
Abstract
Space, time and the social realm are intrinsically linked. While an array of studies have tried to untangle these factors and their influence on human behaviour, hardly any have taken their effects into account at the same time. To disentangle these factors, we try to predict future encounters between students and assess how important social, spatial and temporal features are for prediction. We phrase our problem of predicting future encounters as a link-prediction problem and utilise set of Random Forest predictors for the prediction task. We use data collected by the Copenhagen network study; a study unique in scope and scale and tracks 847 students via mobile phones over the course of a whole academic year. We find that network and social features hold the highest discriminatory power for predicting future encounters.
Introduction
Few would doubt that space, time and the social realm are intrinsically linked. Geography has always been interested in the role spatial, temporal and social factors play in shaping human behaviour. However, it can be rather difficult to separate the effect an individual factor has on human behaviour from other dynamics. After all, human behaviour is inherently interwoven with space and time. As Hägerstrand (1970: 10) emblematically stated ‘“somewhere” is always critically tied to the “somewhere” of a moment earlier’. In fact, social networks and travel patterns of individuals seem to co-evolve over time (Alessandretti, 2018; Arentze and Timmermans, 2008).
Several studies tried to disentangle space, time and social factors in recent years. Backstrom et al. (2010) showed that the probability of friendship between people decreases with distance. Scellato et al. (2011a) studied the properties of location-based social networks and found that about 40% of all links in location-based social networks were shorter than 100 km. Lambiotte et al. (2008) concluded that the likelihood of a tie in a mobile communications network followed a gravity model (i.e. the likelihood of a tie between two users decreased exponentially with distance). Toole et al. (2015) employed the coupling of social ties and mobility behaviour to build a mobility model that included choices based on social contacts. They showed that the ratio of acquaintances, co-workers and friends/family in a person’s ego network shaped their mobility behaviour. Studying the mobility patterns and virtual interactions of people, Larsen et al. (2006) argued that nearby strong ties were crucial for an individual’s network as they found that phone calls, texting and face-to-face meetings became less regular with distance. The characteristics of one’s social networks such as also systematically shaped travel behaviour (Carrasco et al., 2008; Kowald et al., 2013).
Recently researchers also called attention to how space itself could influence personal relationships (Adams et al., 2012). Boessen et al. (2017) discovered that the built environment had a significant effect on how people socialised. They highlighted the potential role the built environment could have for fostering the formation of social ties. Both Butts et al. (2012) and Doreian and Conti (2012) showed that the structure of social networks could be partly explained by spatial factors.
Noulas et al. (2015) and Scellato et al. (2011b) both utilised the social and spatial properties of location-based social networks to propose a link-prediction model. Brown et al. (2013) developed a model for the evolution of city-wide location-based social networks, which demonstrated that friends tended to meet at specific – more ‘social’ – places. De Domenico et al. (2013) used the mobility data of friends to improve user movement prediction. Last, Cho et al. (2011) built a mobility model incorporating both periodic movement of individuals as well as corporeal travel induced by social ties.
An extensive amount of research has already been conducted on the interplay between the social realm, place and time. However, studies so far were either limited to a very specific type of network or did not jointly deal with all three factors. On the one hand, several studies that accounted for spatial and temporal features focused on a narrow set of social interactions such as online social networks or encounters in face-to-face networks. One group of research projects studied very topical online social networks such as the Foursquare network (Scellato et al., 2011b) or the Flickr network (Crandall et al., 2010), while another group focused on studies of face-to-face encounters solely in highly structured and defined settings such as a museum, a conference, or a primary school (Isella et al., 2011; Stehle et al., 2011; Zhao et al., 2011). Whereas Noulas et al. (2015) analysed spatial, temporal and social features but focused on networks of places instead of individuals.
On the other hand, studies that analysed more broadly defined social networks did not assess spatial and temporal features at the same time. Although Yang et al. (2013) used information about when and in which network configuration people have met as features for their link-prediction algorithm, they did not incorporate spatial features. Sekara et al. (2016) utilised the regularity of social group structures to predict missing members of the group. However, place did not play a role in their subsequent prediction task. While Wang et al. (2011) successfully employed the similarity of trajectories of users for predicting phone calls between users, they did not take any other temporal or spatial features into account.
In short, we believed that a joint assessment of spatial, temporal and social features is crucial for understanding the true dynamics behind social encounters as human interactions might be spatially, temporally and/or socially confounded with each other.
Consequently, our contribution consisted of three parts: ascertaining whether geographic places themselves hold discriminatory power, assessing the ‘simultaneous’ predictive information of geographic, temporal and social features for a changing network of encounters and understanding if different types of social encounters networks influence the overall predictability.
Overall, we tried to better understand what factors drive the evolution of a human social encounter network, and how we could use salient features for predicting future encounters.
Data
The data we used for this article consisted of the dataset collected by the Copenhagen Network Study (Stopczynski et al., 2014). The dataset tracked 847 students at the Danmarks Tekniske Universitet (Technical University of Denmark, hereafter DTU) for a couple of years using smartphones provided by the researchers. Around 22% of the students in the study were female and around 78% male. The research subjects were typically between 19 and 21 years old.
