
Abstract
Scholarship posits that the state is the most powerful actor in “race-making” via its institutionalization of racial categories, especially through national censuses. Yet whether census ethnoracial categories correspond to experientially existing social groups crafted through everyday boundary making is an empirical question. When census categories misalign with micro-level boundaries, inferences drawn from census data may seriously misrepresent intergroup relations. Using unique, multidimensional data on self-classified Hispanics in the United States, the author estimates the degree and correlates of (mis)alignment between Hispanics’ racial self-classifications on a closed-ended, census-style race question and their racial self-identification on an open-ended question. The author finds substantial misalignment between racial self-classification and self-identification, with self-rated skin tone and reflected appraisal particularly important for white (mis)alignment and immigrant generation status strongly associated with the use of hyphenated American identifications. The author concludes that although the state exhibits “race-making” power, reliance on census race categories alone misrepresents Hispanics’ ethnoracial boundary making practices, distorting inferences about the larger U.S. racial structure. Including a Hispanic option on the census race question improves overlap between state and everyday racial categories, but a Hispanic racial self-identification is by no means a universal convention.
Largely influenced by Bourdieu’s (1985) conceptualization of the state as holding a monopoly on “official naming” in constructing classification systems, a growing literature describes how states play a central role in “making race” through the imposition and institutionalization of ethnoracial categories (Bailey 2008; Bailey, Fialho, and Loveman 2018; Loveman 2014; Sue, Riosmena, and Telles 2024; Wacquant 2024). National censuses, to which states are increasingly adding ethnoracial questions (Loveman 2014, 2021; Morning 2008), contribute to this process by inculcating the idea that societies are composed of mutually exclusive ethnoracial groups (Brubaker, Loveman, and Stamatov 2004; Lieberman and Singh 2017). Yet states never hold an absolute monopoly on dividing the social world, including ethnoracial division, because classification is always contested (Bourdieu 1989, 2018). Codifying categories on census forms reveals little about their salience in the lived experiences of persons so categorized (Brubaker 2002; Jenkins 1994). A direct test of state race-making, then, is the extent to which everyday ethnoracial subjectivities mirror state-sanctioned categories (Bailey et al. 2018; Bourdieu 1989; Lieberman and Singh 2012, 2017).
Although the degree of alignment between state categories and lay identifications is both an open empirical question and a metric of state-led race-making, scholars have long lamented that such congruence is rarely demonstrated in detail (Bailey et al. 2018; Brubaker et al. 2004; Roth 2016; Sue et al. 2024). This is not merely a theoretical concern. The dominant approach to studying ethnoracial boundary making, difference, and inequality rests on the use of state categories and their ubiquitous presence on surveys (Monk 2022). Yet the uncritical use of such categories risks reifying classification systems that poorly reflect on-the-ground experiences (Brubaker 2002; Menjívar 2023), misrepresenting intergroup relations (Loveman 2014), and obscuring how inequality operates beyond the purview of the state (Monk 2022). Alternatively, when lay identifications align with state categories (Croll and Gerteis 2019), such congruence lends support to the power of the state’s classificatory vision and bolsters confidence in social research using those categories.
Treating lay identification with census ethnoracial categories as an empirical question, I examine the paradigmatic example of the Hispanic 1 category in the United States. In some respects, the state’s relatively recent construction of this ambiguous panethnic label has succeeded. Most people with known Latin American ancestry self-classify as Hispanic on the census (Emeka and Vallejo 2011), and evidence suggests growing primary identification with Hispanic as an ethnoracial category (Martínez and Gonzalez 2021). Paradoxically, its success as an ethnic category may challenge the state’s racial classification system, as many self-classified 2 Hispanics eschew traditional racial options in favor of the residual “some other race” category. Much of the quantitative literature assumes this selection signals dissatisfaction with state racial categories (Brown, Hitlin, and Elder 2006, 2007; Telles 2018), a finding echoed in interview-based research (Dowling 2014; Flores-González 2017; Rodriguez 2000).
Despite recognition that state racial categories often fail to capture the ethnoracial boundaries self-classified Hispanics experience, the quantitative literature focuses on placing these individuals in the U.S. racial structure on the basis of closed-ended questions that mirror census race options and omit a Hispanic racial category (Bonilla-Silva 2004; Brown et al. 2006, 2007; Campbell and Rogalin 2006; Frank, Akresh, and Lu 2010; Golash-Boza and Darity 2008; Irizarry, Monk, and Cobb 2023; Michael and Timberlake 2007; Pulido and Pastor 2013; Stokes-Brown 2012; Vargas 2015). Critical perspectives emphasize the inadequacy of these categories but lack tools to assess the degree of misalignment between the state categories used and respondents’ own racial identifications (Brown et al. 2007; Flores, Telles, and Ventura 2024; Vargas, Valle, and Dhuman 2025). By contrast, interview-based studies compare census-style responses with respondents’ self-descriptions, showing that most Hispanics view their race in ethnic terms (e.g., Mexican, Puerto Rican, Dominican) or conceptualize Hispanic as a racial category (Dowling 2014; Flores-González 2017; Flores-González, Aranda, and Vaquera 2014; Rodriguez 2000; Roth 2012). Although these studies provide depth, they cannot systematically test whether racial self-identification patterns correspond to broader markers of ethnoracial boundary making, such as phenotype or reflected appraisal. Consequently, scholars are left with an uneven portrait of how the state categories we rely on, through their (mis)alignment with everyday boundaries, shape (mis)representations of where and how Hispanics are located within the U.S. racial structure, a persistent topic of debate in the sociology of race and ethnicity (Alba 2020; Mora and Rodríguez-Muñiz 2017).
Using unique nationally representative data, I compare respondents’ racial self-classifications—what Bailey (2008) termed “census race”—using a closed-ended census-style question, with their racial self-identifications using an open-ended question. Treating open-ended responses as a proxy for everyday identification (Bailey et al. 2018; Croll and Gerteis 2019; Landale and Oropesa 2002), I extend Bailey et al.’s (2018) concept of “dimension alignment”: the within-individual concordance between state-codified ethnoracial categories and lay ethnoracial identifications. I ask, (1) What is the degree of dimension alignment among self-classified Hispanics? and (2) What are its correlates?
