
Abstract
Identifying market segments can improve the fit and performance of hedonic price models. In this paper, we present a novel approach to market segmentation based on the use of machine learning techniques. Concretely, we propose a two-stage process. In the first stage, classification trees with interactive basis functions are used to identify non-orthogonal and non-linear submarket boundaries. The market segments that result are then introduced in a spatial econometric model to obtain hedonic estimates of the implicit prices of interest. The proposed approach is illustrated with a reproducible example of three major Spanish real estate markets. We conclude that identifying market sub-segments using the approach proposed is a relatively simple and demonstrate the potential of the proposed modelling strategy to produce better models and more accurate predictions.
Introduction
Hedonic price analysis is one of the most widely-used approaches for the study and valuation of properties in real estate markets. This approach is attractive due to its strong theoretical grounding and appealing interpretation (Rosen, 1974). Indeed, when hedonic price models are estimated using multiple linear regression the coefficients of the model are thought to capture the implicit prices of attributes in a bundled good. In this way, while a room may lack an explicit price in the valuation of a property, the coefficient of a hedonic price model quantifies its implicit value. Such decomposition of the price of a bundled good into the implicit prices of its constituent parts is important for multiple reasons: this analysis is the industry standard for property assessment for tax purposes (Morillo et al., 2017); these models are used to quantify the willingness to pay for non-market environmental amenities (Montero et al., 2018), including air quality and open spaces and similarly they can be used to assess the cost of disamenities (e.g., Von Graevenitz, 2018).
The need to assess property values in a transparent, accurate, and precise way has led to numerous developments. A strand of research has aimed at enhancing the performance of models by incorporating spatial information. Geographic Information Systems (GIS) in particular have been used to make explicit some attributes of properties and their environments that might otherwise be overlooked (Paterson and Boyle, 2002). The use of spatial data, in turn, has brought increased attention to the question of statistical sufficiency and therefore the need for approaches that appropriately consider the issues of spatial association and spatial heterogeneity in hedonic price analysis (Pace and Gilley, 1997; Paez et al., 2001). As a result, there has been a proliferation of studies that apply spatial statistical or econometric methods to the issue of property valuation (Paez, 2009). Recent applications include the use of hierarchical spatial autoregressive models (Cellmer et al., 2019), moving windows approaches (Páez et al., 2008), spatial filtering (Helbich and Griffith, 2016), and kriging techniques (Montero-Lorenzo et al., 2009), among others.
In addition to interest in spatial data, the application of machine learning techniques for hedonic price analysis has also become an active topic of research. There are at least two distinct ways in which machine learning can be used for hedonic price analysis. In some studies, the role of machine learning algorithms is to process information that would otherwise be difficult or impossible to obtain using non-automated means. The information obtained is then used as an input in econometric hedonic models. For example, Humphreys et al. (2019) and Nowak and Sayago-Gomez (2018) used machine learning classifiers to ethnically profile buyers and sellers based on last names to understand whether potential cultural biases and/or discrimination issues exist in property transactions. In other research, machine learning algorithms replace the conventional hedonic price model (Hu et al., 2019; Yoo et al., 2012; Füss and Koller, 2016). The evidence available shows that machine learning methods can perform remarkably well, but can also be seen as black boxes with low interpretability (see James et al., 2013).
Our objective in this paper is to introduce a novel approach that retains the interpretability of econometric approaches, but is enhanced by the identification of spatial market segments obtained from the use of machine learning techniques. We propose a two-stage approach. In the first stage, classification trees are implemented to identify homogeneous spatial market segments. The number of market segments is endogenous, and, compared to Füss and Koller (2016), the use of interactive basis functions (see Paez et al., 2019) can accommodate non-orthogonal and non-linear decision boundaries. The market segments are then introduced as covariates in an econometric model. This approach can potentially enhance the model without compromising its interpretability.
A reproducible case study of property values in three major markets in Spain helps to illustrate the proposed approach. Following recommendations for openness and reproducibility in geospatial research (Paez, 2021), this paper is accompanied by a fully documented and open data product (see Arribas-Bel et al., 2021), and the code is embedded in a self-contained R markdown document. The results show that modeling prices using the approach proposed to identify spatial market segments improves the fit of the models and can in addition enhance the quality of predictions.
Spatial market segmentation
The importance of housing submarkets has long been recognized in the literature (e.g., Rapkin et al., 1953). Market differentiation can be the result of a variety of processes operating separately or in conjunction, including substitution, differentiation, and variations in consumer preferences (Galster, 1996). In principle, this implies a degree of homogeneity within the market segment that differentiates it from other segments. According to (Thibodeau, 2003, pp. 4–5) a spatial housing submarket “defines a geographic area where the price of housing per unit of housing service is constant.” Given the non-tradeable nature of location, research has shown the relevance of spatial market segments (Bourassa et al., 2007; Royuela and Duque, 2013; Usman et al., 2020).
Submarket analysis is often implemented in a pragmatic way, encompassing regional boundaries, for instance those of metropolitan regions, cities, or municipalities. It has long been recognized, though, that submarkets may exist at smaller scales (e.g., Rapkin et al., 1953). In particular, the pioneering work of Alonso (Alonso, 1964) on urban structure led to the realization of the importance of geography in terms of differentiation of real estate property. Since then, vast amounts of empirical evidence have contributed to demonstrate just how commonplace differences in hedonic prices are at the intraurban scale. Concurrently, market segmentation has been shown to be not only a conceptually sound practice (see Watkins, 2001), but also conducive to higher quality models and improved predictive performance, in particular when geography is explicitly taken into consideration (Páez et al., 2008).
Numerous approaches have been proposed to identify market segments. Some are based on expert opinion, such as from appraisers (Wheeler et al., 2014). Many others are data-driven, using statistical or machine learning techniques (e.g., Helbich et al., 2013; Wu et al., 2018). Heuristic approaches also exist that exploit the latent homogeneity in values (Royuela and Duque, 2013). Implementation of market segments in hedonic price models can be accomplished by means of fixed effects (i.e., dummy variables) for sub-regions (e.g., Bourassa et al., 2007), spatial drift by means of a trend surface (e.g., Pace and Gilley, 1997), spatially autoregressive models (e.g., Pace et al., 1998), switching regressions (e.g., Islam and Asami, 2011; Paez et al., 2001), multilevel and/or Bayesian models (e.g., Wheeler et al., 2014), or by means of spatially moving windows or non-parametric techniques to obtain soft market segments (Páez et al., 2008; Hwang and Thill, 2009). As is commonly the case, there is no one technique that performs consistently better than the alternatives in every case, since performance depends to some extent on the characteristics of the process being modeled (Usman et al., 2020). It is therefore valuable to explore alternative approaches to identify and model market segments, to further enrich the repertoire of techniques available to analysts.
A recent proposal along these lines is due to Füss and Koller (2016), who suggest using decision trees to identify and model market segments. James et al. (2013) list some attractive features of decision trees. They are relatively simple to estimate and intuitive to interpret. They divide attribute space into a set of mutually exclusive and collectively exhaustive regions, and thus are ideally suited for market segmentation. By design, the regions generated are spatially compact and internally homogeneous. And they can outperform other regression techniques. Market segments derived from a decision tree can be used in combination with other modeling techniques, such as a second-stage tree regression (with fixed effects for the market segments from the preliminary tree regression), linear models, or models with spatial or spatio-temporal effects, such as space-time autoregression. Füss and Koller (2016) compare several different modeling techniques. Their findings confirm that introducing a form of market segmentation greatly improves prediction accuracy, and the use of tree-based market segments does so more than the use of an a priori zoning system defined by ZIP codes. Furthermore, accounting for residual spatial pattern in the form of a spatial autoregressive model further improves the accuracy of estimation.
