
Abstract
Recently, a DCNet consisting of a dense relation distillation module and a context-aware aggregation module has achieved remarkable performance for the few-shot object detection task. In this article, we aim to improve the DCNet from the following two aspects. First, we design an adaptive attention module, which is equipped in the front of the dense relation distillation module, and can be trained together with the remainder parts of the DCNet. After training, the adaptive attention module helps to enhance foreground features and to suppress the background features. Second, we introduce a large-margin Softmax into the dense relation distillation module. The large-margin Softmax with a hyperparameter can normalize features without reducing the discriminability between different classes. We conduct extensive experiments on the PASCAL visual object classes and the Microsoft common objects in context data sets. The experimental results show that the proposed method can work under the few-shot scenario and achieves the mean average precision of 50.8% on the PASCAL visual object classes data set and 13.1% on the Microsoft common objects in context data set, which both outperform the existing baselines. Moreover, ablation studies and visualizations validate the usefulness of the adaptive attention module and the large-margin Softmax. The proposed method can be applied to recognize rare patterns in fabric images or detect clothes with new styles in natural scene images.
Keywords
Introduction
With the rapid development of machine learning technology, databases with numerous annotated samples have promoted the research progress of object detection. Methods based on CNNs (Convolutional Neural Networks) have made remarkable breakthroughs. However, the detection performance of the existing methods highly relies on the number of annotations. In some special applications, such as lesion detection, 1 recognizing rare diseases, 2 or rare patterns in cultural relics, 3 there are few available samples, and thus a lack of sufficient annotations. Therefore, when facing to these tough circumstances, generic CNN-based methods4–8 may fail to achieve acceptable performance with the risk of being trapped in overfitting. To meet these application requirements,1–3 few-shot object detection9–17 has been a research hotspot in recent years.
In the few-shot object detection community, meta-learning-based methods9–11,18,19 aim to extract images’ meta-features that can memorize prediction gradients. Yan et al. 18 extended Faster/Mask region-based convolutional neural network (R-CNN) via a meta-learner over region-of-interest features. Kang et al. 19 extracted meta-features from base classes, and generalized them to detect novel classes based on an end-to-end episodic few-shot learning scheme. Data augmentation methods12–15 resort to increase the amount of data through fetching video frames or processing images. However, since most of the data augmentation processing will inevitably introduce additional noise, these methods usually achieve suboptimal detection performance. Misra et al. 12 assume the availability of abundant unannotated samples for semi-supervised training, while Ren et al. 15 need to set processing parameters manually. Obviously, these requirements violate the spirit of few-shot learning. Transfer-learning-based methods16,17 convert the meta-features from the source domain (support set) to the target domain (query set), and synthesize representative query features by fusing the knowledge learned from the support domain. Chen et al. 16 designed a low-shot transfer module consisting of transfer knowledge and background suppression regularizations. The transfer module can be seamlessly integrated into some generic object detection model, like Faster R-CNN. 4 Hu et al. 17 proposed a novel DCNet, which mainly consists of a DRD (Dense Relation Distillation) module and a CAA (Context-Aware Aggregation) module. The former establishes dense matching relationships between support and query features over the spatial dimension, while the latter targets adaptively fusing multiple features over the scale dimension.
Despite these successes, there still exists room for improvements. In the existing works,16,17 raw features directly serve as inputs to the meta-learner or feature-transfer. It is helpful to enhance the foreground features and to suppress the background features in advance. Moreover, the existing works16,17 usually use the Softmax to normalize features. Unfortunately, the traditional Softmax may smooth object features, thereby reducing the discriminability between different classes.
In this article, we aim to improve the recently proposed DCNet 17 from the following two aspects. First, we design an adaptive attention module, which combines the support features and then dynamically modulates the query features. The adaptive attention module is configured in front of the DRD module, and can be trained together with the other part of the DCNet. After training, the adaptive attention module can extract fine-grained features for each query object, and suppress interference at the same time. Second, we introduce a Large-Margin (LM) Softmax 20 to prevent feature smoothness. We conduct extensive experiments on PASCAL visual object classes (VOC) 2007/202121,22 and Microsoft (MS) common objects in context (COCO) 23 data sets. Experimental results show that the improved method reaches higher detection accuracy (mean Average Precision (mAP)) than the original DCNet. 17 Moreover, ablation studies demonstrate that the adaptive attention module and the LM Softmax indeed enhance the query features in terms of in-class representativeness and between-class separability.
The rest of this article is organized as follows. The section “Revisit DCNet” gives a brief introduction of the DCNet. 17 In the section “Our Proposal,” we describe the adaptive attention module and the LM Softmax. In the section “Experiments,” we exhibit our experimental results. The final section, “Conclusion”, concludes this article.
Revisit DCNet
In this section, we briefly introduce the DCNet, 17 which is the baseline of our proposal. The flow diagram of the DCNet 17 is shown in Figure 1. The DCNet 17 is mainly composed of a feature extractor, a DRD module, a CFA (Context-aware Feature Aggregation) module, and an RPN (Region Proposal Network) module. The feature extractor is based on a pretrained CNN-like ResNet-101, 24 and is used to extract the raw features of the support and query images. The DRD module, which follows the framework of transfer learning, establishes dense matching relationships between the support and query features for each pair of spatial positions. In the DRD module, a Softmax is used to normalize the support features. After training, the support features can be transferred to the query feature in a forward propagation. The CFA module captures the deep features and fuses them in a multi-scale manner. The RPN module with region-of-interest alignment produces a fine-grained feature for the query image, and a detection head on the top of the DCNet performs the object detection.