I find substantial misalignment between census categories and the terms Hispanics use to describe themselves, some of which are associated with key aspects of ethnoracial identity formation, such as self-rated skin tone, reflected appraisal, and immigrant generation. Using qualitative insights from open-ended responses and descriptive quantitative analyses in a larger survey context, I describe the complexity and multiplicity of categories and concepts many Hispanics use with respect to their ethnoracial identifications, arguing that, while adding a Hispanic racial category to the census represents an improvement in overlap between state and lay ethnoracial identifications, it ultimately works to reify a state category—Hispanic—that is by no means the dominant form of self-identification. These findings carry implications for interpreting census data following the adoption of the new combined race/ethnicity question with a Hispanic racial category (OMB 2024).
The State, National Censuses, and Race-Making
The state is not the only actor engaged in symbolic struggles over classification to establish which groups “exist” (Bourdieu 2018; Emigh, Riley, and Ahmed 2015). Yet scholarship documents states’ distinct role in race-making by outlining their unique capacity to naturalize and elevate the salience of certain boundaries through official nomination and category institutionalization (Bailey et al. 2018). In the Bourdieusian tradition, the state holds a monopoly over legitimate symbolic violence. This often takes the form of “official nomination,” in which categories and qualifications become accepted points of view, forming a “repository of common sense” (Bourdieu 1989:22). The legitimacy of the state confers a universally approved perspective, freeing holders of official categories from symbolic struggle (Bourdieu 1989). In short, the state’s classification schemes carry symbolic weight unmatched by any other actor (Brubaker and Cooper 2000).
State race-making typically involves institutionalizing ethnoracial categories across bureaucratic domains. A rich literature emphasizes the role of national censuses, which increasingly feature ethnoracial questions (Loveman 2014, 2021; Morning 2008). Lieberman and Singh (2017) argued that official statistics generated through census enumeration shape social realities by influencing identification, mobilization, and conflict. Censuses encourage the adoption of “mental models” of social division and function as “switching mechanisms” that direct particular ethnoracial boundaries toward salience. As censuses resolve ambiguity over which categories matter, individuals become more likely to identify with and organize along state-defined lines (Lieberman and Singh 2012, 2017). States therefore “make race” when ground-level racial boundaries align with those codified in censuses (Bailey et al. 2018).
The United States offers a particularly strong case. It has a centuries-long history of racial classification (Nobles 2000), and its administrative apparatuses use census racial categories across institutional settings, standardized through the Office of Management and Budget (OMB). The United States is also a racially stratified society, and linking census classifications to material resource access has amplified the state’s influence over racial boundaries (Lieberman and Singh 2012). In the post–civil rights era, racial data are crucial for tracking antidiscrimination compliance, helping crystallize group boundaries and prompting advocacy for new categories (Bailey et al. 2018; Nobles 2000). Notable examples include the addition of the Hispanic origin question in 1980, following activism by Mexican, Puerto Rican, and Cuban communities (Mora 2014a, 2014b), and the forthcoming Hispanic racial category in a combined race/ethnicity question on the 2030 census (OMB 2024). These efforts reflect an understanding of the benefits of formal state recognition.
The Micropolitics of Categories
A category does not a group make. Even with the state’s symbolic authority, Bourdieu (1989) emphasized that “there are always, in any society, conflicts between symbolic powers that aim at . . . constructing groups” (p. 22). Thus, the state cannot establish an absolute monopoly over classification. Ordinary actors have considerable room to maneuver, often using state categories selectively and infusing them with alternative meanings (Brubaker et al. 2004). Brubaker (2002) called this the “micropolitics of categories”: “the ways in which the categorized appropriate, internalize, subvert, evade, or transform the categories that are imposed on them” (p. 170). Examining the micropolitics of categories provides a view from below for assessing how well official classifications correspond to everyday racial boundary-making and group formation.
The Hispanic category illustrates these dynamics particularly well. Institutionalized in 1980 as a panethnic category on the short-form census, Hispanic identification remains heterogeneous and contested. The U.S. Census Bureau constructs and codifies “Hispanic” as an ethnic category, as opposed to a racial category, by asking for Hispanic self-classification on a stand-alone Hispanic origin question segregated from the racial self-classification question, which itself does not include a Hispanic option. According to the state, then, Hispanics are an ethnic group with multiple potential racial identifications. Although in practice, self-classified Hispanics in the census data are often treated as a racial group parallel to other racial groups (e.g., “non-Hispanic whites,” “non-Hispanic Blacks”) in social scientific and demographic analyses (Vargas et al. 2025). Although most with Latin American ancestry in the United States self-classify as Hispanic (Emeka and Vallejo 2011), debate persists over whether Hispanic serves as a primary identity (Martínez and Gonzalez 2021). Its absence from the census race question has led many to select “some other race,” raising concerns about the accuracy of official racial categories in capturing lived ethnoracial understandings.
Several studies examine how Hispanics navigate and resist these categories. Dowling (2014) found that white and “some other race” census categories did not reflect the racial self-understandings of her Mexican American respondents, who primarily identified as Mexican and/or Hispanic. Choices on census forms were shaped by political ideology: selecting “white” often reflected attempts to process discrimination or assert belonging in a white-dominated society. Similarly, Flores-González (2017) found that Hispanic millennials rejected existing racial categories, expressing racial identities based on national origin and Hispanicity. Her respondents viewed Hispanic as a racial category and positioned themselves within a diverse “racial middle.” Notably, many felt that the absence of a fitting census race category cast them outside the imagined American community—as “citizens but not Americans” (Flores-González 2017).
Dimension Alignment: Theory, Empirics, and Application
Theories of race-making and group formation highlight the state’s capacity to shape identification practices. But whether people adopt state categories in everyday life remains an empirical question. Drawing on multidimensional conceptualizations of race, Bailey et al. (2018) propose “dimension alignment,” which compares racial self-classification via state categories to colloquial self-identification. Because state race-making assumes people will increasingly identify with state labels and recognize coethnics accordingly (Lieberman and Singh 2012), dimension alignment provides a metric to assess this process. Assuming states do not simply coopt popular preexisting categories, greater dimension alignment indicates greater state influence.
