
Abstract
Background
Artificial intelligence (AI) and large language models (LLMs), are potential tools for enhancing healthcare delivery and clinical research. Presently, there is a scarcity of research regarding the viewpoints of medical students toward LLMs. This study aims to explore the perceptions of LLMs and their applications among this demographic.
Methods
A cross-sectional study was done using an online survey. It was designed using Google Forms and circulated from July 2023 to August 2023. The target population included medical students from Ecuador, Ethiopia, India, Mauritius, Pakistan, United Arab Emirates (UAE), and the United States (USA).
Results
A total of 1180 responses were collected from 10 medical colleges across 7 countries. The UAE had the largest number of responses (31.7%), followed by Ecuador (17.6%), and Mauritius (13.7%). And 77.4% respondents were already aware about LLMs before attempting the survey, most popularly, ChatGPT. Participants were most familiar with the specific use of LLMs in research (46%), and the lowest familiarity was seen in the use of LLMs in healthcare (37%). More than half of the participants (52%) support the use of LLMs healthcare, yet a significant number of them remained neutral (37%) or disagreed (31%) on LLMs being safe in this context.
Conclusion
While most of the medical students are aware of LLMs and their applications, the multinational survey demonstrated hesitancy among medical students in fully adopting LLMs into healthcare practice and clinical research. This study prompts further exploration of medical students’ attitudes and acceptance concerning the integration of LLMs for research methodologies, ethical considerations, and healthcare practice.
Introduction
The rapid advancement of artificial intelligence (AI) and natural language processing (NLP) technologies has opened up new possibilities in various fields, including the healthcare industry.1,2 Large language models (LLMs), powered by deep learning algorithms and trained on massive amounts of data, have gained significant attention due to their potential applications in generating human-like text and facilitating language-based tasks. 3 , Specific implementations of LLMs, such as OpenAI's ChatGPT and Google's Gemini, have demonstrated remarkable capabilities in understanding and generating human-like text, making them potential tools for enhancing healthcare delivery, clinical research, and medical education.4,5
In the context of medical education and research, LLMs have the potential to enhance learning experiences, facilitate information retrieval, and contribute to knowledge generation.6,7 A 2022 study explored the knowledge and perceptions of medical students and interns regarding the increasing role of AI in medicine. The study found that over 65% believed that AI would impact their specialty choice, and 78% believed that every medical student should receive training on AI competencies. 8
Recent studies, including those Alkhaaldi et al 9 and Tangadulrat et al, 10 have explored medical students’ perceptions of AI, including LLMs. However, focused investigations into the global perspectives of LLM use among medical students necessitate further exploration.
The primary aim of this cross-sectional study is to explore medical students’ perceptions of LLMs and assess their knowledge, opinions, and readiness for the integration of LLMs in healthcare, research, and medical education. By gathering data through a structured survey, we seek to investigate the awareness, understanding, and potential concerns related to the usage of LLMs among medical students.
Methods
Study Design and Timeline
The study is a cross-sectional survey using a self-designed questionnaire. Data was collected over 3 weeks from July 17 to August 7, 2023. The target population for this study included medical students from Ecuador, Ethiopia, India, Mauritius, Pakistan, United Arab Emirates (UAE), and the United States (USA). The reporting of this study conforms to the STROBE statement of cross-sectional studies (see Supplemental File 1).
Questionnaire and Validation
The survey covered 4 main areas. The first section assessed the student's awareness and utility of LLMs. The subsequent sections explored the specific application of LLMs in healthcare, research, and medical education, with regard to the areas of perception, knowledge, and willingness for LLMs in these fields. Finally, the survey concluded with questions related to the student's demographics. In total, the survey contained 35 questions, in which 28 were related to the study itself and 7 about demographic data.
The survey first underwent an internal validation stage by the core team. In this validation, the team members and mentors reviewed each question for content and construct validity. This was to ensure that the questions are seeking the information they intend to as well as they are not leading the respondents one way or another. Additionally, some questions were merged or deleted to avoid the duplication of content. It was then externally validated by four experts in the field of healthcare with adequate background in LLMs who suggested adding, removing, or modifying certain questions for further improvement of the quality and relevance of the survey tool.
Survey Dissemination Strategy and Data Extraction
The core team consisting of 7 researchers based in the UAE, USA, and Pakistan interacted via a dedicated LLM Research WhatsApp group in weekly meetings via video conferencing. An email and WhatsApp template was made to increase efficiency and reduce communication errors when distributing the survey link. Each core team member sent the survey to their networks using in-person messaging tools, mainly WhatsApp messages, Instagram direct messages, Snapchat messages, and emails. The core team then recruited the next group of collaborators who represented other countries (Ecuador, Ethiopia, India, Mauritius, Pakistan, and USA) and were in-charge of survey administration for their respective countries. The country leads were contacted via direct messaging, and each lead took up the responsibility of disseminating the survey in their local networks. Utilization of the “hub and spoke model” proved to be effective in gathering these responses, with the “hub” being the core team and the “spokes” being the collaborators.11,12 Additionally, we employed a snowball sampling technique, where initial participants were asked to forward the survey to few other potential respondents, leading to a cascading recruitment process. A digital survey banner was designed for promotional messaging. A promotional YouTube video was recorded by the core team members and was shared to garner a greater number of responses and to increase the awareness of this study. 13 The responses collected were extracted to a Microsoft Excel Sheet for further analysis.
