
Abstract
Quantitative sociologists have recognized the challenges of studying Latinx Americans, given their unique racial heterogeneity and unique measurement in surveys through dedicated Latinx-ethnicity questions. Using the National Longitudinal Study of Adolescent to Adult Health, the author examines who identifies as Hispanic/Latinx when the option is a permitted response on a combined race/ethnicity question. The study reveals that national origin, connection to Latinx communities, racial appearance, and consistency in prior ethnic identification as Latinx affect the likelihood of racial identification as Latinx. These associations have heterogeneous consequences for modeling social outcomes in samples with both Latinx and non-Latinx respondents. Latinx Americans divide on skin tone in models of education and health, but they divide on national origin in models of interracial dating. This suggests that researchers should operationalize Latinxs using measures recognizing a modal group of Latinx-only identifiers while capturing heterogeneity by skin tone and national origin across the broader ever-Latinx population.
Under President Donald Trump, the U.S. Census Bureau decided against Obama-era plans to collect racial/ethnic information in a combined question and returned to its method, since the 1980 census, of asking separate questions for race and Latinx ethnicity. 1 Implemented for the 2020 census, this decision delays a reform that many sociologists have supported for more than a decade, in particular since Campbell and Rogalin’s (2006) analysis of Latinx racial identification. However, some researchers may have seen a silver lining in the decision: the collection of at least one more census that can be used to track differences between Latinxs who self-identify as White, as Black, and as Some Other Race 2 (Choi 2020; LaVeist-Ramos et al. 2012; López 2013). Using measures of Latinx heterogeneity unavailable to Campbell and Rogalin, I expand their landmark analysis to further examine how quantitative social scientists should measure the Latinx population.
Campbell and Rogalin (2006) took advantage of the May 1995 Race and Ethnicity Supplement to the Current Population Survey, which asked a subset of its respondents both the combined race/ethnicity question and the separate race and Latinx-ethnicity questions. They examined which respondents racially identify as Latinx for the combined question among those who chose both Latinx ethnicity and non-Latinx race in the separate questions. They found that nearly 20 percent of Latinx ethnic identifiers identified racially by non-Latinx labels on the combined question, whereas nearly 75 percent identified exclusively as Latinx, including 97 percent of the Latinx ethnic identifiers who had chosen Some Other Race. They also found that the likelihood of racially identifying as Latinx-only was higher among respondents who were from younger age cohorts, had national origins in Mexico or Puerto Rico, spoke Spanish at home, and lived in metropolitan areas with more Latinxs. On the basis of these findings, they argued that measuring Latinxs using a Latinx-ethnicity question creates a low threshold for Latinx identification that in turn obscures how a Latinx racial identity is of primary salience to the vast majority of their respondents, especially among younger cohorts. Although they cautioned that the “best” way to measure Latinxs depends on different constituencies and goals, their work has been cited as support for the argument that surveys should shift to using the combined-question format (Hitlin, Brown, and Elder 2007).
Using the National Longitudinal Study of Adolescent to Adult Health (Add Health), I expand Campbell and Rogalin’s (2006) analysis with measures of racial classification by observers, skin tone, and consistency in prior ethnic identification as Latinx across multiple panels (Harris 2009). Add Health is a panel study that asked the separate race and ethnicity questions in multiple panels, before asking the combined race/ethnicity question in wave V (2016–2018). It also asked its interviewers (1) to racially classify respondents on the basis of appearance alone and (2) to rate respondents’ skin tones. Another critical aspect of Add Health is the ability to track unobserved Multiracials who identify with a single race in public settings (Miville et al. 2005). This is especially useful for tracking part-Latinx respondents because the separate Latinx-ethnicity question typically does not permit multiple responses unlike the race question or the combined race/ethnicity question (Miyawaki 2016). In addition, Add Health has collected a wide range of health-related data from its respondents, allowing researchers to examine the consequences of different Latinx specifications for modeling different social processes. Table 1 presents the Add Health wording for the separate race and ethnicity questions and the combined race/ethnicity question.
Select Race/Ethnicity Questions in the National Longitudinal Study of Adolescent to Adult Health.
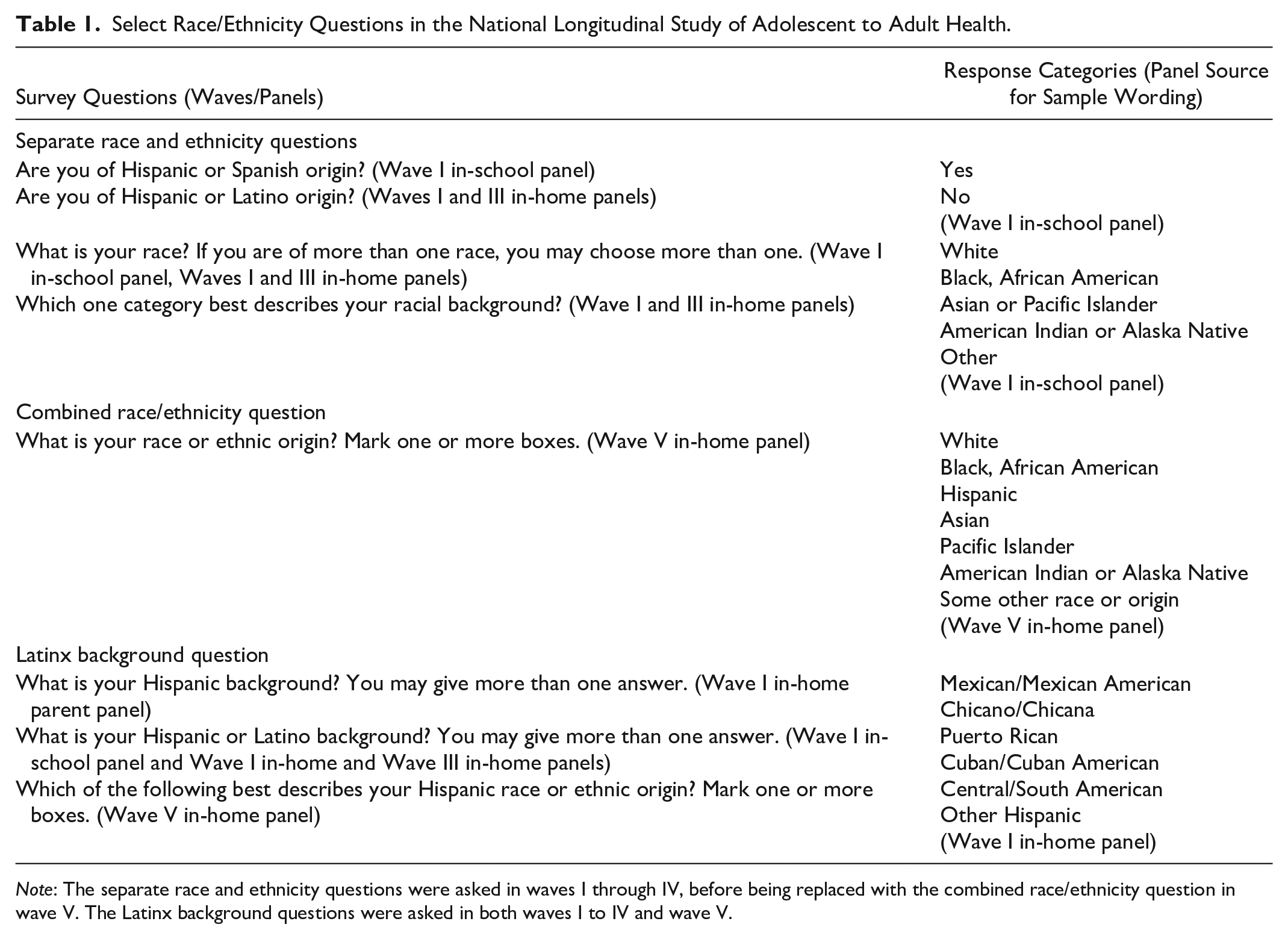
Note: The separate race and ethnicity questions were asked in waves I through IV, before being replaced with the combined race/ethnicity question in wave V. The Latinx background questions were asked in both waves I to IV and wave V.
In this article, I first discuss how Latinx heterogeneity in racial appearance and patterns of identification illustrate the general process of racial identification. Second, I describe how I use Add Health to examine which respondents racially identify as Latinx among respondents who ever identified as ethnically Latinx in an earlier panel. Third, I present my findings that national origin, connection to Latinx communities, racial appearance, and consistency in Latinx identification affect the likelihood of exclusively identifying as Latinx on the combined race/ethnicity question. In turn, these associations have heterogeneous consequences for modeling social outcomes in samples with both Latinx and non-Latinx respondents. Latinx Americans divide on skin tone in models of education and health, but they divide on national origin in models of interracial dating. On the basis of these findings, I recommend that researchers operationalize Latinxs using measures recognizing a modal group of Latinx-only identifiers while capturing heterogeneity by skin tone and national origin across the broader ever-Latinx population. Last, I discuss how my findings illustrate the uniquely hypersituational salience of Latinx identification in the United States and raise questions for future research.
