
Abstract
We use a graph convolutional neural network (GCN) for regional development prediction with population, railway network density, and road network density of each municipality as development indicators. By structuring the long-term time series data from 2833 municipalities in Switzerland during the years 1910–2000 as graphs over time, the GCN model interprets the indicators as node features and produces an acceptable prediction accuracy on their future values. Moreover, SHapley Additive exPlanations (SHAPs) are used to make the results of this approach explainable. We develop an algorithm to obtain SHAP values for the GCN and a sensitivity indicator to quantify the marginal contributions of the node features. This explainable GCN with SHAP decomposes the indicator into the contribution by the previous status of the municipality itself and the influence from other municipalities. We show that this provides valuable insights into understanding the history of regional development. Specifically, the results demonstrate that the impacts of geographical and economic constraints and urban sprawl on regional development vary significantly between municipalities and that the constraints are more important in the early 20th century. The model is able to include more information and can be applied to other regions and countries.
Introduction
Regional development is the result of interaction among various factors. Population concentrations arise due to job opportunities, and, in turn, the increasing travel demand induces extensions to the transportation services. There are a wide range of models to describe these dynamics. Most land-use interaction models use detailed information and do not focus on long-term regional development. Instead, data-driven approaches usually rely on regression approaches. In this research, we explain the cyclic relationship between population concentration and transport infrastructure development considering the transportation network structure over a period of 100 years by a graph convolutional approach. As part of this, and in order to gain insights into the differences between influential factors in different regions and different periods, we derive SHapley Additive exPlanation (SHAP) values to interpret this deep learning model.
Our motivation to use a graph-based approach is based on the hypothesis that it is the connectedness and attributes of cities in the vicinity and the infrastructure itself that influence regional development. Graph convolutional networks (GCNs) can incorporate information from neighboring connected nodes to the target node. They have been widely applied to many real-world phenomena that can be represented as graph structures, including biology studies and work on social networks (Wu et al., 2019). GCN approaches are also applied for transportation network studies. In particular, there are a range of studies on short-term traffic prediction. As an exemplary approach, we refer to Lee and Rhee (2020) who use a graph with multiple attributes, as was also done in this study. Further, Yu et al. (2018) predict short-term traffic flow and speed with convolution performed on the spatial and temporal dimension. An approach for general demand forecasting using a spatio–temporal convolutional approach is proposed by Wang et al. (2018) and applied to ride-sourcing data. Another stream of research uses image-processing methods for transport problems. Recently, Bapaume et al. (2021) utilized a GCN approach to forecast metro train loads. The line loadings of the metro system are represented as an image based on the time-space diagram of the trains with colors representing loads at a station for specific run. To the best of our knowledge, graph convolutional approaches have, however, not been used to model long-term regional development.
The paper is organized as follows. After this introduction, we review the literature on land-use models and research using historic time-series data to predict urban developments. In “Graph convolutional learning framework”, we introduce our general proposed deep learning model framework, and in “Interpretation with SHAP values”, we introduce an adaptation of SHAP for result interpretation. Between these two sections, in “Model inputs”, we discuss our input data. We put this section ahead of “Interpretation with SHAP values” as it allows us to better illustrate the kind of SHAP values that we obtained. “Switzerland case study” then describes the prediction results and model interpretation using a century of Swiss data. This is followed by the conclusions.
Long-term transport land-use interaction studies
Various types of models have been developed for predicting urban or regional development to help city planners and policy makers to simulate different scenarios and estimate the influences of policies and strategies. Three typical types of urban/regional growth models dominate: land use-transport interaction (LUTI) models, agent-based models, and cellular automata (CA)-based models (Li and Gong, 2016).
An LUTI models the population, land-use, transport, and travel demand interactions seen as a reciprocal process subject to the spatial and temporal constraints such as government budgets, technical limitations, and topographical obstacles; see Xie and Levinson (2011) for an example and more detailed discussion. Agent-based models can flexibly describe a system from the behavior of components that are involved and have been applied in a diverse range of topics (Chen, 2012; Waddell, 2002). In the field of urban planning, it uses real drivers of land-use change and looks into the interaction among those drivers of urban development. This type of model has been implemented in some platforms such as “Swarm”. While LUTI and agent-based models are usually applied at local scales with detailed datasets, CA models can be applied at regional scales and use more general datasets such as terrain, land-use maps, transport networks, or locations instead of actual drivers for urban/regional growth (Li and Gong, 2016). The basis for these models is the definition of grid cells that evolve according to certain transition rules based on the states of adjacent cells (Otgonbayar et al., 2018).
