
Abstract
This paper describes a new dataset release containing harmonised census tables from the 2021 and 2022 UK Censuses. The release is the first unified dataset covering all four UK nations at the smallest available geographic level: Output Areas in England, Wales, and Scotland, and Data Zones in Northern Ireland. The UK’s three census agencies: ONS (England and Wales), NRS (Scotland), and NISRA (Northern Ireland) release their data separately, each with distinct variables, formats, and disclosure controls. Through a process of matching, standardisation, and aggregation, 190 comparable variables are produced. The dataset is made available as a series of topic tables indexed across all 239,023 of the UK’s small-area geographies. By providing a standardised dataset, this work enables seamless UK-wide analyses, facilitating cross-national comparisons and supporting research and public policy development.
Keywords
Introduction
Census data remain one of the most important sources of demographic information for public policy decision making and academic research (Killick et al., 2016) as they generate insight that captures the demographic, social, and economic characteristics of individuals, households, and neighbourhoods. In addition to underpinning academic research and policy making in the UK, given their open license, the availability of these data encourages the creation of derived data products such as nationwide socio-economic classifications or indicators (Stillwell, 2017; Wyszomierski et al., 2024).
The conduct and administration of the 2021/22 population censuses across the UK varied between its constituent countries. The four countries of the UK were covered by three separate censuses, conducted by the Office of National Statistics for England and Wales, the National Records of Scotland (NRS) for Scotland, and the Northern Ireland Statistics and Research Agency (NISRA) for Northern Ireland. Census data are released separately by the respective agencies after a period of processing and disclosure control.
Working with census data on a UK-wide basis has been a long-standing challenge across multiple census rounds. Differences across the constituent nations in how census data are collected, processed, and released create barriers to research requiring unified UK-wide data, necessitating expert knowledge to navigate these complexities. This is illustrated by work harmonising census migration and commuting interaction data (Stillwell and Duke-Williams, 2007) and producing consistent estimates of cross-border migration within the UK (Lomax et al., 2013). For the 2011 census, a unified dataset was produced by the UK Data Service to enable researchers to work more readily with UK-wide census data (Dymond-Green, 2017). However, to date, no equivalent unified dataset has been produced for the 2021/22 census.
Census response and online completion rates (National Records of Scotland, 2024; Northern Ireland Statistics and Research Agency, 2022; Office for National Statistics, 2022).
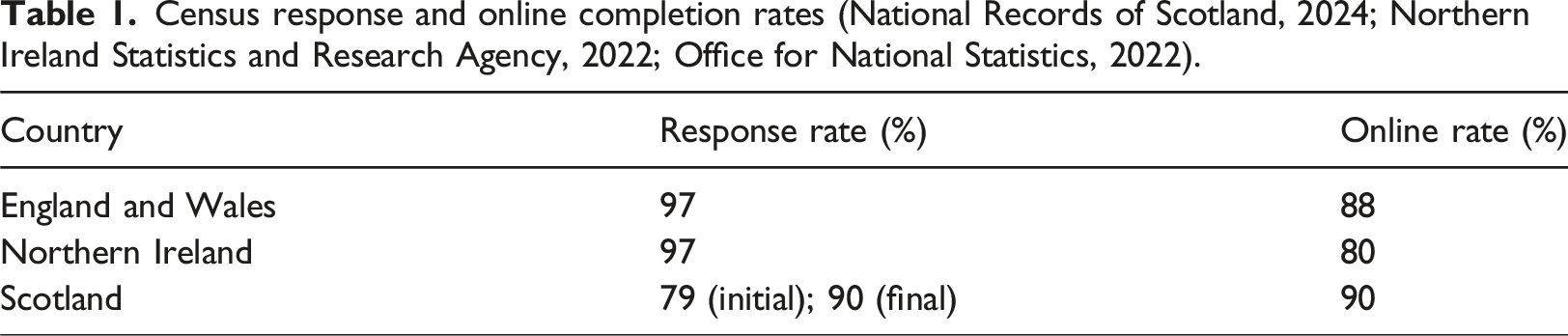
The Office for Statistics Regulation noted that conducting a census at the height of COVID-19 pandemic in 2021 has meant that some of the topic data would reflect the pandemic conditions or controls. In particular, statistics on employment, economic activity, commutes, and household structures “may well be unusual or changed” in 2021 (Office for Statistics Regulation, 2025a; 2025b). Similar issues were also noted in Scotland despite the 12-month delay (National Records of Scotland, 2024). Without extensive resurveying, it is not possible to control for such issues endogenously. As such, our approach for the unified UK-wide census dataset is to acknowledge these issues within the underlying survey and highlight them in the metadata of tables where they are most acute. There is also the general caveat outside of pandemic-specific issues in that there is a date misalignment between 2021 and 2022.
Within this context, our paper presents reproducible code that has been used to create an integrated UK-wide 2021/22 small-area census dataset. Each table that we have created includes detailed notes describing the compatibility of the variables across the three censuses, outlining cases where aggregations or adjustments were necessary due to differences in definitions, classifications, or response categories. The resulting data product facilitates UK-wide research while maintaining a clear link to the original census data sources.