The results reported by Füss and Koller (2016) are appealing. However, the modeling strategy that they implement inherits a limitation of tree regression, namely, the relatively inflexible way in which attribute space is partitioned using recursive binary splits. What this means is that market segments obtained in this way are limited to rectangular shapes (see page 1359 in Füss and Koller, 2016). While prediction accuracy reportedly improves with tree-based segmentation of the market, it might be desirable to define market segments more flexibly so that they are not constrained to rectangular shapes. Second, estimates of a regression tree are the mean of the values contained in the volume of a leaf, which means they are constants for each leaf. In a geographical application, the leaves are mutually exclusive and collectively exhaustive partitions of geographical space. Using the residuals in the second step of the modelling strategy induces spatial autocorrelation, since all properties in the same segment will be given estimated residuals that are constants in each market segment. The issue here is that by introducing spatial autocorrelation in the second step some of the spatial information about location is obscured since there is zero spatial variation in the estimated residuals for a given market segment.
We address these two issues by using interactive basis functions (Paez et al., 2019) to induce non-orthogonal and non-linear decision boundaries in our models of market segments. Further, by moving the analysis of market segments to the first stage of the analysis, we obtain market segments with good homogeneity properties, and any spatial autocorrelation is dealt with by means of the spatial econometric model in the second step. The modelling strategy is described in more detail next.
Modeling strategy and methods
Modeling strategy
We propose a two-stage modelling strategy, as follows: 1. Estimate a first stage classification tree using the prices and the coordinates of the observations only (similar to trend surface analysis, see Unwin, 1978). • Map the regions R
m
that result: these are the m = 1, …, M submarkets. • Overlay the observations on the tree-based regions and create a set of m indicator variables for submarket membership: I
m
= I(y
i
∈ R
m
); when the argument of the indicator function is true (i.e., when observation y
i
is in R
m
) then I
m
= 1, otherwise I
m
= 0. 2. Estimate a second-stage hedonic price model that incorporates the indicator variables for submarkets obtained in first stage including spatial interaction effects and other relevant covariates.
Note that the modeling strategy proposed here differs from the one proposed by Füss and Koller (2016) in that the market areas are identified by these authors based on the residuals of a preliminary regression, whereas we identify them based on the prices directly. It is worth noting that these two strategies reflect different heuristics. Identification of market areas based on the prices implies that market areas are formed based on unitary properties before properties are assessed as bundles of attributes. Identification of market areas based on the residuals, on the other hand, implies that properties are first seen as bundles of attributes and that submarkets form based on other non-identified attributes.
Methods
Two methodologies are combined in the modeling strategy. For first-stage, we apply the well-known algorithm of classification trees with the objective of identify spatial submarkets. The algorithm is applied using the variation suggested by Paez et al. (2019) to obtain non-orthogonal and non-linear boundaries via interactive basis functions. A sort description of this methodology is present in the supplementary material. For the second-stage we apply spatial econometric methodologies to solve the presence of spatial autocorrelation in the residual of the classical hedonic models. Supplementary material available online describe the spatial econometric regression models estimate. These methods are implemented using several open-source R-packages. The
Data
The empirical examples to follow correspond to large cities in Spain. The real estate market is one of the most important sectors of the Spanish economy, and the largest urban areas in Spain are important points of reference for the real estate market in the country. The three largest markets are Madrid (the national capital with 3.2 million inhabitants), Barcelona (1.6 million), and Valencia (0.8 million inhabitants). The focus of our application is on property prices in these cities. Micro-data from official sources are not available in Spain; instead, we draw our data from an online real estate database, Idealista.com (the leading real estate portal in Spain).
The data are documented and prepared for sharing publicly in the form of an open data product (Arribas-Bel et al., 2021) under the structure of a R-package free available from a repository 2 and a data paper describe the full data set. The database is for postings during 2018, and the analysis uses the last quarter of the year. We use the asking price as a proxy for the selling price; this is common practice in many real estate studies (e.g., López et al., 2015; Chasco et al., 2018). For the three data sets we consider the most frequent type of property in Spain, namely, the flat (hereon termed “houses”); this excludes other types of properties, such as duplex, chalets, and attics, which conform separate real estate markets.
The data sets used in the analysis correspond to the last quarter of 2018 and include a total of n = 44,270 for Madrid, n = 23,334 for Barcelona, and n = 14,018 for Valencia. The distribution of prices displays a long tail in all three cities, and following conventional practice it is log-transformed. The coordinates are converted from latitude and longitude to northing and easting in meters, and then rescaled and centered using the corresponding city’s Central Business District as a false origin. These transformations have no impact on the analysis, and rescaling and centering of the coordinates is necessary for the correct implementation of the interactive basis functions in decision trees (see Paez et al., 2019: pp. 188–189).
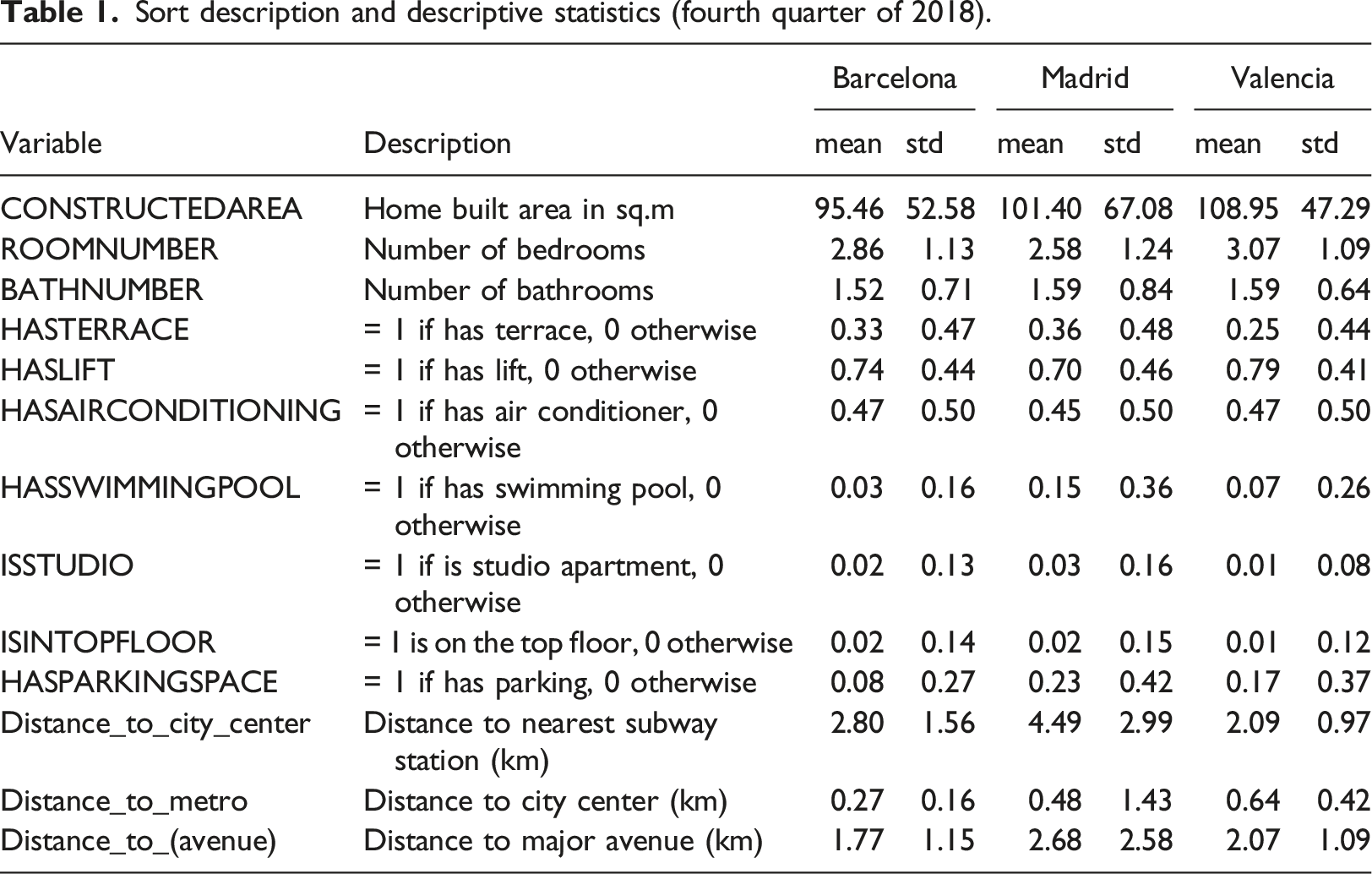
Sort description and descriptive statistics (fourth quarter of 2018).