Extending this concept, I examine the Hispanic category. Before its institutionalization on the 1980 census, Hispanic was not a widely used self-descriptor; rather, the state helped “make Hispanics” through collaboration with ethnic activists and media elites (Mora 2014b). Today, about 94 percent of adults with Latin American ancestry self-classify as Hispanic (Emeka and Vallejo 2011), and respondents in multiple qualitative studies use the term in self-descriptions (Flores-González 2017; Roth 2016). Paradoxically, its success as an ethnic label challenges the state’s racial classification system, as many Hispanics opt for “some other race.” With mounting evidence that self-identified Hispanics prefer to describe their race using Hispanic or national-origin categories (Croll and Gerteis 2019; Mathews et al. 2017), dimension alignment becomes a critical tool for understanding divergence from state racial categories.
Most of the survey-based literature relies exclusively on closed-ended racial classification questions using state categories that omit a Hispanic racial option (Golash-Boza and Darity 2008; Irizarry et al. 2023). The dominant approach, which I replicate before diverging from in this study, typically seeks to understand how Hispanics are integrating into (or challenging) the U.S. racial structure by assigning them a place in the racial structure according to their racial self-classification. Implicitly, racial self-classification is taken as a proxy for racial identification in that it signals proximity or attachment to a racial category selected on a survey instrument. Because racial self-classification is measured separately from Hispanic origin, these models reproduce the census’s treatment of “Hispanic” as ethnic rather than racial. Although some scholars acknowledge the limitations of state categories (Brown et al. 2007), they cannot test the extent or implications of misalignment. Significant misalignment throws into sharp relief the need to examine when self-classification serves as a useful proxy for self-identification (Roth 2016) and how discordance between those two dimensions of race may result in significantly different conclusions regarding the object of study.
Other approaches yield complementary insights but also have limits. Census Bureau experiments show that adding a Hispanic racial option reduces “some other race” selection (Mathews et al. 2017), but lack within-individual data and omit relevant identity measures like phenotype and reflected appraisal. Qualitative research captures how people identify in their own words but cannot assess patterns or correlates of identification at scale.
Landale and Oropesa (2002) and Croll and Gerteis (2019) conducted the only quantitative analyses of dimension alignment among self-classified Hispanics in the United States, to my knowledge. Landale and Oropesa (2002) compared racial self-classification via a closed-ended question on birth certificates to open-ended racial identification among Puerto Rican mothers, finding that although most mothers self-classified as white on birth certificates, most mothers shifted into either Puerto Rican or Hispanic/Latina racial identifications when asked to self-describe. Although prescient, it is difficult to ascertain to what extent the results apply to the general Hispanic population given their sample is limited to Puerto Rican mothers split across six U.S. states and Puerto Rico in the mid-1990s. Croll and Gerteis (2019) found similar patterns of racial self-identification among self-classified Hispanics in the general U.S. population, but did not directly estimate dimension alignment because they ignored Hispanic respondents’ racial self-classification responses in favor of treating Hispanics as a cohesive racial group based on the Hispanic origin question.
Using unique data that include racial self-classification via state categories (closed-ended question) and colloquial racial self-identification (open-ended question), I estimate dimension (mis)alignment among a nationally representative sample of self-classified Hispanics (respondents who marked “yes” on the census Hispanic origin question, irrespective of their race). Doing so allows me to respond directly to calls for applied research on the interplay between state categories and ethnoracial identification and group formation (Bailey et al. 2018; Brubaker and Cooper 2000; Brubaker et al. 2004; Monk 2022; Roth 2016; Sue et al. 2024). As such, I analyze Hispanics’ racial self-identification patterns in ways that avoid the pitfalls of focusing on state ethnoracial categories alone; namely, I avoid the reification of state classificatory schemes that misrepresent everyday practices of ethnoracial identification. Moreover, I offer rare estimates of within-individual dimension (mis)alignment that yield novel insights. A within-individual methodological design affords the opportunity to assess whether and how important aspects of ethnoracial identity formation—here, self-rated skin tone, reflected appraisal via interpretations of respondents’ “street race” (López et al. 2018), immigrant generation status, and Spanish and English language ability—are associated with (mis)alignment across state and lay ethnoracial categories. Namely, estimating the correlates of dimension (mis)alignment offers the benefits of assessing whether conventional analyses using racial self-classification omit important aspects of selection into racial self-identification and reveals potential patterns of selection into categories only accessible through open-ended responses. Although the cross-sectional nature of the data only offer a snapshot of Hispanic racial identifications at a specific juncture, the data speak to struggles over identification, a consequential manifestation of which is the approaching adoption of a combined race/ethnicity question with a stand-alone Hispanic category on the census (OMB 2024).
Data and Methods
This study uses data from the 2021 National Survey of Latinos (NSL), a survey administered to a nationally representative sample of 3,375 self-classified Hispanics 3 residing in the United States as part of Pew Research Center’s (2021) American Trends Panel (ATP) Wave 86. The 2021 NSL is a uniquely valuable dataset because it is, to my knowledge, the largest and most recent nationally representative survey of the U.S. Hispanic population that includes information on the multiple dimensions of race. Crucially, it is the largest survey to collect open-ended information on the racial identification of U.S. Hispanics, aside from post-2020 restricted census data. The 2021 NSL includes 1,900 Hispanic adults from the ATP and 1,475 from Ipsos’s KnowledgePanel. Pew works with Ipsos to recruit panelists for the ATP, a nationally representative panel using address-based sampling with randomization to the household level. KnowledgePanel is the largest online, nationally representative panel of U.S. adults and uses address-based sampling methodology.
Of the 3,375 original respondents, I restrict the sample to the 90 percent who marked “white” or “some other race” on the closed-ended racial self-classification question. The purpose of this study is to estimate (mis)alignment across state and lay racial categories and their correlates. “White” and “some other race” are racial categories on the U.S. Census and the only ones with sufficient observations for reliable inference. 4 I further restrict the sample to respondents with nonmissing data on the dependent variables: closed-ended racial self-classification and open-ended racial self-identification. The missingness rate for the closed-ended self-classification item is 3.50 percent. I do not impute values for this item, because of the low rate of missingness and the absence of strong auxiliary predictors. I perform multiple imputation by chained equations for the 3 percent of the sample missing data on skin tone, immigrant generation, and income. 5 Imputing missing values for these independent variables does not affect the study’s substantive findings. Interested readers may consult models without imputed values in the Appendix (Tables A2–A4).
