
Abstract
Background and Aims
Children with developmental language disorder (DLD) have difficulty learning new words, but we know little about whether and to what extent their word-learning ability improves over time. Our primary goal was to compare the rate of development of word learning abilities, specifically the encoding of new lexical-semantic information, in children with DLD and their age-mates with typical language development (TLD). Secondary goals were to examine variation in outcomes according to the aspect of word knowledge under consideration, the word-learning context, and the cognitive abilities of the learners.
Methods
Children with DLD (n= 38) and TLD (n = 45) participated in two experiments each year from Grades 1 to 4. In each, they were taught a new set of 12 novel words and their referents. The experiments involved a cross-situational word learning context (Study 1) and ostensive naming and mutual exclusivity contexts (Study 2). Post-training probes measured knowledge of the phonological form of the word and the link between the word and its referent. In Year 1, we measured various aspects of cognition. Linear mixed models with fixed effects for diagnostic group, year, and context yielded main outcomes.
Results
Children with DLD were less able than peers with TLD to learn form- and link information in all three contexts and in all four years, but their relative rate of growth across the years was similar. Neither form- nor link-learning was consistently harder than the other for the DLD group; however, the size of the TLD-DLD performance gap was especially large for form learning in the ostensive naming (most direct) training context. The lower cognitive abilities of children with DLD, especially phonological short-term memory and receptive vocabulary knowledge, accounted for variance in form and link learning. With cognitive scores in the statistical models, the TLD-DLD gap in link learning was no longer significant.
Conclusions
As a group, primary school children with DLD present with weaknesses in word learning abilities but age-appropriate rates of improvement in those abilities over time. The problem reflects their lower verbal cognition. The extent of the problem varies with the context in which the word is learned and the aspect of word knowledge that is measured as an outcome.
Implications
The implication for scientists is that a diversity of contexts and outcome measures must be included in future research. The implication for clinicians is two-fold. First, brief opportunities to learn word forms in ostensive naming contexts may be leveraged for dynamic assessments, as it is this learning goal and this learning context that most effectively distinguished DLD from TLD. Second, when treating a child with DLD, the common practice of direct teaching is unlikely to be effective unless active engagement, sufficiently high dosage, optimally sized target sets, and rich vocabulary instruction are included.
Developmental language disorder (DLD) is a highly prevalent neurodevelopmental condition that limits spoken and written language learning, comprehension, and expression and leaves individuals vulnerable to broader impacts on academic performance (Ziegenfusz et al., 2022), employment (Conti-Ramsden et al., 2018), and mental health (Nudel et al., 2023). As a group, people with DLD have, among other symptoms, vocabularies characterized by less breadth and depth than expected for their age (McGregor et al., 2013). That is, they have less lexical-semantic knowledge than their peers with typical language development (TLD).
Lexical-semantic knowledge is the product of our exposure to words in the language in meaningful contexts and the sensory and cognitive mechanisms that allow us to learn from these exposures. Our lexicons vary greatly one from the other because exposures vary with amount and quality of schooling, what and how often we read, and numerous other experiences. That said, some variance clearly reflects inter-individual differences in the mechanisms that support word learning. In the case of DLD, we hypothesize that it is a mechanistic limitation, not a difference in experience, that results in low levels of lexical-semantic knowledge, simply put, many people with DLD have difficulties learning new words.
Evidence in support of this thesis involves multiple studies in which people with DLD and peers with typical language development (TLD) are given equivalent experiences to learn new words and the DLD group outcomes are lower. Only by altering those experiences by providing more exposure to new words (Gray, 2003; 2004; McGregor, Arbisi-Kelm et al., 2020) or more supportive learning contexts (Haebig et al., 2019; McGregor, Gordon et al., 2017; Pomper et al., 2022; van Berkel-van Hoof et al., 2019) will the DLD group approach comparable levels of word learning as their peers. The word learning problems of monolingual English-speaking children with DLD are well documented, but there is also growing evidence from other language communities including monolingual speakers of Dutch (Broedelet et al., 2023; van Berkel-van Hoof et al., 2019), Hebrew (Barak et al., 2022), and French (Krzemien et al., 2021), as well as bilinguals who speak Cantonese and English (Kan, 2024), Hebrew and Russian (Barak et al., 2022), Spanish and Catalan (Ahufinger et al., 2021), Spanish and English (Kapantzoglou et al., 2012), and Spoken Arabic and Modern Standard Arabic (Ghawi-Dakwar & Saiegh-Haddad, 2025).
In a meta-analysis of 28 cross-sectional studies (244 effect sizes) involving participants with mean ages as young as 3;7 (years; months) and as old as 12;3, Kan and Windsor (2010) concluded that children with DLD perform approximately 0.6 SDs lower on word learning tasks than their age-mates. As for the specific mechanistic limitations that may contribute, children with lower receptive language abilities and lower nonverbal IQs were more likely to have poor word learning outcomes than those stronger in those domains.
Lexical-semantic knowledge builds over time as exposures accrue and word-learning abilities develop. Three longitudinal studies demonstrate that the vocabulary knowledge of children with DLD accrues at age-expected rates as measured from ages 6 to 10 years (Norbury et al., 2021), 8 to 16 years (McGregor et al., 2013), and 2;6 to 15 years (Rice & Hoffman, 2015). Rice and Hoffman (2015) continued to follow their participants from 15 to 21 years, and, at that later stage of development, people with DLD began to lag behind their peers in receptive vocabulary knowledge. Typical accrual from 2;6 to 16 years should not be taken to mean that children with DLD learn as many words as their peers each year but, instead, that they are adding words to their lexicons at a rate that maintains, rather than narrows or widens, the lexical-semantic knowledge gap between TLD and DLD children. Unless children with DLD are consistently getting more word exposures than their peers, it would seem that their ability to accrue vocabulary knowledge at the same relative rate must reflect an age-appropriate rate of the development of word-learning abilities during these years.
To test this hypothesis, and to more fully understand the word-learning problems associated with DLD, we used a longitudinal design to determine how the ability to learn new words changes over the first four years of primary school in children with DLD or TLD. To our knowledge this is the first study to examine longitudinal change in spoken word learning ability among children with DLD, but interested readers may wish to see Factor and Goffman (2022) for a parallel study in the manual domain. To provide a more nuanced understanding, we focused on the encoding of both phonological word forms and the link between forms and their semantic referents in three different word learning contexts. Next, we motivate these methodological decisions.
Stages of Word Learning
Word learning is a gradual process (Wojcik, 2013). When a person encounters a word for the first time, a fragile memory trace may be formed. This stage, referred to as encoding (Melton, 1963), is supported by the medial temporal lobe and the hippocampus (Davis & Gaskell, 2009). With time (Walker, 2005), sleep (Dumay & Gaskell, 2007; Gais, Lucas & Born, 2006), and (at least in infants) food (Valiante et al., 2006), that memory may begin to consolidate. Consolidation involves the transfer of the memory trace to the neocortex (Dudai, 2004). A consolidated memory is stronger and less vulnerable to decay than a newly encoded memory. Once the word is reencountered, additional information may be added to the memory trace via processes of re-encoding, and that memory may then reconsolidate (Lee et al., 2017).
When we taught novel words to adults with DLD and TLD via passive study or active retrieval training, those with DLD recalled fewer of the new words immediately post training, suggesting poorer encoding. However, the two groups demonstrated similar consolidation abilities, in that both groups retained what they had encoded over shorter (20 min) or longer (1 day, 1 week) retention intervals (words learned via passive study at a 1-day retention interval being an exception), suggesting largely intact consolidation (McGregor, Gordon et al., 2017). In McGregor, Eden et al. (2020), we directly tested the hypothesis that the word learning problems associated with DLD are characterized by a weakness in encoding but strengths in consolidation and reconsolidation. Again, we found consistent evidence of poor encoding. The DLD and TLD groups were similarly able to retain what they had encoded when measured 1 day or 1 month after training; however, the DLD group did demonstrate more forgetting than their peers with TLD at the 1-week interval, again demonstrating that retention may not always be age-appropriate, but it is a relative strength for those with DLD. Finally, additional exposures to the words following the initial training boosted performance equivalently in both groups, revealing that re-encoding and re-consolidation are also strengths.
Although our participants were young adults, these patterns of relative strengths and weaknesses have been replicated in studies of children with DLD in multiple labs. Calabrese et al. (2025) conducted a meta-analysis of 46 studies to determine the extent to which children with DLD performed more poorly than their age-mates during encoding (78 effect sizes), consolidation (8 effect sizes), and reconsolidation (19 effect sizes). The mean effect for encoding was large and significant (d = .82), whereas the mean effects for consolidation (d = −.2) and reconsolidation (d = .23) were small and not significant.
Cognitive abilities in the domains of verbal working or short-term memory (often measured with nonword repetition tasks) and extant vocabulary knowledge (most often measured with receptive vocabulary tests) moderated the effect of encoding. In other words, even within the DLD group there were individual differences, and those who came to the task with higher vocabulary knowledge and verbal working memory tended to be the better word learners. The role of verbal short-term memory was also reflected in the finding that longer words yielded larger effect sizes than shorter words. Although not considered in Calabrese et al. (2025), other aspects of cognitive function, such as attention switching and inhibition are also associated with word encoding ability (Kapa & Erikson, 2020).
Aspect of Word Knowledge to be Learned
In the Kan and Windsor (2010) meta-analysis, word learning was measured in three different ways across studies: 1) In 12 studies, the child was given an array of toys and was asked to follow a command that included the target word (e.g, “Show me, Tigger is [newly taught verb] Minnie.” [Skipp et al., 2002]); 2) In another 12 studies, the child was shown a single referent and was asked, “What's this?;” and 3) In seven studies the child was given an array of (pictured) referents and was asked to “Point to the [newly taught noun].” To accomplish any of these tasks, one must have knowledge of the semantic referent, the phonological form of the target word, and the link between the two; however, the task in the first set of studies puts greater burden on semantic knowledge; the second set puts greater burden on phonological word form knowledge; and the third set puts greater burden on linking the word form to the semantic referent.
Children with DLD demonstrate poorer word learning than their age-mates with TLD on all three tasks; however, the effect sizes for the diagnostic group differences were larger for the tasks that depended highly on semantic knowledge (g = .52) and link knowledge (g = .64) than for those that depended highly on word form knowledge (g = .26). As Kan and Windsor note, this does not necessarily mean that learning to link words to referents or learning the meanings of words is harder for people with DLD than learning the word forms. Because it is more difficult to produce than recognize a newly learned word, the finding could reflect floor effects (see also Ghawi-Dakwar & Saiegh-Haddad, 2025).
In fact, studies published since the 2010 meta-analysis often report that, relative to link learning, word form learning represents a significant challenge for children and adults with DLD (Jackson et al., 2021; McGregor, Arbisi-Kelm et al., 2020; Pomper et al., 2022), although this might be especially true of those who have DLD with co-occurring dyslexia (Alt et al., 2019). As Benham et al. (2018) elegantly demonstrate, children with DLD do not configure novel phonological sequences as efficiently as children with TLD, and their attempted productions of newly trained word forms are less accurate and more variable.
Word Learning Contexts
Most—but certainly not all—research on word learning in the DLD population involves direct teaching contexts (i.e., structured tasks that involve repeated presentations of words and their referents, naming, and supportive cues, Jackson et al., 2019), but most word learning in the real world does not (Bloom, 2002). The word learning challenges associated with DLD have also been observed in less direct contexts including animated stories (Oetting et al., 1995; Rice et al., 1992; Rice et al., 1994), shared book reading (Nash & Donaldson, 2005; Smeets et al., 2014; Storkel et al., 2019), written texts (McGregor et al., 2024; Steele & Watkins, 2010), and college lectures (Becker & McGregor, 2016). These contexts provide varying supports for—and demands upon—the learner, but on average, those with DLD exhibit poorer learning in all contexts.
Experimental word learning paradigms involve manipulation of context to examine the effects of learner engagement (Haebig et al., 2019; Jackson et al., 2021; Leonard et al., 2021 [Studies 1 and 3]; McGregor, Gordon et al., 2017; Pomper et al., 2022) and the need for the learner to make inferences ((McGregor et al., 2024; Steele & Watkins, 2010) and aggregate information over time (Broedelet et al., 2023). Although the outcomes for the DLD groups in these studies are typically lower than those of the TLD groups, in a few cases, increased engagement (Haebig et al., 2019) or support (Pomper et al., 2022) ameliorated group differences on some aspects of word learning.
The Current Studies
To summarize, the extant literature supports the conclusions that 1) as a group, people with DLD have difficulty learning new words; 2) the extent of the word learning difficulty varies with receptive vocabulary, nonverbal IQ, phonological short-term memory, and executive function; 3) the encoding of new words seems to be the bottleneck, whereas consolidation and re-consolidation are relative strengths; 4) it is unclear whether phonological or semantic aspects of word learning are more problematic; and finally, 5) the difficulty is evident in a range of word learning contexts.
These conclusions motivate the current project, as summarized in Table 1. We compared children with DLD and their age-mates with TLD as they performed novel word learning tasks in each of four years, from grade 1 to grade 4 (roughly 7 to 10 years of age). Given the robust support for the encoding hypothesis, we chose to focus on performance during and immediately after training to capture the learning stage that is most vulnerable for people with DLD. We probed outcomes of both phonological and semantic aspects of word learning with task type held constant, specifically, alternative forced choice (3AFC) recognition probes. We also examined the cognitive mechanisms that explained variation in learning outcomes.
Overview of the Project.

One innovation of the current study is that we examined word learning abilities in more than one word learning context within the same sample of participants. Given that word-learning (and word-learning difficulties) emerge within a variety of contexts in the real-world, we have designed three laboratory tasks that vary in contexts and, thus, learning demands. The contexts are Cross-Situational (CS), which places heavy demands on the aggregation of information across episodes, Mutual Exclusivity (ME), which places heavy demands on inference, and Ostensive Naming (ON), which eliminates the ambiguity of the word form to referent linkage. CS and ME reflect aspects of the word-learning contexts we encounter in everyday life whereas ON captures aspects of word-learning that might take place in a classroom or language intervention session where direct teaching takes place. By examining word-learning in these three contexts, we aim to determine the extent to which the word-learning problems associated with DLD are context-dependent.
To ease the burden on the reader, we have divided the paper into two separate studies. The first examines learning during and immediately after CS exposures. The second compares learning outcomes in more implicit (ME) and explicit (ON) contexts. Because the same participants and outcome measures apply to both studies, we begin by describing those commonalities.
General Method
Ethics and Preregistration
To ensure ethical treatment of human subjects, this project was approved by the Internal Review Board of Boys Town National Research Hospital. It was preregistered in 2017 at The Research Registry under the title The Dynamics of Word Learning in Children with Developmental Language Disorder: A Prospective Cohort Study (preregistration ID#3425). This paper addresses Aims 1 and 2 of the preregistration; outcomes associated with Aim 3 were published in McGregor et al., 2024. The project, as carried out, differed from the preregistration in four ways:
The preregistered target sample size was 40 children with DLD and 40 age-mates with TLD, but due to recruitment challenges, we enrolled 38 children with DLD. We exceeded our target somewhat for the TLD group, enrolling 45. The proposed measures of verbal working memory and visual short-term and working memory were subtests of the Automated Working Memory Assessment (AWMA, Alloway, 2007), but that assessment was phased out when we began the study. We were able to use the verbal working memory task from the AWMA, which involved backward digit recall stimuli, but we changed to the Corsi Block-Tapping task (Farrell Pagulayan et al., 2006) to measure visual short-term memory and the Odd-One-Out task (Henry, 2001) to measure visual working memory. The preregistered cut-off for exclusion on the Perceptual Index of the Wechsler Abbreviated Scales of Intelligence–Second Edition (Wechsler, 2011) was 75 or below; we used 70 instead to be consistent with the Diagnostic and Statistical Manual of Mental Disorders (DSM-5: American Psychiatric Association, 2013). The preregistered cut-off for categorizing participants into DLD or TLD groups was 80 or lower on the Test of Narrative Language-2. Instead, we used a cutoff of 92 because it has been shown to maximize sensitivity and specificity of DLD identification (Gillam & Pearson, 2017).