Literature Review
Latinx identification provides a revealing illustration of the complexity of racial identification, wherein race and ethnicity are indistinct social constructions 3 at the micro-level (Hitlin et al. 2007), that are also embedded in a historically specific macro-level process that classifies people into racial groups on the basis of real or imagined corporeal attributes and positions them relative to other groups within national systems of social stratification further embedded within a global system of White supremacy (Bonilla-Silva 1997; Golash-Boza 2016). Regarding racial identification at the micro-level, Roth (2016) distilled the literature into a typology of race dimensions: racial identity, racial self-classification, observed race, reflected race, phenotype, and racial ancestry.
Figure 1 integrates Roth’s (2016) discussion of the dimensions into a social-psychological process with three stages (i.e., time 1, time 2, and time 3) as a heuristic for highlighting unique aspects of Latinx identification. Quantitative researchers often have access to information about racial self-classification, that is, the race one selects from a menu of preestablished options, such as a respondent’s choice of a racial category in response to a survey question. As a “time 3” indicator, racial self-classification is the most appropriate indicator when used as a covariate for summarizing racial processes while estimating the association between the nonracial variables of interest (Connelly, Gayle, and Lambert 2016).
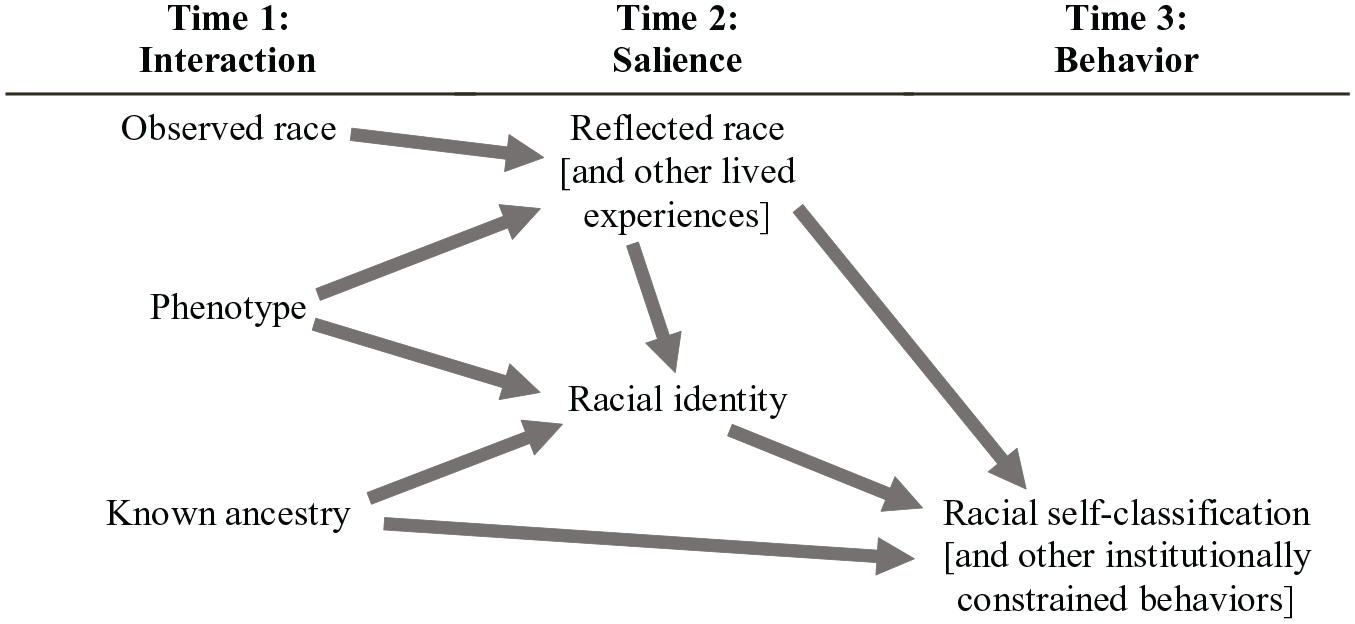
Racial identification as a multidimensional process.
However, researchers also use racial self-classification as a proxy for other dimensions of race and, as a result, advance potentially narrow interpretations of its coefficients. These other dimensions include one’s subjective self-identification (i.e., racial identity), the race one believes others assume them to be (i.e., reflected race), and the race others believe one to be (i.e., observed race). From “time 1” to “time 2,” observed race is theorized to influence reflected race by influencing one’s lived experience, such as encounters with racial stereotyping, racial profiling, and discrimination, whether in public settings when the classification is based on appearance or in more organized settings such as workplaces and schools when it is based on interaction. In turn, reflected race is theorized to influence racial identity, and together, reflected race and racial identity are theorized to influence institutionally constrained behaviors such as racial self-classification as well as voting, residential decision making, and social network formation. In turn, these behaviors lead back to “time 1” and “time 2” to form a recurring cycle of interaction, salience, and behavior that constructs racial identification at the micro-level. For example, one can include among the “time 3” behaviors the practices of (1) racially classifying other individuals which reciprocally contributes to “time 1” for those others, (2) revising one’s presentation of self to influence others’ classification of one’s own observed race, and more complexly (3) altering one’s networks to select the “others” with whom one engages in identity work from code-switching to group bonding (Cross et al. 2017; Feliciano 2016; King and DaCosta 1996).
Latinxs’ racial identification is complicated by its distinctive institutional measurement (i.e., at time 3) as an ethnic identification separate from racial identification, even though most Latinxs racially self-classify as Latinx-only when given the opportunity (Campbell and Rogalin 2006). When the separate-question format requires them to choose a non-Latinx racial self-classification, many reject the remaining options for the “other race” option (Hitlin et al. 2007) or select a self-classification that, for many Latinxs, deviates from their racial appearance (i.e., phenotype) and racial ancestry (i.e., known ancestry based primarily on family history), at least by U.S. rules for racial classification (Dowling 2015; Golash-Boza and Darity 2008). To other Americans, many Latinxs who self-identify as White do not appear to be White, and many who appear to be Black self-identify instead by other racial labels including White (Darity, Dietrich, and Hamilton 2005; Vargas 2015). Despite this well-known discordance between Latinxs’ observed race and their non-Latinx racial self-classification, data limitations have forced researchers to continue using non-Latinx self-classification as a proxy for Latinxs’ observed race (e.g., LaVeist-Ramos et al. 2012) even while acknowledging that “Latin[xs] are more likely to select racial identities that conflict with external appraisals” (Irizarry 2015, 575).
The critical reason for this discordance is that the micro-level process presented in Figure 1 is structured not only by the macro-level process of social construction in the United States but also by migration from, and continuing contact with, a sending region with a distinctive and also heterogeneous macro-level process (Roth 2012; Telles 2018). The history of Spanish and Portuguese colonization in Latin America means that Latinx Americans have also been exposed to alternative systems for classifying people into racial groups with (1) similar labels as in the United States (i.e., Whites and Blacks) but (2) different rules of classification based on not only ancestry but also phenotype and social class, with numerous consequences such as normalizing the classification of family members into different racial groups (Saenz and Morales 2015; Telles and Sue 2009). In fact, these alternative systems have included state efforts to embrace racially mixed national identities on the basis of their specific demographic histories (Roth 2012). As a result, identifying as White (or Black) has had different meanings in the United States and Latin America as well as between Cuba and Mexico.
If we think of Figure 1 as representing a repeating cycle nested within both the life course and macro-level processes, then migration to the United States leads to Latinx immigrants’ (1) being newly observed as “Latinx” in contrast with non-Latinxs; (2) being newly observed as “Black” in contrast with their premigration racial identity; (3) having new encounters with racial stereotyping, profiling, and discrimination; (4) confronting new institutional options for racial self-classification; and (5) developing new identities informed by U.S. schema, such as (a) a street race based on how other Americans observe one’s race in street-level interactions, (b) self-classification as “White” to signal American social belonging, and (c) a panethnic solidarity based on a shared history of colonialism and myriad ties to Latin America (Baca Zinn and Zambrana 2019; Frank, Akresh, and Lu 2010; López, Vargas et al. 2018; Newby and Dowling 2007; Rodriguez 2000).