Instead of the above-described simulation or model approaches, data-driven approaches based on time-series data and regression analysis have also been gaining popularity. Our case study is based on the Swiss data that have been used by Tschopp et al. (2006) and Fuhrer (2019). These studies have been using accessibility derived from historical time series data of the Swiss transportation networks together with historical records of traveling speed to quantify the long-term influences of the transport system. Tschopp et al. (2006) discuss the impact of accessibility on the demographics and the economy of Swiss municipalities for the years 1950–2000 using multi-level regression analysis. Fuhrer’s work studies the time period from 1720 to 2010. The work discusses a method to construct the historical transportation networks and to calculate accessibility and productivity impacts for the different time periods. Another historic study is the one by Li et al. (2021). Their work looks at the impact of accessibility for population dynamics during the Sui-Tang period in the 7th and 8th century. The study points out the importance of the Grand Canal and describes accessibility as an amplifier for the population dynamics caused by wars. Among work using more detailed data from the 19th and 20th century, we refer to Lahoorpoor and Levinson (2019) who described a positive feedback between tram development and population growth in different districts of Sydney. Akgüngür et al. (2011) described the positive effect of the rail expansion in the Ottoman Empire on population distribution and economic development using correlation analysis. Further studies on rail expansion and development in Europe have been carried out by Kasraian et al. (2016a) and Mimeur et al. (2018). For a full review of empirical studies using long-term historical data and its land-use impacts, we refer to the review paper of Kasraian et al. (2016b). To the best of our knowledge, none of these studies has used a graph-based machine learning approach to understand the relationship between accessibility and population development, which is the focus of this study.
Graph convolutional learning framework
We define municipalities as nodes with features and relations among municipalities as edges. The number of nodes is fixed while node features and edges change over time. For each time step
Each node has
The structure of the deep learning model with its different building blocks is shown in Figure 1. The model consists of two repeating blocks where each block contains one graph convolutional layer (GraphConv) and one “GraphU-net” layer, a jumping knowledge layer and a linear output layer. In Supplemental Material, we describe the key features of these layers and refer to the literature for detailed further discussion. Deep learning model structure.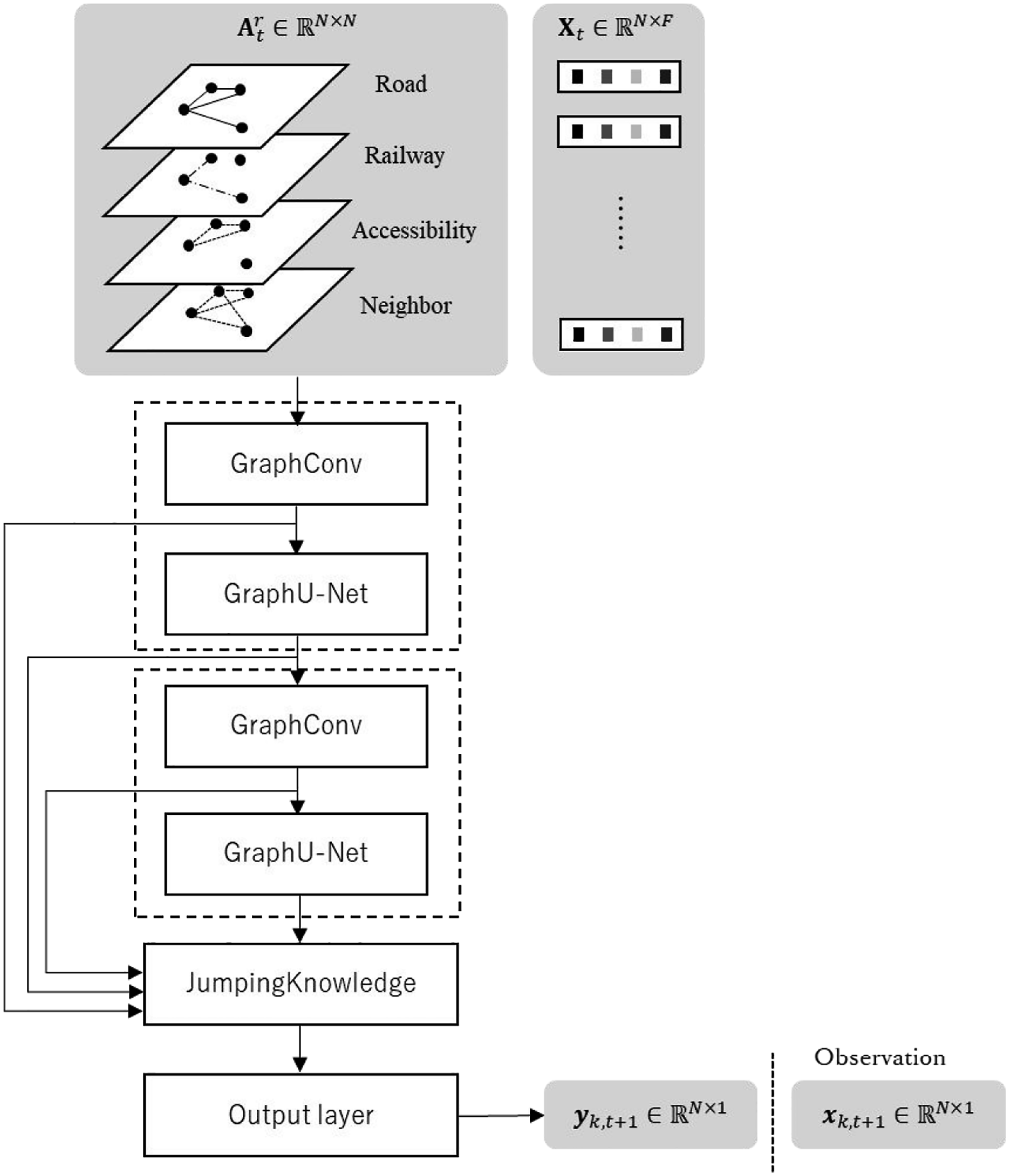