The dataset contained call and text logs, GPS traces, scans of WiFi access points, as well as scans of nearby Bluetooth devices of the students. The scale of the dataset provided an unprecedented level of detail and at the same time breath of the daily life of a cohort of students. For the first time a significant portion of participants’ ‘everyday’ peers was covered by a study.
While data were collected for 24 months from September 2013 to September 2015, the study was initially designed to only collect data for one year. Consequently the first academic year provided the highest sample rate of behaviour and we focused our analysis on the first academic year.
Problem definition
A common way of dealing with social relations within populations is to view social ties – in our case social encounters – as edges (hereafter also links and ties) in a graph. Conceptualising social relations as edges in a graph had the advantage that analysing social relations as graphs was fairly well studied problem and allowed me to rely on state-of-the-art methods for predicting future encounters (Peng et al., 2015). Furthermore, viewing the problem as a time-varying graph enabled us to account for social network dynamics. In particular, we phrased the problem of predicting an encounter as a link-prediction problem in a time-varying graph Gt that represents encounters.
Encounter
For our study we defined an encounter as physical proximity as measured by a smartphone via a Bluetooth measurement. We used a Bluetooth signal of −80 dBm or stronger to indicate encounters as Sekara and Lehmann (2014) showed this to be a reliable cut-off value for close and unobstructed physical proximity for this dataset. Given that we were only interested in time spent at stop locations, this meant an encounter in our study represented either the physical co-location of two students in the same room or in close proximity outdoors. Sekara et al. (2016) used this definition of face-to-face encounter to study the evolution and structure of dynamic social networks.
However, we were not interested in predicting short encounters that are only due to chance but rather in more meaningful, longer encounters. Thus, we adopted the convention of the Rochester Interaction Record for meaningful encounters, where they were defined to last at least 10 minutes (Reis and Wheeler, 1991).
Social encounter graph
To construct the time-varying, undirected social encounter graph
Link prediction
As we conceptualised social encounters as edges in a graph, the problem of predicting future encounters between any two students became equivalent to predicting whether an edge between nodes in the graph existed. More formally, in a human encounter network Gt, the link-prediction task is to predict whether e at time t + n exists for the vertices
Predicting future encounters
After defining our problem in the previous section, we specify how we implement our approach for predicting links between nodes. In particular, we describe which algorithm we used for prediction, which features we used for predicting future encounters and how we built our models.
Random forests
Random forests consistently performed well in link-prediction tasks (Peng et al., 2015). We thus opted to use them for our prediction task (Pedregosa and Varoquaux, 2011). At its core, random forests are an ensemble learning algorithm for classification built upon decision trees. However, decision trees are sensitive to initial conditions (Altmann et al., 2010) and can easily over-fit the data (Ho, 2002). To deal with these problems Breiman (2001) proposed to use a set of decision trees. He defined a random forest as a classifier that consists of a collection of tree-structured classifiers
Recall that we were trying to predict future social encounters between
Features
We generally used features that had been used in the literature for our link-prediction task. All our features accounted for the general likelihood of an encounter occurring, for the various contexts an encounter could take place in, or were derived from the encounter graph of the students.
The three contexts we were particularly interested in understanding their role for encounters were time, space and social factors and thus most of our features were related to them. In order to assess the predictive information of each of those contexts, we created the following five sets of features:
Baseline features
Baseline features accounted for the idea that two students that met each other often and frequently were more likely to meet each other in the future than two students who hardly ever met. We constructed as baseline features for all our models whether the two nodes met in the previous time period or in other words whether we could observe a tie between them (edge), the amount of elapsed time since the last meeting (recency) and the total amount of time we observed two nodes together (time spent together) as described in Yang et al. (2013).
Temporal features
The time related features captured variations in temporal behavioural patterns as when two students met could in itself be an important clue for the type of relationship between two students. For example, if two students only ever meet during normal working hours then they are most likely just colleagues at university, but if they also meet after work or on the weekend then their relationship should be qualitatively different. Let M now be the set of all meetings between two nodes u, v in the training period. We built a feature vector (hour-of-day(M)) of length 24, that counted the total amount of the encounters between u and v at every hour of the day as well as feature vector (day-of-the-week(M)) of length 7, that counted the total amount of encounters between students at every day of the week. If an encounter occurred in more than one bucket, we distributed it proportionally for both hour-of-the-day as well as day-of-the-week. We also included the current hour of the day as well as the current day of the week as a feature, so that each R could keep track of when and where the current encounter occurred.
Spatial features
We observed that there was a difference in whether two people meet at a place a lot of people visit and thus with high place entropy or at ‘quieter’ place with low place entropy. Or in other words, if two students met at the university, a very popular place for students, the information content of that meeting was relatively low, but if two people met at their respective homes then this was a much more unlikely and more noteworthy event. We thus derived the minimum place entropy of the set of all observed locations of meetings between any u, as feature as well (Scellato et al., 2011b).
We also inferred the relative importance of each venue for each user u by measuring the amount of time a user spent there. We then ranked the venues by the relative importance for each user. Arguably the more time a student spent at a location the more important that location was for that student; encounters at more important locations as measured by the time students spent there could thus signify a more important social relationship as well. We thus also included the maxRank(relativeImportance(u, v)) of any meeting between u, v.
