
Abstract
Local land-use plans help guide future development, but it is often difficult to compare content across jurisdictions, making regional coordination and plan evaluation challenging. This research reviews federal, state, and local data infrastructure guidance for land-use plans and compares such guidance to compliance with a California use-case. Findings indicate a number of obstacles to fostering data sharing and comparative analysis of plans: there is currently no central repository of land-use plans; plans are not uniform in format and are often out of date; many plans are not machine-readable thereby inhibiting text extraction, and planning language varies so greatly that there are numerous synonyms for terms of interest. Nonetheless, we demonstrate that the creation of digital platforms for archiving and searching across plans is currently feasible and enables large-scale quantitative analysis. Based on currently available metadata in existing land-use plans, we designed and piloted a structured database to enable users to search for terms and phrases across over 500 land-use plans. To center issues of social equity, the open access platform was developed in collaboration with state agencies and community organizations focused on environmental justice. Based on the pilot, we conclude with a framework for both developing plan data infrastructure given current constraints in standardized plan metadata and availability as well as guidance for plan formatting using FAIR standards (Findable, Accessible, Interoperable, and Reusable).
Introduction
This research explores the state of art in planning data democracy and pilots a public-facing solution. Increasingly, directives on environmental impacts and strategic environmental assessment require standard content for individual plan review; yet documents are rarely assembled in one place to allow the public to search across multiple plans and compare contents. As a result, it is difficult for oversight agencies, the public, and researchers to rapidly compare plan contents or systematically track plan updates. The aim of this research is to address such critical gaps in data sharing and policy coordination by introducing a framework for (1) federating local land-use plan data and (2) enabling diverse stakeholders to search across plans. Specifically, we ask: If policymakers, researchers, and community members could easily search across plans, how could the currently available data best be presented for use—and which uses? The overarching argument of this research is that data infrastructure to create a plan search engine will support comparative analysis, public engagement and education, policy oversight, and local coordination. We begin by introducing data science terminology, reviewing recent advances, and outlining the potential benefits of data infrastructure for the many communities that planners serve.
Broadly, this research builds on the concept of “smart cities,” a theme that originated from new technological advancements such as digitalization, the world wide web, Internet of Things (IoT), information and communication technology (ICT), artificial intelligence (AI), and the proliferation of smartphones in the late 2000s (for review, see Kontokosta, 2021; Kitchin, 2014; Kim et al., 2021). Anticipating such uses, many governments are now adopting digital standards (such as Project Open Data Metadata Schema (DCAT-US v1.1), Open311, and the Human Services Data Specification). The idea behind the smart city concept is that, in part, greater data democracy and analytics can inform more efficient and equitable practices (Liu et al., 2021). Such efforts rely on advances in both computer science and urban planning. For example, Boeing (2017, 2017b, 2019, 2020a, 2020b, 2022); Boeing et al., (2022) demonstrated methods of harvesting street data from satellite imagery, compiling multiple jurisdictions, and analyzing street networks for connectivity, traffic planning, air pollution, and health outcomes. In another example, AI can be used to highlight the differences between existing and proposed floorplan images to assess expected density increases as demonstrated by the Turing Institute (2019), located at the British Library, and named after the pioneering 1950s computer scientist Dr Alan Turing.
Similarly, recent advances in Large Language Models, such as predictive text or Chat PT, allow analysis of large text-based datasets. As Optical Character Recognition (OCR) improves, so will accurate classification of text and images, thereby enabling greater machine learning. Until such time, large-scale efforts to classify policies within plans for standard plan evaluation tend to rely on large-scale research teams. For example, building a state- or national-level zoning atlas (e.g., Bronin, 2022) currently requires hundreds of human eyes to read zoning maps and re-classify zoning typologies and policies. To enable more automated processing like OCR efforts, we demonstrate with this research how plans could be better formatted and federated while also showcasing novel methods given current data constraints.
Like images used in early land-use and street grid classifications, plans are unstructured documents. Further complicating methods to construct analysis tools, plans draw on numerous languages (written, numerical, tables, cartographic, and visual images) to present multiple topics that represent broad community visions and goals. As Wildavsky (1973) quipped, “planning is everything” and covers diverse subjects, from road repair to air quality (Brinkley and Stahmer, 2021). Unlike satellite imagery, plans are designed to test new policy and development approaches according to both the local jurisdiction’s values as well as advances in the field of planning. They have predictive value. Yet, in such evolution, plans are often updated piecemeal, with some elements adopted decades earlier than others. No singular format is used and there is a wide range of approaches both within a single plan and across plans. For example, some plans are presented as a frequently updated webpage, others are hundreds of pages of text. Such differences in format, timing of updates and available metadata create challenges for building data infrastructure. Further, the language used in planning policy is in constant flux with multiple synonyms referring to the same topic (e.g., homeless, unhoused, and housing insecure). The result is that users of any plan-related ICT will require additional educational support. To better frame plan ICT, we highlight user groups and the potential functionality.
Public uses
The benefits of developing ICT for planning documents extend to the public, developers, planners, researchers, and oversight agencies. At their base, plans commit jurisdictions to long-term development objectives, setting funding commitments, land-use, and zoning. The planning process increasingly relies on expertise from people who live in the locale but may not possess planning expertise (Slotterback and Lauria, 2019). Campbell (2009, 2012) outlined a history of city-to-city learning exchanges, finding that “the best learners are deliberate and systematic,” actively searching for new knowledge by first reviewing hard data, stored in documents, such as plans. In such efforts, public-facing ICT data infrastructure could assist in community engagement and planning education to help inform public opinion and community input. But currently, it is easier for the public to find and compare recipes online than it is for them to find and compare climate policies across neighboring jurisdictions. In short, a lack of data infrastructure hinders informed decision-making. Plan ICT built to support public engagement will need educational and outreach materials, as well as a simple user interface in a familiar format, such as a search bar—a standard feature in any internet search engine.
