
Abstract
Urban homelessness is a complex issue rooted in structural inequalities and spatial disparities, significantly affecting urban life and well-being. Existing research often relies on survey-based or linear regression methods, which are limited in scope, coverage, and their ability to capture nonlinear associations. This study addresses these gaps by combining homeless incident reports from New York City’s 311 service with multi-source urban big data and employing a Light Gradient Boosting Machine (LightGBM) model alongside SHapley Additive Explanations (SHAP). Through a census tract-level analysis, we examine how socioeconomic, built environment, transportation, and urban landscape factors relate to homelessness incidence. Our findings show that (1) the importance of predictive factors varies across location types, for instance, information, and communication POIs are most predictive in commercial areas, while felony crime and median income dominate in residential zones; (2) socioeconomic and built environment features are consistently more important than transportation and visual landscape indicators; and (3) many factors exhibit nonlinear relationships and threshold effects, such as sharp increases in homelessness beyond a median rent of $1800 or Gini index of 0.53. These findings offer new insights into the spatial distribution and drivers of homelessness and underscore the value of interpretable machine learning in urban analytics. By identifying key environmental thresholds, this study provides evidence-based guidance for spatially targeted urban interventions, such as prioritizing support services in high-risk areas and designing inclusive public spaces that can help mitigate homelessness and promote more sustainable and equitable cities.
Keywords
Introduction
Urban homelessness is a pervasive and complex issue that underscores profound socioeconomic disparities and significantly impacts the quality of urban life globally (Ford et al., 2014; Fowle, 2022). It not only presents a socioeconomic challenge but also poses a severe humanitarian crisis, influencing public health, safety, and urban social dynamics (Majumder et al., 2023; Onapa et al., 2022). This issue is particularly severe in the global metropolis like New York City (NYC), NYC sheltered approximately 85,677 individuals nightly as of July 2023, showing the stark contrast between the affluent cityscape and the plight of those without stable living conditions (Homeless, 2019).
Apart from its visible manifestations, homelessness also has severe consequences on the economy (Anguche, 2024; Quigley and Raphael, 2001), society (Constantinescu and Brasoveanu, 2020; Schütz, 2016), and public policy (Hill, 1994; Kiesler, 1991). It is reflective of the breakdown of housing markets, social welfare systems, and city management, often calling attention to the disparities in the allocation of wealth, health, and opportunity (Cleveland, 2020; Dobson, 2022; Hennigan, 2017). Homelessness is also associated with increased rates of chronic illness (Bensken et al., 2021; Lewer et al., 2019), mental illness (Currie et al., 2014; Folsom et al., 2005), and exposure to environmental hazards (Goodling, 2020; Van et al., 2024), placing disproportionate pressure on public health programs and emergency services. Economically, it represents both direct economic costs, through increased utilization of shelters, hospitals, and law enforcement (Berk and MacDonald, 2010; Hwang et al., 2011; Klaassen et al., 2022; Salit et al., 1998), as well as indirect costs, including decreased labor force participation and productivity (Tam et al., 2003; Zlotnick et al., 2002). In addition, chronic homelessness also erodes public trust in urban institutions and challenges the legitimacy of policies claiming to ensure inclusive and equitable development (Willison, 2021). Understanding the drivers of homelessness is thus not only a matter of empirical analysis, but also a pressing policy priority in the pursuit of sustainable, just, and resilient cities.
Homelessness is influenced by a variety of urban factors that often interact in complex ways (Mago et al., 2013; Shelton et al., 2009). For instance, socioeconomic disparities such as income inequality and unemployment may exacerbate housing affordability issues, forcing individuals into unstable living conditions (Foster and Kleit, 2015; Stansfield and Semenza, 2023; Zhu et al., 2023). At the same time, the built environment, including land use patterns and transportation infrastructure, interacts with socioeconomic variables to shape access to essential services and opportunities (Derrien et al., 2023; Jocoy and Del Casino Jr., 2010). For example, areas with high median rents and limited public transportation options may disproportionately impact low-income individuals, creating environments where homelessness is more likely (Barton and Gibbons, 2017; Bocarejo et al., 2014). Similarly, urban landscapes, such as green spaces, can mitigate stress or exclusion but may also overlap with socioeconomic factors like crime density, influencing whether these spaces are accessible to vulnerable populations (Bogar and Beyer, 2016; Rose, 2019). The complexities of homelessness require thorough investigation, particularly within urban contexts where diverse factors interplay. Therefore, NYC’s substantial homeless population and the intricate urban dynamics provide a valuable context for exploring the nonlinear relationships and threshold effects between various urban environmental factors and homelessness.
Previous studies investigating the factors affecting homelessness have often relied on surveys and questionnaires, which are limited by respondent bias and incomplete data coverage (Nishio et al., 2017; Racionero-Plaza et al., 2021). Additionally, these studies tend to focus on individual aspects of homelessness rather than exploring how different environmental factors interact to shape homelessness dynamics. For example, Wusinich et al. (2019) used interviews with 43 unsheltered homeless individuals to examine their challenges in accessing public services, revealing a preference for staying in subway stations to stay warm during cold weather. The 1996 National Survey of Homeless Assistance Providers and Clients (Aron, 2002) found that 30% of unsheltered homeless participants sell recyclables or belongings to make money, highlighting the appeal of commercial areas. Furthermore, existing research often uses traditional linear regression models, such as Ordinary Least Squares (OLS), which can only reveal linear relationships. Ee and Zhang (2022) employed OLS and Geographically Weighted Regression (GWR) to examine the global and local relationships between homelessness and crime, while Jarvis (2015) used OLS and interviews to show the negative effect of Check-In Centers on homelessness. There remains a significant gap in utilizing multi-source urban environmental data and nonlinear regression methods to better investigate these factors and associations.
Unlike traditional linear regression models, machine learning (ML) models can capture the nonlinear relationships between environmental factors and homelessness. Recent advancements in ML, including models like Random Forest (RF), eXtreme Gradient Boosting, and Light Gradient Boosting Machine (LightGBM), have proven effective in processing multi-source big data and uncovering complex relationships in homelessness studies (Chen et al., 2024; VanBerlo et al., 2021; Walters et al., 2021). However, these models often face a trade-off between predictive accuracy and interpretability, leading to the challenge of the “black box” effect, where understanding the local impact of each variable becomes difficult (Doshi-Velez and Kim, 2017; Rudin, 2019).
To address the “black box” issue, interpretable machine learning (IML) methods have emerged to clarify the decision-making processes of advanced models (Adadi and Berrada, 2018). Techniques such as SHapley Additive exPlanations (SHAP) (Lundberg and Lee, 2017), Local Interpretable Model-agnostic Explanations (Ribeiro et al., 2016), and Partial Dependence Plots (Friedman, 2001) aim to offer transparency and insight into ML models. SHAP, based on cooperative game theory, has become a preferred method in urban studies for its ability to provide both global and local interpretability (Deb and Smith, 2021), crucial for identifying key factors influencing complex issues like homelessness (Kim and Lee, 2023; Yi et al., 2024). While VanBerlo et al. (2021) used an ML approach to predict chronic homelessness and explored contributing factors, their study did not account for unsheltered homeless individuals or examine the nonlinear and spatially heterogeneous relationships. Additionally, few studies have compared the relative importance of environmental features across location types or identified specific impact thresholds.
To address these gaps, this study leveraged multi-source urban big data and IML to explore the relative importance of features, and the nonlinear relationships between environmental factors and different location types of homelessness. Specifically, we aimed to answer the following research questions: (1) Do the contributions of environmental features vary across different location types (e.g., street, commercial, and residential), and what patterns emerge across these contexts? (2) What is the overall relative importance of socioeconomic, built environment, transportation, and visual landscape features in explaining homelessness? (3) What nonlinear and threshold effects exist in the relationship between these features and homelessness incidence, and how can they help interpret spatial variations in vulnerability?
Related works
Socioeconomic and built environment determinants of urban homelessness
Homelessness is a multifaceted social issue, variously defined and conceptualized across disciplines. The U.S. Department of Housing and Urban Development (HUD) defines homelessness as the condition of individuals lacking a fixed, regular, and adequate nighttime residence, encompassing those living in shelters, transitional housing, cars, abandoned buildings, and public spaces. Similarly, the European Typology of Homelessness and Housing Exclusion (ETHOS) distinguishes between rooflessness, houselessness, and inadequate housing (Amore et al., 2011). The World Health Organization (WHO) also introduces the concept of “hidden homelessness,” which includes individuals without a secure place to live who are not visibly residing on the streets or in shelters. Despite these variations in definition, the common thread is a lack of stable housing. Our study aligns with these definitions, examining both encampment homelessness, where individuals establish makeshift residences in public spaces, and general homelessness, representing those without secure housing.
Existing literature has extensively examined how socioeconomic factors contribute to homelessness, primarily identifying correlational relationships, though some studies have also articulated causal mechanisms. Income inequality and poverty rates are consistently linked with higher homelessness incidence, as economic disparities reduce housing affordability, pushing vulnerable populations into unstable living situations (O’flaherty, 1996; Byrne et al., 2021; Sharam and Hulse, 2014). Lower educational attainment has been causally linked to higher homelessness risk due to diminished economic mobility and reduced access to stable employment opportunities (Parrott et al., 2022). Furthermore, neighborhood racial and demographic composition impacts homelessness incidence through systemic inequalities affecting access to housing, employment, and social support (Fowle, 2022; Fusaro et al., 2018). Crime rates exhibit a complex, primarily positive relationship with homelessness; higher crime density can foster socioeconomic instability, discourage local investment, and reduce social cohesion, indirectly exacerbating homelessness (Berk and MacDonald, 2010; Ee and Zhang, 2022; Kelling and Bratton, 1997). For example, Fischer et al. (2008) found that homelessness, particularly when accompanied by psychological distress, causally increases both non-violent and violent crime rates, highlighting a reciprocal relationship that exacerbates homelessness conditions. Similarly, substance abuse, economic hardship, and weakened social networks are documented as interconnected causal pathways that lead individuals toward homelessness (Batterham, 2019; Bradford and Lozano-Rojas, 2024; Vangeest and Johnson, 2002).
