
Abstract
A new unsupervised predictive maintenance analysis method based on the renormalization group approach used to discover critical behavior in complex systems has been proposed. The algorithm analyzes univariate time series and detects critical points based on a newly proposed theorem that identifies critical points using a log-periodic power law function fit. Application of a new algorithm for predictive maintenance analysis of industrial data collected from reciprocating compressor systems is presented. Based on the knowledge of the dynamics of the analyzed compressor system, the proposed algorithm predicts valve and piston rod seal failures well in advance.
Keywords
Introduction
Detecting the symptoms of a failure and predicting when it will occur, in multivariate or univariate time series collected via the Internet of Things (IoT), is central to the concept of predictive maintenance (PM), which is now used in almost every area of industry. PM allows a company to better prepare for a potential failure by redesigning the production process in advance or creating a workaround when shutdown is not possible. Thus minimizing the costs and the effort of standard maintenance operations through predictive engineering.
Predicting failures, provided by PM, can be very profitable for a company, under the condition that PM minimizes the number of false warnings (false positives) and maximizes the number of correctly predicted events (true positives).
Let us define failure as the termination of the ability of a part of an industrial device to perform the required function with the required efficiency. Another aspect of a failure that needs to be specified is how it can manifest itself. A failure can develop gradually or appear as a sudden event. In this work, we consider only those failures that develop over time.
Creating a properly working PM process faces two main problems:
related to the determination of time when a failure occurred in the considered technological process or IoT data, the development or the application of the best algorithm (based on physical description, machine learning [ML], or statistical methods) to the data being analyzed.
Proper identification of the failure in IoT data (data labeling process) is a very difficult task and usually requires very specialized knowledge. For various reasons (economic and technological), not every failure requires corrective action. This is because the required efficiency that defines a failure in the monitored unit may depend on the degree of reliance of the process on the considered failure. Sometimes, a minor failure is not a sufficient reason to stop a monitored machinery or a production process. The determination of so-called good IoT data, that is, the data when the monitored device behaves normally, is also a data labeling process that requires expertise. In this work, every action that defines the state of the data is considered a data labeling process.
Attempts to build a solution based on supervised ML models will encounter the following problems:
the complexity of the data labeling process, the model degradation: due to the evolution of IoT data, it is necessary to update the supervised model because the current one starts to behave incorrectly. Such an update forces the creation of new training data necessary for a new supervised model (new data labeling process), and the complex process of monitoring the predictions of the currently working model. This is a difficult task, especially when dealing with a small number of predicted failures (Białek et al., 2024; Kivimäki et al., 2025; Müller et al., 2024).
In published works on failure prediction using supervised solutions (Carvalho et al., 2019; Çınar et al., 2020; Ran et al., 2024; Soori et al., 2023), the authors omit the need for a continuous data labeling process, as well as the need to monitor the degradation of the running model. Thus, an important economic part of PM projects based on supervised models is passed over in silence. In review articles (Carvalho et al., 2019; Çınar et al., 2020; Ran et al., 2024; Soori et al., 2023), methods based on neural network architecture are placed in the category of unsupervised methods. However, these methods also require labeled training data. In this article, the term “unsupervised method” is understood only as a solution that does not require any knowledge of labeled data and any information about the state of the input data as good/healthy or anomalous.
The complex and expensive cycle of building and implementing a supervised method for a PM process, sketched above, strongly suggests that unsupervised approaches are a better tool for building PM processes. An unsupervised solution removes the necessity of:
a complex data labeling process running at all times as a part of a supervised model and monitoring of the deterioration of the model quality and thus re-creating models by training them on updated training data.
This paper describes an unsupervised failure prediction method (Lobodzinski & Cuquel, 2024) used to monitor reciprocating compressor systems based on a concept called log-periodic power law (LPPL) proposed in Johansen and Sornette (2000), and Sornette (2003a, 2003b). The LPPL mechanism is used to predict disasters in financial data (Lin et al., 2014), earthquakes (Sornette & Sammis, 1995), avalanches, and similar phenomena (Lei & Sornette, 2024).
However, due to the different nature of the data analyzed, the LPPL method cannot be applied in the same way as for bubble (or antibubble) detection in economic time series. Due to the different definitions of PM failure in industrial applications, modifications need to be made to the LPPL method. In the case of data describing the financial market, the variable that directly characterizes changes in the system under analysis is examined. Such a variable is, for example, the index of the analyzed financial market or the prices of shares.
In the case of a machine (e.g., compressor or other systems containing a number of subsystems), the analysis uses indirect data collected by sensors. It is not possible to measure the direct changes causing the failure (e.g., material degradation, cracks, etc.) but it is possible to measure changes resulting from the influence of deteriorating machine components on the measured values.
In the description of the application of the presented method, such indirect data are, for instance, changes in the opening angle of suction or discharge valves inside the compression chamber as a function of the volume in the cylinder chamber expressed by the angle of rotation of the crankshaft. In other words, degradative (unmonitored) changes affect measured variable changes in less visible (more distorted) ways than in the case of a direct measurement of variables.
The principle of operation of the proposed method is based on the detection of such behavior in the analyzed data, which is in accordance with the LPPL. Finding such a functional behavior in the data is equivalent to finding the critical point of the system. It corresponds to the situation in which the system begins to work with decreasing efficiency, which is a signature of future failure. The point in the time series thus identified defines the start of the countdown to the predicted failure. Let us call the trend change point the initial breakdown (IB). The concept of detecting an IB point for use in predicting failure is similar to the concept of detecting a trend change point in a time series. Therefore, it is not necessary to predict the time of failure in the future. All that is needed is to determine whether a given point in the time series is or is not an IB starting point.
If it is known that the current point in the analyzed time series is an IB point, then based on the knowledge of the dynamics of the monitored device, it is possible to determine the time window in the future (in units of the device’s operating time) in which the failure will occur. It should be emphasized that the determination of the IB point is not equivalent to the detection of anomalies. Anomalies in the behavior of the unit should be expected only in the time window of the expected failure. The concept of a time window in the future during which a failure is predicted is due to the fact that it is not possible to predict the exact time of failure of the monitored device using the presented method. This is mainly due to unpredictable events, such as changes in the load of the device, periods when the device is off, or independent maintenance activities.