Based on Oldenburg’s seminal paper (Oldenburg and Brissett, 1982), we derived geographic contexts in which encounters occurred as features as well. Oldenburg argued that in order for communities to thrive they needed places away from the home (‘first place’) and the workplace (‘second place’); hence they needed ‘third places’. Examples of third places were cafes, clubs and parks. Several studies used Oldenburg’s concept of ‘third places’ to highlight the importance they played for social encounters (e.g. see among others Glover and Parry (2009); Mair (2009) and Rosenbaum et al. (2007)). Others used a classification similar to Oldenburg’s to understand and predict human mobility on a larger scale (Cho et al., 2011; Eagle and Pentland, 2009).
Analogous to Oldenburg we distinguished between several different geographic settings a student could be in: the home, the university, a third place and other. We inferred the locations as follows:
First, we found the home location for each student by clustering all his or her location measurements between 11 p.m. and 4 a.m. using DBSCAN (Ester et al., 1996)
1
into the set of spatial clusters C. We used DBSCAN as we did not have to specify the amount of clusters beforehand as we do not know how many clusters each individual might have. Each cluster
Second, for assigning students to the university context we mapped the campus of their university and checked whether students were within 50 metres of the campus. As some students lived in dormitories on campus we gave precedence to the home location when assigning location measurements to their respective contexts.
Third, to infer third places we adopted the approach of Sekara et al. (2016) for inferring significantly more important contexts given a distribution of observed times in a given context. For each student, we constructed the set of all the stop locations S a student visits. For each
Let context(u, v) now be the function that counts the amount of time two nodes
Last, we included the Jaccard similarity,
Social features
We also accounted for the social setting an encounter occurs in. While it would have been preferable to be able to account for all currently present people, our dataset only allows us to count other students currently present. If two students met at the university during a course this was nothing extraordinary in our dataset, but if two students met alone on the campus there was a higher likelihood that they were socialising. Let now
What is more, the social configuration two students met in could also play an important role for predicting future encounters. Building upon the concept of triadic-closure, that is the phenomenon in social network that friends of friends are likely to become friends themselves, Yang et al. (2013) proposed to use triadic periods as a feature for predicting encounters. The main idea was to count the different possible arrangements of triads in the encounter graph, or in other words the different possible configurations of co-locations at a particular location. This is equivalent to accounting for the immediate neighbourhood of every u in Gt.
Interestingly Bianconi et al. (2014) showed that triadic closure was a leading driver in how social networks evolve. And triadic periods likely accounted for the dynamic of triadic closure in the encounter graph as well.
Network topology features
In previous studies on link-prediction features derived from the wider network topology of the social graphs were used extensively. The core idea of all network metrics is that friends of friends are likely to become friends themselves. However, they differ in how they formulate this idea mathematically. In particular, we included preferential attachment (PA), weighted prop flow (weighted PF) and Adamic-Adar (AA) (Peng et al., 2015) after seeing favourable performance for those three metrics when designing our experiments. The PA metric indicates that new nodes will more likely attach to nodes that already have a high degree. It is defined as
Evaluating temporal prediction models
We used the first academic term for building and validating our model, whereas we tested our hypotheses on the second academic term of the dataset, where each term consisted of 13 weeks. As we were dealing with time series data, we used one-step forecasts with re-estimation as described in Hyndman and Athanasopoulos (2013) to make sure our models did not have access to training data from the future, where a step was 12.5% of the data and we used at least 50% of the available data to train each model. In other words, we evaluated our model at four different time points for the second half of the available data, where we retrained our model for each time point with all available data at that time point.
Search space
Every
Feature preparation interval
We had to decide on how many temporal slices of Gt we used to construct our features. However, several of the features we were interested in representing longer term dynamics between students such as the places they usually met and how similar their trajectories were, whereas several other features such as the other people present at a current meeting represented shorter term dynamics. We thus opted to introduce a longer term feature preparation interval
Yang et al. (2013) showed that the length of the feature preparation interval has an impact on the performance of the resulting link prediction. To determine the most appropriate hyper-parameters for our model, we tested the performance of our model with various values of
Cross-validation precision-recall AUC scores.