Regarding the built environment, studies suggest both direct and indirect relationships with homelessness incidence. Land use patterns and urban functions directly shape service availability, influencing housing options and service accessibility for homeless populations (Kuhn and Culhane, 1998; Ranasinghe and Valverde, 2006). Accessibility to transportation infrastructure shows a nuanced relationship; higher accessibility is typically positively correlated with homelessness, as these areas offer greater mobility, resource access, and shelter options, thereby attracting vulnerable populations (Canham et al., 2023; Jocoy and Del Casino Jr., 2010; Murphy, 2019). Conversely, proximity to police stations often has an inverse correlation, as homeless individuals may avoid areas with increased surveillance and eviction risks (DePastino, 2003; Rossi, 1991). Urban visual features, derived from street-level imagery, offer additional insights. Empirical studies suggest that urban green spaces (UGS) can improve mental well-being and reduce environmental stressors (Li et al., 2015; Wang et al., 2025). UGS are of great significance for people experiencing homelessness not merely as a necessity or last resort, but more importantly as spaces that align with individual preferences and help fulfill personal needs (Koprowska et al., 2020). Walkability, reflecting pedestrian-friendly urban design, has shown a negative correlation with homelessness as walkable areas typically foster social cohesion and support networks, indirectly mitigating homelessness vulnerability (Frank et al., 2006; Speck, 2018). Urban enclosure, indicating dense building configurations and limited open spaces, generally positively correlates with homelessness due to providing sheltered and discrete locations preferred by homeless populations (Ma et al., 2021; Sewell, 1993).
Based on the insights from prior empirical studies, our research systematically selected variables representing these theoretically and empirically established socioeconomic and built environment factors.
Applications of interpretable machine learning methods
In recent years, remarkable advancements in machine learning have given rise to sophisticated models capable of deciphering complex data relationships (Chen and Guestrin, 2016; He et al., 2016; Vaswani et al., 2017). However, this evolution often comes with a trade-off between predictive precision and model interpretability, giving rise to the notion of the “black box” (Caruana et al., 2015; Doshi-Velez and Kim, 2017; Rudin, 2019). To address this, IML methods have surfaced as an essential resolution, shedding light on the decision-making processes of these advanced models (Adadi and Berrada, 2018). These methods include a variety of techniques, such as SHapley Additive exPlanations (SHAP) (Lundberg and Lee, 2017), Local Interpretable Model-agnostic Explanations (LIME) (Ribeiro et al., 2016), and Partial Dependence Plots (PDP) (Friedman, 2001), each aiming to offer transparency and insight into the functionalities of machine learning models.
SHAP has been preferred in urban studies over methods like LIME due to its consistent and model-agnostic interpretability. SHAP is grounded in cooperative game theory (Lundberg and Lee, 2017), specifically the concept of Shapley values. It can both provide global and local interpretability (Deb and Smith, 2021) and precise explanations of model predictions, which is crucial in addressing complex issues like homelessness by identifying key contributing factors. For instance, Yi et al. (2025) combined random forest and SHAP to assess vegetated and built-up areas’ independent effects on heat exposure environment. Similarly, Kim and Lee (2023) employed urban big data, LightGBM, and SHAP to explore the nonlinear association between crime and urban environment, proposing policy implications for improving public safety and sustainability. Additionally, Hatami et al. (2023) applied SHAP to uncover the impact of the built environment on commuting mode choices, underscoring the significance of dense, diverse, and accessible regions in fostering sustainable transportation. Ji et al. (2022) employed XGBoost and SHAP to investigate nonlinear correlations and interaction effects between the built environment and cycling distance, identifying the crucial roles of road network configurations and bicycle lane facilities in shaping cycling activities. Kim and Kim (2022) formulated a random forest-based model to predict heat-related mortality in urban settings, achieving notable accuracy and pinpointing key influential factors through SHAP interpretation.