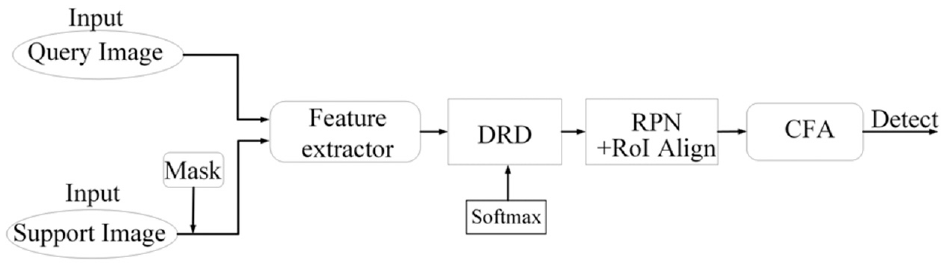
The flow diagram of the DCNet.
As analyzed in section “Revisit DCNet,” raw features are directly input to the DRD module without refinement. In addition, the traditional Softmax used in the DRD module may smooth the object features so as to reduce the discriminability between different classes.
Our Proposal
In this article, we design an adaptive attention module, which is configurated in front of the DRD module for refining features. Moreover, we introduce an LM Softmax into the DRD module that replaces the traditional Softmax. The structure of the improved DCNet is shown in Figure 2. In our proposal, the raw features—namely, the outputs of the feature extractor—will be processed by the adaptive attention module in advance. The adaptive attention module combines support features, and allocates an attention score to each pixel of the query image. The adaptive attention module can be trained together with the other part of the DCNet. 17 After training, a higher (lower) attention score will be adaptively allocated to each object (background) pixel. As such, the adaptive attention module helps the DRD module to enhance the foreground features and to suppress the background features. In addition, an LM Softmax is equipped into the DRD module. Compared with the traditional Softmax, the LM Softmax helps the DRD module to produce more representative in-class features and more separable between-class features.
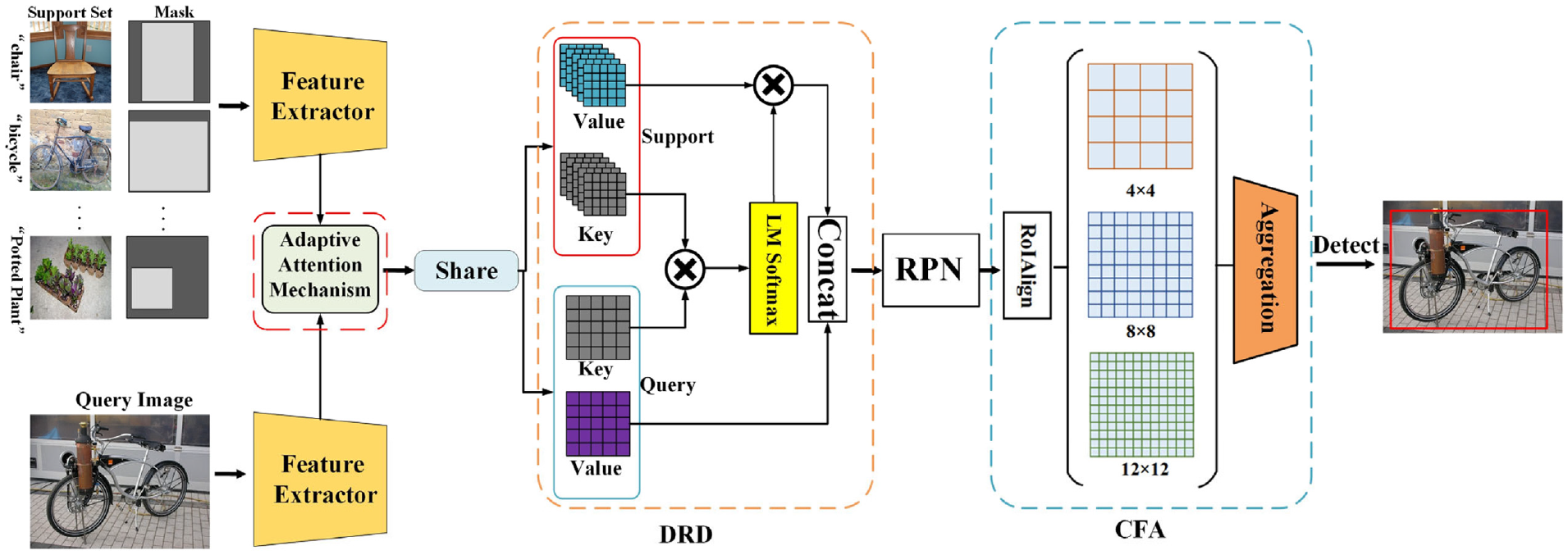
The structure of the improved DCNet. An adaptive attention module and an LM Softmax are added to the original DCNet.
Adaptive Attention Module
The adaptive attention module is designed to process the outputs of feature extractor. In this article, a pretrained ResNet-101 24 is used as the feature extractor. In the training phase, a query image and N support images together with their masks are input to the feature extractor. Note that the N support images come from N object classes, with one image corresponding to one class. All the extracted features serve as the inputs to the adaptive attention module. The structure diagram of the adaptive attention module is shown in Figure 3.