Sample Size
The total number of medical students across 10 medical schools was estimated to be 7916. Assuming that 50% of the population was accessible to the study, with a 5% margin of error, and 95% confidence interval, sample size was determined to be of 367. This number was calculated using the sample size calculator by Raosoft, Inc. (http://www.raosoft.com/samplesize.html).
Ethical Considerations
The study was deemed IRB-exempt from Mayo Clinic Institutional Review Board.
The study adhered to rigorous ethical protocols to ensure participant privacy and data protection. Participant responses were collected using secure Google Forms, which anonymized all submissions to prevent identification.
Results
Demographics
The data extracted from the study included 1180 responses from 10 medical schools across 7 countries illustrated in Figure 1. The highest response was from UAE with 374 responses (31.7%) followed by Ecuador with 208 responses (17.6%) and Mauritius with 162 responses (13.7%). Pakistan had a total of 135 responses (11.4%) and Ethiopia had 116 responses (9.8%). The countries with the least responses were India with 113 responses (9.6%), and USA with 65 responses (5.5%).

Distribution of Responses According to Country.
Majority of respondents were females (N = 719, 60.9%) followed by males (N = 459, 38.9%). There were also two respondents (0.2%) who selected “Other” as their gender.
The most common age group of respondents was 23 years (N = 192, 16.3%). It was also noted that 6 respondents selected “≥30 years” for their age. The mean age was 21.7. More than half the respondents were from the preclinical years (N = 651, 55.2%) and the remaining were in the clinical years (N = 529, 44.8%) of medical school, therefore the most common year group were third year medical students (N = 235, 19.9%) and second year medical students with 228 responses (19.3%). Analysis of the clinical specialities showed that medical students with an interest in pursuing surgery acquired the most responses at 162 responses (13.7%) followed by internal medicine at 154 responses (13.1%). There were minimal responses indicating interest in pulmonology and immunology, (N = 3 responses 0.25%) and only 2 individuals expressing interest in nuclear medicine (0.17%).
Most respondents (N = 953, 80.8%) had no research publications authored at the time of the survey, however 227 respondents (19.2%) have published at least one research paper at the time of this survey. From this pool of respondents, only 2 responses had more than 20 papers published as shown in Table 1.
Participant demographics.

Familiarity Toward LLMs
The study reports 898 respondents (76.1%) being already familiar with LLMs before taking the survey and a total of 1656 responses were obtained from this population. The most popular LLMs were ChatGPT (N = 866, 52.3%) followed by Microsoft Copilot (N = 292, 17.6%) and Gemini (N = 184, 11.1%). The least popular LLMs were Gorilla (N = 130, 7.9%) followed by Med-PaLM (N = 110, 6.6%) and Falcon LLM (N = 74, 4.5%).
Only 646 (72%) participants who are already familiar with LLMs have used it before. A total of 927 responses were obtained regarding the use of LLMs. The most used platform was ChatGPT (N = 612, 66%), followed by Microsoft Copilot (N = 134, 14.5%) and Gemini (N = 93, 10%). The least used platforms were Med-PaLM (N = 42, 4.5%), followed by Gorilla (N = 25, 2.7%) and Falcon LLM (N = 21, 2.3%)
Among the respondents, 692 of them were introduced to LLMs through social media (58.6%) followed by word-of-mouth (N = 547, 46.4%). Books/magazines and online courses seemed to have the least exposure to LLMs with 108 responses (9.2%) and 172 responses (14.6%), respectively.
On the 5-point Likert scale, the majority (51%) expressed either very or somewhat familiar with the various ways people can utilize LLMs. People were most familiar with the specific use of LLMs in research (N = 184, 46%), followed by 41% (N = 165) in medical education and the lowest familiarity was seen in the use of LLMs in healthcare (N = 107, 37%), tabulated in Table 2.
Level of awareness and experience with LLMs.

Abbreviation: LLM, large language model.