2021/2022 UK census compatibility and comparability
The release of small-area census tables occurs separately for each UK nation, following the independent publication schedules of their respective statistical agencies. Outside of the issues related to the Pandemic, many of the separate small-area census tables released are broadly comparable between countries. However, some important differences emerge in terms of the questions asked, variable descriptions provided, disclosure controls, and release formats. Such factors create obstacles for less expert users of census data in UK-wide analyses, and acutely so, given that many key differences are not immediately apparent. As an illustrative example, the ONS and NRS did not include a question about the number of rooms in a household, asking only about the number of bedrooms due to questionnaire space constraints. NISRA did not ask about either rooms or bedrooms and instead used Land & Property Services data to construct a variable for the total number of rooms. In England and Wales, the Valuation Office Agency provided an alternative source of data for the number of rooms. Scotland, however, sourced their response from the survey and did not use supplementary data to construct a total room variable. As a result, there are no fully equivalent measures for the number of rooms or number of bedrooms across the UK, which has been available in previous censuses (Stillwell, 2017).
Furthermore, variable categorisations differ between countries for certain questions, driven by differences in demographic makeup that impact disclosure controls and by the priorities of the respective nations. For example, published small-area tables related to ethnicity have significant discrepancies between the nations. For instance, both England and Scotland include a distinct category for individuals identifying as having Bangladeshi ethnicity, whereas in Northern Ireland, this category is absent due to the low proportion of this population there. Conversely, Northern Ireland includes a category for individuals of Filipino ethnicity, which is absent from the classifications used in England, Wales, and Scotland, reflecting the higher proportion of this group within Northern Ireland. Additionally, the categorisation of Irish Travellers differs between the nations: Northern Ireland records “Irish Traveller” as a distinct ethnic category from “White.” In contrast, in England, Wales, and Scotland, the variable “Irish Traveller” is nested within the broader “White” category. While such differences are logical within the context of the different nations, they are an additional challenge for the analyst wishing to harmonise variables for UK-wide analysis.