Although their U.S.-born descendants primarily experience the process of racial identification in the United States, similar to other postimmigrant generation Americans, their interpretations of those experiences are also influenced by the perspectives of their immigrant parents and coethnic communities, especially concerning the known ancestry of their family and ethnic group (Dhingra 2007). In the long term, Latinxs’ presence in the United States is shifting its categories and rules for racial classification; however, in the meantime, the self-classification of Latinx Americans is a noisy indicator of their lived experiences, unless it is supplemented by measures of heterogeneity that bridge the gap with Latin American cultures of racial identification (Golash-Boza and Darity 2008; Telles 2018).
An important bridge is provided by how other Americans classify Latinx racially and treat them accordingly. Many researchers have found that racial appearance influences Latinxs’ socioeconomic outcomes through discrimination based on their observed race (Frank et al. 2010; Perreira and Telles 2014; Telles and Murguia 1990). Building on this literature, Feliciano and Robnett (2014) examined whether racial appearance also affects how Latinxs accept other racial groups. Using Internet dating profiles, they examined how Latinxs’ observed race affects whom they include or exclude as potential dates, and they found that “self-identified Latinos exhibit dating choice patterns that are similar to those of the [U.S.] racial group they are viewed by others as belonging to” (p. 316). In brief, racial appearance differentiates Latinxs’ experiences of both racial stratification and interracial contact.
Feliciano (2016) extended this research to examining the specific phenotypes that influence how others racially classify Latinxs by comparing how skin tone, nose shape, lip shape, hair type, and body type shape the racial classification of photos on Internet dating profiles. She found that skin tone is the major criterion observers use to place others in White, Black, and Latinx categories. A dark-skin rule rather than a one-drop rule appears to influence classification as Black by observers of all races, whereas medium skin tones are associated with classification as Latinx and light skin tones with classification as White. As a consequence, “individuals whose self-identities do not match these phenotypic associations are more likely to experience discordant classification from outsiders” (p. 407). In sum, her observers recognized a Latinx phenotype while also classifying nearly 20 percent of self-identified Latinx daters as non-Latinx, in comparison with classifying only 2 percent of self-identified Black daters as non-Black and 7 percent of White daters as non-White. These findings confirm the role of observed race and skin tone as important mechanisms for racialized assimilation or the segmented racialization of (1) most Latinxs as a new racial category and (2) other Latinxs as Whites or Blacks (Golash-Boza and Darity 2008). In brief, regardless of how they racially self-classify on the separate race question, their classification by others influences their social outcomes.
Last, a third source of heterogeneity among Latinxs is Multiracial identification, which refers to both (1) individuals who identify as part Latinx (Miyawaki 2016) and (2) the definition of the Latinx category itself as a Multiracial category because of the putatively greater tolerance of race mixing in Latin America (Telles and Sue 2009). Because of the restriction of Latinx-ethnicity questions to a single response, Multiracial identification is an unobserved factor in quantitative research on Latinx identification. In brief, how much is Multiracial identification behind the associations between Latinx identification, racial appearance, and their social outcomes? On the one hand, Campbell and Rogalin (2006) found that only 7 percent of their respondents identify as Multiracial when presented with the combined race/ethnicity question. On the other hand, their sample was based on a single panel, which did not allow them to track patterns of inconsistent Latinx identification, which may be associated with Multiracial identification. Examining racial inconsistency in Add Health, Shiao (2019) found that most inconsistent identifiers switch between Multiracial self-classification and single-race self-classification in different panels, and he recommended placing these respondents in the Multiracial category along with the smaller population of consistently Multiracial identifiers. 4 This recommendation is consistent with Emeka and Vallejo’s (2011) finding that some Latinx Multiracials self-classify as non-Latinx on the Latinx-ethnicity question while also reporting Latinx ancestry on a separate question. Although classifying inconsistent Latinx identifiers as Multiracials would not include those who never self-classify as Latinx, this approach permits the identification of Latinx Multiracials who occasionally identify as Latinx. Conversely, it also allows researchers to examine whether Latinx heterogeneity in racial appearance characterizes both Multiracials as well as “Monoracials.”
Research Questions and Hypotheses
I consider three research questions:
Who identifies as Latinx when a Latinx response is permitted in a survey’s combined race/ethnicity question, rather than in a separate Latinx-ethnicity question?
How does Latinx racial identification vary by individuals’ observed race, skin tone, and the consistency of their Latinx ethnic identification in other survey panels?
What are the consequences of different specifications of Latinx heterogeneity for modeling racial stratification and interracial contact in samples with both Latinx and non-Latinx respondents?
On the basis of the literature discussed above, I propose the following hypotheses:
Hypothesis 1: Confirming Campbell and Rogalin (2006), individuals are more likely to racially identify as Latinx-only if they have national origins in Mexico or Puerto Rico, have more connections to Latinx communities, and have attained more education.
Hypothesis 2: Individuals are also more likely to racially identify as Latinx if they are perceived as “other race” and as having intermediate skin tones and if they have consistently identified as ethnically Latinx (Feliciano 2016; Feliciano and Robnett 2014; Shiao 2019).
Hypothesis 3: Specifying Latinxs as a racial group with heterogeneous racial appearance and patterns of identification improves the fit of models estimating the social outcomes of racial stratification and interracial contact, in comparison with the usual practice of specifying Latinxs as an ethnic “one drop” population (Hitlin et al. 2007; López, Vargas et al. 2018; Saenz and Morales 2015; Vargas et al. 2021).
Data and Methods
Add Health uses a multistage sample that began with a nationally representative sample of schools, from which it constructed a sampling frame of more than 100,000 students (Harris 2009). In the first wave of data collection in 1994 to 1995, the study administered “in-school” interviews with an original sample of 90,118 students when they were 11 to 20 years of age, along with in-home interviews in 1995 with a subsample of 20,745 students and 17,700 parents. The study returned to the in-home sample of students for four additional waves of interviews in 1996 (wave II), 2001 to 2002 (wave III), 2007 to 2008 (wave IV), and 2016 to 2018 (wave V) when respondents reached 33 to 43 years of age. In my analysis, I use Add Health’s restricted-use data from the wave I in-school panel; the wave I in-home panel; the wave I in-home parent panel; and the wave III, wave IV, and wave V in-home panels.
I matched Add Health respondents across these six panels into a combined sample with 91,040 unique respondents, including 16,030 respondents who ever identify as Latinx in any panel and 1,748 respondents who identify as Latinx on the combined race/ethnicity question in wave V, to which 1,293 identified as Latinx exclusively. To use measures of racial/ethnic consistency, I focus on the 19,990 respondents with at least one valid pair of racial self-classification information (i.e., nonmissing) across multiple panels. Within the valid-pairs sample, I construct two analytic subsets: (1) a Latinx sample of respondents who ever identify as Hispanic or Latinx and have valid responses for the wave V race question and (2) an evaluation sample composed of both Latinx and non-Latinx respondents with valid responses for the wave V race question.
I use the Latinx sample to examine who identifies as Latinx when a Latinx response is included in a combined race/ethnicity question (research question 1) and whether Latinx racial identification varies by national origins, ethnic context, social class, observed race, skin tone, and consistency of Latinx ethnic identification (research question 2), and I use the evaluation sample to compare different specifications of Latinx heterogeneity on how well they improve models for three social outcomes in U.S. population samples that also include Asians, Blacks, Native Americans, and Whites (research question 3).
Latinx Identification Analysis
Table 2 presents the key variables in my analysis of Latinx identification. To examine who identifies as Latinx on the combined question, I use a multinomial logistic regression model of the racial identification that respondents chose in wave V. I operationalize this dependent variable with a four-value measure: Latinx-only, a single non-Latinx race, Latinx Multiracial (i.e., identifying as Latinx and one or more non-Latinx categories), and non-Latinx Multiracial (i.e., identifying with multiple non-Latinx categories). Because the majority of respondents identify by Latinx-only, I use that category as the reference category, consistent with Campbell and Rogalin (2006).
Descriptive Statistics for Latinx Identification Analysis.

Source: National Longitudinal Study of Adolescent to Adult Health restricted-use data.
Note: The analytic sample is the Latinx sample: ever-Latinx respondents with at least one valid pair of racial self-classification information across waves I to V. National origin, observed race, and non-Latinx racial self-classification are based on consistent and exclusive answers across multiple panels for each respondent. GED = General Educational Development; HS = high school; PI = Pacific Islander.