Participants
The participants were 38 children with DLD (16 girls) and 45 children with TLD (25 girls), enrolled when they had completed kindergarten and not begun second grade (i.e., during first grade, summer months inclusive). None of the participants repeated a grade during the study; therefore, years of education remained well matched by diagnostic group throughout. All lived in the United States, and all were monolingual speakers of English. The two groups were matched for age in months. They differed significantly on all other demographic and cognitive measures administered in Year 1 of the study, except for speed of visual processing. (Table 2).
Comparison of Diagnostic Groups on Intake Measures.
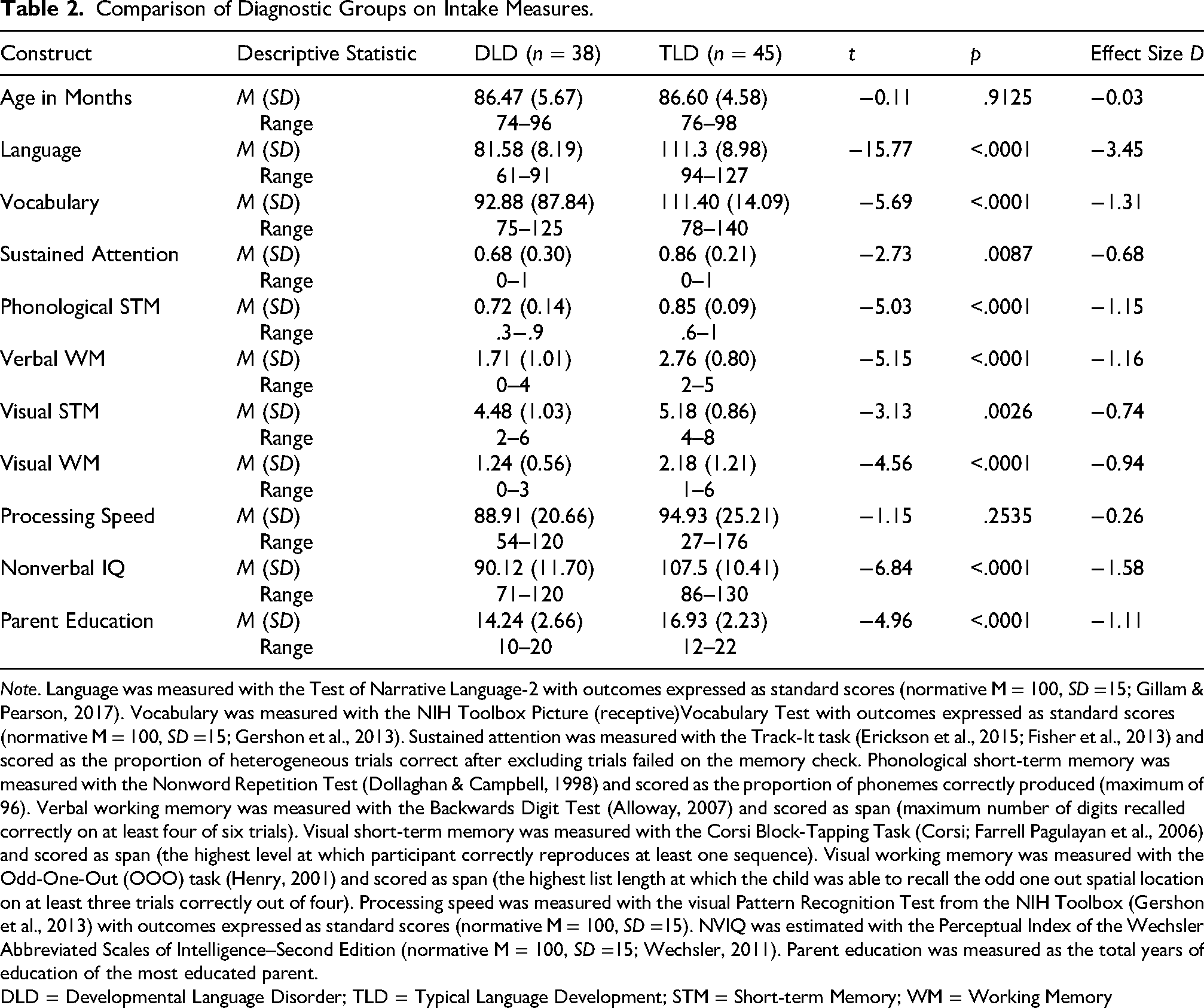
Note. Language was measured with the Test of Narrative Language-2 with outcomes expressed as standard scores (normative M = 100, SD =15; Gillam & Pearson, 2017). Vocabulary was measured with the NIH Toolbox Picture (receptive)Vocabulary Test with outcomes expressed as standard scores (normative M = 100, SD =15; Gershon et al., 2013). Sustained attention was measured with the Track-It task (Erickson et al., 2015; Fisher et al., 2013) and scored as the proportion of heterogeneous trials correct after excluding trials failed on the memory check. Phonological short-term memory was measured with the Nonword Repetition Test (Dollaghan & Campbell, 1998) and scored as the proportion of phonemes correctly produced (maximum of 96). Verbal working memory was measured with the Backwards Digit Test (Alloway, 2007) and scored as span (maximum number of digits recalled correctly on at least four of six trials). Visual short-term memory was measured with the Corsi Block-Tapping Task (Corsi; Farrell Pagulayan et al., 2006) and scored as span (the highest level at which participant correctly reproduces at least one sequence). Visual working memory was measured with the Odd-One-Out (OOO) task (Henry, 2001) and scored as span (the highest list length at which the child was able to recall the odd one out spatial location on at least three trials correctly out of four). Processing speed was measured with the visual Pattern Recognition Test from the NIH Toolbox (Gershon et al., 2013) with outcomes expressed as standard scores (normative M = 100, SD =15). NVIQ was estimated with the Perceptual Index of the Wechsler Abbreviated Scales of Intelligence–Second Edition (normative M = 100, SD =15; Wechsler, 2011). Parent education was measured as the total years of education of the most educated parent.
DLD = Developmental Language Disorder; TLD = Typical Language Development; STM = Short-term Memory; WM = Working Memory
Sample sizes varied over the years due to attrition and occasional technological malfunctions. We report the exact sample sizes in the results sections below.
Subsets of these children also participated in McGregor et al. (2021, 2023, 2024). Also, outcomes from the preregistered project in Year 1 are reported in McGregor et al. (2022) and Pomper et al. (2022) . Because the current paper builds on these by documenting change from Years 1 to 4, we will summarize the findings of the 2022 papers when we introduce the specific studies.
Stimuli
Each participant completed two word-learning tasks in each of the four years, for a total of eight tasks. Therefore, we created eight sets of novel words and assigned them in counterbalanced order across tasks, years, and individuals, so that no word learning targets were encountered by a given person in more than one learning context or more than one year. Each set included 12 words, half monosyllabic and half disyllabic. To reduce noise in the data, we took care to make the sets similar in distribution of onset segments, neighborhood density, and phonotactic probability. The novel words and details about their characteristics, are available in OSF at McGregor et al. (2026, November 28).
Each word was assigned to a pictured referent. The referents were color photographs of real but unfamiliar birds, insects, mammals, or fruits found via internet searches. Each set of 12 included three referents from each of these four categories.
Data Collection
The data collectors (NE and TAK) were assigned participant cases whom they saw for three or four data collection visits during each of the four years of the study. The visits involving novel word learning were scheduled at least one week apart, to reduce interference, but not more than three weeks apart, to control for maturation. In the first and second years of the project, data were collected in a mobile lab van equipped with a table, chairs, and video cameras. Because of the COVID-19 pandemic, we moved to virtual data collection via a secure Zoom link for the third and fourth years of the project. All data collection sessions were digitally recorded. All digital files were reviewed in full to determine whether glitches (of particular concern for the Zoom sessions) prevented the child from hearing or seeing the training or test trials. If a glitch occurred during training, the child's data from all outcome probes were excluded for that particular context and year. If a glitch occurred during the administration of an outcome probe that interfered with more than three of 12 trials, we also deleted those data. The extent of data loss per context, year and outcome measure appears in McGregor et al. (2026, November 28). The highest amount of data loss occurred in Study 1, where we lost five data sets for 3AFC form and five for 3AFC link in Year 3. The lowest amount occurred in Study 2 where we lost one data set for form and one data set for link, both in Year 3.
Outcome Measures
We used two probes to measure learning outcomes: 1) A 3AFC ‘dot task’ (Gordon & McGregor, 2014) measured learning of the phonological word forms (form recognition). The participant heard three novel words; one was a trained target, and the other two were foils created by changing one phoneme in the target. As each word was presented, a dot appeared on the computer screen. After all three word choices and dots were presented, the participant then pointed to the dot corresponding to the word they had learned. 2) A 3AFC picture pointing probe measured the ability to link word forms to their referents (link recognition). The participant saw three referents from the training set and heard one word form. They indicated which of three was named. The 3AFC form recognition task was administered five minutes after the final training cycle, and this was immediately followed by the 3AFC link recognition task. The reverse order would have provided the participants with an additional exposure to the correct word form just prior to the form recognition task. The timing of these probes, being soon after training, was critical as we intended them as measures of encoding, not consolidation. That said, we recognize that these are not pure measures of encoding—sensory and attentional processes are required to perceive the memoranda and retrieval processes are necessary to formulate a response.
With these commonalities explained, we now turn to the studies themselves. In Study 1, we examined word learning abilities in a cross-situational learning context (extension of McGregor et al., 2022). All children participated. In Study 2, we used a between-subject design, comparing word learning abilities in response to direct and indirect instructional contexts (extension of Pomper et al., 2022). We began with a within-subject design, but pilot data suggested that the attempt to learn numerous new words over a short period introduced interference. Therefore, we randomly assigned half of the children from the TLD and DLD diagnostic groups to direct instruction and the other half to indirect instruction. Those assignments held constant over the four years to enable evaluation of change in learning ability.
Study 1: Cross-Situational Learning
In any given real-world context, the intended referent of a new word is often unclear (Quine, 1960); however, learners can leverage word-referent co-occurrences over time and across multiple situations to arrive at the correct mapping. Cross-situational learning is thought to be accomplished via proposing links and confirming or correcting the proposal on subsequent trials (Medina et al., 2011; Trueswell et al., 2013; Woodard et al., 2016), by aggregating the statistics of co-occurring word and referent instances in a more implicit manner over time (Smith & Yu, 2008; Yurovsky et al., 2014), or via a combination of the two (Roembke & McMurray, 2016; Stevens et al., 2017; Xu & Tenenbaum, 2007; Yurovksy & Frank, 2015), with strategy varying according to task demands and the number of words to be learned (Roembke & McMurray, 2016).
Cross-situational word learning is evident from infancy (Smith & Yu, 2008; Vlach & Johnson, 2013; Woodard et al., 2016). However, within the population of learners with typical language development, there are individual differences across learners that pattern with their extant vocabulary knowledge and their memory abilities (Vlach & DeBrock, 2017). Given their weaknesses in these domains, it is not surprising that children with DLD are less able than their age-mates with TLD to learn word-to-referent links from cross-situational information (Ahufinger et al., 2021; Broedelet et al., 2023). Eye-tracking data in Ahufinger et al. (2021) also suggest that children with DLD are less confident in their responses than children with TLD, even when they have made the correct mapping.
McGregor et al. (2022) is a report of cross-situational word learning abilities in a subset of the current participants, 28 children with DLD and 44 with TLD. The data were collected when all participants were in Grade 1. The cross-situational word-learning context (the same one reported here) comprised six cycles of 14 trials each (12 novel word trials and two familiar word filler trials). In each novel word trial, the child saw two pictured referents, heard one novel word, and indicated the word-to-referent link by clicking on the referent that they thought was being named. The foil accompanying each target referent was randomly selected from the remaining 11 targets. In that way, a given referent appeared once as a target in each cycle but also could appear one or more times as a foil. Thus, the learner had two sources of information. First, when a given referent appeared as both a target and a foil within a cycle, the learners could narrow the hypothesis space and achieve above-chance performance. Second, as the given name-referent pairing appeared in each of the six cycles, the learner could acquire the correct mapping. The inclusion of six cycles (i.e., six exposures to the target word-referent pairs) was established via piloting with the goal of keeping learners away from floor or ceiling performance.
At the end of the first trial, the group with DLD performed at chance, and the group with TLD performed above chance. On the sixth and final learning cycle, the children with DLD were above chance but 15% less accurate than their peers with TLD. After training, each learner completed the 3AFC form and link measures. Contrary to prediction, form learning was not disproportionately harder than link learning for the children with DLD relative to their peers. Extant receptive vocabulary knowledge accounted for variance in performance whether measured by accuracy on the final cycle of learning, form recognition, or link recognition.
Hypotheses and Predictions
In Study 1, we repeated the training and outcome measures summarized above to yield data in each year from first to fourth grade. We were primarily interested in the extent to which the two groups of participants improved their word learning outcomes from year to year. Given the outcomes of previous word-learning studies, we hypothesized weaker learning outcomes for the DLD group. Given extant longitudinal comparisons of vocabulary knowledge, we hypothesized that the relative rate of growth in word-learning ability would be similar for the two diagnostic groups. We predicted:
Less accurate word-to-referent linking on the part of the DLD group during cross-situational learning as measured on training trials. Lower form and link recognition outcomes on the part of the DLD group, as measured with 3AFC probes administered immediately after training. Given outcomes in Year 1, a similar effect size for diagnostic group differences on form recognition and link recognition. A main effect of year, such that both diagnostic groups improved word learning abilities over time.
We also aimed to identify cognitive mechanisms that relate to cross-situational learning. Given outcomes in McGregor et al. (2022), we predicted that performance would vary with extant vocabulary size. Per the preregistration, we also tested for relationships between learning outcomes and other cognitive variables including phonological short-term memory, verbal working memory, visual short-term and working memory, sustained attention, processing speed, and nonverbal IQ. We also tested the effect of years of parent education, a proxy for socioeconomic status. We were interested not only in whether any predictor was significant but also whether, with additional important predictors in the model, any effect of diagnostic group remained.
Method
Data Analysis
Analysis involved three steps: one to evaluate performance during learning, another to compare learning outcomes to chance, and a third to evaluate predicted learning outcomes. Code for all data analysis appears in McGregor et al. (2025, November 28).