In practical terms, a researcher who is currently interested in UK-wide analysis using the 2021 and 2022 small-area census data must access each of the three census data extracts separately and verify that the tables of interest contain comparable variables. This may often require a direct comparison of census survey questions. To add further complexity, table and variable naming and formatting can be inconsistent even when derived from identical census questions. This can be particularly problematic for applications that require data to be machine-readable.
This paper therefore presents a harmonised UK-wide set of census variables at the smallest set of available geographies: Output Areas (called Data Zones in Northern Ireland). These areas, first implemented following the 2001 Census, serve as the building blocks for other census geographies. They are designed to be demographically homogeneous units, while also respecting existing natural and administrative boundaries as much as possible (Martin, 2002). Within each nation, Output Areas are designed to have roughly equal populations, but the population target size varies between nations due to differences in population distribution and administrative needs. The population size distribution, by country, can be seen in Figure 1. In England and Wales, Output Areas contain around 125 households (≈300 people), while in Scotland, they are smaller, averaging 50 households (≈125 people). In Northern Ireland, the equivalent units, Data Zones, are larger, with around 200 households (≈500 people). Distributions of the population size of output areas/Data zones for each of the countries of the United Kingdom.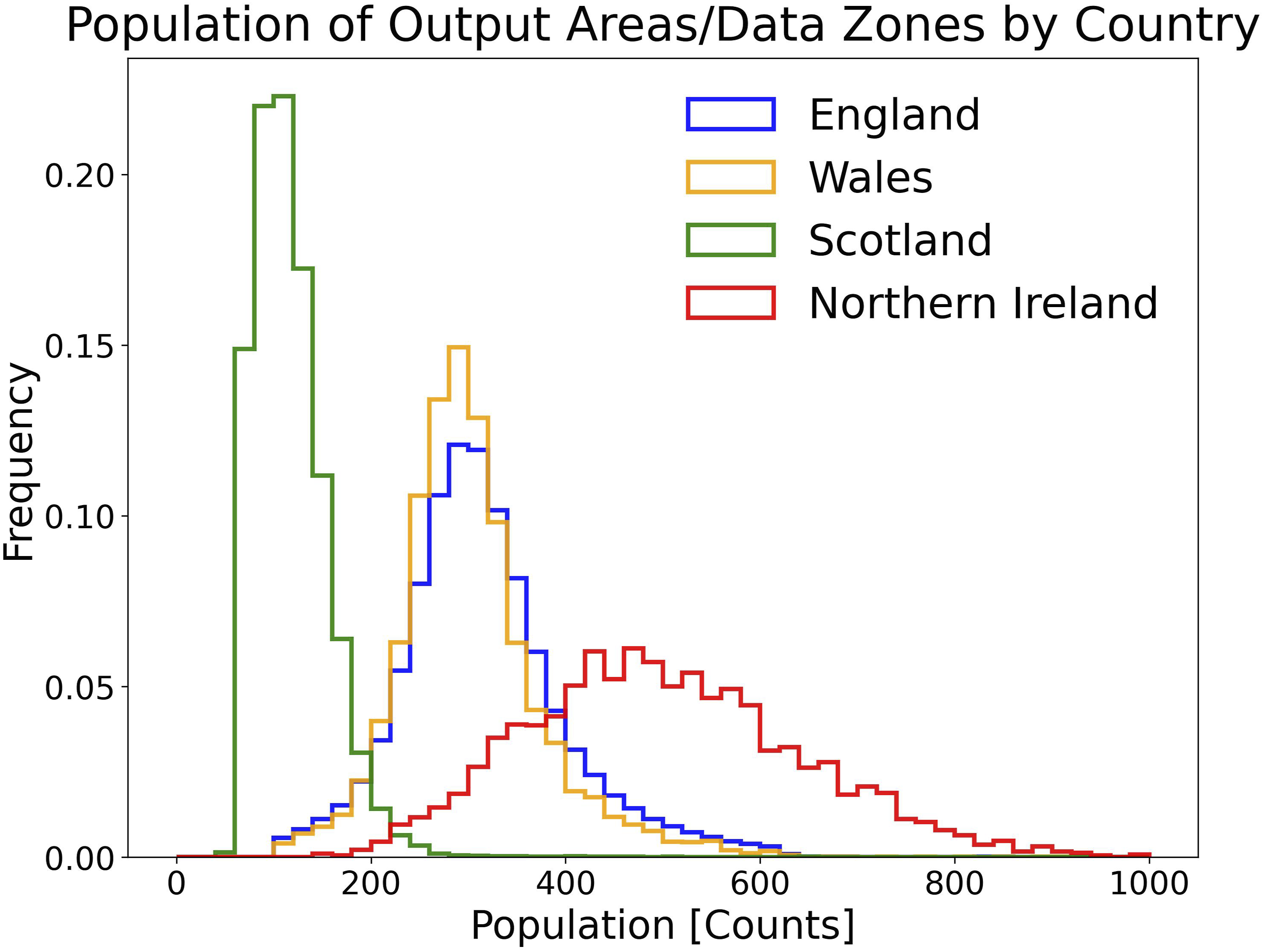
Dataset construction and harmonisation methods
Input data were derived from the most recent Census release for each of the four UK nations, obtained from open-access sources. Data for England and Wales were accessed via the ONS’ Nomis bulk download portal. 1 Scottish census data were obtained as a bulk table download from Scotland’s Census website, 2 as provided by the NRS. For Northern Ireland, data were extracted from the NISRA Flexible Table Builder 3 through automated queries. As no API was available, automated queries were performed using web scraping to retrieve the available tables, allowing direct access to the download URLs for each table. The analysis is restricted to univariate tables, due to limitations in data availability; at the Output Area level, multivariate data are not consistently available, as small population counts often lead to suppression or disclosure control measures.