As independent variables, I include measures of individual demographic characteristics such as national origin, acculturation, proportion of Latinx students in respondents’ schools, proportion of Latinx neighbors in respondents’ communities, and region of the country. Following Campbell and Rogalin’s (2006), I expect a higher likelihood of identifying as Latinx-only among respondents who report national origins in Mexico and Puerto Rico, who come from homes with a non-English dominant language, and who attend schools and live in communities with higher proportions of Latinxs (controlling for region). Regarding national origins, I categorize respondents as Mexican if they consistently and exclusively identified as Mexican/Mexican American or Chicano/Chicana across multiple panels, as Cuban if they consistently and exclusively identified as Cuban, as Puerto Rican if they consistently and exclusively identified as Puerto Rican, as Central/South American if they consistently and exclusively identified as Central or South American, and as multiple, changed, or other (MCO) Latin American for the remainder. I also include age, 5 gender, educational attainment, and current Latinx partner, to replicate Campbell and Rogalin’s analysis.
I expand their analysis with measures of Latinx heterogeneity. For observed race, I construct a measure from the wave I, wave III, and wave IV in-home panels, while addressing Add Health’s omission of the “other race” option after wave I. I classify respondents’ observed race as White, Black, Asian American, or Native American if their interviewers consistently classified them as such, across all three panels. I classify respondents’ observed race as “other race” if they were classified as such in wave I or if their classifications showed any inconsistencies across the three panels. For skin tone, I use the wave III variable that reports interviewers’ classifications of respondent skin color as “black,” “dark brown,” “medium brown,” “light brown,” and “white.” 6
Evaluation of Latinx Specifications
To compare different measures of Latinx identification, I use 10 race/Latinx specifications: (1) the official Add Health race specification; (2) the “best race” specification; (3) the entirely consistent, ever-Latinx (ECEL) specification; (4) the entirely consistent, Latinx-only (ECLO) specification; and (5–10) six additional specifications that combine (a) either the ECEL specification or the ECLO specification and (b) one of three measures of Latinx heterogeneity: observed race, skin tone, and inconsistent Latinx identification (e.g., the ECEL specification supplemented with observed-race measures).
The first two specifications are commonly used methods for classifying Multiracial respondents in Add Health (Shiao 2019). Because they use a single panel to classify each respondent’s race, they include inconsistent Latinx identifiers among both their Latinx and non-Latinx respondents. In contrast, the ECEL and ECLO specifications use racial/ethnic information from multiple panels to separate inconsistent identifiers from consistent identifiers.
The official Add Health specification is a variable supplied with the wave I in-home data. If respondents answer the Latinx-ethnicity question “yes,” they are classified as Latinx regardless of their answer to the race question. Among the remaining respondents, if they mark Black or African American in the race question, they are classified as Black, even if they mark another racial category. This procedure is then repeated with the remaining respondents in the following order: Asian, Native American, Other, and White, that is, a sequential one-drop specification that reduces the White subsample to those who exclusively mark “White” on the race question. I implement a variant of this specification by applying these procedures to the largest panel, the wave I in-school data.
Similarly, the “best race” specification sets aside respondents who answer the Latinx-ethnicity question “yes,” before applying a “best race” question that was asked to respondents about the “one category [that] best describes your racial background” if they answered the race question with multiple non-Latinx responses. As this question does not appear in the in-school data, I construct the variable for this specification using the wave I in-home data.
I base the ECEL and ECLO specifications on Shiao’s (2019) entirely consistent specification, which creates a separate category for MCO race identifiers and reserves the remaining racial categories for respondents who consistently and exclusively marked that category across panels. It uses a two-stage procedure for combining the race and Latinx-ethnicity questions across multiple panels. First, respondents are classified within each panel as Asian American, Black, Latinx, Native American, White, other race, and multiple races, by setting aside those who answer “yes” to the Latinx-ethnicity question and placing the remaining non-Latinx, multiple-race responders into a separate category. Second, respondents are reclassified to a MCO racial category if they are classified as multiple-race responders in any panel or if they change their responses between any panels. That said, because Shiao did not use the wave V panel, the only Latinx Multiracials in his MCO category are the inconsistent Latinx identifiers.
Accordingly, I extend Shiao’s exact procedures to include the wave V panel for the ECEL specification. This treats any Latinx response on the wave V combined race/ethnicity question as equivalent to a “yes” on the Latinx-ethnicity question. In contrast, for the ECLO specification, I take advantage of the inclusion of the Latinx response on the combined question and reclassify respondents who identify as Latinx Multiracials from the Latinx category to the MCO category. Whereas the Latinx category in the ECEL specification includes Multiracials if they consistently answer “yes” to the Latinx-ethnicity question, the Latinx category in the ECLO specification is restricted to consistent Latinx-only identifiers.
I also modify the ECEL and ECLO specifications with three sets of measures for Latinx heterogeneity. The observed-race measures modify the base specification (i.e., ECEL or ECLO) by dividing its Latinxs into three subcategories using respondents’ observed race in waves I, III, and IV: White Latinxs who were consistently observed as White, Black Latinxs who were consistently observed as Black, and other Latinxs for the remaining Latinxs who were observed inconsistently or as other race, Asian, and Native. In models, I include indicator variables for White Latinxs and Black Latinxs, so that the main Latinx category represents other Latinxs.
Similarly, the skin-tone measures modify the base specification (i.e., ECEL or ECLO) by dividing its Latinxs into three subcategories using respondents’ observed skin tone in wave III: white-skinned Latinxs who were observed to have “white” skin, dark-skinned Latinxs who were observed to have dark brown or “black” skin, and brown-skinned Latinxs who were observed to have light brown or medium brown skin. I include indicator variables for white-skinned Latinxs and dark-skinned Latinxs, so that the main Latinx category represents brown-skinned Latinxs.
Third, the national-origin measures modify the base specification by dividing its Latinxs into three subcategories using respondents’ Latinx backgrounds in waves I, III, and IV: (1) consistent and exclusive Cubans, (2) consistent and exclusive Puerto Ricans, and (3) other Latin American for the remaining Latinxs who reported inconsistent or any other backgrounds. I include indicator variables for Cubans and Puerto Ricans, so that the main Latinx category represents other Latin American origins (i.e., predominantly Mexican).
When combined with the ECEL specification, the Latinx-heterogeneity measures model heterogeneity among consistent Latinx identifiers regardless of whether they identify as Latinx-only or Latinx Multiracials in wave V, whereas when combined with the ECLO specification, the Latinx-heterogeneity measures model heterogeneity among the Latinx-only respondents alone. In other words, if the ECLO specification is preferred to the ECEL specification, then a certain measure of Latinx heterogeneity is more consequential among Latinx-only identifiers than among all consistent Latinxs, whereas if the ECEL specification is preferred, then a certain measure of Latinx heterogeneity is consequential for both Latinx-only identifiers and Latinx Multiracials.
Outcome Variables, Covariates, and Evaluation Strategy
To compare the modeling consequences of different Latinx specifications, I consider two racial stratification outcomes and one interracial-contact outcome: educational attainment, self-rated health, and interracial dating history. Education is an important component of racial stratification (Wilson 1980), a critical consequence of which are racial disparities in health (Bratter and Gorman 2011; Williams and Sternthal 2010), whereas interracial relationships are an important indicator of social contact across the boundaries that divide individuals into groups (Kao, Joyner, and Balistreri 2019). In the sociology of Latinx Americans, researchers have found national-origin inequalities in all three domains, which they attribute to (1) differential discrimination against different distributions of racial appearance, most notably among Cubans versus among other Latinx ethnicities, and (2) ethnic differences in group size which affects the availability of coethnic partners (Saenz and Morales 2015).
To measure educational attainment after wave I, I used Add Health’s question on highest degree completed in wave V, supplemented by corresponding questions in waves III and IV if the wave V information was unavailable. I reduced the options to four ordinal categories: postgraduate degree, bachelor’s degree only, high school degree or General Educational Development diploma only, and less than high school. To measure self-rated health after wave I, I used Add Health’s questions in wave V, or if unavailable, the corresponding questions in waves III and IV, and I used their original, five ordinal categories: excellent, very good, good, fair, and poor. Self-rated health has been found to be a persistent predictor of mortality even after nonsubjective measures of health have been included in the same models (Jylhä 2009). To measure interracial dating, I combined Add Health’s inventory of post–wave I “romantic relationships” in wave III; its wave IV inventory of marriages, cohabitation partners, unions resulting in pregnancy, current partners, and partners since 2001 (approximately wave III); and its wave V questions about current partners. I operationalize interracial relationship history as ever having a different-race partner in wave III, IV, or V.
For each outcome, I estimate 10 models, each combining a distinct race/Latinx specification with a shared set of covariates used in research on race specification to control for group differences in age, gender, natal family structure (married parents), socioeconomic status (parental education), acculturation (dominant language at home), religion (any affiliation), and region (Howell and Emerson 2017; Kramer, Burke, and Charles 2015).
