
Abstract
Objective
To determine if statistical and psychometric outcomes differ between tests composed of serial and independent questions. Specific goals include assessing which format provides better reliability and validity, understanding response patterns, and comparing difficulty and discrimination indices under classical test theory.
Methodology
The study involved a single-group design with spiral counterbalance, allowing examinees to answer both formats within a single exam of 220 items. Of these, 200 were independent questions, and 20 were organized into 4 clinical cases with 5 related items each. The exam was administered by computer to anesthesiologists undergoing certification or recertification.
Results
From 2109 candidates, the analysis showed significant differences in internal consistency, with Cronbach's alpha of .790 for independent questions and .527 for serial questions. A moderate positive correlation (r = .488) between scores in the 2 formats was observed. No significant difference was found in difficulty and discrimination indices between formats.
Discussion
Independent questions showed higher reliability, likely due to their lack of dependency, making them more suitable for high-stakes exams. Serial questions, while valuable for assessing integrative reasoning, introduce dependency that affects consistency and may skew outcomes when the initial question is answered incorrectly. Despite similar difficulty and discrimination indices, the unique dependency in serial questions affects their suitability for high-stakes testing.
Conclusions
Independent questions provide a more reliable format for high-stakes exams, but serial questions can enhance assessments by probing various aspects of clinical reasoning within a single case. A balanced approach incorporating both formats may optimize the reliability and validity of medical certification exams, leveraging the strengths of each question type.
Introduction
In the field of medical competency assessments, 1 case-based questions have 2 main approaches: serial questions, where multiple items are derived from a sole case, and independent questions, where each item is derived from a sole case. Both structures offer advantages in the assessment of competencies, but present unique challenges in psychometric terms, especially regarding their consistency and content validity. 2 This study explores the performance of these 2 types of questions in the context of a medical certification examination.
In medical competency-based assessments, case-based questions assess not only factual knowledge but also critical clinical competencies, such as decision-making and diagnostic reasoning. 3 With increasing reliance on high-stakes exams for certification, understanding how different question structures—serial versus independent—impact psychometric outcomes become essential. Independent questions offer clear delineation between cases, supporting robust psychometric analysis. In contrast, serial questions, which depend on a primary correct answer to unlock further understanding, may introduce variability that affects reliability and validity, especially in assessments with high stakes. This study aims to systematically compare these question types to explore their efficacy in competency-based assessments.
A typical example of this is presented below. A 4-year-old girl has developed edema of the eyes and ankles for the past week. BP 100/60 mmHg, HR 110 X’, RR 28 X’. There are edema of both eyes and ++ pitting edema of the ankles. She has abdominal distension with a positive fluid wave. Laboratory: creatinine 0.4 mg/dL, albumin 1.4 g/dL, and cholesterol 569 mg/dL. Urinalysis shows protein ++++, no blood. 1. Which of the following is the most likely diagnosis? A. Acute post-streptococcal glomerulonephritis B. Minimal change nephrotic syndrome* C. Nephrotic syndrome with focal glomerulosclerosis D. Henoch-Schönlein purpura with nephritis
In this example, we can identify the fundamental parts of the reagent
4
:
Stem (base, clinical case): Also known as the statement, it is the statement that gives rise to a response from the examinee. Correct answer: It consists of the answer option that corresponds to what is requested in the stem or base of the reagent. Here, the correct answer is indicated with an asterisk. Distractors: These are those answer options that have a grammatical and semantic concordance with the stem or base of the reagent, but that are incorrect according to what is requested in it.
In this type of item, the clinical case (or stem) is prepared with the purpose of asking a single question, which makes it easier to adhere to the specifications table that is prepared when planning any assessment instrument, where the domains, subdomains, and areas to be explored are established. The clear specification of the assessment instrument determines the limits that the test is intended to have and is essential to evaluate the content validity of the instrument.
5
In the example used, the specifications table establishes that the domain corresponds to glomerulopathies, the subdomain to nephrotic syndrome, and the area it explores to the diagnosis. Based on this approach, each reagent in the exam is independent of each other and explores various domains, subdomains, and areas, as established in the specifications table. Thus, the assessment instrument can be analyzed under classical test theory (CTT) or item response theory (IRT), without violating any assumptions. Both CTT and IRT
6
share some fundamental assumptions and restrictions
7
:
Test-level theory: Both CTT and IRT are fundamentally test-level theories. They are based on the concept of a total test score made up of multiple items.
