
Abstract
Medical decision making is a critical, yet understudied, aspect of medical education. 1 The ability to demonstrate sound medical decision making is among the most highly sought characteristics of medical professionals, 2 such that the American College of Graduate Medical Education (ACGME) has included medical decision making as a core competency in several specialties.3-5 For example, a poorly conducted initial history and physical examination can lead to poor medical decision making in acute care situations and can result in patient death. 6 The role of decision making in the academic sense focuses on the rational and methodical approach to diagnostic reasoning versus the underlying subconscious nature of decision making that generally takes over in uncertain medical situations. 7
As medical students graduate from a wide variety of training programs, there remains significant variability in medical decision making at the initiation of their residency training.8,9 Unfortunately, measuring and quantifying medical decision making is difficult in a consistent form, especially in varying medical conditions, and the training and assessment of medical decision making is still underdeveloped. 10 As medical training continues to evolve, valid assessments will be required to ensure that trainees have achieved and maintained required proficiencies as well as good clinical decision–making skills.
Medical simulation, despite its popularity in critical care training and mainstream assimilation into academia, provides a yet underutilized methodology to train and assess medical decision making in a variety of environments. Importantly, simulation labs provide a standardized environment in which high-fidelity simulations allow a comprehensive evaluation of the entire process from data assimilation, diagnostic planning and interpretation, as well as integrated management actions. The development of a medical decision-making assessment with evidence for validity could support future evaluation, training, and monitoring. The purpose of this study was twofold: 1) to develop the Medical Judgment Metric (MJM), a numerical rubric to quantify good decisions in practice in simulated environments; and 2) to obtain initial preliminary evidence of reliability and validity of the tool.
Methods
Development
The individual judgment items, clinical domains, and competency sections of the initial MJM were created based on the approach of Weber and others, 11 existing ACGME Clinical Competency Committees, 12 and the Association of American Medical Colleges 13 conceptual frameworks for clinical judgment. Over the course of 4 months, a team of medical simulation, emergency medicine, medical decision making, and trauma experts devised a list of medical judgment items not specific to any particular medical condition. The MJM development team defined medical decision making as how people routinely perceive, understand, and judge things to make medical decisions for others measured by a score to quantify good decisions in practice. 14 The MJM medical judgment items were developed with three to six internal anchors (core observed medical behaviors). This methodology is modeled after other validated teamwork/nontechnical skill checklists employed in surgery 15 and trauma 16 that provide several internal anchors in an attempt to improve interrater reliability. Subsequently, the MJM judgment items were stratified into clinical domains that were defined as history and physical, diagnostic, interpretation, and management, with a maximum score of four in each domain on a 0.5 interval scale (see Figure 1a–d). Once the list of medical judgment items and domains were reviewed, items were stratified into competency levels: Novice, Intermediate, Proficient, and Advanced. The intended use of the MJM is for raters to select the items (with core internal anchors) in each domain (history and physical, diagnostic, interpretation, and management) where the maximum score for each domain is 4. The domain scores represented the observed performance during simulation scenarios, thus adding up to an overall performance MJM maximum score of 16.

Medical Judgment Metric: (a) History and Physical domain; (b) Diagnostic domain; (c) Interpretation domain; (d) Management domain. The Medical Judgment Metric (MJM) is a tool that can be applied to anyone interested in assessing medical decision-making capacity. The raters of the MJM should be well experienced physicians.
Content Validity
Using the method by Wynd and others, 17 eight experts from cardiology, emergency medicine, family medicine, and medical simulation backgrounds reviewed the MJM for content validity. Experts were recruited in two waves. In the first wave, n = 4 experts were from a single American College of Surgeons (ACS) verified level I trauma institution in the United States (a Level I Trauma Center is a comprehensive regional resource capable of providing total care for every aspect of injury—from prevention through rehabilitation). 18 In the second wave, n = 4 experts were from other ACS level I trauma institutions in the United States. No expert participated in both waves, and the authors were not eligible to be recruited as experts in the second wave.
In each wave, the experts were asked to rate whether the MJM judgment items, clinical domains, and competency levels were “not relevant,” “somewhat relevant,” “quite relevant,” or “very relevant” content. Also, the content experts were asked to determine if content items should be added, deleted, or modified in each of the clinical domains and competency levels. The MJM was revised after each wave based on the expert agreement for each item, domain, and competency level. The last draft of the MJM was distributed among the MJM development team for final review of flow, ease of use, and formatting for preliminary field-testing.
