
Abstract
In 2018, Silberzahn, Uhlmann, Nosek, and colleagues published an article in which 29 teams analyzed the same research question with the same data: Are soccer referees more likely to give red cards to players with dark skin tone than light skin tone? The results obtained by the teams differed extensively. Many concluded from this widely noted exercise that the social sciences are not rigorous enough to provide definitive answers. In this article, we investigate why results diverged so much. We argue that the main reason was an unclear research question: Teams differed in their interpretation of the research question and therefore used diverse research designs and model specifications. We show by reanalyzing the data that with a clear research question, a precise definition of the parameter of interest, and theory-guided causal reasoning, results vary only within a narrow range. The broad conclusion of our reanalysis is that social science research needs to be more precise in its “estimands” to become credible.
Keywords
Introduction
Are scientific findings credible? Basically, there are two approaches for answering this question. First, one might try to replicate findings. If findings can be successfully replicated, they are credible (valid). This approach has been implemented in various disciplines over the last decade with several large-scale replication audits. Results were quite discomforting in that the audits reported an unexpectedly low replication rate (e.g., see Begley and Ellis 2012; Camerer et al. 2018; Christensen and Miguel 2018; Open Science Collaboration 2015). Across scientific disciplines, this has led to what is known as the “credibility crisis in science.”
A second approach, which has been used less often, is the crowdsourcing approach: Several researchers analyze the same research question with the same data (for a review, see Uhlmann et al. 2019). Science is credible if different researchers come up with a similar answer (this idea can already be found in Merton 1973; Popper 1959). A recent crowdsourcing study was the “many analysts, one data set” project of Silberzahn and colleagues (2018a; hereafter, crowdsourcing initiative [CSI]). In this project, 29 teams analyzed the same research question on racial bias in soccer with the same data. The result was that the answers to the research question given by the 29 teams differed extensively. The authors concluded: “Any single team’s results are strongly influenced by subjective choices during the analysis phase. . . . Taking any single analysis seriously could be a mistake” (Silberzahn and Uhlmann 2015:191). They warned the public and politicians against trusting the results of single social science studies.
The CSI has had a huge impact. It seems to be a standard reference when discussing the (low) credibility of social science research with observational data (see e.g., Damian, Meuleman, and van Oorschot 2019; Reed 2019; Young 2018). Many, especially in media articles and Internet discussions, even concluded that the social sciences may not be rigorous enough: Findings depend to a large extent on who did the research.
Sociology has been quite absent from discussions about a credibility crisis, which is probably mostly due to a lack of evidence on reproducibility (Freese and Peterson 2017; Auspurg and Brüderl Forthcoming). So far, large-scale replication audits have focused on experimental studies published in other disciplines, such as medicine, psychology, and economics. This literature says little about the situation in sociology, in which most studies are based on observational data instead of experimental data. And here comes in the CSI project: It is based on observational data and uses a typical sociological research question on racial bias. Thus, it was the first large-scale study that directly speaks toward the credibility of standard sociological research. And as already mentioned, its results cast serious doubts on the credibility of social research with observational data.
Therefore, it is important to explore the sources for the huge variation in results found in the CSI project. In this article, we start such an investigation. Our main argument will be that the CSI used an unclear research question for the crowd. The teams had to make up their minds on how to interpret the research question. We identify (at least) four different interpretations made by the teams. Consequently, the teams implemented (at least) four different research designs. This produced much variation in the results: It is no wonder that results differ if researchers investigate different research questions.
To demonstrate this, we reanalyze the CSI data with one clear research question. We apply theory-guided causal reasoning to define the parameter of interest precisely. Nevertheless, we all know that social research with observational data is like a “garden of forking paths” (Gelman and Loken 2014). The way from the data to the results is long and needs many decisions. Even with a clear research question and theory-guided causal reasoning, several decisions may not be obvious. Thus, there is model uncertainty. To simulate this, we allow for a huge and systematic amount of model uncertainty that is implemented by means of a multiverse analysis (Steegen et al. 2016; also called multimodel analysis; Young and Holsteen 2017). We show that when estimating hundreds of different model specifications, there is variation in results, but within a much smaller range than found in the CSI.
Our main conclusion will be that the CSI did not “destroy” the credibility of sociological research in general: It only showed that nonrigorous social research may produce inconsistent results. We demonstrate that rigorous social research (based on a clear research question, a precise definition of the parameter of interest, and theory-guided causal reasoning) can be more consistent. Thus, to increase its credibility, sociological research must become more precise in its “estimands” (Lundberg, Johnson, and Stewart 2021).
The article proceeds as follows: In the following sections, we summarize the CSI, discuss its design, present our reanalysis (first our analytic design, then data and results), continue our reanalysis by applying sensitivity analysis, give a summary of our results, and provide a discussion of what we can learn from the CSI and our reanalysis regarding the credibility of sociology. We also offer some suggestions for improving the practice of social science research in general.
Many Hands Make Tight Work? Review of the CSI
In this section, we will shortly summarize the procedures and findings of the CSI (for a detailed description, see Silberzahn et al. 2018a). All researchers were asked to answer the same research question with the same data: Are soccer players with dark skin tone more likely to receive red cards from referees than players with light skin tone? The data were compiled by a sports-statistic company, with the sample being all soccer players in the 2012–2013 season in the first male leagues of four European countries (N = 2,034 players). Information about the interaction of those players with all referees (N = 3,147) whom they encountered across their professional career was obtained (until the time of data collection in 2014). The data were provided in an aggregated form with the single cases being dyads of the players and the referees (N = 146,028). Variables were the number of red and yellow cards the players received in these dyads and some characteristics of the players at the time of the data collection (e.g., their body weight, age, the club they were playing for). Information on the player’s skin tone was provided in the form of two independent ratings based on visual inspections of photographs of the players.