8
True score: In both theories, the true score is defined as the expected value of the observed score. In CTT, the true score simply indicates the expected value of the observed score on repeated tests under the same conditions. Error component: Both theories assume that the raw score obtained by any individual is composed of a true component and a random error component. Invariance of item and person statistics refers to the idea that the statistical properties of items (questions or items of a test) and people (those who respond to the test) should be consistent and comparable, regardless of the group or context in which they are applied.
9
Sample size: Both theories are sensitive to sample size.
10
Independence of items.
10
For ∼30 years, colleges have chosen to conduct medical exams based on serial clinical cases. The tests that are prepared based on serial clinical cases generate groups of questions from a clinical vignette; that is, they are multiple-choice questions associated with a case. They usually consist of the presentation of a case, followed by multiple-choice questions (usually 5). In theory, each question refers to a different aspect of the case, since the clinical situation is considered from different perspectives (diagnosis, epidemiology, treatment, and prognosis); however, this rarely happens. 11
To show what serial clinical cases are like, we will use the example that has been presented so far. Now, the vignette will be the same for the questions that are derived from it, modifying only the question and the answer alternatives. Of course, the individual question already shown can also be used:
Which of the following can corroborate the diagnosis?
A. Renal biopsy B. Clinical picture C. Renal scintigraphy D. Creatinine clearance
What is the treatment of choice for this pathology?
A. Cyclophosphamide B. Cyclosporine C. Corticosteroids D. Rituximab
The example now consists of a vignette from which 3 questions emerge, where the first explores the possible diagnosis, the second asks about diagnostic strategies, and the third, the treatment of choice for the condition that the patient in question has. In this sequence, the questions are not independent; all 3 are related by the clinical case presented, and it is assumed that, if the diagnostic hypothesis presented is erroneous, the 2 subsequent questions, consequently, would also be erroneous.
Given these differences in the methodology used to assess medical knowledge, we decided to conduct this study to determine whether statistical and psychometric methods vary depending on whether the measurement instrument is based on independent questions or related questions.
Objective
General objective
To evaluate whether statistical and psychometric methods behave the same in tests with independent questions versus tests with serial clinical cases where the questions are related to each other by a common clinical case.
Specific objectives
Determine which format provides the best statistical and psychometric performance.
Establish the congruence of responses within serial cases according to responses given by guessing and reasoned answers based on the background of the cases.
Evaluate the performance of the reliability between independent and serial questions.
Compare the performance of the psychometric indices in the CTT between independent and serial questions.
Hypotheses
Higher Consistency in Independent Questions: Independent questions will demonstrate higher internal consistency than serial questions, as they are not affected by the dependency on a correct primary response.
Performance Variation with Serial Questions: Serial questions will show greater variability in performance due to the cumulative impact of errors on subsequent items in the sequence.
Similarity in Psychometric Performance Across Formats: Despite the structural differences, we hypothesize that both question formats will yield comparable results on item difficulty and discrimination, as assessed by CTT.
Methodology
The study reporting adheres to the relevant Equator network guideline, conforms to the STROBE for cross-sectional studies. 12
Study design
The study design was based on a single group with spiral counterbalance, 13 thus allowing a balanced comparison between independent and serial questions in a single exam. 14
A spiral counterbalance ensures that the order of questions is varied for each participant, reducing the potential for bias. The steps used are shown below:
Division of questions
1.1. Single questions: 200 questions 1.2. Serial Questions: 20 questions (grouped into sets) Blocks creation
2.1. Division of 200 single questions into 10 blocks of 20 questions each 2.2. Division of 20 serial questions into 2 blocks of 10 questions each Arrangement in spiral order
3.1. Creation of a spiral pattern where each block of questions is rotated in a specific order. For example:
3.1.1. Participant 1: Block A, Block B, Block C, …, Block J, Serial Block 1, Serial Block 2 3.1.2. Participant 2: Block B, Block C, Block D, …, Block A, Serial Block 2, Serial Block 1 3.1.3. This pattern continues for all participants Randomization within blocks
4.1. Randomization the order of questions within each block to ensure that no 2 participants have the exact same sequence Implementation of design
5.1. We used a spreadsheet to organize and randomize the questions according to the spiral counterbalance design. Here's a simplified example:

This design ensures that each participant receives a unique order of questions, minimizing bias and improving the reliability of the exam results.