Approximately one third of the sample did not respond to the open-ended racial self-identification question, a common challenge for free-response items in survey contexts (Smyth et al. 2010). This question is the outcome of interest, meaning missing data arises from the dependent variable. When this is the case, complete case analysis is the most appropriate approach (Carpenter and Smuk 2021; Hughes et al. 2019; Jakobsen et al. 2017). Without high-quality auxiliary variables, imputing open-ended responses adds no useful information (Jakobsen et al. 2017) and may increase variability and inflate standard errors (Von Hippel 2007). Contrary to popular belief, complete case analysis can yield unbiased results even when data are not missing at random (Bartlett, Harel, and Carpenter 2015). For this study, coefficients are likely asymptotically unbiased whether missingness depends on the outcome alone or on the outcome and confounders.
Even with asymptotically unbiased coefficients, estimation occurs only for a subset of the sample. Bias and representativeness are distinct constructs. To enhance transparency and clarify how inferences should be interpreted, I assess who is represented in two ways. First, I present descriptive statistics for the analytic sample. Second, I model selection into missingness on the open-ended racial self-identification item (see Table A5). Missingness appears to be largely driven by socioeconomic status: the analytic sample is older, more educated, and higher earning than the original sample would be if complete.
As a robustness check for potential attrition bias, I use a method akin to inverse probability of attrition weighting. Rather than relying on propensity scores, I apply entropy balancing to reweight the analytic sample so that it matches the covariate distribution of the original, preattrition sample (Hainmueller 2012). The attrition-weighted results (Tables A6–A8) do not differ from the main results reported in the article.
Measures
Racial Self-Classification (Closed Ended)
A U.S. census-style 6 question measures respondents’ racial self-classifications via the following question: “What is your race or origin?” Mutually exclusive response options included “White,” “Black or African American,” “Asian or Asian American,” “two or more races,” and “some other race or origin.” Analyses are limited to respondents who chose either “white” or “some other race.” When modeled as a binary dependent variable, the closed-ended race question is coded such that “white” takes a value of one and “some other race” takes a value of zero as the reference category. As a general rule, any reference to self-classification in this article refers to responses on closed-ended questions.
Racial Self-Identification (Open Ended)
Respondents offered their racial self-identification in response to the question “In your own words, if you could describe your race or origin in any way you wanted, how would you describe yourself?” Responses were recorded in a textbox. The Pew Research Center back-coded the qualitative responses into 18 detailed categories, including “Latino/Hispanic/Latinx,” “White,” “American,” “Black,” “Afro-Latino,” “Country of Origin–Spanish,” “Mixed,” “Mestizo,” “Asian,” “Human,” “Don’t Believe in Race,” “Indigenous,” “Light Skin Tone Mentioned,” “Darker Skin Tone Mentioned,” “Other Mention,” “Latin American Region,” “Country of Origin–Not Spanish,” and “Other Region–Not Latin American.” I collapsed these into six codes: “Hispanic” (Latino, Hispanic, Latinx, and Afro-Latino), “ethnonational” (Country of Origin–Spanish, Latin American Region, Country of Origin–Not Spanish, and Other Region–Not Latin American), “White,” “American,” “other race” (Black, Asian, Mixed, Mestizo, and Indigenous), and “alternatives” (Human, Don’t Believe in Race, Light Skin Tone Mentioned, Darker Skin Tone Mentioned, Other Mention). 7 Although open-ended questions on racial self-identification are rare, this collapsing approach aligns with Landale and Oropesa (2002) and Croll and Gerteis (2019) in their analyses of Hispanics’ open-ended responses.
Self-Rated Skin Tone
The survey asks, “Which of these most closely matches your own skin color, even if none of them is exactly right?” and includes a figure of skin tones on human hands (see Figure A1), allowing respondents to match themselves on a scale from 1 (lightest) to 10 (darkest). I collapse values 6 through 10 because of small cell sizes.
Reflected Appraisal (Street Race)
Respondents report their reflected appraisal by answering, “How would most people describe you, if, for example, they walked past you on the street? Would they say you are . . .,” with mutually exclusive choices: “white,” “Hispanic or Latino,” “Black or African American,” “Asian or Asian American,” “Native American or Indigenous (the native peoples of the Americas such as Mayan, Quechua or Taino),” “Native Hawaiian or Other Pacific Islander,” “mixed race or multiracial,” and “other.” The item is based on López et al.’s (2018) construct measuring reflected appraisal “at the level of the street” (p. 50). Reflected appraisal, drawn from a long-standing literature on symbolic interactionism (Blumer 1969; Cooley 1902; Mead 1934), is the notion that people construct their self-identification by taking into account how outsiders see them. Racial misclassification across internal perception and external categorization is common in the United States, especially among Hispanics (Vargas 2015; Vargas and Kingsbury 2016; Vargas and Stainback 2016), but people tend to align their ethnoracial self-identification with outsider’s ascriptions and the existing social norms those ascriptions represent (Irizarry et al. 2023; Pirtle and Brown 2016). Prior studies include questions about how individuals think others perceive them (Jones et al. 2008), but the novel form of reflected appraisal used in this study is unique in that it ties those appraisals more directly to physical appearance by asking how people might categorize respondents on the basis of brief interactions (i.e., passing them on the street only), as opposed to asking for reflected appraisal in ways that may conflate race, national origin, and ancestry (López et al. 2018). Although a unique contribution to the literature, it is important to note that “street race” reflected appraisal does not provide a form of the reflected appraisal that occurs over extended interpersonal interactions. Nor does it provide observed race (i.e., asking others to directly categorize the respondents). The 2021 NSL did not collect information on observed race.
Sociodemographic Covariates
Covariates include categorical indicators for language ability (English dominant [reference], bilingual, Spanish dominant), immigrant generation (foreign-born or Puerto Rico–born [reference], second generation, third generation or higher), education (less than high school, high school diploma [reference], some college, college graduate), income (<$30,000 [reference], increments of $10,000 until the category ≥$100,000), age (18–29 years [reference], 50–64 years, ≥65 years), gender (male [reference]), ethnicity (Mexican [reference], Puerto Rican, Cuban, Dominican, Salvadoran, Spanish, other Central American, other South American, other country), and U.S. census region (West [reference], Northeast, Midwest, South).