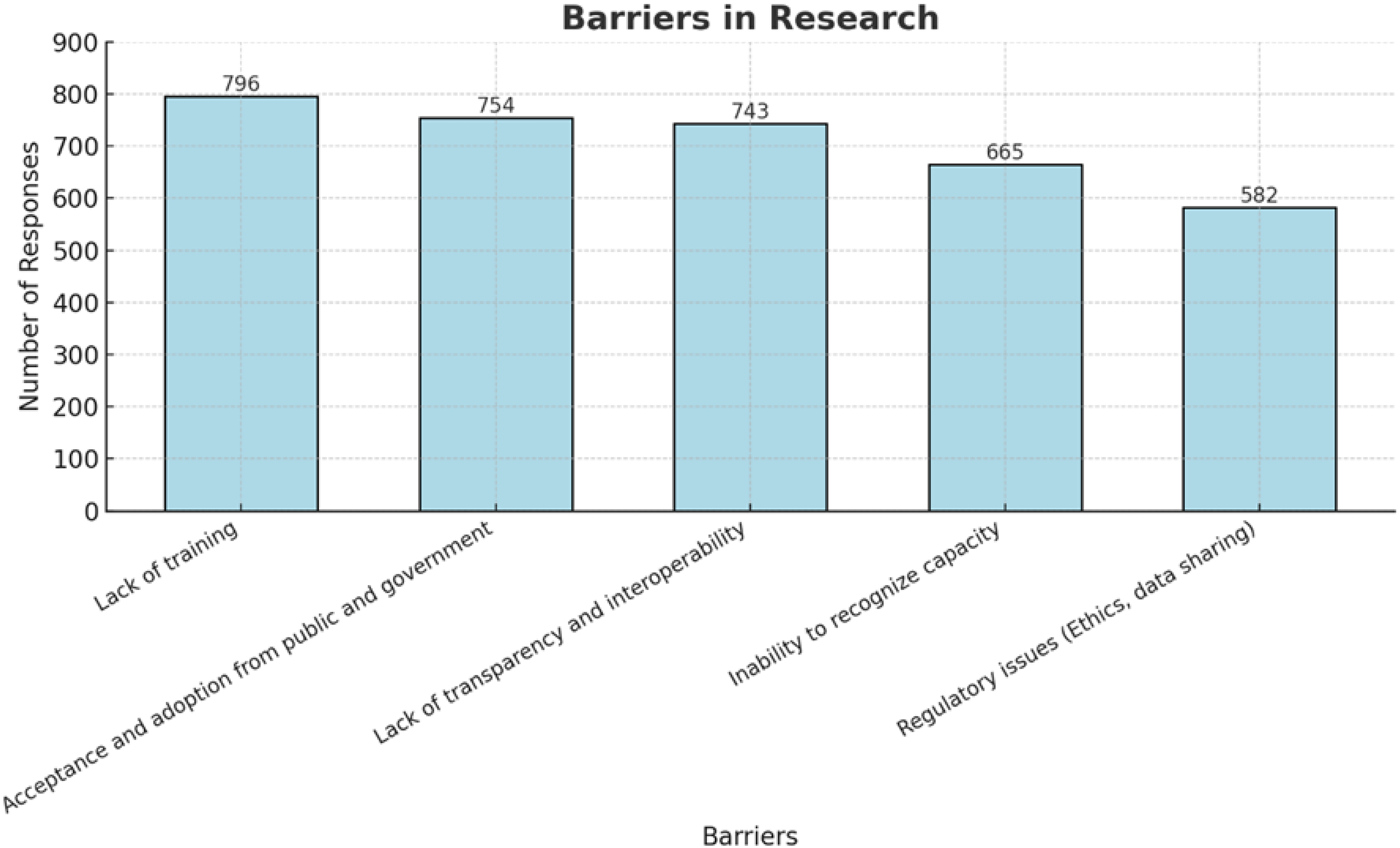
Ethical challenges of LLMs in research were acknowledged by 49% (N = 581). Lastly, regarding LLMs negatively affecting the reliability of research, 40% (N = 467) remained neutral and 31% (N = 130) agreed with this notion. Figure 2 and Table 3 expand further.
Perceptions Regarding Barriers Towards the Use of Large Language Models in Research.
Perceptions of LLM applications.