Materials and methods
The overall analysis workflow is illustrated in Figure 1. It mainly contains three parts: (1) data collection and variable preprocessing; (2) ML model construction, evaluation, and interpretation with SHAP; (3) analyzing results, including feature’s relative importance across different locations, nonlinear relationships, and threshold effects. Overall Analysis Framework. This study consists of three main parts: (1) Collect and extract features from the multi-source urban big data, including socioeconomic features, build environment, urban transportation, urban landscape, and homeless data; (2) Machine learning models’ construction, evaluation, and interpretation with SHAP; (3) Interpretation results analysis.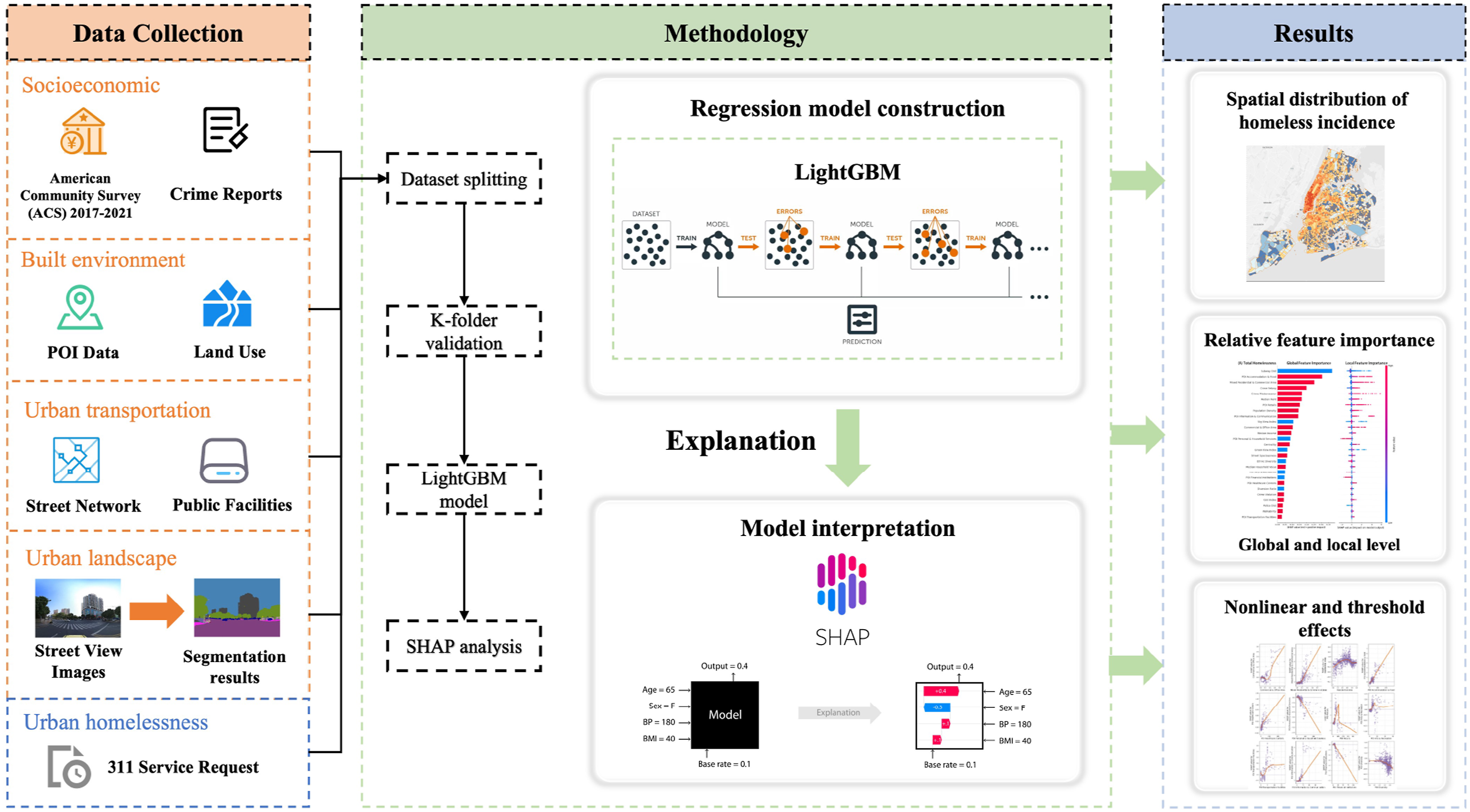
Study area and datasets
Study area
As shown in Figure 2, the study area includes NYC’s five boroughs: the Bronx, Brooklyn, Manhattan, Queens, and Staten Island. Despite its status as a populous and economically vibrant city, NYC faces a severe homelessness crisis. In July 2023, the NYC Department of Homeless Services and the Department of Housing Preservation and Development reported 85,677 individuals experiencing homelessness in the city’s municipal shelter system, including 28,540 children. Additionally, nearly 24,660 single adults sought shelter nightly during the same month. Factors such as high population density, socioeconomic disparities, housing affordability challenges, and limited access to social services exacerbate the homelessness situation in the city. Study area: five boroughs of New York City.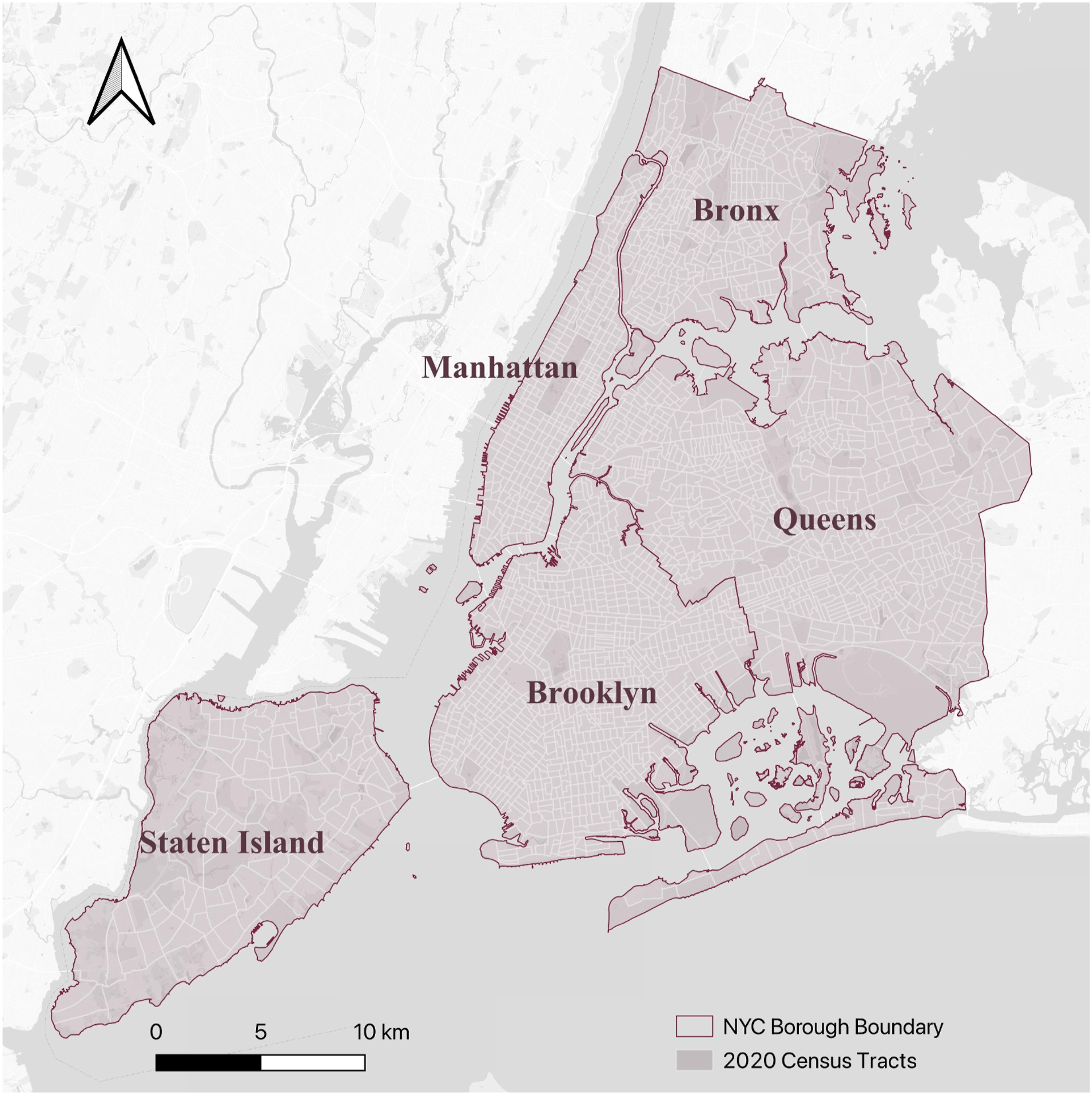
In this study, census tracts were utilized as the spatial units of analysis. A total of 1712 census tracts were included after excluding observations with null values for some variables. The average size of a census tract in is 32.65 km2, and the population density is approximately 208.91 people per km2. This level of granularity allowed for a detailed examination of the relationship between various environmental factors and homelessness, providing insights into the localized dynamics of homelessness within the diverse neighborhoods of NYC.
Data sources
We used data from eight key categories. The homelessness data, consisting of 42,333 records, were sourced from the NYC 311 Service Request dataset and the Department of Homeless Services for 2022. Socioeconomic indicators were drawn from the 2021 American Community Survey (ACS). The 2022 land use data from the NYC Department of City Planning included 857,006 parcels. We also used 150,575 points of interest (POI) data from SafeGraph (2021), and transit data from the General Transit Feed Specification (GTFS) covering bus and subway stations for 2022. Additionally, crime and police station data were obtained from the NYPD, and 191,894 Google Street View (GSV) images were collected during the spring and summer from 2020 to 2022. These comprehensive data sources enable a thorough analysis of homelessness in relation to neighborhood socioeconomics, the built environment, urban transportation, and urban landscape.
Model constructions
Dependent variable
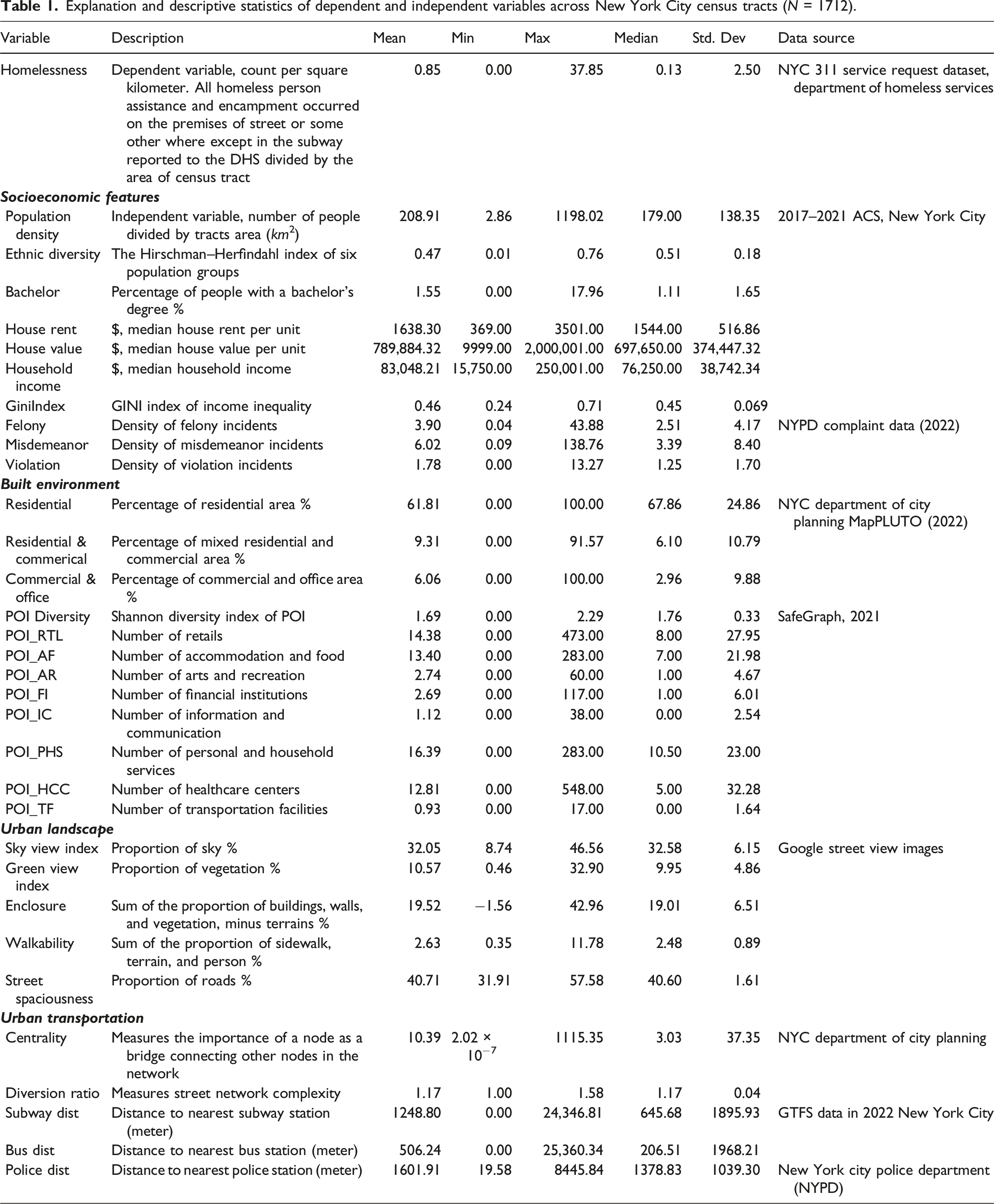
Explanation and descriptive statistics of dependent and independent variables across New York City census tracts (N = 1712).
Independent variables
The independent variables in this study were selected based on a thorough review of the literature. Prior research highlights various factors influencing homelessness, including socioeconomic disparities (e.g., income inequality, unemployment, and educational attainment), built environment characteristics (e.g., land use patterns and public spaces), transportation accessibility, and urban landscape features (e.g., green spaces and public amenities) (Byrne et al., 2021; Chan et al., 2014; Jocoy and Del Casino Jr., 2010; Lin et al., 2022). To ensure comprehensive coverage of these factors, we collected a wide range of indicators, including four main categories: neighborhood socioeconomic, built environment, urban transportation and urban landscape variables. This approach allowed us to construct a holistic dataset to explore the complex and interactive relationships between urban factors and homelessness.
