
Abstract
Approximately half of the US noninstitutionalized population ≥30 y old has periodontitis. An accurate measure for the assessment of periodontitis burden is crucial to assess population-level treatment needs. Nonetheless, because periodontitis ultimately leads to tooth loss, missing periodontal measurements due to tooth loss may pose a critical challenge to accurate periodontitis surveillance in public health. In this study, we aim to propose a novel estimate, the prevalence of periodontitis susceptibility cases, which incorporates both observed values and plausible values at missing teeth generated using multivariate imputation by chained equations (MICE). Using data from the 2009–2012 National Health and Nutrition Examination Survey (NHANES) (
Knowledge Transfer Statement:
Our proposed estimate of periodontitis susceptibility cases addresses the issue of missing teeth, offering an innovative solution through a generative missing data imputation model. The implications of our findings extend to fostering more robust investigations into the relationships between periodontal health and systemic diseases, thereby offering valuable insights to clinicians for informed decision-making. Moreover, the study’s capacity to shape clinical practices and interventions in public health will further fortify health policy strategies.
Keywords
Introduction
Approximately half of the US noninstitutionalized population≥30 y are affected by periodontitis (Eke et al. 2015). Severe periodontitis is estimated to account for 5.3 million disability-adjusted life-years worldwide, corresponding to an average health loss of 97 y per 100,000 persons (Demmer et al. 2015; James et al. 2018), which contributes significantly to the global burden of disease (GBD 2017 Disease and Injury Incidence and Prevalence Collaborators 2018; James et al. 2018; GBD 2019 Ageing Collaborators 2022). An accurate measure for the assessment of periodontitis burden is crucial to assess population-level treatment needs, identify risk factors, evaluate its socioeconomic impact, and ultimately improve public health policies for the prevention and management of periodontitis (Eke et al. 2015).
To establish an estimate for periodontitis prevalence, it is crucial to introduce the periodontitis case definition and classification system. Widely adopted protocols generally involve a comprehensive full-mouth examination to assess disease presence (Eke et al. 2012; Tonetti et al. 2018). Specifically, the 2012 Centers for Disease Control and Prevention (CDC)/American Academy of Pediatrics (AAP) case definition requires the composite measure of interdental clinical attachment loss (iCAL), which is a measure of periodontal tissue loss, and interdental periodontal probing depth (iPD), which is a measure of periodontal inflammation (Eke et al. 2012). Furthermore, recognizing the potential causal link between tooth loss and iCAL (Beck et al. 1997) and periodontitis, Tonetti et al. (2018) recommended incorporating information on tooth loss due to periodontitis into the case definition. However, such information may be limited and subject to recall bias when patients cannot recall their previous treatments in detail.
Consequently, discussions about estimates for periodontitis prevalence have revolved around whether and how to incorporate information for patients who have experienced tooth loss. It is common to exclude missing teeth and apply directly the 2012 CDC/AAP case definition (Eke et al. 2015), which does not require such information, especially when data on tooth loss are limited. Nevertheless, the challenge of missing teeth may still hinder an accurate periodontitis case definition, particularly in more severe cases or among older adults who are more prone to tooth loss (Tyrovolas et al. 2016). When a significant number of teeth are missing, it may become less likely to identify iCAL using existing teeth. Alternatively, periodontitis prevalence estimate may integrate information on tooth loss through careful questionnaire design to include the cause of tooth loss and address recall bias in a cross-sectional study (Ke et al. 2023). Another approach to estimating prevalence involves conditioning the estimates on the total number of missing teeth and then averaging them across the population distribution of the number of missing teeth to obtain a single estimate (Shing 2022; Preisser et al. 2024).
In the present study, we propose a novel prevalence estimate based on periodontitis susceptibility cases. The estimate includes individuals with missing teeth likely due to periodontitis who do not have an adequate number of teeth to fulfill the CDC/AAP case definitions for periodontitis prevalence. These susceptibility cases, in this context, comprise individuals with both observed and missing measurements, reflecting either current and past periodontitis or those likely to have periodontitis without observed status. Through addressing the missing tooth problem, our estimate may potentially better reveal epidemiological associations in disease association studies. Our approach incorporates both observed values from existing teeth and generated plausible values using a generative missing data imputation model. Additionally, the imputation model must consider periodontal disease as the primary cause of tooth loss, as teeth can be lost due to factors other than periodontal disease, such as advanced cavities, fractures, and injuries (Lee et al. 2022).
Multiple imputation (MI) by chained equations (MICE) is a widely applied method for imputing missing clinical data, recognized for its robustness and efficacy (Rubin 1987; van Buuren et al. 1999; Austin et al. 2021). It iteratively imputes missing data by constructing predictive models based on selected predictors, drawing plausible values, and generating multiple imputed data sets that capture the uncertainty in the imputation process. A recent study by Preisser et al. (2024) also presented an MI-based method to improve the prevalence estimate of periodontitis when using partial-mouth recording protocols (PRPs). The authors conducted MI based on a generalized estimating equation framework, incorporating person-level, tooth-level, and site-level covariates and associations for imputing dichotomized site-level indicators of CAL exceeding a threshold. This approach allows for the estimation of periodontitis prevalence and other related metrics using PRPs as if they were full-mouth examinations.
Our study aims to investigate the potential improvements in periodontitis diagnosis and prevalence estimates using the proposed estimating approach based on multiple imputation. We imputed the unobserved measurements in a periodontitis data set using MICE and compared the performance among imputation models constructed using different methods and various sets of predictive variables. To validate our new estimate, we further carefully examined the association between periodontitis prevalence and well-established prognostic factors, including age (Bernabe et al. 2020) and smoking status (Leite et al. 2018), using both observed data and plausible data, providing a comprehensive assessment of the impact of missing data imputation.