This framework can be applied to learn any of the F node features. It is important to note that each feature is learned with separate model runs as the resulting output of this model is an
Model inputs
Overview
The abovementioned model framework is flexible to handle a range of input data. Which data are chosen for the node feature matrix
Edge types: Physical connections and accessibility relations
The four types of edges (relations) are shown in Figure 2. Figure 2(a) illustrates a transportation network with physical connections such as railway lines and roads; Figure 2(b) shows the accessibility relations based on a gravity model, in which the greater the width of the lines, the stronger the relationships between municipalities with lower travel cost for railway and road; and Figure 2(c) shows the connections between neighboring municipalities. These edges are added with the hypothesis that closer municipalities are more likely to have interactions independent of accessibility between these. The neighboring edges are constructed by considering the shared boundaries between polygons of municipalities as edges. Relations between municipalities in regional development (a) based on transport infrastructure, (b) based on accessibility, and (c) based on political boundaries.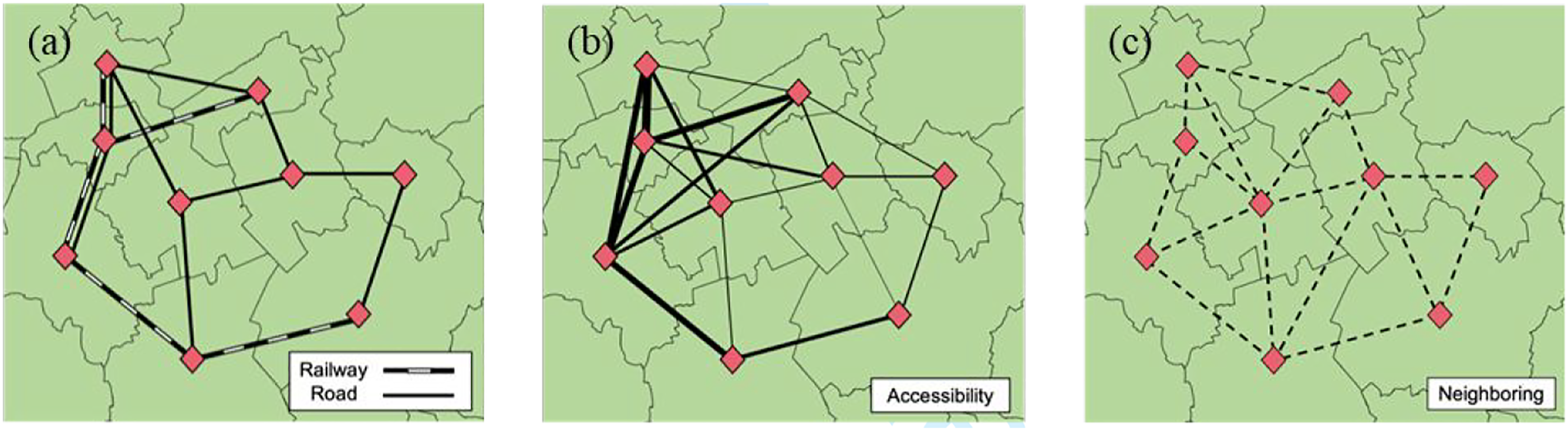
Transportation links that cross the boundary between two municipalities are regarded as edges connecting them. If there are multiple transportation links crossing the boundary between the same pair of nodes when transforming edge connections into an adjacency matrix, then the number of links will be accumulated as the weight in the adjacency matrix to show a stronger transportation connection (see Supplemental Material Figure S1 for an illustration).
We further use cost functions to travel between any single pair to measure the ease of access from

Node features: Population and network density
Recall that
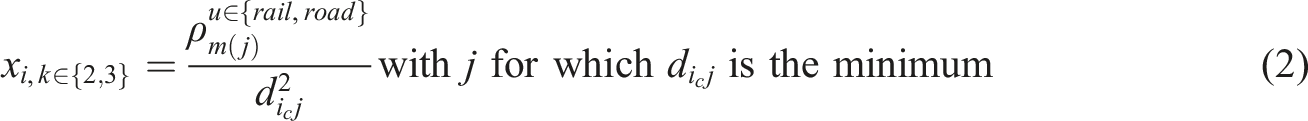
Here,

Node feature “Topographical Difficulty”
Regional development has constraints and is not uniform. The proposed reciprocal relationship between transportation and population development will be faster and more evident when fewer geographical, economic, and technical constraints are present. In mountainous countries, such as Switzerland, the population distribution at any point in history will clearly be influenced by the topography. To control for this, we use GIS data to extract the slope in each mesh utilizing the digital elevation model. We sum up the slopes for all meshes within the polygon of a municipality and then divide by the area of that municipality to obtain the average slope.