Variable harmonisation
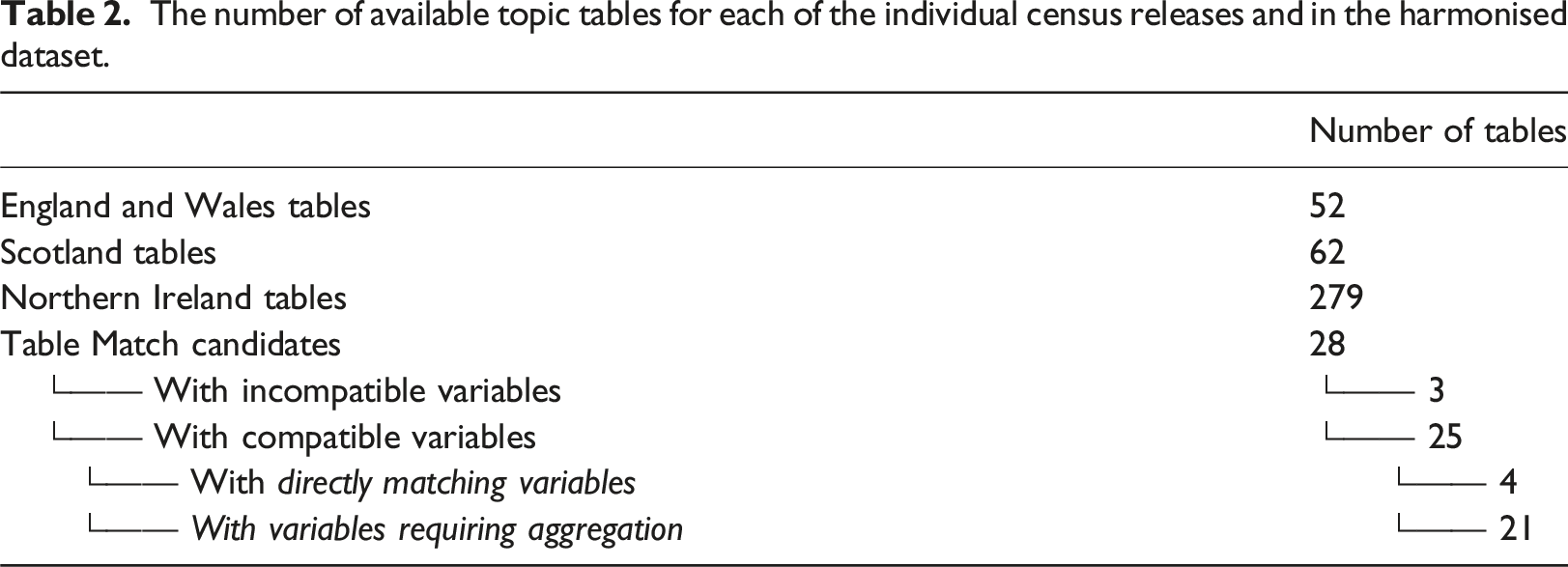
Minor data inconsistencies were first addressed by removing repeated variables and correcting some typographical errors in the variable descriptions. All datasets were standardised into a common tabular structure, with counts for each variable labelled by a unique code and indexed by Output Area/Data Zone code (ONS Geography, 2009). Each variable ID was formatted AAXXXPPPP, where AA is the country code of the dataset, XXX is the table ID, and PPPP is the sequential position of the variable in the table. Table totals are the first variable in each table (with ID AAXXX0001). The country codes are ts for England and Wales, uv for Scotland, and ni for Northern Ireland, with ts and uv chosen to match the original table ID formats in the respective datasets. Table IDs were selected to correspond to those in the original releases for England, Wales, and Scotland, ensuring consistency with other resources. As table codes do not exist in the Northern Ireland release, they were created sequentially to maintain a structured format. Consistent metadata tables were generated as lookup tables for variable codes, providing full variable descriptions, units, and source information. Variables are organised into topic tables matching the structure of the original data releases, resulting in 52 topic tables for England and Wales, 62 for Scotland, and 279 for Northern Ireland. There were significantly more tables for Northern Ireland as NISRA does not use sub-variables, instead releasing separate tables with different levels of variable aggregation for each topic table.
The number of available topic tables for each of the individual census releases and in the harmonised dataset.
Schematic showing the variable assignment and aggregation process for the unified “Ethnic Group” table (uk021) using variables from England and Wales (E & W, table ts021), Scotland (SC, table UV201), and Northern Ireland (NI, table ni060).
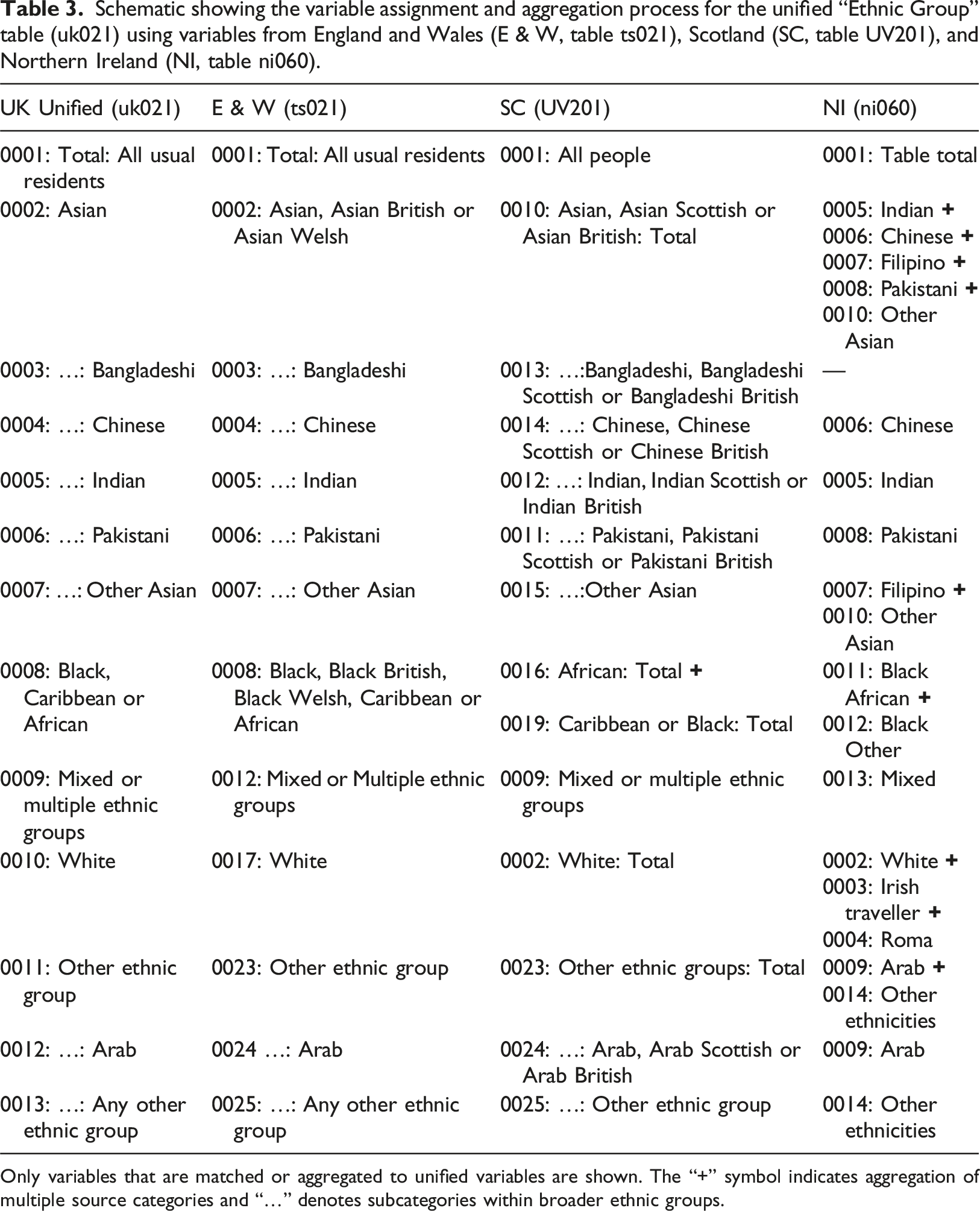
Only variables that are matched or aggregated to unified variables are shown. The “+” symbol indicates aggregation of multiple source categories and “…” denotes subcategories within broader ethnic groups.