Empirical examples
Experimental design
Each city’s data set is split into a training sample and a testing sample using a 7:3 proportion. The training samples are used to estimate the models and the testing samples are used to assess the out-of-sample performance of the models.
We consider four models. First is a Base Model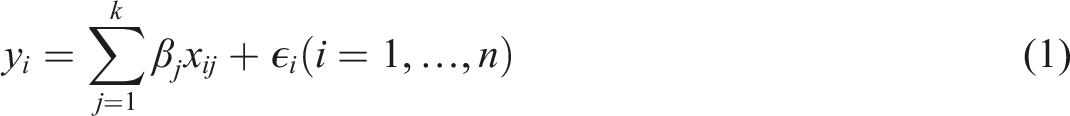
The second is a base model with market segments (Base Model + MS)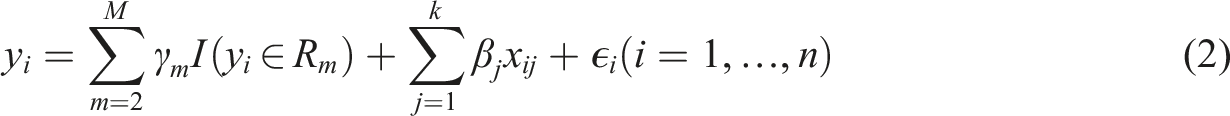
The third is a spatial lag model (Spatial Model)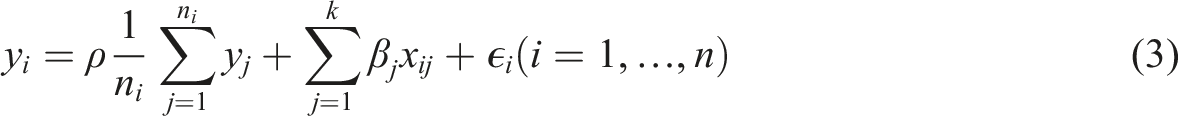
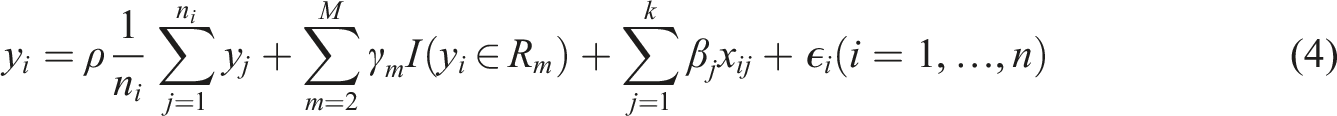
Please note that all models nest in the Spatial Model + MS depending on what restrictions are placed on the parameters. In the Base Model


Spatial weights matrices are constructed using a kth-nearest neighbor criterion, with k = 6 since this approximates the mean degree of connectivity in planar systems (Farber et al., 2009, Table 1). The spatial weights matrices are row-standardized before use in the models. With respect to the interactive basis functions for the decision trees, we consider the following functions (see supplementary material) with u and v as the planar coordinates of the observations, easting and northing, respectively
We first look at the estimated models before discussing the in- and out-of-sample predictive performance of the models.
Modelling results
Models Barcelona (dependent variable is log of price).
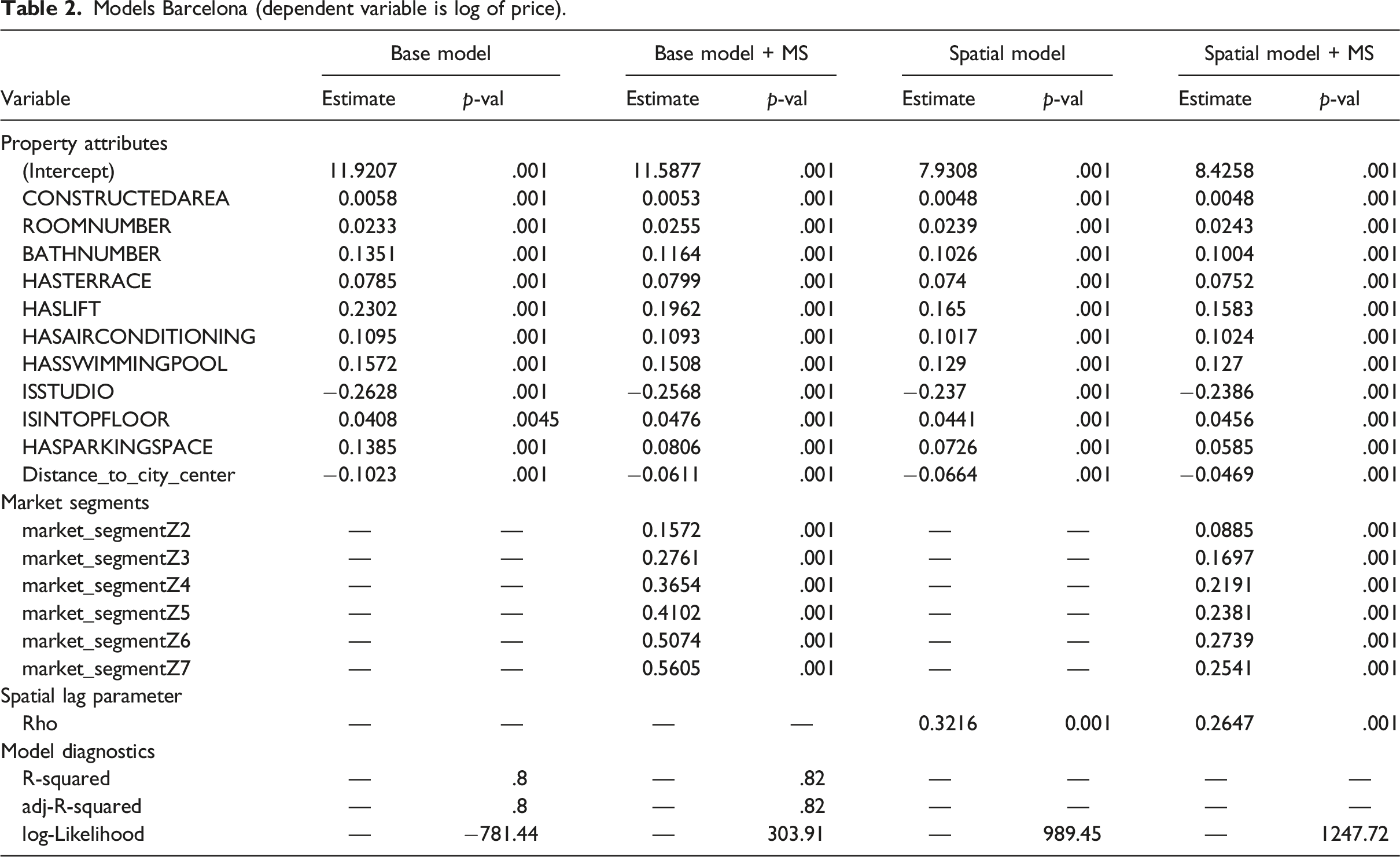
Models Madrid (dependent variable is log of price).
Note. 0.001 in the p-values represents any value less than .001.
