
Abstract
OBJECTIVES
Internal medicine clerkship grades are important for residency selection, but inconsistencies between evaluator ratings threaten their ability to accurately represent student performance and perceived fairness. Clerkship grading committees are recommended as best practice, but the mechanisms by which they promote accuracy and fairness are not certain. The ability of a committee to reliably assess and account for grading stringency of individual evaluators has not been previously studied.
METHODS
This is a retrospective analysis of evaluations completed by faculty considered to be stringent, lenient, or neutral graders by members of a grading committee of a single medical college. Faculty evaluations were assessed for differences in ratings on individual skills and recommendations for final grade between perceived stringency categories. Logistic regression was used to determine if actual assigned ratings varied based on perceived faculty's grading stringency category.
RESULTS
“Easy graders” consistently had the highest probability of awarding an above-average rating, and “hard graders” consistently had the lowest probability of awarding an above-average rating, though this finding only reached statistical significance only for 2 of 8 questions on the evaluation form (P = .033 and P = .001). Odds ratios of assigning a higher final suggested grade followed the expected pattern (higher for “easy” and “neutral” compared to “hard,” higher for “easy” compared to “neutral”) but did not reach statistical significance.
CONCLUSIONS
Perceived differences in faculty grading stringency have basis in reality for clerkship evaluation elements. However, final grades recommended by faculty perceived as “stringent” or “lenient” did not differ. Perceptions of “hawks” and “doves” are not just lore but may not have implications for students’ final grades. Continued research to describe the “hawk and dove effect” will be crucial to enable assessment of local grading variation and empower local educational leadership to correct, but not overcorrect, for this effect to maintain fairness in student evaluations.
Introduction
Internal medicine (IM) clerkship grades, and their derivatives such as class rank and honorary society memberships, are an important factor in the residency selection process.1,2 With the transition of the United States Medical Licensing Exam (USMLE) Step 1 to pass/fail scoring, the importance of clerkship grades will likely increase further.1,2 There is great variability in grading processes among medical schools, such as different grading tiers, percentage of high grades, processes for assigning grades, and components contributing to the grades.3–8 However, 90% of institutions use some form of clinical performance assessment in the calculation of a clerkship grade, comprising, on average, 52.8% of that final grade. 9 Though some amount of subjectivity is inherent and perhaps even desirable for the assessment of clinical performance, 10 there are concerns about the reliability of evaluator data,11–13 as well as differences between evaluators assessing the same performance. 14 Additionally, narrative comments use different language to describe students based on gender and underrepresented-in-medicine status,15–17 with students from racial and ethnic groups underrepresented in medicine systematically receiving lower clerkship grades.15,18,19 It is unsurprising that students do not perceive clerkship grades as fair and accurate. 20
Clerkship grading committee review of individual evaluator data for determination of final grade is recommended as a method to improve the consistency of high-stakes decision making, increase detection of poor performance, and minimize the effect of individual evaluator bias on final grade.21–23 The proposed mechanism of these advantages is a shared mental model of performance expectations, reliable interpretation of available data (clerkship evaluations), and an understanding of shared accountability. 24 An understanding of individual evaluator characteristics could improve interpretation of data from that evaluator,25,26 but the ability of a committee to assess evaluator stringency or leniency has not been previously studied. Knowing whether any given evaluator has a tendency to be a stringent grader (a “hawk”) or a lenient grader (a “dove”) provides a context for the grading committee members as to how the evaluator Likert ratings or comments can be interpreted as compared to others.
We hypothesized that an experienced grading committee can reliably detect patterns of stringency or leniency when exposed to evaluator data over time. We aimed to evaluate a statistical reality of our clerkship grading committee's assessment of evaluators as “hawks” or “doves.”
Methods
Setting and study population
This work was conducted at a large medical school (average class size 276) with several affiliated clinical sites. The IM clerkship is a mandatory 8-week course completed during the third year of medical school at the time of the study. Four weeks of clerkship are completed at the main university hospital, and four weeks are completed at an affiliated site—an academic community medical center.
This study analyzed student evaluations for the 2017-18 and 2018-19 academic years at the Sidney Kimmel Medical College (SKMC). At that time, the clerkship grades were comprised of a score based on students’ clinical performance and other factors including the NBME (National Board of Medical Examiners) subject examination and special projects. For each student, faculty and housestaff who worked with the student in the clinical setting during the clerkship completed a standard Clerkship Evaluation Form. This form is used for every clerkship at the medical college and can be found in supplemental materials (Clerkship Evaluation Form). It consists of two narrative fields, soliciting summative and formative feedback, as well as 8 questions based on competencies and SKMC's medical education program objectives, each rated by evaluators on a 3-point Likert scale (below expected, expected, and above expected). The questions are displayed in Table 1. At the end, each evaluator is asked to recommend a final grade for the student based on their clinical performance. For the academic years included in the analysis, grade choices were Honors, Excellent, Good-Plus, Good, Good-minus, Marginal, and Failure. For each student, evaluations are collected electronically then combined into a single digital composite. A web-based evaluation management software called New Innovations (https://www.new-innov.com) is utilized for this process.