Internal Structure
Preliminary field-testing for clarity and feasibility of the MJM instrument was conducted by administering the instrument in four groups of 10 participants each. Due to the pilot nature of the study, this sample size was chosen to establish feasibility and provide preliminary interrater reliability and validity figures to conduct a future power analysis for further interrater reliability and validity. The groups were recruited to target a variety of experience and skill levels in the medical field from highly educated engineers with no medical background or experience (layperson), physicians completing their postgraduate medical training, and seasoned physicians with mastery level experience, in addition to spanning a wide spectrum of scientific disciplines. Participants undertook four medical simulations: biliary colic, pneumothorax, ST elevation myocardial infarction, and renal colic, which fall into the two most common reasons for emergency intervention: chest pain and abdominal pain. The participants were enrolled on an individual basis in each simulation scenario and each participant completed all four cases. Prior to starting these medical simulations, an unrelated practice simulation was conducted to ensure the comfort of each participant and answer questions about their ability to perform in the medical simulation scenarios. The participants were assessed in a strictly summative manner during all scenarios. The participants did not receive feedback, education, or a debriefing.
In each tested medical simulation, participants were informed that they were in a moderate-sized community hospital emergency department in the United States and were asked to care for the patient as best as possible by identifying the appropriate screening, testing, treatment, and diagnosis. Each participant had access to standard medical equipment and a nurse was available to use the equipment at the command of the participant; however, no training was provided to the participant on how to use the equipment. The full body simulation mannequin was capable of receiving any of the tests and maneuvers as directed by the participant. Verbal and/or visual feedback was provided for all inquiries as well as requested and available tests were provided in a scaled time-delay fashion. All laboratory values, radiographs, electrocardiograms, and representative ultrasound images were provided without interpretation beyond reference laboratory values. Participants were informed if certain tests, treatments, or specialists were not available. An agreed-upon safe word (MUSKRAT) was established prior to starting the medical simulations in the event that the participant felt ill (e.g., due to anxiety) or was injured (e.g., accidental needle stick) during the medical simulation. If any participant in the scenarios said the word “MUSKRAT,” the medical simulation team would immediately end the scenario and attend to the individual in need.
A team of four medical raters with backgrounds in emergency medicine, trauma, and medical simulation scored the participants using the MJM either live or using a video recording of the medical simulation, as all scenarios were recorded. A minimum of three raters was required for each medical simulation. The raters were blinded to the participant’s name and skill level as each participant was assigned a study identification number on scheduling. Each rater (either live or watching the video) was in a separate room and viewing area when they observed the simulation and completed the MJM and critical action evaluation. The raters handed their results to the research coordinator and she was the only one that reviewed and entered the final interpretation of the simulation. For each rater and medical simulation scenario, the numerical MJM total score (across the four domains of the MJM) was examined for interrater reliability using a two-way mixed average score intraclass correlation coefficient (ICC). Since the four expert raters were recruited to serve as our entire population of raters their effects were considered to be fixed.
Participants (ratees) were volunteers who served as representatives of their medical and expertise skillset and therefore their effects were considered to be random. The only other person available to assist the participant was a confederate nurse who only executed requested orders. Each participant did all four cases individually. The two-way mixed model ICC was chosen to account for variation of the rater scores in two ways, the fixed rater effect and the random ratee effect. Since the collective average score of the four raters for each ratee was used in subsequent analyses the average agreement of the score from the raters was selected rather than the individual agreement score. The final model for assessing the interrater reliability between the raters for each medical simulation scenario was the ICC (three-raters or four-raters) model. The ICC (three-raters or four-raters) average measure score then provide a metric for the interrater reliability of the raters by determining the proportion of the variation in average rater scores due to the different ratees. An ICC value approaching 1 indicates a higher reliability.