Participants were licensed Mexican anesthesiologists who registered for a certification or recertification exam and met the administrative requirements of the CNCA. Examinees were from various healthcare institutions and had differing levels of experience. We controlled exam duration (4 h) and randomized the order of question presentation to minimize fatigue effects and question-order bias.
The selection of statistical tests was adjusted to evaluate the differences between the types of questions in terms of reliability and validity. Based on this, the certification and recertification exam of the CNCA was assembled, linked, and equated, according to the specifications table of the Council itself and the design of spiral counterbalance previously described.
Characteristics of the test
The test was structured with 220 questions, of these 200 were based on independent clinical cases from which a single question with 4 answer alternatives is derived, but only one is correct; and 20 questions were structured based on 4 clinical cases, each of which provided 5 questions related to each other and dependent on the clinical vignette posed; in these serial cases, the first question always explores aspects related to the diagnosis, so that other aspects could be explored from there, such as decision-making, treatment, etiology, and so on. As in independent questions, each item had 4 response alternatives with only one correct answer. All questions included in the exam were prepared by the CNCA and previously calibrated based on the board's specifications table.
The test was administered by computer, where the examinees could view the exam, along with any multimedia material that the item required. A maximum time of 4 h will be granted to complete the exam.
Characteristics of examinees
Anesthesiologists who registered to take the certification or recertification exam and who met the administrative requirements established by the CNCA were included. In addition, they had to have completed at least 70% of the exam items.
Statistical Analysis
Descriptive statistics
The descriptive statistical analysis of the study included the various key elements to provide a clear and complete view of the data from the central holding measures, dispersion, and subgroup analysis.
Statistical inference
The established study design, for the purposes of statistical analysis, can be described as a related-subjects design, since each examinee is exposed to both question formats in the same exam.
To evaluate which question format yields better statistical and psychometric performance, the following statistical tests are considered
15
:
We used a Welch t-test to compare difficulty and discrimination indices between serial and independent questions. The Welch t-test was chosen due to unequal variances observed between the 2 groups of items. However, we recognize that item difficulty (a proportion-based statistic) and the nesting of item responses within examinees pose statistical challenges. Specifically, the proportion nature of difficulty data may not strictly fulfill the normality assumption required for a t-test, and the assumption of independence is potentially violated by the nesting of responses. This is precisely one of the troubles that we hypothesized when we decided to do this project. Acknowledging those previous limitations, we considered non-parametric tests, particularly the Mann-Whitney U-test and generalized linear models. Future research could employ these approaches to better handle the binomial distribution of item difficulty and the nested structure of examinees within questions. CTT
16
: This involves calculating item statistics such as item difficulty (proportion of students who answered the item correctly) and item discrimination (correlation between item scores and total exam scores). These statistics are to be compared between the 2 question formats.
For the calculation of difficulty index, we used equation (1), where p = difficulty index, a = persons who correctly responded to the item, and n = persons who responded to the item.
For calculation of discrimination index, we used equation (2), where 
Equation (2) Discrimination index
4. IRT analysis 17 : IRT allows modelling the probability of a correct answer based on the test taker's ability and item characteristics. The parameters of the IRT model (such as item difficulty and item discrimination) are to be compared between the 2 question formats. Though beyond the scope of this article to detail fully, we briefly modeled item characteristic curves and examinee ability parameters for each question format to evaluate how well each discriminated against varying ability levels. Results are available on request.
Results
2109 candidates took the test. The main characteristics of the examinees are presented in Table 1. Gender comparison: the percentages of correct answers between women and men are remarkably similar in both independent and serial questions, with one non-significant difference (P = .356 overall). Age group: there is a downward trend in the percentage of correct answers with increasing age, both in independent and serial questions. The difference between age groups is significant (P < .01). Marital status: there are differences in the percentage of correct answers according to marital status, with the difference between groups being significant (P < .01). Years since residency: a decrease in the percentage of correct answers is observed as the years since the student finished residency increase, with significant differences between groups (P < .01). Type of exam: There is no significant difference in the percentage of correct answers between those who took the exam to become certified versus recertified (P = .114).