The 61 researchers (in 29 teams) that participated until the end of the CSI were recruited by an open call. There were not any restrictions regarding their qualification. Status groups ranged from bachelor’s students to full professors. Substantive backgrounds included sociology, psychology, and economics. The teams worked independently from each other, but there were also some crowd discussions on statistical models, and all teams received feedback from other teams, which was thought to mirror the standard peer-review process for journal publications.
The treatment variable was a 5-point scale ranging from 0 (very light skin) to 1 (very dark skin). The outcome was the likelihood of receiving a red card. Results were reported in odds ratios (ORs). The median OR was 1.31, meaning that players with very dark skin color, compared to players with very light skin color, had 31 percent higher odds of receiving a red card. This is a moderate association of skin color with red cards. Most teams reported results close to the median. But there were also teams that found no association at all or teams that found much stronger effect sizes, reaching up to nearly 200 percent higher odds reported by two “outlier” teams. The range of reported ORs was .9 to 2.9 (a kernel density plot of the estimates, excluding the outliers, is provided in Figure 2b). In addition, there was a large variance in the estimated standard errors, leading partly to different conclusions on statistical significance even when teams found similar effect sizes.
Thus, the main finding was a huge variation in the results produced by the different teams. Accordingly, the leading authors warned against relying on the analyses of one team only (as is standard in published research): The conclusions might depend to a large extent on who did the research.
Why Was the Variation of Results Obtained in the CSI so Large?
Silberzahn and colleagues (2018a) tried to explain the large variation in results by analyzing the impact of different classes of statistical models (e.g., ordinary least squares [OLS]/logit/Poisson regressions; Bayesian methods yes/no) and numbers of covariates that were used by the different teams. However, the attempts to explain the variance by these modeling choices were not very successful (see Silberzahn et al. 2018a, in particular Table 4 and Figure 2).
So what was the main driver of the inconsistency in results? Our conjecture is that it was the unclear research question given to the teams. In rigorous research, one would first give a precise statement of the research question and define the “parameter of interest” (the “theoretical and empirical estimands” as it is called by Lundberg et al. 2021). After that, one would apply relevant theories and causal reasoning to arrive at an identifying research design. With observational data, this would result in the specification of a statistical model including relevant control variables (confounders and mediators; see Elwert and Winship 2014; Kohler, Sweet, and Class 2018). We show in the following that there was no precise research question defined in the CSI. Consequently, each team had to come up with its own interpretation of the research task.
Recall the research task that was set in the CSI: to find out whether players with dark skin tone are more likely to receive red cards than players with light skin tone. How would you interpret this research task? In our opinion, this verbal statement of the research question is quite diffuse. After analyzing the reports submitted by the different teams in the CSI (Silberzahn et al. 2018b; available at https://osf.io/gvm2z), we conclude that in fact, there were at least four different interpretations.
The literal interpretation of the verbal statement is that the parameter of interest is the mean difference in the risk of red cards between dark- and light-skinned players. This is the bivariate association of skin tone and red cards. A simple bivariate analysis answers this descriptive research question, and one should not include any controls.
One might interpret the verbal statement also as a question about discrimination or racial bias. Then the parameter of interest is the direct causal effect of skin tone that remains after netting out confounders and “productivity-relevant” mediators. Discrimination in our context means that players are treated differently solely because of their race that is signaled by their skin tone (for a general review, see Pager and Shepherd 2008). Dark-skin players are more often punished with a red card than light-skin players, all else equal. To correctly estimate this direct skin tone effect, one has to partial out all alternative mechanisms that would be in line with equal treatment, such as player’s position, minutes played, or different baseline rates at which individual players commit fouls (for similar arguments for basketball research, see Price and Wolfers 2010). 1
Equations 1 and 2 formalize the research designs that correspond to the first two research questions (cf. Young and Holsteen 2017:19). The “treatment” variable (skin tone) is denoted with X, and Y is the dependent variable (red cards); i is an indicator for different games, and ε is an error term. The parameters of main interest are β and β*. β measures the bivariate association; β* measures the direct effect of X on Y.


The difference lies in the inclusion of controls
The unbiased estimation of the “discrimination effect”
Examples for mediators have been given before. In the case at hand, it is more difficult to imagine any confounders (i.e., variables that precede the skin tone and at the same time impact the likelihood of red cards). But there might be composition effects (i.e., variables that correlate with skin tone and affect the likelihood of red cards). For instance, age is certainly not an effect of skin tone (i.e., it is not a mediator), but it is correlated with skin tone due to the fact that dark-skin-toned players entered European soccer leagues increasingly in recent years. Composition variables such as age should also be controlled for.
One must not, however, include controls that lead to a backward causal link with the outcome variable because these controls induce a collider or endogenous selection bias (Elwert and Winship 2014; Young and Holsteen 2017:11). In the example at hand, such an endogenous variable could be the number of goals scored by the player. This is because soccer players who receive a red card are sent off for the rest of the game and are also suspended for the next game(s), shortening the possible time in which players can score goals.