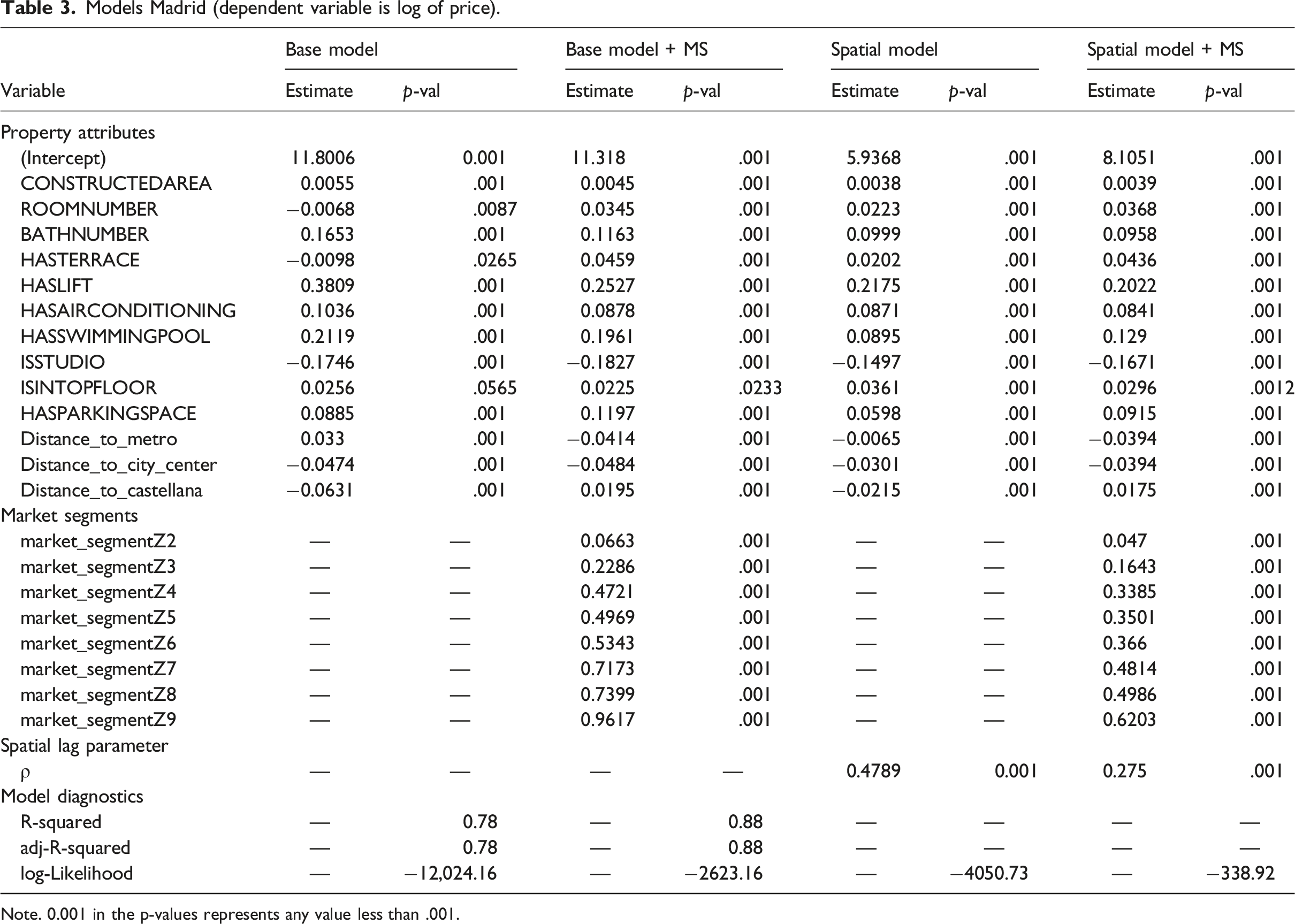
Models Valencia (dependent variable is log of price).
Note. .001 in the p-values represents any value less than .001.
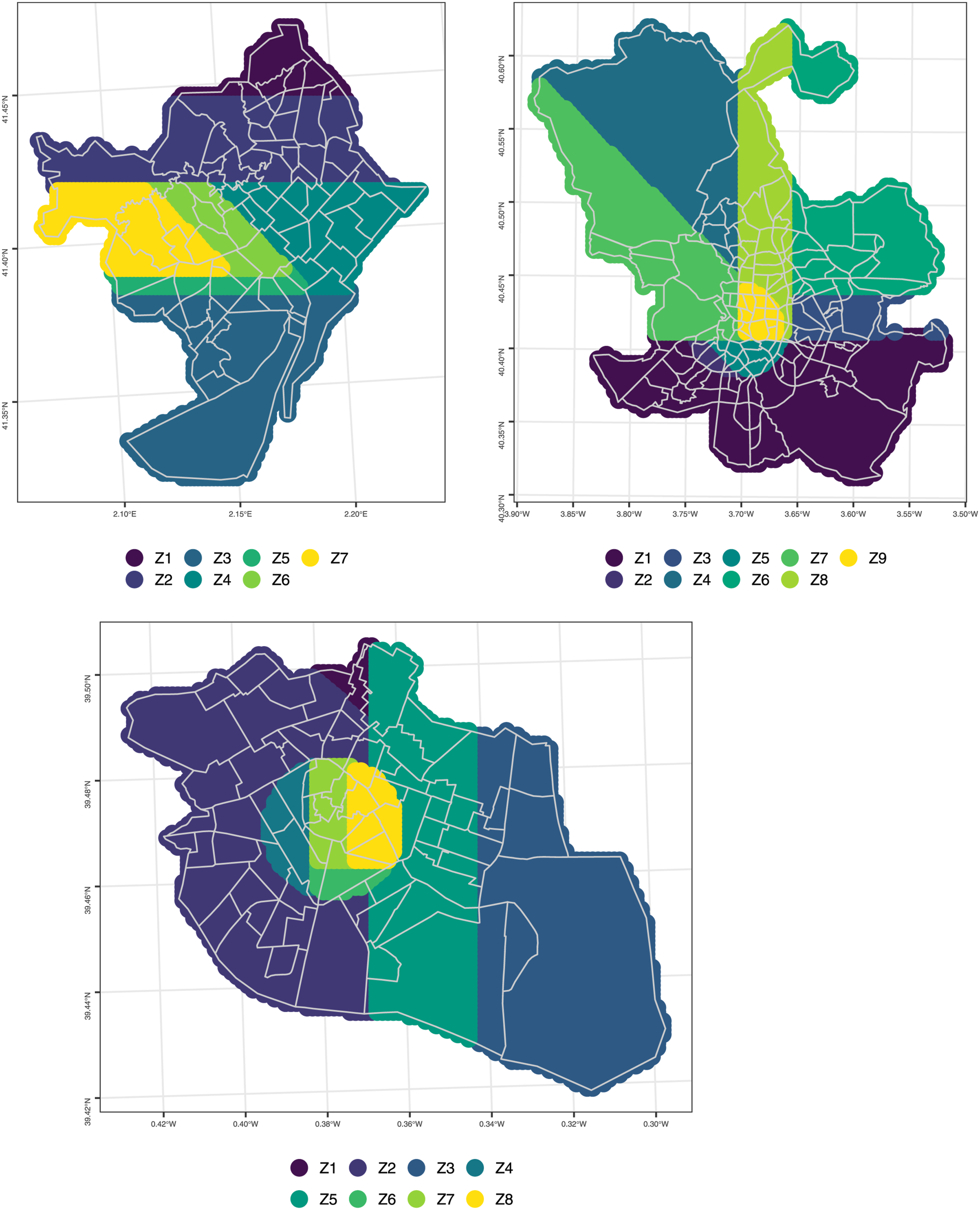
Spatial market segments according to Stage 1 classification tree. Barcelona (upper-left), Madrid (upper-right), and Valencia (bottom-center).
