
Abstract
Introduction
Missing outcome data may undermine interpretation of randomised clinical trials by weakening power and limiting apparent effect size. We assessed bias and inefficiency of two imputation methods commonly used in stroke trials evaluating the efficacy of iv thrombolysis.
Patients and methods
We searched the virtual international stroke trials archive (VISTA)-acute for ischaemic stroke patients with 90-day modified Rankin scale as an outcome, and known thrombolysis status. We excluded any with missing 30-day modified Rankin scale. We planned two analyses; first, we calculated odds ratios for outcome in thrombolysed versus not thrombolysed from imputed-only data, (a) among patients with missing modified Rankin scale 90 and (b) among matched patients with intact data (using propensity score methods and relevant covariates). Imputation approaches were last observation carried forward (LOCF) or multiple imputation. Outcome comparisons used dichotomisation and shift analysis. Thereafter, we calculated whole-population odds ratios using LOCF and multiple imputation (also through dichotomisation and shift analysis); first with the original 1.5% missing outcome data, and then artificially increasing the burden (5%; 10%; 20%; 30%).
Results
We considered 9657 patients from eight of the studies included in VISTA, 3034 (31%) thrombolysed. Missing data replacement by LOCF with analysis by dichotomisation gave the highest estimate of thrombolysis influence. Imputing while increasing the burden of missing data progressively raised the odds ratios estimates, though thresholds for overestimation were 10% for LOCF; 20% for multiple imputation.
Keywords
Introduction
Missing data may be defined as values that are not available but that would be meaningful for analysis if they had been observed. 1 Missing outcome data ought to be distinguished and handled in a different way from missing data in covariates and auxiliary data. Missing outcome data may seriously compromise inferences from clinical trials by reducing statistical power, thereby increasing the chance of type II error.2–4 Faced with missing outcome data, experts have claimed that the highest risk of bias may arise from simply excluding the missing values and analysing only the complete cases (complete-case (CC) analysis). 5 Several ‘imputation’ methods have been proposed to compensate for missing data, to limit the impact.1,3
In the stroke field, the most frequent imputation approach has been last observation carried forward (LOCF),6–16 in which the most recent preceding value is substituted for the missing one. More advanced approaches include estimating-equation methods; among these, multiple imputation (MI) has been favoured after advances in necessary computing power.16–20 Applying MI, multiple sets of plausible values are created from their model-based predictive distributions, and estimates and standard errors are obtained through multiple-imputation combining rules.
We could not identify any previous work within the stroke field that has addressed the effect of imputation strategies, or any assessment of the potential for missingness to undermine interpretation of the results of stroke trials. Our aim was to assess bias and inefficiency of the two most common imputation methods used in the stroke trials testing intravenous thrombolytics; and how these may impact on the estimated odds ratio for treatment efficacy.
Methods
For this study, we used data from acute trials held within the virtual international stroke trials archive (VISTA). We selected patients with ischemic stroke who had received placebo or any drug now known to possess no confirmed influence on stroke outcome; and for whom it was known whether they had received thrombolysis as part of their standard care. We took patients only from studies in which modified Rankin scale (mRS) recorded at day 90 had been a primary or secondary outcome, that had clearly distinguished any missing outcome values from imputed data, and that had recorded vital status to day 90. We investigated certain demographics/biomarkers that we identified from the literature to be related to ischemic stroke. These included age, sex, systolic and diastolic blood pressure at baseline, National Institutes of Health Stroke Scale (NIHSS) at presentation, pre-stroke mRS score, history of hypertension, history of diabetes, history of hyperlipidaemia, history of smoking; history of ischemic heart disease or myocardial infarction, history of heart failure, history of atrial fibrillation, history of stroke or TIA and body mass index. Our outcomes included day 30 and day 90 mRS; but only patients with at least an available mRS30 recording were included in order to perform LOCF.
We generated p values for comparisons of the basal characteristics between groups before and after propensity score matching, using the Chi-Square test for categorical variables and sample t test or Mann Whitney U test for parametric and non-parametric continuous variables. All odds ratios (OR) described here refer to the apparent influence of rtPA in treated vs untreated patients. We planned two sets of analysis.