Research uses
Plan data infrastructure could also support greater research into plan contents. In their meta-analysis of plan evaluation, Berke and Godschalk (2009) note only 16 plan evaluation studies over a 20-year period from 1997 to 2007. In addition, most studies compare tens of plans (33 plans in Berke and Conroy, 2000: 34 plans in Conroy and Berke, 2004: 47 plans in Mui et al., 2021). In explanation, many plans are several hundred pages in length; qualitative coding or even a simple tally of search terms across plans is only recently available with text mining via computer-based information retrieval (e.g., Fu et al., 2022). Further, though public documents, like plans, are often physically accessible, immense labor is involved in assembling plans for comparison, particularly where plans must be translated. In the most ambitious plan evaluation to date, a team of 30 authors qualitatively coded climate action plans from 885 European cities (Reckien et al., 2018). Such large-scale plan comparisons allowed scholars to show that if the planned actions within European cities are nationally representative, the 11 countries investigated would achieve only a 37% reduction in GHG emissions by 2050 (Reckien et a., 2014), falling well short of the 80% reduction recommended. With data infrastructure for plans, some of these barriers to plan evaluation could be overcome, allowing repeat evaluations at lower costs. Further, plans assembled for one purpose could also be evaluated for other topical areas of interest. Efforts to analyze large datasets for patterns could also be aided by standardizing metadata requirements for plans as well as developing central repositories of data. To support research users, plan ICT can include additional data processing, such as text extraction and raw documents for follow-up studies. Further, any search algorithm should not be weighted to fully disclose how data are represented and queries are returned.
Policymaker uses
Because of the current inability to survey across plans, policymakers remain “awash with new directions and intellectual projects,” bathed in an “ether” of largely untested strategies (Healey, 2013: 1510–26). Despite an intense global focus on doing local development better, the mechanism for learning how to do it better remains a “neglected topic” (McFarlane, 2011, p 41). Policies are also often marketed as “cutting edge” by scholars (e.g., Moser et al., 2007; Roggema, 2021) and the popular press (e.g., Raye, 2014; Hensel, 2016) when they may have been tested much earlier or with more mixed success through comparative analysis of implementation and outcomes. Colossal failures in planning (Hall, 1982) offer cautionary tales of innovation gone awry, urging policymakers and advocates to identify proofs of concept for what works and why under similar contexts. For policymakers, a complete and up-to-date search engine for plans allows rapid and real-time searches of policy approaches in place as well as policy diffusion over time.
Research objective
To overcome the above challenges, the aim of this research is to assess the potential for and pilot ICT for land-use plans through an interactive community engagement process that includes community, non-profit, research, and state agency user groups. To further inform our approach, we begin by reviewing best practices in data infrastructure. We then compare those practices with the current state-level plan guidance in the Supplemental Material Files. We focus initially on the state of California because of its reputation as a state with strong land-use planning oversight (Gyourko et al., 2008; IBHS, 2009) and commitment to designing data tools and policies that support local plan efforts. No state, including California, has a publicly searchable database of land-use plans, and the creation of one represents a landmark in planning. Because plans are used by multiple groups, we used an iterative, collaborative research and design process to center social equity and real-time technical planning efforts in platform development. In so doing, we demonstrate the uses of such a database as well as the requirements for its continued maintenance with the addition of new plans. We conclude with future considerations for expanding plan data infrastructure and recommendations for plan formatting to update such data infrastructure more easily.
Background: Data infrastructure
Many ICT open data initiatives take cues from the Open Knowledge Foundation’s (2005) “Open Definition,” Sir Tim Berners-Lee’s (2006) 5-star deployment scheme for open data, and the (2007) “8 Principles of Open Government Data” (co-written by a group of 30 researchers at a 2007 workshop in Sebastopol, CA). In each of these resources, openness is not only defined as making data publicly available, but also ensuring that data is easily discoverable, presented with the highest possible degree of granularity, and published in a non-proprietary, machine-readable format. More broadly, these guiding principles advance efforts to make data FAIR: Findable, Accessible, Interoperable, and Reusable (Wilkinson et al., 2016).
Planning has broadly failed to supply FAIR plan data. For example, guidelines for improving the “FAIR”-ness of data emphasize the importance of indexing data in a searchable repository, describing the creation, contents, and management of data with rich metadata, and ensuring that links to the data will persist over time. To keep such data infrastructure up to date, FAIR guidelines recommend using common metadata vocabularies to characterize data contents, administration, and quality. Planning has no such common metadata guidelines, a gap that our research findings address. Standardized metadata for plans is important to providing critical context for how and when the plan was produced, by whom, and according to what procedures. Widely used metadata schemas like Dublin Core and the Project Open Data Metadata Schema provide a series of standard fields for describing datasets, such as “title,” “creator,” “created date,” “geographic scope,” “type,” “publication date,” and “modification date.” Using standard terms enables users to better interpret database contents, timeliness, and quality. Beyond these benefits, adopting shared metadata schemas improves the discoverability of data, making it possible for machines indexing the data to logically organize and sort them into collections that are more intuitive to browse.