The organization of the paper is as follows. Section 2 briefly describes the current status of unsupervised PM in the industry. Section 3 answers the question of why the logarithmic–periodic oscillation detection method is suitable for detecting sudden failures in an industrial system. Section 4 describes a numerical method for determining failure time points from the data. Section 5 introduces the data used for the analysis presented and the following section 6 shows the results obtained using the new method and compares these results with those obtained using the online statistical method. Finally, section 7 discusses the results and summarizes the advantages and disadvantages of the proposed method. This section also briefly outlines the criteria for selecting data to be used by this method.
Given the introduced definition of “unsupervised method,” as a methodology that does not require knowledge of the state of the input data, the list of existing methods for failure prediction is very limited. Following the work of Giannoulidis et al. (2024, which also includes references to other research works, as well as studies of specific solutions involving a broader understanding of the “unsupervised method”), the spectrum of available solutions can be generally divided into two categories.
Solutions involving the use of prediction techniques to predict points in the future and then compare them with actual data to detect anomalies, as shown in Hundman et al. (2018). Depending on the predictive solutions used, this category of methods requires a large amount of data. In this case, a separate problem is the accuracy of the prediction part. Where the prediction part is a supervised method. Hence the requirement to control it, which makes the whole solution complicated if one wants to use it in practical applications. Solutions based on measurements of distance or similarity used to evaluate the degree of data anomaly. In this case, methods using clustering algorithms (Diez et al., 2016) or determining similarity between time series or data are used. This approach sometimes leads to problems when encountering new data that did not exist in the past. It happens that it makes it impossible to use them for real-time data analysis.
The solution proposed in this paper is an attempt to solve the issues identified in both of the above categories: the problem of demand for large amounts of data and the problem of data changes that do not occur in the past.
The essence of the proposed method is to determine the IB points in the time series of input data. Thus, it is natural to compare the proposed model with online methods that determine trend change points in time series in fully unsupervised mode. Latest advances in statistical online trend change point detection can be found in studies (Edward et al., 2023; Gaetano et al., 2023, 2024; Kes et al., 2024; Pishchagina et al., 2023). The difference between the statistical methods of determining the trend change points and the IB points determined by the proposed method is that in the proposed solution we are based on the search for a specific functional behavior (pattern) in the data. As will be shown later, this pattern is characteristic of physical processes leading to a degradation of the monitored components of the device. A comparison of the results of the two methods, based on the same input data (statistical [Gaetano et al., 2023; Romano et al., 2024] and the proposed model), will be presented and discussed in section 6.
The purpose of the PM method is to provide predictions for future failures of the system described as a set of various components cooperating together. This section illustrates why the LPPL-based algorithm is applicable to failure prediction and describes the basics of the LPPL-based method.
The generalized relation describing the hazard rate

Equation (1) has three classes of solutions depending on the value of

For


Let us assume that the degradation of a working part can be treated as a discontinuous stochastic process associated with a given monitored variable. To simplify the analysis, the second assumption is to treat the degradation changes of physical quantity

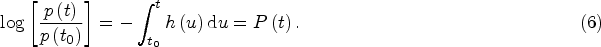
In our case,

Solution (7) is invariant under continuous scale invariance (CSI), which manifests itself through the scaling property of the solution
The basic assumption of the LPPL method is that the described process is near the critical point of the second-order phase transition. With this assumption, the final equation is obtained, the use of which for fitting is known in the literature as the LPPL method (Feigenbaum & Freund, 1996; Sornette et al., 1996).
Let
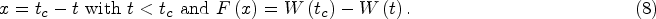
As a starting point for our derivation, the CSI is assumed to exist around critical points.
This allows us to use the renormalization group approach, which permits us to write a certain real function


The solution of equation (9) is the function

The condition of scaling invariance (9) with the general form of the solution postulated by equation (11) can be rewritten as




Therefore, the solution of equation (9) can be expressed, according to Nauenberg (1975), as
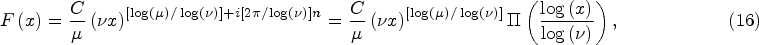
The index
An additional necessary condition that must be satisfied by function (16), or more precisely by its real part, is the trend that is determined by the power law (
The periodic function
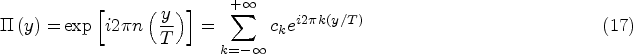
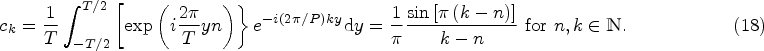
However, nonzero coefficients

In that formulation,

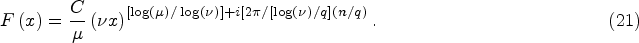
In this case, the expansion of
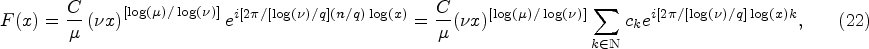
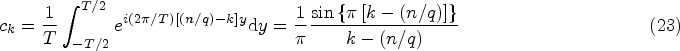
Given the denominator
This allows us to approximate the final form of the function
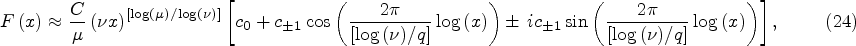
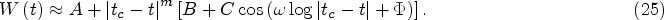
For the purpose of numerical fitting the LPPL function to the data, a transformed version of formula (25) is used, in the form of
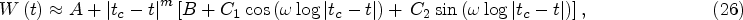
Due to the number of parameters (
Instead of trying to determine the critical time
In particular, our redefined set of arguments
As parameter fitting, the method described in Shu and Zhu (2019) is used, appropriately modified for our purposes, that is, by excluding the parameter corresponding to the
The constraints imposed on the fitting parameters (
Depending on the type of input data to be analyzed, the limits of variation of the parameters to be fitted require careful adjustment.
Having determined all parameters of the fitting LPPL function, in the next step, it is necessary to determine trends based on the identified local maxima and minima of the shape of the fitted function: all local extrema from this set, the To this set of points a straight line is fitted by linear regression. The slope of the line determines the trend for a given category of extremes (maxima or minima).