Materials and Methods
Data Sources, Case Definition, and Variables of Interest
Our analyses were conducted using the 2009–2012 National Health and Nutrition Examination Survey (NHANES) periodontal health data (OHXPER) (Centers for Disease Control and Prevention & National Center for Health Statistics 2024). While a full description can be retrieved from https://wwwn.cdc.gov/nchs/nhanes/default.aspx, a brief can be summarized as follows. The NHANES program investigates the health and nutritional status of the noninstitutionalized population in the United States. It oversamples some specific population groups to increase the survey accuracy in these groups. Its periodontal health data have become an important source for monitoring population oral health and identifying risk factors for periodontal diseases. The data set contains detailed information on the results of the periodontal health examination for a total of 7,006 participants, excluding those with the loss of all 28 teeth and those with missing key demographic and behavioral variables (as specified below). Only interdental sites were included in this analysis; thus, the data for measures assessed at 4 sites, including the distal-facial (DF), mesiofacial (MF), distal-lingual (DL), and mesiolingual (ML) sites, over 28 teeth excluding third molars were used. Accompanied with the periodontal health data, the NHANES project collects demographic data (DEMO), oral health questionnaire data (OHQ), and cigarette use data (SMQ) from the participants. The data were collected under the approval of the CDC/National Center for Health Statistics Ethics Review Board, and all the participants provided written informed consent.
In the present study, we are primarily interested in the prevalence of severe and moderate to severe periodontitis, and thus mild was grouped with no periodontitis in most analyses. We compared prevalence estimates under 2 case definitions: 1) the original 2012 CDC/AAP periodontitis cases (Eke et al. 2012), which relied solely on observed measurements and excluded missing teeth and sites, and 2) the periodontitis susceptibility cases, which imputed plausible values for missing teeth and sites and applied the 2012 CDC/AAP definition to both observed and imputed data. According to the 2012 CDC/AAP case definition, a participant will be diagnosed as having moderate periodontitis if “≥2 interproximal sites with CAL ≥4 mm (not on same tooth), or ≥2 interproximal sites with PD ≥5 mm (not on same tooth)” and severe periodontitis if “≥2 interproximal sites with CAL ≥6 mm (not on same tooth) and ≥1 interproximal site with PD ≥5 mm.” Otherwise, the participant will be classified as having no/mild periodontitis without evidence present of moderate or severe periodontitis.
Additionally, 9 demographic and behavioral variables were selected as covariates of interest, including age, sex, race, smoking status (yes/no), number of missing teeth, and responses to 4 behavioral questions from the oral health questionnaire. Smoking status was determined from the cigarette use data (SMQ), set to “yes” if the subject affirmed both having “smoked at least 100 cigarettes in life” and currently “smoking cigarettes” and otherwise set to “no.” The 4 behavioral questions include “might have gum disease,” “ever had treatment for gum disease,” “teeth became loose without an injury,” and “ever been told of bone loss around teeth,” which can improve the accuracy of periodontitis prediction (Chatzopoulos et al. 2016). Our preliminary analyses showed that all the 9 covariates were associated with average CAL, average PD, the risk of moderate to severe periodontitis, and/or the risk of severe periodontitis (Appendix Tables 1–4) among the subpopulation with no or a small number of missing teeth (≤5).
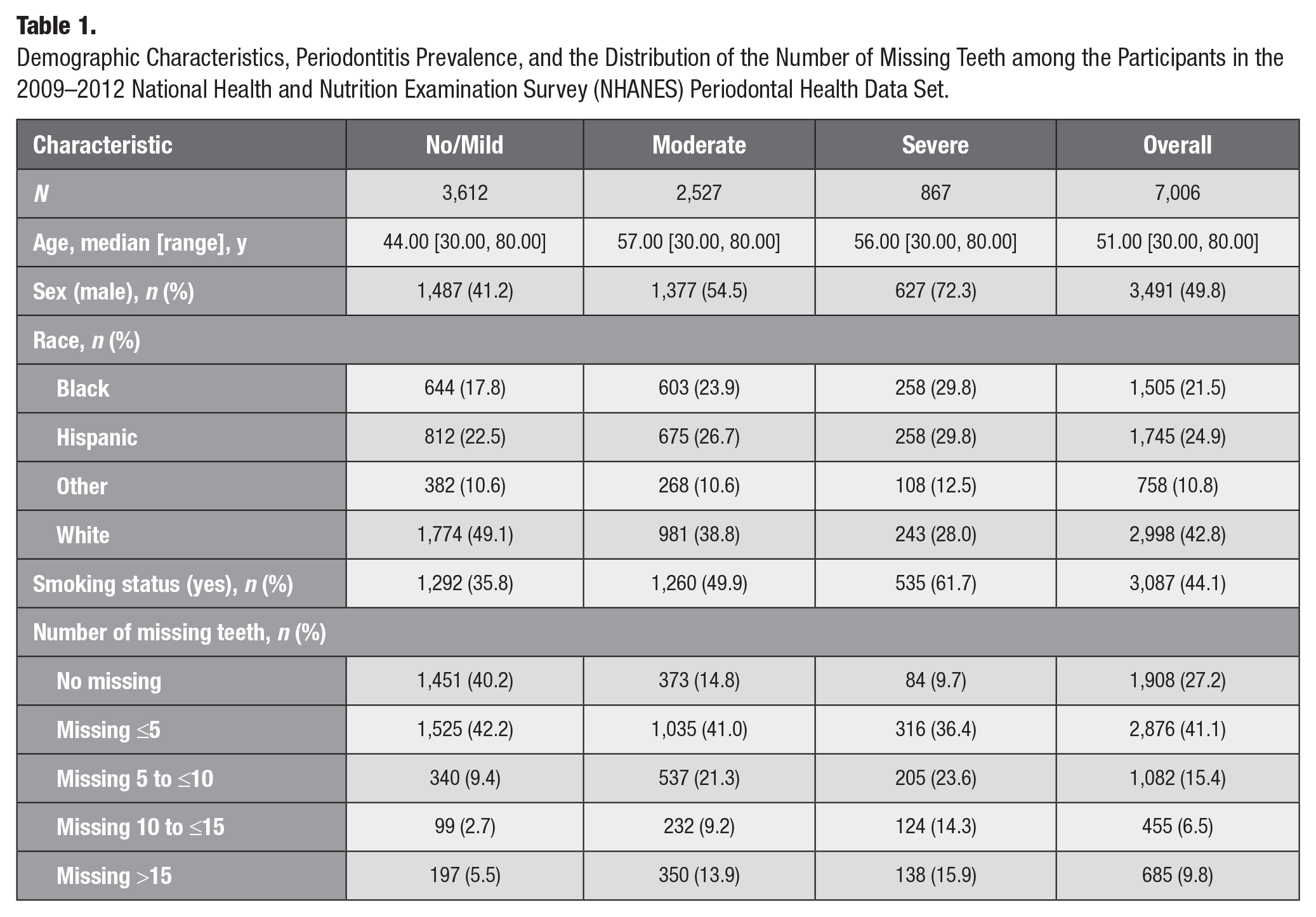
Appendix Figure 1 displays a flow diagram illustrating the inclusion and exclusion of participants in the NHANES periodontal health data set. Table 1 provides demographic characteristics, periodontitis prevalence, and the distribution of the number of missing teeth among the participants in the data set.