Feasibility and advances in open government initiatives
While many open government initiatives are launched with an express aim to improve government transparency and civic participation, research has indicated that local government staff are often the primary users of open government data stored on these portals, in part because mandates to open data place new pressures on governments to centralize, clean, and update data assets for broader consumption (Wilson and Cong, 2021). As a benefit, government staff often cite increased internal data sharing as the most notable benefit to open government data initiatives.
Despite these benefits, research has highlighted recurrent problems with the quality of data stored in open government portals, including incompleteness, inaccessibility, a lack of formatting standards, and poor description (Braunschweig et al., 2012; Colpaert et al., 2013; Reis et al., 2018). Such flaws make data difficult to use in policy benchmarking. Further, many approaches emphasize visual spatial data or simple numerical counts, and not large-scale multi-dimensional texts, like land-use plans. For example, the European Union INSPIRE Directive (2007) establishes data infrastructure standards with implementation rules as well as a data sharing platform. Such efforts build on earlier spatial data products like the CORINE Land Cover database initiated in 1985 to enable comparison of existing land-uses with planned development. While ongoing, there is currently no data infrastructure for the text contained in plans through the INSPIRE effort. This research aims to inform such practical developments.
In tandem with state and national agency approaches, research teams, advocacy groups and for-profit companies have stepped in, aggregating, visualizing and making textual planning data publicly available through digital platforms that promote data sharing and use (Chen et al., 2020; Longley and Harris, 1999). For example, Municode, is an example a specialized commercial search engine which hosts the municipal ordinances of 4200 cities and counties online (Municode, 2021). Municode is the oldest and largest codifier of local law, founded in 1951. This added data infrastructure has allowed numerous comparative research studies on zoning and land-use ordinances ranging from smoking (Coleman, 2008) to backyard poultry legalization (Brinkley and Kingsley, 2018) and is particularly important for law review in informing court cases (Bronin, 2021). Yet, unlike plans, municipal ordinances are often discrete paragraph-length texts that are updated at defined intervals. Recently, data infrastructure has been built by researchers to host and analyze longer policy documents, like national constitutions (Elkins et al., 2018; Elkins and Ginsburg, 2005). Such databases enable large-scale machine learning techniques like topic modeling to assess how constitutions change over time and space (Rockmore et al., 2018). Similar efforts with plans demonstrate an even greater variety of topics and complexity at the local level (Brinkley and Stahmer, 2021; Brinkley and Wagner, 2022). Perhaps because of such complexity, approaches to data infrastructure for plans focus on a more tightly bound plan and topic. For example, in 2018, the New York State Division of Homeland Security and Emergency Services and FEMA produced the nation’s first web-based State-wide Hazard Mitigation Plan in partnership with Dr Catherine Lawson (Mitigate, 2021). The effort aims to urge counties to update plans in relation to the predicted hazards to be eligible for federal funding during disasters. The online map of local plans highlights that over half of the New York counties do not have up-to-date plans and many lack a focus on hazards of interest (Mitigate, 2021). Such plan data infrastructure helps make the public case for plan updates. Indeed, plan developers and consultants often rely on internal databases of plans to assist them with crafting new plans and updates; they also report tangible benefits that justify the investment in ex post data management (e.g., Campagna and Craglia, 2012). Given the above promise of ICT and state of planning data infrastructure, we next turn to the California use-case.
Methods
We begin by examining federal and state-level mandates for land-use planning data infrastructure in comparison with the California use-case. A detailed overview is provided in the Supplemental Technical Material File. Second, we assembled plans for over 450 cities and 58 counties in California, noting variations in plan format (Supp Figure 1). We then review local compliance with state and federal plan requirements for metadata. From this analysis, we conclude what may be feasible for plan formatting going forward as well as how plan data infrastructure may be developed given current constraints.
With partner feedback, we custom-developed a pilot web search platform focused on the text in plans to enable users to search for terms across plans and retrieve plans. The design of this structured, public-facing plan database is based on the plan metadata currently available. Through the pilot development, we demonstrate the uses of such a database as well as the requirements for its continued maintenance with the addition of new plans. We conclude by developing a framework for furthering data infrastructure given current constraints in machine learning and plan making.
Community partners
Following Chen et al. (2020), we engaged in a platform development effort that centered an “iterative process [that] requires peer-review, discussion and edits within the community.” At each stage of the research process, the research team presented findings to state agency representatives and non-profit members of the California Environmental Justice Alliance (CEJA) for feedback to check our understanding of the current state of planning and the problems with information discovery and accessibility needs. We center state agencies and CEJA stakeholders in an intentional effort to build equity and accessibility into the analysis and platform design with partners that are involved in real-time technical planning efforts. The CEJA alliance consists of ten non-profit member organizations that represent more than 35,000 Asian Pacific American, Latinx, and African American residents in communities across the state (CEJA, 2021). CEJA helped motivate the state legislature to pass SB 1000 (Leyva) in 2016 (Cal. Gov. Code, § 65302(h)), which requires local general plans to address Environmental Justice (EJ) in plan updates. EJ is defined in California law as “the fair treatment and meaningful involvement of people of all races, cultures, incomes, and national origins with respect to the development, adoption, implementation, and enforcement of environmental laws, regulations, and policies” (Cal. Gov. Code, § 65040.12, subd. (e)). In addition, CEJA has created a technical planning toolkit to guide local jurisdictions in meeting the state mandate to address EJ (CEJA, 2021). CEJA seeks improved plan data infrastructure to allow (1.) monitoring of local jurisdiction compliance with state mandates, and (2.) informed updates to their technical planning toolkit based on the discovery of model EJ policies and best practices in the development of in general plans. We also sought pilot platform development input from the California Governor’s Office of Planning and Research (OPR), Housing and Community Development (HCD) and California Air Resources Board (CARB), state agencies that provide guidance for general plan development (HCD, 2021a, 2021b).