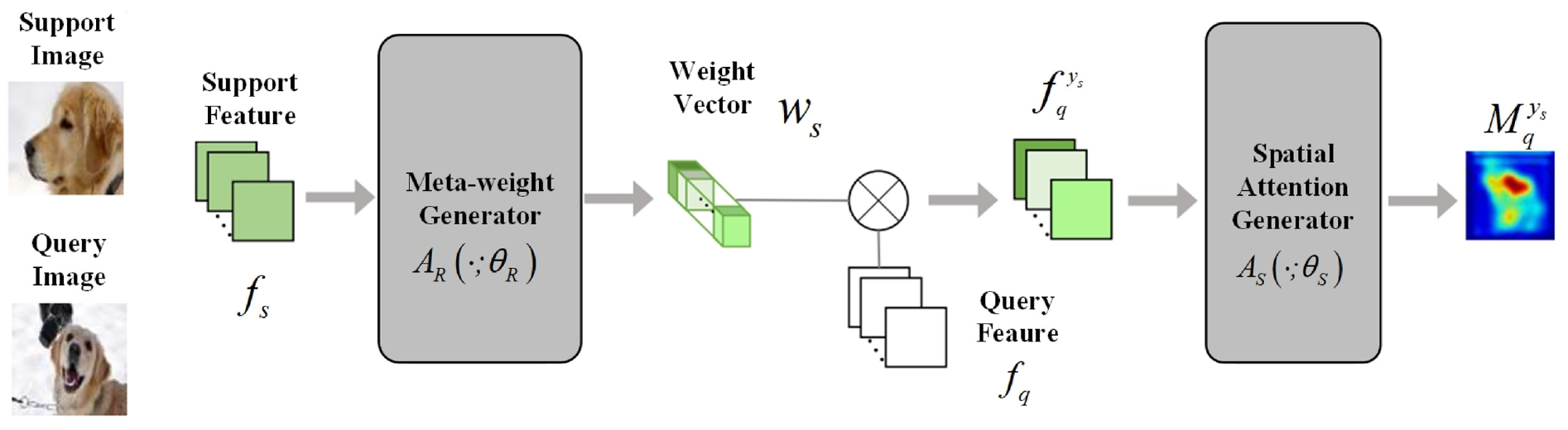
The structure diagram of the adaptive attention module. 25
The adaptive attention module follows the meta-feature re-weighting strategy. 25 It combines the support features, and allocates attention scores for query features. As shown in Figure 3, the adaptive attention module is mainly composed of a meta-weight generator and a spatial attention generator. The former takes the support features as input, and is trained to generate a class-specific meta-weight vector. The meta-weight vector is used to modulate the query feature. Then, the modulated feature is input to the spatial attention generator for score allocation. After training, the spatial attention generator will output a reliable attention map, in which foreground (and background) features are assigned by higher (and lower) attention scores. We give a detailed description of the adaptive attention module in the following.
The meta-weight generator, denoted by
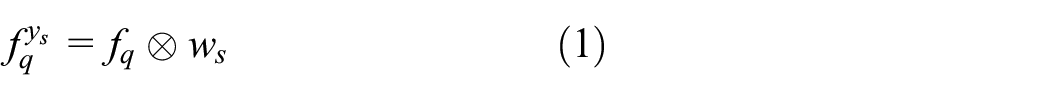
where
Furthermore, the spatial attention generator processes the modulated query feature
To train the adaptive attention module, we shall further process the attention maps. First, we apply a global average pooling to each attention map, which takes the form
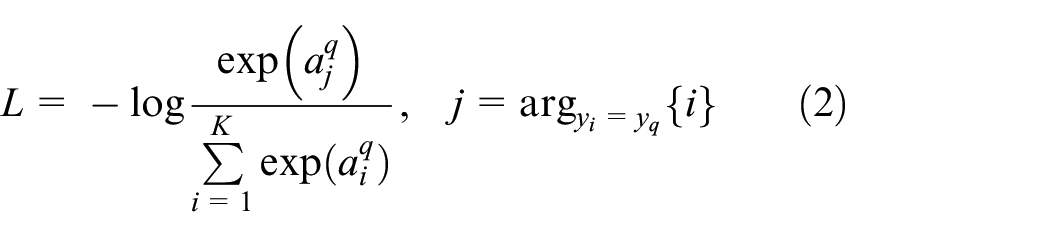
to normalize the confidences. Third, cross-entropy loss function, which measures the consistency between the normalized confidence and the label of
Improved DRD Module with LM Softmax
The DRD module, which is the key part of the DCNet, first transforms the support and query features into a pair of key and value maps in a learnable manner. Then, the traditional Softmax normalizes the key maps and produces a weight matrix. Through training, the weight matrix will establish dense matching relationships between support and query features for each pair of spatial positions. However, the traditional Softmax may smooth object features, and reduces the discriminability between different classes. In this article, we replace the traditional Softmax by an advanced one, called the LM Softmax. 20 Compared with the traditional Softmax, there is an adjustable hyperparameter in the LM Softmax, paving the way for enhancing the feature separability.