Demographic Characteristics, Periodontitis Prevalence, and the Distribution of the Number of Missing Teeth among the Participants in the 2009–2012 National Health and Nutrition Examination Survey (NHANES) Periodontal Health Data Set.
Multiple Imputations for the Missing Measurements
The imputations for the missing iPD and iCAL measurements were conducted using the multiple imputation by chained equations (White et al. 2011) implemented by the “mice” package (version 3.15.0, https://CRAN.R-project.org/package=mice) (van Buuren and Groothuis-Oudshoorn 2011) on the R platform (version 4.2.2, https://cran.r-project.org/) (R Core Team 2022). MICE was first applied to impute nonresponses in blood pressure in a survival analysis (van Buuren et al. 1999). While detailed information may be assessed from van Buuren et al. (1999), in brief, MICE imputes the missing data by consulting on observations of other variables. It imputes the missing values iteratively through specifying predictive models constructed on selected predictors, drawing plausible values from the models and updating the model parameters sequentially across each variable until convergence. It generates a number of imputed data sets, and the variation across these data sets reflects the uncertainty in the imputation. We further postulate that the total number of missing teeth, which can be readily determined in an oral health examination, could serve as a surrogate for the probability of missing teeth and thus as a good predictor for the missing iCAL and iPD measurements.
Ten imputed data sets were generated after 50 iterations and subsequently pooled to reflect the variation of imputation (Little and Rubin 2019). We compared the performance of 2 widely applied imputation methods using predictive mean matching (PMM) and classification and regression trees (CARTs) (van Buuren 2018). These methods generated imputed values based on the distribution of the observed iCAL and iPD measurements, which are discrete values ranging from 0 to approximately 15. We also investigated the performance of different imputation models with and without disease-related covariates of demographic and behavioral information and with and without the total number of lost teeth. Imputation models with these explanatory variables were specified: (a) iCAL and iPD measurements at existing teeth; (b) iCAL and iPD measurements, as well as demographic and behavioral covariates, including smoking status; and (c) iCAL and iPD measurements, as well as demographic and behavioral covariates, including smoking status and the number of missing teeth.
After the imputation for the missing iCAL and iPD measurements, we reevaluated the prevalence of severe and moderate to severe periodontitis in the NHANES data set conforming to the 2012 CDC/AAP case definition (Eke et al. 2012). We contrasted the periodontitis prevalence estimated after the imputation (the prevalence of periodontitis susceptibility cases) with the original prevalence. We compared the trends of the periodontitis prevalence along the number of missing teeth before and after missing data imputation. Moreover, we illustrated the distribution of iCAL and iPD measurements recovered via the imputation at representative teeth, such as the 6 Ramfjord index teeth (Ramfjord 1959).
Table 2 and Figure 1 compare the prevalence estimates of periodontitis at different severity levels based on the 2 case definitions. Appendix Figures 2 and 3 demonstrate the distribution of observed and imputation-recovered iPD and iCAL measurements at the 6 Ramfjord index teeth.
Comparison of Periodontitis Prevalence of Different Severity Based on Different Case Definitions.