The first stage of the modelling strategy is to train a decision tree on the property values using only the coordinates of the observations. The spatial market sub-segments derived from the decision trees are shown in Figure 1. It can be seen there that the algorithm detects seven market sub-segments in Barcelona, nine market sub-segments in Madrid, and eight in Valencia. These submarkets are compact, mutually exclusive, and collectively exhaustive. The smallest market segment is found in Valencia and has 331 recorded transactions; the largest market segment, in contrast, has 7816 recorded transactions and is found in Madrid. The figures show how the use of interactive basis functions leads to flexible boundaries for the sub-markets. In the case of Barcelona, there are some distinctive diagonal shapes reminiscent of the street pattern in the city. In Madrid there is a clear distinction given by the M-30 orbital that surrounds the central almond of the city; in addition, there is Paseo de la Castellana, a major north-south avenue that crosses the city. This avenue divides two zones in the north that tend to include more expensive real estate, whereas the south tends to be lower income and less expensive. In Valencia, the sub-markets identify several zones in the historical center of the city, and then larger regional patterns depending on proximity to the waterfront to the west of the city.
The spatial market sub-segments are coded as dummy variables in the data sets before re-estimating the Base Model with market segments (Base Model + MS). The second model reported in Tables 2–4 shows that the market segments tend to be highly significant, and also improve the fit of the model. In the case of Barcelona, the adjusted coefficient of determination changes to R2 = 0.821, for a modest increase of 3.19%. The introduction of the market segments into the Base Model for Madrid results in an adjusted coefficient of determination of R2 = 0.878, which represents a change of 13.09% relative to the adjusted coefficient of determination of the Base Model. In Valencia, the Base Model with market segments has an adjusted coefficient of determination of R2 = 0.83, for an increase with respect to the Base Model of 4.49%.
It is well-known that spatial heterogeneity and association can co-exist (e.g., Bourassa et al., 2007; Paez et al., 2001). Sub-market identification can assist with spatial heterogeneity, but a process of spatial association could result from the common heuristic of comparative sales used by real estate agents. This process is appropriately represented by a spatial lag model. The third model reported in Tables 2–4 is the Spatial Model, that is the Base Model with a spatial lag (i.e., Equation (3)). Spatial lag models, being non-linear, lack the coefficient of determination of linear regression. Instead, their goodness of fit is evaluated using likelihood measures. It can be seen that there is a substantial improvement in this regard in all three cities. The spatial lag parameter ρ represents the proportion of the mean of the neighboring prices that is reflected in the price of the property at i. In Barcelona, this parameter suggests that approximately 32.16% of the mean of the price of the k = 6 nearest neighbors is reflected in the price at i. This “comparative sales” effect is markedly stronger in Madrid, where it amounts to 47.89% of the mean price of the neighbors. In Valencia, this effect is 40.31%. The spatial lag parameter is significant in all three cases, and the results suggest that comparisons with other properties play a larger role in the determination of prices in Madrid.
The last model that we consider for these case studies is a spatial lag model with market segments. This is the most general of the four models, and we see that the combination of market segments and a spatial lag variable gives the best fit in terms of the log-likelihood, and also reduces the size of the spatial lag coefficient, shifting some of the spatial effect from spatial autocorrelation to spatial heterogeneity.
Impacts spatial model + MS Barcelona (dependent variable is log of price).
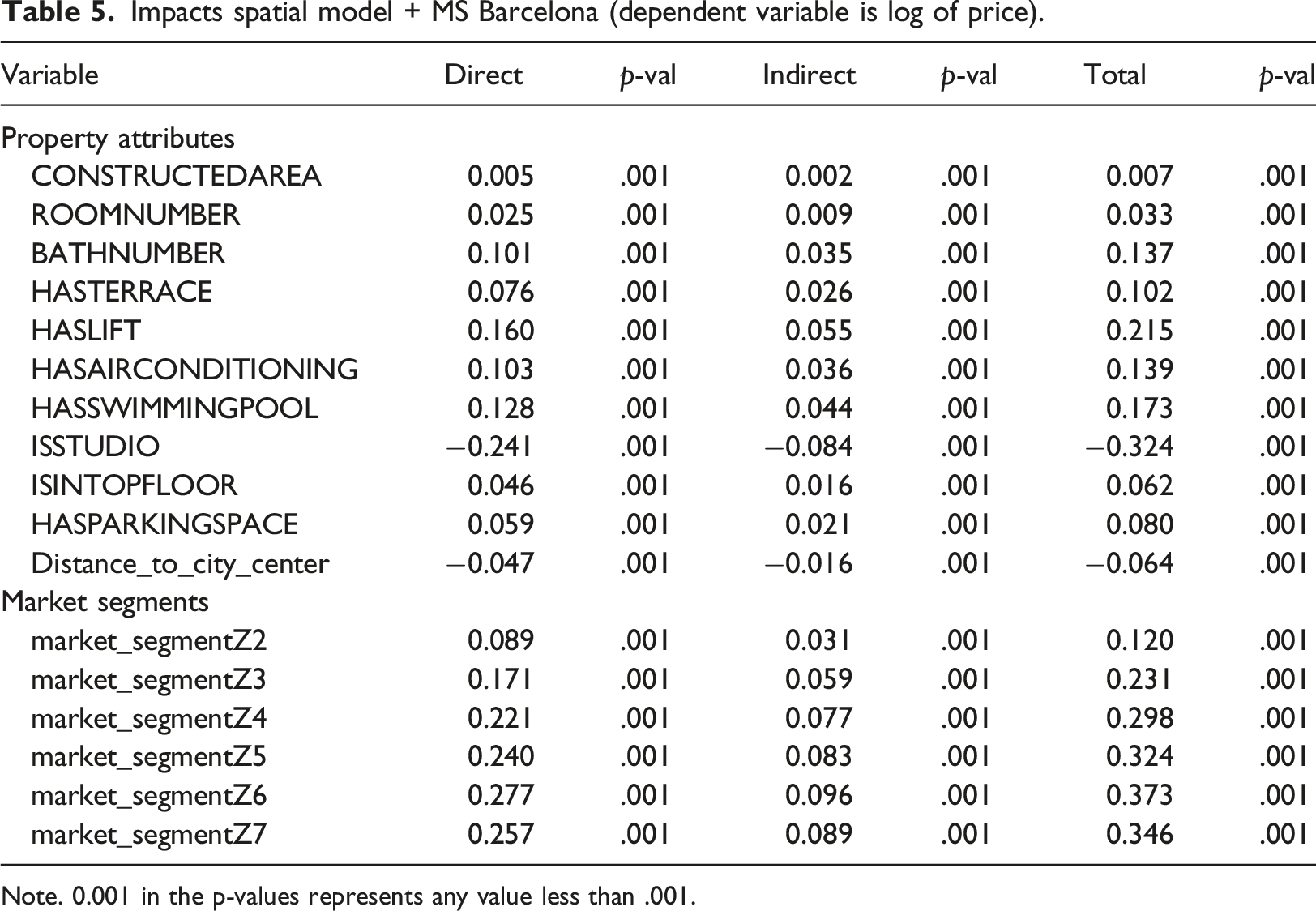
Note. 0.001 in the p-values represents any value less than .001.
Impacts Spatial Model + MS Madrid (dependent variable is log of price).