Quantitative fields of the Clerkship Evaluation Form completed by evaluators for each student.

The IM grading committee is comprised of the clerkship director, all clinical affiliate clerkship site directors, as well as other members of the IM Undergraduate Medical Education (UME) leadership. The grading committee meets at the end of each block to review all evaluations students receive. Members review the summative narratives, as well as the Likert items. Through a discussion, a consensus is achieved, and each student receives a numerical score commensurate with their clinical performance. This score is then used in calculating the final grade for each student.
During the group discussions, the narrative comments are weighed most heavily, although Likert items and each evaluator's final suggested grade are considered. The narrative comments were not analyzed in this study. Quantitative ratings were selected for this analysis due to the ease of quantitative analytics available to the study team. Since the pool of evaluators is finite, each evaluator is known to the members of the grading committee. Additionally, with each faculty member evaluating multiple students over a course of several academic years, patterns in how they fill out evaluations, as well as the language they use in their narratives, are well-known to the grading committee members. In reviewing and interpreting evaluators’ comments and Likert scale ratings, the grading committee considers the level of experience of the evaluator as well as the grading committee members’ global assessment of the evaluator's stringency, assessment acumen, and dedication to the evaluation process – an assessment sometimes informally described among the committee as an evaluator being a “hawk,” a “dove,” or “spot on.” Four of the authors (JZ, SR, JD, and NM) have been members of the Grading Committee for a minimum of 3 years (JZ and SR), and a maximum of 12 years (NM).
Data collection
We extracted evaluation data from the evaluation management software for all IM clerkships completed during the 2017-18 and 2018-19 academic years. The data set consisted of evaluator name, clinical site, and quantitative data available on each evaluation they completed—answers to all Likert-rated questions and evaluator's suggested final grade. Student names, the final grades assigned by the grading committee, and narrative comments were not included in this analysis.
From this data, a convenience sample was created, including only evaluations completed by the faculty at the Thomas Jefferson University Hospital (TJUH) and one of its academic affiliates, Lankenau Medical Center (LMC), due to the multiple authors’ familiarity with the grading patterns of that faculty. Housestaff evaluations of students were excluded. From this sample, a list of faculty names who completed at least one student evaluation during the study period was generated. Each faculty member on the list was rated based on the grading stringency impression as a “hard,” “neutral,” or “easy” grader. One author (JD), who is on staff at LMC, assigned grading stringency categories based on his impressions of faculty at his site; other authors (JZ, SR, and NM) concurred with his assessments. Twenty-three affiliate faculty members completed an evaluation during the study period; all were included in the analysis.
Three authors (JZ, SR, and NM) are on staff at TJUH, where 66 faculty members completed at least one clerkship evaluation during the study period. Each TJUH author assigned ratings to all faculty members for whom they had an impression of grading stringency. Faculty were excluded if zero or only one author had an impression (n = 18 and n = 17, respectively). One faculty member was excluded due to inability to separate evaluations that individual completed as a senior resident in the first year of the study period form those completed as a faculty in the second year of the study period. Impressions were adopted if three authors had a consensus on the stringency impression, or if two had the same impression and the third had no impression. If one author disagreed with the other two, or two authors had different impressions, the impression was discussed; if consensus could not be achieved, the faculty member was excluded (n = 3). For one faculty member, the authors had widely different impressions (one judged the faculty member a “hard” grader, another an “easy” grader) and this faculty member was excluded without discussion. After exclusions, evaluations from 27 TJUH faculty were analyzed.
Statistical analysis
The final sample included in the analysis consisted of 877 student evaluations by 52 faculty members. For each evaluation question, binary logistic regression was used to determine if the odds of having an above-average assigned rating varied based on perceived faculty stringency category. Ordinal logistic regression was used to model the odds of suggesting a certain final clerkship grade. For all logistic regression models, generalized estimating equations were used to account for correlation of grading within each individual faculty grader.
Raw data used for this analysis is available up on request. The Thomas Jefferson University Institutional Review Board evaluated this study and determined it to be exempt from review, waiving the requirement to obtain informed consent.
Results
Table 2 shows the probability of faculty in each stringency category assigning an above-average rating for each of the eight Likert scale questions. Although “easy graders” consistently had the highest probability of awarding an above-average rating, and “hard graders” consistently had the lowest probability of awarding an above-average rating, this finding only reached statistical significance for questions 2 (rating knowledge base, use of evidence-based medicine, application of knowledge in clinical situations, differential diagnoses, and treatment plans; P = .033) and 3 (rating the ability identify own strengths and area of improvement, acceptance of feedback and performance improvement; P = .001).