Then, using the calculated trends of the extreme values of the best LPPL fit, it is determined whether a given point (defined as a pair:
Assume that the function
If both trends
In the presented method, any point that satisfies Theorem 1 is treated as a point initiating a future failure—the IB point.
The formalism described above can be summarized as follows: the appearance of a failure due to deterioration of components in a complex system is preceded by the appearance of a phase transition of the second kind, defined by point IB (critical time point). From this time point, the process of failure development begins. This period (after the time defined by the IB point) can be monitored by detecting anomalies. Anomalies (as a result of reduced process efficiency) occur when the effects of the failure become large enough and begin to affect the behavior of the monitored device.
Determining the time of failure requires knowledge of the dynamics of the monitored system and will be discussed in section 6.
Monitoring data from a reciprocating compressor, describing the pressure-volume (PV) diagram of one of the compression chambers, was used to demonstrate the operation of the method. Based on these, the values of the angle of opening of the suction valve (OSV) expressed by the angle of rotation of the crankshaft were determined. The data is available at Open Science Framework (2017).
This value, for a given cycle described by the PV diagram, is very sensitive to changes in the amount of gas in the chamber, for example, due to its leakage through a broken valve or piston rod seal system. OSV changes are directly dictated by the thermodynamics of the compression process in the compressor chamber. Monitoring the changes in OSV provides a base for compressor diagnostics and allows us to determine compressor efficiency, valve operation, or the condition of the piston seals or piston rod sealing elements (Bloch & Hoefner, 1996).
The data has been averaged to daily values and covers a period of time between 23 August 2019 and 19 January 2022.
In order to compare the results of failure prediction, data identifying the dates of repair interventions with their respective reasons for failure and the dates of observation of anomalous compressor behavior without interruption of operation were used.
Prediction of Failures: Methodology and Results
To test the effectiveness of our algorithm, a backtest of the detection method was conducted on the OSV data, calculating IB points. The range of the variable length of the time series
Intuitively, one can expect that the accuracy of determining the critical points using Theorem (1) will strongly depend on the error of fitting the LPPL curve (26) to the data. The smaller the fitting error, the greater the confidence that a given point of the input time series is indeed an IB point according to Theorem (1). In addition, it is expected that in the vicinity of the true IB breakpoint (before and after it), the method should find some good fits of the LPPL function with a small error, but this is not a necessary criterion for the existence of an IB point for days as time units.
Figure 1 shows two examples of the fit function (26) to data along with calculated criteria for trends determined from maxima and minima of the fitting function satisfying the criteria of Theorem 1.
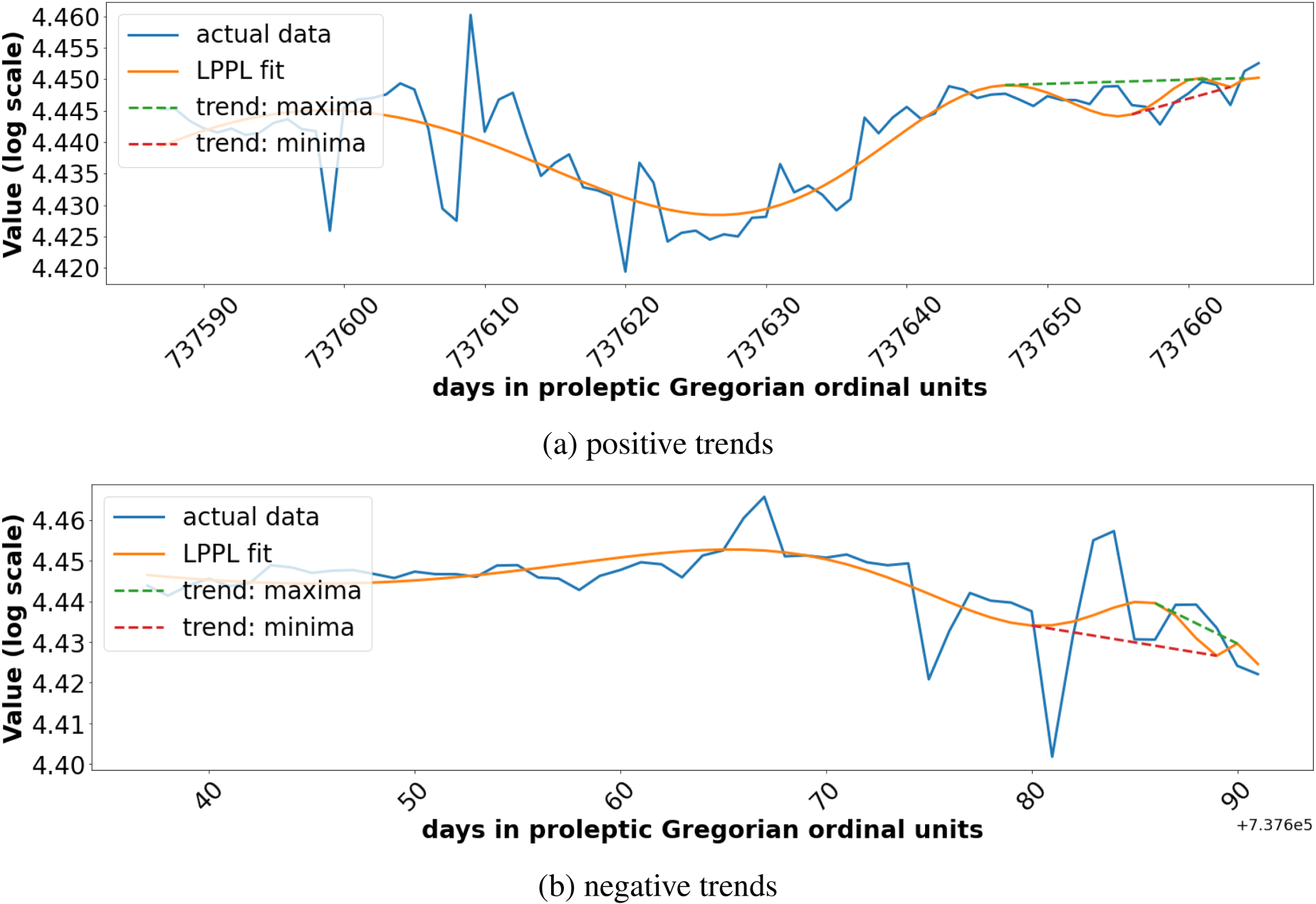
Examples of LPPL Function (26) Fits for Cases with Positive Trends (a) and with Negative Trends (b) For Selected Current Times (Dates in Proleptic Gregorian Ordinal Units). Fit Parameters Calculated for Both Trend Categories: (a) Positive Trend: Current Date:
Figure 2 shows the application of this procedure to the diagnosis of the critical points with additional information about the dates of failure repairs (see the description of Figure 2).