To evaluate the specifications, I use a variation of Guluma and Saperstein’s (2022) approach to comparing different racial specifications on their effectiveness in modeling racial stratification. I use two model-fit criteria, the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), to make comparisons between (1) the non-nested specifications (e.g., the official Add Health specification and the ECLO specification) and (2) the nested specifications (e.g., the ECLO specification without Latinx-heterogeneity measures and the ECLO specification with the skin-tone measures). Both the AIC and BIC are penalized likelihood model selection criteria that are intended to estimate, respectively, how closely a model comes to the true model (AIC) and how likely a model is the true model (BIC), penalized by its number of variables, with a lower or smaller score indicating a better model for both criteria. As a threshold for preference, I use a difference of 7 points for comparing among AIC and among BIC; specifically, a model is preferred over another if its AIC or BIC is at least 7 points lower than another model’s. This threshold is at the upper bound of what Burnham and Anderson (2004) characterized as “considerably [more] support” for AIC scores and solidly within the range of what Raftery (1995) characterized as “strong” evidence for BIC scores.
Limitations
I recognize that Add Health has limitations that reduce the conclusiveness of my analysis. First, Add Health is a cohort study, which limits its generalizability to cohorts that experienced distinct racial socialization because of historical context. Also, despite the presence of racial/ethnic questions in multiple panels, Add Health has asked the combined race/ethnicity question only once and during the Trump era, limiting my confidence that Latinx-only identification is stable. Third, Add Health’s measures of observed race exclude the other-race response after wave I and do not allow a Latinx response, reducing the quality of these measures. In addition, Add Health asks interviewers to answer this question immediately after asking respondents for their racial/ethnic self-classifications, potentially undermining its instruction for interviewers to classify race on appearance alone. Fourth, Add Health’s sole measure of skin tone in wave III uses color-coded response categories instead of the usual labels of very light, light, medium, dark, and very dark in text-based measures (Campbell et al. 2020). In particular, its use of white instead of very light and black instead of very dark may reinforce the association of the skin tones at the extremes with the eponymous racial categories and bias interviewers’ skin tone ratings, especially for White and Black interviewers.
Results of Latinx Identification Analysis
Table 2 shows the unweighted means of key variables in the Latinx identification analysis. Relative to Campbell and Rogalin’s (2006) study, my sample has fewer respondents who identified as Latinx-only on the combined race/ethnicity question in wave V (57 percent vs. 73 percent), a similar percentage who identified with a single non-Latinx race (21 percent vs. 18 percent), and more who identified with multiple races (22 percent vs. 9 percent). My sample is also more educated, is more connected to Latinx communities, and has fewer Mexicans and more Cubans. These differences can be attributed to study design: Add Health is a cohort study comparable with the youngest cohort in their sample and also includes an oversample of Cuban adolescents in its original sampling frame.
In terms of racial appearance, nearly half of my sample’s respondents were classified by Add Health interviewers as White for race (49 percent) and “white” for skin tone (49 percent), whereas fewer than a quarter (22 percent) consistently self-classified as White on the non-Latinx race questions prior to wave V. In comparison, interviewers classified a third of respondents inconsistently or as other race in wave I (34 percent), whereas more than two-thirds of respondents self-classified inconsistently, as other race, or by multiple races (69 percent).
The table also shows the subgroup means of key variables by respondents’ wave V racial identifications. Latinx-only identifiers and Latinx-Multiracial identifiers are more educated, connected to Latinx communities, and Cuban. Both non-Latinx single-race identifiers and non-Latinx Multiracial identifiers are more likely to be classified by interviewers as Black for race, but only non-Latinx single-race identifiers are more likely to self-classify as Black. Last, a full quarter of respondents identify as non-Latinx in one or more earlier panels (i.e., inconsistent Latinx identification), including 86 percent of single-race non-Latinx identifiers and 92 percent of non-Latinx Multiracial identifiers versus only 2 percent of Latinx-only identifiers and 15 percent of Latinx Multiracial identifiers.
Table 3 shows the results of the regression models that replicate Campbell and Rogalin’s (2006) analysis and add measures of Latinx heterogeneity. Model 1 largely confirms Campbell and Rogalin’s findings that connections to Latinx communities and Mexican and Puerto Rican origins are important for understanding patterns of Latinx identification. 7 These patterns also hold for models 2 to 4 which add measures of observed race, observed skin tone, and inconsistency in Latinx self-classification, respectively. Model 2 shows that consistently being observed as Asian, Black, or White reduces the likelihood of Latinx-only identification in wave V. Model 3 shows that relative to having a medium brown skin tone, white skin increases the likelihood of identifying as Latinx Multiracial, light brown skin tone increases the likelihood of identifying as Latinx-only, and dark brown and black skin tones decrease the likelihood of identifying as Latinx-only. Notably, unlike dark brown and black skin, white skin does not significantly increase the likelihood of non-Latinx identification, whereas black skin uniquely increases the likelihood of non-Latinx Multiracial identification.
Racial Identification in Wave V among Ever-Latinx Respondents (Excluded Outcome: Latinx-Only).

Note: AIC = Akaike information criterion; BIC = Bayesian information criterion; CRR = Campbell and Rogalin replication; C/S = Central/South; GED = General Educational Development; HS = high school.
p < .05. **p < .01. ***p < .001 (two-tailed tests of statistical significance).
All three Latinx-heterogeneity models show better fit values than model 1, 8 but the best fit by far is for model 4, which shows that the quarter of respondents who inconsistently identify as Latinx are more likely to identify as Latinx Multiracial than as Latinx-only and even more likely to identify as non-Latinx in wave V. This suggests that Latinx-only identification on the combined question can provide an approximation of consistent Latinx identification when researchers do not have multiple measures of self-classification for the same respondents. In sum, Latinx heterogeneity affects whether respondents identify as Latinx-only in the combined question, which is more likely for those with light brown and medium brown skin tones, who are not consistently classified by interviewers as Asian, Black, or White, and who consistently identified as Latinx in Latinx-ethnicity questions.
Results of Latinx Specification Evaluation
Table A1 in the Appendix shows the unweighted means of select variables, along with group means defined using the ECLO specification. The average educational attainment for respondents is between high school only and bachelor’s only (i.e., between 1.00 and 2.00) for the full education sample and every racial grouping except Native Americans, for whom the average is just below high school only (0.93). The average health rating is between good and very good (i.e., between 3 and 4) for the full health sample and every racial grouping. The mean proportion who dated interracially is 47 percent, with wide variation by race: 29 percent for Whites, 31 percent for Blacks, 48 percent for Latinxs, 55 percent for Asians, 83 percent for Natives, and 97 percent for Multiracials. Across the three outcomes, the means for key covariates are highly similar, including for their respective racial groups.
Table 4 examines which race/Latinx specifications have better fit values for each outcome. Each pair of AIC and BIC values in the table represent a multilevel, mixed-effects logit model for a specific outcome. Each column presents the minimum AIC and BIC values for an outcome and the deviations of the remaining models from that value. Consistent with Shiao (2019), the AIC and BIC values agree that the “best race” specification provides the worst fit for every outcome (i.e., in dashed boxes) among the 10 alternative models in its column. In addition, the other specification that ignores Latinx inconsistency (i.e., the official Add Health specification) provides the second worst fit among the four models without the measures for Latinx heterogeneity (i.e., the “None” rows). In brief, the better models for all three outcomes separate the consistent Latinx identifiers from the inconsistent Latinx identifiers, indicating that Latinxs who do not consistently identify as Latinx have experiences of racial stratification and interracial contact that are distinct from those of consistent Latinx identifiers.
Fit Criteria across Race/Latinx Specifications in Models Estimating Three Outcomes.

Note: The analytic sample is the evaluation sample: Latinx and non-Latinx respondents with at least one valid pair of racial self-classification information across waves I to V. Each AIC and BIC pair represents a multilevel, mixed-effects logit model. For each outcome, each column presents the full fit value for the row model with the minimum AIC and BIC (in boldface type) and the deviations of other models from that value. Triangulating AIC and BIC, the best fits for each outcome are in solid boxes, and the worst fits are in dashed boxes. Add Health = National Longitudinal Study of Adolescent to Adult Health; AIC = Akaike information criterion; BIC = Bayesian information criterion.
For one outcome (i.e., any interracial dating), the AIC and BIC converge decisively on the ECLO specification with the national-origin measures as providing the best-fitting model. In addition, these values categorically prefer the models using the ECLO specification that restricts Latinx to Latinx-only identifiers over the models using the ECEL specification that includes both Latinx-only and Latinx Multiracial identifiers as Latinx.