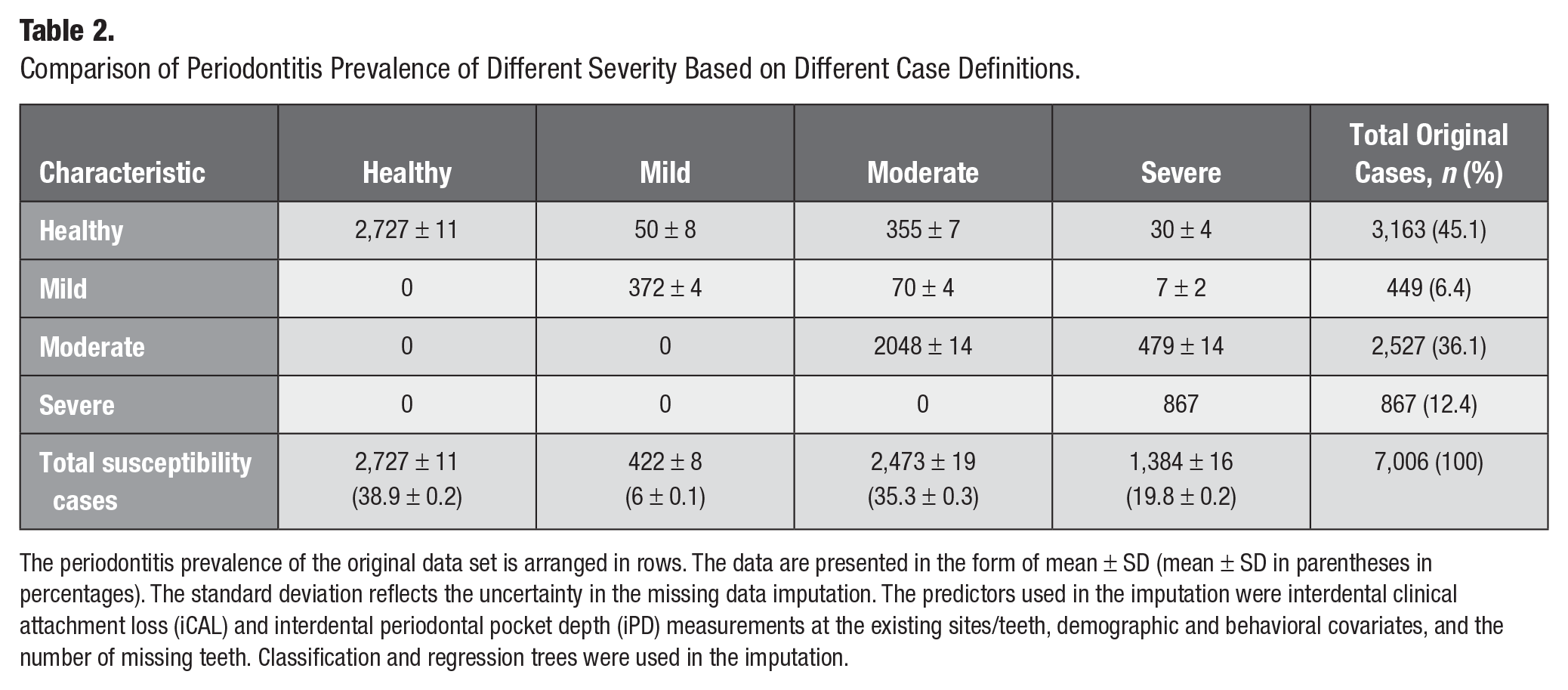
The periodontitis prevalence of the original data set is arranged in rows. The data are presented in the form of mean ± SD (mean ± SD in parentheses in percentages). The standard deviation reflects the uncertainty in the missing data imputation. The predictors used in the imputation were interdental clinical attachment loss (iCAL) and interdental periodontal pocket depth (iPD) measurements at the existing sites/teeth, demographic and behavioral covariates, and the number of missing teeth. Classification and regression trees were used in the imputation.
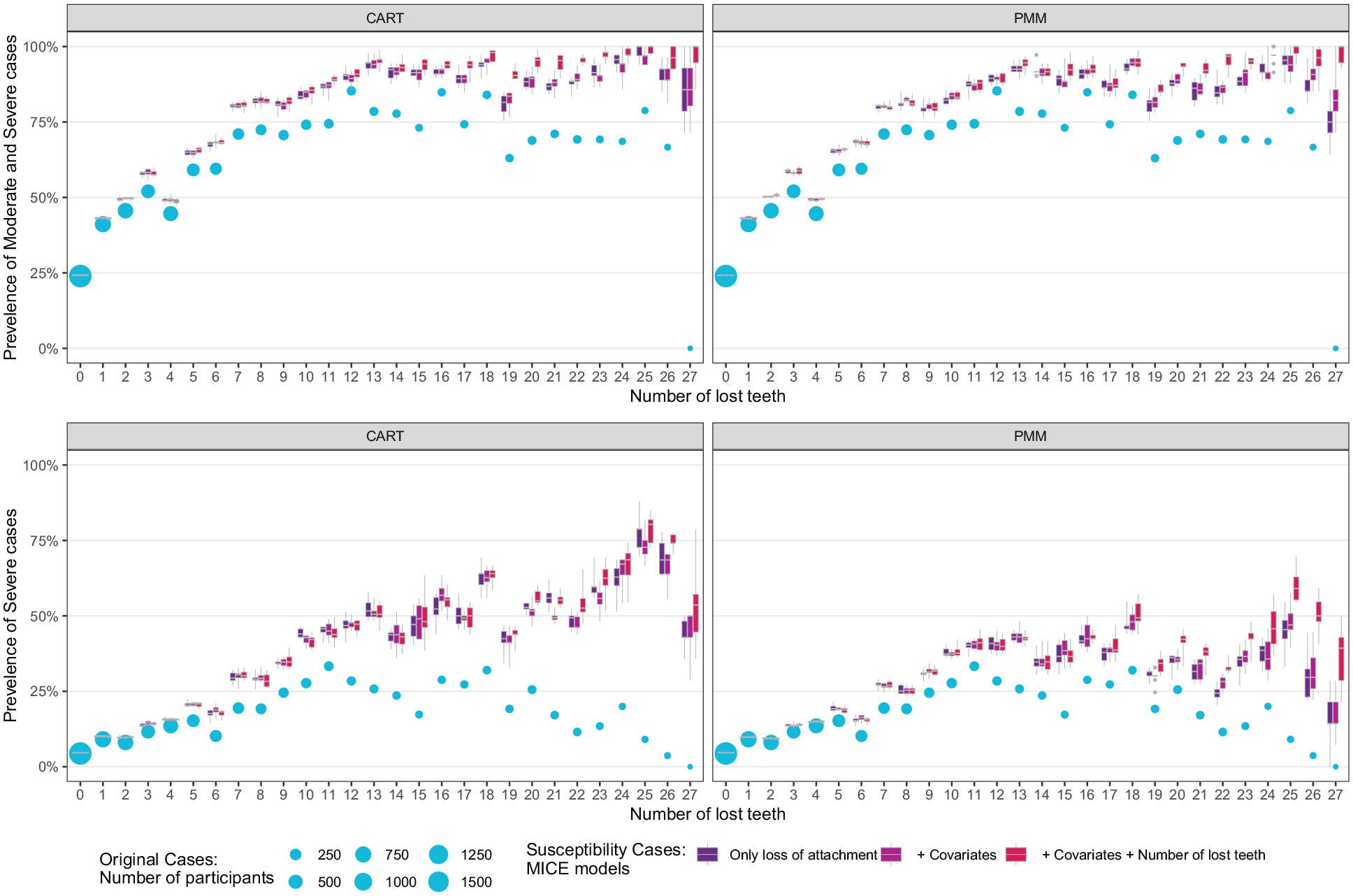
Comparisons of the prevalence estimates of 2012 Centers for Disease Control and Prevention/American Academy of Pediatrics periodontitis cases (circle) and periodontitis susceptibility cases (boxes). The comparison was made by the number of lost teeth (x-axis), severity of disease (top and bottom panels), and missing data imputation methods (colors of boxes). The diameter of the circles indicates the number of participants who have the corresponding number of lost teeth in the 2009–2012 National Health and Nutrition Examination Survey periodontal health data set. The upper/lower hinges of boxes represent the 75th/25th quantiles, and the lines inside boxes indicate the median value of the prevalence across the imputed data sets. The whiskers above/below boxes extend to the maximum/minimum values. CART, classification and regression trees; PMM, predictive mean matching.