Data collection
Most California general plans are publicly available on city websites, but there are no centralized locations for archiving plans nor standards regarding where such plans should appear on the sites. In 2017, Brinkley and Stahmer (2021) collected PDFs of general plans for 421 of California’s 482 cities via their websites. At that time, the plans for 61 cities could not be located on city websites. A second round of data collection was initiated in summer 2020 to locate previously missing plans and county plans. In addition to reviewing municipal websites, this round involved emailing or calling city planning offices to inquire about plans. By the end of the summer of 2020, we had collected the most up-to-date general plans for 457 California cities and all 58 California counties, amounting to about 8 GB in storage space. Digital plans were unavailable for 12 cities (Wildomar, Tulelake, Sand City, Orange Cove, Menifee, Maywood, Maricopa, Los Gatos, Kingsburg, Dos Palos, Blue Lake, and Alturas). The City of Tulelake website (accessed 2022) noted that hard copies of the general plan were only available to be checked out on loan from city hall. While most plans were available as PDFs, some were published as Word documents, as website html files (e.g., City of Ontario), or text files. In these cases, we converted the documents into a PDF, using Adobe Acrobat.
Analysis
Following data collection, we reviewed the current state of data infrastructure for plans in California. This first involved an in-depth review of the California State General Plan Guidelines (OPR, 2021b) and an assessment of the extent to which they aligned with best practice guidelines for data infrastructure, such as FAIR and the Open Definition. Specifically, we analyzed state recommendations for composing, formatting, publishing, describing, and updating plans. We then qualitatively analyzed a random sample of 100 plans for their structure, formatting, available metadata, and the degree to which these elements were standardized across plans. We focused metadata analysis on descriptors such as the plan’s creator, when the plan was created, and when the plan was last updated. In providing an overview of current plan structures, this analysis in Supplemental Material laid the foundation for piloting a platform for federating and searching across general plans.
Pilot platform development
The pilot platform was designed using Python packages optimized for quickly extracting information directly from PDF documents and ElasticSearch (See Supplemental Technical Appendix) to allow multi-word and phrase search queries. In the process of developing this platform, we reflected on the challenges of archiving and searching across plans given the current state of data infrastructure for plans.
Limitations
While this research aims to inform plan development and evaluation, the community engagement component did not engage with cities and counties directly in designing the platform, focusing only on state agencies and a consortium of community-based organizations. Further, plans use several languages (i.e., textual, numerical, images, and maps). This research focuses only on the textual content.
Findings
Findings indicate several challenges to fostering data sharing given the current state of data infrastructure for local land-use plans. Nevertheless, we demonstrate how a search platform for plans can facilitate the identification and review of planning objectives across jurisdictions given the current limitations in structured metadata.
Planning data infrastructure pilot functionality