Characteristics of the test takers and the behavior of correct answers between the global test, the independent questions, and the serial questions.

An internal consistency analysis was performed using Cronbach's alpha coefficient for each type of question. The results show significant differences between independent and serial questions. Table 2 shows that the greatest consistency is found in the overall test (0.814), which decreases when stratifying the independent questions (0.790) and serial questions (0.527). Table 3 shows a comparison of difficulty and discrimination between independent questions and serial questions using CTT.
Analysis of the internal consistency of the test, stratified by independent questions and serial questions

Comparison of difficulty and discrimination between independent questions and serial questions using classical test theory (CTT).

Figure 1 is included in visualizing the distribution of scores and the correlation analysis between the 2 types of questions, finding a Pearson r of .488. This figure shows a moderate correlation between the 2 question formats. Practically, this correlation suggests some overlaps in what each format measures, though each may still capture distinct elements of clinical reasoning. It underscores the potential complementary use of both formats in a balanced assessment.

Correlation graph between the scores obtained in the independent questions versus the serial questions.
The comparison between the psychometric indices of the CTT shows that there are no statistically significant differences in the difficulty or discrimination between independent questions and serial questions.
To individually evaluate each serial clinical case based on the conditional probability 18 of getting subsequent questions right when the first question is wrong, Table 4 was constructed. In the first column, 5 possible combinations are presented when the first question of the clinical case is wrong. The second column shows the probability of finding that combination, and in the rest of the columns, a breakdown of each case analyzed individually is made.
Number of candidates in the serial clinical cases who failed the first question, but answered correctly in the serialization based on what would be the diagnosis.

Table 4 was constructed by analyzing the probability of each response combination across a series of clinical vignettes. First, we identified the probability of a correct response on each question in the sequence. We then multiplied these probabilities to estimate the likelihood of each specific combination (correct-correct, correct-incorrect, etc). We utilized the basic conditional probability formula
19
: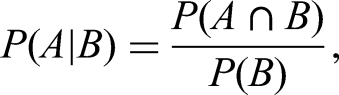
Discussion
Reliability of serial versus independent questions
The findings show that internal consistency is notably lower in serial questions compared to independent ones. This reduced reliability stems from the dependency introduced by the first question in a series, which influences the accuracy of subsequent answers. In high-stakes certification exams, where reliability is crucial, this dependence poses a limitation. While serial questions can evaluate integrative clinical reasoning, their design should minimize the impact of a single mistake. A balanced approach—combining both serial and independent question types—may provide a comprehensive assessment of clinical competence without sacrificing reliability.
Age-related trends in performance
Scores for both serial and independent questions tend to decrease as age increases. Younger physicians, who recently completed their residency, often have more up-to-date knowledge due to recent formal exams. In contrast, older physicians undergoing recertification may not have the same level of immediate exam preparedness. This trend remains consistent when considering the time elapsed since residency completion.
Correlation between question types
A moderate positive correlation (r = .488) was found between scores on independent and serial questions, indicating a tendency for the variables to move together. However, this correlation is not strong enough to predict performance accurately across the 2 formats. One likely reason is the inherent dependency within serial questions: if the first question is missed, subsequent answers are often guessing rather than knowledge-based responses.
Psychometric analysis
Despite differences in internal consistency (Cronbach's α), both question formats displayed similar performance on the difficulty index and discrimination coefficient (rpbis). The difference in the discrimination coefficient between independent (rpbis = .151) and serial (rpbis = .305) questions approached, but did not reach statistical significance (P = .053).
Although the difference in discrimination indices appeared substantial, it did not reach statistical significance (P = .053). The sample size, the variability of the data, and the borderline P-value all suggest that with a larger sample or more items, a significant effect might emerge. Alternatively, the true difference may be smaller than initially observed, underscoring the need for further investigation.
Implications of serial questions
Serial questions can be viewed as small “mini exams” derived from clinical cases that generate multiple interrelated items. 20 Their analysis requires considering the combinatorial nature of correct and incorrect responses. In this study's example, if the first question in a 5-item series is answered incorrectly, the subsequent 4 answers often rely on chance. This reliance on the first question can distort the measurement of true knowledge.