This study investigated neighborhood socioeconomics across five dimensions: Demographics, Education, Housing, Economics, and Crime. For Demographics, we used population density and an ethnic diversity index based on the Hirschman–Herfindahl index (De Nadai et al., 2020), which measures diversity across racial groups. The index, denoted as H, is calculated using the equation
For the built environment, we focused on urban function and land use using SafeGraph’s POI dataset, which includes businesses and amenities categorized by the North American Industry Classification System (NAICS). This dataset provides information such as names, locations, and category codes of various establishments. We selected eight categories for analysis: retail, accommodation and food services, arts and recreation, financial institutions, information and communication, personal and household services, healthcare centers, and transportation facilities. Each POI was mapped to its census tract, allowing us to calculate the number of amenities per tract. To assess POI diversity, we used Shannon entropy, which reflects the order in both categories and the number of POIs (Yue et al., 2017). It is calculated as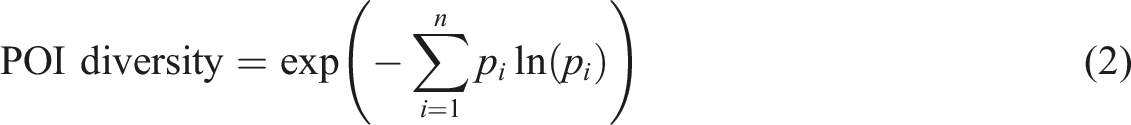
In this equation, n represents the number of POI categories. The term p i denotes the proportion of the ith category of POI within a given census tract.
Land use plays a central role in shaping the urban environment and influences many facets of urban life. In this study, we focused on a selection of key land use categories, namely commercial & office, mixed residential & commercial, and residential, as shown in Figure 3. By examining the proportional area occupied by these various categories of land use, we aim to understand the spatial distribution and composition of diverse land utilizations. 2D and 3D spatial distribution of land use in New York City.
The characteristics of the street network were analyzed using sDNA (Spatial Design Network Analysis). We employed the centrality index to measure how central each street segment is in connecting other segments, quantifying its role in promoting mobility and accessibility. We also used the diversion ratio to assess the complexity and fragmentation of the street network, providing insight into the connectivity of different regions (Meng and Zacharias, 2021). To analyze accessibility to subway and bus stations as well as police stations, we calculated the shortest street network distances using Python. Centroids of each census tract were used as starting points, and the NetworkX library was employed to represent NYC’s street network, incorporating road segments, traffic directions, and road types. This method allowed us to capture spatial variations in public transit and police accessibility across NYC.
For urban landscape analysis, visual features were extracted from Google Street View images. We initially generated sampling points at 50-m intervals along the street network, and then retrieved all available image IDs within approximately 100–200 m of each sampling point using the streetview Python library (https://github.com/robolyst/streetview). All retrieved IDs were then traversed systematically to remove duplicates, ensuring comprehensive coverage. Subsequently, panoramic images were downloaded via the Google Street View API based on these unique IDs. After accounting for seasonal variations, we retained images captured during spring and summer from 2020 to 2022, yielding a final dataset of 191,894 panoramic images. Then, we used the Deeplabv3 + model (Chen et al., 2018), trained on the Cityscape dataset (Cordts et al., 2016), for semantic segmentation. This model, with an accuracy of 82.1%, classifies 19 categories, including roads, sidewalks, buildings, trees, and pedestrians, allowing us to calculate the proportions of each and derive mixed indicators. We focused on five key indicators: green view index (GVI) (Li et al., 2015), sky view index, enclosure (Ma et al., 2021), walkability (Wang et al., 2022), and street spaciousness, as described in Table 1.
Regression models
We built and compared four regression models: Ordinary Least Squares (OLS), Gradient Boosting Regression Tree (Friedman, 2001), Random Forest regression (Breiman, 2001), and LightGBM (Ke et al., 2017). The dataset was split into 80% for training and 20% for testing, and the models were validated using 10-fold cross-validation. We evaluated performance using two metrics: root mean squared error (RMSE) and the coefficient of determination (R2). RMSE measures the average deviation between predicted and actual values, calculated as
where n is the number of data points, y
i
is the actual value, and
Model interpretation with SHAP
SHAP is a powerful technique for interpreting machine learning models, offering insight into the contribution of each feature to the model’s decisions. It uses the concept of Shapley values to fairly and consistently attribute feature importance, treating the model as a cooperative game with features acting as “players.” SHAP quantifies the contribution of each feature by considering all possible feature combinations and their marginal contributions, ensuring fair allocation of feature importance. This allows us to identify the key factors influencing homelessness and quantify their impact. The Shapley value of feature i, denoted as ϕ
i
, is calculated as the weighted average over all possible subsets of the feature group N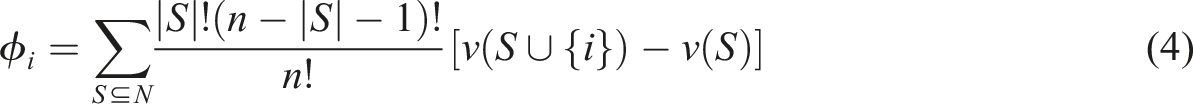
Here, |S| represents the number of features in subset S, n is the total number of features in group N, v(S) is the model output for subset S, and v(S ∪ i) is the model output when feature i is added.
Results
We began by examining the distribution of homeless incidences across different locations, as shown in Figure 4. Streets and sidewalks had the highest number of reports (16,325), followed by subways (12,147). Store/commercial areas and residential houses reported 4625 and 4547 incidences, respectively. Parks/playgrounds accounted for 1977 reports, while the “Other” category had 2164. Highways, bridges, and houses of worship reported lower incidences, with 85, 72, and 391 reports, respectively. Number of homeless incidence across various locations in New York City (2022).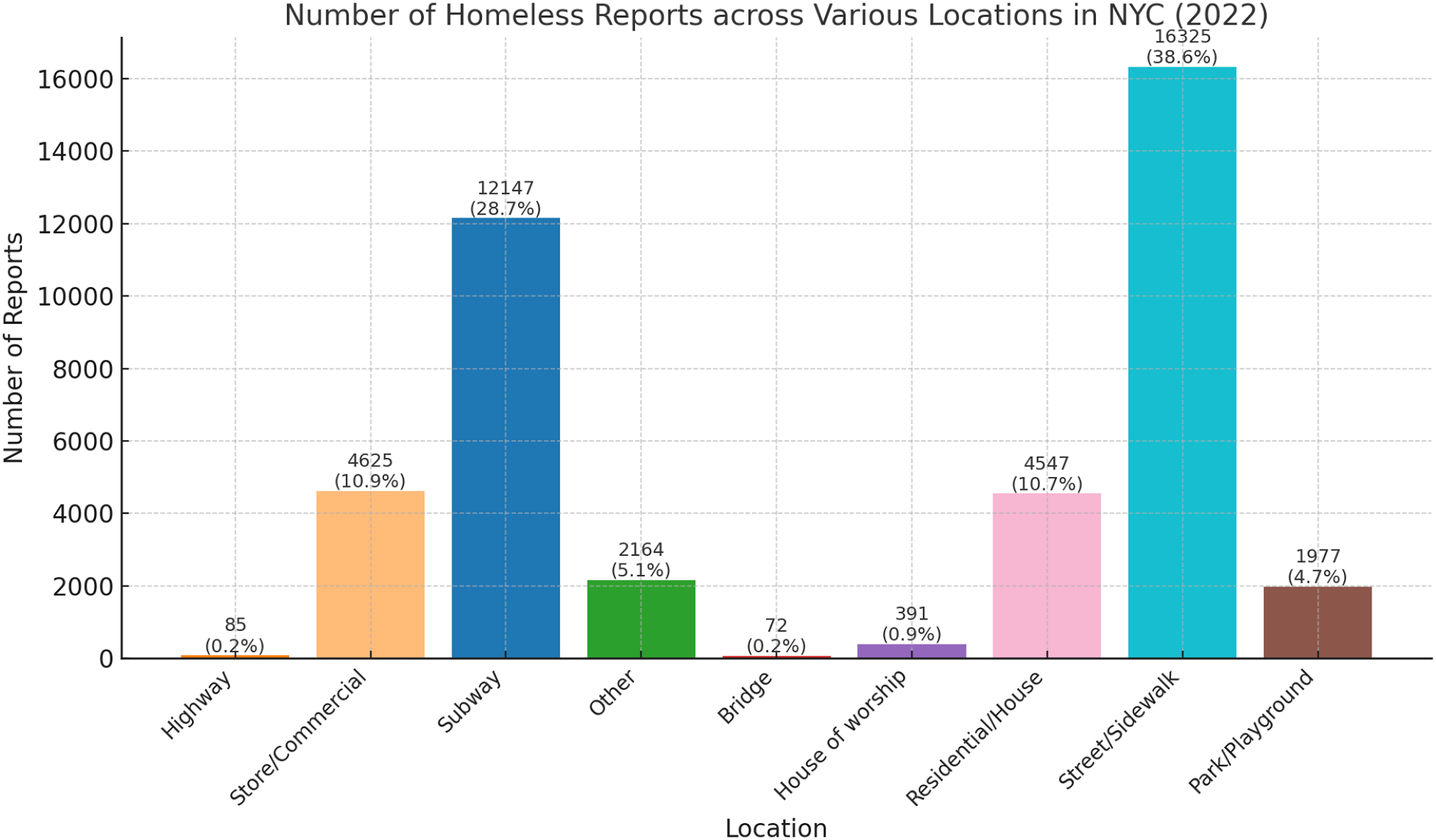
Figure 5 shows the spatial distribution of homelessness per square kilometer across census tracts. A logarithmic transformation was applied to highlight spatial patterns and reduce the effect of outliers. Darker red areas represent higher homeless density, primarily concentrated in Manhattan, with some dispersion into Brooklyn and fewer occurrences in Queens and Staten Island. Spatial distribution of homeless incidence density in New York City (2022).