Furthermore, we consider that at the beginning of the last century, it would have taken longer and would require proportionately more resources to adjust the transportation network to population developments. Given limitations on available data, we suggest that Gross National Income (GNI) can, to some degree, reflect both the economic and technological capability of a country. Considering both topographical obstacles and technological capabilities as one factor constraining (the speed of) regional development, we refer to it as “difficulty” in the sense of “difficulty of developing the transportation infrastructure”. The hypothesis is that more mountainous regions and periods with less GNI will constrain the regional development. Difficulty is our fourth node feature for each municipality

Interpretation with SHAP values
To interpret the “black box” deep learning model, we apply “SHapley Additive exPlanations” (SHAPs) proposed by Lundberg and Lee (2017). If adapting the original concept of Shapley values in game theory to machine learning prediction models, each input feature value of the instance is equivalent to a player in the game, and the output from the prediction model is the payout. Although SHAP values are increasingly used in a wide range of applications using, for example, gradient boosting regression or other machine learning approaches, the difference to our case is the application within the context of a network structure. The explanatory model used in this research is based on DeepExplainer (Lundberg and Lee, 2017). However, DeepExplainer is not applicable for handling deep learning models with graph structured data. Therefore, we used a modified DeepExplainer called GraphExplainer that generates plenty of reference inputs by random permutation of the original input (Fukuda, 2020).
With the concept of SHAP values and GraphExplainer, each input feature can claim its contribution to the predicted value. Let
Finally, we propose a novel indicator derived from self-SHAPs to measure the sensitivity of the prediction output to the changes in the input self-feature. The sensitivity to the features of other nodes is excluded from the discussion as the magnitude of influential-SHAPs is found to be much smaller. Let
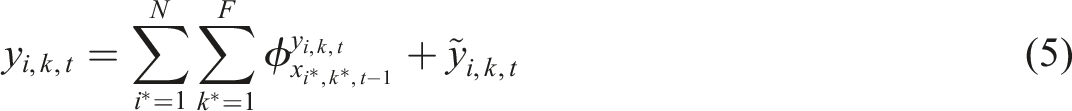
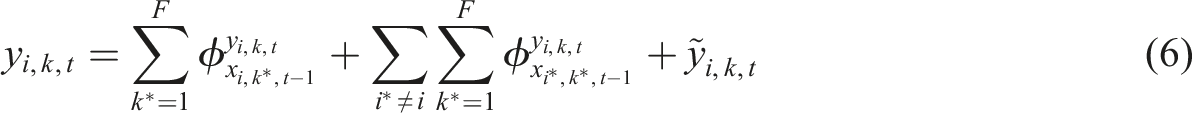

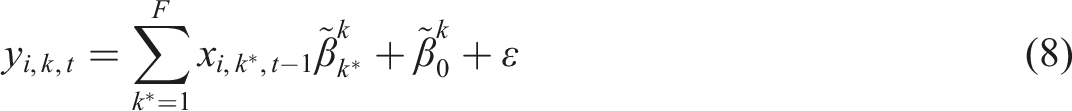
Switzerland case study
Data from Switzerland
We applied the framework explained in the previous sections to the long-term time series infrastructure and population data of Switzerland. These are network data for the years 1910, 1930, 1950, 1960, 1970, 1980, 1990, and 2000. The resident population for each municipality in Switzerland was obtained from the Federal Population Census. The network and population data were obtained from a VISUM model that has been previously used in, for example, Fröhlich et al. (2006) and Axhausen and Hurni (2005). Gross National Income (GNI) shown in Supplemental Material Table S1 was collected from Bairoch (1976) and open data were provided by The World Bank (2020).
For the “topographical difficulty,” we used the 200-meter grid digital elevation model from the Federal Office of Topography “swisstopo” and a map of Swiss municipalities. We extracted the slope and calculated the average slope for each municipality. The map data were also utilized to extract the length of the transportation infrastructure that passes through each municipality. We used 2833 municipalities for which the abovementioned information is complete (see Supplemental Material Figures S4 to S7 for illustrations of the input data).
Model performance and interpretation
Training and testing data for the model.