Statistical Analyses
This study has two central aims: first, to estimate the degree of dimension (mis)alignment between the use of state and lay racial categories, offering context on the multitude of categories a relatively large sample of self-classified Hispanics use to describe their racial self-understandings, and second, to understand how self-classified Hispanics’ ethnoracial boundary construction differs across state and lay contexts by estimating the correlates of dimension (mis)alignment. The analytic procedure proceeds through a series of steps. First, I estimate descriptive statistics for the independent variables used to model racial self-classification and self-identification, disaggregated by respondents’ closed-ended white or some other race classifications. Second, I assess dimension (mis)alignment by estimating respondents’ closed-ended racial self-classifications, open-ended racial self-identifications, and the overlap between those dimensions. Third, I estimate a linear probability model (LPM) regressing census-style closed-ended classification responses (white vs. some other race) on a set of independent variables, focusing on reflected appraisal, self-rated skin tone, language ability, and immigrant generation. The LPM reflects the dominant approach in the literature, relying on a census-style closed-ended question without a Hispanic racial category to model racial heterogeneity among people who mark “yes” on the panethnic Hispanic origin question.
As a final step, I estimate a series of LPMs modeling non–mutually exclusive mentions of each open-ended racial category, disaggregated by white and some other race self-classification. In a sense, I estimate two “layers” of selection: into state-sanctioned categories and into open-ended racial categories. Disaggregating the LPMs by racial self-classification allows identification of patterns missed when relying on state categories alone. Take, for instance, the hypothetical that self-classified Hispanics with darker skin tones are less likely to choose “white” on the census-style self-classification item. If an LPM modeling open-ended white self-identification among those who select “white” on the closed-ended item finds negative selection by skin tone, this would imply that the self-classification model underestimates selection into whiteness, misrepresenting the openness of the white category to self-classified Hispanics.
Open-ended responses also permit modeling selection into categories generally unavailable on the census or social science surveys but that yield important insights for scholars of race/ethnicity and immigration, such as “American” or language that resists racial classification altogether (Croll and Gerteis 2019). These models are oriented toward understanding how patterns of selection differ across state and lay categories and what those patterns suggest about ethnoracial boundary construction more broadly.
This study’s main findings derive from models produced via multiple imputation. 8 All standard errors are heteroskedasticity-robust. Results are generated using StataMP 19.
Results
Descriptive Statistics
Descriptive statistics for the primary independent variables of interest are presented in Table 1, whereas descriptive statistics for all covariates included in the analyses are available in Table A1. I report descriptive statistics for the full sample before disaggregating by racial self-classification (white vs. some other race). About 23 percent of the sample reported a reflected appraisal of white, and 70 percent reported Hispanic or Latino. Just under half (49 percent) appraised their skin tones in the two lightest categories. Immigrants made up 54 percent of the sample, and equal proportions reported being English dominant (28 percent) or Spanish dominant (28 percent). Preliminary tests for statistically significant differences across racial self-classification using a series of Wald tests suggest that compared with some other race self-classified respondents, white self-classified respondents were more likely to report, on average, white reflected appraisals, lighter skin tone, higher immigrant generation, and lower Spanish language dominance.
Descriptive Statistics of the Analytic Sample, Stratified by Closed-Ended Racial Self-Classification.

p < .001.
Dimension (Mis)alignment
A central aim of this study is to estimate the degree of dimension (mis)alignment across state and lay racial categories. Table 2 displays descriptive statistics for closed-ended racial self-classification, non–mutually exclusive open-ended racial self-identification responses, and mutually exclusive responses from those who provided only one open-ended answer. About 62 percent of the analytic sample used only one self-identification category. 9 Among those who selected white or some other race on the closed-ended item, 73 percent chose white and 27 percent some other race. For the open-ended question, just under half of the sample mentioned a category akin to Hispanic, and 45 percent mentioned an ethnonational category (e.g., Mexican, Puerto Rican, Cuban). In total, 86 percent provided a Hispanic and/or ethnonational response. The white category declined markedly across formats, from 73 percent on the closed-ended item to 16 percent on the open-ended item. About 20 percent used “American,” 9 percent mentioned other racial categories (e.g., Mestizo, Indigenous, Black), and 10 percent invoked racial alternatives (e.g., human). Roughly 28 percent used Hispanic as their only response, and 22 percent named only an ethnonational category. Exclusive mentions of white (2 percent), American (2 percent), other racial categories (3 percent), or racial alternatives (5 percent) were rare, suggesting that those categories were usually paired with Hispanic or ethnonational terms. These patterns yield three takeaways: (1) dramatic declines in the use of state racial categories, (2) widespread and roughly equal use of Hispanic and ethnonational categories, and (3) notable heterogeneity in responses including “American” or rejecting racial labels altogether.
Dimension (Mis)alignment across Racial Self-Classification (Closed Ended) and Self-Identification Questions (Open Ended).

Part B of Table 2 shows the four most common open-ended response combinations. About 14 percent of the sample reported simultaneous attachments to ethnonational and American categories. As just under 20 percent mentioned “American,” most did so in hyphenated form (e.g., Mexican-American, Cuban-American). Just under 9 percent combined Hispanic and white, and another 9 percent combined Hispanic and ethnonational. Respondents generally opted for either Hispanic or ethnonational labels, not both. About 5 percent combined ethnonational and white. Overall, white and American categories were usually attached to Hispanic or ethnonational terms, which tended not to be used interchangeably.
Part C of Table 2 presents descriptive statistics for (mis)alignment across the classification and identification questions, disaggregated by racial self-classification. The results are presented both as proportions of the total sample and within each classification group (white or some other race). Among the full analytic sample, the most common pattern was selecting white on the classification item and then reporting Hispanic (36 percent), ethnonational (33 percent), and/or white (16 percent) on the open-ended item. Among those who chose white, 49 percent reported a Hispanic and 45 percent an ethnonational identification; only 21 percent mentioned white self-identification. Among those who chose a some other race classification, 51 percent reported Hispanic and 46 percent ethnonational self-identifications, but only 2 percent self-identified as white. Two broad patterns emerge: (1) most misalignment stems from respondents who self-classified as white, and (2) misalignment primarily reflects widespread adoption of Hispanic and ethnonational self-identifications.