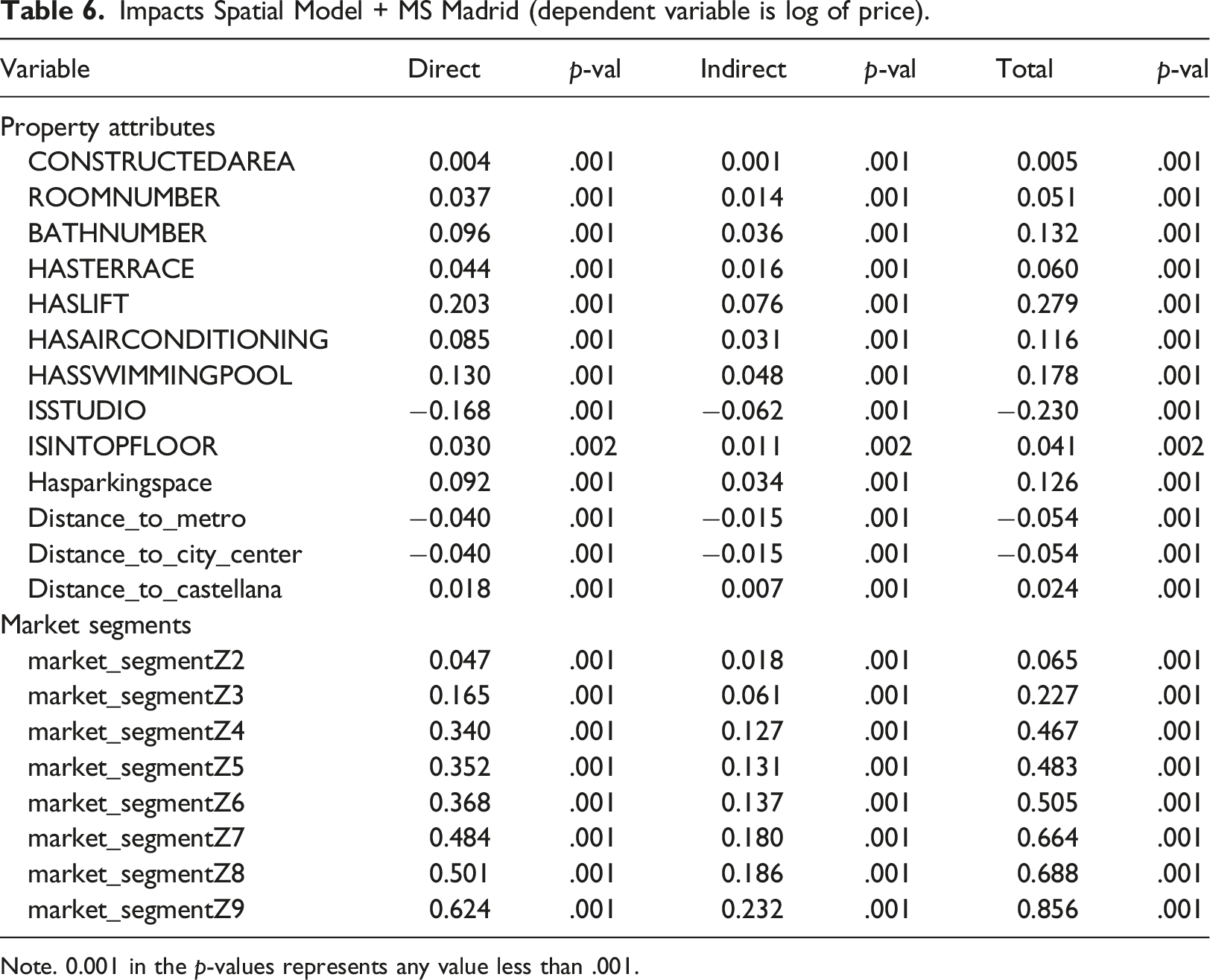
Note. 0.001 in the p-values represents any value less than .001.
Impacts spatial model + MS Valencia (dependent variable is log of price).
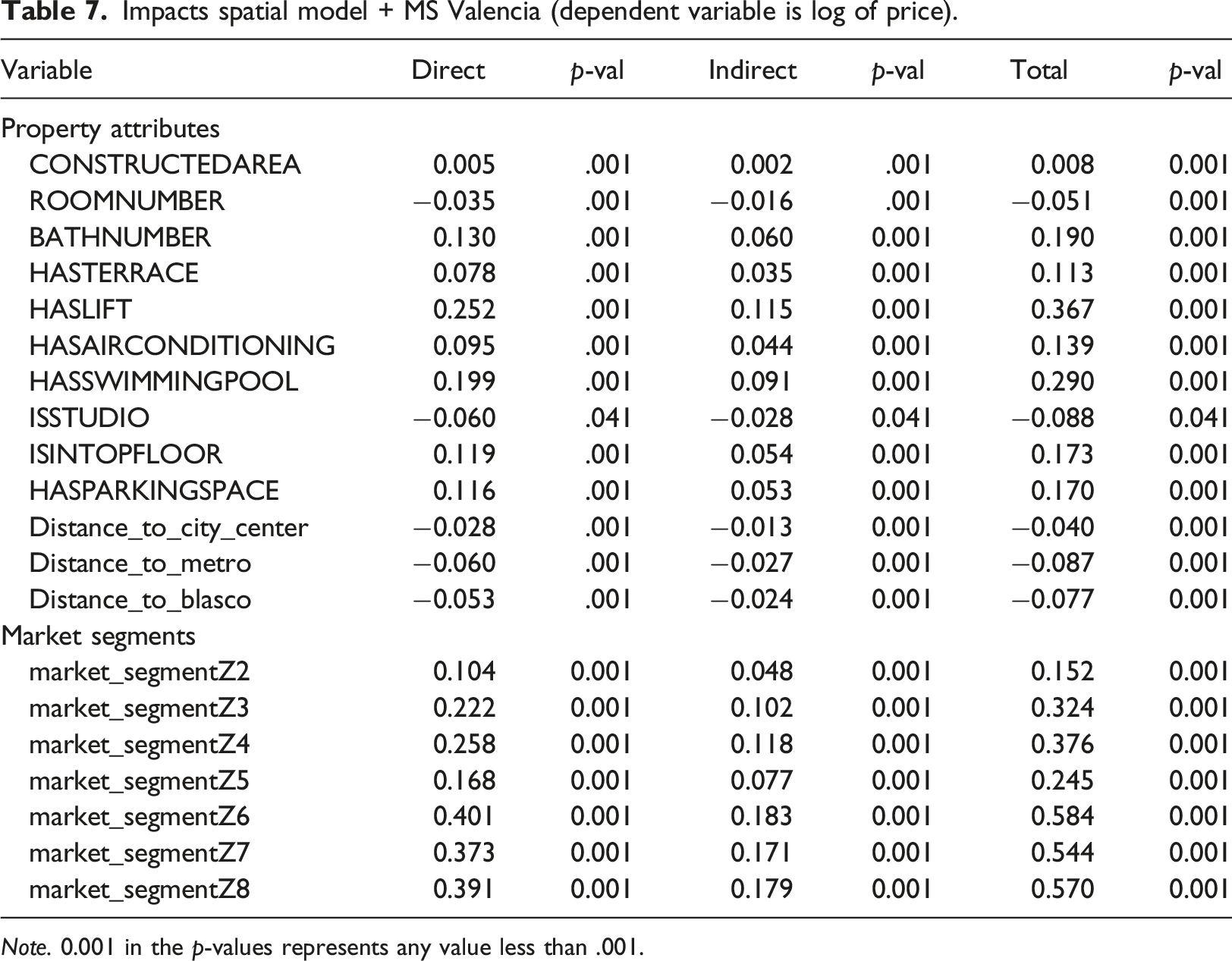
Note. 0.001 in the p-values represents any value less than .001.