For the other outcomes, the AIC and BIC values show less convergence. For educational attainment, the model with the minimum AIC (21,715) uses the ECEL specification with the skin-tone measures. This model has a BIC that is only +4 points worse than the model with the minimum BIC, which, however, has an AIC that is +11 points worse than the model with the minimum AIC. A third model has an AIC only +3 worse and a BIC only +4 worse (“+8” in the table) than the respective values for the minimum-AIC model; like the latter, the third model also includes the skin-tone measures but with the ECLO specification.
For self-rated health, there is a similar albeit inverted pattern: The model with the minimum BIC (30,117) uses the ECLO specification with no measure for Latinx heterogeneity and has an AIC only +4 points worse than the two skin-tone models with the minimum AIC; however, the latter models have BICs +10 and +11 worse than the minimum-BIC model. 9 For both education and health outcomes, the AIC values prefer the models using skin tone, whereas the BIC values prefer the models that omit measures of racial appearance as well as national origin. 10
An important finding in Table 4 is that the addition of the observed-race measures never produces a best-fitting model on any of the outcomes. For example, in models of education, adding observed race to the ECLO specification actually worsens both the AIC by +3 (from +10 above the minimum AIC to +13 in that column) and the BIC by +17 points. Their addition typically fails to improve the AIC while worsening the BIC, similar to the addition of national-origin measures in the education and health models and the addition of skin-tone measures in the interracial dating models. This finding is somewhat at variance with recent findings that Latinxs’ street race is associated with variations in mental health and discrimination experiences (López, Vargas et al. 2018; Vargas et al. 2021); however, it is consistent with Feliciano’s (2016) finding that racialized responses to skin tone provide the primary component of racial-appearance heterogeneity among Latinxs.
I use these AIC and BIC patterns to identify an Occam’s window or subset of better models (Raftery 1995) for focusing my multimodel examination of different race/Latinx specifications and their consequences. Table 5 highlights the main differences between the best and worst fitting models of each outcome, by comparing select parameter estimates across the same four specifications:
the universally worst fitting “best race” specification;
the ECLO specification with national-origin measures, which provides the best fit for modeling interracial dating;
the ECLO specification with the skin-tone measures, which has the second smallest AIC (21,718 [“+3” in Table 5]) and the third smallest BIC (21,880 [“+8” in Table 5]) for educational attainment; and
the ECLO specification with no Latinx-heterogeneity measures, which has the second smallest AIC (29,963 [“+4” in Table 5]) and the smallest BIC (30,117) for health.
Selected Parameter Estimates of Three Outcomes in Log Odds, across Four Selected Race/Latinx Specifications.
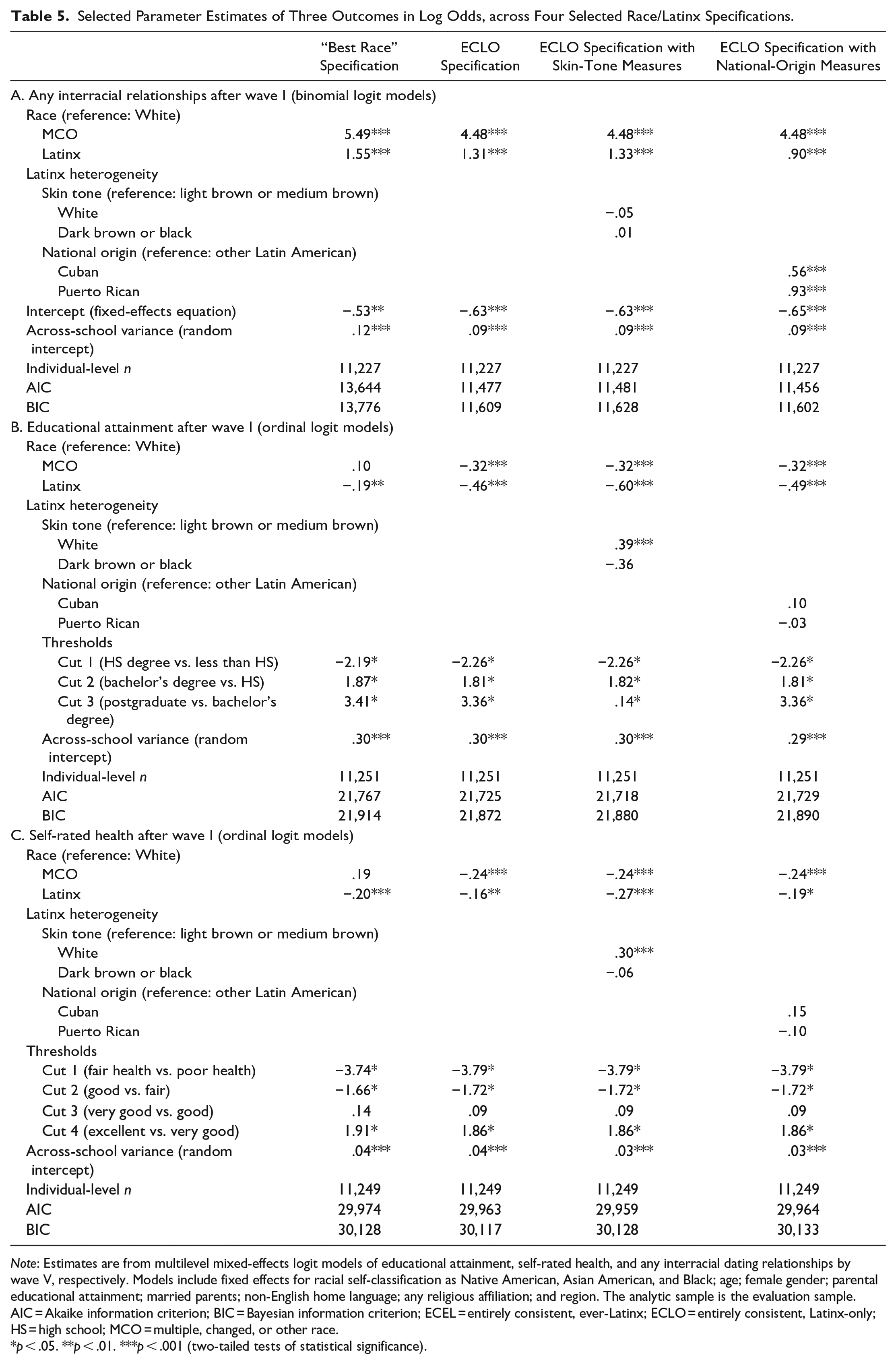
Note: Estimates are from multilevel mixed-effects logit models of educational attainment, self-rated health, and any interracial dating relationships by wave V, respectively. Models include fixed effects for racial self-classification as Native American, Asian American, and Black; age; female gender; parental educational attainment; married parents; non-English home language; any religious affiliation; and region. The analytic sample is the evaluation sample. AIC = Akaike information criterion; BIC = Bayesian information criterion; ECEL = entirely consistent, ever-Latinx; ECLO = entirely consistent, Latinx-only; HS = high school; MCO = multiple, changed, or other race.
p < .05. **p < .01. ***p < .001 (two-tailed tests of statistical significance).
Panel A reports estimates of any interracial relationships after wave I and shows that the ECLO specification with national-origin measures adds a critical finding: both Cubans and Puerto Ricans are more likely than other Latinxs to date non-Latinxs, though all Latinxs are more likely to date interracially than Whites. Notably, the skin-tone measures do not reveal significant Latinx heterogeneity, suggesting that ethnic identification and group size at the national-origin scale are more salient for this outcome (Kao et al. 2019; Saenz and Morales 2015).
Panel B in Table 5 reports estimates of educational attainment after wave I and shows that the “best race” specification underestimates the lower likelihood of educational attainment associated with Latinxs relative to Whites while also missing the lower likelihood associated with Multiracial respondents. In particular, using the “best race” specification would hide how white-skinned Latinxs have a higher likelihood of educational attainment than brown-skinned and dark-skinned Latinxs. Panel C reports estimates of self-rated health after wave I and shows similar patterns to educational attainment: the “best race” specification hides how white-skinned Latinxs have roughly the same health outcomes as Whites and underestimates the worse health of brown-skinned and dark-skinned Latinxs while again missing the poorer health outcomes associated with Multiracials. Notably, in panels B and C, the national-origin measures do not reveal significant Latinx heterogeneity, which is consistent with researchers’ attribution of ethnic inequalities among Latinxs to aggregate variations in skin-tone discrimination (Saenz and Morales 2015).
In sum, I find that the better specifications for modeling Latinx heterogeneity depend on the outcome in question, with a primary divide between outcomes that vary by skin tone and the outcome that varies by national origin. Furthermore, I find that the worst-fitting “best race” specification, which uses the separate race and ethnicity questions from a single panel, deflates estimates of Latinx disadvantage in models of racial stratification while inflating estimates of Latinx participation in interracial dating. This suggests that consistent Latinx-only identifiers have distinct experiences of racial stratification and social contact from other Latinx Americans.