The linguistic diversity of an ever-evolving language of planning resulted in multiple technical approaches to extract text and craft an index. The logic model of database creation (Figure 1) reviews the steps. The linguistic diversity also led the research team to create a search engine as opposed to pre-coding plans for discrete topics. For example, across the corpus, plans contained 162,341 unique words, with 44,570 words that were mentioned more than three times. Given the linguistic diversity, we recommend deploying a broad term indexing software, like ElastiSearch, to allow users greater access to unique terms and phrases. Further, many topics of interest to partners involve phrases (e.g., environmental justice), thereby necessitating advanced indexing software for multi-word terminology. Logic model for planning data infrastructure development.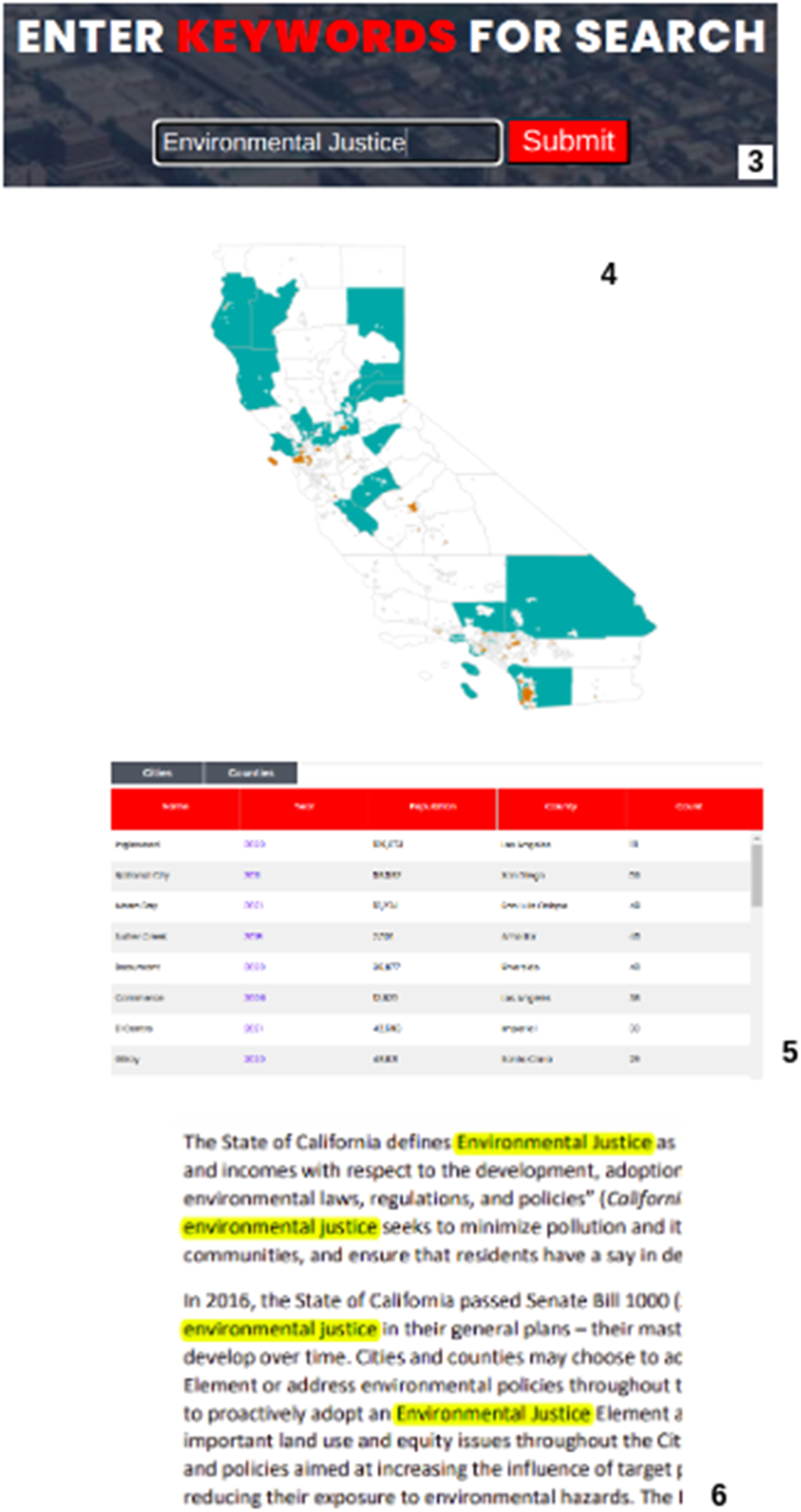
Because planning approaches can be regional or spatially restricted to particular geographies, population sizes, or socioeconomic communities, we recommend displaying results in a map format for public uses. After users search for a term or phrase, the interface displays results spatially (Figure 1; Step 4) and in table form (Figure 1, Step 5). The map shows which cities and counties use the term, enabling users to quickly identify spatial patterns in planning policy (e.g., Figure 2). The table shows how many times the term or phrase is mentioned per plan, the year the plan element was adopted, the population of the jurisdiction based on the 2020 census, and the county that the city is located within (Figure 1, Step 5). The table allows users to sort search returns based on these categories to identify differences across regions, in variously sized cities, and over time. In addition, the tool summarizes how many cities and counties within the database mention the search term or phrase. Because a jurisdiction can have multiple elements within a plan updated over multiple years which all mention the search term, the table (Figure 1, Step 5) reveals all the relevant years plans were adopt for that jurisdiction as well as the total number of cities and counties that mention the term. In this manner, users can see how many jurisdictions address a particular term to assess prevalence while also noting the timing of various terms appearing in the corpus. In addition, users can click on the year of a plan to access the full PDF to read the search terminology in the context of the plan and gather further ancillary data (Figure 1, Step 6). Last, the database was assigned a Digital Object Identifier (DOI) to allow citation and tracking of this version (Figure 1, Step 8). Map visualization of general plan search hits for “wildfire” covering 183/457 cities (orange) and 47/58 counties (blue).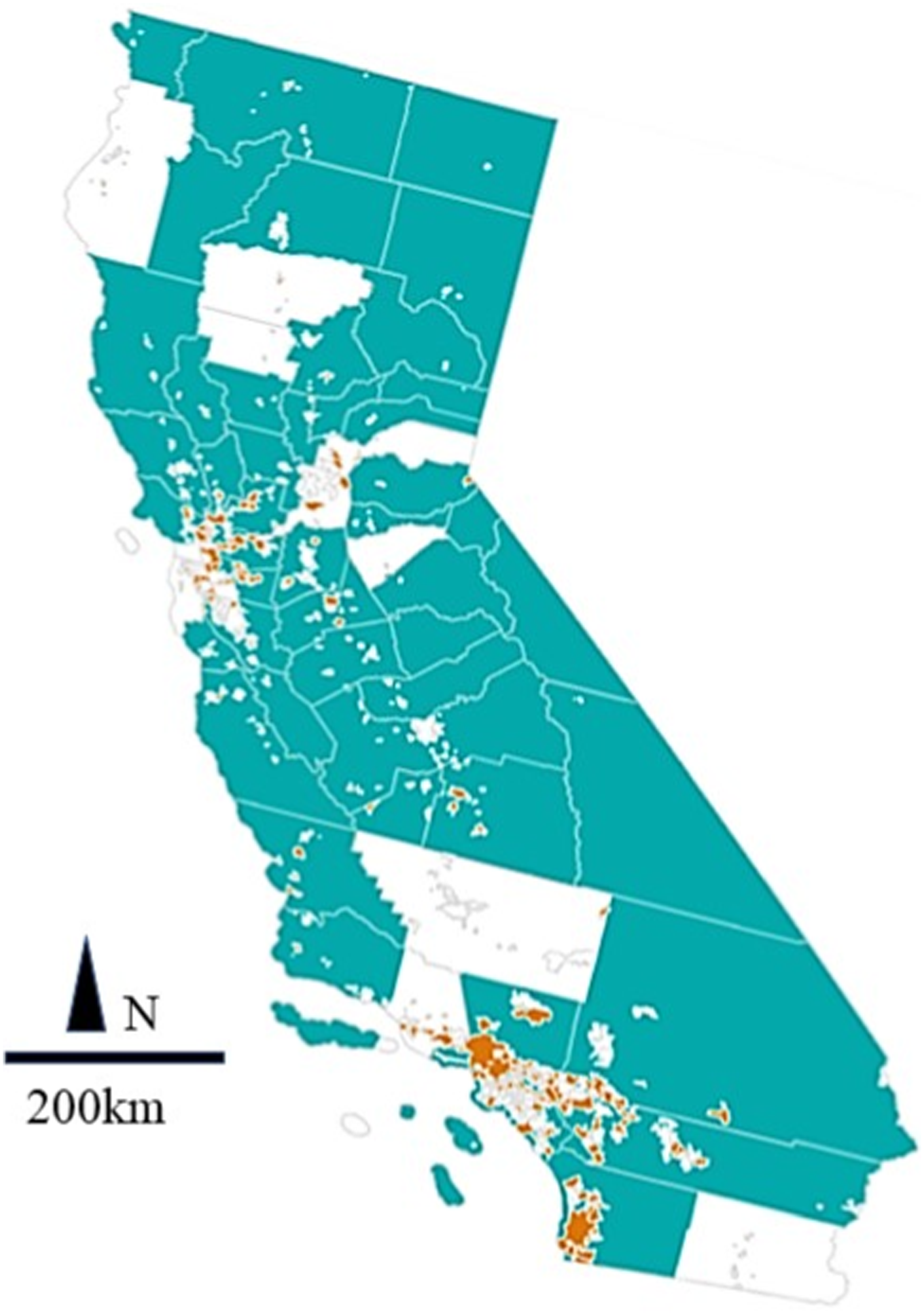
Search terms allow user groups to identify both adoption of new planning objectives and coded language that is associated with planning outcomes. Yet, because planning terminology is in flux, users must already be knowledgeable about planning terms. For example, CEJA uses the database to monitor where and how cities and counties are infusing general plans with Environmental Justice policies to meet the spirit and intent of the state mandate. Currently, only 31 cities and 13 counties mention the term “environmental justice” in their general plans, but many more address environmental justice without labeling it thus. For example, the City of Richmond pioneered efforts to establish “Health in All Policies” (Corburn, 2009; Coburn et al., 2014) into the general plan adopted in 1998, well before the state’s SB 1000 mandate to include EJ in plans. Thus, communities can address EJ in plans without necessarily using the term “environmental justice.” As such, search functions for planning data infrastructure will need to include an extensive index of terms and phrases. One alternative possibility is to pre-code plans for policy presence (e.g., California’s Climate Action Plan Map Portal, n.d.). The result is that platform users are limited in which terms and policies they can access.
