborative filtering algorithm is a kind of recommendation algorithm that completely relies on the behavioral relationship between users and items. The significance of this is to collaborate with feedback and evaluation of users to filter the massive amount of information and filter out the information that users may be interested in. It is mainly divided into user-based collaborative filtering and item-based collaborative filtering; the first one is to recommend the next possible predicted item for the users by calculating the similarity between users, and the other is to make recommendations for users by calculating the similarity between items. The matrix decomposition is implemented mainly by decomposing the co-occurrence matrix generated by collaborative filtering to generate the implicit vectors of users and items, and then making recommendations by the similarity of the implicit vectors of users and items. However, these methods suffer from the problems of system cold start and large data sparsity.
In addition to the feature interaction-based recommendation algorithm besides FM and FFM mentioned above, there are also some combined deep learning models such as Wide&Deep, 13 where the wide part generates items directly related to the user’s historical behavioral items and the deep part is used to learn the combination of higher-order cross-correlations between features. The Deep&Cross 14 model achieves the prediction effect of the model by showing the higher-order feature intersection combinations. In addition, Product-based Neural Network (PNN) 15 performs the combination of features by inner product–outer product. DeepFM learns the relationship between different features by end-to-end to achieve high-order and low-order feature extraction.
There are also a number of models based on sequential information recommendation. Their basic representatives mainly include RNN, which processes temporal data and the GRU model. As a variant of the long short-term memory network (LSTM) model, the GRU model introduces the reset gate and update gate to achieve the learning of sequential module. In recent years, the temporal recommendation models are proposed. The DIN model, based on user history information, introduces attention mechanism, and then calculates the weight information of user history browsing items and candidate items. The DIEN 16 model on this basis adds the sequential model GRU to achieve the development of representing user change trend.
Model