Statistical disclosure control harmonisation
To ensure the anonymity of individuals and households in the censuses, the agencies each carry out a process of statistical disclosure control. The released data is anonymised using two key methods: “Targeted record swapping” and “Cell key perturbation.” Targeted record swapping involves a small percentage of households having their census records swapped with similar households in different geographic areas, with households containing individuals with rare or unique characteristics who might be easier to identify being more likely to be swapped. Cell key perturbation involves small random adjustments being applied to cell counts to prevent the identification of individuals, with smaller cells being more likely to receive larger perturbations (National Records of Scotland, 2020a, 2020b; Northern Ireland Statistics and Research Agency, 2021; Office for National Statistics, 2023).
The input tables for England, Wales, and Scotland used in this dataset have passed additional checks to identify sparse tables which could still be disclosive. The flexible table builder we have used to extract outputs for Northern Ireland suppresses sparse tables at the Data Zone level. This does not apply to any of the univariate tables we have extracted. Therefore, small cell count suppression has not been applied to any of the input variables from any of the agencies. Instead, all cell counts are protected through the perturbation methods described above, meaning that every cell contains a value (including zeros), albeit with small random adjustments applied for disclosure control purposes. The unified tables therefore contain all OAs within each nation, ensuring complete geographic coverage for the released dataset.
While each of the agencies follows a similar disclosure control process, there are differences in how the data are tabulated afterwards. After performing cell key perturbation, the ONS sums the new perturbed values to calculate a new total for that table, whereas the NRS provides the original totals. This leads to occurrences in the Scottish data where for some smaller Output Areas the table total is less than the sum of the sub-variables. Northern Ireland does not include totals in the tables produced by the Flexible Table Builder from which we extract data. To ensure consistency across the unified dataset, we follow the approach used by the ONS for England and Wales: we calculated totals for Northern Ireland based on the sub-variables provided and recalculated Scottish totals, replacing the original values with the sum of the perturbed sub-variables. This totalling procedure is also applied in cases where a table variable is a subtotal, that is, the sum of two or more other table variables.
Due to this approach, the table totals reflect the sum of the perturbed variables. Therefore, totals of households or population will differ across tables even when they conceptually refer to the same measure. In particular, the totals from individual tables should not be interpreted as definitive “single number” estimates of the population or number of households in an OA. This characteristic has been a long-standing feature of ONS census releases (Rees et al., 2005).
Data release
The topic tables included in the harmonised UK release.