Validation of Estimating Procedure through Assessment of Periodontitis Risk Factors
We further validate the proposed estimating procedure using 2 known periodontitis risk factors. Specifically, we tested for association between the periodontitis status, before and after imputation, and 1) chronological age and 2) smoking status. Regarding chronological age, the prevalence of severe periodontitis has been reported to increase with age among the population 10 to 64 y old and stabilize or decrease slightly among those 65 to 94 y old at a global level (Bernabe et al. 2020). To compare with the age patterns on a global level, we classified individuals into distinct age groups at 5-y intervals and assessed the prevalence of periodontitis before and after the multiple imputation.
Tobacco smoking has also been extensively elucidated as a significant risk factor of periodontitis (Leite et al. 2018). To minimize bias, first, we externalized the prognostic factor of smoking by excluding smoking status from our imputation models. Second, we used the propensity score matching method (Rosenbaum and Rubin 1983, 1985) to adjust for confounders. The effect of smoking was likely confounded by the effect of demographic characteristics in NHANES, as the baseline characteristics were probably associated with both smoking and periodontitis. We matched each participant in the smoking group to one in the nonsmoking group who had a comparable propensity score, yielding matched pairs. After the matching, the 2 groups would possess similar baseline characteristics. Therefore, the effect of smoking could be accurately estimated by calculating the difference and/or relative risk (RR) between these 2 groups, which has usually been referred to as the “average treatment effect among the treated” (ATT). The propensity score model of smoking was specified as follows:
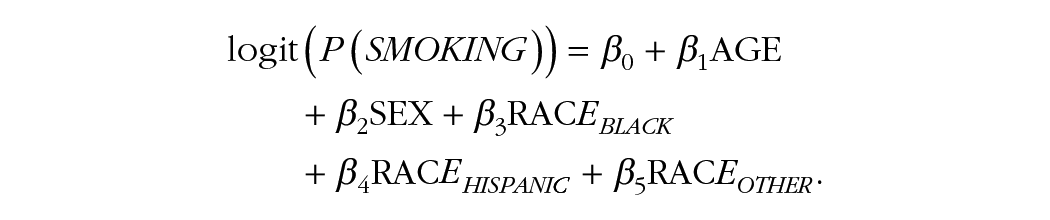
The matching steps were implemented using the “MatchIt” package (version 4.5.0, https://CRAN.R-project.org/package=MatchIt) (Ho et al. 2011) on the R platform (R Core Team 2022) with replacement and a 1-to-1 matching ratio. Matching was conducted separately in each imputed data set, and the ATT of smoking was also calculated separately and then pooled.