In this section, we focus on the DCMPN model proposed in this thesis, which can extract user historical sequence information and fuse location information through CNN. The overall architecture of the model is shown in Figure 1. The model of DCMPN is based on the DIN model and follows the basic model paradigm of embedding vectors as well as multilayer perceptron, which mainly includes five aspects: the original user input layer, the embedding vector layer, the location information fusion and convolutional interest extraction module, the attention mechanism module, and finally the prediction layer.
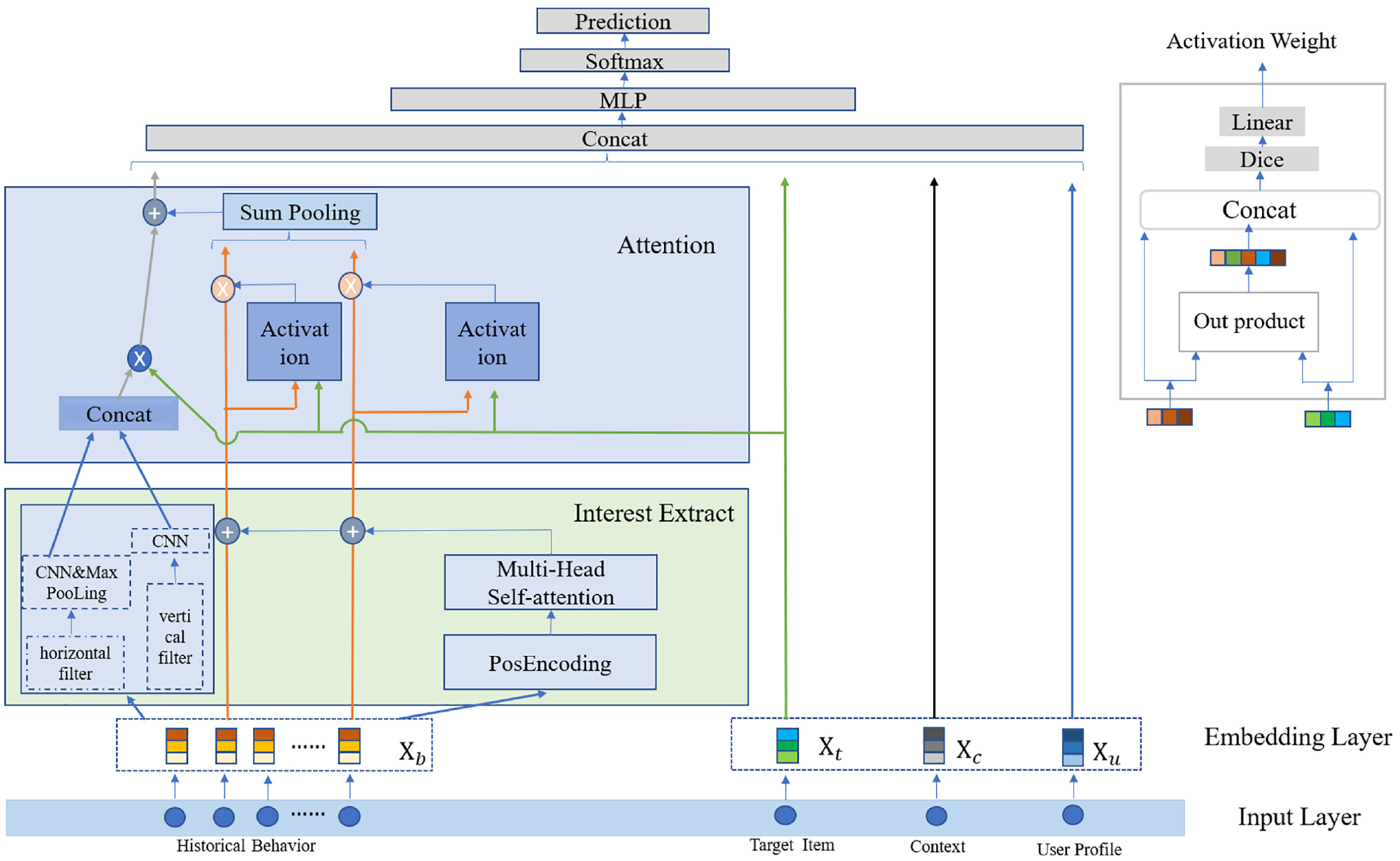
The architecture of DCMPN.
The workflow of the whole model is mainly to use the user’s historical sequence features, target feature items, user’s feature items, and contextual features as the original input of the model, and then the features of these original inputs are embedded in low dimension through the embedding layer. The main feature information extraction is based on the user’s historical sequence features. First, the different preference degrees of the user’s sequence are extracted through two filters of the convolution layer, where the horizontal filter is mainly used to extract the more important feature preference degree in the sequence, and the vertical filter is used for the aggregation of different aspects to extract the influence of the separate previous historical information on the target information to achieve the extraction of the user’s general preference. After being extracted, the information of the two aspects is aggregated, and then the product operation is done with the final target information. The extraction of location information mainly draws on the encoding rules designed for location information in the transformer 17 model. After getting the encoding of location information, the model sends it to the multi-head self-attention module to let the location information of each historical sequence fuse with the information in the contextual sequence, and then the obtained vector is added with the historical sequence information features. At the same time, it does the attention mechanism with the target features, so that the original location information is fused in the historical sequence features, and then the module extracted through the convolutional layer is fused with the weight information assigned through the attention module. Finally, it is sent to the fully connected layer together with the embedded user information, contextual information, and target item information to obtain the final prediction results.