The causal reasoning behind the two research questions is best represented graphically (Figure 1). Whereas the bivariate association is estimated without any controls (Figure 1a), the model specification for estimating the direct effect should include mediators (in black, solid arrows) as controls but not any colliders (in gray, dashed arrows; Figure 1b). The use of such causal diagrams is very helpful to specify and communicate the causal assumptions underlying the identification of the causal effect of interest (for details, see Elwert 2013).

Causal diagrams for two different research questions (RQs).
From the reports submitted by the different teams in the CSI (see the supplementary material in Silberzahn et al. 2018b), one can infer that some teams indeed tried to answer Question 1, whereas the majority of teams focused on Question 2. (We provide exemplary quotes on the teams’ research questions in Table A1 in the Supplemental Material.)
In addition, there were two further interpretations of the research question:
3. Some teams aimed at “Y-centered” research (Ganghof 2005), meaning they did not try at all to partial out the effect of skin tone on red cards. Instead, they focused on maximizing explained variance in Y (likelihood of red cards). Their motivation was to see whether skin tone is among the explaining factors. For this kind of research, covariate selection is based only on statistics of model fit (such as R2 values in regressions). Model fit is often increased in particular by the inclusion of endogenous covariates (colliders) that are not allowed in the X-centered causal research to answer Question 2 (Elwert and Winship 2014; Young and Holsteen 2017).
4. Finally, still other researchers chose an “exploratory” research strategy (for exemplary quotas, see Table A1 in our Supplemental Material). By this strategy, they wanted to get at novel, extreme, or unexpected findings. In the CSI, the researchers focusing on this research strategy seemed to be mostly motivated by the fact of being part of a crowd: Given this setting, they wanted to enlarge the pool of findings that were gathered by the crowd. Thus, they often explicitly used very unorthodox statistical techniques. Their motto was “anything goes.”
Thus, we argue that the results obtained in the CSI showed such a large variation because the 29 teams pursued (at least) four different research questions and therefore used different research designs. Designs according to Questions 1 to 3 led to models that greatly differed in the adjustment set, and accordingly, results differed. Teams that pursued Question 4 used “weird” models and thereby added some outlier results to the CSI.
Analytic Strategy of Our Reanalysis of the CSI Data
Our basic hypothesis is that the CSI produced a large variation in results because the teams did not pursue one research question, but four. The most straightforward strategy to demonstrate this would be to group the 29 research teams according to their research question and to compute the variation within and between the groups. According to our hypothesis, the share of between-group variation should be relatively large. However, we will not follow this research strategy because in many cases, it is quite difficult to classify the teams in a definitive way from the team reports. Most teams did not specify any explicit research question, as would be common in standard research articles, but instead reported only the statistical approach (e.g., kind of regression model) and results. Therefore, the results obtained from this research strategy (grouping teams into four different research questions) would be very uncertain.
Instead, we pursue a different strategy. We reframe our basic hypothesis: The CSI would have produced much less variation in results if the teams would have investigated only one precisely defined research question. Therefore, we chose one of the four research questions and investigated the range of results one could possibly obtain. Instead of starting a new crowdsource exercise, we “simulate” crowdsourcing by allowing for (a reasonable amount of) model uncertainty. If the range of results obtained by this simulation is rather low, we would conclude that rigorous social science research is able to provide a consistent answer for the chosen research question.
For this strategy, we selected the arguably sociologically most interesting research question: Research Question 2 on racial bias. We suppose that Silberzahn and colleagues had this research question in mind. Moreover, this is an X-centered research question, the type most often examined in quantitative sociological studies (for numbers on the European Sociological Review, see Kohler et al. 2018). Finally, discrimination research is certainly central to sociology.
In an ideal world, given a precise definition of the parameter of interest, theory would suggest one optimal model specification, and all researchers would obtain the same result. However, sociological theories, including theories on discrimination, usually provide only a vague idea on the causal association between variables, and there may also be uncertainty about the correct operationalization of concepts or the functional form of regression models. Thus, in the “real” world of social science research, there will be model uncertainty, and researchers will arrive—depending on their specification decisions in the garden of forking paths—at different results. Identifying the effect of this uncertainty on results was exactly the goal of the CSI. Instead of relying on the “manual” work done by crowdsource teams, we simulate the effect of model uncertainty drawing on computer algorithms that allow one to estimate a huge range of possible model specifications (multiverse analysis). This allows for an even larger range of specifications than manual crowdsourcing. Thus, this is an even more conservative test of our hypothesis than a crowdsourcing exercise would provide.
We do not allow for maximum model uncertainty; specifically, we do not allow for anything goes—Research Question 4—but only for reasonable model uncertainty. We argue that discrimination theories and causal methodology at least give some guidance on how to specify a model for investigating Research Question 2. This restricts the model space to a reasonable subspace, which, however, is larger than one because some uncertainty is left.
So, in the following, we basically (1) start from a precisely defined research question informed by discrimination theories and causal reasoning and delineate the space of reasonable model specifications. Then, we (2) apply multiverse analysis to the CSI soccer data to investigate how large the range of results is.
Data and Results
The data recorded player-referee dyads, linking players with the different referees they encountered during their careers (N = 146,028 dyads). The variables informed on the number (nj) of games in the dyad (with j indexing the different dyads), on the number (qj) of red cards the player received from the referee, and on some characteristics of the players and referees at the time of the data collection in 2014. 2
One should condition analyses on the time spent on the playing field: Only active players are at risk of receiving a red card. The data at hand include only a proxy for time spent on the playing field: the number of games played. To adjust our analyses for the numbers of games, we expanded the player-referee data to player-referee-game data. 3 For 483 players, there was no information on the skin tone (or body weight or height). We excluded these players from the following analyses. So, the analyses are based on information from 1,551 players in 371,813 player-referee-game combinations.