Figure 2 and Appendix Figure 4 illustrate the age patterns of periodontitis prevalence estimates based on different case definitions. Figure 3 and Appendix Figure 5 show the ATTs and RRs of smoking on periodontitis across different case definitions.
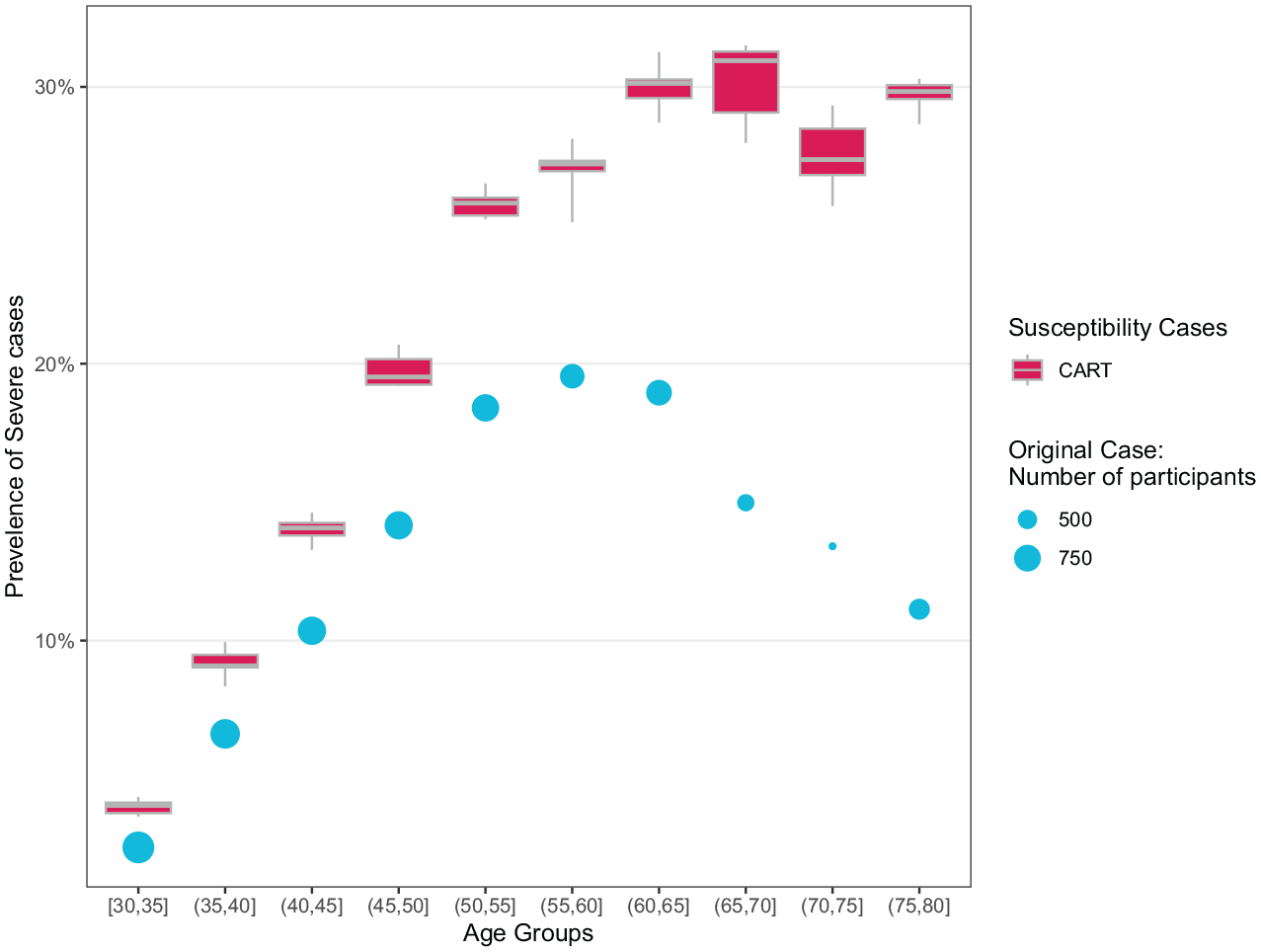
The prevalence of severe periodontitis based on different case definitions in the 2009–2012 National Health and Nutrition Examination Survey periodontal health data set, by age groups. The shapes have the same meaning as in Figure 1, and circles and boxes represent 2012 Centers for Disease Control and Prevention/American Academy of Pediatrics periodontitis cases and periodontitis susceptibility cases, respectively. The predictors used in the imputation were interdental clinical attachment loss (iCAL) and interdental periodontal pocket depth (iPD) measurements at other sites/teeth, demographic and behavioral covariates, and the number of missing teeth. The classification and regression tree (CART) method was used in the imputation. See also Appendix Figure 4 for the prevalence of moderate to severe periodontitis.
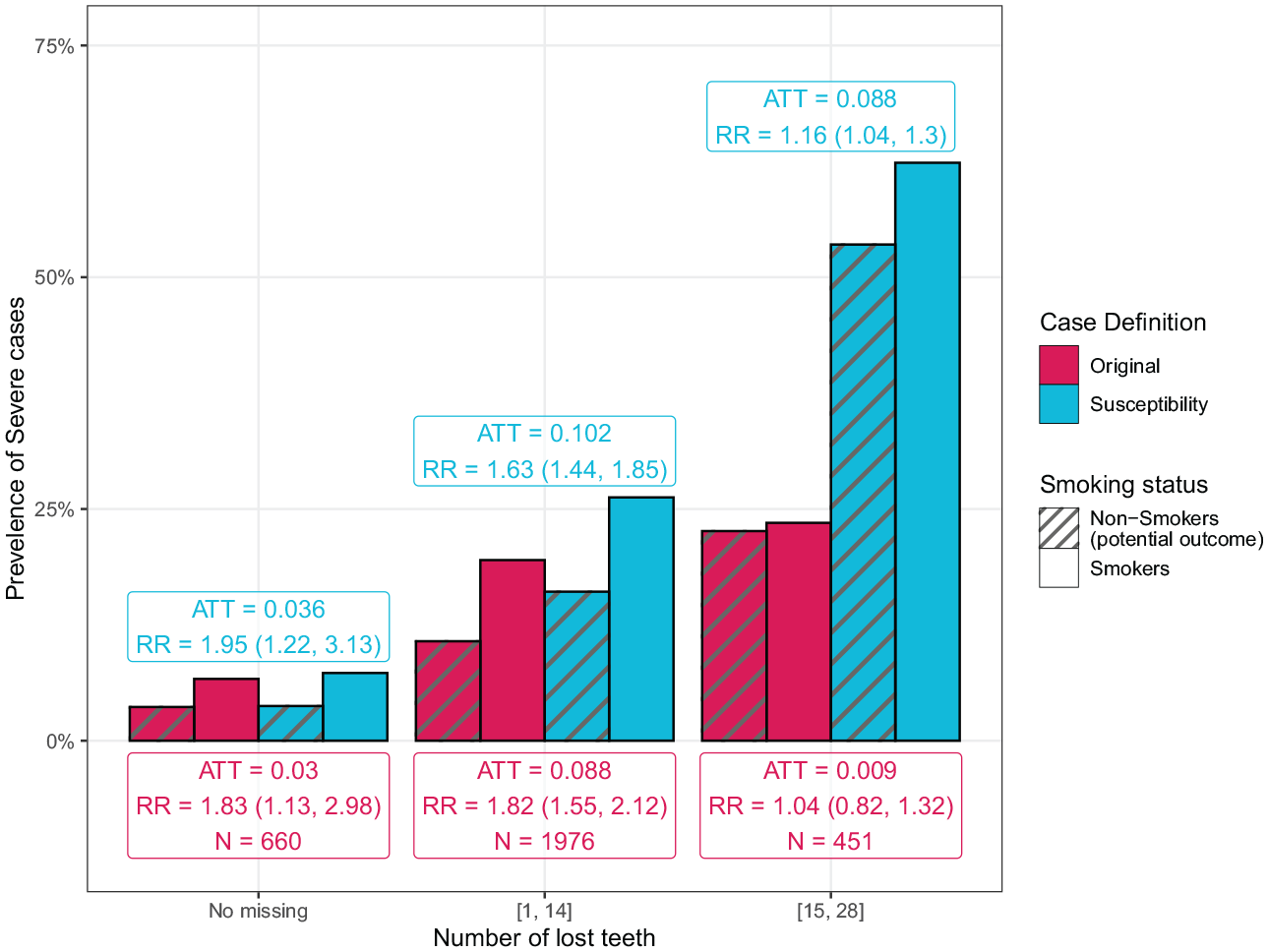
Average treatment effect among the treated (ATT) and the relative risk (RR) of smoking on severe periodontitis based on different case definitions among subpopulations having no tooth lost, 1 to 14 teeth lost, and 15 to 28 teeth lost in the 2009–2012 National Health and Nutrition Examination Survey periodontal health data set. Different colors indicate results of different case definitions. Different bar textures represent the observed prevalence in the smoking group and the potential prevalence in the matched control group, respectively. ATT and RR are calculated as the difference and ratio between the 2 kinds of prevalence, respectively. The numbers in parentheses are the upper and lower limits of a 95% confidence interval of RR. The “N” indicates the number of participants in the smoking group. The predictors used in the imputation were interdental clinical attachment loss (iCAL) and interdental periodontal pocket depth (iPD) measurements at the existing sites/teeth, demographic and behavioral covariates (excluding the smoking status), and the number of missing teeth. Classification and regression trees were used in the imputation. See also Appendix Figure 5 for moderate to severe periodontitis.