Probabilities and odds ratios of giving an above-average rating for questions 1–8 based on stringency impression.

“Easy graders” had a significantly higher odds ratio (OR) of giving an above-average rating as compared to “hard graders” for questions 2 (OR 2.34, 95% CI 1.22-4.48), 3 (OR 2.87, 95% CI 1.44-5.71), 4 (OR 2.36, 95% CI 1.12-4.97), and 8 (OR 2.53, 95% CI 1.03-6.22). Comparing “easy” to “neutral” graders, the OR of giving an above-average rating was significant for questions 2 (OR 2.00, 95% CI 1.06-3.79), 3 (OR 2.20, 95% CI 1.08-4.50), and 8 (OR 2.39, 95% CI 1.026-5.55). Odds ratios for other questions and other stringency comparisons were not significantly different.
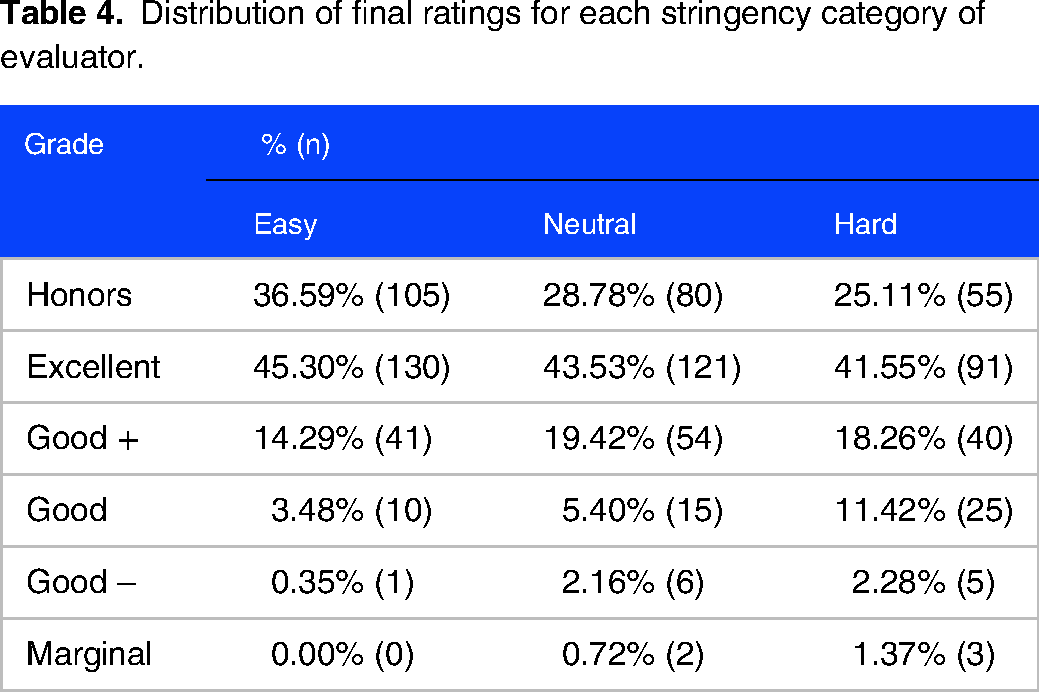
Odds ratio for assigning a higher suggested final grade for each stringency category compared to the others is shown in Table 3

Distribution of final suggested grades assigned by easy, neutral, and hard graders.
Odds ratios for assigning a higher final rating compared to another stringency category.

Distribution of final ratings for each stringency category of evaluator.
Discussion
This analysis demonstrates statistically significant differences in ratings assigned by evaluators perceived by experienced grading committee members to be particularly stringent or lenient in their evaluations. Evaluation items related to three domains of competency 27 demonstrated a statistically significant difference between perceived hard, neutral, and easy graders. A clear difference existed for questions 2 and 3, which assessed knowledge for practice, patient care, and practice-based learning and improvement. Skills mapping to more subjectively assessed domains, like interpersonal and communication skills and professionalism, did not show any significant difference within our study group. There was also no difference in the final suggested grades the evaluators recommended. Despite the lack of statistical significance in many of the evaluation ratings, the expected pattern of outcomes was nearly universal, raising the possibility of type II error.
A general perception exists among medical students that the clerkship grading process is unfair. 20 Identifiable differences in the grading patterns of faculty that complete evaluations may contribute to such opinions, and this perception is borne out by imperfect inter-rater correlation when assessing the same performance. 14 Interestingly, prior studies demonstrated that efforts to train the evaluators in order to improve inter-rater reliability are generally not successful.28,29 Seasoned clerkship directors often have insight into the variability of expectations of medical students among their faculty. These perceptions of faculty are drawn from commentary on student evaluations, as well as various degrees of personal knowledge of the faculty members. Despite similar final grade recommendations across stringency categories, the existence of differences in assessing discrete skills demonstrates that this grading committee's perception of stringency and leniency has some basis in reality. However, the small overall differences, and the lack of detectable difference in final suggested grade, should provide some reassurance to students that being assigned to a hard-grading “hawk” faculty is not a guarantee of a lower grade.