Selection among Closed-Ended Categories
The conventional approach to modeling racial heterogeneity among self-classified Hispanics regresses responses to a closed-ended racial self-classification question on a set of independent variables. Table 3 replicates that approach using an LPM where white racial self-classification (compared with some other race) is the outcome. The main model includes coefficients for reflected appraisal, self-rated skin tone, language ability, and immigrant generation, though full models appear in the Appendix (Tables A9–A11).
Results for Linear Probability Model Regressing Closed-Ended Racial Self-Classification on Covariates.

Note: Models control for education, income, gender, ethnicity, and census region.
p < .01. ***p < .001.
Reflected appraisal and self-rated skin tone were both significant correlates of a white racial self-classification. Compared with a white reflected appraisal, those appraised as Hispanic or Latino (14 percentage points), Asian (36 percentage points), Native American or Indigenous (43 percentage points), mixed race (31 percentage points), or other (32 percentage points) were substantially less likely to self-classify as white. On the skin tone scale, respondents with skin tones of 3 or higher were 11 to 28 percentage points less likely to choose white. Coefficients for language ability and immigrant generation were statistically indistinguishable from zero. Overall, the results suggest that reflected appraisal and skin tone serve as heuristics in boundary construction around state-codified categories. The next section explores whether relying on state-centered racial self-classification alone misses patterns of selection visible in racial self-identification.
Correlates of Dimension (Mis)alignment
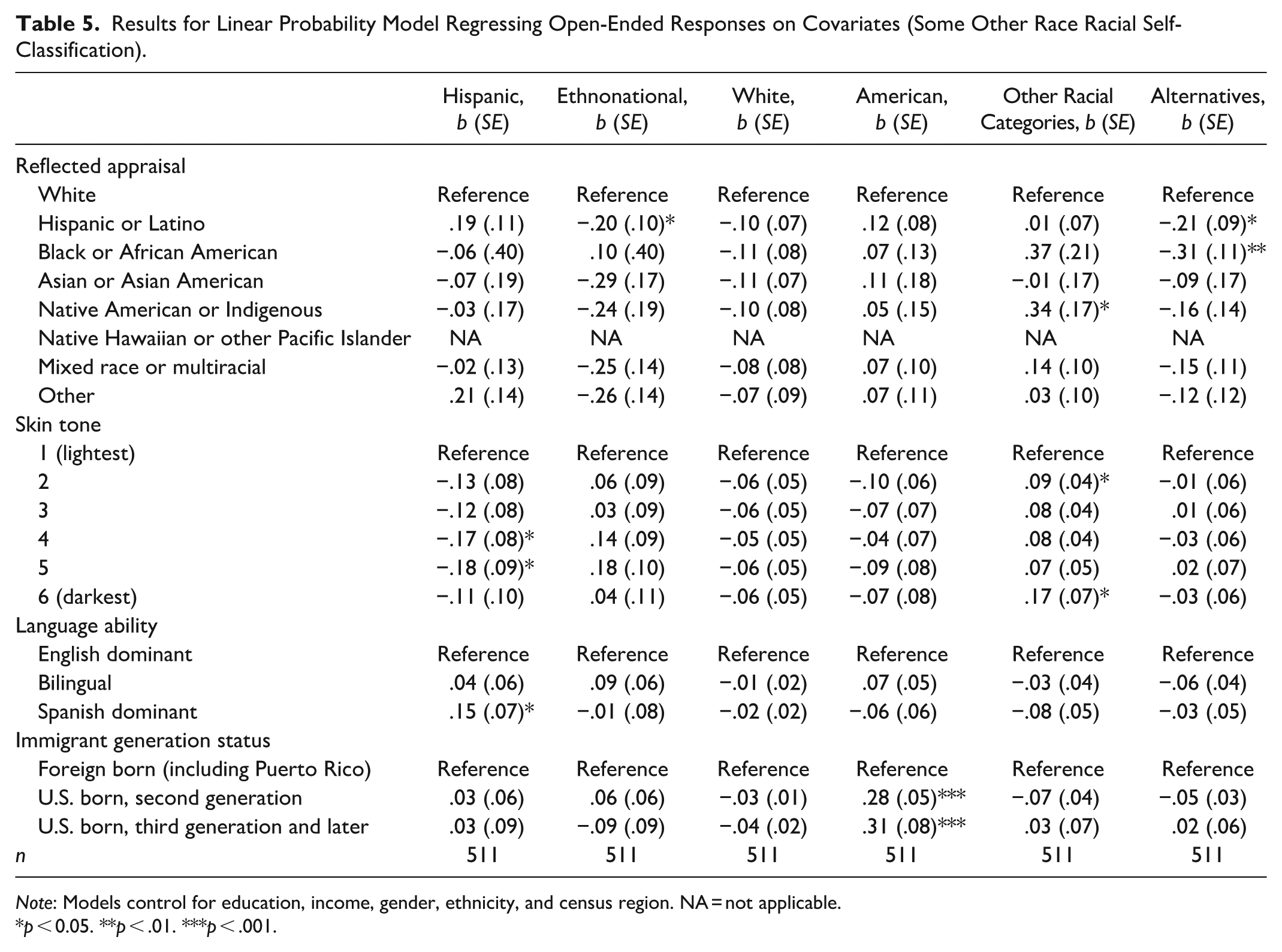
I estimate a series of LPMs modeling non–mutually exclusive mentions of each open-ended racial category, disaggregated by white and some other race self-classification. This disaggregation is key to estimating the correlates of (mis)alignment across state (self-classification) and lay (self-identification) dimensions of race. Table 4 presents models for white self-classifiers; Table 5 does so for some other race self-classifiers.
Results for Linear Probability Models Regressing Open-Ended Responses on Covariates (White Racial Self-Classification).

Note: Models control for education, income, gender, ethnicity, and census region.
p < 0.05. **p < .01. ***p < .001.
Results for Linear Probability Model Regressing Open-Ended Responses on Covariates (Some Other Race Racial Self-Classification).
Note: Models control for education, income, gender, ethnicity, and census region. NA = not applicable.
p < 0.05. **p < .01. ***p < .001.