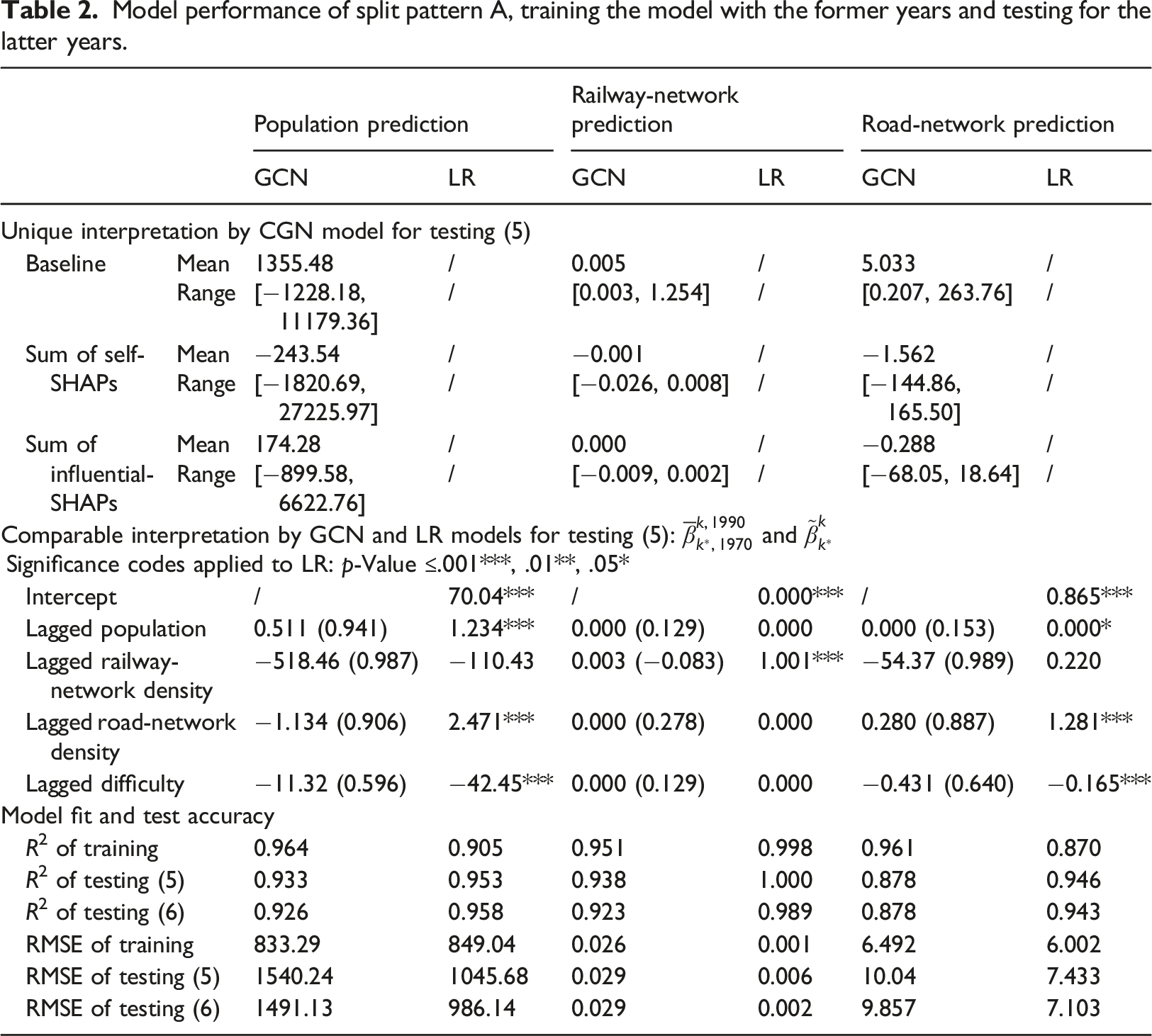
Model performance of split pattern A, training the model with the former years and testing for the latter years.
Model performance of split pattern B, training the model with the latter years and testing with the former years.
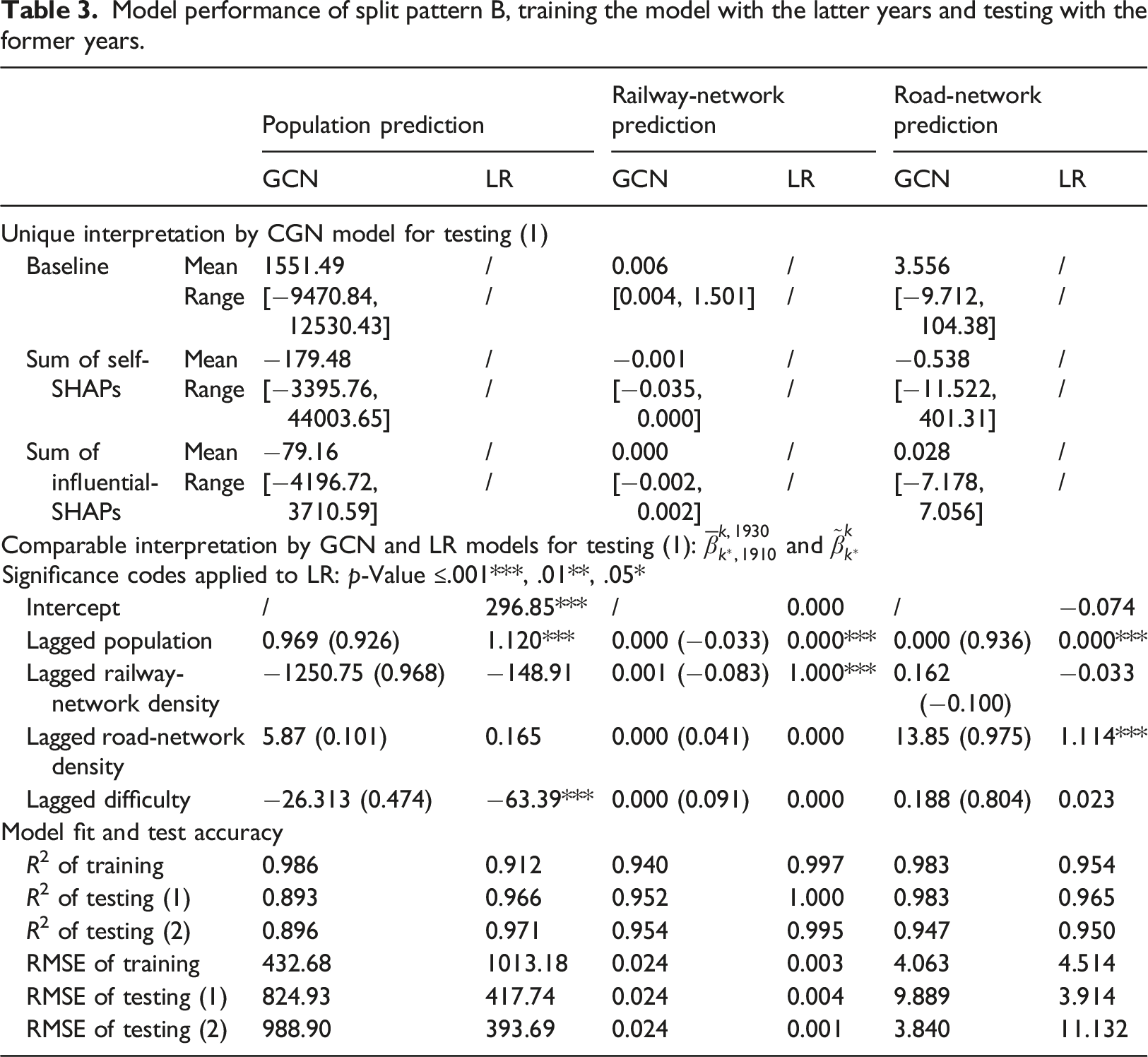
The comparison is divided into three parts. The first part, “Unique interpretation by CGN model,” shows the unique components that form the explanation by GCN on the regional development, which are the three terms of equation (6). We remind the reader that the baseline is node-specific, even if all node features are at their mean due to the asymmetric network topologies. (only in a fully connected network would the baseline be identical for each node). In general, the sum of self-SHAPs has a larger magnitude and a wider range than the sum of influential-SHAP as is shown in the tables. More specifically, the ratio between the absolute sum of self-SHAPs and the prediction value is, on average, 2.036, 0.353, and 2.531 for all nodes in the prediction of the population, railway-network density, and road-network density in 1990, respectively. The ratio between the absolute sum of influential-SHAPs and the prediction is 0.370, 0.073, and 0.952. Therefore, the lagged features of a node itself may predict the future features of the node to a considerable degree, which is confirmed by the equivalently good model fit and prediction accuracy achieved by the LR model using merely the lagged self-feature.