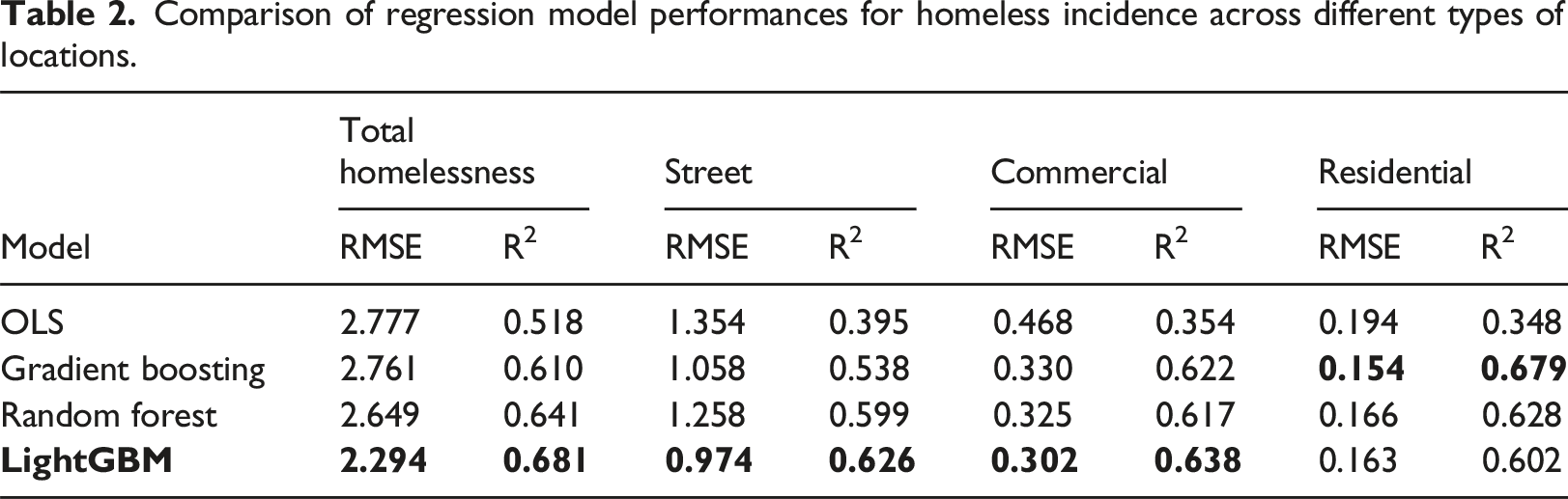
Model evaluation results
Comparison of regression model performances for homeless incidence across different types of locations.
Analysis of features importance in different locations
The global feature importance of variables, as shown in Figure 6, was measured using global SHAP values. Following Xiao et al. (2021), we calculated the mean absolute SHAP values (mean Results of SHAP global and local feature importance for homelessness incidence across four location types: (a) Total Homelessness, (b) Street Homelessness, (c) Commercial Areas, and (d) Residential Areas. The left side of each panel shows global feature importance (mean absolute SHAP values), while the right side visualizes local feature importance, illustrating the positive (red) and negative (blue) impacts of each variable on homelessness incidence.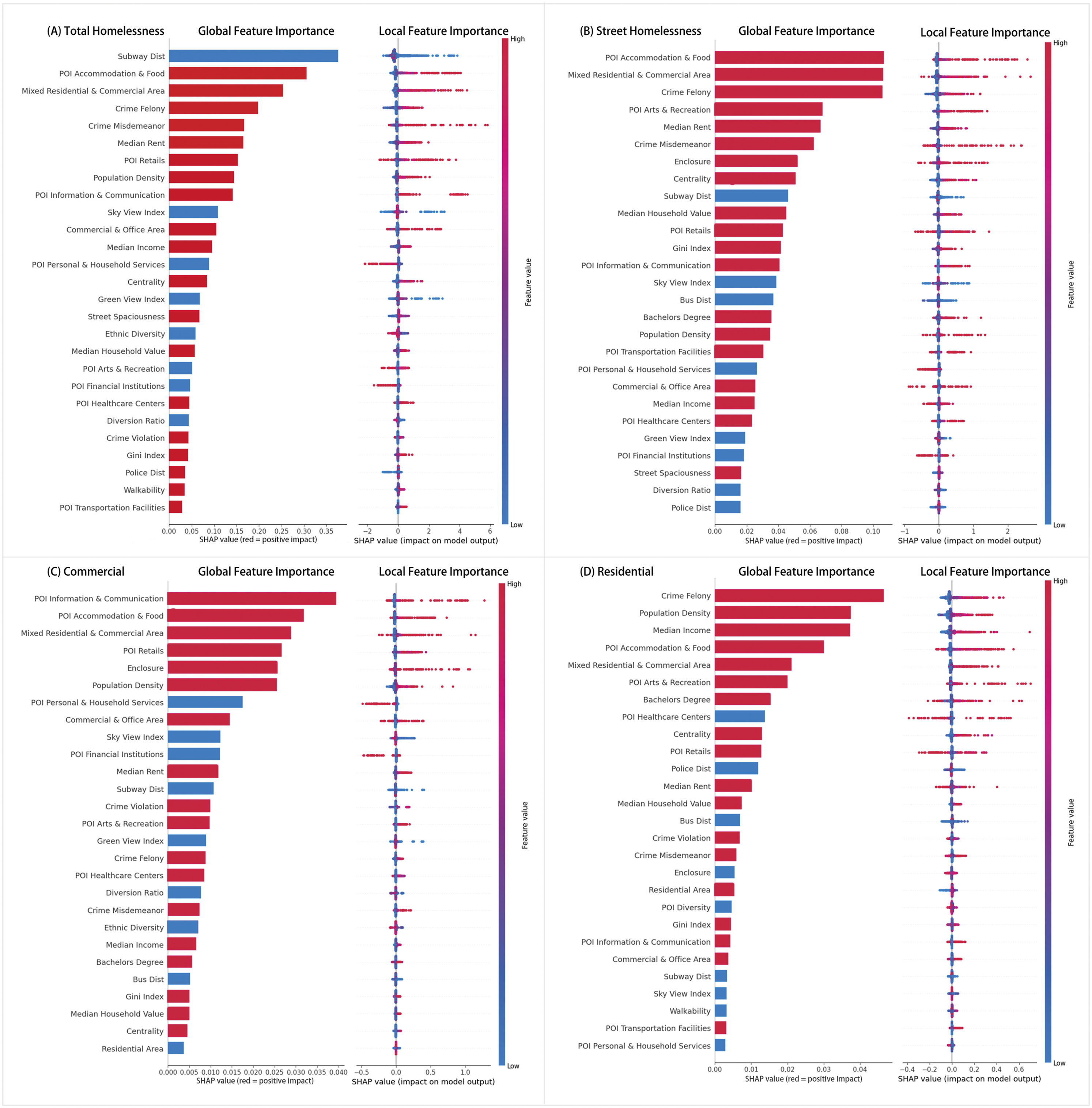
We further analyzed feature importance by location type. For total homelessness, the top five variables were subway distance, POI accommodation and food services, mixed residential/commercial areas, crime incidents, and median rent, highlighting the dominance of built environment and socioeconomic factors. Subway distance was the most important feature, which corresponds to the observed high incidence of reported homelessness in subway locations Figure 4. This likely reflects the tendency of unhoused individuals to seek shelter in areas with greater transit accessibility and foot traffic, rather than suggesting a causal effect of subway proximity on homelessness risk. For street homelessness (Figure 6(b)), the feature importance trends mirrored the overall category but with a reduced importance for subway distance. This similarity is due to street homelessness comprising the majority of cases. In contrast, commercial and residential areas showed more nuanced variations in feature importance and their impacts on homelessness.
In commercial areas (Figure 6(c)), while several top features remain consistent with the overall analysis, their impacts show notable changes. POI information and communication becomes the most influential feature. This may reflect the importance of digital connectivity for unhoused individuals seeking access to services and online resources in central urban areas. The sky view index exhibits a stronger negative association with homelessness. However, this relationship may be partly influenced by the nature of Street View imagery in commercial zones, which often feature limited sky visibility due to higher building density. Financial institutions are associated with lower reported homelessness, though this may reflect exclusionary urban environments where unhoused individuals have fewer opportunities to remain. Finally, the increased relative importance of violent crime, alongside the reduced influence of felony crime, suggests changing spatial dynamics of urban disorder in commercial zones, further investigation is needed to unpack causal mechanisms.
In residential areas (Figure 6(d)), the feature importance rankings reveal several distinct patterns. Felony crime density, population density, and median income show higher importance, suggesting these areas may host more visible or reported homelessness under specific demographic or housing conditions. Notably, homelessness appears more concentrated in medium-to-high density tracts, potentially reflecting the affordability pressures and systemic vulnerabilities in these transitional zones. The increased importance of educational attainment (bachelor’s degree) may point to broader neighborhood socioeconomic profiles, though it is unlikely to represent a direct risk factor for homelessness itself. In contrast, features such as sky view index and proximity to subway stations show decreased importance in residential zones, likely due to the more suburban character of these neighborhoods, where urban form and transit access play a lesser role in shaping homelessness visibility.