Conclusions
Using Add Health to explore patterns in Latinx identification, I have examined Latinx heterogeneity in racial self-classification and its consequences for modeling three outcomes: educational attainment, self-rated health, and interracial dating. My analysis suggests that quantitative researchers should operationalize Latinxs using measures that recognize a modal group of Latinx-only identifiers while capturing heterogeneity by skin tone and national origin across the broader ever-Latinx population. In my analysis of who identifies as Latinx on a combined race/ethnicity question, I have confirmed Campbell and Rogalin’s (2006) findings that connections to Latinx communities and Mexican and Puerto Rican national origins are associated with who self-classifies as Latinx-only. In addition, I find that Latinx-only identification is associated with certain aspects of Latinx heterogeneity: light brown and medium brown skin tones, not being consistently observed as Asian, Black, or White, and consistent self-classification as Latinx in earlier panels.
My results support Feliciano’s (2016) argument that non-Latinx Americans regard “Latinx” as a distinctive racial category that is associated with a phenotype defined by intermediate skin tones. My results also suggest that white-skinned and dark-skinned Latinxs recognize that they do not fit the expected phenotype of being Latinx and may instead self-classify as Latinx Multiracials and even as non-Latinxs. In particular, black-skinned Latinx are the most likely to self-classify as non-Latinx, whereas white-skinned Latinx are more likely to self-classify as Latinx Multiracial but not more likely to identify as non-Latinx than medium-skin toned Latinx. In brief, white-skinned Latinx may experience more social permission to identify as Latinxs than their dark-skinned counterparts, though it is not known how much this permission comes from other Latinxs versus non-Latinxs.
In my analysis of the consequences of different race/Latinx specifications for modeling three social outcomes, I find that the association of Latinx identification with skin tone affects models of educational attainment and self-rated health, that is, processes of racial stratification. However, this association does not significantly affect models of interracial dating, that is, processes of interracial contact. Whereas the negative consequences of being Latinx for education and health are attenuated for white-skinned Latinxs, the relatively high participation of Latinxs in interracial dating is concentrated among not specific skin tones but rather specific national origins (i.e., Cubans and Puerto Ricans).
Furthermore, the AIC and BIC values for the interracial dating models clearly prefer the ECLO specification, which restricts Latinxs to Latinx-only identifiers, over the ECEL specification, which also includes Latinx Multiracials as Latinxs. This suggests that national-origin heterogeneity is stronger among Latinx-only identifiers than among Latinx Multiracials, at least for the processes of interracial contact. In contrast, the model fit values for the racial stratification outcomes do not prefer either ECLO or ECEL to each other and only prefer them to the official Add Health and “best race” specifications. In other words, skin-tone heterogeneity characterizes the experiences of both Latinx-only identifiers and Latinx Multiracials. In sum, specifying Latinxs as consistent Latinx identifiers divided by skin tone improves models of racial stratification, whereas models of interracial contact are improved by specifying Latinxs as consistent Latinx-only identifiers divided by national origin.
These findings have implications for racial/ethnic data collection. The primary value of continuing to ask the separate race and Latinx-ethnicity questions is the collection of data on how Latinxs choose racial self-classifications from among non-Latinx categories, a measurement that is arguably not comparable with the equivalent racial self-classifications of non-Latinxs (e.g., White Latinxs vs. non-Latinx Whites). In contrast, the combined race/ethnicity question allows researchers to directly compare the salience of the Latinx label with the salience of the remaining race labels for Latinxs and to discern Multiracial from Monoracial Latinxs, while still collecting their sub-Latinx ethnic or national origin backgrounds. An even better measurement of Latinx identification would supplement the combined question with questions on racial appearance, such as a question on skin tone, which would render unnecessary the questionable use of self-classified race, or even reflected race (i.e., street race), as a proxy for Latinx racial appearance. 11 Last, if the data collection were longitudinal, researchers could assess consistency in identification by collecting repeated measures of the combined question on the same respondents. Absent repeated measures, one cross-sectional alternative would be to include an ancestry question, as a proxy for ever-Latinxs who racially identify as non-Latinx (Emeka and Vallejo 2011).
My findings also have implications for future research on Latinx Americans. First, the analysis confirms the common assumption that skin-tone heterogeneity contributes to the inequalities observed among Latinxs (1) of different national origins and (2) who self-classify as White, as Black, and as Some Other Race (LaVeist-Ramos et al. 2012; Saenz and Morales 2015), which raises the question of who self-classifies as non-Latinx among Latinxs with the same skin tone. Relatedly, if skin-tone discrimination is an unobserved component of racial stratification among Latinxs, it may confound findings of intersectional inequality using data sets without skin-tone measures (e.g., López, Erwin et al. 2018). For example, in the case of race and gender intersectionality, are the social effects of being Latinx and having darker skin tone equally gendered, or is the Latinx effect similar across gender whereas skin-tone effects primarily affect women? In brief, how much does intersectional inequality depend on skin tone reception as a mechanism? Third, if consistency in identification indicates a significant divide among Latinxs, this raises the question of why some consistently identify as Latinx whereas others do not (e.g., Latinx Multiracial identifiers vs. part Latinxs who identify as non-Latinx). Is consistent identification primarily a function of the same determinants of Latinx racial identification (i.e., skin tone reception, national origin, and connection to Latinx communities), or might it also depend on reciprocal feedback from the “outcomes” of racial stratification and interracial contact (Saperstein and Penner 2012)?
In sum, my findings illustrate what we might term the hypersituational salience of Latinx identification. Similar to Latinx Americans, most Asian Americans experience the classic situational salience of expecting non-Asians to treat them as “Asians” 12 and other Asians to interact with them along ethnic boundaries. However, racial appearance also moderates whether Latinxs can expect non-Latinxs, or even other Latinxs, to treat them as Latinxs or rather as Whites or Blacks. In brief, racial appearance may segment Latinxs’ sense of reflected race (Figure 1) with further consequences for Latinx identification.
That said, Latinxs continue to define their in-group along sub-Latinx ethnic boundaries (e.g., Cuban vs. Mexican). Even though skin tone significantly influences how they fare in processes of racial stratification, it has not replaced the influence of ethnicity on their participation in interracial contact. When coethnic dating partners are less available (Saenz and Morales 2015), rather than regard other Latinxs as equivalent to their ethnic group (i.e., their known ancestry), they may prefer non-Latinx partners over partners from other Latinx ethnicities. Furthermore, if distinct national-origin Latinxs are behind their relatively high rates of intermarriage with both Whites and Blacks (Saenz and Morales 2015), then the potential for Latinxs to bridge White and Black social networks may be an artifact of statistical aggregation, unless they actually have pan-Latinx networks. My findings show qualified support for the racialized assimilation thesis that Latinxs are both transforming and reinforcing U.S. racial boundaries (Golash-Boza and Darity 2008), with the caution that its proponents should not overlook the complex intersection of segmented Latinx racialization with sub-Latinx ethnicity. Not only are Latinxs a heterogeneous population, but different aspects of their heterogeneity matter for different social processes, making Latinx identification a more complex “choice” than simply whether to resist panethnic lumping.
Footnotes
Appendix
Descriptive Statistics for Latinx Specification Evaluation.