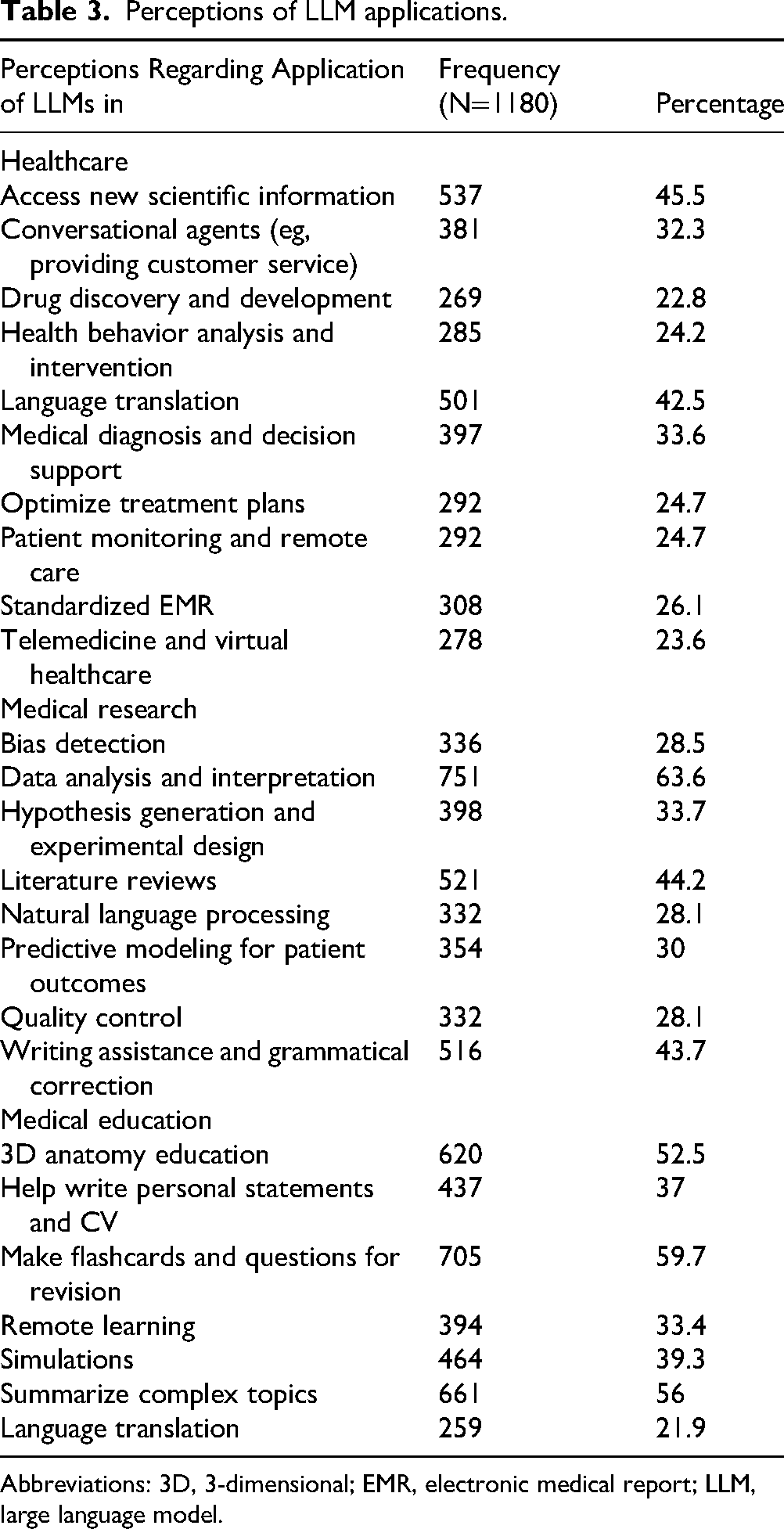
Abbreviations: 3D, 3-dimensional; EMR, electronic medical report; LLM, large language model.
Perception Regarding Applications
With regard to medical education, a significant number of participants (N = 712, 60%) concurred that LLMs simplify understanding medical concepts. This was noted among the 654 respondents (55%) who agreed on the benefit of LLMs offering real-time feedback. Also, 617 participants (52%) acknowledged the use of LLMs in aiding exam revision, while 569 respondents (48%) saw themselves enhancing clinical reasoning and diagnostic skills using this modality.
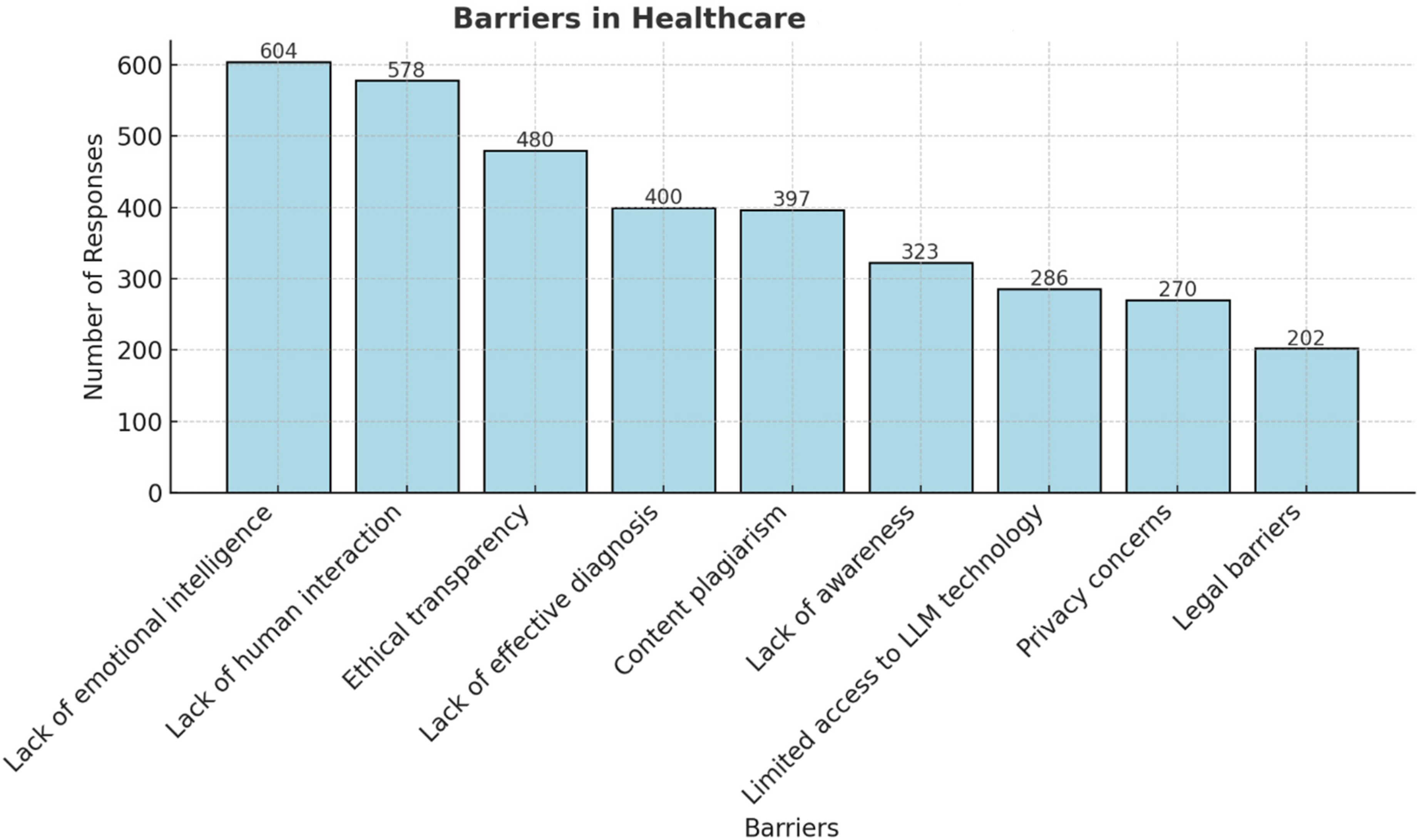
The 3 most commonly perceived applications of LLMs in healthcare were reported to be “access new scientific information” (45.5%), “language translation” (32%), and “medical diagnosis and decision support” (22.8%) whereas the top 3 barriers are “lack of emotional intelligence” (51.2%), “lack of human interaction” (49%), and “ethical transparency” (40.7%) illustrated in Figure 3.
Perceptions regarding Barriers Toward the use of Large Language Models in Healthcare.
The 3 most common applications of LLMs in research were reported to be “data analysis” (63.6%), “literature reviews” (44.2%), and “writing assistance and grammatical correction” (43.7%), whereas the top 3 barriers to LLMs in research are “lack of training in the uses of LLMs” (67.5%), “acceptance and adoption from public and governmen”’ (63.9%) and “lack of transparency and interpretability” (63%), illustrated in Figure 2.
Finally, the 3 most common applications of LLMs in medical education are “flashcards and revision questions” (59.7%), “summarize complex topics” (56%), and “3D anatomy education” (52.5%) summarized in Table 3.
Acceptance/Readiness Toward LLMs