Results
Descriptions of the Analyzed Data Set
The NHANES periodontal health examination dataset (OHXPER) consisted of a total of 9,402 subjects, and 7,006 of them had at least 1 tooth and were associated with demographic and behavioral data (Appendix Fig. 1). Among the 7,006 subjects, 5,098 (72.8%) had at least 1 missing tooth whose CAL and PD measurements were all missing, and 3,394 (48.4%) were defined as having moderate or severe periodontitis cases (Table 1).
Comparisons of Periodontitis Prevalence before and after Imputing Missing iCAL and iPD Measurements
Our estimating procedure increased the prevalence and severity of periodontitis (Table 2). The number of healthy cases decreased from 3,163 (45.1%) using 2012 CDC/AAP case definition to 2,727 ± 11 (38.9% ± 0.2%) using the periodontitis susceptibility case definition. Moreover, the number of severe periodontitis cases increased from 867 (12.4%) to 1,284 ± 16 (19.8% ± 0.2%) after missing data imputation. In addition, most of the redefined severe cases came from participants who were originally moderate, while most of the redefined moderate cases came from those originally healthy. However, the overall prevalence of mild and moderate periodontitis was relatively unchanged.
Our estimating approach also changed the relationship between the periodontitis prevalence and the number of lost teeth (Fig. 1). Using 2012 CDC/AAP case definition, the prevalence of moderate to severe and severe cases initially increased with the total number of lost teeth and then decreased when the number of lost teeth became high, suggesting that diagnosis of periodontitis is likely affected by the missing information. In contrast, the prevalence of periodontitis susceptibility cases almost monotonically increased with the total number of lost teeth after imputation.
Among imputation models with different covariates, the prevalence estimates were comparable between model (a) (iCAL and iPD measurements only) and model (b) (iCAL and iPD measurements, as well as demographic and behavioral covariates, including smoking status) (Fig. 1). Model (c), which included additionally the number of missing teeth, yielded a higher prevalence for severe periodontitis than models (a) and (b). Comparing different imputation methods, both CART and PMM produced a similar trend between the prevalence of periodontitis susceptibility cases and the number of lost teeth (Fig. 1). The CART method resulted in a higher prevalence than PMM when the participants lost a large number of teeth (>20). It was more robust compared to PMM, as different choices of predictors in the imputation models yielded more consistent estimates than PMM (Fig. 1).
Validation of Estimating Procedure through Assessment of Periodontitis Risk Factors
We further validate our proposed estimating procedure by examining the association between age and prevalence of severe (Fig. 2) and moderate to severe susceptibility periodontitis (Appendix Fig. 4) in the original and imputed data sets (using CART). Without missing data imputation, the prevalence of severe periodontitis increased with age among the subpopulation 30 to 60 y old, with the highest prevalence ~20%, and declined drastically among those 60 y or older (Fig. 2). After the imputation, the prevalence generally increased with age and stayed ~30% in the older age groups (Fig. 2).
In our second validation analysis, the ATT of smoking on periodontitis was estimated in 3 subgroups having no teeth lost, 1 to 14 teeth lost, and 15 to 28 teeth lost, respectively, based on the 2012 CDC/AAP case definition and the periodontitis susceptibility case definition (Fig. 3 and Appendix Fig. 5). Among the subpopulations with a relatively smaller number of lost teeth (the number of missing teeth <15), the estimated ATT of smoking on severe susceptibility periodontitis was close to the original one (Fig. 3). Conversely, the estimated ATT increased markedly from 0.009 (RR = 1.04 [0.82–1.32]) to 0.088 (RR = 1.16 [1.04–1.30]) after the imputation (Fig. 3) among the subgroup who had a number of teeth loss >15.
Discussion
In this study, we aim to examine potential improvements in periodontitis diagnosis and prevalence estimates using a novel estimating approach that addresses missing tooth problem via estimating periodontitis susceptibility. Our estimating procedure incorporated both observed values and generated plausible values using a generative multiple imputation model, resulting in increased severity and prevalence estimates compared to the original 2012 CDC/AAP case definition. Furthermore, our estimates revealed stronger associations between periodontitis and tooth loss, age, and smoking status compared to the original estimates.