The second part compares the two sensitivity indicators Marginal contribution of four self-features in the prediction of the population and the road network density: 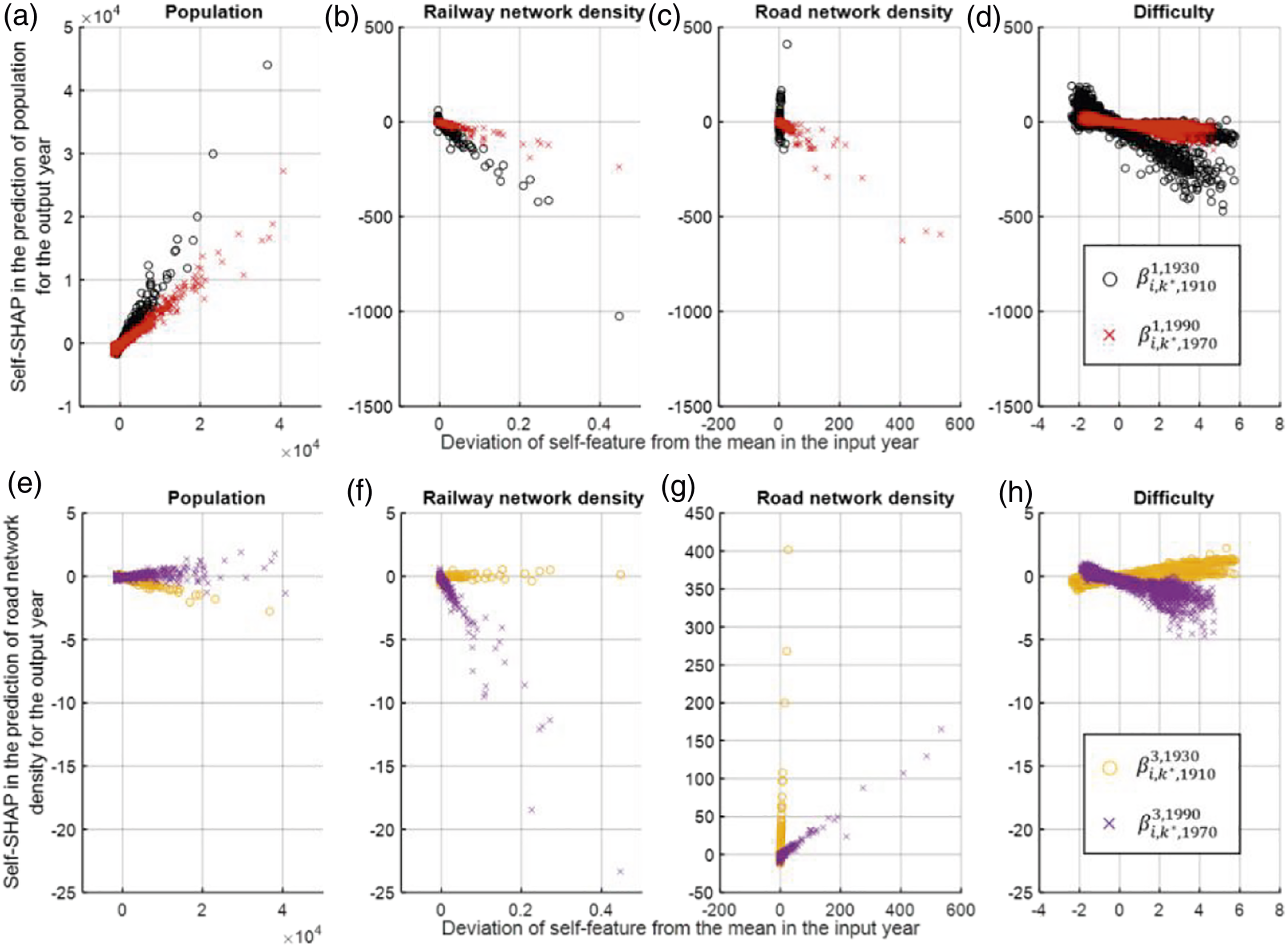
Although we cannot compare the magnitudes of
The third part of Table 3 reports goodness of model fit and test accuracy. R2 and RMSE are used to evaluate the models for each prediction objective. The conclusion is that the prediction accuracy is fairly high by the LR models with only the lagged self-features. The testing R2 of LR is always higher than 0.94, making it extremely difficult for the GCN to overperform. We find that the GCN is slightly overfitting the data in the training stage, and it fails to produce superior results, although the accuracy is acceptable. We conclude that the LR model (and other advanced models) is sufficient for providing good predictions as the population and network features 20 years ago are often similar to the predicted ones. The GCN model and the derived SHAP values, do, however, provide a rich source to interpret the results.
Discussion on SHAP values
We now discuss the self-SHAPs obtained for each node. We recall equation (6) here. The numerator on the right side refers to the y-axis and the denominator to the x-axis of Figure (3). Each subplot of Figure (3) contains two sets of points denoting
Regarding the prediction of population, we can see in Figure 3(a) and (b) that the linear correlation, either positive or negative, was stronger in the early 20th century. It shows that in the late 20th century, the future population of a municipality was less determined by its own population and less decreased by its own railway-network density. This indicates an increasing tendency to move away from municipalities with a large population and a decreasing tendency to move away from municipalities that have a well-developed railway network. It is also noteworthy that the trend in the road-network density has changed drastically in the beginning and end of the 20th century. In the beginning, a high road-network density increased population sharply while it lost the attraction power to the population and even reduced the population in the late 20th century (Figure 3(c)). Taken together, the findings illustrate that residents are now more likely to move out of the municipalities with better accessibility as it becomes easier to commute from other places, and the main factor driving population to move out has shifted from the railway to the road network. We can hence quantify with our model the dynamics between the improvement in the transportation and the development of the suburbs. These findings cannot be obtained from the LR as the coefficient of the road network is positive in both the early and late 20th century cases.