Throughout the project, we defaulted to frequentist models wherever appropriate because they tend to be more familiar to readers. However, the complexity of the analysis of the within-training responses necessitated a hierarchical Bayesian approach. The outcome variable was expressed as an odds ratio (OR), specifically, the odds of a correct answer versus an incorrect answer, which is assumed to follow a Bernoulli distribution (Ber(p)). A logit transformation was then applied to “p” to set up a logistic regression for the probability of successfully identifying each word correctly. The terms in the logistic regression model included a lag effect to capture the fact that the probability of a correct answer may depend upon accuracy in the previous cycle. Other variables in the model included diagnostic group (DLD, TLD), sex (M, F), and cycle (1,…,6), and interactions between diagnostic group and sex, year, cycle, and lag. The model included a random intercept for subject to allow for correlation between repeated observations per participant. A random intercept for word did not improve model fit, so it was removed.
A distribution of vague but proper priors with a mean of 0 and a variance of 100 was placed on the coefficients representing diagnosis, sex, trial, cycle, lag and the interactions. The vague normal prior distribution essentially placed a non-informative prior on beliefs about these estimates, thus allowing the data to drive the model. For the subject effect, a normal prior distribution was used, N (0, 1), with the variance parameter receiving an inverse gamma prior of 0.01 for both shape and scale. There were three chains with random starting values, where each chain ran for 50,000 iterations after a burn-in of 1,000 iterations and thinning of 5. The model was fit using the R package nimble. Convergence was assessed using the Gelman-Rubin R-hat diagnostic.
Next, we examined form and link outcomes. We compared performance by diagnostic group and year against a baseline of chance (chance = 33%); all outcomes appear in the Supplemental Tables. For both form and link, we then ran a linear mixed effects model with a random intercept for each individual and fixed effects for diagnostic group, sex, and year. The dependent variable was proportion of items correctly identified on the recognition probes. Evaluation of residuals indicated that the assumption of normality was not violated by use of proportional data. If interactions occurred, we compared the differences in the least squares means to aid interpretation; these outcomes also appear in Supplemental Tables.
We then repeated those models to determine whether the cognitive variables and parent education (number of years of the more highly educated parent) accounted for variance in outcomes. All test scores were entered as raw scores (i.e., total correct responses) with the exception of the NIH Toolbox Picture Vocabulary Test for which standard scores uncorrected for age are more meaningful (see Gershon et al., 2013). Note that, although there were some correlations among these variables, they did not create a multicollinearity problem. The Variance Inflation Factor values were less than two, with four being the cutoff over which multicollinearity must be addressed (Hair et al., 2009). Therefore, we included each of the individual variables in the model. Estimates were generated using REML, and we used Satterthwaite degrees of freedom. Model selection was performed using AIC. Chronological age never improved model fit so it was omitted from all models.
Results
Learning During Training
In Figure 1, we present the raw data as the mean proportion of referents correctly selected per cycle for the two diagnostic groups in each of the four years. In all years, both groups performed significantly better than chance by the end of cycle 1 (Table S1). When examining referent selection accuracy across each cycle of training, there were main effects of diagnostic group, with the TLD group averaging 33% better learning than the DLD group, and year, such that word learning abilities improved by 6.6% each year (Table 3). There was no effect of sex and no interactions involving diagnostic group.
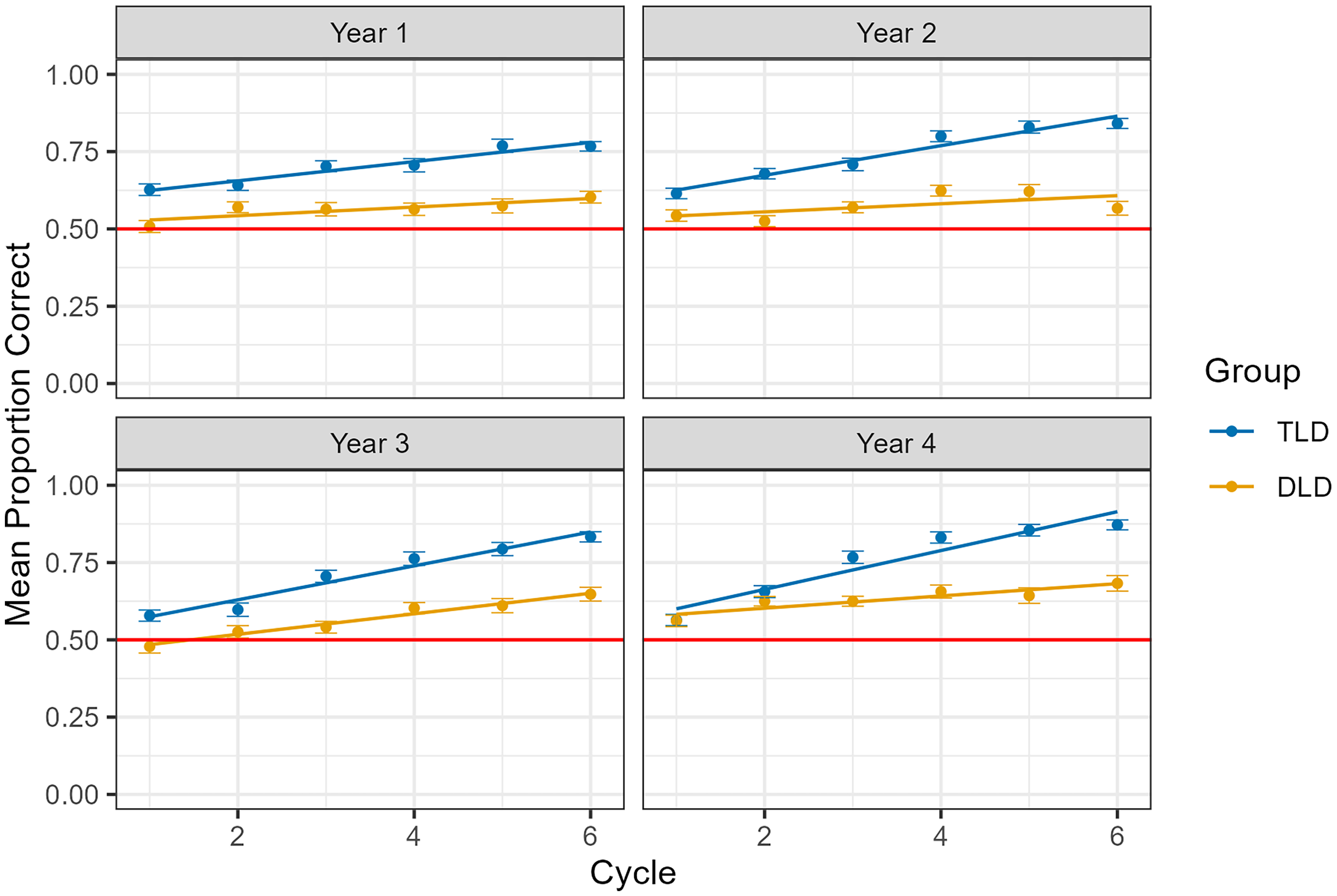
Mean proportion of correct referent selections during cross-situational learning by diagnostic group (developmental language disorder, typical language development) and cycle (1–6). Note that chance is .5. Error bars refer to standard error.
Bayesian Logistic Regression Assessing the Effects of Diagnostic Group, Sex, Year, Cycle and Lag on Cross-Situational Learning.
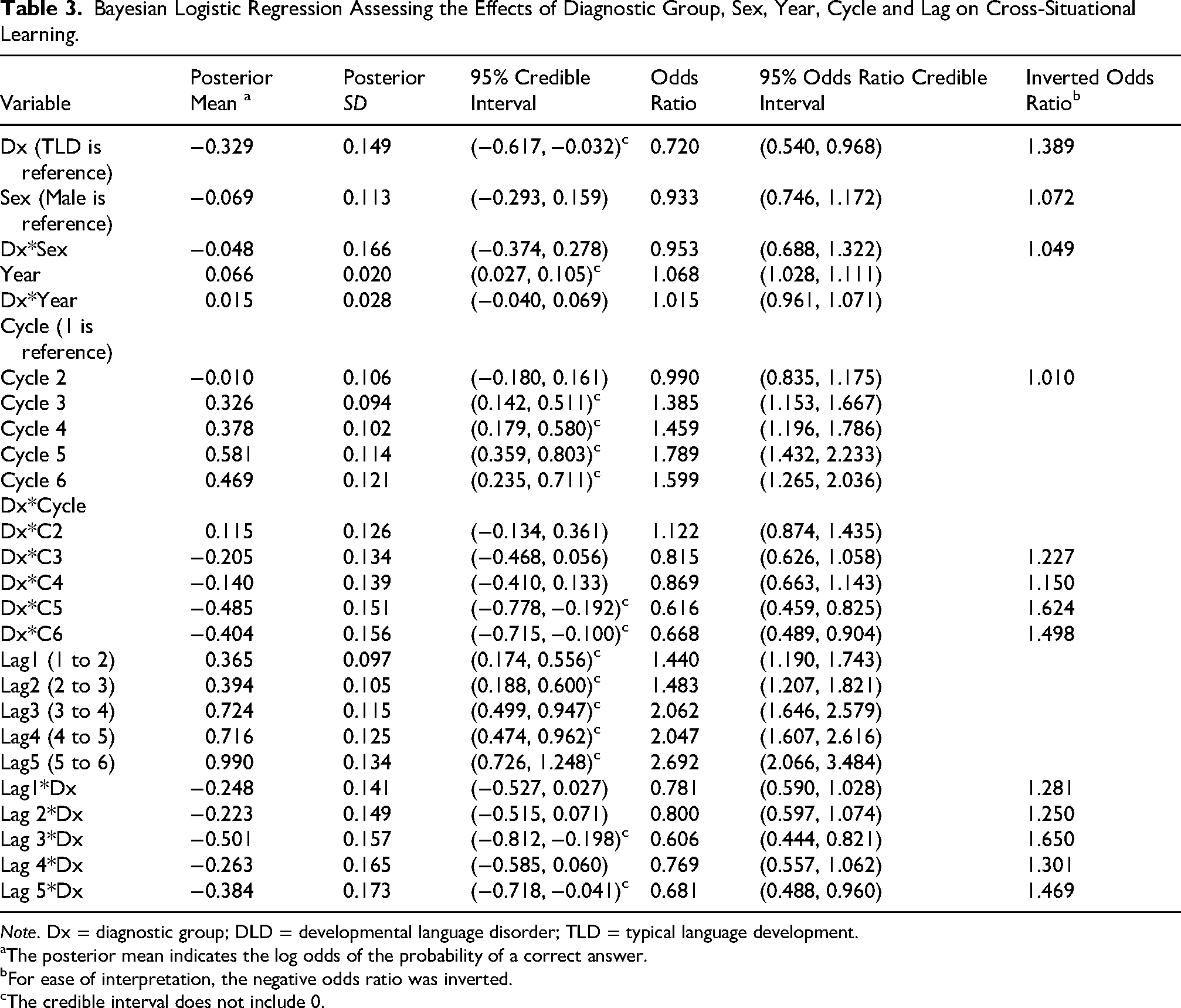
Note. Dx = diagnostic group; DLD = developmental language disorder; TLD = typical language development.
The posterior mean indicates the log odds of the probability of a correct answer.
For ease of interpretation, the negative odds ratio was inverted.
The credible interval does not include 0.
There was an effect of cycle: performance on training cycle 2 did not differ from training cycle 1, but performances on cycles 3, 4, 5, and 6 were reliably higher than cycle 1. There was an interaction between diagnostic group and cycle: Relative to cycle 1, the two groups demonstrated similar changes in level of accuracy on cycles 2, 3, and 4, but on cycles 5 and 6, the TLD group outperformed the DLD group (Table 3). In other words, the gap between the DLD and TLD group was largely the result of the TLD group demonstrating better learning by the end of training (Figure 2).
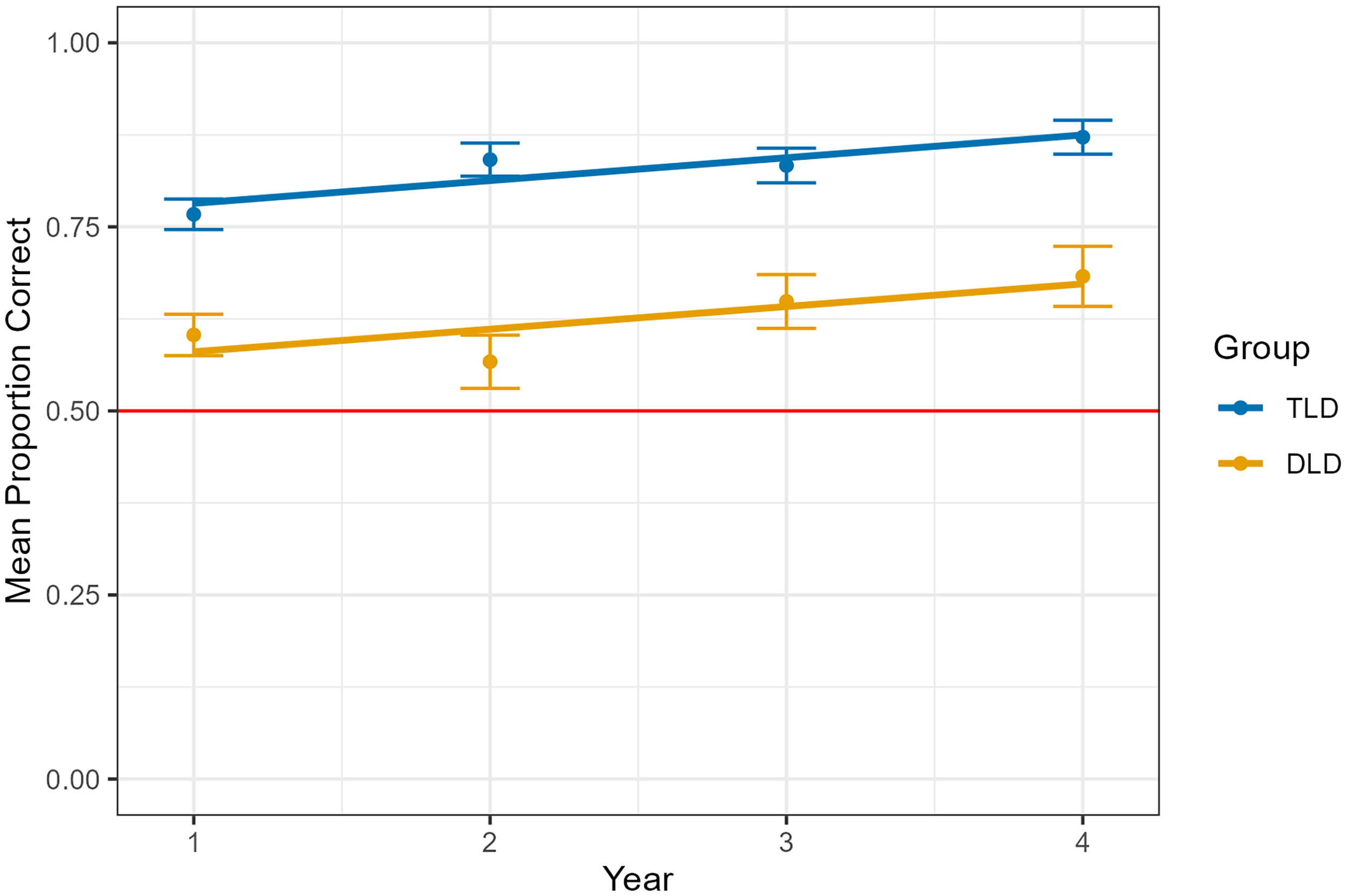
Mean proportion of correct referent selections on the final cycle of cross-situational learning by diagnostic group (developmental language disorder, typical language development) and year. Chance is .50. Error bars refer to standard error.