The issue of missing teeth has been a concern in dental health studies, including those related to severe periodontitis and dental caries (Frencken et al. 2017). Tonetti et al. (2018) suggested incorporating periodontitis-associated tooth loss in the definition of periodontitis severity, and patients with CAL ≥5 mm and periodontitis-associated tooth loss will be categorized as stage III or IV periodontitis. However, while surveys such as NHANES may include a teeth count variable with tooth missingness information, they typically do not include information of causes for tooth loss or may be prone to recall bias due to the cross-sectional nature of these surveys. Thus, when computing “severe periodontitis” cases, researchers routinely delete the cases with missing teeth via a row-wise deletion, which can result in a biased subsample of NHANES and become unsatisfactory in assessing periodontitis burden. To avoid assessing only complete cases, alternatively, our results suggest that we may impute and recover missing measurements through multiple imputation instead of restricting to complete cases when assessing susceptibility to periodontitis (Appendix Figs. 2 and 3). The variation of imputation, which was indicated by standard deviation, was usually small relative to the mean.
The prevalence of periodontitis susceptibility cases has been linked to a list of prognostic factors, including age and smoking, and compared with the periodontitis prevalence based on the 2012 CDC/AAP case definition. Concerning age, our estimates revealed a similar age pattern of severe periodontitis to previous studies. The Global Burden of Disease (GBD) study (Bernabe et al. 2020) found that the prevalence of severe periodontitis increased with age among the population between 10 and 64 y old and became flat or decreased slightly among those between 65 and 95 y old. Compared with this age pattern, our results showed a remarkably similar tendency after the imputation in the NHANES study. Contrarily, the age pattern would demonstrate a hump-curve using the original case definition (Fig. 2). The maximum prevalence of severe periodontitis was estimated as 20% to 25% in the GBD study, as compared to approximately 20% in the NHANES study before imputation and 30% after imputation. The similarity between the 2 studies should also be interpreted with caution because the ethnic composition in NHANES is different from that in the GBD study.
Cigarette smoking is a well-established risk factor for periodontitis (Leite et al. 2018). Smoking has been reported to significantly influence the immune function and fitness, causing chronic inflammation and periodontitis (Loos and Van Dyke 2020). We expected the exposure to tobacco usage would increase the risk for periodontitis. However, the estimated ATT was approximately 0 when applying the original case definition to those affected with a high level of tooth loss (≥15 teeth), and the result was statistically insignificant (P > 0.05). This insignificant smoking effect can arise from the missing tooth problem in this subgroup. After the missing data imputation, the estimated ATT increased significantly from 0.009 to 0.088 in the high tooth loss group, similar to the estimated ATT of 0.102 in the subgroup losing 1 to 14 teeth.
In addition, our results may reflect a higher performance of a specific imputation setting than others, namely, using CART and imputing with the total number of missing teeth (Fig. 1). The CART method was more robust to the choice of the imputation models than PMM. The total number of missing teeth introduced the information of the probability of tooth loss, and incorporating this number as a predictor in the imputation model may help reduce bias.
However, there are limitations in our analysis. First, the estimating approach we proposed for the prevalence of periodontitis susceptibility cases relies on both observed periodontal measurements and imputed plausible values for missing teeth and sites. It is noteworthy that our approach synthesized periodontitis status by combining original observations at existing teeth with generated data at missing teeth. This implies that our estimates are likely to differ or become biased compared to the original prevalence estimate based on the 2012 CDC/AAP case definition, owing to the differences in the case definitions. As the true periodontitis susceptibility status is unknown for NHANES participants with missing teeth, we cannot estimate the bias of our approach. Furthermore, while MICE has been extensively studied and applied in various clinical research (Pedersen et al. 2017), it may not be ideal for imputing missing periodontal health data, as they could be missing not at random. Therefore, our prevalence estimates require validation against an individual’s clinical dental record and periodontitis history to establish clinical relevance before practical application, with particular emphasis on a longitudinal cohort study where the cause for missing teeth can be observed. Second, multiple imputation requires a relatively large sample size to create accurate prediction models and produces multiple imputed data sets to account for imputation uncertainty. Periodontal measures are also possibly subject to measurement error, as they are measured in whole millimeters. Since measurement is discrete, an assumption of multivariate normality might also be a limitation associated with our approach (Bandyopadhyay and Canale 2016). This uncertainty needs to be fully considered when applying our method for periodontitis diagnosis in individual patients.
Conclusion
In summary, we imputed the unobserved periodontal measurements in the NHANES study by employing various imputation methods and models using MICE. We evaluated the prevalence of periodontitis susceptibility cases of different severities before and after imputation. We further validated the imputed results based on 2 well-established prognostic factors of age and smoking. Our results clearly demonstrate an increase in periodontitis prevalence after addressing tooth loss and underscore the importance of properly handling missing measurements.
Author Contributions
L. Zhang, contributed to design, data acquisition, analysis, and interpretation, drafted and critically revised manuscript; M. Xiao, contributed to data analysis, critically revised the manuscript; H. Chu, contributed to conception and design, critically revised the manuscript; G.A. Kotsakis, contributed to conception and design, drafted and critically revised the manuscript; W. Guan, contributed to conception and design, drafted and critically revised manuscript. All authors have their final approval and agree to be accountable for all aspects of work.
Supplemental Material
sj-docx-1-jct-10.1177_23800844241228277 – Supplemental material for Estimating Periodontitis Susceptibility Cases for Epidemiological Studies with Multiple Imputation
Supplemental material, sj-docx-1-jct-10.1177_23800844241228277 for Estimating Periodontitis Susceptibility Cases for Epidemiological Studies with Multiple Imputation by L. Zhang, M. Xiao, H. Chu, G.A. Kotsakis and W. Guan in JDR Clinical & Translational Research
Supplemental Material
sj-docx-2-jct-10.1177_23800844241228277 – Supplemental material for Estimating Periodontitis Susceptibility Cases for Epidemiological Studies with Multiple Imputation
Supplemental material, sj-docx-2-jct-10.1177_23800844241228277 for Estimating Periodontitis Susceptibility Cases for Epidemiological Studies with Multiple Imputation by L. Zhang, M. Xiao, H. Chu, G.A. Kotsakis and W. Guan in JDR Clinical & Translational Research
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by the National Institutes of Health under award number R21 DE031089-02.
Source Code Availability
A supplemental appendix to this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.