Embedding Layer
First, the input layer mainly includes four aspects, among which user characteristics mainly refer to the user id, and the user history sequence information referring to the id of the attractions that the user has rated on the travel website, which is a chronological list of items. This list has the same functional fields as the target item. The target item information mainly refers to some information about the candidate attractions, including the attraction id, attraction category, and so on. Each of these input features can be encoded as a high-dimensional heat vector, and the main purpose of the embedding layer is to reduce the dimensionality of these high-dimensional, sparse vectors to low-dimensional dense vectors for subsequent computation. For example, after the embedding layer, the user sequence information, user information, candidate attraction information, and context information can be represented as
Interest and Location Extraction Layer
CNN convolutional layer: The main learning method of this part is to consider the matrix
The learning method of the filter is mainly divided into two parts, horizontal and vertical. Among them, the horizontal filter mainly uses the filter with height h to learn the embedded historical attraction sequence features fed into the convolutional network, and the number of filters

where
The principle of vertical filter implementation is to choose

where n denotes the length of the user history sequence and

The difference between the vertical filter and the horizontal filter is that the size of the vertical filter must be
Location information extraction: In order to introduce the feature of location coding, the location extraction module is proposed in the paper “Attention Is All You Need.” 17 . It is achieved mainly by adding the location information of words in the word vector when encoding word vectors. For the recommendation of tourist attractions, location information has a great role. By analyzing the location relationship between user sequences, it can make the location encoding between each attraction hidden in the feature, and the location encoding rules here mainly take the following encoding formula:
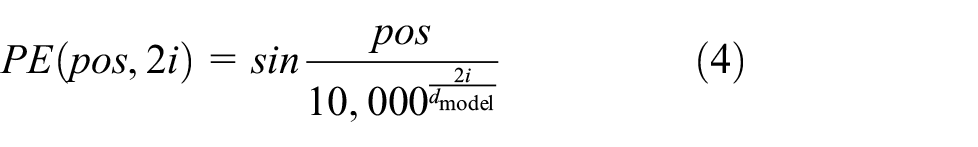
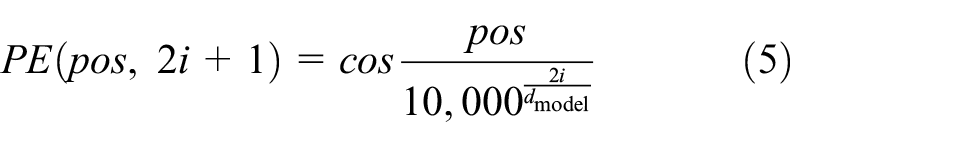
The main reason is that according to the formula
Although the position information encoding can extract the position relationship between sequences of attractions, in order to better fuse the contextual relationship between sequences, the thesis proposes to send the obtained position encoding information to a layer of multi-head self-attention mechanism training. Next, context-encoded information that fuses the relationships between the entire sequences is added to the information after the embedding of the most primitive sequence features, and finally it is sent to the attention mechanism layer. The self-attention mechanism is a special kind of attention mechanism whose inputs are three vectors, including Query vector (q), Key vector (k), and Value vector (v). These vectors are obtained by multiplying the embedding vector P by three different weight matrices
After obtaining the scores calculated for each of the three input vectors q, k, and v for each vector, for the stability of the gradient, it is also necessary to use the score normalization process, achieved by dividing by
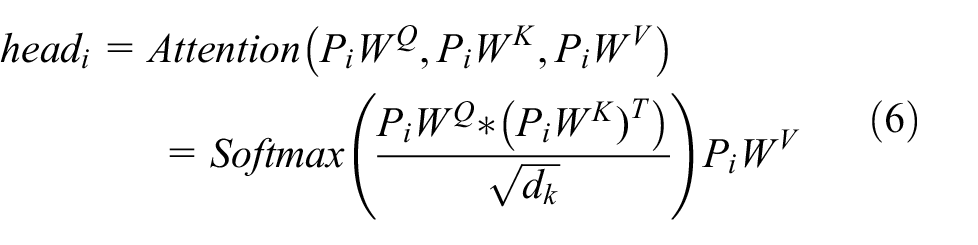
where
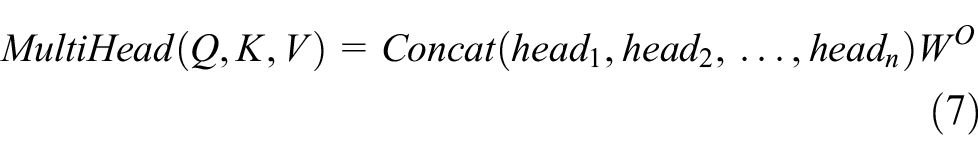
The emergence of the self-attention mechanism enables the extraction of information from the potential subspace of features, while the multi-head self-attention mechanism allows the model to jointly focus on information from different representational subspaces at different locations. Finally, the self-attention mechanism uses a residual network structure to solve the degradation problem of deep learning. It is proved that both the number of parallel heads and the number of layers of multiple heads of the multi-headed self-attentive mechanism have an impact on the experimental results, and a layer of attention mechanism with 8 parallel heads and dimension 128 is adopted in the multi-head self-attentive mechanism in this thesis