There was a consistent effect of lag: accuracy on one cycle predicted accuracy on the next (Table 3). So, for example, participants were more likely to select a target correctly on cycle two if they had correctly selected that same target on cycle 1, more likely to select a target correctly on cycle three if they had correctly selected that same target on cycle 2, and so on. This suggests that the participants were accruing knowledge as they progressed through the learning cycles. However, there was an interaction between diagnostic group and lag such that the TLD group demonstrated a larger lag effect (i.e., greater accrual) than the DLD group in the lags between cycles 3–4 and 5–6. The interaction helps to explain why the DLD group had lower performance by the end of the training.
Learning Outcomes
Form
With the exception of the DLD group in Year 1, all performances on the 3AFC form recognition probe were significantly higher than chance (Table S2).
A linear mixed effects model revealed main effects of diagnostic group and year (Table 4, Figure 3). The DLD group averaged ∼17% lower accuracy compared to those in the TLD group, holding year and sex constant. On average, the proportion of correct scores increased by about 2% each year, holding diagnostic group and sex constant.
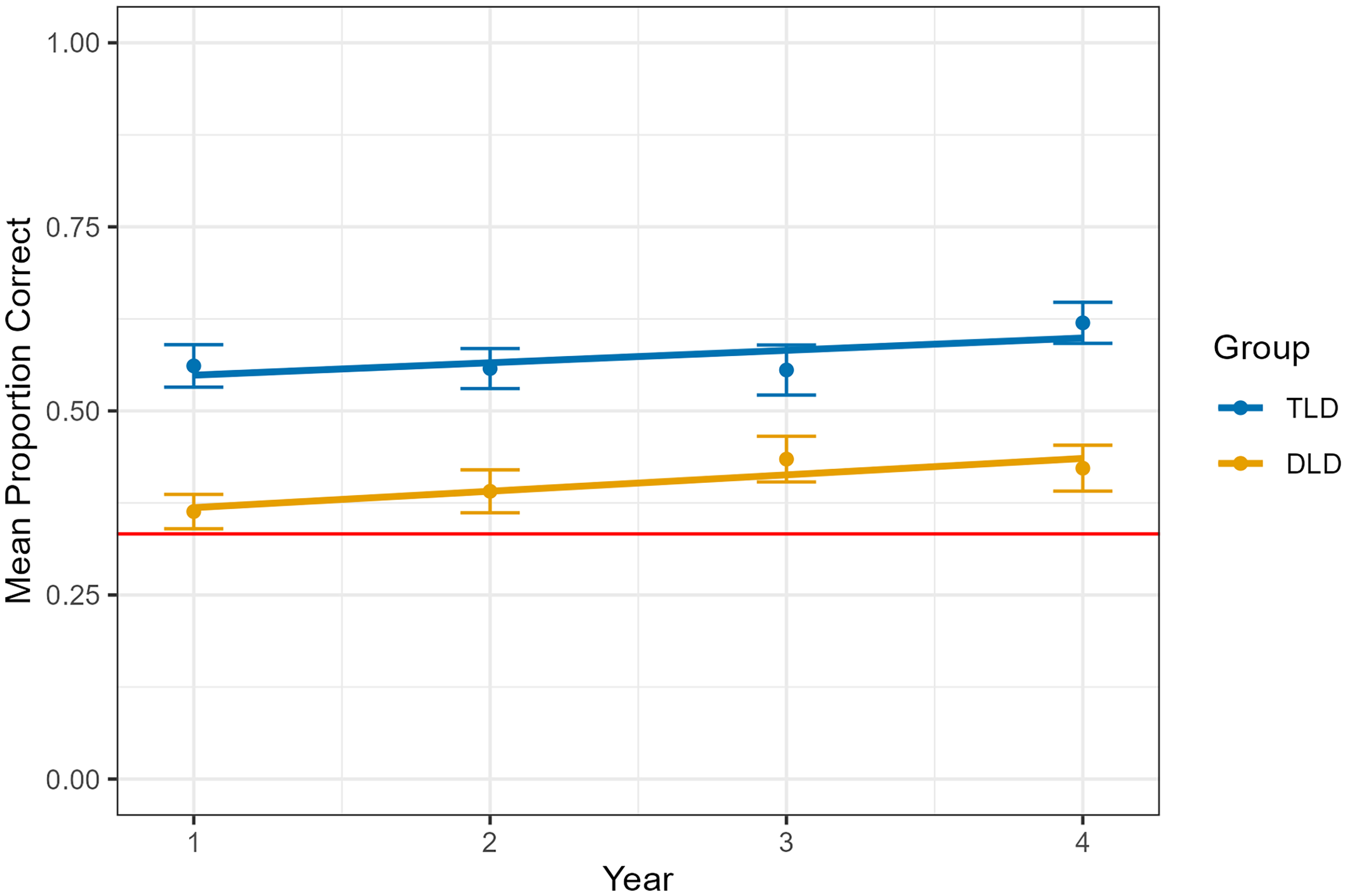
Growth in form recognition after cross-situational learning by diagnostic group (developmental language disorder, typical language development) and year. Error bars refer to standard error.
Fixed Effects Model of Form Recognition.
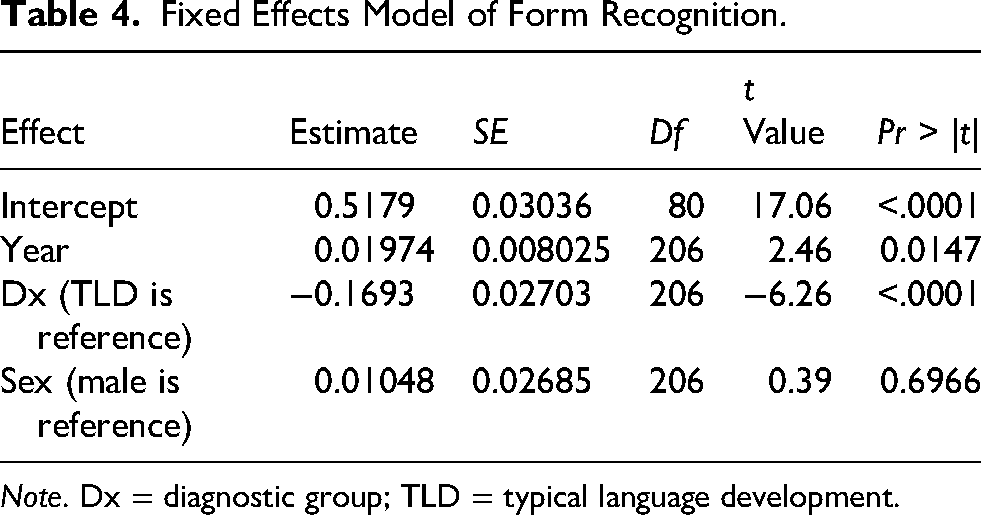
Note. Dx = diagnostic group; TLD = typical language development.
Extant receptive vocabulary and visual working memory were significant predictors of form learning outcomes (Table 5) and, with these scores in the model, the effect of diagnosis was no longer significant. The effect of year remained.
Fixed Effects Model of Form Recognition with Predictors Added.
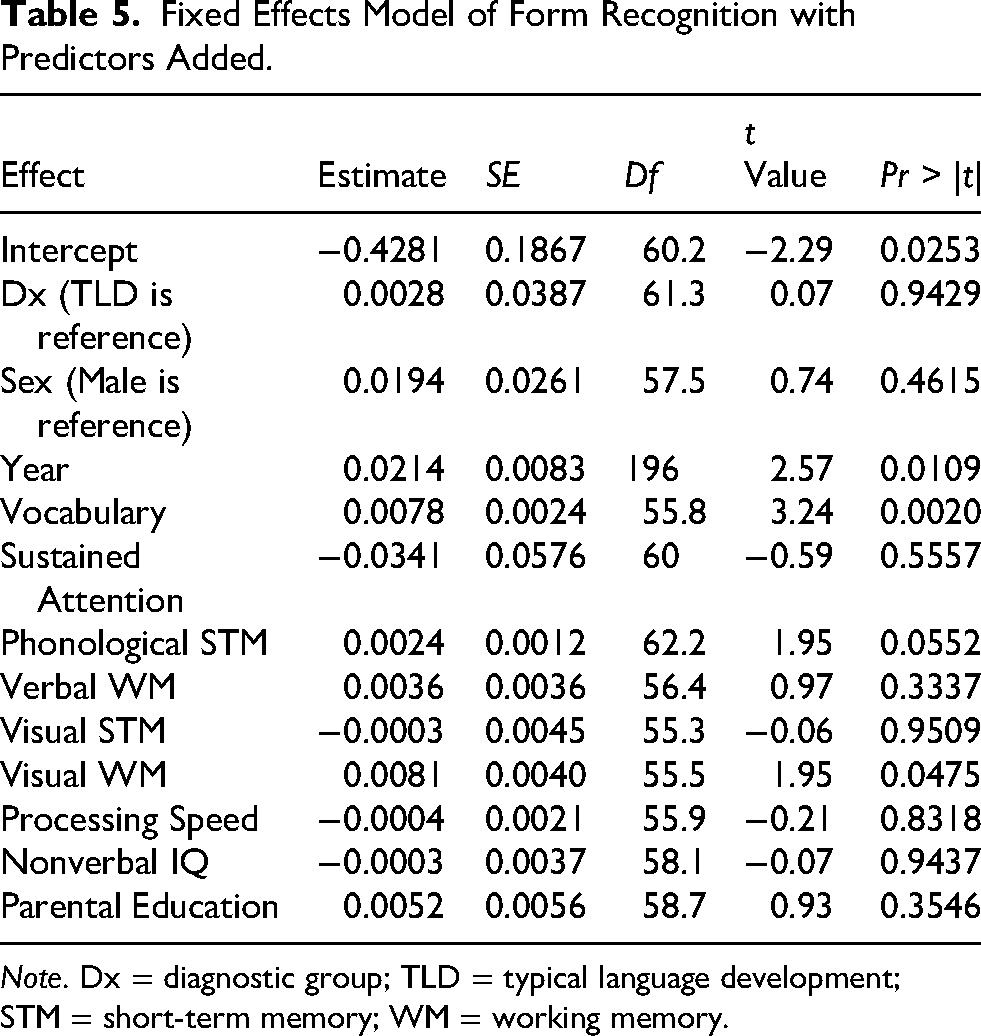
Note. Dx = diagnostic group; TLD = typical language development;
STM = short-term memory; WM = working memory.
Link
Both diagnostic groups performed above chance in all years (Table S3). There was a statistically significant difference between diagnostic groups and an interaction between diagnostic groups and year (Table 6), reflecting a slower rate of improvement in scores on the part of the DLD group (Figure 4). Female sex was also associated with a lower baseline proportion of correct scores.
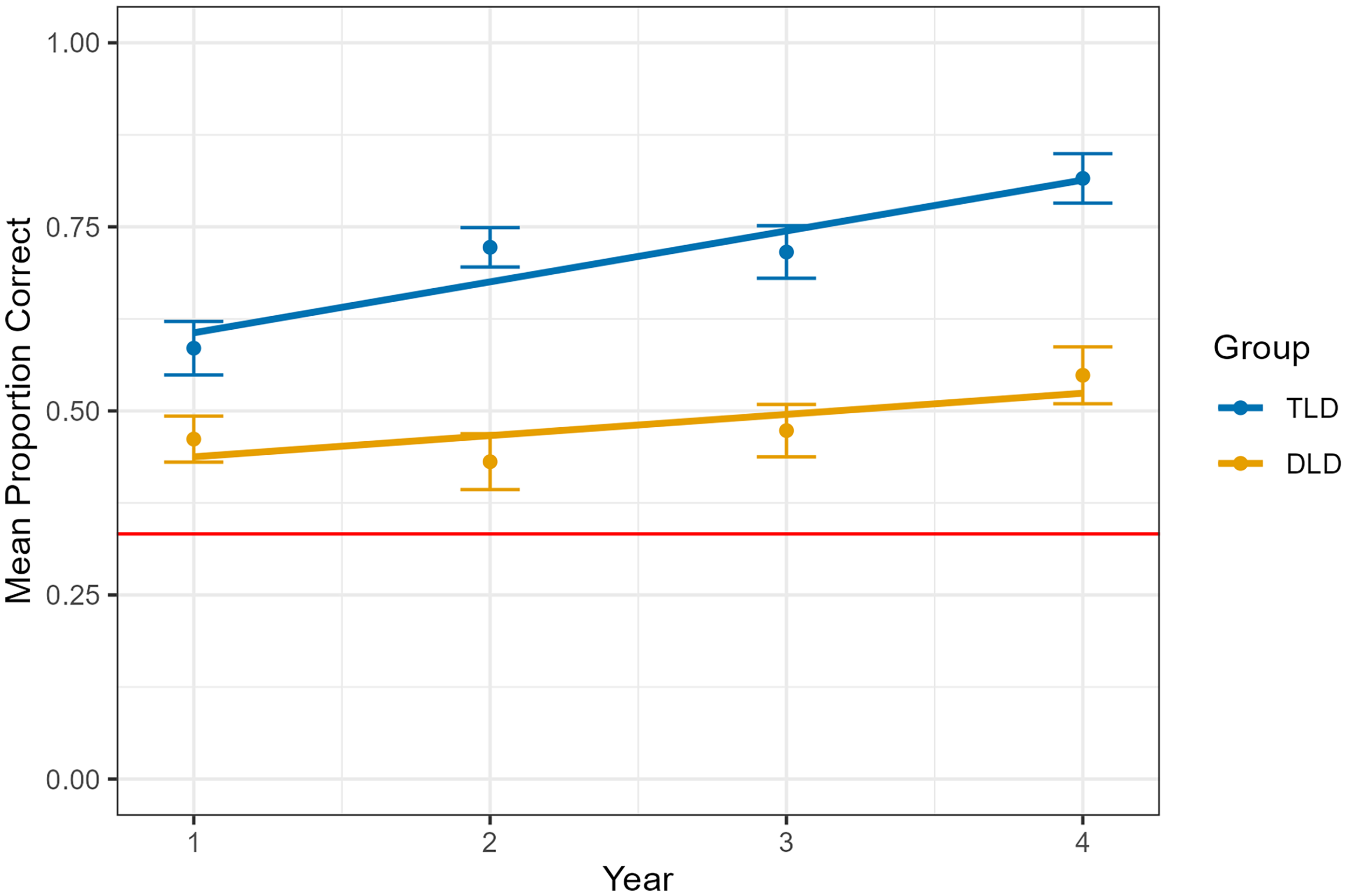
Growth in link recognition after cross-situational learning by diagnostic group (developmental language disorder, typical language development) and year. Error bars refer to standard error.
Fixed Effects Model of Link Recognition After Cross-Situational Learning.