The outcome variable for these expanded data is a 0/1 indicator of whether the player received a red card in a respective game or not. (Soccer players can receive at maximum one red card per game.) Because there was only the aggregate information on the overall number (qj) of red cards on the dyad level, we randomly assigned the red cards on the game level within the dyads. Because there was not any information that was measured on the level of games, the random assignment of red cards was innocuous. The overall probability of a player receiving a red card in a game is .43 percent.
For the treatment variable, skin tone, we used the mean value of the two 5-point ratings that were provided in the data. These ratings ranged between 0, very light skin, and 1, very dark skin (with interrater reliability r = .92).
Now, to get an upper bound for model uncertainty, we had to decide on all model ingredients that seem reasonable for the research question at hand. Model ingredients are the set of potential control variables (adjustment set), the set of different functional forms, and the set of different operationalizations. The combination of all model ingredients defines the model space.
First, we decided on the variables in the adjustment set (an overview and more detailed arguments on the variables in the adjustment set can be found in Table A2 in the Supplemental Material). Remember the general rule: Include all productivity-relevant mediators and composition variables; do not include colliders. Thus, we included the composition variable age in the adjustment set for reasons specified already before. We also included four mediating variables: player’s height and weight (players that are larger/heavier built might more likely receive a red card), player’s position (e.g., red cards are more likely received by defenders), and the proportion of victories per game (indicator for the level of frustration, which may have increased the risk of red cards due to more aggressive playing).
In addition, to provide a conservative test of our hypothesis, we also included two variables in the adjustment set for which it is unclear whether they are mediators or colliders: club and country. Club may be a mediator because clubs might teach different playing styles (e.g., aggressiveness). However, there are also arguments that speak for club as being a collider: The admission to top clubs may depend on both discrimination and the player’s ability to avoid red cards (being issued a red card puts the player’s team in disadvantage). Similar arguments apply for country (see Table A2 in the Supplemental Material). Note that club and country are collinear, and therefore, only one of the two variables can be included in a particular model.
Furthermore, we did not include number of goals per game in the adjustment set because we were very confident that it would induce a backward causal link. Players who receive a red card are sent off for the rest of that game, shortening the possible time in which players can score goals.
Finally, for various reasons, we excluded two variables that potentially could be used in the models. We excluded referee’s IDs because there is no reason to assume that players with different skin tones could self-select into games monitored by specific referees. 4 We also did not use a variable informing on the referee’s country of origin. There might be a country-specific level of prejudice against dark-skin persons, and referees might have internalized these prejudices during their socialization. 5 However, from the perspective of causal models, it only makes sense to include this variable in form of an interaction term with skin tone to explore effect heterogeneity (moderator effects), which is out of the scope of our research goal.
We ran logistic regressions to estimate ORs as they were reported in the CSI. 6 Regressions were run with cluster-robust standard errors to account for the nested data structure with several games being observed for the same player (Rogers 1993).
Because there is uncertainty concerning the functional form and operationalization of some controls, we increased the model space by allowing for variation in this respect. For metric covariates (age, height, weight), we allowed for linear or quadratic specifications (Z or Z + Z²). We also allowed for two alternative operationalizations of the player’s position (using the original categorical variable with 12 levels or, alternatively, only 5 levels).
The combination of all these model ingredients generates a model space of 486 different regression models. The most parsimonious models include no controls 7 —thereby in fact answering Research Question 1; others include the complete adjustment set, and most models are in between. Multiverse analysis runs the whole set of regressions in the model space and thus provides 486 different estimates of the skin-tone effect. 8 We used the Stata ado mrobust provided by Cristobal Young and Katherine Holsteen (2017; see also Muñoz and Young 2018; Young 2018).
First, in Figure 2b, we show a graphical representation of the CSI findings: Median effect size was 1.31, but the variation was quite high, as can be seen by the wide range of the distribution (even though we dropped the two most extreme ORs of 2.9 from the graph). The standard deviation (including the outliers) was .45.
Figure 2a shows the modeling distribution of our reanalysis: The median effect size was 1.28, which is very close to the CSI median. However, despite allowing a very large model uncertainty, the estimates for the skin-tone effect were in a much narrower range than the ones reported in the CSI (SD = .06). 9

Distribution of skin-tone effects estimated by multiverse analysis and the crowdsourcing initiative (CSI).
Our multiverse analysis shows that all (reasonable) model specifications provide substantively very similar answers: All effect sizes were in a narrow range; throughout, all estimates pointed in the same direction (OR > 1); and two thirds (68%) of the estimates were statistically significant at the 5 percent level (for these and further model statistics provided by the mrobust algorithm, see Table A3 in the Supplemental Material).
Also noteworthy is that the distribution of estimates from the multiverse analysis was bimodal, meaning that there were two “clusters” in the model space. These two clusters were close to each other (OR = 1.2 and OR = 1.3). In other applications, the differences in estimates may be more substantial, and in these cases in particular, one may want to learn which covariates are causing the variation in results. The mrobust algorithm also allows one to identify the model ingredients of most influence. In our case, it was the variable club. The mean effect size was –.12 smaller when the models included the club variable. As mentioned previously, one might argue that the club variable is a collider and therefore should not be included in the adjustment set. This would narrow the range of the results even further. However, to provide a conservative test of our hypothesis, we did not exclude this variable from the adjustment set.