Part 1
For this part, we divided the entire population into two groups: group M (missing mRS90) included patients with an available mRS30 but lacking mRS90; group C (complete data) included only those patients for whom both mRS30 and mRS90 were available. First, we matched patients from group C against those in group M using propensity score methods that considered age, gender, rtPA treatment, mRS30, NIHSS, diabetes and atrial fibrillation as the most relevant covariates. The maximum possible number of matches was included (1:n). As a result, we obtained two new groups M* (missing mRS90 matched) and C* (complete data matched), which we used for the rest of the analysis in this part (Table 1). We calculated treatment OR from imputed-only mRS90 data, separately considering both LOCF and MI, using for outcome comparisons first ‘dichotomisation’ (mRS 0–2 vs 3–6) and then ‘shift analysis’. We did this in group M* and also in group C*, by forcing a simulated imputed dataset as if all mRS90 values would be missing. This allowed us to compare the real versus the imputed OR in group C*. We regarded the OR of the real mRS90 data in group C* as the gold standard.
Distribution and comparison of relevant covariates among patients with and without missing data (before and after propensity score matching).
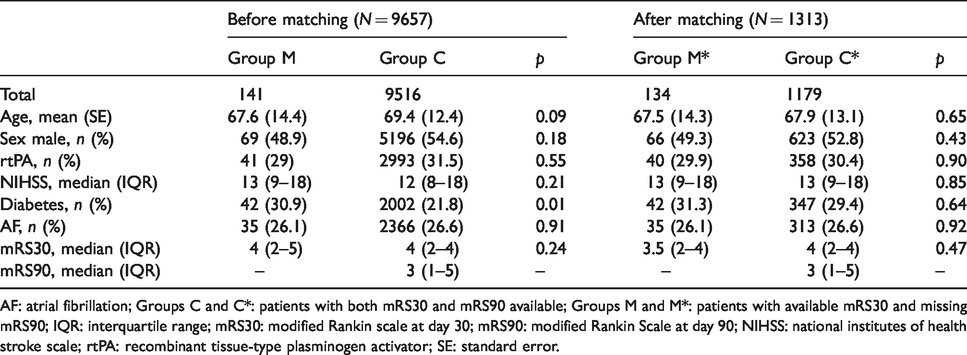
AF: atrial fibrillation; Groups C and C*: patients with both mRS30 and mRS90 available; Groups M and M*: patients with available mRS30 and missing mRS90; IQR: interquartile range; mRS30: modified Rankin scale at day 30; mRS90: modified Rankin Scale at day 90; NIHSS: national institutes of health stroke scale; rtPA: recombinant tissue-type plasminogen activator; SE: standard error.
Part 2
For this part, the whole population was considered. Three strategies were planned for managing missing mRS90 values: imputation through LOCF; imputation through MI; and CC analysis. Whole-population treatment OR were obtained for each strategy. We tested both ‘dichotomisation’ (mRS 0–2 vs 3–6) and ‘shift analysis’ for outcome comparisons. We repeated these analyses in circumstances where we artificially increased the burden of missing data in the whole population from the original 1.5% of missing data to 5%, 10%, 20% and 30% burdens of missing data, respectively. Cancellation of original data to generate missingness was performed randomly, but within patients in group C* (the subset of subjects with complete data, matched through relevant covariates with those with original missing mRS90 data). By doing this, we were assuming that missingness in stroke trials occurs within the subset of patients with certain baseline and clinical characteristics (based in personal unpublished data). By doing this, we aimed to capture the trends and behaviour of the previous modelling methods compared to the named ‘worst possible’ CC analysis. As in previous part 1 of the analysis, we regarded the OR of the real mRS90 data in group C* as the gold standard.
Results
Data from 9991 patients were obtained from eight studies within the VISTA database. After excluding patients with missing mRS30 values (N = 334), we worked with a final population of 9657 patients. This included 141 patients (1.5%) who had missing values for mRS at day 90. Table 1 shows subgroups based on the availability of mRS day 90; the distribution of relevant covariates; and the comparison between groups before and after propensity score matching. We obtained a group M* with a highly preserved number with respect to the original (134/141—the 7 excluded where due to missing values in covariates) and a group C* much smaller than the original (1179/9516) as expected, formed only by patients with similar characteristics to those in group M matched through the prespecified covariates. The ratio group C*/group M* approximated 9:1.