Suppose that the input features to the DRD module are of size
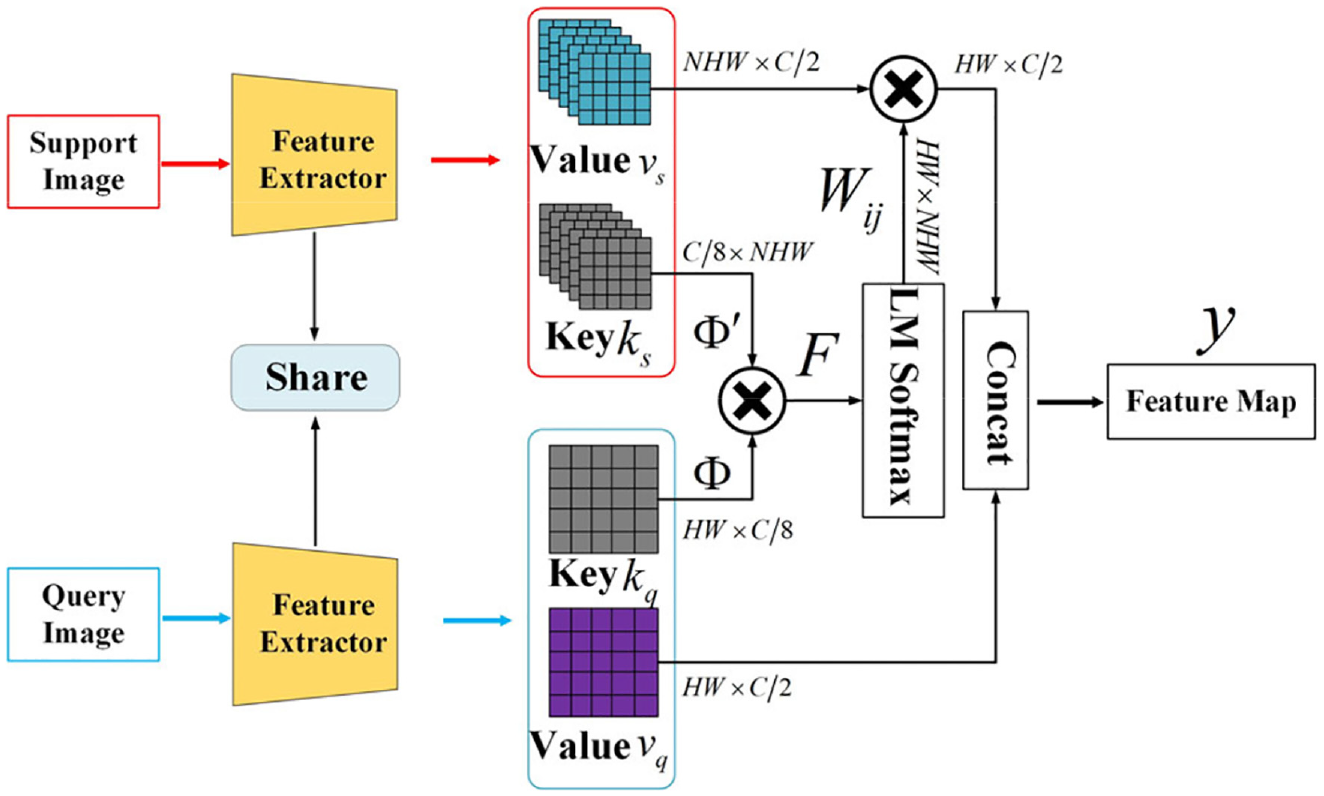
The detailed structure of the DRD module with the LM Softmax.
With these preparations, a weight matrix

where
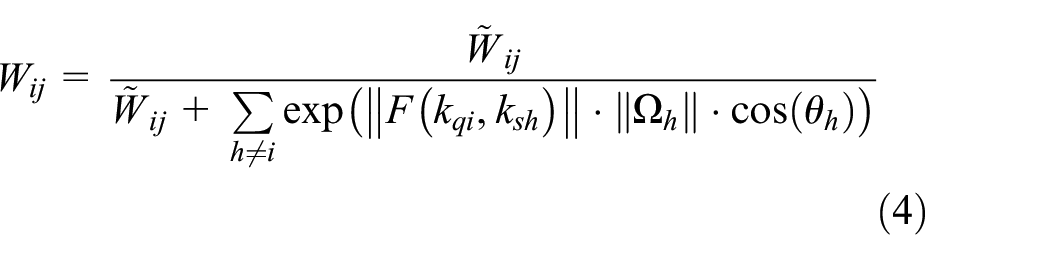
in which
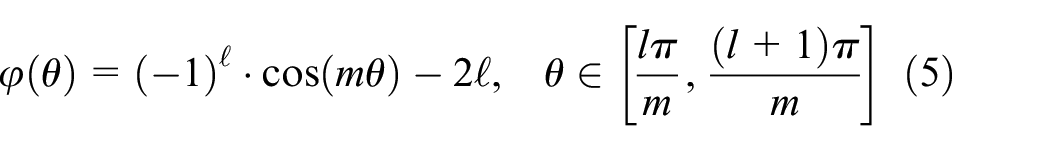
where l is an integer belonging to
The weight matrix is used to activate the value maps

where
Other Parts of the DCNet
The RPN module and the CFA module are two necessary parts in our proposal to achieve reliable detection performance.