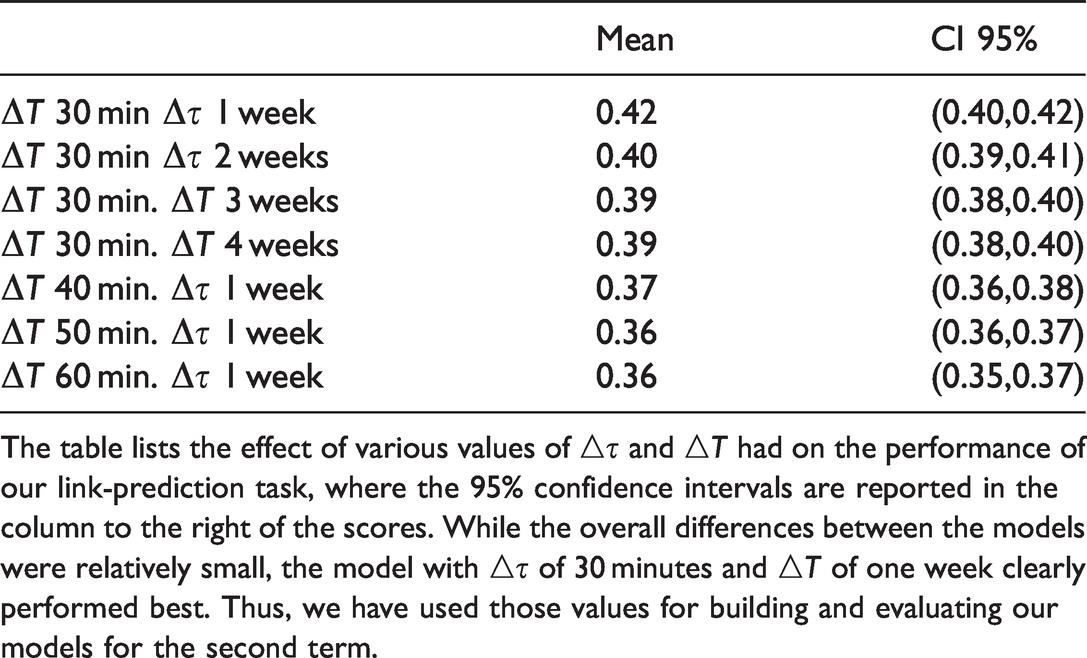
The table lists the effect of various values of
Model construction
In order to test the importance of each domain for predicting future encounters, we constructed several different models. Each of the models we built has access to a different set of features. Should the context of an encounter have played a role than our contextual features should have also been relevant for predicting future encounters. Table 3 lists each model and its corresponding features and also indicates, if the feature was derived using
Model features.
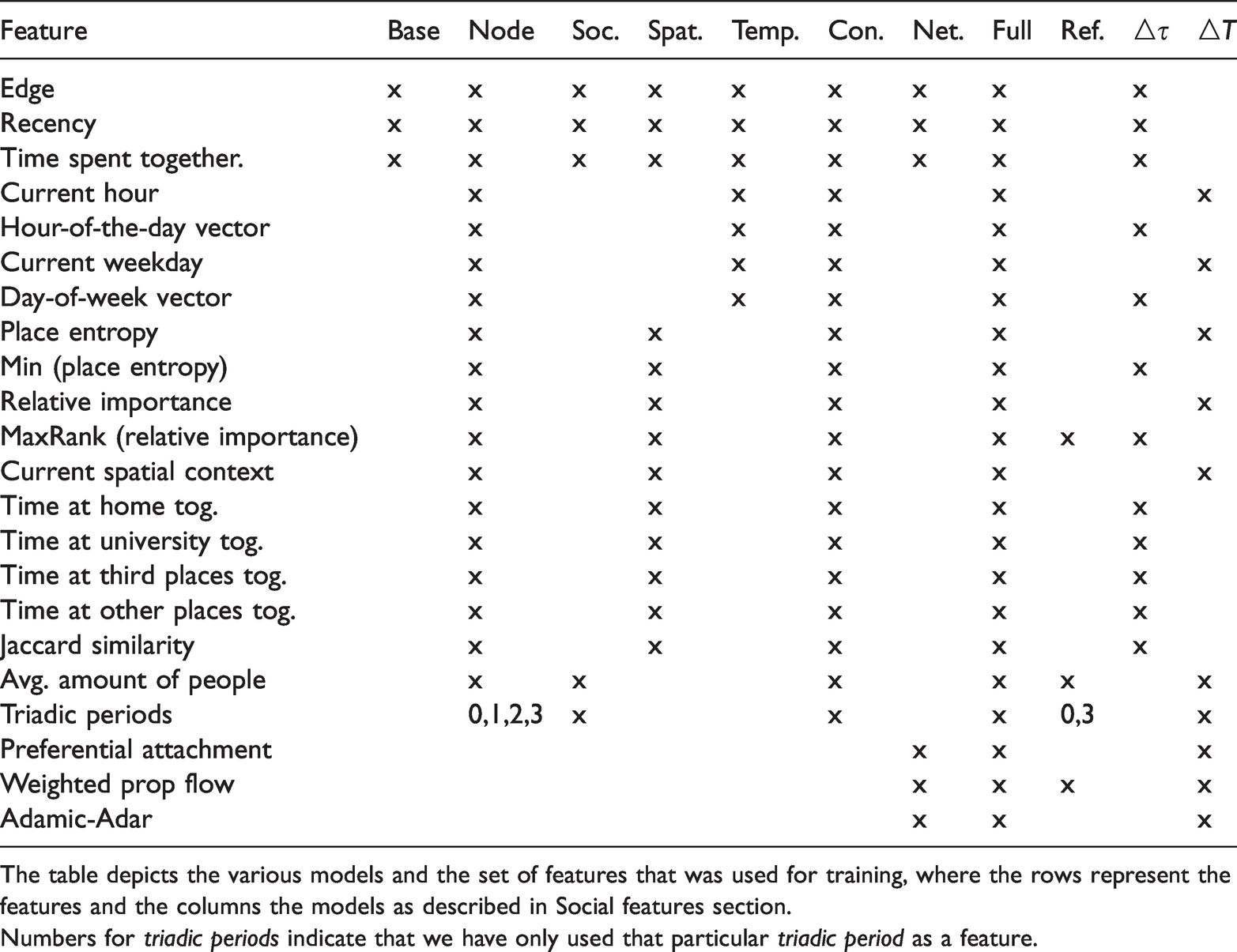
The table depicts the various models and the set of features that was used for training, where the rows represent the features and the columns the models as described in Social features section.