Predictive performance: comparison of models
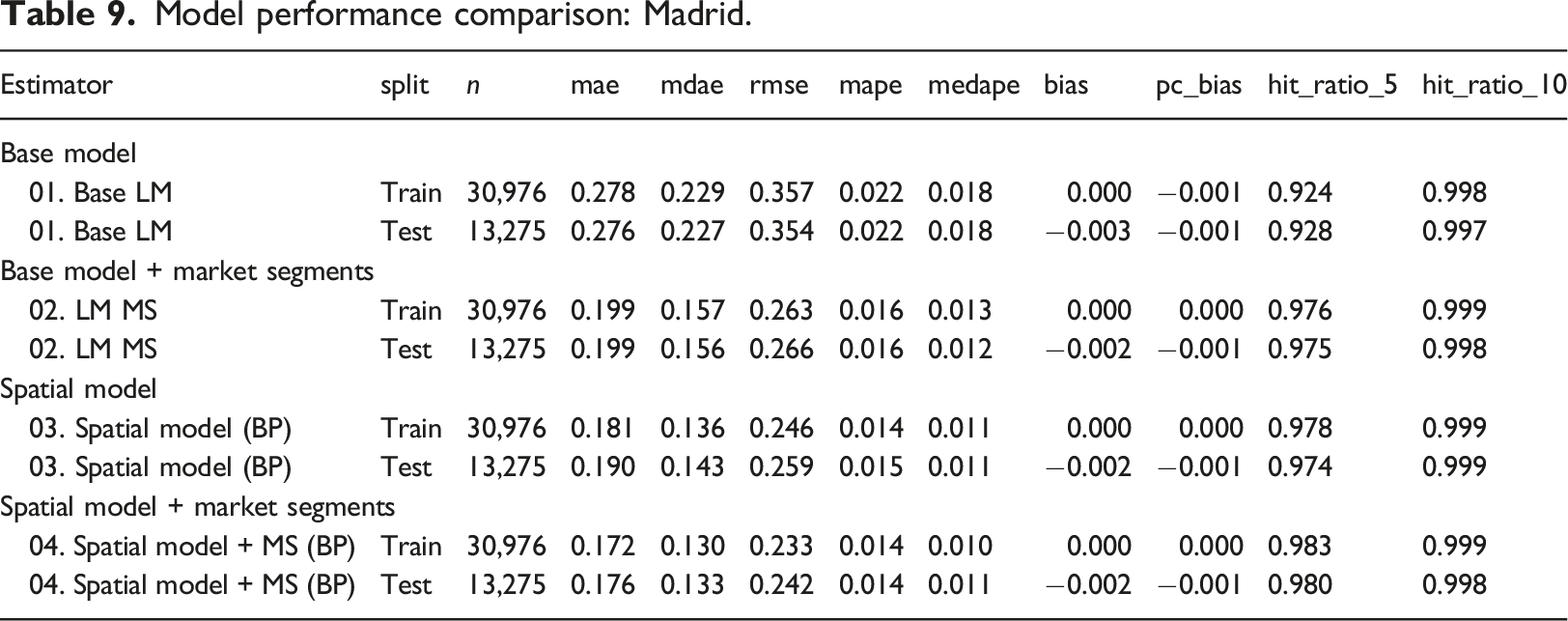
Prediction is a relevant concern in hedonic price analysis. Inspection of the results in Tables 2–4 suggest that the introduction of spatial market segments leads to markedly improved model fits. The measures of performance reported in these tables are based on the training sample exclusively. To conclude this investigation, in this section the predictive performance of the models is compared based on their performance using training (in-sample) as well as testing (out-of-sample) data sets. It is important to recall at this point that test data were not used in the calibration of the models discussed in the preceding sections.
The models without a spatially lagged dependent variable assume that the process is not spatially autocorrelated and therefore prediction requires only observations of the exogenous explanatory variables for the property to be assessed, since the price setting mechanism does not include information about the neighbors. In contrast, prediction with the models with a spatial lagged dependent variable require information regarding neighboring dependent and explanatory variables. This increases the data requirements and increases the computational complexity of prediction. Several approaches to spatial prediction with models that include spatially autocorrelated components are discussed in the literature (e.g., Goulard et al., 2017); these are discussed briefly next.
In case of model (4) two types of prediction based on the data can be considered: in- and out-of-sample predictions. In this paper we follow Goulard et al. (2017) proposal, as follows: we can reorder the observations in equation (4) to obtain the block matrix form below, where the subscript S denotes in-sample (training) data, and the subscript O out-of-sample (testing) data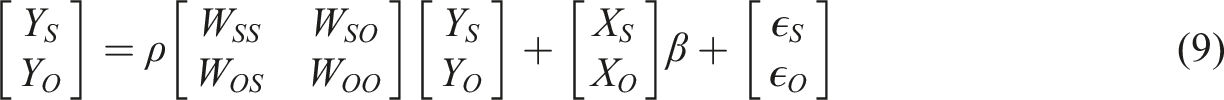
The best predictor (BP) approach is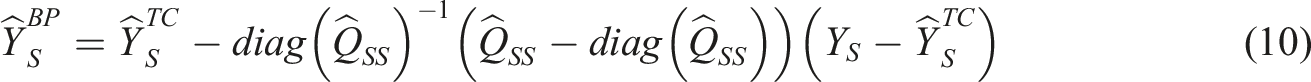
There are four alternatives for out-of-sample prediction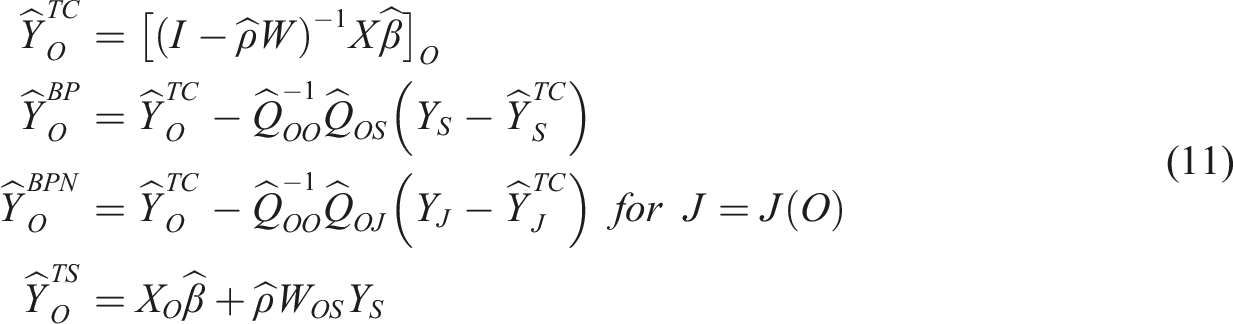
Of the four out-of-sample prediction methods we use the Best Predictor (BP) approach. Further detail on these alternatives can be found in Goulard et al. (2017). These prediction methods are implemented in the R package
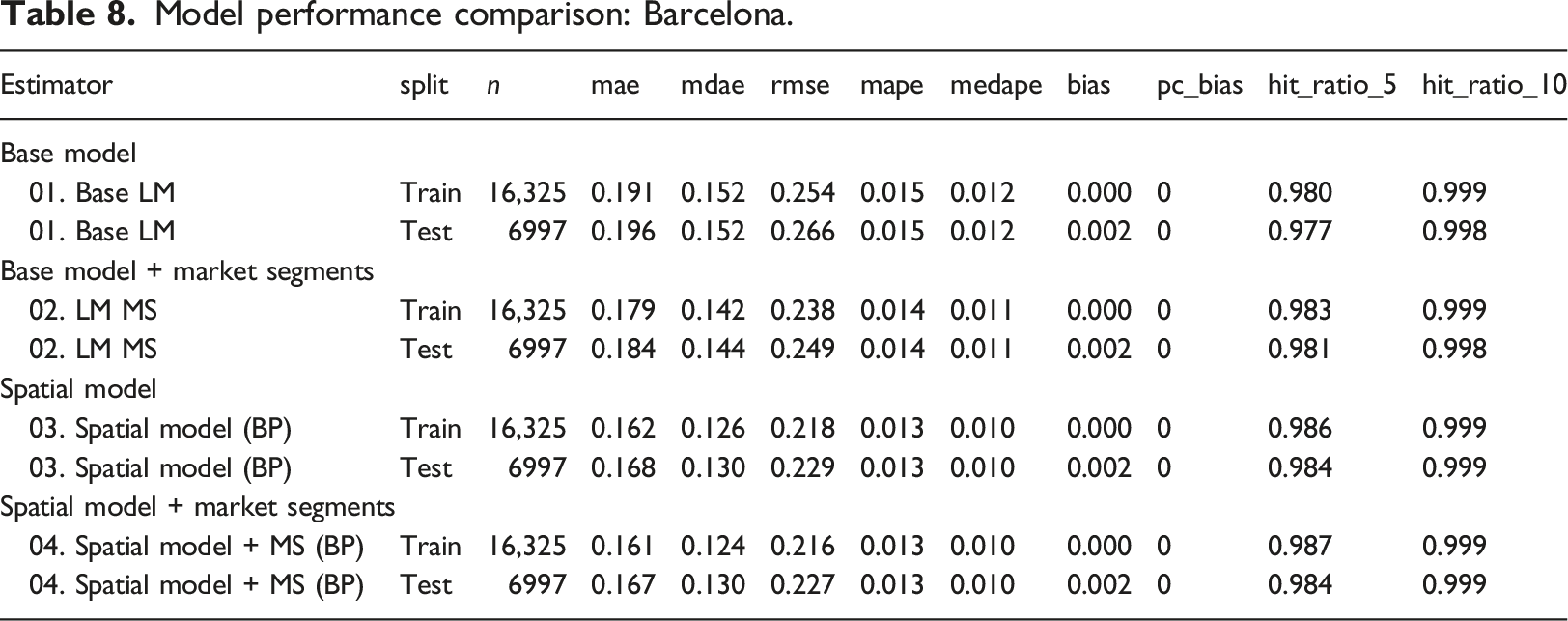
Model performance comparison: Barcelona.