The results further revealed that 608 participants (52%) support LLMs use in healthcare, yet a greater number remained neutral (N = 433, 37%) or disagreed (N = 372, 31%) on LLMs being safe in this context. Moreover, 656 respondents (56%) also rejected the possibility of LLMs replacing healthcare professionals, and 510 respondents (43%) believe that LLMs will gain acceptance in the healthcare field. Furthermore, in the context of LLM in medical research, more than half (N = 644, 55%) agreed that LLMs will have an important role in this field. This is complemented by 737 participants (62%) anticipating ease in conducting research due to LLMs, and 542 respondents (46%) also believe that LLMs will not replace researchers (Table 4).
Readiness for the use of LLMs.

*Rounding up to 2 decimal places results to a total of 100%.
Abbreviation: LLM, large language model.
Discussion
This pertinent study demonstrates the use of LLMs among medical students across medical schools in 7 countries, specifically focusing on its application in healthcare, medical education, and clinical research. Over 75% of participants were already aware of LLMs, particularly ChatGPT. Respondents were most familiar with the specific use of LLMs in research and the least awareness was seen with use of LLMs in healthcare. While 56% of participants rejected the notion that LLMs will replace healthcare workers, the pleurality (43%) nevertheless supported the acceptance of LLMs into the healthcare system. Additionally, 31% had reservations regarding the current safety of LLMs into practice. In the context of medical research, LLMs were seen as a convenient tool to increase the ease and efficacy of conducting research, however, 49% of responses highlighted the need for careful consideration of ethical issues in the incorporation of LLMs in clinical research. Lastly, concerning medical education, a significant proportion agreed LLMs aiding in simplifying medical concepts (56%) and exam revision (60%) especially by reducing cognitive load through dynamic summaries and interactive 3-dimensional (3D) models, allowing them to focus on deeper understanding and efficient exam preparation through personalized flashcards and practice questions.