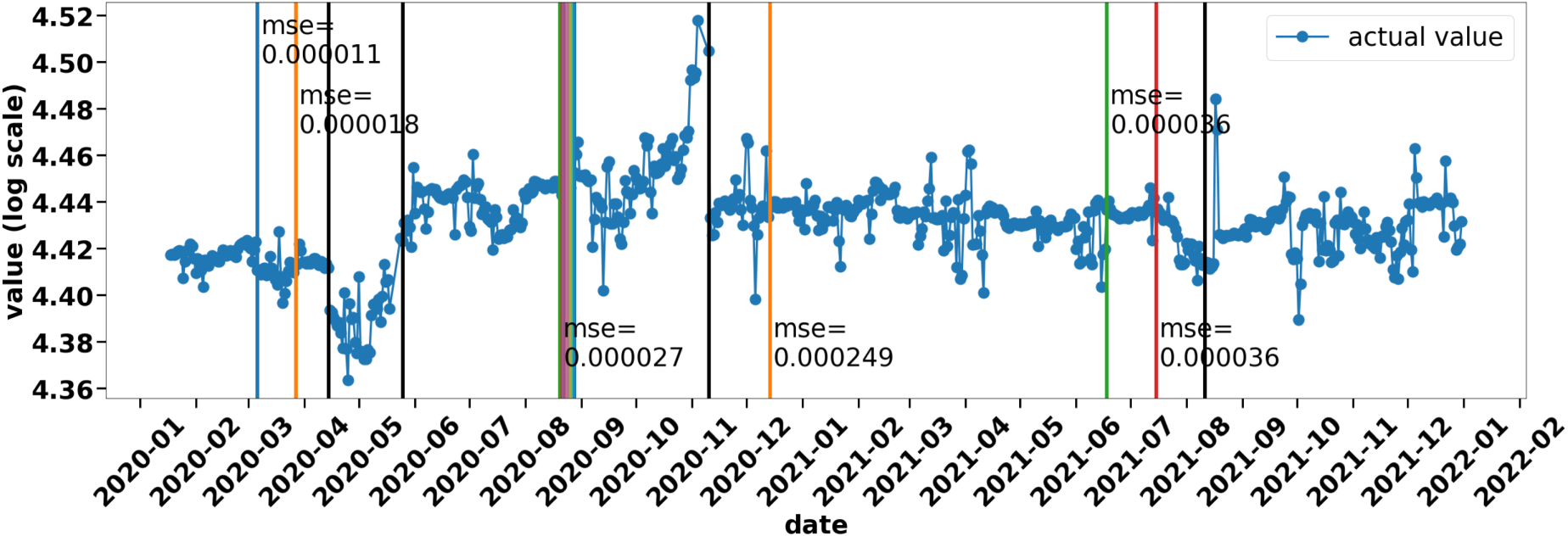
Calculated IB Points for the Analyzed Input Time Series (Marked in the Figure by a Solid Line with Measurement Points). The Vertical Lines of Different Colors Indicate the Diagnosed by the Algorithm IB Points. For Each Group of the IB Points, the Mean Value of the Matching Error (
Figure 2 confirms our initial hypothesis very well. It shows:
groups of points with similar fitting errors at least 14 days before the time of failure identification (repair is usually performed with additional delay due to the compressor operating conditions), dependence of the matching error on the criticality of the failure: the signaling of the grouping of critical points for the beginning of 14 December 2020 is characterized by a large error (
Taking these conclusions into account and comparing the recorded failures and behaviors suggesting problems in compressor operation, classified by experts as insignificant, with the predictions made by the model, it is possible to determine the threshold values of the fitting error (
Classification of calculated IB points:
As shown, sometimes the algorithm detects a larger number of IB points located very close to each other. Such cases were simplified by choosing a single representation (the first IB point of the group) for each group of signals. This was done by assuming that the signal belongs to a group if its distance from the preceding signal is smaller than or equal to 3 days.
By comparing the failure times predicted by the algorithm with their actual occurrence, a criterion for predicting the time window in which the failure will occur can be also determined. One of the parameters for fitting the LPPL function (26) to the data is the length of the chosen sequence of data preceding the analyzed time point
The predicted time period of a failure occurrence is defined as an interval
Definition 2 is based on a knowledge of the dynamics of the device for which the algorithm parameters have been defined. For other devices, all parameters should be selected based on the dynamics of their behavior. The duration of the time window with predicted failure is assumed to be valid for a certain period of time and is up to 90 days.
In the case of compressors, due to the different criticality of failures, some of them may be accepted for a longer period of time (even several months in the case of valve failures) while waiting for a convenient moment for repair.