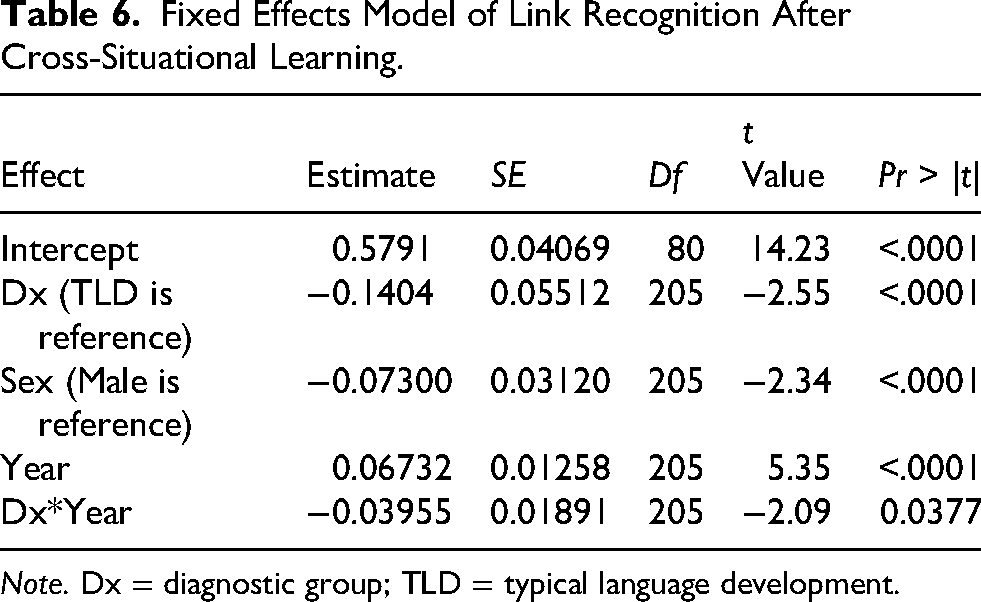
Note. Dx = diagnostic group; TLD = typical language development.
To understand the diagnostic group x year interaction, we compared the differences in the least squares means for each year and diagnostic group (Table S4). There was a significant difference in the mean proportion of correct scores between the DLD and TLD diagnostic groups at each year, with the DLD group consistently showing lower expected proportions; however, this disparity increased over time, from approximately 18% lower in the first year to nearly 30% lower by the fourth year, for a mean of 24% lower compared to the TLD group. Although the mean scores of the DLD group improved over time, a 1-year increase in time was associated with a 3.9% widening of the gap between the DLD and TLD groups.
Extant receptive vocabulary, phonological short-term memory, and verbal working memory scores accounted for significant variance in link learning (Table 7). With these scores in the model, the effects of diagnosis and sex were no longer significant, but the effect of year and the interaction between year and diagnosis remained.
Solution for Fixed Effects Model of Link Recognition After Cross-Situational Learning with Predictors Added.
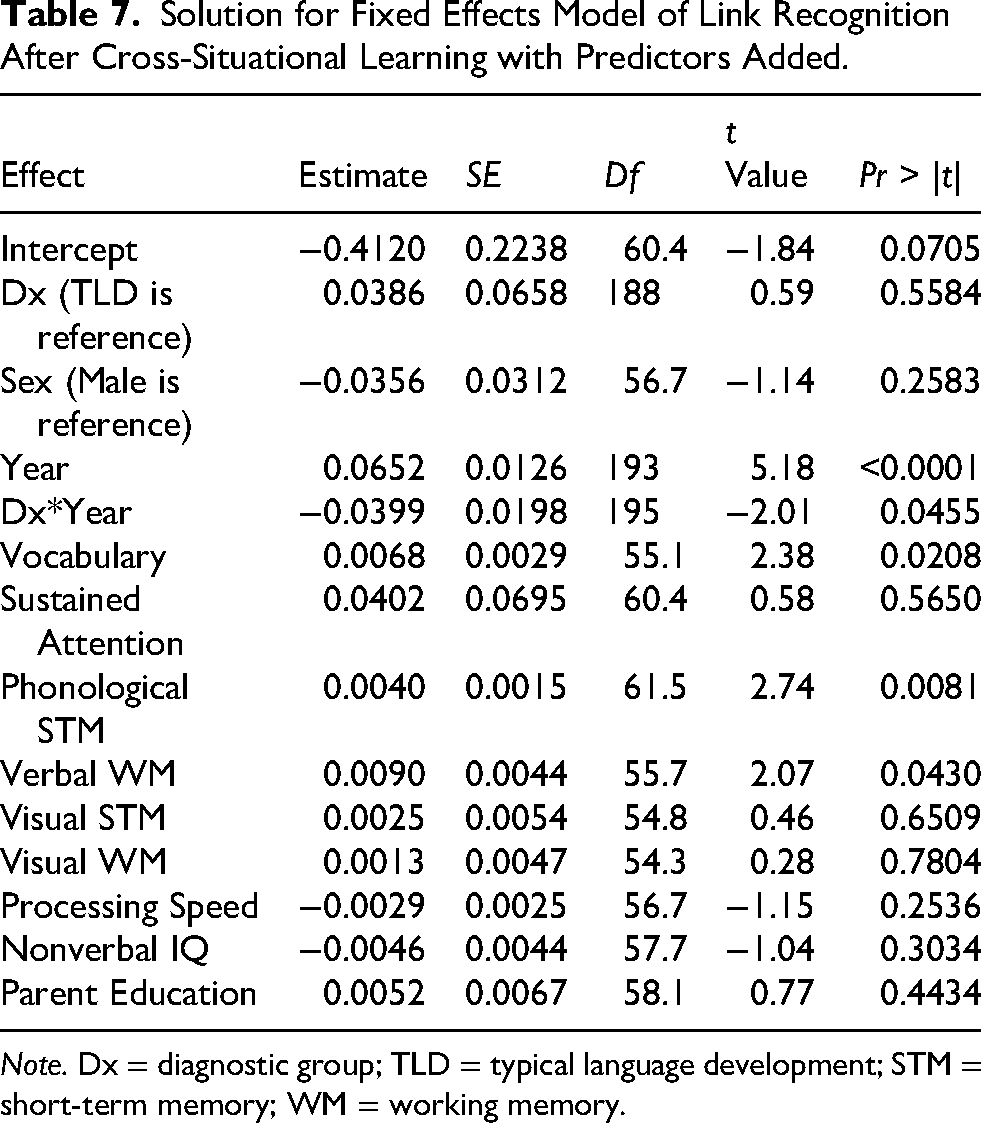
Note. Dx = diagnostic group; TLD = typical language development; STM = short-term memory; WM = working memory.
Study 1 Summary
As predicted, the DLD group demonstrated less accurate word-to-referent linking than the TLD group during cross-situational learning, although the gap was not evident until the final two training cycles. Also, as predicted, the DLD group demonstrated lower form and link recognition outcomes on the 3AFC probes administered immediately after training. Although the DLD group performed above chance on link learning but not form learning in Year 1, the mean size of the performance TLD-DLD gap was somewhat smaller for form learning (17%) than link learning (24%). Both diagnostic groups demonstrated growth in form and link learning over the four years, but, relative to the TLD group, the link learning abilities of the DLD group grew more slowly. Finally, we predicted that performance would vary with extant vocabulary size and that prediction held; however, form learning also varied with visual working memory and link learning also varied with phonological short-term memory and verbal working memory. With cognitive scores in the statistical model, the TLD-DLD performance gap was no longer significant, but the effects of time remained.
Study 2: Learning via Ostensive Naming and Mutual Exclusivity
Many studies of word learning among individuals with DLD involve direct instruction via ostensive naming. The examiner simultaneously presents a new word and its referent, making the learning goal, as well as the word-to-referent link, obvious. Direct instruction contexts are frequent in educational and clinical environments; however, everyday environments primarily comprise indirect learning contexts (Bloom, 2002; Nagy et al., 1985).
In indirect contexts, the primary goal is typically to communicate rather than to teach and learn a new word. When the communication partner utters an unfamiliar word, the referent is often ambiguous, so there is a greater burden on the learner to discern the correct linking. In Study 1, we examined one such context, cross-situational learning; here, we will examine another, mutual exclusivity.
In Carey's foundational work on children's use of the mutual exclusivity heuristic, a teacher asked her preschoolers, “Can you get me the chromium tray, not the red one, the chromium one?” (Carey, 2010, p. 185). When encountering a new word in such a situation, learners commonly assume the new word refers to an unfamiliar referent, rather than a referent for which they already have a word-to-referent link (see meta-analysis of this phenomenon in Lewis et al., 2020). Because they knew the meaning of “red,” the preschoolers were able to infer that chromium must refer to the olive-green tray that sat alongside the red one.
Marulis and Neuman (2010) conducted a meta-analysis of 67 vocabulary teaching studies involving preschoolers and kindergartners with TLD. They found that, relative to baseline, direct instructional contexts (that included not only ostensive naming but definitions and examples) yielded large effects on learning (Hedge's g = 1.11). In contrast, indirect contexts, which involved new words embedded in activities or story books (where more ambiguity and a greater need for inference exists), yielded moderate effects on learning relative to baseline (Hedge's g = .62).
During Year 1, as reported in Pomper et al. (2022), 36 of the current participants with DLD and all 45 of those with TLD were randomly assigned to a direct ON context or an indirect ME context. Both contexts involved five exposures to each of the 12 target word-referent pairs, five being the number of exposures required during piloting to keep learners away from floor or ceiling performance.
In the direct ON instructional context, the novel pictured referent appeared alone as its name was presented. In the indirect ME instructional context, the novel pictured referent appeared alongside a familiar referent from the same semantic category as the name of the novel referent was presented. One aim was to determine whether the DLD and TLD groups benefited equally from the more direct instruction.
After training, we administered the 3AFC form recognition probe followed by the 3AFC link recognition probe. The TLD group demonstrated stronger form and link learning in the ON context than the ME context, but the benefit of ostensive naming for the DLD group was limited to link learning only. The DLD group performed at chance on form recognition in both the ON and ME contexts. Within-group variance in encoding was accounted for by phonological short-term memory abilities.
Hypotheses and Predictions
In Study 2, we repeated the training and outcome measures summarized above in each year to determine the extent to which the two diagnostic groups improved their word learning abilities over the four years of the study. We hypothesized that the DLD group would demonstrate weaker word learning outcomes than the TLD group, but that the rate of growth would be similar for the two diagnostic groups; therefore, we predicted no group x year interaction.
Given Pomper et al. (2022), we predicted:
The TLD group will perform with higher accuracy than the DLD group on both encoding outcomes: 3AFC form and 3AFC link. The effect of diagnostic group will be larger when the learning outcome is measured by form recognition than link recognition. Link outcomes will be better in ON than ME contexts for both groups. For word form outcomes, we predict a diagnostic group x context interaction because only the TLD group will derive the relative benefit of ostensive naming instruction. There will be a main effect of year such that both diagnostic groups demonstrate improved learning outcomes over time.
We also aimed to understand mechanisms of learning in the two diagnostic groups. Given outcomes in Pomper et al. (2022), we predicted that performance would vary with phonological short-term memory. As in Study 1, we also tested the relationships between learning outcomes and socioeconomic status as well as verbal and visual cognitive variables including receptive vocabulary, verbal working memory, visual short-term and working memory, sustained attention, processing speed, and nonverbal IQ.
Method
The participants were 38 children with DLD (16 girls) and 45 children with TLD (25 girls), the same children who participated in Study 1. Individuals from each group were randomly assigned to either the ON or ME contexts. Note that the random assignment did not yield well-matched groups on all variables (Table 8). The children with DLD who were assigned to ME had significantly better verbal memory scores than those assigned to ON. The children with TLD who were assigned to ON had significantly better scores on phonological- and visual short-term memory than those assigned to ME. That said, we entered these variables into the second regression model for all outcomes, thereby accounting for any effect that these differences had on learning outcomes.
Comparison of Intake Characteristics of Subgroups Assigned to the Ostensive Naming (oN) or Mutual Exclusivity (ME) Context.
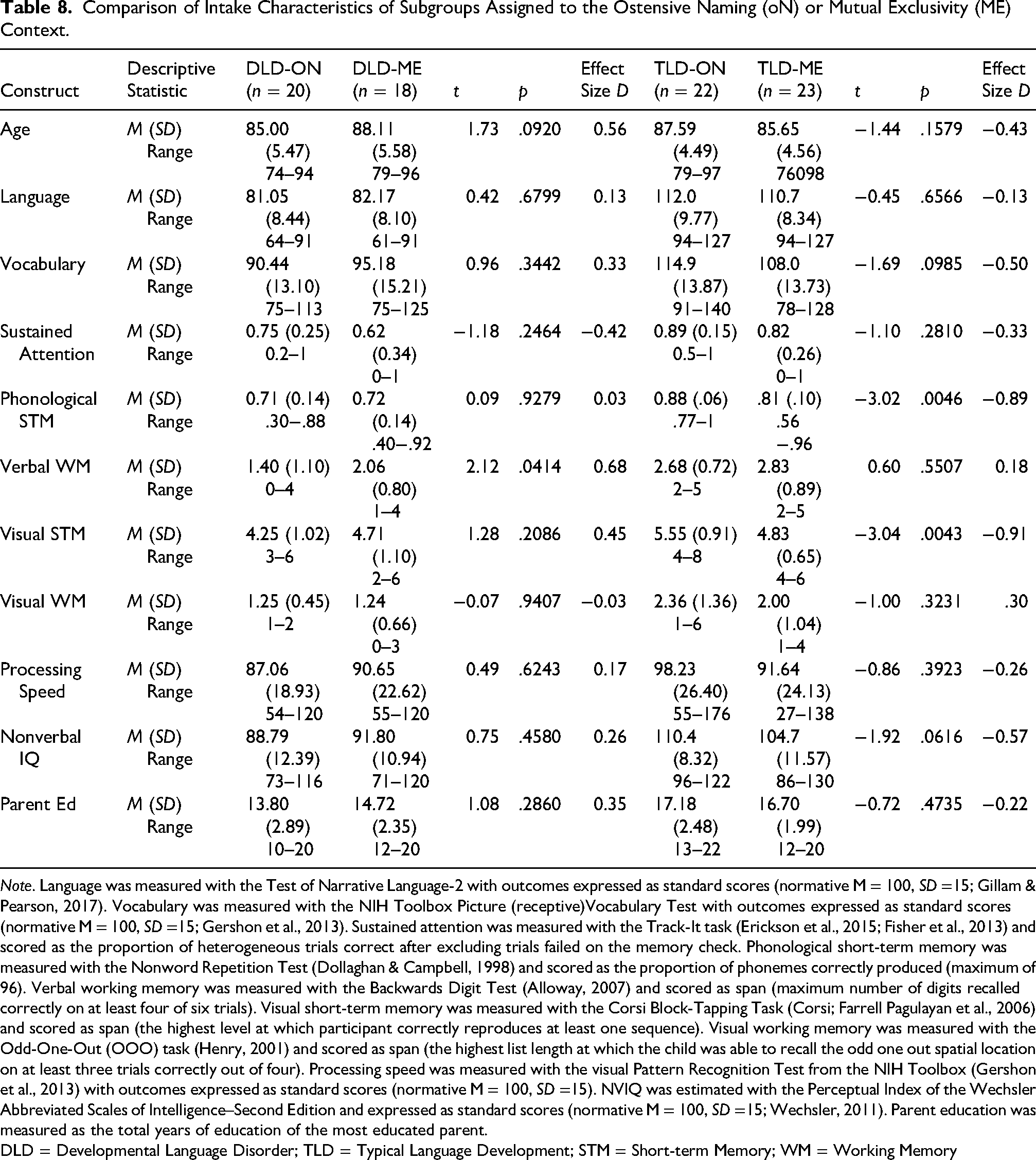
Note. Language was measured with the Test of Narrative Language-2 with outcomes expressed as standard scores (normative M = 100, SD =15; Gillam & Pearson, 2017). Vocabulary was measured with the NIH Toolbox Picture (receptive)Vocabulary Test with outcomes expressed as standard scores (normative M = 100, SD =15; Gershon et al., 2013). Sustained attention was measured with the Track-It task (Erickson et al., 2015; Fisher et al., 2013) and scored as the proportion of heterogeneous trials correct after excluding trials failed on the memory check. Phonological short-term memory was measured with the Nonword Repetition Test (Dollaghan & Campbell, 1998) and scored as the proportion of phonemes correctly produced (maximum of 96). Verbal working memory was measured with the Backwards Digit Test (Alloway, 2007) and scored as span (maximum number of digits recalled correctly on at least four of six trials). Visual short-term memory was measured with the Corsi Block-Tapping Task (Corsi; Farrell Pagulayan et al., 2006) and scored as span (the highest level at which participant correctly reproduces at least one sequence). Visual working memory was measured with the Odd-One-Out (OOO) task (Henry, 2001) and scored as span (the highest list length at which the child was able to recall the odd one out spatial location on at least three trials correctly out of four). Processing speed was measured with the visual Pattern Recognition Test from the NIH Toolbox (Gershon et al., 2013) with outcomes expressed as standard scores (normative M = 100, SD =15). NVIQ was estimated with the Perceptual Index of the Wechsler Abbreviated Scales of Intelligence–Second Edition and expressed as standard scores (normative M = 100, SD =15; Wechsler, 2011). Parent education was measured as the total years of education of the most educated parent.