The RPN module takes the feature map y as input and produces a set of rectangular object proposals, each of which is assigned by an objectness score. Then, the input feature encompassed by each rectangular box is mapped to a lower-dimensional version. Finally, a detection head consisting of two sibling fully connected layers takes the lower-dimensional feature as input and outputs a box-regression value and a box-classification value. Note that a traditional Softmax with no modifications is used in the detection head for fair comparisons. More details can be found in Ren et al. 4
In the DCNet, 17 the CFA module is inserted on the top of RPN module to mine the scale-awareness of features. In our proposal, we also inherit the configuration in Hu et al. 17 for fair comparisons. As shown in Figure 5, the CFA module is comprised of three parallel branches. Each branch contains the same operators but performs at different resolutions 4, 8, and 12. The first operator “Linear” is the two consecutive full-connected layers. The second one “GAP” is the global average pooling. The larger resolution focuses on the contextual semantic information for smaller objects, while the smaller resolution targets capturing overall semantic information for larger objects. In this way, the CFA module can extract the scale-aware features. More details can be found in Hu et al. 17
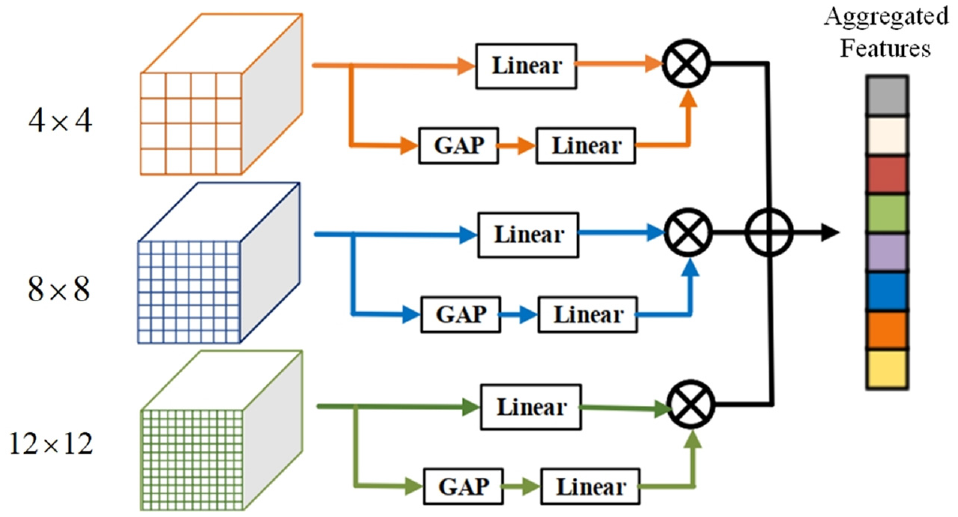
The structure of the CFA module. 17
Experiments
Setups and Settings
In this section, we conduct extensive experiments, including performance comparisons, ablation studies, and visualizations. All the experiments are performed on the data sets of PASCAL VOC 2007/201221,22 and MS COCO. 23 The data sets of the PASCAL VOC series21,22 contain 20 classes. They are airplane, bicycle, bird, boat, bottle, car, bus, cat, dog, cow, sofa, horse, person, dining table, motorbike, potted plant, chair, train, TV monitor, and sheep. The MS COCO data set 23 contains 80 classes. During training, several classes (5 for PASCAL VOC and 20 for MS COCO) are randomly selected as the novel classes, each of which forms a query set. The remaining classes serve as the base classes, corresponding to the support sets. In the few-shot scenario, each novel class only contains k image samples. In our experiments, k is set to 1, 2, 3, 5, and 10 for the PASCAL VOC data set, and to 10 and 30 for the MS COCO data set.
We train the proposed model by the following two stages. In the first stage, the base classes are divided into support and query sets. Note that the feature extractor is pretrained on ImageNet
26
in advance, while the remaining modules are trained together in an end-to-end manner. In the second stage, one novel class corresponds to one query set, and only
For the model training, batch size is set to 4, and the initial learning rate is set to 0.005. We apply an SGD (Stochastic Gradient Descent) optimizer 27 for updating parameters. The learning rate is reduced with the increase in training epochs. We train the models on the set of base classes for 20 epochs. Throughout our experiments, we use Top-1 mAP value as the evaluation metric. The higher the mAP value, the better the detection performance.
Our model is implemented based on the PyTorch framework. All the experiments are performed on a workstation with the operating system Ubuntu18.04.5LTS, CPU Intel Xeon(R)-2150B@3.00 GHz*20, dual GPUs GeForce RTX 2080Ti, and 32 GB memory.
Performance Comparisons
To validate the superiority of our proposal, we conduct performance comparisons on the data sets of PASCAL VOC21,22 and MS COCO. 23 In our experiments, the baselines are Meta R-CNN, 18 Reweight-YOLOv3, 19 and the original DCNet. 17 Moreover, an abbreviation “ATT”—which is short for adaptive attention mechanism—is added into the Meta R-CNN 18 and Reweight-YOLOv3, 19 respectively. This means that the two models are equipped with the adaptive attention mechanism. In total, six models (including ours) were prepared for the performance comparisons. To verify the generalization ability and the robustness of the proposed model, we test the detection performance on three novel sets, which consist of different combinations of the novel classes. The detailed results are listed in Table 1.
Detection performance (mAP) on the PASCAL VOC data set.