For white self-classifiers (Table 4), the strongest selection patterns involve white self-identification. Compared with those with a white reflected appraisal, respondents appraised as Hispanic/Latino (24 percentage points), Black (28 percentage points), Asian (32 percentage points), Native Hawaiian/Pacific Islander (34 percentage points), mixed race (18 percentage points), or other (26 percentage points) were significantly less likely to mention white. Respondents with darker skin tones (values 2–6) were also 11 to 18 percentage points less likely to identify as white. Language ability and immigrant generation were generally insignificant, except for selection into the “American” category: second- and third-generation respondents were 21 and 25 percentage points more likely, respectively, to mention “American.” White was the only category with detectable selection based on skin tone. Reflected appraisal varied in its coefficients; for example, being appraised as Hispanic/Latino increased the probability of reporting “Hispanic” by 14 percentage points, while being appraised as Black increased the probability of Hispanic identification (42 percentage points) but reduced probability of ethnonational (39 percentage points), American (23 percentage points), and other racial identifications (17 percentage).
For some other race self-classifiers (Table 5), fewer patterns of selection into open-ended categories emerged. As seen in Table 2, (mis)alignment patterns were broadly similar across groups, with one key distinction: almost no one who self-classified as some other race identified as white. Marginally significant associations indicate darker skin tone was associated with lower probabilities of Hispanic identification (17 to 18 percentage points). In contrast to results from Table 3 and white self-classified respondents in Table 4, skin tone was not significantly associated with selection into the white category among some other race self-classifiers. The relatively smaller sample size for some other race self-classifiers could have resulted in less precision in estimates across skin tone categories. Additionally, almost no some other race self-classifiers self-identified as white, meaning skin tone was not something that differentiated them on the rare occasions when some respondents did report a white racial self-identification. Spanish dominance was associated with a higher probability (15 percentage points) of Hispanic self-identification. As with white self-classifiers, second- and third-generation respondents were more likely to identify as American, by 28 and 31 percentage points, respectively.
Discussion and Conclusion
I began by tracing two literatures to restate a fundamental tension in the social construction of race/ethnicity: while the state may “make” race by shaping which ethnoracial categories people use, whether and how people adopt those categories in everyday identification remains an empirical question (Bailey et al. 2018; Brubaker 2002). This question matters not only for understanding which groups “exist” as meaningful forms of division (Bourdieu 1985; Wacquant 2024), but because the ubiquity, and perhaps hegemony, of state categories shapes social science research itself (Menjívar 2023; Monk 2022). In some cases, state and lay categorizations align neatly (Croll and Gerteis 2019). When they do not, the unquestioned use of state categories may reify categories we wish to critique (Brubaker 2002; Menjívar 2023) and produce inferences that seriously misrepresent prevailing intergroup relations (Loveman 2014).
Using novel data that include census-style closed-ended and open-ended racial questions, I extend Bailey et al.’s (2018) metric of state race-making—dimension alignment—to the case of the Hispanic category in the United States. I estimate the degree and correlates of (mis)alignment across state (closed-ended) and lay (open-ended) classifications and identifications among self-classified Hispanics. This provides insight into whether, four decades after its official introduction, “Hispanic” has become integrated into ethnoracial self-understandings—and how these may diverge from the state’s view of which racial groups “exist.” I further contextualize processes of ethnoracial boundary construction, operationalized as racial self-classification and identification at the micro-level, by modelling selection into various ethnoracial categories using determinants of ethnoracial identity formation such as reflected appraisal, self-rated skin tone, language ability, and immigrant generation.
If evidence of state race-making lies in the integration of “Hispanic” into racial self-identifications, the results suggest a fair degree of success. Roughly half of respondents used a Hispanic-like term to describe their race, and 28 percent did so exclusively. This aligns with Wacquant’s (2024) observation that the category has evolved from a “paper ethnicity” into “a genuinely felt identity” (p. 109). That Hispanic was the single most common open-ended racial identification is consistent with qualitative work portraying Hispanic as a racialized category distinct from the Black/white binary (Flores-González 2017; Roth 2012). Although there is no clear, quantitative threshold that establishes when a category constitutes an ethnoracial group, frequent evocations of categories provide direct evidence that they constitute common ways of viewing and dividing the social world.
Still, Hispanic was not the dominant form of self-identification. The open-ended format reveals the complexity of racial self-identifications among self-classified Hispanics. Hispanic and ethnonational identifications appeared at similar rates, both alone and in combination, but only 9 percent of respondents used both simultaneously. This echoes prior work showing that a minority view Hispanic as their primary identity, with ethnonational categories more commonly occupying that space (Martínez and Gonzalez 2021). Furthermore, the evidence suggests that self-classified Hispanics did not select out of ethnonational categories across immigrant generations but instead became more likely to add hyphenated American identifications to ethnonational categories. Such patterns could portend a specific form of racialized assimilation in which durable attachments to specific ethnic groups prevent primary identification as Hispanic. To the extent that widespread racial identification as Hispanic requires the homogenization of people with diverse social origins, the homogenization process is far from complete.
Paradoxically, the widespread (if uneven) uptake of Hispanic suggests the state’s success 10 in embedding a strategically ambiguous panethnic category (Mora 2014b) undermines its racial classification system, which still lacks an official Hispanic race option. The implications are significant. Consider the white category: although 73 percent self-classified as white, that figure declined by 78 percent and 97 percent when considering any or exclusive open-ended mentions of white, respectively. Moreover, selection into white self-identification was shaped by reflected appraisal and skin tone in ways not fully captured by closed-ended self-classification. Dimension misalignment reveals that white racial identification among Hispanics is rarer and more selective than state categories suggest, calling into question the degree to which white boundary expansion may encompass the Hispanic population. Yet, constrained by data availability and classification norms, most quantitative work continues to treat census-style classification as a proxy for racial identification. Landale and Oropesa (2002), finding significant misalignment among Puerto Ricans, advised that “closed-ended race questions be disregarded or used very cautiously for the Puerto Rican population” (p. 251). The results here suggest extending that caution to self-classified Hispanics more broadly.