Healthcare and Clinical Practice
Out of the number of respondents using LLMs, a vast majority (96.4%) were accustomed to ChatGPT, as compared to other language models. Given its positive perception on social media, it should come as no surprise that the majority of students learned about it through these platforms. 14 In a 2023 study conducted by Alkhaaldi et al, a majority of recently graduated medical students in the UAE denied using ChatGPT in medical school, however around 63% students planned to use it during residency. 9 The increasing presence of the chatbot and other language models among future physicians warrants close monitoring of its potential influence on their training and professional development.
The perceived applications of large language models in medicine encompass a vast and diverse landscape, impacting nearly every facet of clinical practice. Interestingly, respondents to our survey believed accessing new scientific information (46%) and language translation (42%) to be the most appropriate applications, followed by medical diagnosis and decision support (34%). In terms of accessing new scientific information, LLMs have shown promising potential in encoding clinical knowledge, 15 however, the accuracy of such datasets is seemingly limited to models designed for medical usage as compared to general chatbots available for public use 16 discovered that a synthetic generative LLM was able to outperform NLP models trained using real-world clinical text, and also found that physicians could not differentiate between clinical notes generated by LLMs compared with humans in terms of linguistic readability and clinical relevance. The retrieval of clinical knowledge and information using LLMs may lead to new scientific discoveries for diagnostic aid and therapeutic management, which presents a massive advantage to training and supporting healthcare professionals.
Slightly more than half of respondents (56%) disagreed with the notion that LLMs will replace healthcare workers, placing a point of contention on their authority and limitations in a clinical setting. While some studies suggest that LLMs, particularly multimodal ones, could augment healthcare professionals, 17 others caution that the current limitations, such as inaccuracy and lack of an uncertainty indicator, preclude their autonomous deployment in clinical settings. 18 Furthermore, certain studies have indicated that the performance of the models may not be consistent across different medical specialties. Wilhelm et al 19 discovered error patterns in therapy recommendations generated by language models across the fields of ophthalmology, orthopedics, and dermatology, including general and nonspecific advice when prompted treatment recommendation requests on arbitrarily chosen diseases. Consequently, consideration for distinct needs and specifications of various specialties is necessary before LLMs can reach autonomy in a clinical setting.
However, LLMs have shown promise in assisting healthcare professionals in fields such as personalized medicine and routine documentation, including discharge summaries.19,20 The specialized nature of tasks requiring understanding and interpreting clinical language presents unique challenges for LLMs, but task-specific learning strategies and prompting techniques can enhance their effectiveness in healthcare settings. 21
A lack of human interaction (49%) and emotional intelligence (51%) were ranked as the most common potential barrier in the implementation of LLMs in clinical settings. Despite the promising potential that NLP-based AI systems hold in healthcare, concerns raised on their ability to mimic human interactions remain one of the most significant barriers to their widespread adoption in clinical settings involving patient interactions. This is due particularly to the perceived communication barriers, stemming from patients’ hesitancy in accepting the role of AI in traditional physician–patient interactions. 22 Factors such as the loss in face-to-face interaction and personalized interactions in this context raise concerns about patient safety and the need for transparent and explainable AI. 23 Nadarzynski et al 24 found that participants felt that AI-based chatbot responses were more depersonalized and were worried about its inability to understand the emotionally sophisticated aspects of health, particularly mental health. To bridge the potential communication and emotional gap between users and LLMs in clinical settings, developers should prioritize the incorporation of interactive and engaging social cues. By implementing features that foster trust and connection, such as human-like communication and personalized assistance, it is possible to create an environment tailored to the patient's mental and emotional state, thereby simulating empathy. 22 This focus on enhancing the patient experience could prove key in unlocking the full potential of LLMs as valuable tools within healthcare settings.
When training clinicians, emphasis must be provided on developing new communication skills to effectively interact with AI systems within the care delivery process, while patients need to overcome potential technological apprehension to fully engage with these tools. 25
Clinical Research
A significant number of students (55%) acknowledged the significant role of LLMs in the research field, aligning with findings in various papers. Ruksakulpiwat et al 26 highlight that ChatGPT, although not explicitly designed for medical research, has demonstrated impressive performance in this domain. The growing prominence of LLMs in medical research may be attributed to their ability to identify new research questions and enhance educational understanding. 27 Another study by Wang et al 28 investigated the ability of ChatGPT to produce effective Boolean queries for systematic review. The study involved ChatGPT being trained on a set of extensive prompts on over 100 systematic review topics. The results demonstrated that ChatGPT effectively generated queries leading to a high level of search precision. 28 This capability helps researchers avoid the inclusion of invalid and biased studies, potentially saving both time and healthcare resources.