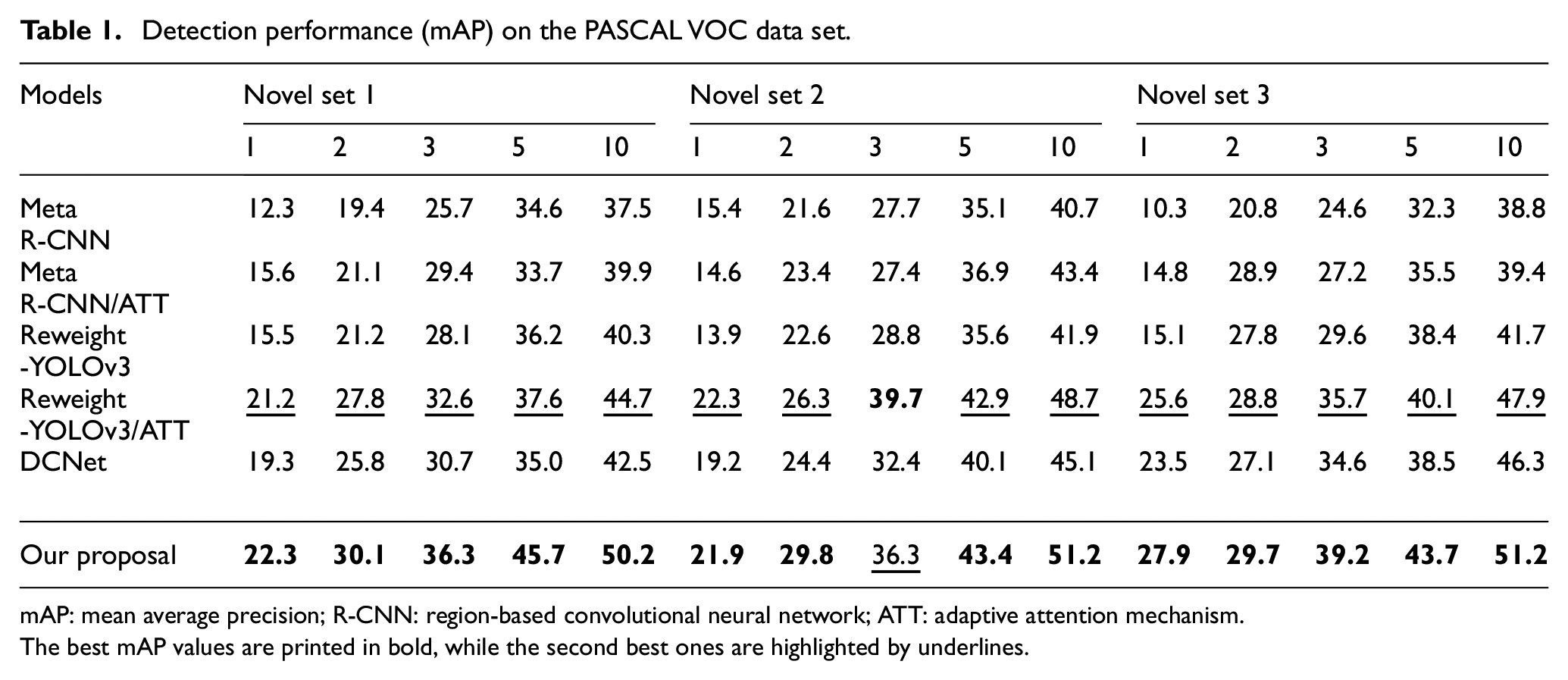
mAP: mean average precision; R-CNN: region-based convolutional neural network; ATT: adaptive attention mechanism.
The best mAP values are printed in bold, while the second best ones are highlighted by underlines.
We can find that, in most cases, our proposal achieves the best mAP values. This demonstrates the effectiveness of the proposed method. Comparing the last two rows of Table 1, we can see that our proposal outperforms the original DCNet. 17 Specifically, when k = 10, our model reaches the mAP value of 50.9%, which is about 6 percentage points higher than the original DCNet. 17 These observations validate that the designed adaptive attention module and the LM Softmax are helpful for the DCNet to boost the detection performance. This is because the adaptive attention module helps to suppress the background interferences, while the LM Softmax can enhance the between-class separability of object features. Comparing Meta R-CNN (Reweight-YOLOv3) and Meta R-CNN/ATT (Reweight-YOLOv3/ATT), we find that equipping the adaptive attention module indeed improves the detection performance. This suggests that the designed adaptive attention module is a plug-and-play tool that can gear toward generic object detection models.4–8 Moreover, we find that the mAP values generally increase with k. This observation also accords with common sense since more image samples provide more object-related information. All these observations and analysis demonstrate that our proposal has better robustness and generalization ability.
For MS COCO data set, we also organize three novel sets, which have different combinations of the novel classes. The corresponding mAP values are listed in Table 2.
Detection performance (mAP) on the MC COCO data set.
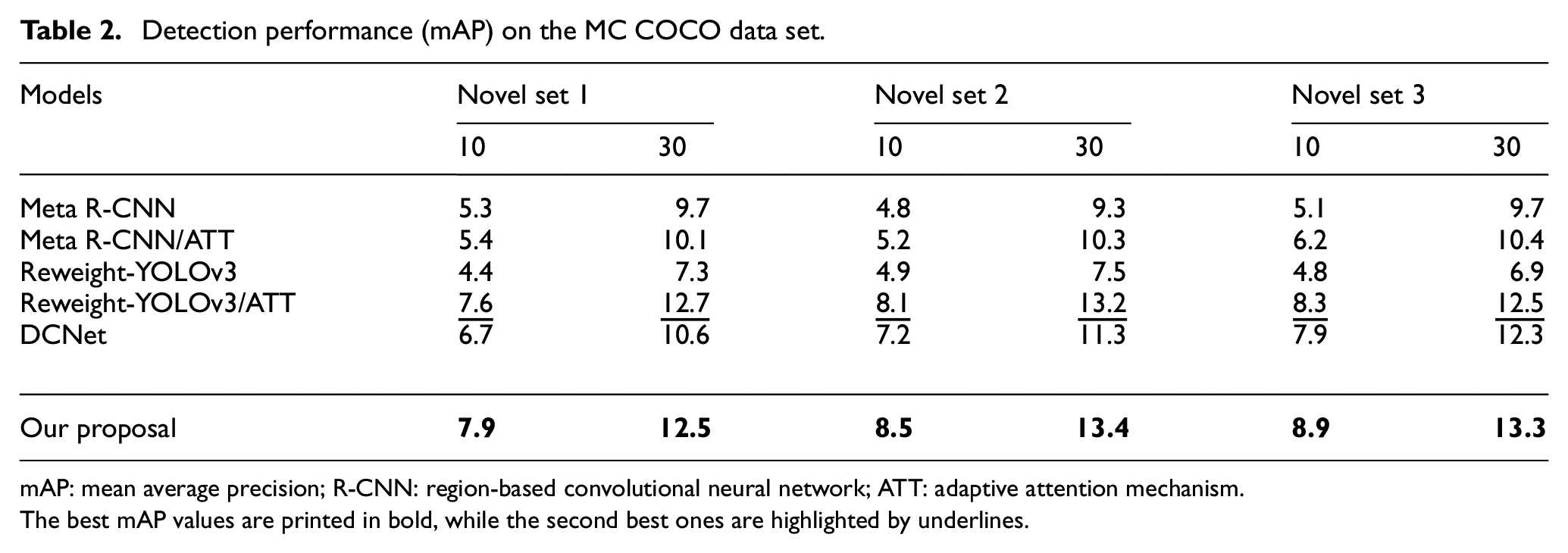
mAP: mean average precision; R-CNN: region-based convolutional neural network; ATT: adaptive attention mechanism.