DLD = Developmental Language Disorder; TLD = Typical Language Development; STM = Short-term Memory; WM = Working Memory
Stimuli and data collection for Study 2 mirrored Study 1. The same frequentist data analysis approaches described in Study 1 also applied to Study 2.
Results
Form
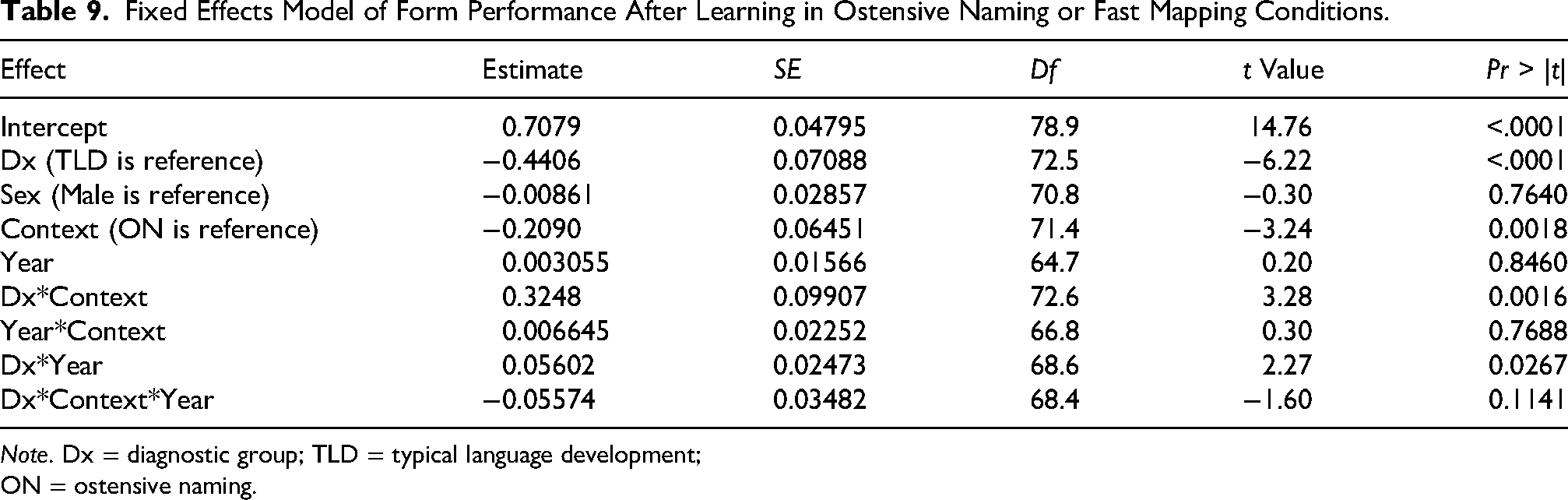
Both diagnostic groups performed above chance on the 3AFC form recognition probe in all years except for the DLD group in Year 1 (Table S5).
Overall results for form appear in Figure 5 and Table 9. There were main effects of diagnostic group favoring TLD and context favoring ON. The effect of the diagnostic group was qualified by two interactions. First, as predicted, there was an interaction between diagnostic group and context (Figure 5, Table S6), reflecting a larger gap between the ME and ON contexts for the TLD group (∼19%) than for the DLD group (<1%). The TLD group, but not the DLD group, benefitted from the direct teaching offered in the ON context. Second, and contrary to prediction, there was also an interaction between diagnostic group and year (Table S7), reflecting steeper growth in the DLD group that served to reduce the TLD-DLD performance gap from ∼25% to ∼17% over the course of the study.
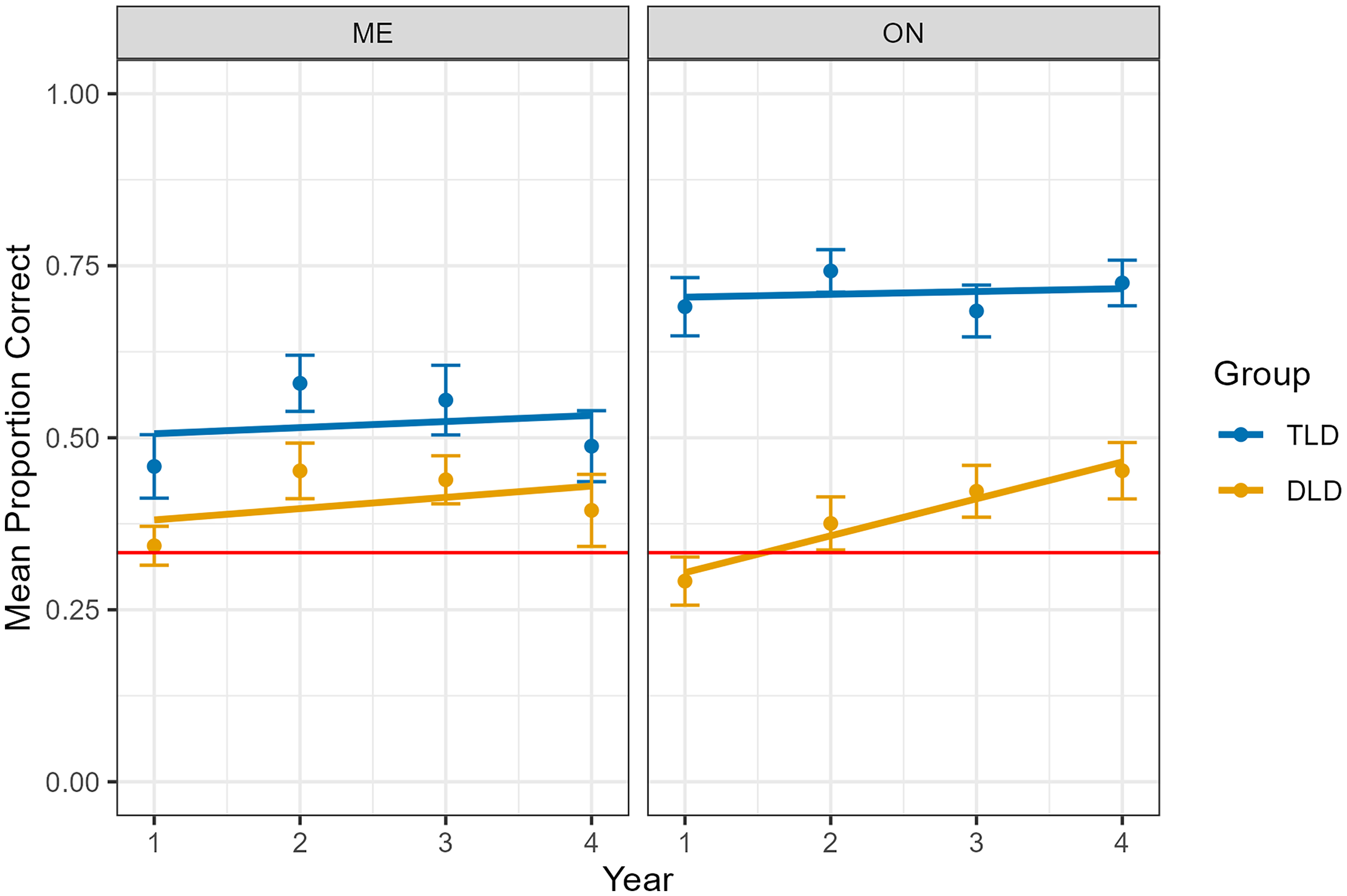
Growth in form recognition after learning in ostensive naming and mutual exclusivity contexts by diagnostic group (developmental language disorder, typical language development) and year. Error bars refer to standard error.
Fixed Effects Model of Form Performance After Learning in Ostensive Naming or Fast Mapping Conditions.
Note. Dx = diagnostic group; TLD = typical language development;
ON = ostensive naming.
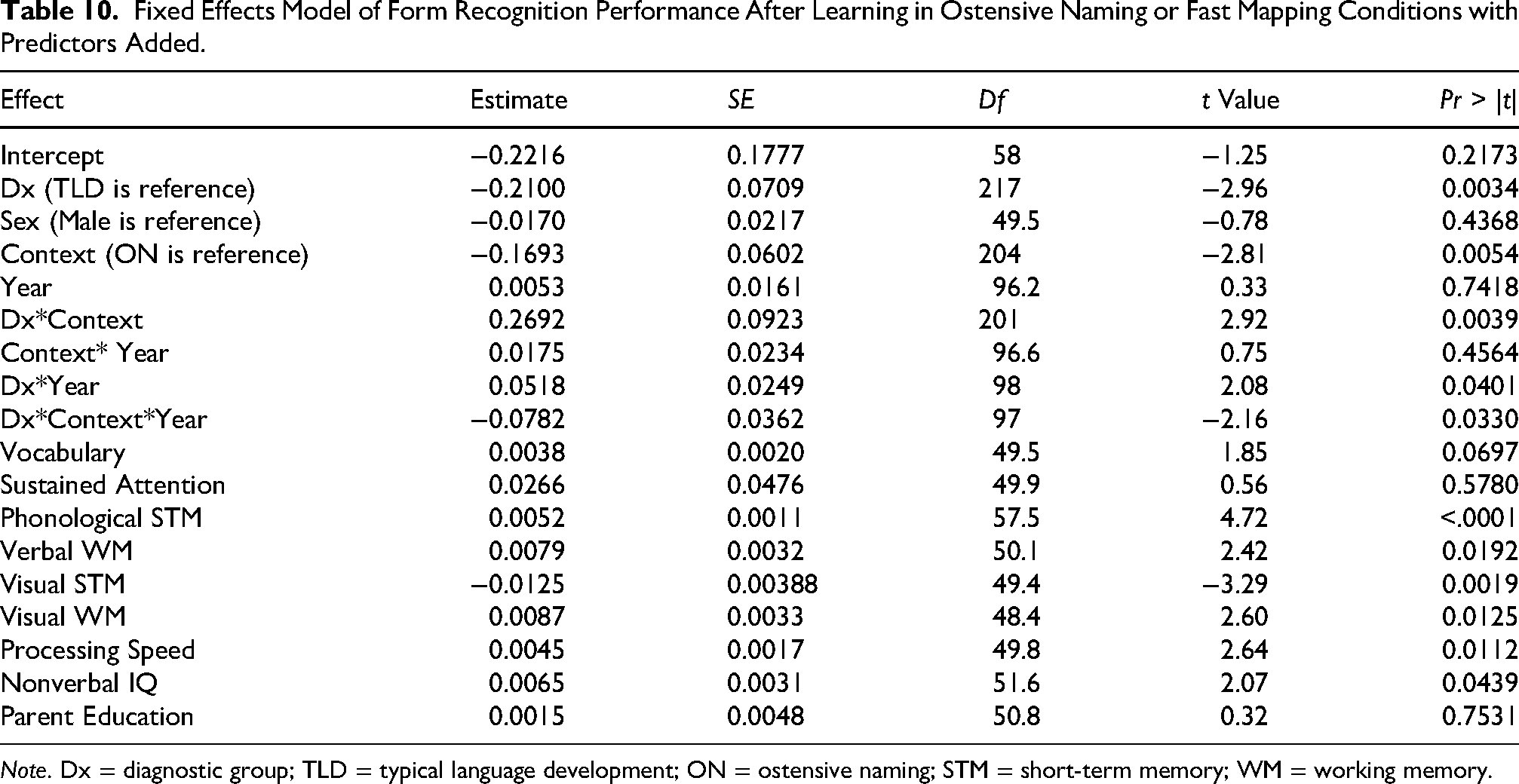
In Table 10, we ran the model again with all predictor variables included. All of the significant effects of the prior model remained, but a number of additional effects were obtained. First, the steeper growth of the DLD group in the ON context was now evinced by a three-way interaction between context, year, and diagnostic group (Table S8). Numerous cognitive abilities contributed to form learning. These were phonological short-term memory, verbal working-memory, visual short-term and working memory, speed of visual processing, and nonverbal IQ, which is also a largely visual task.
Fixed Effects Model of Form Recognition Performance After Learning in Ostensive Naming or Fast Mapping Conditions with Predictors Added.
Note. Dx = diagnostic group; TLD = typical language development; ON = ostensive naming; STM = short-term memory; WM = working memory.
Link
Both diagnostic groups performed above chance on the 3AFC link recognition task in all years (Table S9).
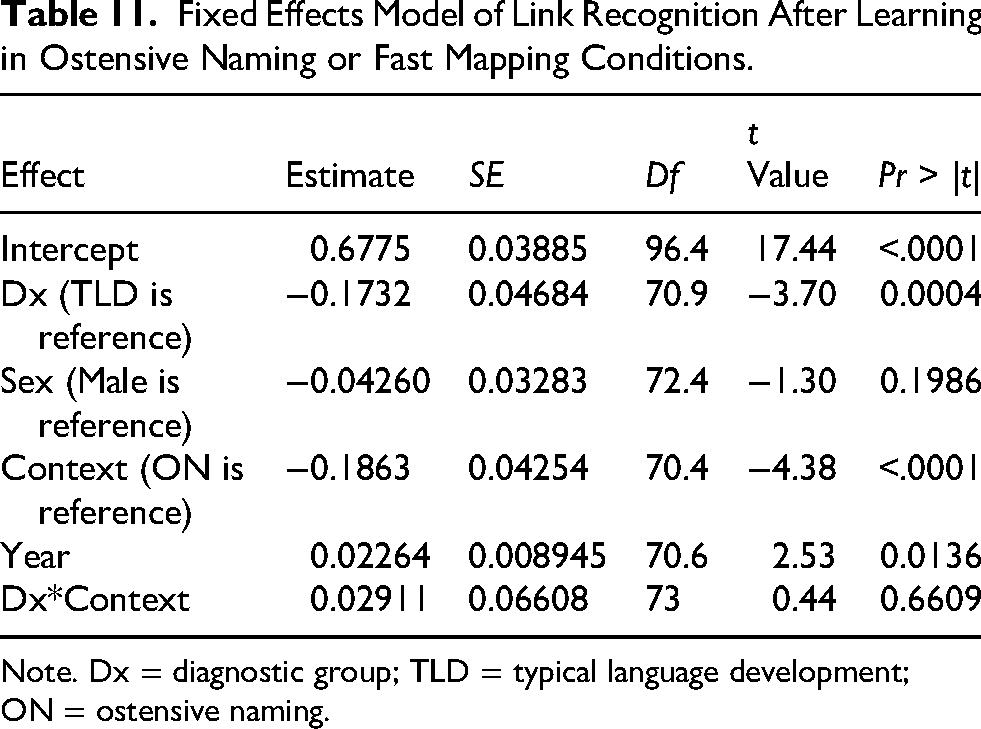
Link accuracy varied with diagnostic group, context, and year (Table 11, Figure 6). On average, the DLD group was ∼17% lower than the TLD group, and performance in the ME context was ∼19% lower than the ON context. Although the gap between the diagnostic groups was numerically larger in the ON condition, the diagnostic group by context interaction was not significant. Growth averaged 2.3% per year. The interactions by year were not significant and were removed from the final model.