Numbers for triadic periods indicate that we have only used that particular triadic period as a feature.
As a benchmark to test our predictions against we first developed a null model for a time-evolving weighted encounter graph with dissolving ties. Our null model was adapted from Newman and Girvan (2004), where the edges of the graph were randomly rewired under the constraint that the expected degree matches the original degree distribution. In our case, this meant that the expected amount of encounter of each node
Besides the null model, we constructed a base model that only contained the baseline features. We further built a temporal model, a social model, a spatial model and a network topology model by adding to the base models the feature set that pertains to that domain. The context model consisted of the baseline features as well as the temporal, spatial and social features. The full model consisted of all features. We also, after our experiments, constructed a refactored model based on top five features of the full model.
Sometimes one however might not have access to the whole network and might only be in possession of node level data. Hence, one is unable to calculate or reliably estimate the features that utilise the wider network topology we described above. We simulated such a scenario by building node model that only incorporated features that could be obtained from the ego-network of a node. In particular, the features for the node model were: The baseline features, and all the spatial, temporal and social features with the limitation that ‘triad 4’ could not be distinguished from ‘triad 1’ and ‘triad 5’ not from ‘triad 3’.
Findings
To compare the performance of our different models we chose to report the precision, the recall, the precision–recall curve and the area under the precision–recall curve (PR AUC), where precision is plotted on the y-axis and recall on the x-axis (Davis and Goadrich, 2006). Precision and recall are defined as follows (Davis and Goadrich, 