To sum up so far, the results of our multiverse analysis support our basic hypothesis. By rigorous social research (using a precisely defined research question and applying theoretically informed causal reasoning), it is possible to arrive at a consistent answer: The soccer data at hand support the conclusion that there is a (moderate) racial bias in the likelihood of receiving a red card. 10
Consistent Results Still Can Be Wrong: Sensitivity to Omitted Variables
Unfortunately, this is not the end of the story. Consistency of results is not the only criterion for credible results. Consistent results obtained with observational data easily can be wrong if there are unobservables. With observational data, there always is the potential of bias due to omitted variables. Thus, we admit that our reanalysis of the CSI data only may have shown that social research can produce consistent results but not necessarily valid results. We are aware of the fact that our result of a (moderate) racial bias may be invalid because important productivity-relevant mediators are missing in the CSI data. However, and this is the good lesson of this section, there are tools that at least allow one to estimate the sensitivity of results to bias caused by omitted variables.
In the following, we want to make scholars aware of the additional insights that can be gained by such sensitivity analyses. Multiverse analysis is helpful in testing the robustness of results against combinations of observed variables (which helps, for instance, to see whether results hinge on “knife edge” model specifications; Muñoz and Young 2018). But multiverse analysis does not help to test the sensitivity in regard to unobserved variables. For this, one has to use different algorithms that give indication toward the sensitivity of results against unobservables.
According to Research Question 2, we are interested in the direct causal effect of skin tone net of productivity relevant mediators. We estimate the effect β* shown in Equation 2: the skin-tone effect conditional on all mediators that are available in the CSI data (Figure 3a). Given the theoretical structure from Figure 3a, causal inference is threatened by two main problems with unobservables. We have to assume (1) that there is no unobserved mediator-outcome confounding 11 and (2) that there are no unobserved productivity-relevant mediators. Methods for checking the sensitivity of results concerning the first assumption are too complex to discuss here (Lundberg et al. 2021 provide an introductory discussion to the subtleties of mediation analysis). Therefore, we focus only on the second assumption in the following.
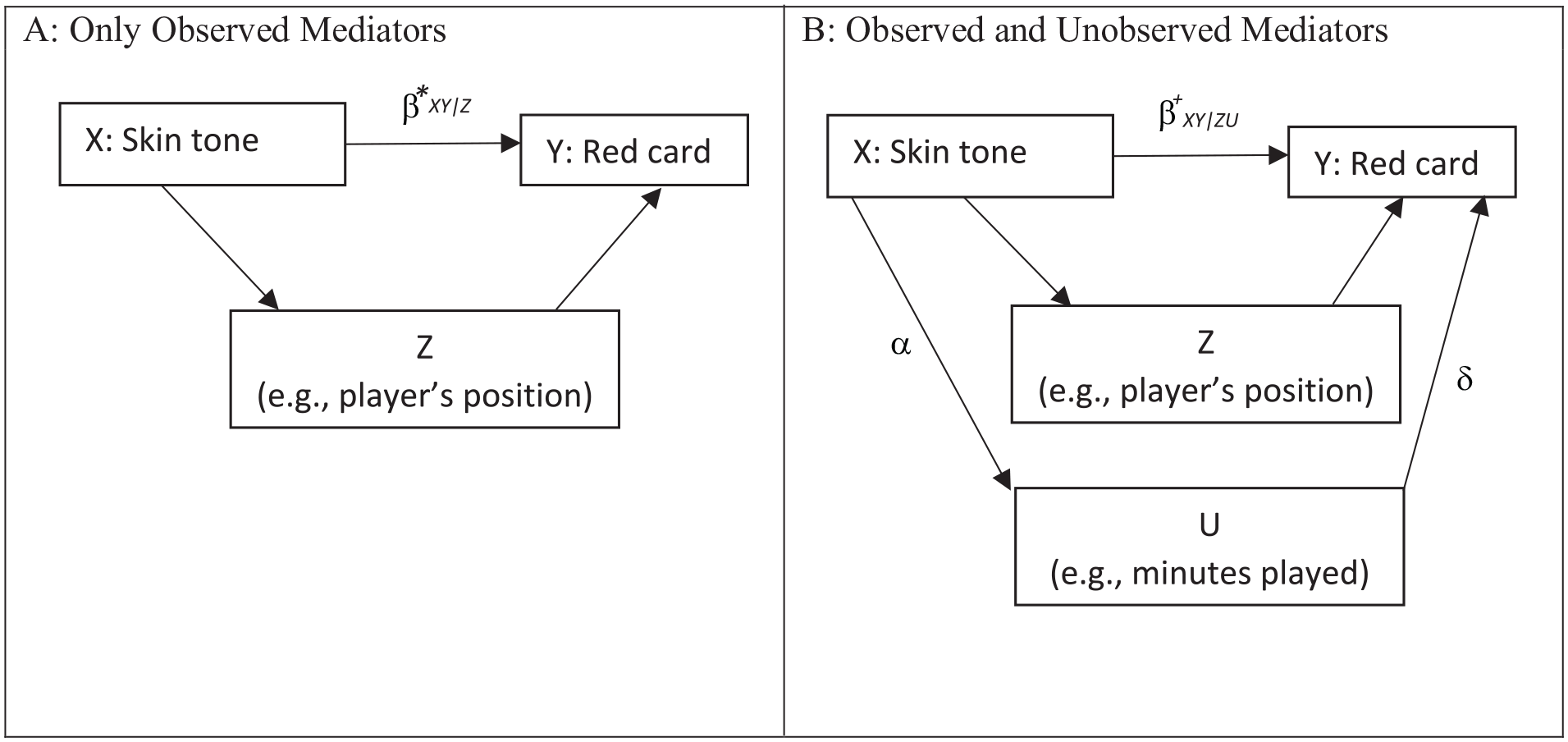
Causal diagram: direct effect estimated with observed and unobserved mediators.