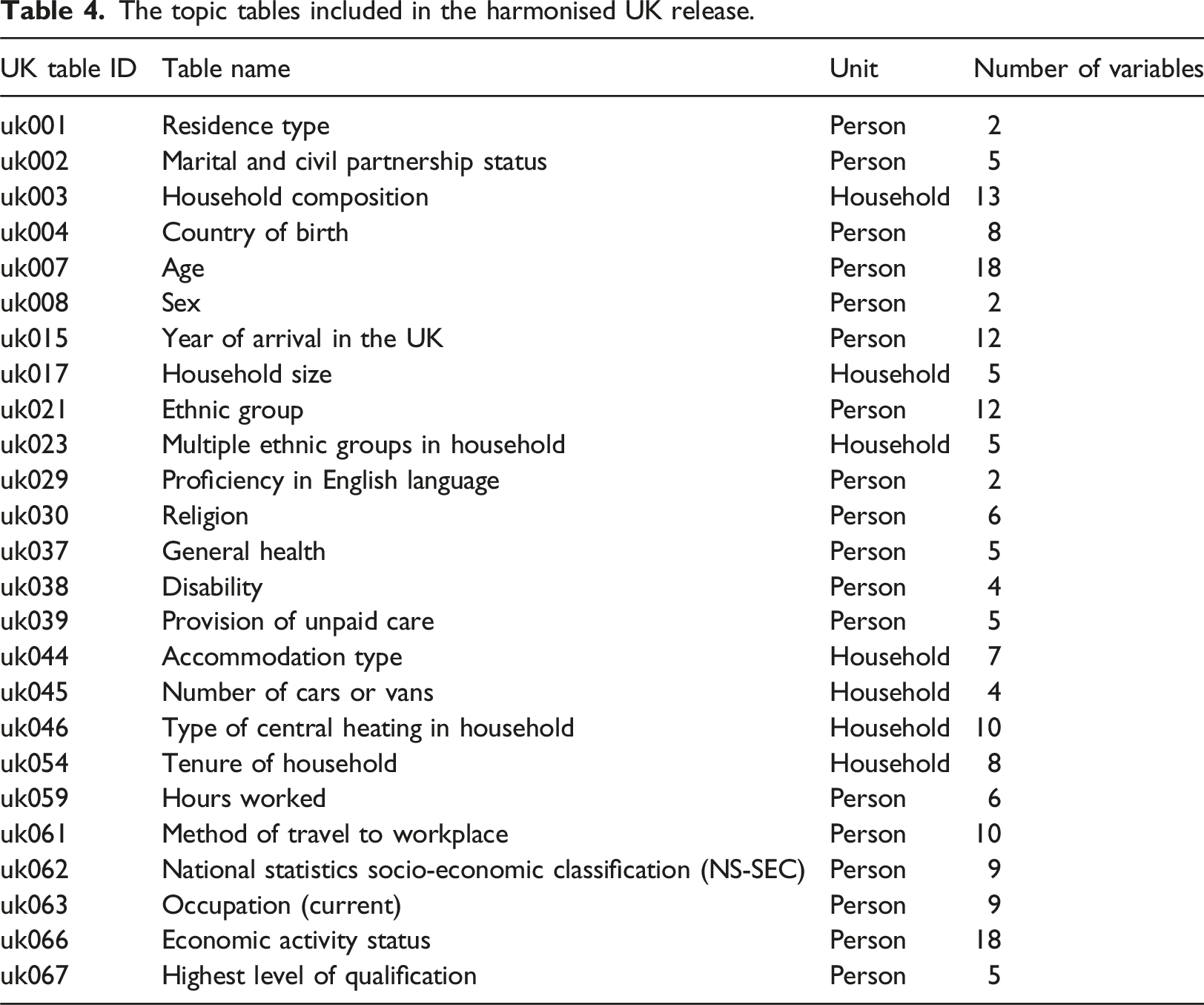
As an additional output, the Python code used to produce the dataset is made available for download. 5 This includes all stages of dataset construction, including accessing the original separate census data, processing these into consistent formats, and combining variables across censuses to produce the final outputs. The code provides a fully reproducible workflow for recreating the unified data, as well as documented lookup tables between variables in the unified data and the original separate census releases.
Internal validation
The harmonisation process was checked by examining summary statistics and the distributions of the unified variables by country. The summary statistics included the mean, median, quartiles, and range. The validation plots for all variables are available in the code repository. The overarching purpose of this validation process was to examine any differences between countries that might have been a result of erroneous assumptions or mistakes in the matching process.
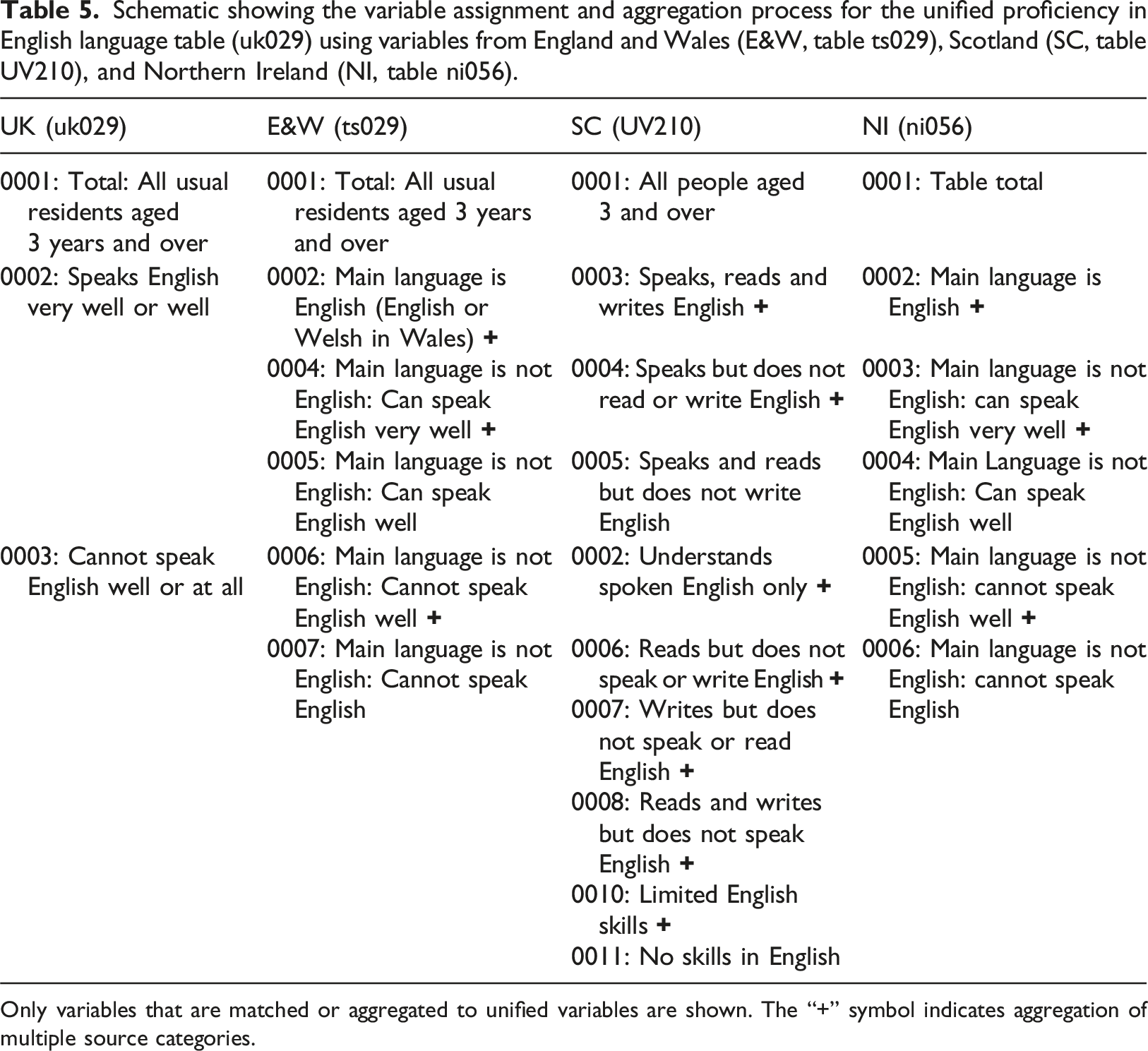
Figure 2 presents an example validation distribution for the variable: “Proficiency in English language: Cannot speak English well or at all.” This variable is an aggregate measure derived from different census questions across the UK nations. In England and Northern Ireland, the Census included a question specifically about spoken English ability, with response options: Very well, Well, Not well, and Not at all. In contrast, Scotland’s Census asked separate questions about individuals’ ability to understand, read, write, and speak English. As a result, Scotland released a nine-category classification of overall English proficiency, incorporating elements from all four skills. Based on the descriptions of these variables, it was determined that two compatible measures could be derived through aggregation: “Can speak English very well or well” and its inverse, “Cannot speak English well or at all.” Table 5 presents a schematic documenting the aggregation used to produce these unified variables. Validation distributions of the aggregated variable “proficiency in English language: Cannot speak English well or at all.” Left: The frequency distribution of the