Considering:
the classification of alerts specified in Definition 1, the selection of the representative of the groups of warnings (by selection of the initial signal for the common group of calculated IB points), Definition 2 specifying the expected time window in which the failure will occur,
the raw results shown in Figure 2 can be redrawn to a new form, as shown in Figure 3. The correlation between the predicted failure times and the actual repair times, or the time periods when experts detected abnormal compressor behavior is very good for the
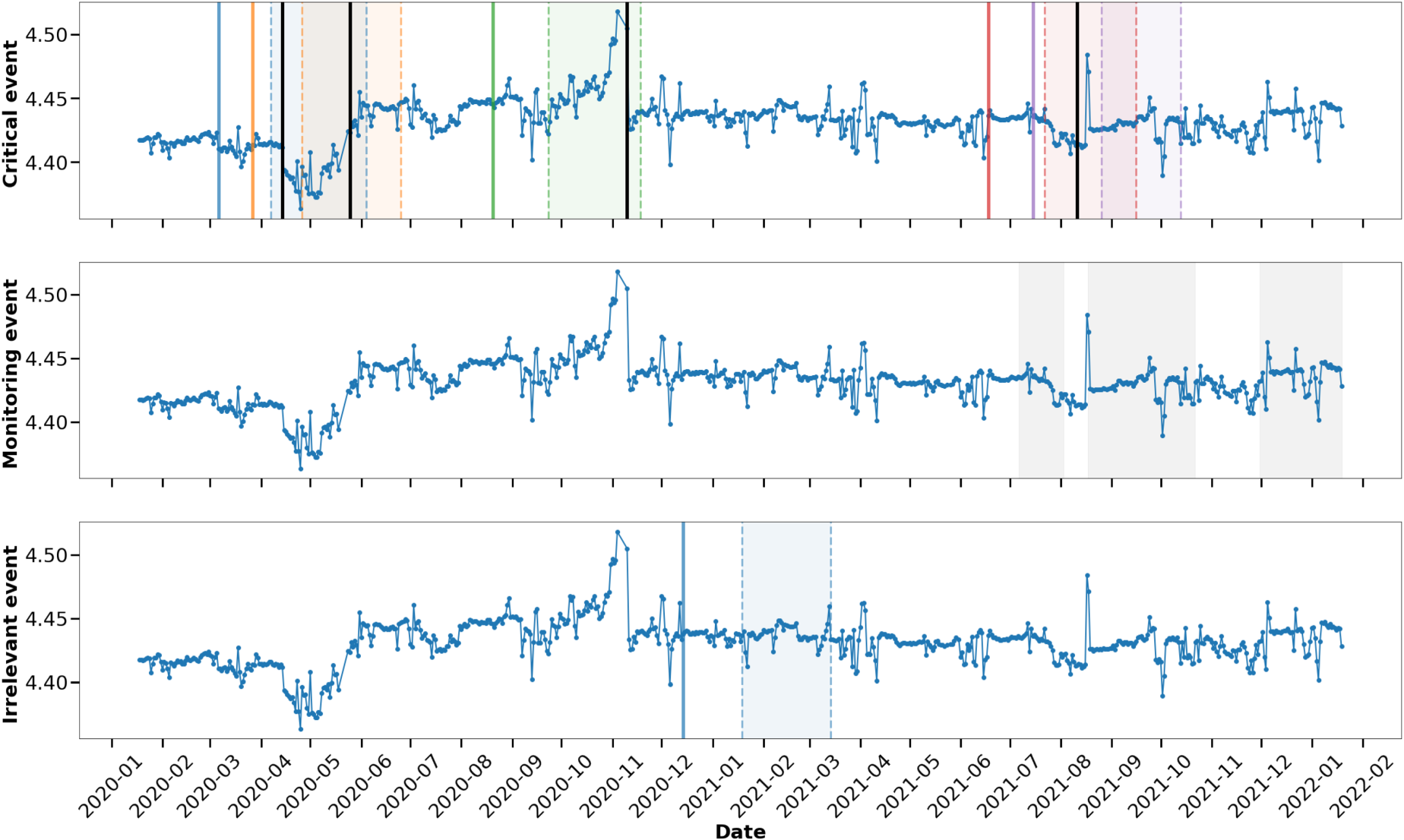
Redrawn Prediction of Failures by the Algorithm in Comparison with Reparation Times and Problems Detected by Experts. The Figure Shows Representations of Groups of Discovered IB Points (Colored and Continuous Single Vertical Lines) and Predicted Failure Time Periods Corresponding to Them According to Definition 2 (Corresponding Colored Areas Bounded by Vertical Dashed Lines). The Categorization of the Criticality of the Forecasted Problems (Definition 1) is Represented by the Splitting into Three Separate Figures, Each for a Separate Criticality Category. The
In the analysis presented here, the input data monitors the change in the opening angle of the suction valves in the compression chamber expressed by the angle of rotation of the crankshaft. The trend identified from the determination of the IB points can be used to guess the type of future failure in the compression chamber (Bloch & Hoefner, 1996). By predicting the trend for times after the IB point, it is possible to try to determine approximately which part will fail—the valve or the piston rod sealing rings. Thus, when the predicted trend of the suction valve opening angle is decreasing, it is likely that the suction valve or piston rod seal rings are failing. If the trend suggests an increase in angle, this behavior indicates a leak in the discharge valve.
Thus, based on Theorem 1 and a physical interpretation of the behavior of the time series, the algorithm is able to predict not only the time window of failure, but also the group of parts that may fail. This provides an opportunity to verify the prediction not only on the basis of event times, but also on the basis of identifying the parts that can fail.
To better illustrate the additional information regarding the location of the future failure, Figure 4 shows the same data as Figure 3 with additional information about the parts that actually failed, the parts in which experts have observed problems and prognosis of failures predicted by the algorithm. Details are given in the description of Figure 4.