A violation of our second assumption is illustrated in Figure 3b. There is an unobserved productivity-relevant mediator denoted U. α denotes the effect of X on U, measured by a bivariate regression, and δ is the effect of U on Y, measured by a multivariable regression. U could be, for instance, unobserved differences in the exact time “at risk” on the playing field (caused by varying numbers of minutes played per game or by varying numbers of overtimes played). In case meaningful unobserved mediators exist (α ≠ 0 and δ ≠ 0), our estimate β* would be biased (∆ = β*XY|Z – β+ XY|ZU ≠ 0).
In the example at hand, the question of whether we can give the skin-tone effect β* a causal interpretation boils down to the question of whether there could be sizable bias due to the omission of meaningful mediators. Technically, the bias that is caused by the omission of a mediator is an “omitted variable bias” (OVB). The size of this OVB is the product of two terms, often called sensitivity parameters: (1) the effect α of the treatment X on the mediator U and (2) the partial effect δ of the mediator U on the outcome Y. 12
We do not know these two parameters. But we can do a kind of thought experiment: How large would these parameters have to be so that the parameter of interest is brought down to a negligible level? To answer this question, one can use general sensitivity analysis (GSA) provided by Harada (2013), which builds on the approach developed by Imbens (2003). The GSA algorithm (provided with the Stata ado gsa) uses the unexplained variance (residuals) to estimate combinations of the two sensitivity parameters (α and δ) that would change the treatment effect (or its test statistic) to a target criterion defined by the user. The size of these estimated sensitivity parameters allows one, then, to judge the likelihood that there might exist an omitted mediator that could “explain away” the treatment effect (here, the skin-tone effect).
We illustrate this with the CSI data. We base the sensitivity test on a logistic regression model that includes the covariates age, weight, height, player’s position (five categories), proportion victories, and country. Using this regression, the estimate of β*XY|Z was 1.29 (OR)—which matches the median estimate found in CSI and also the multiverse analysis very well (see “Data and Results” section). The effect was statistically significant (p = .019). As target criterion for the GSA, we chose a t value of 1.96, which corresponds to a marginally insignificant treatment effect (using the common 5 percent level for statistical significance).
The results of this sensitivity analysis are summarized in the “contour curve” in Figure 4. To ease interpretation, the sensitivity parameters α and δ are converted to partial correlations. The correlation with skin tone (α) is on the x-axis, and the partial correlation with red cards (δ) is on the y-axis. The dots show combinations of these two parameters (simulated unobservables) that would change the skin-tone effect to an insignificant effect (t = 1.96). The curve termed GSA bound is the fitted curve to these dots. For instance, one can see that in case an unobserved mediator would be modestly correlated with skin tone (α = .1), already a small partial correlation of this mediator with the outcome (red cards) of around δ = .05 would be sufficient to turn the skin-tone effect insignificant. In general, one can learn from these analyses that small to modest associations of unobserved mediators with the treatment and outcome variable would explain the (direct) skin-tone effect away.

Contour plot of general sensitivity analysis for the skin-tone effect.
Is it likely that such unobserved mediators exist? We already mentioned the exact minutes played. Another candidate might be season effects (the likelihood of calling fouls might have changed over time). Finally, there might be a baseline rate at which individual players commit fouls (there was already evidence that such variables can significantly vary across athletes with different skin tone; see Price and Wolfers 2010). Given this and also the fact that observed variables, such as player’s weight, showed partial correlations that were close to the GSA bound (see Figure 4), we think that it is fairly likely that the direct skin-tone effect found in the CSI data is not causal but would vanish if these mediators would be controlled. 13
In sum, the result obtained with the CSI data that there is a modest racial bias in receiving red cards is plausibly due to the fact that the data are very limited in measured productivity-relevant mediators. It is very likely that more informative soccer data would show no racial bias in receiving red cards. The more general message here is that poor data and relying only on observed variables may produce very consistent results that are nevertheless wrong. Sensitivity analysis provides a very useful tool to evaluate this type of uncertainty in social research with observational data.
Summary
The CSI organized by Silberzahn et al (2018a) seemed to have demonstrated that social science is not able to provide consistent answers. Their main result was that the answer for a typical sociological research task largely depends on substantive analytical choices made by single researchers; therefore, the social sciences seem to have a credibility problem.
We argued that the CSI underestimated the credibility of social science findings. This was mainly due to the fact that the CSI did not start with a clear research question (and no precisely defined parameter of interest). A high variation in estimates would be problematic only as long as the estimates relate to the same parameter of interest. Teams in the CSI focused, however, on four different research tasks, reaching from descriptive to X-centered causal to Y-centered and to explorative research. Each of these research questions defines a different parameter of interest and requires a different research design to identify this parameter.