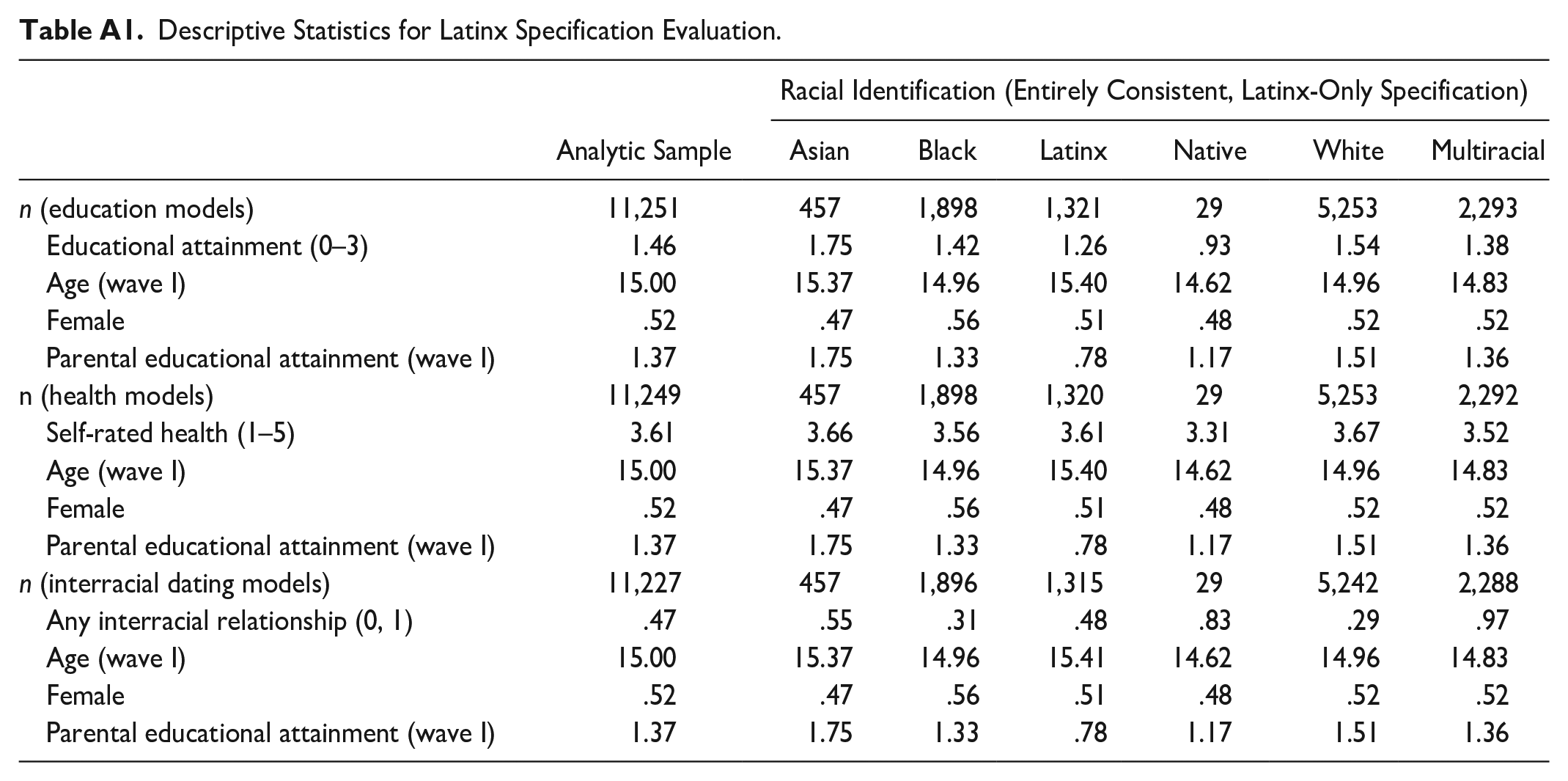
| Analytic Sample | Racial Identification (Entirely Consistent, Latinx-Only Specification) | ||||||
|---|---|---|---|---|---|---|---|
| Asian | Black | Latinx | Native | White | Multiracial | ||
| n (education models) | 11,251 | 457 | 1,898 | 1,321 | 29 | 5,253 | 2,293 |
| Educational attainment (0–3) | 1.46 | 1.75 | 1.42 | 1.26 | .93 | 1.54 | 1.38 |
| Age (wave I) | 15.00 | 15.37 | 14.96 | 15.40 | 14.62 | 14.96 | 14.83 |
| Female | .52 | .47 | .56 | .51 | .48 | .52 | .52 |
| Parental educational attainment (wave I) | 1.37 | 1.75 | 1.33 | .78 | 1.17 | 1.51 | 1.36 |
| n (health models) | 11,249 | 457 | 1,898 | 1,320 | 29 | 5,253 | 2,292 |
| Self-rated health (1–5) | 3.61 | 3.66 | 3.56 | 3.61 | 3.31 | 3.67 | 3.52 |
| Age (wave I) | 15.00 | 15.37 | 14.96 | 15.40 | 14.62 | 14.96 | 14.83 |
| Female | .52 | .47 | .56 | .51 | .48 | .52 | .52 |
| Parental educational attainment (wave I) | 1.37 | 1.75 | 1.33 | .78 | 1.17 | 1.51 | 1.36 |
| n (interracial dating models) | 11,227 | 457 | 1,896 | 1,315 | 29 | 5,242 | 2,288 |
| Any interracial relationship (0, 1) | .47 | .55 | .31 | .48 | .83 | .29 | .97 |
| Age (wave I) | 15.00 | 15.37 | 14.96 | 15.41 | 14.62 | 14.96 | 14.83 |
| Female | .52 | .47 | .56 | .51 | .48 | .52 | .52 |
| Parental educational attainment (wave I) | 1.37 | 1.75 | 1.33 | .78 | 1.17 | 1.51 | 1.36 |
Acknowledgements
I thank Aaron Gullickson and the anonymous reviewers for valuable comments on earlier versions of this article. This research uses data from Add Health, funded by grant P01 HD31921 (Harris) from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD), with cooperative funding from 23 other federal agencies and foundations. Add Health is currently directed by Robert A. Hummer and funded by the National Institute on Aging cooperative agreements U01 AG071448 (Hummer) and U01AG071450 (Aiello and Hummer) at the University of North Carolina at Chapel Hill. Add Health was designed by J. Richard Udry, Peter S. Bearman, and Kathleen Mullan Harris at the University of North Carolina at Chapel Hill.
1
I use Latinx (and Latinxs) as gender-neutral alternatives to using the masculine Latino (and Latinos) to refer to the Hispanic/Latinx population; however, I recognize that most of this population, even in the United States, does not identify by Latinx. I also recognize that Latinx technically excludes people from Spain who are Hispanic but non-Latinx, but I prefer Latinx (and Latino) for its inclusion of Brazilians and other non-Spanish-speaking peoples who share a history of non-British colonization in the Americas.
2
I capitalize all racial categories to avoid naturalizing “whites” and “blacks.”
3
To elaborate, I conceptualize both race and ethnicity as social constructions that (1) involve political and cultural classifications of peoples based typically on physical features and putative ancestry, (2) become salient in interpersonal interactions between and among classified groups, and (3) are embedded in collective memory and institutional histories, rules, and practices (King and DaCosta 1996; ![]() ). Despite their analytic parallels and indistinct salience at the micro-level, they are often constructed in distinct ways at meso- and macro-levels, while also drawing on different constructions of ancestry “traced” to arbitrary places and times; for example, the same person can have ancestors who lived somewhere in Mexico after the U.S.-Mexican War, New Spain during the colonial period, China during the Yuan dynasty, and East Africa before human migration to other continents.
). Despite their analytic parallels and indistinct salience at the micro-level, they are often constructed in distinct ways at meso- and macro-levels, while also drawing on different constructions of ancestry “traced” to arbitrary places and times; for example, the same person can have ancestors who lived somewhere in Mexico after the U.S.-Mexican War, New Spain during the colonial period, China during the Yuan dynasty, and East Africa before human migration to other continents.
4
5
I treat age as a covariate because Campbell and Rogalin’s age finding was for those aged 60 to 90 years versus their younger cohorts, and Add Health is a cohort study whose respondents roughly correspond to their youngest cohort.
6
I explored the possible effects of interviewer race on observed race by comparing the subset of respondents who had Black interviewers in wave III and White interviewers in wave IV or vice versa, but I did not find significant differences in observed race between the Black and White interviewers in Add Health.
7
Some of my findings are consistent with theirs in direction but deviate in statistical significance. For example, in my analysis, having a Latinx partner is significantly associated with Latinx-only identification, whereas in theirs, having a Latinx spouse has a positive but nonsignificant effect.
8
The exception is the BIC value for model 3 (skin tone), which is worse than for model 1.
9
10
In further analysis (not shown), I explored whether supplementing the single-panel specifications of race (i.e., official Add Health and “best race”) with heterogeneity measures affects the AIC and BIC preference for the ECEL and ECLO specifications. In only one situation does adding a heterogeneity measure to a single-panel specification sufficiently improve a fit value to rival the value for the ECEL and ECLO specifications (i.e., models of health with the official Add Health specification with skin-tone measures, but in AIC only). In every other situation, the AIC and BIC continue to prefer the specifications that track consistency in Latinx identification over the single-panel specifications.
11
I recognize that street race is conceptualized as observed race, but its major proponents have actually measured it in terms of reflected race (López, Vargas et al. 2018; Vargas et al. 2021). Indeed, they acknowledge that respondents’ self-report of their “street race [as] White . . . may not necessarily actually represent how they are seen by ‘other Americans’” if their self-classification as White is a way of claiming American social belonging (López, Vargas et al. 2018:57).
12
Some notable exceptions are that South Asian Americans may expect non-Asians to treat them as a distinct category of Asians from other Asians and that Filipino Americans may expect non-Asians to treat them sometimes as Asians and other times as Latinx (Dhingra 2007; ![]() ).
).