From the analysis of imputed-only data (Table 2), we observed that the combination of LOCF with a dichotomisation approach gives the highest OR. This was true for the group with original missing (M*) data (OR 1.33 (1.02–1.65) p = 0.2). The OR was exaggerated and became statistically significant with complete (C*) data (OR 1.72 (1.45–1.99) p = 0.001). Focusing on ORs of real vs imputed data in group C*, the LOCF-OR value was inflated by 37% when using a dichotomisation approach, and by 18% when using a shift analysis approach. The MI-OR were largely unaltered compared with the real values, regardless of the type of approach.
Adjusted OR and p values of imputed-only mRS90 data using LOCF or MI in the group with missing (M*) and without missing data (C*).
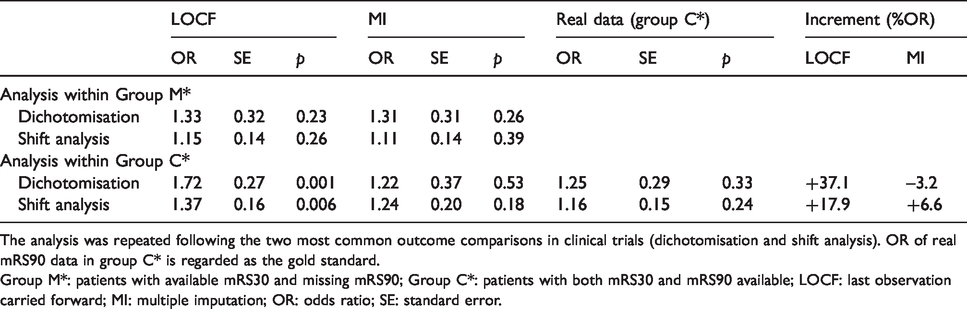
The analysis was repeated following the two most common outcome comparisons in clinical trials (dichotomisation and shift analysis). OR of real mRS90 data in group C* is regarded as the gold standard.
Group M*: patients with available mRS30 and missing mRS90; Group C*: patients with both mRS30 and mRS90 available; LOCF: last observation carried forward; MI: multiple imputation; OR: odds ratio; SE: standard error.
The whole-population OR obtained in part 2 using CC analysis (Table 3) did not differ much with those obtained through either of the modelling analyses (Figures 1 and 2). There was a maximum difference of 17.5% compared with MI in the category that had 30% missing data (dichotomisation approach) and a mean 5% global difference across the remainder of the categories.
Whole population adjusted OR, confidence intervals and p values comparing three different missing data management strategies by the two most common outcome comparisons in clinical trials (dichotomisation and shift analysis).
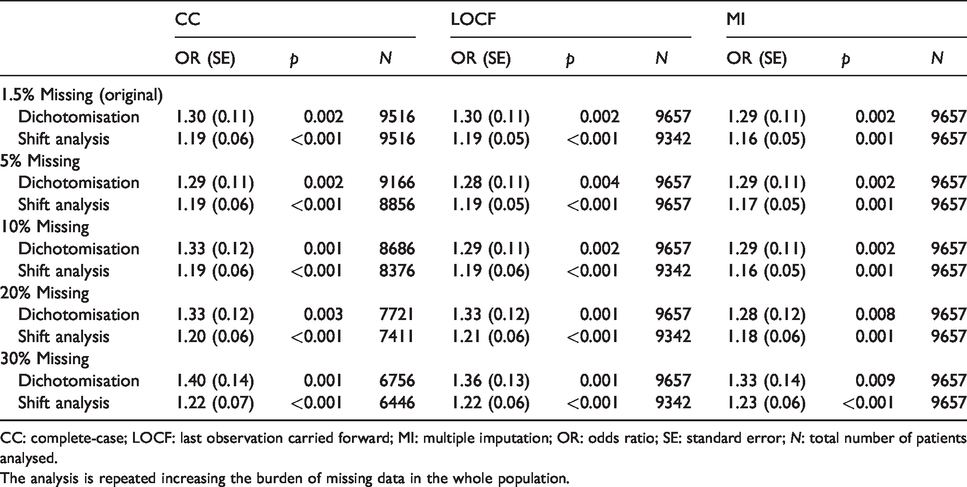
CC: complete-case; LOCF: last observation carried forward; MI: multiple imputation; OR: odds ratio; SE: standard error; N: total number of patients analysed.