Rather than abandon the closed-ended race question, the OMB opted to modify it for the 2030 census by adding a stand-alone “Hispanic or Latino” race option and eliminating the separate Hispanic origin question (OMB 2024). Experimental studies of this combined race/ethnicity question yield findings consistent with this study’s results: self-classified Hispanics prefer a Hispanic option to describe their race/ethnicity, and its inclusion reduces the share of Hispanics identifying as white or some other race, thereby shrinking those populations overall (Compton et al. 2013; Flores et al. 2024; Mathews et al. 2017). Still, this study’s comparison of closed- and open-ended race questions raises three issues about how future census data may delineate racial boundaries. First, fewer respondents identified with a panethnic Hispanic racial category than selected “Hispanic” in the experimental combined question, partly because of the prevalence of ethnonational identifications (e.g., Mexican, Puerto Rican). Even with space for write-in responses, census data cannot fully determine whether panethnic “Hispanic” identification predominates. Second, open-ended responses capture the complexity and multiplicity of racial self-understanding among Hispanics—dimensions largely obscured by closed-ended formats. Third, the inclusion of “Hispanic” as a race option may, over time, institutionalize it as a racial category through a Bourdieusian process in which state recognition legitimizes social classifications. Whether this reform crystallizes and expands “Hispanic” as a lived racial category can only be assessed through analyses such as those presented here, comparing individuals’ census self-classifications with open-ended identifications over time. State race-making is a process, not a static outcome.
The inferences made in this article should be interpreted bearing in mind important limitations. First, the data are cross-sectional. I cannot claim state race-making caused observed identification patterns; such a claim would require longitudinal data tracking self-identification before and after the 1980 introduction of the Hispanic origin question. What I offer is a snapshot of whether, and for whom, a state-constructed category has become meaningful decades later. Given the planned inclusion of a combined race/ethnicity question with a stand-alone Hispanic category, now is the time to collect longitudinal data to examine change over time.
Second, analyses are limited to those who self-classified as white or some other race because of sample size restrictions for the Black, Asian, and two or more races categories. Although most self-classified Hispanics self-classify as white or some other race on the census (U.S. Census Bureau 2023), this study does not represent dynamics that might be unique to other groups such as Afro-Latinos, Hispanics with Asian descent, Indigenous peoples, or Hispanics who identify as mixed/multiracial. Future work should oversample those groups so that quantitative analyses can adequately capture their population dynamics.
Third, although integrating qualitative responses into a quantitative design is a unique strength of this study, no survey can substitute for in-depth interviews. For example, 62 percent of respondents gave only one open-ended response. Without follow-up, it is unclear whether those responses represented primary identifications or reflected item design. Self-identification on surveys remains a key dimension of racial subjectivity, but responses may still diverge from real-world boundary-making. That said, open-ended questions offer perhaps the best chance for moving beyond reified categories (Goldberg 1997).
Bowker and Star (2000) remind us, “The only good classification is a living classification” (p. 326). The U.S. racial classification system, institutionalized via the census, nominates racial groups into being and reproduces the groups it invents. Yet rigid categories capture only fragments of the fluid, negotiated nature of racial self-identification (Goldberg 1997). The OMB’s decision to adopt a combined race/ethnicity item with a Hispanic race option reflects long-standing recognition that existing categories fail to represent how many Hispanics understand their racial subjectivities (Dowling 2014; Rodriguez 2000). Census experiments suggest most self-classified Hispanics will select the new Hispanic race option (Mathews et al. 2017). The results presented here support the idea that this redesign improves alignment between state and lay categories. But they also caution against overinterpretation. High endorsement may reflect satisficing rather than genuine identification. Redesign cannot resolve the contradictions of racial classification; it merely repackages them, demanding continued scrutiny.
Supplemental Material
sj-docx-1-srd-10.1177_23780231251401662 – Supplemental material for Counting Race, Miscounting Identity: The Census and Hispanic Racial Self-Identification
Supplemental material, sj-docx-1-srd-10.1177_23780231251401662 for Counting Race, Miscounting Identity: The Census and Hispanic Racial Self-Identification by Kyle E. Waldman in Socius
Footnotes
Acknowledgements
I thank Mary C. Waters, Alexandra Killewald, and Jody Agius Vallejo for their helpful feedback on prior drafts of the manuscript.
Supplemental Material
Supplemental material for this article is available online.
1
I treat Hispanic and Latino as interchangeable. Hispanic is more consistent with the wording of the census.
2
I refer to Hispanics as “self-classified” when I write about their responses to the Hispanic origin question and “self-identified” when I write about their ethnoracial self-descriptions.
3
Self-classified Hispanics are persons who mark “yes” on the U.S. Census Hispanic origin question.
4
Indeed, the 90 percent of the sample who selected white or some other race reflect the approximately 90 percent of self-classified Hispanics who selected white or some other race on the 2010 U.S. census (Humes, Jones, and Ramirez 2011). This exclusion restriction drops Hispanics who self-classified as Black or African American, Asian or Asian American, and two or more races on the closed-ended question (in total, slightly fewer than 300 respondents, most of whom self-classified as two or more races).
5
I estimate 50 imputations.
6
I refer to this question as a “census-style” question throughout the article because the response categories include some state-sanctioned racial categories (i.e., “white,” “Black or African American,” “Asian or Asian American,” and “some other race”) while omitting others (e.g., “American Indian or Alaska Native” and various Pacific Islander categories). Additionally, the 2020 census design allowed open-ended write-in responses under each traditional race category, blending closed- and open-ended question formats. The 2020 census design did not allow new racial categories to be created from the open-ended responses but was used to recode respondents across the existing closed-ended racial categories. See the ![]() for a detailed description of those changes. Finally, the “two or more races” option on the 2021 NSL survey is a stand-alone option with less detail than the aggregating procedure used across racial categories on the census.
for a detailed description of those changes. Finally, the “two or more races” option on the 2021 NSL survey is a stand-alone option with less detail than the aggregating procedure used across racial categories on the census.
8
As in Bailey et al. (2018), I opt not to use survey weights. The inclusion of survey weights, however, makes no meaningful changes to the substantive results and interested readers may review survey-weighted results in the ![]() ).
).
9
10
I do not mean to argue the state is the only actor that aided in the integration of the Hispanic category. ![]() argued for cross-field effects spanning government officials, ethnic activists, and media elites. This article is less concerned with teasing out the mechanisms by which state categories are integrated into everyday ethnoracial self-understandings and more concerned with the degree to which state categories are so integrated.
argued for cross-field effects spanning government officials, ethnic activists, and media elites. This article is less concerned with teasing out the mechanisms by which state categories are integrated into everyday ethnoracial self-understandings and more concerned with the degree to which state categories are so integrated.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.