The best mAP values are printed in bold, while the second best ones are highlighted by underlines.
As we see, the mAP values are lower than those in Table 1. This is because the MS COCO data set contains more object classes than PASCAL VOC data set. Despite the complex scenes of the MS COCO data set, our proposal still achieves the best detection performance over all three novel sets. When k = 30, the highest mAP value reaches 13.4%. These numerical results, which are consistent with Table 1, corroborate the superiority of our proposal.
Ablation Studies
In the ablation studies, all the experiments are conducted on the novel set 2 of the PASCAL VOC data set with k = 10. We test the contributions of the adaptive attention module and the LM Softmax to the final detection performance. The results of the ablation studies are given in Table 3.
Results of the ablation studies.

LM: large-margin; mAP: mean average precision.
The best mAP value is printed in bold.
Without the adaptive attention module and the LM Softmax, the original model achieves a mAP value of 45.1%. When equipping the adaptive attention module or the LM Softmax, the detection performance becomes better, achieving a 4.7% or 3.2% increase. This indicates the adaptive attention module or the LM Softmax is useful for the original DCNet. 17 Moreover, when we switch on the two modules simultaneously, the mAP value reaches 51.2% (see the last row of Table 3). This result demonstrates that the two modules can cooperate with each other to further boost the detection performance. These ablation studies provide solid evidence as to the reasonability of our proposal.
Visualizations
In this section, we visualize the experimental results that can reveal the working mechanisms of the adaptive attention module and the LM Softmax.
In Figure 6, we exhibit the attention maps generated by the adaptive attention module. Hot and cool colors represent high and low attention scores, respectively. The first row/column of Figure 6 is arranged for query/support images. In Figure 6, the support images are potted plant, sheep, car, and airplane, respectively. The query images are sheep, cow, car, potted plant, and boat, respectively. The visualization results in Figure 6 show that, for a query image, different attention maps will be generated when given different support images. When the query and support images come from the same class, for example, sheep, our adaptive attention module can allocate higher attention scores to the targeted objects. This phenomenon can be found in the attention maps located at (row = 3, column = 2), (2, 5), (4, 4), and (5, 6). On the contrary, when the query and support images come from different classes, the attention scores are low and scattered over the attention map. We observe the phenomenon in the last column of Figure 6. More interestingly, we note that the attention map at (3, 3) has a continuous salient region, even if the query and support images come from different classes. In this example, although the support image belongs to sheep, our adaptive attention module assigns higher scores to the region of cow. This phenomenon is reasonable because both sheep and cow are Bovidae. This demonstrates that the adaptive attention module not only can concentrate on the same-class objects but also has outstanding generalization ability for similar classes.

Visualizations of the attention maps.
In this article, the LM Softmax is introduced into the original DRD module of DCNet. 17 The LM Softmax helps the DRD module to extract features with better in-class representativeness and between-class separability. In this experiment, we visualize the support features of 15 base classes of the PASCAL VOC data set by t-distributed stochastic neighbor embedding (t-SNE). 28 The feature distributions are shown in Figure 7. In Figure 7, different support classes are printed by different colors. As we can see, the feature points belonging to the same class are basically gathered into a cluster. Remarkably, when using the LM Softmax, the feature points of the same class are gathered more compactly. Moreover, we find that feature points of the similar classes share smaller between-class distances. For instance, the feature points of sheep and cow are overlapped closely.