The two main findings of our empirical analyses are as follows. First, we reanalyzed the CSI data to demonstrate that one can indeed achieve much more consistent results when one specifies only one concrete research question and uses theory-guided causal reasoning to derive reasonable model specifications. We focused only on X-centered, causal discrimination research that is common in sociological research and used multiverse analysis to identify the full range of model uncertainty in social research with observational data. Remarkably, our reanalysis very well replicated the median estimate in the CSI, which was a moderate skin-tone effect. However, although we tested a much higher number of alternative model specifications by systematically varying plausible model ingredients in the multiverse analysis (that included hundreds of different model specifications), our results were within a much narrower range (i.e., much more consistent). Our conclusion is therefore that the CSI showed that nonrigorous social research that does not start with a clear research question provides divergent results. However, rigorous social science research is able to provide a more consistent answer.
Second, we argued and demonstrated that consistent results might still be biased. Even when results are very robust to numerous (manually) chosen model specifications, they might not catch the “true” causal effect as long as there is omitted variable bias. This is because results obtained with observational data are always contingent on the information content of the data. If the data do not contain information on important controls, results may be consistent but wrong. Therefore, to be credible, social science research also should be transparent concerning the sensitivity of the results against unobservables. Applying sensitivity analyses to the result obtained with the CSI data, we demonstrated that the result of a modest racial bias in the likelihood of receiving a red card is quite sensitive to unobserved mediators. This indicates that this estimate, although consistent across many different model specifications, is probably not a true causal effect in itself.
Discussion
All in all, we paint a relatively optimistic picture of social research: Only “bad” social research that is not pursuing a clear research task has a strong credibility problem; “good” social research can provide more definitive answers. Nevertheless, one might argue that the CSI mirrored standard flaws in social science research settings and thus depicts a “realistic” picture of social research. We discuss the argument in the following section. Some suggest that crowdsourcing could be a way to enhance the credibility of social research, which we also discuss in the following. Finally, we present our own suggestions for improving social research derived from our reanalysis of the CSI.
Did the CSI Provide a Realistic Picture of Social Science Research?
Skeptics might argue that our optimistic picture is an ideal and not from this world. The CSI used real researchers and thereby showed the current reality of social research. And the current reality is nonrigorous social research of low credibility. We (partly) agree. In fact, in many published articles, there is often only a vague specification of the research question. The parameter of interest is not precisely defined and can be inferred only implicitly by the reader (see Lundberg et al. 2021). There is no clear causal reasoning to justify model specification (Kohler et al. 2018). Furthermore, it is common practice to not only interpret the estimate for the parameter of interest but also to give the effects of the control variables a causal interpretation (Keele, Stevenson, and Elwert 2020).
But on the other side, the CSI overstressed this problem because real social science research would at least specify the broad type of the research question (e.g., descriptive, causal, or exploratory). In addition, it is standard that articles include a theory section that at least implicitly gives a specification of the research question. Thereby, the largest source of variability in the CSI likely did not mirror real research practice.
Furthermore, the CSI did not implement standards of quality control as is typical in the real world of social science research: There was no strict peer review. The CSI implemented only a loose review among the participants, but teams were at their discretion to follow the suggestions of other teams or not. Given that many teams in the CSI were very unexperienced (e.g., consisted of bachelor’s students), this might have added additional variance to the results. Also, because of the exotic methods used by some teams and the many indications of misspecified models (e.g., strongly inflated standard errors), we suspect that most of this research would not have stood serious peer review. 14 Thus, many weird results entered the CSI end report that very likely would have been filtered out by a strict peer-review process. Consequently, in the real world, the variability of results would have been lower.
Finally, crowdsourcing initiatives (and metaresearch more general) might have a systematic bias toward showing that research is not credible. 15 Some teams might be motivated to stand out from the crowd: Particularly creative scientists might not follow the crowd and estimate boring standard regressions but might instead be motivated by the crowdsource setting to use weird methods (i.e., to follow Research Question 4). Another motivation for doing so might be to increase the body of findings and thereby promote evolutionary scientific progress. We argue that in real social research, such motivations exist to a much lesser extent and that weird articles are often screened out by peer review.
Our design, however, also comes with limitations. The most serious limitation is probably that our multiverse approach focused only on model uncertainty, including different categorizations of key variables, but not on uncertainty that can be caused by coding errors or flaws in data preparation. A new crowdsourcing exercise (Breznau et al. 2021) argues that such hidden sources of variation are very common. Thus, our approach might underestimate the variability of real research. Therefore, further developments of automatic robustness analysis that also uncover such hidden sources of model uncertainty would be very helpful.
One might conclude that in the CSI, an overly vague research task and some flawed research that was not filtered out by peer review may have produced an overly pessimistic portrayal of the credibility of real social research. Nevertheless, we recognize that real social research also does not come close to the optimistic picture we have painted. Most likely, current social science research practice lies somewhere in between. More metaresearch on standard research practices is needed to come to more firm conclusions. 16
Crowdsourcing as the Future Mode of Social Research?
How could we improve the credibility of social research? So far, crowdsourcing exercises have not been very successful in finding the reasons for the high variability of results. Therefore, some argue that variability is unavoidable: “Discrepant results and variability in research findings . . . are perhaps unavoidable, and might best be embraced as a normal aspect of the scientific process” (Landy et al. 2020:469). The recent study by Breznau et al. (2021) found “a vast universe of research design variability normally hidden from view in the presentation, consumption, and perhaps even creation of scientific results.” This finding is even more pessimistic: not only that results vary but also that, even more, this variation is for unknown reasons (“a hidden universe of analytical flexibility”; similar results and arguments can be found in Huntington-Klein et al. 2021).