By co-designing the platform with a social-equity focused user, the resulting platform differs from other such data infrastructure efforts in greater data transparency and flexibility. In particular, Environmental Justice is a broad term with a multiplicity of policy approaches, so pre-coding plans for particular topics would both limit the search potential and slow access for users who want to assess terms that exist in only a few plans. For example, no current plan uses the term “anti-racism,” but users may want to monitor and celebrate the first jurisdiction to take such a policy approach. Pre-coding plans would limit such database potential. Further, the Climate Action Plan Mapping Portal (n.d.) search returns include two-to-three sentence lines of policy. Such functions would not work for CEJA users who are interested in seeing the plan terminology in the plan with reference images, tables and maps. Because implementation actions and timelines associated with terminology are often found in other parts of the plan, without access to the full PDF, CEJA would not fully be able to fully assess EJ approaches. As a result, the database we designed allowed CEJA organizations to search for terms, access the plan PDFs and then and conduct more in-depth plan evaluations to highlight specific policy language examples that could be transferrable or serve as inspiration to other cities or counties that are facing challenges. This broad ability to compare within and across plans also allows CEJA organizations to be more effective in their local engagement and capacity-building. For example, particular EJ policies may closely align with regional opportunities (visualized by spatial clustering of search hits) or alignment with funding streams (identified by co-occurrence of search terms and relation within the plan). For this reason, we designed a search that returned hits in both a spatial map context as well as in a table form that would allow for easy sorting based on term mentions, jurisdiction population, and region (county).
Another benefit of the more expansive term indexing approach is that state administrative agencies can also more easily read across plans to pull examples from their general plan guidelines documents. Currently, OPR administers an Annual Planning Survey querying city and county planners about whether their general plan addresses a variety of topics, such as “racial equity” and “climate adaptation and resilience” (OPR, 2021a). With a response rate of nearly 60% in 2020, the information is incomplete. In addition, some cities note that they are addressing topics within their general plan, but there is very little evidence within the plan. For example, 16 cities note that they are addressing “racial equity” in the 2020 Annual Planning Survey (OPR, 2020), but none use this term in their plan and only one plan uses the term “racism” of 457 city plans and 58 counties. In this manner, the ability to search across plans helps organizations like CEJA work with OPR to identify on how well or how poorly cities and counties are meeting state mandates and where additional guidance is needed.