The analysis is repeated increasing the burden of missing data in the whole population.
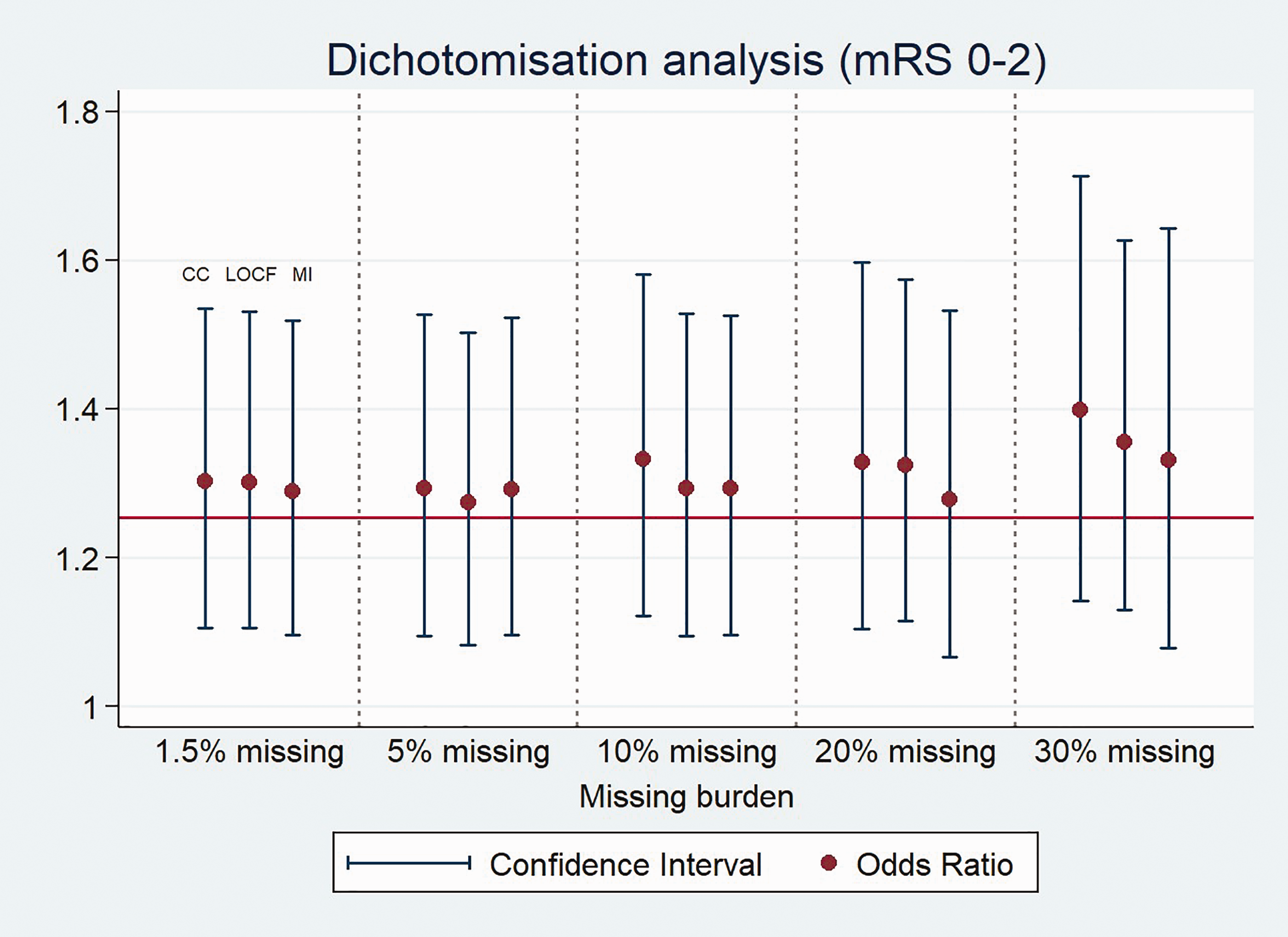
OR variation, following the three different analysis strategies, giving a higher burden of missing data. Outcome comparison through dichotomisation.