2006): In a binary classification task, true positives (TP) are instances correctly labelled as positives, whereas false positives (FP) are incorrectly labelled as positives. Conversely, true negatives (TN) are examples correctly labelled as negatives and false negatives (FN) refer to positive examples erroneously labelled as negatives. Recall is then
The area under the PR curve can then be directly used to compare the performance of different models (i.e. the bigger the area the better the model) and is suited to evaluate the performance of an algorithm if there is a large class imbalance as in our data (Davis and Goadrich, 2006).
Performance of the link-prediction algorithm
First, all models performed significantly better than the null model; however, only the network model had a higher PR AUC score than the base model (Figure 1 as well as Table 4). Unsurprisingly, nodes are not randomly interacting with other nodes but exhibit learnable patterns (at least to a certain degree).
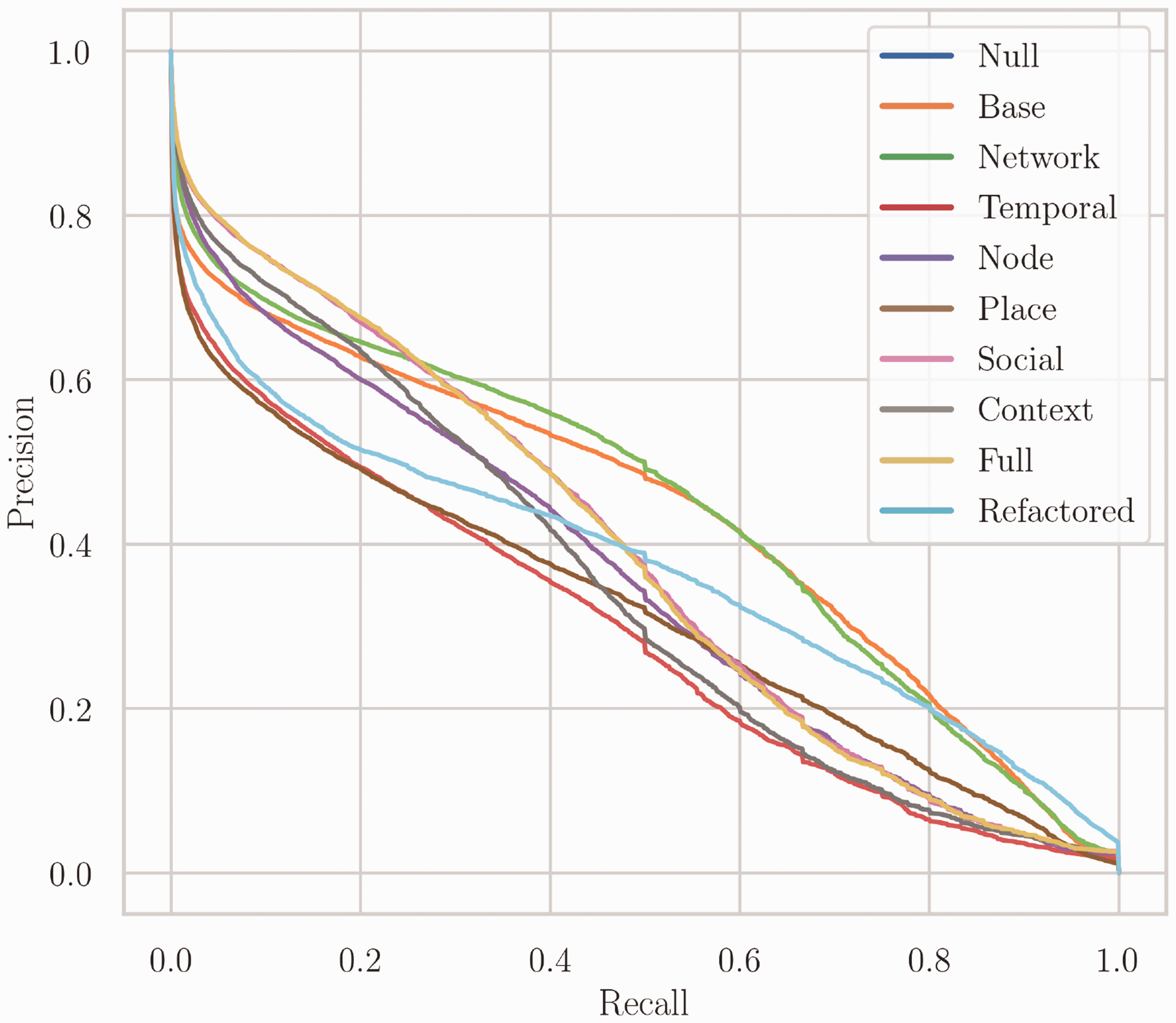
Precision recall curves. The figure depicts the precision-recall curves of the different models. As we fitted a separate tree R for each student, these curves were built by averaging the individual PR curves of each R. The network model performed best, while the base model was only slightly worse overall; in particular those two models managed to keep a relatively high precision score for higher recall values. The social and full model had relatively high precision scores as well.
Model scores.
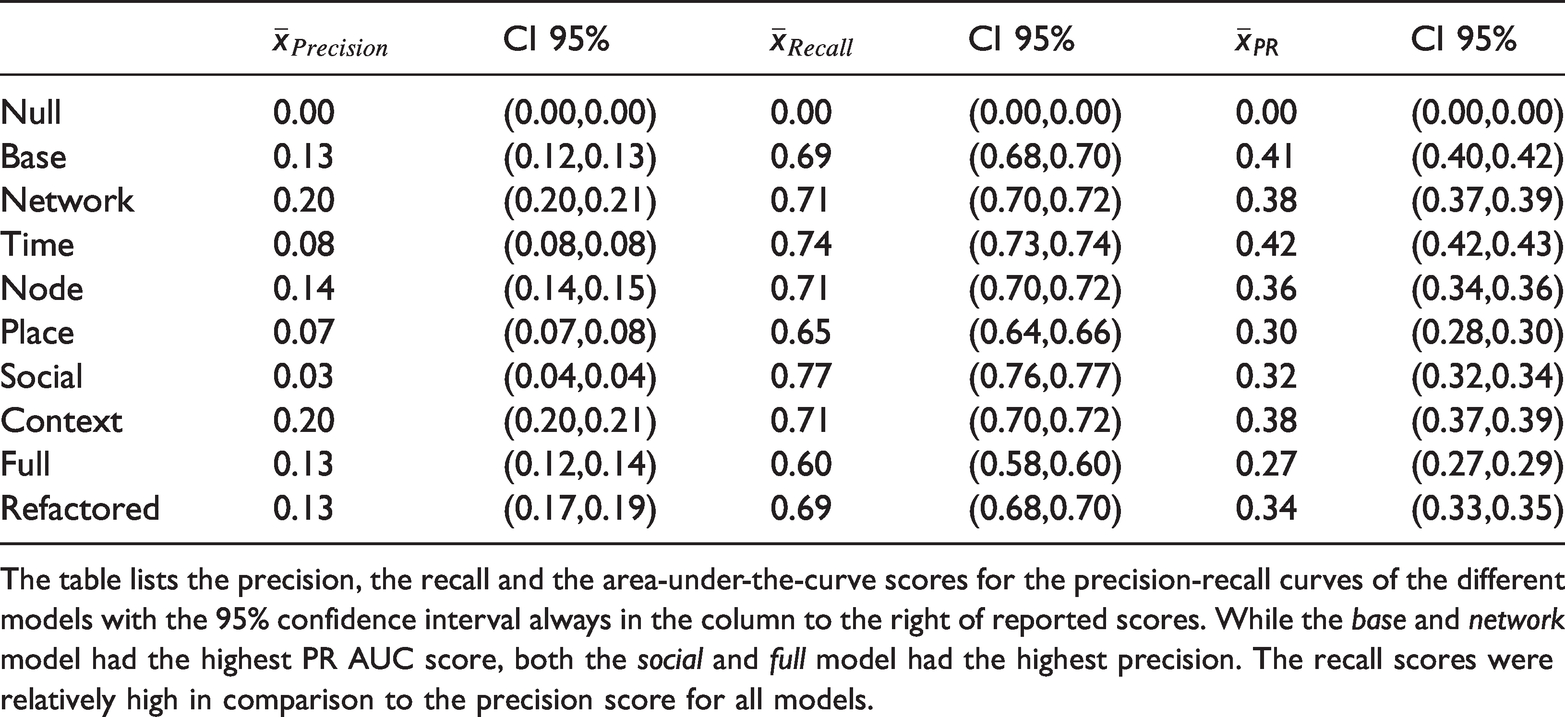
The table lists the precision, the recall and the area-under-the-curve scores for the precision-recall curves of the different models with the 95% confidence interval always in the column to the right of reported scores. While the base and network model had the highest PR AUC score, both the social and full model had the highest precision. The recall scores were relatively high in comparison to the precision score for all models.