Attention Layer
Although the user’s historical review record contains many attraction sequences, we believe that not all attraction sequences play the same role in the candidate attractions to be predicted. For example, if the user has been to an attraction sequence with temples, amusement parks, Huangshan Mountain, West Lake, and so on, when the candidate attraction is also a temple, the weight value of the influence of the first attraction on it will be relatively large. In this thesis, we not only use the original historical attraction sequence embedding information, but also consider the influence of location information in the attraction sequence. The attention mechanism is done by adding these two parts of feature information and then interacting with the candidate attraction feature embedding information to do the attention mechanism. What is more, the model also assigns the corresponding weight to each sequence attraction feature information, and the fused sequence features are defined as:
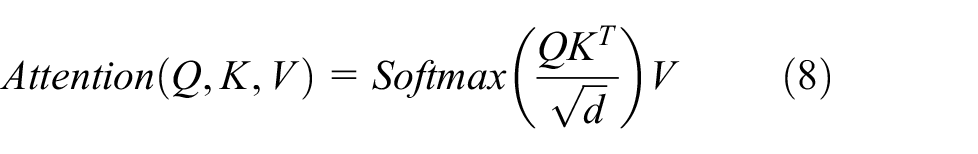
where Q denotes the query, here the candidate attraction id and the stitching of the embedding layer vector of features;, K denotes the key, in this article it refers to the fused sequence features E; d is the embedding dimension of the vector; and V refers to the value, in this article it is the sequence length.
Fully Connected and Output Layers
We add the output a after doing attention interaction and the output o after doing convolutional interest extraction with the product of target vectors, and then send it to the fully connected layer along with user features, candidate attraction feature embedding, and contextual information to obtain higher-level and abstract features. Finally, a softmax operation is performed on the results of the fully connected layer to get the final prediction results.
Experiments
In this section, we focus on the experimental part of the article, including the experimental environment setup, the introduction of the dataset, the comparison model, the evaluation metrics, and the final experimental results.
Experimental Environment
The main experimental environment implemented in the article is the GPU model, which is GeForce RTX 2080Ti, the CUDA version is 10.0, and the CPU model is denoted as Intel(R) Xeon(R) Sliver 4210 CPU@2.20 GHz, capacity of memory is 256 G, CPU@2.20 GHz, capacity of disk is 8T.
Datasets
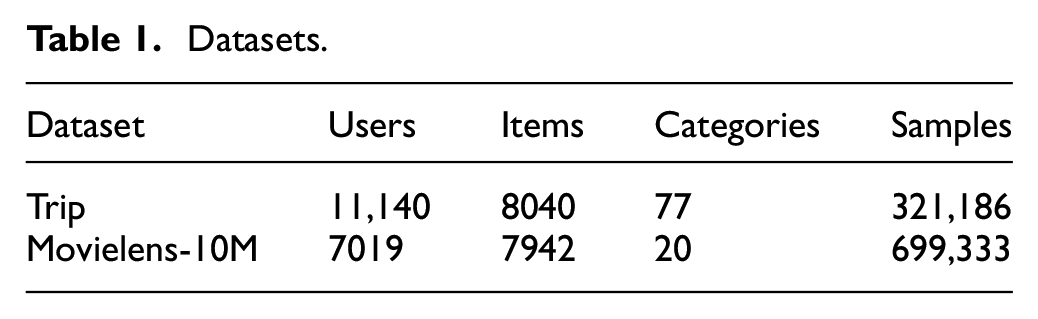
In this article, we mainly use two datasets: the first is the dataset trip crawled from the official website of Ctrip, including the information of attractions and reviews of six popular areas. The six areas are Beijing, Shanghai, Tianjin, Jiangsu, Shandong, Shanxi, and the names of attractions that the users viewed by the time of the comment on the attraction, in which the total amount of data is 1,056,526 after de-duplication of data. In the dataset preprocessing, in order to make the length of the dataset not too long or too short, the intercepted sequence length is between 2 and 500. Considering that not all attractions visited by users are their favorite, it is intended to use users’ rating information as the basis for dividing the positive and negative samples. After the analysis of the dataset, the division value used is 3.5.
Movielens-10M: This dataset contains the metadata set of movies and user attribute information, which is commonly used in recommendation systems for comparison experiments. In order to be consistent with the preprocessing method of the trip dataset, the rating features in the dataset are also used for the division of positive and negative samples in the article. Due to the large number of datasets themselves, one-tenth of the entire data volume was randomly taken as the comparison data for the experiment.