Analysis of nonlinear relationships between environmental factors and homelessness
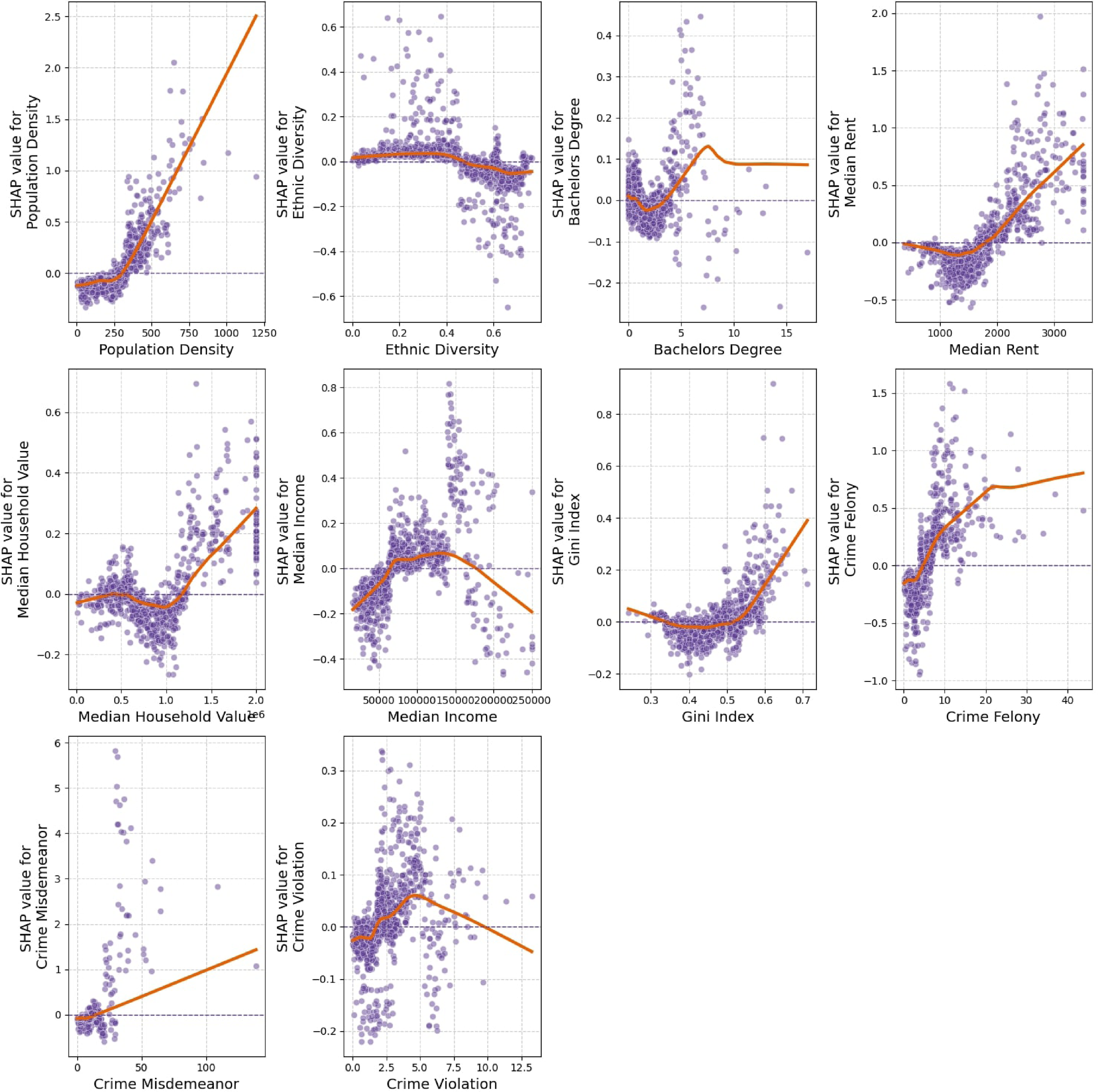
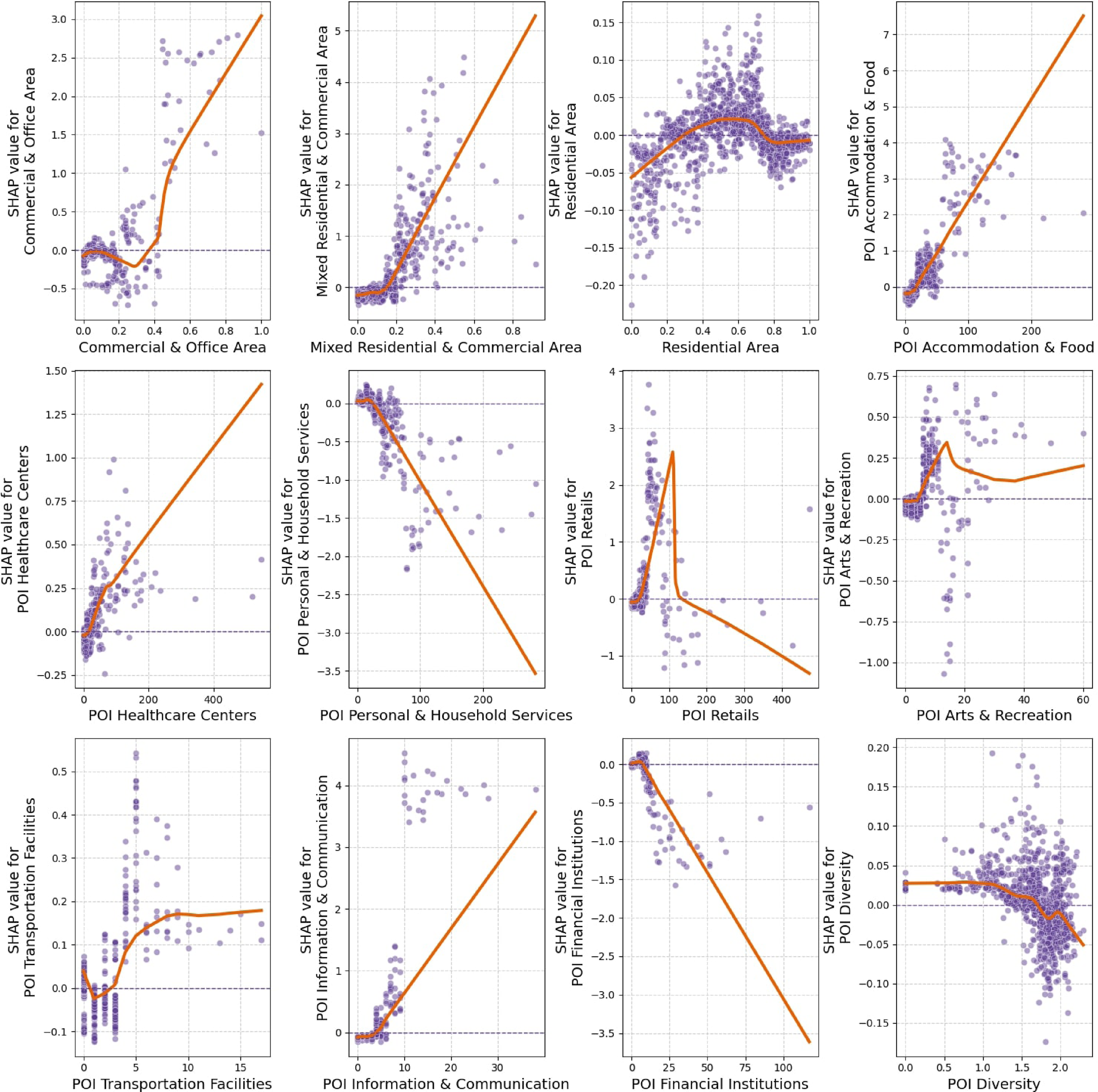
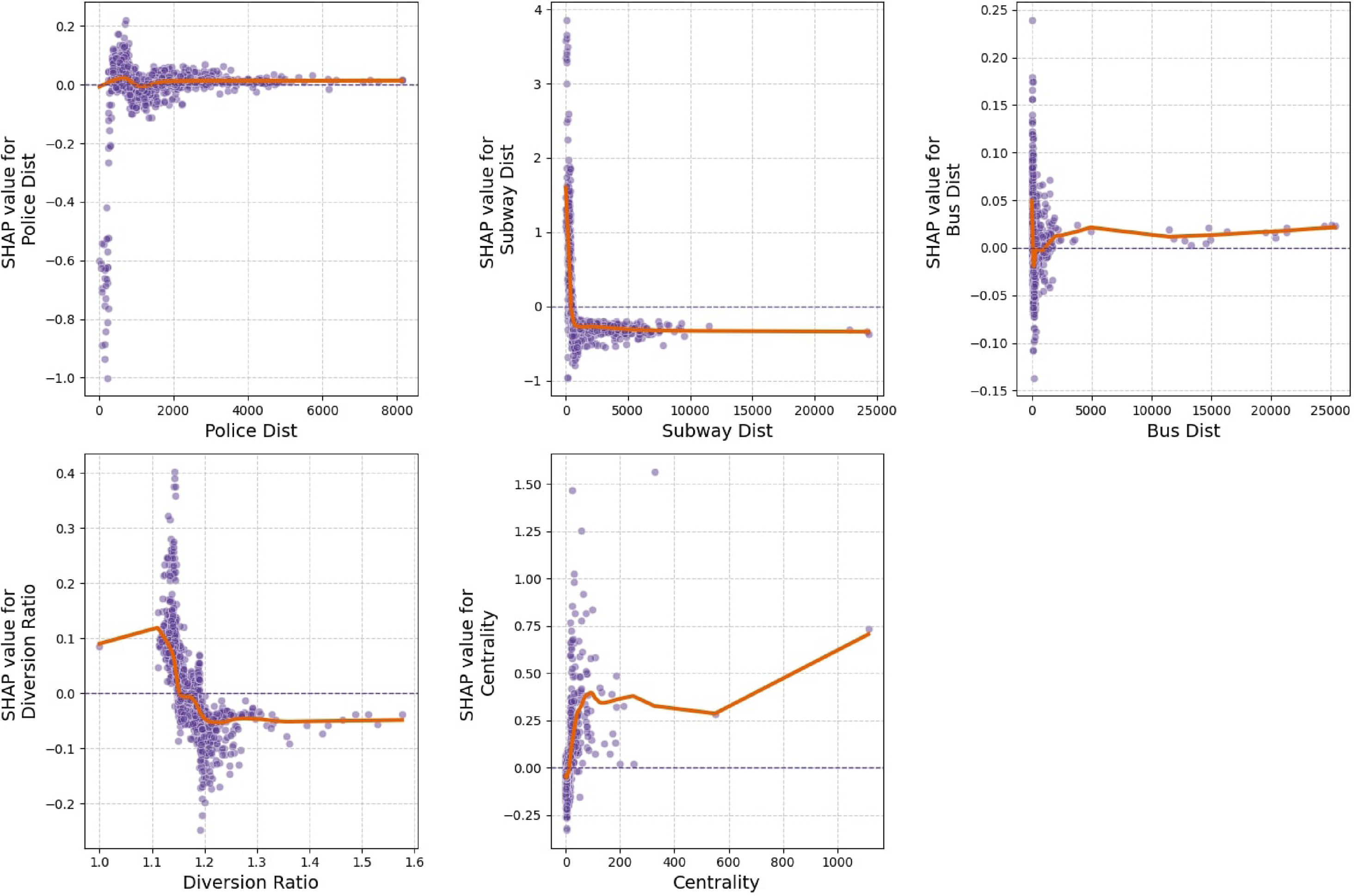
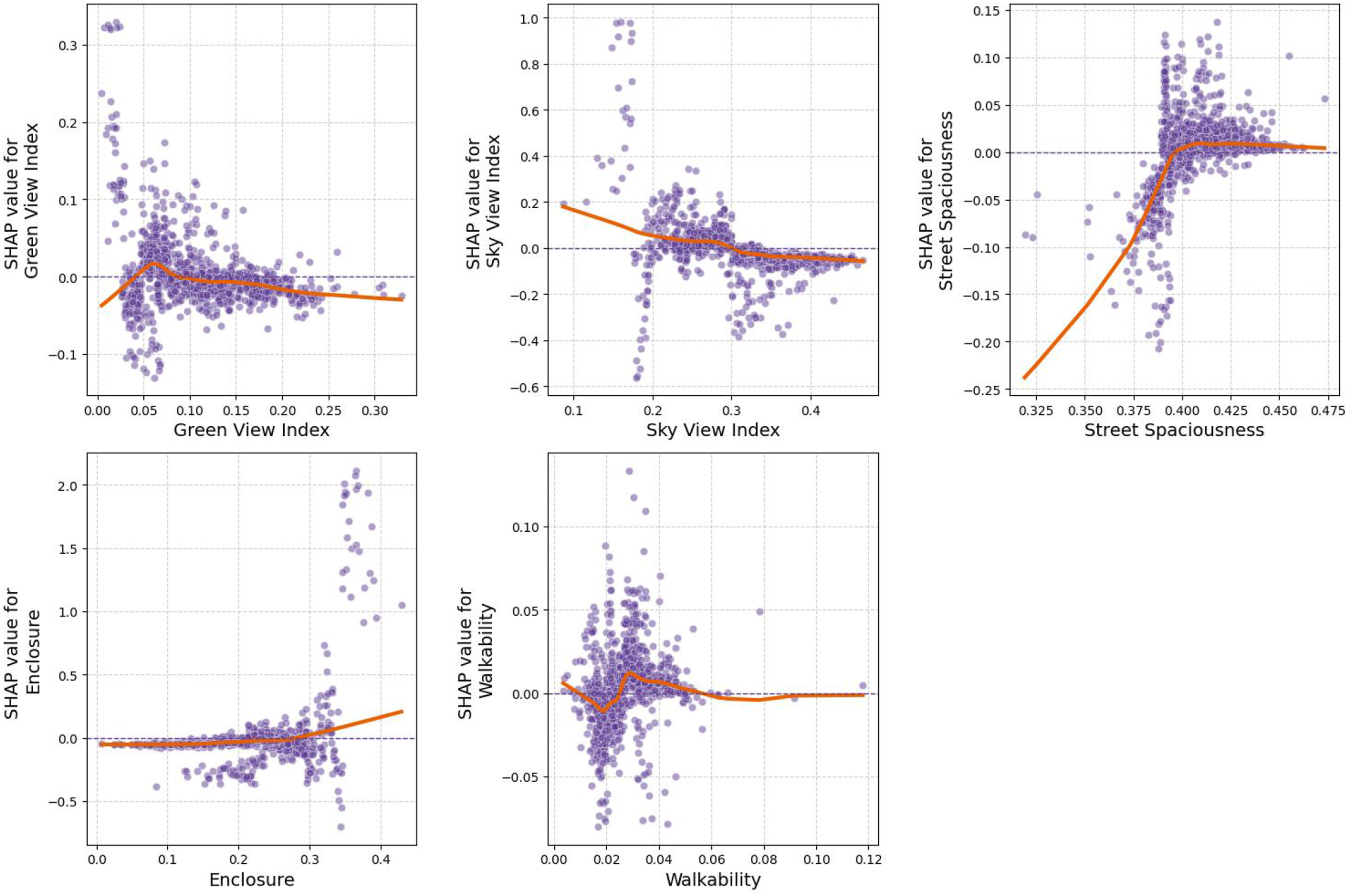
We utilize the Local Dependence Plots (LDPs) to visualize the SHAP values of variables. As shown in Figure 7, we investigated the nonlinear patterns and accurate threshold effects. (1) Socioeconomic variables. The nonlinear relationships with socioeconomic indicators are shown in Figure 7. Variables such as population density, education level, median rent, household value, Gini index, and felony crime exhibit positive associations with reported homelessness. These associations tend to strengthen beyond certain thresholds, specifically, when population density exceeds 300 people/km2, median rent surpasses $1,750, the Gini index exceeds 0.53, or felony crime density exceeds 5 incidence/km2. These patterns are consistent with previous findings that areas facing greater economic inequality, housing market stress, or neighborhood instability may experience elevated homelessness incidence. The relationship between median income and homelessness appears reversed U-shaped: homelessness is relatively lower in both low-income (<$70,000) and high-income (>$175,000) areas, and higher in middle-income areas. This may reflect spatial mismatches where homelessness becomes more visible or clustered in neighborhoods facing gentrification, affordability stress, or transitional socioeconomic dynamics. The observed crime density patterns also align with the feature importance seen in Figure 6, reinforcing the spatial co-location between reported crime and homelessness, although causal interpretation remains complex. (2) Built environment. As shown in Figure 8, reported homelessness incidence is more prevalent in census tracts with greater proportions of mixed residential and commercial land use (over 18%) and commercial/office areas (over 40%). This pattern may indicate a tendency for unhoused individuals to cluster in areas with more foot traffic, service access, or public visibility, rather than suggesting that land use directly causes homelessness. In contrast, predominantly residential areas show relatively stable associations with lower incidence. For POIs, higher numbers of personal and household services, retail businesses, and financial institutions are associated with lower homelessness incidence. These areas may offer greater surveillance or commercial control that limits informal sheltering. On the other hand, greater presence of accommodation and food services, healthcare centers, arts and recreation, and information and communication services shows positive associations with homelessness. These patterns likely reflect the concentration of social service infrastructure or amenity-based clustering rather than direct causal pathways. Lastly, POI diversity shows minimal association with homelessness, suggesting that overall land use mixture is less influential than specific functions or clustering patterns. (3) Urban transportation. As illustrated in Figure 9, proximity to subway and bus stations demonstrates a nonlinear association with reported homelessness. Within approximately 1000 m, homelessness incidence