fraction of the total small-area population for this variable, with separate histograms for each country. Right: Boxplots summarising the distributions with key statistics: the mean, median, standard deviation, minimum, maximum, and percentiles (10th, 25th, 75th, and 90th) displayed. Schematic showing the variable assignment and aggregation process for the unified proficiency in English language table (uk029) using variables from England and Wales (E&W, table ts029), Scotland (SC, table UV210), and Northern Ireland (NI, table ni056). Only variables that are matched or aggregated to unified variables are shown. The “+” symbol indicates aggregation of multiple source categories.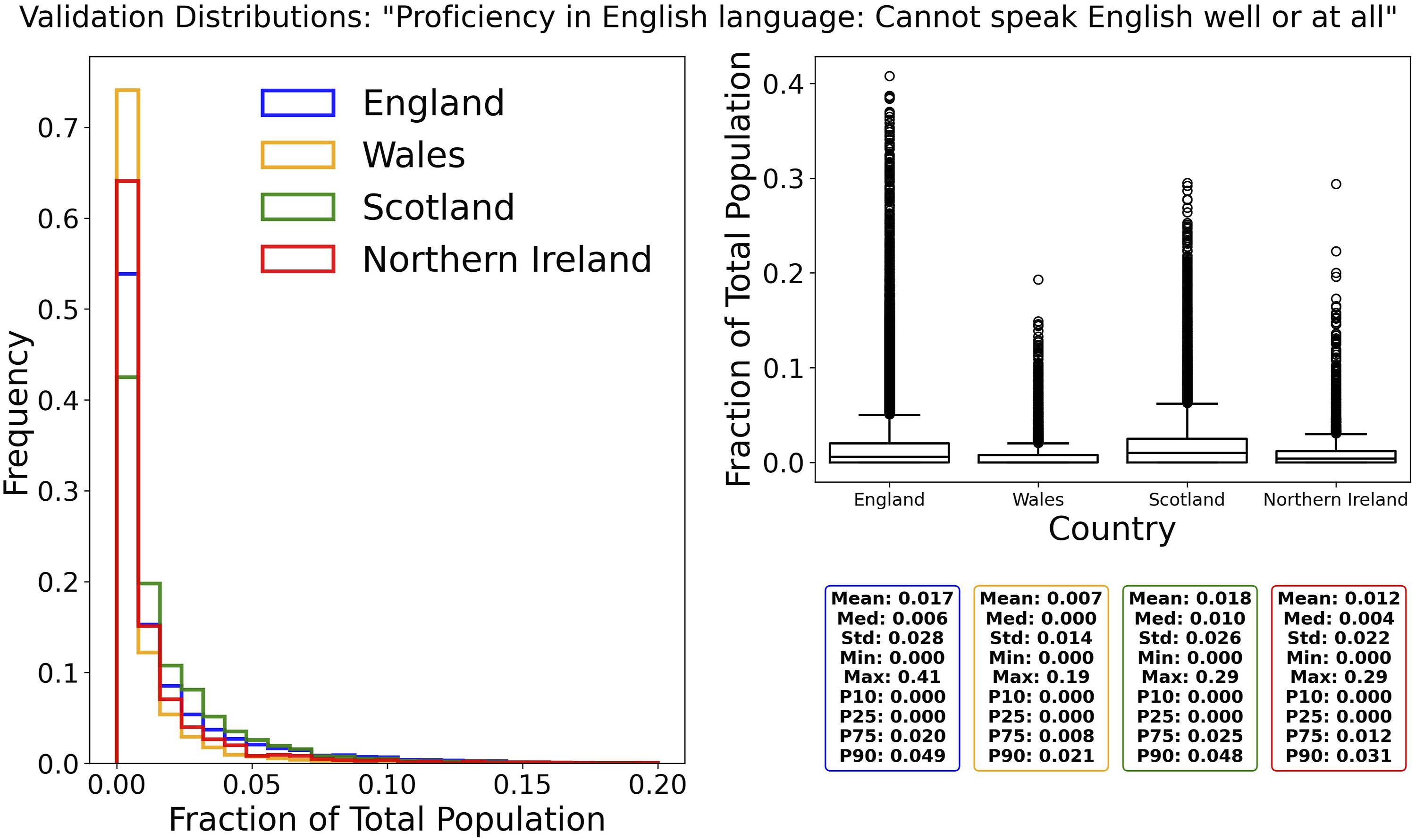
The validation plots demonstrate that these aggregated variables are broadly compatible in their distributions across the different census datasets. As discussed earlier, for such complex cases, details and considerations are included in our metadata so that these can be taken into account when judging the suitability of a table for a particular type of analysis.
Conclusion
The harmonised dataset described in this paper represents the first unified source of 2021/22 small-area census data across the UK, addressing key challenges in data comparability between the Censuses of England, Wales, Scotland, and Northern Ireland. The harmonisation process exposes differences in variable categorisation, disclosure controls, and the use of external data across the four nations. These differences underscore the challenges of working with census data on a cross-national basis.
While this dataset is UK-specific, harmonisation of census and similar population data is a challenge across a wide range of international contexts. Similar difficulties arise in transnational policy evaluation, such as efforts to harmonise and centralise census data across EU member states (Bach, 2019; Pertiwi and Nugrahani, 2020), and in research throughout federated countries where data from multiple jurisdictions must be linked, for example, in Australia (Boyd et al., 2012; Rosman et al., 2016) and Canada (Katz et al., 2018). The fully open and reproducible methodological framework presented here, including the code pipeline with systematic variable mapping, transparent documentation of aggregation decisions, and validation procedures, could be adapted to other multi-jurisdictional harmonisation contexts.