Participants ranked the top research application of LLMs to be “data analysis and interpretation” (64%). Several studies highlight this feature in ChatGPT, indicating its growing role in conducting clinical research. In a systematic review conducted by Sallam et al, 4 which assessed 60 records, it was found that 20 of them cited the efficient analysis of datasets in healthcare research as a notable benefit of using ChatGPT. Such ability to analyze large datasets can produce a foundation for clinical decision making. Furthermore, the mechanism through which language models like ChatGPT are able to analyse vast amounts of data is explained by Jeyaraman et al. 29 Natural language processing techniques, which are the core component of LLMs, can be utilized to extract crucial information from the texts, such as patient records, medical reports, and scientific journals, and present it in a structured way. 29
Nearly half (49%) of the participants held the view that LLMs will pose ethical challenges in research. Some of the significant ethical concerns are highlighted by Xames et al 30 such as unintentional plagiarism. ChatGPT's tendency to reproduce text without appropriate citations or attribution (also known as “hallucinations”) can pose a significant challenge for researchers. Thus, addressing this issue is crucial for researchers to guarantee that ChatGPT generates outputs that adhere to scholarly standards while being accurate and ethical. Another major ethical issue discussed by Xames et al is biases and inaccuracies. This is because conversational AI can amplify and replicate both human and algorithmic biases, creating a difficulty in distinguishing between accurate and misleading information.
When the participants were asked about LLMs potentially replacing researchers, 46% rejected this notion. Despite significant potential in assisting researchers in the processes of conducting a literature search, summarizing information, and language translation, Salvagno et al 31 explores why ChatGPT is not expected to substitute for human researchers. The writing process of a scientific paper currently necessitates the judgment and oversight of human researchers who are experts in the field, to ensure the accuracy, coherence, and credibility of the content before being used or submitted for publication. 31 Interestingly enough, Huespe et al 32 conducted a study and found that a background section generated by GPT-3.5 for a critical care research question was nearly indistinguishable from the writing of a medical researcher. This highlights the potential of LLMs in enhancing the scientific tone of research writing, thereby augmenting the current role of researchers. The article however concluded that LLM generated content should be restricted to improving the grammar and coherence of article drafts, rather than drafting them entirely. 32
Medical Education
Around 59.7% of respondents believed that LLMs have a pivotal role in medical examination preparation and revision, particularly through the use of creating flashcards and practice questions.
Pendergrast et al specifically points toward the role of LLMs in the integration of one of the most popular third-party resources used by medical students known as Anki. They demonstrated how GPT-3.5 can effortlessly be used to generate, select, and tailor flashcards according to the medical school curricula and topic, thereby acting as an efficient tool to aid in academics. 33
A study conducted by Tangadulrat et al 10 found that students were leaning toward ChatGPT as a tool for preparation for practical examination by generating a variety of scenarios and situations, testing the student's skills and knowledge, which would also provide real-time feedback. Precisely, 55.4% of respondents in our survey agreed that LLMs can provide students with access to real-time feedback. Moreover, a paper published by Chan et al 34 also agreed that AI provides real-time feedback, which would help identify any gaps in their learning, hence, enhancing their knowledge.
Moreover, Kung et al 35 revealed that ChatGPT was helpful in preparing medical students for the United States Medical Licensing Examination. Peculiarly, students will find ChatGPT helpful in many ways since it can provide multiple answers to one question, therefore, giving students a wide range of answers to choose from as well as expanding their knowledge. 36
However, it can be argued that there is a tendency of language models to generate false information, which means answers and clinical vignettes might not always be correct. This may be due to the way ChatGPT has been trained with information from a diverse range of datasets, which may not be specific to certain clinical scenarios and prompts. Additionally, a recent paper by Maryam Buholayka et al 37 explicitly stated that ChatGPT may produce invalid answers even though they may seem persuasive to the medical student. They tasked ChatGPT to write a case report based on report draft written by human authors under 5 different prompts. A comparison of the generated case reports showed that ChatGPT failed to uphold patient confidentiality, fabricate references and even conclude with an incorrect final diagnosis.
These concerns were further emphasized by attending physicians, residents and interns in another study, who were concerned about ChatGPT's answers being simple and failed to show a deeper understanding of the topic. 10 This highlights cautious reviewing on the development of LLMs before they can be used as part of the medical curricula.
The implications of our study emphasize the need to incorporate AI literacy and practical training on LLMs in medical curricula. As many students are already familiar with these technologies, curricula could benefit from including modules that address the applications, ethical concerns, and critically evaluate the role of AI in healthcare.
Additionally, providing hands-on experience with LLMs in simulated environments, could enhance students’ skills and confidence in using these tools. This approach would better prepare future healthcare professionals to leverage AI responsibly and effectively, in both research and patient care.
Strengths and Weaknesses
When examining the strengths of the study, the generalisability among target population and diverse participant demographics of the study can be appreciated. This was achieved by gathering 1180 responses across 7 countries, providing a well-rounded representation of the medical student population and enhancing the statistical power of cross-sectional research. At the same time, the large sample size reduces the margin of error and increases the precision of estimates, making the findings more representative of the target population. Furthermore, using an online Google Form enabled the survey to be quickly distributed through various channels like email, social media, and online platforms. This is evident from the total responses generated within 3 weeks of the study initiation. The survey addresses a contemporary and increasingly relevant issue at the intersection of technology and healthcare which has not be studied in literature earlier. Lastly, the study provides actionable insights that can inform future direction to curriculum development, technology integration strategies, and regulatory frameworks in healthcare settings.