appears elevated, potentially reflecting the clustering of unhoused individuals near high-access transit hubs. Beyond this threshold, SHAP values decline and stabilize, suggesting diminished relevance at greater distances. These patterns likely reflect post-homelessness settlement behaviors rather than causal effects. The centrality index, which reflects street network connectivity, also shows a positive association with homelessness. This may indicate that highly connected areas offer greater movement opportunities or public visibility for unhoused populations. In contrast, the diversion ratio, which represents street network complexity shows a threshold effect at 1.2. Below this value, homelessness incidence is slightly elevated, possibly reflecting less monitored or fragmented areas, while beyond 1.2, the association turns negative, suggesting lower clustering in more secluded or hard-to-navigate areas. Regarding proximity to police stations, we observe a small decrease in homelessness incidence within the first 500 m. This may reflect deterrence effects or enforcement activity near law enforcement infrastructure. However, this effect flattens out beyond this threshold, suggesting limited spatial influence at larger distances. (4) Urban landscape. As shown in Figure 10, Both the GVI and SVI show modest negative SHAP values beyond certain thresholds, suggesting a weak inverse association with homelessness. For GVI, the effect becomes more stable and slightly negative after approximately 8%, while SVI’s impact turns increasingly negative beyond 30%. However, these associations may reflect broader urban morphology rather than direct causal mechanisms. For instance, areas with higher GVI and SVI may correspond to lower-density or suburban settings, which typically experience lower visibility of homelessness or may enforce more restrictive public space policies (Neild and Rose, 2018). This interpretation aligns with prior studies noting exclusionary dynamics in highly managed public green spaces. Enclosure and street spaciousness both exhibit positive associations with homelessness when their respective values exceed 0.27 and 0.40. These indicators reflect denser built environments, which may correspond with more heavily urbanized areas where homelessness is both more prevalent and more visible. This suggests a spatial correlation between urban form and where unhoused individuals are reported, rather than a causal effect of enclosure itself. The relationship between walkability and homelessness is more ambiguous, with a weak nonlinear pattern that fluctuates around zero. This may reflect the complex role walkable environments play in shaping public space use, human activity, and visibility. Overall, these urban landscape indicators appear to act more as contextual correlates than direct causal drivers of homelessness. Future research should further investigate how such features interact with land use, policy enforcement, and population density. Nonlinear relationships between homeless incidence and socioeconomic features. Nonlinear relationships between homeless incidence and built environment. Nonlinear relationships between homeless incidence and urban transportation. Nonlinear relationships between homeless incidence and urban landscape.