Therefore, some crowdsourcing enthusiasts conclude that “taking any single analysis seriously could be a mistake” (Silberzahn and Uhlmann 2015:191). Consequently, Landy et al. (2020) argue that we should change the mode of the scientific enterprise: The prevailing mode should no longer be that single teams investigate a research question, but rather, a crowd of teams should investigate a research question, and the unavoidably diverging results should then be averaged somehow (i.e., through some sort of meta-analysis; see Landy et al. 2020).
Although this method of “crowdsourcing hypothesis tests” might be helpful with experimental research (the context of the Landy et al. 2020 study), we do not think that crowdsourcing currently should become the standard for observational data analysis. The majority of observational studies may not be very rigorous. Averaging over these could be counterproductive. For instance, if a field is full of misspecified models, these will dominate the result (as is well known in meta-analysis: “garbage in, garbage out”). Instead, we would suggest that to increase the credibility of social research, it is more helpful to first increase the quality of each single study (for suggestions on this, see the following section). Admittedly, also with rigorous social research, some uncertainty will remain (as shown in the “Data and Results” section). Then multiverse analyses or crowdsourcing might be helpful to uncover the remaining amount of uncertainty.
Finally, we offer a few notes on promising avenues for future crowdsourcing exercises. (1) The model space in crowdsourcing initiatives is naturally limited by the number of teams. Thus, a promising avenue for future replication initiatives could be an innovative combination of crowdsourcing and multiverse analysis. (2) Instead of crowdsourcing in the form of competing teams, the forces of all participating researchers could be joined to deliberate on the “optimal” analysis. This could also reduce the personal harm caused by conflicting results between teams. (3) In addition, a promising avenue for future metaresearch could be crowdsourcing initiatives that explicitly incorporate elements of causal reasoning into their design. For example, one could test different approaches in split-half samples, such as teams working independently or collaboratively on the best causal modeling.
An Alternative First Step: Improving Social Research Practice
In a nutshell, we have argued that it is more productive to increase the quality of any single study rather than crowdsourcing (and then simply averaging) many studies of lower quality. Some practical conclusions can be drawn from our reanalysis that could form a kind of blueprint for better social research. These recommendations are detailed in the following (a very similar list of recommendations was proposed for psychology by Grosz, Rohrer, and Thoemmes 2020; see also Box A1 in the Supplemental Material).
First, good social research should always start from a clearly defined research question and give a precise definition of the parameter of interest. Ideally, this parameter would be derived from a formal, theoretical model. At least, researchers should clearly specify which parameter in their statistical model provides information for their research question. In this regard, research designs should always be optimized for only one parameter of interest (Keele et al. 2020; Kohler et al. 2018). It is generally not possible to answer many different questions with one design. Recently, similar points were made much more forcefully by Lundberg et al. (2021). These authors argue that productive social research must start with precise definitions of the theoretical (research question) and empirical (parameter of interest) estimands. We refer the reader to this article for a much more nuanced treatise of these issues.
Second, good social research should use theory-guided causal reasoning to justify an appropriate model specification for identifying the parameter of interest. It is insufficient to simply throw the “usual suspects” as controls in a regression model. Unfortunately, this is common practice, as shown by Kohler et al. (2018). Instead, the identifying assumptions should be made explicit, preferably through visualization in the form of graphical causal models, such as directed acyclic graphs (see e.g., Elwert and Winship 2014).
Third, robustness analysis of the results should become common practice. Many articles report robustness checks. However, there is evidence that robustness analyses are selectively reported that support the main results at 100 percent (Young and Holsteen 2017). Therefore, we need more serious robustness checks. In this vein, it should become standard to present the full distribution of estimates that can be obtained based on all reasonable specifications. Multiverse analysis, as used in this article, seems particularly promising in this regard. In addition, one can complement summary tables (e.g., descriptive statistics and regression tables) with visualizations that disclose the full variance in raw data and results (Cumming 2014; Healy and Moody 2014). If the robustness analysis shows that results vary widely over the model space, then researchers need to make explicit why they chose their specific model specification. This will increase transparency and credibility of social research.
Fourth, sensitivity analysis should also become standard practice. As we have argued, very consistent answers obtained with observational data may well be wrong. The estimates could be sensitive to unobserved variables. This is particularly relevant when the data contain only a few variables (as is the case with the CSI data). Then the results will be very consistent due to the limited number of controls available, but they are likely to be wrong because important controls are unobserved. Therefore, to achieve full credibility of social science results, one must demonstrate that they are not sensitive to OVB. For this, one could use tools such as those we have used in this article (for more tools for robustness and sensitivity analyses, see Christensen, Freese, and Miguel 2019; Ding and VanderWeele 2016).
Altogether, precise specification of the parameter of interest, transparent reasoning about the assumptions necessary for its identification, and transparency about the robustness and sensitivity of the results to other reasonable model choices are probably the most effective measures to increase credibility in the social sciences.
Supplemental Material
sj-docx-1-srd-10.1177_23780231211024421 – Supplemental material for Has the Credibility of the Social Sciences Been Credibly Destroyed? Reanalyzing the “Many Analysts, One Data Set” Project
Supplemental material, sj-docx-1-srd-10.1177_23780231211024421 for Has the Credibility of the Social Sciences Been Credibly Destroyed? Reanalyzing the “Many Analysts, One Data Set” Project by Katrin Auspurg and Josef Brüderl in Socius
Footnotes
Authors’ Note
We used data and materials from the project page of the CSI (Silberzahn et al. 2018b, https://osf.io/gvm2z/). Our replication files can be found on the following OSF-project page (Auspurg and Brüderl 2021, ![]() ).
).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.