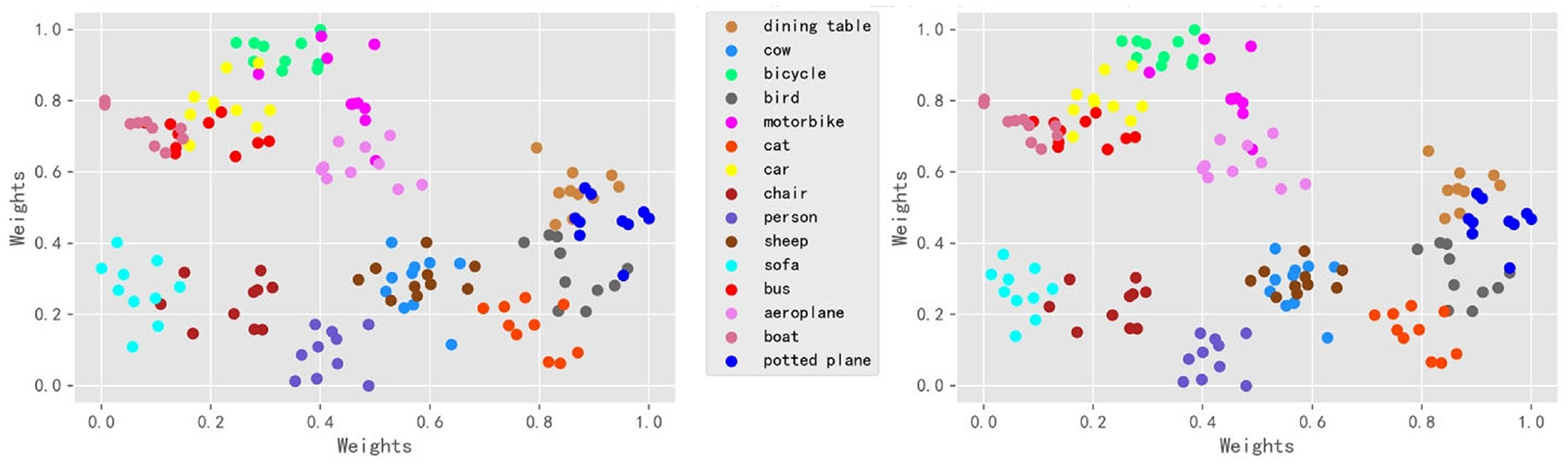
Feature distributions of 15 base classes (PASCAL VOC data set). Feature normalization using the Softmax (the left one) and the LM Softmax (the right one).
Moreover, we calculate standard deviations of support features in a class-wise manner. We exhibit the standard deviations in Figure 8. We find that, when using the LM Softmax, the standard deviations have been effectively reduced. Specifically, the average standard deviation for LM Softmax is 1.05, which is about 15% lower than that for the Softmax. This demonstrates that the LM Softmax can improve the feature separability, and thus validates the reasonability of introducing the LM Softmax.
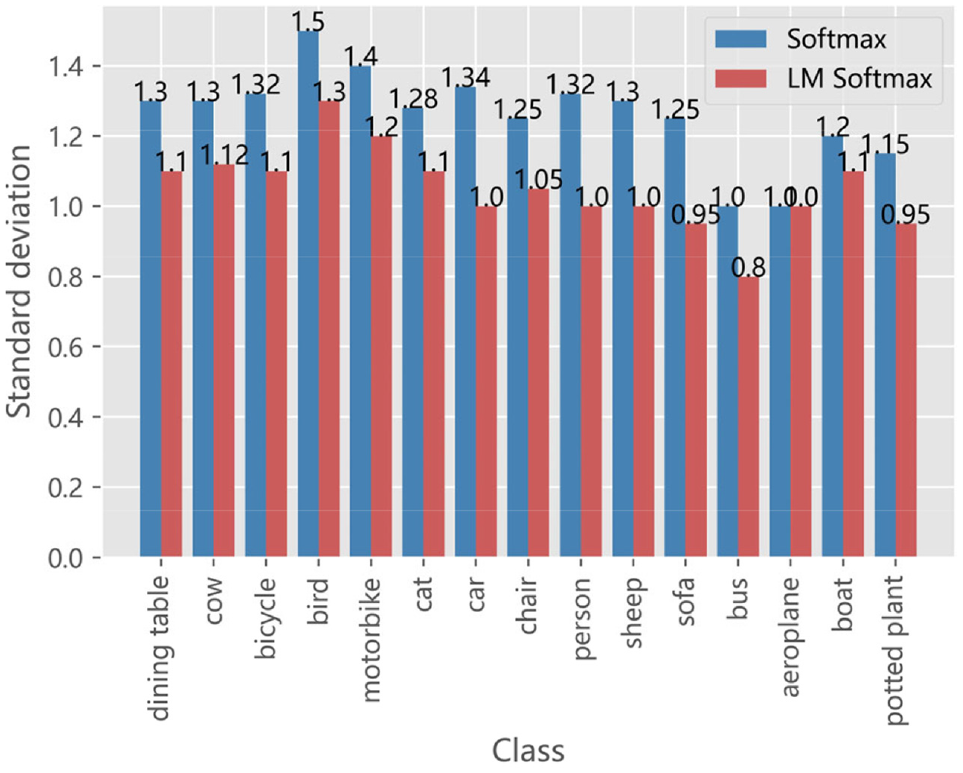
The standard deviation for each class. Feature normalization is based on the Softmax and the LM Softmax, respectively.
Conclusion
In this article, we aim to improve the DCNet 17 by designing an adaptive attention module and introducing an LM Softmax for feature normalization. The adaptive attention module is configured in front of the DRD module, and can be trained together with the other part of the DCNet. After training, the adaptive attention module can enhance the object features and suppress background interference at the same time. In addition, we introduce an LM Softmax 20 into the DRD module of DCNet, 17 which normalizes features without reducing the discriminability between different classes. Experimental results on data sets of PASCAL VOC 2007/202121,22 and MS COCO 23 show that the improved method reaches a higher detection accuracy (mAP) than the original DCNet. 17 The ablation studies and visualizations also demonstrate that the adaptive attention module and the LM Softmax indeed enhance the query features in terms of in-class representativeness and between-class separability. The application potential includes recognizing rare patterns in the cultural relics, or adapting to new styles of clothes for a human parsing system.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Key Research and Development Program of China (2019YFC1521300), supported by the National Natural Science Foundation of China (62001099), and supported by the Fundamental Research Funds for the Central Universities of China (17D110408).