This analysis has limitations. First, narrative comments were not included in the dataset. Many medical schools rely heavily on commentary provided by faculty to determine a final grade for students. A qualitative analysis, examining the differences in narrative comments by perceived grading stringency or leniency, is an important next step to support the existence of perceivable “hawks” (hard graders) and “doves” (easy graders). Perhaps such an investigation could focus on comments reflecting achievement in knowledge for practice, patient care, and practice-based learning and improvement, the domains found in our study to have detectable differences between evaluator categories. This could be particularly critical for schools with a pass-fail clerkship grading system, where evaluator comments may be the only data in the Medical School Performance Evaluation or departmental letter of support that can discriminate between the levels of student achievement; in that case, assignment to a “hawk” in the clerkship could have serious consequences for residency selection.
Another limitation is the inability to connect evaluations with the final grade assigned to the student. Though our findings suggest that some level of clerkship director and grading committee compensation for faculty tendencies is appropriate, we cannot determine if that level of compensation is appropriate. A finding that students are equally likely to obtain a given final grade regardless of the composition of “hawks” and “doves” among their evaluators would demonstrate appropriate grading committee adjustment for these categories when assigning final grade. However, over- or under-compensation is also possible. Though this study demonstrates a reality underlying the categories “hawk” and “dove,” it cannot determine whether this grading committee reacts appropriately to these perceptions.
Additionally, a power analysis was not performed; instead, all available evaluations that met eligibility criteria were included to obtain the largest possible sample size. This limits the reliability of our negative findings. The Clerkship Evaluation Form used to obtain data is not a validated instrument. Although it was not formally pilot tested, it had been in use at our medical school for over a year prior to data collection.
There are other variables that may have impacted our study. Medical students have a wide range of skill levels. We were not able to control for the skill level of the students assigned to a specific evaluator. It is possible some faculty worked with a disproportionate number of lower-performing students compared to their peers, and their “hawk” reputation rests not on the unusually high expectations but rather on unusually weaker students. The affiliate site faculty work with learners from several different medical schools, which may further impact variability in expectations and perception of students from the one medical school studied. Different numbers of contact hours between an individual student and evaluator might have influenced assessments, but this variable was not available.
Lastly, we conducted this assessment within a single grading committee. More research is needed to determine if the ability to detect evaluator stringency is a universal or even a common feature of grading committees, and whether features of a grading committee (eg, meeting structure, membership composition) or its individual members (eg, years of experience in education or on the committee, time dedicated to education) contribute to accurate or inaccurate assessment of evaluator stringency.
Despite these limitations, our findings support a factual basis for perception of evaluators as “hawks” or “doves.” Clerkship directors and those who serve on a grading committee may wish to compare their impressions of the individual evaluators, develop a shared mental model of the “hawks” and “doves,” and perform some form of analysis, meaningful to their grading procedures, to ensure that any compensation for stringency undertaken by their committee is appropriate, such as the variance analyses of Generalizability theory 30 or the method described by Murphy et al. 31
Conclusions
Perceived differences in faculty grading stringency have basis in reality for individual clerkship evaluation elements. However, final grades recommended by faculty perceived as stringent or lenient did not differ. Perceptions of “hawks” and “doves” are not just lore but may not have implications for the final grades. Continued research to describe the “hawk and dove effect” will be crucial to enable assessment of local grading variation and empower local educational leadership to correct, but not overcorrect, for this effect to maintain fairness in student grading. This will become increasingly crucial as factors previously helpful for residency selection, such as the USMLE Step 1, and even clerkship grades, become increasingly pass/fail.
Supplemental Material
sj-docx-1-mde-10.1177_23821205231197079 - Supplemental material for Hawks and Doves: Perceptions and Reality of Faculty Evaluations
Supplemental material, sj-docx-1-mde-10.1177_23821205231197079 for Hawks and Doves: Perceptions and Reality of Faculty Evaluations by Jillian Zavodnick, Jonathan Doroshow, Sarah Rosenberg, Joshua Banks, Benjamin E Leiby and Nina Mingioni in Journal of Medical Education and Curricular Development
Footnotes
Acknowledgement
The authors would like to acknowledge Amanda White for her assistance with data collection.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work did not receive external support, and was funded internally by Sidney Kimmel Medical College's Department of Medicine. Publication made possible in part by support from the Thomas Jefferson University Open Access Fund.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.