The importance of the different features for the full model.

The table shows how important each feature of the full model was for predicting e at time t + n. It only depicts features whose importance was bigger than 0.01. Both triadic closure 0 and number of people were among the most important features indicating the importance of knowing the social context of where encounters took place. Furthermore, weighted prop flow was important as well, highlighting the role the wider social encounter graph played for predicting encounters. In total the top five features accounted for about 50% of the expected contribution to the final prediction.
Second, the models that had the highest PR AUC score were the network and the base model, even though they have access to a lot fewer features than other models. Thus, initially it looked like only a subset of features seemed to be important for the prediction task and some features appeared to even be detrimental for predicting future encounters. The network topology of the social encounter graph G appeared to be very discriminative on its own.
Third, the social and full model had a significantly higher PR AUC score than all models except the base and network model. In particular, with respect to precision both the social and the full model performed much better than any other model, which became apparent not only in the model scores (Table 4) but also in the PRC curves (Figure 1). This indicated that while social features might not have been overall as important as the network topological features, they were still relatively important for correctly predicting whether an encounter occurred.
However, all models had a low precision score compared to the recall scores. This indicated that all models suffered from a relatively large amount of false positives. Given the relatively sparse nature of the social encounter graph G, this finding was not unexpected as there were many more opportunities for false positives than for false positives.
Feature importance
We also investigated the relative importance of the features for predicting future encounters for the full model. Interestingly the top five features – average amount of people, weighted prop flow, triadic closure 0, triadic closure 3 and max(relative importance) accounted for roughly 50% of the expected contribution to the final prediction.
The relative importance of the features was consistent with the low scores for the models that did not include network topological features. Interestingly the social features triadic closure 0 and triadic closure 3 were also important highlighting the process of triadic closure in our dataset and partly explained the comparatively good performance of the social and full model. Triadic closure was consistently shown to be a driving feature of tie formation in networks (Bianconi et al., 2014). This makes sense as when triadic closure occurred, students were already spatially close to each other and thus more likely to encounter each other.
Predicting different types of links
We were also interested in whether the type of relationship (i.e. whether the students were just colleagues, or also socialised outside of university) between nodes affected the predictability of encounters. In order to explore this question, we constructed two new encounter graphs. Recall that Gt was based on all spatial encounters between students regardless of where and when these encounters took place (hereafter
Our experiment showed that our model had the highest PC AUC score of 0.49 (0.48–0.49 95% CI) for
Discussion
The main finding of our research was that features about whom one meets and the wider network topology of the social encounters significantly improved our predictions, while information about when and where one meets did not seem to play an as important role for our prediction task. Furthermore, and in contrast to previous research that information about where individuals meet did not seem to play a pronounced role for predicting future encounters between individuals in our dataset of students (Scellato et al., 2011b; Yang et al., 2013). It appeared that almost all information was already contained in the network topology of G and the social context rather than in the spatial and temporal setting.
One possible explanation for the relatively low importance of spatial and temporal features could be that as students move through their daily lives, the information of where they are is already embedded in who else is physically close. For example, one is with their partner there is a high chance that one is either at home or at the partner’s home; if one is with their friends from university then there is a high chance that one is meeting them at university. In a sense the social contexts individuals (Sekara et al., 2016) inhabit might intrinsically be linked to spatial places. A competing interpretation for our findings could be that as students are already sharing a lot of places, lectures at the university, for this particular demographic additional opportunity to interact might be less relevant.
Our findings highlight the importance to account for the social embedding of ties for studying mobility behaviour. Specifically, our result indicate the importance of jointly assessing spatial, temporal and social features in order to understand the dynamics of social encounters because human interactions can be spatially, temporally and socially confounded with each other. Such a perspective is usually ignored by mobility studies. Applications that might be informed by our findings range from modelling travel behaviour over understanding the spread of communicable diseases to spatial planning. In essence, applications wherein an understanding of both social as well as mobility behaviour is required for accurately modelling human behaviour can benefit from jointly considering spatial, temporal and social features.
Carrasco et al. (2008) argued that it is important for understanding travel behaviour to study ‘the composition and structure of the personal networks in which these ties are embedded’. Building upon that notion, and while out of scope for this work, one interesting route to explore would thus be to not only map but also conceptualise human behaviour not in the traditional dimensions of time and space as in time-geography (Hägerstrand, 1970) but in a reference frame of time, social and spatial dimensions.