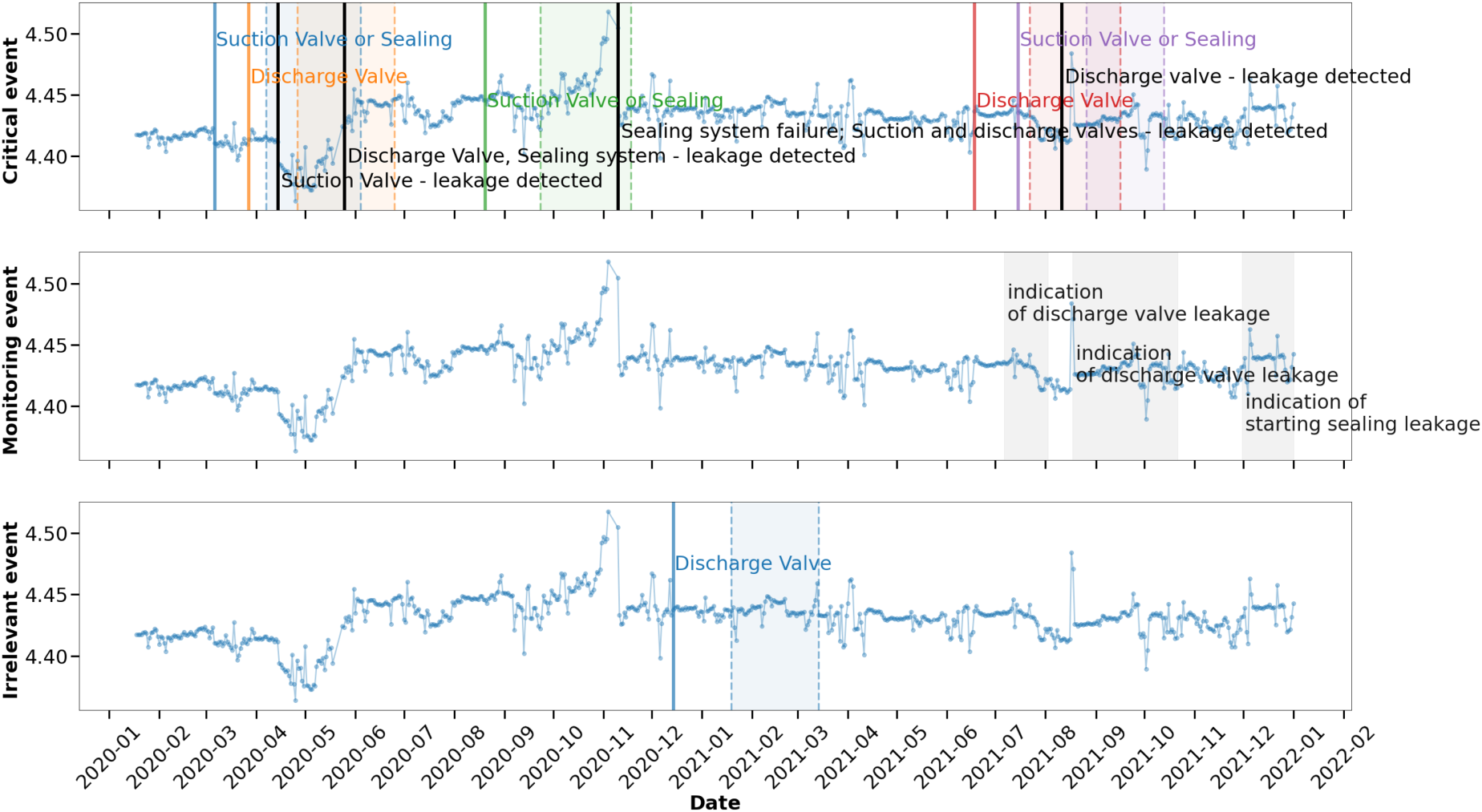
The Same Graphs as in Figure 3 with Added Annotations Describing the Failures Predicted by the Algorithm—Colored Texts (Different from Gray and Black), Reasons for Compressor Reparations—Black Text and Diagnosed Abnormal Compressor Behavior Requiring Monitoring—Gray Text. For Better Visualization, Areas of the Diagnosed Abnormal Behavior of the Compressor that Require Monitoring are Displayed in the “Monitored Event” Category.
For the entire time period analyzed, two cases deviating from this diagnosis are visible
in the category the perturbation identified by experts, started on 30 November 2021 and identified as indication of discharge valve leakage was not predicted by the algorithm at all.
The described method generates IB points before the appearance of anomalies associated with a future failure (section 4). This is why the LPPL-based solution has an advantage over solutions based on anomaly detection as a signature of a forthcoming failure.
It cannot be excluded that the IB points detected by the described method, may be the same as the statistically defined change points in the input trend of the time series. For comparison of the results determined by the discussed solution with the trend change points determined statistically, the online changepoint detection method from the work of Gaetano et al. (2023) was used. This solution is available in the form of the Python library (Romano et al., 2024; changepoint_online).
I ran a model based on the detection of two states of the analyzed data: one focusing on the detection of a decreasing trend, and the other focusing on the changes in the increasing trend. This way, it is possible to track when the analyzed variable increases and when it decreases. This corresponds to the ability to detect the type of future failure, as described in subsection 6.2.
In each iteration of the historical test, two changepoint detectors are run, one focusing on decreasing changes (left detector) and the other on increasing changes (right detector). In the source of the changepoint_online (Romano et al., 2024), this corresponds to the terminology: left and right detectors, respectively. The two detectors work independently of each other. When either model exceeds a threshold value, it is reinitialized.