There are constraints on the degree of harmonisation that can be achieved using the existing openly available data. Differences in release table structures between nations limit the number of variables available in the harmonised dataset. Even when the underlying census question is identical, country-specific decisions on how tables are categorised lead to cases where significant aggregation of individual variables is necessary to achieve a comparable set of variables. An additional limitation arises from the separate application of the statistical disclosure control methods of cell key perturbation and target record swapping, which are performed at the country level before harmonisation. When aggregation is performed, combining multiple values that have been individually perturbed or swapped introduces further distortion. These constraints would not apply if harmonisation was performed on the original data. UK statistical agencies could collaborate to establish an official standardised set of harmonised census outputs. However, in the absence of such a release, the dataset presented here remains the most accessible and comprehensive solution for cross-national 2021/22 census analysis.
By providing 190 harmonised variables across 239,023 small-area geographies, this dataset enables UK-wide demographic analysis at the most granular level that is openly available. Each variable has been individually validated to ensure compatibility. The inclusion of detailed metadata and an open-access code release facilitate reproducibility and accessibility, ensuring that this dataset can be readily utilised for research and policy development.
Footnotes
Ethical considerations
No ethical approval required.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Economic and Social Research Council [ES/Z504464/1, ES/Z50273X/1]
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The UK unified census data product is available to download from the Geographic Data Service at https://data.geods.ac.uk/dataset/unified-uk-census-data. The code pipeline to produce the product is available at ![]() .
.