The performance of our link-prediction algorithm was significantly better when considering all ties rather than just social ties but worse than when considering just university ties. We believe that a better understanding the role different types of relationships play for encounters could be a fruitful avenue for future research.
Last, addressing potential other factors such as the weather, the wider social context an interaction takes place in, and might shed light on dynamics that we could not account for in our study. Thus, studying those factors and their relationship with predicting future encounters would also be an interesting topic for future research.It is an open question whether potential other factors such as the weather or can help improve the prediction of social ties.
However, one has to be careful when generalising from our sample of students to the whole population. While we were not aware of any reason our findings should not also hold for broader population groups, the dataset in our study represented after all just one sample of a network. Furthermore, our classification of geographic places was rather broad and did not allow for a detailed analysis of those factors. We believe that a more fine-grained analysis of the role of geographic place is an interesting prospect for future research, especially in conjunction with an expanded analysis of the predictability of different types of ties.
Descriptive statistics of the features.
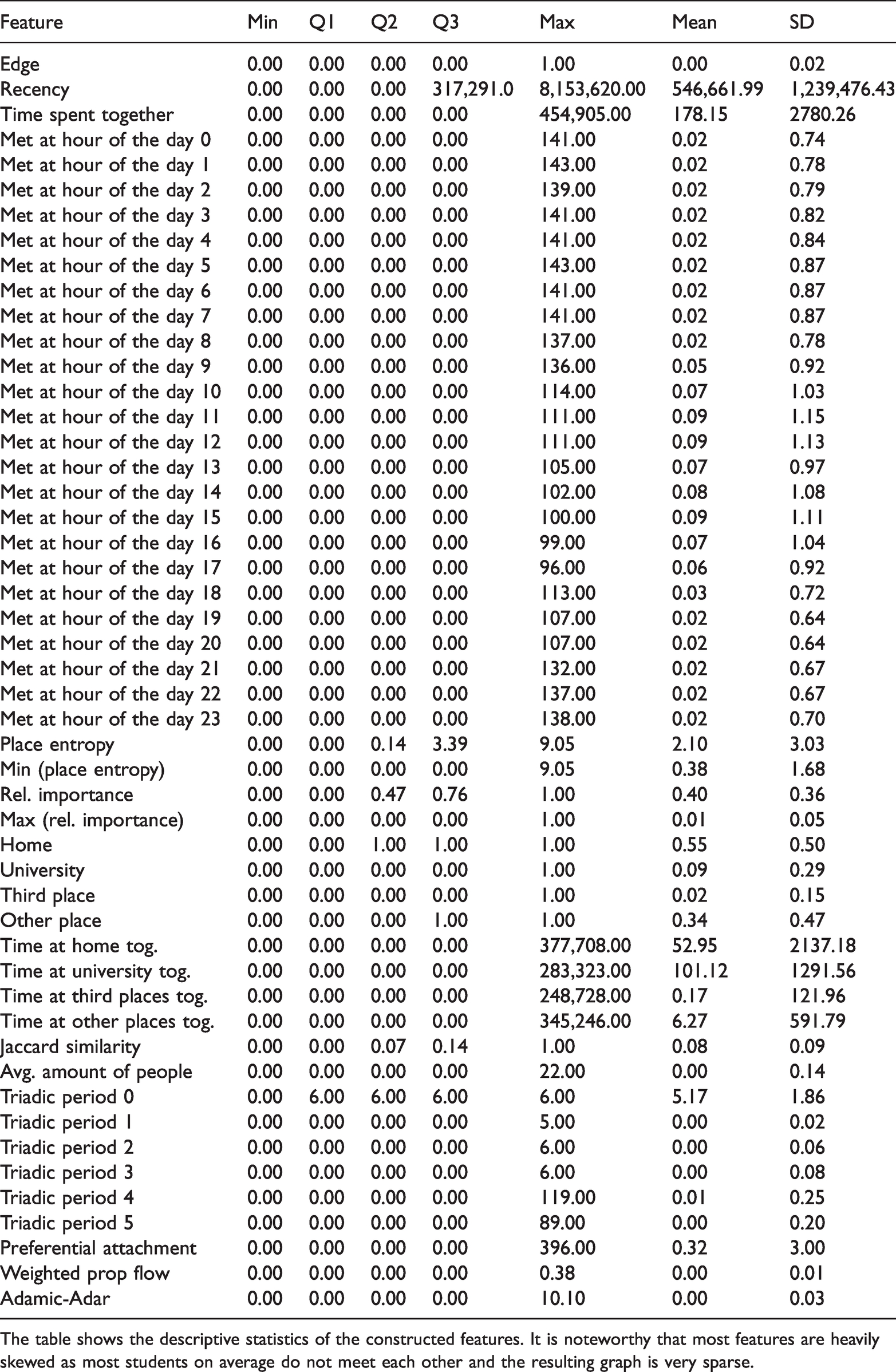
The table shows the descriptive statistics of the constructed features. It is noteworthy that most features are heavily skewed as most students on average do not meet each other and the resulting graph is very sparse.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was in part supported by an Economic and Social Research Council PhD scholarship (ES/J50001X/1).