A comparison of the results of the two methods at the level of determining IB points and trend change points is shown in Figure 5.
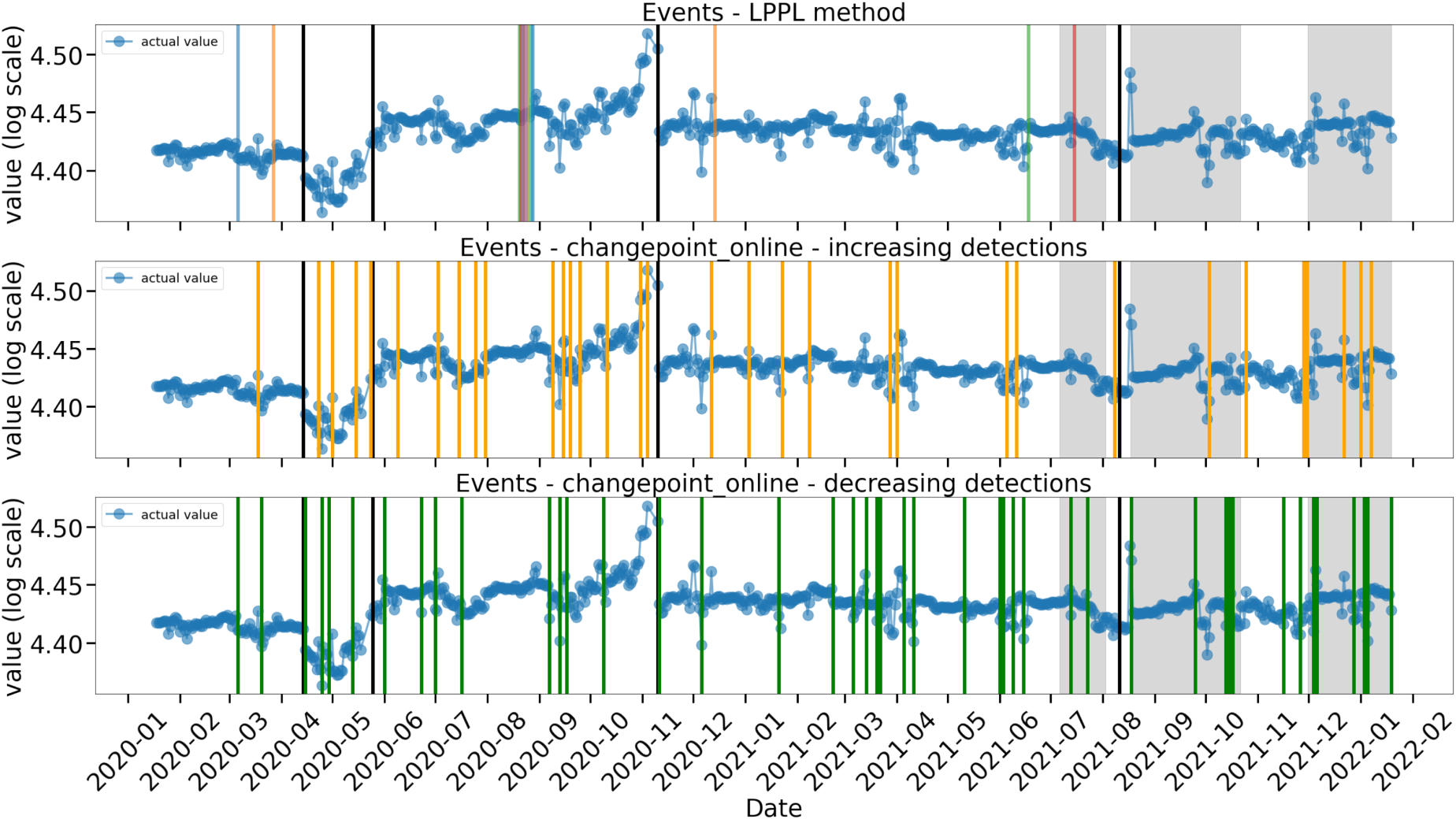
Comparison of the Results of the Presented Method (LPPL Method—Top Figure) with the Statistical Method (Changepoint_Online—Middle and Bottom Figures) at the Level of Determining IB Points and Trend Change Points. The Analyzed Time Series
As shown in Figure 5, the set of IB points determined by the LPPL method (14 alerts) is much smaller than the set of trend change points found by the online statistical method (changepoint_online; 44 left and 33 right detections). This is consistent with intuition because not every trend change point is a signature of change due to device degradation. The selection of all trend change points will create a lot of false signals. Therefore, it is necessary to correctly identify the threshold value to be used for the selection of the best trend change points, which may suggest future failure. The choice of the threshold value should demonstrate the relation between changes in the behavior of the analyzed variable with degradation processes in the monitored device. Such a correlation requires a separate analysis and knowledge of the labeled data. The applied statistical method is unable to predict future failures based solely on determining trend change points in a fully unsupervised manner.
The comparison of information coming from the failure predictions and comparing it with the knowledge from maintenance logs and expert detection of periods of anomalous compressor operation, including the prediction classification, is provided in Table 1.
Detailed Comparison of Model Predictions with Maintenance Logs Entries and Expert Diagnoses.
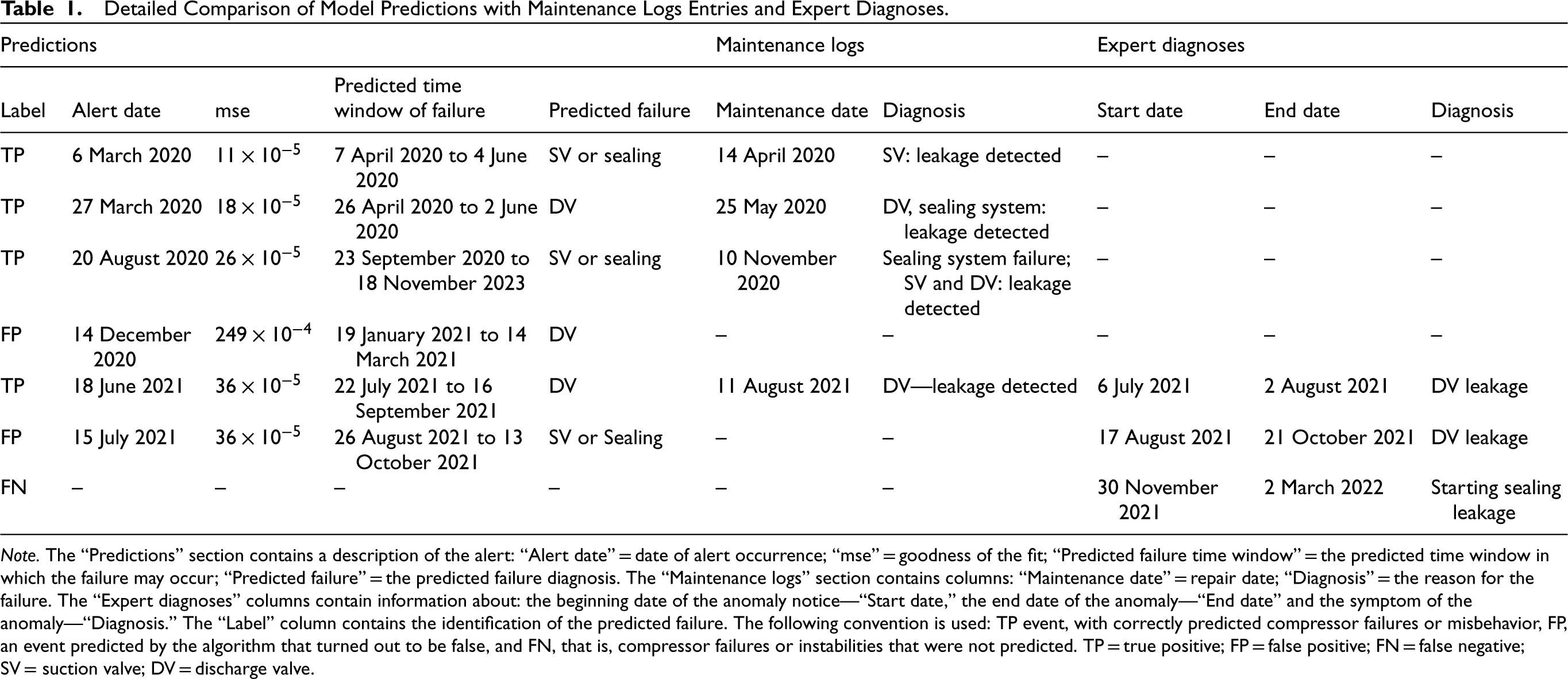
Detailed Comparison of Model Predictions with Maintenance Logs Entries and Expert Diagnoses.