Model performance comparison: Madrid.
Model performance comparison: Valencia.
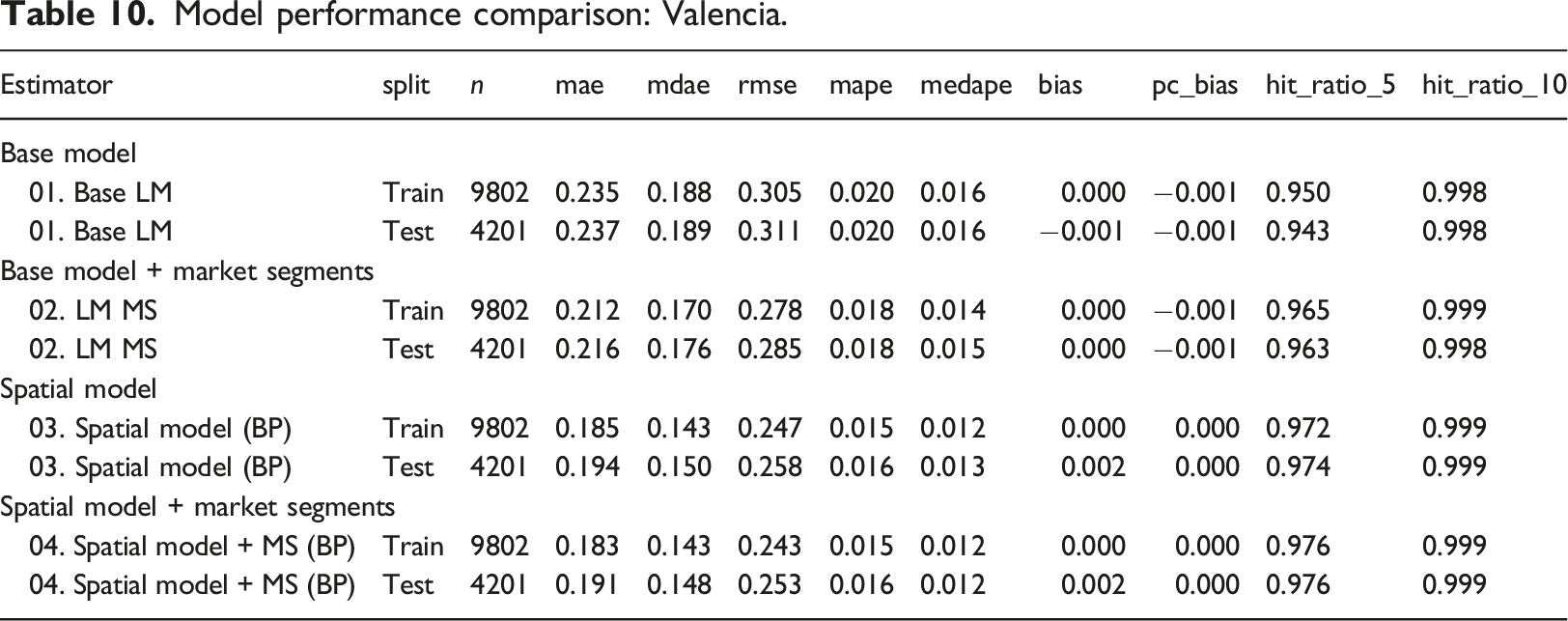
The results indicate that adding market segments and/or a spatially lagged variable improve the linear base model. The spatial model with market segments is comparable to or better than the spatial model without market segments. For example, the in- and out-of-sample predictions in Valencia perform very similarly in these two models. In Madrid and Valencia the results of the spatial model with market segment are superior for both the in-sample and the out-of-sample predictions.
Conclusions
Market segmentation is a topic of interest in the literature on real estate appraisal and valuation. In addition to being conceptually sound, numerous studies throughout the years have demonstrated that the practice of identifying market segments for hedonic price analysis can lead to higher quality models and enhanced performance.
The contribution of this paper has been to demonstrate a modelling strategy to obtain flexible tree-based market segments for use in spatial hedonic price modeling. Implementation of regression trees for market segmentation was proposed in a recent paper by Füss and Koller (2016). Our modelling strategy differs to the one proposed by these authors in two respects: 1) the use of decision trees with flexible (i.e., non-orthogonal and possibly non-linear market boundaries) and 2) the timing of the estimations of the market segments, which in the case of Füss and Koller (2016) is based on the residuals of an initial regression model, whereas in our case it is done in the first step of the modelling strategy.
The results using three large data sets from cities in Spain indicate that modelling the market segments can improve the fit of the models, as well as their predictive performance. The best model consistently included a spatially lagged dependent variable and market segments. The market segments in addition to improving the fit and the predictive performance also reduced the magnitude of the spatial lag parameter, thus allocating some of the spatial effect to regional heterogeneity that would otherwise be assumed to be micro-scale information spillovers. Overall, the results serve to demonstrate the potential of the proposed modelling strategy to produce better models and more accurate predictions.
One direction for future research is to investigate the temporal stability of spatial market segments. It is well known that there are seasonal effects in housing markets, but an open research question is whether spatial market segments experience seasonal variations, both in terms of their geographical extent as well as the magnitude of their effects. Another possibility is that there are longer term trends (e.g., gentrification) that could affect the spatial configuration of the market segments. Both seasonality and/or longer term trends would require multi-year data sets, compared to the single-year data set that we used for this research. For the time being, it is important to note that the results presented in this paper support the argument that the two-step method described in this paper performs well for now-casting or relatively short term forecasts. Given the dearth of information about seasonality and temporal stability of spatial market segments, any attempt to use them for longer term forecasts should be done with caution.
Finally, the study was designed as an example of reproducible research: all code and data used in this research is publicly available which should allow other researchers reproduce our results or expand them in other directions.
Supplemental Material
Supplemental Material - Using machine learning to identify spatial market segments. A reproducible study of major Spanish marketssj-pdf-1-epb-10.1177/2399808323116695
Using machine learning to identify spatial market segments. A reproducible study of major Spanish markets by David Rey-Blanco, Pelayo Arbues, Fernando Lopez and Antonio Paez in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Fernando A. López acknowledge the financial support from project (PID2019-107800GB-I00).
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.