The data volume and characteristics of the two datasets after sequence interception and data reduction are shown in Table 1.
Datasets.
Compared Models
The experiments are mainly compared with the following more classical click-through rate (CTR) prediction models, and each comparison model is described as follows:
Base model: The base model is processed in the same way as DCMPN, but the difference lies in the processing of the sequence information about user’s historical behavior, which is directly fed into the prediction layer in the form of a weighted sum, including user embedding vectors, contextual embedding vectors, and candidate attraction embedding information.
Wide&Deep: 13 The shallow layer is a simple linear model, and the deep layer is a feed forward neural network model, where the linear model and the feed forward neural network model are combined and trained together.
PNN: 15 The operation of dot product is added between the embedding layer and the fully connected layer for full feature extraction.
DeepFM: 7 Capable of learning the interaction of low-order and high-order features, where the low-order learning module FM shares the embedding vector representation of features with the high-order learning module DNN.
DIN: 10 By introducing the attention mechanism applied to user’s history sequences and target options, different weight sizes are assigned to the user’s historical behavior sequence features to better extract user’s interest and maximize the prediction value.
Based on the DIN model, the model proposed in this article introduces the location information between sequences and adopts a multi-head self-attentive mechanism to fully extract the sequence location information. While focusing on the magnitude of interest between the sequence and the target item, a CNN is also used to extract important preference and general preference information for user behavior sequence features and make a product with the target phase. Finally, the extracted historical interest information is fused and spliced with the location information after the interaction with the attention mechanism and sent to the fully connected layer to get the final output.
Experimental Results
Before the experimental results, some parameters used by the model are introduced. The embedding vector dimension of the user is 128, and the embedding vector of the attractions and attraction types is 64. The batch size of the training set is 16, and the batch size of the test set is 128. The learning rate size is set to 0.1, the number of horizontal filters is set to 2, and the convolution kernel is 8. What is more, the number of vertical filters is 8 and the convolution kernel is 1, and every 1000 batches are printed once.
The evaluation index of the experiment is area under the characteristic curve (AUC), which is the area under the receiver operating characteristic (ROC) curve, and the meaning is expressed as the probability of the predicted positive sample before the negative sample. Usually, the value of AUC is between 0.5 and 1. In the case of AUC greater than 0.5, the closer the value of AUC is to 1, the better the diagnosis. The results of the comparison experiment and the results of the ablation experiment are shown in Tables 2 and 3.
Comparison of experimental results.
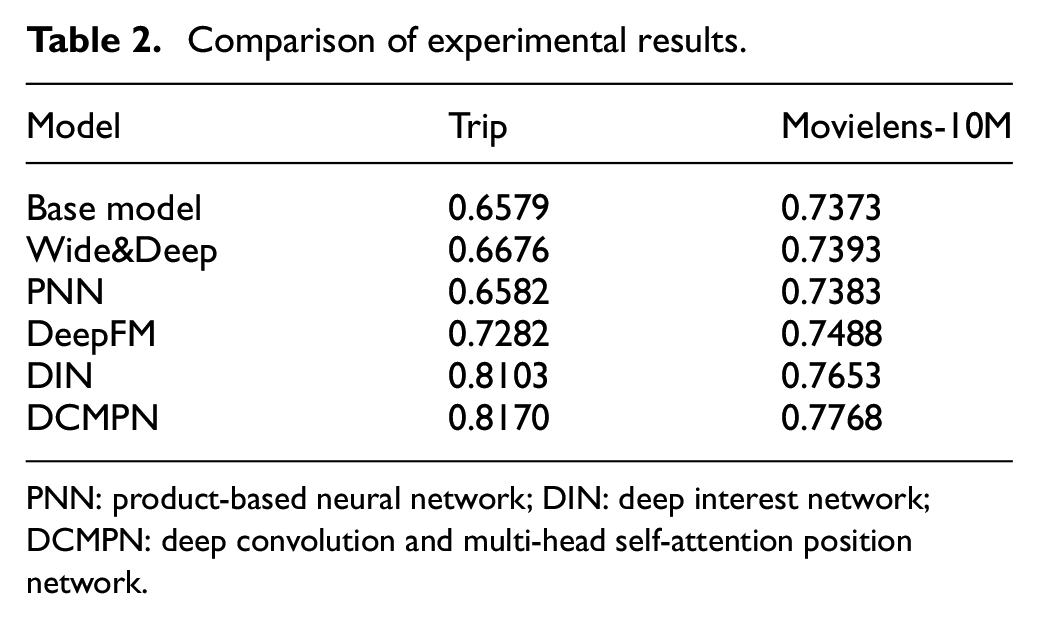
PNN: product-based neural network; DIN: deep interest network; DCMPN: deep convolution and multi-head self-attention position network.