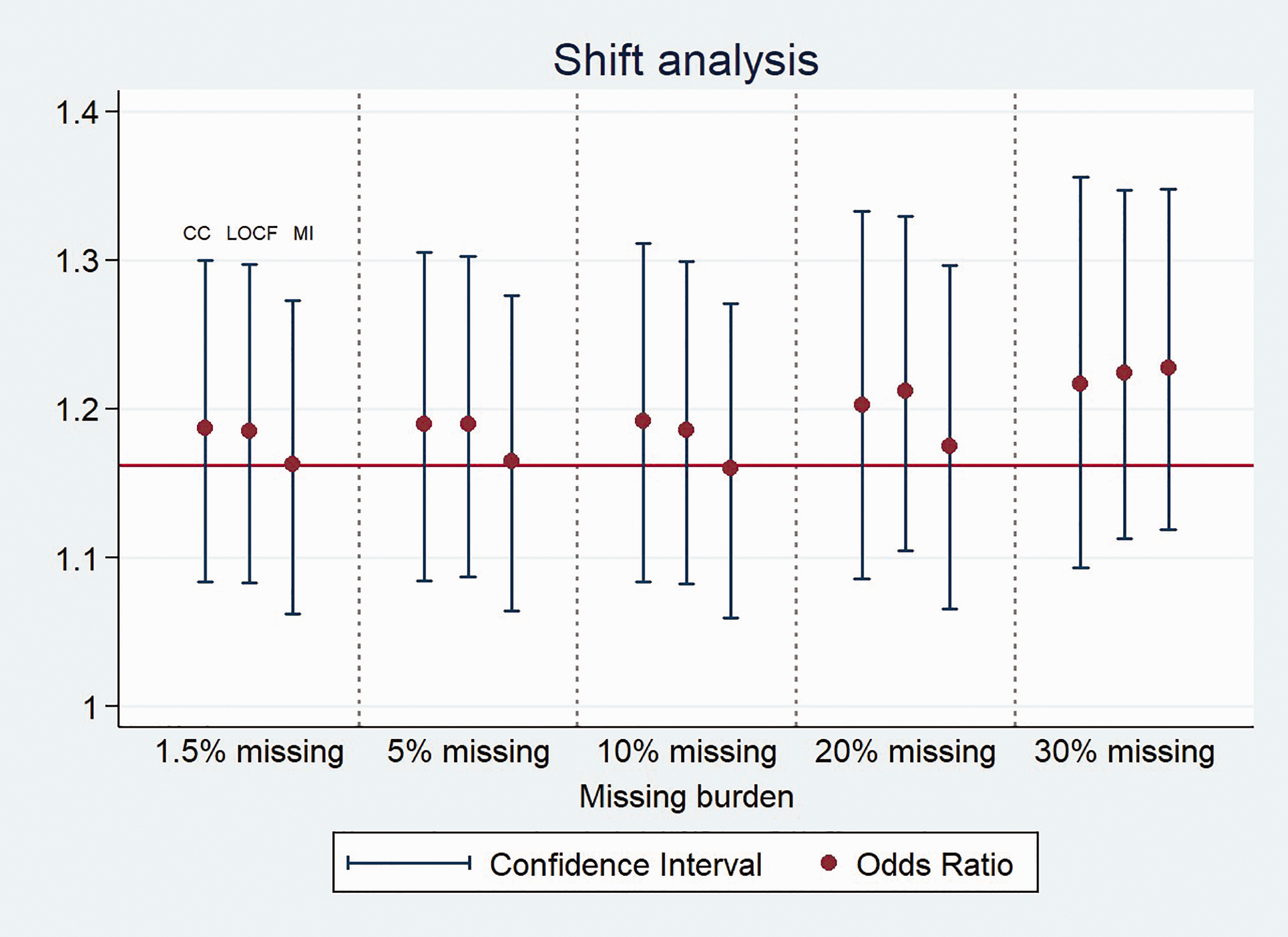
OR variation, following the three different analysis strategies, giving a higher burden of missing data. Outcome comparison through shift analysis.
Discussion
In this work, we have shown that replacing missing outcome data may tend to overestimate outcome differences between thrombolysed versus non-thrombolysed patients, especially if the LOCF rather than MI approach is used. We also found that dichotomisation rather than shift analysis may cause overestimation. However, these distinctions all had minimal impact below a 10% burden of missing data.