The study has several limitations, including reliance on voluntary participants, the survey being only in one language, and the use of self-reported data. To address the challenge of voluntary participation, multiple reminders were sent to nonrespondents, which significantly improved response rates and ensured higher survey completion. For future studies, incorporating incentives such as gift cards could further encourage participation from a more diverse group of respondents. The survey's limitation of being available only in English was mitigated by using simple and clear language to enhance comprehension; however, future surveys should consider translations into multiple languages to improve inclusivity. To minimize social desirability bias associated with self-reported data, participants were assured anonymity at the outset of the survey. Additionally, a pilot test was conducted with a small group before the survey's full rollout to identify and address potential issues, ensuring the reliability of the data collection process.
Another potential limitation of the study could be that some participants may be nonmedical students. However, questions about the medical university attended and year of study were included as indicators, the survey was primarily disseminated among medical students known to the authors and collaborators. This approach likely ensured that the participant pool predominantly consisted of medical students.
Future Research Recommendation
As AI continues to be rapidly adopted in different areas of healthcare, further research is strongly recommended to fully understand its potential, implications, and challenges from medical students’ perspectives.
One key area future studies should explore is how LLMs can be utilized differently in teaching and learning. Such research could contribute to the development of best practices that ensure AI tools are maximally effective for both educators and students. Additionally, investigating the differences in how LLMs are applied during preclinical and clinical years of medical school is important. Such studies could reveal unique needs and opportunities at each stage, enabling tailored approaches to AI integration that address the specific challenges and goals of these phases.
A potential direction for long-term research could involve exploring the impact of using LLMs during medical school and how it affects the clinical practice once they are fully qualified physicians. Does the use of AI tools during training positively or negatively influence clinical decision making and patient care?
It is also imperative to address the identified barriers in application of LLMs for healthcare and research and navigate solutions to increase medical students’ confidence in the usage of these tools.
Lastly, the ethical consideration surrounding the extent of AI integration is a priority. Research addressing ethics can be used for developing ethical frameworks and guidelines that can regulate AI use in medical schools.38,39
Conclusion
The accelerating progression of AI has ushered in novel prospects in healthcare delivery, clinical research, and medical education. This creates a notable gap in understanding the perspectives and utility of LLMs among medical students and its ethical considerations. Although most respondents are already aware of LLMs and their applications, the survey demonstrated that there is still hesitancy among a significant portion of medical students in fully adopting it into healthcare practice, clinical research, and medical education.
This study prompts further exploration of medical students’ attitudes and acceptance concerning the integration of LLMs for future educational strategies, research methodologies, ethical considerations, and healthcare practice.
Supplemental Material
sj-pdf-1-mde-10.1177_23821205251331124 - Supplemental material for Medical Students’ Perceptions of Large Language Models in Healthcare: A Multinational Cross-Sectional Study
Supplemental material, sj-pdf-1-mde-10.1177_23821205251331124 for Medical Students’ Perceptions of Large Language Models in Healthcare: A Multinational Cross-Sectional Study by Faiza Ejas, Sameer Asim Khan, Amina Mujahid, Fatma AlJoker, Hans Mautong, Geovanny Alvarado-Villa, Abhishek Kashyap, Muhammad Umer Yasir, Kindie Woubshet Nigatu, Nethra Jain, Nandhini Iyer, Aman Sandhu, Shahab Sharafat, Sara Yahya, Mohamd Mahmoud Ghaly, Ibrahim Ibrar, Aakanksha Singh, Harpeet Grewal, Ivan Alfredo Huespe, Priyal Mehta, Zara Arshad, Rahul Kashyap and Faisal A Nawaz in Journal of Medical Education and Curricular Development
Footnotes
Acknowledgments
We are grateful to the Global Remote Research Scholars Program for providing the opportunity of global collaboration and keen mentorship for this study in collaboration with Mohammed Bin Rashid University of Medicine and Health Sciences.
ORCID iDs
Ethical Considerations
The study was deemed IRB-exempt from Mayo Clinic Institutional Review Board.
Consent to Participate
Your responses are entirely voluntary. This survey is designed to be anonymous, meaning that there should be no way to connect your responses with you. By completing and submitting the survey, you affirm that you give your consent for your answers to be used for the research and quality improvement purposes.
Author Contributions
FE, SK, AM, and FA were involved in study conception, survey design, data collection, analysis, and prepared the first draft of the manuscript. ZA, RK, and FAN reviewed, edited, and approved the final manuscript. HM, GA-V, AK, UY, KWN, NI, NJ, AS, SS, SY, MMG, and II contributed in data acquisition. AS, HG, IAH, and PM validated the survey. All authors contributed to the manuscript and approved the submitted version.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.