The broader search query capability in combination with a more complete dataset of plans allows users to assess planning topic prevalence as well as absence of policy uptake. As Fulton notes in the “Guide to California Planning,” “no one ever argues for lessening quality of life” (2012, p. 119)—at least not outright. In this sense, the absence of terms can be as important as the presence in plan evaluation. To allow such searches, a near-complete and up-to-date database would need to allow searches for a plethora of synonyms and coded language where usership affords some planning expertise in “reading between the lines.” For example, in building the database, partners have wryly noted that “small town character” appears in 115/457 city general plans and 8/58 county general plans. “Small town character” is often synonymous with signaling that a jurisdiction does not want population growth or added development.
We use a case vignette below to highlight how synonyms and the absence of particular terms reveal a planning focus that is not stated forthrightly. Located in the Sierra Mountains, the City of Truckee was an important stop along the Central Pacific Railroad in the 1860s and played a large role in assembling materials and workers for building the transcontinental railroad eastward. One third of Truckee’s population was Chinese, and Truckee’s Chinatown was second only to San Francisco in its size. The 2025 Truckee general plan adopted in 2006 references this foundational history and the city’s importance in building the transcontinental railroad, but neglects to mention the racism that resulted in the Chinatown being segregated away from the rest of the city and then burnt down, its population driven out of the city. The historic Chinatown was never rebuilt and mention of it is omitted from Truckee’s current historical preservation element, which incidentally mentions “character” a total of 236 times, and “historic” 92 times, but never the words “China,” “Chinese,” or “Chinatown.”
Such findings within individual plans are also prevalent across the planning corpus, prompting scholars and lawyers to make the case for policy changes, such as those proposed by Dr Sara Bronin in her testimony supporting Connecticut’s Senate Bill 1024. Bronin argues that “the term ‘character’ has historically been written into zoning codes as an avenue for discrimination” (Bronin, 2021). With the database of searchable plans, dog whistle terminology across plans will be easier to identify as well as the conspicuous absence of planning focus on particular topics. In the case of Truckee, a historical wrong can be righted. Applied more broadly, such findings indicate the need for a planning focus on systemic corrections beyond individual places. To this end, a centralized and searchable repository of land-use plans enables greater natural language processing to quantify what other language might be associated with particular plan outcomes.
Such considerations are important not only as planning moves toward addressing EJ and anti-racist futures (Walker and Derickson, 2022), but also as local jurisdictions grapple with climate crises. For example, we find that only 183 cities (of 457) and 47 (of 58) counties mention the term “wildfire” in their general plan (Figure 2). While wildfires will not evenly impact communities and general plans are not the only planning documents to detail plans of action, we note that many heavily forested northern cities and counties lack a reference to this term. Such silence in plans might prompt state agencies to work more closely with local jurisdictions to form plans that address pertinent hazards. Conversely, six California cities mention “pandemic,” with San Francisco mentioning the term eight times in its “Community Safety Element,” adopted in 2012. The presence of a pandemic policy speaks to San Francisco’s history in grappling with the 1918 influenza public health crisis (Dolan, 2020) as well as its preparation before the COVID pandemic (Fields et al., 2021). Perhaps because of such planning efforts, San Francisco is reported as being “uniquely prepared” and having “executed by far the most successful initial response to COVID-19 of any major American city” (Duane, 2020). To learn from such examples, it will be important to find not only San Francisco’s pandemic plan but to compare it with other efforts and assess outcomes.
Discussion: A framework for land-use plan Data infrastructure
Overall, this research seeks to inform and assist the “neglected topic” (McFarlane, 2011, p 41) of urban learning, with a focus on data infrastructure for land-use plans. To enable search-and-learn practices, this research reviewed state and local data policies and piloted the creation of a searchable database of plans. As the California case shows, addressing some of the most critical contemporary issues, such as housing and the environment, requires coordination of land-use policy efforts across multiple agencies as well as local, regional, and state levels. However, the lack of FAIR data guidelines for land-use plans, incomplete compliance with existing mandates, and variation in structure and formatting of general plans creates particularly challenging obstacles to designing data infrastructure for land-use plans.
First, we provide recommendations for creating data standards for plans, and then data infrastructure development. To encourage data sharing, states could provide guidance or regulation on plan format. For example, state and federal agencies could require that plans be published in machine-readable formats (such as computer-generated or OCR-readable PDFs) and that images be described with machine-readable tags would help to support text extraction and search while also bringing plans into compliance with ADA. To this end, we recommend that oversight agencies create a format that includes metadata categories for reporting the jurisdiction, plan author and adoption date for each plan component. For example, oversight agencies could provide pre-filed temples or tables for local jurisdictions to amend as HCD does with certain aspects of the Housing element. Further, FAIR guidelines recommend that data publishers assign globally unique and persistent identifiers (such as Digital Object Identifiers or Archival Resource Keys) to published documents. These serve to uniquely identify the content, preserve the link to the content over time, and enable publishers to bind structured metadata to the content.
Second, we recommend the creation of a public-facing plan repository. Such a database could automatically assign identifiers to contributed content in order to better ensure that plans are indexed in a searchable service and that links to them do not break when cities or counties reorganize their local web content. Currently, there are no centralized locations for archiving plans in California nor standards regarding where such plans should appear on city or county websites. We note that nearly 13% of California city plans were not readily available through their official city website. International plan evaluation studies have faced similar challenges (e.g., Reckien et al., 2018).