Relationships With Other Variables
In addition to completing the MJM for each medical simulation, raters were asked to complete a simulation-specific critical action checklist (reporting whether or not the participant had performed actions determined a priori to be critical to management of the patient) and to make a prediction of the patient’s condition at the conclusion of the simulation (loss of life, loss of function, or stabilized). The agreement of the raters in assessing each ratee’s simulation outcome was determined using Fleiss’s Kappa, an extension of Cohen’s Kappa. Only the three raters who completed evaluations for all patient outcomes were included in the determination of the Fleiss’ Kappa values. Since there are more than two raters assigning categorical ratings, Fleiss’ Kappa with 95% confidence interval was calculated to determine the consistency of the raters in evaluating the expected patient outcome. The relationship between MJM scores and outcomes was examined through three-way ROC (receiver operating characteristic curve) analyses of the association between mean (over raters) MJM scores and the expected patient outcome selected by the majority of raters for each video. 19 For each ratee a majority outcome was identified among all rater outcome scores; there was never a split decision in the raters’ outcomes. A partitioning strategy was used to guide the cutoff determination since the outcomes were trichotomous and one partition value may influence another partition value. The ordinality of the outcomes was considered by giving priority to loss of life using a one-versus-all grouped comparison and then by giving priority to stabilization. The volume under the surface generated by the specific cutoffs was determined with chance performance equal to 0.17 and perfect performance equal to 1.00. Finally, an overall agreement between the cutoffs and the outcome predicted directly by the rater for each video was determined using Cohen’s Kappa. Cohen’s Kappa was utilized since the agreement between two categorical measures was assessed for each simulation outcome. The two measures consisted of the majority outcome of the raters and the categorical outcome determined in reference to the cutoff of the mean rater score. For example, if the majority of the raters determined the outcome to be “loss of life” for that subject’s patient and the average rater score was below the cutoff for “loss of life” then those measures were determined to be in agreement. Using this approach, significant Cohen’s Kappa values would then be interpreted as evidence of concurrent validity, that the average rater scores numerically could be used as valid differentiators of simulation outcomes.
Response Process
Finally, a project team member recorded any questions/comments about clarity of the MJM judgment items, clinical domains, competency sections, grammar, syntax, organization, appropriateness, acceptability to the clinical raters, ease of use, and logical flow. All statistical analyses were completed using STATA version 14, SPSS version 23.0, and Microsoft Excel version 2007. Institutional review board approval was obtained for conducting human subjects research.
Results
Content Validity
Content validity (CV) data from the waves of expert reviews were reviewed and items with a 100% agreement rate among raters were retained for the final metric. There were n = 20 statements, items, or domains that did not have 100% or even 50% complete agreement among reviewers (Table 1). Percentage agreements from the reviewers are detailed and voted on by the authors for group categorization as very relevant (75% to 100% relevance to domain), quite relevant (50% to 74% relevance to domain), somewhat relevant (25% to 49% relevance to domain), and not relevant (0% to 24% relevance to domain). Categories of relevance were then collapsed and identified as “relevant” versus “not relevant.” The grey highlight in Table 1 indicates the final category the authors agreed upon for the final draft of the MJM.
Content Validity Index Average Percentage of Agreement on Medical Judgment Metric Items in the Clinical Domains Needing Team Agreement

Internal Structure
Figure 1a through d display the developed MJM domains that the raters used to evaluate in the medical simulations. The ICC values ranged from 0.965 to 0.987, supporting the consistency of the raters across the different participants for each scenario (Table 2).
Reliability of Summed Rater Evaluations by Scenario
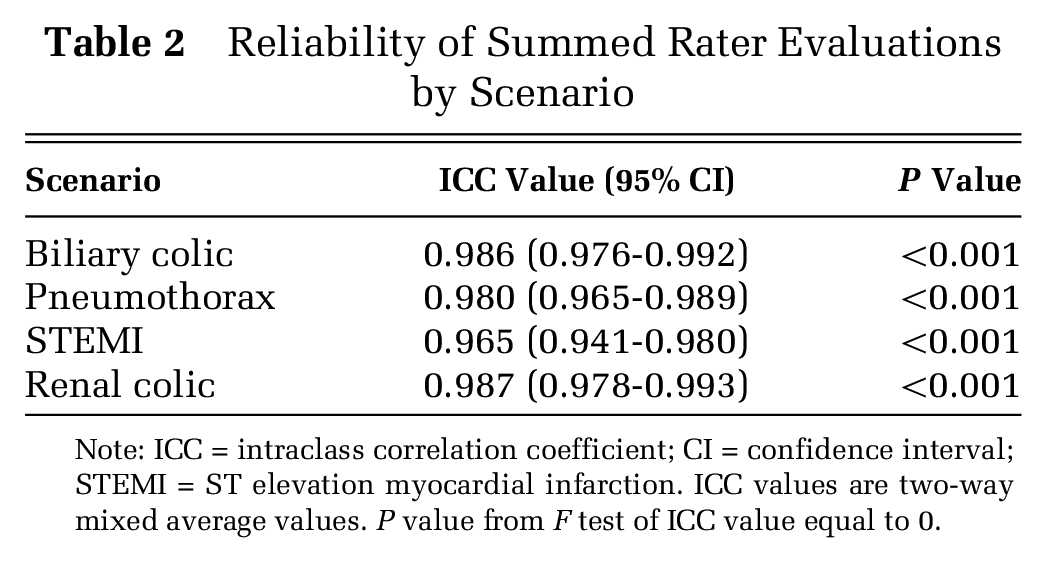
Note: ICC = intraclass correlation coefficient; CI = confidence interval; STEMI = ST elevation myocardial infarction. ICC values are two-way mixed average values. P value from F test of ICC value equal to 0.