By comparing the OR for the apparent influence of rtPA in treated versus non-treated patients from exclusively imputed data (part 1); we tried to purposely maximise the impact of each type of imputation method, in an attempt to observe and compare the tendency of their bias effect. The highest OR were obtained by combining LOCF with the dichotomisation approach. The exaggerated results in group C* compared with those of group M* may be in part due to a higher N though also to incomplete information regarding mechanisms of missingness. 21 On the contrary, MI-OR showed a moderate variation between groups, between approaches for outcome comparison and also compared with the real values in group C*.
From the analysis of the whole-population (part 2), it is surprising to see how only small differences occurred between CC-OR and either of the two imputation methods, at least up to a 10% burden of missing data. On this basis, for iv rtPA trials with a rate of missing data under 10% and sufficient sample size, using CC analysis may be a reasonable option that will simplify trial analysis. At this point, it may be interesting to understand which strategy might better approximate the true population treatment effect; a larger sample size including imputed values, or a smaller sample including only complete data. As our results do not help to clarify this point, specific work on the subject may be needed.
Regarding the trend for the OR under a higher burden of missing data, we saw a progressive increase in the case of the complete case analysis in contrast to a relative stability up to 10% missing burden for LOCF and up to 20% missing burden for MI. There was a relatively steep increase in the higher categories in both cases (equally for both approaches). This may imply that the modelling properties of the LOCF analysis could be lost in populations with a missing data burden above 10% (with a threshold somewhere between 10% and 20%) and for MI in populations with missing data burden above 20% (with a threshold somewhere between 20% and 30%). Even so, the ‘good modelling properties’ of LOCF shown in this study have some attraction, because mRS30 appeared to be the best predictor of mRS90 in our dataset (with a calculated correlation index of 0.9). However, this interpretation may be undermined by the burden of missing mRS30 data that we did not assess, as we had already excluded patients who lacked mRS30. Overall, MI seems to represent a good modelling method for using in stroke trials testing iv rtPA, with a robust performance regardless of the burden of missing data and the approach chosen for outcome comparison. At this point, we should clarify that these results are based on what we consider a reasonable assumption: that missingness in stroke trials occurs within the subset of patients with comorbidities and an a priori poorer prognosis.
The OR obtained using shift analysis were in general lower than those obtained through dichotomisation. This is not surprising: thrombolysis carries a small early risk for haemorrhage and mortality especially among patients with more severe stroke and poor prognosis and thus does not have proportional effects across all categories of mRS (the statistical assumption of proportional odds is not met). 22 This does not undermine use of the shift approach, since the OR for shift remains the best measure of treatment effect across the whole population that was selected for treatment. 23
The results of this work apply exclusively for trials testing iv rtPA. How different modelling analysis would perform in other research scenarios such as observational studies or thrombectomy trials remains unknown as far as we are concern.
Conclusions
In the specific context of acute stroke trials testing iv thrombolytics, replacing missing data by carrying forward the last observation tended to overestimate treatment OR more than MI. How this may affect overall treatment estimates will depend on the burden of missing data and the approach taken for outcome comparison, since ordinal analysis was more robust to these influences than dichotomisation.
Footnotes
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: JFF, KRL, MAD, RMI and PDL have nothing to declare. LHS reports serving on the scientific advisory boards for Genentech (TIMELESS study NCT03785678 Steering Committee, and expert advisory panel on late window thrombolysis), Diffusion Pharma DSMB PHAST-TSC NCT03763929 and as a Continuing medical education symposium organiser or lecturer (Medtronic, Boehringer Ingelheim).
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.not-for-profit sectors.
Ethical approval
VISTA has Institutional ethical approval (University of Glasgow, MVLS ethics) for the use of fully anonymised data for novel research purposes.
Informed consent
Informed consent was not sought for the present study because it uses pooled, anonymised data from a clinical trials resource.
Guarantor
KRL.
Contributorship
JFF researched literature, helped structuring the methods, and wrote the first draft; KRL and LHS discussed the original idea, conceived the study; approved the methods and contributed decisively to the final version of the article; RMI and MAD helped with the methods section and performed all the statistical analyses; PDL helped with the methods and article editing.