Discussion
Comprehensive analysis of nonlinear relationships
The feature importance rankings varied across location types. For total homelessness, subway distance emerged as the most influential factor, aligning with the high number of reports associated with subway stations (Figure 4). This reflects patterns observed in previous studies, which show that unhoused individuals often seek shelter in or near public transit hubs due to their accessibility, relative safety, and shelter from the elements (Chan et al., 2014; Ding et al., 2022; Loukaitou-Sideris et al., 2020). Other consistently high-ranking features include accommodation and food service POIs, mixed residential and commercial land use, and felony crime density, suggesting the relevance of both built environment and socioeconomic conditions.
In commercial areas, information and communication POIs had the highest importance score, a finding that resonates with research highlighting the growing importance of digital access for unhoused populations. As noted in prior qualitative studies, access to mobile connectivity is essential for navigating public services, staying socially connected, and securing employment opportunities (Goodwin-Smith and Myatt, 2013; Humphry, 2014). However, access to these services remains uneven even in city centers (Humphry and Pihl, 2016), which may exacerbate exclusion in digitally underserved commercial zones. In residential areas, variables such as felony crime, population density, and median income were more pronounced. While the positive correlation between crime and homelessness supports literature that associates neighborhood instability with increased displacement (Ee and Zhang, 2022), the role of population density is more complex. Denser areas may offer greater access to social services and opportunities but could also reflect areas with higher visibility or reporting of homelessness.
The LDPs provided further insight into nonlinear associations and threshold effects. For instance, median income showed a reversed U-shaped relationship with homelessness, with elevated risk in middle-income tracts. This aligns with survey-based research that identifies gentrification and displacement pressures as particularly acute in moderately affluent neighborhoods, where housing costs rise but social safety nets may be insufficient (Byrne et al., 2021; Shelton et al., 2009). Median rent exhibited a clear threshold effect: below $1,800, its influence on homelessness was minimal or negative, but above that point, risk increased sharply—supporting the well-documented link between rent burden and housing precarity (Wetzstein, 2017).
Similarly, urban transportation indicators, such as centrality and subway proximity, showed positive associations with homelessness when accessibility was high. This supports earlier findings that central urban areas and well-connected transit hubs tend to attract homeless individuals seeking proximity to vital services (Jocoy and Del Casino Jr., 2010; Lee et al., 2003). However, it is important to interpret these findings cautiously. These factors likely reflect where homelessness is more visible or reported, rather than serving as direct causes.
Finally, urban landscape indicators such as sky view index, green view index, and enclosure revealed weak-to-moderate associations with homelessness. While greater openness (e.g., higher sky view) and vegetation (e.g., higher GVI) were associated with lower homelessness in some areas, this may reflect broader neighborhood typologies, such as lower-density, higher-income districts rather than a direct mitigating effect of these visual features. Without stronger theoretical or qualitative backing, it would be speculative to claim that increasing green space directly reduces homelessness. Indeed, as previous studies note, parks and open areas are often sites of exclusionary policies (e.g., anti-camping laws) that deter rather than support homeless populations (Amster, 2003; Doherty et al., 2008; Speer and Goldfischer, 2020).
In summary, our results emphasize the spatial concentration and contextual visibility of homelessness rather than simple causal pathways. They underscore the need for nuanced, place-specific strategies that consider the broader social and physical environments in which homelessness occurs.
Policy implications
The results from our feature importance and nonlinear analysis can support the identification of areas with elevated homelessness risk, providing data-driven guidance for targeted interventions and resource allocation. Rather than implying direct causality, our findings point to spatial and environmental conditions that correlate with higher concentrations of homelessness and may reflect underlying vulnerabilities or service needs.
For instance, high importance and threshold patterns in features such as median rent, felony crime, and income inequality reinforce the need to address structural socioeconomic drivers, including housing affordability and neighborhood stability. Policies aimed at preserving affordable housing stock, regulating speculative rent increases, and expanding housing-first programs remain central to reducing homelessness risk.
Regarding built environment variables, results suggest that mixed-use and commercial areas with higher accessibility and service density are more likely to see visible homelessness. These findings could inform the co-location of support services—such as drop-in centers, hygiene facilities, or mobile outreach units—within high-accessibility zones where unhoused individuals are already concentrated, ensuring better alignment of services with population needs.
On the urban landscape side, while variables like green view index and sky openness are associated with lower homelessness incidence in certain contexts, we caution against overgeneralizing these findings. Rather than assuming green space directly reduces homelessness, planners should focus on creating inclusive, accessible public spaces that avoid hostile design and support rest, shade, and dignity especially in areas with limited shelter availability. Initiatives like pocket parks, street trees, and community gardens may be most effective when embedded within broader equity and housing strategies (Cui et al., 2024; Dong et al., 2024, 2025; Middle et al., 2014).
Furthermore, the high importance of information and communication POIs in commercial zones reflects the role of digital access in navigating homelessness. Policymakers should consider expanding public WiFi infrastructure, digital literacy support, and access to mobile charging stations, particularly in areas where homeless individuals congregate. Digital exclusion remains a major barrier to accessing services, employment, and community support.
In sum, addressing homelessness requires an integrated policy approach that combines economic, environmental, and spatial strategies. Tackling root causes, such as housing unaffordability and neighborhood inequity while improving environmental conditions and urban design can contribute to more inclusive, sustainable cities. Governments have both a moral imperative and a practical interest in reducing homelessness, as doing so improves public health, reduces pressure on emergency services, and enhances community resilience.
Limitations and future directions
Despite its contributions, this study has several limitations. First, as a case study focused on NYC, the findings may not be generalizable to other cities with different social, economic, and cultural contexts. Future research should apply this analytical framework to other cities or countries to provide comparative insights into urban homelessness across diverse settings. Additionally, we used census tracts as the primary spatial unit, which may introduce the Modifiable Area Unit Problem (MAUP) (Javanmard et al., 2023). Future studies should explore the impact of different spatial units, such as buffers or census blocks, to assess the robustness of the findings.
Second, the homelessness data used in this study was derived from citizen-reported incidents through the NYC 311 Service Request system. While this provided a large dataset, the data is static and does not capture the dynamic nature of homelessness. Future research should incorporate more dynamic data collection methods, such as real-time tracking through a combination of citizen reports, shelter records, and outreach initiatives. Mobile location data, with appropriate privacy safeguards, could also offer insights into the movement patterns of homeless populations, providing a more comprehensive dataset for analysis.
Third, we acknowledge that our classification of homelessness locations may introduce ambiguity, particularly concerning the distinction between “Street” and other categories. Streets often intersect with commercial and residential areas, making it difficult to ensure that incidents classified as occurring on streets are entirely separate from those in adjacent land-use types. While our spatial data is based on reported coordinates, there is an inherent limitation in verifying whether the recorded location precisely reflects where the incident occurred. Future research should explore alternative classification methods, such as integrating land-use data or clustering techniques, to refine spatial accuracy and improve the interpretation of homelessness distribution.
Additionally, this study employed street-level imagery from Google Street View, primarily vehicle-based, which may inadequately represent certain areas, such as narrow streets or residential neighborhoods, particularly when images are taken from wider avenues (Kim et al., 2021). This methodological limitation warrants acknowledgment, as it may impact the representation and sensitivity of visual urban features within our analysis. Future research could incorporate complementary datasets, such as pedestrian-collected imagery or drone-based visual data, to better capture areas less accessible by vehicles and address this gap.
Finally, while we covered several urban factors, this study did not account for others, such as weather conditions, transient population dynamics, or specific city policies, which could significantly influence homelessness. Additionally, we did not incorporate a temporal analysis, which could reveal how homelessness patterns change over time. Future research should include these variables and analyze the temporal dimension to better understand the dynamic nature of homelessness and its relationship with urban policies, seasonal variations, and population shifts.
Conclusion
Using multi-source urban big data, this study conducted a census tract-level analysis across New York City to investigate the nonlinear associations between urban environmental factors and the incidence of homelessness. By employing a Light Gradient Boosting Machine (LightGBM) model in conjunction with SHapley Additive exPlanations (SHAP), we ensured both strong predictive performance and transparent interpretation of feature effects. Our results reveal three major findings: (1) Feature importance varies by location type. For example, in commercial areas, the prevalence of information and communication POIs was most predictive of homelessness, while in residential areas, factors such as felony crime and median income played more substantial roles. (2) Socioeconomic and built environment factors dominate. Variables related to income, housing cost, crime, and land use consistently exhibited higher predictive importance than transportation or urban landscape indicators. Unlike prior studies that relied on linear models or limited-scale surveys, this study systematically compares multiple environmental dimensions using interpretable machine learning across over 1700 spatial units. (3) Nonlinear and threshold effects are common. Homelessness incidence shows rapid increases beyond specific thresholds—for instance, where median rent exceeds $1800 or the Gini index rises above 0.53 highlighting potential tipping points for targeted interventions. By uncovering key environmental correlates and their threshold effects, this study provides valuable empirical evidence for designing spatially sensitive, equity-driven policy responses. While the study does not assert causal mechanisms, it offers a robust data-driven framework to guide future research and policymaking in the pursuit of more inclusive and sustainable urban environments.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation, USA (No. 2314709).
Data Availability Statement
Data will be made available on request.