Note. The “Predictions” section contains a description of the alert: “Alert date” = date of alert occurrence; “mse” = goodness of the fit; “Predicted failure time window” = the predicted time window in which the failure may occur; “Predicted failure” = the predicted failure diagnosis. The “Maintenance logs” section contains columns: “Maintenance date” = repair date; “Diagnosis” = the reason for the failure. The “Expert diagnoses” columns contain information about: the beginning date of the anomaly notice—“Start date,” the end date of the anomaly—“End date” and the symptom of the anomaly—“Diagnosis.” The “Label” column contains the identification of the predicted failure. The following convention is used: TP event, with correctly predicted compressor failures or misbehavior, FP, an event predicted by the algorithm that turned out to be false, and FN, that is, compressor failures or instabilities that were not predicted. TP = true positive; FP = false positive; FN = false negative; SV = suction valve; DV = discharge valve.
Major challenges in the field of industrial application of failure prediction, especially in the unsupervised version, is the number of issues corresponding to the proper identification of failures and behaviors of monitored devices. These difficulties mainly stem from:
the large variety in the types of failures, the small number of failures compared to the amount of data, the large variety of behaviors leading to the same type of failure, the difference in operating conditions, which can cause ambiguity in labeling accurate data.
The problems are very difficult to solve if the methods used to predict failures are based on the analysis of numerical values of input data (by calculating similarities, correlations, logic trees, building natural networks, etc.). Normalization and/or standardization procedures only introduce a common scale to the analyzed data.
The proposed method introduces a new type of procedure, which is based on the search for common functional behavior (26). From the point of view of the numerical values of the analyzed data, the course of the fitted function can be very different for different events—different patterns of the function for different values of fitted parameters. Even when new data appears with values that did not exist in the past, it is possible to determine the IB for a potential event, as the model fits functions to the data.
The IB points determined by this method, upon which the time window of failure occurrence is predicted in the next step, are the trend change points in the data.
To calculate the key performance indicators of the presented algorithm, the generally known indicators can be used:
In the analysis of results (section 6), the limits of acceptance of errors of fitting the LPPL function (26) determining the criticality of the predicted events (Definition 1) were defined on the basis of the results. Therefore, in order to calculate the “Precision” and “Recall” indicators, all results are taken into account without distinguishing them due to the defined criticality.
Comparing the predicted failure periods, taking into account the dates and predicted types of failures with the dates and descriptions of maintenance logs or recorded faults (Figures 3 and 4 and Table 1), the calculated values of TP, FP, and FN are as follows:
Hence,
In summary, the list of advantages and disadvantages of the presented method is a consequence of a paradigm change in data behavior classification, from one based on numerical values to one based on functional similarity.
The proposed model can be applied to very short time series (in our case, the minimum length of the series is only 101 points). There are no problems with data that appears for the first time. In the proposed solution, the part that qualifies certain data as IB is based solely on functional behavior. This universality is due to the renormalization group approach. The simplicity of the final production solution. The most difficult part of the algorithm is fitting the function to the data. Since the method does not contain components based on supervised methods, there is no need to monitor their quality.
The method is applicable to data that describe a physical process that degrades/changes due to perturbations introduced by interacting elements. This is because the method searches for behavior characteristic of phenomena in which phase transitions can be observed. Hence, not all data are appropriate for the described method. Matching the function to the data is based on the proper determination of boundaries of the parameters to be matched (26). This requires individual adjustment of the ranges of change of these parameters and the unit of time in the data to the device being monitored.
The method presented is designed to predict such failures, which are a consequence of a continuous physical process that can be monitored by measurements. In addition, it is necessary to know the time scales specific to the degradation of the monitored equipment. The time unit used by the algorithm should correspond to the time scale units of the degradation process.
This paper presents the application of a methodology for describing critical behavior in complex systems based on the renormalization group approach in unsupervised PM. The proposed algorithm analyzes the behavior of a complex system based on a time series representing the physical behavior of the system. To demonstrate the effectiveness of the algorithm for industrial applications, predictive results are presented for time series describing the thermodynamics of the gas compression process in a monitored reciprocating compressor in one of the compression chambers.
It was shown that failures in the analyzed industrial system can be treated as critical behavior in complex systems. Then the symptoms of future failure appear in the form of LPPL structures for phase transitions in the analyzed time series. Based on the most generalized scheme for describing the behavior of an analyzed system in the vicinity of phase transitions of the second kind based on the LPPL, a new way of predicting failures in compressor systems is proposed.
The presented algorithm is based on three steps. In the first step, the algorithm determines the IB points in the analyzed time series by means of fitting the LPPL function (equation (26)) using the proposed Theorem 1. The second step of the proposed method is based on the knowledge of the dynamics of the monitored system and specifies the time window in which the predicted failure may occur. In the last step, a criticality classification of the predicted failure is carried out, based on the goodness of fit of the LPPL curve to the data (critical event, monitoring event, and insignificant event).
Taking into account the specificity of problem detection in industrial systems (the demand to reduce the number of false alarms and to minimize the number of unpredicted events), it has been demonstrated that it is possible to experimentally determine such an error threshold of fitting the LPPL function to the data that all serious failures can be predicted if the fitting error is smaller than the threshold. In addition, it is also possible to define such thresholds for the LPPL curve-fit error to the data, for which the area of occurrence of less critical failures, that do not require rapid intervention, can be defined.
The method can also be applied to predictive IoT analysis of other industrial systems.
Footnotes
Acknowledgements
The author thanks colleagues from Prognost Systems GmbH for the introduction to the topic of failure detection in compressors and for helpful comments and discussions.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.