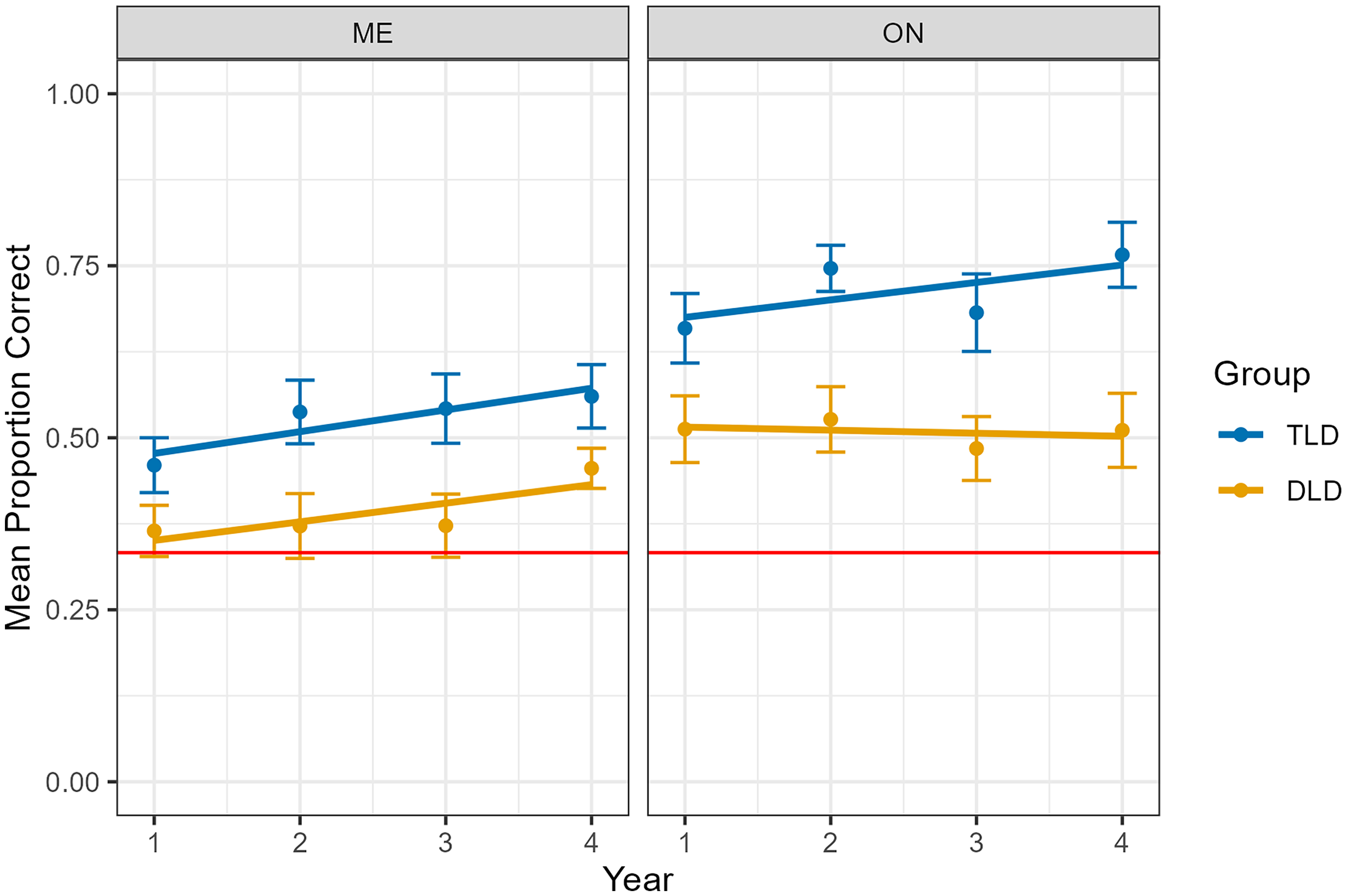
Growth in link recognition after learning in ostensive naming and mutual exclusivity contexts by diagnostic group (developmental language disorder, typical language development) and year. Error bars refer to standard error.
Fixed Effects Model of Link Recognition After Learning in Ostensive Naming or Fast Mapping Conditions.
Note. Dx = diagnostic group; TLD = typical language development;
ON = ostensive naming.
Receptive vocabulary predicted link recognition outcomes, and with all of the cognitive variables added to the model, the effect of diagnostic group was no longer significant, but the effects of year and context remained (Table 12).
Fixed Effects Model of Link Recognition After Learning in Ostensive Naming or Fast Mapping Conditions with Predictors Added.
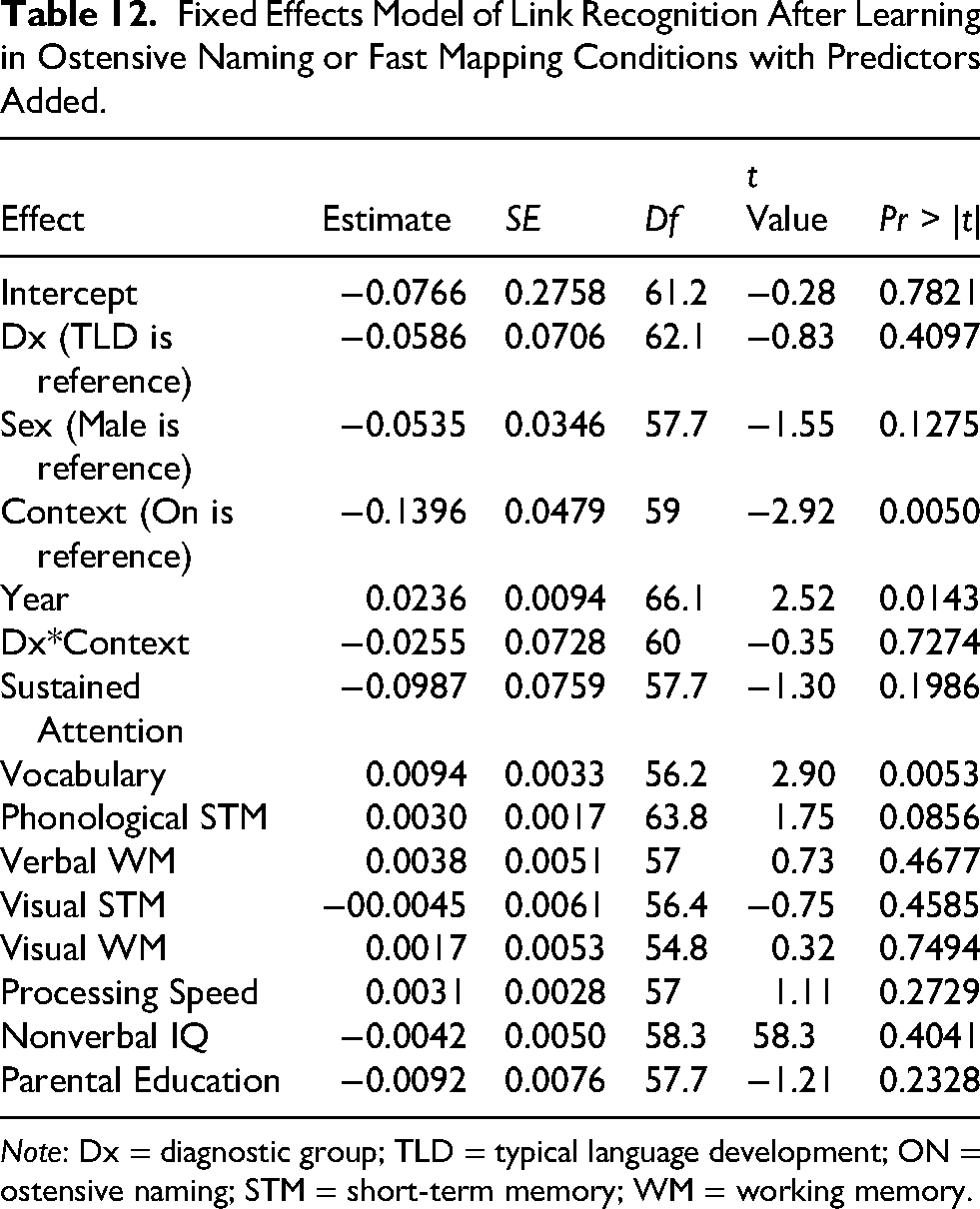
Note: Dx = diagnostic group; TLD = typical language development; ON = ostensive naming; STM = short-term memory; WM = working memory.
Summary of Study 2
As predicted, the TLD group performed with higher accuracy than the DLD group on both encoding outcomes: 3AFC form and 3AFC link. Also, as predicted, both diagnostic groups demonstrated growth in link learning abilities over time; however, form learning abilities grew only for the DLD group and only in the ON context.
We had predicted a larger TLD-DLD performance gap for form than link learning, but that was the case in the ON context only. The TLD group, but not the DLD group demonstrated better form learning in the ON context than the ME context, thus the gap between the DLD and TLD groups in form learning was largest in the ON context.
Contrary to prediction, link learning varied significantly with extant receptive vocabulary size, not phonological short-term memory. Differences in receptive vocabulary (and the other cognitive variables in the model) reduced the TLD-DLD performance gap in link learning to a nonsignificant level, but the effects of time and context remained.
We were not able to account for the TLD-DLD performance gap (or year or context effects) in form learning, although numerous scores on verbal and visual cognitive tasks did predict form learning performance.
Discussion
Primary School Children with DLD Have Difficulty Learning Word Forms and Word-to-Referent Links
As a group, the children with DLD were weaker word learners than their age-mates who have typical language development. They performed less accurately on both form and link learning in all contexts—cross-situational, mutual exclusivity, and ostensive naming. Holding all other variables constant, effect sizes expressed as the difference in percent accuracy between the groups, ranged from a low of 12% to a high of 30% (Table 13). Given that the children were attempting to learn 12 words in each context, this equates to 1.4 to 3.6 fewer words for the DLD group, per year per context.
TLD-DLD Performance Gaps in Accuracy and Growth of Form and Link Learning Abilities.

Note. Gap sizes reflect mean performance difference per year in percentage points (calculated from beta values in linear mixed models, see calculations in the OSF project folder) and mean performance difference per year in number of words (calculated by multiplying the total number of words trained [12] by the relevant percentage value).
Negative numbers indicate that the DLD group value was lower than the TLD group value; positive numbers indicate that the DLD group value was higher than the TLD group value.
DLD = developmental language disorder; TLD = typical language development; wds = number of trained words
To provide perspective, consider that Segbers and Schroeder (2017) estimated that children typically learn 1,278 new nouns per year between Grades 1 to 4, inclusive, for a total of 5,111 new nouns acquired. If we consider only the TLD-DLD learning gap as measured by link recognition (the type of task that yielded the estimate in Segbers & Schroeder), we can conclude that children with DLD learn approximately 230 fewer nouns each year (1,278 [mean # of nouns learned] x .18 [mean size of TLD-DLD learning gap] = 230) or 920 fewer nouns from first to fourth grade (230×4 = 920). This conclusion is surely wrong in the absolute sense. We have likely overestimated the size of the learning gap in terms of learning ability. Although 12 words per day is a reasonable estimate of children's learning rate (Segbers & Schroeder, 2017), it would seldom be the case that children would attempt to learn 12 completely novel words within five or 10 min, the approximate length of our trainings. It is possible that a longer period of time in which to learn the 12 words would afford greater benefit to the DLD than the TLD group. On the other hand, we may have underestimated the size of the effect in terms of words learned because the Segber and Schroeder estimates of learning per year are more conservative than prior estimates (see Anglin et al., 1993). Moreover, we have limited this study to the learning of nouns and thus compared to estimates of the accrual of nouns but, of course, children also learn verbs, adjectives, and function words.
Context Matters
In the meta-analysis conducted by Kan and Windsor (2010), the effect size for the TLD-DLD gap in word form learning was smaller than for link or semantic learning; however, that finding may be artifactual given that outcome probes with differing task demands are frequently used to measures these various aspects of word knowledge. Indeed, in two previous studies where the type of outcome probe was controlled (Jackson et al., 2021; McGregor, Arbisi-Kelm et al., 2020), the TLD-DLD gap in form learning was larger than link or semantic learning.
In the current study, where all outcomes were measured with 3AFC recognition tasks, we found a third pattern: the relative difficulty of form vs. link learning varied with context (Table 13). The TLD-DLD gap for link learning varied from 14% to 24% across contexts; whereas the gap for form learning varied from 12% to 30%. In other words, form learning represented both the smallest challenge and the largest challenge for the DLD groups. Moreover, in the mutual exclusivity context, the TLD-DLD gap for form and link learning was nearly identical, 12% and 14%, respectively. When task type is held constant, as in the current study, there is no evidence to suggest that form is consistently more difficult to learn than link, or vice versa. That said, when form learning is tapped via naming tasks, the TLD-DLD gap tends to be especially large (e.g., Haebig et al., 2019; Leonard et al., 2019, 2021; Souto et al., 2025).
It is notable that the largest TLD-DLD gap was for form learning in the ostensive naming condition. At first blush, this finding may seem counterintuitive because task demands seem lower in the ostensive naming than mutual exclusivity or cross-situational contexts. Ostensive naming involves direct teaching. Compared to the other two contexts, it highlights the target referent in a more obvious manner and requires no inferences. Moreover, ostensive naming enables explicit learning because the goal is clear: try to remember these new words.
That said, the ostensive naming context allowed the learner to be passive whereas the mutual exclusivity and cross-situational contexts obligated a response on each training trial. That response was not an attempt at form retrieval but, rather, an attempt to link the form to its referent (in the cross-situational context) or to answer a question about the referent (in the mutual exclusivity context). Therefore, the smaller TLD-DLD form learning gap in the mutual exclusivity and cross-situational contexts had nothing to do with overt naming practice but, perhaps, the need to pay attention, engage with the material, and make decisions. Such “desirable difficulty” may have helped the learners with DLD to establish more, or more robust, encoding and retrieval routes, (Bjork, 1994; Bjork & Bjork, 2011; Vlach & Sandhofer, 2010). In McGregor, Gordon et al. (2017), we found a similar outcome. Adults with DLD and their peers with TLD learned novel words passively or actively (in this case via retrieval practice). When naming accuracy was probed the next day, there remained a significant TLD-DLD performance gap for the words trained passively, but the gap for words trained actively had closed. The problematic learning of word form targets in the context of passive exposure may be a signature of DLD (see also Leonard et al., 2021).