Ablation experiment results.
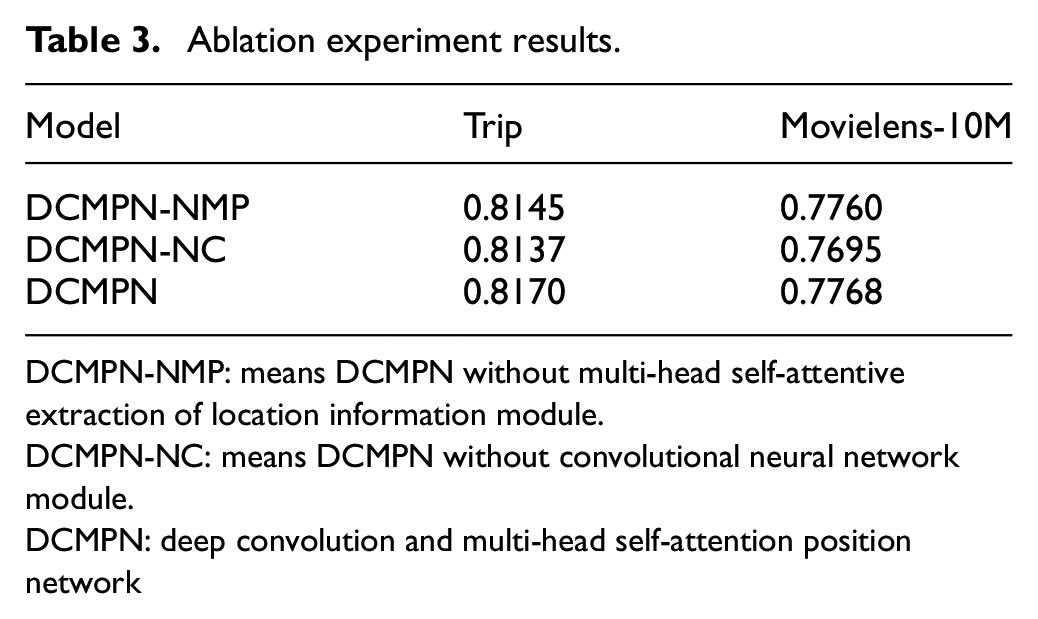
DCMPN-NMP: means DCMPN without multi-head self-attentive extraction of location information module.
DCMPN-NC: means DCMPN without convolutional neural network module.
DCMPN: deep convolution and multi-head self-attention position network
Conclusion
In this article, we propose a deep convolutional interest location extraction network DCMPN as a click-through rate prediction model to predict whether users will accrete the recommended items. The model mainly extracts important preference and general preference information from users’ historical interests by CNN, and incorporates location information after multi-head self-attention extraction in the user history sequence. And the user’s feedback on the items is used as the criterion to classify the positive and negative samples in the preprocessing. The experimental results show that the proposed DCMPN model does outperform some current click-through rate prediction models to achieve the improvement of prediction probability. Although DCMPN is a recommendation model with tourist attractions as the theme, in essence, the model mainly follows the extraction of feature information from historical sequence information in order to accurately recommend users’ next point of interest, so the DCMPN model can also be applied to various fields. Combined with the conference theme, the model is still highly reusable and can be applied to clothing recommendations in fashion and textile-related industries, for example. By inputting users’ historical dressing information, it can perform deep extraction of users’ historical interests. In addition, the advantage of this model is that it achieves the fusion of location information and inter-sequence information, so that it can be used to recommend the type of clothing that the user is interested in. In terms of textiles, it can recommend textile materials such as fabrics that are of interest to the user’s history.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.