Relationships With Other Variables
For the expected patient outcomes derived from the critical action checklists, Fleiss’ Kappa values ranged from 0.791 to 0.906, demonstrating the consistency of the raters in evaluating the outcomes of each simulation (Table 3). Cohen’s Kappa between the outcome predicted by the average MJM score and the outcome expected by the majority of raters ranged from the 0.851 to 0.880, demonstrating the ability of the average rater score to consistently differentiate between the three outcome levels (stabilization, loss of function, or loss of life) for each medical simulation scenario (Table 4).
Reliability of Rater Evaluations by Scenario Outcome

Note: CI = confidence interval; STEMI = ST elevation myocardial infarction. P value from test of Fleiss Kappa value equal to 0.
Concurrent Validation of Categorized Rater Scores to Simulation Outcomes

Note: STEMI = ST elevation myocardial infarction. Average score cutoff is determined by providing priority to loss of life followed by stabilization. The volume under the surface (VUS) is calculated at the fixed cutoff scores with chance performance equal to a VUS value of 0.17 and perfection equal to a VUS value of 1.00.
Discussion
The pilot study reports the development of the MJM tool and its ability to quantify the quality of the medical decision capacity of an individual in four distinct time-critical medical simulations. Specifically, a strong correlation was found of the student’s MJM score (below or above the MJM cutoff) with rater evaluations of “loss of life” or “stabilization;” perhaps the small sample size impaired the ability to discern “loss of function.” Ultimately, the results of this pilot study suggest that quantifying medical decision making is possible with high interrater reliability and close associations with scenario outcome in a medical simulation environment.
High-fidelity medical simulation provides an operational environment in which the MJM can be used to measure medical decision making. Several recent studies have demonstrated the importance and effectiveness of medical simulation complemented by high-quality debriefing enabling the transfer of knowledge, skills, and attitudes to the clinical arena.20-22 Thus, due to its high interrater reliability and evidence suggesting validation, the MJM is a promising evaluation tool as part of a medical education curriculum to measure and subsequently modify the quality of medical decision making. The long-term goal of research into medical decision-making tools is to potentially predict patient outcomes. At this time, there is still little evidence to suggest such tools can predict these outcomes. 23
Several considerations warrant further discussion. As a pilot study, a limited number of participants and scenarios were assessed. All four raters were from the same institution with three having clinical backgrounds in emergency medicine and fellowship training in medical simulation. The fourth rater was a general surgeon. In addition, both the MJM ratings and the critical action checklists with expected patient outcomes were determined by the same raters while viewing each simulation, thus potentially contributing to scoring predictability bias of the outcomes and inflated MJM score associations. Also, the raters’ clinical judgment may be inaccurate in an uncertain clinical environment. While this pilot study was not powered to undertake an analysis of the performance of subsets of the sample, the study design included the evaluation of common critical simulations undertaken by study participants with a wide range of skill and vocational discipline. Also, due to the pilot nature of the study, a “loss of function” outcome in the MJM was not robust (Cohen Kappa) enough to detect significant differences. Additionally, the classification of “loss of life” and “stabilization” using Cohen Kappa demonstrated the magnitude of agreement. Future studies should look at larger sample sizes of students, include a variety of raters from different specialties, and to include a wider variety of scenarios.
Conclusion
Additional research using the MJM is still needed to validate further the ability to measure medical decision making in medical simulation. Despite the strength of these pilot data, greater evidence for validity and interrater reliability will be required from the analysis of a larger sample of participants, medical cases, and a range of complex medical cases for greater generalizability. As of right now, there is still a need to support clinical faculty with additional evaluation metrics, outside of typical skill-based metrics, to assess training progress in medical students, and resident physicians. The MJM provides a promising tool to assess medical decision making.
Footnotes
Acknowledgements
We wish to thank the following participating experts for helping the study team with content and face validity reviews of the MJM: Erik L. Antonsen, MD, PhD; Jeffery D. Kerby, MD, PhD; Lynn M. Hamrich, MD, FAAFP; Tiffany Marchand, MD; Janyce M. Sanford, MD, MBA, FACEP; and Jordan A. Weinberg, MD, FACS.
Financial support for this study was provided entirely by a subcontract with Zin Technologies, Inc. The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.