Such a database could be crowdsourced through volunteer efforts or built into a streamlined plan review process. For example, when plans are submitted for environmental quality review, if the review agency has an Application Programming Interface (API), notifications that a new plan may be adopted can be automatically generated. Similarly, to keep such a database of plans up to date, designers should ensure that plan elements can easily be retrievable by adoption date in order to review the timeliness of updates. Such public-facing maps of out-of-date plans can help community members and oversight agencies identify where additional support is needed to bring all jurisdictions up to date. Further, requiring that those uploading new documents to a plan database provide responses to a series structured fields (such as “created date,” “revised date,” “contact email,” and “elements included”) can ensure that every document in the database is persistently accompanied with metadata that helps data consumers to interpret the content and machines to sort through it. With better formatting and data storage protocols, further updates to a plan database could be automated, for example, with an API that sends a newly adopted plan from oversight agency review directly to the database or indexing and inclusion.
Last, for the creation of a public-facing and searchable database, we recommend that search capabilities remain as broad as possible with the ability to map search hits spatially and in tabular formats as well as retrieve full plan documents. In assessing plan contents, we found the language used for planning topics varied widely by regional culture and over time. Thus, search tools will need to simultaneously educate users on potentials synonyms and deploy indexing software that captures a wide vocabulary. Such considerations will be more important if translation from multiple languages is needed in building international planning data infrastructure. While pre-coding could solve for this issue and enable users to pull up all related mentions of policies, the breadth of planning topics makes coding for even a subset of planning topics laborious. Similarly, images are important contextual markers in plans, and any search functionality should allow the ability to show policies in the context of planning documents and accompanying images. Further, by making our code publicly available on GitHub (Banginwar et al., 2023), we invite developers to innovate and improve on our pilot design and resulting framework and hope future efforts do the same.
Practically, new data tools open opportunities for greater plan coordination from oversight bodies and administrating agencies. Such efforts could be further supported with new enabling legislature and funding. For example, new legislation could require that local jurisdictions report when individual elements and general plans are updated and submit adopted documents to a central agency. The agency could scan such documents to ensure that mandates were achieved. For example, in reporting on meeting EJ mandates, OPR could note how disadvantaged communities were defined, identified and mapped as well as cross-reference which goals and policies are EJ-related. There are precedents to California shifting data infrastructure policies. For example, the Brown Act and California Public Records Act are “sunshine” laws meant to add transparency to local government policymaking by making documents available to the public. Similarly, the 2019 Housing package requires local jurisdictions to report planned housing in a standard format. Similar data standardization requirements in reporting would allow easier comparisons across plans.
The iterative design process with state agencies and non-profit groups provides proof of concept on the benefits of creating and maintaining the above-described planning data infrastructure. Beyond advocates and state agencies, many cities and counties could similarly benefit from standardized forms and accessible data. Local jurisdictions face planning capacity challenges as evidenced by the many plans that are out-of-date, with more than half of California general plans older than 15 years old. “Plug and play” forms and ability to immolate desirable policies more easily could help with simplifying plan updates, meeting state requirements and transferring promising policies that community members support. For many reasons (funding, capacity, expertise, and politics), local governments may do the bare minimum when it comes to complying with state planning law, including general plan requirements. Yet, by making plan drafting easier, it will be important not to lose sight of the rationale for mandates as well as the value of local effort that goes into the planning process and implementation. Though this research primarily focused on plan creation and evaluation, for all the above reasons, data infrastructure is also being innovated to simplify, automate and expedite plan review (e.g., Turing Institute (2019)).
Last, we conclude by noting the current state of planning data infrastructure. While land-use plans are produced with considerable stakeholder input, often made available publicly, and subject to state mandates, the documents themselves and the wealth of information contained within them remain siloed in municipal websites and are structured so variably as to inhibit comparative analysis. In other words, the publication of land-use plans on municipal websites meets only the lowest level of data openness, inhibiting accessibility and opportunities for effective planning.
Conclusion
This collaborative research reviewed state policies and local practices for storing, describing, indexing, and formatting plans and developed a pilot data sharing platform for city and county general plans that is searchable, accessible, interoperable, and reusable. Our landmark state-level database of general plans is the first for California—and nationally. We provide a model for others that wish to make the planning process more transparent and anticipate that this approach will become a model for other states. Following our preliminary work in digitizing and publishing California general plans online, we now have the infrastructure necessary for harvesting and performing exploratory, comparative quantitative analysis of high-dimensional texts, ushering in a new era in plan evaluation for researchers, advocates, policymakers, and enforcement agencies.
Supplemental Material
Supplemental Material - Making plans findable, accessible, interoperable, and reusable with data infrastructure: A search engine for constructing, analyzing, and visualizing planning documents
Supplemental Material for Making plans findable, accessible, interoperable, and reusable with data infrastructure: A search engine for constructing, analyzing, and visualizing planning documents by Lindsay Poirier, Dexter Antonio, Makenna Dettmann, Tiffany Eng, Jennifer Ganata, Sujoy Ghosh, Mirthala Lopez, Ranesh Karma, Asiya Natekal and Catherine Brinkley in Environment and Planning B: Urban Analytics and City Science
Footnotes
Acknowledgments
Thanks are due to Dr Carl Stahmer, who supported early text extraction, along with Jose Flores and Muthia Fahzia for collecting the first test round of general plans. Andrew Leach supported plan verification, along with early versions of spatial visualizations. Thanks are also due to both Brittany Bates and Amay Kharbanda for collecting and formatting the second round of general plans.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Environmental Health Sciences of the National Institutes of Health, #P30ES023513 and California Air Resources Board.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.