Example of combinatorial effects
Using a 5-question serial case with 4 answer choices each yields
Limitations and Implications
The main limitations include the relatively small number of serial questions and the variability among clinical cases. Future evaluations should consider increasing the number of serial items to enhance consistency and reduce random guessing. 22 A thoughtful blend of serial and independent questions, coupled with careful psychometric monitoring, can provide a more nuanced measure of clinical knowledge while maintaining the reliability essential for certification exams.
Increasing the sample size of serial questions in subsequent studies may provide more robust estimates of their psychometric properties. A larger data set would not only enhance statistical power but also clarify whether the observed dependency truly impacts reliability at a practical level.
The present study addresses the comparison between serial and independent questions in medical certification assessments, focusing on the psychometric and methodological aspects of both item formats. From a thorough analysis of the results, we can draw relevant conclusions about their performance and reliability.
(1). Internal consistency: The results show a considerably higher internal consistency in independent questions compared to serial ones, as reflected in the Cronbach alpha coefficients (.790 vs .527). This difference highlights the influence of dependence between serial items, which reduces the reliability of this format. Since serial questions require getting the first question right to correctly answer subsequent questions, it is likely that the results in subsequent questions are more susceptible to chance in case of initial failure. This finding suggests that, for high-stakes examinations, serial questions should be avoided or complemented with another type of assessment to ensure consistency and validity in the results. (2). Correlation between formats: A moderate positive correlation (r = .488) was identified between the scores obtained in independent and serial questions, indicating a relationship, although not significant, between both formats. This result suggests that, although the competencies measured could be similar, the examinees may show variability in performance between the formats. This moderate correlation can be explained, in part, by the dependent structure of the serial questions, which limits the ability to predict scores in a series based on performance in independent questions. Thus, serial items should be interpreted with caution in evaluations where high precision is required in the measurement of competencies. (3). Performance by age and experience: The decreasing trend in performance as age and time elapsed since medical residency increase is consistent in both types of questions. This finding could be related to the natural attrition of knowledge or less practice of exams among older professionals, who usually opt for recertification only when other curricular evaluation mechanisms are not sufficient. This pattern highlights the importance of designing tests adapted to different profiles of examinees, where the evaluation criteria consider clinical experience and constant updating of knowledge. (4). Difficulty and discrimination: Despite the structural differences between the formats, no statistically significant differences were found in the difficulty and discrimination indices when analyzing the items with the CTT. The similarity in these indices suggests that both formats may be valid to discriminate between examinees with distinct levels of clinical competence, although performance in serial questions may be affected to a greater extent by chance if the first question is not answered correctly. (5). Implications for evaluation: Serial questions may offer advantages to exploring the depth of knowledge about a clinical case by covering various aspects (diagnosis, treatment, and prognosis), but they present a challenge in terms of consistency and reliability in high-consequence evaluations. Considering that examinees must get the first question right to optimize their responses to subsequent questions, it is recommended to complement this format with independent questions or use a greater number of serial cases to minimize the effect of chance.
Conclusions
This study's insight into the psychometric performance of serial versus independent questions provides a foundation for more reliable assessment design in medical certification. Given the higher consistency and independence of stand-alone questions, they are preferable for high-stakes exams requiring precision in competency measurement. However, serial questions, if carefully structured, can enrich assessments by offering a multifaceted view of clinical reasoning. Ultimately, the findings suggest a calibrated approach that balances both question types (no higher than 10% serial questions from the total of questions) could optimize the reliability and content validity of medical certification exams.
In conclusion, our findings underscore a trade-off between ensuring reliability and fostering integrative reasoning. While serial questions can engage higher-order thinking by building on prior knowledge, they may also introduce greater measurement error or unfair dependencies. Independent questions, on the other hand, maintain clearer psychometric properties but may not assess integrative skills as well as thoroughly.
Footnotes
Acknowledgments
We thank the CNCA for granting access to data and providing administrative support.
Ethical Considerations
This research was approved by the Comité de Ética del Consejo Nacional de Certificación en Anestesiología, with approval number 2943/022025. All participants in this study provided and signed written informed consent from the moment they registered for the anesthesiology board certification exam.
Author Contributions
VHOC: conception, design, analysis, interpretation of data for the work, drafting the work or revising it critically for important intellectual content, and final approval of the version to be published. JGVG: revising the drafting critically for important intellectual content, and final approval of the version to be published. GQM: revising the drafting critically for important intellectual content, and final approval of the version to be published.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.