The results obtained through our SHAP analysis regarding the impacts of difficulty on the population provide additional insights. Difficulty, which reflects topographical and economic constraints, tended to decrease the population in the future in two diverging ways in the early 20th century as shown in Figure 3(d). Figure 4(a) then distinguishes these two trends of difficulty impacts by different colors with a threshold of −30, which is close to the average sensitivity of difficulty Illustrating the municipalities having two different trends of 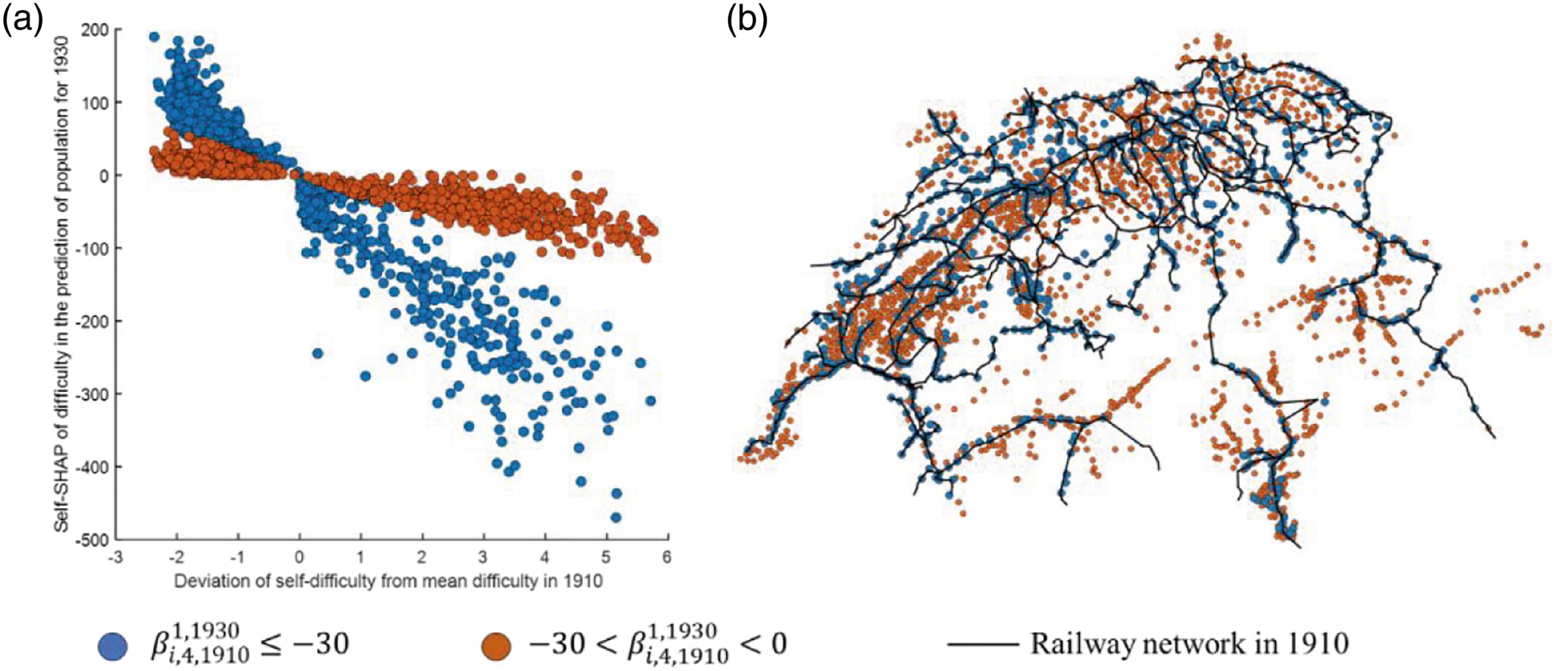
In Supplemental Material Figure S9, we further show the correlation between the four feature values of the target node and the influential-SHAPs for population, rail-network, and road-network predictions. In general, we find that municipalities with smaller population size and worse transport infrastructure (lower network density) are more likely to be influenced by other municipalities.
Conclusion
Considering the importance of predicting complex regional development, as well as the lack of research focusing on long-term regional development, we have proposed a new methodology using deep learning with time series network data to predict long-term regional development. The proposed model explains the reciprocal relationship between population concentration and transport infrastructure development, considering transportation accessibility and road and railway network structures.
The graph-based model consists of several building blocks. The main module is a convolution of features across the node itself and neighboring nodes. This is supported by pooling and jumping modules to avoid having too many parameters and “over-smoothing,” that is averaging out all regional differences. Our assumption is that the regional developments trigger mutual development among the municipalities. In future research, alternative graph structures might also be considered. For example, in the case of centrally governed countries, this could suggest different graphs where each municipality is directly connected to the country’s capital. Moreover, we demonstrated that using the “GraphExplainer”, SHAP values can explain differences in influential factors for different nodes as well as different time periods. Even though simpler models such as linear regression can also provide a good overall fit, we show that the proposed approach can lead to additional insights by providing node and feature specific parameters.
Our results illustrate the changing population dynamics in Switzerland. Compared to several decades ago, predicting population growth or decline today requires a good understanding of the city’s connectedness. We demonstrate that higher connectivity can lead to population decline in surrounding municipalities. At the same time, low accessibility has led to population agglomeration in or near the larger municipalities. Whereas the suburbanization trend is increasing, the trend to move away from the mountainous areas is declining. Hence, one might use the approach presented here to also predict population distribution developments through further reduced distance deterrence as is expected by, for example, high-speed rail and autonomous vehicles. The SHAP values are amongst other powerful ones to illustrate the changing role of the Swiss geography on the population development. We illustrated and discussed the interplay between “geographic and economic difficulty,” rail accessibility, and population movements. Our analysis quantifies the declining role of transport accessibility, and we expect it to continue further given the increasing role of non-physical accessibility.
Supplemental Material
Supplemental Material—Explaining a century of Swiss regional development by deep learning and SHAP values
Supplemental Material for Explaining a century of Swiss regional development by deep learning and SHAP values by Youxi Lai, Wenzhe Sun, Jan-Dirk Schmöcker, Koji Fukuda, and Kay W Axhausen in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Parts of this work were supported by JST SICORP Grant Number JPMJSC20C4, Japan.
Supplemental Material
Supplemental Material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.