This finding holds clinical implications for assessment and treatment. First, it suggests a route to the development of effective dynamic assessments of DLD. In many dynamic assessments, a test-teach-retest approach is used. Given the results of the current study, a useful initial test could be a brief, indirect teaching episode (e.g., determining what the child can learn from several mutual exclusivity exposures). The teaching segment would involve direct instruction that requires only passive listening on the part of the child. The final test probes the word learning outcomes. The current study suggests that, relative to the mutual exclusivity exposures, a typical learner will show enhanced word form learning with direct albeit passive instruction, but a person with DLD will not.
Because this approach to dynamic assessment involves learning novel words, it should be robust across language communities. For example, Kapantzoglou et al. (2012) found that a link recognition probe (termed word identification in the study) administered after direct teaching of three novel words and their referents distinguished bilinguals with DLD and TLD with a sensitivity of 76.9% and a specificity of 80%. Dynamic assessment of word learning should also be robust across communities defined by socioeconomics. Although, on average, children from low-resource communities have lower scores on measures of extant vocabulary size than their better-resourced peers (Guo & Harris, 2000; Lervåg et al., 2019; Norbury et al., 2021; Sirin & Rogers-Sirin, 2005), this relationship does not extend to learning ability (Nikolaeva, 2025). In the current study, years of parent education, a proxy for socioeconomic environment, never predicted learning performance. In short, dynamic assessments are a way to pull apart language learning abilities from vocabulary knowledge as measured by static tests, which we know are often biased (e.g., Stankova et al., 2021; Stockman, 2010). For those who wish to use dynamic assessments with evidence-based cut-points to aid diagnosis, standardized options are available (Petersen et al., 2024; Seymour et al., 2005).
It may be constructive to consider language treatment in light of the finding that children with DLD benefit less from direct teaching than their peers with TLD. Language treatments involve “intentional, systematic actions taken to accelerate, modify, or compensate for inadequate performance, beyond the supports provided in a typical learning environment” (Ukrainetz, 2024, p. 43). The treatment context is often constructed to support explicit learning by ensuring awareness of the learning goal, focused attention, and visual supports. The weak response to ostensive naming in the current study does not mean that language interventionists should abandon direct instruction, but it does suggest that the approach to direct instruction matters. If children with DLD are to benefit, active practice (which was absent in the current study) may be required. Other best practices to consider are optimally sized target sets (which were high and equivalent for DLD and TLD groups here), rich vocabulary instruction (which was absent in the current study), and sufficiently high dosage (which was low and equivalent for DLD and TLD groups here) (Ardanouy et al., 2023; Frizelle et al., 2021; Gordon et al., 2025; Levlin et al., 2022; Peters-Sanders et al., 2019; Storkel et al., 2019). For example, substantially higher cumulative exposures (e.g., 36 in Storkel et al., 2017) may optimize some vocabulary outcomes in young children with DLD (Frizelle et al., 2021).
Would application of any of these best practices reduce the TLD-DLD learning ability gap, or shift both groups upward while preserving the gap? The question should be tested directly, but extant evidence suggests the former. The active learning conditions in McGregor, Gordon et al. (2017) and Haebig et al. (2019) did serve to close the gap. This is, of course, the goal of language intervention.
Primary School Children with DLD Demonstrate age-Appropriate Growth in Word Learning Abilities
We predicted that growth rates in word learning abilities would be similar in the two diagnostic groups and, in six of eight outcome measures, that prediction held. The exceptions were link learning in the cross-situational context, which was characterized by a more modest growth rate for the DLD than the TLD group—about 4% lower— and form learning in the ostensive naming context, which was characterized by a more robust for the DLD than TLD group—about 6% higher (Table 13). We conclude that word learning abilities among primary school students with TLD and DLD grow at roughly comparable rates and the comparable growth in the ability to learn words is key to understanding how children with DLD are able to accumulate vocabulary knowledge at rates that are similar to their peers (McGregor et al., 2013; Norbury et al., 2021; Rice & Hoffman, 2015) despite slower learning over brief time spans (Gray, 2003; 2004). Thus, it seems that, given equivalent opportunities, they learn fewer words, but, each year, both groups of learners improve in their ability to learn words by a similar amount. In that way, the gap between the groups that emerged at some point between the onset of first words and age 2;6 (Rice & Hoffman, 2015) remains consistent.
The pattern would not have to work out this way. Theoretically, children with DLD could catch up to their peers, but by age four or five years, language learning abilities canalize (Bornstein, 2014; Hayiou-Thomas et al., 2014; McKean et al., 2017; Ukoumunne et al., 2012). Thus, it is hard to imagine how primary school children with DLD would be able to develop at a faster rate than typical, even within the context of language intervention. Alternatively, they could not only start later but also develop word learning abilities more slowly and, as a result, the TLD-DLD vocabulary gap would widen over time. Although this is not the case during the primary and secondary school years, it is interesting that Rice and Hoffman (2015) found a relative slowing of vocabulary accrual on the part of adolescents and young adults with DLD. Perhaps the development of word learning abilities asymptotes in adulthood or, perhaps, after leaving school, adults find themselves in more disparate educational and professional environments such that opportunities to learn new words are more limited for learners with DLD. The ultimate test of this account will require a longitudinal study of the development of word learning abilities that spans toddlerhood to adulthood.
Phonological Short-Term Memory and Extant Receptive Vocabulary Partially Account for the Word Learning Problems That Characterize DLD
Although several aspects of visual cognition were relevant to word learning abilities in some contexts, phonological short-term memory and extant receptive vocabulary knowledge were the most robust predictors of performance. Phonological short-term memory, here measured by accuracy of nonword repetition, accounted for variation in the ability to learn word forms in the ON/ME contexts and links in the ON/ME and CS contexts (Table 14). This outcome accords with that reported in Adlof and Patten (2017). They provided children, ages 5 to 12 years, with direct training of six disyllabic words and their referents via a script that included semantic description, 21 exposures to each target word, and three chances to produce each word. After controlling age and extant vocabulary knowledge, nonword repetition performance accounted for 8% of the variance in word form recognition (called phonological recognition in their study) and 13% of the variance in link recognition (called semantic recognition in their study).
Summary of Significant Predictors of Form and Link Outcomes in Cross-Situational (CS), Ostensive Naming (ON), and Fast Mapping (ME) Contexts.

Phonological short-term memory has long been recognized as critical to word learning (Archibald & Joanisse, 2013; Gathercole and Baddeley, 1990; Gathercole et al., 1997). Magnetoencephalography recordings made during word learning suggest that individuals with stronger phonological short-term memory abilities are better able than others to process longer words, resist interference during word processing, and learn words more quickly (Ylinen et al., 2020). Many, but not all, people with DLD have phonological short-term memory limitations (Archibald & Joanisse, 2009), and many, but not all, have word learning problems (Gray, 2004; McGregor, Arbisi-Kelm et al., 2017). Those with phonological short-term memory limitations and those with poor word learning are largely overlapping subsets of the population (Jackson et al., 2021).
Extant receptive vocabulary also accounted for variation in the ability to learn word forms (in the cross-situational context) and word-to-referent links (in the mutual exclusivity and ostensive naming contexts). This finding accords with Gray (2004) who reported that preschoolers’ scores on the Peabody Picture Vocabulary Test-III correlated with post-training comprehension outcomes when probed with a task akin to our link recognition probe as well as word form outcomes when probed with a naming task. Receptive vocabulary scores also correlated with word form recognition performance for newly learned object labels in a study of preschoolers with DLD and TLD conducted by Alt et al. (2004) and with word form production performance in a similar study by Jackson et al. (2016).
The relationship between word learning and vocabulary knowledge is reciprocal. The better the learner, the more words learned, and, conversely, the more extensive the word knowledge, the better the subsequent learning. The influence of extant vocabulary on subsequent vocabulary learning is evident in studies demonstrating, for example, that learning outcomes are better when target word forms are similar to known words and target referents are similar to known referents (Borovsky & Elman, 2006; Hoover et al., 2010; James et al., 2021; McKean et al., 2013; Vitevitch et al., 2014).
Receptive vocabulary and phonological short-term memory work together to support word learning, and this is increasingly the case beyond the preschool years (Baddeley, 2003). In the Embedded-Process Model (Cowan, 2017; 2022), short-term memory is a response to a change in the verbal environment, for example, hearing a word. That stimulus, once perceived, activates relevant knowledge in long term lexical store, including similar structures (e.g., partially shared segments, phonotactics, and prosodic patterns) and meanings (e.g., partially shared functions, physical features, roles in event structures). Comprehension occurs when the activated knowledge matches the input. Learning begins when the input and activated long-term representations do not fully match (Schwering & MacDonald, 2020). In the case of novel word learning, phonological short-term memory supports word form learning by maintaining active representations of individual phonemes in a precise order so that the whole can be mapped onto its referent. A child with a rich vocabulary and sufficient knowledge of the phonotactic properties of their language will have stronger, more robust activated long-term memories on which to encode the new word form and to situate its referent.
Although phonological short-term memory and extant receptive vocabulary size were robust predictors, word learning depends on a complex of additional mechanisms. Visual memory abilities and visual processing speed played a role in some cases, as did nonverbal IQ, which we measured with a visual matrices task (Table 14). Words are learned in a visual world and many word referents are physical objects, features of visual objects, or visually salient actions that must be parsed and linked to word forms. However, that does not make for a satisfactory explanation of the current results because the scores on visual measures accounted for variance in form learning, not link learning. One could argue that visual attention directed to the mouth of the speaker facilitates word form learning—and it does (Fort et al., 2012; Tsang et al., 2018)—but that too fails as an explanation here given that all word forms were presented by the computer in the auditory modality only.
While searching for an explanation, it is useful to consider that seemingly visual measures of cognitive ability engage other aspects of cognition including language (Lancaster et al., 2025). Moreover, verbalization boosts performance on visual tasks and children with DLD are less able than their peers with TLD to leverage verbal mediation to this end (Arslan et al., 2020). Thus, it is possible that the relationships between visual cognition and form learning abilities reduces to additional evidence of the role of verbal cognition.
Finally, it is important to note that the various cognitive processes considered in this longitudinal study of growth in word-learning ability do, themselves, grow over developmental time. Our measures were taken in Year 1 of the study and, thus, they provide a useful baseline of TLD-DLD differences in word-learning mechanisms and the extent to which those mechanisms are associated not only with concurrent but also later word-learning ability. In the future, it will be useful to determine whether these mechanisms develop at similar rates in the two groups and whether their contribution to word-learning remains stable over time.
Limitations and Future Directions
This study is limited in a number of ways. Ours was a small sample, thus it is imperative that our findings are replicated in the future. The slower growth rate for link learning in the cross-situational naming context and the faster growth rate for form learning in the ostensive naming context on the part of the DLD group, if replicated, require explanation. Differential growth rates in the underlying cognitive mechanisms that support link and form learning in these contexts would seem the right place to begin.
Another limitation is that the words to be learned were all labels for object referents. This was a good decision in that noun referents comprise the bulk of word learning in the age range sampled here (Segbers & Schroeder, 2017). However, one should not generalize conclusions based on noun learning to the learning of other word classes or referent types. A third limitation is that we covered only the first four years of formal education and, because word learning abilities change in a nonlinear fashion (Ravid et al., 2020), a longer longitudinal study of growth trajectories will be necessary if we are to fully understand the word learning limitations associated with DLD.
There also remains more work to be done if we are to understand the cognitive underpinnings of the word learning problem associated with DLD. A suitable explanation for the role of visual mechanisms is necessary. Moreover, in several instances, the effect of diagnostic group remained even after entering scores on the eight cognitive measures that we included based on our review of the literature, suggesting that there are yet other mechanisms that we have not accounted for.
The current outcomes also highlight the need to expand the variety of word learning contexts that are included in research studies. The overwhelming number of studies examining word learning in direct teaching contexts in the DLD literature may have skewed our understanding of word learning abilities in this population. Research conducted on incidental learning in more ecologically valid environments will be especially pertinent.
Finally, the form-learning difficulties of the DLD group in the direct teaching contexts suggest that we can leverage such contexts for dynamic assessments. We stress that, while dynamic assessments are essential for populations who are mis-served by current assessments of static knowledge, they are likely to be best practice for the assessment of all people with DLD. We must continue to develop dynamic assessments because these, by definition, tap learning ability. At its roots, DLD is a learning problem.
Conclusions
To conclude, in this the first longitudinal study of spoken word learning abilities in the DLD population, we have garnered evidence of robust gaps in learning ability relative to peers with TLD but, at least in the primary school years, roughly equivalent rates of improvement in those abilities. Both word forms and the linking of forms to their semantic referents are vulnerable learning targets, and children with DLD who present with weak phonological short-term memory and a small extant receptive vocabulary are more likely than others to demonstrate these learning problems. Finally, not all word learning contexts are equivalent and that variation turns out to be more important than we, as a field, had realized.
Supplemental Material
sj-docx-1-dli-10.1177_23969415261448861 - Supplemental material for Word Learning Ability Varies Across Contexts and Time: A Longitudinal Study of Primary School Children with Developmental Language Disorder
Supplemental material, sj-docx-1-dli-10.1177_23969415261448861 for Word Learning Ability Varies Across Contexts and Time: A Longitudinal Study of Primary School Children with Developmental Language Disorder by Karla K. McGregor, Nichole Eden, Timothy Arbisi-Kelm and Jacob Oleson in Autism & Developmental Language Impairments
Footnotes
Acknowledgments
We are forever thankful for the generosity of the children and caregivers who participated in this project over the course of four years. The project benefited from the input of Drs. Angela AuBuchon, Katherine Gordon, Justin Kueser, Julia Nikolaeva, Ron Pomper, Claire Selin, and Erin Smolak.
Ethical Considerations
Ethical approval: This research was approved by the Internal Review Board of Boys Town National Research Hospital (approval no. 17-04-XP) on June 21, 2017. Consent to participate: Written informed consent to participate in this study was provided by the participants’ legal guardians/next of kin. Participants gave verbal assent.
Author Contributions
Conceptualization: KKM; Data curation: TAK, JO; Formal analysis: JO; Funding acquisition: KM; Investigation: NE, TAK; Methodology: KKM, TAK; Project administration: NE; Software: TAK; Supervision: KKM; Validation: NE, TAK: Visualization: JO; Writing-Original: KKM; Writing-Review and Editing: KKM, TAK, JO.
Funding
This research was supported by the National Institute on Deafness and Other Communication Disorders of the National Institutes of Health under (award no. 2R01DC011742, K. McGregor, P.I.). Members of the Technical Core at Boys Town National Research Hospital were instrumental in moving the data collection to a virtual platform during the COVID19 pandemic. They are funded by the National Institute of General Medical Sciences of the National Institutes of Health under award number P20GM109023 L. Liebold, P.I.) The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institutes of Health, (grant number 2R01DC011742, P20GM109023).
Declaration of Conflicting Interest
Salary support for the authors was provided by the National Institutes of Health, Boys Town National Research Hospital (KKM, NE, TAK) and the University of Iowa (JO). Karla McGregor conducts volunteer advocacy work for the DLD community as the Chair of DLDandMe.org.
Data Availability Statement
All de-identified data and statistical analysis code are available at McGregor, K. K., Eden, N., Arbisi-Kelm, T., & Oleson, J. (2025, November 28). Dynamics of Word Learning. Retrieved from osf.io/r56s7
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.